オンプレミス Schema Registry のチュートリアル¶
Looking for Schema Management Confluent Cloud docs? You are currently viewing Confluent Platform documentation. If you are looking for Confluent Cloud docs, check out Schema Management on Confluent Cloud.
概要¶
このチュートリアルでは、Confluent Schema Registry を使用するためのステップバイステップのワークフローを紹介しています。Avro データの読み取りと書き込み、進化するスキーマの互換性チェックができるようにクライアントアプリケーションを設定する方法について見ていきましょう。また、Schema Registry の機能が統合された Confluent Control Center の使用方法についても説明します。
このチュートリアルは、ローカル環境の Confluent Platform で実行することを意図して制作されています。Confluent Cloud クラスターをご利用の方は、Confluent Cloud での実行を意図した Confluent Cloud Schema Registry チュートリアルを「Confluent Cloud Schema Registry のチュートリアル」でご覧ください。
セットアップ¶
前提条件¶
このチュートリアルに取り組む前に、「Schema Registry のチュートリアル」で Schema Registry の概念を簡単に押さえておきましょう。
ローカルマシンに次のソフトウェアがインストールされていることを確認します。
- Confluent Platform
- Confluent CLI
- Confluent Platform 実行用の Java 1.8 または 1.11
- クライアント Java コードをコンパイルするための Maven
- Schema Registry の REST エンドポイントに対するクエリから返された結果の書式を整えるための
jqツール
環境のセットアップ¶
「Confluent Platform のクイックスタート」を使用して、単一ノードの Confluent Platform 開発環境をセットアップします。1 行の confluent local コマンドで、Schema Registry や Control Center など、ローカルマシン上で動作するサービスを備えた基本的な Kafka クラスターを用意できます。
confluent local services start出力は以下のようになります。
Starting zookeeper zookeeper is [UP] Starting kafka kafka is [UP] Starting schema-registry schema-registry is [UP] Starting kafka-rest kafka-rest is [UP] Starting connect connect is [UP] Starting ksql-server ksql-server is [UP] Starting control-center control-center is [UP]
Confluent example リポジトリのクローンを GitHub から作成し、
clients/avro/サブディレクトリで作業します。ここにはこのチュートリアルでコンパイルし実行するサンプルコードが含まれます。git clone https://github.com/confluentinc/examples.git
cd examples/clients/avrogit checkout 7.1.1-postローカルマシンで実行する Kafka と Schema Registry の接続情報をすべて含んだローカル構成ファイルを作成し、
$HOME/.confluent/java.configに保存します。ここで、$HOME は、ユーザーのホームディレクトリです。ファイルの内容は次のようになります。# Kafka bootstrap.servers=localhost:9092 # Confluent Schema Registry schema.registry.url=http://localhost:8081
transactions トピックの作成¶
このチュートリアルのエクササイズでは、transactions というトピックとの間でメッセージの生成と消費を行います。Control Center でこのトピックを作成してください。
http://localhost:9021/ で Control Center のウェブインターフェイスに移動します。
重要
Control Center がオンラインになるまでに 1 ~ 2 分かかる場合があります。
クリックして対象のクラスターに移動し、Topics を選択して、Add a topic をクリックします。
トピックに
transactionsという名前を付けて、Create with defaults をクリックします。
新しいトピックが表示されます。

スキーマの定義¶
開発者がまず行うべきことは、データの基本的なスキーマへの合意です。クライアントアプリケーションは次の "契約" を結ぶことになります。
- プロデューサーがスキーマを使ってデータを書き込みます。
- そのデータをコンシューマーが読み取ることができるようになります。
最初の状態の Payment スキーマ(Payment.avsc)を考えてみます。このスキーマを表示するには、次のコマンドを実行します。
cat src/main/resources/avro/io/confluent/examples/clients/basicavro/Payment.avsc
スキーマの定義に注目してください。
{
"namespace": "io.confluent.examples.clients.basicavro",
"type": "record",
"name": "Payment",
"fields": [
{"name": "id", "type": "string"},
{"name": "amount", "type": "double"}
]
}
このスキーマで定義されている内容は次のとおりです。
namespace: スキーマ名の競合を防止するための完全修飾名type: Avro のデータ型 (record、enum、union、array、map、fixedなど)name: この名前空間における一意のスキーマ名fields:recordの単純データ型または複合データ型。このレコードの先頭にあるのは id というフィールドで、そのデータ型は string です。このレコードの 2 つ目にあるのは amount というフィールドで、そのデータ型は double です。
Avro でデータを書き込むクライアントアプリケーション¶
Maven¶
このチュートリアルでは、Maven を使用してプロジェクトと依存関係を構成します。Avro を使用した Kafka プロデューサーまたはコンシューマーを含んだ Java アプリケーションでは、pom.xml ファイルに、特に次のものを追加する必要があります。
- Confluent Maven リポジトリ
- Confluent Maven プラグインリポジトリ
- データを Avro としてシリアル化するための依存関係(
org.apache.avro.avroおよびio.confluent.kafka-avro-serializer) - ソーススキーマから Java クラスファイルを生成するための
avro-maven-pluginプラグイン
pom.xml ファイルには、次のものを含めることもできます。
- 進化するスキーマの互換性をチェックするためのプラグイン(
kafka-schema-registry-maven-plugin)
完全な pom.xml の例については、こちらの pom.xml を参照してください。
Avro の構成¶
Avro データと Schema Registry を使用する Kafka アプリケーションは、少なくとも次の 2 つの構成パラメーターを指定する必要があります。
- Avro のシリアライザーまたはデシリアライザー
- Schema Registry に接続するためのプロパティ
アプリケーションで使用できる Avro レコードの種類は、基本的に次の 2 つです。
- コードによって生成された特定のクラス
- 汎用的なレコード
このチュートリアルの例では、特定の Payment クラスの使用方法を紹介しています。コードによって生成された特定のクラスを使用するためには、実際のスキーマに対応した Java クラスを定義してコンパイルする必要がありますが、コード内での扱いやすさの点では、こちらの方が有利です。
ただし、それ以外のシナリオで、随時任意の型のデータを扱う必要があり、なおかつ実際のレコードタイプに使用する Java クラスがない場合は、GenericRecord <streams-data-avro> を使用してください。
Confluent Platform には、"reflection Avro" フォーマットのデータを書き込んだり読み取ったりするためのシリアライザーとデシリアライザーも用意されています。詳細については、「リフレクションベースの Avro シリアライザーと逆シリアライザー」を参照してください。
Java プロデューサー¶
このクライアントアプリケーション内の Java プロデューサーは、Kafka の値(または Kafka のキー)に使用する Avro シリアライザーと Schema Registry の URL を構成する必要があります。これで、Kafka の値が Payment クラスであるレコードを、このプロデューサーで書き込むことができます。
プロデューサーコードの例¶
プロデューサーを作成する際、アプリケーションのコードによって生成された Payment クラスを使用するようにメッセージの値クラスを構成します。以下に例を示します。
...
import io.confluent.kafka.serializers.KafkaAvroSerializer;
...
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, KafkaAvroSerializer.class);
...
KafkaProducer<String, Payment> producer = new KafkaProducer<String, Payment>(props));
final Payment payment = new Payment(orderId, 1000.00d);
final ProducerRecord<String, Payment> record = new ProducerRecord<String, Payment>(TOPIC, payment.getId().toString(), payment);
producer.send(record);
...
pom.xml に avro-maven-plugin が含まれているため、Payment クラスはコンパイルの過程で自動的に生成されます。
この例では、Kafka ブローカーと Schema Registry への接続情報を、コードに渡された構成ファイルから取得しています。接続情報をクライアントアプリケーションで直接指定する場合は、こちらの java テンプレート を参照してください。
Java プロデューサーの完全な例については、プロデューサーの例 を参照してください。
プロデューサーの実行¶
シェルで、examples/clients/avro から次のコマンドを実行します。
このプロデューサーを実行するには、まずプロジェクトをコンパイルします。
mvn clean compile package
Control Center のナビゲーションメニュー(http://localhost:9021/)から、クラスターが選択されていることを確認して、Topics をクリックします。
次に、
transactionsトピックをクリックし、Messages タブに移動します。このトピックにはまだメッセージが生成されていないので、メッセージは表示されません。
Avro フォーマットのメッセージを
transactionsトピックに生成するProducerExampleを実行します。先ほど作成したファイルのパス$HOME/.confluent/java.configを渡してください。mvn exec:java -Dexec.mainClass=io.confluent.examples.clients.basicavro.ProducerExample \ -Dexec.args="$HOME/.confluent/java.config"
このコマンドの実行には、少し時間がかかります。完了すると、次のように表示されます。
... Successfully produced 10 messages to a topic called transactions [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ ...
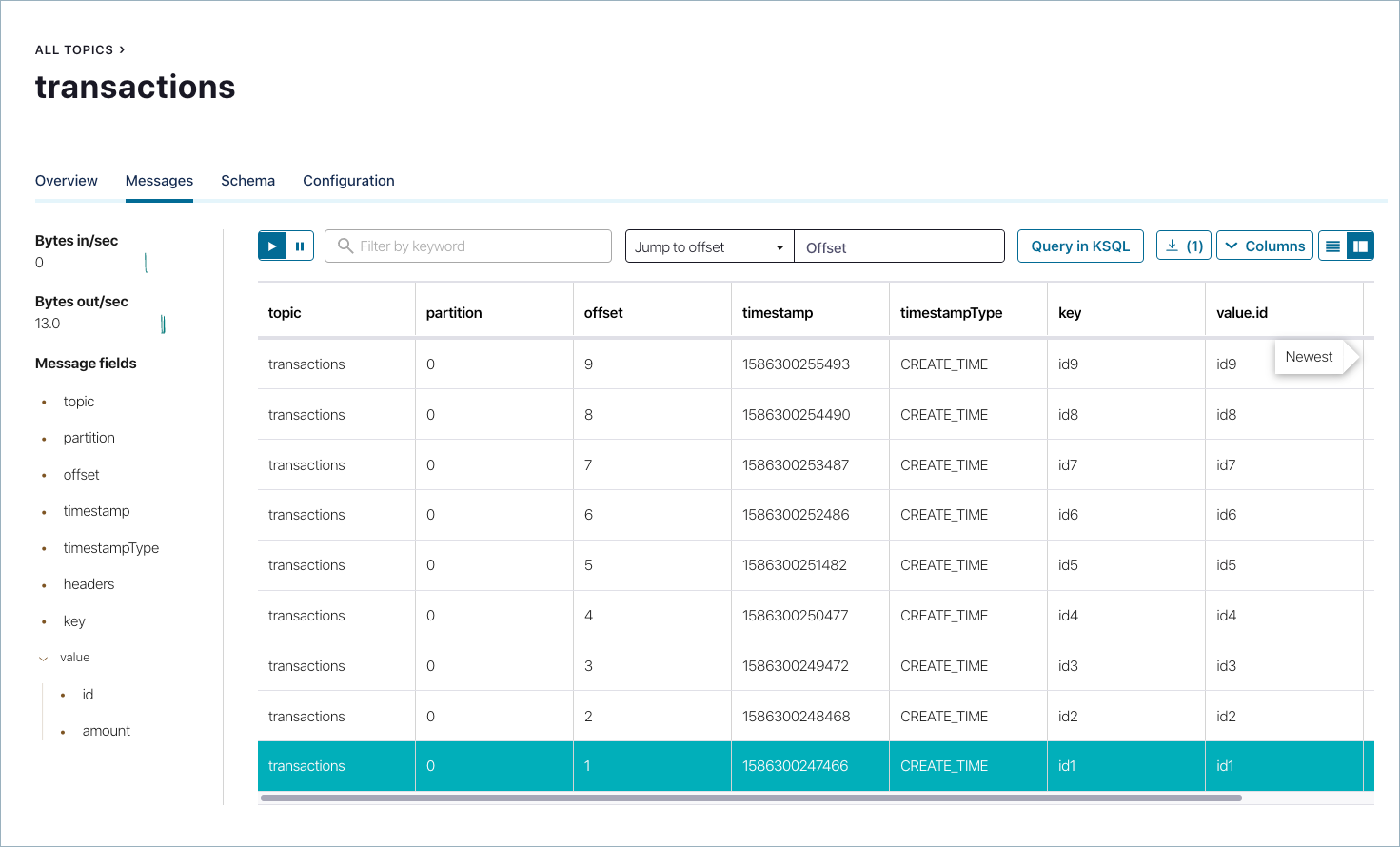
これで、Control Center からメッセージを確認できるはずです。
transactionsトピックをチェックしてみましょう。Avro としてシリアル化されたデータが新たに到着すると、そのデータが動的に逆シリアル化されます。http://localhost:9021/ で、左側のクラスターにクリックして移動し、 Topics ->
transactions-> Messages の順に移動します。ちなみに
データが表示されない場合は、プロデューサーを再度実行し、正常に完了したことを確認して、もう一度 Control Center を見てください。メッセージはコンソールに保持されないので、プロデューサーを実行したらすぐに確認する必要があります。
Java コンシューマー¶
このクライアントアプリケーション内の Java コンシューマーは、Kafka の値(または Kafka のキー)に使用する Avro 逆シリアライザーと Schema Registry の URL を構成する必要があります。これで、Kafka の値が Payment クラスであるレコードを、このコンシューマーで読み取ることができます。
コンシューマー コードの例¶
デフォルトでは、各レコードが Avro GenericRecord に逆シリアル化されます。ただし、このチュートリアルでは、アプリケーションのコードによって生成された Payment クラスを使用してレコードを逆シリアル化する必要があります。そのため、Avro SpecificRecord を使用するようにデシリアライザーを構成します。つまり、SPECIFIC_AVRO_READER_CONFIG を true に設定します。以下に例を示します。
...
import io.confluent.kafka.serializers.KafkaAvroDeserializer;
...
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, KafkaAvroDeserializer.class);
props.put(KafkaAvroDeserializerConfig.SPECIFIC_AVRO_READER_CONFIG, true);
...
KafkaConsumer<String, Payment> consumer = new KafkaConsumer<>(props));
consumer.subscribe(Collections.singletonList(TOPIC));
while (true) {
ConsumerRecords<String, Payment> records = consumer.poll(100);
for (ConsumerRecord<String, Payment> record : records) {
String key = record.key();
Payment value = record.value();
}
}
...
pom.xml に avro-maven-plugin が含まれているため、Payment クラスはコンパイルの過程で自動的に生成されます。
この例では、Kafka ブローカーと Schema Registry への接続情報を、コードに渡された構成ファイルから取得しています。接続情報をクライアントアプリケーションで直接指定する場合は、こちらの java テンプレート を参照してください。
Java コンシューマーの完全な例については、コンシューマーの例 を参照してください。
コンシューマーの実行¶
このコンシューマーを実行するには、まずプロジェクトをコンパイルします。
mvn clean compile package
BUILD SUCCESSメッセージは、プロジェクトがビルドされ、コマンドプロンプトが再び利用可能な状態になったことを意味します。次に、
ConsumerExampleを実行します(前述のProducerExampleは既に実行済みであるものとします)。先ほど作成したファイルのパス$HOME/.confluent/java.configを渡してください。mvn exec:java -Dexec.mainClass=io.confluent.examples.clients.basicavro.ConsumerExample \ -Dexec.args="$HOME/.confluent/java.config"
次のように表示されます。
... key = id0, value = {"id": "id0", "amount": 1000.0} key = id1, value = {"id": "id1", "amount": 1000.0} key = id2, value = {"id": "id2", "amount": 1000.0} key = id3, value = {"id": "id3", "amount": 1000.0} key = id4, value = {"id": "id4", "amount": 1000.0} key = id5, value = {"id": "id5", "amount": 1000.0} key = id6, value = {"id": "id6", "amount": 1000.0} key = id7, value = {"id": "id7", "amount": 1000.0} key = id8, value = {"id": "id8", "amount": 1000.0} key = id9, value = {"id": "id9", "amount": 1000.0} ...
Ctrl + Cを押して停止します。
その他の Kafka クライアント¶
このチュートリアルは、Avro および Schema Registry の一元化されたスキーマ管理と互換性チェックについて説明することを目的としています。例を単純化するために、このチュートリアルでは、Java のプロデューサーとコンシューマーを中心に取り上げていますが、他の Kafka クライアントも同じように動作します。Avro や Schema Registry と連携する他の Kafka クライアントの例については、次の記事を参照してください。
一元化されたスキーマ管理¶
Schema Registry 内のスキーマの表示¶
ここまでで、Avro データをシリアル化するプロデューサーと Avro データを逆シリアル化するコンシューマーが完成しました。プロデューサーは、Schema Registry にスキーマを登録し、コンシューマーは、Schema Registry からスキーマを取得します。
Control Center のナビゲーションメニュー( http://localhost:9021/)から、左側でクラスターが選択されていることを確認して、Topics をクリックします。
transactionsトピックをクリックして Schema タブに移動し、このトピックの最新のスキーマを Schema Registry から取得します。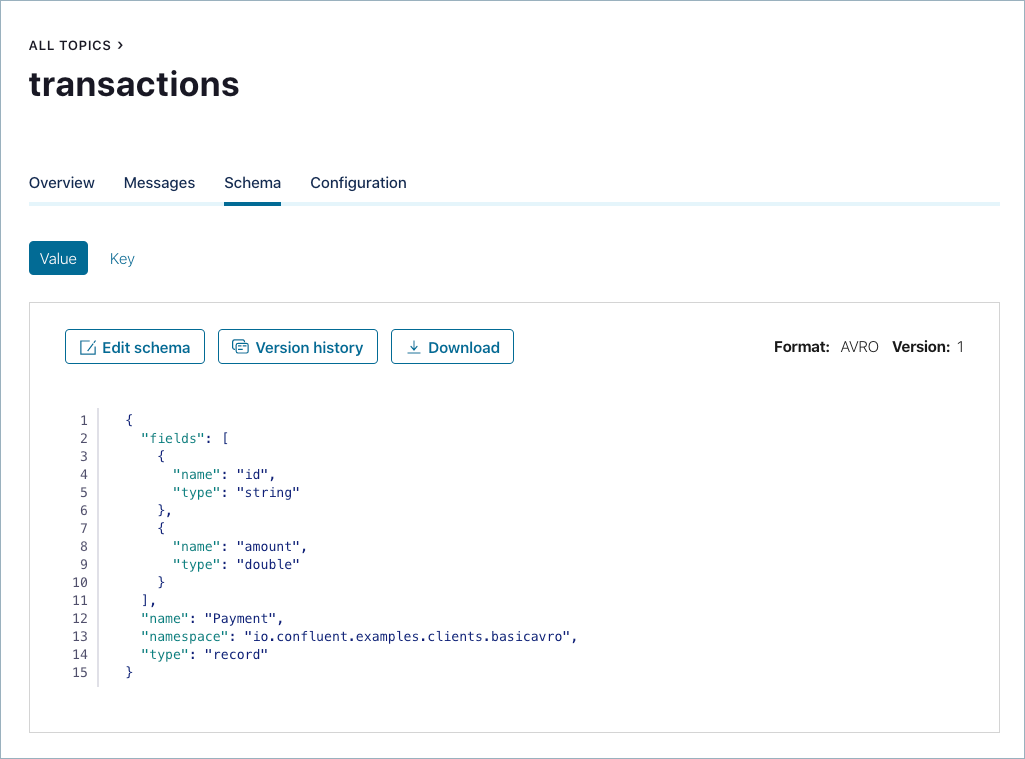
このスキーマは、Java クライアントアプリケーション用に定義されているスキーマファイル と同じです。
curl を使用した Schema Registry との対話¶
curl コマンドを使用して Schema Registry の REST エンドポイントに直接接続し、サブジェクトや関連するスキーマを表示することもできます。
Schema Registry に登録されているすべてのサブジェクトを表示するには、次のコマンドを使用します(Schema Registry がローカルマシンで実行され、ポート 8081 でリッスンしているものとします)。
curl --silent -X GET http://localhost:8081/subjects/ | jq .上のコマンドを実行すると、次のような結果が出力されます。
[ "transactions-value" ]
この例では、Kafka のトピックである
transactionsに、値(つまり "ペイロード")が Avro であるメッセージが含まれています。また、Schema Registry のサブジェクト名は、デフォルトによりtransactions-valueとなっています。このサブジェクトの最新のスキーマをさらに詳しく表示するには、次のコマンドを使用します。
curl --silent -X GET http://localhost:8081/subjects/transactions-value/versions/latest | jq .上のコマンドを実行すると、次のような結果が出力されます。
{ "subject": "transactions-value", "version": 1, "id": 1, "schema": "{\"type\":\"record\",\"name\":\"Payment\",\"namespace\":\"io.confluent.examples.clients.basicavro\",\"fields\":[{\"name\":\"id\",\"type\":\"string\"},{\"name\":\"amount\",\"type\":\"double\"}]}" }
このバージョンのスキーマで定義されている内容は次のとおりです。
subject: トピックtransactions内のメッセージに使用されるスキーマが進化できる範囲version: このサブジェクトのスキーマのバージョン。サブジェクトごとに 1 から始まります。id: グローバルに一意のスキーマバージョン ID(すべてのサブジェクトのすべてのスキーマで一意)schema: スキーマのフォーマットを定義する構造
上に示した
curlコマンドの出力では、スキーマが、エスケープされた JSON になっていることに注目してください。二重引用符の前にバックスラッシュが記述されています。スキーマ ID に基づいて、関連するスキーマを取得することもできます。Schema Registry の REST エンドポイントに対し、次のようにクエリーを実行します。
curl --silent -X GET http://localhost:8081/schemas/ids/1 | jq .次のような結果が出力されます。
{ "schema": "{\"type\":\"record\",\"name\":\"Payment\",\"namespace\":\"io.confluent.examples.clients.basicavro\",\"fields\":[{\"name\":\"id\",\"type\":\"string\"},{\"name\":\"amount\",\"type\":\"double\"}]}" }
メッセージ内のスキーマ ID¶
Schema Registry と連携するということは、Kafka メッセージを書き込む際に、Avro スキーマ全体を含める必要がないということです。代わりに、Kafka メッセージはスキーマ ID を付けて書き込まれます。スキーマとスキーマ ID との間で同じマッピングを得るためには、メッセージを書き込むプロデューサーと、そのメッセージを読み取るコンシューマーとが、同じ Schema Registry を使用している必要があります。
この例では、プロデューサーが Payments 用の新しいスキーマを Schema Registry に送信します。Schema Registry は、この Payments スキーマを transactions-value サブジェクトに登録し、1 というスキーマ ID をプロデューサーに返します。スキーマとスキーマ ID との間のこのマッピングは、以降、プロデューサーがメッセージを書き込むときのためにキャッシュされます。したがって、プロデューサーが Schema Registry に問い合わせを行うのは、スキーマの初回書き込み時のみです。
コンシューマーは、このデータを読み取る際、1 という Avro スキーマ ID を参照して、Schema Registry にスキーマリクエストを送信します。Schema Registry は、スキーマ ID 1 に関連付けられているスキーマを取得して、それをコンシューマーに返します。スキーマとスキーマ ID との間のこのマッピングは、以降、コンシューマーがメッセージを読み取るときのためにキャッシュされます。したがって、コンシューマーが Schema Registry に問い合わせを行うのは、スキーマ ID の初回読み取り時のみです。
スキーマの自動登録¶
クライアントアプリケーションは、デフォルトで新しいスキーマを自動的に登録します。新しいトピックに新しいメッセージを生成する場合、新しいスキーマを自動的に登録しようと試みます。これは開発環境では非常に便利ですが、本稼働環境では、クライアントアプリケーションで新しいスキーマを自動的に登録することはお勧めしません。クライアントアプリケーションの外部でスキーマを登録し、スキーマがいつ Schema Registry に登録され、どのように進化するかを制御することがベストプラクティスです。
アプリケーション内でスキーマの自動登録を無効にするには、次の例のように構成パラメーター auto.register.schemas=false を設定します。
props.put(AbstractKafkaAvroSerDeConfig.AUTO_REGISTER_SCHEMAS, false);
ちなみに
use.latest.versionを有効にする場合は、auto.register.schemasを false に設定してスキーマの自動登録を無効にしたうえで、use.latest.versionを true に設定する必要があります(デフォルトとは逆の設定)。use.latest.versionを正しく機能させるには、オプションauto.register.schemasを false に設定する必要があります。auto.register.schemasを false に設定すると、イベントタイプの自動登録が無効になるので、サブジェクト内の最新のスキーマがオーバーライドされることはありません。use.latest.versionが true に設定されている場合、シリアライザーは、サブジェクトから最新のスキーマバージョンを検索し、それをシリアル化に使用します。use.latest.versionが false(デフォルト)に設定されている場合、シリアライザーは、サブジェクトからイベントタイプを探しますが、その検出に失敗します。Kafka Connect の Schema Registry の「構成オプション」も参照してください。
構成オプション
auto.register.schemasは Confluent Platform の機能であり、Apache Kafka® では利用できません。
アプリケーションの外部からスキーマを手動で登録するには、Control Center を使用します。
まず、test という新しいトピックを作成します。その方法は、このチュートリアルの中で先ほど transactions という名前の新しいトピックを作成したときと同じです。次に、Schema タブから、Set a schema をクリックして新しいスキーマを定義します。次の値を指定してください。
namespace: スキーマ名の競合を防止するための完全修飾名type: Avro のデータ型 (record、enum、union、array、map、fixedのいずれか)name: この名前空間における一意のスキーマ名fields:recordの単純データ型または複合データ型。このレコードの先頭にあるのはidというフィールドで、そのデータ型はstringです。このレコードの 2 つ目にあるのはamountというフィールドで、そのデータ型はdoubleです。
仮に、先ほど使用したものと同じスキーマを定義する場合、スキーマエディターに次のように入力することになります。
{
"type": "record",
"name": "Payment",
"namespace": "io.confluent.examples.clients.basicavro",
"fields": [
{
"name": "id",
"type": "string"
},
{
"name": "amount",
"type": "double"
}
]
}
Schema Registry の REST エンドポイントに直接接続して、test トピックに使用する新しいサブジェクトのスキーマを定義する場合は、次のコマンドを実行してください。
curl -X POST -H "Content-Type: application/vnd.schemaregistry.v1+json" \
--data '{"schema": "{\"type\":\"record\",\"name\":\"Payment\",\"namespace\":\"io.confluent.examples.clients.basicavro\",\"fields\":[{\"name\":\"id\",\"type\":\"string\"},{\"name\":\"amount\",\"type\":\"double\"}]}"}' \
http://localhost:8081/subjects/test-value/versions
このサンプル出力では、1 という ID のスキーマが作成されます。
{"id":1}
スキーマ進化と互換性¶
スキーマの進化¶
このチュートリアルではこれまで、グローバルに一意のスキーマ ID をクライアントアプリケーションが登録したり取得したりできる一元化されたスキーマ管理こそ、Schema Registry の利点であると捉えてきました。しかし、Schema Registry の最大の価値は、スキーマの進化への対応です。API は進化しても、新旧のバージョンの API に依存するすべてのアプリケーションとの互換性が確保されている必要があります。同様に、スキーマも進化します。そしてやはり、新旧のバージョンのスキーマに依存するすべてのアプリケーションとの互換性が確保されていなければなりません。このスキーマ進化は、時間の経過に伴ってアプリケーションやデータに現れる自然な性質です。
Schema Registry にはスキーマの進化が考慮されており、プロデューサーとコンシューマーとの間の契約違反を防ぐための互換性チェック機構が備わっています。そのため、プロデューサーとコンシューマーが別々にアップデートされ、それぞれのスキーマが個別に進化したとしても、プロデューサーとコンシューマーは新旧のデータを確実に読み取ることができます。プロデューサーとコンシューマーは分離されたアプリケーションであり、異なるチームによって開発されることもあるため、Kafka ではこのことが特に重要となります。
推移的な互換性のチェックは、特定のサブジェクトに複数のバージョンのスキーマがある場合に重要です。互換性が推移的である場合、新しいスキーマの互換性が登録済みの全スキーマに対してチェックされます。互換性が推移的でない場合、新しいスキーマの互換性は最新のスキーマに対してのみチェックされます。
たとえば、あるサブジェクトに X-2、X-1、X の順序で変化する 3 つのスキーマがある場合:
- 推移的 : X-2 <==> X-1、X-1 <==> X、X-2 <==> X のいずれについても互換性が確保されます。
- 非推移的 : X-2 <==> X-1 と X-1 <==> X では互換性が確保されますが、X-2 <==> X については必ずしも互換性が確保されません。
漸進的には互換性を持ち、推移的には互換性を持たない スキーマ変更の例 を参照してください。
Confluent Schema Registry のデフォルトの互換性タイプ BACKWARD は非推移的です。つまり、BACKWARD_TRANSITIVE ではありません。このため、新しいスキーマの互換性は最新のスキーマに対してのみチェックされます。
次の互換性タイプがあります。
BACKWARD: (デフォルト)新しいスキーマを使用するコンシューマーは、一番最後に登録されたスキーマを使用するプロデューサーからの出力データを読み取ることができます。BACKWARD_TRANSITIVE: 新しいスキーマを使用するコンシューマーは、既に登録されている任意のスキーマを使用するプロデューサーからの出力データを読み取ることができます。FORWARD: 一番最後に登録されたスキーマを使用するコンシューマーが、新しいスキーマを使用するプロデューサーからの出力データを読み取ることができます。FORWARD_TRANSITIVE:既に登録されている任意のスキーマを使用するコンシューマーが、新しいスキーマを使用するプロデューサーからの出力データを読み取ることができます。FULL: 新しいスキーマには、一番最後に登録されたスキーマに対する前方互換性と後方互換性があります。FULL_TRANSITIVE: 新しいスキーマには、既に登録されている任意のスキーマに対する前方互換性と後方互換性があります。NONE: スキーマの互換性チェックを無効にします。
互換性タイプの詳細については、「スキーマ進化と互換性」を参照してください。
互換性チェックでの不合格¶
Schema Registry はプロデューサーとコンシューマーとの間の契約を維持するために、進化するスキーマの互換性をチェックします。Schema Registry による互換性チェックがなければ、スキーマの変更によってアプリケーションの動作に支障が生じる可能性があります。
Payment スキーマの例で、企業が個々の支払いについて、新しい情報、たとえば売上の発生場所を表す region フィールドを追跡することになったとしましょう。この新しい region フィールドを含んだ Payment2a スキーマ を考えてみます。
cat src/main/resources/avro/io/confluent/examples/clients/basicavro/Payment2a.avsc
{
"namespace": "io.confluent.examples.clients.basicavro",
"type": "record",
"name": "Payment",
"fields": [
{"name": "id", "type": "string"},
{"name": "amount", "type": "double"},
{"name": "region", "type": "string"}
]
}
Schema Registry のデフォルトの互換性は BACKWARD です。まずは、この新しいスキーマに後方互換性があるかどうかを考えてみましょう。region フィールドのない従来のスキーマを使ってプロデューサーが書き込んだデータを、コンシューマーは、この新しいスキーマを使用して読み取ることができるでしょうか。答えは No です。従来のスキーマが使用されたデータを、コンシューマーは読み取ることができません。従来のデータには region フィールドがないためです。したがって、このスキーマには後方互換性がありません。
Confluent では Schema Registry Maven プラグイン を提供しています。このプラグインを使用して、互換性チェックを開発過程で行ったり、CI/CD パイプラインに統合したりすることができます。
サンプルの pom.xml にはこのプラグインが含まれ、互換性チェックが有効になっています。
...
<properties>
<schemaRegistryUrl>http://localhost:8081</schemaRegistryUrl>
<schemaRegistryBasicAuthUserInfo></schemaRegistryBasicAuthUserInfo>
</properties>
...
<build>
<plugins>
...
<plugin>
<groupId>io.confluent</groupId>
<artifactId>kafka-schema-registry-maven-plugin</artifactId>
<version>${confluent.version}</version>
<configuration>
<schemaRegistryUrls>
<param>${schemaRegistryUrl}</param>
</schemaRegistryUrls>
<userInfoConfig>${schemaRegistryBasicAuthUserInfo}</userInfoConfig>
<subjects>
<transactions-value>src/main/resources/avro/io/confluent/examples/clients/basicavro/Payment2a.avsc</transactions-value>
</subjects>
</configuration>
<goals>
<goal>test-compatibility</goal>
</goals>
</plugin>
...
</plugins>
</build>
現在は、Schema Registry 内の transactions-value サブジェクトに対して、新しい Payment2a スキーマの互換性をチェックするように構成されています。
互換性チェックを実行し、不合格になることを確認します。
mvn io.confluent:kafka-schema-registry-maven-plugin:test-compatibility
返されるエラーメッセージは次のとおりです。
... [ERROR] Schema examples/clients/avro/src/main/resources/avro/io/confluent/examples/clients/basicavro/Payment2a.avsc is not compatible with subject(transactions-value) ...
新しいスキーマである
Payment2aを Schema Registry に手動で登録してみましょう。これは、Control Center を使用していない場合に、Java 以外のクライアントで互換性をチェックする際に便利な方法です。curl -X POST -H "Content-Type: application/vnd.schemaregistry.v1+json" \ --data '{"schema": "{\"type\":\"record\",\"name\":\"Payment\",\"namespace\":\"io.confluent.examples.clients.basicavro\",\"fields\":[{\"name\":\"id\",\"type\":\"string\"},{\"name\":\"amount\",\"type\":\"double\"},{\"name\":\"region\",\"type\":\"string\"}]}"}' \ http://localhost:8081/subjects/transactions-value/versions
想定していたとおり、スキーマに互換性がないというエラーメッセージが Schema Registry から返され、スキーマが拒否されます。
{"error_code":409,"message":"Schema being registered is incompatible with an earlier schema"}
互換性チェックでの合格¶
後方互換性 を確保するためには、新しいフィールドが存在しなかった場合のデフォルト値を新しいスキーマで想定しておく必要があります。
regionにデフォルト値を与えたアップデート後の Payment2b スキーマ を考えてみます。このスキーマを表示するには、次のコマンドを実行します。cat src/main/resources/avro/io/confluent/examples/clients/basicavro/Payment2b.avsc
次のように出力されます。
{ "namespace": "io.confluent.examples.clients.basicavro", "type": "record", "name": "Payment", "fields": [ {"name": "id", "type": "string"}, {"name": "amount", "type": "double"}, {"name": "region", "type": "string", "default": ""} ] }UI から
transactionsトピックをクリックして Schema タブに移動し、transactionsトピックの最新のスキーマを Schema Registry から取得します。Edit Schema をクリックします。
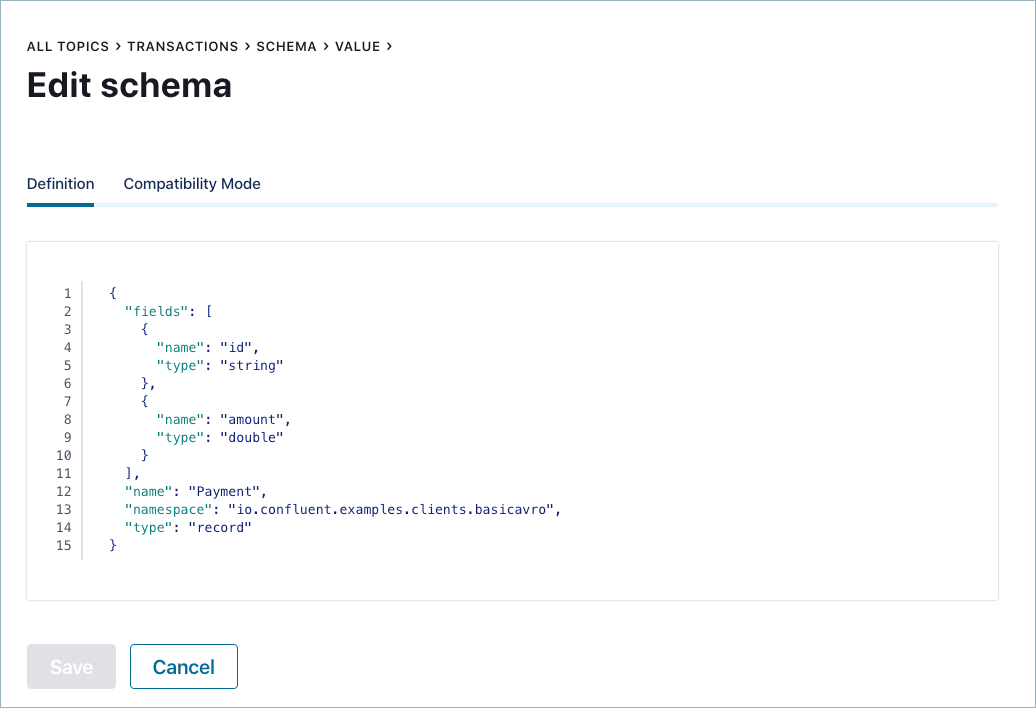
もう一度新しいフィールド
regionを追加しますが、今回は、次のようにデフォルト値を追加します。その後、Save をクリックします。{ "name": "region", "type": "string", "default": "" }
新しいスキーマが受け入れられたことを確認します。
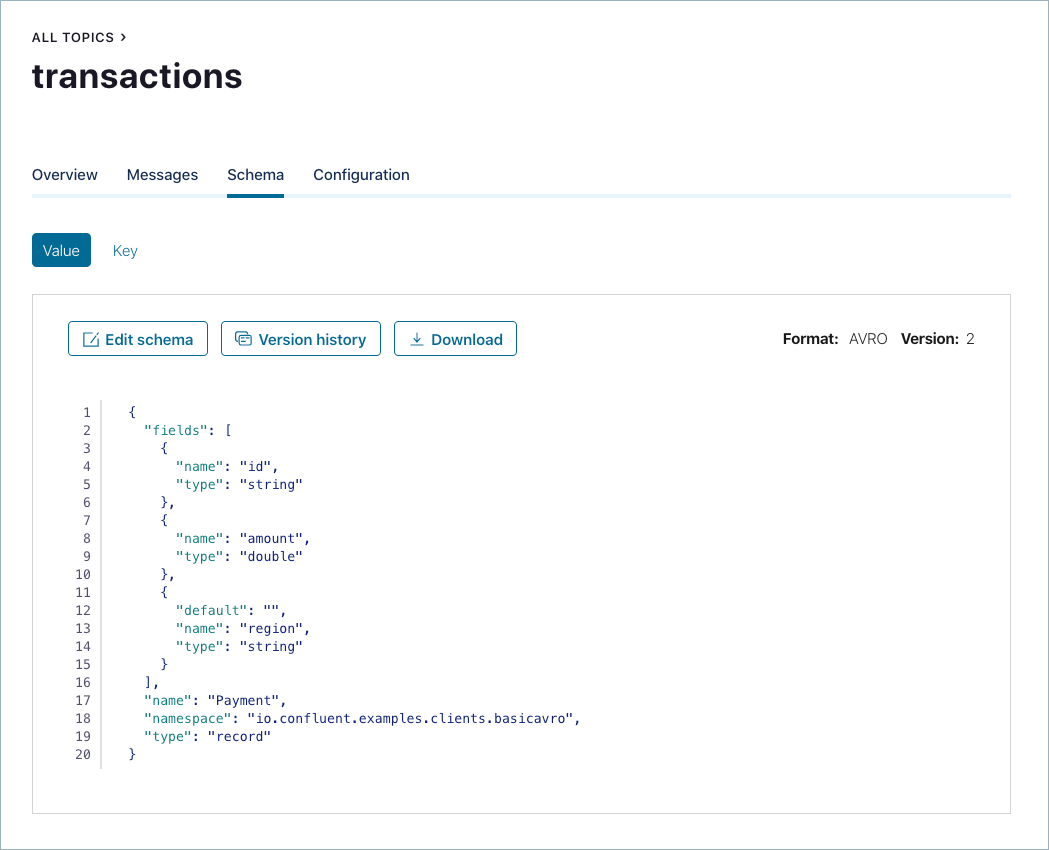
注釈
無効な Avro についてのエラーメッセージが表示された場合は、構文をチェックしてください(引用符やコロン、閉じかっこ、直前のフィールドとのコンマ区切りなど)。
登録されているスキーマバージョンについて考えてみます。
transactionsトピックのtransactions-valueという Schema Registry サブジェクトには次の 2 つのスキーマが存在します。- バージョン 1:
Payment.avsc - バージョン 2:
Payment2b.avsc。regionフィールドがデフォルト値(空の値)とともに追加されています。
- バージョン 1:
引き続き UI の
transactionsトピックの Schema タブで、Version history をクリックし、Turn on version diff を選択して 2 つのバージョンを比較します。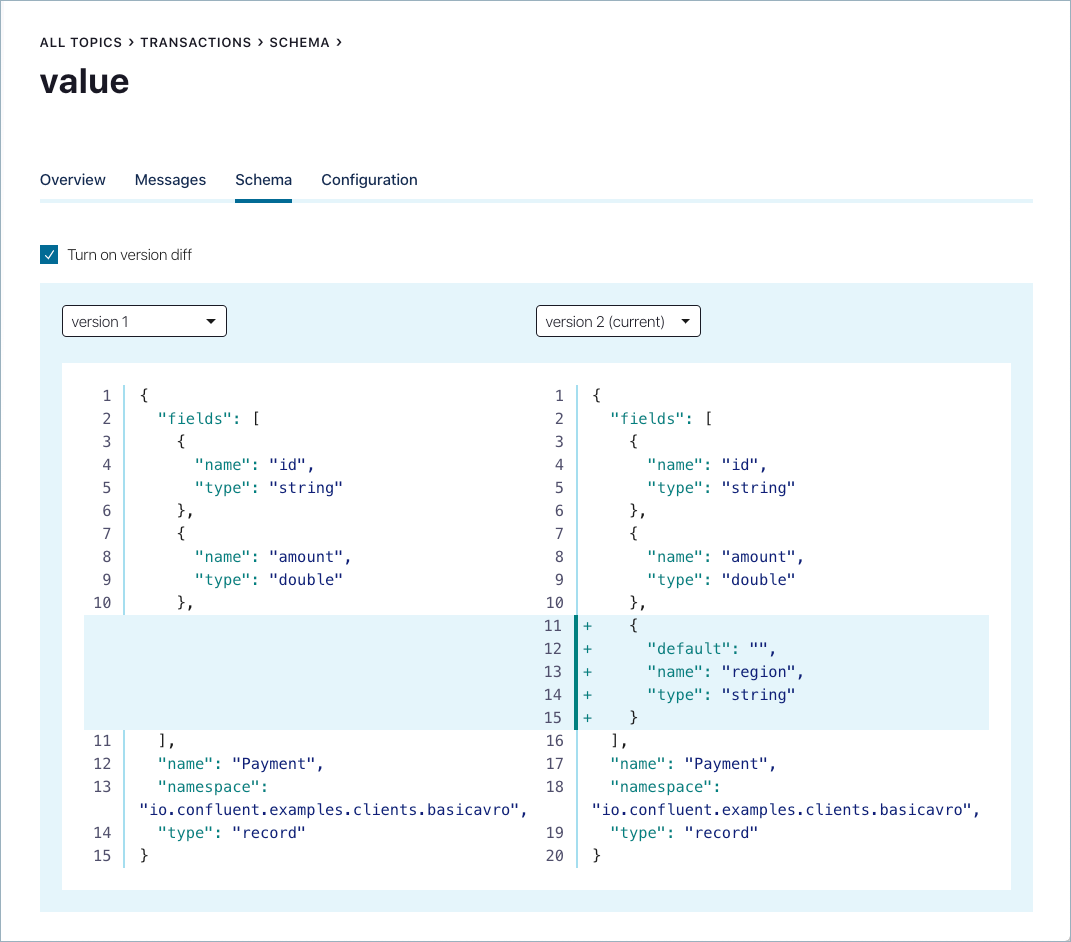
コマンドラインで Schema Registry Maven プラグイン に戻り、
Payment2a.avscではなくPayment2b.avscを参照するように pom.xml を更新します。互換性チェックを再実行し、合格になることを確認します。
mvn io.confluent:kafka-schema-registry-maven-plugin:test-compatibility
次のメッセージが返されたことを確認します。これはスキーマが互換性チェックに合格したことを示します。
... [INFO] Schema examples/clients/avro/src/main/resources/avro/io/confluent/examples/clients/basicavro/Payment2b.avsc is compatible with subject(transactions-value) ...
Schema Registry の REST エンドポイントに直接接続して、新しいスキーマ
Payment2bを登録する場合は、次のコマンドを実行してください。問題なく実行されるはずです。curl -X POST -H "Content-Type: application/vnd.schemaregistry.v1+json" \ --data '{"schema": "{\"type\":\"record\",\"name\":\"Payment\",\"namespace\":\"io.confluent.examples.clients.basicavro\",\"fields\":[{\"name\":\"id\",\"type\":\"string\"},{\"name\":\"amount\",\"type\":\"double\"},{\"name\":\"region\",\"type\":\"string\",\"default\":\"\"}]}"}' \ http://localhost:8081/subjects/transactions-value/versions
上の
curlコマンドは、成功した場合、新しいスキーマのバージョンidを返します。{"id":2}
Schema Registry にある
transactions-valueの最新のサブジェクトを表示します。curl --silent -X GET http://localhost:8081/subjects/transactions-value/versions/latest | jq .このコマンドからは、
transactions-valueトピックの最新の Schema Registry サブジェクトが返されます。JSON 形式で表記されたスキーマのバージョン番号、ID、説明などが含まれます。{ "subject": "transactions-value", "version": 2, "id": 2, "schema": "{\"type\":\"record\",\"name\":\"Payment\",\"namespace\":\"io.confluent.examples.clients.basicavro\",\"fields\":[{\"name\":\"id\",\"type\":\"string\"},{\"name\":\"amount\",\"type\":\"double\"},{\"name\":\"region\",\"type\":\"string\",\"default\":\"\"}]}" }
次の変更点に注目してください。
version:1から2に変わっています。id:1から2に変わっています。schema: デフォルト値を含む新しいregionフィールドでアップデートされています。
互換性タイプの変更¶
デフォルトの互換性タイプは backward ですが、グローバルに、またはサブジェクト単位で変更することができます。
UI からサブジェクトごとに互換性タイプを変更するには、transactions トピックをクリックして Schema タブに移動し、transactions トピックの最新のスキーマを Schema Registry から取得します。Edit Schema をクリックし、Compatibility Mode をクリックします。
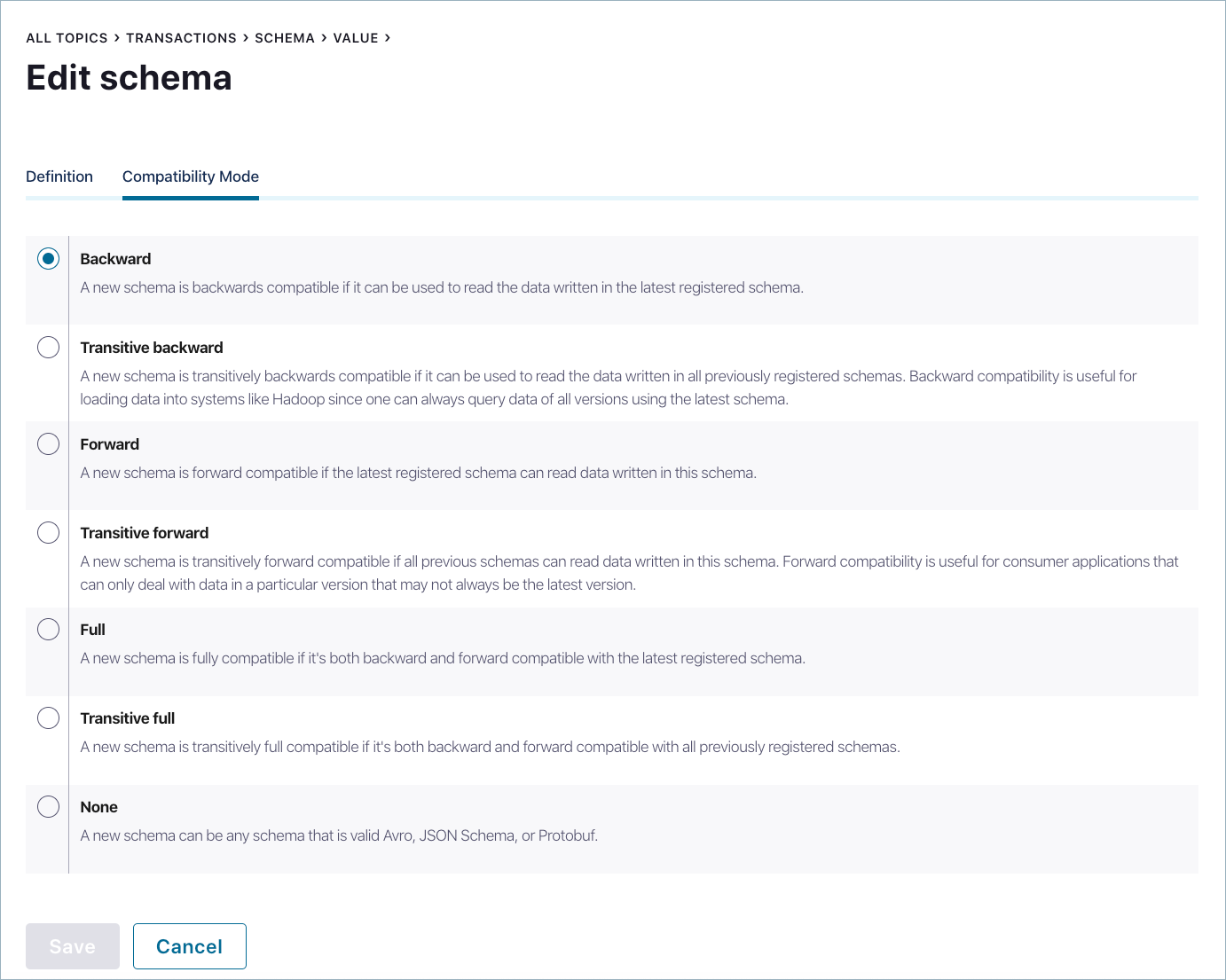
このトピックの互換性はデフォルトの backward に設定されていますが、必要に応じて変更することができます。
Schema Registry の REST エンドポイントに直接接続して、transactions トピックである transactions-value サブジェクトの互換性タイプを変更する場合は、次のサンプルコマンドを実行してください。
curl -X PUT -H "Content-Type: application/vnd.schemaregistry.v1+json" \
--data '{"compatibility": "BACKWARD_TRANSITIVE"}' \
http://localhost:8081/config/transactions-value
次のステップ¶
- ブログの投稿記事: Why Avro For Kafka Data
- ブログの投稿記事: Yes, Virginia, You Really Do Need a Schema Registry
- ブログの投稿記事: 17 Ways to Mess Up Self-Managed Schema Registry
- Apache Avro® 公式サイト: How to get started with Apache Avro using Java Clients
- Confluent でサポートされるスキーマフォーマット、および Avro、Protobuf、JSON スキーマを使用してクライアントを構成する方法: フォーマット、シリアライザー、逆シリアライザー
- 実践: 「Schema Registry API の使用例」では、HTTP および HTTPS を使用するさまざまな curl コマンドを紹介
- Confluent Control Center でのスキーマの管理に関するユーザーガイド: トピックのスキーマを管理する
- Schema Registry の本稼働環境へのデプロイ: 本稼働環境での Schema Registry の実行
- 全体像: 「Confluent Platform のデモ(cp-demo)」では、完全な Confluent Platform デプロイのコンテキストでの Schema Registry を、さまざまなタイプのセキュリティを有効にして紹介