Streams の DSL¶
Kafka Streams の DSL(ドメイン固有言語)は、Streams Processor API を基盤として構築されています。DSL はほとんどのユーザーに推奨されますが、特に初心者の方にお勧めします。ほとんどのデータ処理操作は、わずか数行の DSL コードで表すことができます。
概要¶
Processor API と比較して、DSL でのみサポートされる機能には以下があります。
- ストリームとテーブル を抽象化した組み込みの KStream 、 KTable 、および GlobalKTable 。実際のほとんどのユースケースでは、ストリームとデータベースまたはテーブルの一方だけが必要となるのではなく、両方を組み合わせる必要があります。このため、ストリームとテーブルに対する十分なサポートがきわめて重要な意味を持ちます。たとえば、リアルタイムで更新される顧客の 360 度ビューを作成するユースケースがあるとします。この場合、アプリケーションでは、顧客に関連するイベントの多数の入力 "ストリーム" を、継続的に更新される顧客の 360 度ビューを含む出力 "テーブル" に変換します。
- 宣言型で関数型のプログラミングスタイル。 ステートレスな変換 (
mapやfilterなど)に加え、 集約 (countやreduceなど)、 結合 (leftJoinなど)、および ウィンドウ化 (セッションウィンドウ など)のような ステートフルな変換 を使用できます。
DSL を使用すると、アプリケーションで プロセッサートポロジー (論理的な処理プラン)を定義できます。これは次の手順で行います。
- Kafka のトピックから読み取られる 1 つ以上の入力ストリーム を指定します。
- これらのストリームに対する 変換 を構成します。
- 結果の出力ストリームを Kafka のトピックに書き戻す か、 Kafka Streams の対話型クエリ (REST API など)を通じて、アプリケーションの処理結果を他のアプリケーションに直接公開します。
アプリケーションが実行されると、定義されたプロセッサートポロジーが継続的に実行されます(つまり、処理プランが実行に移されます)。以下では、DSL を使用してストリーム処理アプリケーションを作成するためのステップバイステップガイドを提供します。
DSL を使用して Kafka Streams アプリケーションを構築したら、基盤となっている Topology を確認できます。そのためには、まず StreamsBuilder#build() を実行します。これは Topology オブジェクトを返します。次に、Topology#desribe() を呼び出して Topology を確認します。Topology の記述の詳細については、「トポロジーの記述」を参照してください。
利用可能な API 機能の網羅的なリストについては、 Kafka Streams の Javadoc も参照してください。
Kafka からのソースストリームの作成¶
Apache Kafka® トピックからアプリケーションへのデータの読み取りは簡単です。次の操作がサポートされています。
| Kafka からの読み取り | 説明 |
|---|---|
ストリーム
|
指定された Kafka 入力トピックから KStream を作成し、データを レコードストリーム として解釈します。 KStream の場合、各アプリケーションインスタンスのローカル KStream インスタンスには、入力トピックのパーティションの サブセット からデータが取り込まれるだけです。すべてのアプリケーションインスタンスを合わせることで、全体として、入力トピックのすべてのパーティションが読み取られ、処理されます。 import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.kstream.KStream;
StreamsBuilder builder = new StreamsBuilder();
KStream<String, Long> wordCounts = builder.stream(
"word-counts-input-topic", /* input topic */
Consumed.with(
Serdes.String(), /* key serde */
Serdes.Long() /* value serde */
);
Serde を明示的に指定しない場合、構成 のデフォルトの Serde が使用されます。 Kafka 入力トピック内のレコードのキーまたは値の型が、構成されているデフォルトの Serde と一致しない場合は、Serde を明示的に指定 する必要があります。デフォルトの Serde の構成、使用可能な Serde、および独自のカスタム Serde の実装については、「Kafka Streams のデータ型とシリアル化」を参照してください。
|
テーブル
|
指定された Kafka 入力トピックを KTable に読み取ります。トピックは changelog ストリームとして解釈され、同じキーのレコードは、そのキーに対する UPSERT、つまり INSERT/UPDATE(レコード値が KTable の場合、各アプリケーションインスタンスのローカル KTable インスタンスには、入力トピックのパーティションの サブセット からデータが取り込まれるだけです。すべてのアプリケーションインスタンスを合わせることで、全体として、入力トピックのすべてのパーティションが読み取られ、処理されます。 テーブル(より正確には、テーブルを支える内部 ステートストア )の名前を指定する必要があります。これは、テーブルに対する Kafka Streams の対話型クエリ をサポートするための要件です。名前を指定しない場合、テーブルはクエリ可能にならず、ステートストアには内部名が割り当てられます。 Serde を明示的に指定しない場合、構成 のデフォルトの Serde が使用されます。 Kafka 入力トピック内のレコードのキーまたは値の型が、構成されているデフォルトの Serde と一致しない場合は、Serde を明示的に指定 する必要があります。デフォルトの Serde の構成、使用可能な Serde、および独自のカスタム Serde の実装については、「Kafka Streams のデータ型とシリアル化」を参照してください。
|
グローバルテーブル
|
指定された Kafka 入力トピックを GlobalKTable に読み取ります。トピックは changelog ストリームとして解釈され、同じキーのレコードは、そのキーに対する UPSERT、つまり INSERT/UPDATE(レコード値が GlobalKTable の場合、各アプリケーションインスタンスのローカル GlobalKTable インスタンスには、入力トピックのすべてのパーティションからデータが取り込まれます。全体として、入力トピックのすべてのパーティションが、すべてのアプリケーションインスタンスによって消費されます。 テーブル(より正確には、テーブルを支える内部 ステートストア )の名前を指定する必要があります。これは、テーブルに対する Kafka Streams の対話型クエリ をサポートするための要件です。名前を指定しない場合、テーブルはクエリ可能にならず、ステートストアには内部名が割り当てられます。 import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.kstream.GlobalKTable;
StreamsBuilder builder = new StreamsBuilder();
GlobalKTable<String, Long> wordCounts = builder.globalTable(
"word-counts-input-topic",
Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as(
"word-counts-global-store" /* table/store name */)
.withKeySerde(Serdes.String()) /* key serde */
.withValueSerde(Serdes.Long()) /* value serde */
);
Kafka 入力トピック内のレコードのキーまたは値の型が、構成されているデフォルトの Serde と一致しない場合は、Serde を明示的に指定 する必要があります。デフォルトの Serde の構成、使用可能な Serde、および独自のカスタム Serde の実装については、「Kafka Streams のデータ型とシリアル化」を参照してください。
|
ストリームの変換¶
KStream および KTable インターフェイスでは、さまざまな変換操作がサポートされています。これらの各操作は、基盤のプロセッサートポロジーに接続された 1 つ以上のプロセッサーにつなげることができます。KStream と KTable は厳密に型指定されているため、これらの変換操作はすべてジェネリック関数として定義され、入力と出力のデータ型をユーザーが指定できます。
一部の KStream 変換では、1 つ以上の KStream オブジェクトが生成されます。たとえば、KStream の filter と map では、別の KStream が 1 つ生成されます。また、KStream の split では複数の KStream を生成できます。
その他の変換の中には、KTable オブジェクトを生成するものがあります。たとえば、KStream の集約からは KTable が生成されます。これにより、Kafka Streams では、計算された値が既にダウンストリームの変換オペレーターに生成された後も、引き続き 順序外のレコード の到達時に値を更新できます。
KTable の変換操作で行えるのは、もう 1 つの KTable を生成することだけです。ただし、Kafka Streams DSL には、KTable 表現を KStream に変換する特別な関数が用意されています。このような変換メソッドはすべてチェーン化できるため、複雑なプロセッサートポロジーを構成できます。
これらの変換操作について、以下のサブセクションで説明します。
ステートレスな変換¶
ステートレスな変換では、処理にステートが必要とされないため、ストリームプロセッサーにステートストアを関連付ける必要がありません。Kafka 0.11.0 以降では、ステートレスな KTable 変換の結果を具現化することができます。これにより、結果に対する Kafka Streams の対話型クエリ の実行が可能になります。KTable を具現化するために、以下のステートレスな操作はそれぞれ、オプションの queryableStoreName 引数を使用して 拡張 できます。
| 変換 | 説明 |
|---|---|
分岐
|
指定された述語に基づいて、 述語は順番に評価されます。レコードは、最初に一致した出力ストリームにのみ配置されます。つまり、n 番目の述語が true に評価されると、レコードは n 番目のストリームに配置されます。一致する述語がない場合、レコードは破棄されます。 分岐は、たとえば、レコードを複数の異なるダウンストリームトピックにルーティングする場合に便利です。 KStream<String, Long> stream = ...;
Map<String, KStream<String, Long>> branches =
stream.split(Named.as("Branch-"))
.branch((key, value) -> key.startsWith("A"), /* first predicate */
Branched.as("A"))
.branch((key, value) -> key.startsWith("B"), /* second predicate */
Branched.as("B"))
.defaultBranch(Branched.as("C"))
);
// KStream branches.get("Branch-A") contains all records whose keys start with "A"
// KStream branches.get("Branch-B") contains all records whose keys start with "B"
// KStream branches.get("Branch-C") contains all other records
// Java 7 example: cf. `filter` for how to create `Predicate` instances
|
フィルター
|
各要素に対してブール型関数を評価し、関数が true を返した要素を保持します(KStream の詳細、KTable の詳細)。 KStream<String, Long> stream = ...;
// A filter that selects (keeps) only positive numbers
// Java 8+ example, using lambda expressions
KStream<String, Long> onlyPositives = stream.filter((key, value) -> value > 0);
// Java 7 example
KStream<String, Long> onlyPositives = stream.filter(
new Predicate<String, Long>() {
@Override
public boolean test(String key, Long value) {
return value > 0;
}
});
|
逆フィルター
|
各要素に対してブール型関数を評価し、関数が true を返した要素を破棄します(KStream の詳細、KTable の詳細)。 KStream<String, Long> stream = ...;
// An inverse filter that discards any negative numbers or zero
// Java 8+ example, using lambda expressions
KStream<String, Long> onlyPositives = stream.filterNot((key, value) -> value <= 0);
// Java 7 example
KStream<String, Long> onlyPositives = stream.filterNot(
new Predicate<String, Long>() {
@Override
public boolean test(String key, Long value) {
return value <= 0;
}
});
|
FlatMap
|
1 つのレコードを受け取り、ゼロまたは 1 つ以上のレコードを生成します。レコードのキーと値、およびそれぞれの型を変更できます(詳細)。 データを再パーティション化するようにストリームをマーク: KStream<Long, String> stream = ...;
KStream<String, Integer> transformed = stream.flatMap(
// Here, we generate two output records for each input record.
// We also change the key and value types.
// Example: (345L, "Hello") -> ("HELLO", 1000), ("hello", 9000)
(key, value) -> {
List<KeyValue<String, Integer>> result = new LinkedList<>();
result.add(KeyValue.pair(value.toUpperCase(), 1000));
result.add(KeyValue.pair(value.toLowerCase(), 9000));
return result;
}
);
// Java 7 example: cf. `map` for how to create `KeyValueMapper` instances
|
FlatMap(値のみ)
|
1 つのレコードを受け取り、ゼロまたは 1 つ以上のレコードを生成します。元のレコードのキーは保持されます。レコードの値と、値の型を変更できます(詳細)。
// Split a sentence into words.
KStream<byte[], String> sentences = ...;
KStream<byte[], String> words = sentences.flatMapValues(value -> Arrays.asList(value.split("\\s+")));
// Java 7 example: cf. `mapValues` for how to create `ValueMapper` instances
|
Foreach
|
終端操作。 各レコードに対してステートレスなアクションを実行します(詳細)。
処理の保証に関する注意 : アクションの副作用(外部システムへの書き込みなど)は Kafka によって追跡できないため、通常、Kafka の利点である処理の保証は適用されません。 KStream<String, Long> stream = ...;
// Print the contents of the KStream to the local console.
// Java 8+ example, using lambda expressions
stream.foreach((key, value) -> System.out.println(key + " => " + value));
// Java 7 example
stream.foreach(
new ForeachAction<String, Long>() {
@Override
public void apply(String key, Long value) {
System.out.println(key + " => " + value);
}
});
|
GroupByKey
|
既存のキーでレコードをグループ化します(詳細)。 グループ化は、ストリームまたはテーブルを集約 する場合の前提条件であり、後続の操作のためにデータが適切にパーティション化("キー付け")されることを保証します。 明示的な Serde の設定が必要な場合 : 注釈 グループ化とウィンドウ化: 関連する操作として ウィンドウ化 があります。これは、"同じキー" でグループ化されたレコードを、"ウィンドウ" と呼ばれる単位に "サブグループ化" する方法を制御するもので、ウィンドウ化された 集約 やウィンドウ化された 結合 などのステートフルな操作で使用されます。 データの再パーティション化は、ストリームに再パーティション化のマークが付けられている場合にのみ発生します。 KStream<byte[], String> stream = ...;
// Group by the existing key, using the application's configured
// default serdes for keys and values.
KGroupedStream<byte[], String> groupedStream = stream.groupByKey();
// When the key and/or value types do not match the configured
// default serdes, we must explicitly specify serdes.
KGroupedStream<byte[], String> groupedStream = stream.groupByKey(
Grouped.with(
Serdes.ByteArray(), /* key */
Serdes.String()) /* value */
);
|
GroupBy
|
Groups the records by a new key, which may be of a different key type.
When grouping a table, you may also specify a new value and value type.
グループ化は、ストリームまたはテーブルを集約 する場合の前提条件であり、後続の操作のためにデータが適切にパーティション化("キー付け")されることを保証します。 明示的な Serde の設定が必要な場合: 注釈 グループ化とウィンドウ化: 関連する操作として ウィンドウ化 があります。これは、"同じキー" でグループ化されたレコードを、"ウィンドウ" と呼ばれる単位に "サブグループ化" する方法を制御するもので、ウィンドウ化された 集約 やウィンドウ化された 結合 などのステートフルな操作で使用されます。 常にデータの再パーティション化が発生: KStream<byte[], String> stream = ...;
KTable<byte[], String> table = ...;
// Java 8+ examples, using lambda expressions
// Group the stream by a new key and key type
KGroupedStream<String, String> groupedStream = stream.groupBy(
(key, value) -> value,
Grouped.with(
Serdes.String(), /* key (note: type was modified) */
Serdes.String()) /* value */
);
// Group the table by a new key and key type, and also modify the value and value type.
KGroupedTable<String, Integer> groupedTable = table.groupBy(
(key, value) -> KeyValue.pair(value, value.length()),
Grouped.with(
Serdes.String(), /* key (note: type was modified) */
Serdes.Integer()) /* value (note: type was modified) */
);
// Java 7 examples
// Group the stream by a new key and key type
KGroupedStream<String, String> groupedStream = stream.groupBy(
new KeyValueMapper<byte[], String, String>>() {
@Override
public String apply(byte[] key, String value) {
return value;
}
},
Grouped.with(
Serdes.String(), /* key (note: type was modified) */
Serdes.String()) /* value */
);
// Group the table by a new key and key type, and also modify the value and value type.
KGroupedTable<String, Integer> groupedTable = table.groupBy(
new KeyValueMapper<byte[], String, KeyValue<String, Integer>>() {
@Override
public KeyValue<String, Integer> apply(byte[] key, String value) {
return KeyValue.pair(value, value.length());
}
},
Grouped.with(
Serdes.String(), /* key (note: type was modified) */
Serdes.Integer()) /* value (note: type was modified) */
);
|
コグループ
|
コグループ化により、複数の入力ストリームを単一の操作で集約できます。異なる(既にグループ化された)入力ストリームは、キーの型が一致している必要があります。値の型は異なっていてもかまいません。 それぞれの コグループでは、前提条件として入力ストリームがグループ化されているため、再パーティション化は発生しません。これらのグループを作成する過程で、ストリームに再パーティション化のマークが付けられている場合は、既に再パーティション化が完了しています。 KGroupedStream<byte[], String> groupedStreamOne = ...;
KGroupedStream<byte[], Long> groupedStreamTwo = ...;
// Java 8+ examples, using lambda expressions
// Create new cogroup from the first stream (the value type of the CogroupedStream is the value type of the final aggregation result)
CogroupedStream<byte[], Integer> cogroupedStream = groupedStreamOne.cogroup(
(aggKey, newValue, aggValue) -> aggValue + Integer.parseInteger(newValue) /* adder for first stream */
);
// Add the second stream to the existing cogroup (note, that the second input stream has a different value type than the first input stream)
cogroupedStream.cogroup(
groupedStreamTwo,
(aggKey, newValue, aggValue) -> aggValue + newValue.intValue() /* adder for second stream */
);
// Aggregate all streams of the cogroup
KTable<byte[], Integer> aggregatdTable = cogroup.aggregate(
() -> 0, /* initializer */
Materialized.as("aggregated-stream-store") /* state store name */
.withValueSerde(Serdes.Integer() /* serde for aggregate value */
);
// Java 7 examples
// Create new cogroup from the first stream (the value type of the CogroupedStream is the value type of the final aggregation result)
CogroupedStream<byte[], Integer> cogroupedStream = groupedStreamOne.cogroup(
new Aggregator<byte[], String, Integer>() { /* adder for first stream */
@Override
public Integer apply(byte[] aggKey, String newValue, Integer aggValue) {
return aggValue + Integer.parseInteger(newValue);
}
}
);
// Add the second stream to the existing cogroup (note, that the second input stream has a different value type than the first input stream)
cogroupedStream.cogroup(
groupedStreamTwo,
new Aggregator<byte[], String, Integer>() { /* adder for second stream */
@Override
public Integer apply(byte[] aggKey, Long newValue, Integer aggValue) {
return aggValue + newValue.intValue();
}
}
);
// Aggregate all streams of the cogroup
KTable<byte[], Integer> aggregatdTable = cogroup.aggregate(
new Initializer<Integer>() { /* initializer */
@Override
public Integer apply() {
return 0;
}
},
Materialized.as("aggregated-stream-store") /* state store name */
.withValueSerde(Serdes.Integer() /* serde for aggregate value */
);
|
マップ
|
1 つのレコードを受け取り、1 つのレコードを生成します。レコードのキーと値、およびそれぞれの型を変更できます(詳細)。 データを再パーティション化するようにストリームをマーク: KStream<byte[], String> stream = ...;
// Java 8+ example, using lambda expressions
// Note how we change the key and the key type (similar to `selectKey`)
// as well as the value and the value type.
KStream<String, Integer> transformed = stream.map(
(key, value) -> KeyValue.pair(value.toLowerCase(), value.length()));
// Java 7 example
KStream<String, Integer> transformed = stream.map(
new KeyValueMapper<byte[], String, KeyValue<String, Integer>>() {
@Override
public KeyValue<String, Integer> apply(byte[] key, String value) {
return new KeyValue<>(value.toLowerCase(), value.length());
}
});
|
マップ(値のみ)
|
Takes one record and produces one record, while retaining the key of the original record. You can modify the record value and the value type. (KStream details, KTable details)
KStream<byte[], String> stream = ...;
// Java 8+ example, using lambda expressions
KStream<byte[], String> uppercased = stream.mapValues(value -> value.toUpperCase());
// Java 7 example
KStream<byte[], String> uppercased = stream.mapValues(
new ValueMapper<String>() {
@Override
public String apply(String s) {
return s.toUpperCase();
}
});
|
マージ
|
2 つのストリームのレコードを、より大きい 1 つのストリームにマージします(詳細)。 マージされたストリームでは、異なるストリームからのレコード間の順序は保証されません。ただし、各入力ストリーム内での相対的な順序は保持されます(つまり、同じ入力ストリーム内のレコードは順番に処理されます)。 KStream<byte[], String> stream1 = ...;
KStream<byte[], String> stream2 = ...;
KStream<byte[], String> merged = stream1.merge(stream2);
|
ピーク
|
各レコードに対してステートレスなアクションを実行し、ストリームを変更せずに返します(詳細)。
処理の保証に関する注意 : アクションの副作用(外部システムへの書き込みなど)は Kafka によって追跡できないため、通常、Kafka の利点である処理の保証は適用されません。 KStream<byte[], String> stream = ...;
// Java 8+ example, using lambda expressions
KStream<byte[], String> unmodifiedStream = stream.peek(
(key, value) -> System.out.println("key=" + key + ", value=" + value));
// Java 7 example
KStream<byte[], String> unmodifiedStream = stream.peek(
new ForeachAction<byte[], String>() {
@Override
public void apply(byte[] key, String value) {
System.out.println("key=" + key + ", value=" + value);
}
});
|
出力
|
終端操作。 レコードを
KStream<byte[], String> stream = ...;
// print to sysout
stream.print(Printed.toSysOut());
// print to file with a custom label
stream.print(Printed.toFile("streams.out").withLabel("streams"));
|
再パーティション化
|
パーティション数を指定して、ストリームの再パーティション化を手動でトリガーします(詳細)。
KStream<byte[], String> stream = ... ;
KStream<byte[], String> repartitionedStream = stream.repartition(Repartitioned.numberOfPartitions(10));
|
SelectKey
|
各レコードに新しいキーを割り当てます。キーの型を変更することもできます(詳細)。
データを再パーティション化するようにストリームをマーク: KStream<byte[], String> stream = ...;
// Derive a new record key from the record's value. Note how the key type changes, too.
// Java 8+ example, using lambda expressions
KStream<String, String> rekeyed = stream.selectKey((key, value) -> value.split(" ")[0])
// Java 7 example
KStream<String, String> rekeyed = stream.selectKey(
new KeyValueMapper<byte[], String, String>() {
@Override
public String apply(byte[] key, String value) {
return value.split(" ")[0];
}
});
|
ストリームからテーブル
|
イベントストリームをテーブルまたは changelog ストリームに変換します(詳細)。 KStream<byte[], String> stream = ...;
KTable<byte[], String> table = stream.toTable();
|
テーブルからストリーム
|
このテーブルの changelog ストリームを取得します(詳細)。 KTable<byte[], String> table = ...;
// Also, a variant of `toStream` exists that allows you
// to select a new key for the resulting stream.
KStream<byte[], String> stream = table.toStream();
|
ステートフルな変換¶
ステートフルな変換では、入力の処理と出力の生成がステートに依存して行われるため、ストリームプロセッサーに ステートストア が関連付けられている必要があります。たとえば、集約操作では、ウィンドウごとの最新の集約結果を収集するために、ウィンドウ化のステートストアが使用されます。結合操作では、定義されたウィンドウ境界内でそれまでに受信されたレコードをすべて収集するために、ウィンドウ化のステートストアが使用されます。
ステートストアはフォールトトレラントです。障害が発生すると、Kafka Streams は、処理を再開する前にすべてのステートストアを完全に復元します。詳細については、「フォールトトレランス」を参照してください。
DSL で利用できるステートフルな変換には次のようなものがあります。
- 集約
- 結合
- ウィンドウ化 (集約や結合の一部として)
- Processor API の統合のための カスタムのプロセッサーとトランスフォーマーの適用 (ステートフルにもなり得る)
以下の図は、これらの関係を示したものです。
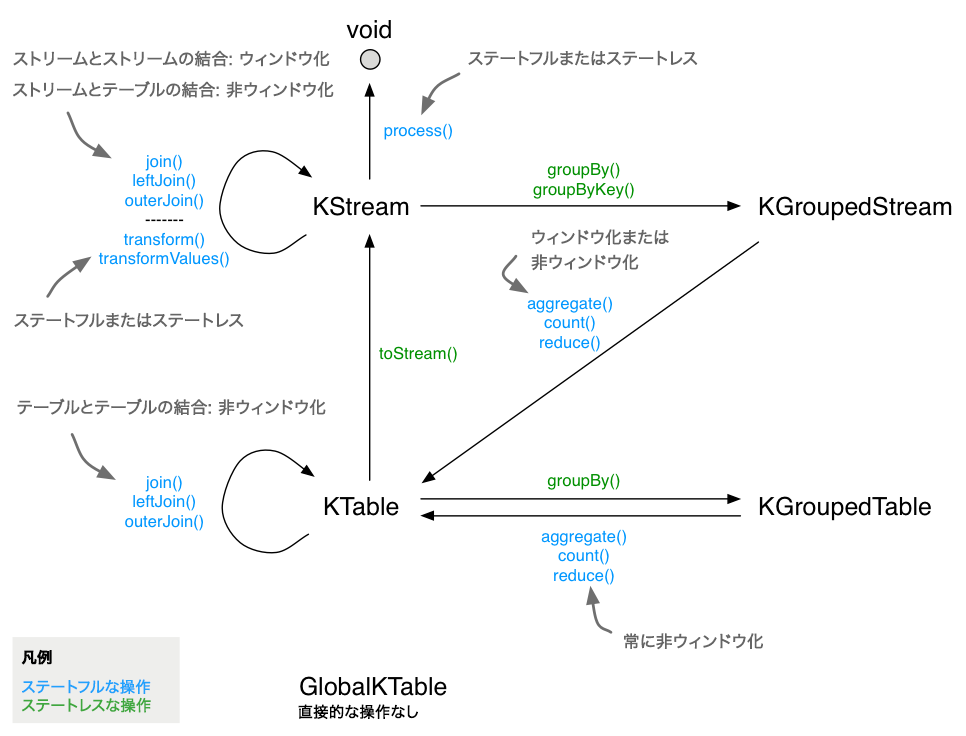
DSL でのステートフルな変換。¶
ここでは、ステートフルなアプリケーションの例として WordCount のアルゴリズムを紹介します。
ラムダ式を使用する Java 8+ での WordCount の例を以下に示します(完全なコードについては、WordCountLambdaIntegrationTest を参照してください)。
// Assume the record values represent lines of text. For the sake of this example, you can ignore
// whatever may be stored in the record keys.
KStream<String, String> textLines = ...;
KStream<String, Long> wordCounts = textLines
// Split each text line, by whitespace, into words. The text lines are the record
// values, i.e. you can ignore whatever data is in the record keys and thus invoke
// `flatMapValues` instead of the more generic `flatMap`.
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
// Group the stream by word to ensure the key of the record is the word.
.groupBy((key, word) -> word)
// Count the occurrences of each word (record key).
//
// This will change the stream type from `KGroupedStream<String, String>` to
// `KTable<String, Long>` (word -> count).
.count()
// Convert the `KTable<String, Long>` into a `KStream<String, Long>`.
.toStream();
Java 7 での WordCount の例を以下に示します。
// Code below is equivalent to the previous Java 8+ example above.
KStream<String, String> textLines = ...;
KStream<String, Long> wordCounts = textLines
.flatMapValues(new ValueMapper<String, Iterable<String>>() {
@Override
public Iterable<String> apply(String value) {
return Arrays.asList(value.toLowerCase().split("\\W+"));
}
})
.groupBy(new KeyValueMapper<String, String, String>() {
@Override
public String apply(String key, String word) {
return word;
}
})
.count()
.toStream();
集約¶
groupByKey または groupBy を使用してキーでレコードを グループ化 し、 KGroupedStream または KGroupedTable を取得したら、 reduce などの操作を通じて集約することができます。集約はキーに基づく操作です。つまり、常に同じキーを持つレコード(特にレコードの値)が操作の対象となります。集約は、 ウィンドウ化 されたデータにも、ウィンドウ化されていないデータにも実行できます。
重要
フォールトトレランスをサポートし、望ましくない動作を避けるには、イニシャライザーとアグリゲーターがステートレスでなければなりません。集約結果は、イニシャライザーとアグリゲーターの戻り値として渡す必要があります。クラスのメンバー変数は、障害の発生時にデータが失われる可能性があるため、使用しないでください。
| 変換 | 説明 |
|---|---|
集約
|
ローリング集約。 グループ化されたキーに基づいて、(ウィンドウ化されていない)レコードの値を集約します。集約は "グループ化されたストリーム" を集約する場合は、イニシャライザー(
KGroupedStream<byte[], String> groupedStream = ...;
KGroupedTable<byte[], String> groupedTable = ...;
// Java 8+ examples, using lambda expressions
// Aggregating a KGroupedStream (note how the value type changes from String to Long)
KTable<byte[], Long> aggregatedStream = groupedStream.aggregate(
() -> 0L, /* initializer */
(aggKey, newValue, aggValue) -> aggValue + newValue.length(), /* adder */
Materialized.as("aggregated-stream-store") /* state store name */
.withValueSerde(Serdes.Long()) /* serde for aggregate value */
);
// Aggregating a KGroupedTable (note how the value type changes from String to Long)
KTable<byte[], Long> aggregatedTable = groupedTable.aggregate(
() -> 0L, /* initializer */
(aggKey, newValue, aggValue) -> aggValue + newValue.length(), /* adder */
(aggKey, oldValue, aggValue) -> aggValue - oldValue.length(), /* subtractor */
Materialized.as("aggregated-table-store") /* state store name */
.withValueSerde(Serdes.Long()) /* serde for aggregate value */
);
// Java 7 examples
// Aggregating a KGroupedStream (note how the value type changes from String to Long)
KTable<byte[], Long> aggregatedStream = groupedStream.aggregate(
new Initializer<Long>() { /* initializer */
@Override
public Long apply() {
return 0L;
}
},
new Aggregator<byte[], String, Long>() { /* adder */
@Override
public Long apply(byte[] aggKey, String newValue, Long aggValue) {
return aggValue + newValue.length();
}
},
Materialized.as("aggregated-stream-store")
.withValueSerde(Serdes.Long())
);
// Aggregating a KGroupedTable (note how the value type changes from String to Long)
KTable<byte[], Long> aggregatedTable = groupedTable.aggregate(
new Initializer<Long>() { /* initializer */
@Override
public Long apply() {
return 0L;
}
},
new Aggregator<byte[], String, Long>() { /* adder */
@Override
public Long apply(byte[] aggKey, String newValue, Long aggValue) {
return aggValue + newValue.length();
}
},
new Aggregator<byte[], String, Long>() { /* subtractor */
@Override
public Long apply(byte[] aggKey, String oldValue, Long aggValue) {
return aggValue - oldValue.length();
}
},
Materialized.as("aggregated-stream-store")
.withValueSerde(Serdes.Long())
);
このセクションの最後にある例では、集約のセマンティクスが視覚的に示されています。 |
集約(ウィンドウ化)
|
ウィンドウ化された集約。 ウィンドウごと に、グループ化されたキーに基づいてレコードの値を集約します。集約は "グループ化されたストリーム" を集約する場合は、イニシャライザー( ウィンドウ化された
import java.time.Duration;
KGroupedStream<String, Long> groupedStream = ...;
CogroupedKStream<String, Long> cogroupedStream = ...;
// Java 8+ examples, using lambda expressions
// Aggregating with time-based windowing (here: with 5-minute tumbling windows)
KTable<Windowed<String>, Long> timeWindowedAggregatedStream = groupedStream.windowedBy(TimeWindows.of(Duration.ofMinutes(5)))
.aggregate(
() -> 0L, /* initializer */
(aggKey, newValue, aggValue) -> aggValue + newValue, /* adder */
Materialized.<String, Long, WindowStore<Bytes, byte[]>>as("time-windowed-aggregated-stream-store") /* state store name */
.withValueSerde(Serdes.Long())); /* serde for aggregate value */
// Aggregating with time-based windowing (here: with 5-minute tumbling windows)
// (note: the required "adder" aggregator is specified in the prior `cogroup()` call already)
KTable<Windowed<String>, Long> timeWindowedAggregatedStream = cogroupedStream.windowedBy(TimeWindows.of(Duration.ofMinutes(5)))
.aggregate(
() -> 0L, /* initializer */
Materialized.<String, Long, WindowStore<Bytes, byte[]>>as("time-windowed-aggregated-stream-store") /* state store name */
.withValueSerde(Serdes.Long())); /* serde for aggregate value */
// Aggregating with time-based windowing (here: with 5-minute sliding windows and 30-minute grace period)
KTable<Windowed<String>, Long> timeWindowedAggregatedStream = groupedStream
.windowedBy(SlidingWindows.withTimeDifferenceAndGrace(Duration.ofMinutes(5), Duration.ofMinutes(30)))
.aggregate(
() -> 0L, /* initializer */
(aggKey, newValue, aggValue) -> aggValue + newValue, /* adder */
Materialized.<String, Long, WindowStore<Bytes, byte[]>>as("time-windowed-aggregated-stream-store") /* state store name */
.withValueSerde(Serdes.Long())); /* serde for aggregate value */
// Aggregating with time-based windowing (here: with 5-minute sliding windows and 30-minute grace period)
// (note: the required "adder" aggregator is specified in the prior `cogroup()` call already)
KTable<Windowed<String>, Long> timeWindowedAggregatedStream = cogroupedStream
.windowedBy(SlidingWindows.withTimeDifferenceAndGrace(Duration.ofMinutes(5), Duration.ofMinutes(30)))
.aggregate(
() -> 0L, /* initializer */
Materialized.<String, Long, WindowStore<Bytes, byte[]>>as("time-windowed-aggregated-stream-store") /* state store name */
.withValueSerde(Serdes.Long())); /* serde for aggregate value */
// Aggregating with session-based windowing (here: with an inactivity gap of 5 minutes)
KTable<Windowed<String>, Long> sessionizedAggregatedStream = groupedStream.windowedBy(SessionWindows.with(Duration.ofMinutes(5)).
aggregate(
() -> 0L, /* initializer */
(aggKey, newValue, aggValue) -> aggValue + newValue, /* adder */
(aggKey, leftAggValue, rightAggValue) -> leftAggValue + rightAggValue, /* session merger */
Materialized.<String, Long, SessionStore<Bytes, byte[]>>as("sessionized-aggregated-stream-store") /* state store name */
.withValueSerde(Serdes.Long())); /* serde for aggregate value */
// Aggregating with session-based windowing (here: with an inactivity gap of 5 minutes)
// (note: the required "adder" aggregator is specified in the prior `cogroup()` call already)
KTable<Windowed<String>, Long> sessionizedAggregatedStream = cogroupedStream.windowedBy(SessionWindows.with(Duration.ofMinutes(5)).
aggregate(
() -> 0L, /* initializer */
(aggKey, leftAggValue, rightAggValue) -> leftAggValue + rightAggValue, /* session merger */
Materialized.<String, Long, SessionStore<Bytes, byte[]>>as("sessionized-aggregated-stream-store") /* state store name */
.withValueSerde(Serdes.Long())); /* serde for aggregate value */
// Java 7 examples (omitting `cogroupedStream` for brevity)
// Aggregating with time-based windowing (here: with 5-minute tumbling windows)
KTable<Windowed<String>, Long> timeWindowedAggregatedStream = groupedStream.windowedBy(TimeWindows.of(Duration.ofMinutes(5)))
.aggregate(
new Initializer<Long>() { /* initializer */
@Override
public Long apply() {
return 0L;
}
},
new Aggregator<String, Long, Long>() { /* adder */
@Override
public Long apply(String aggKey, Long newValue, Long aggValue) {
return aggValue + newValue;
}
},
Materialized.<String, Long, WindowStore<Bytes, byte[]>>as("time-windowed-aggregated-stream-store")
.withValueSerde(Serdes.Long()));
// Aggregating with session-based windowing (here: with an inactivity gap of 5 minutes)
KTable<Windowed<String>, Long> sessionizedAggregatedStream = groupedStream.windowedBy(SessionWindows.with(Duration.ofMinutes(5)).
aggregate(
new Initializer<Long>() { /* initializer */
@Override
public Long apply() {
return 0L;
}
},
new Aggregator<String, Long, Long>() { /* adder */
@Override
public Long apply(String aggKey, Long newValue, Long aggValue) {
return aggValue + newValue;
}
},
new Merger<String, Long>() { /* session merger */
@Override
public Long apply(String aggKey, Long leftAggValue, Long rightAggValue) {
return rightAggValue + leftAggValue;
}
},
Materialized.<String, Long, SessionStore<Bytes, byte[]>>as("sessionized-aggregated-stream-store")
.withValueSerde(Serdes.Long()));
動作の詳細:
このセクションの最後にある例では、集約のセマンティクスが視覚的に示されています。 |
カウント
|
ローリング集約。 グループ化されたキーに基づいてレコードの数をカウントします(KGroupedStream の詳細、KGroupedTable の詳細)。
KGroupedStream<String, Long> groupedStream = ...;
KGroupedTable<String, Long> groupedTable = ...;
// Counting a KGroupedStream
KTable<String, Long> aggregatedStream = groupedStream.count();
// Counting a KGroupedTable
KTable<String, Long> aggregatedTable = groupedTable.count();
|
カウント(ウィンドウ化)
|
ウィンドウ化された集約。 ウィンドウごと に、グループ化されたキーに基づいてレコードの数をカウントします(TimeWindowedKStream の詳細、SessionWindowedKStream の詳細)。 ウィンドウ化された
import java.time.Duration;
KGroupedStream<String, Long> groupedStream = ...;
// Counting a KGroupedStream with time-based windowing (here: with 5-minute tumbling windows)
KTable<Windowed<String>, Long> aggregatedStream = groupedStream.windowedBy(
TimeWindows.of(Duration.ofMinutes(5))) /* time-based window */
.count();
// Counting a KGroupedStream with sliding windows time-based windowing (here: with 5-minute sliding windows and 30-minute grace period)
KTable<Windowed<String>, Long> aggregatedStream = groupedStream.windowedBy(
SlidingWindows.withTimeDifferenceAndGrace(Duration.ofMinutes(5), Duration.ofMinutes(30))) /* time-based window */
.count();
// Counting a KGroupedStream with session-based windowing (here: with 5-minute inactivity gaps)
KTable<Windowed<String>, Long> aggregatedStream = groupedStream.windowedBy(
SessionWindows.with(Duration.ofMinutes(5))) /* session window */
.count();
動作の詳細:
|
縮小
|
ローリング集約。 グループ化されたキーに基づいて、(ウィンドウ化されていない)レコードの値を結合します。現在のレコードの値が最後の縮小値と結合され、新しい縮小値が返されます。 "グループ化されたストリーム" を縮小する場合は、"アダー" リデューサー(
KGroupedStream<String, Long> groupedStream = ...;
KGroupedTable<String, Long> groupedTable = ...;
// Java 8+ examples, using lambda expressions
// Reducing a KGroupedStream
KTable<String, Long> aggregatedStream = groupedStream.reduce(
(aggValue, newValue) -> aggValue + newValue /* adder */);
// Reducing a KGroupedTable
KTable<String, Long> aggregatedTable = groupedTable.reduce(
(aggValue, newValue) -> aggValue + newValue, /* adder */
(aggValue, oldValue) -> aggValue - oldValue /* subtractor */);
// Java 7 examples
// Reducing a KGroupedStream
KTable<String, Long> aggregatedStream = groupedStream.reduce(
new Reducer<Long>() { /* adder */
@Override
public Long apply(Long aggValue, Long newValue) {
return aggValue + newValue;
}
});
// Reducing a KGroupedTable
KTable<String, Long> aggregatedTable = groupedTable.reduce(
new Reducer<Long>() { /* adder */
@Override
public Long apply(Long aggValue, Long newValue) {
return aggValue + newValue;
}
},
new Reducer<Long>() { /* subtractor */
@Override
public Long apply(Long aggValue, Long oldValue) {
return aggValue - oldValue;
}
});
このセクションの最後にある例では、集約のセマンティクスが視覚的に示されています。 |
縮小(ウィンドウ化)
|
ウィンドウ化された集約。 ウィンドウごと に、グループ化されたキーに基づいてレコードの値を結合します現在のレコードの値が最後の縮小値と結合され、新しい縮小値が返されます。キーまたは値が ウィンドウ化された
import java.time.Duration;
KGroupedStream<String, Long> groupedStream = ...;
// Java 8+ examples, using lambda expressions
// Aggregating with time-based windowing (here: with 5-minute tumbling windows)
KTable<Windowed<String>, Long> timeWindowedAggregatedStream = groupedStream.windowedBy(
TimeWindows.of(Duration.ofMinutes(5)) /* time-based window */)
.reduce(
(aggValue, newValue) -> aggValue + newValue /* adder */
);
// Aggregating with time-based windowing (here: with 5-minute sliding windows and 30-minute grace period)
KTable<Windowed<String>, Long> timeWindowedAggregatedStream = groupedStream
.windowedBy(SlidingWindows.withTimeDifferenceAndGrace(Duration.ofMinutes(5), Duration.ofMinutes(30)) /* time-based window */)
.reduce(
(aggValue, newValue) -> aggValue + newValue /* adder */
);
// Aggregating with session-based windowing (here: with an inactivity gap of 5 minutes)
KTable<Windowed<String>, Long> sessionzedAggregatedStream = groupedStream.windowedBy(
SessionWindows.with(Duration.ofMinutes(5))) /* session window */
.reduce(
(aggValue, newValue) -> aggValue + newValue /* adder */
);
// Java 7 examples
// Aggregating with time-based windowing (here: with 5-minute tumbling windows)
KTable<Windowed<String>, Long> timeWindowedAggregatedStream = groupedStream.windowedBy(
TimeWindows.of(Duration.ofMinutes(5)) /* time-based window */)
.reduce(
new Reducer<Long>() { /* adder */
@Override
public Long apply(Long aggValue, Long newValue) {
return aggValue + newValue;
}
});
// Aggregating with session-based windowing (here: with an inactivity gap of 5 minutes)
KTable<Windowed<String>, Long> timeWindowedAggregatedStream = groupedStream.windowedBy(
SessionWindows.with(Duration.ofMinutes(5))) /* session window */
.reduce(
new Reducer<Long>() { /* adder */
@Override
public Long apply(Long aggValue, Long newValue) {
return aggValue + newValue;
}
});
動作の詳細:
このセクションの最後にある例では、集約のセマンティクスが視覚的に示されています。 |
ストリームの集約のセマンティクスの例: KGroupedStream → KTable の例を以下に示します。初期状態のストリームとテーブルは空です。"KTable aggregated " の列では、変更されたステートが太字で強調表示されています。(hello, 1) のようなエントリは、キーが hello で値が 1 のレコードを表します。セマンティクスの表の可読性を高めるために、すべてのレコードはタイムスタンプ順に処理されるものとします。
// Key: word, value: count
KStream<String, Integer> wordCounts = ...;
KGroupedStream<String, Integer> groupedStream = wordCounts
.groupByKey(Grouped.with(Serdes.String(), Serdes.Integer()));
KTable<String, Integer> aggregated = groupedStream.aggregate(
() -> 0, /* initializer */
(aggKey, newValue, aggValue) -> aggValue + newValue, /* adder */
Materialized.<String, Long, KeyValueStore<Bytes, byte[]>as("aggregated-stream-store" /* state store name */)
.withKeySerde(Serdes.String()) /* key serde */
.withValueSerde(Serdes.Integer()); /* serde for aggregate value */
注釈
レコードキャッシュの影響: 説明の目的から、以下の "KTable aggregated " 列は、時間の経過に伴うテーブルのステートの変更を非常に細かく示しています。実際には、ステートの変更をこれほど細かく確認できるのは、 レコードキャッシュ が無効になっている場合だけです(デフォルトは有効)。レコードキャッシュが有効な場合は、たとえば、タイムスタンプ 4 と 5 の行の出力結果が 圧縮 され、KTable のキー kafka に対するステートの変更は 1 回だけになる可能性があります((kafka, 1) から直接 (kafka, 3) に変更)。一般に、レコードキャッシュを無効にするのはテストやデバッグの目的に限定し、通常の状況ではレコードキャッシュを有効にしておくことをお勧めします。
KStream wordCounts |
KGroupedStream groupedStream |
KTable aggregated |
|||
|---|---|---|---|---|---|
| タイムスタンプ | 入力レコード | グループ化 | イニシャライザー | アダー | ステート |
| 1 | (hello, 1) | (hello, 1) | 0(hello に対して) | (hello, 0 + 1) | (hello, 1)
|
| 2 | (kafka, 1) | (kafka, 1) | 0(kafka に対して) | (kafka, 0 + 1) | (hello, 1)
(kafka, 1)
|
| 3 | (streams, 1) | (streams, 1) | 0(streams に対して) | (streams, 0 + 1) | (hello, 1)
(kafka, 1)
(streams, 1)
|
| 4 | (kafka, 1) | (kafka, 1) | (kafka, 1 + 1) | (hello, 1)
(kafka, 2)
(streams, 1)
|
|
| 5 | (kafka, 1) | (kafka, 1) | (kafka, 2 + 1) | (hello, 1)
(kafka, 3)
(streams, 1)
|
|
| 6 | (streams, 1) | (streams, 1) | (streams, 1 + 1) | (hello, 1)
(kafka, 3)
(streams, 2)
|
|
テーブルの集約のセマンティクスの例: KGroupedTable → KTable の例を以下に示します。初期状態のテーブルは空です。"KTable aggregated " の列では、変更されたステートが太字で強調表示されています。(hello, 1) のようなエントリは、キーが hello で値が 1 のレコードを表します。セマンティクスの表の可読性を高めるために、すべてのレコードはタイムスタンプ順に処理されるものとします。
// Key: username, value: user region (abbreviated to "E" for "Europe", "A" for "Asia")
KTable<String, String> userProfiles = ...;
// Re-group `userProfiles`. Don't read too much into what the grouping does:
// its prime purpose in this example is to show the *effects* of the grouping
// in the subsequent aggregation.
KGroupedTable<String, Integer> groupedTable = userProfiles
.groupBy((user, region) -> KeyValue.pair(region, user.length()), Serdes.String(), Serdes.Integer());
KTable<String, Integer> aggregated = groupedTable.aggregate(
() -> 0, /* initializer */
(aggKey, newValue, aggValue) -> aggValue + newValue, /* adder */
(aggKey, oldValue, aggValue) -> aggValue - oldValue, /* subtractor */
Materialized.<String, Long, KeyValueStore<Bytes, byte[]>as("aggregated-table-store" /* state store name */)
.withKeySerde(Serdes.String()) /* key serde */
.withValueSerde(Serdes.Integer()); /* serde for aggregate value */
注釈
レコードキャッシュの影響: 説明の目的から、以下の "KTable aggregated " 列は、時間の経過に伴うテーブルのステートの変更を非常に細かく示しています。実際には、ステートの変更をこれほど細かく確認できるのは、 レコードキャッシュ が無効になっている場合だけです(デフォルトは有効)。レコードキャッシュが有効な場合は、たとえば、タイムスタンプ 4 と 5 の行の出力結果が 圧縮 され、KTable のキー kafka に対するステートの変更は 1 回だけになる可能性があります((kafka, 1) から直接 (kafka, 3) に変更)。一般に、レコードキャッシュを無効にするのはテストやデバッグの目的に限定し、通常の状況ではレコードキャッシュを有効にしておくことをお勧めします。
KTable userProfiles |
KGroupedTable groupedTable |
KTable aggregated |
|||||
|---|---|---|---|---|---|---|---|
| タイムスタンプ | 入力レコード | 解釈 | グループ化 | イニシャライザー | アダー | サブトラクター | ステート |
| 1 | (alice, E) | INSERT alice | (E, 5) | 0(E に対して) | (E, 0 + 5) | (E, 5)
|
|
| 2 | (bob, A) | INSERT bob | (A, 3) | 0(A に対して) | (A, 0 + 3) | (A, 3)
(E, 5)
|
|
| 3 | (charlie, A) | INSERT charlie | (A, 7) | (A, 3 + 7) | (A, 10)
(E, 5)
|
||
| 4 | (alice, A) | UPDATE alice | (A, 5) | (A, 10 + 5) | (E, 5 - 5) | (A, 15)
(E, 0)
|
|
| 5 | (charlie, null) | DELETE charlie | (null, 7) | (A, 15 - 7) | (A, 8)
(E, 0)
|
||
| 6 | (null, E) | 無視 | (A, 8)
(E, 0)
|
||||
| 7 | (bob, E) | UPDATE bob | (E, 3) | (E, 0 + 3) | (A, 8 - 3) | (A, 5)
(E, 3)
|
|
結合¶
ストリームやテーブルは結合することもできます。実際の多くのストリーム処理アプリケーションは、ストリーミングの結合として記述されています。たとえば、オンラインショップの稼働を支えるアプリケーションでは、新しいデータレコード(顧客トランザクションなど)にコンテキスト情報を関連付けるために、更新され続ける複数のデータベーステーブル(販売価格、在庫、顧客情報など)へのアクセスが必要になることがあります。このようなシナリオでは、大規模なテーブル参照を低い処理レイテンシで実行する必要があります。ここでよく使用されるパターンは、"変更データキャプチャー" と Kafka の Connect API を組み合わせてデータベース内の情報を Kafka で利用できるようにしてから、Streams API を使用して、そのテーブルとストリームの ローカル結合を非常に高速かつ効率的に実行 するアプリケーションを実装する方法です。この方法なら、ネットワーク経由でリモートデータベースに各レコードを照会するクエリをアプリケーションで作成する必要はありません。この例では、Kafka Streams の KTable の概念により、ローカルステートストアの各テーブルの最新のステート(スナップショット)を追跡できるため、処理レイテンシが大幅に削減されるとともに、ストリーミングの結合を実行するときのリモートデータベースの負荷も軽減されます。
サポートされる結合操作を以下に示します。「ステートフルな変換」の 概要セクション の図も参照してください。オペランドに応じて、結合は ウィンドウ化 された結合とウィンドウ化されない結合のどちらかになります。
| 結合オペランド | 種類 | (内部)結合 | 左結合 | 外部結合 | デモアプリケーション |
|---|---|---|---|---|---|
| KStream から KStream | ウィンドウ化 | サポートあり | サポートあり | サポートあり | StreamToStreamJoinIntegrationTest |
| KTable から KTable | 非ウィンドウ化 | サポートあり | サポートあり | サポートあり | TableToTableJoinIntegrationTest |
| KStream から KTable | 非ウィンドウ化 | サポートあり | サポートあり | サポートなし | StreamToTableJoinIntegrationTest |
| KStream から GlobalKTable | 非ウィンドウ化 | サポートあり | サポートあり | サポートなし | GlobalKTablesExample |
| KTable から GlobalKTable | 該当なし | サポートなし | サポートなし | サポートなし | 該当なし |
以降のセクションでは、それぞれのケースについて詳しく説明します。
結合時の共同パーティション化の要件¶
結合時には、入力データが共同パーティション化されている必要があります。これにより、結合の両側にある同じキーを持つ入力レコードが、処理中に同じストリームタスクに配信されることが保証されます。結合時のデータの共同パーティション化は、ユーザーの責任で行う必要があります。
ちなみに
可能であれば、結合に グローバルテーブル ( GlobalKTable)を使用することを検討してください。グローバルテーブルでは共同パーティション化は必要ありません。
データの共同パーティション化の要件を以下に示します。
- 結合の入力トピック(左側と右側)の パーティション数が同じ であること。
- 入力トピックに "書き込む" すべてのアプリケーションの パーティション戦略が一致 していて、同じキーを持つレコードが同じパーティション番号に配信されること。言い換えると、入力データのキースペースが、パーティション間で同じように分散される必要があります。たとえば、Kafka の Java Producer API を使用するアプリケーションは、同じパーティショナーを使用する必要があり(プロデューサー設定
"partitioner.class"、別名ProducerConfig.PARTITIONER_CLASS_CONFIGを参照)、Kafka の Streams API を使用するアプリケーションは、KStream#to()などの操作を実行するときに同じStreamPartitionerを使用する必要があることを意味します。さいわい、すべてのアプリケーションでデフォルトのパーティショナー関連設定を使用していれば、パーティション化戦略を気にする必要はありません。
なぜデータの共同パーティション化が必要なのでしょうか。KStream-KStream、KTable-KTable、および KStream-KTable 結合は、レコードのキーに基づいて実行されるため(leftRecord.key == rightRecord.key など)、結合の入力ストリームや入力テーブルがキーによって共同パーティション化されている必要があります。
唯一の例外は KStream-GlobalKTable 結合 です。この場合は、GlobalKTable の基盤にある changelog ストリームの "すべて" のパーティションが、それぞれの KafkaStreams インスタンスで利用可能になります。つまり、各インスタンスに changelog ストリームの完全なコピーが保持されるため、共同パーティション化は必要ありません。さらに、KeyValueMapper によって、KStream から GlobalKTable へのキーベースでない結合を実行できます。
注釈
Kafka Streams による共同パーティション化の要件の部分検証 : Kafka Streams は、パーティションの割り当てを行うステップの中で、結合の両側のパーティションの数が一致しているかどうかを実行時に確認します。一致しない場合は、TopologyBuilderException (ランタイム例外)がスローされます。ただし、Kafka Streams では、結合の入力ストリームや入力テーブル間でパーティション化戦略が一致しているかどうかを検証することはできません。これを保証するのはユーザーの役割です。
データの共同パーティション化の保証 : 結合の入力がまだ共同パーティション化されていない場合は、これを手動で実行する必要があります。使用できる手順の概要を以下に示します。
ボトルネックを避けるには、パーティションが少ない方のトピックを再パーティション化して、大きいパーティション数に合わせることをお勧めします。パーティションが多い方のトピックを再パーティション化して、小さいパーティション数に合わせることも可能です。ストリームとテーブルの結合では、KStream を再パーティション化することをお勧めします。これは、KTable を再パーティション化すると 2 つ目のステートストアが作成される場合があるためです。テーブルとテーブルの結合では、KTable のサイズを確認し、小さい方の KTable を再パーティションすることを検討してください。
- 結合の入力 KStream または KTable のうち、基になっている Kafka トピックのパーティション数が少ない方を特定します。ここでは、このストリームまたはテーブルを "SMALLER" と呼び、結合のもう一方の側を "LARGER" と呼びます。使用できる Kafka トピックのパーティション数を確認するには、たとえば、CLI ツール
bin/kafka-topicsに--describeオプションを付けて実行します。 - アプリケーション内で、"SMALLER" のデータを再パーティション化します。データを再パーティション化するときには、必ず "LARGER" と同じパーティショナーを使用する必要があります。
- "SMALLER" が KStream の場合 :
KStream#repartition(Repartitioned.numberOfPartitions(...)) - "SMALLER" が KTable の場合 :
KTable#toStream#repartition(Repartitioned.numberOfPartitions(...).toTable())
- "SMALLER" が KStream の場合 :
- アプリケーション内で、"LARGER" と新しいストリームまたはテーブルとの結合を実行します。
KStream-KStream 結合¶
KStream-KStream 結合は、常に ウィンドウ化 された結合になります。そうでなければ、結合の実行に使用される内部ステートストア(スライディングウィンドウ または "バッファ")のサイズが無限に増大してしまうためです。ストリームとストリームの結合では、一方の側の新しい入力レコードから、他方の側で一致する "レコードごと" に結合出力が生成されます。結合ウィンドウ内には、このような一致するレコードが "複数" 存在する可能性があることに注意が必要です(例として、後に示す結合セマンティクスの表でタイムスタンプが 15 の行を参照してください)。
結合の出力レコードは、ユーザーが提供する ValueJoiner を利用して、実質的に次のように作成されます。
KeyValue<K, LV> leftRecord = ...;
KeyValue<K, RV> rightRecord = ...;
ValueJoiner<LV, RV, JV> joiner = ...;
KeyValue<K, JV> joinOutputRecord = KeyValue.pair(
leftRecord.key, /* by definition, leftRecord.key == rightRecord.key */
joiner.apply(leftRecord.value, rightRecord.value)
);
| 変換 | 説明 |
|---|---|
内部結合(ウィンドウ化)
|
このストリームと別のストリームの内部結合を実行します。この操作はウィンドウ化されますが、結合されたストリームの型は データの共同パーティション化が必要: 両側の入力データが 共同パーティション化 されている必要があります。 ストリームのデータの再パーティション化は、ストリームに再パーティション化のマークが付けられている場合にのみ発生します(両方がマークされている場合は、両方が再パーティション化されます)。
import java.time.Duration;
KStream<String, Long> left = ...;
KStream<String, Double> right = ...;
// Java 8+ example, using lambda expressions
KStream<String, String> joined = left.join(right,
(leftValue, rightValue) -> "left=" + leftValue + ", right=" + rightValue, /* ValueJoiner */
JoinWindows.of(Duration.ofMinutes(5)),
Joined.with(
Serdes.String(), /* key */
Serdes.Long(), /* left value */
Serdes.Double()) /* right value */
);
// Java 7 example
KStream<String, String> joined = left.join(right,
new ValueJoiner<Long, Double, String>() {
@Override
public String apply(Long leftValue, Double rightValue) {
return "left=" + leftValue + ", right=" + rightValue;
}
},
JoinWindows.of(Duration.ofMinutes(5)),
Joined.with(
Serdes.String(), /* key */
Serdes.Long(), /* left value */
Serdes.Double()) /* right value */
);
動作の詳細:
詳しい説明については、このセクションの最後にあるセマンティクスの概要を参照してください。 |
左結合(ウィンドウ化)
|
このストリームと別のストリームの左結合を実行します。この操作はウィンドウ化されますが、結合されたストリームの型は データの共同パーティション化が必要: 両側の入力データが 共同パーティション化 されている必要があります。 ストリームのデータの再パーティション化は、ストリームに再パーティション化のマークが付けられている場合にのみ発生します(両方がマークされている場合は、両方が再パーティション化されます)。
import java.time.Duration;
KStream<String, Long> left = ...;
KStream<String, Double> right = ...;
// Java 8+ example, using lambda expressions
KStream<String, String> joined = left.leftJoin(right,
(leftValue, rightValue) -> "left=" + leftValue + ", right=" + rightValue, /* ValueJoiner */
JoinWindows.of(Duration.ofMinutes(5)),
Joined.with(
Serdes.String(), /* key */
Serdes.Long(), /* left value */
Serdes.Double()) /* right value */
);
// Java 7 example
KStream<String, String> joined = left.leftJoin(right,
new ValueJoiner<Long, Double, String>() {
@Override
public String apply(Long leftValue, Double rightValue) {
return "left=" + leftValue + ", right=" + rightValue;
}
},
JoinWindows.of(Duration.ofMinutes(5)),
Joined.with(
Serdes.String(), /* key */
Serdes.Long(), /* left value */
Serdes.Double()) /* right value */
);
動作の詳細:
詳しい説明については、このセクションの最後にあるセマンティクスの概要を参照してください。 |
外部結合(ウィンドウ化)
|
このストリームと別のストリームの外部結合を実行します。この操作はウィンドウ化されますが、結合されたストリームの型は データの共同パーティション化が必要: 両側の入力データが 共同パーティション化 されている必要があります。 ストリームのデータの再パーティション化は、ストリームに再パーティション化のマークが付けられている場合にのみ発生します(両方がマークされている場合は、両方が再パーティション化されます)。
import java.time.Duration;
KStream<String, Long> left = ...;
KStream<String, Double> right = ...;
// Java 8+ example, using lambda expressions
KStream<String, String> joined = left.outerJoin(right,
(leftValue, rightValue) -> "left=" + leftValue + ", right=" + rightValue, /* ValueJoiner */
JoinWindows.of(Duration.ofMinutes(5)),
Joined.with(
Serdes.String(), /* key */
Serdes.Long(), /* left value */
Serdes.Double()) /* right value */
);
// Java 7 example
KStream<String, String> joined = left.outerJoin(right,
new ValueJoiner<Long, Double, String>() {
@Override
public String apply(Long leftValue, Double rightValue) {
return "left=" + leftValue + ", right=" + rightValue;
}
},
JoinWindows.of(Duration.ofMinutes(5)),
Joined.with(
Serdes.String(), /* key */
Serdes.Long(), /* left value */
Serdes.Double()) /* right value */
);
動作の詳細:
詳しい説明については、このセクションの最後にあるセマンティクスの概要を参照してください。 |
ストリームとストリームの結合のセマンティクス : 以下では、ストリームとストリームの結合のさまざまなバリエーションのセマンティクスを示します。表の可読性を高めるために、(1)すべてのレコードは同じキーを持ち(このため、表ではキーが省略されています)、(2)すべてのレコードはタイムスタンプ順に処理されるものとします。ここでは、結合のウィンドウサイズが 15 秒、猶予期間が 5 秒としています。
注釈
猶予期間の指定に、現在は非推奨になっている古い API(JoinWindows.of(...).grace(...))を使用すると、左結合や外部結合の結果が早すぎるタイミングで出力され、以下に示すものとは異なる結果となる可能性があります。
内部結合、左結合、および外部結合の各列は、結合のどちらか一方の側で新しい入力レコードが受信されたときに、それぞれ join、leftJoin、および outerJoin メソッドを通じて、ユーザーが提供する ValueJoiner に引数として渡されるデータを表します。表のセルが空の場合は、ValueJoiner が呼び出されないことを示します。
| タイムスタンプ | 左側(KStream) | 右側(KStream) | (内部)結合 | 左結合 | 外部結合 |
|---|---|---|---|---|---|
| 1 | null | ||||
| 2 | null | ||||
| 3 | A | ||||
| 4 | a | [A, a] | [A, a] | [A, a] | |
| 5 | B | [B, a] | [B, a] | [B, a] | |
| 6 | b | [A, b], [B, b] | [A, b], [B, b] | [A, b], [B, b] | |
| 7 | null | ||||
| 8 | null | ||||
| 9 | C | [C, a], [C, b] | [C, a], [C, b] | [C, a], [C, b] | |
| 10 | c | [A, c], [B, c], [C, c] | [A, c], [B, c], [C, c] | [A, c], [B, c], [C, c] | |
| 11 | null | ||||
| 12 | null | ||||
| 13 | null | ||||
| 14 | d | [A, d], [B, d], [C, d] | [A, d], [B, d], [C, d] | [A, d], [B, d], [C, d] | |
| 15 | D | [D, a], [D, b], [D, c], [D, d] | [D, a], [D, b], [D, c], [D, d] | [D, a], [D, b], [D, c], [D, d] | |
| ... | |||||
| 40 | E | ||||
| ... | |||||
| 60 | F | [E,null] | [E,null] | ||
| ... | |||||
| 80 | f | [F,null] | [F,null] | ||
| ... | |||||
| 100 | G | [null,f] |
KTable-KTable 結合¶
KTable-KTable 結合は、常に "ウィンドウ化されない" 結合です。これは、リレーショナルデータベースにおける対応する結合と一貫性を持つように設計されています。両側の KTables の changelog ストリームがローカルステートストアに具現化され、 テーブルデュアル の最新のスナップショットを表します。結合結果として、結合操作の changelog ストリームを表す新しい KTable が生成されます。
結合の出力レコードは、ユーザーが提供する ValueJoiner を利用して、実質的に次のように作成されます。
KeyValue<K, LV> leftRecord = ...;
KeyValue<K, RV> rightRecord = ...;
ValueJoiner<LV, RV, JV> joiner = ...;
KeyValue<K, JV> joinOutputRecord = KeyValue.pair(
leftRecord.key, /* by definition, leftRecord.key == rightRecord.key */
joiner.apply(leftRecord.value, rightRecord.value)
);
| 変換 | 説明 |
|---|---|
内部結合
|
このテーブルと別のテーブルの内部結合を実行します。結果として、結合の "現在" の結果を表すように更新され続ける KTable が生成されます:platform:(詳細)|streams/javadocs/javadoc/org/apache/kafka/streams/kstream/KTable.html#join-org.apache.kafka.streams.kstream.KTable-org.apache.kafka.streams.kstream.ValueJoiner-。 データの共同パーティション化が必要: 両側の入力データが 共同パーティション化 されている必要があります。 KTable<String, Long> left = ...;
KTable<String, Double> right = ...;
// Java 8+ example, using lambda expressions
KTable<String, String> joined = left.join(right,
(leftValue, rightValue) -> "left=" + leftValue + ", right=" + rightValue /* ValueJoiner */
);
// Java 7 example
KTable<String, String> joined = left.join(right,
new ValueJoiner<Long, Double, String>() {
@Override
public String apply(Long leftValue, Double rightValue) {
return "left=" + leftValue + ", right=" + rightValue;
}
});
動作の詳細:
詳しい説明については、このセクションの最後にあるセマンティクスの概要を参照してください。 |
左結合
|
このテーブルと別のテーブルの左結合を実行します:platform:(詳細)|streams/javadocs/javadoc/org/apache/kafka/streams/kstream/KTable.html#leftJoin-org.apache.kafka.streams.kstream.KTable-org.apache.kafka.streams.kstream.ValueJoiner-。 データの共同パーティション化が必要: 両側の入力データが 共同パーティション化 されている必要があります。 KTable<String, Long> left = ...;
KTable<String, Double> right = ...;
// Java 8+ example, using lambda expressions
KTable<String, String> joined = left.leftJoin(right,
(leftValue, rightValue) -> "left=" + leftValue + ", right=" + rightValue /* ValueJoiner */
);
// Java 7 example
KTable<String, String> joined = left.leftJoin(right,
new ValueJoiner<Long, Double, String>() {
@Override
public String apply(Long leftValue, Double rightValue) {
return "left=" + leftValue + ", right=" + rightValue;
}
});
動作の詳細:
詳しい説明については、このセクションの最後にあるセマンティクスの概要を参照してください。 |
外部結合
|
このテーブルと別のテーブルの外部結合を実行します:platform:(詳細)|streams/javadocs/javadoc/org/apache/kafka/streams/kstream/KTable.html#outerJoin-org.apache.kafka.streams.kstream.KTable-org.apache.kafka.streams.kstream.ValueJoiner-。 データの共同パーティション化が必要: 両側の入力データが 共同パーティション化 されている必要があります。 KTable<String, Long> left = ...;
KTable<String, Double> right = ...;
// Java 8+ example, using lambda expressions
KTable<String, String> joined = left.outerJoin(right,
(leftValue, rightValue) -> "left=" + leftValue + ", right=" + rightValue /* ValueJoiner */
);
// Java 7 example
KTable<String, String> joined = left.outerJoin(right,
new ValueJoiner<Long, Double, String>() {
@Override
public String apply(Long leftValue, Double rightValue) {
return "left=" + leftValue + ", right=" + rightValue;
}
});
動作の詳細:
詳しい説明については、このセクションの最後にあるセマンティクスの概要を参照してください。 |
テーブルとテーブルの結合のセマンティクス : 以下では、テーブルとテーブルの結合のさまざまなバリエーションのセマンティクスを示します。表の可読性を高めるために、(1)すべてのレコードは同じキーを持ち(このため、表ではキーが省略されています)、(2)すべてのレコードはタイムスタンプ順に処理されるものとします。内部結合、左結合、および外部結合の各列は、結合のどちらか一方の側で新しい入力レコードが受信されたときに、それぞれ join、leftJoin、および outerJoin メソッドを通じて、ユーザーが提供する ValueJoiner に引数として渡されるデータを表します。表のセルが空の場合は、ValueJoiner が呼び出されないことを示します。
| タイムスタンプ | 左側(KTable) | 右側(KTable) | (内部)結合 | 左結合 | 外部結合 |
|---|---|---|---|---|---|
| 1 | null(トゥームストーン) | ||||
| 2 | null(トゥームストーン) | ||||
| 3 | A | [A, null] | [A, null] | ||
| 4 | a | [A, a] | [A, a] | [A, a] | |
| 5 | B | [B, a] | [B, a] | [B, a] | |
| 6 | b | [B, b] | [B, b] | [B, b] | |
| 7 | null(トゥームストーン) | null(トゥームストーン) | null(トゥームストーン) | [null, b] | |
| 8 | null(トゥームストーン) | null(トゥームストーン) | |||
| 9 | C | [C, null] | [C, null] | ||
| 10 | c | [C, c] | [C, c] | [C, c] | |
| 11 | null(トゥームストーン) | null(トゥームストーン) | [C, null] | [C, null] | |
| 12 | null(トゥームストーン) | null(トゥームストーン) | null(トゥームストーン) | ||
| 13 | null(トゥームストーン) | ||||
| 14 | d | [null, d] | |||
| 15 | D | [D, d] | [D, d] | [D, d] |
KTable-KTable 外部キー結合¶
KTable-KTable 外部キー結合は、常に "ウィンドウ化されない" 結合です。外部キー結合は SQL での結合に似ています。大まかな例を次に示します。
この操作の出力は、結合結果を含む新しい KTable です。
両側の KTables の changelog ストリームがローカルステートストアに具現化され、テーブルデュアルの最新のスナップショットを表します。左側のレコードに外部キーエクストラクター関数が適用され、新しい中間レコードが作成されます。この中間レコードを使用して、右側のテーブルで対応するプライマリキーが検索され、結合されます。結果として、結合操作の changelog ストリームを表す新しい KTable が生成されます。
左側の KTable には、右側の KTable の同じキーにマッピングされるレコードが複数存在する可能性があります。左側の 1 つの KTable エントリに対する更新は、右側の KTable に対応するキーが存在すれば、単一の出力イベントになります。一方、右側の KTable エントリに対する単一の更新は、左側の KTable で同じ外部キーを持つレコードのそれぞれを更新する結果となります。
| 変換 | 説明 |
|---|---|
内部結合
|
このテーブルと別のテーブルの外部キー内部結合を実行します。結果として、結合の "現在" の結果を表すように更新され続ける KTable が生成されます:platform:(詳細)|streams/javadocs/javadoc/org/apache/kafka/streams/kstream/KTable.html#join-org.apache.kafka.streams.kstream.KTable-java.util.function.Function-org.apache.kafka.streams.kstream.ValueJoiner-。 KTable<String, Long> left = ...;
KTable<Long, Double> right = ...;
//This foreignKeyExtractor simply uses the left-value to map to the right-key.
Function<Long, Long> foreignKeyExtractor = (x) -> x;
// Java 8+ example, using lambda expressions
KTable<String, String> joined = left.join(right,
foreignKeyExtractor,
(leftValue, rightValue) -> "left=" + leftValue + ", right=" + rightValue /* ValueJoiner */
);
動作の詳細:
詳しい説明については、このセクションの最後にあるセマンティクスの概要を参照してください。 |
左結合
|
このテーブルと別のテーブルの外部キー左結合を実行します:platform:(詳細)|streams/javadocs/javadoc/org/apache/kafka/streams/kstream/KTable.html#leftJoin-org.apache.kafka.streams.kstream.KTable-java.util.function.Function-org.apache.kafka.streams.kstream.ValueJoiner-。 KTable<String, Long> left = ...;
KTable<Long, Double> right = ...;
//This foreignKeyExtractor simply uses the left-value to map to the right-key.
Function<Long, Long> foreignKeyExtractor = (x) -> x;
// Java 8+ example, using lambda expressions
KTable<String, String> joined = left.leftJoin(right,
foreignKeyExtractor,
(leftValue, rightValue) -> "left=" + leftValue + ", right=" + rightValue /* ValueJoiner */
);
動作の詳細:
詳しい説明については、このセクションの最後にあるセマンティクスの概要を参照してください。 |
テーブルとテーブルの外部キー結合のセマンティクス : 以下では、テーブルとテーブルの外部キー内部結合および外部キー左結合のバリエーションのセマンティクスを示します。レコードごとにキーと値が示されています。レコードはオフセットの昇順で処理されます。内部結合と左結合の各列は、結合のどちらか一方の側で新しい入力レコードが受信されたときに、それぞれ join および leftJoin メソッドを通じて、ユーザーが提供する ValueJoiner に引数として渡されるデータを表します。表のセルが空の場合は、ValueJoiner が呼び出されないことを示します。この例では、foreignKeyExtractor 関数は単に左側の値を出力として使用します。
| レコードオフセット | 左側の KTable(K、抽出された FK) | 右側の KTable(FK、VR) | (内部)結合 | 左結合 |
|---|---|---|---|---|
| 1 | (k,1) | (1,foo) | (k,1,foo) | (k,1,foo) |
| 2 | (k,2) | (k,null) | (k,2,null) | |
| 3 | (k,3) | (k,null) | (k,3,null) | |
| 4 | (3,bar) | (k,3,bar) | (k,3,bar) | |
| 5 | (k,null) | (k,null) | (k,null,null) | |
| 6 | (k,1) | (k,1,foo) | (k,1,foo) | |
| 7 | (q,10) | (q,10,null) | ||
| 8 | (r,10) | (r,10,null) | ||
| 9 | (10,baz) | (q,10,baz), (r,10,baz) | (q,10,baz), (r,10,baz) |
KStream-KTable 結合¶
KStream-KTable 結合は、常に "ウィンドウ化されない" 結合です。これにより、KStream(レコードストリーム)から新しいレコードを受信したときに、KTable(changelog ストリーム)に対して "テーブル参照" を実行できます。ユースケースの 1 つとして、ユーザーアクティビティのストリーム(KStream)に最新のユーザープロファイル情報(KTable)を関連付ける例が考えられます。
結合の出力レコードは、ユーザーが提供する ValueJoiner を利用して、実質的に次のように作成されます。
KeyValue<K, LV> leftRecord = ...;
KeyValue<K, RV> rightRecord = ...;
ValueJoiner<LV, RV, JV> joiner = ...;
KeyValue<K, JV> joinOutputRecord = KeyValue.pair(
leftRecord.key, /* by definition, leftRecord.key == rightRecord.key */
joiner.apply(leftRecord.value, rightRecord.value)
);
| 変換 | 説明 |
|---|---|
内部結合
|
このストリームとテーブルの内部結合を実行し、実質的にテーブル参照を行います:platform:(詳細)|streams/javadocs/javadoc/org/apache/kafka/streams/kstream/KStream.html#join-org.apache.kafka.streams.kstream.KTable-org.apache.kafka.streams.kstream.ValueJoiner-。 データの共同パーティション化が必要: 両側の入力データが 共同パーティション化 されている必要があります。 ストリームのデータの再パーティション化は、ストリームに再パーティション化のマークが付けられている場合にのみ発生します。
KStream<String, Long> left = ...;
KTable<String, Double> right = ...;
// Java 8+ example, using lambda expressions
KStream<String, String> joined = left.join(right,
(leftValue, rightValue) -> "left=" + leftValue + ", right=" + rightValue, /* ValueJoiner */
Joined.keySerde(Serdes.String()) /* key */
.withValueSerde(Serdes.Long()) /* left value */
);
// Java 7 example
KStream<String, String> joined = left.join(right,
new ValueJoiner<Long, Double, String>() {
@Override
public String apply(Long leftValue, Double rightValue) {
return "left=" + leftValue + ", right=" + rightValue;
}
},
Joined.keySerde(Serdes.String()) /* key */
.withValueSerde(Serdes.Long()) /* left value */
);
動作の詳細:
詳しい説明については、このセクションの最後にあるセマンティクスの概要を参照してください。 |
左結合
|
このストリームとテーブルの左結合を実行し、実質的にテーブル参照を行います:platform:(詳細)|streams/javadocs/javadoc/org/apache/kafka/streams/kstream/KStream.html#leftJoin-org.apache.kafka.streams.kstream.KTable-org.apache.kafka.streams.kstream.ValueJoiner-。 データの共同パーティション化が必要: 両側の入力データが 共同パーティション化 されている必要があります。 ストリームのデータの再パーティション化は、ストリームに再パーティション化のマークが付けられている場合にのみ発生します。
KStream<String, Long> left = ...;
KTable<String, Double> right = ...;
// Java 8+ example, using lambda expressions
KStream<String, String> joined = left.leftJoin(right,
(leftValue, rightValue) -> "left=" + leftValue + ", right=" + rightValue, /* ValueJoiner */
Joined.keySerde(Serdes.String()) /* key */
.withValueSerde(Serdes.Long()) /* left value */
);
// Java 7 example
KStream<String, String> joined = left.leftJoin(right,
new ValueJoiner<Long, Double, String>() {
@Override
public String apply(Long leftValue, Double rightValue) {
return "left=" + leftValue + ", right=" + rightValue;
}
},
Joined.keySerde(Serdes.String()) /* key */
.withValueSerde(Serdes.Long()) /* left value */
);
動作の詳細:
詳しい説明については、このセクションの最後にあるセマンティクスの概要を参照してください。 |
ストリームとテーブルの結合のセマンティクス : 以下では、ストリームとテーブルの結合のさまざまなバリエーションのセマンティクスを示します。表の可読性を高めるために、(1)すべてのレコードは同じキーを持ち(このため、表ではキーが省略されています)、(2)すべてのレコードはタイムスタンプ順に処理されるものとします。内部結合と左結合の各列は、結合のどちらか一方の側で新しい入力レコードが受信されたときに、それぞれ join および leftJoin メソッドを通じて、ユーザーが提供する ValueJoiner に引数として渡されるデータを表します。表のセルが空の場合は、ValueJoiner が呼び出されないことを示します。
| タイムスタンプ | 左側(KStream) | 右側(KTable) | (内部)結合 | 左結合 |
|---|---|---|---|---|
| 1 | null | |||
| 2 | null(トゥームストーン) | |||
| 3 | A | [A, null] | ||
| 4 | a | |||
| 5 | B | [B, a] | [B, a] | |
| 6 | b | |||
| 7 | null | |||
| 8 | null(トゥームストーン) | |||
| 9 | C | [C, null] | ||
| 10 | c | |||
| 11 | null | |||
| 12 | null | |||
| 13 | null | |||
| 14 | d | |||
| 15 | D | [D, d] | [D, d] |
KStream-GlobalKTable 結合¶
KStream-GlobalKTable 結合は、常に "ウィンドウ化されない" 結合です。これにより、KStream(レコードストリーム)から新しいレコードを受信したときに、 GlobalKTable (changelog ストリーム全体)に対して "テーブル参照" を実行できます。ユースケースの 1 つとして、"スター型クエリ" または "スター型結合" があります。たとえば、ユーザーアクティビティのストリーム(KStream)に、最新のユーザープロファイル情報(GlobalKTable)とその他のコンテキスト情報(その他の GlobalKTable)を関連付けます。
高レベルでは、KStream-GlobalKTable 結合は KStream-KTable 結合 に非常によく似ています。しかし、パーティション化されたテーブルと比べてグローバルテーブルでは、 ある程度のコスト はかかりますが、はるかに高い柔軟性がもたらされます。
- データの共同パーティション化 は必要ありません。
- より効率的な "スター型結合" が可能です。スター型結合では、1 つの大規模な "ファクト" ストリームを、複数の "ディメンション" テーブルに結合します。
- 外部キーに対する結合が可能です。つまり、ストリーム内のレコードのキーだけでなく、レコード値のデータに基づいてテーブルのデータを参照できます。
- データに大きいな偏りがあるためにホットパーティションが発生しやすい状況に対応でき、多くのユースケースが実行可能になります。
- 複数の結合を連続して実行する必要がある場合、たいていは対応するパーティション化された KTable よりも高い効率を得ることができます。
結合の出力レコードは、ユーザーが提供する ValueJoiner を利用して、実質的に次のように作成されます。
KeyValue<K, LV> leftRecord = ...;
KeyValue<K, RV> rightRecord = ...;
ValueJoiner<LV, RV, JV> joiner = ...;
KeyValue<K, JV> joinOutputRecord = KeyValue.pair(
leftRecord.key, /* by definition, leftRecord.key == rightRecord.key */
joiner.apply(leftRecord.value, rightRecord.value)
);
| 変換 | 説明 |
|---|---|
内部結合
|
このストリームとグローバルテーブルの内部結合を実行し、実質的にテーブル参照を行います:platform:(詳細)|streams/javadocs/javadoc/org/apache/kafka/streams/kstream/KStream.html#join-org.apache.kafka.streams.kstream.GlobalKTable-org.apache.kafka.streams.kstream.KeyValueMapper-org.apache.kafka.streams.kstream.ValueJoiner-。
ストリームのデータの再パーティション化は、ストリームに再パーティション化のマークが付けられている場合にのみ発生します。 KStream<String, Long> left = ...;
GlobalKTable<Integer, Double> right = ...;
// Java 8+ example, using lambda expressions
KStream<String, String> joined = left.join(right,
(leftKey, leftValue) -> leftKey.length(), /* derive a (potentially) new key by which to lookup against the table */
(leftValue, rightValue) -> "left=" + leftValue + ", right=" + rightValue /* ValueJoiner */
);
// Java 7 example
KStream<String, String> joined = left.join(right,
new KeyValueMapper<String, Long, Integer>() { /* derive a (potentially) new key by which to lookup against the table */
@Override
public Integer apply(String key, Long value) {
return key.length();
}
},
new ValueJoiner<Long, Double, String>() {
@Override
public String apply(Long leftValue, Double rightValue) {
return "left=" + leftValue + ", right=" + rightValue;
}
});
動作の詳細:
|
左結合
|
このストリームとグローバルテーブルの左結合を実行し、実質的にテーブル参照を行います:platform:(詳細)|streams/javadocs/javadoc/org/apache/kafka/streams/kstream/KStream.html#leftJoin-org.apache.kafka.streams.kstream.GlobalKTable-org.apache.kafka.streams.kstream.KeyValueMapper-org.apache.kafka.streams.kstream.ValueJoiner-。
ストリームのデータの再パーティション化は、ストリームに再パーティション化のマークが付けられている場合にのみ発生します。 KStream<String, Long> left = ...;
GlobalKTable<Integer, Double> right = ...;
// Java 8+ example, using lambda expressions
KStream<String, String> joined = left.leftJoin(right,
(leftKey, leftValue) -> leftKey.length(), /* derive a (potentially) new key by which to lookup against the table */
(leftValue, rightValue) -> "left=" + leftValue + ", right=" + rightValue /* ValueJoiner */
);
// Java 7 example
KStream<String, String> joined = left.leftJoin(right,
new KeyValueMapper<String, Long, Integer>() { /* derive a (potentially) new key by which to lookup against the table */
@Override
public Integer apply(String key, Long value) {
return key.length();
}
},
new ValueJoiner<Long, Double, String>() {
@Override
public String apply(Long leftValue, Double rightValue) {
return "left=" + leftValue + ", right=" + rightValue;
}
});
動作の詳細:
|
ストリームとテーブルの結合のセマンティクス : この結合のセマンティクスは KStream-KTable 結合 と同じです。唯一の違いとして、KStream-GlobalKTable 結合では、ユーザーが提供する KeyValueMapper により、最初に左側の入力レコードがテーブルのキースペースに "マッピング" されます。これはテーブル参照の前に行われます。
ウィンドウ化¶
ウィンドウ化では、集約 や 結合 などのステートフル操作において、どのように同じキーを持つレコードをグループ化し、ウィンドウと呼ばれる単位に分けるかを制御します。ウィンドウはレコードキーごとに追跡されます。
注釈
関連する操作である グループ化 では、後続の操作のためにデータが適切にパーティション化("キー付け")されるように、同じキーを持つすべてのレコードをグループ化します。グループ化の後で、ウィンドウ化によって 1 つのキーのレコードをさらにサブグループ化できます。
たとえば、結合操作では、定義されたウィンドウ境界内でそれまでに受信されたレコードをすべて格納するために、ウィンドウ化のステートストアが使用されます。集約操作では、ウィンドウごとの最新の集約結果を格納するために、ウィンドウ化のステートストアが使用されます。ステートストア内の古いレコードは、指定された ウィンドウ保持時間 の経過後にパージされます。Kafka Streams は、少なくともこの指定時間、ウィンドウが維持されることを保証します。デフォルト値は 1 日ですが、Materialized#withRetention() を通じて変更できます。
DSL では、以下の種類のウィンドウがサポートされます。
| ウィンドウ名 | 動作 | 簡単な説明 |
|---|---|---|
| タンブリング時間ウィンドウ | 時間ベース | 固定サイズで重複のない、ギャップレスのウィンドウ |
| ホッピング時間ウィンドウ | 時間ベース | 固定サイズで重複のあるウィンドウ |
| スライディング時間ウィンドウ | 時間ベース | レコードのタイムスタンプ間の差を取り扱う、固定サイズで重複のあるウィンドウ |
| セッションウィンドウ | セッションベース | 動的なサイズで重複のない、データドリブンのウィンドウ |
このセクションの最後には、 カスタム時間ウィンドウ を実装する例が示されています。
タンブリング時間ウィンドウ¶
タンブリング時間ウィンドウは、ホッピング時間ウィンドウの特殊なケースであり、ホッピング時間ウィンドウと同じく時間間隔に基づくウィンドウです。これは、固定サイズで重複のない、ギャップレスのウィンドウをモデル化します。タンブリングウィンドウは、ウィンドウの "サイズ" という単一のプロパティによって定義されます。タンブリングウィンドウは、ウィンドウサイズが進行間隔に等しいホッピングウィンドウです。タンブリングウィンドウは重複しないため、1 つのデータレコードは 1 つのウィンドウにのみ所属することになります。
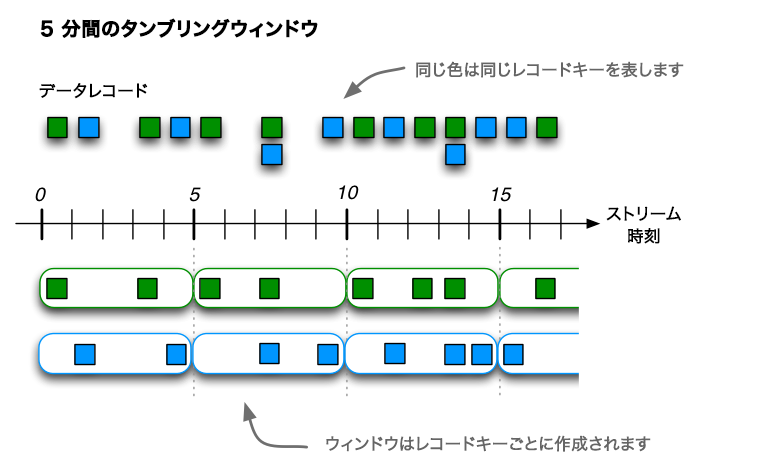
この図は、データレコードのストリームをタンブリングウィンドウでウィンドウ化する例を示しています。定義上、進行間隔はウィンドウサイズに等しいため、ウィンドウが重複することはありません。この図では、時間の数値は分単位で表されます。たとえば、t=5 は "5 分時点" に位置していることを意味します。実際には、Kafka Streams の時間単位はミリ秒であるため、時間の数値に 60 * 1,000 をかけて、分をミリ秒に変換する必要があります(たとえば、t=5 は t=300,000 になります)。¶
タンブリングウィンドウは "エポック" に揃えられます。間隔の下限はウィンドウ内に含まれ、上限は除外されます。"エポックに揃えられる" とは、最初のウィンドウがゼロのタイムスタンプから始まることを意味します。たとえば、サイズが 5000 ミリ秒のタンブリングウィンドウがある場合、そのウィンドウ境界は [0;5000),[5000;10000),... になると想定され、[1000;6000),[6000;11000),... には なりません 。 [1452;6452),[6452;11452),... のように "ランダム" になることもありません。
次のコードは、サイズが 5 分のタンブリングウィンドウを定義します。
import java.time.Duration;
import org.apache.kafka.streams.kstream.TimeWindows;
// A tumbling time window with a size of 5 minutes (and, by definition, an implicit
// advance interval of 5 minutes).
Duration windowSizeMs = Duration.ofMinutes(5);
TimeWindows.of(windowSizeMs);
// The above is equivalent to the following code:
TimeWindows.of(windowSizeMs).advanceBy(windowSizeMs);
タンブリングウィンドウを使用したカウントの例を以下に示します。
// Key (String) is user ID, value (Avro record) is the page view event for that user.
// Such a data stream is often called a "clickstream".
KStream<String, GenericRecord> pageViews = ...;
// Count page views per window, per user, with tumbling windows of size 5 minutes
KTable<Windowed<String>, Long> windowedPageViewCounts = pageViews
.groupByKey(Grouped.with(Serdes.String(), genericAvroSerde))
.windowedBy(TimeWindows.of(Duration.ofMinutes(5)))
.count();
ホッピング時間ウィンドウ¶
ホッピング時間ウィンドウは、時間間隔に基づくウィンドウです。これは、固定サイズで重複する(可能性のある)ウィンドウをモデル化します。ホッピングウィンドウは、ウィンドウの "サイズ" と "進行間隔" ("ホップ" とも呼ばれます)という 2 つのプロパティによって定義されます。進行間隔は、ウィンドウが進行する量を、直前のウィンドウからの相対値で指定します。たとえば、サイズが 5 分で進行間隔が 1 分のホッピングウィンドウを構成できます。ホッピングウィンドウは重複させることができ、それが一般的でもあるため、1 つのデータレコードが複数のウィンドウに属する可能性があります。
注釈
ホッピングウィンドウとスライディングウィンドウ : ホッピングウィンドウは、他のストリーム処理ツールでは "スライディングウィンドウ" と呼ばれることがあります。Kafka Streams は、学術文献で使用される用語に従っています。学術用語では、スライディングウィンドウとホッピングウィンドウのセマンティクスが異なっています。
次のコードは、サイズが 5 分で進行間隔が 1 分のホッピングウィンドウを定義します。
import java.time.Duration;
import org.apache.kafka.streams.kstream.TimeWindows;
// A hopping time window with a size of 5 minutes and an advance interval of 1 minute.
// The window's name -- the string parameter -- is used to e.g. name the backing state store.
Duration windowSizeMs = Duration.ofMinutes(5);
Duration advanceMs = Duration.ofMinutes(1);
TimeWindows.of(windowSizeMs).advanceBy(advanceMs);
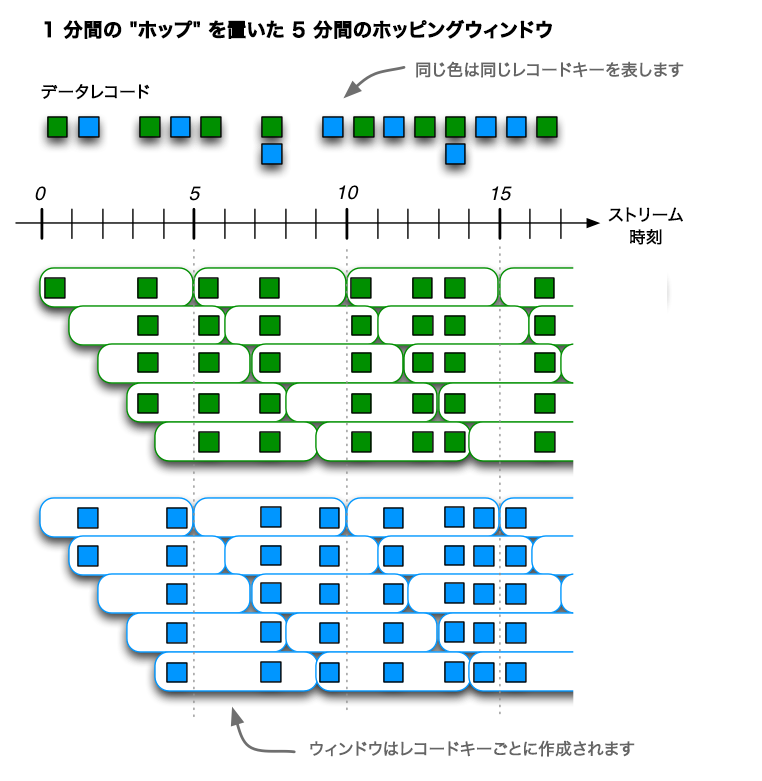
この図は、データレコードのストリームをホッピングウィンドウでウィンドウ化する例を示しています。この図では、時間の数値は分単位で表されます。たとえば、t=5 は "5 分時点" に位置していることを意味します。実際には、Kafka Streams の時間単位はミリ秒であるため、時間の数値に 60 * 1,000 をかけて、分をミリ秒に変換する必要があります(たとえば、t=5 は t=300,000 になります)。¶
ホッピングウィンドウは "エポック" に揃えられます。間隔の下限はウィンドウ内に含まれ、上限は除外されます。"エポックに揃えられる" とは、最初のウィンドウがゼロのタイムスタンプから始まることを意味します。たとえば、サイズが 5000 ミリ秒で進行間隔("ホップ")が 3000 ミリ秒のホッピングウィンドウがある場合、そのウィンドウ境界は [0;5000),[3000;8000),... になると想定され、[1000;6000),[4000;9000),... には なりません 。 [1452;6452),[4452;9452),... のように "ランダム" になることもありません。
ホッピングウィンドウを使用したカウントの例を以下に示します。
// Key (String) is user ID, value (Avro record) is the page view event for that user.
// Such a data stream is often called a "clickstream".
KStream<String, GenericRecord> pageViews = ...;
// Count page views per window, per user, with hopping windows of size 5 minutes that advance every 1 minute
KTable<Windowed<String>, Long> windowedPageViewCounts = pageViews
.groupByKey(Grouped.with(Serdes.String(), genericAvroSerde))
.windowedBy(TimeWindows.of(Duration.ofMinutes(5).advanceBy(Duration.ofMinutes(1))))
.count()
既に説明したウィンドウ化されない集約とは異なり、ウィンドウ化された集約では、キーの型が Windowed<K> の "ウィンドウ化された KTable" が返されます。これは、異なるウィンドウから生成された同じキーの集約値を区別するためです。対応するウィンドウインスタンスおよび埋め込まれているキーは、それぞれ Windowed#window() と Windowed#key() で取得できます。
スライディング時間ウィンドウ¶
スライディングウィンドウは、ホッピングウィンドウやタンブリングウィンドウとは大きく異なります。Kafka Streams では、スライディングウィンドウは 結合操作 にのみ使用され、JoinWindows クラスと、SlidingWindows クラスを使用して指定できるウィンドウ化された集約を使用できます。
スライディングウィンドウは、時間軸の進行に従って継続的にスライドする固定サイズのウィンドウをモデル化します。このモデルでは、(対称的なウィンドウの場合に)タイムスタンプの差がウィンドウサイズ内に収まれば、2 つのデータレコードは同じウィンドウに含まれると見なされます。スライディングウィンドウが時間軸に沿って移動するので、レコードがスライディングウィンドウの複数のスナップショットに収まる可能性がありますが、レコードの一意の組み合わせは、1 つのスライディングウィンドウスナップショットにのみ表示されます。
次のコード例では、時間差が 10 分で猶予期間が 30 分のスライディングウィンドウを定義します。
import org.apache.kafka.streams.kstream.SlidingWindows;
// A sliding time window with a time difference of 10 minutes
Duration windowTimeDifference = Duration.ofMinutes(10);
Duration grace = Duration.ofMinutes(30);
SlidingWindows.withTimeDifferenceAndGrace(windowTimeDifference, grace);
ちなみに
上で示したように、スライディングウィンドウでは猶予期間の設定が "必要" です。時間ウィンドウとセッションウィンドウの場合は、猶予期間の設定は省略可能で、デフォルトは 24 時間です。
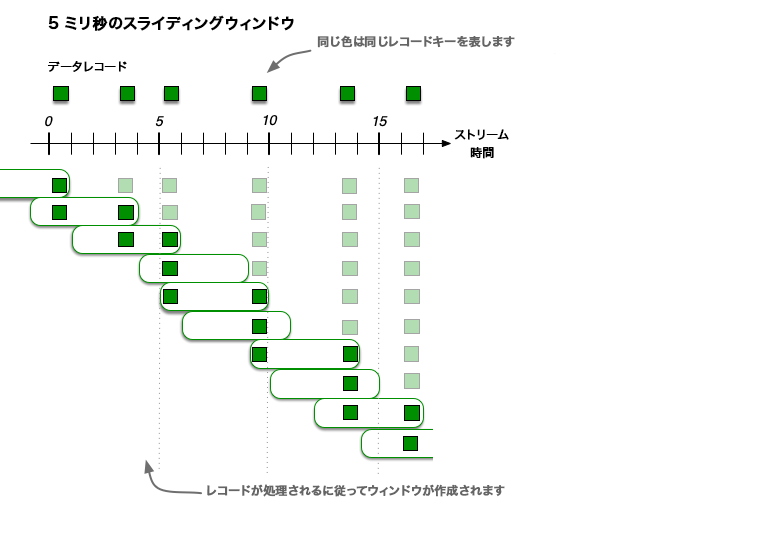
この図は、データレコードのストリームをスライディングウィンドウでウィンドウ化する例を示しています。スライディングウィンドウスナップショットの重複は、レコードの時刻によって異なります。この図では、時間の数値はミリ秒単位で表されます。たとえば、t=5 は "5 ミリ秒時点" に位置していることを意味します。¶
スライディングウィンドウはエポックに揃えられるのではなく、データレコードのタイムスタンプに揃えられます。ホッピングウィンドウやタンブリングウィンドウとは異なり、スライディングウィンドウの時間間隔の下限と上限は、"両方とも" ウィンドウ内に含まれます。
セッションウィンドウ¶
セッションウィンドウは、キーに基づくイベントを "セッション" に集約するために使用されます。このプロセスは "セッション化" と呼ばれます。セッションは、定義済みの 非アクティブギャップ ("アイドル状態")によって区切られた アクティブ期間 を表します。処理されたイベントが既存のセッションの非アクティブギャップに含まれる場合、そのイベントは既存のセッションにマージされます。イベントがセッションギャップに含まれない場合は、新しいセッションが作成されます。
セッションウィンドウには、他の種類のウィンドウと比べて次のような違いがあります。
- すべてのウィンドウはキー間で独立して追跡されます。たとえば、通常、キーが異なるウィンドウは開始時刻と終了時刻も異なります。
- ウィンドウサイズは可変です。同じキーに対するウィンドウでも、通常はサイズが異なります。
セッションウィンドウを使用するアプリケーションの主な目的は、ユーザー行動分析 です。セッションベースの分析は、単純なメトリクス(ニュースウェブサイトやソーシャルプラットフォームへのユーザーの訪問数など)から、より複雑なメトリクス(顧客コンバージョンファネルやイベントフローなど)まで多岐に渡ります。
次のコードは、非アクティブギャップが 5 分のセッションウィンドウを定義します。
import java.time.Duration;
import org.apache.kafka.streams.kstream.SessionWindows;
// A session window with an inactivity gap of 5 minutes.
SessionWindows.with(Duration.ofMinutes(5));
上記のセッションウィンドウの例を使用して、6 個のレコードからなる入力ストリームの動作を見てみましょう。最初の 3 つのレコードが到達すると(下図の上部)、レコードの処理後に 3 つのセッションが作成されます(下部を参照)。2 つは緑色のレコードキーに対応するもので、そのうち 1 つのセッションは 0 分時点で開始して終了し(図の都合でセッションが 0 分から 1 分まで進むように見えますが、実際はそうではありません)、もう 1 つは 6 分時点で開始して終了します。残りの 1 つのセッションは青色のレコードキーに対応し、2 分時点で開始して終了します。
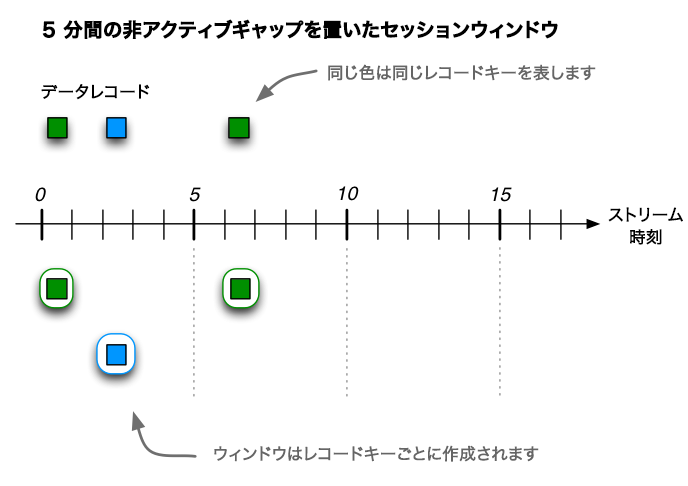
3 個の入力レコードの受信後に検出されるセッション。2 つは緑色のレコードキーのレコードで(t=0 と t=6)、1 つは青色のレコードキーのレコードです(t=2)。この図では、時間の数値は分単位で表されます。たとえば、t=5 は "5 分時点" に位置していることを意味します。実際には、Kafka Streams の時間単位はミリ秒であるため、時間の数値に 60 * 1,000 をかけて、分をミリ秒に変換する必要があります(たとえば、t=5 は t=300,000 になります)。¶
その後、3 つの追加レコード(2 つの順序外のレコードを含む)を受信した場合、緑色のレコードキーに対応する既存の 2 つのセッションは、時間 0 で開始して時間 6 で終了する単一のセッションにマージされ、合計 3 つのレコードで構成されるようになります。青色のレコードキーに対応する既存のセッションは、時間 5 で終了するように拡張され、合計 2 個のレコードで構成されるようになります。最後に、青色のキー用に、時間 11 で開始して終了する新しいセッションが作成されます。
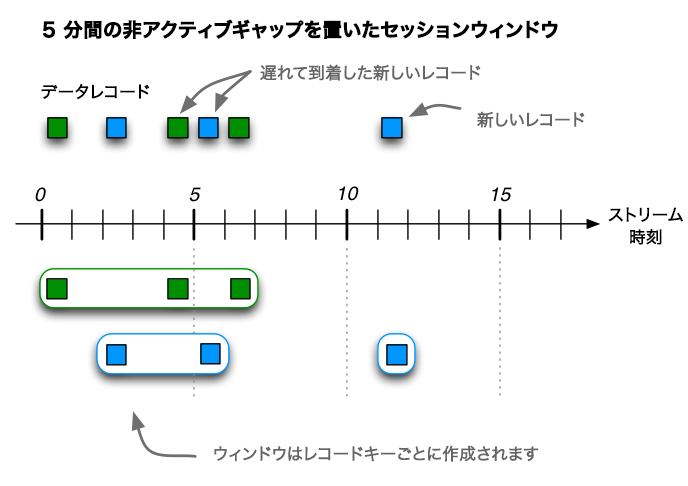
6 個の入力レコードの受信後に検出されるセッション。2 つの順序外のレコードが t=4(緑)と t=5(青)にあることに注目してください。これらによって、セッションのマージとセッションの拡張がそれぞれ引き起こされます。¶
セッションウィンドウを使用したカウントの例を見てみましょう。ここでは、New York Times のようなニュースウェブサイトの読者の行動を分析しようとしています。セッションの定義として、"読者が 5 分間(= 非アクティブギャップ)に 1 回以上別のページを表示(クリック)している限り 1 回の訪問と見なし、連続した単一の閲覧セッションとして扱う" ものとします。この入力データのストリームから計算しようとしているのは、セッションごとのページビュー数です。
// Key (String) is user ID, value (Avro record) is the page view event for that user.
// Such a data stream is often called a "clickstream".
KStream<String, GenericRecord> pageViews = ...;
// Count page views per session, per user, with session windows that have an inactivity gap of 5 minutes
KTable<Windowed<String>, Long> sessionizedPageViewCounts = pageViews
.groupByKey(Grouped.with(Serdes.String(), genericAvroSerde))
.windowedBy(SessionWindows.with(Duration.ofMinutes(5)))
.count();
ウィンドウの最終結果¶
Kafka Streams では、ウィンドウ化された計算では結果が継続的に更新されます。ウィンドウに新しいデータが到達すると、新しく計算された結果がダウンストリームに出力されます。最新の結果を常に利用できるため、これは多くのアプリケーションにとって理想的です。Kafka Streams は、継続的なプログラミングとシームレスな計算を実現するために設計されています。ただし、アプリケーションによっては、ウィンドウ化された計算の最終結果に対して のみ アクションの実行が必要になることもあります。よくある例として、更新をサポートしていないシステムにアラートの送信や結果の配信を行う場合が当てはまります。
たとえば、ユーザーごとのイベントのカウントが 1 時間単位でウィンドウ化されているとします。1 時間にユーザーが受け取ったイベントが 3 つ "未満" の場合にアラートを送信しようとしていますが、これが簡単ではありません。十分な数のイベントが発生するまで、最初はすべてのユーザーがこの条件に一致します。したがって、いずれかのユーザーが条件に一致したときにアラートを送信するという単純なアプローチは使用できません。特定のウィンドウでそれ以上イベントが発生しないとわかるまで待ってから、アラートを送信する必要があります。
Kafka Streams には、このロジックを定義する最適な方法が用意されています。ウィンドウ化された計算を定義したら、中間結果を suppress (抑制)し、ウィンドウの 終了 時に最終的なカウントを各ユーザーに出力することができます。
以下に例を示します。
KGroupedStream<UserId, Event> grouped = ...;
grouped
.windowedBy(TimeWindows.of(Duration.ofHours(1)).grace(Duration.ofMinutes(10)))
.count()
.suppress(Suppressed.untilWindowCloses(unbounded()))
.filter((windowedUserId, count) -> count < 3)
.toStream()
.foreach((windowedUserId, count) -> sendAlert(windowedUserId.window(), windowedUserId.key(), count));
このプログラムのキーとなる部分は以下のとおりです。
grace(Duration.ofMinutes(10))- これにより、ウィンドウで受け入れる順序外の(または遅延した)イベントを制限できます。たとえば、09:00 ~ 10:00 のウィンドウは、10:10 まで順序外のレコードを受け入れます。10:10 になると、ウィンドウは クローズ されます。
.suppress(Suppressed.untilWindowCloses(...))- これにより、ウィンドウが閉じるまで何も出力せず、その後で最終結果を出力するように抑制演算子を構成します。たとえば、ユーザー
Uが 09:00 から 10:10 の間に 10 個のイベントを受け取ったとします。抑制のダウンストリームのfilterでは、ウィンドウ化されたキー@09:00-10:00に対して 10:10 までイベントは受信されず、その後で値が10のイベントが 1 つだけ受信されます。これがウィンドウ化されたカウントの最終結果です。 unbounded()- これにより、ウィンドウが閉じるまでイベントを格納するバッファが構成されます。本稼働環境のコードでは、バッファに使用されるメモリーの量に上限を設けることができますが、この単純な例では上限のないバッファを作成しています。
特筆すべき点として、抑制は他のあらゆる Kafka Streams 演算子と変わらないため、count から分岐を生じるトポロジーを構築できます。1 つは抑制され、1 つは抑制されない 2 つの処理に分岐することも、異なる構成の複数の抑制に分岐することもできます。これにより、必要な場合に抑制を適用し、不要な場合はデフォルトの継続的な更新動作を適用することが可能です。
詳細については、Suppressed 構成オブジェクトの JavaDoc と KIP-328 を参照してください。
例: カスタム時間ウィンドウ¶
Kafka Streams クライアントライブラリが提供するウィンドウの実装に加えて、Java の Windows 抽象クラス を継承することで、独自のユースケースに合わせたカスタム時間ウィンドウを作成できます。
streams/window のサンプル には、毎日午後 6 時に開始する日単位のウィンドウのカスタム実装が含まれています。
この例では、夏時間 のあるタイムゾーンを扱う場合に発生する可能性のある問題も示されています。
プロセッサーとトランスフォーマーの適用(Processor API の統合)¶
既に説明した ステートレス および ステートフル な変換だけでなく、DSL から Processor API を利用することもできます。これが役に立つシナリオは数多く考えられます。
- カスタマイズ : DSL ではまだ利用できない、カスタマイズした特別なロジックを実装する必要がある場合。
- 必要に応じて使いやすさに高い柔軟性を融合 : 通常は DSL の表現力を利用しながら、処理の特定のステップで、DSL よりも高い柔軟性と調整作業が必要になる場合。たとえば、トピック、パーティション、オフセット情報などの レコードのメタデータ にアクセスできるのは Processor API だけです。しかし、それだけのために完全に Processor API に切り替えるのは望ましくない場合があります。
- 他のツールからの移行: 命令型 API を提供する他のストリーム処理テクノロジーからの移行中、従来のコードを今すぐ DSL に完全移行するよりも、Processor API に移行する方がすばやく簡単に済む場合。
| 変換 | 説明 |
|---|---|
処理
|
終端操作。 各レコードに これは本質的に、 例については、javadocs を参照してください。 |
変換
|
各レコードに 各入力レコードはゼロまたは 1 つ以上の出力レコードに変換されます(ステートレスな データを再パーティション化するようにストリームをマーク :
例については、javadocs を参照してください。また、エンドツーエンドの完全なデモは、MixAndMatchLambdaIntegrationTest に用意されています。 |
変換(値のみ)
|
各レコードに 各入力レコードは、厳密に 1 つの出力レコードに変換されます(出力レコードをゼロまたは複数にすることはできません)。
例については、javadocs を参照してください。 |
以下の例では、KStream#process() メソッドを通じて、ページビュー数が定義済みのしきい値に達したらメール通知を送信するカスタムの Processor を利用する方法を示します。
まず、Processor インターフェイスを実装するカスタムストリームプロセッサー、 PopularPageEmailAlert を実装する必要があります。
// A processor that sends an alert message about a popular page to a configurable email address
public class PopularPageEmailAlert implements Processor<PageId, Long, Void, Void> {
private final String emailAddress;
private ProcessorContext<Void, Void> context;
public PopularPageEmailAlert(String emailAddress) {
this.emailAddress = emailAddress;
}
@Override
public void init(ProcessorContext<Void, Void> context) {
this.context = context;
// Here you would perform any additional initializations such as setting up an email client.
}
@Override
void process(Record<PageId, Long>) {
// Here you would format and send the alert email.
//
// In this specific example, you would be able to include information about the page's ID and its view count.
}
@Override
void close() {
// Any code for clean up would go here, for example tearing down the email client,
// and anything else you created in the init() method.
// This processor instance will not be used again after this call.
}
}
ちなみに
この例には示されていませんが、ストリームプロセッサーでは、ProcessorContext#getStateStore() を呼び出すことで利用可能な任意のステートストアにアクセスできます。利用可能なステートストアとは、(1)対応する KStream#process() メソッド呼び出し(これは Processor#process() とは別のメソッドです)で指定されたものと、(2)すべてのグローバルストアです。グローバルストアは明示的にアタッチする必要はなく、読み取り専用アクセスだけが許可されます。
次に、DSL で KStream#process を使用して PopularPageEmailAlert プロセッサーを利用できます。
KStream<String, GenericRecord> pageViews = ...;
// Send an email notification when the view count of a page reaches one thousand.
pageViews.groupByKey()
.count()
.filter((PageId pageId, Long viewCount) -> viewCount == 1000)
// PopularPageEmailAlert is your custom processor that implements the
// `Processor` interface, see above.
.process(() -> new PopularPageEmailAlert("alerts@yourcompany.com"));
KTable の出力レートの制御¶
論理的に、KTable は継続的に更新されるテーブルです。これらの更新は、新しいデータが利用可能になるたびにダウンストリームのオペレーターに伝達され、全体の計算が可能な限り最新の状態に保たれます。ほとんどのプログラムが記述するのは一連の論理的な変換であり、更新レートはプログラムの動作に組み込まれていません。
このような場合、更新レートはパフォーマンス上の問題であり、関連する構成によって対処するのが最適な方法です。
ただし、アプリケーションによっては、更新レート自体が重要なセマンティクスプロパティになることがあります。
KTable#suppress 演算子を使用すると、更新レートの制限を レコードキャッシュ の副作用として実現するのではなく、直接適用することができます。
以下に例を示します。
KGroupedTable<String, String> groupedTable = ...;
groupedTable
.count()
.suppress(untilTimeLimit(Duration.ofMinutes(5), maxBytes(1_000_000L).emitEarlyWhenFull()))
.toStream();
この構成では、 suppress のダウンストリームで各キーが 5 分ごとに 1 回だけ更新されます(時間は実際の時刻ではなくストリーム時刻です)。
その 5 分間、各キーの最新のステートをメモリー内のバッファに保持する必要があることに注意してください。オプションを指定することで、このバッファに使用するメモリーの最大量(この場合は 1 MB)を制御できます。また、レコード数に制限を設けるオプションもあり、両方の制限を未指定のままにすることもできます。
さらに、バッファがいっぱいになった場合の動作を選択することもできます。この例では緩いアプローチを採用し、5 分の時間制限に達する前に最も古いレコードを出力して、バッファの使用量を減らしています。または、処理を停止してアプリケーションをシャットダウンする方法もあります。これは極端な対処に見えるかもしれませんが、5 分の時間制限を確実に適用できます。アプリケーションをシャットダウンした後で、より多くのメモリーをバッファに割り当てて処理を再開することもできます。ただし、多くのアプリケーションには早期に出力する方法が適しています。
詳細については、Suppressed 構成オブジェクトの JavaDoc と KIP-328 を参照してください。
Kafka へのストリームの書き戻し¶
ストリームやテーブルは、Kafka トピックに(継続的に)書き戻すことができます。以下で詳しく説明するように、状況によっては、出力データが Kafka に書き込まれるまでの過程で再パーティション化される場合があります。
| Kafka への書き込み | 説明 | |
|---|---|
To
|
終端操作。 レコードを Kafka トピックに書き込みます。(KStream の詳細)。 次のような場合、serde を明示的に指定する必要があります。
KStream<String, Long> stream = ...;
KTable<String, Long> table = ...;
// Write the stream to the output topic, using the configured default key
// and value serdes of your `StreamsConfig`.
stream.to("my-stream-output-topic");
// Write the stream to the output topic, using explicit key and value serdes,
// (thus overriding the defaults of your `StreamsConfig`).
stream.to("my-stream-output-topic", Produced.with(Serdes.String(), Serdes.Long());
// Write the stream to the output topics, the topic name is dynamically deteremined for
// each record; also using explicit stream partitioner to determine which partition
// of the topic to send to
stream.to(
(key, value, recordContext) -> // topicNameExtractor
if (myPattern.matcher(key).matches) {
"special-stream-output-topic"
} else {
"normal-stream-output-topic"
},
Produced.streamPartitioner(
(topic, key, value, numPartitions) ->
if (topic.equals("special-stream-output-topic")) {
specialHash(key, value, numPartitions)
} else {
md5Hash(key, value, numPartitions)
}
)
);
以下の条件のいずれかに該当する場合、データの再パーティション化が発生します。
|
注釈
Kafka 以外のシステムに書き込む場合 : データを Kafka に書き戻すだけでなく、処理の最後に カスタムプロセッサー をストリームシンクとして適用して、たとえば外部データベースに書き込むこともできます。ただし、これは推奨されるパターンではないため、代わりに Kafka Connect API を使用することを強くお勧めします。それでもこのようなシンクプロセッサーを使用する場合、外部システムとの通信時にメッセージデリバリーのセマンティクスを保証する(たとえば、デリバリーの失敗時に再試行したり、メッセージの重複を防いだりする)のは、開発者の責任となることに注意してください。
Scala 用 Kafka Streams DSL¶
Kafka Streams には、以下の機能を提供する Java API の Scala ラッパーが用意されています。
- Scala における型推論の強化。
- アプリケーションコードにおけるボイラープレートの削減。
- 元の Java API と同様の通常のビルダースタイル構造。
- 暗黙的なシリアライザーと逆シリアライザーによる抽象化の強化と冗長性の軽減。
- コンパイル時の型の安全性の強化。
Scala 用 Kafka Streams DSL で提供されるすべての機能は、org.apache.kafka.streams.scala というルートパッケージ名の下にあります。
パブリックで使用される Java API の型の多くがラップされています。ユーザーは以下の Scala 抽象化を使用できます。
org.apache.kafka.streams.scala.StreamsBuilderorg.apache.kafka.streams.scala.kstream.KStreamorg.apache.kafka.streams.scala.kstream.KTableorg.apache.kafka.streams.scala.kstream.KGroupedStreamorg.apache.kafka.streams.scala.kstream.KGroupedTableorg.apache.kafka.streams.scala.kstream.SessionWindowedKStreamorg.apache.kafka.streams.scala.kstream.TimeWindowedKStream
ライブラリには、適切なセマンティクスのために使用する必要のある、いくつかのユーティリティ抽象化とユーティリティモジュールも含まれています。
org.apache.kafka.streams.scala.ImplicitConversions: Scala と Java クラス間の暗黙的な変換をスコープに取り込むクラス。org.apache.kafka.streams.scala.Serdes: インプリシットとしてインポートできるコア Serde と、カスタム Serde を作成するヘルパーを含むクラス(「暗黙の Serde」を参照してください)。
ライブラリは、2 つのバージョンの Scala でクロスビルドされています。Scala 2.13 に対してコンパイルされたライブラリを参照するには、maven の pom.xml に以下のコードを追加します。
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams-scala_2.13</artifactId>
<version>7.1.1-ccs</version>
</dependency>
SBT を使用する場合は、以下のようにして適切なライブラリを参照できます。
libraryDependencies += "org.apache.kafka" %% "kafka-streams-scala" % "3.1.0"
使用サンプル¶
ライブラリは、Kafka Streams の元の Java 抽象化を Scala ラッパーオブジェクト内にラップすることで機能します。すべての Scala 抽象化は、対応する Java 抽象化と同じ名前が付いていますが、ライブラリの別のパッケージに含まれています。たとえば、Scala クラス org.apache.kafka.streams.scala.StreamsBuilder は org.apache.kafka.streams.StreamsBuilder のラッパーであり、org.apache.kafka.streams.scala.kstream.KStream は org.apache.kafka.streams.kstream.KStream のラッパーです。
最終的に、コードは Java API を使用する場合と同じように構築されますが、Scala から直接 Java API を使用する場合と比べて型アノテーションが少なくなります。型アノテーションの使用量の違いは、例を見るとはっきりとわかります。
以下に典型的な WordCount プログラムの例を示します。この例では、Scala の StreamsBuilder を使用して、Java KStream のラッパーである KStream のインスタンスを構築します。次にテーブルを変換し、Java KTable のラッパーである KTable を取得します。
import java.time.Duration
import java.util.Properties
import org.apache.kafka.streams.kstream.Materialized
import org.apache.kafka.streams.scala.ImplicitConversions._
import org.apache.kafka.streams.scala._
import org.apache.kafka.streams.scala.kstream._
import org.apache.kafka.streams.{KafkaStreams, StreamsConfig}
object WordCountApplication extends App {
import Serdes._
val props: Properties = {
val p = new Properties()
p.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-application")
p.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka-broker1:9092")
p
}
val builder: StreamsBuilder = new StreamsBuilder
val textLines: KStream[String, String] = builder.stream[String, String]("TextLinesTopic")
val wordCounts: KTable[String, Long] = textLines
.flatMapValues(textLine => textLine.toLowerCase.split("\\W+"))
.groupBy((_, word) => word)
.count(Materialized.as("counts-store"))
wordCounts.toStream.to("WordsWithCountsTopic")
val streams: KafkaStreams = new KafkaStreams(builder.build(), props)
streams.start()
sys.ShutdownHookThread {
streams.close(Duration.ofSeconds(10))
}
}
上記のコードスニペットでは、Serde、Grouped、Produced、Consumed、Joined のいずれも明示的に提供する必要はありません。また、構成で指定されているいずれの Serde にも依存しません。実際、構成に指定されたすべての Serde は、Scala API によって無視されます。後の「暗黙の Serde」セクションで説明するように、すべての Serde と Grouped、Produced、Consumed、Joined は暗黙の Serde によって処理されます。構成ベースの Serde にまったく依存しないため、このライブラリは完全にタイプセーフです。Serde、Grouped、Produced、Consumed、Joined のいずれかのインスタンスが存在しない場合、コンパイル時エラーが発生します。
暗黙の Serde¶
ライブラリでは、トポロジー全体で何度も Serde を指定する必要をなくすために、Scala の暗黙パラメーター が使用されます。ユーザーは、暗黙の Serde や Grouped、Produced、Repartitioned、Consumed、Joined の暗黙の値を 1 回指定することで、コードの冗長性を低減できます。
さらにライブラリには、よく使用される型の Serde が org.apache.kafka.streams.scala.Serdes にバンドルされています。このクラスのメンバーをインポートすると、標準データ型に対して serde を指定する必要がなくなります。
以下に例を示します。
// Serdes brings into scope pre-defined implicit Serdes
// that will set up all Grouped, Produced, Consumed and Joined instances.
// So all APIs below that accept Grouped, Produced, Consumed or Joined will
// get these instances automatically
import Serdes._
import org.apache.kafka.streams.scala.Serdes._
import org.apache.kafka.streams.scala.ImplicitConvertions._
val builder = new StreamsBuilder()
val userClicksStream: KStream[String, Long] = builder.stream(userClicksTopic)
val userRegionsTable: KTable[String, String] = builder.table(userRegionsTopic)
// The following code fragment does not have a single instance of Grouped,
// Produced, Consumed or Joined supplied explicitly.
// All of them are taken care of by the implicit Serdes imported by Serdes
val clicksPerRegion: KTable[String, Long] =
userClicksStream
.leftJoin(userRegionsTable)((clicks, region) => (if (region == null) "UNKNOWN" else region, clicks))
.map((_, regionWithClicks) => regionWithClicks)
.groupByKey
.reduce(_ + _)
clicksPerRegion.toStream.to(outputTopic)
上記のコードスニペットで何が行われているか、少し詳しく見ていきましょう。
- このコードスニペットは、構成で定義されている Serde のいずれにも依存しません。実際、構成の一部として定義された Serde はすべて無視されます。
- すべての Serde はスコープ内のインプリシットから選択されます。
import Serdes._により、必要なすべての Serde がスコープ内に取り込まれます。 - 必要な Serde がインポートされたインプリシットによって提供されない場合、コンパイル時エラーが発生します。
- このコードは、実際の変換に焦点を当てて整然とまとめられています。
ユーザー定義の Serde¶
コアの Serde では十分でなく、カスタムの Serde を定義する必要がある場合も、使い方は上記とまったく同じです。暗黙の Serde を定義し、ストリーム変換の構築を開始します。以下に AvroSerde を使用する例を示します。
// domain object as a case class
case class UserClicks(clicks: Long)
// An implicit Serde implementation for the values we want to
// serialize as avro
implicit val userClicksSerde: Serde[UserClicks] = new AvroSerde
// Primitive Serdes
import Serdes._
// And then business as usual ..
val userClicksStream: KStream[String, UserClicks] = builder.stream(userClicksTopic)
val userRegionsTable: KTable[String, String] = builder.table(userRegionsTopic)
// Compute the total per region by summing the individual click counts per region.
val clicksPerRegion: KTable[String, Long] =
userClicksStream
// Join the stream against the table.
.leftJoin(userRegionsTable)((clicks, region) => (if (region == null) "UNKNOWN" else region, clicks.clicks))
// Change the stream from <user> -> <region, clicks> to <region> -> <clicks>
.map((_, regionWithClicks) => regionWithClicks)
// Compute the total per region by summing the individual click counts per region.
.groupByKey
.reduce(_ + _)
// Write the (continuously updating) results to the output topic.
clicksPerRegion.toStream.to(outputTopic)
ユーザー定義の Serde の完全な例は、ライブラリ内のテストクラスに含まれています。
注釈
このウェブサイトには、Apache License v2 の条件に基づいて Apache Software Foundation で開発されたコンテンツが含まれています。