コネクター開発者ガイド¶
このガイドでは、Apache Kafka® と別のシステムとの間でデータを移動するための、Kafka Connect 用の新しいコネクターを開発者が記述する方法について説明します。Kafka Connect の重要な概念をいくつか確認した後、シンプルなコネクターを作成する方法について説明します。
ちなみに
- コネクターの作成方法の詳細については、ブログ記事「How to Write a Connector for Kafka Connect – Deep Dive into Configuration Handling」を参照してください。
- Confluent Hub では、新しいコネクターの開発を歓迎しています。作成したコネクターを Confluent Hub でホストするには、「Confluent Hub への貢献」を参照してください。
主要な概念と API¶
コネクターとタスク¶
Kafka と別のシステムとの間でデータをコピーするには、データのプル元またはプッシュ先として使用するシステム用に Kafka コネクター をインスタンス化します。コネクターには 2 つのフレーバーがあります。1 つは、別のシステムからデータをインポートする SourceConnector、もう 1 つは、別のシステムにデータをエクスポートする SinkConnector です。たとえば、JDBCSourceConnector ではリレーショナルデータベースを Kafka にインポートすることができ、HDFSSinkConnector では Kafka トピックのコンテンツを HDFS ファイルにエクスポートすることができます。
Connector クラスの実装自体は、データのコピーを実行しません。このクラスの構成で、コピーする一連のデータを記述し、Connector はそのジョブを一連の Task に分割して、Kafka Connect ワーカーに分散できるようにします。Task にも対応する 2 つのフレーバー、SourceTask と SinkTask があります。オプションとして、Connector クラスの実装では、外部システムのデータの変更のモニタリングと、タスク再構成のリクエストができます。
各 Task は、コピーするデータの割り当てを取得したら、データのサブセットを Kafka から、または Kafka へコピーする必要があります。コネクターがコピーするデータは、パーティションストリーム で表される必要があります。これは、各パーティションが、オフセットを持つレコードの順序付きシーケンスとなっている、Kafka トピックのモデルに似ています。タスクごとに、処理するパーティションのサブセットが割り当てられます。場合によっては、このマッピングが明確で、一連のログファイルの中の 1 つのファイルをパーティション、ファイル内の 1 行を 1 つのレコード、オフセットをファイル内の位置と考えることができる場合もあります。これに対して、このモデルのマッピングがもう少し複雑な場合もあります。JDBC コネクターでは、それぞれのテーブルを 1 つのパーティションに対応付けることができますが、オフセットはそれほど明確ではありません。マッピングの方法の 1 つとして、タイムスタンプ列を使用してクエリを生成し、インクリメンタルに新しいデータを返す方法があります。この場合、最後のクエリ時のタイムスタンプをオフセットとして使用することができます。
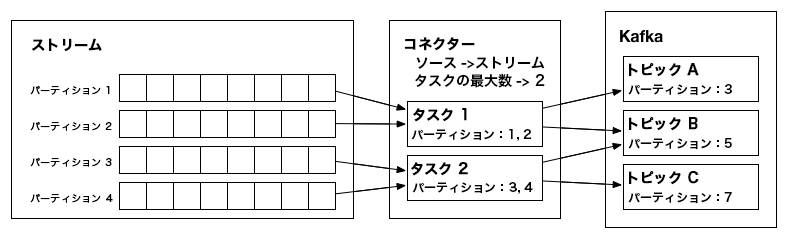
入力 "パーティション" からデータをコピーし、"レコード" を Kafka に書き込む、2 つの "タスク" を作成したソース "コネクター" の例。¶
パーティションとレコード¶
各パーティションは、キーと値を持つレコードの順序付きシーケンスです。キーと値のどちらにも、org.apache.kafka.connect.data パッケージのデータ構造で表現される、複雑な構造を使用できます。多くのプリミティブ型に加え、配列、構造体、ネストしたデータ構造がサポートされています。ほとんどの型について、java.lang.Integer、java.lang.Map、java.lang.Collection などの Java 標準のデータ型をそのまま使用できます。構造化レコードについては、Struct クラスを使用する必要があります。
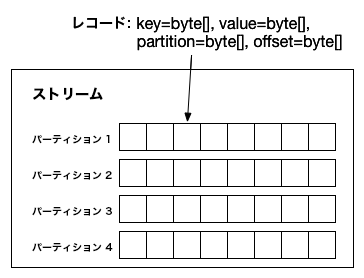
パーティションストリーム: コネクターがすべてのソースシステムとシンクシステムのマッピングを行う必要があるデータモデル。各レコードにキーと値(スキーマを含む)、パーティション ID、そのパーティション内のオフセットが含まれます。¶
パーティション内のレコードの構造と互換性を追跡できるように、各レコードに スキーマ を含めることができます。スキーマは一般に、データソースに基づいてオンザフライで生成されるため、SchemaBuilder クラスが含まれており、スキーマの構築が非常に容易になっています。
このランタイムデータフォーマットでは、特定のシリアル化フォーマットは前提とされていません。この変換は コンバーター の実装で処理されます。コンバーターでは、org.apache.kafka.connect.data ランタイムフォーマットと、byte[] で表されるシリアル化データの間の変換が行われます。コネクターの開発者がこの変換の詳細を考慮する必要はありません。
レコードには、キーと値に加えて、パーティション ID とオフセットが含まれます。これらは、フレームワークで、処理されたデータのオフセットを定期的にコミットするために使用されます。障害の発生時には、最後にコミットされたオフセットの時点から処理を再開でき、不要な再処理やイベントの重複を避けることができます。
動的なコネクター¶
すべてのコネクターでパーティションが常に一定とは限りません。そのため、Connector の実装では、再構成が必要となるような変更がないか、外部システムをモニタリングする必要もあります。たとえば、JDBCSourceConnector の例では、コネクター が一連のテーブルを各 タスク に割り当てることができます。新しいテーブルが作成された場合は、構成を更新して、その新しいテーブルをいずれかの タスク に割り当てることができるように、そのテーブルの作成を検出できる必要があります。再構成が必要な変更( タスク 数の変更)が検出されたら、フレームワークに通知し、対応する タスク をフレームワークが更新します。
シンプルなコネクターの開発¶
コネクターの開発で必要なことは、コネクター と タスク という 2 つのインターフェイスの実装だけです。ファイルから行を読み取り、ファイルに行を書き込むシンプルなコネクターの例が、org.apache.kafka.connect.file パッケージの Kafka Connect のソースコードに含まれています。SourceConnector/SourceTask クラスで、ファイルから行を読み取るソースコネクターが実装されており、SinkConnector/SinkTask クラスで、各レコードをファイルに書き込むシンクコネクターが実装されています。
ちなみに
サンプルの全体を確認するには、サンプルソースコード を参照してください。以下のセクションでは、主な手順とコードスニペットのみを紹介します。
コネクターの例¶
SourceConnector について、簡単な例で説明します。SinkConnector の実装も非常に類似しています。まず、SourceConnector から継承するクラスを作成し、解析後の構成情報(読み取り元のファイル名とデータの送信先のトピック)を保存するフィールドを追加します。
public class FileStreamSourceConnector extends SourceConnector {
private String filename;
private String topic;
入力を行う最も簡単なメソッドは getTaskClass() です。実際にデータを読み取るために、ワーカープロセスでインスタンス化する必要があるクラスを指定します。
@Override
public Class<? extends Task> getTaskClass() {
return FileStreamSourceTask.class;
}
以下では、FileStreamSourceTask クラスを定義します。次に、標準のライフサイクルメソッドである start() と stop() を追加します。
@Override
public void start(Map<String, String> props) {
// The complete version includes error handling as well.
filename = props.get(FILE_CONFIG);
topic = props.get(TOPIC_CONFIG);
}
@Override
public void stop() {
// Nothing to do since no background monitoring is required
}
最後に、実装の中核となるのが taskConfigs() の処理です。今回は、単一のファイルの処理のみを行います。 maxTasks 引数に従って複数のタスクを生成することが可能ですが、ここでは、エントリが 1 つだけのリストを返します。
@Override
public List<Map<String, String>> taskConfigs(int maxTasks) {
ArrayList<Map<String, String>> configs = new ArrayList<>();
// Only one input partition makes sense.
Map<String, String> config = new HashMap<>();
if (filename != null)
config.put(FILE_CONFIG, filename);
config.put(TOPIC_CONFIG, topic);
configs.add(config);
return configs;
}
タスクが複数の場合でも、このメソッドの実装は通常、非常にシンプルです。必要なことは、入力タスクの数を判定して、分配するだけです。入力タスク数の確認には、データの取得元のリモートサービスにアクセスする必要があります。タスクの負荷分散については一般的なパターンがいくつかあり、処理を簡素化できるように、ConnectorUtils でいくつかのユーティリティが提供されています。
このシンプルな例では、動的な入力には対応していないことに注意してください。タスク構成の更新をトリガーする方法については、次のセクションの解説を参照してください。
タスクの例 - ソースタスク¶
次に、対応する SourceTask の実装について説明します。小規模なクラスですが、このガイドですべてを説明すると長くなりすぎます。実装の説明をするうえで、ここで使用するヘルパーメソッドについては詳しく解説しませんが、ソースコードを参照することで全体を確認できます。
コネクターと同じように、ベースとなる適切な タスク クラスから継承するクラスを作成する必要があります。標準のライフサイクルメソッドも必要です。
public class FileStreamSourceTask extends SourceTask {
private String filename;
private InputStream stream;
private String topic;
private Long streamOffset;
public void start(Map<String, String> props) {
filename = props.get(FileStreamSourceConnector.FILE_CONFIG);
stream = openOrThrowError(filename);
topic = props.get(FileStreamSourceConnector.TOPIC_CONFIG);
}
@Override
public synchronized void stop() {
stream.close()
}
これらは少し単純化されていますが、これらのメソッドは比較的シンプルなもので、実行する必要があるのは、リソースの割り当てと解放だけであることを示しています。この実装には、注意すべき点が 2 つあります。1 つ目は、start() メソッドでは、前回のオフセットからの再開処理は行われないことです。これについては、後のセクションで説明します。2 つ目は、stop() メソッドが同期されていることです。この同期が必要なのは、SourceTask には専用のスレッドが割り当てられるので、ブロックが無期限に続く可能性があり、ワーカー内の別のスレッドからの呼び出しで停止する必要があるためです。
次に、タスクの中心的な機能を実装します。入力システムからレコードを取得し、List<SourceRecord> を返す poll() メソッドです。
@Override
public List<SourceRecord> poll() throws InterruptedException {
try {
ArrayList<SourceRecord> records = new ArrayList<>();
while (streamValid(stream) && records.isEmpty()) {
LineAndOffset line = readToNextLine(stream);
if (line != null) {
Map sourcePartition = Collections.singletonMap("filename", filename);
Map sourceOffset = Collections.singletonMap("position", streamOffset);
records.add(new SourceRecord(sourcePartition, sourceOffset, topic, Schema.STRING_SCHEMA, line));
} else {
Thread.sleep(1);
}
}
return records;
} catch (IOException e) {
// Underlying stream was killed, probably as a result of calling stop. Allow to return
// null, and driving thread will handle any shutdown if necessary.
}
return null;
}
ここでも、細部は省略されていますが、重要な手順は確認できます。 poll() メソッドが繰り返し呼び出され、呼び出しのたびに、ループしてファイルからレコードを読み取ります。1 行読み取るごとに、ファイルのオフセットも追跡します。この情報を使用して、出力の SourceRecord を作成します。ここには、ソースパーティション(単一のファイルの読み取りなので 1 つだけ)、ソースオフセット(ファイル内の位置)、出力トピック名、出力値(この値が常に文字列であることを示すスキーマを含む、行)の 4 つの情報が含まれます。SourceRecord コンストラクターの別のバリアントでは、特定の出力パーティションとキーを含めることもできます。
この実装では、通常の Java InputStream インターフェイスが使用されており、データが存在しない場合はスリープします。Kafka Connect では各タスクに専用のスレッドが用意されるため、これで問題ありません。タスクの実装では、基本の poll() インターフェイスに準拠する必要がありますが、実装方法にはかなりの柔軟性があります。この場合、NIO ベースの実装の方が効率的ですが、このシンプルなアプローチでも十分であり、簡単に実装でき、以前のバージョンの Java との互換性もあります。
この例では使用していませんが、SourceTask には、commit() と commitRecord() という、ソースシステムのオフセットをコミットするための 2 つの API が用意されています。これらの API は、メッセージの確認応答のメカニズムを持つソースシステム用に提供されています。これらのメソッドをオーバーライドすると、ソースシステムのメッセージが Kafka に書き込まれたときに、ソースコネクターが一括または個別にメッセージの確認応答を行うことができます。
commit() API では、poll() で返されたオフセットに応じて、ソースシステムのオフセットを保存します。この API の実装では、コミットが完了するまでブロックする必要があります。commitRecord() API では、SourceRecord が Kafka に書き込まれた後、各レコードについてソースシステムのオフセットを保存します。Kafka Connect ではオフセットが自動的に記録されるため、SourceTask でこの処理を実装する必要はありません。コネクターがソースシステムのメッセージの確認応答を行う必要がある場合、通常、必要になるのは一方の API のみです。
シンクタスク¶
前のセクションでは、シンプルな SourceTask の実装方法について説明しました。SourceConnector と SinkConnector とは異なり、SourceTask と SinkTask のインターフェイスは大きく異なります。 SourceTask ではプル型のインターフェイス、SinkTask ではプッシュ型のインターフェイスが使用されるためです。どちらもライフサイクルのメソッドは共通ですが、SinkTask はインターフェイスが大きく異なります。
public abstract class SinkTask implements Task {
... [ lifecycle methods omitted ] ...
public void initialize(SinkTaskContext context) {
this.context = context;
}
public abstract void put(Collection<SinkRecord> records);
public abstract void flush(Map<TopicPartition, Long> offsets);
public void open(Collection<TopicPartition> partitions) {}
public void close(Collection<TopicPartition> partitions) {}
}
SinkTask のドキュメント に詳細が記載されていますが、このインターフェイスは SourceTask と同様にシンプルなものです。put() メソッドに実装の大部分が含まれます。一連の SinkRecord を受け付け、必要な変換を実行し、送信先システムに保存します。このプロセスでは、復帰する前に、データがすべて送信先システムに書き込まれたことを保証する必要はありません。実際には、多くの場合、なんらかの内部バッファが役立ちます。バッファによりレコードのバッチ全体を一度に送信することができ(Kafka のプロデューサーのように)、ダウンストリームのデータストアにイベントを挿入するオーバーヘッドを減らすことができます。SinkRecord には、基本的に SourceRecord と同じ情報(Kafka トピック、パーティション、オフセット、イベントのキーと値)が含まれます。
flush() メソッドはオフセットのコミット処理で使用されます。それにより、タスクは障害から復旧して、イベントが失われることのない安全なポイントから再開できます。このメソッドでは、未処理のデータがあれば送信先システムにプッシュし、書き込みに対して確認応答があるまでブロックする必要があります。offsets パラメーターは多くの場合無視できますが、実装で厳密に 1 回のデリバリーを実現するために、オフセット情報を送信先ストアに保存する必要がある場合など、場合によっては役立ちます。たとえば、HDFS コネクターでこれを行い、アトミックな移動操作を使用することにより、flush() 操作でデータとオフセットを HDFS の最終的な場所にアトミックにコミットすることができます。
SinkTask では内部的には、Kafka コンシューマーを使用してデータのポーリングを行います。コネクターのタスクで使用されるコンシューマーインスタンスはいずれも、同じコンシューマーグループに属します。タスクの再構成や障害が発生すると、コンシューマーグループのバランス調整がトリガーされます。バランス調整では、トピックパーティションが新しい一連のタスクに再割り当てされます。Kafka コンシューマーのバランス調整の詳細については、「コンシューマー」セクションを参照してください。
コンシューマーはシングルスレッドであるため、put() や flush() の処理にはコンシューマーセッションのタイムアウトより長い時間がかからないようにする必要があることに注意してください。時間がかかりすぎると、そのコンシューマーはグループから除外され、パーティションのバランス調整がトリガーされ、バランス調整が完了するまで他のすべてのタスクの進行が停止することになります。
バランス調整において、リソースが適切に解放され、割り当てられるように、SinkTask にはさらに 2 つのメソッド、close() と open() が用意されています。これらは、SinkTask の実行を担う KafkaConsumer のベースとなるバランス調整のコールバックと結びついています。
close() メソッドは、SinkTask に割り当てられたパーティションのライターをクローズするために使用されます。このメソッドは、コンシューマーのバランス調整操作が開始される前、および SinkTask によるデータのフェッチが停止された後に呼び出されます。クローズされた後は、新しいパーティションが開かれるまで、Connect は新しいレコードをタスクに書き込みません。close() メソッドは、バランス調整が開始される前に SinkTask に割り当てられたすべてのトピックパーティションにアクセスできます。一般に、すべてのトピックパーティションのライターをクローズし、すべてのトピックのパーティションについてステートを適切に保持できるようにすることをお勧めします。ただし、実装において、一部のトピックパーティションのライターをクローズすることもできます。その場合は、目的とするデリバリーの保証が得られるように、バランス調整の前後のステートについて注意深く判断する必要があります。
open() メソッドは、コンシューマーのバランス調整が行われる場合に、新しく割り当てられたパーティション用のライターを作成するために使用されます。このメソッドは、パーティションの再割り当てが完了した後、および SinkTask によるデータのフェッチが開始される前に呼び出されます。
close() または open() でエラーが発生すると、タスクが停止し、失敗のステータスが報告され、対応するコンシューマーインスタンスが終了されます。このコンシューマーのシャットダウンによりバランス調整がトリガーされ、このタスクのトピックパーティションがこのコネクターの他のタスクに再割り当てされます。
前回のオフセットからの再開¶
SourceTask の実装では、各レコードにパーティション ID(入力ファイル名)とオフセット(ファイル内の位置)を含めました。フレームワークではこれを利用して定期的にオフセットをコミットすることで、障害発生時にタスクを復旧できるようにし、再処理され重複する可能性のあるイベント数を最小限に抑えます(または、スタンドアロンモードの場合やジョブの再構成、負荷のバランス調整などにより Kafka Connect が正常に停止された場合は、最新のオフセットから再開できるようにします)。このコミット処理はフレームワークによって完全に自動化されていますが、適切な場所から再開できるように入力を遡って適切な位置をシークする方法がわかるのはコネクターのみです。
起動時に適切に再開するため、タスクでは、initialize() メソッドに渡された SourceContext を使用して、オフセットデータにアクセスできます。initialize() では、もう少しコードを追加して、オフセットが存在する場合はオフセットを読み取り、その位置までシークします。
stream = new FileInputStream(filename);
Map<String, Object> offset = context.offsetStorageReader().offset(Collections.singletonMap(FILENAME_FIELD, filename));
if (offset != null) {
Long lastRecordedOffset = (Long) offset.get("position");
if (lastRecordedOffset != null)
seekToOffset(stream, lastRecordedOffset);
}
この実装には、注意すべき重要な点が 2 つあります。1 つ目は、このコネクターのオフセットは、プリミティブ型の Long であることです。ただし、Map や List などのより複雑な構造もオフセットとして使用することができます。2 つ目は、返されるデータは "スキーマなし" であることです。オフセットをシリアル化する コンバーター でスキーマの追跡ができる保証はないため、スキーマなしにする必要があります。これにより、コネクター開発者にとっては、信頼性の高いオフセットの解析を実現するのが少し難しくなりますが、シリアル化フォーマットの選択の柔軟性が高くなります。
もちろん、入力パーティションごとに多数のキーを読み取ることが必要な場合もあります。入力パーティションが 1 つになるのは、このようにシンプルなコネクターの場合のみです。OffsetStorageReader インターフェイスでは、一括読み取りを実行して、すべてのオフセットを効率的に読み込み、適切な位置まで各入力パーティションをシークして、そのオフセットを適用することもできます。
コネクターのメトリクス¶
カスタムコネクターを開発する場合、コネクターのコードでアップデートを行う必要はありません。メトリクスは、Kafka Connect フレームワークによって収集されエクスポートされます。詳細については、Apache Kafka のコード で Connect JMX メトリクスの収集を参照してください。
カスタムコネクターを開発する場合は、例として JDBC コネクターのオープンソースコード を使用できます。Connect メトリクスの詳細については、以下のドキュメントも参照してください。
動的な入力/出力パーティション¶
Kafka Connect は、多数のジョブを作成して各テーブルを個別にコピーするのではなく、データベース全体をコピーするなど、データを一括でコピーするジョブを定義するためのものです。このような設計になっているため、コネクター用の一連の入力パーティションまたは出力パーティションが時間の経過とともに変化する可能性があります。
ソースコネクターは、データベース内のテーブルの追加や削除など、変更の有無についてソースシステムをモニタリングする必要があります。ソースコネクターが変更を検出した場合、再構成が必要であることを、ConnectorContext オブジェクトを介してフレームワークに通知する必要があります。たとえば、SourceConnector で次のようにします。
if (inputsChanged()) {
this.context.requestTaskReconfiguration();
}
フレームワークは即座に新しい構成情報をリクエストしてタスクを更新し、タスクの再構成を行う前に、タスクが進捗情報を正常にコミットできるようにします。SourceConnector では、現時点ではこのモニタリングはコネクターの実装に依存することに注意してください。このモニタリングを実行するためのスレッドが必要な場合、コネクターがそのスレッドの割り当てを行う必要があります。
この変更のモニタリングを行うコードは Connector 内でのみ処理され、タスク側ではモニタリングについて何も行う必要がないのが理想です。しかし、一般によくあることとして、データベースからテーブルが削除された場合など、入力システムで入力パーティションの 1 つが破棄された場合、変更によりタスクにも影響が及ぶ可能性があります。Connector が変更についてポーリングを行う必要がある場合にはよくあることですが、Connector より前に Task が問題に直面した場合、次のエラーについては Task で処理を行う必要があります。幸い、これは通常、適切な例外をキャッチして処理することで、シンプルに対処できます。
SinkConnector は通常、パーティションの追加についてのみ対応する必要があります。追加されたパーティションは出力の新しいエントリに変換できます。Kafka Connect フレームワークは、正規表現を使用したサブスクリプションによって一連の入力トピックが変更された場合など、Kafka の入力に対するすべての変更を管理します。SinkTask では、新しい入力パーティションを受け付ける必要があり、それにより、ダウンストリームシステムで新しいリソースの作成が必要になることがあります(データベース内に新しいテーブルを作成するなど)。このような場合に最も扱いにくいのは、複数の SinkTask が新しい入力パーティションを初めて認識し、同時に新しいリソースの作成を試行したことにより競合が発生した場合でしょう。これに対して SinkConnector の場合は通常、動的な一連のパーティションに対応するために特別なコードは必要ありません。
構成の検証¶
Kafka Connect では、実行するためにコネクターを送信する前に、コネクターの構成を検証することができ、エラーに関するフィードバックおよび推奨値を確認できます。この機能を利用するには、コネクターの開発時に config() を実装して、構成の定義をフレームワークに公開する必要があります。
FileStreamSourceConnector では、以下のコードで構成を定義し、その構成の定義をフレームワークに公開します。
private static final ConfigDef CONFIG_DEF = new ConfigDef()
.define(FILE_CONFIG, Type.STRING, Importance.HIGH, "Source filename.")
.define(TOPIC_CONFIG, Type.STRING, Importance.HIGH, "The topic to publish data to");
public ConfigDef config() {
return CONFIG_DEF;
}
ConfigDef クラスを使用して、想定される一連の構成を指定します。それぞれの構成について、名前、型、デフォルト値、ドキュメント、グループ情報、グループ内の順序、構成値の幅、UI での表示用の名前を指定できます。さらに、Validator クラスをオーバーライドすることにより、単一の構成の検証に使用される特別な検証ロジックを提供できます。また、構成と構成の間に依存関係が存在する場合があるため、他の構成の値に従って、たとえば、有効な値や構成の可視性が変更される可能性があります。この課題に対処するため、ConfigDef を使用することにより、1 つの構成に従属する構成を指定すること、および、Recommender を実装して、有効な値の取得や、現在の構成値に基づく構成の可視性の設定を行うことができます。
Connector の validate() メソッドでは、デフォルトの検証が実装されています。この実装では、許可されている構成のリストが、構成エラーおよび各構成の推奨値とともに返されます。ただし、構成の検証には、推奨値は使用されません。デフォルトの実装のオーバーライドを提供して、構成の検証をカスタマイズし、推奨値を使用することができます。
スキーマの操作¶
FileStream コネクターは、シンプルでありながら、明確な構造を持つデータも含まれているため(各行は単なる文字列です)、例として優れています。ほぼすべてのコネクターで、より複雑なデータフォーマットを持つスキーマが必要になるでしょう。
より複雑なデータを作成するには、org.apache.kafka.connect.data API を使用する必要があります。大部分の構造化レコードは、プリミティブ型の Schema および Struct に加え、2 つのクラスとのやり取りが必要になります。
包括的なリファレンスについては、API のドキュメントを参照してください。ここでは、Schema と Struct の作成に関する簡単な例を紹介します。
Schema schema = SchemaBuilder.struct().name(NAME)
.field("name", Schema.STRING_SCHEMA)
.field("age", Schema.INT_SCHEMA)
.field("admin", new SchemaBuilder.boolean().defaultValue(false).build())
.build();
Struct struct = new Struct(schema)
.put("name", "Barbara Liskov")
.put("age", 75)
.build();
ソースコネクターを実装している場合、いつ、どのようにスキーマを作成するかを決定する必要があります。可能な限り、スキーマの再計算は避ける必要があります。たとえば、コネクターで固定のスキーマが使用されることが保証される場合は、スキーマを静的に作成し、1 つのインスタンスを再利用します。
ただし、多くのコネクターでは動的なスキーマが使用されます。一例としてデータベースコネクターが挙げられます。単一のテーブルのみを考えてみても、ユーザーが ALTER TABLE コマンドを実行する可能性があるため、コネクターの存続期間を通じて、1 つのテーブルに対してスキーマが固定ということはありません。コネクターは、このような変更を検出し、更新された Schema を作成して、適切に対応できる必要があります。
シンクコネクターは通常、よりシンプルです。シンクコネクターはデータを消費する側であり、スキーマを作成する必要はないためです。ただし、受け取ったスキーマが想定されているフォーマットであることを検証する必要はあります。スキーマが一致しない場合(これは通常は、アップストリームプロデューサーで無効なデータが生成され、送信先システム向けに適切な変換ができないことを示しています)、シンクコネクターは例外をスローして、このエラーを Kafka Connect フレームワークに通知する必要があります。
Confluent Platform に同梱の AvroConverter を使用すると、スキーマは内部的に Confluent Schema Registry に登録されます。そのため、新しいスキーマは送信先トピックの互換性要件を満たす必要があります。
スキーマ進化¶
Kafka Connect では、SchemaProjector にユーティリティが用意されており、互換性のあるスキーマ間で Kafka Connect のデータ API を使用して値をプロジェクションすることができます。互換性のないスキーマが与えられた場合は例外がスローされます。SchemaProjector の使用方法は簡単です。以下の例は、バージョン 2 のソーススキーマからバージョン 3 のターゲットスキーマに sourceStruct をプロジェクションする方法を示しています。バージョン 3 では、デフォルト値を持つフィールドが 1 つ追加されています。これら 2 つのスキーマには互換性があるため、targetStruct には 2 つのフィールドが含まれ、field2 には 123 という値が設定されます。これは、このフィールドのデフォルト値です。
Schema source = SchemaBuilder.struct()
.version(2)
.field("field", Schema.INT32_SCHEMA)
.build();
Struct sourceStruct = new Struct(source);
sourceStruct.put("field", 1);
Schema target = SchemaBuilder.struct()
.version(3)
.field("field", Schema.INT32_SCHEMA)
.field("field2", SchemaBuilder.int32().defaultValue(123).build())
.build();
Struct targetStruct = (Struct) SchemaProjector.project(source, sourceStruct, target);
このユーティリティは、コネクターでスキーマの進化に対応し、スキーマの互換性を維持する必要がある場合に役立ちます。たとえば、HDFS コネクターで後方互換性を維持する必要がある場合、ファイルごとに使用できるスキーマは 1 つのみであるため、メッセージが HDFS に書き込まれる前に、古いスキーマが使用されているメッセージをコネクターで認識された最新のスキーマにプロジェクションする必要があります。これにより、HDFS に書き込まれる最新のファイルでは最新のスキーマが使用されます。最新のスキーマは、すべてのデータのクエリに使用することができ、後方互換性が維持されます。
スキーマの互換性の詳細については、「データのシリアル化とスキーマの進化」セクションを参照してください。
テスト¶
コネクターのテストには困難が伴う場合があります。Kafka Connect コネクターは 2 つのシステム(Kafka とコネクターの接続先システム)とやり取りしますが、それらのシステムはモックの作成が難しい場合があるためです。実際には統合テストのような "単体テスト" を記述したくなることもあるでしょう。外部サービスのモックを作成する際には、コネクタークラスとタスククラスの機能をそれぞれ別々にテストする方法が優れています。
十分な単体テストが完了してから、別途、統合テストを追加して、エンドツーエンドの機能を検証することをお勧めします。
パッケージ化¶
Once you've developed and tested your connector, you must package it so that it can be easily installed into Kafka Connect installations. The two techniques described here both work with Kafka Connect's plugin path mechanism.
コネクターをパッケージ化して、他のユーザーが使用できるように配布することを計画している場合、作成したコードの使用許諾および著作権保護を適切に行い、コードで使用するライブラリおよびディストリビューションに含めるライブラリのすべてについて使用許諾と著作権を遵守する義務があります。
アーカイブの作成¶
コネクターをパッケージ化する最も一般的な方法は、tarball または ZIP アーカイブを作成する方法です。アーカイブには、他のコネクターの実装に対して一意の名前を持つ単一のディレクトリを含める必要があります。そのため、多くの場合は、コネクターの名前とバージョンを含めます。サードパーティのライブラリを含め、コネクターで必要な JAR ファイルおよびその他のリソースファイルはすべて、トップレベルディレクトリ内に配置する必要があります。ただし、アーカイブには、Kafka Connect の API やランタイムライブラリを含めないようにする必要があることに注意してください。
To install the connector, a user simply unpacks the archive into the desired location.
Having the name of the archive's top-level directory be unique makes it easier to unpack
the archive without overwriting existing files. It also makes it easy to place this
directory on Installing Connect Plugins
or for older Kafka Connect installations to add the JARs to the CLASSPATH.
Uber JAR の作成¶
もう 1 つの方法として、コネクターの JAR ファイルおよびその他のリソースファイルをすべて含む "uber JAR" を作成する方法があります。ディレクトリの内部構造は不要です。
To install, a user simply places the connector's uber JAR into one of the directories listed in Installing Connect Plugins.
おすすめの関連情報¶
- ブログ記事: 「How to Write a Connector for Kafka Connect – Deep Dive into Configuration Handling」
- ブログ記事 : Kafka Connect API を使用して Apache Kafka コネクターを作成する 4 つの手順
注釈
Confluent Hub では、新しいコネクターの開発を歓迎しています。作成したコネクターを Confluent Hub でホストするには、「Confluent Hub への貢献」を参照してください。