Multi-Region Clusters¶
Confluent Server は多くの場合、複数の可用性ゾーンまたは近隣データセンターにわたって実行されます。可用性ゾーンまたは近隣データセンター内のブローカー間のコンピューターネットワークが、信頼性、レイテンシ、帯域幅、またはコストの点で異なっている場合、メッセージを生成および消費するときのレイテンシが増大し、スループットが低下し、コストが増加する可能性があります。
これを抑えるために、以下の 3 つの機能が Confluent Server に追加されました。
- フォロワーフェッチ
- オブザーバー
- レプリカ配置
フォロワーフェッチ¶
この機能導入以前は、すべての消費および生成操作がリーダー上で実行されていました。Multi-Region Clusters では、クライアントはフォロワーから消費することができます。これにより、クライアントとブローカー間のデータセンター間トラフィックの量が大幅に減少します。
フォロワーフェッチを有効にするには、以下の設定を server.properties ファイルに構成します。ここで、broker.rack はブローカーの位置を指定します。これはラックである必要はなく、ブローカーが存在するリージョンを指定できます。
replica.selector.class=org.apache.kafka.common.replica.RackAwareReplicaSelector
broker.rack=<region>
コンシューマー側では、client.rack をクライアントプロパティとして設定します。Apache Kafka® 2.3 以降のクライアントは、指定した client.rack ID と一致する broker.rack を持つフォロワーから読み取ります。
client.rack=<rack-ID>
ちなみに
- この機能は、
confluent-kafkaパッケージでも提供されています。 - フォロワーが同期されていない場合でも、コンシューマーはフォロワーからメッセージを消費できます。たとえば、
westおよびeastラックがある場合、westが 1 時間停止してから再起動すると、そのブローカーは同期されていませんが、eastからデータを複製して追い付き始めます。この追い付き期間にwestのコンシューマーはこれらの "同期されていない" フォロワーレプリカから消費して、eastへの長いネットワークホップを回避できます。ただし、これは、コンシューマーが要求するオフセットが同期されていないフォロワーに存在する場合に限ります。コンシューマーが同期されていないフォロワーを追い抜くと、eastにいると考えられるリーダーからのフェッチを開始します。
オブザーバー¶
歴史的に、レプリカにはリーダーとフォロワーの 2 種類があります。Multi-Region Clusters には、3 種類目のレプリカである "オブザーバー" が導入されています。デフォルトでは、オブザーバーは同期レプリカ(ISR)に参加しませんが、フォロワーと同様にリーダーに追い付こうとします。フォロワーフェッチを使用すると、クライアントはオブザーバーからも消費することができます。
オブザーバーは ISR に参加しないことによって、データを非同期でレプリケートする機能を提供します。Confluent Server では、トピックのパーティションの高基準値は、ISR のすべてのメンバーがメッセージをレプリケートしたことを確認応答するまで増加しません。acks=all を使用するクライアントのスループットは、特にレイテンシが大きく、帯域幅が低いネットワークがデータセンター間に含まれている場合は低下する可能性があります。オブザーバーを使用すると、1 つのリージョン内ではデータを同期してレプリケートし、リージョン間では非同期でレプリケートするトピックを定義できます。デフォルトでは、これらのオブザーバーは ISR に参加しないため、除外メッセージのスループットとレイテンシに影響を与えません。なぜなら、トピックのパーティションリーダーは、オブザーバーにメッセージがレプリケートされるのを待たずに、リクエストの確認応答をプロデューサーに送信できるからです。
このドキュメント のメトリックに関するセクションで説明するメトリクスを使用すると、リーダーに追い付いているレプリカ(通常の同期レプリカとオブザーバー)の数をモニタリングできます。
オブザーバーの自動昇格¶
注釈
オブザーバーの自動昇格は、Confluent Platform 6.1 で導入されたレプリカ配置のバージョン 2 でのみ使用できます。バージョン 2 を使用するには、レプリカ配置 JSON で "version": 2 を指定します。詳細については、「レプリカ配置」を参照してください。
オブザーバーの自動昇格 は、オブザーバーが同期レプリカリスト(ISR)に昇格されるプロセスです。これは、特定の機能低下のシナリオではメリットがある場合があります。たとえば、あるパーティションで、最小同期レプリカ数の制限を下回るほどブローカーの障害が発生した場合は、そのパーティションが通常はオフラインになります。オブザーバーの自動昇格を設定している場合は、1 つ以上のオブザーバーが ISR 内でフォロワーの代わりとなるため、フォロワーが復元されるまで、パーティションをオンライン状態に保つことができます。フォロワーが復元される(追い付かれて、ISR に再参加する)と、オブザーバーは自動的に ISR から降格されます。
この動作は、トピックのレプリカ配置ポリシーの observerPromotionPolicy フィールドによって制御されています。設定できる値は、次のとおりです。
under-min-isr: トピックのmin.insync.replicasの構成を ISR サイズが下回ると、オブザーバーが昇格されます。たとえば、パーティションがISR=3およびmin.insync.replicas=2である場合は、ISR 内の 2 つのレプリカに障害が発生すると、オブザーバーが昇格されます。under-replicated: トピックのレプリカ配置ポリシーで構成されているレプリカ数を ISR サイズが下回ると、オブザーバーが昇格されます。たとえば、パーティションがISR=3およびmin.insync.replicas=2である場合は、ISR 内の 1 つのレプリカに障害が発生すると、オブザーバーが昇格されます。leader-is-observer: 現在のパーティションリーダーがオブザーバーである場合にのみオブザーバーが昇格されます。
重要
デフォルトの observerPromotionPolicy は under-min-isr です。この動作は、デフォルトのバージョン 1 レプリカ配置から変更されています。従来の動作を使用するには、レプリカ配置のバージョン 1 を使用するか、observerPromotionPolicy を leader-is-observer に構成します。
このドキュメント のメトリックのセクションで説明しているメトリック ObserversInIsrCount には、現在、ISR 内にあるオブザーバーの数が表示されます。
ブログ記事「Automatic Observer Promotion Brings Fast and Safe Multi-Datacenter Failover with Confluent Platform 6.1」も参照してください。
レプリカ配置¶
レプリカ配置では、レプリカをトピック内のパーティションに割り当てる方法を定義します。この機能は、各ブローカーに対して構成する broker.rack プロパティに依存します。たとえば、オブザーバーを使用するトピックを作成するには、kafka-topics で新しい --replica-placement フラグを指定して、内部プロパティ confluent.placement.constraints を構成します。
kafka-topics --create \
--bootstrap-server kafka-west-1:9092 \
--topic testing-observers \
--partitions 3 \
--replica-placement /etc/confluent/testing-observers.json \
--config min.insync.replicas=2
/etc/confluent/testing-observers.json ファイルの内容は以下のようになります。
{
"version": 2,
"replicas": [
{
"count": 3,
"constraints": {
"rack": "us-west"
}
}
],
"observers": [
{
"count": 2,
"constraints": {
"rack": "us-east"
}
}
],
"observerPromotionPolicy":"under-min-isr"
}
replicas フィールドには、同期レプリカが満たす必要がある制約のリストが含まれています。observers フィールドには、非同期レプリカ(オブザーバー)が満たす必要がある制約のリストが含まれています。上の例では、Confluent Server によって 3 つのパーティションを持つ 1 つのトピックが作成されます。各パーティションには、5 つのレプリカが割り当てられています。そのうちの 3 つは同期レプリカで、broker.rack は us-west です。残りの 2 つはオブザーバーで、broker.rack は us-east です。制約を満たすことができず、Confluent Server が指定された制約に一致する十分なブローカーを見つけることができない場合、トピックの作成は失敗します。
kafka-topics --bootstrap-server localhost:9092 --describe を実行した場合、トピックは以下のようになります。
Topic: test-observers PartitionCount: 3 ReplicationFactor: 5 Configs: segment.bytes=1073741824,confluent.placement.constraints={"version":1,"replicas":[{"count":3,"constraints":{"rack":"us-west"}}],"observers":[{"count":2,"constraints":{"rack":"us-east"}}]}
Topic: test-observers Partition: 0 Leader: 1 Replicas: 1,2,3,4,5 Isr: 1,2,3 Offline: Observers: 4,5
Topic: test-observers Partition: 1 Leader: 2 Replicas: 2,3,1,5,4 Isr: 2,3,1 Offline: Observers: 5,4
Topic: test-observers Partition: 2 Leader: 3 Replicas: 3,1,2,4,5 Isr: 3,1,2 Offline: Observers: 4,5
上の例では、最初のパーティションで、acks=all のプロデューサーは、生成されたメッセージをブローカー 1、2、および 3 がレプリケートした後に、トピックのパーティションリーダー 1 から確認応答を受信します。ブローカー 4 および 5 もデータを可能な限り迅速にレプリケートしますが、リーダーは、ブローカー 4 および 5 からの確認応答を待機せずにプロデューサーに確認応答を送信できます。
注釈
レプリカ配置制約の重複は許可されていません。たとえば、以下のレプリカ配置 JSON は無効です。
# INVALID
"version": 2,
"replicas": [
{
"count": 2,
"constraints": {
"rack": "us-west"
}
},
{
"count": 1,
"constraints": {
"rack": "us-east"
}
}
],
"observers": [
{
"count": 1,
"constraints": {
"rack": "us-east"
}
}
]
}
しかし、以下のレプリカ配置制約は有効です。
# VALID
"version": 2,
"replicas": [
{
"count": 2,
"constraints": {
"rack": "us-west"
}
},
{
"count": 1,
"constraints": {
"rack": "us-east-a"
}
}
],
"observers": [
{
"count": 1,
"constraints": {
"rack": "us-east-b"
}
}
]
}
アーキテクチャ¶
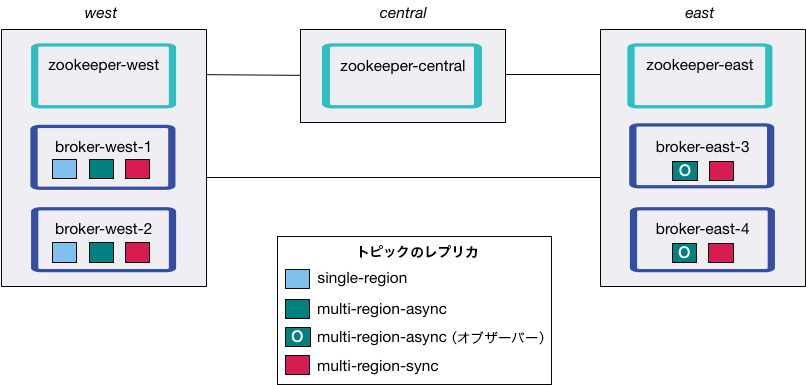
ベストプラクティスとして、マルチリージョンクラスターは 3 つ以上のデータセンターにわたってデプロイしてください。これは、ネットワークパーティションイベント発生時のスプリットブレインを回避するためです。たとえば、以下のように ZooKeeper をデプロイできます。
- DC1: 2 つの ZooKeeper ノード
- DC2: 2 つの ZooKeeper ノード
- DC3: 1 つの ZooKeeper ノード
Kafka ブローカーは各データセンター(DC)にデプロイされている必要はありません。ZooKeeper のアンサンブルは、ネットワークパーティションイベントの発生時に Kafka ノードのクォーラムが維持されるようにデプロイする必要があります。3 つ以上のデータセンターにデプロイされたマルチリージョンクラスターでは、これが最も簡単です。
2 つのデータセンターのデプロイは可能ですが、このアーキテクチャでは、ネットワークパーティションの発生時に優先データセンターがすべてのリーダー選出(3 つの ZooKeeper ノード、2 つの ZooKeeper ノードなど)に勝利するか、または手動介入によって勝利するデータセンターを選定するための ZooKeeper クォーラムを再構成する必要があります。
オブザーバーのフェイルオーバー¶
注釈
このセクションでは、パーティションのすべてのレプリカの障害に関して説明しています。部分的な障害に自動的に対処するには、「オブザーバーの自動昇格」を参照してください。
すべての同期レプリカがオフラインの場合、オブザーバーをリーダーとして選出できます。Confluent Server には、リーダー選出を手動でトリガーするためのコマンド( kafka-leader-election)が含まれています。このコマンドを使用すると、ISR に参加していないオブザーバーを含むオンラインレプリカをリーダーとして選出するリクエストをコントローラーに送信できます。ISR に参加していないレプリカまたはオブサーバーをリーダーとして選出することを、"クリーンではないリーダーの選出" と呼びます。
クリーンではないリーダーの選出では、新しいリーダーは、確認応答済みの最大オフセットまでの生成済みレコードをすべて保持していない可能性があります。そのため、すべてのトピックのパーティションログが、確認応答済みの最大オフセットの前のオフセットまで 切り捨てられる 場合があります。
重要
クリーンではないリーダーの選出によるデータ損失を最小限に抑えるには、オブザーバーのレプリケーションをモニタリングして、遅延が大きくなりすぎないようにする必要があります。
たとえば、us-west-1 と us-west-2 にまたがるクラスターがあり、us-west-1 のすべてのブローカーを失ったとします。
トピックのレプリカが
us-west-2にあり、ISR に含まれている場合、それらのブローカーが自動的にリーダーに選出され、クライアントは引き続きメッセージを生成および消費します。トピックのレプリカにオブザーバーが含まれており、それらが
us-west-2にあって ISR に参加していない場合、クリーンではないリーダーの選出を実行できます。トピックのパーティションを指定するプロパティファイルを作成します。
cat unclean-election.json { "version": 1, "partitions": [ {"topic": "testing-observers", "partition": 0} ] }以下のコマンドを実行すると、オブザーバーが ISR に参加します。
kafka-leader-election --bootstrap-server kafka-west-2:9092 \ --election-type UNCLEAN --path-to-json-file unclean-election.json
ブローカーが復旧した後に優先リーダーにフェイルバックするには、以下のコマンドを実行します。
kafka-leader-election --bootstrap-server kafka-west-1:9092 \ --election-type preferred --all-topic-partitions
auto.leader.rebalance.enableが設定されている場合、優先リーダーへの切り替えは自動的に発生します。また、優先リーダーの選定は、leader.imbalance.per.broker.percentageおよびleader.imbalance.check.interval.secondsにも基づきます。優先リーダーの選定を要求するには、以下を実行します。kafka-leader-election --bootstrap-server localhost:9092 --election-type PREFERRED --topic foo
メトリクス¶
Confluent Server では、トピックのパーティションの正常性とステートを調べるためにモニタリングする必要があるメトリクスがいくつかあります。これらのメトリクスの一部を以下に示します。
ReplicasCount- JMX での完全なオブジェクト名はkafka.cluster:type=Partition,name=ReplicasCount,topic=<topic-name>,partition=<partition-id>です。トピックのパーティションに割り当てられているレプリカ(同期レプリカとオブザーバー)の数をレポートします。ObserverReplicasCount- JMX での完全なオブジェクト名はkafka.cluster:type=Partition,name=ObserverReplicasCount,topic=<topic-name>,partition=<partition-id>です。トピックのパーティションに割り当てられているオブザーバーの数をレポートします。InSyncReplicasCount- JMX での完全なオブジェクト名はkafka.cluster:type=Partition,name=InSyncReplicasCount,topic=<topic-name>,partition=<partition-id>です。ISR に含まれているレプリカの数をレポートします。CaughtUpReplicasCount- JMX での完全なオブジェクト名はkafka.cluster:type=Partition,name=CaughtUpReplicasCount,topic=<topic-name>,partition=<partition-id>です。トピックのパーティションリーダーに追い付いていると見なされるレプリカの数をレポートします。オブザーバーは追い付いている場合でも ISR には参加していないため、この値は ISR のサイズより大きくなる場合があります。IsNotCaughtUp- JMX での完全なオブジェクト名はkafka.cluster:type=Partition,name=IsNotCaughtUp,topic=<topic-name>,partition=<partition-id>です。一部のレプリカがパーティションリーダーに追い付いていないと見なされる場合は 1(true)をレポートします。ObserversInIsrCount- JMX での完全なオブジェクト名はkafka.cluster:type=Partition,name=ObserversInIsrCount,topic=<topic-name>,partition=<partition-id>です。現在、ISR 内にあるオブザーバーの数をレポートします。
パーティションの再割り当て¶
Confluent Platform 5.5 では、新しいブローカー設定が追加されました。この設定を使用すると、自動生成されるトピックに対するパーティション配置制約をより簡単に構成できます。confluent.log.placement.constraints を設定して、クラスターのデフォルトのレプリカ配置制約を定義します。以下に例を示します。
confluent.log.placement.constraints={"version": 1,"replicas": [{"count": 2, "constraints": {"rack": "west"}}], "observers": [{"count": 2, "constraints": {"rack": "east"}}]}
トピックのレプリカ配置制約、およびトピックのパーティションへのレプリカの割り当てを変更できます。kafka-configs コマンドラインツールを使用すると、レプリカ配置制約を変更できます。以下に例を示します。
kafka-configs --bootstrap-server kafka-west-1:9092 --entity-name testing-observers --entity-type topics --alter --replica-placement /etc/confluent/testing-observers.json
/etc/confluent/testing-observers.json ファイルの内容は以下のようになります。
{
"version": 1,
"replicas": [
{
"count": 3,
"constraints": {
"rack": "us-west"
}
}
],
"observers": [
{
"count": 2,
"constraints": {
"rack": "us-east"
}
}
]
}
レプリカ配置 JSON ファイルの内容については、「レプリカ配置」セクションを参照してください。
重要
トピックの構成を変更しても、トピックのパーティションへのレプリカの割り当ては変更されません。トピック構成のレプリカ配置の変更の後にパーティションの再割り当てを行う必要があります。confluent-rebalancer コマンドラインツールは、レプリカ配置制約にも対応する再割り当てをサポートしています。詳細については、「データの自動バランス調整」を参照してください。
たとえば、以下のコマンドを実行して、トピックのレプリカ配置制約に一致する再割り当てを開始します。この場合、Confluent Platform 5.5 以降を使用する必要があります。5.5 以降には、再割り当ての対象となる一連のトピックを制限するための --topics および --exclude-internal-topics フラグが含まれています。これにより、バランス調整全体の範囲が小さくなり、時間も短縮されます。--replica-placement-only を使用すると、レプリカ配置制約を満たさないパーティションのみで再割り当てを実行できます。
confluent-rebalancer execute --bootstrap-server kafka-west-1:9092 --replica-placement-only --throttle 10000000 --verbose
再割り当てのステータスをモニタリングするには、以下のコマンドを実行します。
confluent-rebalancer status --bootstrap-server kafka-west-1:9092
再割り当てを終了するには、以下のコマンドを実行します。
confluent-rebalancer finish --bootstrap-server kafka-west-1:9092
confluent-rebalancer 5.4.0 以降(Confluent Platform 5.4.0 以降に付属しています)を必ず使用してください。
バージョン 5.5.0 と 5.5.0 Kafka クラスターを使用すると、新機能を活用し、--topics、--exclude-internal-topics、または --replica-placement-only でバランス調整の範囲を制限できます。
詳細と例については、「データの自動バランス調整」を参照してください。
レプリカのモニタリング¶
kafka-replica-status.sh コマンドを使用すると、パーティションに割り当てられているレプリカのステータス(現在のモードやレプリケーションステートに関する情報を含む)をモニタリングできます。
たとえば、以下のコマンドでは、最初のパーティションの testing-observers トピックを構成するすべてのレプリカに関する情報が表示されます。
kafka-replica-status.sh --bootstrap-server localhost:9092 --topics testing-observers --partitions 0 --verbose
この例の出力は以下のようになります。
./bin/kafka-replica-status.sh --bootstrap-server localhost:9092 --topics testing-observers --partitions 0 --verbose
Topic: testing-observers
Partition: 0
Replica: 1
IsLeader: true
IsObserver: false
IsIsrEligible: true
IsInIsr: true
IsCaughtUp: true
LastCaughtUpLagMs: 0
LastFetchLagMs: 0
LogStartOffset: 0
LogEndOffset: 10000
Topic: testing-observers
Partition: 0
Replica: 2
...
出力の内容は以下のとおりです。
Topic(< String>): レプリカのトピックです。Partition(< Integer>): レプリカのパーティションです。Replica(< Integer>): レプリカのブローカー ID です。isLeader(< Boolean>): レプリカが ISR リーダーかどうかです。isObserver(< Boolean>): レプリカがオブザーバーかどうか。そうでない場合は従来のレプリカです。isIsrEligible(< Boolean>): レプリカが ISR セットの候補かどうか。isInIsr(< Boolean>): レプリカが ISR セットに含まれているかどうか。isCaughtUp(< Boolean>): レプリカのログがリーダーに十分に追い付いており、同期されているとみなされるかどうか。ただし、追い付いているレプリカが ISR セットに含まれているとは限りません。たとえば、レプリカがオブザーバーである場合や、トピック配置制約により ISR に追加できないフォロワーである場合があります。lastFetchLagMs(< Long>) : 最後のフェッチリクエストをレプリカから受信してからの期間(単位: ミリ秒)。リーダーの場合、これは常に「0」ですが、リーダーがレプリカからフェッチリクエストを受信していない場合は「-1」になることがあります。lastCaughtUpLagMs(< Long>) : "追い付いている" とみなされたレプリカから最後のフェッチリクエストを受信してからの期間(単位: ミリ秒)。リーダーの場合、これは常に「0」ですが、リーダーがレプリカからフェッチリクエストを受信していない場合は「-1」になることがあります。logStartOffset/logEndOffset:(< Long>): リーダーから見たレプリカのログの開始および終了ログオフセットです。リーダーがレプリカからフェッチリクエストを受信していない場合、これらは「-1」になることがあります。
その他の便利なフラグは以下のとおりです。
--topics: レプリカステータスを取得するためのコンマ区切りのトピックです。--partitions: トピックのパーティション ID または ID 範囲のコンマ区切りリスト(「5,10-20」など)です。--verbose: 属性を 1 行に 1 つずつ冗長モードで出力します。--json: 出力を JSON フォーマットで出力します。--leaders: パーティションリーダーのみを表示するか、「exclude」が指定されている場合はリーダーを省略します。--observers: オブザーバーレプリカのみを表示するか、「exclude」が指定されている場合はオブザーバーを省略します。--exclude-internal: 内部トピックを出力から除外します。--version: Confluent Server のバージョンを表示します。
サンプル¶
Multi-Region Clusters の詳細な例を試すには、「チュートリアル: マルチリージョンクラスター」全体を実行します。このチュートリアルでは、レイテンシとパケット損失を挿入することでリージョン間の距離をシミュレーションし、マルチリージョン環境での新しい機能の価値を示します。
Multi-Region Clusters と他の Confluent 製品の使用¶
- Multi-Region Clusters と Self-Balancing Clusters の両方を使用している場合は、すべてのブローカーで ブローカーラック を指定する必要があります。開始時のブローカーと、Self-Balancing を有効にして追加したブローカーは、それぞれの
server.propertiesファイルでbroker.rackのリージョンまたはラックを指定する必要があります。詳細については、「Self-Balancing」ドキュメントの「レプリカ配置とマルチリージョンクラスター」を参照してください。 - オペレータータスクはサポートされていません。
おすすめの関連情報とリソース¶
- ブログ記事: 「Automatic Observer Promotion Brings Fast and Safe Multi-Datacenter Failover with Confluent Platform 6.1」
- ブログ記事: How Krake Makes Floating Workloads on Confluent Platform
- ブログ記事: Multi-Region Clusters with Confluent Platform 5.4
- ポッドキャスト: Resurrecting In-Sync Replicas with Automatic Observer Promotion featuring Anna McDonald
- ポッドキャスト: Disaster Recovery with Multi-Region Clusters in Confluent Platform