
Schema Linking on Confluent Platform
Use Schema Linking to keep schemas in sync across two Schema Registry clusters, typically alongside Cluster Linking for full data synchronization. The quick start below walks through creating and using exporters for Schema Linking on your clusters, followed by reference material for schema contexts and exporters. Contexts are also useful outside of Schema Linking to organize schemas into purpose-specific groups and create virtual “sub-registries.”
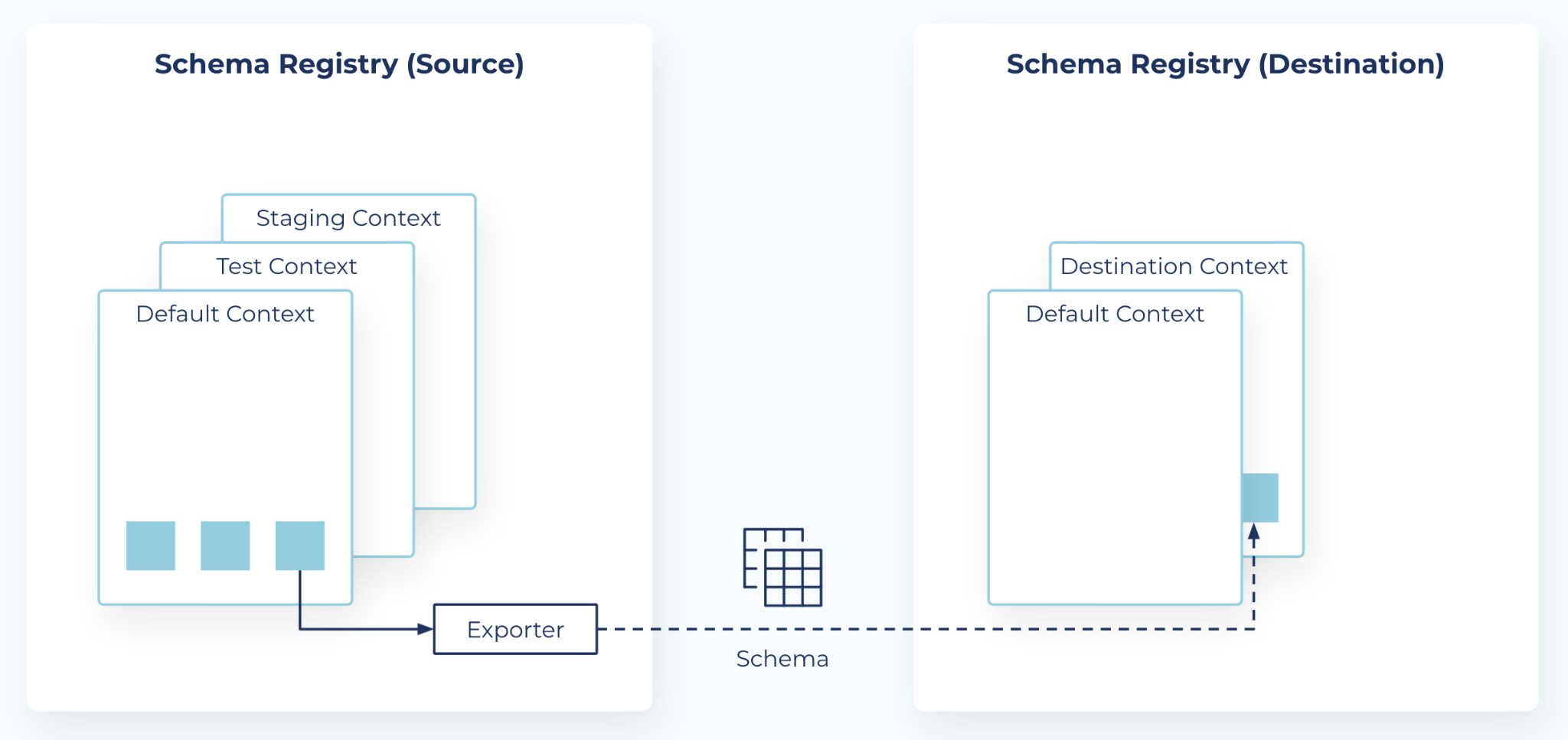
Schema Linking syncs schemas between two Schema Registry clusters.
Contexts and exporters
Schema Linking uses two Schema Registry concepts, schema contexts and schema exporters:
Contexts - A context is an independent scope in Schema Registry. Use contexts to create separate “sub-registries” within one Schema Registry cluster, each with its own schema IDs and subject names. The same schema ID in different contexts can represent different schemas.
A single dot,
., represents the default context. An explicit context starts with a dot and uses more dots as separators, such as.mycontext.subcontext, like absolute Unix paths. Two contexts that share a prefix have no implicit relationship.Exporters - A schema exporter runs inside Schema Registry and exports schemas from one Schema Registry cluster to another. Use the Schema Registry REST API to create, pause, resume, and destroy exporters. An exporter acts like a “mini-connector” that performs change data capture for schemas.
Limitations and considerations
On Confluent Cloud, the exporter limit per environment is 10 with the Essentials package and 100 with the Advanced package. Refer to the Packages documentation.
A single exporter can transfer any number of schemas; there is no upper limit on schemas per exporter.
Prerequisites
Schema Linking is supported on Confluent Platform 7.0 and later versions, and on Confluent Cloud as described in Schema Linking on Confluent Cloud. Schema Linking is not supported on Confluent Community editions. To learn more, see Confluent Platform Packages.
Quick Start
If you’d like to jump in and try out Schema Linking now, follow the steps below. At the end of the Quick Start, you’ll find deep dives on contexts, exporters, command options, and APIs, which may make more sense after you’ve experimented with some hands-on examples.
Tip
Be sure to configure all properties described in the tables below. If you get a 404 error when using the exporters API or schema-exporter commands, you likely did not configure the Schema Registry properties files to enable Schema Linking, as described below.
Set up source and destination environments
Set up two ZooKeepers, Confluent Servers (brokers), and Schema Registries, to serve as source and destination, along with a single Confluent Control Center (Legacy) with access to both. Use the following existing properties files as a basis for these new versions of the files:
Template File | New Files |
|---|---|
etc/kafka/zookeeper.properties | zookeeper0.properties, zookeeper1.properties |
etc/kafka/server.properties | server0.properties, server1.properties |
etc/schema-registry/schema-registry.properties | schema-registry0.properties, schema-registry1.properties |
etc/confluent-control-center/control-center-dev.properties | control-center-multi-sr.properties |
Use the following configurations for these files.
Tip
To learn more about this configuration, see Enabling Multi-Cluster Schema Registry.
Files | Configurations |
|---|---|
zookeeper0.properties |
|
zookeeper1.properties |
|
server0.properties |
The following configurations are specific to multi-cluster Schema Registry setup for this broker:
|
server1.properties |
The following configurations are specific to multi-cluster Schema Registry setup for this broker:
|
schema-registry0.properties |
The following configurations are specific to Schema Linking; they should be the same in both Schema Registry properties files:
|
schema-registry1.properties |
The following configurations are specific to Schema Linking; they should be the same in both Schema Registry properties files:
|
control-center-multi-sr.properties |
The configurations for |
Footnotes
Start the clusters
Start the ZooKeepers.
Start the Confluent Server brokers
Start the Schema Registry clusters.
Start Confluent Control Center (Legacy).
The following example start commands assume the properties files are in the <path-to-confluent>/etc/ directories shown below, and that you are running the commands from <path-to-confluent>.
Start ZooKeepers
./bin/zookeeper-server-start etc/kafka/zookeeper0.properties
./bin/zookeeper-server-start etc/kafka/zookeeper1.properties
Start the Kafka brokers
./bin/kafka-server-start etc/kafka/server0.properties
./bin/kafka-server-start etc/kafka/server1.properties
Start Schema Registry clusters
./bin/schema-registry-start etc/schema-registry/schema-registry0.properties
./bin/schema-registry-start etc/schema-registry/schema-registry1.properties
Start Control Center
./bin/control-center-start etc/confluent-control-center/control-center-multi-sr.properties
Create schemas on the source
Create at least two or three schemas in the source environment; at least one of which has a qualified subject name.
Create topics and associated schemas in Confluent Control Center (Legacy) (Control Center (Legacy) runs at
http://localhost:9021/).This will produce schema subjects with the naming scheme
<topic>-value. (You cannot create qualified subjects from Control Center (Legacy). Use the Schema Registry API for this.)Create schemas with both qualified and unqualified subject names, with the syntax:
:.<context-name>:<subject-name>.To create a schema with an unqualified subject name, simply provide a name such as
coffeeordonuts.To create a schema with a qualified subject name in a specified context, use the REST API with the syntax:
:.<context-name>:<subject-name>. For example::.snowcones:salesor:.burgers:locations
Here is an example of using the Schema Registry API to create a schema with an unqualified subject name.
curl -v -X POST -H "Content-Type: application/json" --data @/path/to/test.avro <source sr url>/subjects/donuts/versions
The above
curlcommand calls the file that contains this Avro schema.{ "schema": "{ \"type\": \"record\", \"connect-name\": \"myname\", \"connect-donuts\": \"mydonut\", \"name\": \"test\", \"doc\": \"some doc info\", \"fields\": [ { \"type\": \"string\", \"doc\": \"doc for field1\", \"name\": \"field1\" }, { \"type\": \"int\", \"doc\": \"doc for field2\", \"name\": \"field2\" } ] }" }
Use the Schema Registry API to list subjects on the source, passing in the prefix.
curl --silent -X GET <source sr url>/subjects?subjectPrefix=":.<context-name>:<subject-name>" | jq
For example:
curl --silent -X GET http://localhost:8081/subjects?subjectPrefix=":*:" | jq
Your output should resemble:
":.snowcones:sales", "coffee-value", "donuts"
You are ready to create and test exporters for Schema Linking across your two clusters and registries. Run the exporter commands shown below from $CONFLUENT_HOME; that is, from the top level of your Confluent Platform directory.
Create a configuration file for the exporter
Your schema exporter will read the schemas in the SOURCE environment and export linked copies to the destination.
Create ~/config.txt which you will use to create exporters, and fill in the URL the exporter needs to access the DESTINATION cluster:
schema.registry.url=<destination sr url>
Using credentials (optional)
To test a local instance of Confluent Platform for this tutorial, you do not need credentials.
If you want to require authentication, you must first configure Schema Registry for Basic HTTP authentication, and idealy, to also use HTTPS for secure communication.
Once Schema Registry is configured to use basic authentication per the above instructions, you would add credentials to end of your ~/config.txt file as shown:
schema.registry.url=<destination sr url>
basic.auth.credentials.source=USER_INFO
basic.auth.user.info=fred:letmein
The above example, and the required configurations in Schema Registry to support it, are described in the steps to configure Schema Registry for Basic HTTP authentication.
With the credentials in this file, each time you call --config-file ~/config.txt in the commands described below, you would then automatically pass these credentials in along with the Schema Registry URL.
In addition to the parameters for basic HTTP authentication, you can use the config file to pass any of the client configurations described in Clients to Schema Registry.
Tip
To communicate with a source Schema Registry cluster configured with Basic HTTP authentication using the Confluent CLI, you must pass --basic.auth.credentials.source and --basic.auth.user.info with proper credentials, or if you use bearer token authentication, provide credentials in --bearer.auth.credentials.source and --bearer.auth.token flags.
Create the exporter on the source
Use the Confluent Platform CLI to create an exporter on the source.
Create a new exporter using the schema-exporter --create command.
./bin/schema-exporter --create --name <name-of-exporter> --subjects ":*:" \
--config-file ~/config.txt
--schema.registry.url <source sr url>
For example, this command creates an exporter called “my-first-exporter” that will export all schemas (":*:"), including those in specific contexts as well as those in the default context:
./bin/schema-exporter --create --name my-first-exporter --subjects ":*:" \
--config-file ~/config.txt \
--schema.registry.url http://localhost:8081/
The following command syntax creates an exporter that exports only the subjects donuts and coffee in a custom context, context1.
schema-exporter --create --name exporter1 --subjects donuts,coffee \
--context-type CUSTOM --context-name context1 \
--config-file ~/config.txt \
--schema.registry.url <source sr url>
More options for exporters
If you used the first example above, then the exporter you just created is relatively basic, in that it just exports everything. As you’ll see in the next section, this is an efficient way to get an understanding of how you might organize, export, and navigate schemas with qualified and unqualified subject names.
Keep in mind that you can create exporters that specify to export only specific subjects and contexts using this syntax:
schema-exporter --create <exporterName> --subjects <subjectName1>,<subjectName2> \
--context-type CUSTOM --context-name <contextName> \
--config-file ~/config.txt
Replace anything within
<>with a name you like.subjectsare listed as a comma-separated string list, such as “pizzas,sales,customers”.subjects,context-type, andcontext-nameare all optional.context-nameis specified ifcontext-typeis CUSTOM.subjectsdefaults to*, andcontext-typedefaults to AUTO.
Alternatively, if you take all the defaults and do not specify --subjects when you create an exporter, you will get an exporter that exports schemas in all contexts/subjects, including the default context
./bin/schema-exporter --create --name my-first-exporter \
--config-file ~/config.txt \
--schema.registry.url http://localhost:8081/
If you want to export the default context only, specify --subjects to be :.:* With this type of exporter, schemas on the source that have qualified subject names will not be exported to the destination.
Another optional parameter you can use with schema-exporter --create and schema-exporter --update is --subject-format. This specifies a format for the subject name in the destination cluster, and may contain ${subject} as a placeholder which will be replaced with the default subject name. For example, dc_${subject} for the subject orders will map to the destination subject name dc_orders.
You can create and run multiple exporters at once, so feel free to circle back at the end of the Quick Start to create and test more exporters with different parameters.
Verify the exporter is running and view information about it
List available exporters.
./bin/schema-exporter --list \ --schema.registry.url <source sr url>
For example:
./bin/schema-exporter --list --schema.registry.url http://localhost:8081
Your exporter will show in the list.
[my-first-exporter]
Describe the exporter.
./bin/schema-exporter --describe --name <exporterName> \ --schema.registry.url <source sr url>
For example:
./bin/schema-exporter --describe --schema.registry.url http://localhost:8081 --name my-first-exporter
Your output should resemble:
{"name":"my-first-exporter","subjects":[":*:"],"contextType":"AUTO","context":".","config":{"schema.registry.url":"http://localhost:8082"}}
Get configurations for the exporter.
./bin/schema-exporter --get-config --name <exporterName> \ --schema.registry.url <source sr url>
For example:
./bin/schema-exporter --get-config --name my-first-exporter --schema.registry.url http://localhost:8081
Your output should resemble:
{schema.registry.url=http://localhost:8082}
Get the status of exporter.
./bin/schema-exporter --get-status --name <exporterName> \ --schema.registry.url <source sr url>
For example:
./bin/schema-exporter --get-status --name my-first-exporter --schema.registry.url http://localhost:8081
Your output should resemble:
{"name":"my-first-exporter","state":"RUNNING","offset":9,"ts":1635890864106}
Finally, as a check, get a list of schema subjects on the source.
To do this, use the API call with the subject prefix, as shown:
curl --silent -X GET http://localhost:8081/subjects?subjectPrefix=":*:" | jq
":.snowcones:sales", "coffee-value", "donuts"
Check that the schemas were exported
Now that you have verified that the exporter is running, and you know which schemas you created on the source, check to see that your schemas were exported to the destination.
Run the following API call to view schema subjects on the destination.
curl --silent -X GET http://localhost:8082/subjects?subjectPrefix=":*:" | jq
":.QWE7LDvySmeV6Sg81B3jUg-schema-registry.snowcones:sales", ":.QWE7LDvySmeV6Sg81B3jUg-schema-registry:coffee-value", ":.QWE7LDvySmeV6Sg81B3jUg-schema-registry:donuts"
List only schemas in particular contexts.
curl --silent -X GET '<destination sr url>/subjects?subjectPrefix=:.<context-name>:<subject-name>' | jq
For example, to find all subjects under the context
snowconeson the source, use the following command:curl --silent -X GET 'http://localhost:8081/subjects?subjectPrefix=:.snowcones:' | jq
If you have a single subject under the
snowconescontext, your output will resemble:":.snowcones:sales"To list all subjects under the context
snowconeson the destination, use the same command syntax. Note that you must include the long IDs at the beginning of subject names on the destination because these are part of the prefixes:curl --silent -X GET http://localhost:8082/subjects?subjectPrefix=":.QWE7LDvySmeV6Sg81B3jUg-schema-registry.snowcones:" | jq
Your output will resemble:
":.QWE7LDvySmeV6Sg81B3jUg-schema-registry.snowcones:sales"
Tip
If you used the optional parameter --subject-format when you created the exporter on the source, check to see that the exported subjects on the destination map to the subject rename format you specified.
Pause the exporter and make changes
Pause the exporter.
Switch back to the SOURCE, and run the following command to pause the exporter.
./bin/schema-exporter --pause --name <exporterName> \ --schema.registry.url <source sr url>
For example:
./bin/schema-exporter --pause --name my-first-exporter --schema.registry.url http://localhost:8081
You should get output verifying that the command was successful. For example:
Successfully paused exporter my-first-exporter.Check the status, just to be sure.
./bin/schema-exporter --get-status --name <exporterName> \ --schema.registry.url <source sr url>
Your output should resemble:
{"name":"my-first-exporter","state":"PAUSED","offset":9,"ts":1635890864106}
Reset schema exporter offset, then get the status.
./bin/schema-exporter --reset --name <exporterName> \ --schema.registry.url <source sr url>
For example:
./bin/schema-exporter --reset --name my-first-exporter --schema.registry.url http://localhost:8081
The status will show that the offset is reset. For examples:
Successfully reset exporter my-first-exporter
Update exporter configurations or information.
You can choose to update any of
subjects,context-type,context-name, orconfig-file. For example:./bin/schema-exporter --update --name <exporterName> --context-name <newContextName>
Resume schema exporter.
./bin/schema-exporter --resume --name <exporterName> --schema.registry.url <source sr url>
For example:
./bin/schema-exporter --resume --name my-first-exporter --schema.registry.url http://localhost:8081
Your output should resemble:
Successfully resumed exporter my-first-exporter
Delete the exporter
When you are ready to wrap up your testing, pause and then delete the exporter(s) as follows.
Pause the exporter.
./bin/schema-exporter --pause --name <exporterName> \ --schema.registry.url <source sr url>
For example:
./bin/schema-exporter --pause --name my-first-exporter --schema.registry.url http://localhost:8081
Delete the exporter.
./bin/schema-exporter --delete --name <exporterName> \ --schema.registry.url <source sr url>
For example:
./bin/schema-exporter --delete --name my-first-exporter --schema.registry.url http://localhost:8081
Your output should resemble:
Successfully deleted exporter my-first-exporter
This concludes the Quick Start. The next sections are a deep dive into Schema Linking concepts and tools you just tried out.
Contexts
What is a context?
A schema context, or simply context, is essentially a grouping of subject names and schema IDs. A single Schema Registry cluster can host any number of contexts. Each context can be thought of as a separate “sub-registry”. A context can also be copied to another Schema Registry cluster, using a schema exporter.
How contexts work
Following are a few key aspects of contexts and how they help to organize schemas.
Schemas and schema IDs are scoped by context
Subject names and schema IDs are scoped by context so that two contexts in the same Schema Registry cluster can each have a schema with the same ID, such as 123, or a subject with the same name, such as mytopic-value, without any problem.
To put this another way, subject names and schema IDs are unique per context. You can have schema ID 123 in context .mycontext and schema ID 123 in context .yourcontext and these can be different from one another.
Caution
Since schema IDs are unique per context, linking different sources to the same context on the destination could result in schema ID conflicts on the destination.
Default context
Any schema ID or subject name without an explicit context lives in the default context, which is represented as a single dot .. An explicit context starts with a dot and can contain any parts separated by additional dots, such as .mycontext.subcontext. You can think of context names as similar to absolute Unix paths, but with dots instead of forward slashes (in this analogy, the default schema context is like the root Unix path). However, there is no relationship between two contexts that share a prefix.
Global context
Schema Registry supports a global configuration context using the special context name :.__GLOBAL:. When looking up a configuration or mode with defaultToGlobal, the lookup proceeds from the subject to the context, and then to the global context (:.__GLOBAL:). The global context is only valid for configuration and mode settings; it cannot be used to store subjects or schemas. For contexts without global configuration, compatibility is handled per context. To learn more, see Schema Evolution and Compatibility for Schema Registry on Confluent Platform.
The global context provides a hierarchical configuration lookup mechanism:
Subject level: Configuration is first checked at the specific subject level.
Context level: If not found at the subject level, configuration is checked at the context level.
Global level: Finally, if not found at the context level, configuration falls back to the global context (
:.__GLOBAL:).
This hierarchy allows you to:
Set default configurations that apply across all contexts using the global context.
Override global defaults with context-specific configurations.
Further override with subject-specific configurations for fine-grained control.
The global context is particularly useful for establishing organization-wide defaults for compatibility modes while maintaining the flexibility to customize behavior for specific contexts or subjects as needed.
Qualified subjects
A subject name can be qualified with a context, in which case it is called a qualified subject. When a context qualifies a subject, the context must be surrounded by colons. An example is :.mycontext:mysubject. A subject name that is unqualified is assumed to be in the default context, so that mysubject is the same as :.:mysubject (the dot representing the default context).
The one exception to this rule is in the case of a subject name specified for a schema reference. In this case, if the subject name of the schema reference is not qualified with an explicit context, it inherits the context in which the root schema resides.
For example, if the following set of schema references are associated with a schema in a subject in the .prod context:
[
{
"name": "io.confluent.examples.avro.Customer",
"subject": "customer",
"version": 1
},
{
"name": "io.confluent.examples.avro.Product",
"subject": "product",
"version": 1
},
{
"name": "io.confluent.examples.avro.Order",
"subject": "order",
"version": 1
}
]
then, the subject names above, customer, product, and order, will refer to the subjects :.prod:customer, :.prod:product, and :.prod:order, respectively.
There are two ways to pass a context to the REST APIs.
Using a qualified subject
A qualified subject can be passed anywhere that a subject name is expected. Most REST APIs take a subject name, such as POST /subjects/{subject}/versions.
There are a few REST APIs that don’t take a subject name as part of the URL path:
/schemas/ids/{id}/schemas/ids/{id}/subjects/schemas/ids/{id}/versions
The three APIs above can now take a query parameter named “subject” (written as ?subject), so you can pass a qualified subject name, such as /schemas/ids/{id}?subject=:.mycontext:mysubject, and the given context is then used to look up the schema ID.
Using a base context path
As mentioned, all APIs that specify an unqualified subject operate in the default context. Besides passing a qualified subject wherever a subject name is expected, a second way to pass the context is by using a base context path. A base context path takes the form /contexts/{context} and can be prepended to any existing Schema Registry path. Therefore, to look up a schema ID in a specific context, you could also use the URL /contexts/.mycontext/schemas/ids/{id}.
A base context path can also be used to operate with the default context. In this case, the base context path takes the form “/contexts/:.:/”; for example, /contexts/:.:/schemas/ids/{id}. A single dot cannot be used because it is omitted by some URL parsers.
Multi-Context APIs
All the examples so far operate in a single context. There are three APIs that return results for multiple contexts.
/contexts/subjects/schemas?subjectPrefix=:*:
The first two APIs, /contexts and /subjects, return a list of all contexts and subjects, respectively. The other API, /schemas, normally only operates in the default context. This API can be used to query all contexts by passing a subjectPrefix with the value :*:, called the context wildcard. The context wildcard matches all contexts.
Specifying a context name for clients
When using a client to talk to Schema Registry, you may want the client to use a particular context. An example of this scenario is when migrating a client from communicating with one Schema Registry to another. You can achieve this by using a base context path, as defined above. To do this, simply change the Schema Registry URL used by the client from https://<host1> to https://<host2>/contexts/.mycontext.
Note that by using a base context path in the Schema Registry URL, the client will use the same schema context for every Schema Registry request. However, an advanced scenario might involve a client using different contexts for different topics. To achieve this, you can specify a context name strategy to the serializer or deserializer:
context.name.strategy=com.acme.MyContextNameStrategy
The context name strategy is a class that must implement the following interface:
/**
* A {@link ContextNameStrategy} is used by a serializer or deserializer to determine
* the context name used with the schema registry.
*/
public interface ContextNameStrategy extends Configurable {
/**
* For a given topic, returns the context name to use.
*
* @param topic The Kafka topic name.
* @return The context name to use
*/
String contextName(String topic);
}
Again, the use of a context name strategy should not be common. Specifying the base context path in the Schema Registry URL should serve most needs.
Exporters
What is an Exporter?
Previously, Confluent Replicator was the primary means of migrating schemas from one Schema Registry cluster to another, as long as the source Schema Registry cluster was on-premise. To support schema migration using this method, the destination Schema Registry is placed in IMPORT mode, either globally or for a specific subject.
The new schema exporter functionality replaces and extends the schema migration functionality of Replicator. Schema exporters reside within a Schema Registry cluster, and can be used to replicate schemas between two Schema Registry clusters in Confluent Cloud.
Schema Linking
You use schema exporters to accomplish Schema Linking, using contexts and/or qualified subject names to sync schemas across registries. Schema contexts provide the conceptual basis and namespace framework, while the exporter does the heavy-lift work of the linking.
Schemas export from the source default context to a new context on the destination
By default, a schema exporter exports schemas from the default context in the source Schema Registry to a new context in the destination Schema Registry. The destination context (or a subject within the destination context) is placed in IMPORT mode. This allows the destination Schema Registry to use its default context as usual, without affecting any clients of its default context.
The new context created by default in the destination Schema Registry will have the form .lsrc-xxxxxx, taken from the logical name of the source.
Schema Registry clusters can export schemas to each other
Two Schema Registry clusters can each have a schema exporter that exports schemas from the default context to the other Schema Registry. In this setup, each side can read from or write to the default context, and each side can read from (but not write to) the exported context. This allows you to match the setup of Cluster Linking, where you might have a source topic and a read-only mirror topic on each side.
Customizing exporters
There are various ways to customize which contexts are exported from the source Schema Registry, and which contexts are used in the destination Schema Registry. The full list of configuration properties is shown below.
How many exporters are allowed per Schema Registry?
The limit on the number of exporters allowed at any one time per Schema Registry is 10.
Configuration options
An exporter has these main configuration properties:
nameA unique name for the exporter.
subjectsThis can take several forms:
A list of subject names, for example,
[ "subject1", "subject2" ]A singleton list containing a subject name prefix that ends in a wildcard, such as
["mytopic*"]A singleton list containing a lone wildcard,
["*"], that indicates all subjects in the default context. This is the default.A singleton list containing the context wildcard,
[":*:"], that indicates all contexts.A singleton list containing a context prefix that ends in a wildcard, such as
[":.mycontext:*"], to export subjects from multiple contexts that match the pattern (for example,.mycontext1and.mycontext2).A singleton list containing a subject prefix within a specific context, such as
[":.mycontext:mysubjects-*"], to export subjects that match the prefix within that context.
subject-formatThis is an optional parameter you can use to specify a format for the subject name in the destination cluster. You can specify
${subject}as a placeholder, which will be replaced with the default subject name. For example,dc_${subject}for the subjectorderswill map to the destination subject namedc_orders.context-typeOne of:
AUTO - Prepends the source context with an automatically generated context, which is
.lsrc-xxxxxxfor Confluent Cloud. This is the default.CUSTOM - Prepends the source context with a custom context name, specified in
contextbelow.NONE - Copies the source context as-is, without prepending anything. This is useful to make an exact copy of the source Schema Registry in the destination.
DEFAULT - Replaces the source context with the default context. This is useful for copying schemas to the default context in the destination. (Note: DEFAULT is available on Confluent Cloud as of July 2023, and on Confluent Platform starting with version 7.4.2.)
REPLACE - Replaces the source context with the context name specified in
contextbelow. REPLACE drops the source context. All exported subjects land in the destination under the replacement context, regardless of which context they came from in the source.
For example, if the source has subjects
:.:orders-valueand:.nondefault:products-valueand you setcontext-type: REPLACEwithcontext-name: .archive, they land in the destination as:.archive:orders-valueand:.archive:products-value.Using the same source subjects, the other context types map them as follows:
With
context-type: AUTO, they land as:.lsrc-xxxxxx:orders-valueand:.lsrc-xxxxxx.nondefault:products-value. AUTO prepends the generated context and keeps the source context for non-default subjects.With
context-type: CUSTOMandcontext-name: .archive, they land as:.archive:orders-valueand:.archive.nondefault:products-value. CUSTOM prepends the custom context and keeps the source context for non-default subjects.With
context-type: NONE, they land unchanged as:.:orders-valueand:.nondefault:products-value.
context-nameA context name to be used with the CUSTOM or REPLACE
contextTypeabove.configA set of configurations for creating a client to talk to the destination Schema Registry, which can be passed in a config file (for example,
--config-file ~/<my-config>.txt). Typically, this includes:schema.registry.url- The URL of the destination Schema Registry. Theschema.registry.urlmust contain a valid, fully-qualified domain name and not just an IP address. For example,https://my-registry.example.comwould meet this requirement buthttps://192.168.1.1would not.basic.auth.credentials.source- Typically “USER_INFO”basic.auth.user.info- Typically of the form<api-key>:<api-secret>
System topics and security configurations
The following configurations for system topics are available:
exporter.config.topic- Stores configurations for the exporters. The default name for this topic is_exporter_configs, and its default/required configuration is:numPartitions=1,replicationFactor=3, andcleanup.policy=compact.exporter.state.topic- Stores the status of the exporters. The default name for this topic is_exporter_states, and its default/required configuration is:numPartitions=1,replicationFactor=3, andcleanup.policy=compact.
If you are using role-based access control (RBAC), exporter.config.topic and exporter.state.topic require ResourceOwner on these topics, as does the _schemas internal topic. See also, Use Role-Based Access Control (RBAC) in Confluent Cloud and Configuring Role-Based Access Control for Schema Registry on Confluent Platform.
If you are configuring Schema Registry on Confluent Platform using the Schema Registry Security Plugin, you must activate both the exporter and the Schema Registry security plugin by specifying both extension classes in the $CONFLUENT_HOME/etc/schema-registry/schema-registry.properties files:
resource.extension.class=io.confluent.kafka.schemaregistry.security.SchemaRegistrySecurityResourceExtension,io.confluent.schema.exporter.SchemaExporterResourceExtension
The configuration for the exporter resource extension class in the schema-registry.properties is described in Set up source and destination environments in Schema Linking on Confluent Platform.
Lifecycle and states
Schema Registry stores schemas in a Kafka topic. A schema exporter uses the topic offset to determine its progress.
When a schema exporter is created, it begins in the STARTING state. While in this state, it finds and exports all applicable schemas already written to the topic. After exporting previously registered schemas, the exporter then enters the RUNNING state, during which it will be notified of any new schemas, which it can export if applicable. As schemas are exported, the exporter will save its progress by recording the latest topic offset.
If you want to make changes to the schema exporter, you must first “pause” it, which causes it to enter the PAUSED state. You can pause an exporter at any point in its lifecycle. The exporter can then be resumed after the proper changes are made. Upon resuming, the exporter will find and export any applicable schemas since the last offset that it recorded.
While an exporter is paused, it can also be “reset”, which will cause it to clear its saved offset and re-export all applicable schemas when it resumes. To accomplish this, the exporter starts off again in STARTING state after a reset, and follows the same lifecycle.
To update an exporter’s configuration, such as adding subjects to its subject list, pause the exporter, apply the update, and reset it before resuming. An exporter tracks its progress as an offset and exports only schemas registered after that offset. Schemas already registered for the newly added subjects fall before that offset. Without a reset, the exporter skips them and exports only schemas registered after it resumes. A reset clears the recorded offset. The exporter then re-scans from the start and exports all matching schemas, including the existing ones for the newly added subjects.
The states of a schema exporter at various stages in its lifecycle are summarized below.
State | Description |
|---|---|
STARTING | The exporter finds and exports all applicable previously registered schemas for the topic. This is the starting state, or the state after a reset. |
RUNNING | The exporter is notified of new schemas, exports them if applicable, and tracks progress by recording last topic offset. |
PAUSED | An exporter can be paused; for example, to make configuration changes. When it resumes, the exporter finds and exports schemas since the last recorded offset. |
REST APIs
Schema Registry supports the following REST APIs, as fully detailed in Exporters in the Schema Registry API documentation:
Task | API |
|---|---|
Gets a list of exporters for a tenant | GET /exporters |
Creates a new exporter | POST /exporters |
Gets info about an exporter | GET /exporters/{name} |
Gets the config for an exporter | GET /exporters/{name}/config |
Gets the status of an exporter | GET /exporters/{name}/status |
Updates the information for an exporter | PUT /exporters/{name}/config |
Pauses an exporter | PUT /exporters/{name}/pause |
Resumes an exporter | PUT /exporters/{name}/resume |
Resets an exporter, clears offsets | PUT /exporters/{name}/reset |
Deletes an exporter | DELETE /exporters/{name} |
Deployment strategies and Schema Linking
Schema Linking can replicate schemas between Schema Registry clusters as follows:
A schema link sends data from a “source cluster” to a “destination cluster”. The supported cluster types are shown in the table below.
Source Schema Registry Cluster Options | Destination Schema Registry Cluster Options |
|---|---|
Confluent Cloud with internet networking | Confluent Cloud with internet networking |
Confluent Cloud with internet networking | Confluent Platform 7.0+ with an IP address accessible over the public internet |
Confluent Platform 7.0+ | Confluent Platform 7.0+ |
Confluent Platform 7.0+ | Confluent Cloud with internet networking |
Schema Linking can also be used in both directions between two clusters, allowing each side to continue to receive both reads and writes for schemas.
With regard to Confluent Cloud and Confluent Platform solutions, you would use Schema Linking with Cluster Linking to mirror from one instance to the other. Any use of Confluent Platform in these setups require Confluent Platform 7.0.+ or later.
To learn more about Cluster Linking and mirror topics, see Cluster Linking for Confluent Platform and Geo-replication with Cluster Linking on Confluent Cloud.
Access Control (RBAC) for Schema Linking Exporters
RBAC for Schema Linking is available on Confluent Platform 7.0.9, 7.1.7, 7.2.5, 7.3.2, 7.3.3, 7.4.0, and later versions.
You must set the following property to enforce RBAC for Schema Linking on Confluent Platform: schema.linking.rbac.enable=true. To learn more about this configuration option, see the entry for schema.linking.rbac.enable in Schema Registry Configuration Options.
RBAC role bindings for schema exporters on Confluent Platform are shown below. To learn more, see Role-Based Access Control Predefined Roles and Configuring Role-Based Access Control for Schema Registry.
Role | All access to exporter endpoints |
|---|---|
SystemAdmin | ✔ |
UserAdmin | |
ClusterAdmin | ✔ |
Operator | |
SecurityAdmin | |
ResourceOwner | ✔ (only if Subject = * ) |
DeveloperRead | |
DeveloperWrite | |
DeveloperManage |
Table Legend:
✔ = Yes
Blank space = No
Note
If you have schema exporters running, removing permissions for one or more subjects for an account will not prevent that user account from accessing these subjects in the DESTINATION if the DESTINATION Schema Registry is different from the source. Therefore, as a precaution you should also remove permissions for these subjects for the account in the DESTINATION Schema Registry.
The schema exporter will stop running if permissions are removed from the DESTINATION Schema Registry for the account that created the schema exporter.
If you want to grant permissions to specific schema contexts, you can do so using the Prefix rule and grant permissions with prefix as
:.schema_context:*.