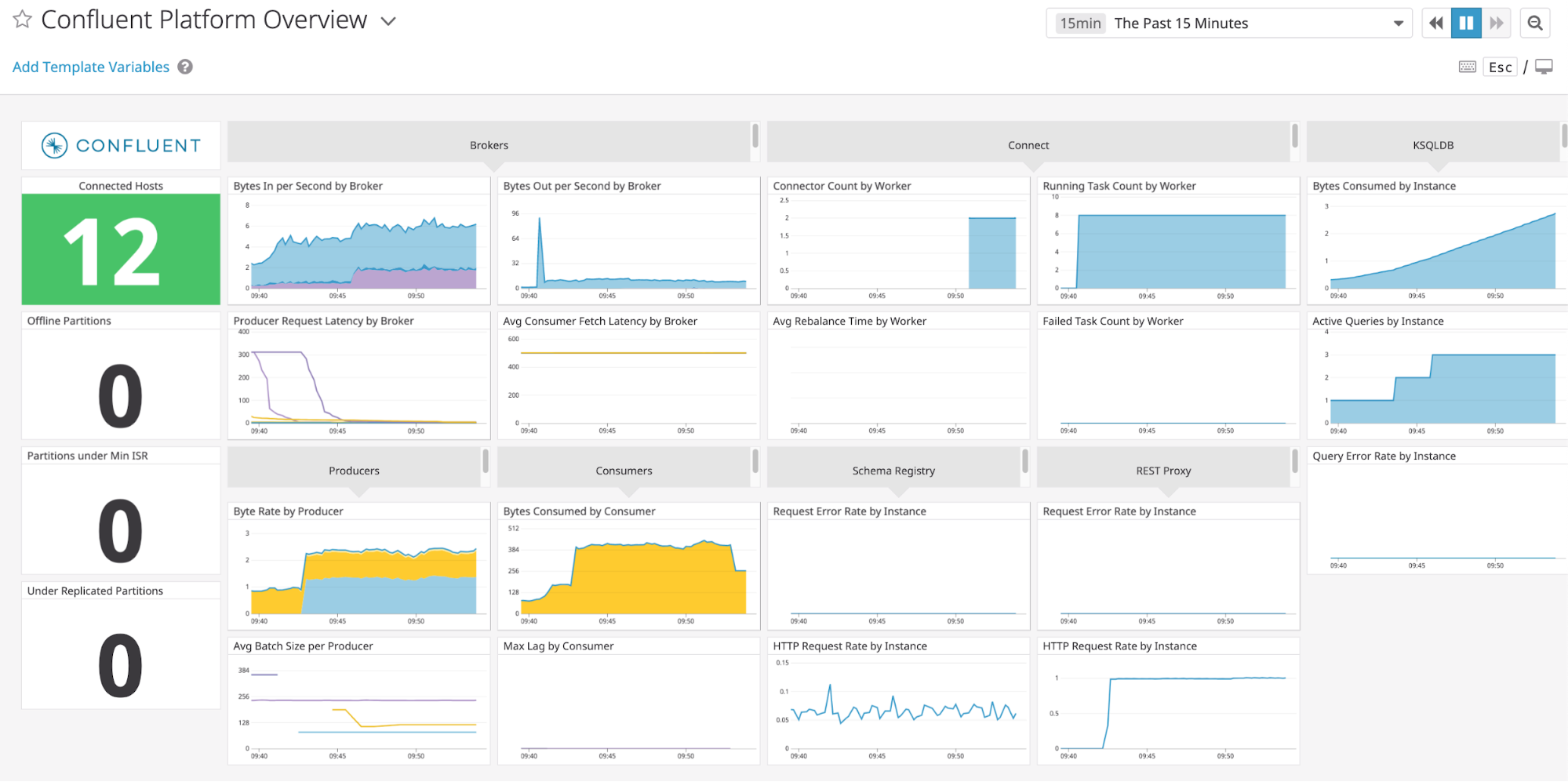
Module 1: Deploy Confluent Platform Demo Environment Using Script
Run on-premises Confluent Platform cluster
cp-demo is a Docker environment and has all services running on one host. It is meant exclusively to easily demo Confluent Platform, but in production, do not deploy all Confluent Platform services on a single host.
Also, in production, Confluent Control Center (Legacy) should be deployed with a valid license in management mode in conjunction with Confluent Health+ for monitoring.
If you prefer non-Docker examples, please go to confluentinc/examples GitHub repository.
After you run through the guided tutorial below, apply the concepts you learn here to build your own event streaming pipeline in Confluent Cloud, a fully managed, cloud-native event streaming platform powered by Kafka. When you sign up for Confluent Cloud, use the promo code CPDEMO50 to receive an additional $50 free usage (details).
Prerequisites
This example has been validated with:
Docker engine version 20.10.12
Docker Compose version 2.4.1
Java version 11.0.8
Ubuntu 18.04
OpenSSL 1.1.1
git
curl
jq
Setup
You can run this demo locally with Docker or in a cloud IDE with Gitpod.
Docker
This demo has been validated with Docker as described in Prerequisites. If you are using Docker:
In Docker’s advanced settings, increase the memory dedicated to Docker to at least 8 GB (default is 2 GB) and ensure Docker is allocated at least 2 CPU cores.
Clone the confluentinc/cp-demo GitHub repository:
git clone https://github.com/confluentinc/cp-demo
Navigate to the
cp-demodirectory and switch to the Confluent Platform release branch:cd cp-demo git checkout 7.5.15-post
Gitpod
This demo is enabled to run with Gitpod, but support for the Gitpod workflow is best effort from the community. If you are using Gitpod, the demo will automatically start after the Gitpod workspace is ready. VIZ=false is used to save system resources.
Login into Confluent Control Center (Legacy) (port 9021) by clicking on Open Browser option in the pop-up:
or by selecting Remote Explorer on the left sidebar and then clicking on the Open Browser option corresponding to the port you want to connect to:
Start
Within the cp-demo directory, there is a single script that runs the cp-demo workflow end-to-end. It generates the keys and certificates, brings up the Docker containers, and configures and validates the environment. You can run it with optional settings:
CLEAN: controls whether certificates are regeneratedC3_KSQLDB_HTTPS: controls whether Confluent Control Center (Legacy) and ksqlDB server useHTTPorHTTPS(default:falseforHTTP). This option is not supported with Gitpod.VIZ: enables Elasticsearch and Kibana (default:true)
To run
cp-demothe first time with defaults, run the following command. The very first run downloads all the required Docker images (~15 minutes) and sets up the environment (~5 minutes)../scripts/start.sh
On subsequent runs, if you have not deleted the generated certificates and the locally built Connect image, they will be reused. To force them to be rebuilt, you can set
CLEAN=true.CLEAN=true ./scripts/start.sh
cp-demosupports access to the Confluent Control Center (Legacy) GUI via eitherhttp://(the default) or securehttps://, the latter employing a self-signed CA and certificates generated during deployment. In order to run ksqlDB queries from Confluent Control Center (Legacy) later in this tutorial, both ksqlDB and Confluent Control Center (Legacy) must be running in eitherhttporhttpsmode. To runcp-demoinhttpsmode, setC3_KSQLDB_HTTPS=truewhen startingcp-demo:C3_KSQLDB_HTTPS=true ./scripts/start.sh
Elasticsearch and Kibana increase localhost memory requirements for
cp-demo. For users who want to runcp-demowith a smaller memory footprint, opt-out of these components by settingVIZ=falsewhen startingcp-demo.VIZ=false ./scripts/start.sh
After the start script completes, run through the pre-flight checks below and follow the guided tutorial through this on-premises deployment.
Pre-flight Checks
Before going through the tutorial, check that the environment has started correctly. If any of these pre-flight checks fails, consult the Troubleshooting the Scripted Confluent Platform Demo section.
Verify the status of the Docker containers show
Upstate.docker-compose psYour output should resemble:
Name Command State Ports ------------------------------------------------------------------------------------------------------------------------------------------------------------ connect bash -c sleep 10 && cp /us ... Up 0.0.0.0:8083->8083/tcp, 9092/tcp control-center /etc/confluent/docker/run Up (healthy) 0.0.0.0:9021->9021/tcp, 0.0.0.0:9022->9022/tcp elasticsearch /bin/bash bin/es-docker Up 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp kafka1 bash -c if [ ! -f /etc/kaf ... Up (healthy) 0.0.0.0:10091->10091/tcp, 0.0.0.0:11091->11091/tcp, 0.0.0.0:12091->12091/tcp, 0.0.0.0:8091->8091/tcp, 0.0.0.0:9091->9091/tcp, 9092/tcp kafka2 bash -c if [ ! -f /etc/kaf ... Up (healthy) 0.0.0.0:10092->10092/tcp, 0.0.0.0:11092->11092/tcp, 0.0.0.0:12092->12092/tcp, 0.0.0.0:8092->8092/tcp, 0.0.0.0:9092->9092/tcp kibana /bin/sh -c /usr/local/bin/ ... Up 0.0.0.0:5601->5601/tcp ksqldb-cli /bin/sh Up ksqldb-server /etc/confluent/docker/run Up (healthy) 0.0.0.0:8088->8088/tcp openldap /container/tool/run --copy ... Up 0.0.0.0:389->389/tcp, 636/tcp restproxy /etc/confluent/docker/run Up 8082/tcp, 0.0.0.0:8086->8086/tcp schemaregistry /etc/confluent/docker/run Up 8081/tcp, 0.0.0.0:8085->8085/tcp streams-demo /app/start.sh Up 9092/tcp tools /bin/bash Up zookeeper /etc/confluent/docker/run Up (healthy) 0.0.0.0:2181->2181/tcp, 2888/tcp, 3888/tcpJump to the end of the entire
cp-demopipeline and view the Kibana dashboard at http://localhost:5601/app/dashboards#/view/Overview . This is a cool view and validates that thecp-demostart script completed successfully.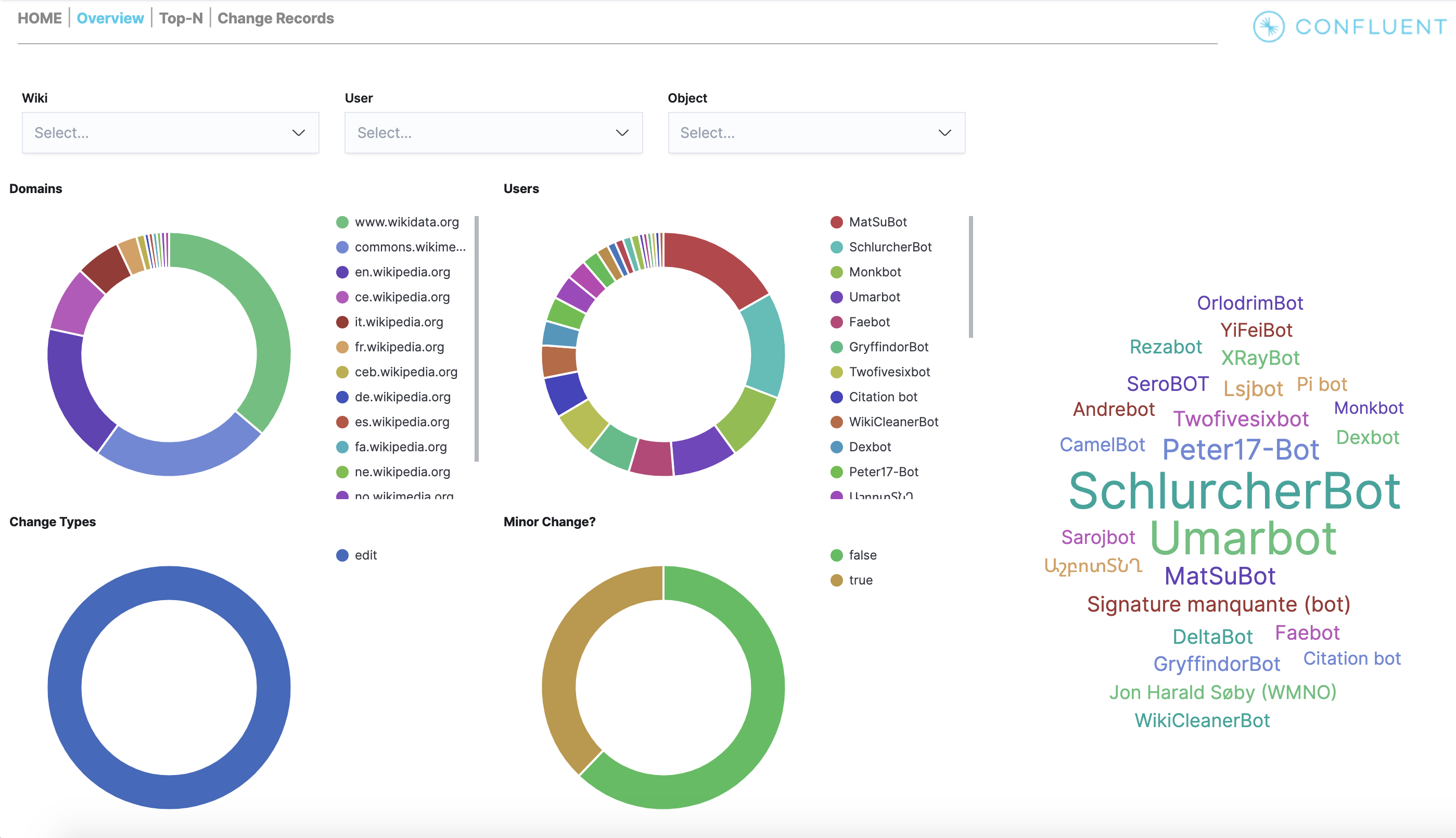
View the full Confluent Platform configuration in the docker-compose.yml file.
View the Kafka Streams application configuration in the client configuration file, set with security parameters to the Kafka cluster and Schema Registry.
Guided Tutorial
Log into Confluent Control Center (Legacy)
If you ran
cp-demowithC3_KSQLDB_HTTPS=false(which is the default), log into the Confluent Control Center (Legacy) GUI from a web browser at the following URL:http://localhost:9021
If you ran
cp-demowithC3_KSQLDB_HTTPS=true(not supported with Gitpod), log into the Confluent Control Center (Legacy) GUI from a web browser at the following URL:https://localhost:9022
The browser will detect a self-signed, untrusted certificate and certificate authority, and issue a privacy warning as shown below. To proceed, accept this certificate using your browser’s process for this, which will then last for the duration of that browser session.
Chrome: click on
Advancedand when the window expands, click onProceed to localhost (unsafe).
Safari: open a new private browsing window (
Shift + ⌘ + N), click onShow Detailsand when the window expands, click onvisit this website.
At the login screen, log into Confluent Control Center (Legacy) as
superUserand passwordsuperUser, which has super user access to the cluster. You may also log in as other users to learn how each user’s view changes depending on their permissions.
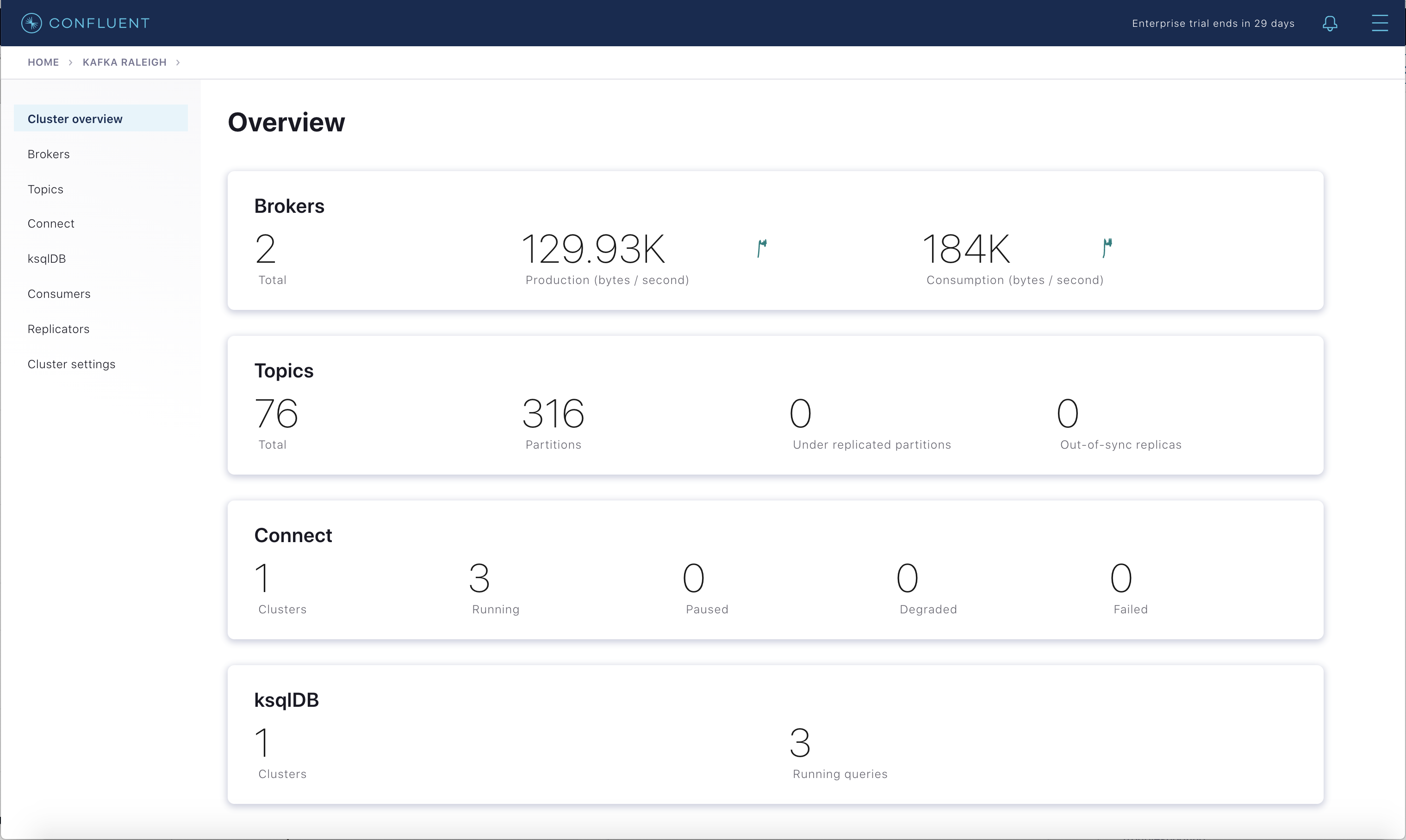
Brokers
Select the cluster named “Kafka Raleigh”.

Click on “Brokers”.
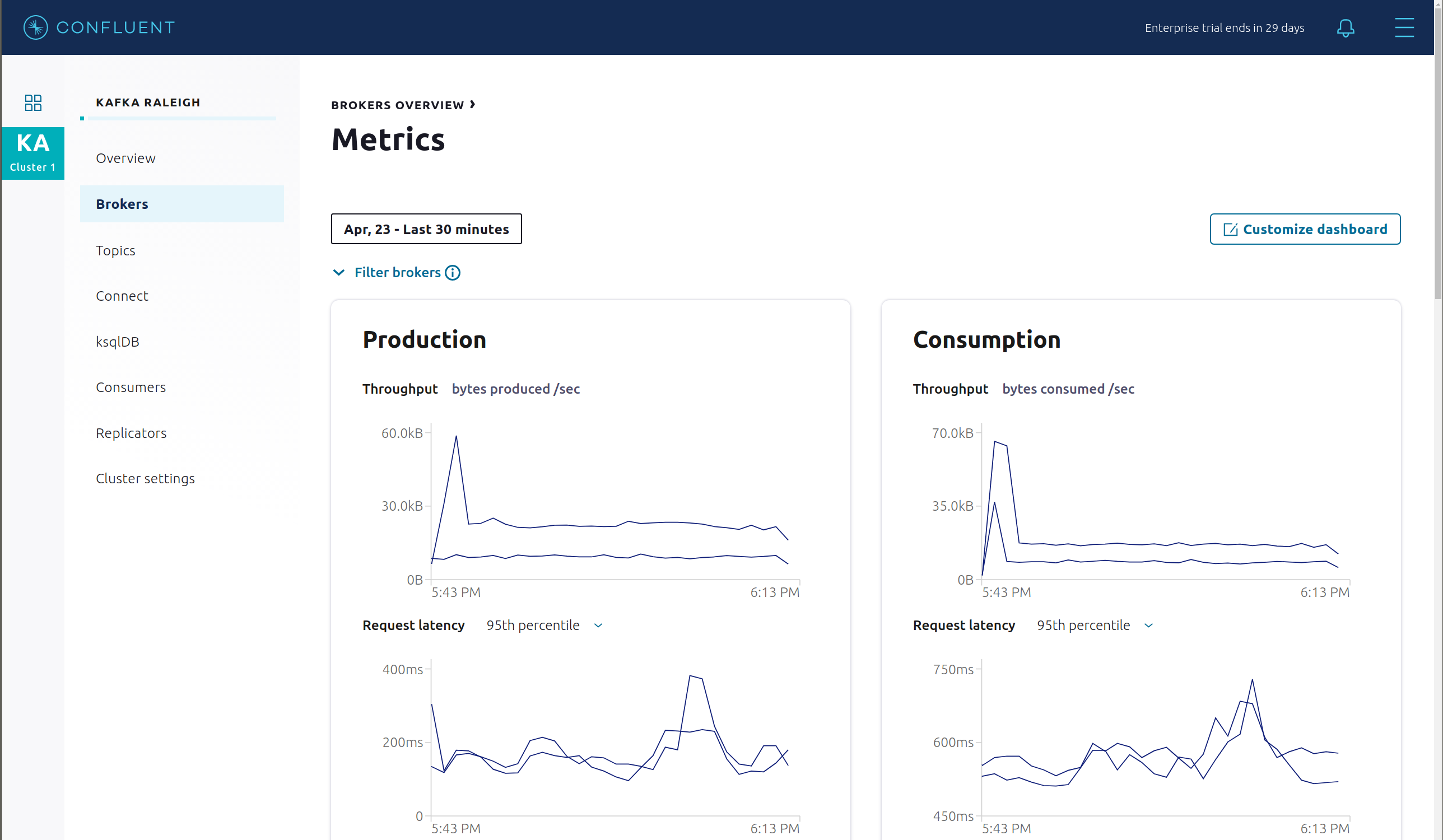
View the status of the brokers in the cluster:
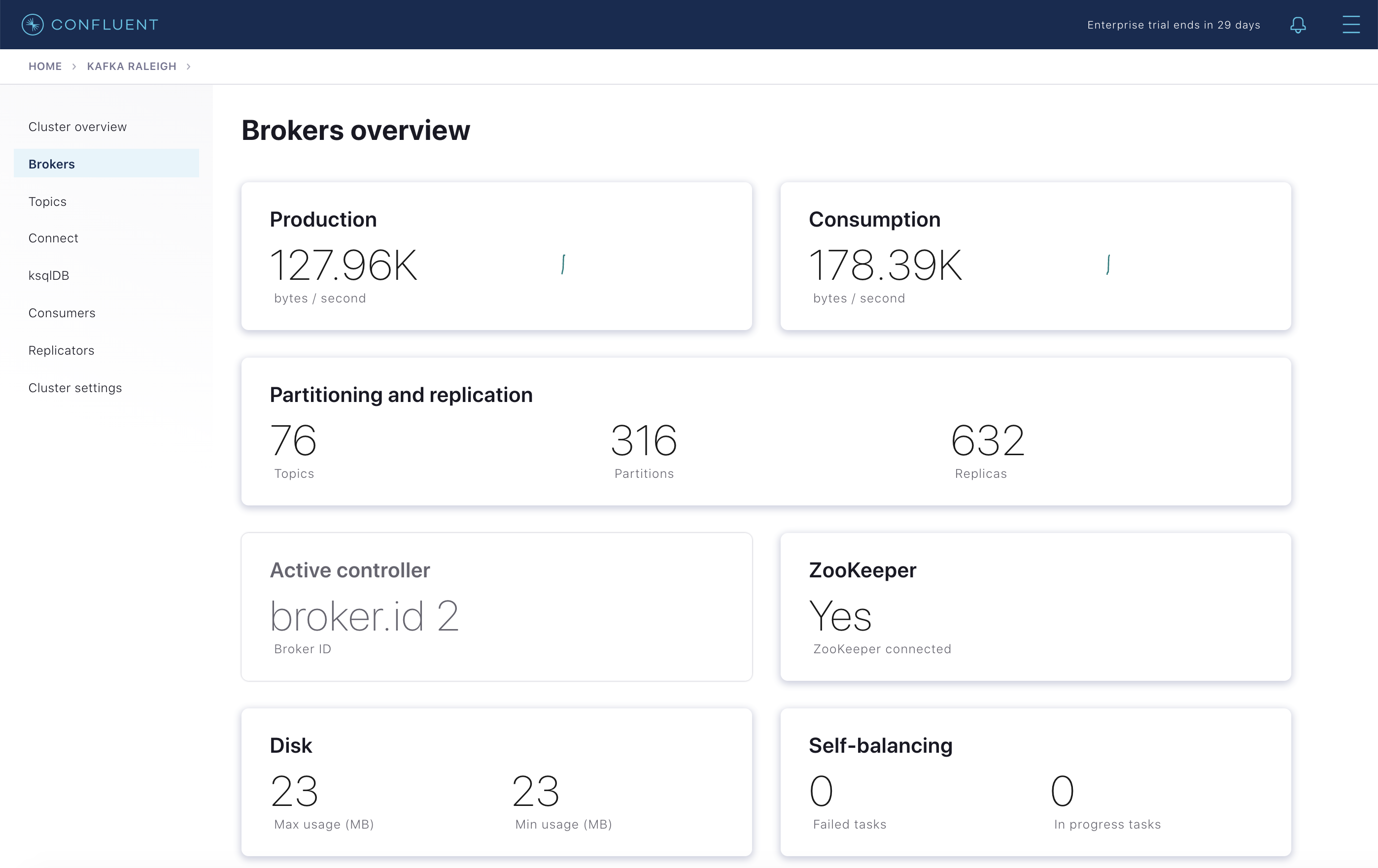
Click through on Production or Consumption to view: Production and Consumption metrics, Broker uptime, Partitions: online, under replicated, total replicas, out of sync replicas, Disk utilization, System: network pool usage, request pool usage.
Topics
Confluent Control Center (Legacy) can manage topics in a Kafka cluster. Click on “Topics”.
Scroll down and click on the topic
wikipedia.parsed.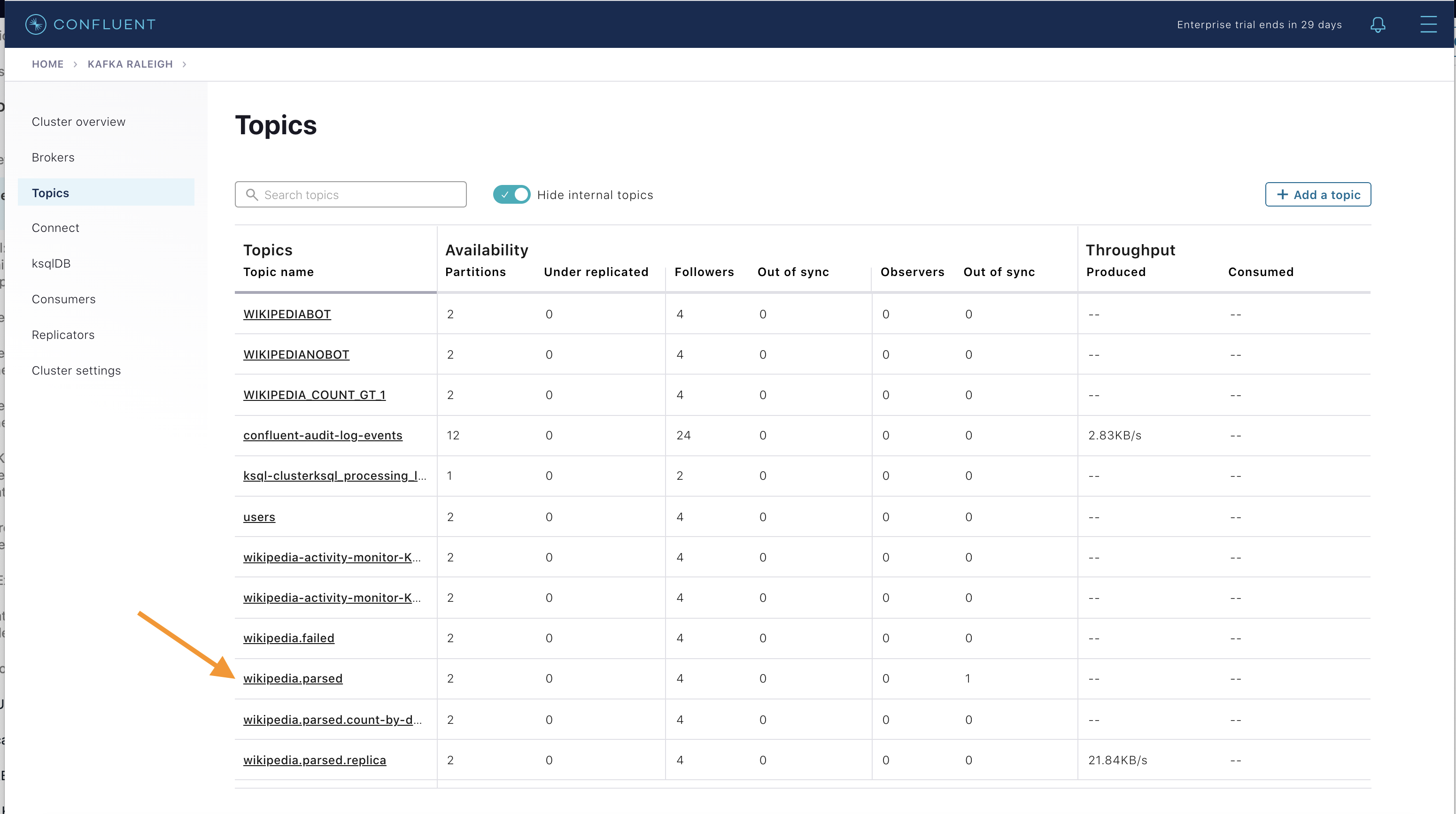
View an overview of this topic:
Throughput
Partition replication status
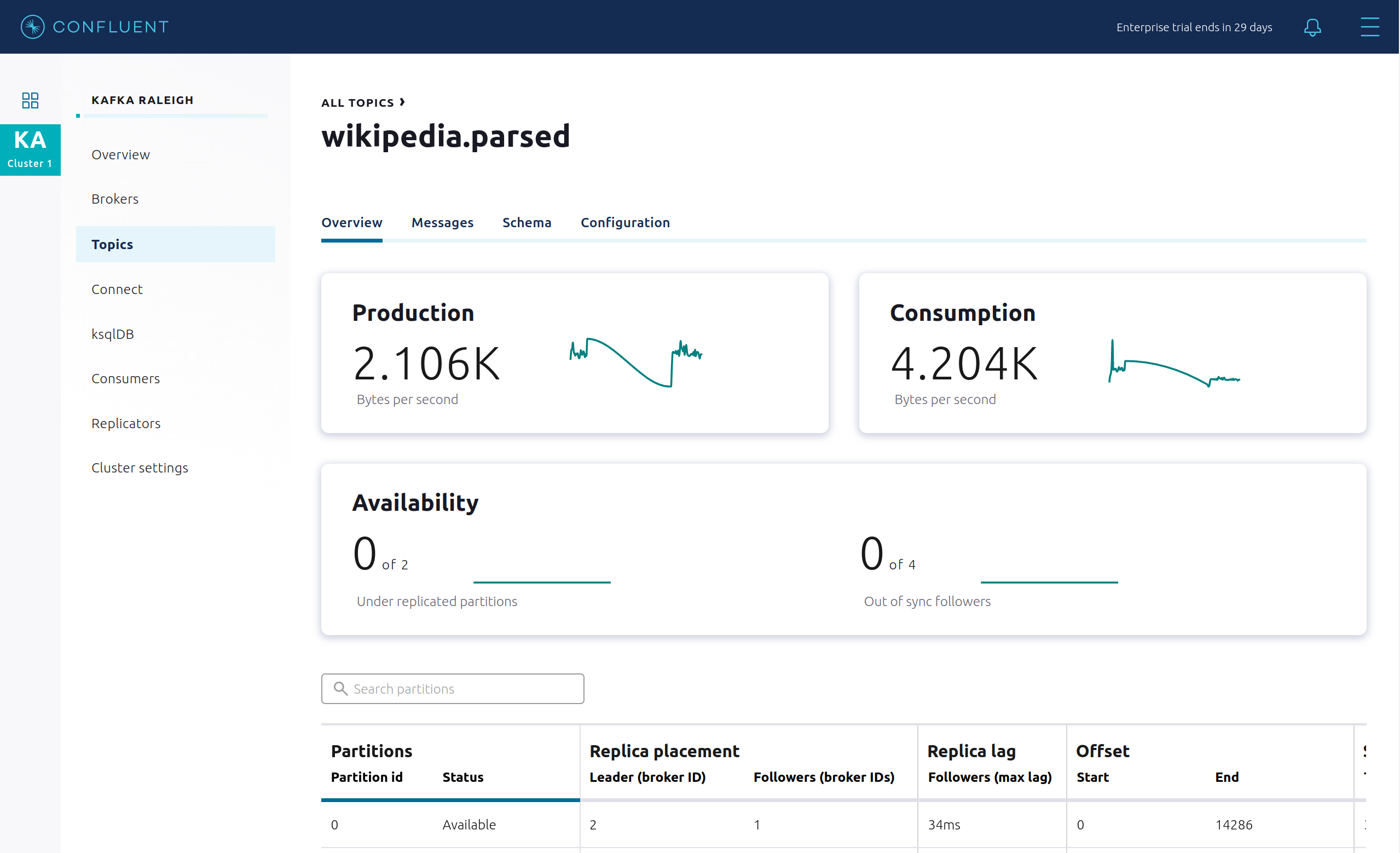
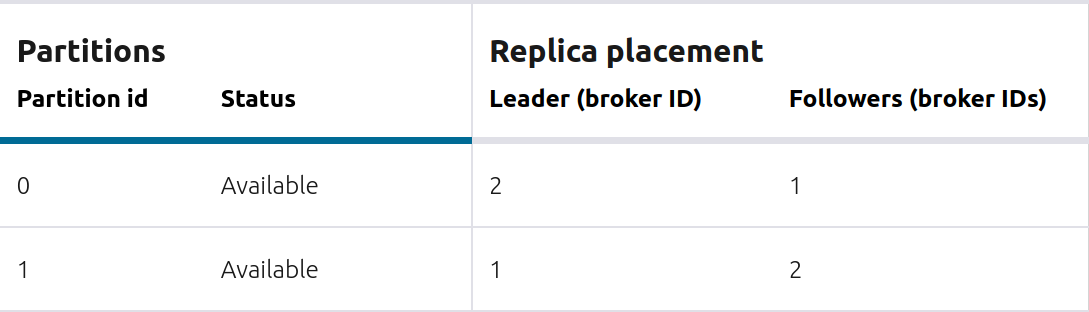
View which brokers are leaders for which partitions and where all partitions reside.
Inspect messages for this topic, in real-time.
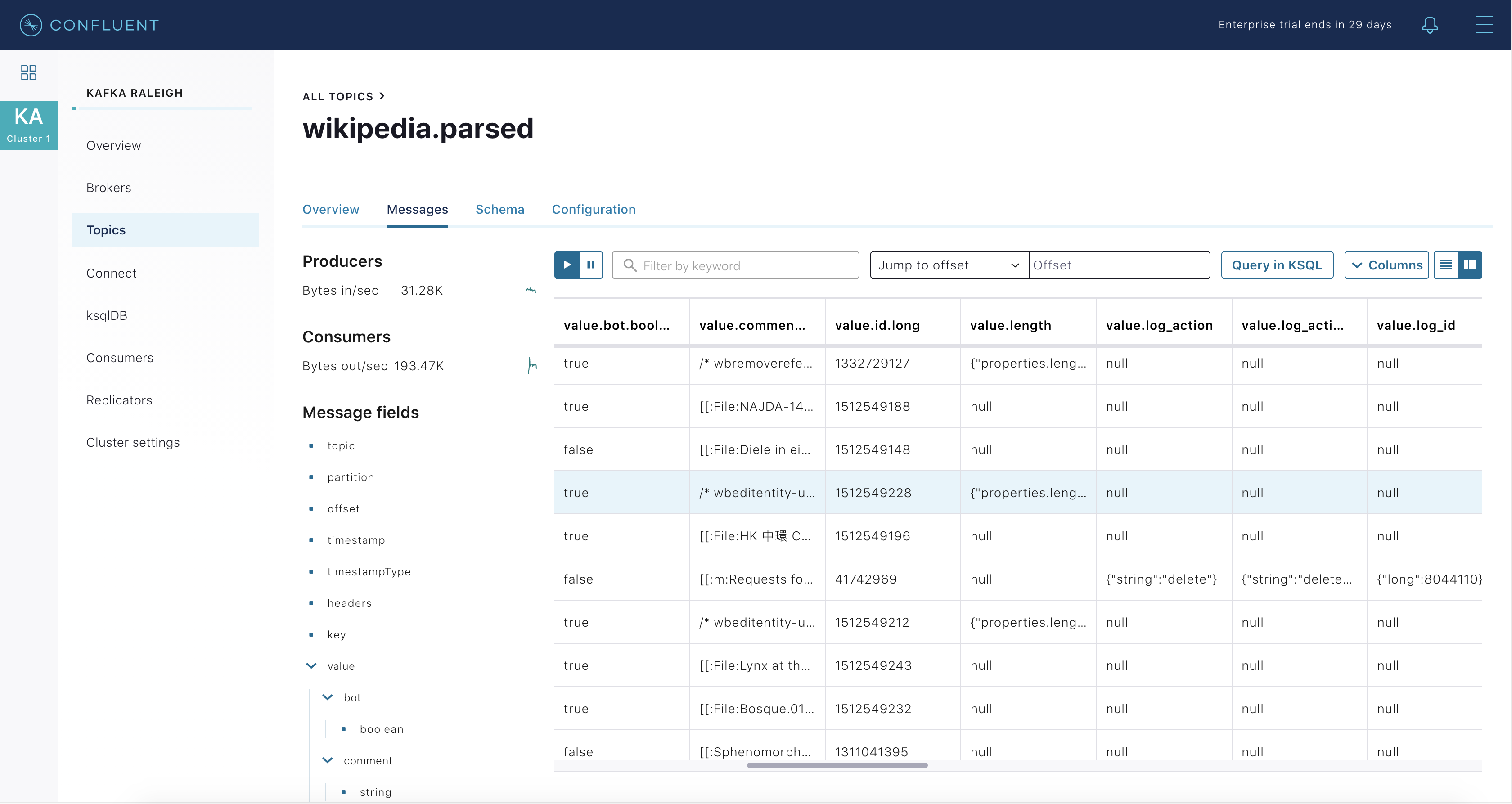
View the schema for this topic. For
wikipedia.parsed, the topic value is using a Schema registered with Schema Registry (the topic key is just a string).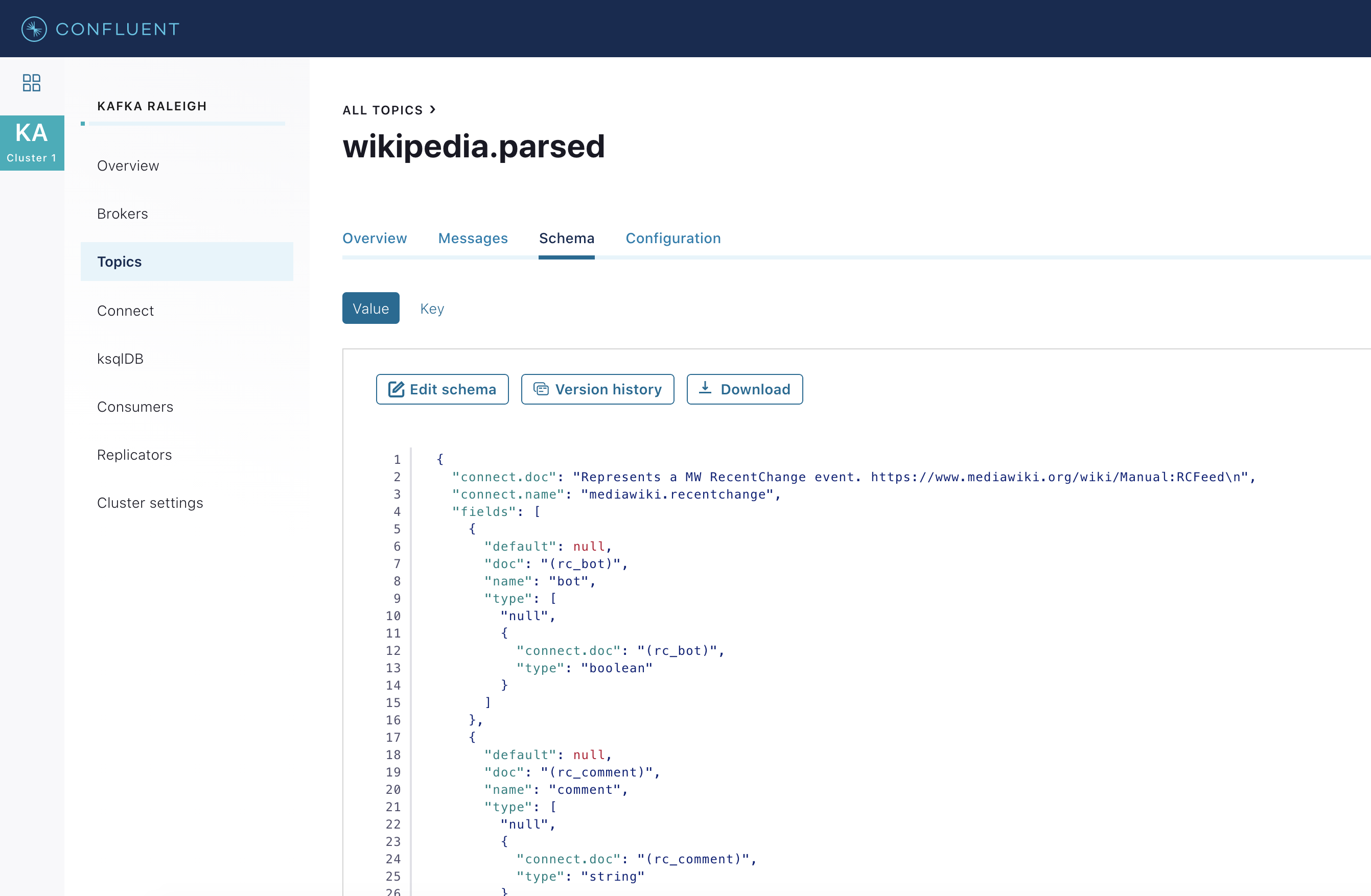
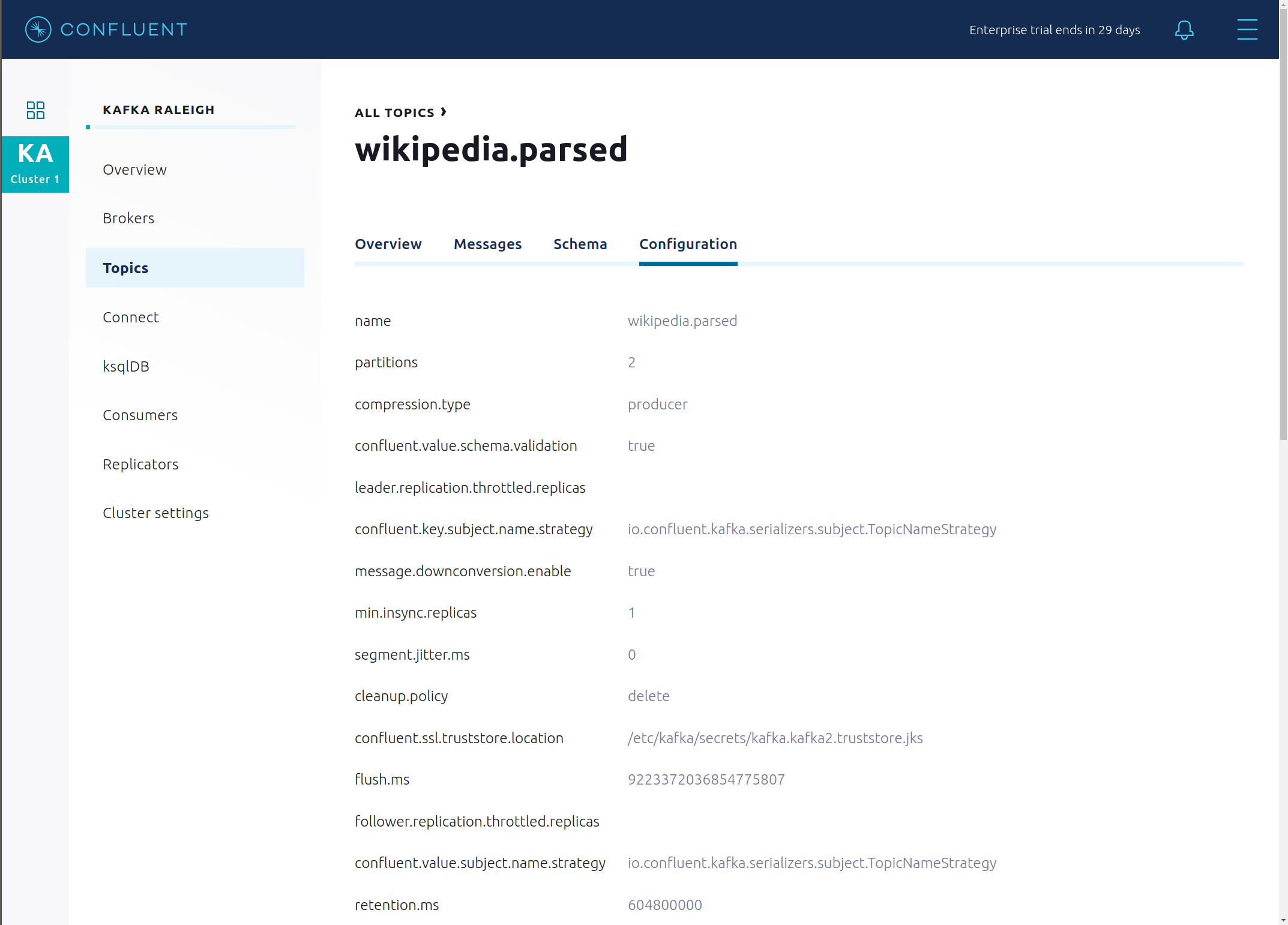
View configuration settings for this topic.
Return to “All Topics”, click on
wikipedia.parsed.count-by-domainto view the output topic from the Kafka Streams application.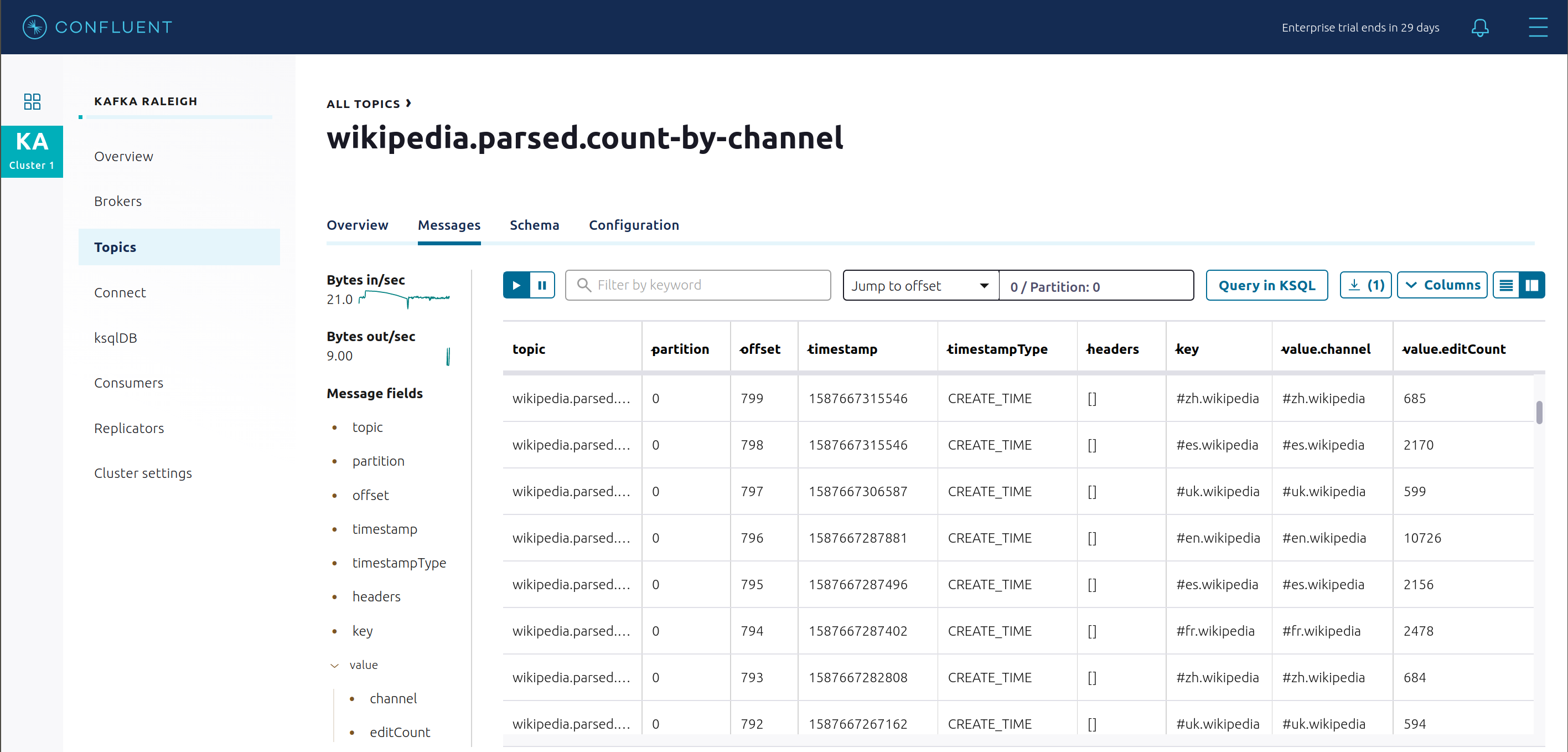
Return to the
All topicsview and click the + Add a topic button on the top right to create a new topic in your Kafka cluster. You can also view and edit settings of Kafka topics in the cluster. Read more on Confluent Control Center (Legacy) topic management.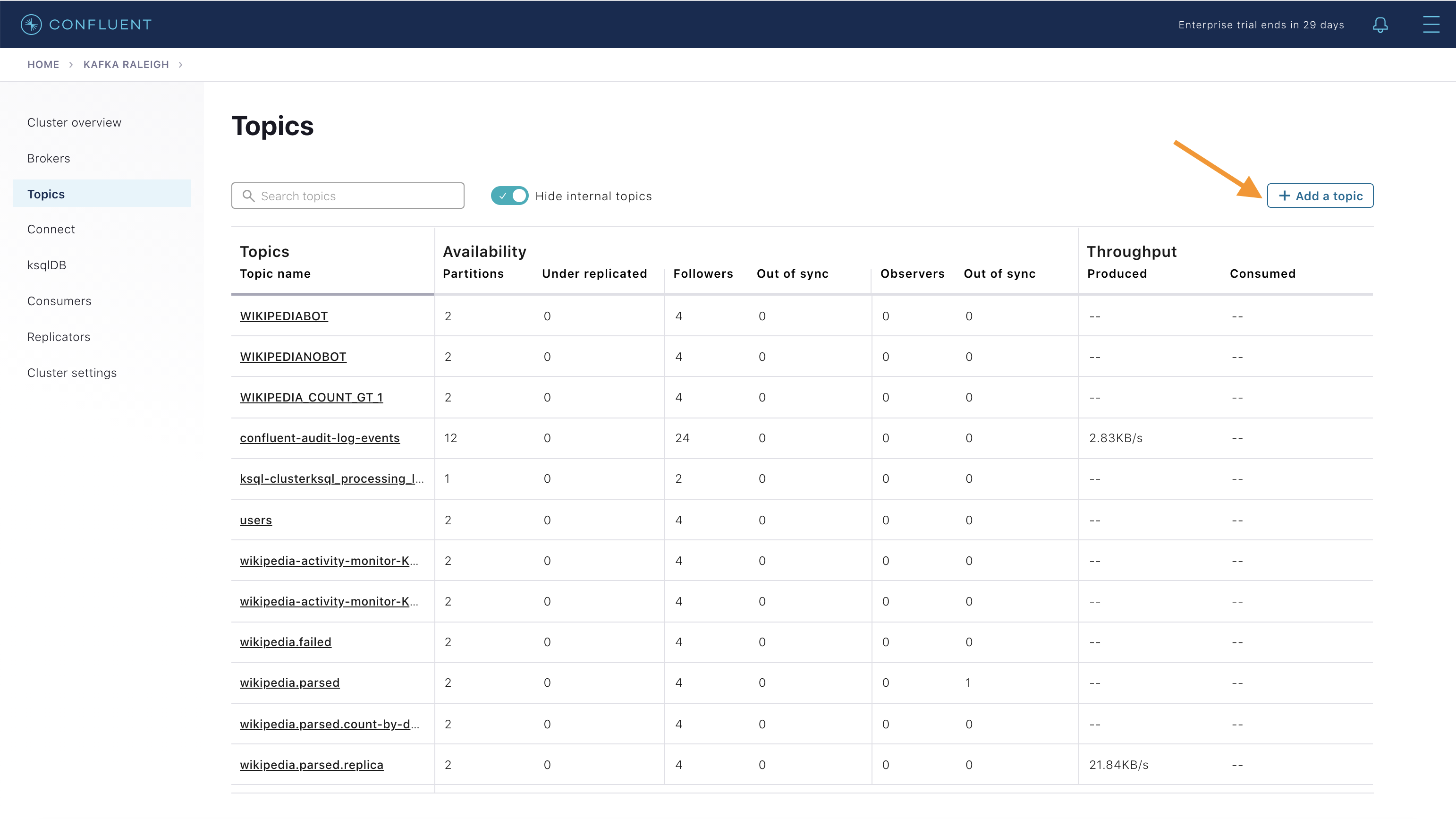
Kafka Connect
This example runs two connectors:
SSE source connector
Elasticsearch sink connector
They are running on a Connect worker that is configured with Confluent Platform security features. The Connect worker’s embedded producer is configured to be idempotent, exactly-once in order semantics per partition (in the event of an error that causes a producer retry, the same message—which is still sent by the producer multiple times—will only be written to the Kafka log on the broker once).
The Kafka Connect Docker container is running a custom image which has a specific set of connectors and transformations needed by
cp-demo. See this Dockerfile for more details.Confluent Control Center (Legacy) uses the Kafka Connect API to manage multiple connect clusters. Click on “Connect”.
Select
connect1, the name of the cluster of Connect workers.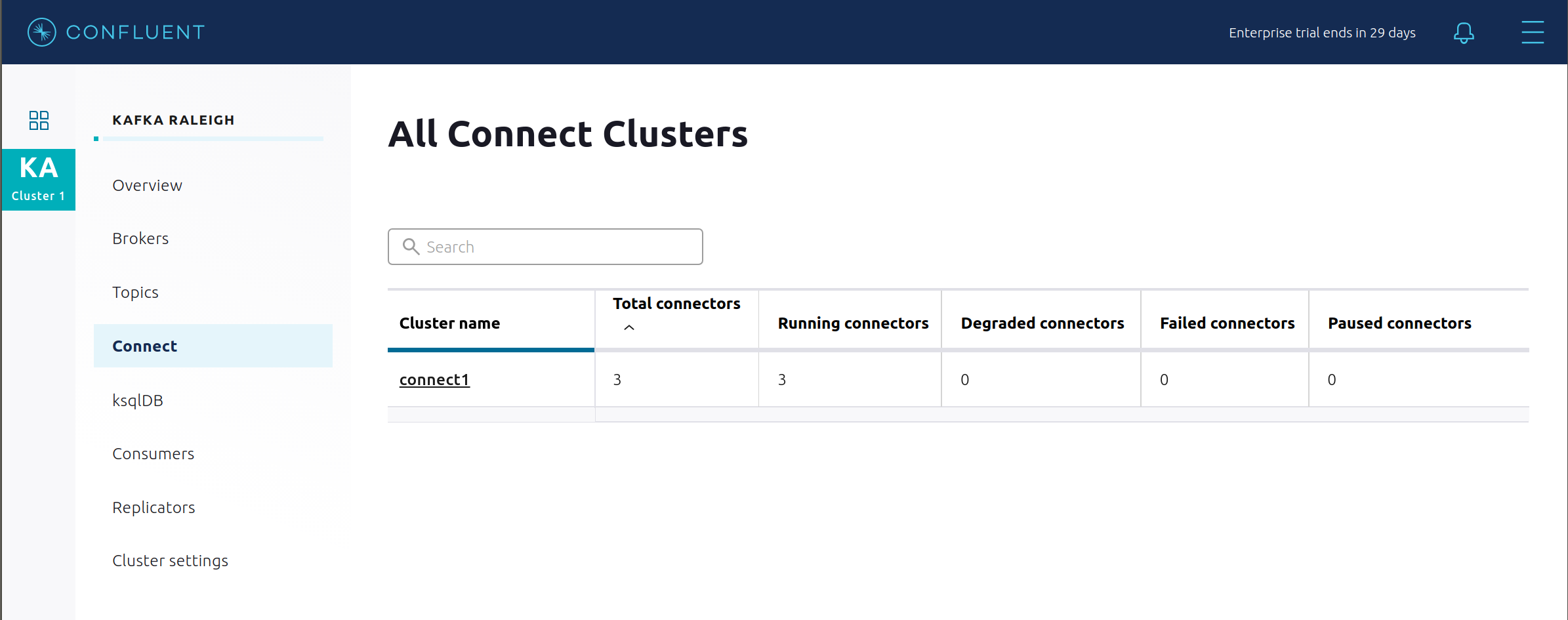
Verify the connectors running in this example:
source connector
wikipedia-sse: view the example’s SSE source connector configuration file.sink connector
elasticsearch-ksqldbconsuming from the Kafka topicWIKIPEDIABOT: view the example’s Elasticsearch sink connector configuration file.
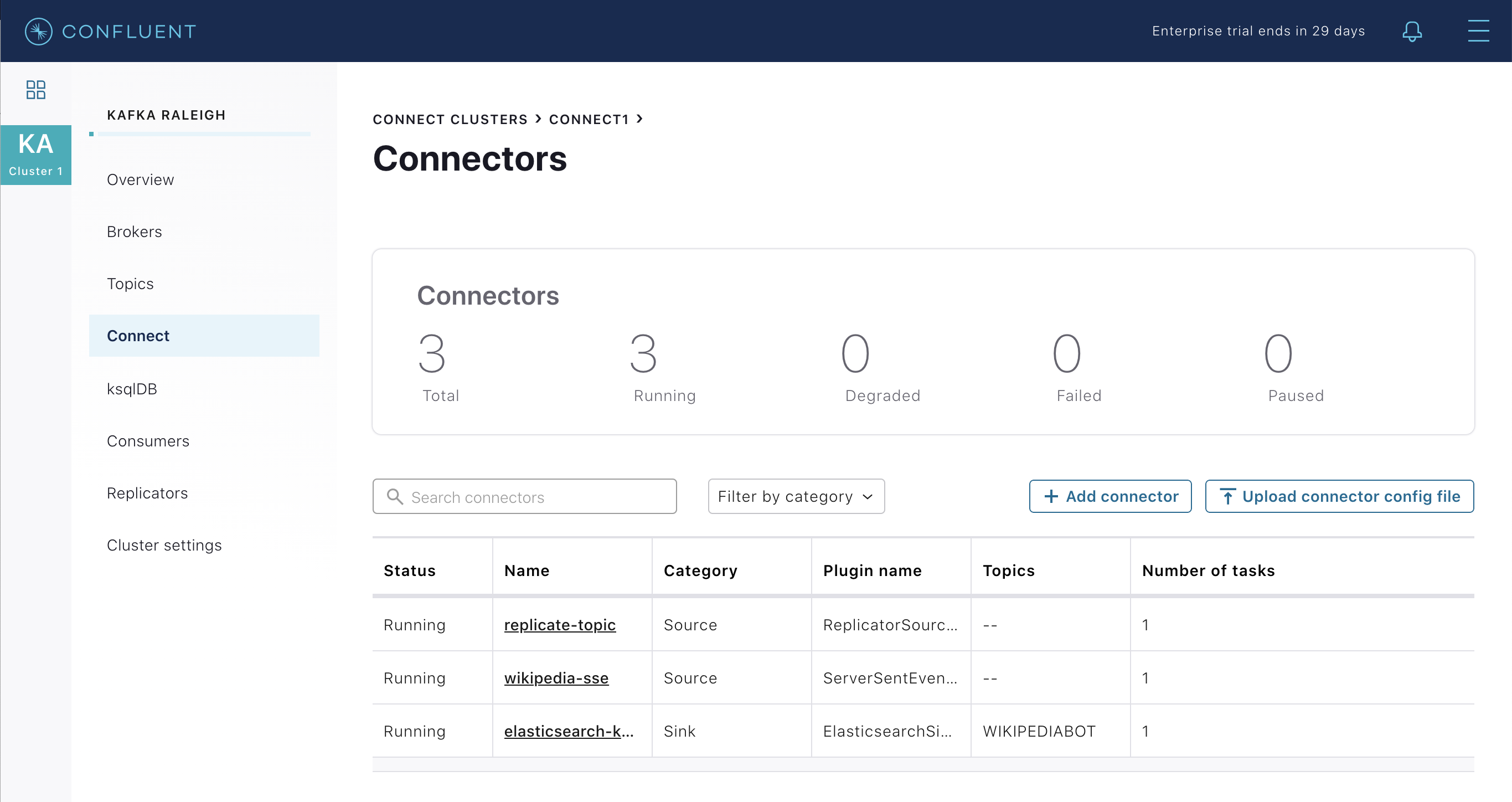
Click any connector name to view or modify any details of the connector configuration and custom transforms.
ksqlDB
In this example, ksqlDB is authenticated and authorized to connect to the secured Kafka cluster, and it is already running queries as defined in the ksqlDB command file. Its embedded producer is configured to be idempotent, exactly-once in order semantics per partition (in the event of an error that causes a producer retry, the same message—which is still sent by the producer multiple times—will only be written to the Kafka log on the broker once).
In the navigation bar, click ksqlDB.
From the list of ksqlDB applications, select
wikipedia.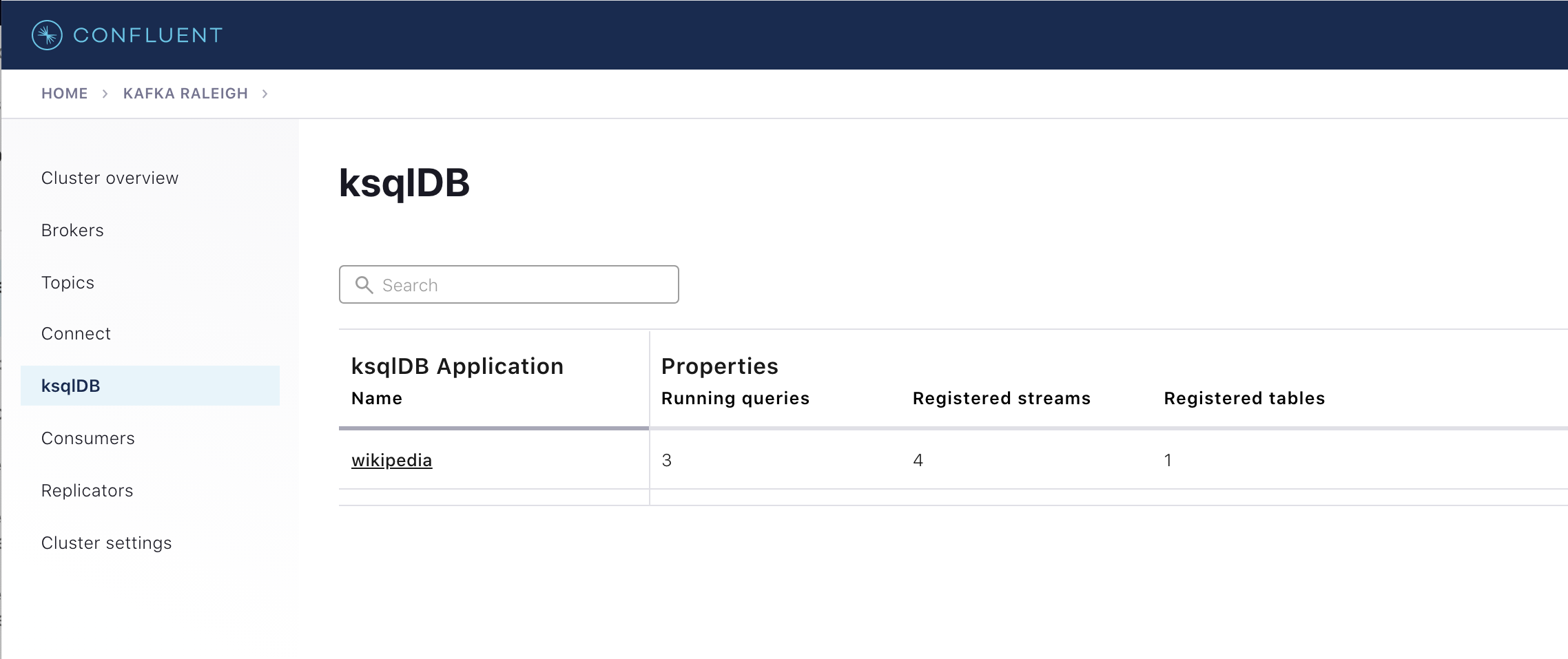
View the ksqlDB Flow to see the streams and tables created in the example, and how they relate to one another.
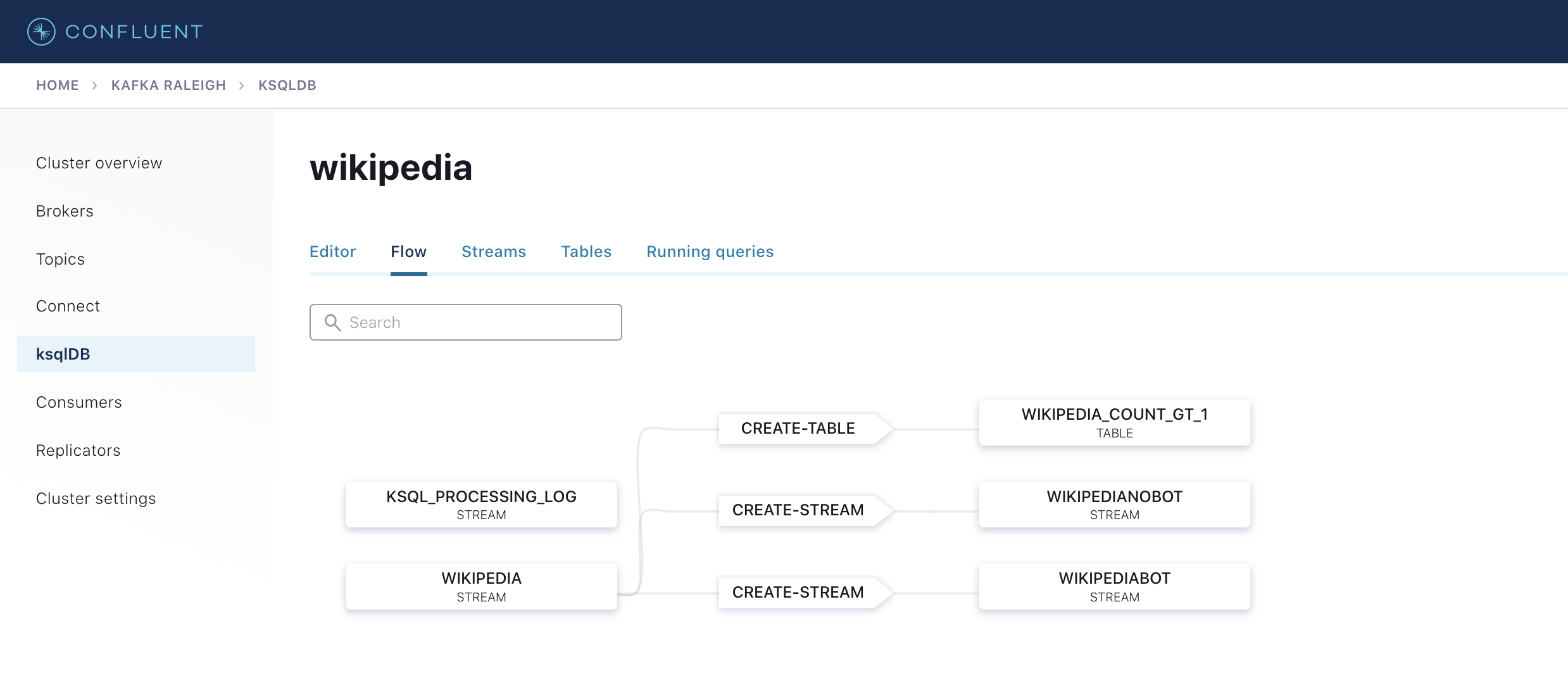
Use Confluent Control Center (Legacy) to interact with ksqlDB, or run ksqlDB CLI to get to the ksqlDB CLI prompt.
docker-compose exec ksqldb-cli bash -c 'ksql -u ksqlDBUser -p ksqlDBUser http://ksqldb-server:8088'
View the existing ksqlDB streams. (If you are using the ksqlDB CLI, at the
ksql>prompt typeSHOW STREAMS;)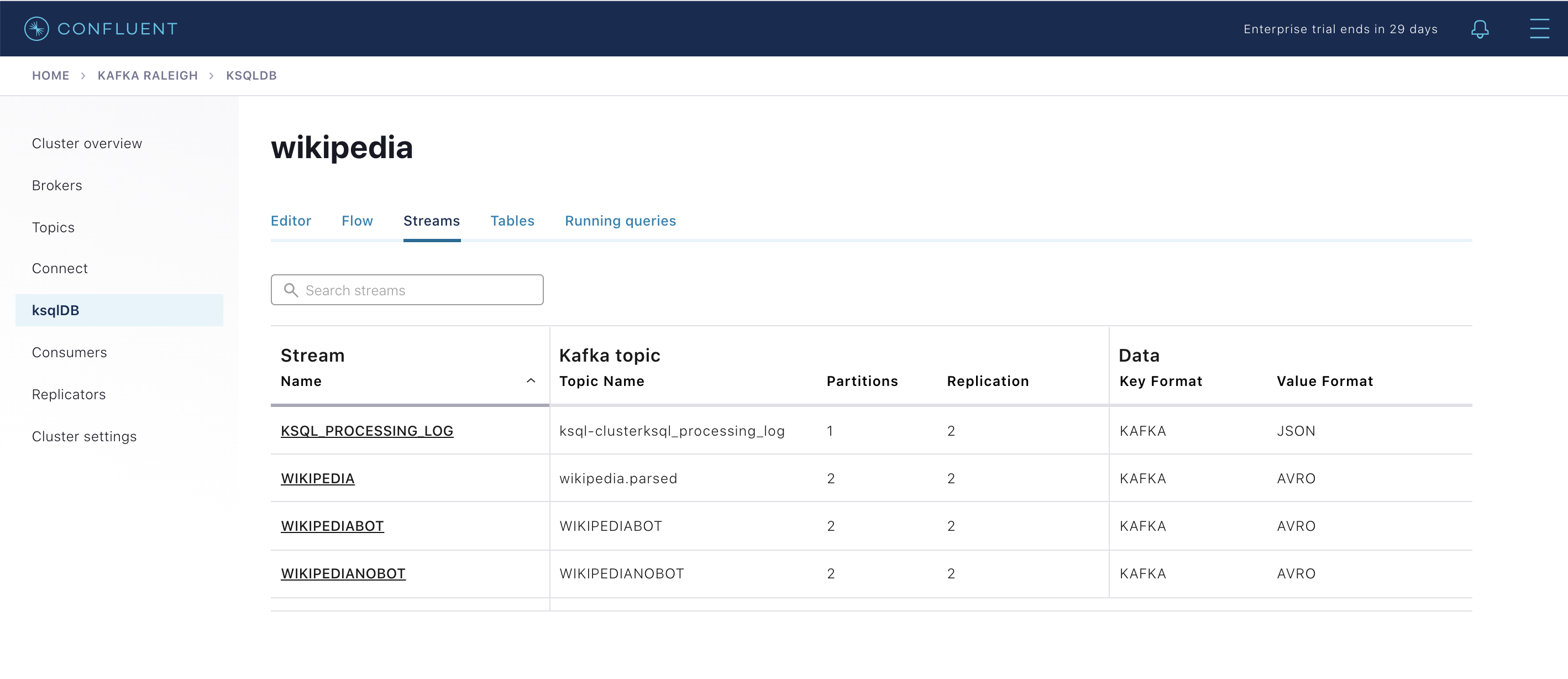
Click on
WIKIPEDIAto describe the schema (fields or columns) of an existing ksqlDB stream. (If you are using the ksqlDB CLI, at theksql>prompt typeDESCRIBE WIKIPEDIA;)
View the existing ksqlDB tables. (If you are using the ksqlDB CLI, at the
ksql>prompt typeSHOW TABLES;). One table is calledWIKIPEDIA_COUNT_GT_1, which counts occurrences within a tumbling window.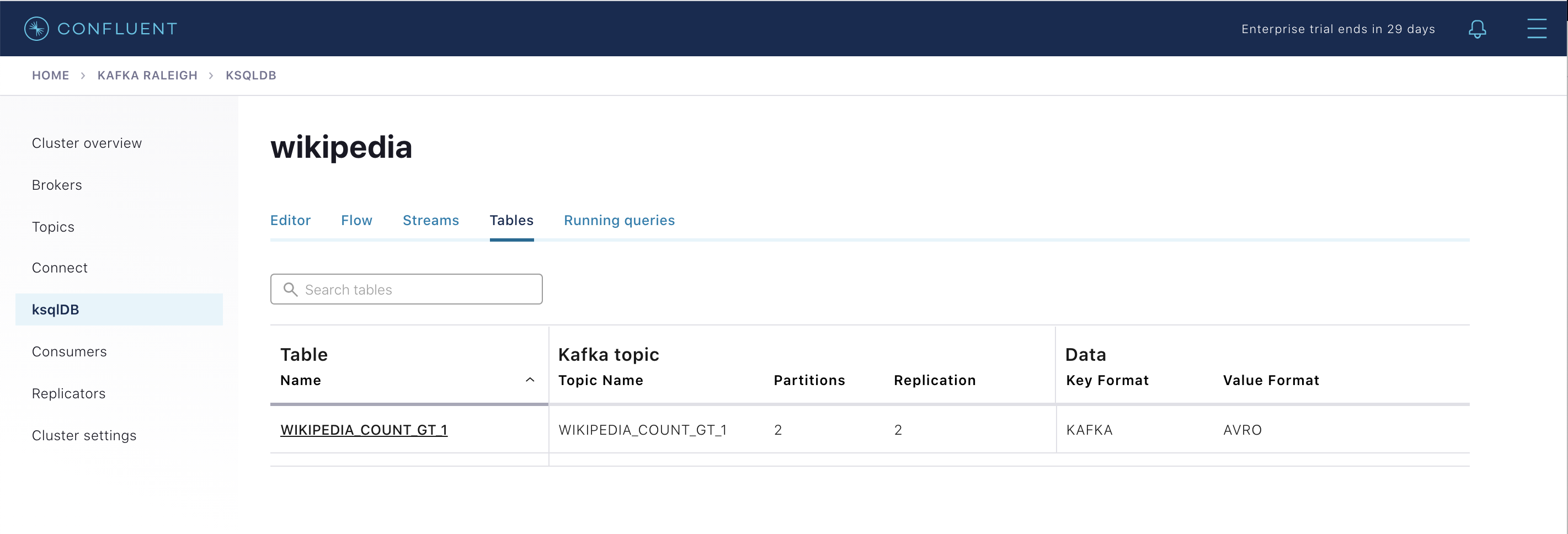
View the existing ksqlDB queries, which are continuously running. (If you are using the ksqlDB CLI, at the
ksql>prompt typeSHOW QUERIES;).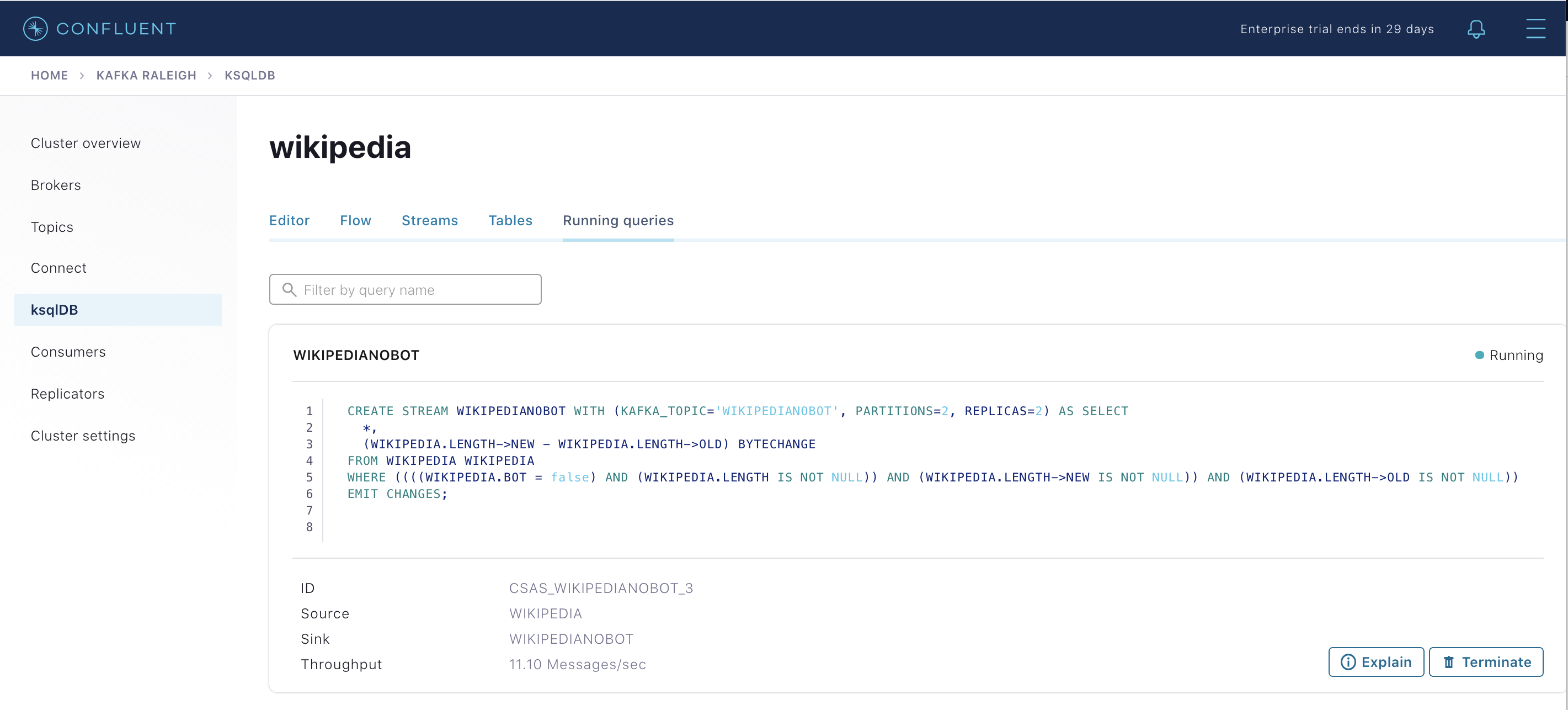
View messages from different ksqlDB streams and tables. Click on your stream of choice and then click Query stream to open the Query Editor. The editor shows a pre-populated query, like
select * from WIKIPEDIA EMIT CHANGES;, and it shows results for newly arriving data.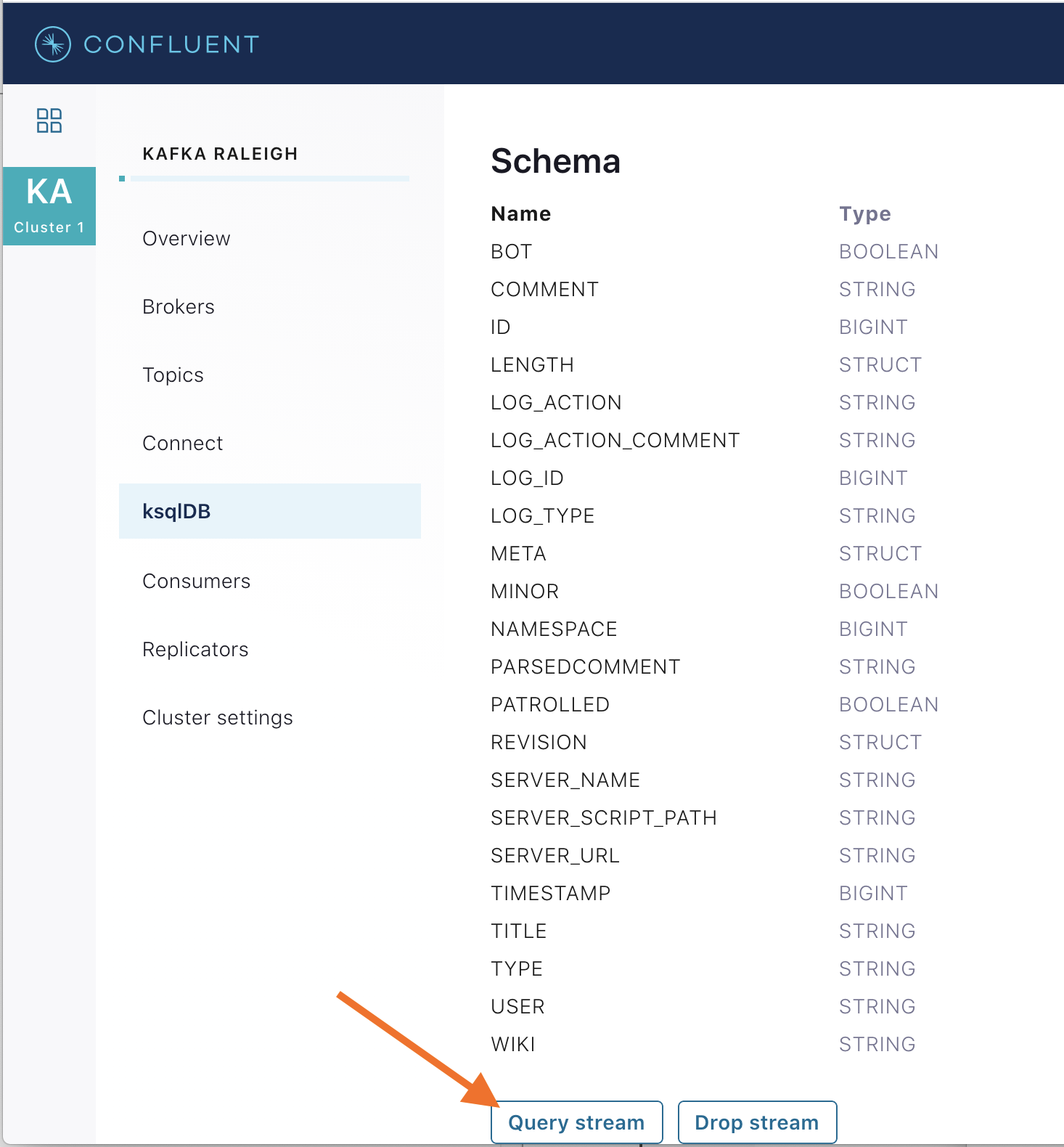
Click ksqlDB Editor and run the
SHOW PROPERTIES;statement. You can see the configured ksqlDB server properties and check these values with the docker-compose.yml file.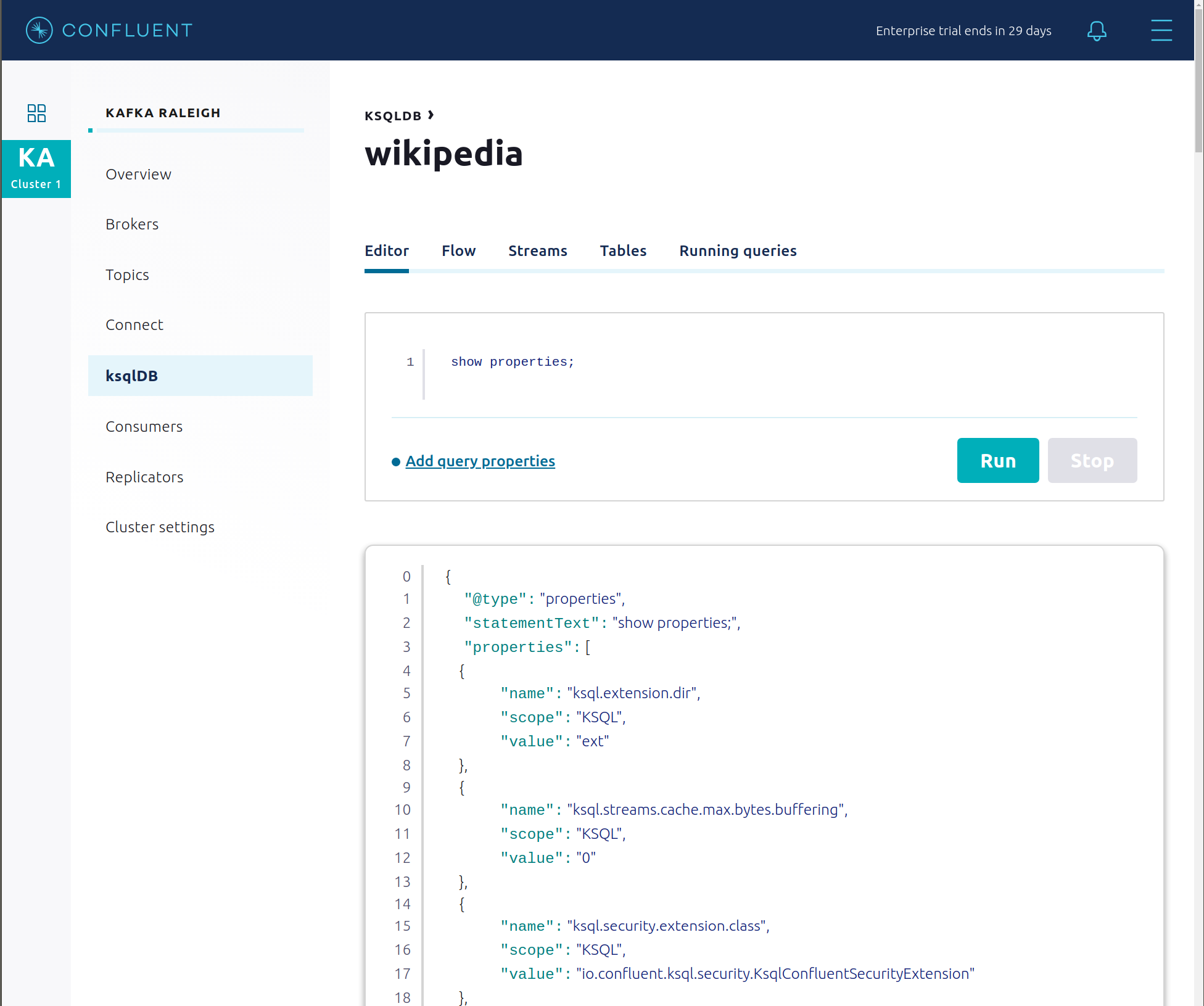
The ksqlDB processing log captures per-record errors during processing to help developers debug their ksqlDB queries. In this example, the processing log uses mutual TLS (mTLS) authentication, as configured in the custom log4j properties file, to write entries into a Kafka topic. To see it in action, in the ksqlDB editor run the following “bad” query for 20 seconds:
SELECT 1/0 FROM wikipedia EMIT CHANGES;
No records should be returned from this query. ksqlDB writes errors into the processing log for each record. View the processing log topic
ksql-clusterksql_processing_logwith topic inspection (jump to offset 0/partition 0) or the corresponding ksqlDB streamKSQL_PROCESSING_LOGwith the ksqlDB editor (setauto.offset.reset=earliest).SELECT * FROM KSQL_PROCESSING_LOG EMIT CHANGES;
Consumers
Confluent Control Center (Legacy) enables you to monitor consumer lag and throughput performance. Consumer lag is the topic’s high water mark (latest offset for the topic that has been written) minus the current consumer offset (latest offset read for that topic by that consumer group). Keep in mind the topic’s write rate and consumer group’s read rate when you consider the significance the consumer lag’s size. Click on “Consumers”.
Consumer lag is available on a per-consumer basis, including the embedded Connect consumers for sink connectors (e.g.,
connect-elasticsearch-ksqldb), ksqlDB queries (e.g., consumer groups whose names start with_confluent-ksql-ksql-clusterquery_), console consumers (e.g.,WIKIPEDIANOBOT-consumer), etc. Consumer lag is also available on a per-topic basis.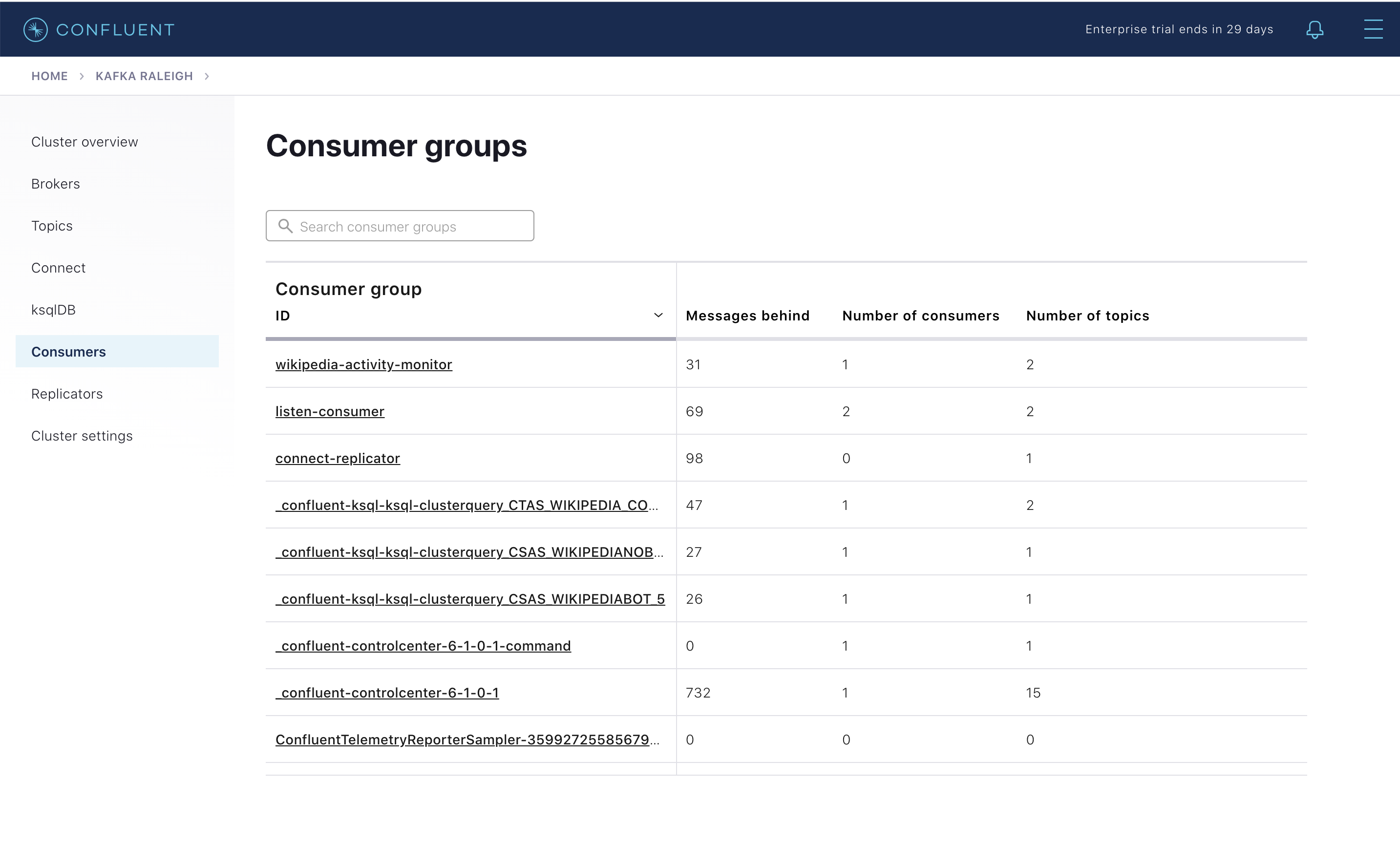
View consumer lag for the persistent ksqlDB “Create Stream As Select” query
CSAS_WIKIPEDIABOT, which is displayed as_confluent-ksql-ksql-clusterquery_CSAS_WIKIPEDIABOT_5in the consumer group list.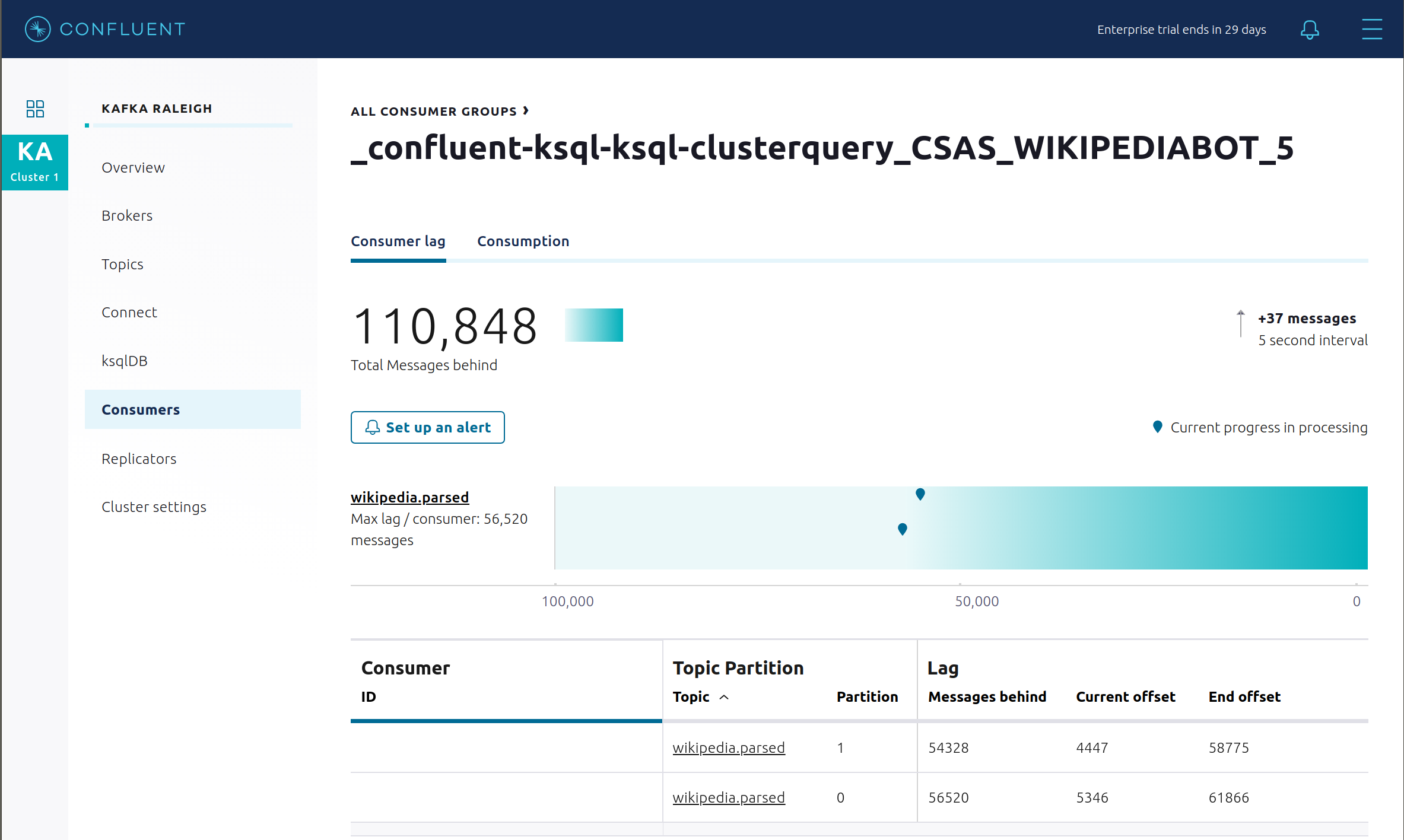
View consumer lag for the Kafka Streams application under the consumer group id
wikipedia-activity-monitor. This application is run by the cnfldemos/cp-demo-kstreams Docker container (application source code). The Kafka Streams application is configured to connect to the Kafka cluster with the following client configuration file.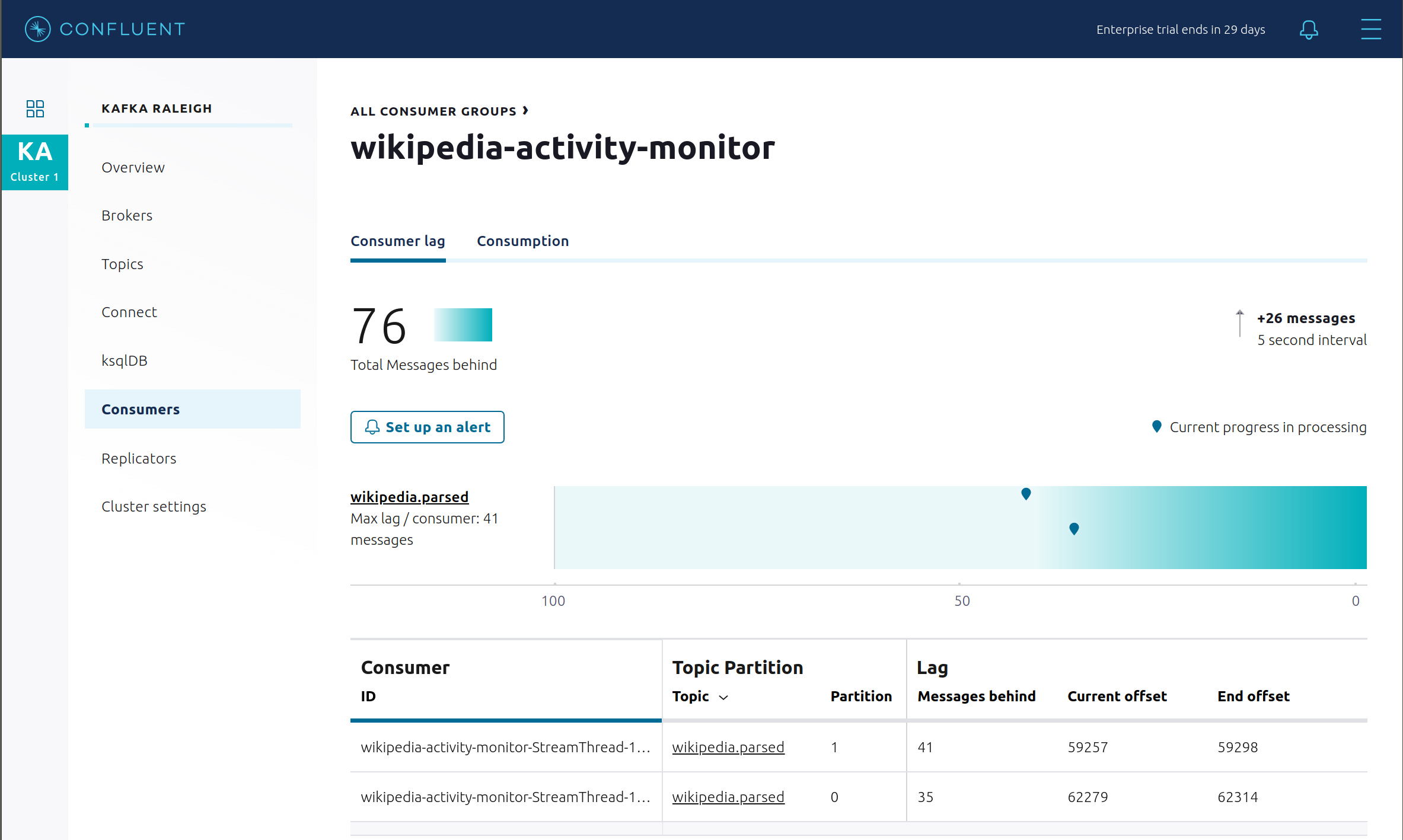
Consumption metrics are available on a per-consumer basis. These consumption charts are only populated if Confluent Monitoring Interceptors are configured, as they are in this example. You can view
% messages consumedandend-to-end latency. View consumption metrics for the persistent ksqlDB “Create Stream As Select” queryCSAS_WIKIPEDIABOT, which is displayed as_confluent-ksql-ksql-clusterquery_CSAS_WIKIPEDIABOT_5in the consumer group list.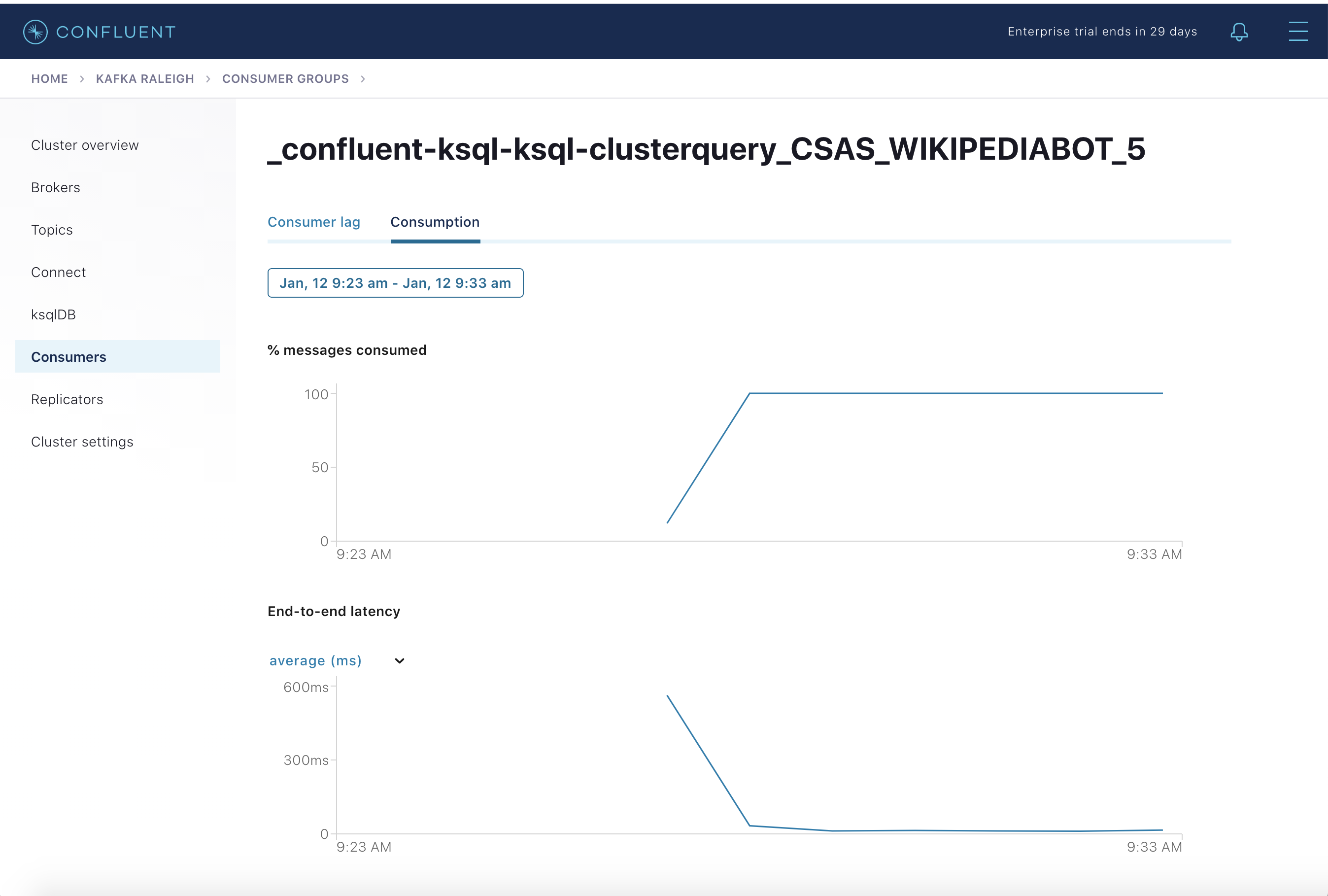
Confluent Control Center (Legacy) shows which consumers in a consumer group are consuming from which partitions and on which brokers those partitions reside. Confluent Control Center (Legacy) updates as consumer rebalances occur in a consumer group. Start consuming from topic
wikipedia.parsedwith a new consumer groupappwith one consumerconsumer_app_1. It runs in the background../scripts/app/start_consumer_app.sh 1
Let this consumer group run for 2 minutes until Confluent Control Center (Legacy) shows the consumer group
appwith steady consumption. This consumer groupapphas a single consumerconsumer_app_1consuming all of the partitions in the topicwikipedia.parsed.
Add a second consumer
consumer_app_2to the existing consumer groupapp../scripts/app/start_consumer_app.sh 2
Let this consumer group run for 2 minutes until Confluent Control Center (Legacy) shows the consumer group
appwith steady consumption. Notice that the consumersconsumer_app_1andconsumer_app_2now share consumption of the partitions in the topicwikipedia.parsed.
From the Brokers -> Consumption view, click on a point in the Request latency line graph to view a breakdown of latencies through the entire request lifecycle.
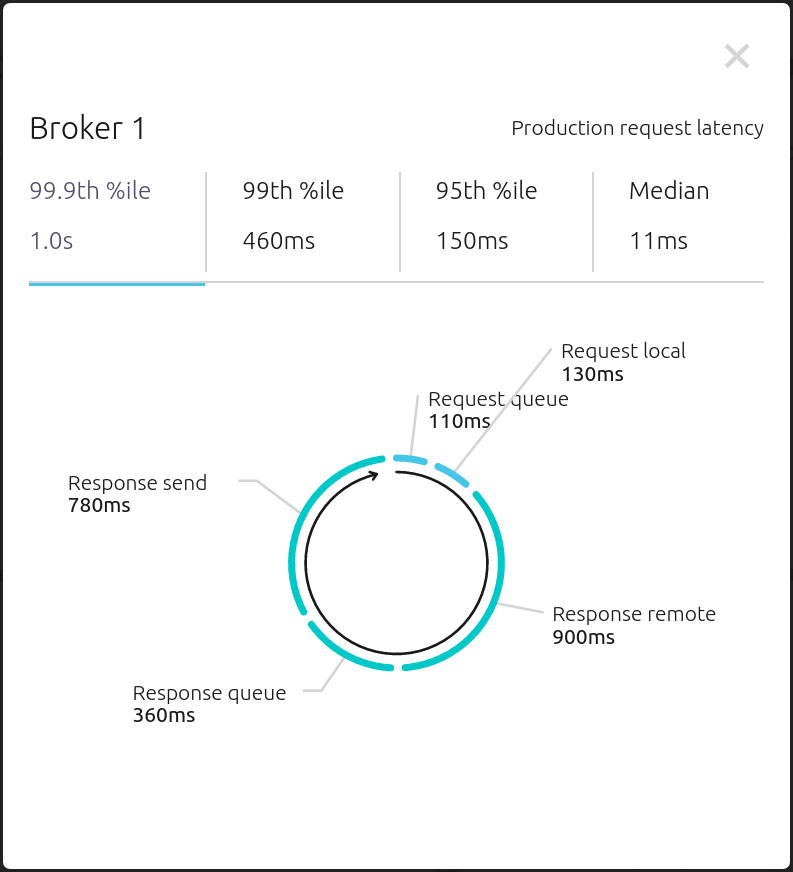
Security
Overview
All components and clients in cp-demo make full use of Confluent Platform’s extensive security features.
Role-Based Access Control (RBAC) for authorization. Give principals access to resources using role-bindings.
Note
RBAC is powered by the Metadata Service (MDS) which uses Confluent Server Authorizer to connect to an OpenLDAP directory service. This enables group-based authorization for scalable access management.
SSL for encryption and mTLS for authentication. The example automatically generates SSL certificates and creates keystores, truststores, and secures them with a password.
ZooKeeper is configured with mTLS and SASL/DIGEST-MD5 authentication.
You can see each component’s security configuration in the example’s docker-compose.yml file.
Note
This example showcases a secure Confluent Platform for educational purposes and is not meant to be complete best practices. There are certain differences between what is shown in the example and what you should do in production:
Authorize users only for operations that they need, instead of making all of them super users
If the
PLAINTEXTsecurity protocol is used, theseANONYMOUSusernames should not be configured as super usersConsider not even opening the
PLAINTEXTport ifSSLorSASL_SSLare configured
ZooKeeper has two listener ports:
Name | Protocol | In this example, used for … | ZooKeeper |
|---|---|---|---|
N/A | SASL/DIGEST-MD5 | Validating trial license for REST Proxy and Schema Registry. (no TLS support) | 2181 |
N/A | mTLS | Broker communication (kafka1, kafka2) | 2182 |
Each broker has five listener ports:
Name | Protocol | In this example, used for … | kafka1 | kafka2 |
|---|---|---|---|---|
N/A | MDS | Authorization via RBAC | 8091 | 8092 |
INTERNAL | SASL_PLAINTEXT | CP Kafka clients (e.g. Confluent Metrics Reporter), SASL_PLAINTEXT | 9091 | 9092 |
TOKEN | SASL_SSL | Confluent Platform service (e.g. Schema Registry) when they need to use impersonation | 10091 | 10092 |
SSL | SSL | End clients, (e.g. stream-demo), with SSL no SASL | 11091 | 11092 |
CLEAR | PLAINTEXT | No security, available as a backdoor; for demo and learning only | 12091 | 12092 |
End clients (non-CP clients):
Authenticate using mTLS via the broker SSL listener.
If they are also using Schema Registry, authenticate to Schema Registry via LDAP.
If they are also using Confluent Monitoring interceptors, authenticate using mTLS via the broker SSL listener.
Should never use the TOKEN listener which is meant only for internal communication between Confluent components.
If you wish to authenticate clients with username and password via LDAP, you would create a new SASL PLAIN client listener with Confluent’s LdapAuthenticateCallbackHandler. This is omitted from the demo for simplicity.
See client configuration used in the example by the
streams-democontainer running the Kafka Streams applicationwikipedia-activity-monitor.
Broker Listeners
Verify the ports on which the Kafka brokers are listening with the following command, and they should match the table shown below:
docker-compose logs kafka1 | grep "Registered broker 1" docker-compose logs kafka2 | grep "Registered broker 2"
For example only: Communicate with brokers via the PLAINTEXT port, client security configurations are not required
# CLEAR/PLAINTEXT port docker-compose exec kafka1 kafka-consumer-groups \ --list \ --bootstrap-server kafka1:12091
End clients: Communicate with brokers via the SSL port, and SSL parameters configured via the
--command-configargument for command line tools or--consumer.configfor kafka-console-consumer.# SSL/SSL port docker-compose exec kafka1 kafka-consumer-groups \ --list \ --bootstrap-server kafka1:11091 \ --command-config /etc/kafka/secrets/client_without_interceptors_ssl.config
If a client tries to communicate with brokers via the SSL port but does not specify the SSL parameters, it fails
# SSL/SSL port docker-compose exec kafka1 kafka-consumer-groups \ --list \ --bootstrap-server kafka1:11091
Your output should resemble:
ERROR Uncaught exception in thread 'kafka-admin-client-thread | adminclient-1': (org.apache.kafka.common.utils.KafkaThread) java.lang.OutOfMemoryError: Java heap space ...
Communicate with brokers via the SASL_PLAINTEXT port, and SASL_PLAINTEXT parameters configured via the
--command-configargument for command line tools or--consumer.configfor kafka-console-consumer.# INTERNAL/SASL_PLAIN port docker-compose exec kafka1 kafka-consumer-groups \ --list \ --bootstrap-server kafka1:9091 \ --command-config /etc/kafka/secrets/client_sasl_plain.config
Authorization with RBAC
Verify which users are configured to be super users.
docker-compose logs kafka1 | grep "super.users ="
Your output should resemble the following. Notice this authorizes each service name which authenticates as itself, as well as the unauthenticated
PLAINTEXTwhich authenticates asANONYMOUS(for demo purposes only):kafka1 | super.users = User:admin;User:mds;User:superUser;User:ANONYMOUS
From the Confluent Control Center (Legacy) UI, in the Administration menu, click the Manage role assignments option. Click on
Assignmentsand then the Kafka cluster ID. From theTopiclist, verify that the LDAP userappSAis allowed to access a few topics, including any topic whose name starts withwikipedia. This role assignment was done duringcp-demostartup in the create-role-bindings.sh script.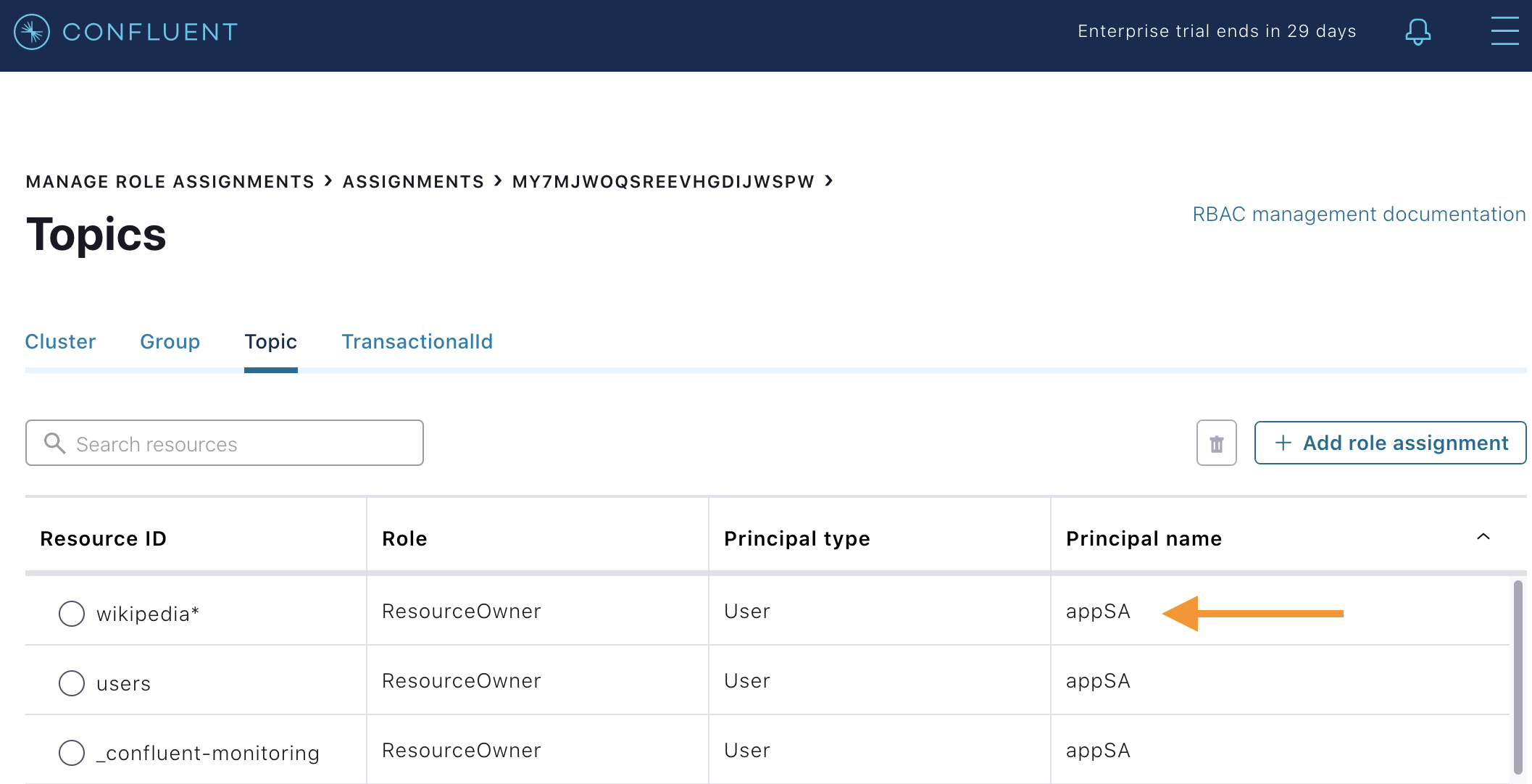
Verify that LDAP user
appSA(which is not a super user) can consume messages from topicwikipedia.parsed. Notice that it is configured to authenticate to brokers with mTLS and authenticate to Schema Registry with LDAP.docker-compose exec connect kafka-avro-console-consumer \ --bootstrap-server kafka1:11091,kafka2:11092 \ --consumer-property security.protocol=SSL \ --consumer-property ssl.truststore.location=/etc/kafka/secrets/kafka.appSA.truststore.jks \ --consumer-property ssl.truststore.password=confluent \ --consumer-property ssl.keystore.location=/etc/kafka/secrets/kafka.appSA.keystore.jks \ --consumer-property ssl.keystore.password=confluent \ --consumer-property ssl.key.password=confluent \ --property schema.registry.url=https://schemaregistry:8085 \ --property schema.registry.ssl.truststore.location=/etc/kafka/secrets/kafka.appSA.truststore.jks \ --property schema.registry.ssl.truststore.password=confluent \ --property basic.auth.credentials.source=USER_INFO \ --property basic.auth.user.info=appSA:appSA \ --group wikipedia.test \ --topic wikipedia.parsed \ --max-messages 5
Verify that LDAP user
badappcannot consume messages from topicwikipedia.parsed.docker-compose exec connect kafka-avro-console-consumer \ --bootstrap-server kafka1:11091,kafka2:11092 \ --consumer-property security.protocol=SSL \ --consumer-property ssl.truststore.location=/etc/kafka/secrets/kafka.badapp.truststore.jks \ --consumer-property ssl.truststore.password=confluent \ --consumer-property ssl.keystore.location=/etc/kafka/secrets/kafka.badapp.keystore.jks \ --consumer-property ssl.keystore.password=confluent \ --consumer-property ssl.key.password=confluent \ --property schema.registry.url=https://schemaregistry:8085 \ --property schema.registry.ssl.truststore.location=/etc/kafka/secrets/kafka.badapp.truststore.jks \ --property schema.registry.ssl.truststore.password=confluent \ --property basic.auth.credentials.source=USER_INFO \ --property basic.auth.user.info=badapp:badapp \ --group wikipedia.test \ --topic wikipedia.parsed \ --max-messages 5
Your output should resemble:
ERROR [Consumer clientId=consumer-wikipedia.test-1, groupId=wikipedia.test] Topic authorization failed for topics [wikipedia.parsed] org.apache.kafka.common.errors.TopicAuthorizationException: Not authorized to access topics: [wikipedia.parsed]
Create role bindings to permit
badappclient to consume from topicwikipedia.parsedand its related subject in Schema Registry.Get the Kafka cluster ID:
KAFKA_CLUSTER_ID=$(curl -s https://localhost:8091/v1/metadata/id --tlsv1.2 --cacert scripts/security/snakeoil-ca-1.crt | jq -r ".id")
Create the role bindings:
# Create the role binding for the topic ``wikipedia.parsed`` docker-compose exec tools bash -c "confluent iam rbac role-binding create \ --principal User:badapp \ --role ResourceOwner \ --resource Topic:wikipedia.parsed \ --kafka-cluster-id $KAFKA_CLUSTER_ID" # Create the role binding for the group ``wikipedia.test`` docker-compose exec tools bash -c "confluent iam rbac role-binding create \ --principal User:badapp \ --role ResourceOwner \ --resource Group:wikipedia.test \ --kafka-cluster-id $KAFKA_CLUSTER_ID" # Create the role binding for the subject ``wikipedia.parsed-value``, i.e., the topic-value (versus the topic-key) docker-compose exec tools bash -c "confluent iam rbac role-binding create \ --principal User:badapp \ --role ResourceOwner \ --resource Subject:wikipedia.parsed-value \ --kafka-cluster-id $KAFKA_CLUSTER_ID \ --schema-registry-cluster-id schema-registry"Verify that LDAP user
badappnow can consume messages from topicwikipedia.parsed.docker-compose exec connect kafka-avro-console-consumer \ --bootstrap-server kafka1:11091,kafka2:11092 \ --consumer-property security.protocol=SSL \ --consumer-property ssl.truststore.location=/etc/kafka/secrets/kafka.badapp.truststore.jks \ --consumer-property ssl.truststore.password=confluent \ --consumer-property ssl.keystore.location=/etc/kafka/secrets/kafka.badapp.keystore.jks \ --consumer-property ssl.keystore.password=confluent \ --consumer-property ssl.key.password=confluent \ --property schema.registry.url=https://schemaregistry:8085 \ --property schema.registry.ssl.truststore.location=/etc/kafka/secrets/kafka.badapp.truststore.jks \ --property schema.registry.ssl.truststore.password=confluent \ --property basic.auth.credentials.source=USER_INFO \ --property basic.auth.user.info=badapp:badapp \ --group wikipedia.test \ --topic wikipedia.parsed \ --max-messages 5
View all the role bindings that were configured for RBAC in this cluster.
./scripts/validate/validate_bindings.sh
Because ZooKeeper is configured for SASL/DIGEST-MD5, any commands that communicate with ZooKeeper need properties set for ZooKeeper authentication. This authentication configuration is provided by the
KAFKA_OPTSsetting on the brokers. For example, notice that the consumer throttle script runs on the Docker containerkafka1which has the appropriate KAFKA_OPTS setting. The command would otherwise fail if run on any other container aside fromkafka1orkafka2.Next step: Learn more about security with the Security Tutorial.
Data Governance with Schema Registry
All the applications and connectors used in this example are configured to automatically read and write Avro-formatted data, leveraging the Confluent Schema Registry.
The security in place between Schema Registry and the end clients, e.g. appSA, is as follows:
Encryption: TLS, e.g. client has
schema.registry.ssl.truststore.*configurationsAuthentication: bearer token authentication from HTTP basic auth headers, e.g. client has
basic.auth.user.infoandbasic.auth.credentials.sourceconfigurationsAuthorization: Schema Registry uses the bearer token with RBAC to authorize the client
View the Schema Registry subjects for topics that have registered schemas for their keys and/or values. Notice the
curlarguments include (a) TLS information required to interact with Schema Registry which is listening for HTTPS on port 8085, and (b) authentication credentials required for RBAC (using superUser:superUser to see all of them).docker exec schemaregistry curl -s -X GET \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ -u superUser:superUser \ https://schemaregistry:8085/subjects | jq .
Your output should resemble:
[ "WIKIPEDIA_COUNT_GT_1-value", "wikipedia-activity-monitor-KSTREAM-AGGREGATE-STATE-STORE-0000000003-repartition-value", "wikipedia.parsed.replica-value", "WIKIPEDIABOT-value", "WIKIPEDIANOBOT-value", "_confluent-ksql-ksql-clusterquery_CTAS_WIKIPEDIA_COUNT_GT_1_7-Aggregate-GroupBy-repartition-value", "wikipedia.parsed.count-by-domain-value", "wikipedia.parsed-value", "_confluent-ksql-ksql-clusterquery_CTAS_WIKIPEDIA_COUNT_GT_1_7-Aggregate-Aggregate-Materialize-changelog-value" ]
Instead of using the superUser credentials, now use client credentials noexist:noexist (user does not exist in LDAP) to try to register a new Avro schema (a record with two fields
usernameanduserid) into Schema Registry for the value of a new topicusers. It should fail due to an authorization error.docker-compose exec schemaregistry curl -X POST \ -H "Content-Type: application/vnd.schemaregistry.v1+json" \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ --data '{ "schema": "[ { \"type\":\"record\", \"name\":\"user\", \"fields\": [ {\"name\":\"userid\",\"type\":\"long\"}, {\"name\":\"username\",\"type\":\"string\"} ]} ]" }' \ -u noexist:noexist \ https://schemaregistry:8085/subjects/users-value/versionsYour output should resemble:
{"error_code":401,"message":"Unauthorized"}
Instead of using credentials for a user that does not exist, now use the client credentials appSA:appSA (the user appSA exists in LDAP) to try to register a new Avro schema (a record with two fields
usernameanduserid) into Schema Registry for the value of a new topicusers. It should fail due to an authorization error, with a different message than above.docker-compose exec schemaregistry curl -X POST \ -H "Content-Type: application/vnd.schemaregistry.v1+json" \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ --data '{ "schema": "[ { \"type\":\"record\", \"name\":\"user\", \"fields\": [ {\"name\":\"userid\",\"type\":\"long\"}, {\"name\":\"username\",\"type\":\"string\"} ]} ]" }' \ -u appSA:appSA \ https://schemaregistry:8085/subjects/users-value/versionsYour output should resemble:
{"error_code":40301,"message":"User is denied operation Write on Subject: users-value"}
Create a role binding for the
appSAclient permitting it access to Schema Registry.Get the Kafka cluster ID:
KAFKA_CLUSTER_ID=$(curl -s https://localhost:8091/v1/metadata/id --tlsv1.2 --cacert scripts/security/snakeoil-ca-1.crt | jq -r ".id")
Create the role binding:
# Create the role binding for the subject ``users-value``, i.e., the topic-value (versus the topic-key) docker-compose exec tools bash -c "confluent iam rbac role-binding create \ --principal User:appSA \ --role ResourceOwner \ --resource Subject:users-value \ --kafka-cluster-id $KAFKA_CLUSTER_ID \ --schema-registry-cluster-id schema-registry"Again try to register the schema. It should pass this time. Note the schema id that it returns, e.g. below schema id is
9.docker-compose exec schemaregistry curl -X POST \ -H "Content-Type: application/vnd.schemaregistry.v1+json" \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ --data '{ "schema": "[ { \"type\":\"record\", \"name\":\"user\", \"fields\": [ {\"name\":\"userid\",\"type\":\"long\"}, {\"name\":\"username\",\"type\":\"string\"} ]} ]" }' \ -u appSA:appSA \ https://schemaregistry:8085/subjects/users-value/versionsYour output should resemble:
{"id":9}
View the new schema for the subject
users-value. From Confluent Control Center (Legacy), click Topics. Scroll down to and click on the topic users and select “SCHEMA”.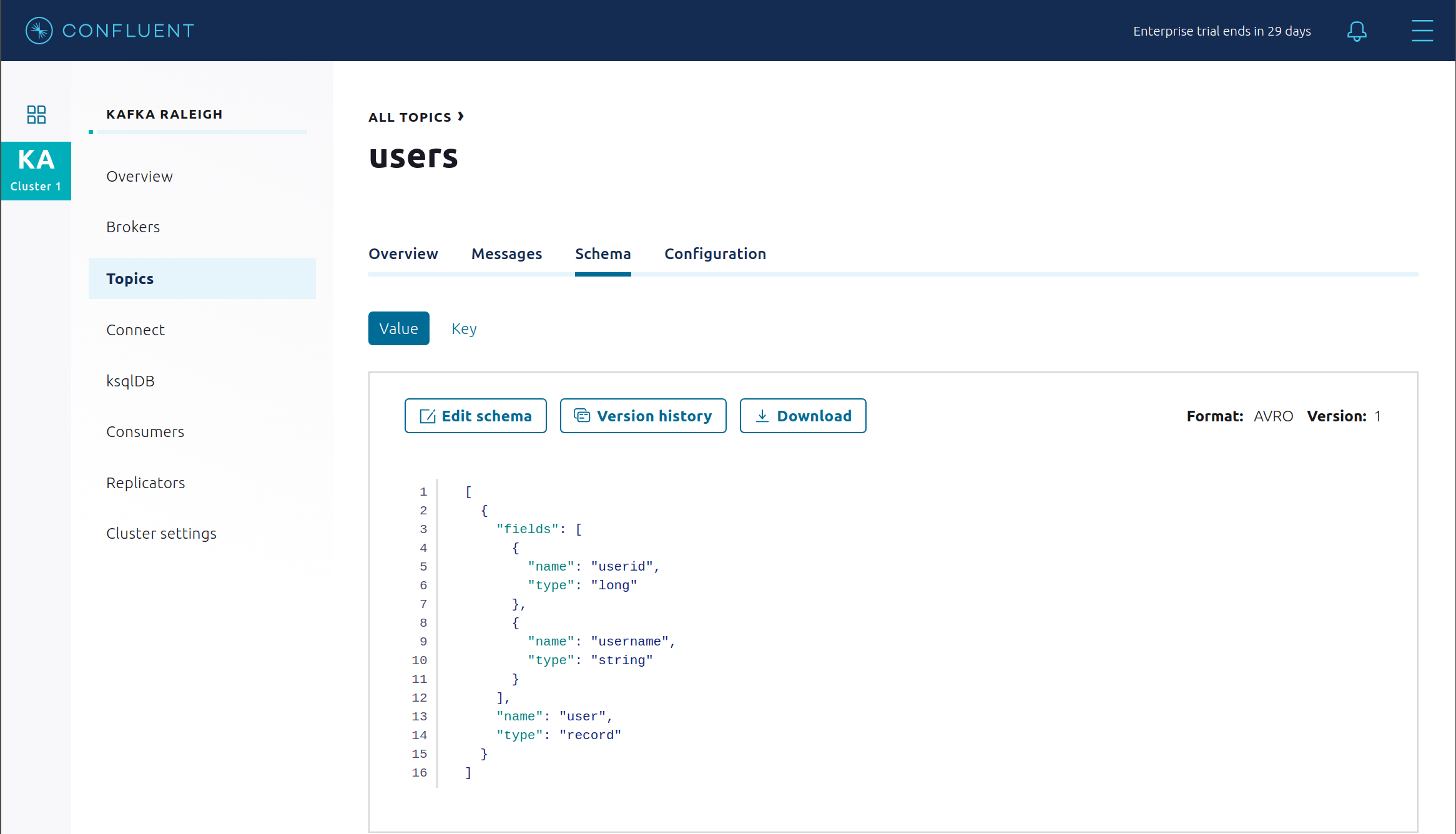
You may alternatively request the schema via the command line:
docker exec schemaregistry curl -s -X GET \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ -u appSA:appSA \ https://schemaregistry:8085/subjects/users-value/versions/1 | jq .
Your output should resemble:
{ "subject": "users-value", "version": 1, "id": 9, "schema": "{\"type\":\"record\",\"name\":\"user\",\"fields\":[{\"name\":\"username\",\"type\":\"string\"},{\"name\":\"userid\",\"type\":\"long\"}]}" }
Describe the topic
users. Notice that it has a special configurationconfluent.value.schema.validation=truewhich enables Schema Validation, a data governance feature in Confluent Server that gives operators a centralized location within the Kafka cluster itself to enforce data format correctness. Enabling Schema ID Validation allows brokers configured withconfluent.schema.registry.urlto validate that data produced to the topic is using a valid schema.docker-compose exec kafka1 kafka-topics \ --describe \ --topic users \ --bootstrap-server kafka1:9091 \ --command-config /etc/kafka/secrets/client_sasl_plain.config
Your output should resemble:
Topic: users PartitionCount: 2 ReplicationFactor: 2 Configs: confluent.value.schema.validation=true Topic: users Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2 Offline: Topic: users Partition: 1 Leader: 2 Replicas: 2,1 Isr: 2,1 Offline:
Now produce a non-Avro message to this topic using
kafka-console-producer.docker-compose exec connect kafka-console-producer \ --topic users \ --broker-list kafka1:11091 \ --producer-property security.protocol=SSL \ --producer-property ssl.truststore.location=/etc/kafka/secrets/kafka.appSA.truststore.jks \ --producer-property ssl.truststore.password=confluent \ --producer-property ssl.keystore.location=/etc/kafka/secrets/kafka.appSA.keystore.jks \ --producer-property ssl.keystore.password=confluent \ --producer-property ssl.key.password=confluent
After starting the console producer, it will wait for input. Enter a few characters and press enter. It should result in a failure with an error message that resembles:
ERROR Error when sending message to topic users with key: null, value: 5 bytes with error: (org.apache.kafka.clients.producer.internals.ErrorLoggingCallback) org.apache.kafka.common.InvalidRecordException: This record has failed the validation on broker and hence be rejected.
Close the console producer by entering
CTRL+C.Describe the topic
wikipedia.parsed, which is the topic that the kafka-connect-sse source connector is writing to. Notice that it also has enabled Schema ID Validation.docker-compose exec kafka1 kafka-topics \ --describe \ --topic wikipedia.parsed \ --bootstrap-server kafka1:9091 \ --command-config /etc/kafka/secrets/client_sasl_plain.config
Next step: Learn more about Schema Registry with the Schema Registry Tutorial.
Confluent REST Proxy
The Confluent REST Proxy is running for optional client access. This demo showcases Confluent REST Proxy in two modes:
Standalone service, listening for HTTPS requests on port 8086
Embedded service on the Kafka brokers, listening for HTTPS requests on port 8091 on
kafka1and on port 8092 onkafka2(these REST Proxy ports are shared with the broker’s Metadata Service (MDS) listener)
Standalone REST Proxy
For the next few steps, use the REST Proxy that is running as a standalone service.
Use the standalone REST Proxy to try to produce a message to the topic
users, referencing schema id9. This schema was registered in Schema Registry in the previous section. It should fail due to an authorization error.docker-compose exec restproxy curl -X POST \ -H "Content-Type: application/vnd.kafka.avro.v2+json" \ -H "Accept: application/vnd.kafka.v2+json" \ --cert /etc/kafka/secrets/restproxy.certificate.pem \ --key /etc/kafka/secrets/restproxy.key \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ --data '{"value_schema_id": 9, "records": [{"value": {"user":{"userid": 1, "username": "Bunny Smith"}}}]}' \ -u appSA:appSA \ https://restproxy:8086/topics/usersYour output should resemble:
{"offsets":[{"partition":null,"offset":null,"error_code":40301,"error":"Not authorized to access topics: [users]"}],"key_schema_id":null,"value_schema_id":9}
Create a role binding for the client permitting it produce to the topic
users.Get the Kafka cluster ID:
KAFKA_CLUSTER_ID=$(curl -s https://localhost:8091/v1/metadata/id --tlsv1.2 --cacert scripts/security/snakeoil-ca-1.crt | jq -r ".id")
Create the role binding:
# Create the role binding for the topic ``users`` docker-compose exec tools bash -c "confluent iam rbac role-binding create \ --principal User:appSA \ --role DeveloperWrite \ --resource Topic:users \ --kafka-cluster-id $KAFKA_CLUSTER_ID"Again try to produce a message to the topic
users. It should pass this time.docker-compose exec restproxy curl -X POST \ -H "Content-Type: application/vnd.kafka.avro.v2+json" \ -H "Accept: application/vnd.kafka.v2+json" \ --cert /etc/kafka/secrets/restproxy.certificate.pem \ --key /etc/kafka/secrets/restproxy.key \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ --data '{"value_schema_id": 9, "records": [{"value": {"user":{"userid": 1, "username": "Bunny Smith"}}}]}' \ -u appSA:appSA \ https://restproxy:8086/topics/usersYour output should resemble:
{"offsets":[{"partition":1,"offset":0,"error_code":null,"error":null}],"key_schema_id":null,"value_schema_id":9}
Create consumer instance
my_avro_consumer.docker-compose exec restproxy curl -X POST \ -H "Content-Type: application/vnd.kafka.v2+json" \ --cert /etc/kafka/secrets/restproxy.certificate.pem \ --key /etc/kafka/secrets/restproxy.key \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ --data '{"name": "my_consumer_instance", "format": "avro", "auto.offset.reset": "earliest"}' \ -u appSA:appSA \ https://restproxy:8086/consumers/my_avro_consumerYour output should resemble:
{"instance_id":"my_consumer_instance","base_uri":"https://restproxy:8086/consumers/my_avro_consumer/instances/my_consumer_instance"}Subscribe
my_avro_consumerto theuserstopic.docker-compose exec restproxy curl -X POST \ -H "Content-Type: application/vnd.kafka.v2+json" \ --cert /etc/kafka/secrets/restproxy.certificate.pem \ --key /etc/kafka/secrets/restproxy.key \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ --data '{"topics":["users"]}' \ -u appSA:appSA \ https://restproxy:8086/consumers/my_avro_consumer/instances/my_consumer_instance/subscriptionTry to consume messages for
my_avro_consumersubscriptions. It should fail due to an authorization error.docker-compose exec restproxy curl -X GET \ -H "Accept: application/vnd.kafka.avro.v2+json" \ --cert /etc/kafka/secrets/restproxy.certificate.pem \ --key /etc/kafka/secrets/restproxy.key \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ -u appSA:appSA \ https://restproxy:8086/consumers/my_avro_consumer/instances/my_consumer_instance/records
Your output should resemble:
{"error_code":40301,"message":"Not authorized to access group: my_avro_consumer"}Create a role binding for the client permitting it access to the consumer group
my_avro_consumer.Get the Kafka cluster ID:
KAFKA_CLUSTER_ID=$(curl -s https://localhost:8091/v1/metadata/id --tlsv1.2 --cacert scripts/security/snakeoil-ca-1.crt | jq -r ".id")
Create the role binding:
# Create the role binding for the group ``my_avro_consumer`` docker-compose exec tools bash -c "confluent iam rbac role-binding create \ --principal User:appSA \ --role ResourceOwner \ --resource Group:my_avro_consumer \ --kafka-cluster-id $KAFKA_CLUSTER_ID"Again try to consume messages for
my_avro_consumersubscriptions. It should fail due to a different authorization error.# Note: Issue this command twice due to https://github.com/confluentinc/kafka-rest/issues/432 docker-compose exec restproxy curl -X GET \ -H "Accept: application/vnd.kafka.avro.v2+json" \ --cert /etc/kafka/secrets/restproxy.certificate.pem \ --key /etc/kafka/secrets/restproxy.key \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ -u appSA:appSA \ https://restproxy:8086/consumers/my_avro_consumer/instances/my_consumer_instance/records docker-compose exec restproxy curl -X GET \ -H "Accept: application/vnd.kafka.avro.v2+json" \ --cert /etc/kafka/secrets/restproxy.certificate.pem \ --key /etc/kafka/secrets/restproxy.key \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ -u appSA:appSA \ https://restproxy:8086/consumers/my_avro_consumer/instances/my_consumer_instance/records
Your output should resemble:
{"error_code":40301,"message":"Not authorized to access topics: [users]"}
Create a role binding for the client permitting it access to the topic
users.Get the Kafka cluster ID:
KAFKA_CLUSTER_ID=$(curl -s https://localhost:8091/v1/metadata/id --tlsv1.2 --cacert scripts/security/snakeoil-ca-1.crt | jq -r ".id")
Create the role binding:
# Create the role binding for the group my_avro_consumer docker-compose exec tools bash -c "confluent iam rbac role-binding create \ --principal User:appSA \ --role DeveloperRead \ --resource Topic:users \ --kafka-cluster-id $KAFKA_CLUSTER_ID"Again try to consume messages for
my_avro_consumersubscriptions. It should pass this time.# Note: Issue this command twice due to https://github.com/confluentinc/kafka-rest/issues/432 docker-compose exec restproxy curl -X GET \ -H "Accept: application/vnd.kafka.avro.v2+json" \ --cert /etc/kafka/secrets/restproxy.certificate.pem \ --key /etc/kafka/secrets/restproxy.key \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ -u appSA:appSA \ https://restproxy:8086/consumers/my_avro_consumer/instances/my_consumer_instance/records docker-compose exec restproxy curl -X GET \ -H "Accept: application/vnd.kafka.avro.v2+json" \ --cert /etc/kafka/secrets/restproxy.certificate.pem \ --key /etc/kafka/secrets/restproxy.key \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ -u appSA:appSA \ https://restproxy:8086/consumers/my_avro_consumer/instances/my_consumer_instance/records
Your output should resemble:
[{"topic":"users","key":null,"value":{"userid":1,"username":"Bunny Smith"},"partition":1,"offset":0}]
Delete the consumer instance
my_avro_consumer.docker-compose exec restproxy curl -X DELETE \ -H "Content-Type: application/vnd.kafka.v2+json" \ --cert /etc/kafka/secrets/restproxy.certificate.pem \ --key /etc/kafka/secrets/restproxy.key \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ -u appSA:appSA \ https://restproxy:8086/consumers/my_avro_consumer/instances/my_consumer_instance
Embedded REST Proxy
For the next few steps, use the REST Proxy that is embedded on the Kafka brokers. Only REST Proxy API v3 is supported this time.
Create a role binding for the client to be granted
ResourceOwnerrole for the topicdev_users.Get the Kafka cluster ID:
KAFKA_CLUSTER_ID=$(curl -s https://localhost:8091/v1/metadata/id --tlsv1.2 --cacert scripts/security/snakeoil-ca-1.crt | jq -r ".id")
Create the role binding:
# Create the role binding for the topic ``dev_users`` docker-compose exec tools bash -c "confluent iam rbac role-binding create \ --principal User:appSA \ --role ResourceOwner \ --resource Topic:dev_users \ --kafka-cluster-id $KAFKA_CLUSTER_ID"Create the topic
dev_userswith embedded REST Proxy.Get the Kafka cluster ID:
KAFKA_CLUSTER_ID=$(curl -s https://localhost:8091/v1/metadata/id --tlsv1.2 --cacert scripts/security/snakeoil-ca-1.crt | jq -r ".id")
Use
curlto create the topic:docker exec restproxy curl -s -X POST \ -H "Content-Type: application/json" \ -H "accept: application/json" \ -d "{\"topic_name\":\"dev_users\",\"partitions_count\":64,\"replication_factor\":2,\"configs\":[{\"name\":\"cleanup.policy\",\"value\":\"compact\"},{\"name\":\"compression.type\",\"value\":\"gzip\"}]}" \ --cert /etc/kafka/secrets/mds.certificate.pem \ --key /etc/kafka/secrets/mds.key \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ -u appSA:appSA \ "https://kafka1:8091/kafka/v3/clusters/$KAFKA_CLUSTER_ID/topics" | jqList topics with embedded REST Proxy to find the newly created
dev_users.Get the Kafka cluster ID:
KAFKA_CLUSTER_ID=$(curl -s https://localhost:8091/v1/metadata/id --tlsv1.2 --cacert scripts/security/snakeoil-ca-1.crt | jq -r ".id")
Use
curlto list the topics:docker exec restproxy curl -s -X GET \ -H "Content-Type: application/json" \ -H "accept: application/json" \ --cert /etc/kafka/secrets/mds.certificate.pem \ --key /etc/kafka/secrets/mds.key \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ -u appSA:appSA \ https://kafka1:8091/kafka/v3/clusters/$KAFKA_CLUSTER_ID/topics | jq '.data[].topic_name'
Your output should resemble below. Output may vary, depending on other topics you may have created, but at least you should see the topic
dev_userscreated in the previous step."_confluent-monitoring" "dev_users" "users" "wikipedia-activity-monitor-KSTREAM-AGGREGATE-STATE-STORE-0000000003-changelog" "wikipedia-activity-monitor-KSTREAM-AGGREGATE-STATE-STORE-0000000003-repartition" "wikipedia.failed" "wikipedia.parsed" "wikipedia.parsed.count-by-domain" "wikipedia.parsed.replica"
Failed Broker
To simulate a failed broker, stop the Docker container running one of the two Kafka brokers.
Stop the Docker container running Kafka broker 2.
docker-compose stop kafka2
After a few minutes, observe the Broker summary show that the number of brokers has decreased from 2 to 1, and there are many under replicated partitions.
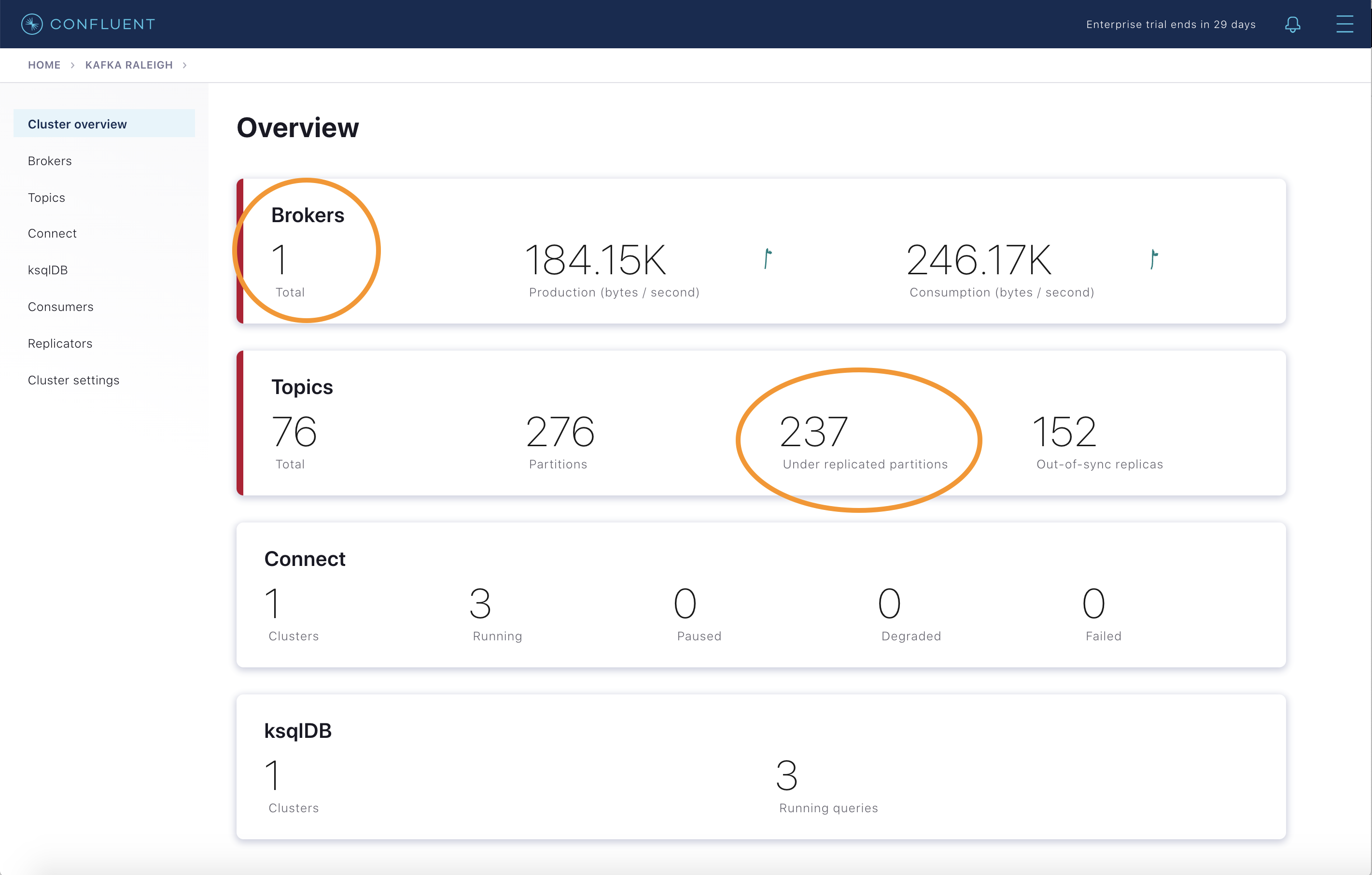
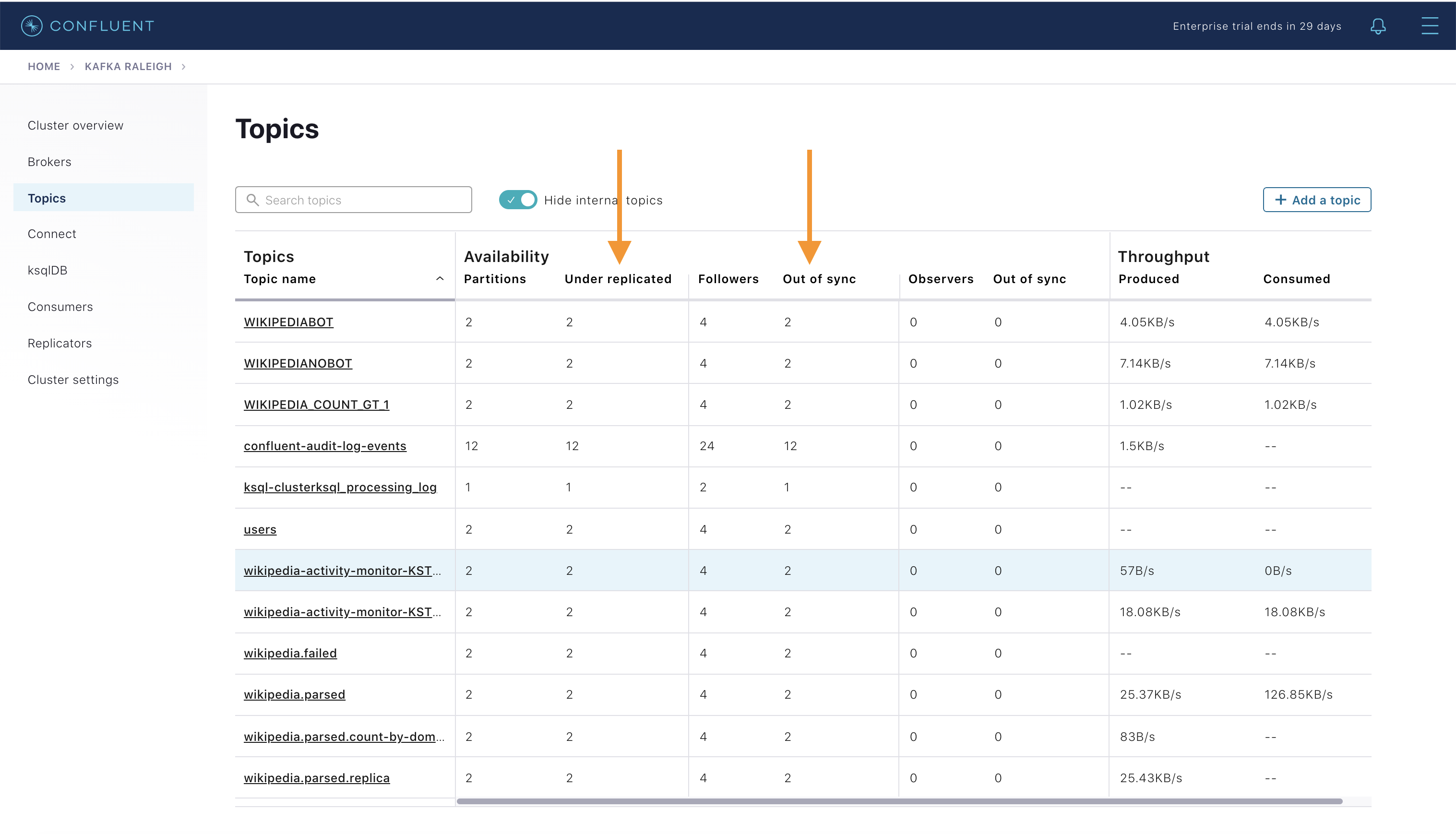
View Topic information details to see that there are out of sync replicas.
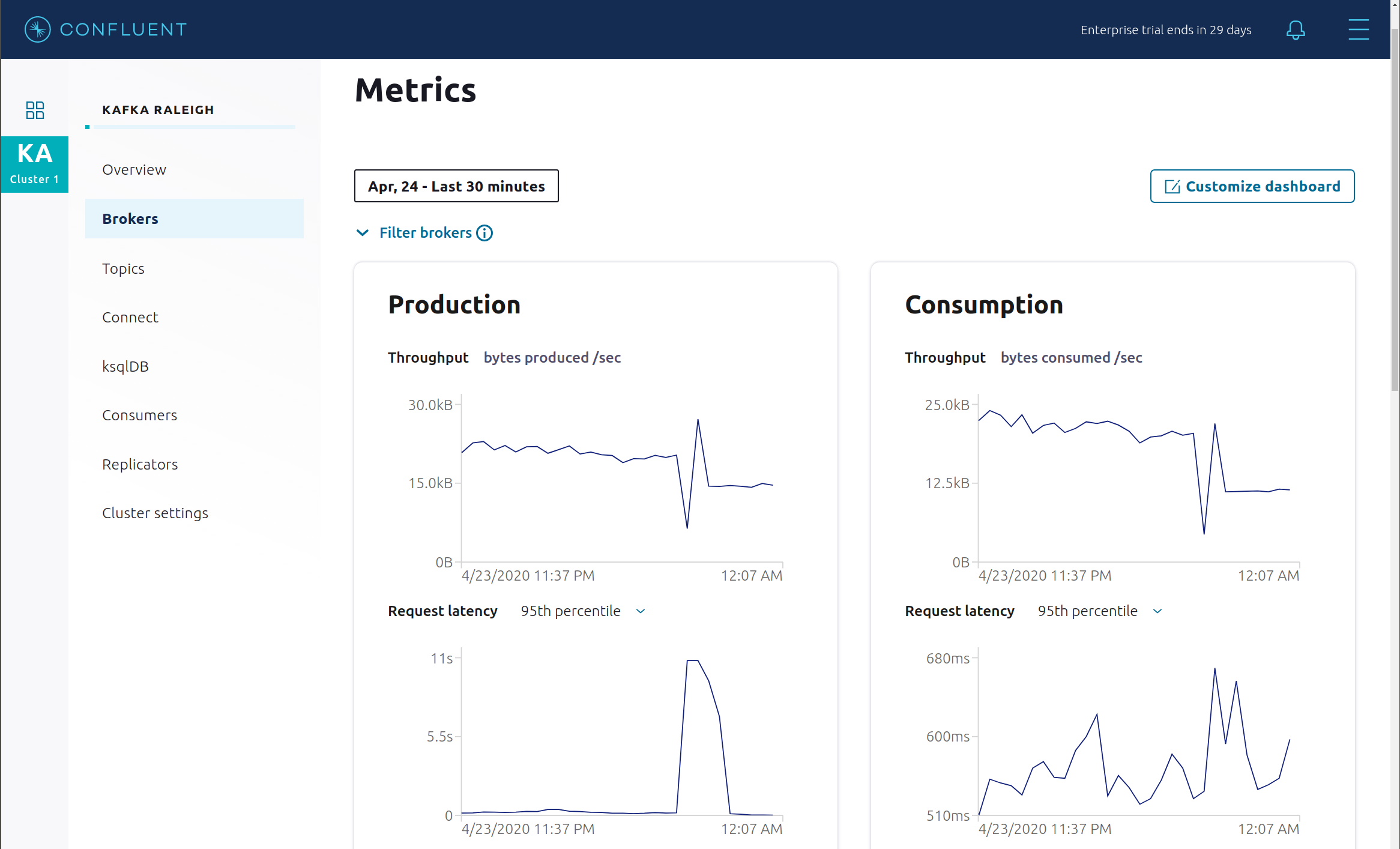
Look at the production and consumption metrics and notice that the clients are all still working.
Restart the Docker container running Kafka broker 2.
docker-compose start kafka2
After about a minute, observe the Broker summary in Confluent Control Center (Legacy). The broker count has recovered to 2, and the topic partitions are back to reporting no under replicated partitions.
Click on the broker count
2inside the “Brokers” box and when the “Brokers overview” pane appears, click inside the “Partitioning and replication” box to view when broker counts changed.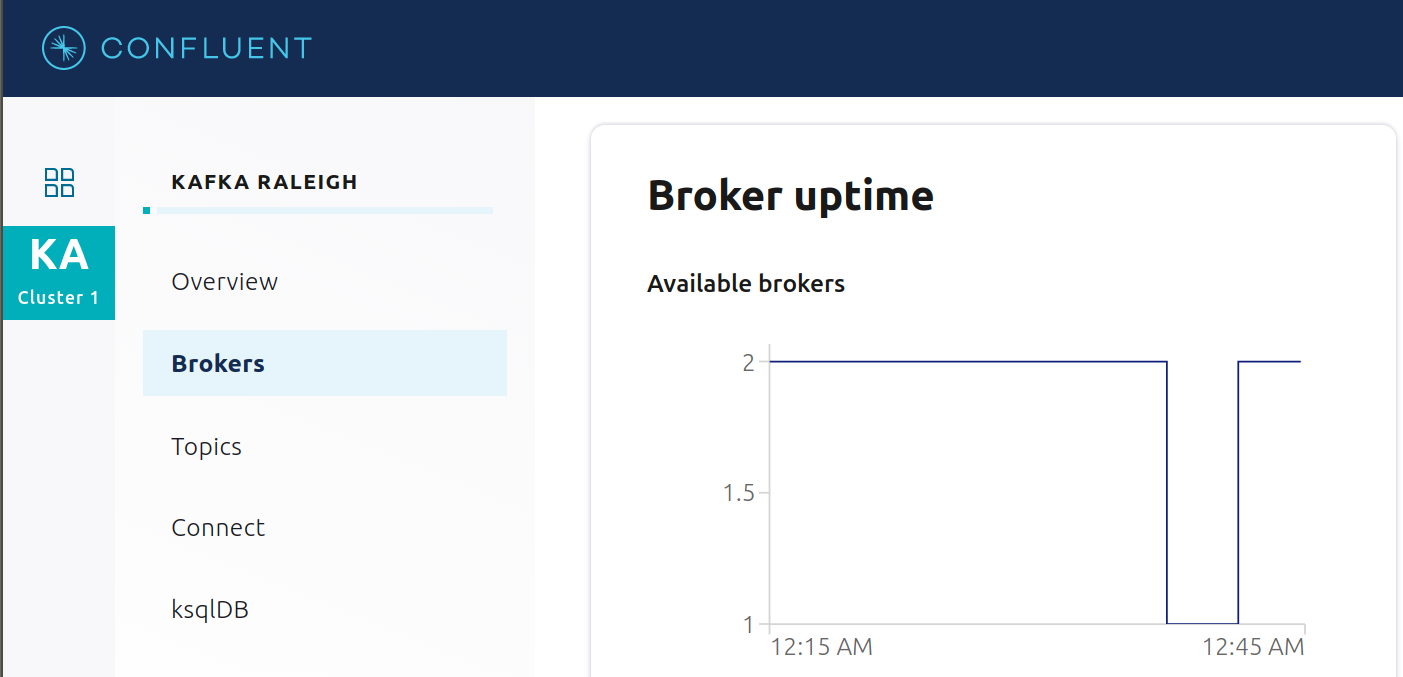
Alerting
There are many types of Control Center (Legacy) alerts and many ways to configure them. Use the Alerts management page to define triggers and actions, or click on individual resources to setup alerts from there.
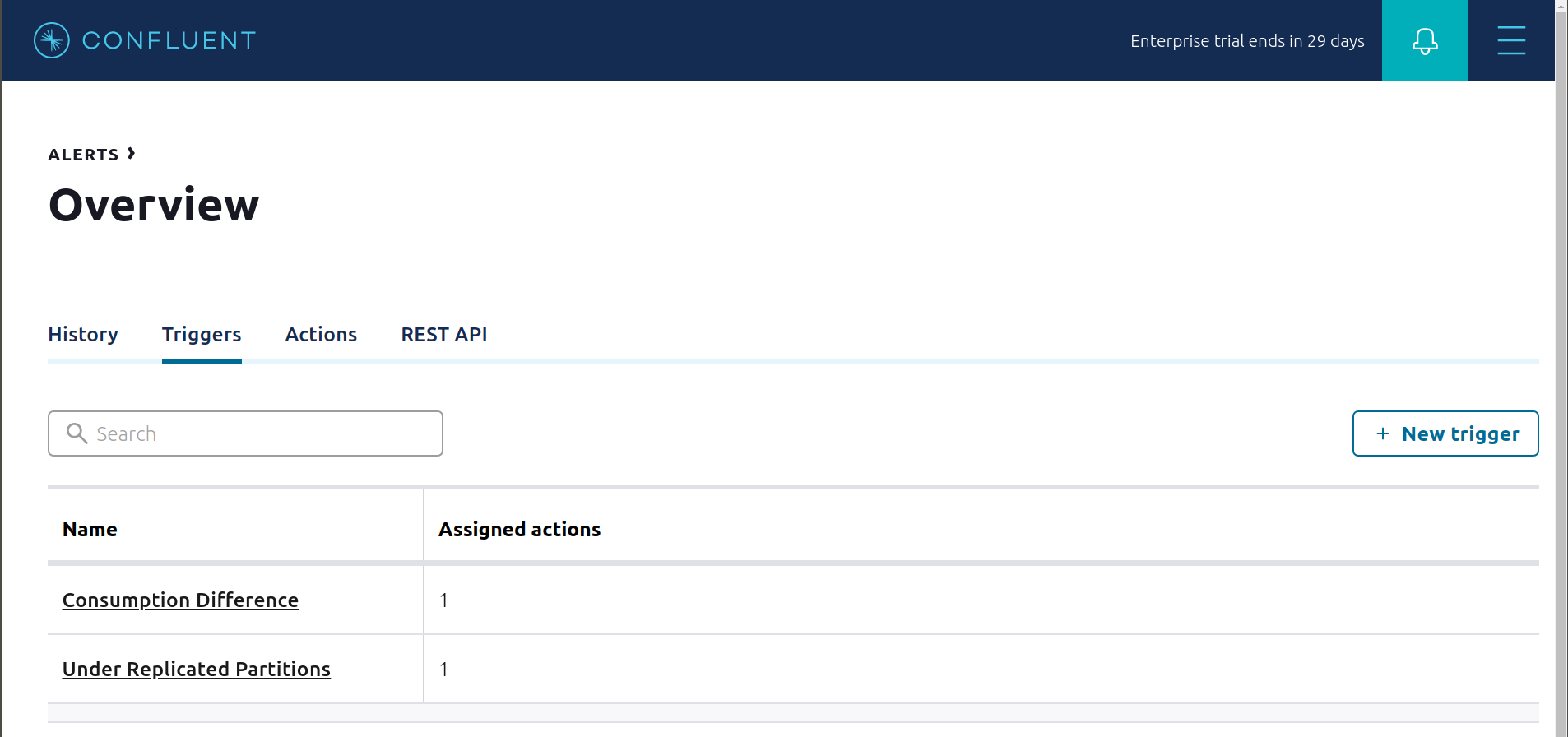
This example already has pre-configured triggers and actions. View the Alerts
Triggersscreen, and clickEditagainst each trigger to see configuration details.The trigger
Under Replicated Partitionshappens when a broker reports non-zero under replicated partitions, and it causes an actionEmail Administrator.The trigger
Consumption Differencehappens when consumption difference for the Elasticsearch connector consumer group is greater than0, and it causes an actionEmail Administrator.
If you followed the steps in the failed broker section, view the Alert history to see that the trigger
Under Replicated Partitionshappened and caused an alert when you stopped broker 2.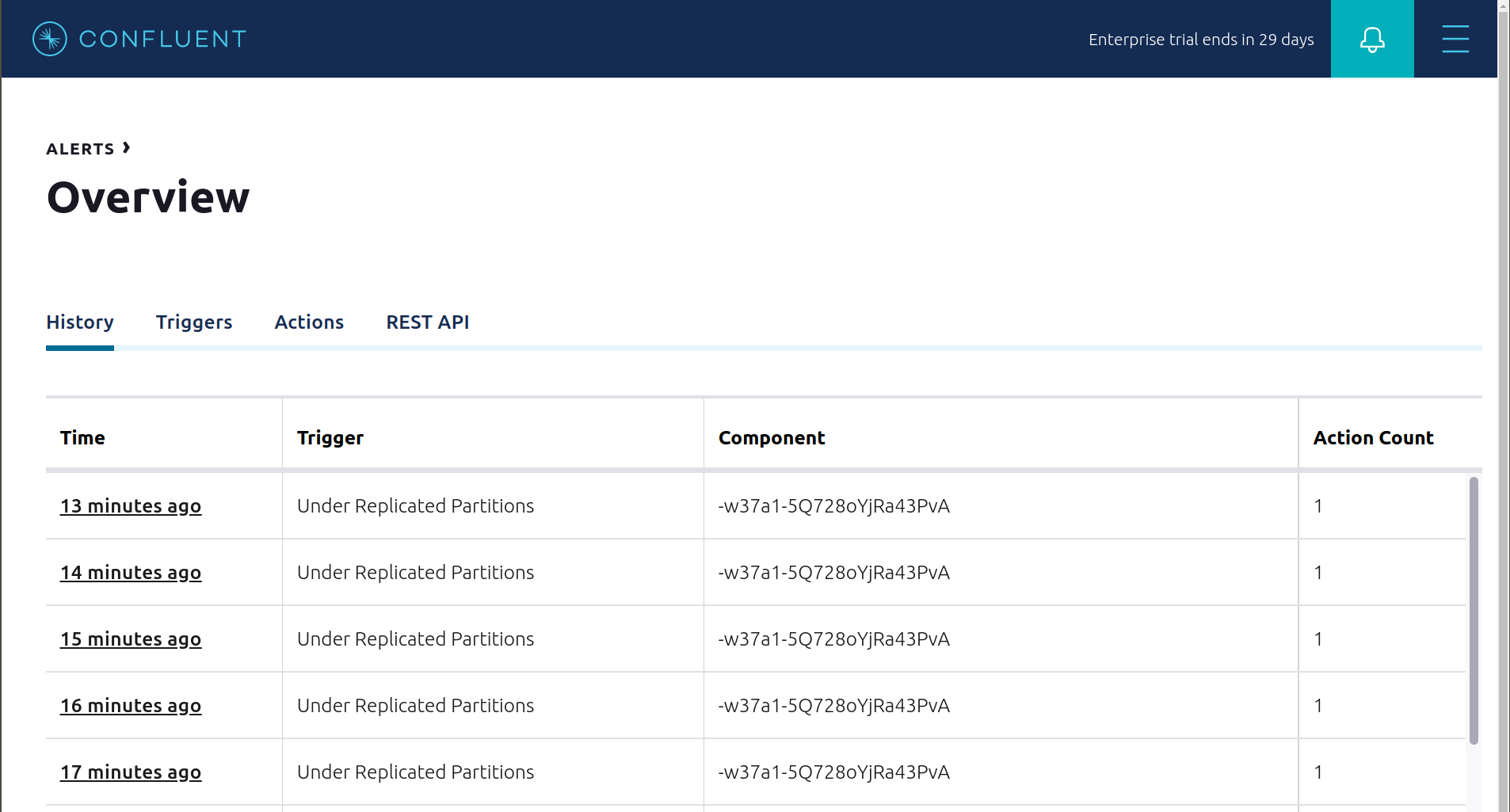
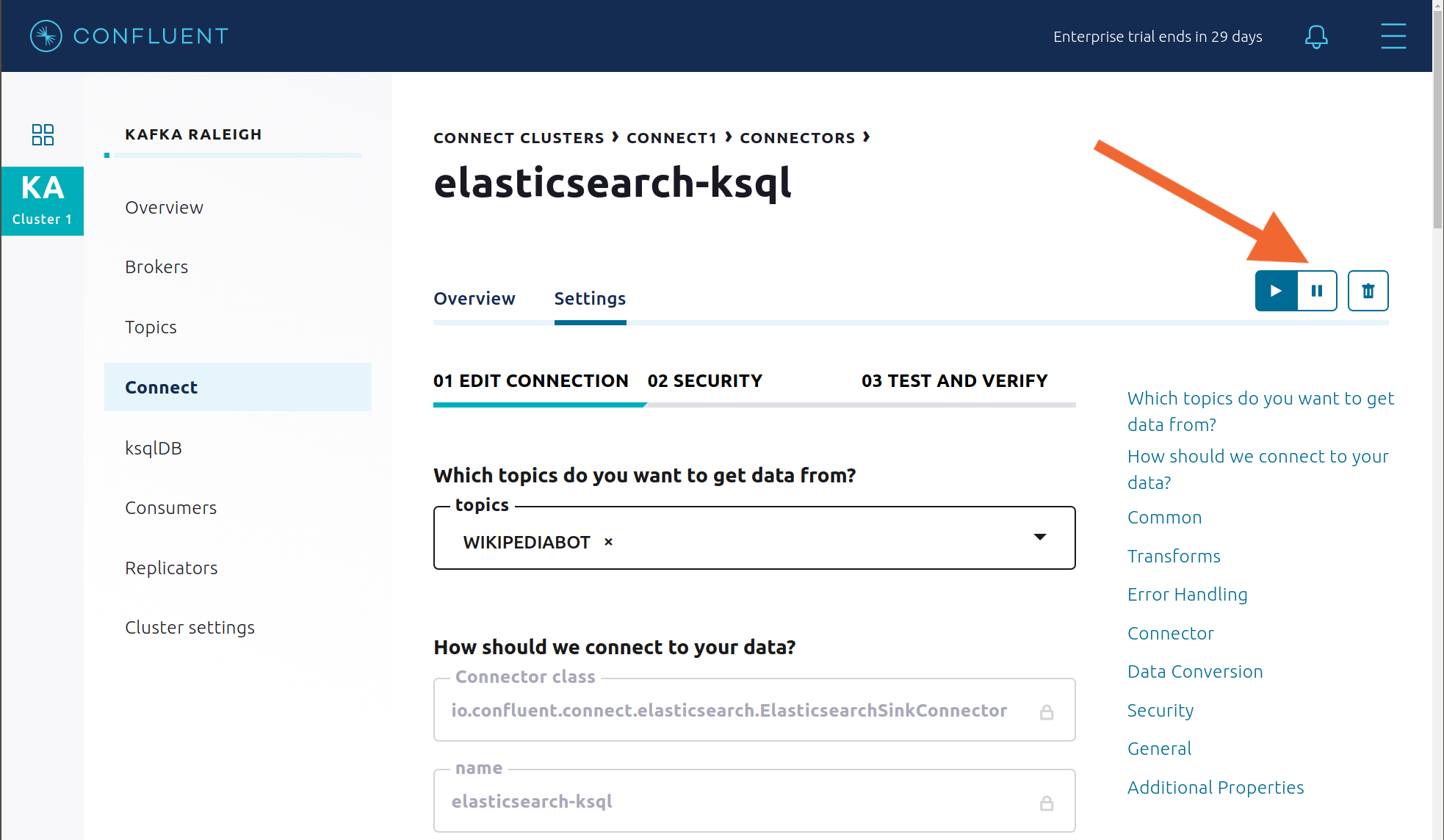
You can also trigger the
Consumption Differencetrigger. In the Kafka Connect -> Sinks screen, edit the running Elasticsearch sink connector.In the Connect view, pause the Elasticsearch sink connector in Settings by pressing the pause icon in the top right. This stops consumption for the related consumer group.
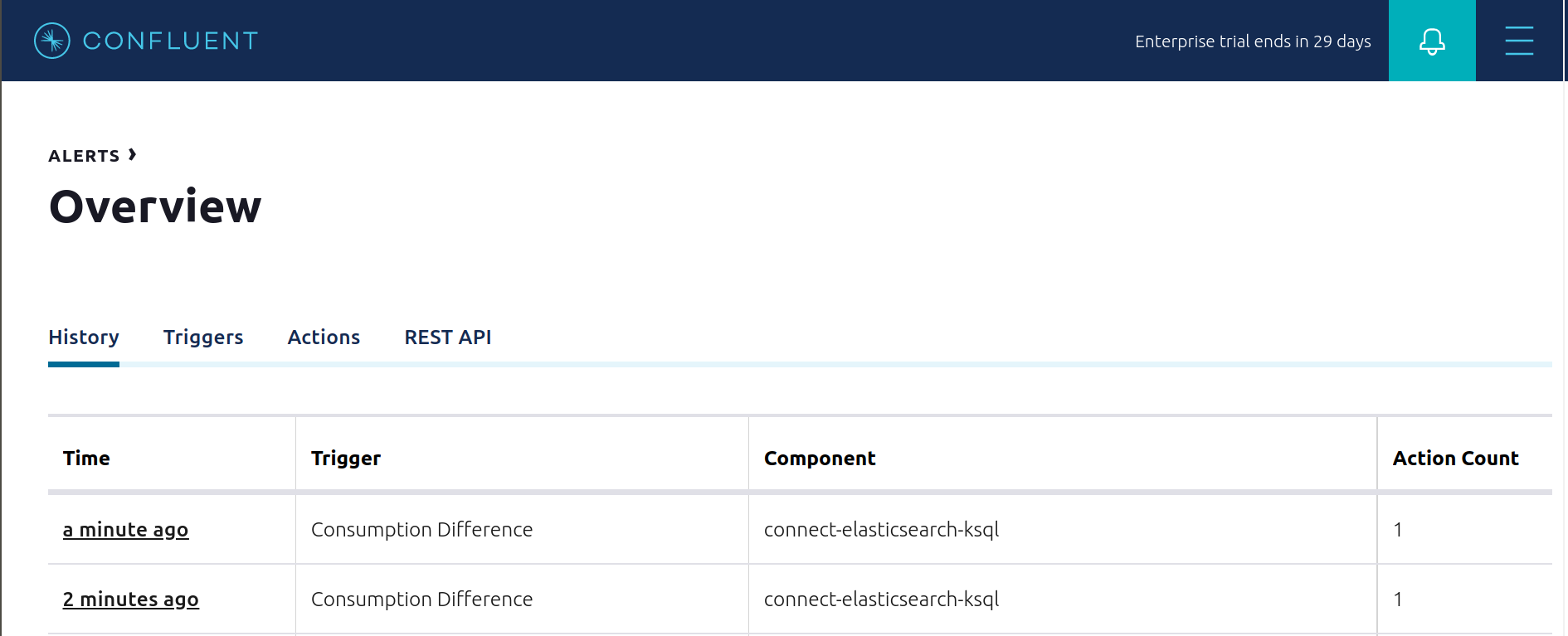
View the Alert history to see that this trigger happened and caused an alert.
Confluent Self-Balancing Clusters
Self-Balancing Clusters automates your resource workload balancing, provides failure detection and self-healing, and allows you to add or decommission brokers as needed, with no manual tuning required. This simplifies scale-up and scale-down operations, ensuring workload is assigned to new brokers and automating recovery in case of a failure.
This section showcases two features of Self-Balancing Clusters:
Adding a new broker to the cluster (scale-up): observe Self-Balancing Clusters rebalance the cluster by assigning existing partitions to the new broker.
Simulating a failure by killing a broker: observe Self-Balancing Clusters reassign the failed broker’s replicas to the remaining brokers.
Before running this section:
Self-Balancing requires 15 minutes to initialize and collect metrics from brokers in the cluster, so after starting
cp-demo, wait at least this time before proceeding.Because these steps add a third broker, ensure you have adequate resources allocated to Docker.
Run scripts/sbc/add-broker.sh to add a new broker
kafka3to the cluster../scripts/sbc/add-broker.sh
The script returns when Self-Balancing Clusters has acknowledged the broker addition and started a rebalance task.
Open Control Center (Legacy) at http://localhost:9021 and navigate to
Brokers. The Self-balancing panel shows 1 in-progress task.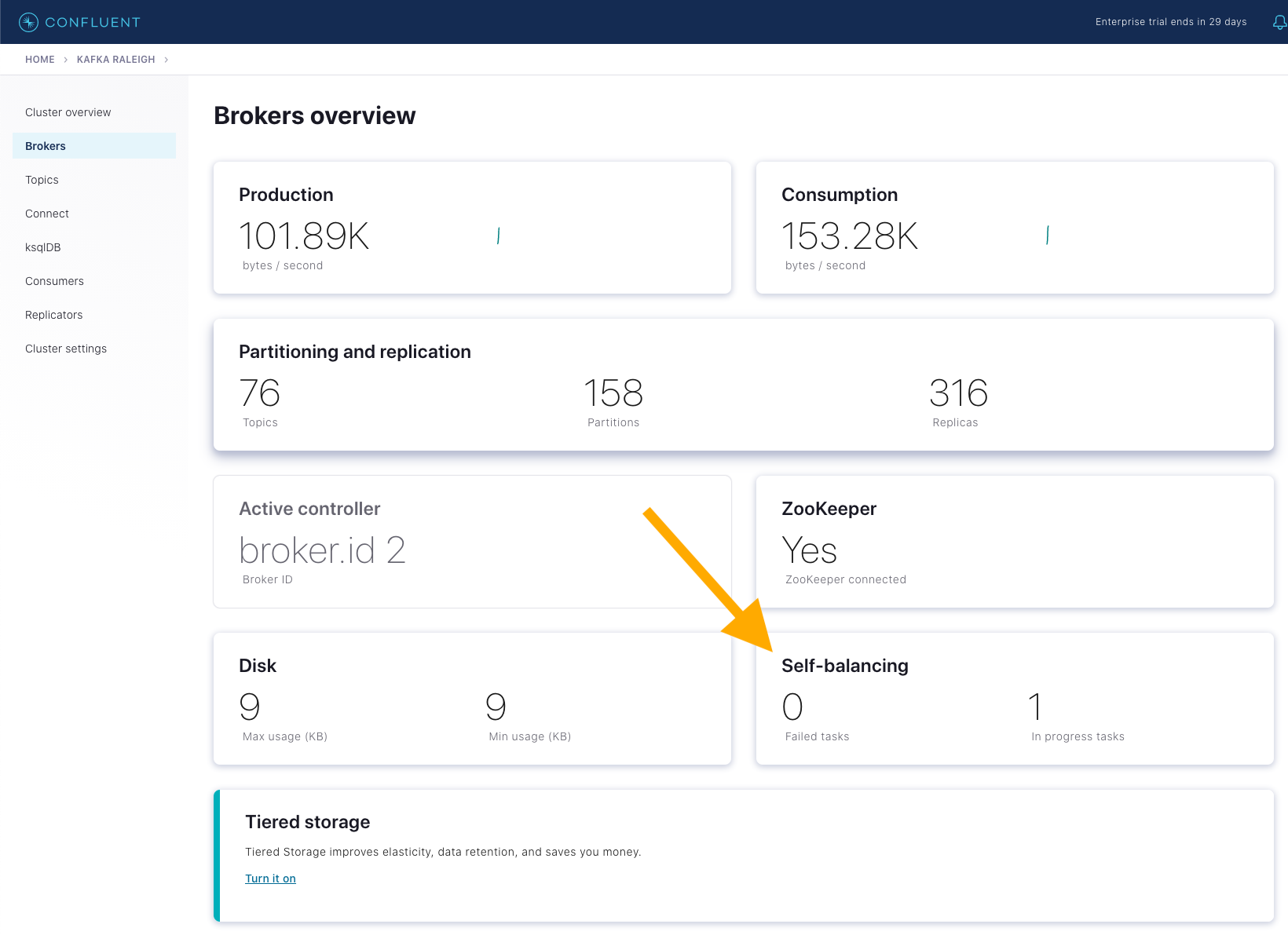
Click on the panel and locate the in-progress add-broker task for broker with ID
broker.3.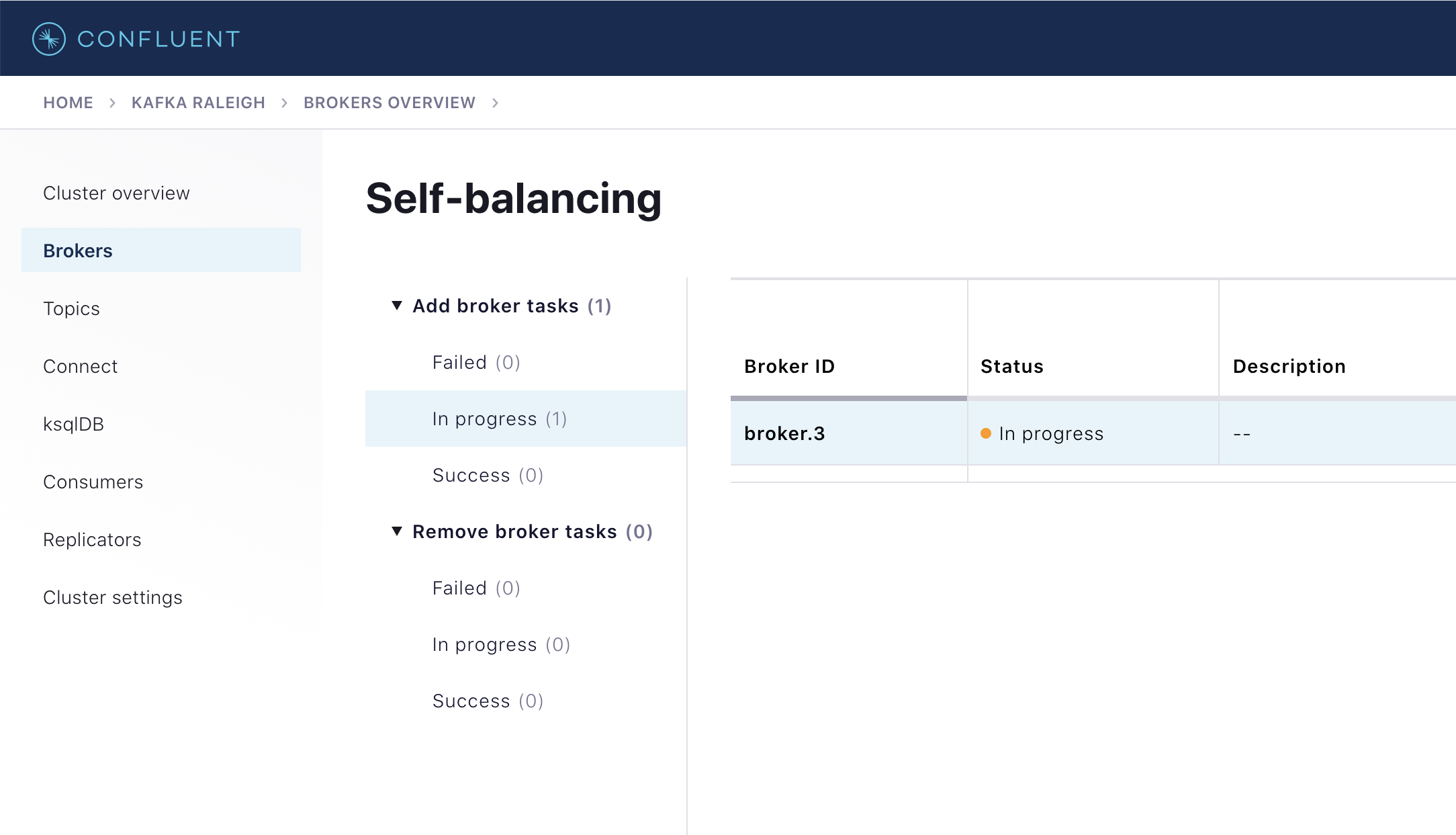
The add-broker rebalance task progresses through stages
PLAN_COMPUTATION,REASSIGNMENTand finallyCOMPLETED. The time spent in each phase varies depending on the hardware you are running. Check the status using the following scripts to read the broker logs:./scripts/sbc/validate_sbc_add_broker_plan_computation.sh ./scripts/sbc/validate_sbc_add_broker_reassignment.sh ./scripts/sbc/validate_sbc_add_broker_completed.sh
After a few minutes, when rebalancing has completed, the add-broker rebalance task in Confluent Control Center (Legacy) moves to
Success. Run the following command to view replica placements for all topic-partitions in the cluster:docker-compose exec kafka1 kafka-replica-status \ --bootstrap-server kafka1:9091 \ --admin.config /etc/kafka/secrets/client_sasl_plain.config
Look for instances of
3in theReplicacolumn, showing that rebalancing has assigned partition replicas (leaders and followers) to the new broker.Simulate a broker-failure by running scripts/sbc/kill-broker.sh to kill the previously-added broker
kafka3:./scripts/sbc/kill-broker.sh
This script returns when Self-Balancing Clusters has detected the broker failure and the recovery wait-time
KAFKA_CONFLUENT_BALANCER_HEAL_BROKER_FAILURE_THRESHOLD_MShas expired, triggering replica reassignment from thekafka3broker to the original two brokers. Note that incp-demo, the threshold time has been set to 30 seconds, which is artificially low but useful in a demo environment.Monitor the progress of replica-reassignment from the failed broker, which eventually reduces the under-replicated partitions in the cluster back to zero. To track completion of self-healing, check the
Self-Balancingpanel in Confluent Control Center (Legacy), or run the following scripts:./scripts/sbc/validate_sbc_kill_broker_started.sh ./scripts/sbc/validate_sbc_kill_broker_completed.sh
When self-healing has completed, the Kafka cluster should no longer have any under-replicated partitions that were previously assigned to failed broker
kafka3. Confirm this by running this command and verifying no output, meaning no out-of-sync replicas:docker exec kafka1 kafka-replica-status \ --bootstrap-server kafka1:9091 \ --admin.config /etc/kafka/secrets/client_sasl_plain.config \ --verbose | grep "IsInIsr: false"
Monitoring
This tutorial has demonstrated how Confluent Control Center (Legacy) helps users manage their Confluent Platform deployment and how it provides monitoring capabilities for the cluster and applications. For a practical guide to optimizing your Kafka deployment for various service goals including throughput, latency, durability and availability, and useful metrics to monitor for performance and cluster health for on-premises Kafka clusters, see the Optimizing Your Apache Kafka Deployment whitepaper.
For most Confluent Platform users the Confluent Control Center (Legacy) monitoring and integrations are sufficient for production usage in their on-premises Apache Kafka® deployments. There are additional monitoring solutions for various use cases, as described below.
Metrics API
The Confluent Cloud Metrics API is a REST API you can use to query timeseries metrics. You can use the Metrics API to get telemetry data for both the on-premises Confluent Platform cluster as well as the Confluent Cloud cluster.
On-prem metrics (enabled by Telemetry Reporter) using the endpoint https://api.telemetry.confluent.cloud/v2/metrics/hosted-monitoring/query
Note
The hosted monitoring endpoint is in preview and the endpont will eventually be renamed https://api.telemetry.confluent.cloud/v2/metrics/health-plus/query
Confluent Cloud metrics using the endpoint https://api.telemetry.confluent.cloud/v2/metrics/cloud/query
See the Confluent Cloud Metrics API Reference for more information.
The Metrics API and Telemetry Reporter powers Health+, the fully-managed monitoring solution for Confluent Platform. You can enable Health+ for free and add premium capabilities as you see fit.
Popular third-party monitoring tools like Datadog and Grafana Cloud integrate with the Metrics API out-of-the-box, or if you manage your own Prometheus database, the Metrics API can also export metrics in Prometheus format.

See Module 2: Deploy Hybrid Confluent Platform and Confluent Cloud Environment to play hands-on with the Metrics API.
JMX
Some users wish to integrate with other monitoring solutions like Prometheus, Grafana, Datadog, and Splunk. The following JMX-based monitoring stacks help users setup a ‘single pane of glass’ monitoring solution for all their organization’s services and applications, including Kafka.
Here are some examples of monitoring stacks that integrate with Confluent Platform:
JMX Exporter + Prometheus + Grafana (runnable with cp-demo from https://github.com/confluentinc/jmx-monitoring-stacks):
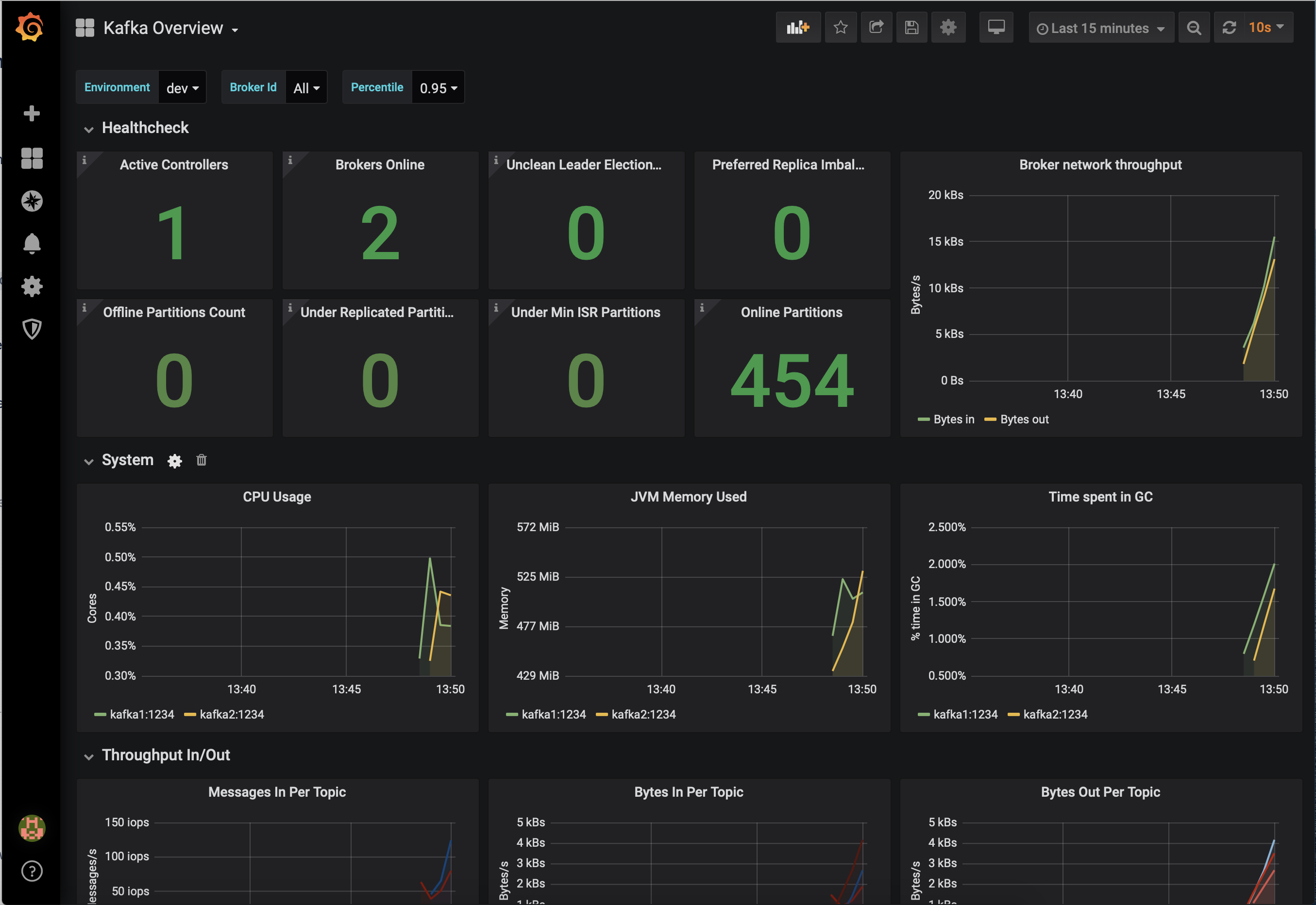
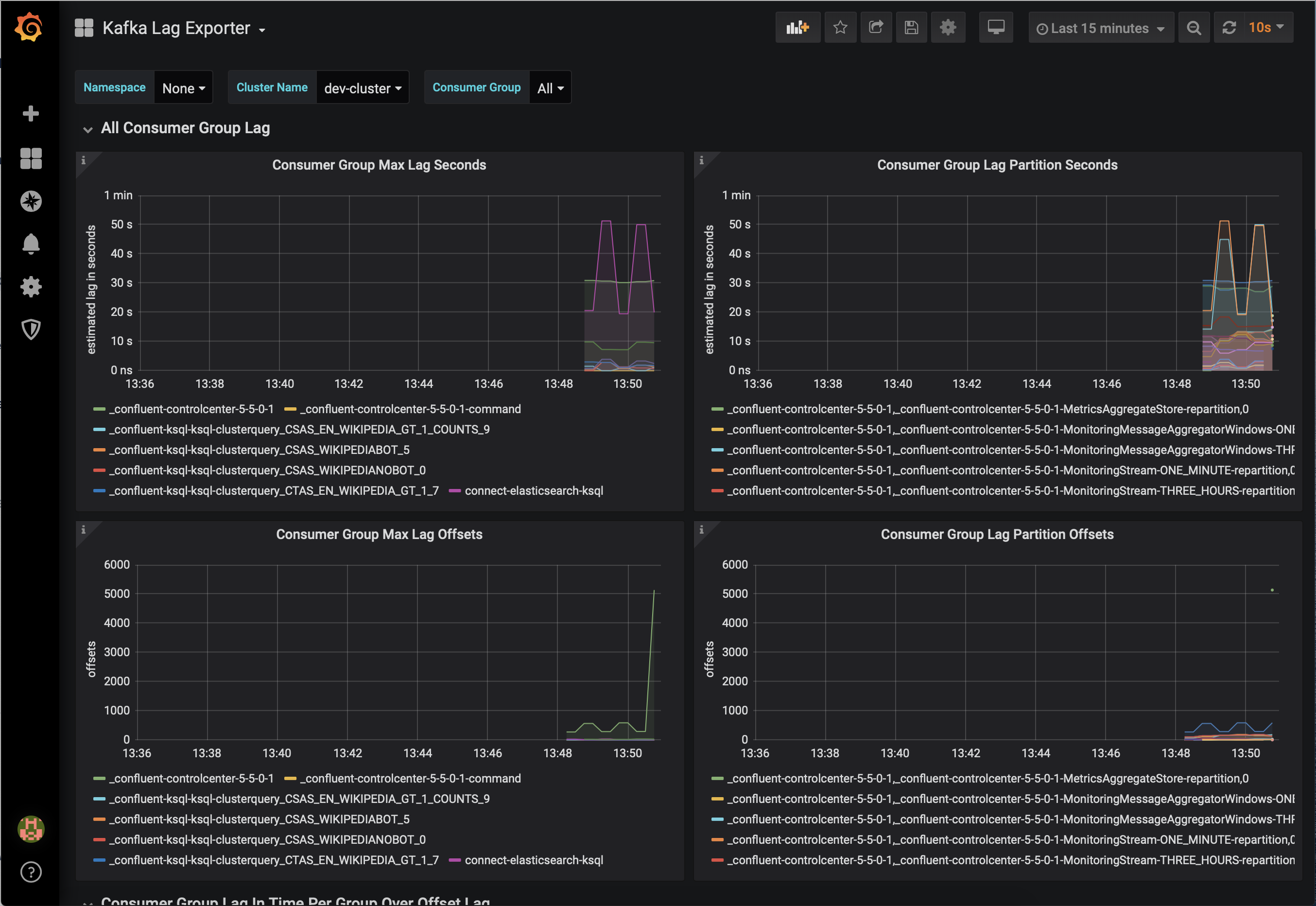

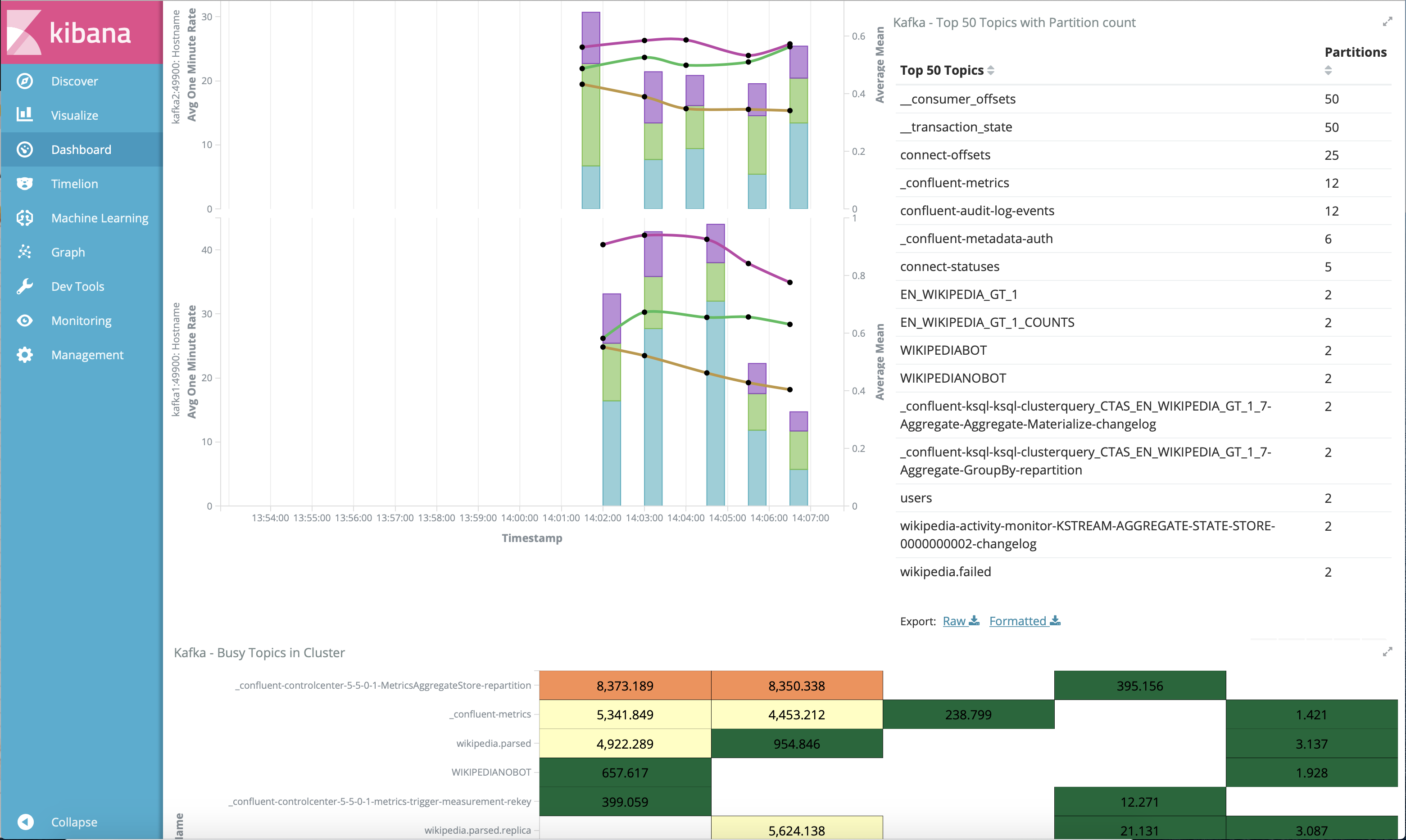
Jolokia + Elasticsearch + Kibana (runnable with cp-demo from https://github.com/confluentinc/jmx-monitoring-stacks):
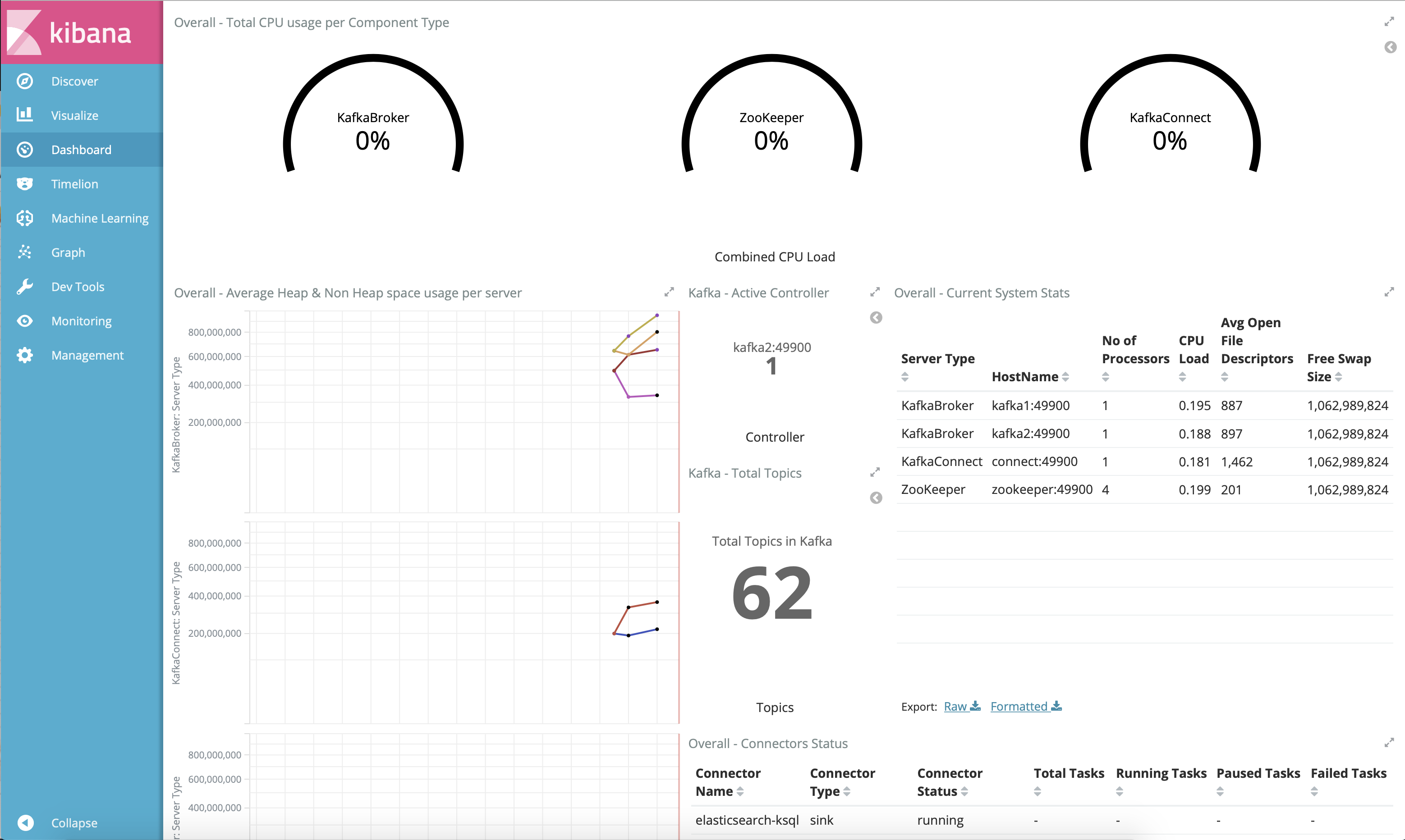
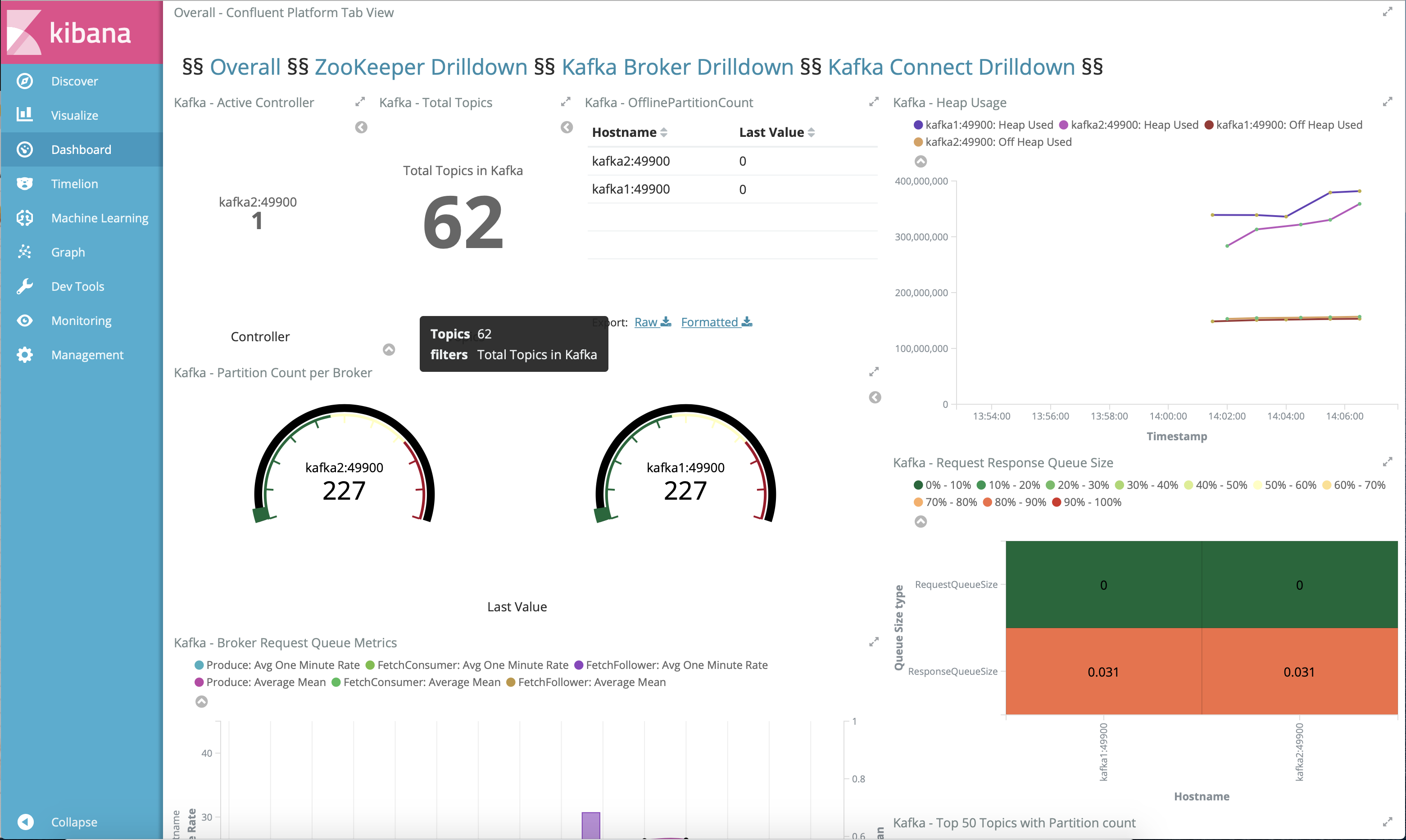
Monitoring Confluent Platform with Datadog: