Important
You are viewing documentation for an older version of Confluent Platform. For the latest, click here.
What is Confluent Platform?¶
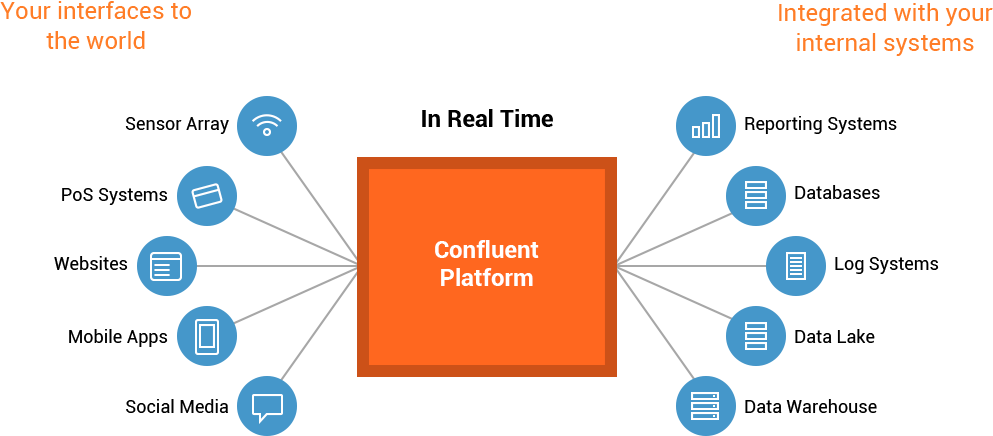
Confluent Platform is a streaming platform that enables you to organize and manage data from many different sources with one reliable, high performance system.
Stream Data Platform
A streaming platform provides not only the system to transport data, but all of the tools needed to connect data sources, applications, and data sinks to the platform.
What is included in Confluent Platform?¶
Overview¶
Confluent Platform makes it easy build real-time data pipelines and streaming applications. By integrating data from multiple sources and locations into a single, central streaming platform for your company, Confluent Platform lets you focus on how to derive business value from your data rather than worrying about the underlying mechanics such as how data is being transported or massaged between various systems. Specifically, the Confluent Platform simplifies connecting data sources to Kafka, building applications with Kafka, as well as securing, monitoring, and managing your Kafka infrastructure.
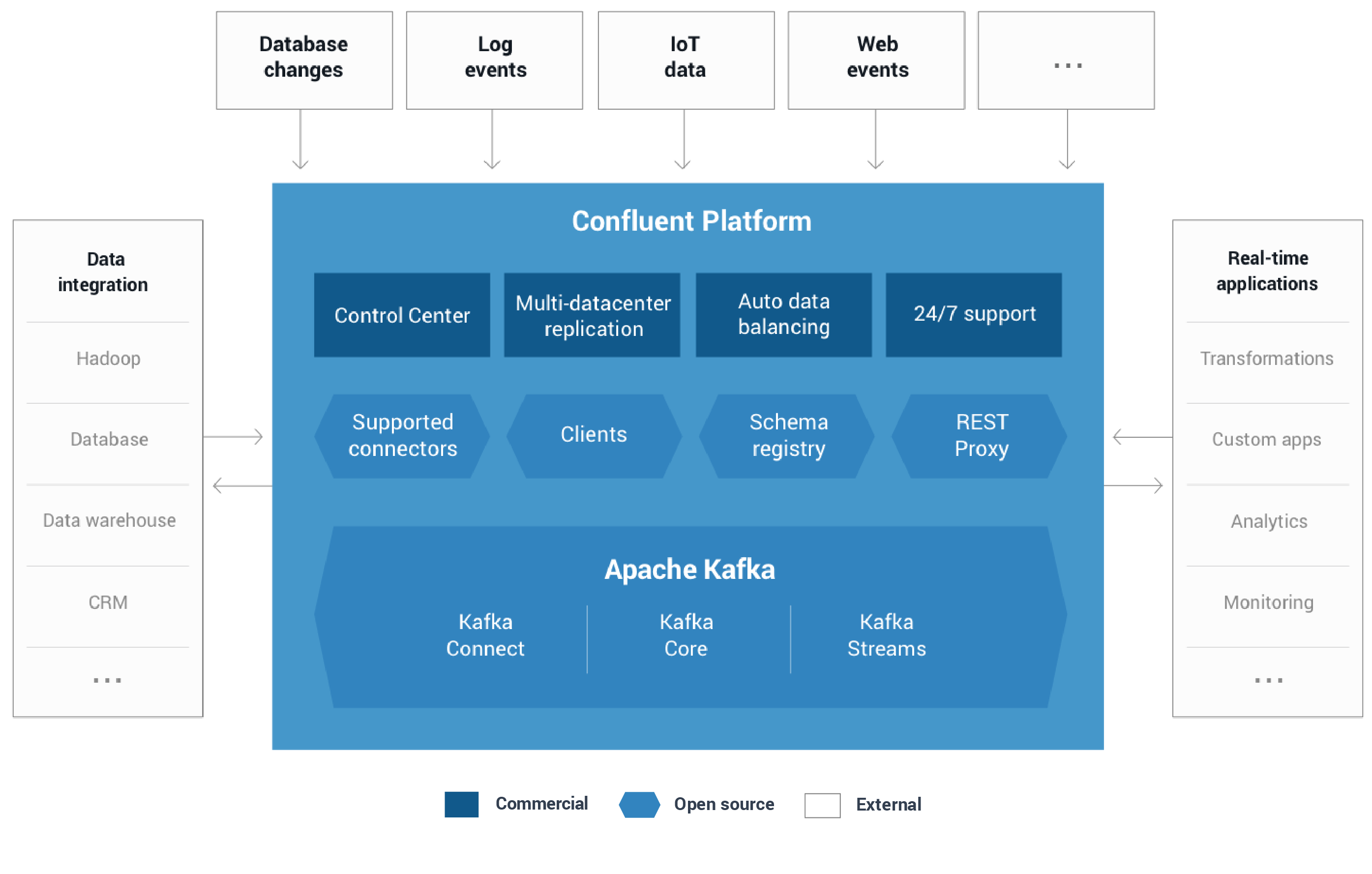
Confluent Platform Components
As its backbone, Confluent Platform leverages Apache Kafka, the most popular open source distributed streaming platform. It has three key capabilities:
- Publish and subscribe to streams of records
- Store streams of records in a fault tolerant way
- Process streams of records
It is used by hundreds of companies for many different use cases including collecting user activity data, system logs, application metrics, stock ticker data, and device instrumentation signals.
The Apache Kafka open source project consist of two key components:
- Kafka Brokers (open source). Kafka brokers that form the messaging, data persistency and storage tier of Apache Kafka
- Kafka Java Client APIs (open source)
- Producer API (open source). Java Client that allows an application to publish a stream records to one or more Kafka topics.
- Consumer API (open source). Java Client that allows an application to subscribe to one or more topics and process the stream of records produced to them.
- Streams API (open source). Allows an application to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, effectively transforming the input streams to output streams. It has a very low barrier to entry, easy operationalization, and a high-level DSL for writing stream processing applications. As such it is the most convenient yet scalable option to process and analyze data that is backed by Kafka.
- Connect API (open source). A component to stream data between Kafka and other data systems in a scalable and reliable way. It makes it simple to configure connectors to move data into and out of Kafka. Kafka Connect can ingest entire databases or collect metrics from all your application servers into Kafka topics, making the data available for stream processing. Connectors can also deliver data from Kafka topics into secondary indexes like Elasticsearch or into batch systems such as Hadoop for offline analysis.
Note
Confluent is committed to maintaining, enhancing, and supporting the open source Apache Kafka project. As this documentation discusses, the version of Kafka in Confluent Platform may contain patches over the matching open source version but is fully compatible with the matching open source version.
New releases of Confluent Platform include the latest release of Apache Kafka and additional tools and services that make it easier to build and manage a streaming platform. Confluent Platform is available in two flavors:
- Confluent Platform Open Source This is 100% open-source. In addition to the components included with Apache Kafka, Confluent Open Source includes services
and tools that is frequently used with Kafka. This makes Confluent Open Source the best way to get started with setting up a Kafka-based
streaming platform. Confluent Open Source includes:
- Clients for C, C++, Python and Go programming languages.
- Connectors for JDBC, ElasticSearch, and HDFS.
- Schema Registry for managing metadata for Kafka topics.
- REST Proxy for integrating with web applications.
- Confluent Platform Enterprise This takes it to the next level by addressing requirements of modern enterprise streaming applications. It includes Confluent Control Center for end-to-end monitoring of event streams, MDC Replication for managing multi-datacenter deployments, and Automatic Data Balancing for optimizing resource utilization and easy scalability of Kafka clusters. Collectively, the components of Confluent Enterprise give your team a simple and clear path towards establishing a consistent yet flexible approach for building an enterprise-wide streaming platform for a wide array of use cases.
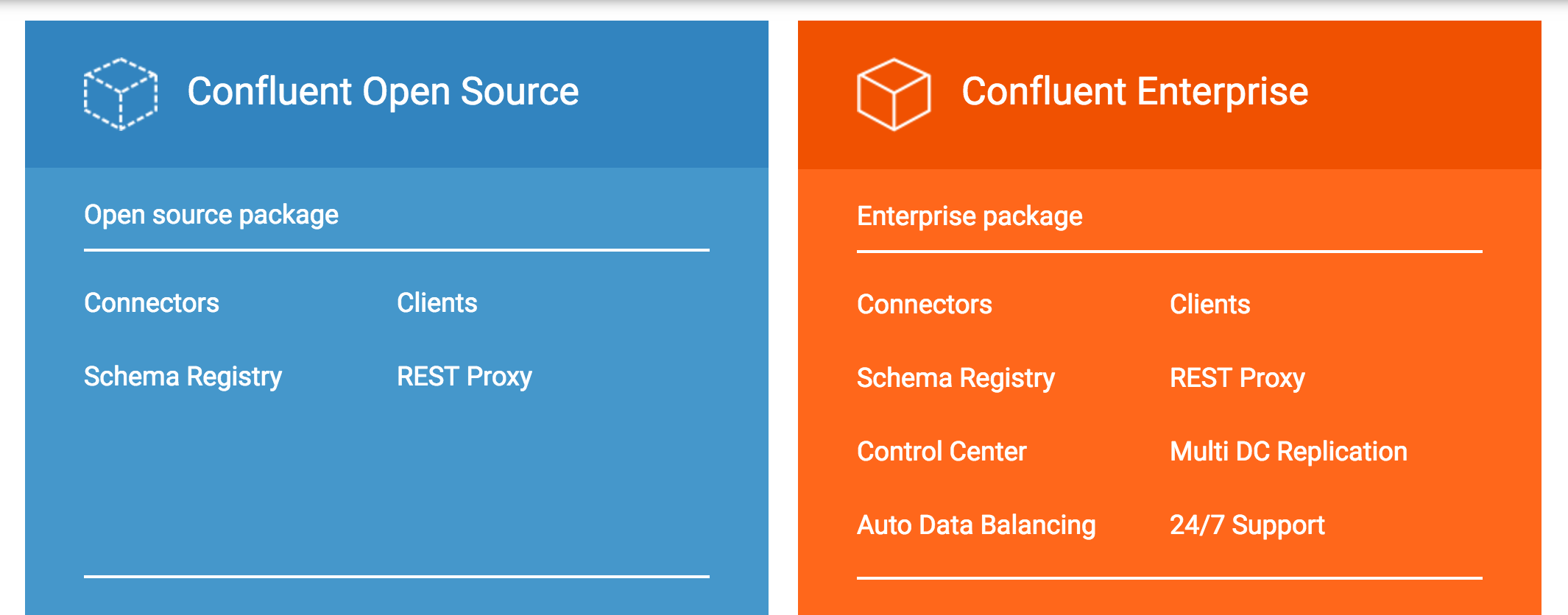
The capabilities of these components are briefly summarized in the following sections.
Confluent Open Source¶
Confluent Open Source includes the latest Apache Kafka version. In addition, it includes the following critical Confluent Open Source components that make it easy to set up a production ready stream platform.
Confluent Connectors¶
Connectors leverage the Kafka Connect API to connect Apache Kafka to other data systems such as Apache Hadoop. Confluent Platform provides connectors for the most popular data sources and sinks, and include fully tested and supported versions of these connectors with Confluent Platform.
Tip
Beyond the Confluent connectors listed below, which are part of Confluent Platform, you can find further connectors at the Kafka Connector Hub.
Kafka Connect JDBC Connector¶
The Confluent JDBC connector provides both source and sink connectors. The source connector allows you to import data from any JDBC-compatible relational database into Kafka. The sink connector allows you to export data from Kafka topics to any relational database. By using JDBC, this connector can support a wide variety of databases without requiring custom code for each one.
For more information, see the Confluent JDBC connector documentation.
Kafka Connect HDFS Connector¶
The Confluent HDFS Connector allows you to export data from Kafka topics to HDFS in a variety of formats and integrates with Hive to make data immediately available for querying with Hive.
For more information, see Confluent HDFS Connector.
Kafka Connect Elasticsearch Connector¶
You can move data from Kafka to Elasticsearch with the Confluent Elasticsearch Connector. It writes data from a Kafka topic to an Elasticsearch index, including all data for topics that have the same type.
For more information, see the Confluent Elasticsearch Connector documentation.
Kafka Connect S3 Connector¶
The Confluent S3 Connector allows you to move data from Kafka to S3 and supports Avro and JSON format.
For more information, see the Confluent S3 Connector documentation.
Confluent Clients¶
C/C++ Client Library¶
The library librdkafka is the C/C++ implementation of the Apache Kafka protocol, containing both Producer and Consumer support. It was designed with message delivery, reliability and high performance in mind. Current benchmarking figures exceed 800,000 messages per second for the producer and 3 million messages per second for the consumer. This library includes support for many new features Kafka 0.10, including message security. It also integrates easily with libserdes, our C/C++ library for Avro data serialization (supporting Schema Registry).
For more information, see the Kafka Clients documentation.
Python Client Library¶
A high-performance client for Python.
For more information, see the Kafka Clients documentation.
Go Client Library¶
Confluent Open Source also consist of a full-featured, high-performance client for Go.
For more information, see the Kafka Clients documentation.
.Net Client Library¶
Confluent Open Source bundles a full featured, high performance client for .Net.
For more information, see the Kafka Clients documentation.
KSQL¶
KSQL is the open source streaming SQL engine for Apache Kafka®. It provides an easy-to-use yet powerful interactive SQL interface for stream processing on Kafka, without the need to write code in a programming language such as Java or Python. KSQL is scalable, elastic, fault-tolerant, and real-time. It supports a wide range of streaming operations, including data filtering, transformations, aggregations, joins, windowing, and sessionization.
KSQL supports these use cases:
- Streaming ETL
- Apache Kafka is a popular choice for powering data pipelines. KSQL makes it simple to transform data within the pipeline, readying messages to cleanly land in another system.
- Real-time Monitoring and Analytics
- Track, understand, and manage infrastructure, applications, and data feeds by quickly building real-time dashboards, generating metrics, and creating custom alerts and messages.
- Data exploration and discovery
- Navigate and browse through your data in Kafka.
- Anomaly detection
- Identify patterns and spot anomalies in real-time data with millisecond latency, allowing you to properly surface out of the ordinary events and to handle fraudulent activities separately.
- Personalization
- Create data driven real-time experiences and insight for users.
- Sensor data and IoT
- Understand and deliver sensor data how and where it needs to be.
- Customer 360-view
- Achieve a comprehensive understanding of your customers across every interaction through a variety of channels, where new information is continuously incorporated in real-time.
For more information, see the KSQL documentation.
Confluent Schema Registry¶
One of the most difficult challenges with loosely coupled systems is ensuring compatibility of data and code as the system grows and evolves. With a messaging service like Kafka, services that interact with each other must agree on a common format, called a schema, for messages. In many systems, these formats are ad hoc, only implicitly defined by the code, and often are duplicated across each system that uses that message type.
As requirements change, it becomes necessary to evolve these formats. With only an ad-hoc definition, it is very difficult for developers to determine what the impact of their change might be.
Confluent Schema Registry enables safe, zero downtime evolution of schemas by centralizing the management of schemas written for the Avro serialization system. It tracks all versions of schemas used for every topic in Kafka and only allows evolution of schemas according to user-defined compatibility settings. This gives developers confidence that they can safely modify schemas as necessary without worrying that doing so will break a different service they may not even be aware of.
Schema Registry also includes plugins for Kafka clients that handle schema storage and retrieval for Kafka messages that are sent in the Avro format. This integration is seamless – if you are already using Kafka with Avro data, using Schema Registry only requires including the serializers with your application and changing one setting.
For more information, see the Schema Registry documentation.
Confluent REST Proxy¶
Apache Kafka and Confluent provide native clients for Java, C, C++, and Python that make it fast and easy to produce and consume messages through Kafka. These clients are usually the easiest, fastest, and most secure way to communicate directly with Kafka.
But sometimes, it isn’t practical to write and maintain an application that uses the native clients. For example, an organization might want to connect a legacy application written in PHP to Kafka. Or suppose that a company is running point-of-sale software that runs on cash registers, written in C# and runing on Windows NT 4.0, maintained by contractors, and needs to post data across the public internet. To help with these cases, Confluent Platform includes a REST Proxy. The REST Proxy addresses these problems.
The Confluent REST Proxy makes it easy to work with Kafka from any language by providing a RESTful HTTP service for interacting with Kafka clusters. The REST Proxy supports all the core functionality: sending messages to Kafka, reading messages, both individually and as part of a consumer group, and inspecting cluster metadata, such as the list of topics and their settings. You can get the full benefits of the high quality, officially maintained Java clients from any language.
The REST Proxy also integrates with Schema Registry. It can read and write Avro data, registering and looking up schemas in Schema Registry. Because it automatically translates JSON data to and from Avro, you can get all the benefits of centralized schema management from any language using only HTTP and JSON.
For more information, see the Confluent REST Proxy documentation.
Confluent Enterprise¶
Automatic Data Balancing¶
As clusters grow, topics and partitions grow at different rates, brokers are added and removed and over time this leads to unbalanced workload across datacenter resources. Some brokers are not doing much at all, while others are heavily taxed with large or many partitions, slowing down message delivery. When executed, automatic data balancing monitors your cluster for number of brokers, size of partitions, number of partitions and number of leaders within the cluster. It allows you to shift data to create an even workload across your cluster, while throttling rebalance traffic to minimize impact on production workloads while rebalancing.
For more information, see the automatic data balancing documentation.
Multi-Datacenter Replication¶
Confluent Enterprise makes it easier than ever to maintain multiple Kafka clusters in multiple data centers. Managing replication of data and topic configuration between data centers enables use-cases such as:
- Active-active geo-localized deployments: allows users to access a near-by data center to optimize their architecture for low latency and high performance
- Centralized analytics: Aggregate data from multiple Kafka clusters into one location for organization-wide analytics
- Cloud migration: Use Kafka to synchronize data between on-prem applications and cloud deployments
The Multi-Datacenter Replication feature allows configuring and managing replication for all these scenarios from either Confluent Control Center or command-line tools.
Confluent Control Center¶
Confluent Control Center is a GUI-based system for managing and monitoring Apache Kafka. It allows you to easily manage Kafka Connect, to create, edit, and manage connections to other systems. It also allows you to monitor data streams from producer to consumer, assuring that every message is delivered, and measuring how long it takes to deliver messages. Using Control Center, you can build a production data pipeline based on Apache Kafka without writing a line of code. Control Center also has the capability to define alerts on the latency and completeness statistics of data streams, which can be delivered by email or queried from a centralized alerting system.
JMS Client¶
Confluent Enterprise now includes a JMS-compatible client for Apache Kafka. This Kafka client implements the JMS 1.1 standard API, using Apache Kafka brokers as the backend. This is useful if you have legacy applications using JMS, and you would like to replace the existing JMS message broker with Apache Kafka. By replacing the legacy JMS message broker with Apache Kafka, existing applications can integrate with your modern streaming platform without a major rewrite of the application.
Confluent Security Plugins¶
Confluent Security Plugins are used to add security capabilities to various Confluent Open Source tools and products.
Currently, there is a plugin available for Kafka REST Proxy which helps in authenticating the incoming requests and propagating the authenticated principal to requests to Kafka. This enables Kafka REST Proxy clients to utilize the multi-tenant security features of the Kafka broker. For more information, see Confluent Security Plugins.