
Schema Registry for Confluent Platform
Schema Registry provides a centralized repository for managing and validating schemas for topic message data, and for serialization and deserialization of the data over the network. Producers and consumers to Kafka topics can use schemas to ensure data consistency and compatibility as schemas evolve. Schema Registry is a key component for data governance, helping to ensure data quality, adherence to standards, visibility into data lineage, audit capabilities, collaboration across teams, efficient application development protocols, and system performance. Schema Registry is available on both Confluent Cloud and Confluent Platform. This overview is applicable to both, with the few specifics that are unique to Schema Registry on Confluent Cloud or Confluent Platform clarified where necessary.
Choose the Right Path for Schema Management
Start free on Confluent Cloud or Download Confluent Platform.
Confluent Cloud offers a fully managed Schema Registry with built-in scalability, zero infrastructure overhead, and $400 in free credits. This is ideal for fast starts and lower total cost of ownership.
Confluent Platform gives you full control with a self-managed deployment, advanced customizability, and on-prem support.
Quick starts
The Schema Registry tutorials provide full walkthroughs on how to enable client applications to read and write Avro data, check schema version compatibility, and use the UIs to manage schemas.
Schema Registry Tutorial on Confluent Cloud: Sign up for Confluent Cloud and use the Confluent Cloud Schema Registry Tutorial to get started.
Schema Registry Tutorial on Confluent Platform: Download Confluent Platform and use the Confluent Platform Schema Registry Tutorial to get started.
For a quick hands on introduction, jump to the Schema Registry module of the free Apache Kafka 101 course to learn why you would need a Schema Registry, what it is, and how to get started. Also see the free Schema Registry 101 course to learn about the schema formats and how to build, register, manage and evolve schemas.
On Confluent Cloud, try out the interactive tutorials embedded in the Cloud Console. Take this link to sign up or sign in to Confluent Cloud, and try out the guided workflows directly in Confluent Cloud.
To learn about schema formats, create schemas, and use producers and consumers to send messages to topics, see Test drive Avro schema, Test drive Protobuf schema, and Test drive JSON Schema.
About Schema Registry
Schema Registry is a key component of Stream Governance, available in Essentials and Advanced Stream Governance packages on Confluent Cloud, and as a premium feature of self-managed Confluent Platform. Schema Registry provides a centralized repository for managing and validating schemas used in data processing and serialization (into and out of binary format). As an event based system, Confluent brokers uses Schema Registry to intelligently transfer Kafka topic message data and events between producers and consumers.
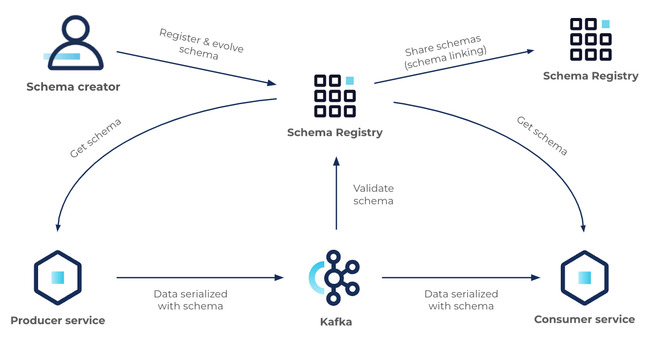
Schema Registry provides several benefits, including data validation, compatibility checking, versioning, and evolution. It also simplifies the development and maintenance of data pipelines and reduces the risk of data compatibility issues, data corruption, and data loss.
Schema Registry enables you to define schemas for your data formats and versions, and register them with the registry. Once registered, the schema can be shared and reused across different systems and applications. When a producer sends data to a message broker, the schema for the data is included in the message header, and Schema Registry ensures that the schema is valid and compatible with the expected schema for the topic.
Data ecosystem
Schema Registry provides the following services:
Allows producers and consumers to communicate over a well-defined data contract in the form of a schema
Controls schema evolution with clear and explicit compatibility rules
Optimizes the payload over the wire by passing a schema ID instead of an entire schema definition
At its core, Schema Registry has two main parts:
A REST service for validating, storing, and retrieving Avro, JSON Schema, and Protobuf schemas
Serializers and deserializers that plug into Apache Kafka® clients to handle schema storage and retrieval for Kafka messages across the three formats
Schema Registry seamlessly integrates with the rest of the Confluent ecosystem:
Kafka is integrated with Schema Registry through Schema ID Validation on Confluent Platform and Schema ID Validation on Confluent Cloud.
Connect is integrated with Schema Registry with converters.
ksqlDB, Confluent REST Proxy, and the Confluent CLI are integrated with Schema Registry through serialization formats.
Both the Confluent Cloud Console and Control Center (Legacy) for Confluent Platform are integrated with Schema Registry through the message browsers on those UIs.
Understanding schemas
A schema defines the structure of message data. It defines allowed data types, their format, and relationships. A schema acts as a blueprint for data, describing the structure of data records, the data types of individual fields, the relationships between fields, and any constraints or rules that apply to the data.
Schemas are used in various data processing systems, including databases, message brokers, and distributed event and data processing frameworks. They help ensure that data is consistent, accurate, and can be efficiently processed and analyzed by different systems and applications. Schemas facilitate data sharing and interoperability between different systems and organizations.
Common data problems solved by Schema Registry
Schema Registry solves the following common problems of working with large scale data systems:
Data inconsistency: A registry ensures that all system data adheres to agreed upon schemas. This reduces risk of data inconsistency and increases data quality.
Incompatible data formats: With multiple data producers and consumers, different applications may use different data formats. Schema Registry solves this problem by providing centralized schema management and validation, to ensure that all message data is compatible.
Schema evolution: Schemas often change over time, which can cause compatibility issues between different versions of the schema. Schema Registry supports schema versioning, ensuring that different versions of the schema can be used simultaneously without causing compatibility issues.
Schema ID validation: Schema Registry checks that data produced to a topic is using a valid schema ID in Schema Registry. This ensures that data conforms to a standard format, reducing risk of data loss or corruption.
Data governance: Schema Registry a central location to manage and version data schemas. This simplifies governance by enabling easy tracking of schema changes, maintaining schema evolution history, and ensuring data compliance with regulatory requirements.
Schema Registry features and benefits
Schema Registry helps improve reliability, flexibility, and scalability of systems and applications by providing a standard way to manage and validate schemas used by producers and consumers.
Schema Registry provides the following advantages with regard to data management:
Centralized schema management and storage, which makes it easier to track and maintain different versions of schemas used by various producers and consumers.
Ability to logically group schemas using schema contexts to create any number of separate “sub-registries” within one Schema Registry. Contexts serve as the basis for Schema Linking, and are also useful in scenarios that require more nuanced schema management.
Schema ID validation, which means Schema Registry validates the structure and compatibility of schemas. This ensures that topic message data conforms to a standard format and is error-free, reducing the risk of data loss or corruption.
Compatibility checking of schemas between producers and consumers to ensure that message data can be consumed by different applications and systems without resulting in errors or data loss due to message formatting.
Versioning of schemas, which allows for updates to schemas without breaking compatibility with existing data. This provides a smooth transition to new versions of a schema with continued support for legacy data, and reduces the need for expensive and time-consuming data migration.
Simplified development, by providing a standard way to define and manage schemas. This reduces the amount of custom code needed to manage schema changes and makes it easier to onboard new developers to a project.
Compatibility and schema evolution
Apache Kafka® producers write data to Kafka topics and Kafka consumers read data from Kafka topics. There is an implicit “contract” that producers write data with a schema that can be read by consumers, even as producers and consumers evolve their schemas. Schema Registry helps ensure that this contract is met with compatibility checks.
It is useful to think about schemas as APIs. Applications depend on APIs and expect any changes made to APIs are still compatible and applications can still run. Similarly, streaming applications depend on schemas and expect any changes made to schemas are still compatible and they can still run. Schema evolution requires compatibility checks to ensure that the producer-consumer contract is not broken. This is where Schema Registry helps: it provides centralized schema management and compatibility checks as schemas evolve.
To learn more about how Schema Registry manages compatibility, see the following topic in either the Confluent Cloud or Confluent Platform documentation:
Confluent Cloud documentation: Schema Evolution and Compatibility for Schema Registry
Confluent Platform documentation: Schema Evolution and Compatibility for Schema Registry
Data serialization
A schema is typically used in data serialization, which is the process of converting data structures or objects into a format that can be transmitted across a network or stored in a file. In this context, a schema defines the format of the serialized data and is used to validate the data as it is being deserialized by another system or application. Confluent Schema Registry supports Avro, JSON Schema, and Protobuf serializers and deserializers (serdes). When you write producers and consumers using these supported formats, they handle the details of the wire format for you, so you don’t have to worry about how messages are mapped to bytes.
Always start with a Schema Registry
If you start without Schema Registry and retrofit later, you increase the workload by using custom code as a base that you must then pull re-do to some extent.
Starting from the beginning of a project with Schema Registry is a best practice for several reasons, some of which are already explained in previous sections:
Prevents data inconsistency and increases data quality.
Simplifies data governance.
Reduces development time. Starting with Schema Registry eliminates the need for custom code to manage and validate schemas. This also cuts costs and increases development productivity.
Facilitates collaboration by providing a standard interface for sharing schemas across different teams and applications. This facilitates collaboration and helps to avoid potential data integration issues.
Improves system performance. Schema Registry validates and optimizes schemas for efficient data exchange, which can improve system performance and reduce processing time.
Confluent Cloud Schema Registry
Schema Registry is built into Confluent Cloud. You must opt for either the Essentials or Advanced package to use it.
For information about Schema Registry Essentials and Advanced packages, see Packages, Features, and Limits.
To learn about working with schemas on Confluent Cloud, see Manage Schemas in Confluent Cloud.
To learn about Stream Governance, see Stream Governance on Confluent Cloud.
What’s supported
Serialization formats Avro, Protobuf, and JSON Schema (called JSON_SR) are supported out of the box by Schema Registry on Confluent Cloud and Confluent Platform. For a deep dive on serializers and schema formats, see Formats, Serializers, and Deserializers for Schema Registry on Confluent Platform.
ksqlDB supports these and additional serialization formats, as described in ksqlDB Serialization Formats, but only Avro, Protobuf, and JSON Schema (JSON_SR) are supported by Schema Registry. JSON and PROTOBUF_NOSR, which are supported ksqlDB, are not supported by Schema Registry.
Recursive type references are not supported. Although the Avro and JSON Schema specifications allow recursive types, downstream consumers built on the Kafka Connect
ConnectSchemaclass, including Tableflow and Flink, fail when they encounter a cyclic schema. To learn more, see KAFKA-3910.
Confluent Platform license
If you are using Schema Registry on Confluent Platform, this licensing information applies.
Schema Registry is licensed under the Confluent Community License.
A Confluent Enterprise license is required for the Schema Registry Security Plugin, for broker-side Schema ID Validation on Confluent Server, and for Schema Linking on Confluent Platform. For complete license information for Confluent Platform, see Manage Confluent Platform Licenses.
You can use the plugin and Schema ID Validation under a 30-day trial period without a license key, and thereafter under an Enterprise (Subscription) License as part of Confluent Platform.
To learn more more about the security plugin, see License for Schema Registry Security Plugin and Install and Configure the Schema Registry Security Plugin.