Control Center の構成¶
Control Center は Confluent Platform のコンポーネントであり、Confluent Platform バンドルの一部として インストール されます。
システム要件¶
Control Center の完全なシステム要件については、Confluent Platform のシステム要件 を参照してください。
重要
Control Center を使用するには、アプリケーションを実行するホストにアクセスできる必要があります。ユーザーは、Control Center がデータを扱うために使用するネットワークポートを 構成 できます。Control Center はウェブアプリケーションのため、プロキシを使用してアクセスを制御したりセキュアにできます。
モード¶
Confluent Platform バージョン 7.0.0 から、Control Center では、ユーザーが 2 つのモードから選択できるようになりました。1 つは "標準" モードで、以前のバージョンの Confluent Control Center と同様に、管理およびモニタリングサービスが含まれています。もう 1 つは "インフラストラクチャ軽減" モードで、モニタリングサービスが無効となり、Control Center の運用によるリソースの負荷が低下します。モードは、モードプロパティ で構成します。Control Center のモードを明示的に設定しない場合、Confluent Control Center はデフォルトで標準モードになります。
データの保持¶
Control Center では、クラスターメタデータおよびユーザーデータ(アラートのトリガーおよびアクション)が _confluent-command トピックに保管されます。このトピックはアップグレード時に変更されません。このトピックをリセットするには、confluent.controlcenter.command.topic 構成を別の名前(_confluent-command-2 など)に変更し、Control Center を再起動します。これにより、クラスターメタデータのインデックス再作成が行われ、すべてのトリガーおよびアクションが削除されます。
保持期間のデフォルト¶
Control Center での保持期間のデフォルト設定は次のとおりです。
- モニタリングトピック(
_confluent-monitoring): 3 日分のデータ - メトリクストピック(
_confluent-metrics): 3 日分のデータ - コマンドトピック(
_confluent-command): 1 日分のデータ - 各内部トピック: 7 日分のデータ(内部メトリクスおよびモニタリングトピック を除く)
つまりメンテナンスのために Control Center を 24 時間停止してもデータは失われません。
これらの値は、以下の構成パラメーターを設定することにより変更できます。
confluent.monitoring.interceptor.topic.retention.msconfluent.metrics.topic.retention.msconfluent.controlcenter.internal.topics.retention.ms
構成は可能ですが、コマンドトピックの保持期間(confluent.controlcenter.command.topic.retention.ms)を短縮しても Control Center の使用量に対する影響はごくわずかです。
内部メトリクスおよびモニタリングの保持¶
Control Center には、集約のために使用する、他の内部トピックもあります。これらのトピック上のデータは、データ型に基づいた異なる保持期間で維持されます。
- 内部ストリームモニタリングデータは 2 つの保持レベルで維持されます。詳細データは 96 時間、履歴データは 700 日です。たとえば、同じ数のトピックに対してデータの詳細度の読み取りを行っているクライアントの数と書き込みを行っているクライアントの数が同数の場合、必要な領域の量は、96 時間実行するために必要な量のおよそ 2 倍です。
- 内部メトリクスデータの保持期間は 7 日です。1 つのクラスターにあるトピックのパーティションの数が一定している場合、メトリクスデータ用に使用されるデータの量は直線的に増加し、7 日間の累積で最大限に達します。
Control Center のデフォルトでは、可用性とフォールトトレランスのためにすべてのトピックのパーティション上に 3 つのコピーを保管します。
「Control Center 構成リファレンス」に、すべての構成オプションが掲載されています。
参考
この構成の動作例については、Confluent Platform デモ を参照してください。構成リファレンスについては、デモの docker-compose.yml ファイル を参照してください。
パーティションおよびレプリケーション¶
以下の行を適切なプロパティファイル(<path-to-file>/etc/confluent-control-center/control-center.properties)に追加することにより、Control Center のパーティション(<num-partitions> )およびレプリケーション(<num-replication>)の数の設定を定義します。
confluent.controlcenter.internal.topics.partitions=<num-partitions>
confluent.controlcenter.internal.topics.replication=<num-replication>
confluent.controlcenter.command.topic.replication=<num-replication>
confluent.monitoring.interceptor.topic.partitions=<num-partitions>
confluent.monitoring.interceptor.topic.replication=<num-replication>
confluent.metrics.topic.partitions=<num-partitions>
confluent.metrics.topic.replication=<num-replication>
詳細については、「Control Center 構成リファレンス」を参照してください。
マルチクラスター構成¶
Control Center を使用して、複数の Apache Kafka® クラスターを管理およびモニタリングできます。または、Confluent Health+ を使用してマルチクラスター構成をモニタリングすることもできます。詳細については、「Health+ の有効化」を参照してください。
インターセプターおよび Metrics Reporter からのすべてのメトリックデータには Kafka クラスター ID によってタグが付けられ、Control Center 内でクラスター ID ごとに集約されます。クラスター ID は Apache Kafka によってランダムに生成されますが、Control Center を使用してわかりやすい名前を割り当てることができます。
注釈
Control Center 内のマルチクラスター構成では、追加の接続構成を追加するときにクラスター ID ではなくクラスター <name> を指定する場合は、パラメーター文字列に .streams を含めないでください。詳細については、接続構成 の設定に関する説明を参照してください。
前提条件¶
- Control Center をインストールし、標準モードで実行していること。
- 複数の Kafka クラスターが既に実行されていること。Control Center で新しいクラスターをデプロイすることはできません。
- モニタリングを有効にするために、各 Kafka クラスターで Confluent Metrics Reporter が構成されていること。
- 各 Kafka クラスターが独自の
confluent.controlcenter.kafka.<name>.bootstrap.servers構成を使用して Control Center 構成内に指定されていること。詳細については、「Control Center 構成リファレンス」を参照してください。
参考
Control Center およびマルチクラスター構成の動作例については、 マルチデータセンターの GitHub のデモ を参照してください。構成リファレンスについては、デモの docker-compose.yml を参照してください。
マルチクラスター環境にインターセプターおよび Metrics Reporter のプラグインを構成する基本的な方式には、直接 と レプリケーション の 2 通りがあります。いずれの方式でも、単一の Control Center サーバーをインストールし、単一の Kafka クラスターに接続します。このクラスターが Control Center のストレージおよびコーディネーターとして動作します。
- 直接 : 直接方式を使用する場合、プラグインでは Control Center クラスターにデータを直接レポートすることになります。ご使用のネットワークトポロジーでインターセプターおよび Metrics Reporter から Control Center クラスターへの直接通信が許可されている場合は、直接方式をお勧めします。
- レプリケーション : レプリケーション方式を使用する場合、プラグインではアクセスできるローカル Kafka クラスターにデータをレポートすることになります。Replicator プロセスによってデータが Control Center クラスターにコピーされます。詳細については、 Replicator のクイックスタート を参照してください。レプリケートされた構成はインターセプターをデプロイするにあたって簡単に使用できます。デフォルトではインターセプターはローカルクラスターにレポートすることになるためです。この方式を使用するのは、ネットワークトポロジーによって Control Center プラグインが Control Center クラスターと直接通信できない場合や、Replicator の使用経験があり操作に慣れている場合です。
直接
Control Center Kafka クラスターにメトリクスデータを直接送信するようにインターセプターを構成できます。このクラスターは、モニタリング対象のクライアントの接続先である Kafka クラスターとは別にすることができます。
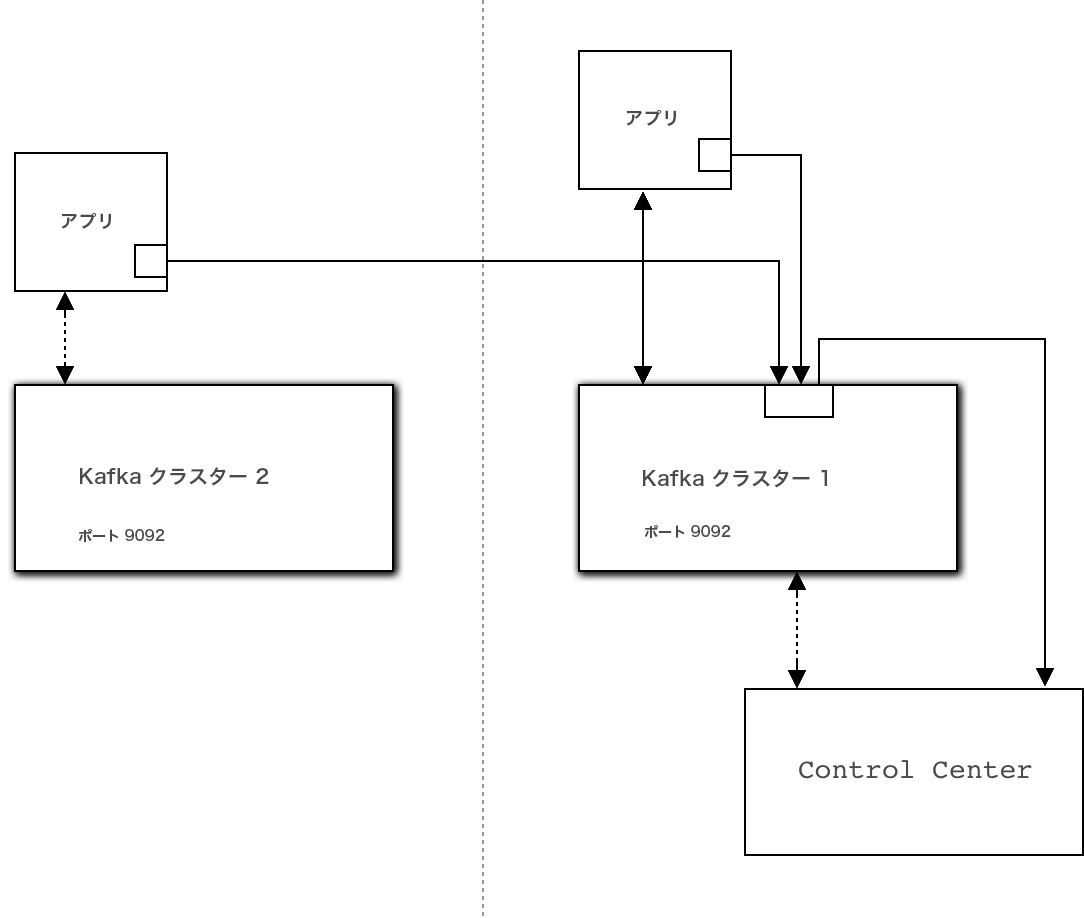
直接構成の例です。実線は、インターセプターデータのフローを示します。¶
この方式の第一のメリットは、モニタリング対象のクラスターの可用性の問題に関して、堅牢な保護機能を提供できることです。
第一のデメリットは、すべての Kafka クライアントに Control Center Kafka クラスター接続パラメーターを構成する必要があることです。特に Confluent Control Center のセキュリティ が有効にされている場合は、時間がかかる可能性があります。
次にクライアントの構成の一例を示します。
bootstrap.servers=kafka-cluster-1:9092 # this is the cluster your clients are talking to
confluent.monitoring.interceptor.bootstrap.servers=kafka-cluster-2:9092 # this is the Control Center cluster
レプリケーション
デフォルトでは、インターセプターおよび Metrics Reporter は、モニタリング対象と同じ Kafka クラスターにデータを送信します。Confluent Replicator を使用すると、Control Center によって使用されている Kafka クラスター内にこのデータを転送してマージできます。_confluent-monitoring トピックおよび _confluent-metrics トピックは Control Center クラスターにレプリケートされる必要があります。
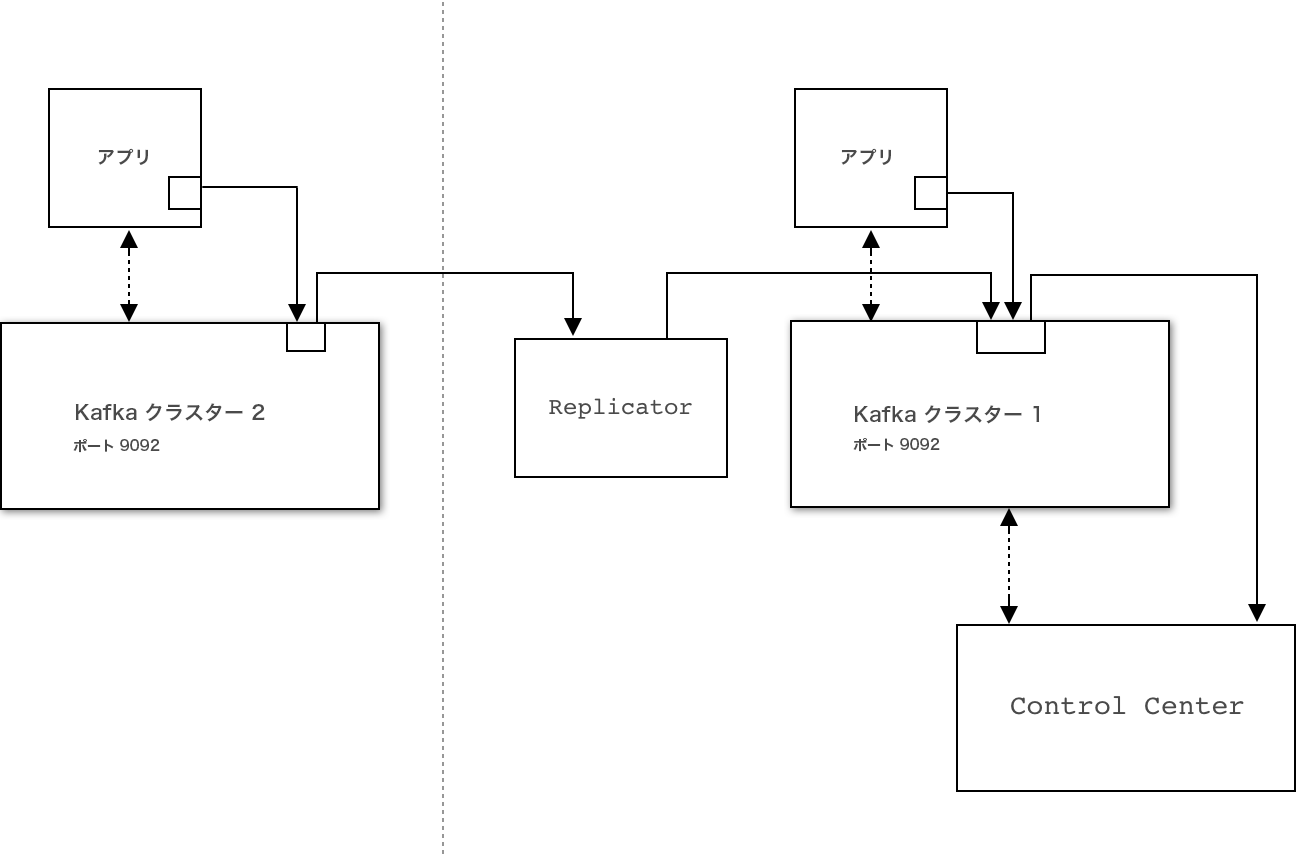
レプリケーション構成の例です。実線は、インターセプターおよびクラスターのデータのフローを示します。¶
専用メトリックデータクラスター¶
モニタリングデータは既存の Kafka クラスターに送信するか、送信先専用クラスターを構成することができます。
Control Center 専用の Kafka クラスターを用意することには、以下のようなメリットがあります。
- Control Center を独自の Kafka クラスター上でホストすることにより、モニタリング対象の生成クラスターの可用性に依存しません。たとえば、重大な生成問題が発生しているときも、引き続きアラートを受信して Control Center モニタリング情報を表示できます。生成で大きな障害が起きているときこそ、これらのメトリクスが最も必要とされます。
- アップグレードが簡単です。将来のバージョンの Control Center では、おそらく Kafka の新機能が利用されます。Control Center 用に別の Kafka クラスターを使用すれば、アップグレードパスに生成 Kafka クラスターが含まれていない場合に Control Center の将来のバージョンに搭載される新機能を簡単に利用できる可能性があります。
- クラスターはセキュリティ要件が低く、前述の直接方式を実装しやすい可能性があります。
- Control Center では、メトリクス収集のために大量のディスク領域とスループットを必要とします。Control Center に独自の専用クラスターを割り当てることにより、Control Center のワークロードが本稼働環境のトラフィックと干渉しないことが保証されます。
Control Center に独自の Kafka クラスターを割り当てる主なデメリットは、専用クラスターに追加の仮想または物理ハードウェア、セットアップ、およびメンテナンスが必要である点です。
飽和テスト¶
Control Center には、シミュレーションされたモニタリングデータを使った飽和テストが実施されています。テストの目的は、いくつかの重要なディメンションに沿って、Control Center で正常にモニタリングできる最大サイズのクラスターを突き止めることです。
テストのセットアップ¶
以下の要素で構成される、Confluent Cloud 上で実行されている Kafka クラスターです。
- AWS EC2 r4.xlarge 上で実行されている 4 台の Kafka ノード。
- 232 個の初期トピックパーティション(内部トピックを含む)。
- レプリケーション係数 3。各トピックパーティションには 3 つのレプリカがあり、各パーティションレプリカが独自のメトリクスを送信します。トピックパーティションの合計が X 個の場合、3X 個のパーティションについてパーティションレベルのメトリクスが送信されます。
- 1 つの初期ユーザートピックパーティション。
- 3 つの Kafka ブローカー。
- AWS EC2 m4.2xlarge 上で、標準モードで実行されている 1 つの Confluent Control Center インスタンス。
- 負荷を生成する 2 つのノード。1 つはブローカーモニタリング用、1 つはストリームモニタリング用です。
- 各ユーザートピックはパーティション 12 個で作成されています。
- 8 個の ストリームスレッド。これは
confluent.controlcenter.streams.num.stream.threadsのデフォルト構成です。 - JDK 8
ブローカーモニタリング¶
3 台のブローカーがあり、プロデューサーおよびコンシューマーを持たない単一のクラスターによるシミュレーションで Kafka メトリクスが生成されました。Control Center 上でラグを観察するまで、シミュレートされたクラスター上のパーティションの数を増やしました。
結果: 10,000 個のパーティションまで増やすことができました。Control Center は、着信メトリクスを遅れなく処理します。
注意事項: サイジングまたはネットワークトポロジーに変更があると、結果は異なります。
ストリームモニタリング¶
3 台のブローカーがあり、250 個のトピックに 5000 個のパーティションがある 1 つのクラスターを想定してメトリクスが生成されました。コンシューマーグループの数を 5,000 単位で 1 ~ 100,000 まで増やし、消費の完全性とラグに関するデータを報告させました。シミュレートされた各コンシューマーグループには、単一のパーティションから読み取る単一のコンシューマーを含めました。
結果 : 20,000 コンシューマーグループの時点で Control Center がこのサーバーサイズでは着信データを処理できなくなり、レポートが遅れていました。
注意事項: 20,000 コンシューマーまでテストしましたが、プロデューサーはありませんでした。この点は、モニタリング容量に影響した可能性があります。
デプロイの例¶
内部でテストした Control Center セットアップの例をいくつか示します。
ブローカーモニタリング¶
- 環境:
- Confluent Control Center × 1(EC2 m4.2xlarge 上で実行)
- Kafka ブローカー× 3
- ZooKeeper × 1
- トピック× 200
- トピックあたりのパーティション× 10
- レプリケーション係数 3
- デフォルトの JVM の設定
- デフォルトの Control Center 構成
- デフォルトの Kafka 構成
- 予期される結果:
- Control Center ステートストアのサイズは 1 時間あたり 50 MB 以下
- Kafka のログのサイズは 1 時間あたり 500 MB 以下(ブローカーあたり)
- 平均 CPU 負荷は 7% 以下
- 割り当てられる Java オンヒープメモリーは 580 MB 以下、オフヒープメモリーは 100 MB 以下
- ページキャッシュを含む、割り当てられたメモリーの合計は 3.6 GB 以下
- ネットワーク読み取りの利用率は 150 KB/秒以下
- ネットワーク書き込みの利用率は 170 KB/秒以下
ストリームモニタリング¶
- 環境:
- Confluent Control Center × 1(EC2 m4.2xlarge 上で実行)
- Kafka ブローカー× 3
- ZooKeeper × 1
- トピック× 30
- トピックあたりのパーティション× 10
- コンシューマー× 150
- コンシューマーグループ× 50
- レプリケーション係数 3
- デフォルトの JVM の設定
- デフォルトの Control Center 構成
- デフォルトの Kafka 構成
- 予期される結果:
- Control Center ステートストアのサイズは 1 時間あたり 1 GB 以下
- Kafka のログのサイズは 1 時間あたり 1 GB 以下(ブローカーあたり)
- 平均 CPU 負荷は 8% 以下
- 割り当てられる Java オンヒープメモリーは 600 MB 以下、オフヒープメモリーは 100 MB 以下
- ページキャッシュを含む、割り当てられたメモリーの合計は 4 GB 以下
- ネットワーク読み取りの利用率は 160 KB/秒以下
- ネットワーク書き込みの利用率は 180 KB/秒以下
次のステップ¶
- トラブルシューティングについては、「Control Center のトラブルシューティング」を参照してください。
- ストリームモニタリングを含む完全な例については、「Confluent Platform のクイックスタート」を参照してください。