Streams アプリケーションの実行¶
Kafka Streams ライブラリを使用する Java アプリケーションは、追加の構成や要件なしで実行できます。Kafka Streams では、アプリケーションのさまざまなステートの通知を受信する機能も提供しています。ランタイムステータスをモニタリングする機能については、「モニタリングガイド」で説明されています。
Kafka Streams アプリケーションの起動¶
Java アプリケーションを Fat JAR ファイルとしてパッケージ化した後、以下のようにアプリケーションを起動できます。
# Start the application in class `com.example.MyStreamsApp`
# from the fat JAR named `path-to-app-fatjar.jar`.
java -cp path-to-app-fatjar.jar com.example.MyStreamsApp
アプリケーションをこのようにパッケージ化する方法の詳細については、「Streams のコード例」を参照してください。
アプリケーションを起動することは、アプリケーションの Kafka Streams インスタンスを起動することです。アプリケーションの複数のインスタンスを実行できます。一般的なシナリオでは、アプリケーションの複数のインスタンスが並列に実行されます。詳細については、「並列処理モデル」を参照してください。
アプリケーションインスタンスの実行が開始されると、定義されたプロセッサートポロジーが 1 つ以上のストリームタスクとして初期化されます。プロセッサートポロジーでステートストアが定義されている場合は、初期化中にそれらも構築されます。詳細については、「ワークロードのバランス調整中のステートの復元」セクションを参照してください。
アプリケーションの柔軟なスケーリング¶
Kafka Streams では、柔軟でスケーラブルなストリーム処理アプリケーションを構築できます。アプリケーションの実行中でも、ダウンタイムやデータ損失を生じることなく、処理機能を動的に追加したり削除したりできます。このため、アプリケーションは障害発生時の回復性が高く、必要に応じてメンテナンスを実行することもできます(ローリングアップグレードなど)。
この柔軟性の詳細については、「並列処理モデル」セクションを参照してください。Kafka Streams では、Kafka ワイヤプロトコル に直接組み込まれている Apache Kafka® のグループ管理機能が利用されます。これが Kafka Streams アプリケーションの柔軟性を実現する基盤となっています。つまり、グループのメンバーが連携し、協調して、Kafka でのデータの消費と処理を行います。さらに Kafka Streams は、アプリケーションインスタンスが任意のタイミングで増減する可能性のある環境で、ステートフルな処理を提供し、フォールトトレラントなステートを実現します。
アプリケーションへの処理容量の追加¶
ストリーム処理アプリケーションの処理容量を増やす必要がある場合は、ストリーム処理アプリケーションの別のインスタンスを起動できます。たとえば、たとえば、インスタンスを別のマシンで起動するだけでスケールアウトできます。アプリケーションのインスタンスは互いを認識し、自動的に処理の共有を開始します。具体的には、既存のインスタンスから新しいインスタンスに対して、既存のインスタンスで実行されていたストリームタスク(の一部)が引き渡されます。1 つのインスタンスから別のインスタンスにストリームタスクを移動すると、それらのストリームタスクの処理とすべての内部ステートが移行されます(ストリームタスクのステートは、対応する changelog トピックからステートを復元することでターゲットインスタンスに再作成されます)。
アプリケーションのさまざまなインスタンスは、それぞれ独自の JVM プロセスで実行されます。したがって、各インスタンスでは、それぞれの JVM プロセスで利用可能なすべての処理容量を(アプリケーションの Kafka Streams 以外の部分で使用される容量を除いて)活用することができます。インスタンスの追加実行によってアプリケーションの処理容量を増やすことができるのはこのためです。新しいインスタンスを実行することで追加される正確な容量は、搭載されている CPU コアの数、使用可能なメインメモリーと Java ヒープ領域、ローカルストレージ、ネットワーク帯域幅など、新しいインスタンスが実行される環境に依存します。同様に、アプリケーションの実行中のインスタンスを停止すると、対応する処理容量が削除されることになります。
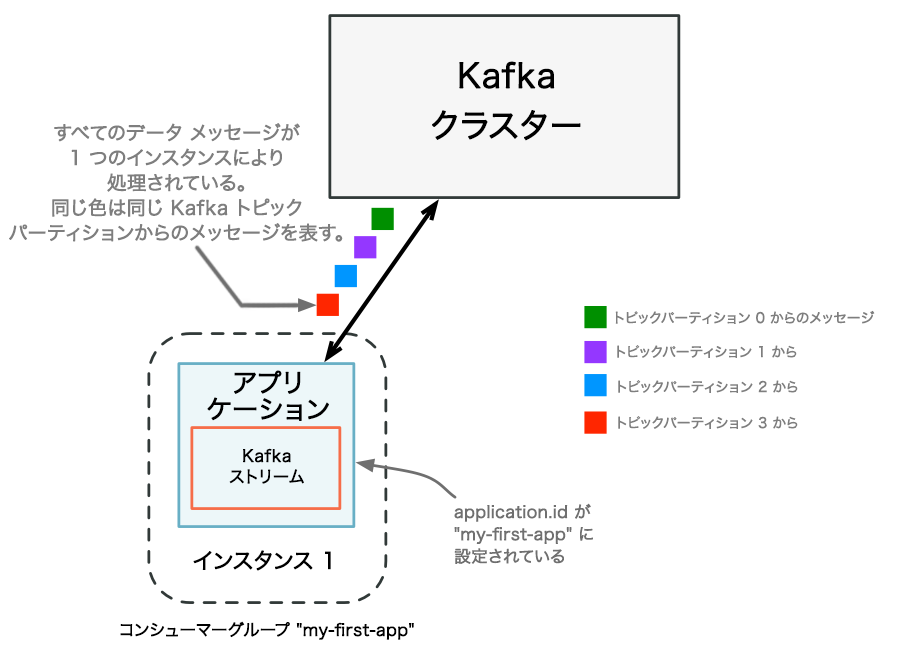
処理容量の追加前 : Kafka Streams アプリケーションの単一のインスタンスだけが実行されています。この時点では、アプリケーションに対応する Kafka コンシューマーグループに含まれるメンバーは 1 つ(このインスタンス)だけです。すべてのデータはこの単一のインスタンスで読み取られ、処理されます。¶
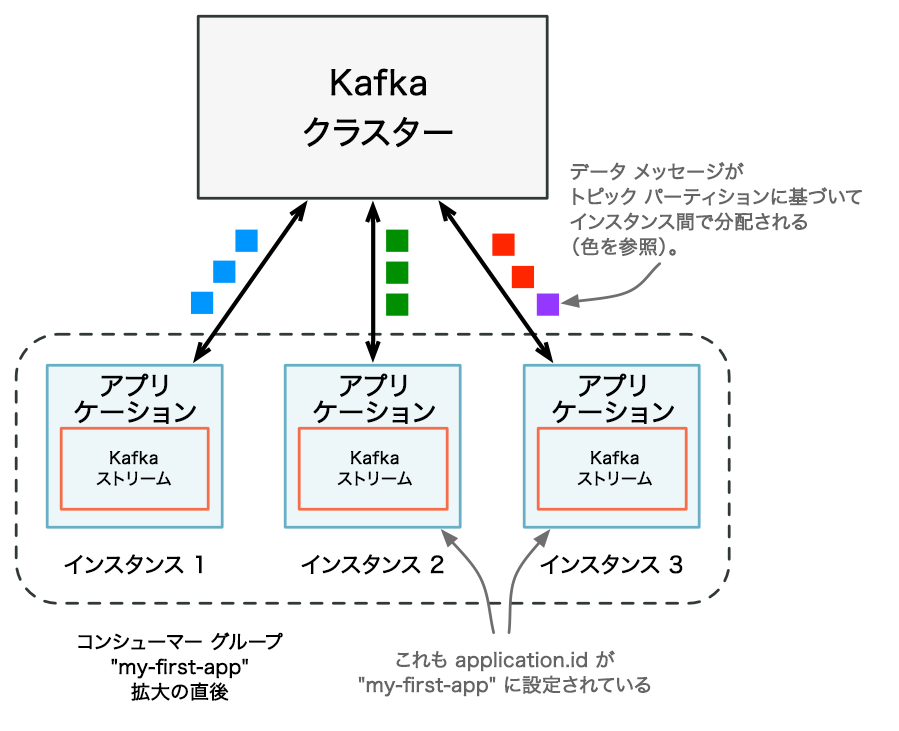
処理容量の追加後 : Kafka Streams アプリケーションの 2 つのインスタンスが追加で実行され、自動的にアプリケーションの Kafka コンシューマーグループに参加します。グループには現在、合計 3 つのメンバーが含まれます。これらの 3 つのインスタンスは、互いの間で自動的に処理を分割します。分割は、データの読み取り元の Kafka トピックパーティションに基づいて行われます。¶
アプリケーションからの処理容量の削除¶
処理容量を減らすには、ストリーム処理アプリケーションのインスタンスの実行を停止します(たとえば、4 つのインスタンスのうちの 2 つをシャットダウンします)。停止したインスタンスは自動的にアプリケーションのコンシューマーグループから離脱し、アプリケーションの残りのインスタンスが自動的に処理を引き継ぎます。停止したインスタンスで実行されていたストリームタスクは、残りのインスタンスによって引き継がれます。1 つのインスタンスから別のインスタンスにストリームタスクを移動すると、それらのストリームタスクの処理とすべての内部ステートが移行されます。ストリームタスクのステートは、changelog トピックからターゲットインスタンスに再作成されます。
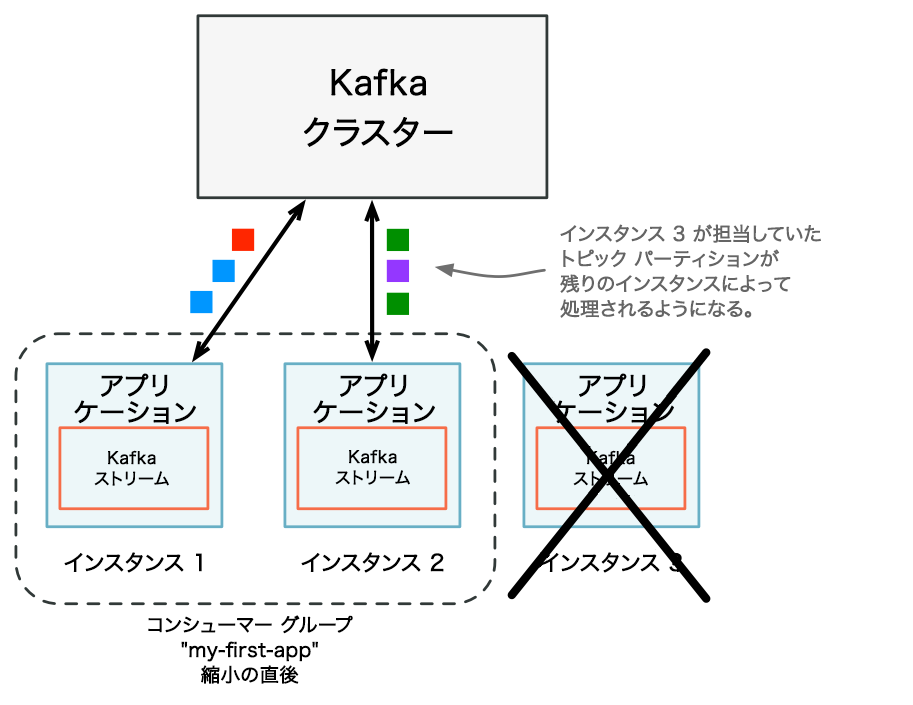
ワークロードのバランス調整中のステートの復元¶
タスクが移行されると、アプリケーションインスタンスで処理が再開される前に、タスクの処理ステートが完全に復元されます。これによって正しい処理結果が保証されます。Kafka Streams でのステートの復元は、通常、対応する changelog トピックを再生してステートストアを再構成することで行われます。レプリケートされたローカルステートストアを使用して、changelog に基づく復元のレイテンシを最小限に抑えるには、num.standby.replicas を指定します。アプリケーションインスタンスでストリームタスクが初期化または再初期化されるとき、次のようにステートストアが復元されます。
- ローカルステートストアが存在しない場合は、changelog が最も古いオフセットから現在のオフセットまで再生されます。これにより、ローカルステートストアが最新のスナップショットに再構築されます。
- ローカルステートストアが存在する場合は、changelog が前回チェックポイントされたオフセットから再生されます。変更が適用され、ステートが最新のスナップショットに復元されます。この方法では、適用先が changelog の小さい部分になるため、必要な時間が短縮されます。
詳細については、「スタンバイレプリカ」を参照してください。
バージョン 2.6 では、Kafka Streams はウォームアップレプリカを使用して、タスクの復元の大部分をバックグラウンドで実行します。ウォームアップレプリカは、タスクのステートを大量に復元する必要のあるインスタンスに割り当てられます。ステートフルなアクティブタスクは、ステートが acceptable.recovery.lag で構成された範囲内にあるインスタンスにのみ割り当てられます。このため、タスクの移行時にそのタスクでダウンタイムが発生することはほとんどありません。タスクは、移行先のインスタンスでステートの復元が行われている間、既にキャッチアップされているインスタンス上にアクティブなまま残ります。Kafka Streams は、復元が終了したウォームアップタスクを 定期的に調べ、準備ができたものをアクティブタスクに移行します。
注釈
ただし、どのインスタンスにもキャッチアップされたバージョンのタスクがなければ、このタスクの可用性は適用されません。この場合、Kafka Streams では、キャッチアップしていないインスタンスにアクティブタスクを割り当てるしかなく、changelog からタスクのステートを復元する処理はブロックしなければなりません。高可用性がアプリケーションにとって重要な場合は、スタンバイを有効にすることを強くお勧めします。
実行するアプリケーションインスタンス数の決定¶
Kafka Streams アプリケーションの並列性は、主に入力トピックのパーティション数によって決まります。たとえば、アプリケーションが 1 つのトピックから読み取る場合、そのトピックに 10 個のパーティションがあるとすると、アプリケーションのインスタンスは最大 10 個実行できます。それ以上のインスタンスも実行できますが、それらはアイドル状態になります。
トピックパーティションの数は、Kafka Streams アプリケーションの並列処理の上限であり、アプリケーションの実行インスタンス数の上限です。
アプリケーションインスタンス間でバランスの取れたワークロード処理を実現し、処理のホットスポットが生じるのを防ぐには、データと処理のワークロードを分散する必要があります。
- データは、トピックパーティション間で均等に分散する必要があります。たとえば、2 つのトピックパーティションにそれぞれ 100 万件のメッセージがある状況は、1 つのパーティションに 200 万件のメッセージがあり、もう 1 つに何もないよりも好ましい状況です。
- 処理のワークロードも、トピックパーティション間で均等に分散する必要があります。たとえば、メッセージの処理時間が大きく異なる場合、処理能力を集中的に使用するメッセージは同じパーティション内に格納せず、パーティション間で分散する方が良策です。
注釈
このウェブサイトには、Apache License v2 の条件に基づいて Apache Software Foundation で開発されたコンテンツが含まれています。