Important
You are viewing documentation for an older version of Confluent Platform. For the latest, click here.
Docker Quick Start¶
This quick start provides a basic guide for deploying a Kafka cluster along with all Confluent Platform components in your Docker environment. By the end of this quickstart, you will have a functional Confluent deployment against which you can run any number of applications.
To keep things simple, you can start with a single node Docker environment. Details on more complex target environments are available later in this documentation (More Tutorials). You will also be configuring Kafka and ZooKeeper to store data locally in their Docker containers. You should refer to the documentation on Docker external volumes for examples of how to add mounted volumes to your host machines. Mounted volumes provide a persistent storage layer for deployed containers, which allows images such as cp-kafka and cp-zookeeper to be stopped and restarted without losing their stateful data.
If you’re running on Windows, you’ll need to use Docker Machine to start the Docker host. Docker runs natively on Linux and macOS, so the Docker host will be your local machine if you go that route. If you are running on Windows, be sure to allocate at least 4 GB of RAM (6 GB is recommended) to the Docker Machine.
Installing and Running Docker¶
For this quickstart, you can use Docker Compose or Docker client.
Getting Started with Docker Compose¶
Docker Compose is a powerful tool that enables you to launch multiple Docker images in a coordinated fashion. It is ideal for platforms like Confluent. Before you get started, you will need to install both the core Docker Engine and Docker Compose. Once you’ve done that, you can follow the steps below to start up the Confluent Platform services.
Windows Only: Create and configure the Docker Machine
Important: If you are using Docker for Mac or Docker for Windows, you can skip this step.
docker-machine create --driver virtualbox --virtualbox-memory 6000 confluentNext, configure your terminal window to attach it to your new Docker Machine:
docker-machine env confluent
Clone the Confluent Platform Docker Images Github Repository.
git clone https://github.com/confluentinc/cp-docker-images
An example Docker Compose file is included that will start up ZooKeeper and Kafka. Navigate to
cp-docker-images/examples/kafka-single-node, where it is located. Alternatively, you can download the file directly from GitHub.Start the ZooKeeper and Kafka containers in detached mode (
-d). Run this command from the directory that contains thedocker-compose.ymlfile. For example, use this path to launch a single node environment:cd <path-to-cp-docker-images>/examples/kafka-single-node/ docker-compose up -dYou should see the following:
Pulling kafka (confluentinc/cp-kafka:latest)... latest: Pulling from confluentinc/cp-kafka ad74af05f5a2: Already exists d02e292e7b5e: Already exists 8de7f5c81ab0: Already exists ed0b76dc2730: Already exists cfc44fa8a002: Already exists f441b84ed9ba: Already exists d42bb38e2f0e: Already exists Digest: sha256:61373cf6eca980887164d6fede2552015db31a809c99d6c3d5dfc70867b6cd2d Status: Downloaded newer image for confluentinc/cp-kafka:latest Creating kafkasinglenode_zookeeper_1 ... Creating kafkasinglenode_zookeeper_1 ... done Creating kafkasinglenode_kafka_1 ... Creating kafkasinglenode_kafka_1 ... done
Tip: You can run this command to verify that the services are up and running:
docker-compose ps
You should see the following:
Name Command State Ports ----------------------------------------------------------------------- kafkasinglenode_kafka_1 /etc/confluent/docker/run Up kafkasinglenode_zookeeper_1 /etc/confluent/docker/run Up
If the state is not Up, rerun the
docker-compose up -dcommand.Now check the ZooKeeper logs to verify that ZooKeeper is healthy.
docker-compose logs zookeeper | grep -i bindingYou should see the following:
zookeeper_1 | [2016-07-25 03:26:04,018] INFO binding to port 0.0.0.0/0.0.0.0:32181 (org.apache.zookeeper.server.NIOServerCnxnFactory)
Next, check the Kafka logs to verify that broker is healthy.
docker-compose logs kafka | grep -i startedYou should see the following:
kafka_1 | [2017-08-31 00:31:40,244] INFO [Socket Server on Broker 1], Started 1 acceptor threads (kafka.network.SocketServer) kafka_1 | [2017-08-31 00:31:40,426] INFO [Replica state machine on controller 1]: Started replica state machine with initial state -> Map() (kafka.controller.ReplicaStateMachine) kafka_1 | [2017-08-31 00:31:40,436] INFO [Partition state machine on Controller 1]: Started partition state machine with initial state -> Map() (kafka.controller.PartitionStateMachine) kafka_1 | [2017-08-31 00:31:40,540] INFO [Kafka Server 1], started (kafka.server.KafkaServer)
Test the broker by following these instructions.
Now you can take this basic deployment for a test drive. You’ll verify that the broker is functioning normally by creating a topic and producing data to it. You’ll use the client tools directly from another Docker container.
Create a topic named
fooand keep things simple by just giving it one partition and one replica. For a production environment you would have many more broker nodes, partitions, and replicas for scalability and resiliency.docker-compose exec kafka \ kafka-topics --create --topic foo --partitions 1 --replication-factor 1 --if-not-exists --zookeeper localhost:32181
You should see the following:
Created topic "foo".
Verify that the topic was created successfully:
docker-compose exec kafka \ kafka-topics --describe --topic foo --zookeeper localhost:32181
You should see the following:
Topic:foo PartitionCount:1 ReplicationFactor:1 Configs: Topic: foo Partition: 0 Leader: 1 Replicas: 1 Isr: 1
Publish some data to your new topic. This command uses the built-in Kafka Console Producer to produce 42 simple messages to the topic.
docker-compose exec kafka \ bash -c "seq 42 | kafka-console-producer --request-required-acks 1 --broker-list localhost:29092 --topic foo && echo 'Produced 42 messages.'"
After running the command, you should see the following:
Produced 42 messages.
Read back the message using the built-in Console consumer:
docker-compose exec kafka \ kafka-console-consumer --bootstrap-server localhost:29092 --topic foo --from-beginning --max-messages 42
If everything is working as expected, each of the original messages you produced should be written back out:
1 .... 42 Processed a total of 42 messages
You must explicitly shut down Docker Compose. For more information, see the [docker-compose down](https://docs.docker.com/compose/reference/down/) documentation. This will delete all of the containers that you created in this quickstart.
docker-compose down
The confluentinc/cp-docker-images GitHub repository has several other interesting examples of docker-compose.yml files that you can use.
Getting Started with Docker Client¶
Note
The following steps show each Docker container being launched in detached mode and how to access the logs for those detached containers. If you prefer to run the containers in the foreground, you can do so by replacing the
-d(“detached”) flag with-it(“interactive”). Containers launched in interactive mode will stream the log messages for the Confluent service directly to the terminal window. For that reason, you’ll need a separate terminal for each Docker image launched in interactive mode.
Docker Network¶
Create the Docker network that is used to run the Confluent containers.
Important
A Docker network is required to enable DNS resolution across your containers. The default Docker network does not have DNS enabled.
$ docker network create confluent
ZooKeeper¶
Start ZooKeeper. You’ll need to keep this service running throughout, so use a dedicated terminal window if you plan to launch the image in the foreground.
$ docker run -d \ --net=confluent \ --name=zookeeper \ -e ZOOKEEPER_CLIENT_PORT=2181 \ confluentinc/cp-zookeeper:4.1.5-SNAPSHOTThis command instructs Docker to launch an instance of the
confluentinc/cp-zookeeper:4.1.5-SNAPSHOTcontainer and name itzookeeper. Also, the Docker networkconfluentand the required ZooKeeper parameterZOOKEEPER_CLIENT_PORTare specified. For a full list of the available configuration options and more details on passing environment variables into Docker containers, see the configuration reference docs.Use the following command to check the Docker logs to confirm that the container has booted up successfully and started the ZooKeeper service.
$ docker logs zookeeperWith this command, you’re referencing the container name that you want to see the logs for. To list all containers (running or failed), you can always run
docker ps -a. This is especially useful when running in detached mode.When you output the logs for ZooKeeper, you should see the following message at the end of the log output:
[2016-07-24 05:15:35,453] INFO binding to port 0.0.0.0/0.0.0.0:2181 (org.apache.zookeeper.server.NIOServerCnxnFactory)Note that the message shows the ZooKeeper service listening at the port you passed in as
ZOOKEEPER_CLIENT_PORTabove.If the service is not running, the log messages should provide details to help you identify the problem. Some common errors include:
- Insufficient resources. In rare occasions, you may see memory allocation or other low-level failures at startup. This will only happen if you dramatically overload the capacity of your Docker host.
Kafka¶
Start Kafka.
$ docker run -d \ --net=confluent \ --name=kafka \ -e KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181 \ -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://kafka:9092 \ -e KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1 \ confluentinc/cp-kafka:4.1.5-SNAPSHOTNote
You’ll notice that the
KAFKA_ADVERTISED_LISTENERSvariable is set tolocalhost:9092. This makes Kafka accessible from outside the container by advertising its location on the Docker host. You also passed in the ZooKeeper port that you used when launching that container a moment ago. Because you are using--net=host, the hostname for the ZooKeeper service can be left atlocalhost.Also notice that
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTORis set to 1. This is needed when you are running with a single-node cluster. If you have three or more nodes, you do not need to change this from the default.Check the logs to see the broker has booted up successfully:
$ docker logs kafkaYou should see the following at the end of the log output:
.... [2016-07-15 23:31:00,295] INFO [Kafka Server 1], started (kafka.server.KafkaServer) ... ... [2016-07-15 23:31:00,349] INFO [Controller 1]: New broker startup callback for 1 (kafka.controller.KafkaController) [2016-07-15 23:31:00,350] INFO [Controller-1-to-broker-1-send-thread], Starting (kafka.controller.RequestSendThread) ...
Now you can take this very basic deployment for a test drive. You’ll verify that the broker is functioning normally by creating a topic and producing data to it. You’ll use the client tools directly from another Docker container.
First, you’ll create a topic. You’ll name it
fooand keep things simple by just giving it one partition and only one replica. Production environments with more broker nodes would obviously use higher values for both partitions and replicas for scalability and resiliency.$ docker run \ --net=confluent \ --rm confluentinc/cp-kafka:4.1.5-SNAPSHOT \ kafka-topics --create --topic foo --partitions 1 --replication-factor 1 --if-not-exists --zookeeper zookeeper:2181You should see the following:
Created topic "foo".Before moving on, verify that the topic was created successfully:
$ docker run \ --net=confluent \ --rm \ confluentinc/cp-kafka:4.1.5-SNAPSHOT \ kafka-topics --describe --topic foo --zookeeper zookeeper:2181You should see the following:
Topic:foo PartitionCount:1 ReplicationFactor:1 Configs: Topic: foo Partition: 0 Leader: 1001 Replicas: 1001 Isr: 1001Next, you’ll publish some data to your new topic:
$ docker run \ --net=confluent \ --rm \ confluentinc/cp-kafka:4.1.5-SNAPSHOT \ bash -c "seq 42 | kafka-console-producer --request-required-acks 1 --broker-list kafka:9092 --topic foo && echo 'Produced 42 messages.'"This command will use the built-in Kafka Console Producer to produce 42 simple messages to the topic. After running the command, you should see the following:
Produced 42 messages.To complete the story, you can read back the message using the built-in Console consumer:
$ docker run \ --net=confluent \ --rm \ confluentinc/cp-kafka:4.1.5-SNAPSHOT \ kafka-console-consumer --bootstrap-server kafka:9092 --topic foo --from-beginning --max-messages 42If everything is working as expected, each of the original messages you produced should be written back out:
1 .... 42 Processed a total of 42 messages
Schema Registry¶
Now that you have Kafka and ZooKeeper up and running, you can deploy some of the other components included in Confluent Platform. You’ll start by using the Schema Registry to create a new schema and send some Avro data to a Kafka topic. Although you would normally do this from one of your applications, you’ll use a utility provided with Schema Registry to send the data without having to write any code.
First, start the Schema Registry container:
$ docker run -d \ --net=confluent \ --name=schema-registry \ -e SCHEMA_REGISTRY_KAFKASTORE_CONNECTION_URL=zookeeper:2181 \ -e SCHEMA_REGISTRY_HOST_NAME=schema-registry \ -e SCHEMA_REGISTRY_LISTENERS=http://0.0.0.0:8081 \ confluentinc/cp-schema-registry:4.1.5-SNAPSHOTAs you did before, you can check that it started correctly by viewing the logs.
$ docker logs schema-registryFor the next step, you’ll publish data to a new topic that will leverage the Schema Registry. For the sake of simplicity, you’ll launch a second Schema Registry container in interactive mode, and then execute the
kafka-avro-console-producerutility from there.$ docker run -it --net=confluent --rm confluentinc/cp-schema-registry:4.1.4-SNAPSHOT bashDirect the utility at the local Kafka cluster, tell it to write to the topic
bar, read each line of input as an Avro message, validate the schema against the Schema Registry at the specified URL, and finally indicate the format of the data.# /usr/bin/kafka-avro-console-producer \ --broker-list kafka:9092 --topic bar \ --property schema.registry.url=http://schema-registry:8081 \ --property value.schema='{"type":"record","name":"myrecord","fields":[{"name":"f1","type":"string"}]}'Once started, the process will wait for you to enter messages, one per line, and will send them immediately when you hit the
Enterkey. Try entering a few messages:{"f1": "value1"} {"f1": "value2"} {"f1": "value3"}Note
If you hit
Enterwith an empty line, it will be interpreted as a null value and cause an error. You can simply start the console producer again to continue sending messages.When you’re done, use
Ctrl+CorCtrl+Dto stop the producer client. You can then typeexitto leave the container altogether. Now that you’ve written Avro data to Kafka, you should check that the data was actually produced as expected to consume it. Although the Schema Registry also ships with a built-in console consumer utility, you’ll instead demonstrate how to read it from outside the container on your local machine via the REST Proxy. The REST Proxy depends on the Schema Registry when producing/consuming Avro data, so you’ll need to pass in the details for the detached Schema Registry container you launched above.
REST Proxy¶
This section describes how to deploy the REST Proxy container and then consume data from the Confluent REST Proxy service.
First, start up the REST Proxy:
$ docker run -d \ --net=confluent \ --name=kafka-rest \ -e KAFKA_REST_ZOOKEEPER_CONNECT=zookeeper:2181 \ -e KAFKA_REST_LISTENERS=http://0.0.0.0:8082 \ -e KAFKA_REST_SCHEMA_REGISTRY_URL=http://schema-registry:8081 \ -e KAFKA_REST_HOST_NAME=kafka-rest \ confluentinc/cp-kafka-rest:4.1.5-SNAPSHOTFor the next two steps, you’re going to use CURL commands to talk to the REST Proxy. Your deployment steps thus far have ensured that both the REST Proxy container and the Schema Registry container are accessible directly through network ports on your local host. The REST Proxy service is listening at http://localhost:8082 As above, you’ll launch a new Docker container from which to execute your commands:
$ docker run -it --net=confluent --rm confluentinc/cp-schema-registry:4.1.4-SNAPSHOT bashThe first step in consuming data via the REST Proxy is to create a consumer instance.
# curl -X POST -H "Content-Type: application/vnd.kafka.v1+json" \ --data '{"name": "my_consumer_instance", "format": "avro", "auto.offset.reset": "smallest"}' \ http://kafka-rest:8082/consumers/my_avro_consumerYou should see the following:
{"instance_id":"my_consumer_instance","base_uri":"http://kafka-rest:8082/consumers/my_avro_consumer/instances/my_consumer_instance"}Your next
curlcommand will retrieve data from a topic in your cluster (barin this case). The messages will be decoded, translated to JSON, and included in the response. The schema used for deserialization is retrieved automatically from the Schema Registry service, which you told the REST Proxy how to find by setting theKAFKA_REST_SCHEMA_REGISTRY_URLvariable on startup.# curl -X GET -H "Accept: application/vnd.kafka.avro.v1+json" \ http://kafka-rest:8082/consumers/my_avro_consumer/instances/my_consumer_instance/topics/barYou should see the following:
[{"key":null,"value":{"f1":"value1"},"partition":0,"offset":0},{"key":null,"value":{"f1":"value2"},"partition":0,"offset":1},{"key":null,"value":{"f1":"value3"},"partition":0,"offset":2}]
Confluent Control Center¶
The Control Center application provides enterprise-grade capabilities for monitoring and managing your Confluent deployment. Control Center is part of the Confluent Enterprise offering; a trial license will support the image for the first 30 days after your deployment.
Stream Monitoring¶
This portion of the quick start provides an overview of how to use Confluent Control Center with console producers and consumers to monitor consumption and latency.
You’ll launch the Control Center image the same as you’ve done for earlier containers, connecting to the ZooKeeper and Kafka containers that are already running. This is also a good opportunity to illustrate mounted volumes.
Now you start Control Center, binding its data directory to the directory you just created and its HTTP interface to port 9021.
$ docker run -d \ --name=control-center \ --net=confluent \ --ulimit nofile=16384:16384 \ -p 9021:9021 \ -v /tmp/control-center/data:/var/lib/confluent-control-center \ -e CONTROL_CENTER_ZOOKEEPER_CONNECT=zookeeper:2181 \ -e CONTROL_CENTER_BOOTSTRAP_SERVERS=kafka:9092 \ -e CONTROL_CENTER_REPLICATION_FACTOR=1 \ -e CONTROL_CENTER_MONITORING_INTERCEPTOR_TOPIC_PARTITIONS=1 \ -e CONTROL_CENTER_INTERNAL_TOPICS_PARTITIONS=1 \ -e CONTROL_CENTER_STREAMS_NUM_STREAM_THREADS=2 \ -e CONTROL_CENTER_CONNECT_CLUSTER=http://kafka-connect:8082 \ confluentinc/cp-enterprise-control-center:4.1.5-SNAPSHOTYou may notice that you have specified a URL for the Kafka Connect cluster that does not yet exist. Not to worry, you’ll work on that in the next section.
Control Center will create the topics it needs in Kafka. Check that it started correctly by searching its logs with the following command:
$ docker logs control-center | grep StartedYou should see the following:
[2016-08-26 18:47:26,809] INFO Started NetworkTrafficServerConnector@26d96e5{HTTP/1.1}{0.0.0.0:9021} (org.eclipse.jetty.server.NetworkTrafficServerConnector) [2016-08-26 18:47:26,811] INFO Started @5211ms (org.eclipse.jetty.server.Server)To see the Control Center UI, open the link http://localhost:9021 in your browser.
If you are running Docker Machine, the UI will be running at http://<docker-host-ip>:9021 where the Docker Host IP is the address displayed by running the command
docker-machine ip confluent. If your Docker daemon is running on a remote machine (such as an AWS EC2 instance), you’ll need to allow TCP access to that instance on port 9021. This is done in AWS by adding a “Custom TCP Rule” to the instance’s security group; the rule should all access to port 9021 from any source IP.Initially, the Stream Monitoring UI will have no data.
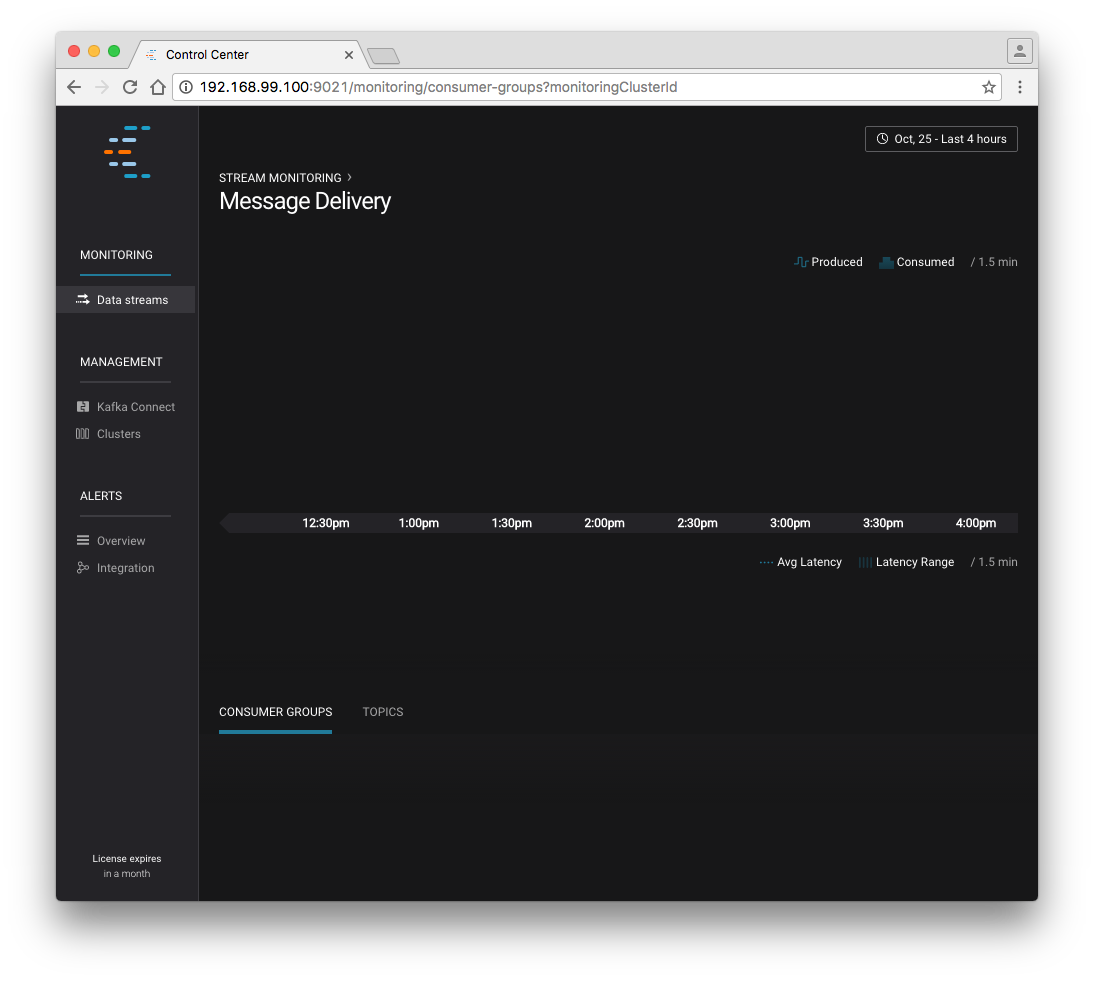
Confluent Control Center Initial View
Next, you’ll run the console producer and consumer with monitoring interceptors configured and see the data in Control Center. First you need to create a topic for testing.
$ docker run \ --net=confluent \ --rm confluentinc/cp-kafka:4.1.5-SNAPSHOT \ kafka-topics --create --topic c3-test --partitions 1 --replication-factor 1 --if-not-exists --zookeeper zookeeper:2181Now use the console producer with the monitoring interceptor enabled to send data
$ while true; do docker run \ --net=confluent \ --rm \ -e CLASSPATH=/usr/share/java/monitoring-interceptors/monitoring-interceptors-4.1.5-SNAPSHOT.jar \ confluentinc/cp-kafka-connect:4.1.5-SNAPSHOT \ bash -c 'seq 10000 | kafka-console-producer --request-required-acks 1 --broker-list kafka:9092 --topic c3-test --producer-property interceptor.classes=io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor --producer-property acks=1 && echo "Produced 10000 messages."' sleep 10; doneThis command will use the built-in Kafka Console Producer to produce 10000 simple messages on a 10 second interval to the
c3-testtopic. After running the command, you should see the following:Produced 10000 messages.The message will repeat every 10 seconds, as successive iterations of the shell loop are executed. You can terminate the client with a
Ctrl+C.You’ll use the console consumer with the monitoring interceptor enabled to read the data. You’ll want to run this command in a separate terminal window (prepared with the
eval $(docker-machine env confluent)as described earlier).$ OFFSET=0 $ while true; do docker run \ --net=confluent \ --rm \ -e CLASSPATH=/usr/share/java/monitoring-interceptors/monitoring-interceptors-4.1.5-SNAPSHOT.jar \ confluentinc/cp-kafka-connect:4.1.5-SNAPSHOT \ bash -c 'kafka-console-consumer --consumer-property group.id=qs-consumer --consumer-property interceptor.classes=io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor --bootstrap-server kafka:9092 --topic c3-test --offset '$OFFSET' --partition 0 --max-messages=1000' sleep 1; let OFFSET=OFFSET+1000 doneIf everything is working as expected, each of the original messages you produced should be written back out:
1 .... 1000 Processed a total of 1000 messagesYou’ve intentionally setup a slow consumer to consume at a rate of 1000 messages per second. You’ll soon reach a steady state where the producer window shows an update every 10 seconds while the consumer window shows bursts of 1000 messages received every 1 second. The monitoring activity should appear in the Control Center UI after 15 to 30 seconds. If you don’t see any activity, use the scaling selector in the upper left hand corner of the web page to select a smaller time window (the default is 4 hours, and you’ll want to zoom in to a 10-minute scale). You will notice there will be moments where the bars are colored red to reflect the slow consumption of data.
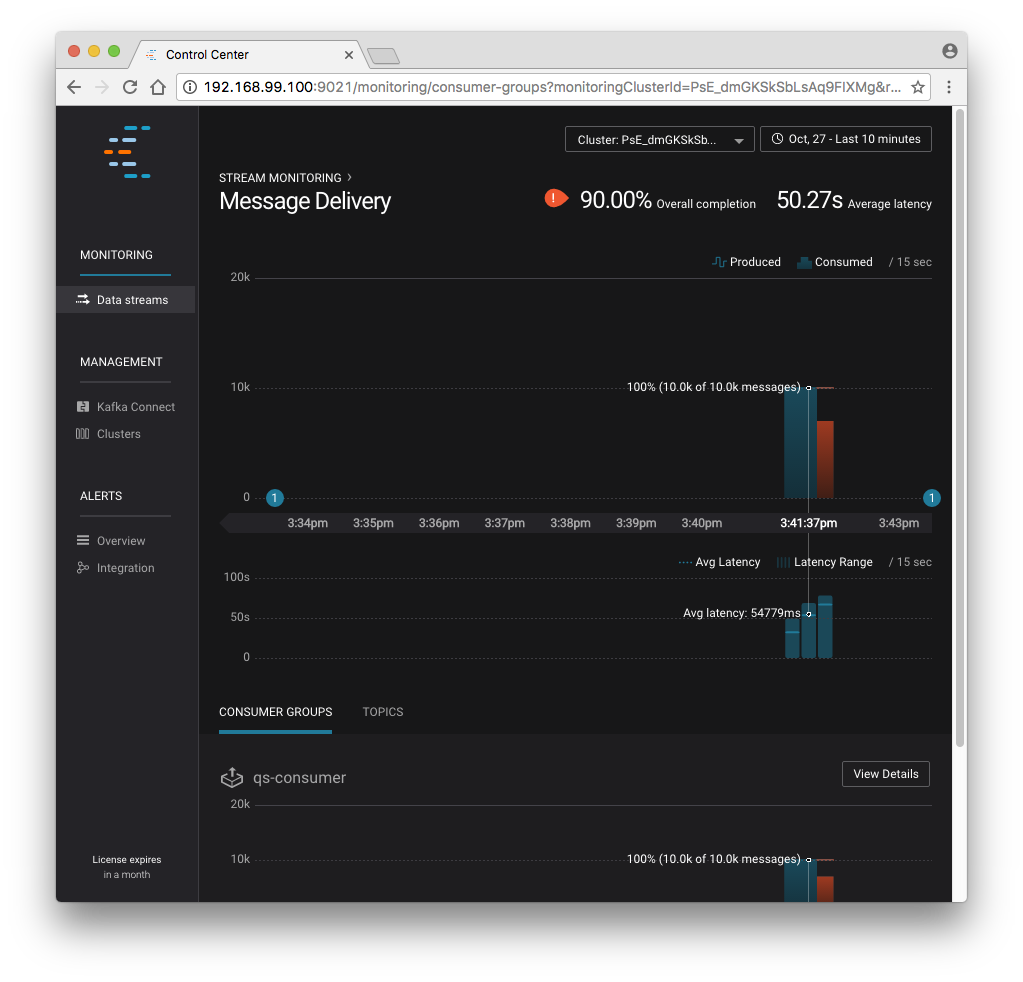
Alerts¶
Confluent Control Center provides alerting functionality to notify you when anomalous events occur in your cluster. This section assumes the console producer and consumer you launched to illustrate the stream monitoring features are still running in the background.
The Alerts and Overview link on the lefthand navigation sidebar displays a history of all triggered events. To begin receiving alerts, you’ll need to create a trigger. Click the “Triggers” navigation item and then select “+ New trigger”.
Let’s configure a trigger to fire when the difference between your actual consumption and expected consumption is greater than 1000 messages:
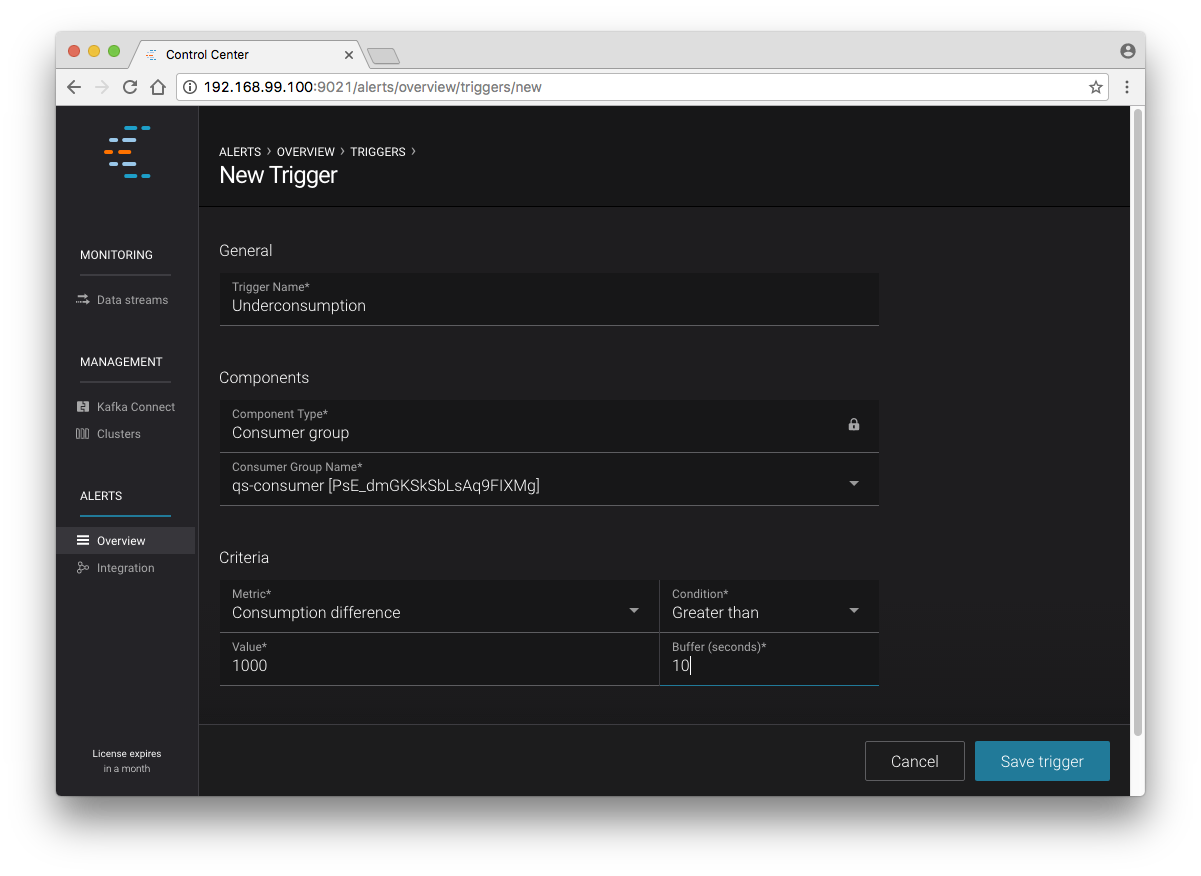
New trigger
Set the trigger name to be “Underconsumption”, which is what will be displayed
on the history page when your trigger fires. You need to select a specific
consumer group (qs-consumer) for this trigger. That’s the name of
the group you specified above in your invocation of
kafka-console-consumer.
Set the trigger metric to be “Consumption difference” where the condition is “Greater than” 1000 messages. The buffer time (in seconds) is the wall clock time you will wait before firing the trigger to make sure the trigger condition is not too transient.
After saving the trigger, Control Center will now prompt us to associate an action that will execute when your newly created trigger fires. For now, the only action is to send an email. Select your new trigger and choose maximum send rate for your alert email.
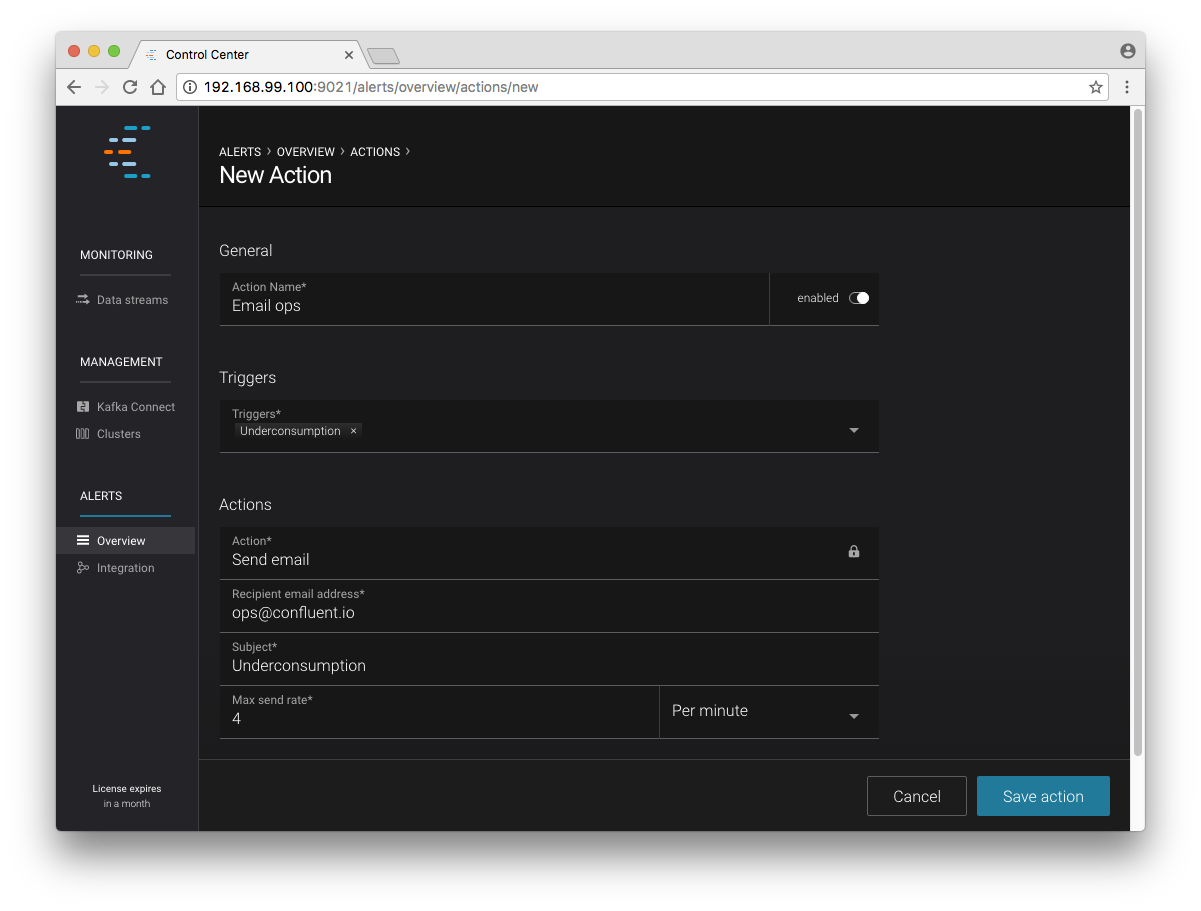
New action
Let’s return to your trigger history page. In a short while, you should see a new trigger show up in your alert history. This is because you setup your consumer to consume data at a slower rate than your producer.
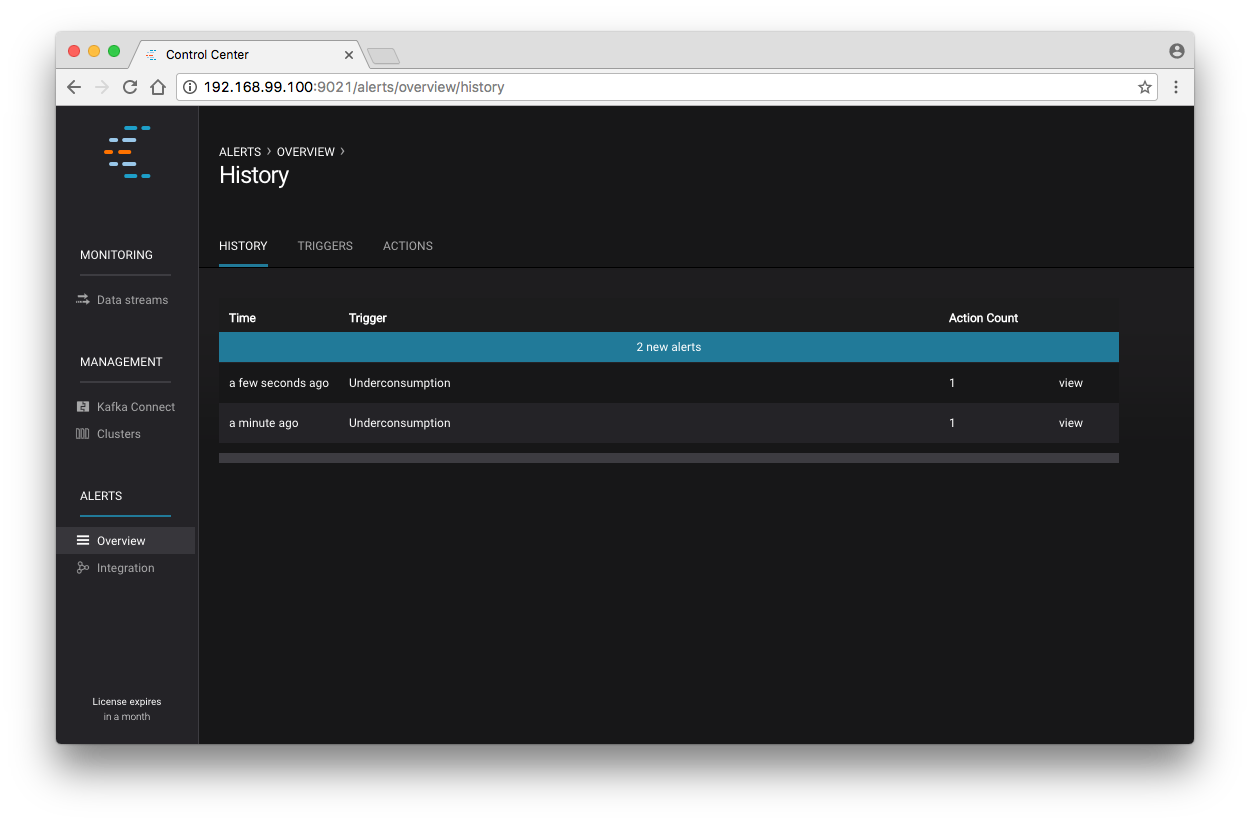
A newly triggered event
Kafka Connect¶
Getting Started¶
In this section, you’ll create a simple data pipeline using Kafka Connect. You’ll start by reading data from a file and writing that data to a new file. You will then extend the pipeline to show how to use Connect to read from a database table. This example is meant to be simple for the sake of this quickstart. If you’d like a more in-depth example, please refer to the Using a JDBC Connector with Avro data tutorial.
First, let’s start up a container with Kafka Connect. Connect stores all its stateful data (configuration, status, and internal offsets for connectors) directly in Kafka topics. You will create these topics now in the Kafka cluster you have running from the steps above.
$ docker run \ --net=confluent \ --rm \ confluentinc/cp-kafka:4.1.5-SNAPSHOT \ kafka-topics --create --topic quickstart-offsets --partitions 1 --replication-factor 1 --if-not-exists --zookeeper zookeeper:2181Note
It is possible to allow connect to auto-create these topics by enabling the autocreation setting. However, it is recommended that you do it manually, as these topics are important for connect to function and you’ll likely want to control settings such as replication factor and number of partitions.
Next, create a topic for storing data that you’ll be sending to Kafka.
docker run \ --net=confluent \ --rm \ confluentinc/cp-kafka:4.1.5-SNAPSHOT \ kafka-topics --create --topic quickstart-data --partitions 1 --replication-factor 1 --if-not-exists --zookeeper zookeeper:2181
Now you should verify that the topics are created before moving on:
$ docker run \ --net=confluent \ --rm \ confluentinc/cp-kafka:4.1.5-SNAPSHOT \ kafka-topics --describe --zookeeper zookeeper:2181
For this example, you’ll create a FileSourceConnector, a FileSinkConnector and directories for storing the input and output files.
First, let’s start a Connect worker in distributed mode. This command points Connect to the three topics that you created in the first step of this quickstart.
$ docker run -d \ --name=kafka-connect \ --net=confluent \ -e CONNECT_PRODUCER_INTERCEPTOR_CLASSES=io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor \ -e CONNECT_CONSUMER_INTERCEPTOR_CLASSES=io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor \ -e CONNECT_BOOTSTRAP_SERVERS=kafka:9092 \ -e CONNECT_REST_PORT=8082 \ -e CONNECT_GROUP_ID="quickstart" \ -e CONNECT_CONFIG_STORAGE_TOPIC="quickstart-config" \ -e CONNECT_OFFSET_STORAGE_TOPIC="quickstart-offsets" \ -e CONNECT_STATUS_STORAGE_TOPIC="quickstart-status" \ -e CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR=1 \ -e CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR=1 \ -e CONNECT_STATUS_STORAGE_REPLICATION_FACTOR=1 \ -e CONNECT_KEY_CONVERTER="org.apache.kafka.connect.json.JsonConverter" \ -e CONNECT_VALUE_CONVERTER="org.apache.kafka.connect.json.JsonConverter" \ -e CONNECT_INTERNAL_KEY_CONVERTER="org.apache.kafka.connect.json.JsonConverter" \ -e CONNECT_INTERNAL_VALUE_CONVERTER="org.apache.kafka.connect.json.JsonConverter" \ -e CONNECT_REST_ADVERTISED_HOST_NAME="kafka-connect" \ -e CONNECT_LOG4J_ROOT_LOGLEVEL=DEBUG \ -e CONNECT_LOG4J_LOGGERS=org.reflections=ERROR \ -e CONNECT_PLUGIN_PATH=/usr/share/java \ -e CONNECT_REST_HOST_NAME="kafka-connect" \ -v /tmp/quickstart/file:/tmp/quickstart \ confluentinc/cp-kafka-connect:4.1.5-SNAPSHOTCheck to make sure that the Connect worker is up by running the following command to search the logs:
$ docker logs kafka-connect | grep startedYou should see the following:
[2016-08-25 18:25:19,665] INFO Herder started (org.apache.kafka.connect.runtime.distributed.DistributedHerder) [2016-08-25 18:25:19,676] INFO Kafka Connect started (org.apache.kafka.connect.runtime.Connect)Next, let’s create the directory where you’ll store the input and output data files.
$ docker exec kafka-connect mkdir -p /tmp/quickstart/fileYou will now create your first connector for reading a file from disk. To do this, start by creating a file with some data.
$ docker exec kafka-connect sh -c 'seq 1000 > /tmp/quickstart/file/input.txt'
Now create the connector using the Kafka Connect REST API.
The next step is to create the File Source connector.
$ docker exec kafka-connect curl -s -X POST \ -H "Content-Type: application/json" \ --data '{"name": "quickstart-file-source", "config": {"connector.class":"org.apache.kafka.connect.file.FileStreamSourceConnector", "tasks.max":"1", "topic":"quickstart-data", "file": "/tmp/quickstart/file/input.txt"}}' \ http://kafka-connect:8082/connectorsAfter running the command, you should see the following:
{"name":"quickstart-file-source","config":{"connector.class":"org.apache.kafka.connect.file.FileStreamSourceConnector","tasks.max":"1","topic":"quickstart-data","file":"/tmp/quickstart/file/input.txt","name":"quickstart-file-source"},"tasks":[]}Before moving on, check the status of the connector using curl as shown below:
$ docker exec kafka-connect curl -s -X GET http://kafka-connect:8082/connectors/quickstart-file-source/statusYou should see the following output including the
stateof the connector asRUNNING:{"name":"quickstart-file-source","connector":{"state":"RUNNING","worker_id":"kafka-connect:8082"},"tasks":[{"state":"RUNNING","id":0,"worker_id":"kafka-connect:8082"}]}
Now that the connector is up and running, try reading a sample of 10 records from the quickstart-data topic to check if the connector is uploading data to Kafka, as expected.
$ docker run \ --net=confluent \ --rm \ confluentinc/cp-kafka:4.1.5-SNAPSHOT \ kafka-console-consumer --bootstrap-server kafka:9092 --topic quickstart-data --from-beginning --max-messages 10You should see the following:
{"schema":{"type":"string","optional":false},"payload":"1"} {"schema":{"type":"string","optional":false},"payload":"2"} {"schema":{"type":"string","optional":false},"payload":"3"} {"schema":{"type":"string","optional":false},"payload":"4"} {"schema":{"type":"string","optional":false},"payload":"5"} {"schema":{"type":"string","optional":false},"payload":"6"} {"schema":{"type":"string","optional":false},"payload":"7"} {"schema":{"type":"string","optional":false},"payload":"8"} {"schema":{"type":"string","optional":false},"payload":"9"} {"schema":{"type":"string","optional":false},"payload":"10"} Processed a total of 10 messagesSuccess! You now have a functioning source connector! Now you can bring balance to the universe by launching a File Sink to read from this topic and write to an output file. You can do so using the following command:
$ docker exec kafka-connect curl -X POST -H "Content-Type: application/json" \ --data '{"name": "quickstart-file-sink", "config": {"connector.class":"org.apache.kafka.connect.file.FileStreamSinkConnector", "tasks.max":"1", "topics":"quickstart-data", "file": "/tmp/quickstart/file/output.txt"}}' \ http://kafka-connect:8082/connectorsYou should see the output below in your terminal window, confirming that the
quickstart-file-sinkconnector has been created and will write to/tmp/quickstart/file/output.txt:{"name":"quickstart-file-sink","config":{"connector.class":"org.apache.kafka.connect.file.FileStreamSinkConnector","tasks.max":"1","topics":"quickstart-data","file":"/tmp/quickstart/file/output.txt","name":"quickstart-file-sink"},"tasks":[]}As you did before, check the status of the connector:
$ docker exec kafka-connect curl -s -X GET http://kafka-connect:8082/connectors/quickstart-file-sink/statusYou should see the following:
{"name":"quickstart-file-sink","connector":{"state":"RUNNING","worker_id":"kafka-connect:8082"},"tasks":[{"state":"RUNNING","id":0,"worker_id":"kafka-connect:28082"}]}Finally, you can check the file to see if the data is present.
$ docker exec kafka-connect cat /tmp/quickstart/file/output.txtIf everything worked as planned, you should see all of the data you originally wrote to the input file:
1 ... 1000
Monitoring in Control Center¶
Next you’ll see how to monitor the Kafka Connect connectors in Control Center. Because you specified the monitoring interceptors when you deployed the Connect container, the data flows through all of your connectors will monitored in the same ways as the console producer/consumer tasks you executed above. Additionally, Control Center allows us to visually manage and deploy connectors, as you’ll see now.
Select the Management / Kafka Connect link in the Control Center navigation bar. Select the
SOURCESandSINKStabs at the top of the page to see that both the source and sink are running.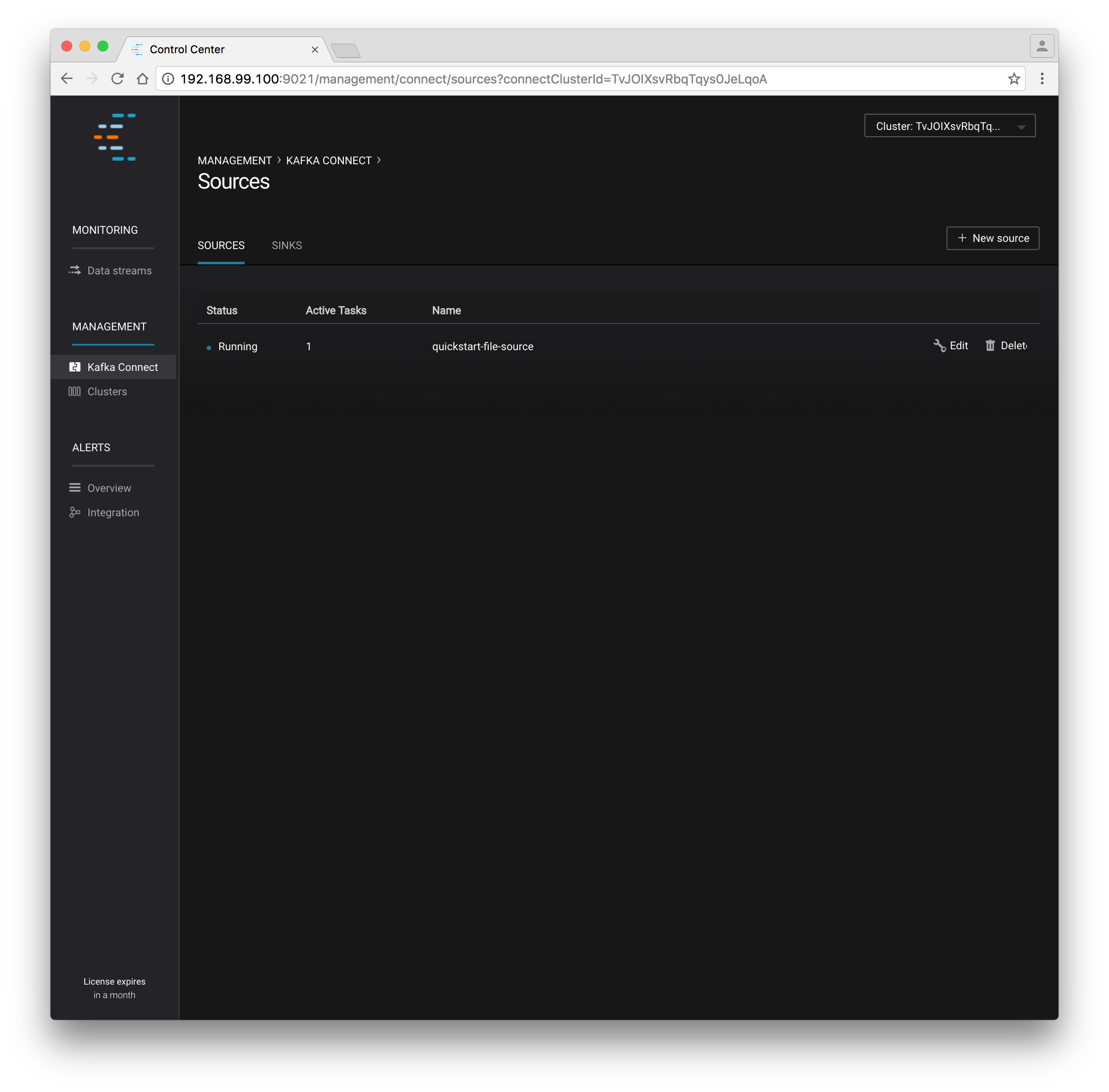
Confluent Control Center showing a Connect source
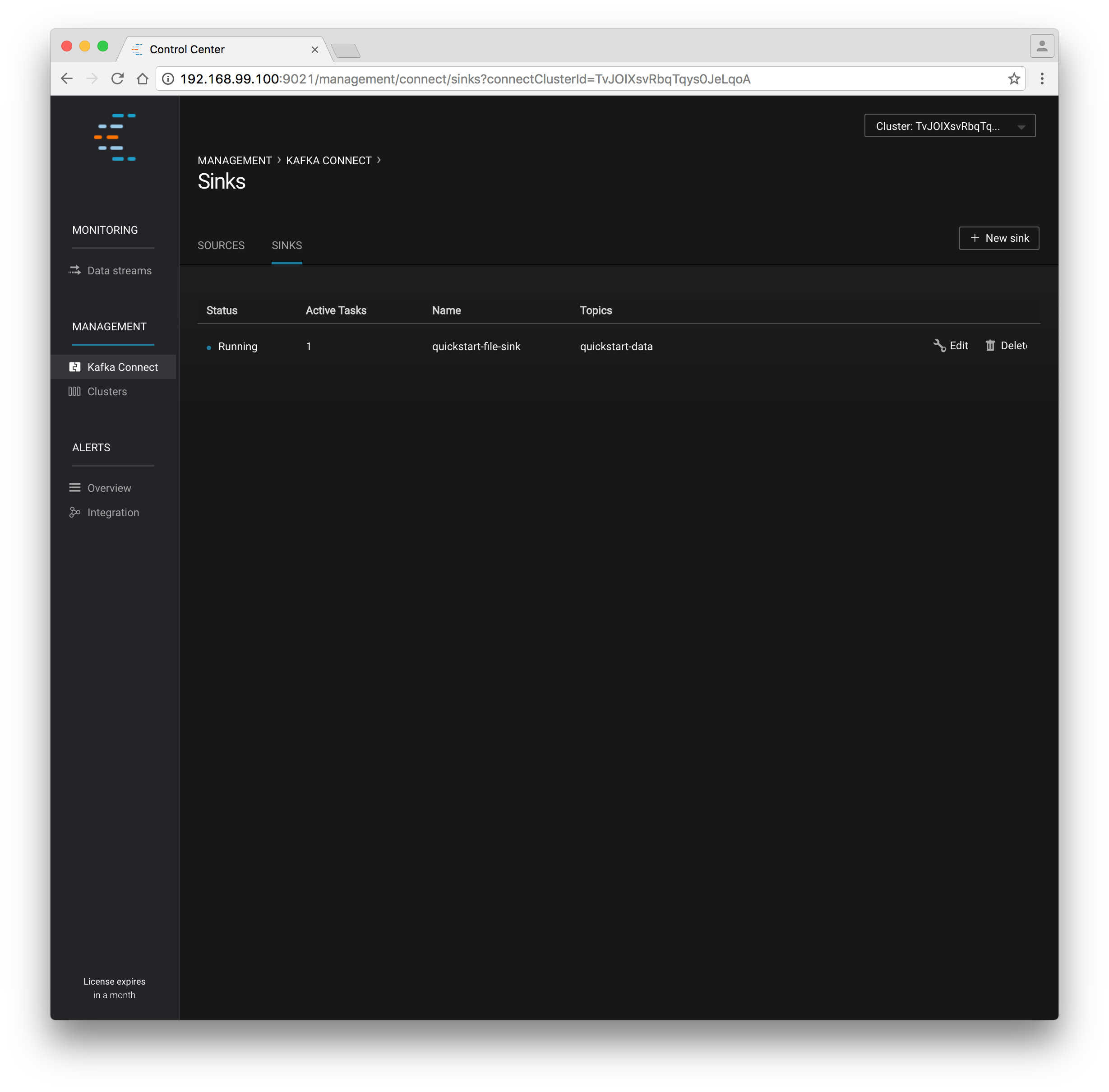
Confluent Control Center showing a Connect sink
You should start to see stream monitoring data from Kafka Connect in the Control Center UI from the running connectors. Remember that the file contained only 1000 messages, so you’ll only see a short spike of topic data.
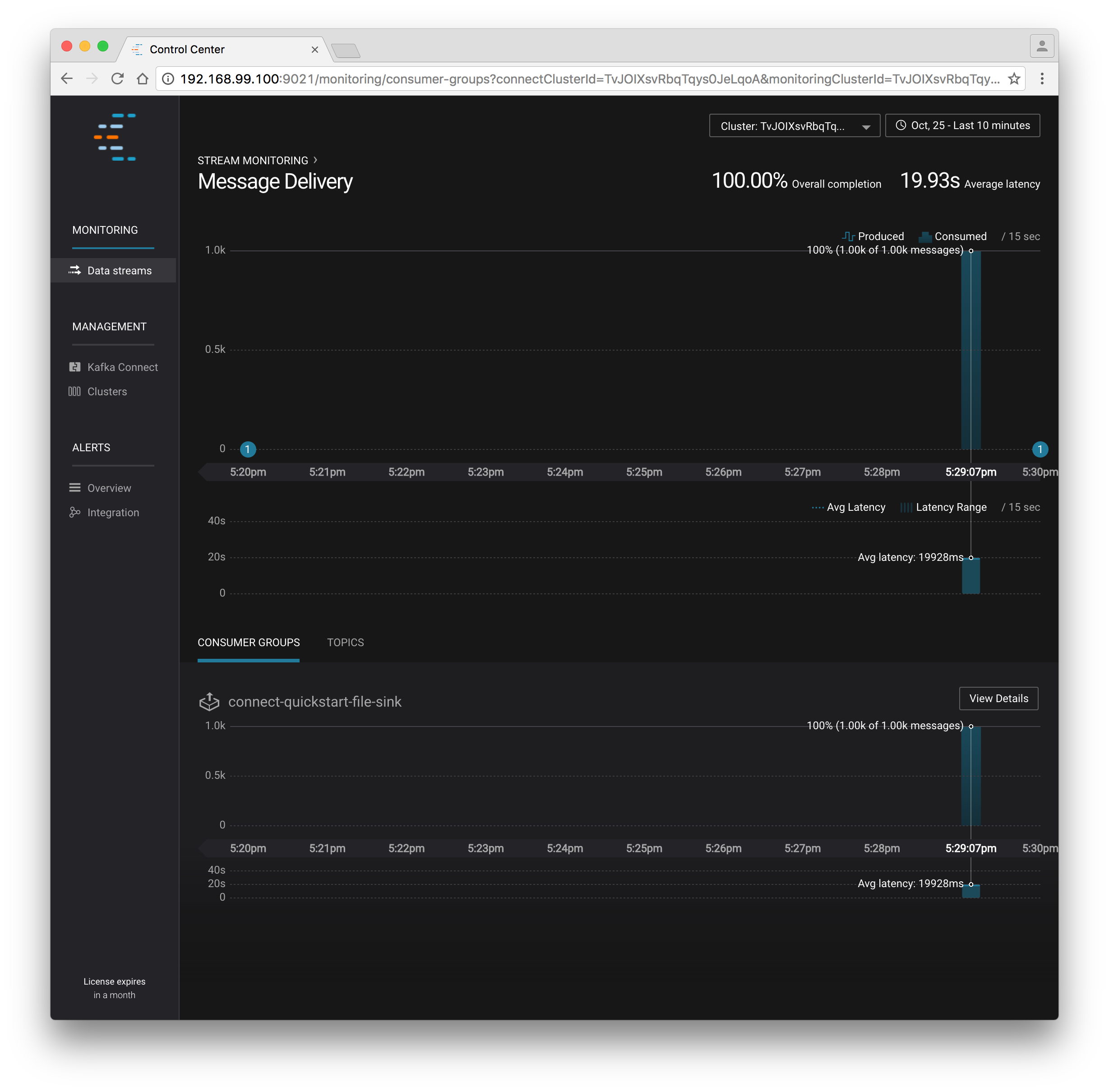
Confluent Control Center monitoring Kafka Connect
Cleanup¶
After you’re done, cleanup is simple. Run the command docker rm -f $(docker ps -a -q) to delete all the containers you created in the steps above, docker volume prune to remove any remaining unused volumes, and docker network rm confluent to delete the network we created.
If you are running Docker Machine, you can remove the virtual machine with this command: docker-machine rm confluent.