システム正常性(非推奨のビュー)¶
システム正常性ビューは、Apache Kafka® クラスターの正常性に関する詳細なデータを、ブローカーとトピックそれぞれを中心とした 2 つの観点から提供します。
注釈
このビューは非推奨であり、Confluent Platform 5.3 以降のバージョンではデフォルトで使用できません。これを再度有効にするには、適切な control-center.properties ファイル内で confluent.controlcenter.deprecated.views.enable=true を設定します。以前のビューを戻す場合、RBAC を Control Center 内で有効にできません。以前のビューは RBAC が有効になっている環境では表示できないためです。このビュー内に提示される情報は、RBAC が有効化された状態で、再設計された現在の GUI のさまざまな場所でも利用可能です。最新のモニタリングおよびシステム正常性情報については、「1 つのコンシューマーグループについて消費の詳細を表示する」および「ブローカー」を参照してください。
ナビゲーション¶
Control Center プロパティファイル内でこの非推奨の機能を有効にすると、クラスターナビゲーションサブメニューに System health オプションが表示されます。
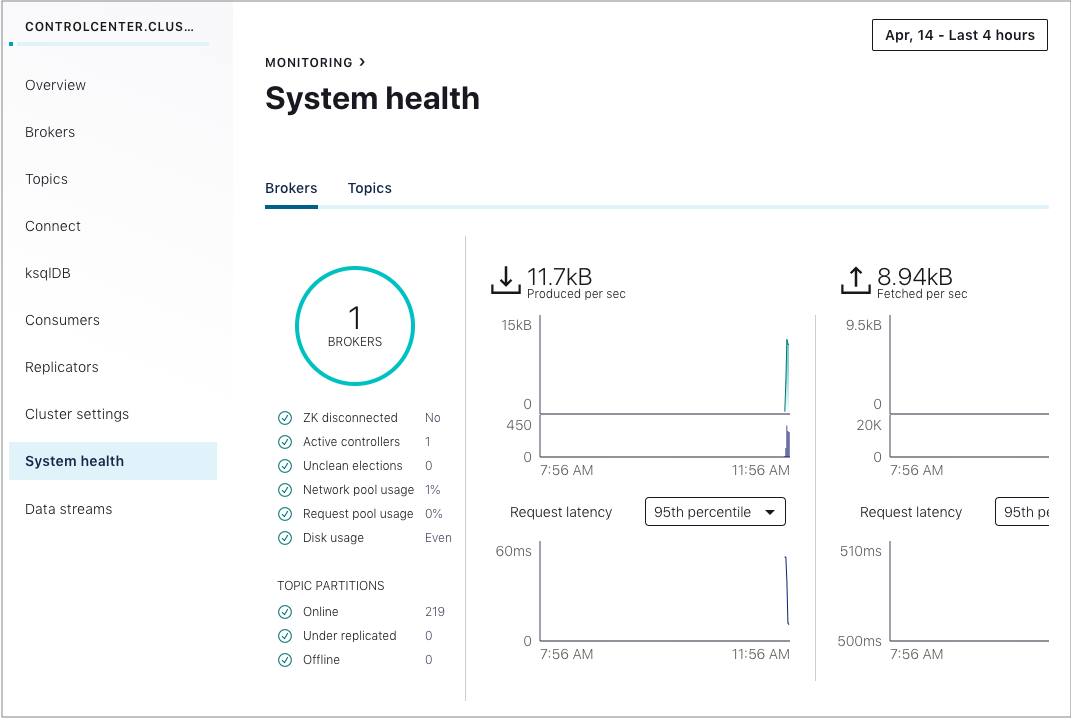
このビュー内でシステム正常性を確認するには、次の手順に従います。
Brokers タブをクリックしてブローカーのビューを表示するか、Topics タブをクリックしてトピックのビューを表示します。
左側のナビゲーション上の使用率メトリクスをクリックして、詳細情報を表示します。
省略記号(
...)をクリックし、トピックテーブルの各行で View details を選択します。Brokers ビューのタブでは、リクエストレイテンシパーセンタイルのドロップダウンからパーセンタイルを選択できます。
ちなみに
リクエストレイテンシパーセンタイルは、Brokers タブ内でのみ使用できます。
UI の共通点¶
- チャートツールチップ
- 各チャートにマウスオーバーすると、同じようなスタイルのツールチップが表示されます。これらのツールチップには複数のメトリクスが同時に表示されることがあり、それぞれアイコンを伴います。アイコンは良好であることを示すチェックマークか、問題があることを示す X 記号です。
- テーブルメトリックの検証
- 選択したテーブルメトリクスは外観が変わり、赤い下線で潜在的な問題を示します。赤い下線の付いたテキストにマウスオーバーすると、説明のツールチップが表示されます。
ブローカーの各種メトリクス¶
- ブローカー数
- 現在オンラインで、Confluent Metrics Reporter が有効になっている、クラスター内のブローカーの合計数です。ブローカー数がクラスター内のブローカーの数未満であり、レプリケーション数が不足しているトピックパーティションがある場合は、ブローカーテーブルで欠落しているブローカーを調査します。ブローカーログを調べて、WARN または ERROR のメッセージを確認します。
- ZooKeeper の切断
- 前回のインターバルで少なくとも 1 つのブローカーが ZooKeeper から切断されました。これが Yes の場合は、ブローカーと ZooKeeper の間のネットワーク接続およびレイテンシをチェックし、ZooKeeper が稼働していることを確認します。必要に応じて、ブローカー構成パラメーター
zookeeper.session.timeout.msを調整します。 - クリーンでない選出
前回のインターバルでレポートされた、クラスター内のクリーンでないパーティションリーダー選出の数です。
非同期レプリカ間でクリーンでないリーダー選出が維持され、前のリーダーが失われる前に同期されていなかったメッセージがある場合、データ損失の恐れがあります。したがって、クリーンでない選出の数が 0 より大きい場合は、ブローカーログを調べてリーダーが再選出された理由を判別し、WARN または ERROR メッセージを探してください。ブローカー構成パラメーター
unclean.leader.election.enableをfalseに設定して、一連の同期レプリカから外れているレプリカが決してリーダーに選出されないようにすることを検討してください。- ネットワークプール使用率
- すべてのブローカーの平均ネットワークプール容量使用率、つまり、ネットワークプロセッサースレッドがアイドルではなかった時間の割合です。ネットワークプール使用率が 70% を超える場合は、生成リクエストレイテンシおよびフェッチリクエストレイテンシのメトリクスを調べて、ブローカーで最も時間のかかっている部分を特定してください。ブローカー構成パラメーター
num.network.threadsの値を大きくすることを検討してください。 - リクエストプール使用率
- すべてのブローカーの平均リクエストハンドラー容量使用率、つまり、リクエストハンドラースレッドがアイドルではなかった時間の割合です。リクエストプール使用率が 70% を超える場合は、生成リクエストレイテンシおよびフェッチリクエストレイテンシのメトリクスを調べて、ブローカーで最も時間のかかっている部分を特定してください。ブローカー構成パラメーター
num.io.threadsの値を大きくすることを検討してください。 - ディスク使用量
- クラスター内のすべてのブローカーのディスク使用量分布です。すべてのブローカーサイズの相対的絶対平均差が 10% を超えており、任意の 2 つのブローカー間で差異が 1 GB を超えている場合、ディスク使用量に偏りがあると判別されます。ディスク使用量に偏りがある場合は、Confluent Auto Data Balancer を使用してクラスターのリバランスを行うことを検討してください。
- オンラインのトピックパーティション
- クラスター内でオンラインになっている(つまり、ブローカーを実行している)トピックパーティションの合計数です。オンラインのトピックパーティションの数がクラスター内のトピックパーティションの数未満である場合は、Topics タブに示されるトピックメトリクスを調べてください。
- Under replicated topic partitions
レプリケーション数が不足している(つまり同期レプリカ数がレプリケーション係数未満のパーティションである)、クラスター内のトピックのパーティションの合計数です。
レプリケーション数が不足しているトピックパーティションの数が 0 より大きい場合は、Topics タブに示されるトピックメトリクスと、トピックパーティションが欠落しているブローカーを調べてください。ブローカーログを調べて、WARN または ERROR のメッセージを確認します。
- オフラインのトピックパーティション
クラスター内のオフラインであるトピックパーティションの合計数です。これはレプリカを持つブローカーが停止しているか、クリーンでないリーダーの選出が無効であるときにレプリカが同期しておらず、したがってリーダーに選出されるブローカーがない(メッセージが失われないためにはこれが望ましい)場合に発生します。
オフライントピックパーティションの数が 0 より大きい場合は、Topics タブに示されるトピックメトリクスと、トピックパーティションが欠落しているブローカーを調べてください。ブローカーログを調べて、WARN または ERROR のメッセージを確認します。
チャートの作成とフェッチ¶
クライアントが Kafka にデータを書き込むときは、クライアントがリーダーブローカーにプロデュースリクエストを送信し、リーダーブローカーがプロデュースリクエストを処理して応答をクライアントに送信します。クライアントが Kafka からデータを読み出すときは、クライアントがリーダーブローカーにフェッチリクエストを送信し、リーダーブローカーがフェッチリクエストを処理して応答をクライアントに送信します。クラスターが最適なパフォーマンスを確実に発揮する状態にするには、これらのプロデュースおよびフェッチのリクエストのスループットおよびレイテンシを監視することが重要です。
システム正常性ビューのブローカーおよびトピックの各タブで、プロデュースリクエストとフェッチリクエストのサマリーを確認できます。
左側にはプロデュースされたメトリクスが表示され、右側にはフェッチされたメトリクスが表示されます。
Brokers または Topics のいずれかのタブで、ブローカーまたはトピックのテーブルの個別行にマウスオーバーすると、チャート内に該当する個々のブローカーまたはトピックのリクエスト統計がオーバーレイされます。
一番上のチャートにマウスオーバーすると、特定のインターバルについてリクエストスループットを参照できます。
- プロデュース/フェッチされた 1 秒あたりのバイト数
- このクラスターに対してプロデュースされたか、このクラスターからフェッチされたデータの 1 秒あたりの合計バイト数です。
- 成功したリクエスト
- 1 分間のインターバルでこのクラスターに対してプロデュースされたか、このクラスターからフェッチされた、成功したリクエストの合計数です。
- 失敗したリクエスト
- 1 分間のインターバルでこのクラスターに対してプロデュースされたか、このクラスターからフェッチされた、失敗したリクエストの合計数です。
ブローカーメトリクステーブル¶
- ID
- このブローカーの ID
- Throughput
Bytes in: このブローカーに対してプロデュースされた 1 秒あたりのバイト数です。
Bytes out: このブローカーからフェッチされた 1 秒あたりのバイト数です(内部レプリケーショントラフィックは対象外)。
- Latency (produce)
- このブローカーに対する生成リクエストの平均、95、99、99.9 パーセンタイルでのレイテンシです(単位: ミリ秒)。
- Latency (fetch)
- このブローカーに対するフェッチリクエストの平均、95、99、99.9 パーセンタイルでのレイテンシです(単位: ミリ秒)。
- Partition replicas
- このブローカーによって提供されるパーティションレプリカの合計数です。
- Segment
- このブローカーによって提供されるログセグメントのバイト単位での合計サイズです(インデックスサイズを除く)。
- Rack
- このブローカーのラック ID です。
トピックの各種メトリクス¶
- トピック数
クラスター内のトピックの合計数です。トピック数が想定よりも少ない場合は、欠落しているトピックに対してクライアントがプロデュースかコンシュームを行っていることを確認します。
ちなみに
以下の内部トピックはトピック合計数に含まれません。
__consumer_offsets __transaction_state
- 同期レプリカ
リーダーと同期しているクラスター内のトピックのパーティションレプリカの合計数、つまり各(トピックのパーティション * トピックのレプリケーション係数)の合計です。
同期レプリカの数がクラスター内のレプリカの数未満の場合は、非同期レプリカのあるトピックをトピックテーブルから識別し、トピックの 詳細を表示 して非同期のブローカーを判別します。ブローカーログを調べて原因を判別します。
- 非同期レプリカ
- リーダーと非同期である、クラスター内のトピックパーティションレプリカの合計数です。非同期レプリカの数が 0 より大きい場合は、非同期レプリカのあるトピックをトピックテーブルから識別し、トピックの 詳細を表示 して非同期のブローカーを判別します。ブローカーログを調べて原因を判別します。
トピックメトリクステーブル¶
- Name
- トピック名です。
- Throughput
Bytes in: このトピックに対してプロデュースされた 1 秒あたりのバイト数です。
Bytes out: このトピックからフェッチされた 1 秒あたりのバイト数です(内部レプリケーショントラフィックは対象外)。
- Partition replicas
Total: このトピックのパーティションレプリカの合計数です。
In sync: 同期パーティションレプリカの合計数です。
Out of sync: 非同期パーティションレプリカの合計数です。
- Partitions
Total: このトピックのパーティションの数です。
Under replicated: レプリケーション数が不足している、つまり同期レプリカ数がレプリケーション係数未満のパーティションの数です。
- Segment
Count: すべてのパーティションリーダーを対象とした、このトピックのログセグメントの数です。
Size: このトピックのログのバイト単位のサイズです(レプリカを含みません)。
- Offset
Start: すべてのパーティションを対象とした、このトピックの最小オフセットです。
End: すべてのパーティションを対象とした、このトピックの最大オフセットです。