Kafka のデプロイ後の作業¶
クラスターを本稼働環境にデプロイした後に、クラスターの実行を良好な状態に保つためのツールおよびベストプラクティスがあります。このセクションでは、動的な構成設定、ログレベルの変更、パーティションの再割り当て、トピックの削除について説明します。
ログ記録¶
Apache Kafka® はいくつかのログを出力します。ログの場所はパッケージ形式によって異なり、kafka_logs_dir は、rpm 形式および debian 形式では /var/log/kafka になり、アーカイブ形式では $base_dir/logs になります。デフォルトのログレベルは INFO です。このレベルでは適度な量の情報が提供されますが、ログが膨大にならないように、かなり少なくなるように設計されています。
ちなみに
confluent local コマンドを使用して Confluent Platform をインストールした場合、ログを表示するには、confluent local services kafka log コマンドを実行します。
問題をデバッグする場合、特にレプリカが ISR から外れる問題では、ログレベルを DEBUG に上げると役に立つことがあります。
サーバーからのログは logs/server.log に出力されます。
log4j.properties ファイルを変更してノードを再起動することもできますが、面倒な作業であり不必要なダウンタイムを伴います。
コントローラー¶
Kafka ではクラスター内の 1 つのブローカーが選出されてコントローラーになります。コントローラーにはクラスター管理の役割があり、ブローカーの障害、リーダー選出、トピックの削除などのイベントに対処します。
コントローラーはブローカーに組み込まれているため、コントローラーからのログはサーバーログと区別されて logs/controller.log に出力されます。このログにある ERROR、FATAL、WARN のエントリは、管理者が注目する必要がある重要なイベントです。
ステート変化ログ¶
コントローラーは Kafka クラスター内のすべてのリソースに対するステート管理を行います。このリソースには、トピック、パーティション、ブローカー、レプリカが含まれます。ステート管理の一環として、リソースのステートがコントローラーによって変更された場合、コントローラーは logs/state-change.log に保管されている特別なステート変化ログにアクションを記録します。このログはトラブルシューティングに役立ちます。たとえば、あるパーティションがしばらくの間オフラインになっている場合、リーダー選出操作の失敗によってそのパーティションがオフラインになったのかを知るために役に立つ情報が、このログから得られることがあります。
このログのデフォルトのログレベルは TRACE です。
リクエストのログ記録¶
Kafka では、ブローカーによって処理されたすべてのリクエストをログに記録することができます。そのログでは、生成と消費のリクエストだけでなく、コントローラーによってブローカーに送信されたリクエストやメタデータリクエストも記録されます。
デフォルトの設定は次のとおりです。
log4j.logger.kafka.request.logger=WARN, requestAppender
このログを
DEBUGレベルで有効にするには、次のように設定します。log4j.logger.kafka.request.logger=DEBUG, requestAppender
このログが
DEBUGレベルで有効になっている場合は、各リクエストのレイテンシに関する情報がコンポーネントごとに分けられたレイテンシとともに含まれているので、どこがボトルネックになっているかを確認できます。このログを
TRACEレベルで有効にするには、次のように設定します。log4j.logger.kafka.request.logger=TRACE, requestAppender
このログが
TRACEレベルで有効になっている場合は、DEBUGレベルで記録される情報に加え、リクエストのコンテンツもログに記録されます。大量のログ記録によってクラスターのパフォーマンスが低下する可能性があるため、このログを長時間
TRACEレベルに設定しておくことはお勧めしません。
管理者の操作¶
このセクションでは、本稼働環境の Kafka クラスターを管理するために使用できるさまざまな管理ツールについて説明します。自動化されていない便利な操作もあり、Kafka の bin/ ディレクトリに置かれているツールを使用してトリガーすることができます。
トピックの追加¶
トピックを手作業で追加するか、存在していないトピックに対して初めてデータがパブリッシュされたときに自動的に作成するかを選択できます。トピックが自動作成された場合に使用されるデフォルトのトピック構成を調整することもできます。
トピックはトピックツールを使用して追加および変更します。
bin/kafka-topics --bootstrap-server localhost:9092 --create --topic my_topic_name \
--partitions 20 --replication-factor 3 --config x=y
レプリケーション係数によって、書き込まれた各メッセージをレプリケートするサーバーの数が制御されます。レプリケーション係数を 3 にしている場合、最大 2 つのサーバーで障害が発生しても、データにアクセスできなくなることはありません。レプリケーション係数として 2 または 3 を使用することをお勧めします。データの消費は中断されず、ユーザーが意識することもなく、マシンを再起動できます。
パーティション数によって、トピックが分散されるログの数が制御されます。パーティション数はいくつかのことに影響を及ぼします。まず、各パーティションは単一のサーバーに完全に収まっている必要があります。そのため、20 個のパーティションを使用する場合は、フルデータセット(および読み取りと書き込みの負荷)が 20 台以下のサーバー(レプリカは除く)で処理されることになります。そして、パーティション数はコンシューマーの最大並列性に影響を及ぼします。
コマンドラインで追加される構成によって、サーバーのデフォルト設定(データの保持期間など)がオーバーライドされます。トピックごとの構成の全容は、こちらに記載しています。
トピックの変更¶
トピックの構成やパーティション分割を変更するには、同じトピックツールを使用します。
パーティションの追加
bin/kafka-topics --bootstrap-server localhost:9092 --alter --topic my_topic_name \
--partitions 40
パーティションの 1 つのユースケースとして、データがその意味に基づいてパーティション分割されていて、パーティションを追加しても既存のデータのパーティション分割が変更されない場合、コンシューマーがそのパーティションに依存していると、そのコンシューマーの処理を妨げる可能性があることに注意する必要があります。つまり、データが hash(key) % number_of_partitions を使用してパーティション分割されている場合に、パーティションを追加すると、このパーティション分割はシャッフルされますが、Kafka がデータをなんらかの方法で自動的に再分配することはありません。
構成の追加
bin/kafka-configs --bootstrap-server localhost:9092 --alter --entity-type topics --entity-name my_topic_name --add-config x=y
構成の削除
bin/kafka-configs --bootstrap-server localhost:9092 --alter --entity-type topics --entity-name my_topic_name \
--deleteConfig x
Kafka では、トピックのパーティション数を減らすことは現時点ではサポートされていないことに注意してください。
トピックの削除¶
トピックツールを使用してトピックを削除することもできます。
bin/kafka-topics --bootstrap-server localhost:9092 --delete --topic my_topic_name
正常なシャットダウン¶
Kafka クラスターはブローカーのシャットダウンや障害を自動的に検出して、そのマシン上のパーティションの新しいリーダーを選出します。これは、サーバーに障害が発生している場合、またはメンテナンスや構成変更のためにサーバーが意図的に停止された場合のどちらでもあっても行われます。後者の場合、Kafka では、サーバーを強制終了するのではなくより正常に停止するためのメカニズムがサポートされています。サーバーが正常に停止された場合、次のことを利用して 2 つの最適化が行われます。
- 再起動時にログのリカバリ(つまり、ログの末尾にあるすべてのメッセージのチェックサムの検証)が必要になることを避けるために、すべてのログをディスクに同期させます。ログのリカバリには時間がかかるので、そうすることによって意図的な再起動の時間が短縮されます。
- シャットダウンする前に、そのサーバーがリーダーであるすべてのパーティションを別のレプリカに移行します。そうすることによって、リーダーシップの譲渡が迅速化され、各パーティションが使用不可になる時間が最小限に抑えられて数ミリ秒になります。
強制終了以外の手段でサーバーが停止された場合は常にログの同期が自動的に行われますが、制御されたリーダーシップの移行には controlled.shutdown.enable=true という特別な設定を使用する必要があります。
制御されたシャットダウンは、そのブローカーでホストされているすべてのパーティションにレプリカがある(つまり、レプリケーション係数が 1 より大きく、少なくとも 1 つのレプリカが存続している)場合にのみ成功することに注意してください。最後のレプリカをシャットダウンするとそのトピックのパーティションが使用不可になるので、通常はこの処理が望まれます。
ローリング再起動¶
ソフトウェアアップグレード、ブローカー構成のアップデート、またはクラスターのメンテナンスを行う必要がある場合は、Kafka クラスター内のすべてのブローカーを再起動する必要があります。この場合、ブローカーを一度に 1 つずつ再起動するローリング再起動を利用することができます。ブローカーを一度に 1 つずつ再起動してダウンタイムを回避することによって、エンドユーザーに高可用性が提供されます。
ダウンタイムを回避するためのいくつかの考慮事項を以下に示します。
- Confluent Control Center を使用して、ローリング再起動時のブローカーのステータスをモニタリングします。
- 1 つのブローカーの再起動中は 1 つのレプリカが使用不可ですが、残りの同期状態のレプリカの数が
min.insync.replicasで構成されている数より多ければ、クライアントではダウンタイムは発生しません。 - ブローカーが停止する前にトピックのパーティションのリーダーシップが移行されるように、
controlled.shutdown.enable=trueを設定してブローカーを実行します。 - アクティブなコントローラーであるブローカーは最後に再起動する必要があります。そうすることによって、各ブローカーの再起動時にアクティブなコントローラーが移動しないことが保証されます。コントローラーが移動すると、再起動に時間がかかることになります。
ローリング再起動を開始する前に以下のことを行います。
- クラスターが正常であり、レプリケーション数が不足しているパーティションがないことを検証します。Control Center で、クラスターの Overview に移動して、Under replicated partitions の値を観察します。レプリケーション数が不足しているパーティションがある場合は、ローリング再起動を行う前にその理由を調べます。
- クラスター内のどの Kafka ブローカーがアクティブなコントローラーであるかを特定します。アクティブなコントローラーでは、メトリック
kafka.controller:type=KafkaController,name=ActiveControllerCountに対して1が報告され、それ以外のブローカーでは0が報告されます。
ローリング再起動では以下のワークフローに従います。
1 つのブローカーに接続し、アクティブなコントローラーは最後に残して、そのブローカーのプロセスを正常に停止します。
kill -9コマンドは使用してはいけません。そのブローカーのシャットダウンが完了するまで待ちます。ちなみに
これらの手順では、ZIP または TAR アーカイブを使用して Confluent Platform をインストールしているという想定に基づいています。詳細については「オンプレミスのデプロイ」を参照してください。
bin/kafka-server-stop
ソフトウェアアップグレード またはシステム構成の変更を行っている場合は、このブローカーで以下の手順に従います(ブローカーのプロパティの変更だけを行っている場合は、ブローカーを停止する前に任意でこの手順を行うこともできます)。
ブローカーのプロパティファイルを指定して、ブローカーのバックアップを開始します。
bin/kafka-server-start etc/kafka/server.properties
クラスター内の次のブローカーの再起動に進む前に、ブローカーが完全に再起動して遅れを取り戻すまで待ちます。リーダーのフェイルオーバーをできるだけクリーンに行うには、待つことが重要です。ブローカーが遅れを取り戻したことを確認するには、Control Center で、そのクラスターの Overview に移動して、Under replicated partitions の値を観察します。再起動中のブローカーに置かれているトピックのパーティションにはデータがレプリケートされないので、ブローカーの再起動中はこの値が増加します。
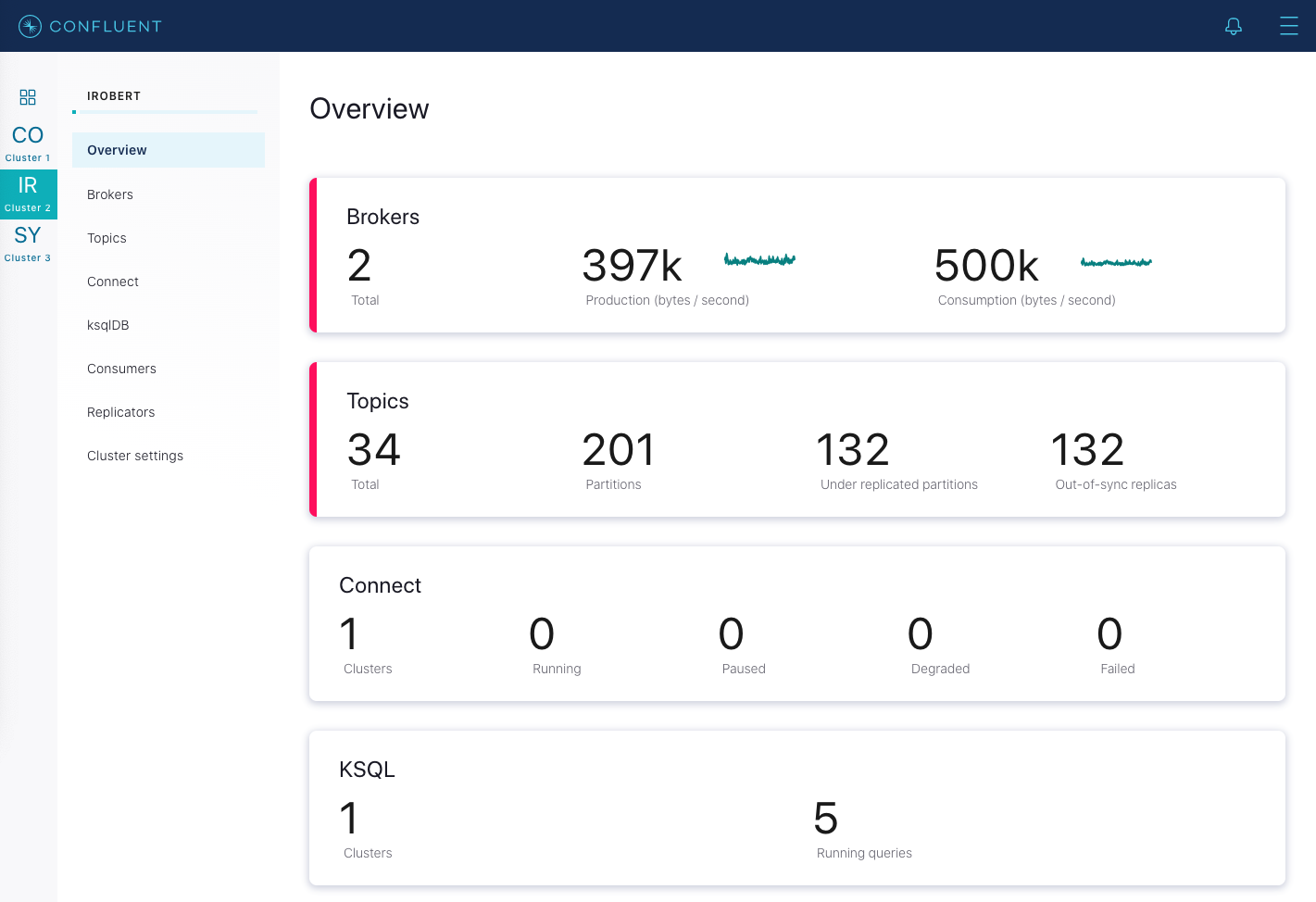
ブローカーが再起動して遅れを取り戻すと、この数値が再起動前の元の値(正常なクラスターでは
0)に戻ります。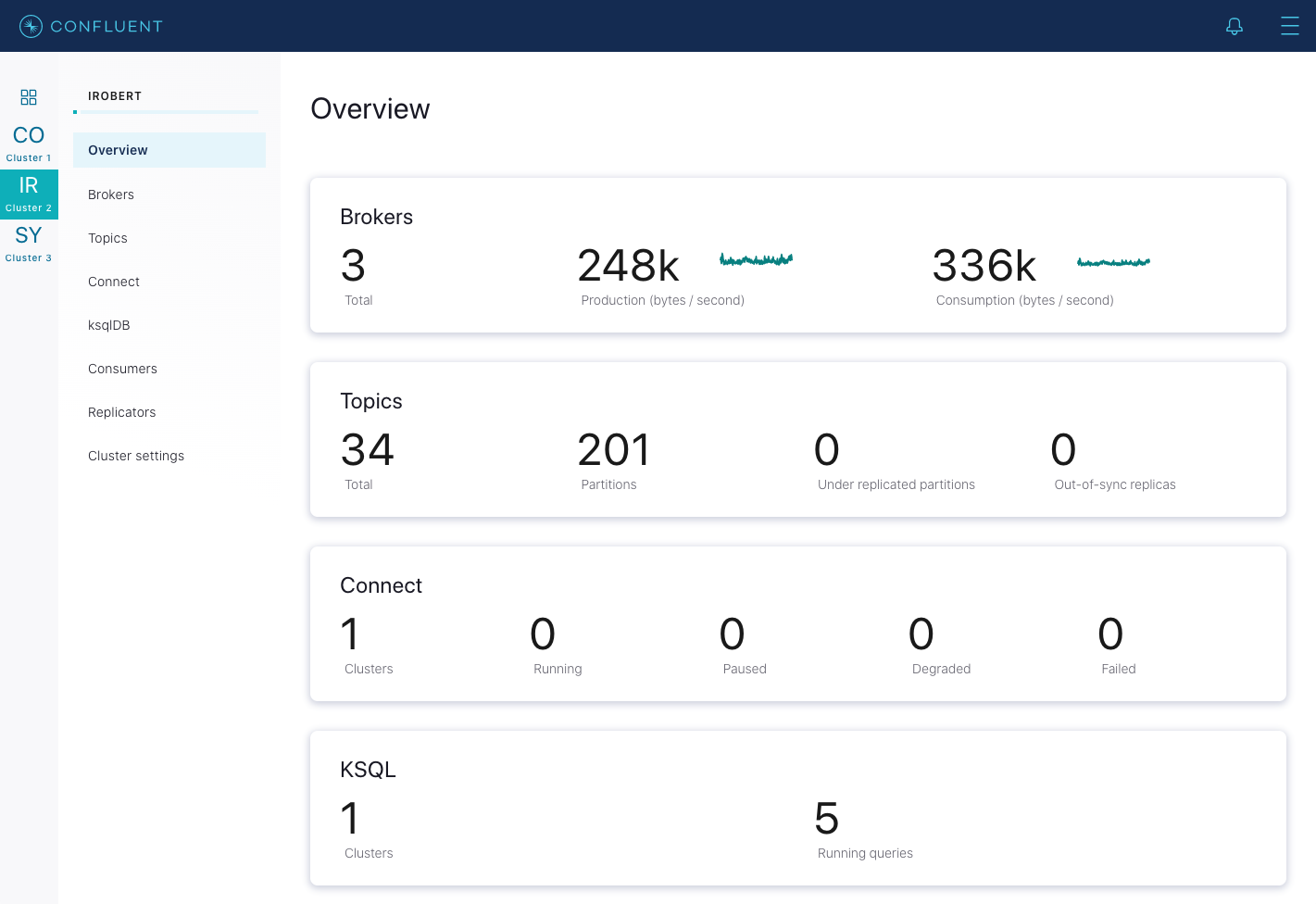
各ブローカーで上記の手順を繰り返して、アクティブなコントローラー以外のすべてのブローカーを再起動します。その後に、アクティブなコントローラーを再起動します。
クラスターのスケーリング(Kafka クラスターへのノードの追加)¶
ちなみに
「Self-Balancing Clusters」、「データの自動バランス調整」、「マルチノード環境の構成」、「マルチブローカーのクラスターの実行」も参照してください。
Kafka クラスターへのサーバーの追加は簡単です。一意のブローカー ID を割り当てて、新しいサーバー上で Kafka を起動するだけです。ただし、新しいサーバーにはデータパーティションは自動的に割り当てられないので、パーティションを新しいサーバーに移動しない限り、新規トピックが作成されるまで、そのサーバーでは何も行われません。そのため、通常は、クラスターにマシンを追加するときに既存のデータの一部を新しいマシンに移行します。データを移行する理由としてよくあるのは、ブローカーを廃止する場合や、(バランスが悪くなっているときに)クラスター全体でデータのバランスを調整する場合です。
Confluent Platform 6.0.0 からは、Self-Balancing Clusters を使用して、パーティション間でのデータの分散を自動的に管理できます。Self-Balancing Clusters では、Kafka ノード(ブローカー)が追加または削除されたときなど、さまざまなメトリクスと要因に基づき、必要に応じてバランス調整が自動的に開始されます。
Confluent Platform の 6.x より前のバージョンでは、データの移行を手動で開始する必要がありますが、そのプロセスは完全に自動化されています。その裏で、Kafka がパーティションを移動するときに、送信先マシン上に新しいレプリカを、移行しているパーティションのフォロワーとして追加します。新しいレプリカではレプリケートが許可されていて、完全に遅れを取り戻すと、そのレプリカは同期状態としてマークされます。その後に、元のサーバー上にある既存のレプリカが削除されて、移動が完了します。
Confluent Platform には confluent-rebalancer ツールとオープンソースの Kafka kafka-reassign-partitions ツールが付属しています。Confluent Rebalancer には以下の利点があります。
- データの移動を最小限に抑えます。
- クラスターレベルとトピックレベルの両方でデータのバランスを調整します(トピックレベルだけではありません)。
- ブローカー間でディスク使用量のバランスを調整します。また、ラック間とブローカー間でリーダー数とレプリカ数のバランスを調整します。
- ブローカーの廃止をサポートします。
- 機能停止状態であるブローカーからのパーティションの移動をサポートします。
confluent-rebalancer については、個別の ページ で説明しています。
オープンソースのパーティション再割り当てツールは、互いに排他的な次の 3 つのモードで実行できます。
--generate: このモードでは、トピックのリストとブローカーのリストを指定すると、指定したトピックのすべてのパーティションを新しいブローカーに移動するための候補となる再割り当てが生成されます。このオプションでは、トピックとターゲットブローカーのリストを指定して、パーティションの再割り当て計画を簡単に生成できます。--execute: このモードでは、ユーザーが指定した再割り当て計画に基づいてパーティションの再割り当てを開始します(--reassignment-json-fileオプションを使用)。管理者が手作業で作成したカスタム再割り当て計画、または --generate オプションを使用して指定した再割り当て計画のいずれかを指定できます。--verify: このモードでは、直前に実行した--executeで指定されているすべてのパーティションの再割り当てのステータスを検証します。ステータスは、"successfully completed"、"failed"、"in progress" のいずれかです。
パーティション再割り当てツールには、廃止されるブローカーに対する再割り当て計画を自動的に生成する機能はまだありません。廃止されるブローカーがある場合は、廃止されるブローカーでホストされているすべてのパーティションのレプリカを残りのブローカーに移動するための再割り当て計画を、管理者が考える必要があります。その再割り当てでは、廃止されるブローカーから別の 1 つのブローカーだけに、すべてのレプリカが移動しないように考慮する必要があるので、かなり面倒な作業になることがあります。上記で説明したように、 confluent-rebalancer にはこの場合のサポートが組み込まれています。
レプリケーション係数の増加¶
レプリケーション係数を増やすためには kafka-reassign-partitions ツールを使用します。指定したパーティションのレプリケーション係数を増やすには、カスタム再割り当ての json ファイルで追加のレプリカ数を指定し、--execute オプションを付けてこのツールを実行します。次の例では、トピック foo のパーティション 0 のレプリケーション係数を 1 から 3 に増やしています。レプリケーション係数を増やす前は、そのパーティションの唯一のレプリカがブローカー 5 に存在していました。レプリケーション係数を増やすにあたって、ブローカー 6 と 7 でレプリカを追加しています。
最初の手順は、カスタム再割り当て計画を手作業で json ファイルに作成することです。
cat increase-replication-factor.json
{"version":1,
"partitions":[
{"topic":"foo",
"partition":0,
"replicas":[5,6,7]
}
]
}
次に、その json ファイルを --execute オプションで使用して、再割り当てプロセスを開始します。
bin/kafka-reassign-partitions --bootstrap-server localhost:9092 --reassignment-json-file increase-replication-factor.json --execute
Current partition replica assignment
{"version":1,
"partitions":[
{"topic":"foo",
"partition":0,
"replicas":[5]
}
]
}
Save this to use as the ``--reassignment-json-file`` option during rollback
Successfully started reassignment of partitions
{"version":1,
"partitions":[
{"topic":"foo",
"partition":0,
"replicas":[5,6,7]
}
]
}
パーティションの再割り当てのステータスを確認するには、このツールの --verify オプションを使用します。--execute オプションを指定したときと同じ increase-replication-factor.json を --verify オプションで使用する必要があることに注意してください。
bin/kafka-reassign-partitions --bootstrap-server localhost:9092 --reassignment-json-file increase-replication-factor.json --verify
Reassignment of partition [foo,0] completed successfully
kafka-topics ツールを使用して、レプリケーション係数が増えていることを検証することもできます。
bin/kafka-topics --bootstrap-server localhost:9092 --topic foo --describe
Topic:foo PartitionCount:1 ReplicationFactor:3 Configs:
Topic: foo Partition: 0 Leader: 5 Replicas: 5,6,7 Isr: 5,6,7
データ移行中の帯域幅使用量の制限¶
Kafka では、マシン間でレプリカを移動するために使用される帯域幅に上限を設定して、レプリケーショントラフィックにスロットルを適用できます。これは、クラスターのバランス調整、新規ブローカーのブートストラップ、ブローカーの追加や削除などのデータを多用する操作を行う場合に、ユーザーに与える影響を限定することに役立ちます。
スロットルを適用するために使用できる 3 つのインターフェイスがあります。最も単純で最も安全な方法は、 confluent-rebalancer または kafka-reassign-partitions を起動するときにスロットルを適用することですが、kafka-configs を使用してスロットル値を直接表示および変更することもできます。
たとえば、次のコマンドを使用してバランス調整を実行すれば、帯域幅が 50 MBps を上回らずにパーティションの移動が行われます。
bin/kafka-reassign-partitions --bootstrap-server myhost:9092 --execute
--reassignment-json-file bigger-cluster.json —throttle 50000000
このスクリプトを実行すると、スロットルが適用されていることがわかります。
…
The throttle limit was set to 50000000 B/s
Successfully started reassignment of partitions.
バランス調整時にスロットルを変更する場合、たとえば、より速く完了するようにスループットを向上させる場合は、同じ reassignment-json-file を指定して execute コマンドを次のように再実行します。
bin/kafka-reassign-partitions --bootstrap-server localhost:9092 --execute
--reassignment-json-file bigger-cluster.json --throttle 700000000
There is an existing assignment running.
The throttle limit was set to 700000000 B/s
バランス調整が完了すると、管理者は --verify オプションを使用して、バランス調整のステータスを確認することができます。バランス調整が完了し、--verify が実行されると、そのスロットルは取り除かれます。ここで重要なことは、バランス調整が完了したときに、管理者が --verify オプション付きでコマンドを実行することで、そのスロットルをタイミングよく取り除くことです。そうしなかった場合、通常のレプリケーショントラフィックにスロットルが適用されることがあります。
--verify オプション付きで実行されて、再割り当てが完了している場合は、このスクリプトによって、そのスロットルが取り除かれていることが確認されます。
bin/kafka-reassign-partitions --bootstrap-server localhost:9092 --verify
--reassignment-json-file bigger-cluster.json
Status of partition reassignment:
Reassignment of partition [my-topic,1] completed successfully
Reassignment of partition [mytopic,0] completed successfully
Throttle was removed.
管理者は kafka-configs を使用して、割り当てられている構成を検証することもできます。スロットリング処理を制御するために使用される 2 組のスロットル構成があります。1 つはスロットル値そのものであり、次の動的プロパティを使用してブローカーレベルで構成されています。
leader.replication.throttled.rate
follower.replication.throttled.rate
もう一つは、スロットル対象のレプリカの列挙値セットです。
leader.replication.throttled.replicas
follower.replication.throttled.replicas
これらはトピックごとに構成されています。これらの 4 つの構成値は kafka-reassign-partitions によって自動的に割り当てられます(後述を参照)。
スロットルのメカニズムは、replication.throttled.replicas のリストにあるパーティションに対する受信レートと送信レートを各ブローカーで測定することによって機能します。これらのレートが replication.throttled.rate 構成と比較されて、スロットルを適用する必要があるかどうかが判断されます。スロットルが適用されているレプリケーションのレート(スロットルのメカニズムで使用)は次の JMX メトリクスに記録されるので、それらの値を外部からモニタリングできます。
MBean:kafka.server:type=LeaderReplication,name=byte-rate
MBean:kafka.server:type=FollowerReplication,name=byte-rate
スロットル制限の構成を表示する場合
bin/kafka-configs --describe --bootstrap-server localhost:9092 --entity-type brokers
Configs for brokers '2' are leader.replication.throttled.rate=1000000,follower.replication.throttled.rate=1000000
Configs for brokers '1' are leader.replication.throttled.rate=1000000,follower.replication.throttled.rate=1000000
この出力では、レプリケーションプロトコルのリーダー側とフォロワー側の両方に適用されているスロットルが示されています。デフォルトでは、スロットルが適用された同じスループット値が両側に割り当てられます。
スロットルが適用されたレプリカの一覧を表示する場合
bin/kafka-configs --describe --bootstrap-server localhost:9092 --entity-type topics
Configs for topic ‘my-topic' are leader.replication.throttled.replicas=1:102,0:101,follower.replication.throttled.replicas=1:101,0:102
この出力では、リーダー側のスロットルがブローカー 102 のパーティション 1 とブローカー 101 のパーティション 0 に適用されていることが示されています。同様に、フォロワー側のスロットルがブローカー 101 のパーティション 1 とブローカー 102 のパーティション 0 に適用されています。
デフォルトでは、kafka-reassign-partitions は、バランス調整前に存在するすべてのレプリカにリーダー側スロットルを適用し、そのいずれかがリーダーになります。移動先すべてにフォロワー側スロットルを適用します。ブローカー 101,102 にレプリカがあり、102,103 に再割り当てされるパーティションがあれば、そのパーティションに対するリーダー側スロットルが 101,102 (バランス調整時にリーダーである可能性がある)に適用され、フォロワー側スロットルが 103 のみ(移動先)に適用されます。
必要であれば、kafka-configs で --alter スイッチを指定して、スロットル構成を手動で変更することもできます。
レプリケーションのスロットルを使用する場合は、特に以下の点に注意する必要があります。
- スロットルの除去
再割り当てが完了したときに、スロットルをタイミングよく取り除く必要があります(confluent-rebalancer --finish または kafka-reassign-partitions --verify を実行する)。
- 進捗の確保
着信書き込みレートと比べてスロットルの設定が低すぎる場合、レプリケーションが進まない可能性があります。これは次の条件を満たす場合に発生します。
max(BytesInPerSec) > throttle
ここで、BytesInPerSec は、各ブローカーへのプロデューサーの書き込みスループットをモニタリングするメトリックです。
管理者は、次のメトリックを使用して、バランス調整中にレプリケーションが進んでいるかどうかをモニタリングできます。
kafka.server:type=FetcherLagMetrics,name=ConsumerLag,clientId=([-.\w]+),topic=([-.\w]+),partition=([0-9]+)
このラグは通常、レプリケーション中には常に減少します。このメトリックが減少していない場合、管理者は前述の手順に従ってスロットルのスループットを増やす必要があります。
- レプリケーション中の長時間の遅延の回避
スロットルのスループットは、長時間不足した状態にレプリカが陥らないために十分な値である必要があります。適切で控えめな経験則として、スロットル値を #brokers MB/s (#brokers はクラスター内のブローカーの数)より大きくしておきます。
低いスロットル値を使用する場合、管理者はレプリケーションに使用されるレスポンスサイズを、次の関係に基づいて調整することができます。
Worst-Case-Delay = replica.fetch.response.max.bytes x #brokers / throttle
その場合、管理者は、遅延が replica.lag.time.max.ms (一部のパーティション、特に小さいパーティションでは、バランス調整が完了する前に ISR に入る可能性がある)、または外側のスロットルウィンドウ((replication.quota.window.size.seconds x replication.quota.window.num) またはコネクションタイムアウト replica.socket.timeout.ms)を超えることがないように、スロットル値と replica.fetch.response.max.bytes のいずれかまたは両方を適切に調整する必要があります。
replica.fetch.response.max.bytes のデフォルト値は 10 MB であり、遅延は 10 秒(replica.lag.time.max.ms)未満であるため、スロットル値を #brokers MBps 未満にしないという経験則が導かれます。
この関係をよりよく理解するために、1 つの例について考えてみます。5 ノードのクラスターがあり、デフォルト設定を使用しているとします。クラスター全体でスロットル値を 10 MBps に設定し、新しいブローカーを追加します。ブートストラップブローカーは、サイズが 10 MB( replica.fetch.response.max.bytes のデフォルト値)のリクエストを使用して、他の 5 つのブローカーからレプリケートします。ブートストラップブローカーに同時に届く最大のペイロードは 50 MB です。その場合、フォロワー側スロットルにより、ブートストラップブローカーで、後続のレプリケーションリクエストが (50 MB / 10 MBps) = 5 秒遅延することになりますが、これは許容できます。しかし、スロットル値を 1 MBps に設定すると、遅延は最大 50 秒になり、これは許容できません。
ラック間でのレプリカ数のバランス調整¶
ラック認識機能により、同じパーティションのレプリカを異なるラック間に分散して配置することができます。これにより、Kafka がブローカーの障害に対して提供する保証の範囲がラックの障害に拡張されて、データ消失のリスクが、1 つのラックに配置されているすべてのブローカーで同時に障害が発生した場合に限定されます。この機能を、ブローカーの他のグループ化(EC2 のアベイラビリティゾーンなど)に適用することもできます。
ブローカー構成にプロパティを追加することで、ブローカーが特定のラックに属するように指定できます。
broker.rack=my-rack-id
トピックが作成または変更される場合、またはレプリカが再分配される場合に、ラック制約が優先されて、できるだけ多くのラックにレプリカが分散されます。1 つのパーティションが、ラック数とレプリケーション係数のどちらか小さい方の数に分散されます。
レプリカをブローカーに割り当てるために使用されるアルゴリズムでは、ブローカーがラック間でどのように分散されているかにかかわらず、ブローカーあたりのリーダーの数は一定であることが保証されています。これによって、バランスの取れたスループットが確保されます。
ただし、ラックに割り当てられているブローカーの数が異なる場合は、レプリカの割り当てが均等ではなくなります。ブローカーの数が少ないラックではレプリカの数が多くなるため、ストレージの使用量が増加し、レプリケーションに費やすリソースが増加します。そのため、ラックあたりのブローカーが同数になるように構成するのが賢明です。
注意
現時点では、ラック認識機能はアップグレード中には有効にできないため、Confluent Platform バージョンのアップグレードの前または完了後にラック認識機能を有効にする必要があります。
クライアントクォータの適用¶
バージョン 0.9 以降の Kafka クラスターには、生成リクエストおよびフェッチリクエストにクォータを適用する機能があります。クォータは、実際には、クライアント ID ごとに定義されているバイトレートしきい値です。クライアント ID によって、リクエストを行っているアプリケーションが論理的に識別されます。そのため、1 つのクライアント ID がプロデューサーおよびコンシューマーの複数のインスタンスで使用されることがあり、それらのインスタンスすべてに対して単一のエンティティとしてクォータが適用されます。つまり、client-id="test-client" に対する生成クォータが 10 MBps である場合、このクォータは ID が同じであるすべてのインスタンス間で共有されます。
クォータにより、非常に大量のデータを生成または消費するプロデューサーまたはコンシューマーによってブローカーのリソースが占有されて、ネットワークが飽和状態にならないように、ブローカーが保護されます。これは大規模なマルチテナントクラスターでは特に重要です。不適切な動作の少数のクライアントのせいで、適切な動作のクライアントのユーザーエクスペリエンスが低下する可能性があるためです。実際は、Kafka をサービスとして実行している場合に、クォータによって、契約上の合意に従って API の制限を適用できるようになります。
デフォルトでは、一意のクライアント ID ごとに、クラスターによって構成されているバイト/秒単位の固定クォータ(quota.producer.default、quota.consumer.default)が与えられています。このクォータはブローカー単位で定義されています。各クライアントのパブリッシュまたはフェッチが ブローカーあたり X バイト/秒を超えると、そのクライアントに対してスロットルが適用されます。
ブローカーはクォータ違反を検出した場合にエラーは返しません。その代わりに、クォータを超過しているクライアントの処理を遅らせようとします。ブローカーは、クォータ違反のクライアントがクォータを下回るために必要な遅延の量を算出して、その時間だけレスポンスを遅らせます。この手法により、クライアントはクォータ違反を意識しなくて済みます(クライアント側メトリクスの範囲外である)。また、クライアントは特別なバックオフや再試行動作を実装する必要がなくなり、クライアントでの実装に関係なくクォータが確実に適用されます。クライアントにスロットルが適用されている場合は、クライアントおよびブローカーでの JMX メトリクスで確認できます。
クォータ違反を迅速に検出および是正することができるように、クライアントのバイトレートは複数の短いウィンドウ(例: 1 秒のウィンドウを 30 回)にわたって測定されます。通常、測定時間枠を大きく(たとえば、30 秒あたり 10 ウィンドウ)すると、長い遅延の後に大量のトラフィックが一気に発生することになり、ユーザーエクスペリエンスの観点で好ましくありません。
クォータを増やす(または減らす)必要があるクライアント ID に対して、デフォルトのクォータをオーバーライドすることができます。そのメカニズムは、トピックごとのログ構成のオーバーライドに似ています。
デフォルトでは、各クライアント ID に無制限のクォータが与えられています。次の構成では、プロデューサーとコンシューマーのクライアント ID ごとのデフォルトのクォータを 10 MBps に設定しています。
quota.producer.default=10485760
quota.consumer.default=10485760
クライアントごとにカスタムクォータを設定することもできます。
bin/kafka-configs --bootstrap-server localhost:9092 --alter --add-config 'producer_byte_rate=1024,consumer_byte_rate=2048' --entity-name clientA --entity-type clients
Updated config for clientId: "clientA".
特定のクライアントのクォータを記述するには次のようにします。
bin/kafka-configs --bootstrap-server localhost:9092 --describe --entity-name clientA --entity-type clients
Configs for clients:clientA are producer_byte_rate=1024,consumer_byte_rate=2048
パフォーマンス改善のヒント¶
トピックのパーティション数の選定¶
実際には正解はありませんが、さまざまなトレードオフがあるので、ここに記載しています。単純な答えとして、パーティション数によってコンシューマーの最大並列性が決まるので、必要になるとユーザーが想定するコンシューマーの最大並列性に基づいてパーティション数を設定する必要があります。総パーティション数が 10,000 までのクラスターは問題なく機能します。10,000 を超える場合については積極的にはテストされていません(機能するはずですが、保証はされていません)。
検討すべきトレードオフの網羅的なリストを以下に示します。
- パーティションは基本的にはログファイルのディレクトリです。
- 各パーティションは 1 つのマシンに完全に収まっている必要があります。そのため、トピックのパーティションが 1 つだけである場合は、単一のマシンの能力を超えて書き込みレートまたは保持をスケーリングすることはできません。1000 個のパーティションがある場合、1000 台のマシンを使用できる可能性があります。
- 各パーティションはすべて順序付けされています。すべての書き込みに対して全体的な順序付けが必要な場合は、パーティションを 1 つだけ使用します。
- 各パーティションは、各コンシューマーグループ内のコンシューマーの複数のスレッドまたはプロセスで消費されることはありません。そのため、各プロセスを単一スレッド方式で消費し、パーティション内でのコンシューマーに対する順序を保証することができます(順序付けされたメッセージのパーティションを分割して複数のコンシューマーに分配した場合、メッセージが正しい順序で保管されたとしても、時には順不同で処理されることがあります)。
- 多数のパーティションを単一プロセスで消費することもできるので、1000 個のパーティションすべてを単一プロセスで消費するように構成することもできます。言い換えると、パーティション数はコンシューマーの最大並列性の上限であることになります。
- パーティション数が多いほどファイル数が多くなるので、書き込みを適切にバッファリングしてより大きい書き込みに合体させるのに十分なメモリーがない場合は、書き込みがより細かくなる可能性があります。
- 各パーティションは ZooKeeper の複数の znode に相当します。ZooKeeper はあらゆるものをメモリーに保持するため、最終的に制御が利かなくなる可能性があります。
- パーティション数が多いほど、リーダーのフェイルオーバー時間が長くなります。各パーティションは迅速(数ミリ秒)に処理されますが、数千のパーティションがある場合はそれが合計されることになります。
- コンシューマーの位置をチェックポイントに設定する場合、パーティションごとに 1 つのオフセットを保管することになり、パーティション数が多いほど、位置のチェックポイントのコストが大きくなります。
- パーティションの数を後から増やすことはできますが、増やした場合にトピック内のデータの再編成は試行されません。そのため、キーの意味に基づいたパーティション分割に依存している処理がある場合は、後からパーティション数の増加が必要になったときに、古いパーティションの下位のトピックから新しいパーティションのより上位のトピックにデータを手作業でコピーする必要があります。
I/O 数およびファイル数は実際には #partitions/#brokers 程度であるため、ブローカー数を増やすことで問題は修正されます。しかし、ZooKeeper はクラスター内のすべてのパーティションを処理するので、マシン数を増やしても役に立ちません。
仮想メモリーの調整¶
Linux の仮想メモリーは、システムのワークロードが収まるように自動的に調整されます。Kafka はシステムのページキャッシュに大きく依存しているので、仮想メモリーシステムがディスクにスワップアウトされると、十分なメモリーがページキャッシュに割り当てられなくなる可能性があります。一般的には、スワッピングは Kafka のあらゆる面のパフォーマンスに顕著な悪影響を及ぼすので、回避する必要があります。
スワップ領域を構成していなければ、スワッピングに関連するパフォーマンスの問題を完全に回避することができます。ただし、システムに壊滅的な問題が発生した場合に、スワッピングは重要な安全メカニズムになります。たとえば、スワッピングを設定しておくと、メモリー不足になった場合でも、OS でプロセスが強制終了されることがなくなります。
スワッピングによるパフォーマンス低下の問題を回避すると同時にセーフティネットを確保するためには、vm.swappiness パラメーターを非常に小さな値(「1」など)に設定します。 vm.swappiness の値は、ページキャッシュからページを取り除くのではなく、仮想メモリーサブシステムでスワップ領域をどの程度使用するかのパーセンテージを表しています。このパラメーターの値が大きいほど、カーネルはより積極的にスワップを行います。ページキャッシュのサイズを減らす方が、スワップを調整するより得策です。ただし、この値を 0 にすると、どのような状況であってもスワップが許可されなくなって、このパラメーターを使用した場合に与えられるセーフティネットが失われるので、この値を 0 にすることはお勧めしません。
ラグが発生しているレプリカ¶
ISR は、リーダーと完全に同期されているレプリカのセットです。言い換えれば、ISR のすべてのレプリカでは、コミットされたすべてのメッセージがローカルログに書き込み済みです。定常状態では、ISR には常にパーティション内のすべてのレプリカが含まれています。時には、いくつかのレプリカが同期状態のレプリカのリストから外れることがあります。その原因としては、レプリカで障害が発生していることや、レプリカの処理に時間がかかっていることが考えられます。
レプリカが一定のしきい値を超えてリーダーと異なっている場合に、そのレプリカが ISR から外れることがあります。これは次のパラメーターで制御されています。
replica.lag.time.max.msこのパラメーターは通常、ブローカーの障害を確実に検出できる値に設定されています。リーダーからのメッセージのフェッチレート(
kafka.server:type=ReplicaFetcherManager,name=MinFetchRate,clientId=Replica)を測定してレプリカの最小フェッチレートを観察することによって、この値を適切に設定することもできます。そのレートがnであれば、このパラメーターの値を1/n * 1000より大きな値に設定します。
コンシューマーのスループットの向上¶
最初に、コンシューマーが処理に時間がかかっているだけなのか、停止しているのかを割り出します。それには、コンシューマーがプロデューサーより遅れているメッセージ数を表す、最大ラグのメトリック kafka.consumer:type=ConsumerFetcherManager,name=MaxLag,clientId=([-.\w]+) をモニタリングします。モニタリングするもう一つのメトリックは、コンシューマーの最小フェッチレート kafka.consumer:type=ConsumerFetcherManager,name=MinFetchRate,clientId=([-.\w]+) です。コンシューマーの MinFetchRate がほぼ 0 に低下していれば、コンシューマーは停止している可能性が高いと考えられます。MinFetchRate がゼロではなく、比較的一定で、コンシューマーのラグが増加していれば、コンシューマーがプロデューサーより時間がかかっていることを表しています。その場合の典型的な解決策は、コンシューマーの並列度を増やすことです。この場合、トピックのパーティション数を増やすことが必要になる場合があります。
大容量のメッセージサイズへの対処¶
メッセージの最大サイズはデフォルトの 1 MB のままにしておくことを強くお勧めします。最大メッセージサイズを増やすことが不可欠である場合に、考慮すべき多くの影響のいくつかを以下に示しています。また、メッセージの圧縮や分割の使用などの選択肢も検討します。
- ヒープの断片化
- 一貫して大容量のメッセージが続く場合は、ブローカー側でヒープの断片化が発生する可能性が高くなるので、一貫したパフォーマンスを維持するためには JVM の大幅な調整が必要になります。
- ダーティなページキャッシュ
- ページキャッシュに存在しなくなったメッセージにアクセスするには時間がかかります。メッセージが大容量になるほど、ページキャッシュに収まるメッセージ数が少なくなるので、パフォーマンスが低下します。
- Kafka クライアントのバッファサイズ
- クライアント側のデフォルトのメッセージサイズは小容量(1 MB 未満)のメッセージ向けに調整されています。大容量のメッセージを適切に処理するためには、プロデューサーとコンシューマーの両方でクライアント側のバッファサイズを調整する必要があります。
max.message.bytesに関する 解説 を参照してください。
より大容量のメッセージに対処できるように Kafka を構成するためには、必要とするレベル(プロデューサー、コンシューマー、トピックのいずれか)で以下の構成パラメーターを設定します。この構成がすべてのトピックで必要である場合はブローカー構成で設定できますが、前述の理由により、そうすることはお勧めしません。
| スコープ | 構成パラメーター | 注意事項 |
|---|---|---|
| トピック | max.message.bytes |
最大メッセージサイズをトピックレベルで設定することをお勧めします。 |
| ブローカー | message.max.bytes |
最大メッセージサイズをブローカーレベルで設定することはお勧めしません。 |
| プロデューサー | max.request.size |
最大メッセージサイズをプロデューサーレベルで変更する場合に必要です。 |
batch.size、buffer.memory |
これらのパラメーターはパフォーマンス調整に使用します。 | |
| コンシューマー | fetch.max.bytes、max.partition.fetch.bytes |
最大メッセージサイズをコンシューマーレベルで設定する場合に使用します。 |
たとえば、2 MB のメッセージに対処できるようにする場合は、次のように構成する必要があります。
トピックの構成
max.message.bytes=2097152
プロデューサーの構成
max.request.size=2097152
# This will allow 5 messages per batch (1 batch = 1 partition) if all messages is 2MB.
batch.size=10485760
# This will allow 10 batches to be held in memory at any one time if all messages is 2MB
buffer.memory=104857600
コンシューマーの構成
# This will allow consuming maximum 5 records per partition if all messages is 2MB.
max.partition.fetch.bytes=10485760
# This will allow consuming 10 partitions if all messages is 2MB.
fetch.max.bytes=104857600.
より大容量のメッセージに対処できるように Kafka を構成することに加えて、ブローカーが受信するサイズを減らして前述の理由のいくつかを回避するために、プロデューサーレベルでメッセージを圧縮することを検討します。
ソフトウェアアップデート¶
ソフトウェアアップデートは、 ローリング再起動 方式で クラスターをアップグレードする ことによって行います。
注釈
Kafka 0.7.x(2012 年にリリース)を実行している場合 : 前述のアップデート手順は、0.7 から 0.8 へのアップグレード時だけは機能しません。0.7 から 0.8 へのアップグレードについては、『 Migrating from 0.7 to 0.8 』移行ガイドを参照してください。