Streams のアーキテクチャ¶
このセクションでは、Kafka Streams の内部の動作について説明します。
Kafka Streams では、Apache Kafka® のプロデューサー API とコンシューマー API を基盤とし、Kafka のネイティブ機能を利用してデータの並列性、分散協調、フォールトトレランス、操作の簡易性が提供されるため、アプリケーション開発が簡素化されます。
次の図は、Kafka Streams API を使用するアプリケーションの構造を示しています。これは、複数のストリームスレッドを含む Kafka Streams アプリケーションの論理ビューです。各ストリームスレッドには複数のストリームタスクが含まれています。
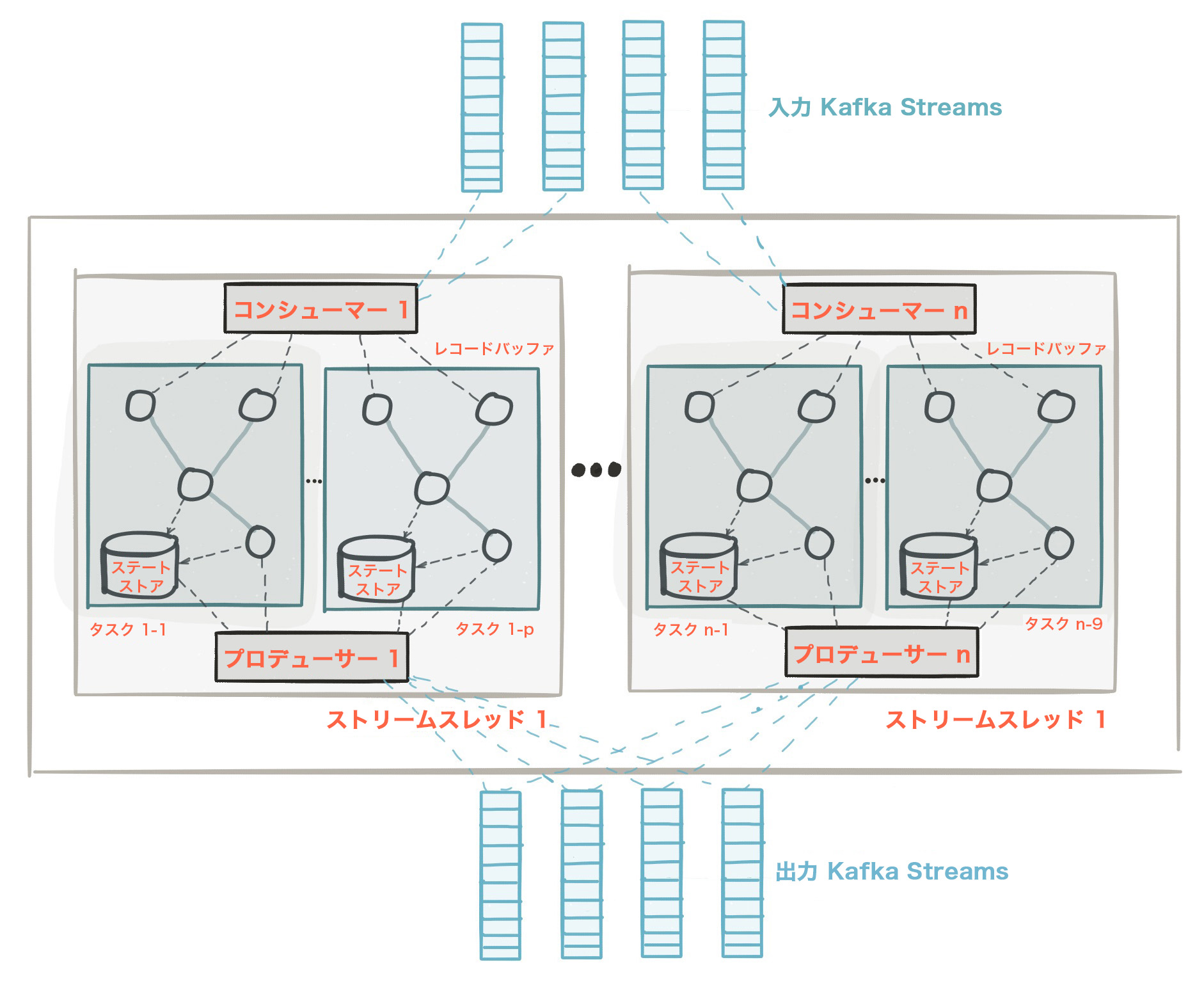
ちなみに
イベントストリームを介して接続された多数のストリームプロセッサーまたはマイクロサービスのチェーンから、Kafka トランザクションが、正確で再現性のある結果を提供するしくみについては、「Building Systems Using Transactions in Apache Kafka」を参照してください。
プロセッサートポロジー¶
プロセッサートポロジー、または単に トポロジー とは、アプリケーションのストリーム処理の計算ロジックを定義するものです。つまり、入力データがどのように出力データに変換されるかを表します。トポロジーは、ストリーム (エッジ)または共有 ステートストア によって接続された ストリームプロセッサー (ノード)を図示するものです。トポロジーには、次の 2 つの特殊なプロセッサーが含まれています。
- ソースプロセッサー: ソースプロセッサーは、アップストリームプロセッサーを持たない特殊な種類の ストリームプロセッサー です。1 つ以上の Kafka トピックからレコードを消費し、ダウンストリームプロセッサーに転送することで、トピックからトポロジーへの入力ストリームを生成します。
- シンクプロセッサー: シンクプロセッサーは、ダウンストリームを持たない特殊な種類のストリームプロセッサーです。アップストリーム プロセッサーから受信したレコードを、指定された Kafka トピックに送信します。
ストリーム処理アプリケーションでは、このようなトポロジーを 1 つ以上定義することができますが、通常は 1 つだけ定義します。開発者は、低レベルの Processor API を使用するか、この API を基盤とした Kafka Streams DSL を通じてトポロジーを定義できます。
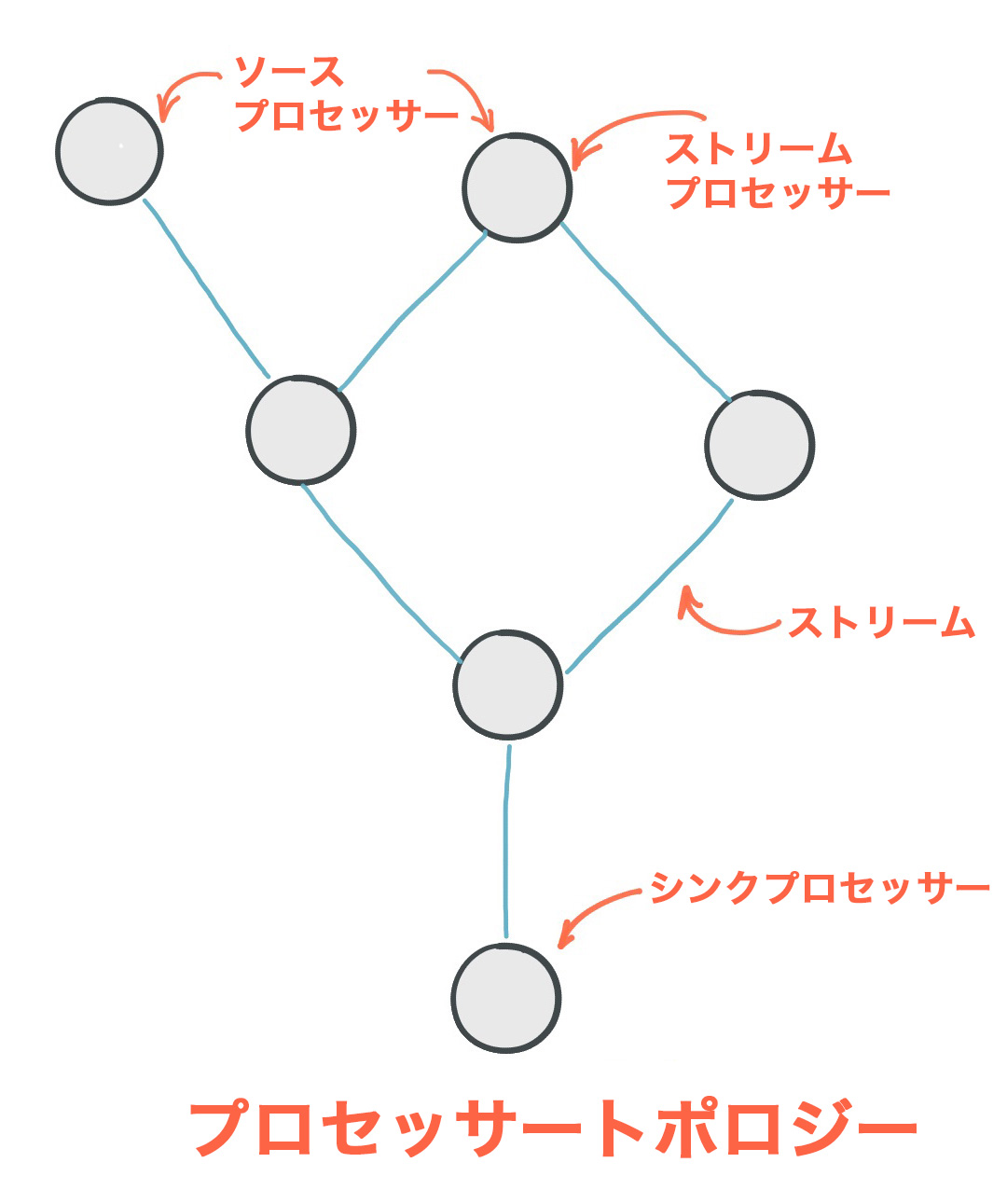
プロセッサートポロジーは、単にストリーム処理コードの論理的な抽象化です。実行時には、この論理トポロジーがインスタンス化され、アプリケーションの内部で並列処理用に複製されます(「並列処理モデル」を参照してください)。
並列処理モデル¶
ストリームパーティションとタスク¶
Kafka のメッセージング層では、データをパーティションに分けて格納および伝送します。Kafka Streams では、データをパーティションに分けて "処理" します。どちらの場合も、このパーティション化によって、データのローカル性、柔軟性、拡張性、高パフォーマンス、フォールトトレランスが実現されます。
Kafka Streams では、並列処理モデルの論理単位として、ストリームパーティション と ストリームタスク の概念が使用されます。並列処理のコンテキストでは、Kafka Streams と Kafka の間に密接な関係があります。
- 各 ストリームパーティション は、データレコードの全順序シーケンスであり、Kafka の "トピックパーティション" にマップされます。
- ストリームマップ内の データレコード は、Kafka の該当するトピックの メッセージ にマップします。
- Kafka でも Kafka Streams でも、データレコードの キー によってデータのパーティション化が定義されます。つまり、データがどのようにトピック内の特定のパーティションにルーティングされるかが決まります。
アプリケーションのプロセッサートポロジーは、複数のストリームタスクに分割することでスケーリングされます。具体的には、Kafka Streams が、アプリケーションの入力ストリームパーティションに基づいて固定数のストリームタスクを作成します。各タスクには、入力ストリーム(Kafka トピック)からのパーティションのリストが割り当てられます。ストリームタスクへのストリームパーティションの割り当てが変わることはない ため、ストリームタスクは、アプリケーションの並列処理における固定単位となります。各タスクは、割り当てられたパーティションに基づいて独自のプロセッサートポロジーをインスタンス化します。さらに、割り当てられたパーティションごとにバッファを維持し、これらのレコードバッファから、入力データのレコードを一度に 1 つずつ処理します。結果として、手動操作を必要とすることなく、各ストリームタスクが独立して並列的に処理されます。
アプリケーションで実行できる 最大限の並列処理 は、ストリームタスクの最大数が上限となります。ストリームタスクの最大数は、アプリケーションが読み取っている入力トピックのパーティションの最大数によって決まります。たとえば、入力トピックに 5 個のパーティションがある場合、最大 5 個のアプリケーションインスタンスを実行できます。これらのインスタンスは協調してトピックのデータを処理します。入力トピックのパーティションよりも多くのアプリケーションインスタンスを実行すると、"超過分" のアプリケーションインスタンスも開始されますが、それらはアイドル状態になります。ただし、処理中のインスタンスのいずれかが停止すると、アイドル状態のインスタンスの 1 つがその処理を引き継いで再開します。FAQ では、より 詳しい説明と例 を紹介しています。
注釈
サブトポロジー(サブグラフ): Kafka Streams アプリケーションで複数のプロセッサートポロジーが指定されている場合、各タスクでは、1 つのトポロジーだけが処理用にインスタンス化されます。さらに、単一のプロセッサートポロジーが、独立した複数のサブトポロジー(サブグラフ)に分解されることがあります。サブトポロジーは、トポロジー内で親/子として、またはステートストアを介して、すべてが "推移的" に接続される一連のプロセッサーから成っています。この場合、異なるサブトポロジー同士がトピックを通じてデータを交換しますが、ステートストアは共有されません。各タスクでは、処理のためにこのようなサブトポロジーを 1 つだけインスタンス化することができます。これにより、計算ワークロードがさらに複数のタスクにスケールアウトされます。
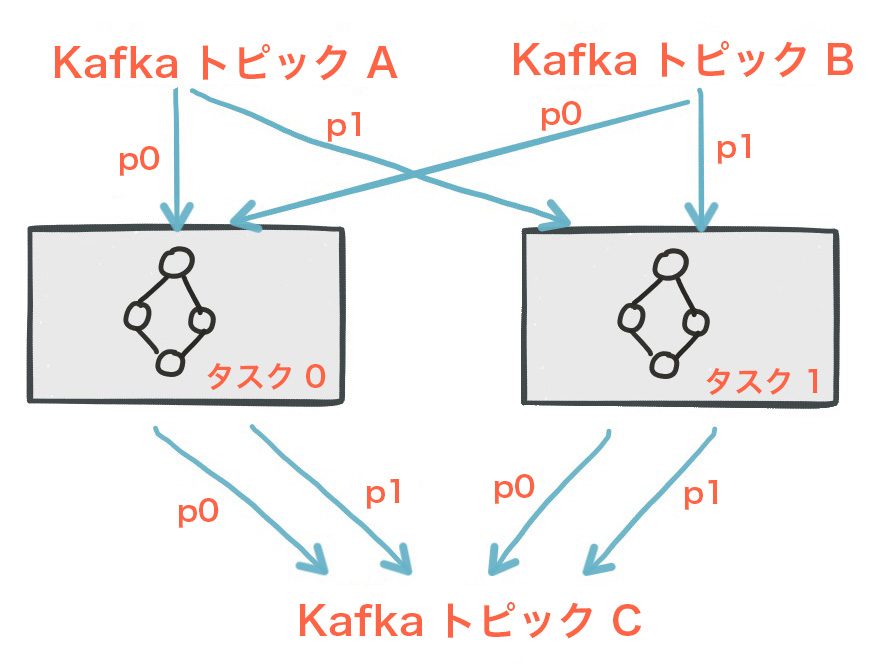
入力ストリームからパーティションが 1 つずつ割り当てられた 2 つのタスク。¶
Kafka Streams はリソースマネージャーではなく、ストリーム処理アプリケーションが実行される場所で "動作" するライブラリであると理解することが重要です。アプリケーションの複数のインスタンスは、同じマシン上または複数のマシンで実行されます。ライブラリによって、これらの実行中のアプリケーションインスタンスにタスクを 自動的に分散 することができます。タスクへのパーティションの割り当てが変わることはありません。いずれかのアプリケーションインスタンスで障害が発生した場合は、そのインスタンスに割り当てられていたすべてのタスクが 他のインスタンスで再起動 され、同じストリームパーティションから消費が継続されます。
注釈
トピックパーティションはタスクに割り当てられ、タスクはすべてのインスタンスにわたるすべてのスレッドに割り当てられます。このとき、ロードバランシングとステートフルタスクの持続性とのトレードオフを最適化する試みが行われます。Kafka Streams では、この割り当てに StreamsPartitionAssignor クラスが使用され、別のアサイナーに変更することはできません。別のアサイナーを使用しようとしても、Kafka Streams によって無視されます。
スレッドモデル¶
Kafka Streams では、1 つのアプリケーションインスタンス内で処理を並列化するためにライブラリで使用できる スレッド の数を、ユーザーが構成できるようになっています。各スレッドでは、1 つ以上のストリームタスクを、それぞれのプロセッサートポロジーで別々に実行できます。
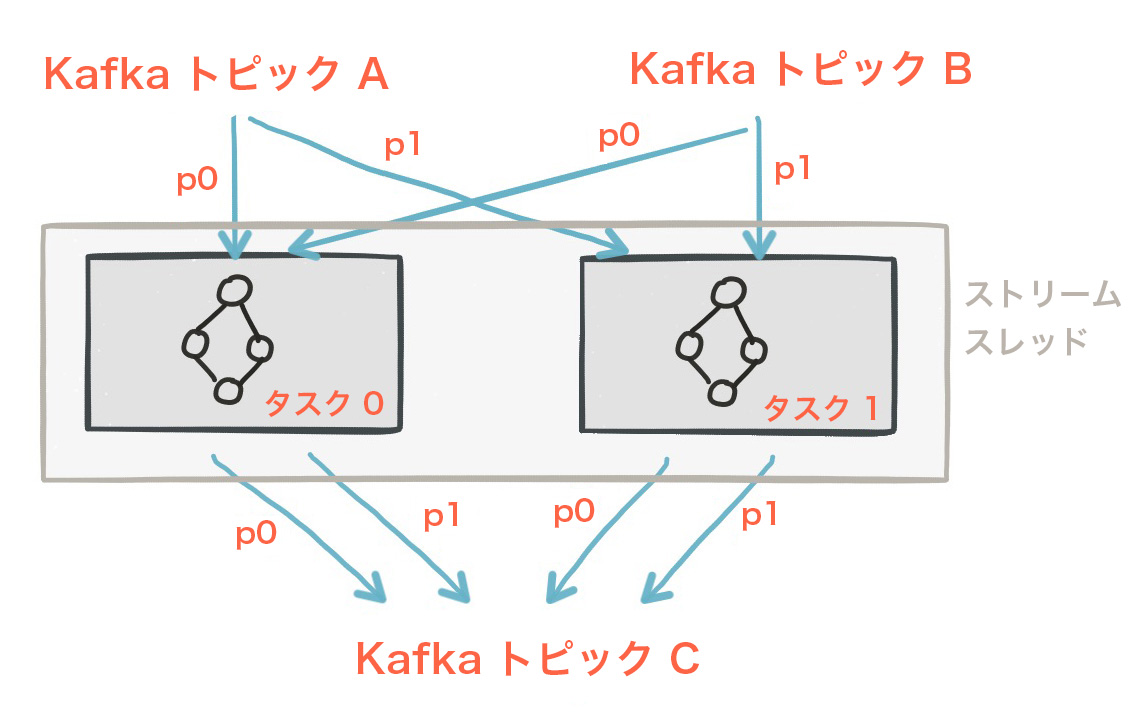
2 つのストリームタスクを実行する 1 つのストリームスレッド。¶
より多くのストリームスレッドやアプリケーションインスタンスを開始することは、トポロジーを複製して Kafka パーティションの別のサブセットを処理することに等しく、実質的に処理の並列化と変わりません。特筆すべき点として、スレッド間には共有されるステートがないので、スレッド間の協調は必要ありません。このため、アプリケーションインスタンス間およびスレッド間で、非常に簡単に複数のトポロジーを並列実行できます。さまざまなストリームスレッド間での Kafka トピックパーティションの割り当ては、Kafka のサーバー側調整 機能を利用して、Kafka Streams によって透過的に処理されます。
前述のとおり、Kafka Streams を使用したストリーム処理アプリケーションのスケーリングは簡単です。アプリケーションの追加のインスタンスを開始するだけで、Kafka Streams によって、アプリケーションインスタンスで実行中の各ストリームタスクに対するパーティションの分散化が実現されます。アプリケーションのスレッドは、入力 Kafka トピックパーティションと同じ数まで開始できます。この要件に従えば、アプリケーションのすべての実行インスタンスで、すべてのスレッド(厳密にはスレッドが実行するストリームタスク)に対して処理対象の入力パーティションが少なくとも 1 つ割り当てられることになります。
Kafka 2.8 以降では、Kafka Streams クライアントを拡張する場合とほぼ同じ方法でストリームスレッドを拡張できます。ストリームスレッドを追加または削除するだけで、Kafka Streams がパーティションの再配分を処理します。また、スレッドを追加して停止したストリームスレッドを置き換えることもできます。これにより、実行中のスレッドの数を回復するためにクライアントを再起動する必要がなくなります。
例¶
Kafka Streams の並列処理モデルを理解するために、例を見ていきましょう。
2 つのトピック A と B から消費する Kafka Streams アプリケーションがあるとします。各トピックには 3 つのパーティションがあります。スレッド数が 2 に構成された 1 台のマシンでこのアプリケーションを起動した場合、2 つのストリームスレッド instance1-thread1 と instance1-thread2 が実行されます。Kafka Streams は、このトポロジーを 3 つのタスクに分割します。これは、入力トピック A と B のパーティション数の最大値が max(3, 3) == 3 であるためです。次に、6 個の入力トピックパーティションを、これらの 3 つのタスクに均等に分散させます。この場合、各タスクには、各入力トピックから 1 つずつパーティションが割り当てられます。つまり、タスクごとに合計 2 つのパーティションのレコードを処理することになります。最後に、これらの 3 つのタスクが、利用できる 2 つのスレッド間で可能な限り均等に分散されます。この例では、最初のスレッドが 2 つのタスクを実行し(4 つのパーティションが消費されます)、2 番目のスレッドが 1 つのタスクを実行します(2 つのパーティションが消費されます)。
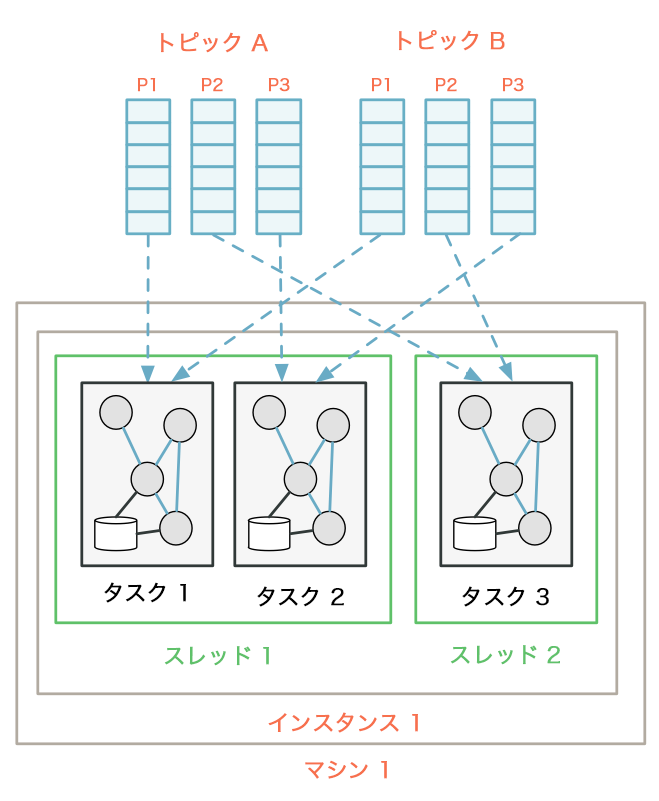
ここで、データ量が大幅に増加したため、このアプリケーションを後からスケールアウトする必要が生じたとしましょう。別のマシンを追加して、同じアプリケーションのスレッドを 1 つだけ開始することにします。新しいスレッド instance2-thread1 が作成され、入力パーティションが次のように再割り当てされます。
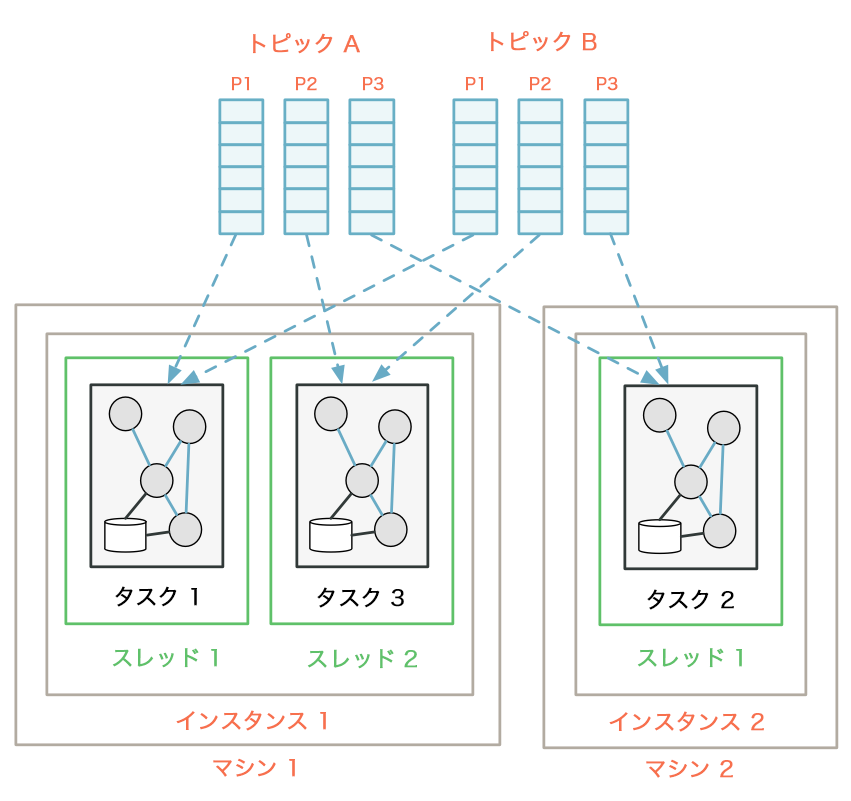
再割り当てが行われると、一部のパーティションと、それらに対応するタスクおよびローカルステートストアが、既存のスレッドから新しく追加されたスレッドに "移行" されます(この例では、最初のマシンの instance1-thread1 から、ストリームタスク 2 が 2 番目のマシンの instance2-thread1 に移行されています)。結果として Kafka Streams は、アプリケーションインスタンス間のワークロードのバランスを、Kafka トピックパーティション単位で効果的に調整します。
同じアプリケーションのインスタンスをさらに追加した場合はどうなるでしょうか。これはある時点まで可能です。つまり、実行インスタンスの数が、読み取ることのできる入力パーティションの数と同じになるまでは、インスタンスを増やすことができます。同数になったら、まずトピック A と B のパーティションの数を増やさない限り、それ以上のアプリケーションインスタンスを開始しても意味はありません。開始した場合、アプリケーションが過剰にプロビジョニングされ、アイドル状態のインスタンスがパーティションの割り当てを待機することになりますが、実際には割り当てられない可能性があります。
ステート¶
Kafka Streams には "ステートストア" 用意されており、ストリーム処理アプリケーションでデータを格納してクエリを実行するために使用できます。これは、ステートフル操作 を実装する場合に重要な機能です。Kafka Streams DSL では、たとえば、count() や aggregate() などのステートフル操作を呼び出している場合、または ストリームをウィンドウ化 している場合に、このようなステートストアの作成と管理が自動的に行われます。
Kafka Streams アプリケーションのすべてのストリームタスクには、1 つ以上のローカルステートストアを埋め込むことができます。ローカルステートストアには API 経由でアクセスし、処理に必要なデータを格納したりクエリを実行したりできます。これらのステートストアには、RocksDB データベース、メモリー内のハッシュマップ、または別の扱いやすいデータ構造を使用できます。Kafka Streams では、ローカルステートストアに対して フォールトトレランス と自動回復機能が提供されます。
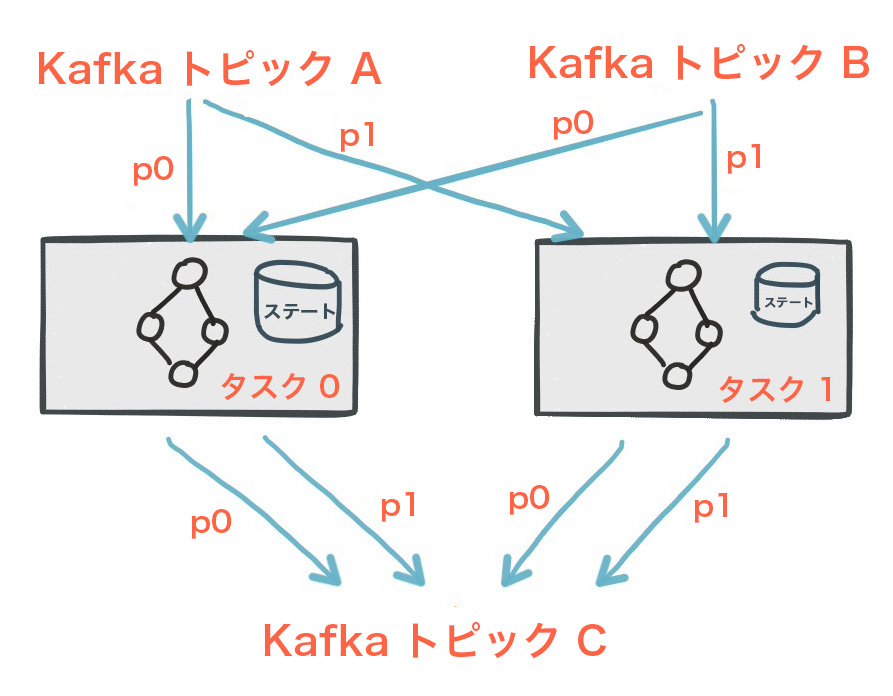
専用のローカルステートストアを持つ 2 つのストリームタスク¶
Kafka Streams アプリケーションは通常、多数のアプリケーションインスタンスとして実行 されます。Kafka Streams は データをパーティションに分けて処理 するため、アプリケーション全体のステートは、アプリケーションの実行インスタンスのローカルステートストアに伝達されます。Kafka Streams API では、count() などのステートフル操作や 対話型クエリ を通じて、アプリケーションのステートストアをローカルでも(アプリケーションインスタンスのレベルでも)全体にわたってでも("論理" アプリケーションのレベルでも)操作できます。
メモリー管理¶
レコードキャッシュ¶
Kafka Streams では、処理トポロジーのインスタンスに使用される合計メモリー(RAM)サイズを指定できます。このメモリーは、レコードをステートストアに書き込む前や、ダウンストリームの他のノードに転送する前に、レコードを内部にキャッシュしたり圧縮したりするために使用されます。これらのキャッシュは、DSL と Processor API でわずかに実装が異なります。
指定されたキャッシュサイズは、トポロジーの Kafka Stream スレッド間で均等に分配されます。メモリーは各インスタンスのすべてのスレッドで共有されます。各スレッドにはメモリープールが維持され、キャッシュ用にタスクのプロセッサーノードからアクセスできます。これは特に、集約を実行し、ステートストアを保持するステートフルプロセッサーノードによって使用されます。
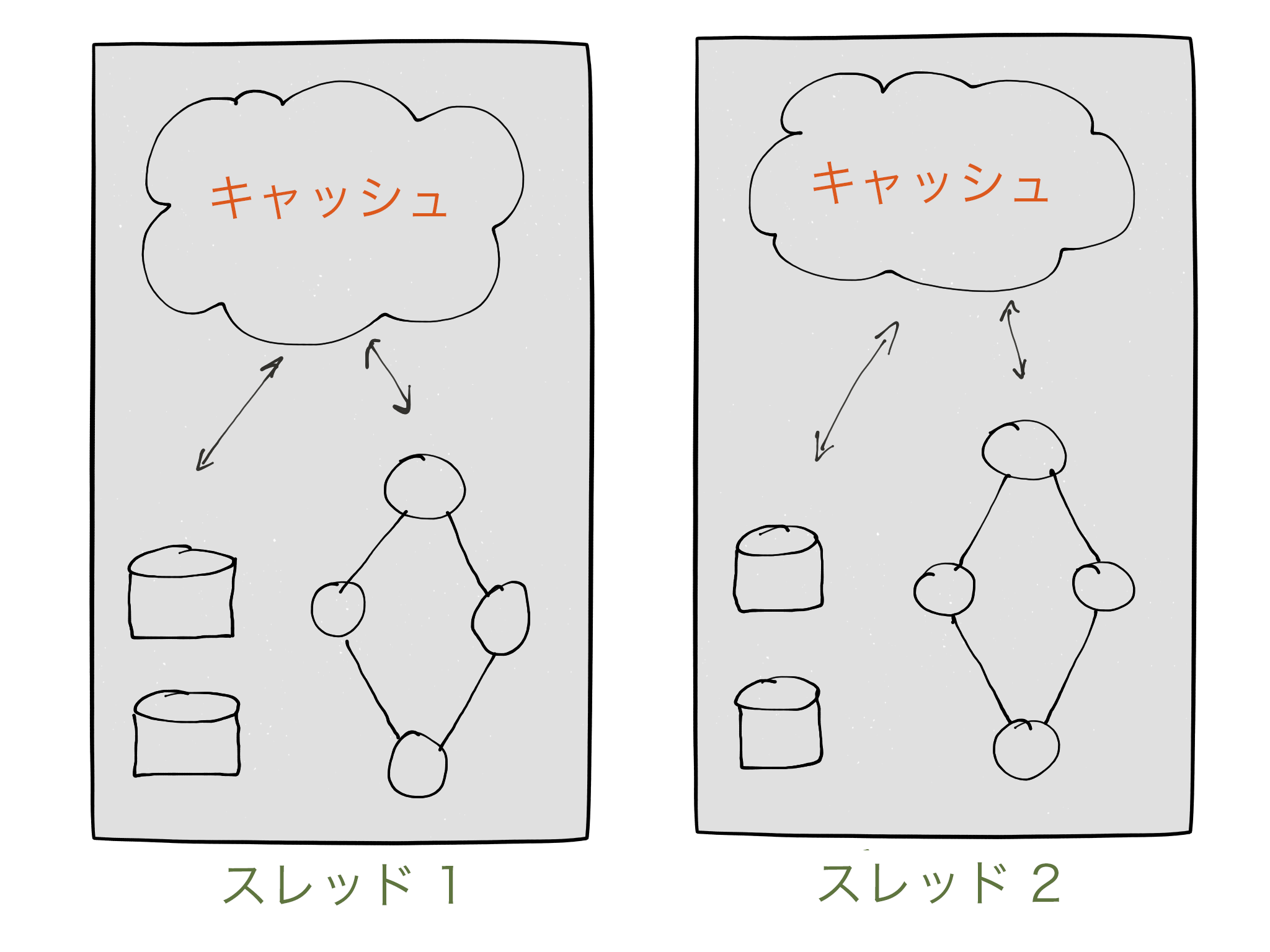
キャッシュには 3 つの機能があります。第 1 に、ステートストアからのデータの読み取りを高速化する読み取りキャッシュとして機能します。第 2 に、ステートストアのライトバックバッファとなります。ライトバックキャッシュを使用すると、各レコードを個別にステートストアに送信する代わりに、複数のレコードの一括送信が可能になります。同じキーを持つレコードはキャッシュ内で圧縮されるため、ステートストアに送信されるリクエストの数(および、永続ステートストアの場合は Kafka に格納される changelog トピック)の削減にもなります。第 3 に、ライトバックキャッシュにより、ダウンストリームのプロセッサーノードに送信されるレコードの数も削減されます。
これらのキャッシュを利用すると、API で明示的な処理操作を呼び出さなくても、次のようなトレードオフを選択することができます。
- キャッシュサイズを小さくした場合: ダウンストリームの更新速度が上がり、更新間隔が短くなります。
- キャッシュサイズを大きくした場合: ダウンストリームの更新速度が下がり、更新間隔が長くなります。通常、この結果の例として Kafka へのネットワーク IO が減少し、RocksDB を使用するステートストアに対するローカルディスク IO が削減されます。
キャッシュサイズにかかわらず(キャッシュな無効な場合も含めて)、最終的な計算結果は同じです。したがって、キャッシュを有効にしても無効にしても問題はありません。更新の圧縮がいつどのように行われるかを予測することはできません。これは、次のようなさまざまな要因に左右されます。
- キャッシュサイズ。
- 処理されるデータの特性。
commit.interval.msなどの構成パラメーター。
詳細については、開発者ガイドの「Kafka Streams のメモリー管理」を参照してください。
フォールトトレランス¶
Kafka Streams は、Kafka の内部にネイティブに統合されたフォールトトレランス機能を基に構築されています。Kafka パーティションは可用性が高く複製されるため、ストリームデータが Kafka に永続化されると、アプリケーションで障害が発生して再処理が必要になった場合でもデータを利用できます。Kafka Streams 内のタスクは、Kafka コンシューマークライアント で提供されるフォールトトレランス機能を利用して障害に対処します。タスクを実行しているマシンで障害が発生した場合、Kafka Streams は、実行中の残りのアプリケーションインスタンスの 1 つで自動的にタスクを再起動します。
さらに Kafka Streams では、ローカルステートストアにも障害に対する堅牢性が提供されます。ステートストアごとに changelog Kafka トピックの複製が保持され、そこであらゆるステートの更新が追跡されます。これらの changelog トピックもパーティション化され、各ローカルステートストアのインスタンス、およびそのストアにアクセスするタスクに、それぞれ専用の changelog トピックパーティションが割り当てられます。changelog トピックでは ログ圧縮 が有効になり、古いデータが安全にパージされ、トピックが無制限に増大するのを防ぎます。タスクを実行していたマシンで障害が発生し、それらのタスクが別のマシンで再起動されると、Kafka Streams は、新しく開始されたタスクの処理を再開する前に対応する changelog トピックを再生して、関連付けられたステートストアのコンテンツを障害前の状態に復元します。結果として、障害処理はエンドユーザーに完全に透過的に行われます。
ちなみに
最適化: タスクの(再)初期化のコストは、通常、ステートストアに関連付けられた changelog トピックを再生してステートを復元する時間に大きく左右されます。この復元時間を最小化するには、ローカルステートのスタンバイレプリカを保持するようにアプリケーションを構成します。スタンバイレプリカとは、ステートを完全に複製したコピーです。タスクを移行するとき、Kafka Streams は、このようなスタンバイレプリカが既に存在するアプリケーションインスタンスにタスクを割り当てることで、タスクの(再)初期化コストを最小化します。詳細については、開発者ガイドの「オプションの構成パラメーター」で「num.standby.replicas」を参照してください。2.6 以降の Kafka Streams では、ステートのローカルコピーが完全に同期されたインスタンスがあれば、確実にそのインスタンスにタスクが割り当てられるようになっています。スタンバイタスクにより、障害が発生した場合に、同期された状態のインスタンスが存在する可能性が高まります。
タイムスタンプによるフロー制御¶
Kafka Streams では、データレコードのタイムスタンプを使用してストリームの進行状況を調整します。そのために、時刻に基づいてすべてのソースストリームの同期を試みます。デフォルトでは、Kafka Streams はアプリケーションに イベント時刻の処理セマンティクス を提供します。これは特に、アプリケーションで複数のストリーム(つまり Kafka トピック)を処理していて、大量の履歴データがある場合に重要になります。たとえば、分析アルゴリズムのバグ修正によってアプリケーションのビジネスロジックが大幅に変更され、過去のデータを再処理する必要が生じたとします。Kafka から大量の過去のデータを取得することは簡単ですが、フロー制御が適切でないと、トピックパーティション間でデータの処理が同期されず、誤った結果が生成される可能性があります。
「Streams の概念」のセクションで説明したように、Kafka Streams の各データレコードはタイムスタンプに関連付けられています。ストリームタスクは、ストリームレコードバッファ内のレコードのタイムスタンプに基づいて、すべての入力ストリームから次に処理する割り当てパーティションを決定します。ただし、Kafka Streams が処理のために 1 つのストリーム内のレコードを並べ替えることはありません。並べ替えると Kafka のデリバリーセマンティクスが崩れ、障害からの回復が難しくなるためです。ストリーム間で常に厳密にレコードのタイムスタンプに従って実行順序を適用できるとは限らないため、このフロー制御はベストエフォート型です。実際、厳密な実行順序を適用するには、システムがすべてのストリームからすべてのレコードを受け取るまで待つか(あまり現実的ではありません)、MillWheel のウォーターマーク のような、タイムスタンプ境界や発見的評価に関する追加情報を挿入する必要があります。
バックプレッシャー¶
Kafka Streams では、バックプレッシャーメカニズムは必要がないため使用されません。深さ優先の処理戦略により、Kafka から消費された各レコードは、プロセッサーの(サブ)トポロジー全体を通して処理され、(必要に応じて)|ak| に書き戻されてから、次のレコードが処理されます。結果として、接続された 2 つのストリームプロセッサー間でレコードがメモリー内にバッファリングされることはありません。また、Kafka Streams が内部で利用する Kafka のコンシューマークライアントは、プルベースのメッセージングモデルで動作します。このモデルでは、受信データレコードの読み取り速度をダウンストリームプロセッサーが制御できます。
独立した複数のサブトポロジーを含むプロセッサートポロジーの場合も同様で、互いに独立して処理されます(「並列処理モデル」を参照)。たとえば、次のコードで定義されるトポロジーには、2 つの独立したサブトポロジーがあります。
stream1.to("my-topic");
stream2 = builder.stream("my-topic");
サブトポロジー間のデータ交換は Kafka 経由で行われ、直接的なデータ交換は発生しません(上の例では、データは "my-topic" というトピックを介して交換されます)。したがって、このシナリオでもバックプレッシャーメカニズムは必要ありません。
注釈
このウェブサイトには、Apache License v2 の条件に基づいて Apache Software Foundation で開発されたコンテンツが含まれています。