Schema Registry の概要¶
Looking for Schema Management Confluent Cloud docs? You are currently viewing Confluent Platform documentation. If you are looking for Confluent Cloud docs, check out Schema Management on Confluent Cloud.
Confluent Schema Registry は、メタデータを提供するためのレイヤーを担っており、Avro®、 JSON Schema、 Protobuf の スキーマ を格納したり取得したりするための RESTful インターフェイスを公開しています。また、指定された サブジェクト命名方法 に基づいてすべてのスキーマの履歴(バージョン管理対応)を格納するほか、複数の 互換性設定 を備えており、構成済みの互換性設定や各種スキーマの拡張機能によってスキーマの進化にも対応します。サポートされたいずれかのフォーマットで送信された Kafka メッセージについて、そのスキーマの格納と取得をつかさどるシリアライザーが用意されていて、それを Apache Kafka® クライアントにプラグインすることができます。
Schema Registry は、Kafka ブローカーから切り離されています。プロデューサーとコンシューマーがトピックにデータをパブリッシュしたりトピックのデータ(メッセージ)を読み取ったりするために通信する相手は、あくまで Kafka です。同時に、メッセージのデータモデルを表すスキーマを送信したり取得したりするために Schema Registry とも通信を行います。
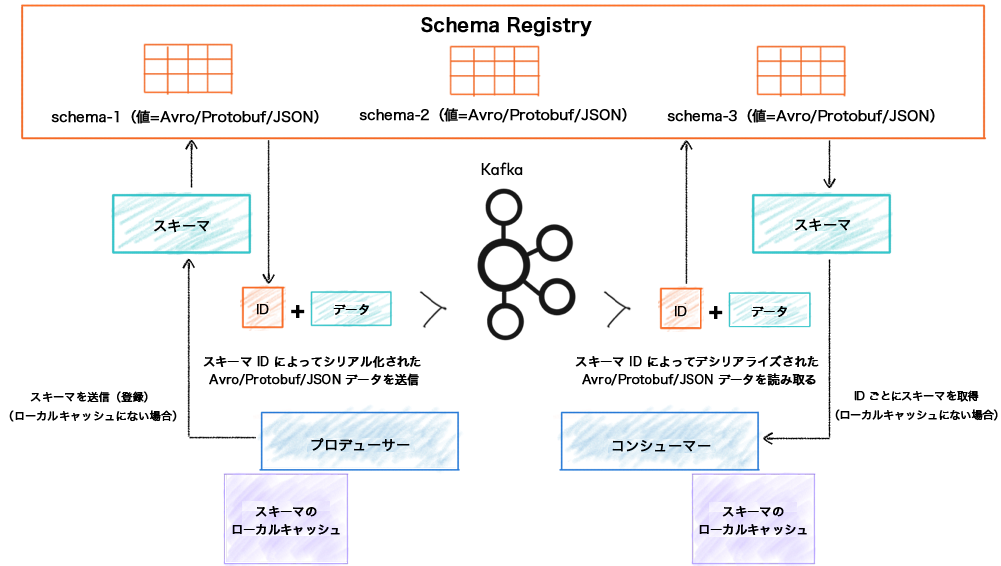
スキーマの格納と取得に使用される Confluent Schema Registry¶
Schema Registry は、スキーマのための分散ストレージレイヤーで、その基盤となるストレージメカニズムには Kafka が使用されます。いくつかの重要な設計方針を次に示します。
- 登録されている各スキーマには、グローバルに一意の ID が割り当てられます。割り当てられた ID は、単調に増加すること、また一意であることが保証されています。ただし、必ずしも連続性を持って増加するとは限りません。
- Kafka は、堅牢なバックエンドとしての役割を果たし、Schema Registry とそこに格納されているスキーマの状態を記録する先書きの changelog として機能します。
- Schema Registry は、単一プライマリアーキテクチャの分散設計になっており、プライマリ選出は、(構成により) ZooKeeper または Kafka が調整します。
参考
Schema Registry の実際の例については、 Confluent Platform のデモ をご覧ください。ストリーム処理に ksqlDB を使用して、Kafka ストリーミング ETL(Schema Registry を含む)をデプロイする方法が紹介されています。
スキーマ、サブジェクト、トピック¶
まず、いくつかの用語と Schema Registry の文脈での使われ方を簡単に押さえておきましょう。Kafka の "トピック"、"スキーマ"、"サブジェクト" について説明します。
Kafka の "トピック" はメッセージを格納します。また、それぞれのメッセージはキー/値ペアになっており、そのキーと値のどちらかまたは両方を Avro、JSON、Protobuf のいずれかにシリアル化することができます。データフォーマットの構造は、"スキーマ" によって定義されます。Kafka のトピックとスキーマには別々の名前を使用できます。Schema Registry は、スキーマが進化できる範囲を定義しますが、その範囲にあたるのが "サブジェクト" です。サブジェクトの名前は、構成されている サブジェクト命名方法 によって決まり、デフォルトではトピック名からサブジェクト名を得る設定になっています。
Starting with Confluent Platform 5.5.0, you can modify the subject name strategy on a per-topic basis. See トピックのサブジェクト命名方法を変更する to learn more.
スキーマの定義 例は、 Schema Registry のチュートリアル で紹介しています。
Confluent Platform 7.0.0 から Schema Linking がプレビュー版として提供されました。「Confluent Platform の Schema Linking」を参照してください。
Starting with Confluent Platform 5.2.0, you can use Confluent Replicator to migrate schemas from one Schema Registry to another, and automatically rename subjects on the target registry.
Kafka のシリアライザーとデシリアライザーの背景¶
ネットワーク上でデータを送信したり、それをファイルに格納したりする際、そのデータをバイトにエンコードする手段が必要となります。データのシリアル化は、長い歴史のある分野ですが、ここ数年でかなり進化してきました。初期に使われていたプログラミング言語固有のシリアル化(Java シリアル化など)は、データを他の言語で消費する際の利便性が問題となります。そこで、言語に依存しないフォーマット(純粋な JSON など)が普及してきましたが、これには厳密に定義されたスキーマフォーマットがありません。
厳密に定義されたフォーマットがないことには、重大な欠点が 2 つあります。
- データコンシューマーがデータプロデューサーからのデータを解釈できない : 構造に不備があると、それらのフォーマットでデータを消費するのが困難になります。フィールドが勝手に追加、削除されたり、データが壊れることもあるからです。データフィードを消費するアプリケーションやチームが全社的に増えていくにつれて、この欠点はより深刻化します。つまり、上流のチームが思い付くままに独断でデータフォーマットに変更を加えることができるとすれば、下流の全コンシューマーがデータを(今までどおり)解釈することはきわめて困難になります。そこに欠けているのは、プロデューサーとコンシューマーとの間におけるデータの "契約"(以下のスキーマを参照)です。API のコントラクトのようなものが欠けているのです。
- オーバーヘッドがあり冗長 : シリアル化されたフォーマットでは、フィールド名と型の情報がすべてのメッセージでまったく同一であるにもかかわらず、それらを明示的に表現する必要があるため冗長になります。
言語の垣根を越えたいくつかのシリアル化ライブラリが台頭してきました。これらのライブラリでは、データ構造がスキーマによってきちんと定義されている必要があります。そうしたライブラリの例として、Avro、Thrift、Protocol Buffers、JSON スキーマ があります。スキーマがある利点は、データの構造や型、意味が(ドキュメントを通じて)明確に指定されることです。また、スキーマがあることで、データをより効率的にエンコードできるようになります。Confluent Platform でサポートされているデフォルトのフォーマットは Avro です。
たとえば Avro スキーマでは、データ構造が JSON フォーマットで定義されます。次の Avro スキーマでは、name と favorite_number という、それぞれ string 型と int 型の 2 つのフィールドを使用してユーザーレコードが指定されています。
{"namespace": "example.avro",
"type": "record",
"name": "user",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": "int"}
]
}
この Avro スキーマを使用すれば、たとえば Java オブジェクト(POJO)をバイトにシリアル化した後、さらにそれらのバイトを再び Java オブジェクトに逆シリアル化することができます。
Avro では、データのシリアル化時だけでなく、データの逆シリアル化時にもスキーマが必要となります。スキーマがデコード時に提供されるため、フィールド名などのメタデータが、データ内に明示的にエンコードされている必要はありません。そのため、Avro データのバイナリエンコードは非常にコンパクトになります。
Avro、JSON、Protobuf フォーマットへの対応と拡張性¶
Confluent Platform でサポートされるデフォルトのスキーマフォーマットとして最初に選ばれたのは Avro です。Avro フォーマット用の Kafka シリアライザーとデシリアライザーも提供されました。
Confluent Platform では、Confluent Platform の本来のデフォルトフォーマットである Avro に加えて、プロトコルバッファ と JSON スキーマ がサポートされています。こうした新しいシリアル化フォーマットのサポートは Schema Registry に限らず、Confluent Platform 全体に及んでいます。さらに、Schema Registry は、カスタムスキーマ形式をスキーマプラグインとして追加できる拡張性を備えています。
Avro とともに Protobuf と JSON Schema にも対応した新しい Kafka シリアライザーとデシリアライザーが提供されています。Protobuf メッセージや JSON シリアル化可能なオブジェクトをシリアル化する際、これらのシリアライザーでスキーマを自動的に登録できます。Protobuf シリアライザーでは、インポートされているすべてのスキーマを再帰的に登録することが可能です。
これらのシリアライザーと逆シリアライザーは、Java、.NET、Python を含む複数の言語で利用できます。
Schema Registry は、同時に複数のフォーマットをサポートします。たとえば、あるサブジェクトには Avro スキーマを使用し、別のサブジェクトには Protobuf スキーマを使用できます。さらに、Protobuf と JSON Schema には、どちらも独自の互換性ルールがあるため、Avro と同様、Protobuf スキーマの進化にも後方互換性または前方互換性を確保することができます。
Confluent Platform の Schema Registry では、import ステートメントをモデル化することにより、Protobuf での スキーマ参照 もサポートされます。
詳細については、「フォーマット、シリアライザー、逆シリアライザー」を参照してください。
スキーマ ID の割り当て¶
スキーマ ID の割り当ては常にプライマリノードで行われ、また、スキーマ ID は必ず単調に増加します。
Kafka のプライマリ選出では、スキーマ ID は必ず、Kafka ストアに書き込まれた最後の ID に基づきます。プライマリの再選出中のバッチ割り当ては、<kafkastore.topic> ストア内のすべてのレコードが新しいプライマリに反映された後でのみ実行されます。
Kafka バックエンド¶
Kafka は、Schema Registry のストレージバックエンドとして使用されます。単一のパーティションを持つ特殊な Kafka のトピック <kafkastore.topic> (デフォルトでは _schemas)は、高可用性の先書きログとして使用されます。すべてのスキーマ、サブジェクト/バージョン、ID のメタデータ、互換性設定は、このログにメッセージとして追加されます。したがって、Schema Registry インスタンスは、_schemas トピックのメッセージを生成したり消費したりすることになります。たとえば、サブジェクトに新しいスキーマが登録されたり、互換性設定に対するアップデートが登録されたりすると、このログにメッセージが生成されます。Schema Registry は、バックグラウンドスレッドで _schemas ログからメッセージを消費します。新しい _schemas メッセージを消費するたびに、そのローカルキャッシュをアップデートすることで、新しく追加されたスキーマや互換性設定を反映します。このように、Kafka ログからローカルの状態をアップデートすることで、堅牢性と順序、さらに回復の容易性が確保されています。
ちなみに
Schema Registry のトピックは圧縮されるため、Kafka 保持ポリシーに関係なく、常時、各キーの最新の値が保持されます。これは kafka-configs で確認できます。
kafka-configs --bootstrap-server localhost:9092 --entity-type topics --entity-name _schemas --describe
出力は以下のようになります。
Configs for topic '_schemas' are cleanup.policy=compact
単一プライマリアーキテクチャ¶
Schema Registry は、単一プライマリアーキテクチャを使用した分散サービスとして動作するように設計されています。この構成では、プライマリとなる Schema Registry インスタンスは、どのような場合でも最大で 1 つとなります(異常な「ゾンビ状態のプライマリ」は除く)。ベースとなる Kafka ログに書き込みをパブリッシュできるのはプライマリだけですが、読み取りリクエストは、すべてのノードが直接処理できます。セカンダリノードは現在のプライマリに登録リクエストを転送し、プライマリからの応答を返すだけで間接的に登録リクエストを処理します。Confluent Platform 4.0 以降では、プライマリ選出は Kafka グループプロトコルを使用して実行されます。(ZooKeeper ベースのプライマリ選出は、Confluent Platform 7.0.0 で削除されたことに注意してください。)
注釈
同じクラスター内のノード間で複数の選出モードが混ざらないよう注意してください。プライマリが複数生じて運用上の問題につながります。
Kafka コーディネーターのプライマリ選出¶
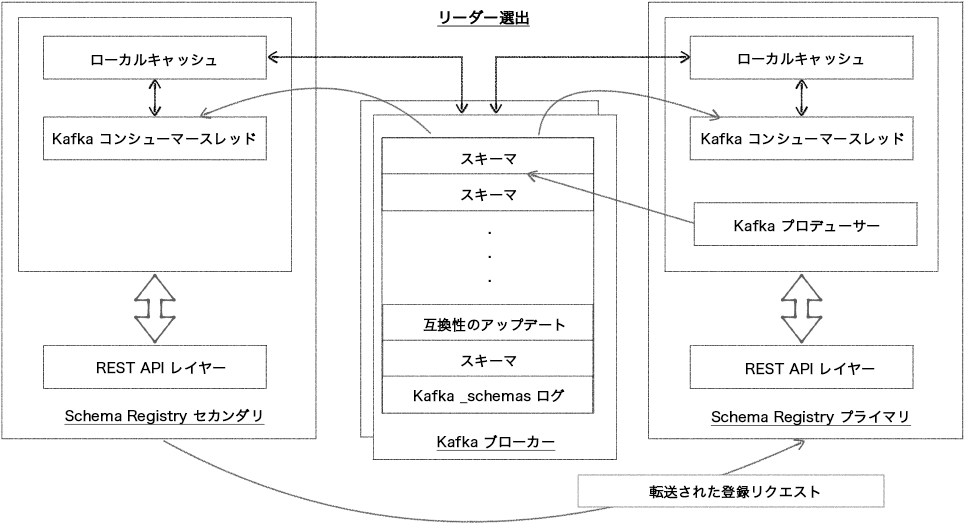
Kafka ベースの Schema Registry¶
Kafka ベースのプライマリ選出は、kafkastore.connection.url が構成されておらず、かつ Kafka ブートストラップブローカー <kafkastore.bootstrap.servers> が指定されている場合に選択されます。Kafka グループプロトコルは、プライマリの候補ノード(leader.eligibility=true)の中からいずれか 1 つをプライマリとして選出します。常に Kafka ベースのプライマリ選出を使用することをお勧めします。(ZooKeeper ベースのリーダー選出は、Confluent Platform 7.0.0 で削除されました。「ZooKeeper のプライマリ選出から Kafka のプライマリ選出への移行」を参照してください。)
Schema Registry は、マルチコロケーション構成にも対応できるように設計されています。詳細については、「マルチデータセンター構成」を参照してください。
ZooKeeper のプライマリ選出¶
重要
ZooKeeper のリーダー選出は、Confluent Platform 7.0.0 で削除されました。代わりに Kafka のリーダー選出を使用してください。詳細については、「ZooKeeper のプライマリ選出から Kafka のプライマリ選出への移行」を参照してください。
単一プライマリ構成の高可用性¶
Confluent Platform のサービスは、その多くが実質的にステートレス(状態を Kafka に格納し、起動時に必要に応じて読み込みます)であり、リクエストを自動的にリダイレクトすることができます。これらのサービスは、他のあらゆるステートレスアプリケーションをデプロイするときと同じように扱うことができ、また、複数のインスタンスをデプロイすることにより、実質的にコスト負担なしで高可用性機能を導入することができます。Schema Registry の状態がすべて各インスタンスに読み込まれるため、どのノードでも、READ リクエストを処理することができ、また、WRITE リクエストをどうプライマリに転送するかもすべてのノードが把握しています。
推奨されるアプローチとして、Schema Registry クライアントの schema.registry.url プロパティに、Schema Registry インスタンス URL を使用して高可用性クライアント用の Schema Registry サーバーを複数定義することで、Schema Registry インスタンスのクラスター全体を使用してフェイルオーバーの手段を提供できます。
また、一連のサーバーに対する変更の扱いも容易になり、すべてのアプリケーションを再構成、再起動する必要がありません。同じことは、REST プロキシや Kafka Connect にも当てはまります。
ごく少数のノードからなる単純な構成であれば、シンプルなマルチノードデプロイと単一プライマリ選出プロトコルにより、Schema Registry のフェイルオーバーも容易になります。
または、schema.registry.url には単一の URL を使用しながら、Schema Registry インスタンスのクラスター全体を使用することもできます。ただし、この構成では、スキーマレジストリクライアントに公開される schema.registry.url は 1 つだけであるため、ダイナミック DNS または仮想 IP セットアップ内の別の Schema Registry インスタンスへのフェイルオーバーはサポートされません。
スキーマの移行(Confluent Cloud とセルフマネージド型)¶
Confluent Platform 7.0.0 から Schema Linking がプレビュー版として提供されました。「Confluent Platform の Schema Linking」を参照してください。
Confluent Platform 5.2.0 以降、Replicator を使用して、
セルフマネージド型クラスターからターゲットクラスターにスキーマを移行することができます。移行先は、セルフマネージド型クラスターでも Confluent Cloud 内のクラスターでもかまいません。
- セルフマネージド型クラスターから Confluent Cloud へのスキーマの移行について、そのコンセプトの概要とクイックスタートチュートリアルについては、「Confluent Cloud へのスキーマの移行」を参照してください。
- セルフマネージド型クラスター間でスキーマを移行するデモについては、「スキーマの移行」および「Replicator スキーマ変換のサンプル」を参照してください。
ライセンス¶
Schema Registry は、Confluent Community ライセンス に基づきライセンスされています。
Schema Registry セキュリティプラグイン とブローカー側の Confluent Server 上の Schema Validation には、Confluent Enterprise ライセンスが必要です。
プラグインと Schema Validation は、ライセンスキーがなくても 30 日間試用でき、その後は、Confluent Platform の構成要素として エンタープライズ(契約プラン)ライセンス で提供されます。
セキュリティプラグインの詳細については、「Schema Registry セキュリティプラグインのライセンス」および「Schema Registry セキュリティプラグインのインストールと構成」を参照してください。
ちなみに
Confluent Platform の完全なライセンス情報については、「Confluent Platform ライセンス」を参照してください。
おすすめの関連情報¶
- Schema Registry のチュートリアル (Confluent Cloud およびオンプレミス)
- Confluent Cloud におけるスキーマ管理のクイックスタート
- Avro、Protobuf、および JSON フォーマットを使用した自動 Confluent Cloud クイックスタートの実行
- Control Center を使用してオンプレミス環境のスキーマを管理する方法
- Schema Registry のインストールと構成
- 本稼働環境での Schema Registry の実行
- Confluent Server 上の Schema Validation
- Schema Registry の構成オプション
- 開発者向け: 「フォーマット、シリアライザー、逆シリアライザー」および「Schema Registry 開発の概要」