
Use Broker-Side Schema ID Validation on Confluent Cloud
Schema ID Validation enables the broker to verify that data produced to a Kafka topic uses a valid schema ID in Schema Registry that is registered according to the subject naming strategy. (See also, Schemas, subjects, and topics.)
Schema Validation does not perform data introspection, but rather checks that the schema ID in the Wire Format is registered in Schema Registry under a valid subject.
You must use a serializer and deserializer (serdes) that respect the Wire format, or use a Confluent supported serde, as described in Formats, Serializers, and Deserializers.
Limitations
Schema validation feature does not reject tombstone records, records with a null value, even if there is no schema ID associated with the record. Messages with a null value or a null key will pass validation. This is a design choice that supports effective data management and deletion in compacted topics.
Prerequisites
Schema ID Validation on Confluent Cloud is only available on Dedicated clusters through the hosted Schema Registry. Confluent Cloud brokers cannot use self-managed instances of Schema Registry, only the Confluent Cloud hosted Schema Registry. (Schema validation is available for on-premises deployments through Confluent Enterprise).
You must have a Schema Registry enabled for the environment in which you are using Schema ID Validation.
Schema ID Validation is bounded at the level of an environment. All dedicated clusters in the same environment share a Schema Registry. Clusters do not have visibility into schemas across different environments.
Schema ID Validation Configuration options on a topic
Schema ID Validation is set at the topic level with the following parameters.
Property | Description |
|---|---|
| When set to |
| When set to |
| Set the subject name strategy for the message key. The default is |
| Set the subject name strategy for the message value. The default is |
| Set the specific schema context that will be searched by the broker when validating the schema ID of the message key and value. The default value of this property is |
Tip
Value schema and key schema validation are independent of each other; you can enable either or both.
The subject naming strategy is tied to Schema ID Validation. This will have no effect when Schema ID Validation is not enabled.
Get the latest version of the Confluent CLI
Got Confluent CLI? Make sure it’s up-to-date.
Run
confluent updateto get the latest version of the Confluent CLI. Once you’ve upgraded, check out this handy Confluent CLI commands reference available here.To learn more about the Confluent CLI and migration paths, see Install Confluent CLI, Migrate to the latest version of the Confluent CLI, and Run multiple CLIs in parallel.
Enable Schema ID Validation from the Confluent CLI
You can enable Schema ID Validation on a topic when you create a topic or modify an existing topic on any Dedicated cluster.
The command syntax to enable Schema ID Validation is as follows:
confluent kafka topic <create|update> <topic-name> --config confluent.<key|value>.schema.validation=true
For example, this command creates a topic called flights with schema validation enabled on the value schema:
confluent kafka topic create flights --config confluent.value.schema.validation=true
With this configuration, if a message is produced to the topic flights that does not have a valid schema for the value of the message, an error is returned to the producer, and the message is discarded.
If a batch of messages is sent and at least one is invalid, then the entire batch is discarded.
If you do not specify a different subject naming strategy, io.confluent.kafka.serializers.subject.TopicNameStrategy is used by default. You can modify the naming strategies used for either or both the message key and message value schemas. For example, the following command sets the subject naming strategy on the topic flights to use io.confluent.kafka.serializers.subject.RecordNameStrategy.
confluent kafka topic update flights --config confluent.value.subject.name.strategy=io.confluent.kafka.serializers.subject.RecordNameStrategy
The following naming strategies are available as accepted values for confluent.value.subject.name.strategy.
Strategy | Description |
|---|---|
TopicNameStrategy | Derives subject name from topic name. (This is the default.) |
RecordNameStrategy | Derives subject name from record name, and provides a way to group logically related events that may have different data structures under a subject. |
TopicRecordNameStrategy | Derives the subject name from topic and record name, as a way to group logically related events that may have different data structures under a subject. |
Note
The full class names for the above strategies consist of the strategy name prefixed by io.confluent.kafka.serializers.subject., as shown in the examples in this section.
Enable Schema ID Validation on a topic from the Confluent Cloud Console
To set Schema ID Validation on a topic from the Cloud Console:
Navigate to a topic.
Click the Configuration tab.
Click Edit Settings.
Click Switch to expert mode.
In Expert mode, change the settings for
confluent.value.schema.validationand/orconfluent.key.schema.validationfrom false to true.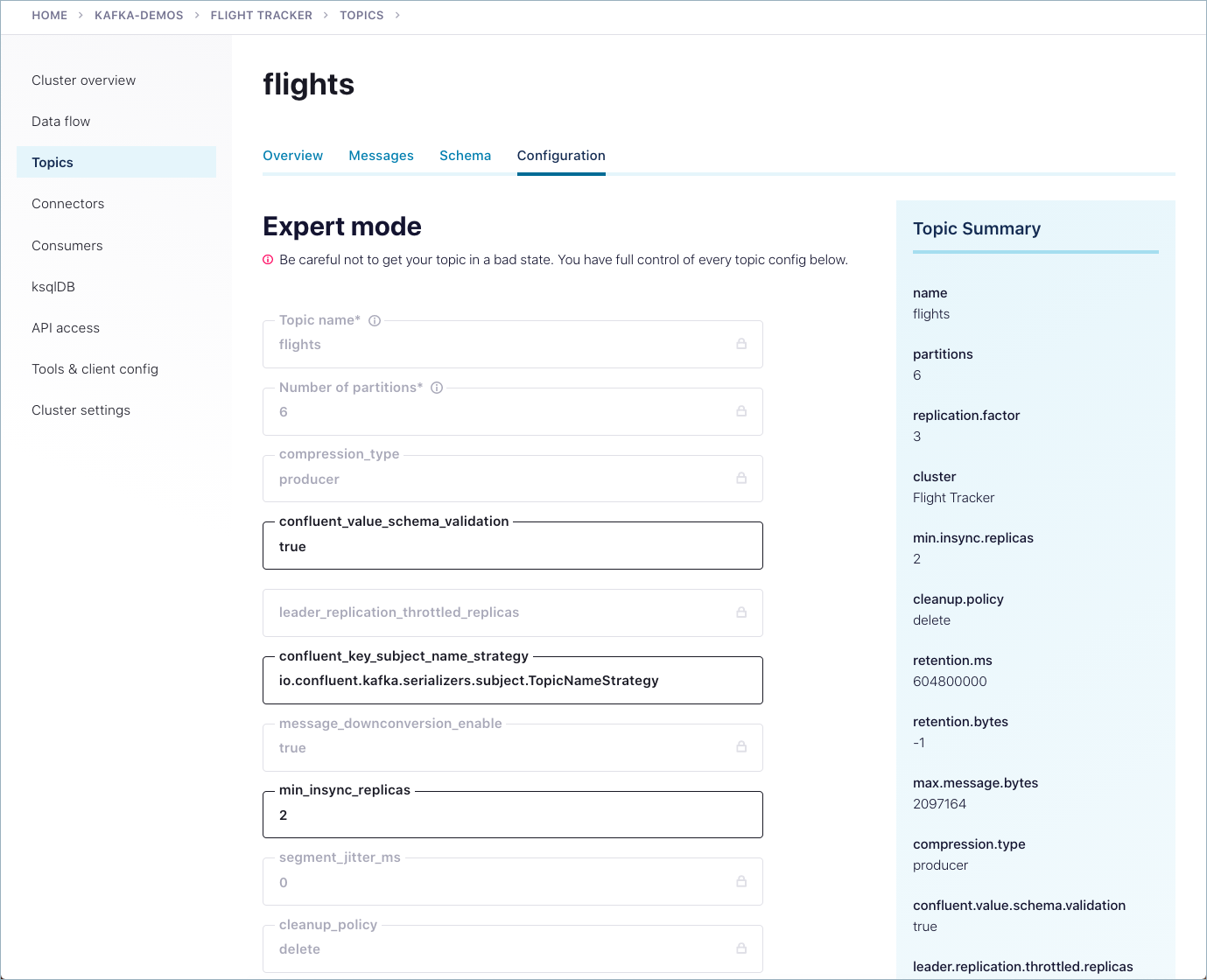
Tip
If the schema validation configuration entries do not appear in Expert mode, make sure that you are working with a Dedicated cluster. As indicated in the Prerequisites, this feature is only available on Dedicated clusters; the configuration entries will not show up on other types of clusters.
If you do not specify a different naming strategy,
TopicNameStrategyis used by default.
You can modify the naming strategies used for either or both the message key and message value schemas. These settings are also available in Expert mode on the selected topic. Set these now, if desired.
Click Save changes.
To disable Schema ID Validation, set these same configuration options to false.
Schema ID Validation demo
You can test Schema ID Validation by following along with this short demo.
Create a test topic called
players-mapleeither from the web UI or the Confluent CLI. Do not specify the Schema ID Validation setting, so that your topic defaults tofalse.Here is the command to use from the Confluent CLI:
confluent kafka topic create players-maple
This creates a topic with no broker validation on records produced to the test topic, which is what you want for the first part of the demo.
In a new command window for the producer (logged into Confluent Cloud and on the same environment and cluster), run this command to produce a serialized record (using the default string serializer) to the topic
players-maple.confluent kafka topic produce players-maple --parse-key=true --delimiter=,
The command is successful because you currently have Schema ID Validation disabled for this topic. If broker Schema ID Validation had been enabled for this topic, the above command to produce to it would not be permitted.
Type your first message at the producer prompt as follows:
1,PierreKeep this session of the producer running.
Open a new command window for the consumer (logged into Confluent Cloud and on the same environment and cluster), and enter this command to read the messages:
confluent kafka topic consume players-maple --from-beginning --print-key=true
The output of this command is
1 Pierre.Keep this session of the consumer running.
Now, set Schema ID Validation for the topic
players-mapletotrue.confluent kafka topic update players-maple --config confluent.value.schema.validation=true
Tip
You can also update this setting on the Confluent Cloud Console in expert mode for the configuration on the
players-mapletopic.Return to the producer session, and type a second message at the prompt.
2,FrederikYou will get an error because Schema ID Validation is enabled and the messages we are sending do not contain schema IDs:
Error: producer has detected an INVALID_RECORD error for topic players-mapleIf you subsequently disable Schema ID Validation (use the same command to set it to
false), then type and resend the same or another similarly formatted message, the message will go through. (For example, produce3,Ben.)The messages that were successfully produced also show in your web browser in Topics > players-maple > Messages. You may have to select a partition or jump to a timestamp to see messages sent earlier.
What Schema ID Validation checks and how it works
When Schema ID Validation is enabled on a topic, it checks for the following on each message:
The message produced to the topic has an associated schema. (The message must have an associated schema ID, which indicates it has a schema.)
The schema must match the topic.
The demo above is a straight-forward way to demonstrate that Schema ID Validation is working, using the Confluent CLI.
In practice, you would typically send an Avro object, Protobuf object, or Jackson-serializable POJO as a function of a client application. In this case, Schema ID Validation derives the schema based on the object. The schema is sent to Schema Registry, which checks to see if the schema exists in the subject. If it does, Schema Registry uses the schema ID of that version. If it doesn’t, Schema Registry throws an error if the client has auto schema registration set to false, or will register the schema if the client has auto schema registration set to true.
Auto schema registration is set in the client application. By default, client applications automatically register new schemas. You can disable auto schema registration on your clients, which is typically recommended in production environments. To learn more, see Disabling Auto Schema Registration in the Confluent Platform documentation.
Use a specific schema context with schema validation
Set the confluent.schema.validation.context.name to a specific schema context, for example: .mycontext or mycontext, which will be used by the broker to search for subjects when validating the schema ID of message keys and values.
If the value of this property is set to a specific schema context, for example: .mycontext, then this specific schema context will be used to search for the subject name and perform schema validation. If the configured “context.name” .mycontext does not exist in the Schema Registry, schema validation will fail and messages will be rejected.
The default value of this property is default. The behaviour of this default value depends on the SubjectNameStrategy being used with schema validation.
If using TopicNameStrategy, the subject name is searched across all schema contexts:
If it exists in the default schema context, then this subject will be used to perform schema validation.
If it does not exist in the default schema context, the subject name will be searched across all available contexts and the first subject name found will be used to perform schema validation.
If using RecordNameStrategy or TopicRecordNameStrategy, the subject is searched only in the default context.
If the subject is not found in the default context, the schema validation will fail. Therefore, make sure that the producers are referring to the correct schema context.
To learn more about how to configure the correct schema context in clients, see Specifying a context name for clients.
You can use the Confluent CLI, Terraform, or Schema Registry APIs to set this property. Currently, it is not supported on the Confluent Cloud Console.
Troubleshoot
If the tutorial and examples above do not work or you do not see or have access to confluent.value.schema.validation, check for the following:
Schema validation is only available on dedicated clusters through the hosted Schema Registry. Make sure that the cluster you are using is a Dedicated Kafka cluster (not Basic, Standard, or Enterprise).
Schema validation requires that Schema Registry is enabled on the environment. Make sure you have Schema Registry enabled for the environment in which you are using Schema ID Validation.
Messages with null keys or values will pass schema validation
If you have confluent.value.schema.validation enabled, and produce a Kafka message with null value, it will pass schema validation, even though the value does not follow the protocol defined for the Wire format (because it is null).
If you have confluent.key.schema.validation enabled and produce a Kafka message with a null key, it will pass schema validation even though the key does not follow the protocol defined for the Wire format (because it is null).