
Geo-replication with Cluster Linking on Confluent Cloud
The following sections provide an overview of Cluster Linking on Confluent Cloud, including an explanation of what it is and how it works, success stories, supported cluster types, and a tutorial.
Get Started for Free
Sign up for a Confluent Cloud trial and get $400 of free credit.
What is Cluster Linking?
Cluster Linking on Confluent Cloud is a fully-managed service for replicating data from one Confluent cluster to another. Programmatically, it creates perfect copies of your topics and keeps data in sync across clusters. Cluster Linking is a powerful geo-replication technology for:
Multi-cloud and global architectures powered by real-time data in motion
Data sharing between different teams, lines of business, or organizations
High Availability (HA) and Disaster Recovery (DR) during an outage of a cloud provider’s region
Data and workload migration from a Apache Kafka® cluster to Confluent Cloud or Confluent Platform cluster to Confluent Cloud
Protect Tier 1, customer-facing applications and workloads from disruption by creating a read-replica cluster for lower-priority applications and workloads
Hybrid cloud architectures that supply real-time data to applications across on-premises datacenters and the cloud
Syncing data between production environments and staging or development environments
Cluster Linking is fully-managed in Confluent Cloud, so you don’t need to manage or tune data flows. Its usage-based pricing puts multi-cloud and multi-region costs into your control. Cluster Linking reduces operational burden and cloud egress fees, while improving the performance and reliability of your cloud data pipelines.
Success stories
The following organizations have used Cluster Linking for migration, disaster recovery, and data sharing use cases.
In this technical presentation at Current 2022, SAS described their zero-downtime migration using Cluster Linking Zero Down Time Move From Apache Kafka to Confluent The two Cluster Linking limitations mentioned in the presentation have been resolved.
The Real-Time Inter-Agency Data Sharing With Kafka presentation shows how Kafka and Cluster Linking have transformed how government agencies share data: in real-time with faster onboarding of new data sets, real-time event notification, reduced cost for data sharing, and enhanced and enriched data sets for improved data quality.
1-800-flowers.com used Cluster Linking for a disaster recovery strategy and for multi-cloud data movement. For more information, see minute 46 of this webinar.
“In three months, we went from having no DR strategy to a production multi-cloud DR capability based on real-time data architecture that also supported high performance regional applications.”
Confluent Sets Data in Motion Across Hybrid and Multicloud Environments for Real-Time Connectivity Everywhere lists success stories implementing Cluster Linking under the subheading “Cluster Linking: Seamlessly Connect Applications and Data Systems Across Hybrid and Multicloud Architectures”
Freeman talks about building a hybrid cloud and high availability and disaster recovery architecture
SAS talks about completing a large-scale migration
New Kafka Tier, No Kafka Tears, published in Maker Stories by Wealthsimple, describes using Cluster Linking for migration to scale up existing Kafka systems
Namely describes their data migration project in “Everywhere: Cloud Cluster Linking” under the subtopic Simplify geo-replication and multi-cloud data movement with Cluster Linking
SAS used Cluster Linking to migrate to Confluent for Kubernetes and other cloud-native solutions. Read the full story in SAS Powers Instant, Real-Time Omnichannel Marketing at Massive Scale with Confluent’s Hybrid Capabilities, under the subtopic “A much easier migration thanks to Cluster Linking”.
How it works
Cluster Linking mirrors data directly from one Confluent cluster to another. You can establish a cluster link between a source cluster and a destination cluster in a different region, cloud, line of business, or organization. You choose which topics to replicate from the source cluster to the destination. You can even mirror consumer offsets and ACLs, making it straightforward to move Kafka consumers from one cluster to another.

In one command or API call, you can create a cluster link from one cluster to another. A cluster link acts as a persistent bridge between the two clusters.
confluent kafka link create tokyo-sydney
--source-bootstrap-server pkc-867530.ap-northeast-1.aws.confluent.cloud:9092
--source-cluster lkc-42492
--source-api-key AP1K3Y
--source-api-secret ********
Tip
--source-cluster-id was replaced with --source-cluster in version 3 of confluent CLI, as described in the command reference for confluent kafka link create.
To mirror data across the cluster link, you create mirror topics on your destination cluster.
confluent kafka mirror create clickstream.tokyo
--link tokyo-sydney
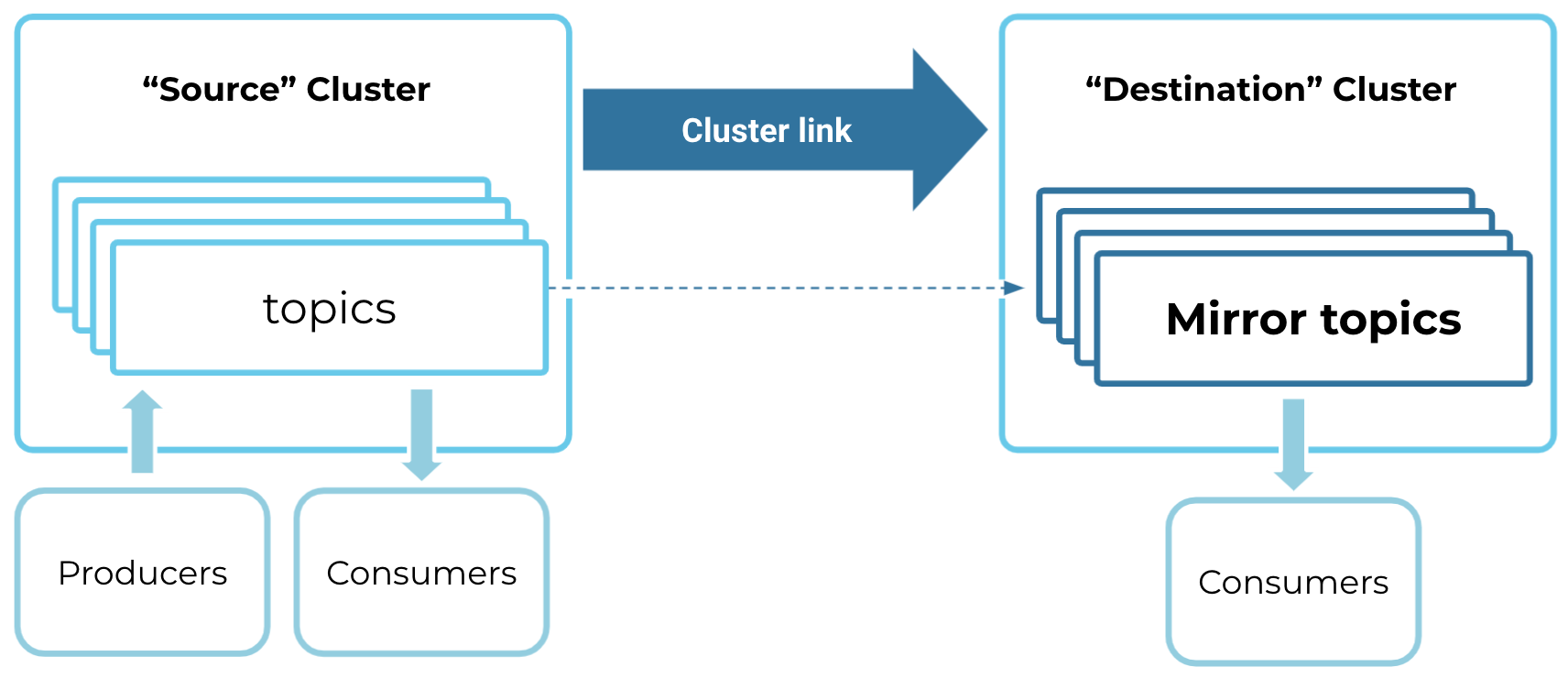
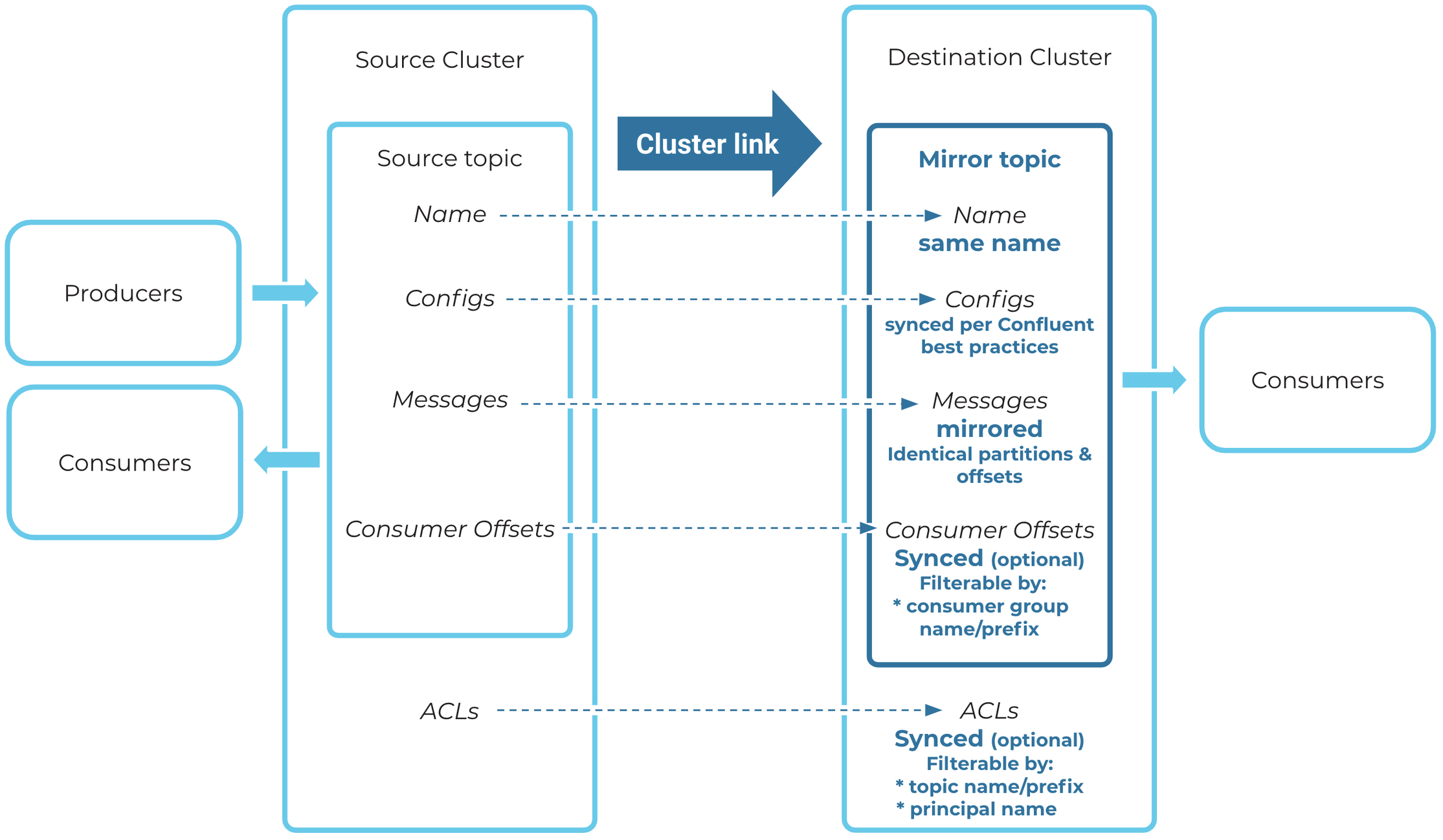
A mirror topic is a read-only copy of a source topic that replicates messages byte-for-byte, preserving partition and offset positions. Any messages produced to the source topic are mirrored to the mirror topic with the same messages going to the same partition and same offset. Mirror topics can be consumed the same as any other topic.
Cluster links and mirror topics are the building blocks you can use to create scalable, consistent architectures across regions, clouds, teams, and organizations.
Cluster Linking replicates essential metadata.
Cluster Linking syncs topic configurations between the source and mirror topics. It syncs some configurations but not others.
For mirror topics, you can enable consumer offset sync, which syncs consumer offsets from the source topic to the mirror topic. You can also filter it to specific consumer groups.
You can enable ACL sync, which syncs all ACLs on the cluster, not just the mirror topics. You can filter by topic name or principal name.
These features are covered in the various Tutorials.
Tip
Cluster Linking can use egress static IP addresses on AWS destination clusters.
Use cases
Cluster Linking supports the following use cases in Confluent Cloud. Many of these are demonstrated in the Tutorials and in tutorials specific to each use case.
Global and Multi-Cloud Replication: Move and aggregate real-time data across regions and clouds. By making geo-local reads of real-time data possible, this can act like a content delivery network (CDN) for your Kafka events throughout the public cloud, private cloud, and at the edge.
Data Sharing: Share data in real-time with other teams, lines-of-business, or organizations.
Data Migration: Migrate data and workloads from one cluster to another.
Disaster Recovery and High Availability: Create a disaster recovery cluster, and fail over to it during an outage.
Tiered Separation of Critical Applications: Protect Tier 1, customer-facing applications and workloads from disruption by creating a read-replica cluster for lower-priority applications and workloads.
Cluster Linking mirroring throughput (the bandwidth used to read data or write data to your cluster) is counted against your Fixed limits and recommended guidelines.
Feature support varies based on cluster type
There are restrictions on Cluster Linking features with regard to Basic, Standard, and Enterprise clusters, Private Networking, and Kafka Streams, and Kafka Transactions.
For details on capabilities of cluster types, see Kafka Cluster Types in Confluent Cloud, and the Cluster Linking capabilities sections for Basic, Standard, Enterprise, and Dedicated cluster types.
For a Cluster Linking support matrix per cluster type, see Supported cluster types.
For supported cluster combinations for Private Networking, see Supported cluster combinations in Manage Private Networking for Cluster Linking on Confluent Cloud.
For details on limitations with regard to Kafka transactions, security requirements, management, and more, see Limitations.
Supported cluster types
A cluster link sends data from a “source cluster” to a “destination cluster”. The supported cluster types are shown in the following table. Unsupported cluster types and other limits are described in Limitations.
Cluster links using private networking are now supported across Azure, AWS, and Google Cloud cloud providers with some limitations, as described in supported cluster combinations specific to private networking.
Source Cluster Options | Destination Cluster Options |
|---|---|
Any Dedicated or Enterprise Confluent Cloud cluster | |
Dedicated Confluent Cloud cluster, Enterprise cluster with private networking or Freight clusters on AWS with private networking | Dedicated or Enterprise Confluent Cloud cluster under certain networking circumstances, or Freight clusters on AWS with private networking, see Manage Private Networking for Cluster Linking on Confluent Cloud. |
Kafka 3.0+ or Confluent Platform 7.0+ with public internet IP addresses on all brokers [1] | Any Dedicated or Enterprise Confluent Cloud cluster |
Kafka 3.0+ or later without public endpoints [1] | A Dedicated Confluent Cloud cluster with VPC Peering or VNet Peering, or Enterprise cluster |
Confluent Platform 7.1+ (even behind a firewall) | Any Dedicated or Enterprise Confluent Cloud cluster under certain networking circumstances, see Manage Private Networking for Cluster Linking on Confluent Cloud. |
| Confluent Platform 7.0+ even behind a firewall. |
If the source cluster is not a Confluent Cloud cluster, then it must be running version 2.8 of the
inter.broker.protocol(IBP), and preferably IBP 3.0 or later version.Basic and Standard clusters can be source of destination initiated links, but cannot be used as the source of source-initiated links.
For cluster links using public networking, the source cluster and destination cluster can be in different regions, cloud providers, organizations, or Confluent Cloud environments.
Dedicated legacy clusters are not supported as a destination with Cluster Linking. You should seamlessly migrate to Dedicated clusters to use Cluster Linking.
Clusters in the Azure
qatarcentralregion cannot be source or destination clusters for Cluster Linking when the remote cluster is also a Confluent Cloud cluster.
Footnotes
How to check the cluster type
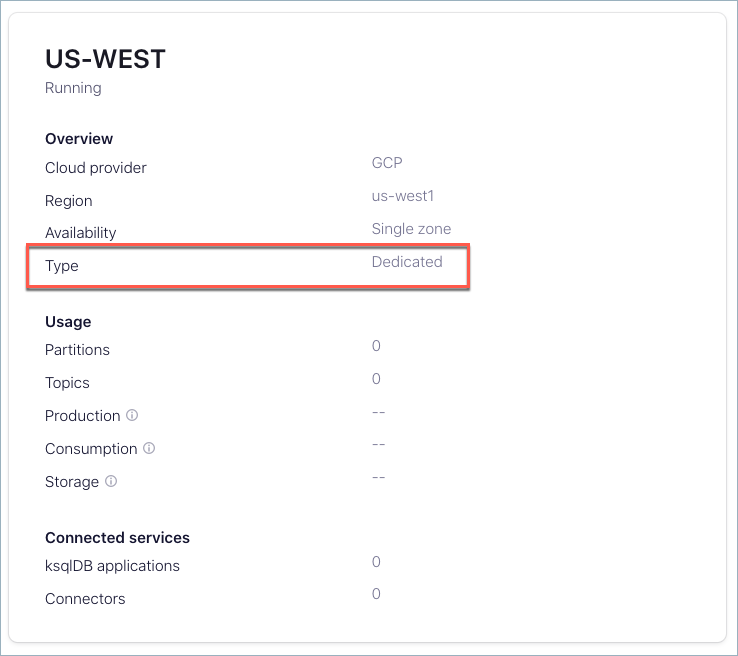
To check a Confluent Cloud cluster’s type and endpoint type:
Log on to Confluent Cloud.
Select an environment.
Select a cluster.
The cluster type is shown on the summary card for the cluster.
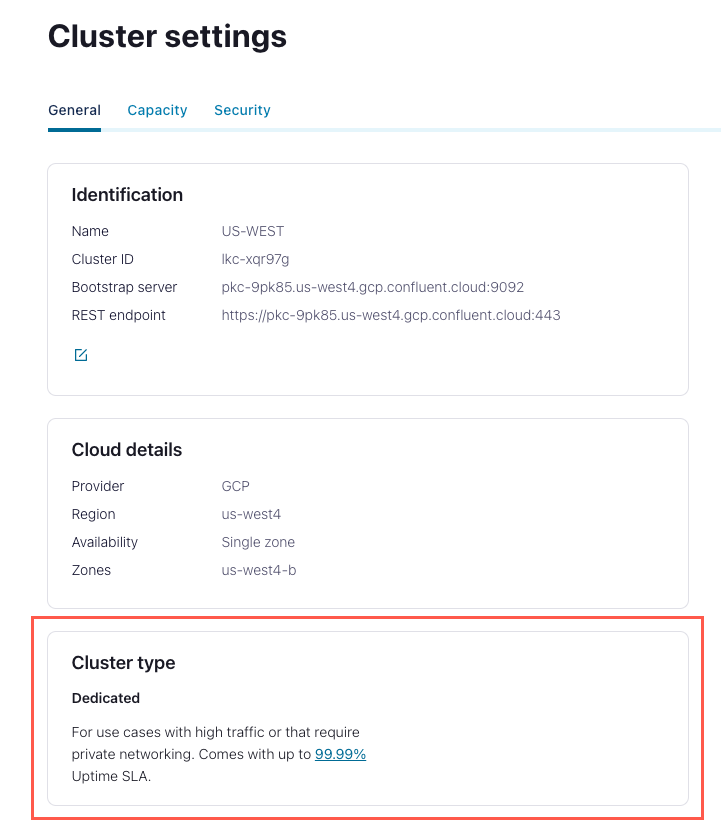
Alternatively, select the cluster, and select Cluster settings from the left menu. The cluster type is shown on the summary card for “Cluster type”.
From the left menu under Cluster overview for a Enterprise cluster, select the Networking menu item to view the endpoint type. Only Dedicated clusters have the Networking tab; Basic and Standard clusters always have Internet networking. Networking is defined when you first create the Enterprise cluster.
Support for Cluster Linking from external sources
You can use any Kafka 3.0+ cluster as a source cluster for Cluster Linking, including external sources such as Amazon MSK. Link the external source cluster to a Confluent Cloud destination cluster.
Linking from external sources is detailed in the following scenarios:
Pricing
Cluster Linking pricing is based on two dimensions: the number of cluster links and the volume of mirroring throughput to or from the cluster.
For a detailed breakdown of how Cluster Linking is billed, including guidelines for using metrics to track your costs, see Cluster Linking in Confluent Cloud Billing.
More general information about pricing for Confluent Cloud is on the website on the Confluent Cloud pricing page.
Getting started
Just getting started with Cluster Linking? Here are a few suggestions for next steps.
Tutorials
To get started, try one or more tutorials, each of which maps to a use case.
Mirror topics
Read-only, mirror topics that reflect the data in original (source) topics are the building blocks of Cluster Linking. For details on how mirror topics work, see Mirror Topics.
Commands and prerequisites
The destination cluster can use the confluent kafka link command to create a link from the source cluster. The following prerequisite steps are needed to run the tutorials during the Preview.
To try out Cluster Linking on Confluent Cloud:
Install Confluent Cloud if you do not already have it, as described in Install Confluent CLI.
To learn more about Confluent Cloud in general, see Quick Start for Confluent Cloud.
Log on to Confluent Cloud.
Update your Confluent CLI to ensure you have an up-to-date version of the Cluster Linking commands. See Get the latest version of the Confluent CLI in the quick start for details.
The
confluent kafka linkcommand has the following subcommands or flags.Command
Description
createCreate a new cluster link.
deleteDelete a previously created cluster link.
describeDescribes an existing cluster link.
listLists existing cluster links.
updateUpdates a property for an existing cluster link.
The
confluent kafka mirrorcommand has the following subcommands or flags.Command
Description
describeDescribe a mirror topic.
failoverFailover the mirror topics.
listList all mirror topics in the cluster or under the given cluster link.
pausePause the mirror topics.
promotePromote the mirror topics.
resumeResume the mirror topics.
Follow the tutorials to try out Cluster Linking. The commands are demonstrated in the tutorials.
CLI tips
For a complete list of commands, see the Confluent CLI command reference. Following are some generic strategies for saving time on command line workflows.
Save command output to a text file
To keep track of information, save the output of the Confluent Cloud commands to a text file. If you do so, ensure you safeguard API keys and secrets afterwards by deleting the file or moving only the security codes to safer storage. To redirect command output to a file, you can use either of these methods and manually add in headings for organization:
To redirect output to a file, use Linux syntax such as
<command> > notes.txtto run the first command and create the notes file, and then<command> >> notes.txtto append further output.- To save command output to a file and view it in the terminal at the same time, pipe the command to tee.
Use
<command> | tee notes.txtfor the first command to create the file. For later commands, use add the-aflag to append instead of overwrite. For example,<command> | tee -a notes.txt.
Use configuration files to store data you will use in commands
Create configuration files to store API keys and secrets, detailed configurations for cluster links, or security credentials for clusters external to Confluent Cloud. Examples of this are provided in (Usually optional) Use a config File in the topic data sharing tutorial and in Create the cluster link for the disaster recovery tutorial.
Use environment variables to store resource information
You can streamline your command line workflows by saving permissions and cluster data in shell environment variables. Save API keys and secrets, resources such as IDs for environments, clusters, or service accounts, and bootstrap servers, then use the variables in Confluent commands.
For example, create variables for an environment and clusters:
export CLINK_ENV=env-abc123
export USA_EAST=lkc-qxxw7
export USA_WEST=lkc-1xx66
Then use these in commands:
confluent environment use $CLINK_ENV
Now using "env-abc123" as the default (active) environment.
confluent kafka cluster use $USA_EAST
Set Kafka cluster "lkc-qxxw7" as the active cluster for environment "env-abc123".
Put it all together in commands
Assuming you’ve created environment variables for your clusters, API keys, and secrets, and have cluster link configuration details in a file called link.config, here is an example of creating a cluster link named “east-west-link” using variables and your configuration file.
confluent kafka link create east-west-link \
--cluster $DESTINATION_ID \
--source-cluster $ORIG_ID \
--source-bootstrap-server $ORIG_BOOT \
--config link.config
Scaling Cluster Linking
Because Cluster Linking fetches data from source topics, the first scaling unit to inspect is the number of partitions in the source topics. Having enough partitions lets Cluster Linking mirror data in parallel. Having too few partitions can make Cluster Linking bottleneck on partitions that are more heavily used.
In Confluent Cloud, Cluster Linking scales with the ingress and egress quotas of your cluster. Cluster Linking is able to use all remaining bandwidth in a cluster’s throughput quota: 150 MB/s per CKU egress on a Confluent Cloud source cluster or 50 MB/s per CKU ingress on a Confluent Cloud destination cluster, whichever you reach first. Therefore, to scale Cluster Linking throughput, adjust the number of CKUs on either the source, the destination, or both.
Note
On the destination cluster, Cluster Linking write takes lower priority than Kafka clients producing to that cluster; Cluster Linking will be throttled first.
Confluent proactively monitors all cluster links in Confluent Cloud and will perform tuning when necessary. If you find that your cluster link is not hitting these limits even after a full day of sustained traffic, contact Confluent Support.
To learn more, see recommended guidelines for Confluent Cloud.
In a Confluent Platform or Kafka cluster, you can scale Cluster Linking throughput as follows:
On the cluster link configurations, change the number of fetcher threads or change the fetch size to get better batching. For more information, see Configuration options on the cluster link for Confluent Platform.
Improve the cluster’s maximum throughput by scaling the brokers vertically or horizontally.
Use the options listed under Cluster Link Replication Configurations to tune cluster link performance, which helps scale cluster link throughput.
Limitations
Cluster Linking has limitations related to cluster types, networking, Kafka transactions, security, and performance.
Cluster types and networking
Currently supported cluster types are described in Supported cluster types.
Enterprise legacy clusters are not supported as a destination with Cluster Linking. You should seamlessly migrate to Dedicated clusters to use Cluster Linking.
A given cluster can only be the destination for 10 cluster links. Cluster Linking does not currently support by default aggregating data from more than 10 sources. The limit can be raised significantly for these aggregation use cases. To inquire about raising the cluster link limit to a single cluster for an aggregation use case, contact Confluent Support.
Kafka transactions such as “exactly once” semantics not supported on mirror topics
Cluster Linking is not integrated with Kafka transactions, including “exactly once” semantics. Using Cluster Linking to mirror topics that contain transactions or exactly once semantics is not supported.
Security
Cluster links on Confluent Cloud that use OAuth must be created using either the Confluent CLI or REST API. Creating cluster links that use OAuth is not currently supported in the Confluent Cloud Console.
To learn more, see information about the Security model for Cluster Linking.
ACL syncing
A key feature of Cluster Linking is the capability to sync ACLs between clusters. This is useful when moving clients between clusters for a migration or failover. This feature does have some limitations and best practices to consider, summarized below.
In Confluent Cloud, ACL sync is only supported between two Confluent Cloud clusters that belong to the same Confluent Cloud organization. ACL sync is not supported between two Confluent Cloud clusters in different organizations, or between a Confluent Platform and a Confluent Cloud cluster. This is because the principals used in Confluent Cloud are service accounts unique to one Confluent Cloud organization.
Do not include in the sync filter ACLs that are managed independently on the destination cluster. This is to prevent cluster link migration from deleting ACLs that were added specifically on the destination and should not be deleted. To learn more, see Configure cluster link behavior and Syncing ACLs from source to destination cluster.
ACL sync and prefixing cannot be enabled together on a single cluster link. ACLs can always be synced on a separate link; just create a new link and configure it to sync ACLs. For more details, see Limitations on prefixing in Mirror Topics.
ACL sync does not support filtering resources using a prefix pattern. For more details, see Limitations on filtering ACLs.
Terraform
If using Terraform to create and manage a cluster link, Terraform can only create and manage cluster links that are between two Confluent Cloud clusters. It cannot create or manage cluster links to or from an external cluster, such as an open-source Kafka cluster or a Confluent Platform cluster.
Kafka protocol limits for consumer group configuration strings
Individual configuration strings and metadata arrays have a maximum size of 32,767 characters.
Impact on consumer group synchronization
Large migrations with many consumer groups can exceed this limit if you define a long list of groups in a single filter such as consumer.groups.include.
Solution
Break large migrations into multiple cluster links using:
Narrower filter patterns
Wildcard regular expressions (regex) patterns
Multiple smaller cluster links instead of one large link
Management limitations
Cluster links must be created and managed on the destination cluster.
Cluster links can only be created with destination clusters that are Dedicated or Enterprise Confluent Cloud clusters. For full details on supported cluster combinations, see this high level table in this overview: Supported cluster types and the detailed breakdown in the private networking section: Supported cluster combinations.
Consumer group offsets that are deleted on the destination cluster, especially those that are auto-deleted, persist instead of being removed as expected. To prevent extended retention of inactive consumer group offsets, increase
offsets.retention.minuteson the destination cluster by at least doubleoffsets.retention.check.interval.ms. This ensures data is deleted on the source before it is deleted on the destination, preventing re-replication of offsets that are deleted on the source.In Confluent Platform 7.1.0 and later, REST API calls to list and get source-initiated cluster links will have their destination cluster IDs returned under the parameter
source_cluster_id.Mirror topics count against a cluster’s topic limits, partition limits, or storage limits; just like other topics.
There is no limit to the number of topics or partitions a cluster link can have, up to the destination cluster’s maximum number of topics and partitions.
A cluster can have at most 10 cluster links targeting it as the destination; that is, not more than 10 cluster links that are replicating data to it. Some aggregation use cases may require more than 10 cluster links on one destination cluster. The limit can be raised significantly for these aggregation use cases. To inquire about raising the cluster link limit to a single cluster for an aggregation use case, contact Confluent Support.
By definition, a mirror topic can only have one cluster link and one source topic replicating data to it. Alternatively, a single topic can be the source topic for an unlimited number of mirror topics.
Before deleting a cluster link, verify that all mirror topics are in the
STOPPEDstate. If any are in thePENDING_STOPPEDstate, deleting a cluster link can cause irrecoverable errors on those mirror topics due to a temporary limitation.You can configure how often the sync processes for consumer offset sync, ACL sync, and topic configuration sync run. The interval at which syncs can occur is limited to at most once per second (1000 ms minimum). You can set a longer interval so that syncs occur less often, but not more frequently than once per second.
The reverse commands,
reverse-and-startandreverse-and-pause, do not support prefixed cluster links. If a cluster link is configured with acluster.link.prefix, you cannot use reverse APIs to swap mirroring directions during disaster recovery or failover scenarios.
Unmanaged cluster links in the Confluent Cloud Console
In the Confluent Cloud Console, you might see a cluster link with a system-generated name or ID that you didn’t create. In most cases, this entry is the source side of a cluster link that another cluster created, using this cluster as its source.
By default, a cluster link is destination-initiated. The destination cluster hosts the link configuration and initiates the network connection to the source cluster. Because of this, the source cluster merely displays a read-only entry representing the inbound connection. This entry cannot be managed or modified from the source cluster. You must perform all lifecycle and configuration changes directly on the destination cluster that owns the link.
When you delete the cluster link from the destination cluster, the corresponding unmanaged entry on this cluster is also removed.
No action is required if your existing cluster links are healthy and replication is working as expected. Contact Confluent Support if:
Replication is unhealthy or incomplete.
The unmanaged entry remains after you delete the cluster link or after a failover.
You have a billing question about a displayed unmanaged link.
A cluster is charged for every cluster link where it serves as the source or the destination. The unmanaged entry here reflects a charge to this cluster. For details, see Cluster Linking in Billing Dimensions.
Feature support and permissions requirements for Cloud Console
You must be a CloudClusterAdmin, EnvironmentAdmin, or OrganizationAdmin to create a cluster link or mirror topics in the Confluent Cloud Console. Using the UI without these roles will yield a permissions error when attempting to create a cluster link. To learn more, see Manage Security for Cluster Linking on Confluent Cloud.
You must be an OrganizationAdmin to use the first source-cluster option: “Confluent Cloud (in my org)” because you must be authorized to create a Service Account. Using that option without the OrganizationAdmin role will yield a permissions error when attempting to create a cluster link. To learn more, see Manage Security for Cluster Linking on Confluent Cloud.
Performance limits
- Throughput
For Cluster Linking, throughput indicates bytes-per-second of data replication. The following performance factors and limitations apply.
The data that Cluster Linking replicates, measured in bytes per second, counts toward the destination cluster’s produce limits, also called ingress or write limits. Because Kafka client writes take priority over Cluster Linking writes, the Metrics API reports the two separately as
received_bytesfor Kafka clients andcluster_link_destination_response_bytesfor Cluster Linking writes.Cluster Linking consumes from the source cluster similar to Kafka consumers. Throughput in bytes-per-second of data replication is treated the same as consumer throughput. Cluster Linking will contribute to any quotas and hard or soft limits on your source cluster. The Kafka client reads and Cluster Linking reads are therefore included in the same metric in the Metrics API:
sent_bytesCluster Linking is able to max out the throughput of your CKUs. The physical distance between clusters is a factor of Cluster Linking performance. Confluent monitors cluster links and optimizes their performance. Unlike Replicator and Kafka MirrorMaker 2, Cluster Linking does not have a unique scaling, or tasks. You do not need to scale up or scale down your cluster links to increase performance.
- Connections
Cluster Linking connections count towards any connection limits on your clusters.
- Request rate
Cluster Linking contributes requests which count towards your source cluster’s request rate limits.
Tip
See more Q&A at Cluster Linking.
Known issues
Considerations for deleting source topics
Do not delete a source topic for an active mirror topic, as it can cause issues with Cluster Linking. Instead, follow these steps as a best practice:
Use the
promoteorfailovercommands to stop or delete any active mirror topics that read from the source topic you want to delete.Then, you can safely delete the source topic.
To learn more, see Source Topic Deletion in Mirror Topics.
On source-initiated links, a Confluent Platform source cluster that links to a KRaft destination must be 7.1.0 or later
Cluster Linking with a source-initiated link between a source cluster running Confluent Platform 7.0.x or earlier (non-KRaft) and a destination cluster running in KRaft mode is not supported. Link creation may succeed, but the connection will ultimately fail with a SOURCE_UNAVAILABLE error message. To work around this issue, make sure the source cluster is running Confluent Platform version 7.1.0 or later. If you have links from a Confluent Platform source cluster to a Confluent Cloud destination cluster, you must upgrade your source clusters to Confluent Platform 7.1.0 or later to avoid this issue.
This limitation only applies to source-initiated links. A regular cluster link can be created between a KRaft destination cluster and a non-KRaft source cluster, as long as the destination cluster can connect to the source cluster.