
Configure Multi-Region Clusters in Confluent Platform
Confluent Server is often run across availability zones or nearby datacenters. If the computer network between brokers across availability zones or nearby datacenters is dissimilar, in term of reliability, latency, bandwidth, or cost, this can result in higher latency, lower throughput and increased cost to produce and consume messages.
To mitigate this, three distinct pieces of functionality were added to Confluent Server:
Follower-Fetching
Observers
Replica Placement
Follower-Fetching
Before the introduction of this feature, all consume and produce operations took place on the leader. With Multi-Region Clusters, clients are allowed to consume from followers. This dramatically reduces the amount of cross-datacenter traffic between clients and brokers.
To enable follower fetching, configure these settings in your server.properties file, where broker.rack identifies location of the broker. It doesn’t have to be rack, but can be region in which broker resides:
replica.selector.class=org.apache.kafka.common.replica.RackAwareReplicaSelector
broker.rack=<region>
On the consumer side, set client.rack as the client property. Apache Kafka® 2.3 clients or later will then read from followers that have matching broker.rack as the specified client.rack ID.
client.rack=<rack-ID>
Tip
This feature is also available in the
confluent-kafkapackage.A consumer can consume messages from a follower even if the follower is out-of-sync. For example, given a
westand aneastrack, ifwestis down for an hour, and then restarts, its brokers will be out of sync but will start to catch up by replicating data fromeast. During this catch up period, consumers inwestcan consume from these “out of sync” follower replicas, and thus avoid the long network hop over toeast, as long as the out of sync followers have the offset that the consumers request. If a consumer gets “ahead” of the out-of-sync followers, then it will start to fetch from the leader, which could be ineast.
Observers
Historically there are two types of replicas: leaders and followers. Multi-Region Clusters introduces a third type of replica, observers. By default, observers will not join the in-sync replicas (ISR) but will try to keep up with the leader just like a follower. With follower-fetching, clients can also consume from observers.
By not joining the ISR, observers give operators the ability to asynchronously replicate data. In Confluent Server the high watermark for a topic partition is not increased until all members of the ISR acknowledge they have replicated a message. Clients using acks=all can suffer from throughput issues, especially when high latency, low bandwidth networks across datacenters are involved. With observers, you can define topics that synchronously replicate data within one region, but replicate the data asynchronously between regions. By default, these observers do not join the ISR, so they do not affect the throughput and latency of precluding messages since the topic partition leader doesn’t need to wait for them to get replicated to the observers before acknowledging the request back to the producer.
You can use the metrics described in the metric section of this document to monitor the number of replicas (normal synchronous replicas and observers) that are caught up with the leader.
Note
A common deployment is to run two data centers each containing a KRaft controller and a broker, and a third location that hosts only a controller so that a quorum can be established. In this setup, if there is a network partition between the brokers, but not between the controller instances, then manual action is required to restore the cluster to health, even if Automatic Observer Promotion is in use. If you have this type of deployment, it is important to be aware of this potential failure scenario and set up appropriate monitoring, alerting, and procedures to address it.
Automatic observer promotion
Note
Automatic observer promotion is only available with Replica Placement version 2 introduced in Confluent Platform 6.1. To use version 2 specify "version": 2 in your replica placement JSON. For more information see Replica placement
Automatic Observer Promotion is the process whereby an observer is promoted into the in-sync replicas list (ISR). This can be advantageous in certain degraded scenarios. For instance, if there have been enough broker failures for a given partition to be below its minimum in-sync replicas constraint then that partition would normally become offline. With automatic observer promotion, one or more observers can take the place of followers in the ISR keeping the partition online until the followers can be restored. Once followers have been restored (they are caught up and have rejoined the ISR) then the observers are automatically demoted from the ISR.
This behaviour is controlled by the observerPromotionPolicy field in a topic’s replica placement policy. It can have values:
under-min-isr: observers will be promoted if the ISR size drops below the topic’smin.insync.replicasconfiguration. For instance, given a partition withISR=3andmin.insync.replicas=2, an observer would be promoted if two replicas in the ISR failed.under-replicated: observers will be promoted if the ISR size drops below the configured count of replicas in the topic’s replica placement policy. For instance, given a partition withISR=3andmin.insync.replicas=2, an observer would be promoted if one replica in the ISR failed.leader-is-observer: if the current partition leader is an observer. Ifleader-is-observeris used, observers will only join the ISR if a user intervenes manually. A user must calluncleanleader election on an observer node to make that observer the partition’s leader. Then, other observers will also join the ISR in order to satisfy min-ISR, if needed. This is always the behavior if"version": 1is used in the replica placement policy.
Important
The default observerPromotionPolicy is under-min-isr which is a change from the default version 1 replica placement behaviour. To use the legacy behaviour, use replica placement version 1 or configure observerPromotionPolicy to leader-is-observer
The metric ObserversInIsrCount described in the metric section of this document displays the number of observers that are currently in the ISR.
To learn more, see this blog post: Automatic Observer Promotion Brings Fast and Safe Multi-Datacenter Failover with Confluent Platform 6.1.
Replica placement
New features, limitations, and supported releases
Starting with Confluent Platform 7.3.0 and inter.broker.protocol.version 3.3, Multi-Region Clusters observers and replicas can be in the same rack, as described in example 2 below.
Matching racks are supported for Auto Data Balancer.
Configuration notes
Using the same rack for both replicas and observers in a topic’s replica placement requires the cluster’s brokers to have
inter.broker.protocol.versionof at least3.3. This was an issue with earlier versions of Confluent Platform running ZooKeeper which required upgrades, as described in Upgrade Confluent Platform and Steps for upgrading to 7.8.x (ZooKeeper mode). However, as of Confluent Platform 7.5, ZooKeeper is deprecated in favor of KRaft and these tutorials demonstrate using KRaft. To learn more about running Kafka in KRaft mode, see KRaft Overview for Confluent Platform. To learn about upgrading from ZooKeeper to KRaft, see Steps for upgrading to 7.8.x (KRaft-mode).If you have set
confluent.log.placement.constraintsin the brokerserver.propertiesfiles, do not create topics using--replication-factorif you want those constraints applied to new topics. Specifying a replication factor when creating a new topic results in the placement constraints being ignored for that topic.
How it works
Replica placement defines how to assign replicas to the partitions in a topic. This feature relies on the broker.rack property configured for each broker. For example, you can create a topic that uses observers with the new --replica-placement flag on kafka-topics to configure the internal property confluent.placement.constraints.
kafka-topics --create \
--bootstrap-server kafka-west-1:9092 \
--topic testing-observers \
--partitions 3 \
--replica-placement /etc/confluent/testing-observers.json \
--config min.insync.replicas=2
Where the file (in this case, /etc/confluent/testing-observers.json) contains:
{
"version": 2,
"replicas": [
// array of objects of this shape:
{
"count": <integer>,
"constraints": {
"rack": <string>, // name of a broker.rack group to assign these replicas
}
}
],
"observers": [ // optional
// array of objects of this shape:
{
"count": <integer>,
"constraints": {
"rack": <string>, // name of a broker.rack group to assign these observers
}
}
],
"observerPromotionPolicy": "under-min-isr" or "under-replicated" or "leader-is-observer" // optional
}
The field replicas contains a list of constraints that must be satisfied by the sync replicas. The field observers contains a list of constraints that must be satisfied by the async replicas (observers).
Each unique rack string can only be specified once in replicas and/or once in observers. The total number of brokers with a given broker.rack must be greater than or equal to the total number of replicas and observers with that "rack" in this JSON.
Tip
Internal topics (system-generated) should have the same constraints as normal topics. Internal topics can use their defaults if the default replica placement is configured in the broker.
Example 1: Replicas and observers in different racks
Here is an example replica placement JSON showing replicas in rack us-west and observers in rack us-east:
{
"version": 2,
"replicas": [
{
"count": 3,
"constraints": {
"rack": "us-west"
}
}
],
"observers": [
{
"count": 2,
"constraints": {
"rack": "us-east"
}
}
],
"observerPromotionPolicy":"under-min-isr"
}
In the example above, Confluent Server will create one topic with three partitions. Each partition will be assigned five replicas. Three of the replicas will be sync replicas with a broker.rack equal to us-west while two of the replicas will be observers with a broker.rack equal to us-east. If the constraint cannot be satisfied and Confluent Server fails to find enough brokers matching specified constraint, topic creation will fail.
Tip
When a topic is created with a replica placement policy, all of its preferred leaders will be in the first rack listed in the replica placement policy. If you run Quick Start for Auto Data Balancing in Confluent Platform or Manage Self-Balancing Kafka Clusters in Confluent Platform, the preferred leaders will be redistributed among all racks that have replicas.
Here is what the topic will look like when you run kafka-topics --bootstrap-server localhost:9092 --describe:
Topic: test-observers PartitionCount: 3 ReplicationFactor: 5 Configs: segment.bytes=1073741824,confluent.placement.constraints={"version":1,"replicas":[{"count":3,"constraints":{"rack":"us-west"}}],"observers":[{"count":2,"constraints":{"rack":"us-east"}}]}
Topic: test-observers Partition: 0 Leader: 1 Replicas: 1,2,3,4,5 Isr: 1,2,3 Offline: Observers: 4,5
Topic: test-observers Partition: 1 Leader: 2 Replicas: 2,3,1,5,4 Isr: 2,3,1 Offline: Observers: 5,4
Topic: test-observers Partition: 2 Leader: 3 Replicas: 3,1,2,4,5 Isr: 3,1,2 Offline: Observers: 4,5
In the above example, for first partition, a producer with acks=all will get an acknowledgement back from the topic partition leader 1 after brokers 1, 2 and 3 have replicated the produced message. Brokers 4 and 5 will also replicate the data as quickly as possible but the leader can send the producer an acknowledgement without waiting for an acknowledgement from brokers 4 and 5.
Example 2: Replicas and observers in the same rack
Here is another example of a JSON replica placement, which contains replicas and observers in the same rack. To read more about the usefulness of patterns like this one, see the blog post, Automatic Observer Promotion Brings Fast and Safe Multi-Datacenter Failover with Confluent Platform 6.1.
{
"version": 2,
"replicas": [
{
"count": 2,
"constraints": {
"rack": "New York"
}
},
{
"count": 2,
"constraints": {
"rack": "Boston"
}
}
],
"observers": [
{
"count": 1,
"constraints": {
"rack": "New York"
}
},
{
"count": 1,
"constraints": {
"rack": "Boston"
}
}
],
"observerPromotionPolicy":"under-min-isr"
}
This example configures both the New York and the Boston racks each with two synchronous replicas and one observer.
Tip
When an existing topic’s replica placement constraint changes, it does not automatically move its partitions to satisfy the new constraint. Either Auto-Data Balancer or Manage Self-Balancing Kafka Clusters in Confluent Platform must be run to move the partitions into the new replica placement constraint’s state.
Default placement constraints for internal topics and manually created topics
A default replica placement constraint can be defined for manually created topics, as well as for internal topics. This will be applied at topic creation time, if already defined:
confluent.log.placement.constraints: applied to all manually created topicsconfluent.offsets.topic.placement.constraints: applied to the consumer offsets topicconfluent.transaction.state.log.placement.constraints: applied to the transaction state log topic
In newer versions of Control Center (Legacy) and in Control Center, Control Center will inherit the broker replica placement constraints by default. For Multi-Region Clusters, the replica placement policy is inherited from the broker for a multi-region cluster. This is done so that Confluent Control Center internal topics can have replica placement, as otherwise they would be created in a single region.
For all other internal topics (for example, Connect, metrics, telemetry, command, and so on) there is no default replica placement constraint; these must be applied and enforced manually.
Architecture
As a best practice, deploy multi-region clusters across three or more data centers to avoid split-brain in the event of a network partition event. A KRaft deployment might look like this:
DC1: Two KRaft nodes
DC2: Two KRaft nodes
DC3: One KRaft node
Note that Kafka brokers do not necessarily need to be deployed in each data center (DC). The KRaft ensemble should be deployed so that if a network partition event occurs, a quorum of Kafka nodes remains. This is easiest in a three or more datacenter multi-region cluster.
A two datacenter deployment is possible, but this architecture will require either a preferred datacenter to win all leader elections (for example, three KRaft nodes, two KRaft nodes) in the event of a network partition, or manual intervention to reconfigure the KRaft quorum to elect the winning datacenter.
Observer failover
Note
This sections refers to the failure of all replicas for a partition. To handle partial failures automatically see Automatic observer promotion
In the event that all of the sync replicas are offline, it is possible to elect an observer as leader. Confluent Server includes a command (kafka-leader-election) to manually trigger leader election. This command can be used to send a request to the controller to elect an online replica, including an observer, as a leader even if they are not part of the ISR. Electing a replica or observer as leader when it is not in ISR is called “unclean leader election”.
In an unclean leader election, it is possible for the new leader to not have all of the produced records up to the largest offset that was acknowledged. This can result in the truncation of all the topic partition logs to an offset that is before the largest acknowledged offset.
Important
To minimize possible data loss caused by unclean leader election, monitor observer replication to make sure that it is not falling too far behind.
For example, if you have a cluster spanning us-west-1 and us-west-2, and you lose all brokers in us-west-1:
If a topic has replicas in
us-west-2in the ISR, those brokers would automatically be elected leader and the clients would continue to produce and consume.If a topic has replicas, including observers, in
us-west-2not in the ISR, the user can perform unclean leader election:Create a properties file that specifies the topic partitions:
cat unclean-election.json { "version": 1, "partitions": [ {"topic": "testing-observers", "partition": 0} ] }Run this command and the observers will join the ISR:
kafka-leader-election --bootstrap-server kafka-west-2:9092 \ --election-type UNCLEAN --path-to-json-file unclean-election.json
To fail back to the preferred leaders after the brokers have recovered, run this command:
kafka-leader-election --bootstrap-server kafka-west-1:9092 \ --election-type preferred --all-topic-partitions
A switch to the preferred leader happens automatically when
auto.leader.rebalance.enableis set. The selection of the preferred leader is also subject toleader.imbalance.per.broker.percentageandleader.imbalance.check.interval.seconds. To prompt the selection of preferred leaders, run:kafka-leader-election --bootstrap-server localhost:9092 --election-type PREFERRED --topic foo
Metrics
In Confluent Server there are a few metrics that should be monitored for determining the health and state of a topic partition. Some to these metrics are enumerated below:
ReplicasCount- In JMX the full object name iskafka.cluster:type=Partition,name=ReplicasCount,topic=<topic-name>,partition=<partition-id>. It reports the number of replicas (sync replicas and observers) assigned to the topic partition.ObserverReplicasCount- In JMX the full object name iskafka.cluster:type=Partition,name=ObserverReplicasCount,topic=<topic-name>,partition=<partition-id>. It reports the number of observers assigned to the topic partition.InSyncReplicasCount- In JMX the full object name iskafka.cluster:type=Partition,name=InSyncReplicasCount,topic=<topic-name>,partition=<partition-id>. It reports the number of replicas in the ISR.CaughtUpReplicasCount- In JMX the full object name iskafka.cluster:type=Partition,name=CaughtUpReplicasCount,topic=<topic-name>,partition=<partition-id>. It reports the number of replicas that are consider caught up to the topic partition leader. Note that this may be greater than the size of the ISR as observers may be caught up but are not part of ISR.IsNotCaughtUp- In JMX the full object name iskafka.cluster:type=Partition,name=IsNotCaughtUp,topic=<topic-name>,partition=<partition-id>. It reports 1 (true) if not all replicas are considered caught up to the partition leader.ObserversInIsrCount- In JMX, the full object name iskafka.cluster:type=Partition,name=ObserversInIsrCount,topic=<topic-name>,partition=<partition-id>. It reports the number of observers that are currently in the ISR.
Partition reassignment
In Confluent Platform 5.5, a new broker setting was added which makes it easier to configure partition placement constraints for auto generated topics. Set confluent.log.placement.constraints to define a default replica placement constraint for the cluster. For example:
confluent.log.placement.constraints={"version": 1,"replicas": [{"count": 2, "constraints": {"rack": "west"}}], "observers": [{"count": 2, "constraints": {"rack": "east"}}]}
You can change the replica placement constraints of a topic and the assignment of replicas to the partitions of a topic. You can use the kafka-configs command line tool to change the replica placement constraints. For example:
kafka-configs --bootstrap-server kafka-west-1:9092 --entity-name testing-observers --entity-type topics --alter --replica-placement /etc/confluent/testing-observers.json
Where the /etc/confluent/testing-observers.json file contains:
{
"version": 1,
"replicas": [
{
"count": 3,
"constraints": {
"rack": "us-west"
}
}
],
"observers": [
{
"count": 2,
"constraints": {
"rack": "us-east"
}
}
]
}
See the Replica placement section for a description of the content of the replica placement JSON file.
Important
Changing the configuration of a topic does not change the replica assignment for the topic partition. Changing the replica placement of a topic configuration must be followed by a partition reassignment. The confluent-rebalancer command line tool supports reassignment that also accounts for replica placement constraints. To learn more, see Quick Start for Auto Data Balancing in Confluent Platform.
For example, run the commands below to start a reassignment that matches the topic’s replica placement constraints. Note you should use Confluent Platform 5.5 or newer, which now includes --topics and --exclude-internal-topics flags to limit the set of topics that are eligible for reassignment. This will decrease the overall rebalance scope and therefore time. --replica-placement-only can be used to perform reassignment only on partitions that do not satisfy the replica placement constraints.
confluent-rebalancer execute --bootstrap-server kafka-west-1:9092 --replica-placement-only --throttle 10000000 --verbose
Run this command to monitor the status for the reassignment:
confluent-rebalancer status --bootstrap-server kafka-west-1:9092
Run this command to finish the reassignment:
confluent-rebalancer finish --bootstrap-server kafka-west-1:9092
Tip
If you have set
confluent.log.placement.constraintsin the brokerserver.propertiesfiles, do not create topics using--replication-factorif you want those constraints applied to new topics. Specifying a replication factor when creating a new topic results in the placement constraints being ignored for that topic.Make sure you use
confluent-rebalancer5.4.0 or later (packaged with Confluent Platform 5.4.0 or later).Use version 5.5.0 with a 5.5.0 Kafka cluster to leverage the new capabilities and limit the scope of the rebalance with
--topics,--exclude-internal-topics, or--replica-placement-only.
For more information and examples, see Quick Start for Auto Data Balancing in Confluent Platform.
Monitoring replicas
You can use the command kafka-replica-status.sh to monitor the status of replicas assigned to a partition, including information about their current mode and replication state.
For example, the following displays information about all replicas that constitute the testing-observers topic for the first partition:
kafka-replica-status.sh --bootstrap-server localhost:9092 --topics testing-observers --partitions 0 --verbose
The output for the example is:
./bin/kafka-replica-status.sh --bootstrap-server localhost:9092 --topics testing-observers --partitions 0 --verbose
Topic: testing-observers
Partition: 0
Replica: 1
IsLeader: true
IsObserver: false
IsIsrEligible: true
IsInIsr: true
IsCaughtUp: true
LastCaughtUpLagMs: 0
LastFetchLagMs: 0
LogStartOffset: 0
LogEndOffset: 10000
Topic: testing-observers
Partition: 0
Replica: 2
...
The output provided is:
Topic(<String>): The topic for the replica.Partition(<Integer>): The partition for the replica.Replica(<Integer>): The broker ID for the replica.isLeader(<Boolean>): Whether the replica is the ISR leader.isObserver(<Boolean>): Whether the replica is an observer, otherwise a traditional replica.isIsrEligible(<Boolean>): Whether the replica is a candidate to be in the ISR set.isInIsr(<Boolean>): Whether the replica is in the ISR set.isCaughtUp(<Boolean>): Whether the replica’s log is sufficiently caught up to the leader such that it’s considered to be in sync. However, note that a replica being caught up doesn’t necessarily mean the replica is in the ISR set. For example, the replica may be an observer, or a follower that cannot be included in the ISR due to topic placement constraints.lastFetchLagMs(<Long>): The duration, in milliseconds, since the last fetch request was received from the replica. This will always be ‘0’ for the leader, and may be ‘-1’ if the leader hasn’t received a fetch request from the replica.lastCaughtUpLagMs(<Long>): The duration, in milliseconds, since the last fetch request was received from the replica in which it was considered “caught up”. This will always be ‘0’ for the leader, and may be ‘-1’ if the leader hasn’t received a fetch request from the replica.logStartOffset/logEndOffset: (<Long>): The starting/ending log offset for the replica’s log from the leader’s perspective. These may be ‘-1’ if the leader hasn’t received a fetch request from the replica.
Additional useful flags are:
--topics: Comma-separated topics to retrieve replica status for.--partitions: Comma-separated list of partition IDs or ID ranges for the topic(s); for example, ‘5,10-20’.--verbose: Print output in a verbose manner with one attribute per line.--json: Print output in JSON format.--leaders: Show only partition leaders, or omit leaders if ‘exclude’ is provided.--observers: Show only observer replicas, or omit observers if ‘exclude’ is provided.--exclude-internal: Excludes internal topics from the output.--version: Display Confluent Server version.
Example
To try a detailed Multi-Region Clusters example, run the end-to-end Tutorial: Multi-Region Clusters on Confluent Platform. The tutorial injects latency and packet loss to simulate the distances between the regions and showcases the value of the new capabilities in a multi-region environment.
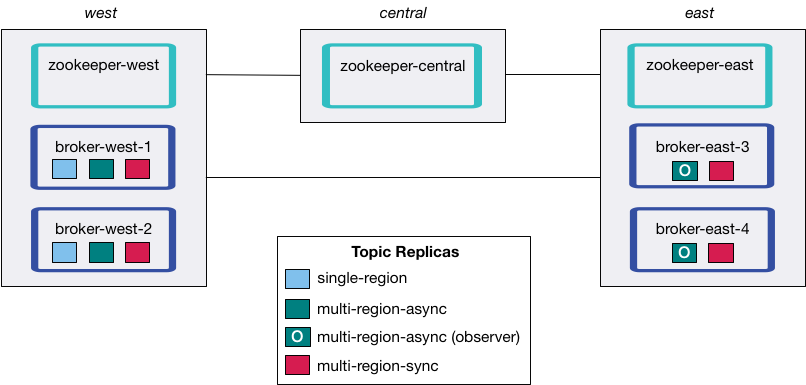
Using Multi-Region Clusters with other Confluent Products
If you are using both Multi-Region Clusters and Manage Self-Balancing Kafka Clusters in Confluent Platform, you must specify the broker rack on all brokers. Your starting set of brokers and any brokers you add with Self-Balancing enabled must have a region or rack specified for
broker.rackin each of theirserver.propertiesfiles. To learn more, see Replica placement and multi-region clusters in the Self-Balancing documentation.Operator tasks are not supported.
Tiered storage is not supported due to the limitations/implementation of many object stores (singular region, eventual consistent replication, one bucket for whole cluster, and so forth).
Starting with Confluent Platform 7.5 Multi-Region Clusters are available for new KRaft clusters.