Schema Registry のシングルデータセンターデプロイとマルチデータセンターデプロイ¶
Looking for Schema Management Confluent Cloud docs? You are currently viewing Confluent Platform documentation. If you are looking for Confluent Cloud docs, check out Schema Management on Confluent Cloud.
以下のセクションでは、Kafka のリーダー選出を使用するシングルデータセンターデプロイとマルチデータセンターデプロイについて説明します。
ZooKeeper のリーダー選出は、Confluent Platform 7.0.0 で削除されたことに注意してください。代わりに、Kafka リーダー選出を使用してください。Kafka のリーダー選出にアップグレードするには、「ZooKeeper のプライマリ選出から Kafka のプライマリ選出への移行」を参照してください。
シングルデータセンター構成¶
シングルデータセンター(単一拠点)内では、マルチノード、マルチブローカーのクラスターによって、Kafka データがノード間でレプリケーションされます。
プロデューサーは、トピックのパーティションリーダーに対して書き込みを行い、コンシューマーは、トピックのパーティションリーダーからデータを読み取ります。データはリーダーによってフォロワーにレプリケートされ、メッセージが複数のブローカーにコピーされます。
プロデューサーとコンシューマーのパラメーターの構成を通じて、メッセージの堅牢性や高可用性など、さまざまな目的にシングルクラスターデプロイを最適化することができます。
Kafka プロデューサーは、acks 構成パラメーターを設定 することで、書き込みに成功したと見なされるタイミングを制御することができます。たとえばプロデューサーを acks=all に設定した場合、リーダーブローカーがプロデューサーに応答する前に、クラスター内の他のブローカーは、データを受信したことへの確認応答を行う必要があります。
リーダーブローカーで障害が発生した場合、フォロワーブローカーがリーダーとして選出され、その新しいリーダーを通じてクライアントアプリケーションがメッセージの書き込みと読み取りを続行できるようになったとき、Kafka クラスターは復旧します。
Kafka の選出¶
推奨されるデプロイ¶
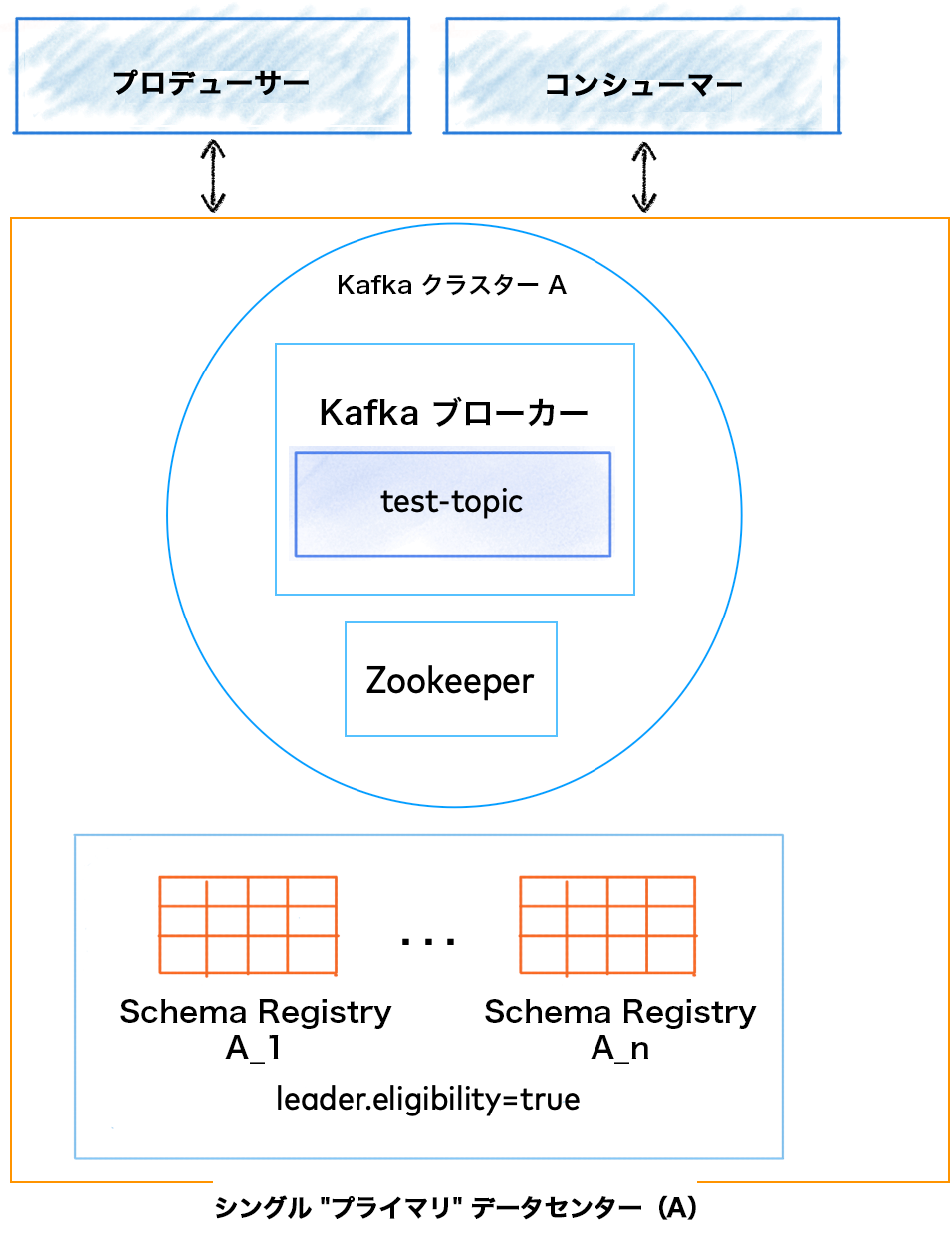
シングルデータセンター(Kafka のクラスター間レプリケーションを使用)¶
上の画像は、シングルデータセンター(DC A)を表しています。この例では、リーダ選出に Kafka が使用されています。リーダー選出には、この方法が推奨されます。
注釈
ZooKeeper を使用して単一のクラスターをセットアップすることもできますが、この構成は推奨されません。Kafka のリーダー選出が推奨されます。
重要な設定¶
kafkastore.bootstrap.servers- これはプライマリ Kafka クラスター(この例では DC A)を参照している必要があります。schema.registry.group.id-schema.registry.group.idは、コンシューマーのgroup.idとして使用されます。シングルデータセンター構成の場合、この設定は、クラスター内のすべてのノードで統一してください。リーダー選出に Kafka が使用されている場合、Kafka グループのgroup.idはschema.registry.group.id(設定されている場合)によってオーバーライドされます。(この構成がない場合、group.idは "schema-registry" になります)leader.eligibility- シングルデータセンター構成では、Schema Registry インスタンスはすべて Kafka クラスターに対してローカルとなるため、leader.eligibilityは true に設定されている必要があります。
ランブック¶
Schema Registry を単一のデータセンターで実行しているとき、プライマリノードがダウンしました。どうすればよいのでしょうか。まず、他の Schema Registry インスタンスは引き続きリクエストを処理できることに注意してください。
- 1 つの Schema Registry ノードがダウンしても、別のノードがリーダーとして選出され、クラスターは自動的に復旧します。
- ノードを再起動すると、そのノードはフォロワーとして復旧します(既に新しいリーダーが選出されているため)。
マルチデータセンター構成¶
Confluent Schema Registry を使用して複数のデータセンター(DC)を束ねることで、データがサイト間で同期されます。データ損失の防止効果が一層高まり、またレイテンシも小さくなります。マルチデータセンターデプロイでは、1 つのデータセンターを "プライマリ" に指定し、その他すべてのデータセンターを "セカンダリ" に指定することが推奨されます。"プライマリ" データセンターで障害が発生して復旧不能になった場合は、以下の「ランブック」に記載の手順に従い、それまでの "セカンダリ" データセンターを新しい "プライマリ" に手動で指定する必要があります。
Kafka の選出¶
推奨されるデプロイ¶
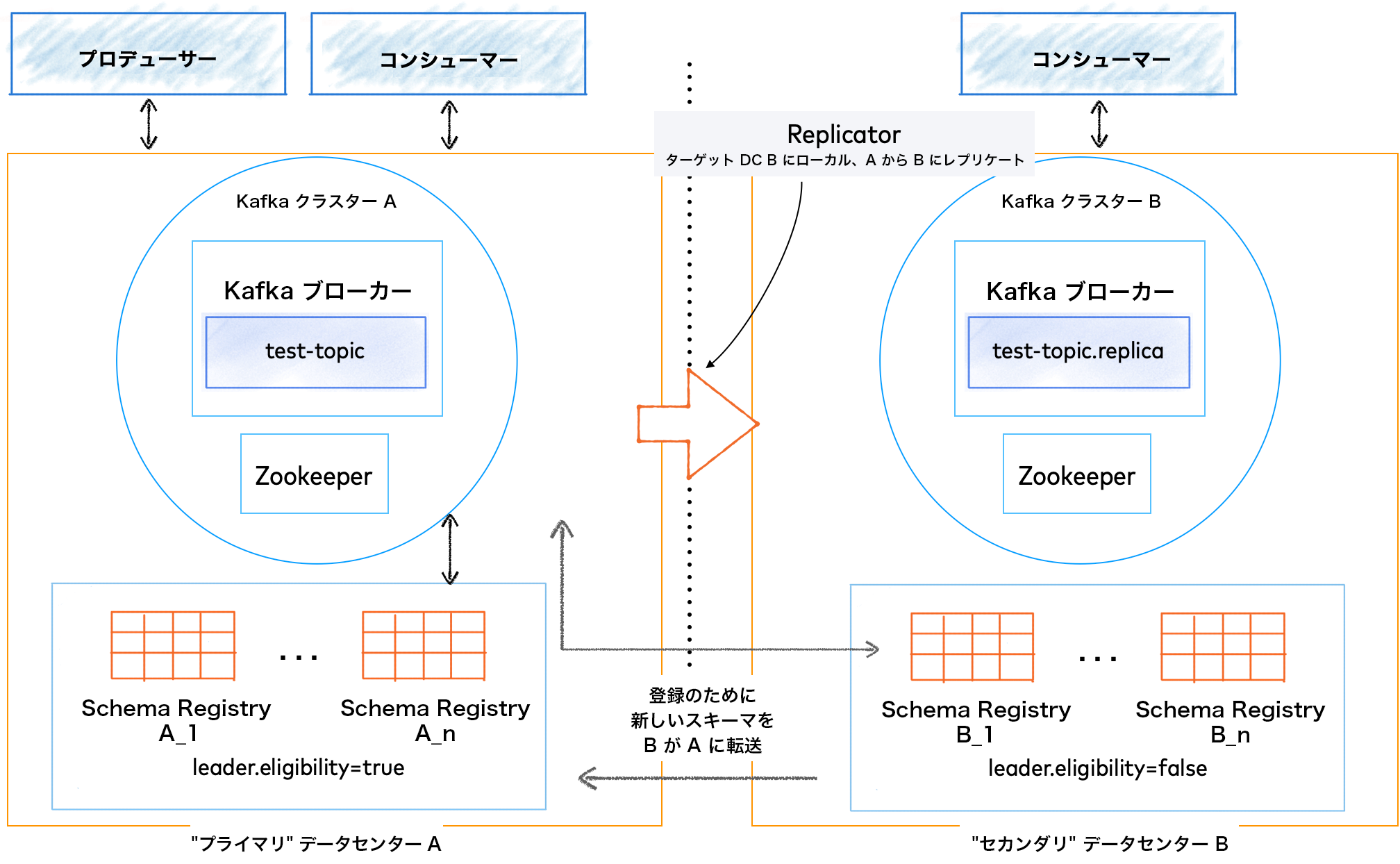
マルチデータセンター(Kafka ベースのプライマリ選出を使用)¶
上の画像は、DC A と DC B という 2 つのデータセンターを表しています。どちらも、オンプレミス、Confluent Cloud 内、または クラウドへのブリッジ ソリューション内に配置することができます。2 つのデータセンターにはそれぞれ、独自の Apache Kafka® クラスター、ZooKeeper クラスター、Schema Registry が存在します。
どちらのデータセンターの Schema Registry ノードも DC A のプライマリ Kafka クラスターにリンクされており、セカンダリデータセンター(DC B)は Schema Registry への書き込みをプライマリ(DC A)に転送しています。この構成をサポートするためには、2 つのサイト間で、Schema Registry のノードとホスト名がアドレス指定可能、かつルーティング可能でなければならない点に注意してください。
DC B の Schema Registry インスタンスは、leader.eligibility が false に設定されています。つまり、両方のデータセンターがオンラインで、かつ安定した状態で運用されているときには、どのインスタンスもリーダーに選出することはできません。
DC A の完全喪失を防ぐために、Kafka クラスター A(ソース)は Kafka クラスター B(ターゲット)にレプリケートされます。これは、ターゲットクラスター(DC B)のローカルで Replicator を実行することによって行われます。
このアクティブ/パッシブ構成では、Replicator が一方向に実行され、Kafka のデータと構成がアクティブ DC A からパッシブ DC B にコピーされます。どちらのデータセンターの Schema Registry インスタンスも、DC A の内部 _schemas トピックを参照します。ディザスターリカバリの目的では、この 内部スキーマトピック そのものをレプリケートする必要があります。DC A で障害が発生した場合、システムは DC B にフェイルオーバーします。このため、DC B には _schemas トピックのコピーが必要です。
ちなみに
このフェイルオーバーのシナリオでは、スキーマの移行 と同じ構成全体が必要とされるわけではありません。スキーマの移行とは異なり、schema.registry.topic または schema.subject.translator.class は設定しないでください。
プロデューサーは、アクティブクラスターにのみデータを書き込みます。コンシューマーは全体的な設計に応じて、アクティブクラスターからのみデータを読み取り、パッシブクラスターはディザスターリカバリ専用とするか、両方のクラスターからデータを読み取り、地域のローカルキャッシュで読み取りを最適化することができます。
一方のデータセンターで部分的または全体的な障害が発生した場合でも、アプリケーションはセカンダリデータセンターにフェイルオーバーすることができます。
ACL とセキュリティ¶
マルチ DC セットアップで ACL を有効にしている場合は、スキーマの ACL トピックをレプリケートする必要があります。
動作が停止すると、ACL がスキーマとともにキャッシュされます。プライマリ Kafka クラスターで障害が発生しても、Schema Registry では ACL 付きの READ が実行され続けます。
- Schema Registry のセキュリティ戦略とプロトコルの概要については、「Schema Registry のセキュリティの概要」を参照してください。
- Schema Registry に関連するロールの ACL を構成する方法については、「Schema Registry ACL オーソライザー」を参照してください。
- Kafka トピックベースの ACL を定義する方法については、「トピック ACL オーソライザー」を参照してください。
- Schema Registry でロールベースの認可を使用する方法については、「Schema Registry のロールベースアクセス制御の構成」を参照してください。
- Replicator ドキュメントの「セキュリティと ACL の構成」も参照してください。
重要な設定¶
kafkastore.bootstrap.servers- これはプライマリ Kafka クラスター(この例では DC A)を参照している必要があります。schema.registry.group.id- リーダー選出に Kafka が使用されている場合、この設定を使用すると、Kafka グループのgroup.idがオーバーライドされます。この構成がない場合、group.idは "schema-registry" になります。単一の Kafka クラスターに対して複数の Schema Registry クラスターを実行する場合は、各クラスターでこの設定を一意にする必要があります。leader.eligibility-leader.eligibilityが false に設定されている Schema Registry サーバーは、リーダー選出時にフォロワーとして維持されることが保証されます。"セカンダリ" データセンターの Schema Registry インスタンスは、これが false に設定されている必要があります。共有 Kafka (プライマリ)クラスターにローカルな Schema Registry インスタンスは、これが true に設定されている必要があります。
新しいスキーマを DC B から DC A に転送するためには、ホスト名がデータセンターの境界を越えて到達可能であり解決されることが必要です。
セットアップ¶
稼動している Schema Registry があると仮定して、新しい "セカンダリ" データセンター("DC B" とします)に Schema Registry インスタンスを追加するために推奨される手順は以下のとおりです。
- DC B で、Kafka の
unclean.leader.election.enableが false に設定されていることを確認します。 - DC B で、"プライマリ" データセンター(DC A)の Kafka をソースに、DC B の Kafka をターゲットにして Replicator を実行します。
- DC B の Schema Registry の構成ファイルで、DC A の Kafka クラスターを参照するように
kafkastore.bootstrap.serversを設定し、leader.eligibilityを false に設定します。 - これらの構成で新しい Schema Registry インスタンスを起動します。
ランブック¶
Schema Registry が複数のデータセンターで実行されていて、"プライマリ" データセンターを喪失した場合、どうすればよいのでしょうか。まず、Kafka への書き込みを伴わないリクエストについてはすべて、"セカンダリ" で実行されている他の Schema Registry インスタンスが引き続き処理できることに注意してください。たとえば、既存の ID の GET リクエストや、既にレジストリに存在するスキーマの POST リクエストがそれに該当します。これらのインスタンスが新しいスキーマを登録することはできません。
- 可能であれば、これまでどおりに Kafka と Schema Registry を起動して、"プライマリ" データセンターを回復させます。
- 新しいデータセンター("DC B" とします)を "プライマリ" に指定する必要がある場合は、DC B の
kafkastore.bootstrap.serversがそのローカル Kafka クラスターを参照するようにその構成を変更し、さらに、leader.eligibilityが true になるように Schema Registry の構成ファイルをアップデートします。 - それらの新しい構成で Schema Registry インスタンスをローリング再起動します。
マルチクラスター Schema Registry¶
以前のディザスターリカバリのシナリオでは、通常、1 つの Schema Registry は複数の環境に対応し、各環境には複数の Kafka クラスターが含まれている可能性があります。
バージョン 5.4.1 以降の Confluent Platform では、複数のスキーマレジストリを実行し、一意の Schema Registry をマルチクラスター環境内の各 Kafka クラスターに関連付ける機能をサポートしています。このようなタイプのデプロイの主な目標は、ディザスターリカバリではなく、大規模な組織で多様かつ大量のデータセットのガバナンスをサポートするために、特殊用途のレジストリを追加して拡張できるようにすることです。
この構成の詳細については、「マルチクラスター Schema Registry の有効化」を参照してください。
おすすめの記事¶
- マルチクラスターとマルチデータセンターのデプロイ全般については、「Overview」を参照してください。
- ディザスターリカバリのユースケースと設計上の構成に関するより広範な説明については、ホワイトペーパー「Multi-Datacenter Apache Kafka Deployments」を参照してください。
- シングルプライマリアーキテクチャの詳細を含め、Confluent Platform におけるスキーマ管理の概要については、「Schema Registry の概要」および「単一プライマリ構成の高可用性」を参照してください。
- Schema Registry は Confluent Cloud でも利用できます。既存のクラスターをクラウドに拡張したりリフトアンドシフトしたりする方法について詳しくは、「スキーマの移行」を参照してください。