クラウド ETL のサンプル¶
このサンプルでは、100% クラウドサービスを実現するためにビルドされたエンドツーエンドクラウド ETL デプロイ全体を紹介します。
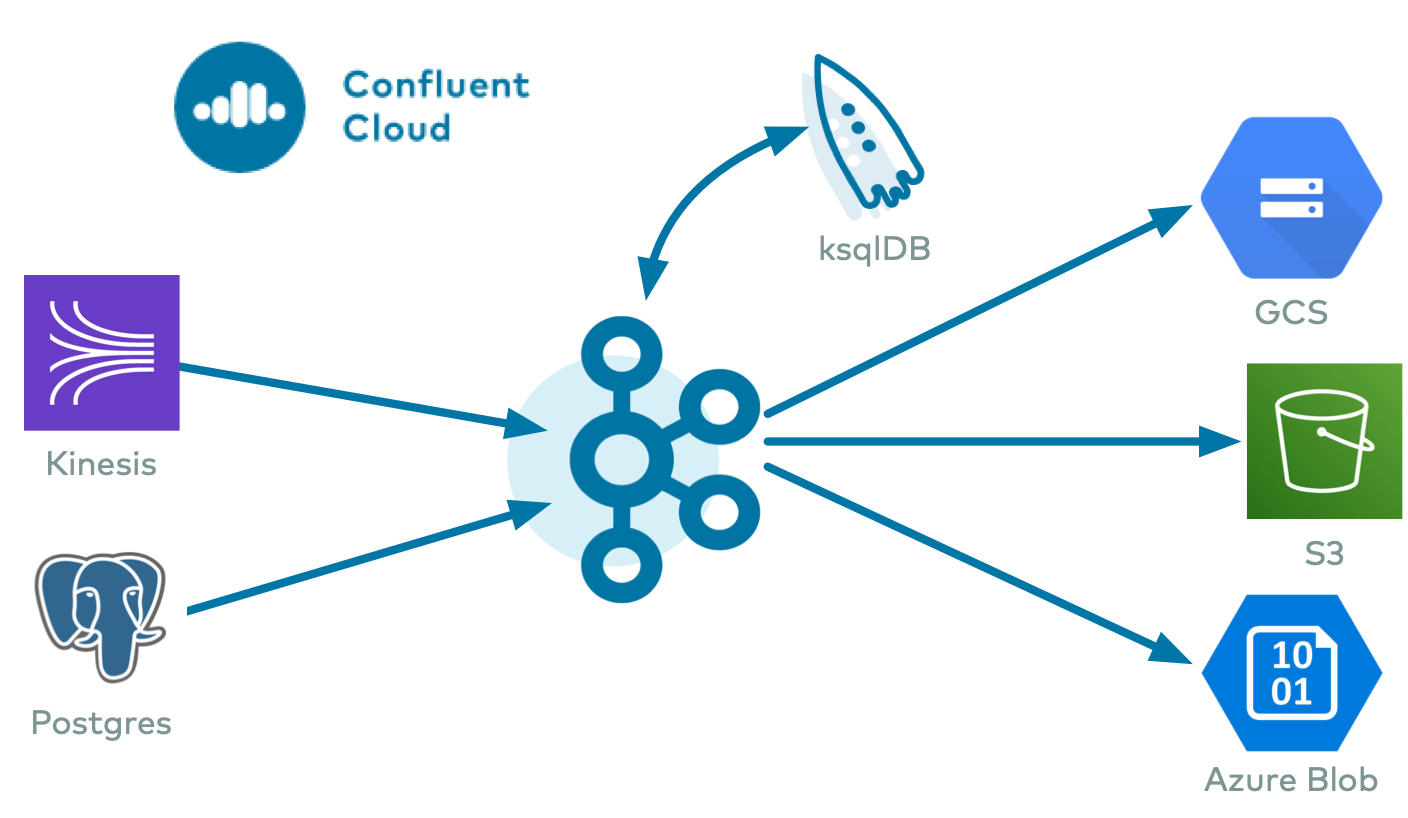
- クラウドソースコネクター: 次のクラウドサービスのいずれかから、Confluent Cloud の Kafka のトピックにデータを書き込みます。
- クラウドシンクコネクター: Confluent Cloud の Kafka のトピックから、次のクラウドストレージのいずれかにデータを書き込みます。
- Confluent Cloud ksqlDB: Kafka に対するリアルタイムのデータ処理を可能にするストリーミング SQL エンジン
- Confluent Cloud Schema Registry: スキーマの一元管理と、スキーマの進化に伴う互換性チェック
概要¶
企業がクラウドに移行するアプリケーションの数は増え続けており、そうした中でオンプレミス ETL(抽出、変換、読み込み)パイプラインもクラウドに移行されるとともに、新しい ETL パイプラインがビルドされています。このサンプル では、Confluent Cloud 上のすべてのフルマネージド型サービスを活用するクラウド ETL ソリューションを紹介しています。
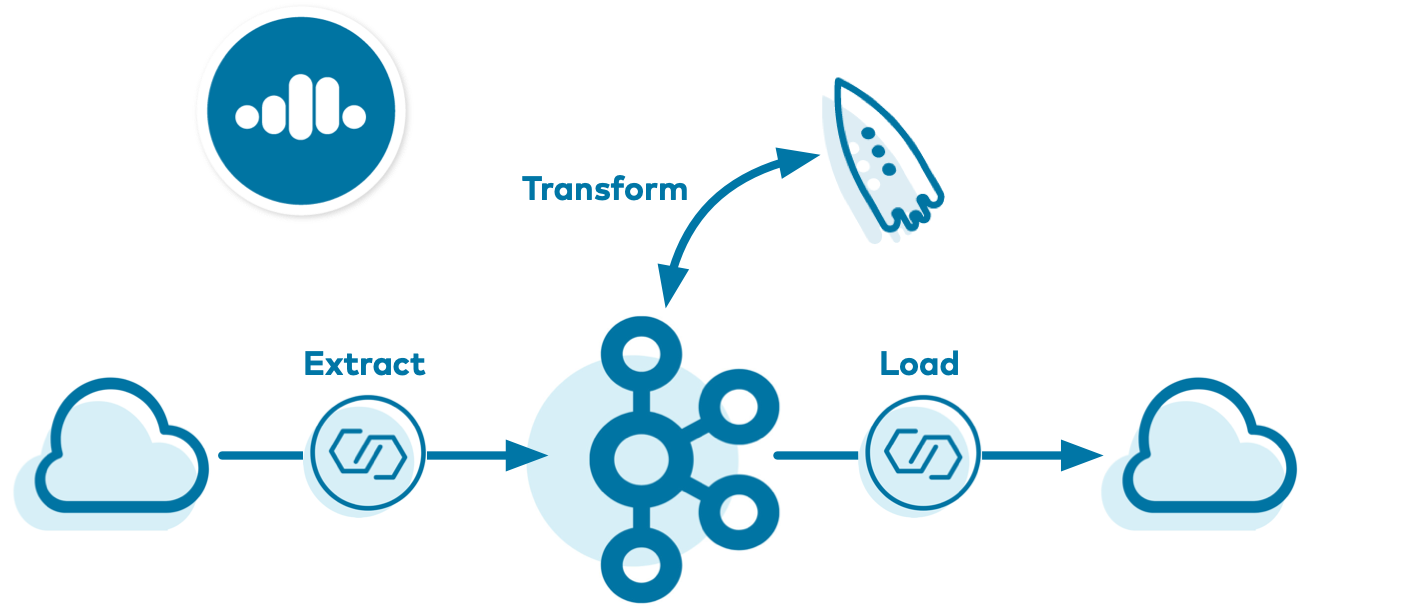
これらのリアルタイムクラウド ETL パイプラインには多くの強力なユースケースがありますが、このサンプルでは、その中の 1 つである、複数のクラウドプロバイダーにわたるログ取り込みパイプラインを紹介します。このサンプルでは、Confluent CLI を使用して、AWS Kinesis ストリームまたは AWS RDS PostgreSQL データベースから Confluent Cloud へとデータを読み取るソースコネクターを作成します。そして、そのデータを処理する Confluent Cloud ksqlDB アプリケーションを作成します。最後にシンクコネクターが、目的のプロバイダーのクラウドストレージ(GCP GCS、AWS S3、または Azure Blob)に出力データを書き込みます。
最終的に、複数のクラウドプロバイダーにわたって、クラウドで 100% 実行されるイベントストリーミング ETL が実現されます。これにより、以下が可能になります。
- フル機能のイベントストリーミングプラットフォーム上でのビジネスアプリケーションのビルド
- 複数のクラウドプロバイダー(AWS、GCP、Azure)とオンプレミスデータセンターに対応
- Kafka を使用した、Single Source of Truth(信頼できる唯一の情報源)へのデータの集計
- ksqlDB の機能を活用したストリーム処理
ちなみに
Confluent Cloud でのクラウド ETL パイプラインのビルドについては、この ブログの投稿 を参照してください。
データフロー¶
データセットは一連のログメッセージであり、このサンプルでは、eventlogs.json でキャプチャされた模擬データです。これは、以下のようになります。
{"eventSourceIP":"192.168.1.1","eventAction":"Upload","result":"Pass","eventDuration":3}
{"eventSourceIP":"192.168.1.1","eventAction":"Create","result":"Pass","eventDuration":2}
{"eventSourceIP":"192.168.1.1","eventAction":"Delete","result":"Fail","eventDuration":5}
{"eventSourceIP":"192.168.1.2","eventAction":"Upload","result":"Pass","eventDuration":1}
{"eventSourceIP":"192.168.1.2","eventAction":"Create","result":"Pass","eventDuration":3}
| コンポーネント | 消費元 | 生成先 |
|---|---|---|
| Kinesis/PostgreSQL Source Connector | Kinesis ストリームまたは RDS PostgreSQL テーブル | kafka のトピック eventlogs |
| ksqlDB | eventlogs |
ksqlDB ストリームおよびテーブル |
| GCS/S3/Blob Sink Connector | ksqlDB テーブル COUNT_PER_SOURCE、SUM_PER_SOURCE |
GCS/S3/Blob |
前提条件¶
クラウドサービス¶
- Confluent Cloud
- AWS および(オプションの)GCP または Azure へのアクセス
ローカルツール¶
- Confluent CLI v2.5.0 以降。
--save引数を使用してログイン済みであること。この引数で、Confluent Cloud のユーザーログイン認証情報が保存されるか、ローカルのnetrcファイルに対するトークン(SSO の場合)が更新されます。 - Confluent CLI v1 (オプション)
gsutilCLI。ユーザーの資格情報で適切に初期化済み:(オプション)デスティネーションが GCP GCS の場合awCLI。ユーザーの資格情報で適切に初期化済み: AWS Kinesis または RDS PostgreSQL に使用、(オプション)デスティネーションが AWS S3 の場合azCLI。ユーザーの資格情報で適切に初期化済み:(省略可)デスティネーションが Azure Blob Storage の場合psql:(省略可)ソースが RDS PostgreSQL の場合jqcurltimeout: bash スクリプトにより、一定の期間の後にコンシューマープロセスを終了するために使用されます。timeoutは、ほとんどの Linux ディストリビューションで使用できますが、macOS では使用できません。macOS ユーザーの方は、「macOS の場合のインストール手順」を参照してください。python
チュートリアルの実行コスト¶
注意¶
Confluent Cloud のすべてのサンプルでは、課金される可能性のある実際の Confluent Cloud リソースを使用しています。サンプルで、新しい Confluent Cloud 環境、Kafka クラスター、トピック、ACL、サービスアカウントに加えて、コネクターや ksqlDB アプリケーションのように時間で課金されるリソースを作成する場合があります。想定外の課金を避けるために、慎重に リソースのコストを確認 してから開始してください。Confluent Cloud のサンプルの実行を終了したら、サービスへの時間単位の課金を回避するためにすべての Confluent Cloud リソースを破棄し、リソースが削除されたことを確認します。
また、このサンプルでは、次のような他のクラウドプロバイダーの実際のリソースも使用します。
- AWS Kinesis または RDS PostgreSQL
- 構成に応じて、クラウドストレージプロバイダー(GCP GCS、AWS S3、または Azure Blob)
サンプルの実行¶
セットアップ¶
このサンプルは、Kinesis または RDS PostgreSQL、デスティネーションストレージサービス、および Confluent Cloud の実際のリソースとやり取りするため、これらのサービスと通信できるよう、いくつかの初期パラメーターをセットアップする必要があります。
このサンプルでは、サンプルの実行に必要なリソースを備えた、新しい Confluent Cloud 環境を作成します。既に説明したように、このサンプルでは実際の Confluent Cloud リソースを使用するため、課金が発生する可能性があります。サンプルを起動する前に、慎重にリソースのコストを見積もってください。
confluentinc/examples GitHub リポジトリのクローンを作成し、
7.1.1-postブランチをチェックアウトします。git clone https://github.com/confluentinc/examples cd examples git checkout 7.1.1-post
cloud-etlのサンプルのディレクトリに変更します。cd cloud-etlconfig/demo.cfg にあるサンプル構成ファイルを変更します。ソースに適切な資格情報およびパラメーターを設定します。
- AWS Kinesis
DATA_SOURCE='kinesis'KINESIS_STREAM_NAMEKINESIS_REGIONAWS_PROFILE
- AWS RDS(PostgreSQL)
DATA_SOURCE='rds'DB_INSTANCE_IDENTIFIERRDS_REGIONAWS_PROFILE
- AWS Kinesis
config/demo.cfg にある同じサンプル構成ファイルで、送信先のクラウドストレージプロバイダーに必要なパラメーターを設定します。
- GCP GCS
DESTINATION_STORAGE='gcs'GCS_CREDENTIALS_FILEGCS_BUCKET
- AWS S3
DESTINATION_STORAGE='s3'S3_PROFILES3_BUCKET
- Azure Blob
DESTINATION_STORAGE='az'AZBLOB_STORAGE_ACCOUNTAZBLOB_CONTAINER
- GCP GCS
コマンド
confluent login --saveで、Confluent Cloud のユーザー名とパスワードを使用して Confluent Cloud にログインします。--save引数により、Confluent Cloud ユーザーログイン資格情報が保存されるか、ローカルのnetrcファイルに対してトークン(SSO の場合)が更新されます。confluent login --save
実行¶
このサンプルでは、Confluent Cloud 向け ccloud-stack ユーティリティ を使用して、完全マネージドサービスのスタックを Confluent Cloud に自動的に作成します。デフォルトでは、ccloud-stack ユーティリティにより、リージョン us-west-2 にあるクラウドプロバイダー aws の新しい Confluent Cloud 環境にリソースが作成されます。既存の Confluent Cloud 環境を再利用する場合、または aws と us-west-2 がターゲットとなるプロバイダーやリージョンではない場合は、サンプルを実行する前に、その他の ccloud-stack オプション を構成することができます。
サンプルを実行します。サンプルの起動時に、Confluent Cloud クラスター用のクラウドプロバイダーとリージョンを設定します。このとき、設定するクラウドプロバイダーとリージョンが、送信先となるクラウドストレージプロバイダーおよびリージョンと一致する必要があります。これにより、数分で Confluent Cloud と他のプロバイダーに新しいリソースが作成されます。
# Example for running to AWS S3 in us-west-2 CLUSTER_CLOUD=aws CLUSTER_REGION=us-west-2 ./start.sh # Example for running to GCP GCS in us-west2 CLUSTER_CLOUD=gcp CLUSTER_REGION=us-west2 ./start.sh # Example for running to Azure Blob in westus2 CLUSTER_CLOUD=azure CLUSTER_REGION=westus2 ./start.sh
このスクリプトの実行中に、Confluent Cloud 向け ccloud-stack ユーティリティ によってフルマネージド型リソースの新しい Confluent Cloud スタックが作成され、すべての接続情報、クラスター ID、および認証情報を含むローカル構成ファイルが生成されます。これは、他のデモ/自動化の際に便利です。このローカル構成ファイルを表示すると、
SERVICE ACCOUNT IDがスクリプトによって自動生成されています。cat stack-configs/java-service-account-<SERVICE ACCOUNT ID>.config
出力は以下のようになります。
# -------------------------------------- # Confluent Cloud connection information # -------------------------------------- # ENVIRONMENT ID: <ENVIRONMENT ID> # SERVICE ACCOUNT ID: <SERVICE ACCOUNT ID> # KAFKA CLUSTER ID: <KAFKA CLUSTER ID> # SCHEMA REGISTRY CLUSTER ID: <SCHEMA REGISTRY CLUSTER ID> # KSQLDB APP ID: <KSQLDB APP ID> # -------------------------------------- security.protocol=SASL_SSL sasl.mechanism=PLAIN bootstrap.servers=<BROKER ENDPOINT> sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username='<API KEY>' password='<API SECRET>'; basic.auth.credentials.source=USER_INFO schema.registry.basic.auth.user.info=<SR API KEY>:<SR API SECRET> schema.registry.url=https://<SR ENDPOINT> ksql.endpoint=<KSQLDB ENDPOINT> ksql.basic.auth.user.info=<KSQLDB API KEY>:<KSQLDB API SECRET>
Confluent Cloud Console にログインします。
コネクター¶
サンプルにより、Confluent CLI コマンド
confluent connect createを使用して Kafka Connect コネクターが自動的に作成されました。このコマンドでは、コネクター構成ディレクトリ の以下のコネクター構成ファイルが渡されています。- AWS Kinesis Source Connector 構成ファイル
- PostgreSQL Source Connector 構成ファイル
- GCS Sink Connector 構成ファイル
- GCS Sink Connector および Avro 構成ファイル
- S3 Sink Connector 構成ファイル
- S3 Sink Connector および Avro 構成ファイル
- Azure Blob Sink Connector 構成ファイル
- Azure Blob Sink Connector および Avro 構成ファイル
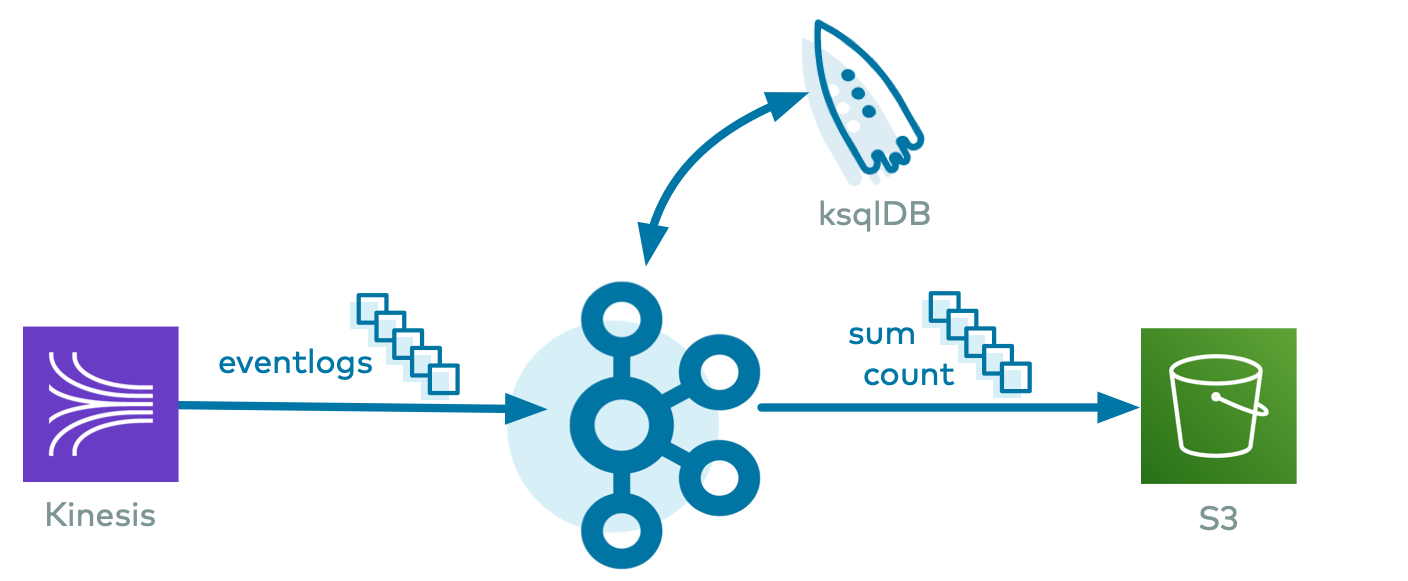
たとえば、Kinesis からデータを取得するようにサンプルを構成した場合は、次の AWS Kinesis コネクター構成ファイル が実行されます。
{ "name": "demo-KinesisSource", "connector.class": "KinesisSource", "tasks.max": "1", "kafka.api.key": "$CLOUD_KEY", "kafka.api.secret": "$CLOUD_SECRET", "aws.access.key.id": "$AWS_ACCESS_KEY_ID", "aws.secret.key.id": "$AWS_SECRET_ACCESS_KEY", "kafka.topic": "$KAFKA_TOPIC_NAME_IN", "kinesis.region": "$KINESIS_REGION", "kinesis.stream": "$KINESIS_STREAM_NAME", "kinesis.position": "TRIM_HORIZON" }Kinesis をソース、S3 をシンクとしてサンプルを実行した場合のパイプラインは、次のようになります。
Confluent CLI を使用して、このクラスターで作成されたすべてのフルマネージド型コネクターを一覧表示します。
confluent connect list
出力は以下のようになります。
ID | Name | Status | Type | Trace +-----------+---------------------+---------+--------+-------+ lcc-2jrx1 | demo-S3Sink-no-avro | RUNNING | sink | lcc-vnrqp | demo-KinesisSource | RUNNING | source | lcc-5qwrn | demo-S3Sink-avro | RUNNING | sink |
実行中のいずれかのコネクターの詳細情報を表示します。この場合は、AWS Kinesis コネクターに対応する
lcc-vnrqpです。confluent connect describe lcc-vnrqp
出力は以下のようになります。
Connector Details +--------+--------------------+ | ID | lcc-vnrqp | | Name | demo-KinesisSource | | Status | RUNNING | | Type | source | | Trace | | +--------+--------------------+ Task Level Details TaskId | State +--------+---------+ 0 | RUNNING Configuration Details Config | Value +---------------------+---------------------------------------------------------+ name | demo-KinesisSource kafka.api.key | **************** kafka.api.secret | **************** schema.registry.url | https://psrc-4yovk.us-east-2.aws.confluent.cloud cloud.environment | prod kafka.endpoint | SASL_SSL://pkc-4kgmg.us-west-2.aws.confluent.cloud:9092 kafka.region | us-west-2 kafka.user.id | 73800 kinesis.position | TRIM_HORIZON kinesis.region | us-west-2 kinesis.stream | demo-logs aws.secret.key.id | **************** connector.class | KinesisSource tasks.max | 1 aws.access.key.id | ****************
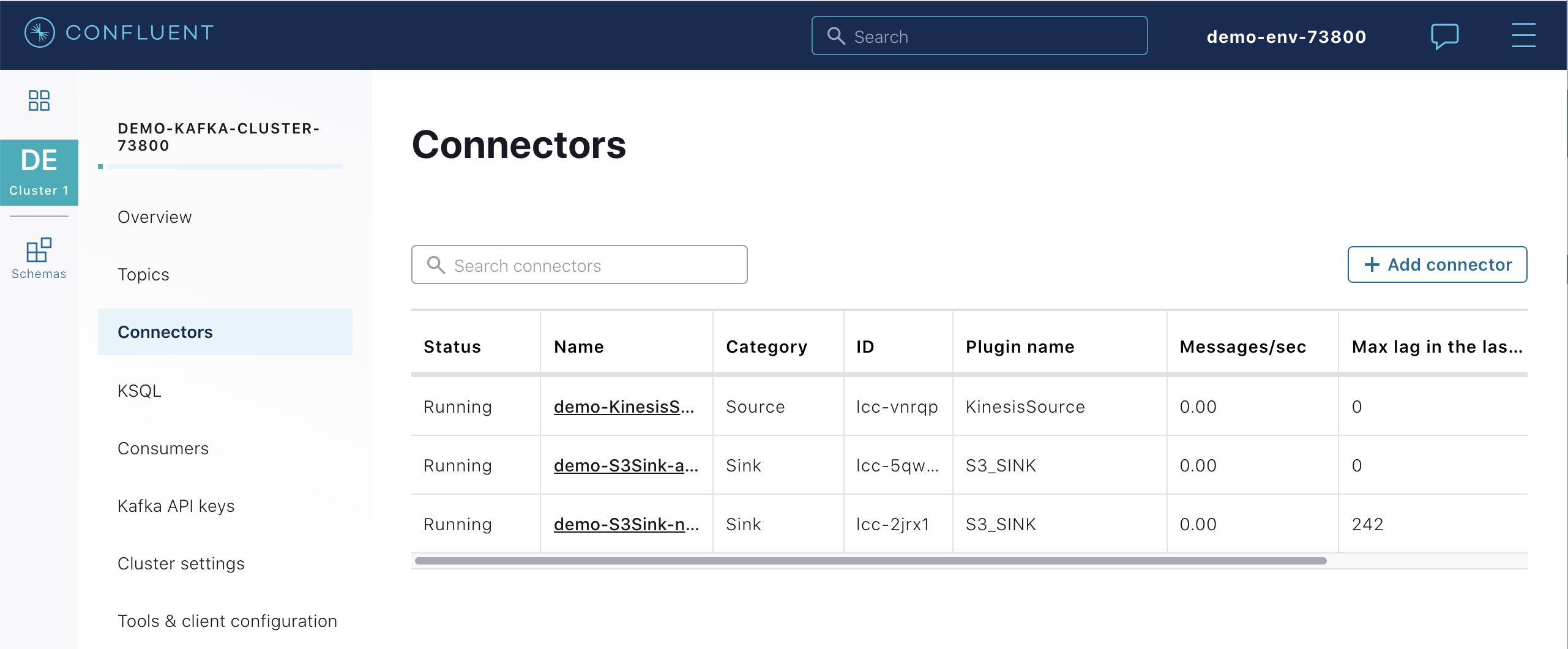
同じコネクターを Confluent Cloud Console から表示します。
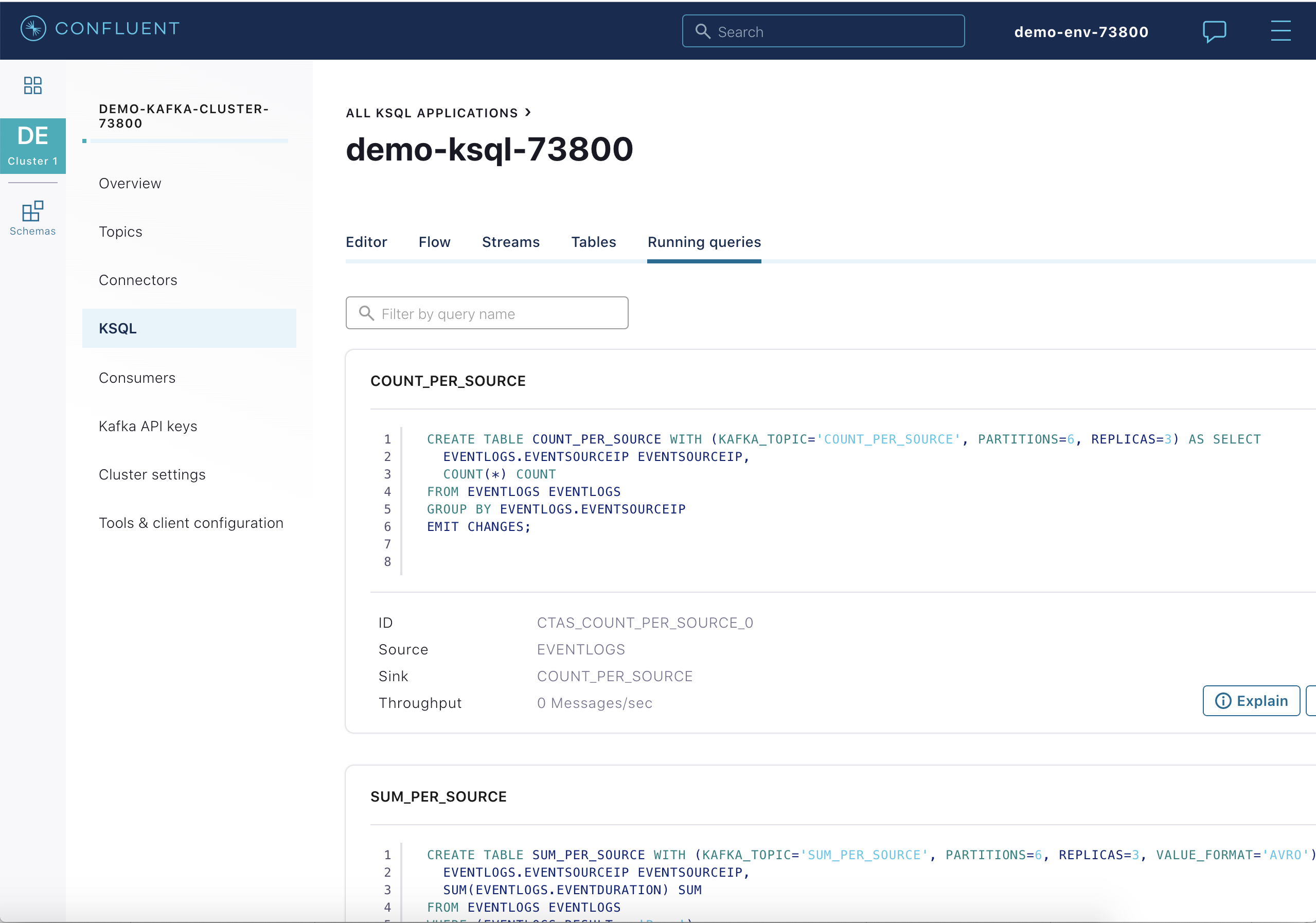
ksqlDB¶
Confluent Cloud Console で、使用する Kafka クラスターを選択し、ksqlDB タブをクリックして ksqlDB アプリケーションでの フロー を表示します。

このフローは、この ksqlDB ステートメント のセットの結果です。ksqlDB テーブル
COUNT_PER_SOURCEが JSON フォーマットで生成されており、その基盤となる Kafka のトピックはCOUNT_PER_SOURCEです。また、ksqlDB テーブルSUM_PER_SOURCEも Avro フォーマットで生成されており、その基盤となる Kafka のトピックはSUM_PER_SOURCEです。CREATE STREAM eventlogs (eventSourceIP VARCHAR, eventAction VARCHAR, result VARCHAR, eventDuration BIGINT) WITH (KAFKA_TOPIC='eventlogs', VALUE_FORMAT='JSON'); CREATE TABLE count_per_source WITH (KAFKA_TOPIC='COUNT_PER_SOURCE', PARTITIONS=6) AS SELECT eventSourceIP, COUNT(*) as count FROM eventlogs GROUP BY eventSourceIP EMIT CHANGES; CREATE TABLE sum_per_source WITH (KAFKA_TOPIC='SUM_PER_SOURCE', PARTITIONS=6, VALUE_FORMAT='AVRO') AS SELECT eventSourceIP as ROWKEY, as_value(eventSourceIP) as eventSourceIP, SUM(EVENTDURATION) as sum FROM eventlogs WHERE (RESULT = 'Pass') GROUP BY eventSourceIP EMIT CHANGES;
Confluent Cloud ksqlDB エディターまたはその REST API を使用して ksqlDB アプリケーションとやり取りします。
curl -X POST $KSQLDB_ENDPOINT/ksql \ -H "Content-Type: application/vnd.ksql.v1+json; charset=utf-8" \ -u $KSQLDB_BASIC_AUTH_USER_INFO \ -d @<(cat <<EOF { "ksql": "SHOW QUERIES;", "streamsProperties": {} } EOF )
出力は以下のようになります。
[ { "@type": "queries", "statementText": "SHOW QUERIES;", "queries": [ { "queryString": "CREATE TABLE COUNT_PER_SOURCE WITH (KAFKA_TOPIC='COUNT_PER_SOURCE', PARTITIONS=6, REPLICAS=3) AS SELECT\n EVENTLOGS.EVENTSOURCEIP EVENTSOURCEIP,\n COUNT(*) COUNT\nFROM EVENTLOGS EVENTLOGS\nGROUP BY EVENTLOGS.EVENTSOURCEIP\nEMIT CHANGES;", "sinks": [ "COUNT_PER_SOURCE" ], "sinkKafkaTopics": [ "COUNT_PER_SOURCE" ], "id": "CTAS_COUNT_PER_SOURCE_0", "statusCount": { "RUNNING": 1 }, "queryType": "PERSISTENT", "state": "RUNNING" }, { "queryString": "CREATE TABLE SUM_PER_SOURCE WITH (KAFKA_TOPIC='SUM_PER_SOURCE', PARTITIONS=6, REPLICAS=3, VALUE_FORMAT='AVRO') AS SELECT\n EVENTLOGS.EVENTSOURCEIP ROWKEY,\n AS_VALUE(EVENTLOGS.EVENTSOURCEIP) EVENTSOURCEIP,\n SUM(EVENTLOGS.EVENTDURATION) SUM\nFROM EVENTLOGS EVENTLOGS\nWHERE (EVENTLOGS.RESULT = 'Pass')\nGROUP BY EVENTLOGS.EVENTSOURCEIP\nEMIT CHANGES;", "sinks": [ "SUM_PER_SOURCE" ], "sinkKafkaTopics": [ "SUM_PER_SOURCE" ], "id": "CTAS_SUM_PER_SOURCE_5", "statusCount": { "RUNNING": 1 }, "queryType": "PERSISTENT", "state": "RUNNING" } ], "warnings": [] } ]
Confluent Cloud Schema Registry のトピック
SUM_PER_SOURCEの Avro スキーマを表示します。curl --silent -u <SR API KEY>:<SR API SECRET> https://<SR ENDPOINT>/subjects/SUM_PER_SOURCE-value/versions/latest | jq -r '.schema' | jq .
出力は以下のようになります。
{ "type": "record", "name": "KsqlDataSourceSchema", "namespace": "io.confluent.ksql.avro_schemas", "fields": [ { "name": "EVENTSOURCEIP", "type": [ "null", "string" ], "default": null }, { "name": "SUM", "type": [ "null", "long" ], "default": null } ] }
同じクエリを Confluent Cloud Console から表示します。
検証¶
サンプルの実行後に、read-data.sh スクリプトを実行して、Kinesis、Kafka、およびクラウドストレージからデータを表示します。
./read-data.sh stack-configs/java-service-account-<SERVICE ACCOUNT ID>.config
出力は以下のようになります。
Data from Kinesis stream demo-logs --limit 10: {"eventSourceIP":"192.168.1.1","eventAction":"Upload","result":"Pass","eventDuration":3} {"eventSourceIP":"192.168.1.1","eventAction":"Create","result":"Pass","eventDuration":2} {"eventSourceIP":"192.168.1.1","eventAction":"Delete","result":"Fail","eventDuration":5} {"eventSourceIP":"192.168.1.2","eventAction":"Upload","result":"Pass","eventDuration":1} {"eventSourceIP":"192.168.1.2","eventAction":"Create","result":"Pass","eventDuration":3} {"eventSourceIP":"192.168.1.1","eventAction":"Upload","result":"Pass","eventDuration":3} {"eventSourceIP":"192.168.1.1","eventAction":"Create","result":"Pass","eventDuration":2} {"eventSourceIP":"192.168.1.1","eventAction":"Delete","result":"Fail","eventDuration":5} {"eventSourceIP":"192.168.1.2","eventAction":"Upload","result":"Pass","eventDuration":1} {"eventSourceIP":"192.168.1.2","eventAction":"Create","result":"Pass","eventDuration":3} Data from Kafka topic eventlogs: confluent-v1 local services kafka consume eventlogs --cloud --config stack-configs/java-service-account-<SERVICE ACCOUNT ID>.config --from-beginning --property print.key=true --max-messages 10 5 {"eventSourceIP":"192.168.1.5","eventAction":"Upload","result":"Pass","eventDuration":4} 5 {"eventSourceIP":"192.168.1.5","eventAction":"Create","result":"Pass","eventDuration":1} 5 {"eventSourceIP":"192.168.1.5","eventAction":"Delete","result":"Fail","eventDuration":1} 5 {"eventSourceIP":"192.168.1.5","eventAction":"Upload","result":"Pass","eventDuration":4} 5 {"eventSourceIP":"192.168.1.5","eventAction":"Create","result":"Pass","eventDuration":1} 5 {"eventSourceIP":"192.168.1.5","eventAction":"Delete","result":"Fail","eventDuration":1} 5 {"eventSourceIP":"192.168.1.5","eventAction":"Upload","result":"Pass","eventDuration":4} 5 {"eventSourceIP":"192.168.1.5","eventAction":"Create","result":"Pass","eventDuration":1} 5 {"eventSourceIP":"192.168.1.5","eventAction":"Delete","result":"Fail","eventDuration":1} 5 {"eventSourceIP":"192.168.1.5","eventAction":"Upload","result":"Pass","eventDuration":4} Data from Kafka topic COUNT_PER_SOURCE: confluent-v1 local services kafka consume COUNT_PER_SOURCE --cloud --config stack-configs/java-service-account-<SERVICE ACCOUNT ID>.config --from-beginning --property print.key=true --max-messages 10 192.168.1.5 {"EVENTSOURCEIP":"192.168.1.5","COUNT":1} 192.168.1.5 {"EVENTSOURCEIP":"192.168.1.5","COUNT":2} 192.168.1.5 {"EVENTSOURCEIP":"192.168.1.5","COUNT":3} 192.168.1.5 {"EVENTSOURCEIP":"192.168.1.5","COUNT":4} 192.168.1.5 {"EVENTSOURCEIP":"192.168.1.5","COUNT":5} 192.168.1.5 {"EVENTSOURCEIP":"192.168.1.5","COUNT":6} 192.168.1.5 {"EVENTSOURCEIP":"192.168.1.5","COUNT":7} 192.168.1.5 {"EVENTSOURCEIP":"192.168.1.5","COUNT":8} 192.168.1.5 {"EVENTSOURCEIP":"192.168.1.5","COUNT":9} 192.168.1.5 {"EVENTSOURCEIP":"192.168.1.5","COUNT":10} Data from Kafka topic SUM_PER_SOURCE: confluent-v1 local services kafka consume SUM_PER_SOURCE --cloud --config stack-configs/java-service-account-<SERVICE ACCOUNT ID>.config --from-beginning --property print.key=true --value-format avro --property basic.auth.credentials.source=USER_INFO --property schema.registry.basic.auth.user.info=$SCHEMA_REGISTRY_BASIC_AUTH_USER_INFO --property schema.registry.url=$SCHEMA_REGISTRY_URL --property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer --max-messages 10 192.168.1.2 {"EVENTSOURCEIP":{"string":"192.168.1.2"},"SUM":{"long":1}} 192.168.1.2 {"EVENTSOURCEIP":{"string":"192.168.1.2"},"SUM":{"long":4}} 192.168.1.2 {"EVENTSOURCEIP":{"string":"192.168.1.2"},"SUM":{"long":5}} 192.168.1.2 {"EVENTSOURCEIP":{"string":"192.168.1.2"},"SUM":{"long":8}} 192.168.1.2 {"EVENTSOURCEIP":{"string":"192.168.1.2"},"SUM":{"long":11}} 192.168.1.2 {"EVENTSOURCEIP":{"string":"192.168.1.2"},"SUM":{"long":12}} 192.168.1.2 {"EVENTSOURCEIP":{"string":"192.168.1.2"},"SUM":{"long":15}} 192.168.1.2 {"EVENTSOURCEIP":{"string":"192.168.1.2"},"SUM":{"long":16}} 192.168.1.2 {"EVENTSOURCEIP":{"string":"192.168.1.2"},"SUM":{"long":19}} 192.168.1.2 {"EVENTSOURCEIP":{"string":"192.168.1.2"},"SUM":{"long":22}} Objects in Cloud storage gcs: gs://confluent-cloud-etl-demo/topics/COUNT_PER_SOURCE/year=2020/month=02/day=26/hour=03/COUNT_PER_SOURCE+1+0000000000.bin gs://confluent-cloud-etl-demo/topics/COUNT_PER_SOURCE/year=2020/month=02/day=26/hour=03/COUNT_PER_SOURCE+1+0000001000.bin gs://confluent-cloud-etl-demo/topics/COUNT_PER_SOURCE/year=2020/month=02/day=26/hour=03/COUNT_PER_SOURCE+1+0000002000.bin gs://confluent-cloud-etl-demo/topics/COUNT_PER_SOURCE/year=2020/month=02/day=26/hour=03/COUNT_PER_SOURCE+1+0000003000.bin gs://confluent-cloud-etl-demo/topics/COUNT_PER_SOURCE/year=2020/month=02/day=26/hour=03/COUNT_PER_SOURCE+1+0000004000.bin gs://confluent-cloud-etl-demo/topics/COUNT_PER_SOURCE/year=2020/month=02/day=26/hour=03/COUNT_PER_SOURCE+3+0000000000.bin gs://confluent-cloud-etl-demo/topics/COUNT_PER_SOURCE/year=2020/month=02/day=26/hour=03/COUNT_PER_SOURCE+3+0000001000.bin gs://confluent-cloud-etl-demo/topics/COUNT_PER_SOURCE/year=2020/month=02/day=26/hour=03/COUNT_PER_SOURCE+3+0000002000.bin gs://confluent-cloud-etl-demo/topics/COUNT_PER_SOURCE/year=2020/month=02/day=26/hour=03/COUNT_PER_SOURCE+3+0000003000.bin gs://confluent-cloud-etl-demo/topics/COUNT_PER_SOURCE/year=2020/month=02/day=26/hour=03/COUNT_PER_SOURCE+3+0000004000.bin gs://confluent-cloud-etl-demo/topics/SUM_PER_SOURCE/year=2020/month=02/day=26/hour=03/SUM_PER_SOURCE+1+0000000000.avro gs://confluent-cloud-etl-demo/topics/SUM_PER_SOURCE/year=2020/month=02/day=26/hour=03/SUM_PER_SOURCE+1+0000001000.avro gs://confluent-cloud-etl-demo/topics/SUM_PER_SOURCE/year=2020/month=02/day=26/hour=03/SUM_PER_SOURCE+1+0000002000.avro gs://confluent-cloud-etl-demo/topics/SUM_PER_SOURCE/year=2020/month=02/day=26/hour=03/SUM_PER_SOURCE+1+0000003000.avro gs://confluent-cloud-etl-demo/topics/SUM_PER_SOURCE/year=2020/month=02/day=26/hour=03/SUM_PER_SOURCE+3+0000000000.avro gs://confluent-cloud-etl-demo/topics/SUM_PER_SOURCE/year=2020/month=02/day=26/hour=03/SUM_PER_SOURCE+3+0000001000.avro gs://confluent-cloud-etl-demo/topics/SUM_PER_SOURCE/year=2020/month=02/day=26/hour=03/SUM_PER_SOURCE+3+0000002000.avro gs://confluent-cloud-etl-demo/topics/SUM_PER_SOURCE/year=2020/month=02/day=26/hour=03/SUM_PER_SOURCE+3+0000003000.avro
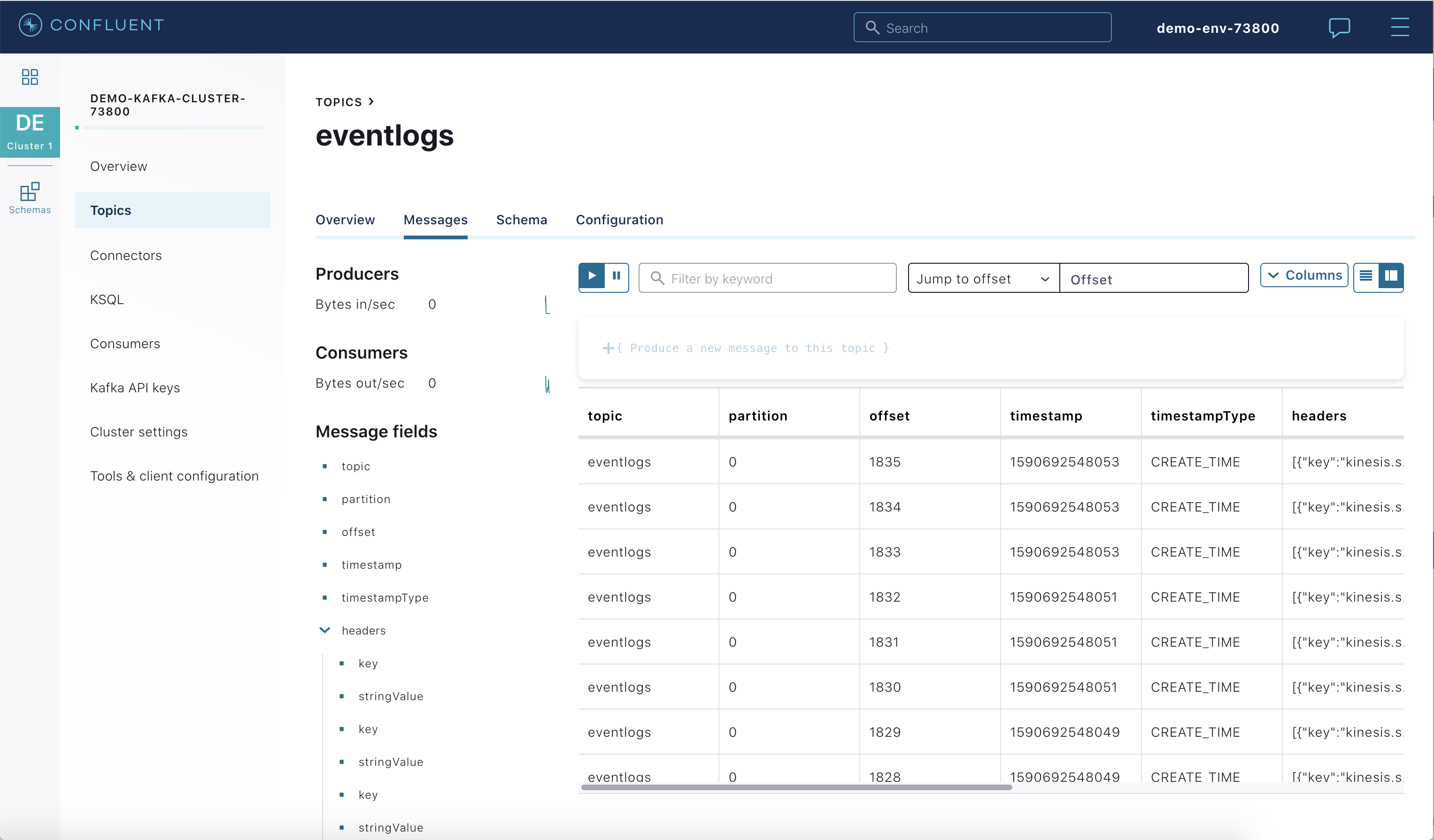
ソースにさらにエントリを追加し、Confluent Cloud Console または CLI に表示されるメッセージを見て、パイプラインを介してそれらのエントリが伝播されるのを確認します。
Kinesis を実行している場合:
./add_entries_kinesis.sh
RDS PostgreSQL を実行している場合:
./add_entries_rds.sh
Confluent Cloud Console で新しいメッセージを表示します。
サンプルの停止¶
Confluent Cloud のすべてのサンプルでは、実際の Confluent Cloud リソースを使用しています。Confluent Cloud のサンプルの実行を終了したら、予定外の課金を回避するために、すべての Confluent Cloud リソースが破棄されていることを直接確認してください。
詳細¶
サンプルを停止し、すべてのリソースのクリーンアップを行い、Kafka のトピックを削除します。フルマネージド型コネクターを削除し、クラウドストレージ内のデータを削除します。
./stop.sh stack-configs/java-service-account-<SERVICE ACCOUNT ID>.config
Confluent Cloud 内のリソースが破棄されたことを必ず確認してください。
その他のリソース¶
- その他の Confluent Cloud サンプルについては、Confluent Cloud のサンプルの概要 を参照してください。