ksqlDB を使用したクリックストリームデータ分析パイプライン¶
この手順では、環境をセットアップし、Docker コンテナーからクリックストリームデータ分析のチュートリアルを実行する方法を、順を追って説明します。
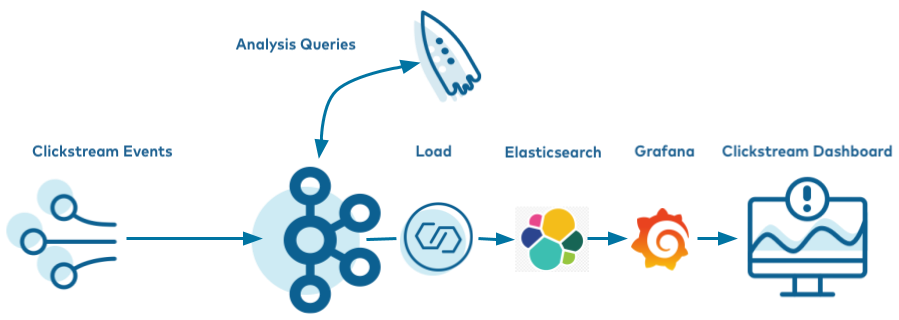
- 前提条件:
- Docker
- Docker バージョン 1.11 またはそれ以降が インストールされ動作している。
- Docker Compose が インストール済みである 。Docker Compose は、Docker for Mac ではデフォルトでインストールされます。
- Docker メモリーに最小でも 6 GB が割り当てられている。Docker Desktop for Mac を使用しているとき、Docker メモリーの割り当てはデフォルトで 2 GB です。Docker のデフォルトの割り当てを 6 GB に変更できます。Preferences、Resources、Advanced の順に移動します。
- インターネット接続
- Confluent Platform で現在サポートされる オペレーティングシステム
- Docker でのネットワークと Kafka
- 内部コンポーネントと外部コンポーネントが Docker ネットワークに通信できるように、ホストとポートを構成します。詳細については、こちらの記事 を参照してください。
- (オプション)`curl <https://curl.se/>`__.
- 以下の手順では、Docker Compose ファイルをダウンロードします。ダウンロードにはさまざまな方法がありますが、この手順では、ファイルのダウンロードに使用できる明示的な curl コマンドを説明します。
- Docker
- ホストとして Linux を使用している場合は、Elasticsearch コンテナーが正常に起動するために、次のコマンドを最初に実行する必要があります。
sudo sysctl -w vm.max_map_count=262144
チュートリアルのダウンロードと実行¶
このチュートリアルは、Docker Compose を使用して作成されています。必要なネットワーキングと依存関係を含む、複数の Docker イメージがまとめられています。このイメージは、サイズがかなり大きいため、ご使用のネットワーク接続によってはダウンロードに 10 ~15 分かかる場合があります。
confluentinc/examples GitHub リポジトリのクローンを作成します。
git clone https://github.com/confluentinc/examples.git
examples/clickstreamディレクトリに移動し、Confluent Platform リリースブランチに切り替えます。cd examples/clickstream git checkout 6.2.4-post
Confluent Platform に慣れる必要がある新規ユーザーには、クリックストリームチュートリアルの手順を自分で操作して完了することをお勧めします。その場合は、次のセクションにスキップしてください。または、チュートリアルの手順をすべて自動化する次のスクリプトで、ソリューション全体をエンドツーエンドで実行することもできます。
./start.sh
このサンプルで説明されている概念は、Confluent Cloud にも適用できます。Confluent Cloud では、セルフマネージド型ではなく、フルマネージド型のコネクターや ksqlDB アプリケーションを使用することもできます。試してみるには、Confluent Cloud インスタンスを作成し(新しい環境を作成する簡単な方法については、「Confluent Cloud 向け ccloud-stack ユーティリティ」を参照してください)、
kafka-connect-datagenコネクターをデプロイして、ksqlDB クエリーを送信してから、Elasticsearch コネクターから Confluent Cloud を参照します。
起動¶
kafka-connect-datagen(ソースコネクター)およびkafka-connect-elasticsearch(シンクコネクター)用の Jar ファイルを取得します。docker run -v $PWD/confluent-hub-components:/share/confluent-hub-components confluentinc/ksqldb-server:0.8.0 confluent-hub install --no-prompt confluentinc/kafka-connect-datagen:0.4.0 docker run -v $PWD/confluent-hub-components:/share/confluent-hub-components confluentinc/ksqldb-server:0.8.0 confluent-hub install --no-prompt confluentinc/kafka-connect-elasticsearch:10.0.2
Docker でチュートリアルを起動します。
docker-compose up -d
約 1 分後に、
docker-compose psステータスコマンドを実行して、すべてが正しく開始されていることを確認します。docker-compose ps
出力は以下のようになります。
Name Command State Ports --------------------------------------------------------------------------------------------------------- control-center /etc/confluent/docker/run Up 0.0.0.0:9021->9021/tcp elasticsearch /usr/local/bin/docker-entr ... Up 0.0.0.0:9200->9200/tcp, 9300/tcp grafana /run.sh Up 0.0.0.0:3000->3000/tcp kafka /etc/confluent/docker/run Up 9092/tcp ksqldb-cli /bin/sh Up ksqldb-server bash -c # Manually install ... Up 0.0.0.0:8083->8083/tcp, 0.0.0.0:8088->8088/tcp schema-registry /etc/confluent/docker/run Up 8081/tcp tools /bin/bash Up zookeeper /etc/confluent/docker/run Up 2181/tcp, 2888/tcp, 3888/tcp
クリックストリームデータの作成¶
すべての Docker コンテナーが動作していることを確認したら、模擬データを生成するソースコネクターを作成します。このデモでは、ksqlDB で組み込み Connect ワーカーを活用します。
ksqlDB CLI を起動します。
docker-compose exec ksqldb-cli ksql http://ksqldb-server:8088次のコマンドを成功するまで実行して、Ensure the ksqlDB サーバーがリクエストを受信できる状態であることを確認します。
show topics;
出力は以下のようになります。
Kafka Topic | Partitions | Partition Replicas ----------------------------------------------- -----------------------------------------------
ksqlDB ステートメントを実行するスクリプト create-connectors.sql を実行して、模擬データを生成するソースコネクターを 3 つ作成します。
RUN SCRIPT '/scripts/create-connectors.sql';
出力は以下のようになります。
CREATE SOURCE CONNECTOR datagen_clickstream_codes WITH ( 'connector.class' = 'io.confluent.kafka.connect.datagen.DatagenConnector', 'kafka.topic' = 'clickstream_codes', 'quickstart' = 'clickstream_codes', 'maxInterval' = '20', 'iterations' = '100', 'format' = 'json', 'key.converter' = 'org.apache.kafka.connect.converters.IntegerConverter'); Message --------------------------------------------- Created connector DATAGEN_CLICKSTREAM_CODES --------------------------------------------- [...]
これで、
clickstreamジェネレーターが実行され、クリックのストリームのシミュレーションを行います。clickstreamトピックのメッセージをサンプリングします。print clickstream limit 3;
出力は以下のようになります。
Key format: HOPPING(JSON) or TUMBLING(JSON) or HOPPING(KAFKA_STRING) or TUMBLING(KAFKA_STRING) or KAFKA_STRING Value format: JSON or KAFKA_STRING rowtime: 2020/06/11 10:38:42.449 Z, key: 222.90.225.227, value: {"ip":"222.90.225.227","userid":12,"remote_user":"-","time":"1","_time":1,"request":"GET /images/logo-small.png HTTP/1.1","status":"302","bytes":"1289","referrer":"-","agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36"} rowtime: 2020/06/11 10:38:42.528 Z, key: 111.245.174.248, value: {"ip":"111.245.174.248","userid":30,"remote_user":"-","time":"11","_time":11,"request":"GET /site/login.html HTTP/1.1","status":"302","bytes":"14096","referrer":"-","agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36"} rowtime: 2020/06/11 10:38:42.705 Z, key: 122.152.45.245, value: {"ip":"122.152.45.245","userid":11,"remote_user":"-","time":"21","_time":21,"request":"GET /images/logo-small.png HTTP/1.1","status":"407","bytes":"4196","referrer":"-","agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36"} Topic printing ceased
実行中の 2 番目のデータジェネレーターは HTTP ステータスコード用です。
clickstream_codesトピックのメッセージをサンプリングします。print clickstream_codes limit 3;
出力は以下のようになります。
Key format: KAFKA_INT Value format: JSON or KAFKA_STRING rowtime: 2020/06/11 10:38:40.222 Z, key: 200, value: {"code":200,"definition":"Successful"} rowtime: 2020/06/11 10:38:40.688 Z, key: 404, value: {"code":404,"definition":"Page not found"} rowtime: 2020/06/11 10:38:41.006 Z, key: 200, value: {"code":200,"definition":"Successful"} Topic printing ceased
3 番目のデータジェネレーターはユーザー情報用です。
clickstream_usersトピックのメッセージをサンプリングします。print clickstream_users limit 3;
出力は以下のようになります。
Key format: KAFKA_INT Value format: JSON or KAFKA_STRING rowtime: 2020/06/11 10:38:40.815 Z, key: 1, value: {"user_id":1,"username":"Roberto_123","registered_at":1410180399070,"first_name":"Greta","last_name":"Garrity","city":"San Francisco","level":"Platinum"} rowtime: 2020/06/11 10:38:41.001 Z, key: 2, value: {"user_id":2,"username":"akatz1022","registered_at":1410356353826,"first_name":"Ferd","last_name":"Pask","city":"London","level":"Gold"} rowtime: 2020/06/11 10:38:41.214 Z, key: 3, value: {"user_id":3,"username":"akatz1022","registered_at":1483293331831,"first_name":"Oriana","last_name":"Romagosa","city":"London","level":"Platinum"} Topic printing ceased
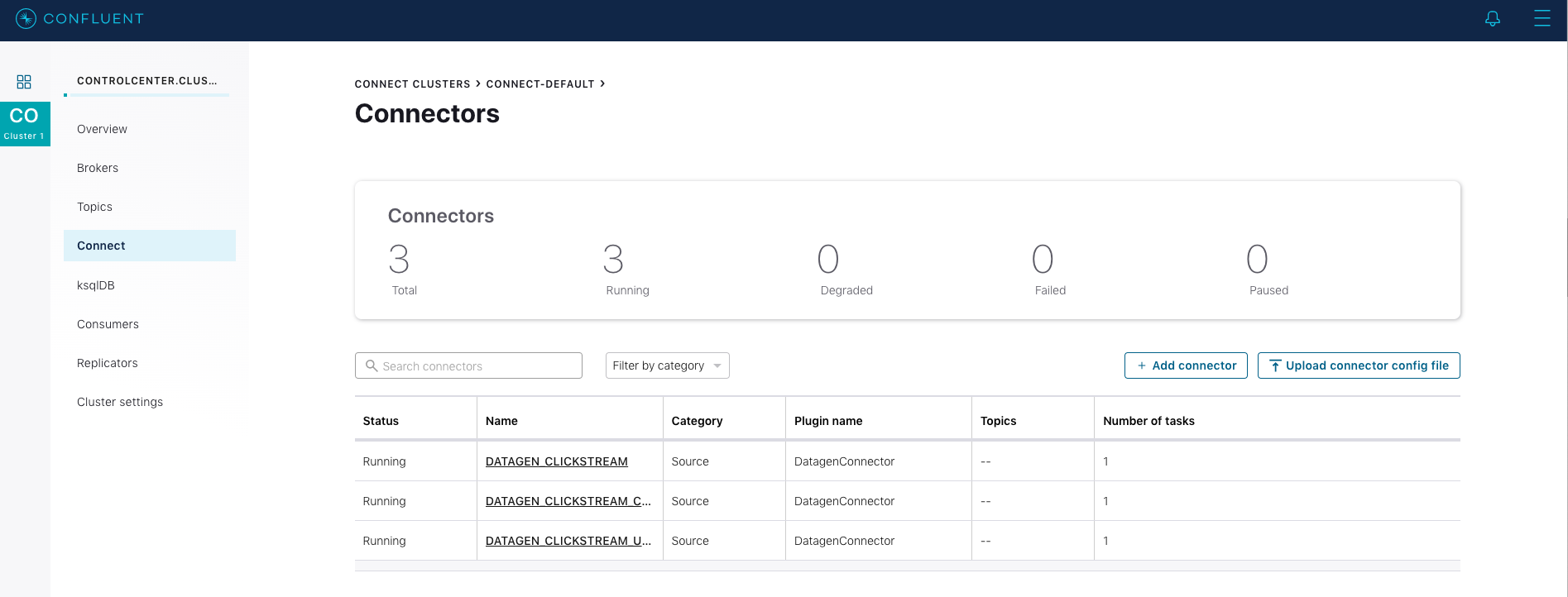
http://localhost:9021 にある Confluent Control Center UI に移動し、ksqlDB CLI で作成した 3 つの kafka-connect-datagen ソースコネクターを表示します。
ksqlDB へのストリーミングデータの読み込み¶
チュートリアルアプリを実行する statements.sql ファイルを読み込みます。
重要: この手順を実行する前に、ksql-datagen ユーティリティを実行してクリックストリームデータ、ステータスコード、およびユーザーのセットを作成しておく必要があります。
RUN SCRIPT '/scripts/statements.sql';
出力には、空白のメッセージ、または次のような
実行ステートメントが表示されます。CREATE STREAM clickstream ( _time bigint, time varchar, ip varchar, request varchar, status int, userid int, bytes bigint, agent varchar ) with ( kafka_topic = 'clickstream', value_format = 'json' ); Message ---------------- Stream created ---------------- [...]RUN SCRIPTコマンドが完了したら、CTRL+Dコマンドでksqldb-cliを終了します。
データの検証¶
http://localhost:9021 にある Confluent Control Center UI に移動し、ksqlDB ビュー
Flowを表示します。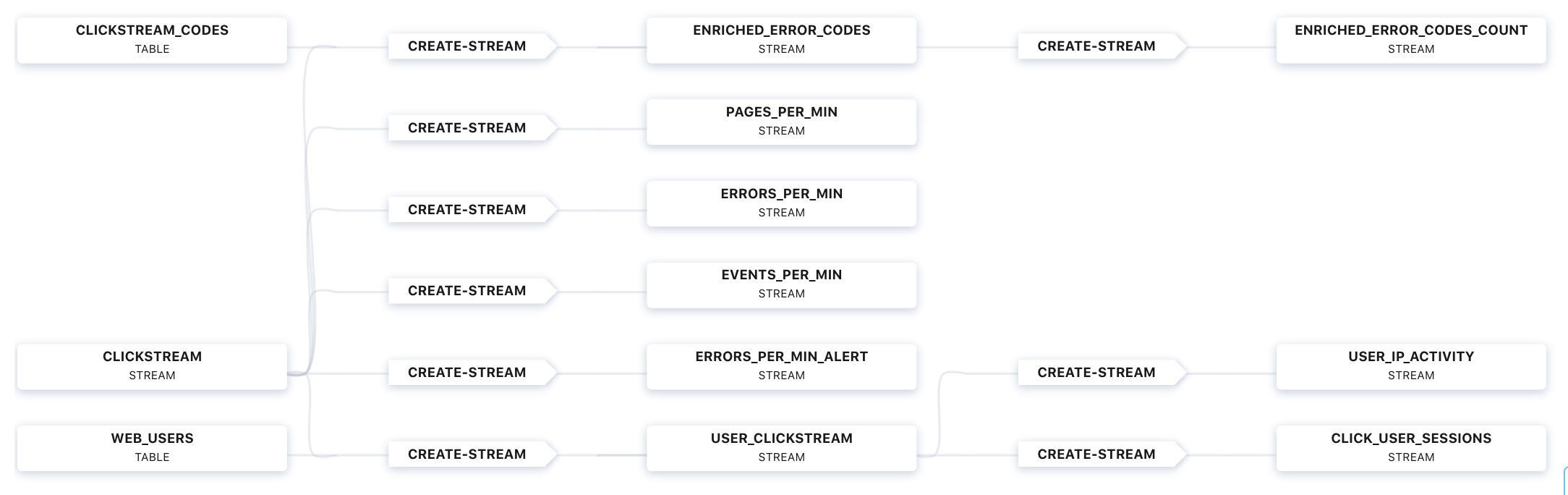
さまざまなテーブルとストリームでデータがストリーミングされていることを確認します。ストリーム
CLICKSTREAMに対してクエリを実行します。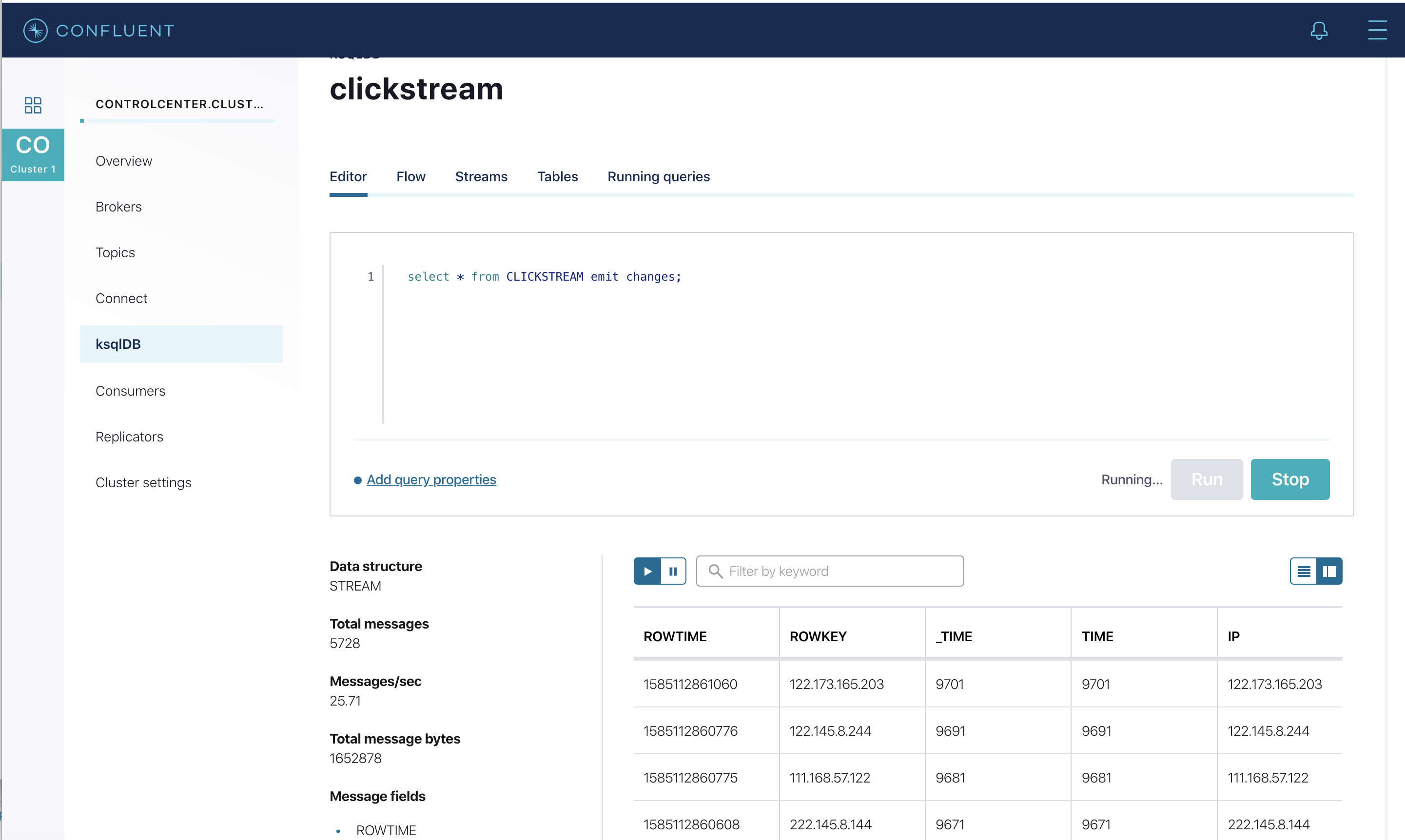
Grafana のクリックストリームデータの読み込み¶
Elasticsearch と Grafana に ksqlDB テーブルを送信します。
必要な Elasticsearch ドキュメントマッピングテンプレートをセットアップします。
docker-compose exec elasticsearch bash -c '/scripts/elastic-dynamic-template.sh'
次のコマンドを実行して、Elasticsearch と Grafana に ksqlDB テーブルを送信します。
docker-compose exec ksqldb-server bash -c '/scripts/ksql-tables-to-grafana.sh'
出力は以下のようになります。
Loading Clickstream-Demo TABLES to Confluent-Connect => Elastic => Grafana datasource ================================================================== Charting CLICK_USER_SESSIONS -> Remove any existing Elastic search config -> Remove any existing Connect config -> Remove any existing Grafana config -> Connecting KSQL->Elastic->Grafana click_user_sessions -> Connecting: click_user_sessions -> Adding Kafka Connect Elastic Source es_sink_CLICK_USER_SESSIONS -> Adding Grafana Source [...]ダッシュボードを Grafana に読み込みます。
docker-compose exec grafana bash -c '/scripts/clickstream-analysis-dashboard.sh'
出力は以下のようになります。
Loading Grafana ClickStream Dashboard
http://localhost:3000 にある Grafana ダッシュボードに移動します。ユーザー名
userとパスワードuserを入力します。そして、Clickstream Analysis Dashboardに移動します。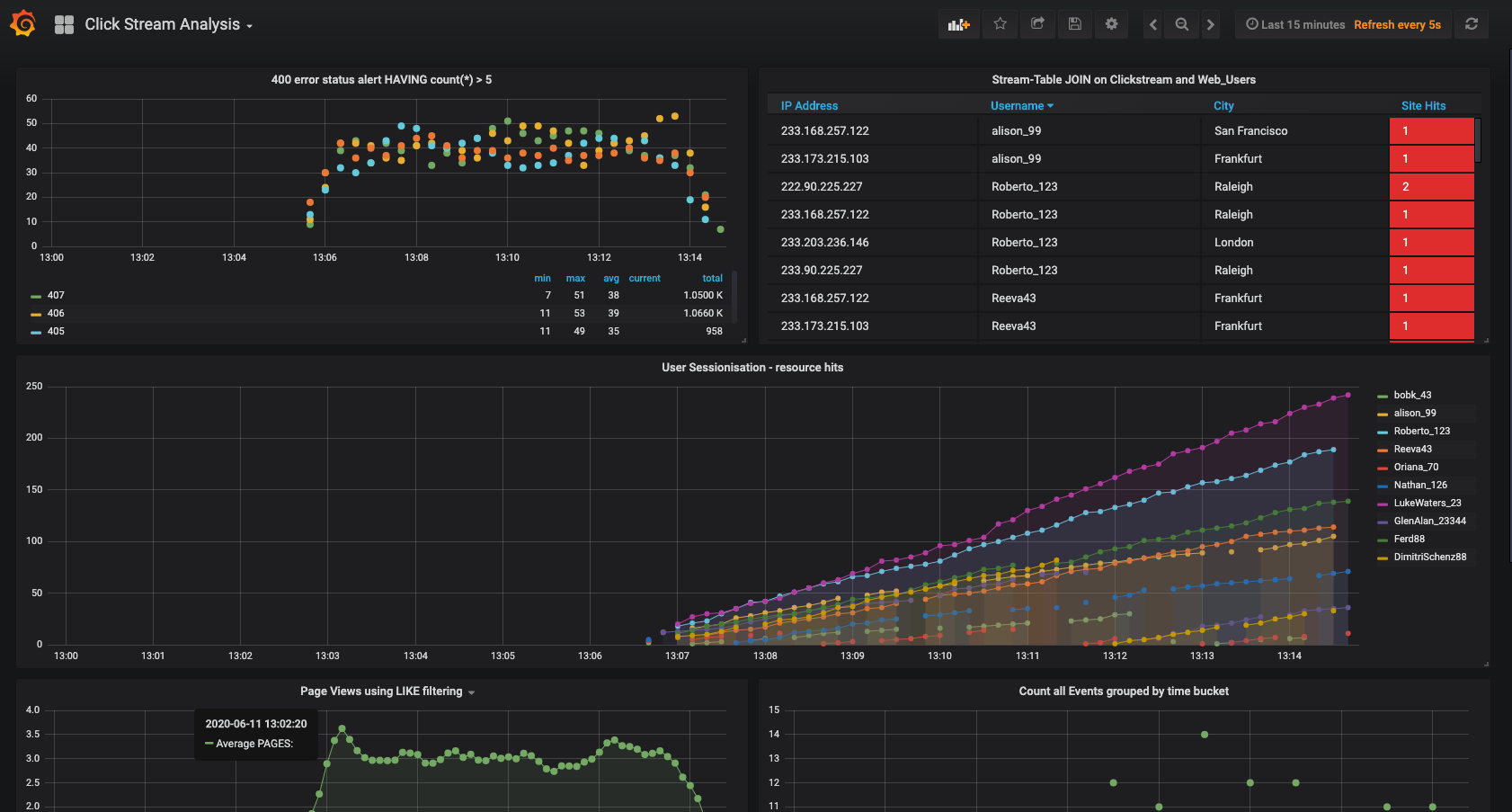
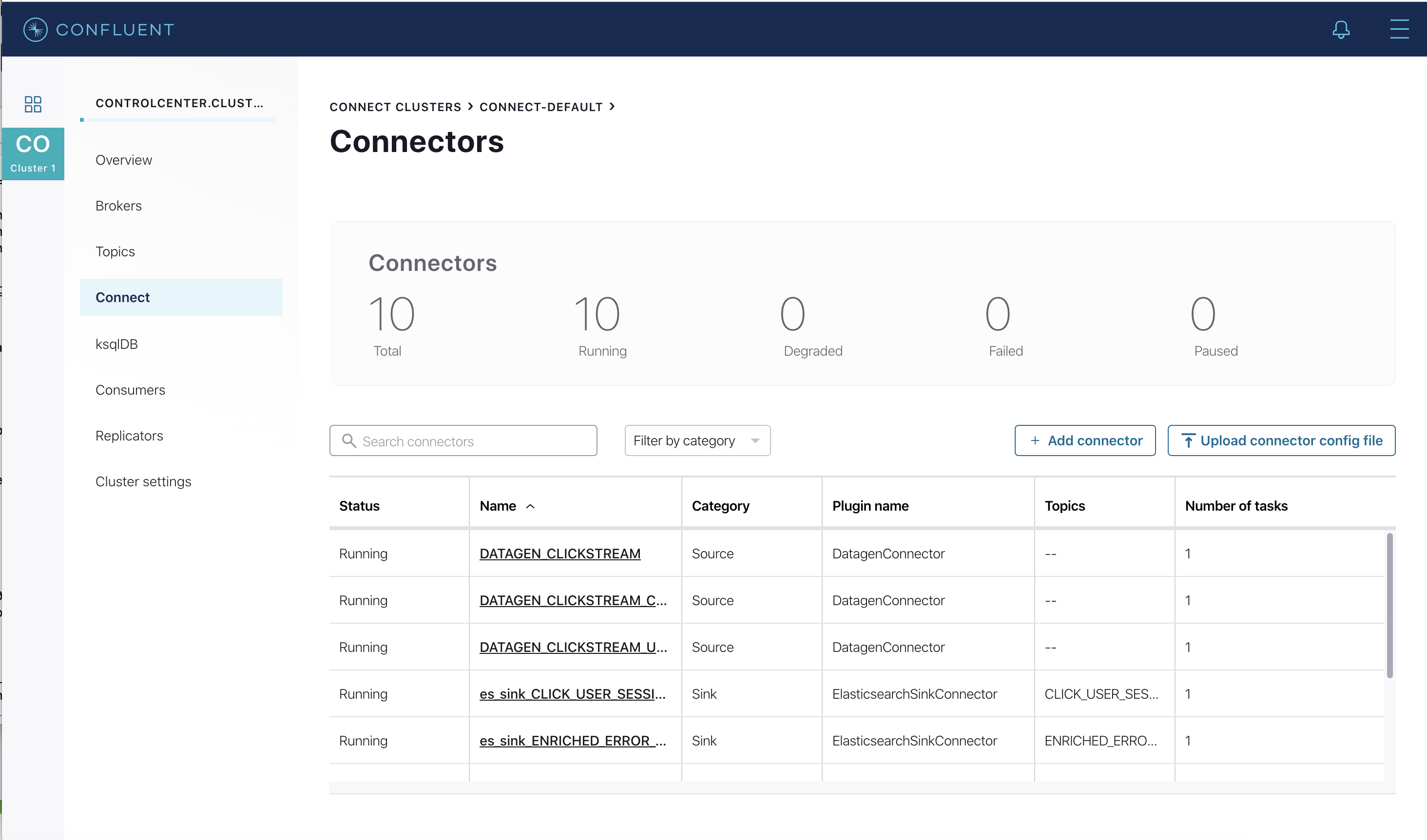
http://localhost:9021 の Confluent Control Center UI で、実行中のコネクターを再度表示します。3 つの kafka-connect-datagen ソースコネクターが ksqlDB CLI で、7 つの Elasticsearch Sink Connector が ksqlDB REST API で作成されています。
データのセッション化¶
デモで作成されたテーブルの 1 つ、CLICK_USER_SESSIONS には、特定のユーザーセッションのユーザーアクティビティの数が表示されます。ユーザーのすべてのクリックは、現在のセッションのユーザーアクティビティの合計にカウントされます。30 秒間、ユーザーが非アクティブであった(アクティビティがなかった)場合は、その次のアクティビティから新しいセッションにカウントされます。
クリックストリームのデモでは、スクリプトによりユーザーセッションのシミュレーションを行います。このスクリプトでは、DATAGEN_CLICKSTREAM コネクターを 90 秒おきに一時停止し、35 秒間、非アクティブ状態にします。30 秒を超える期間、DATAGEN_CLICKSTREAM コネクターを停止することで、個々のユーザーセッションを確認できます。
実際のセッション時間枠では一般に、より長い非アクティブ時間が使用されます。ただしデモでは、セッションの例を妥当な時間内に確認できるよう 30 秒という時間を使用しています。
ユーザーの動作をモニタリングするため、セッション時間枠はさまざまです。また、実装されている他の時間枠では時間のみが考慮されます。
セッションデータを生成するには、次のステートメントを examples/clickstream ディレクトリから実行します。
./sessionize-data.sh
スクリプトにより、実行中の処理についてのいくつかのステートメントがコンソールに発行されます。
Grafana でのデータの表示¶
http://localhost:3000 にある Grafana ダッシュボードに移動します。ユーザー名
userとパスワードuserを入力します。そして、Clickstream Analysis Dashboardに移動します。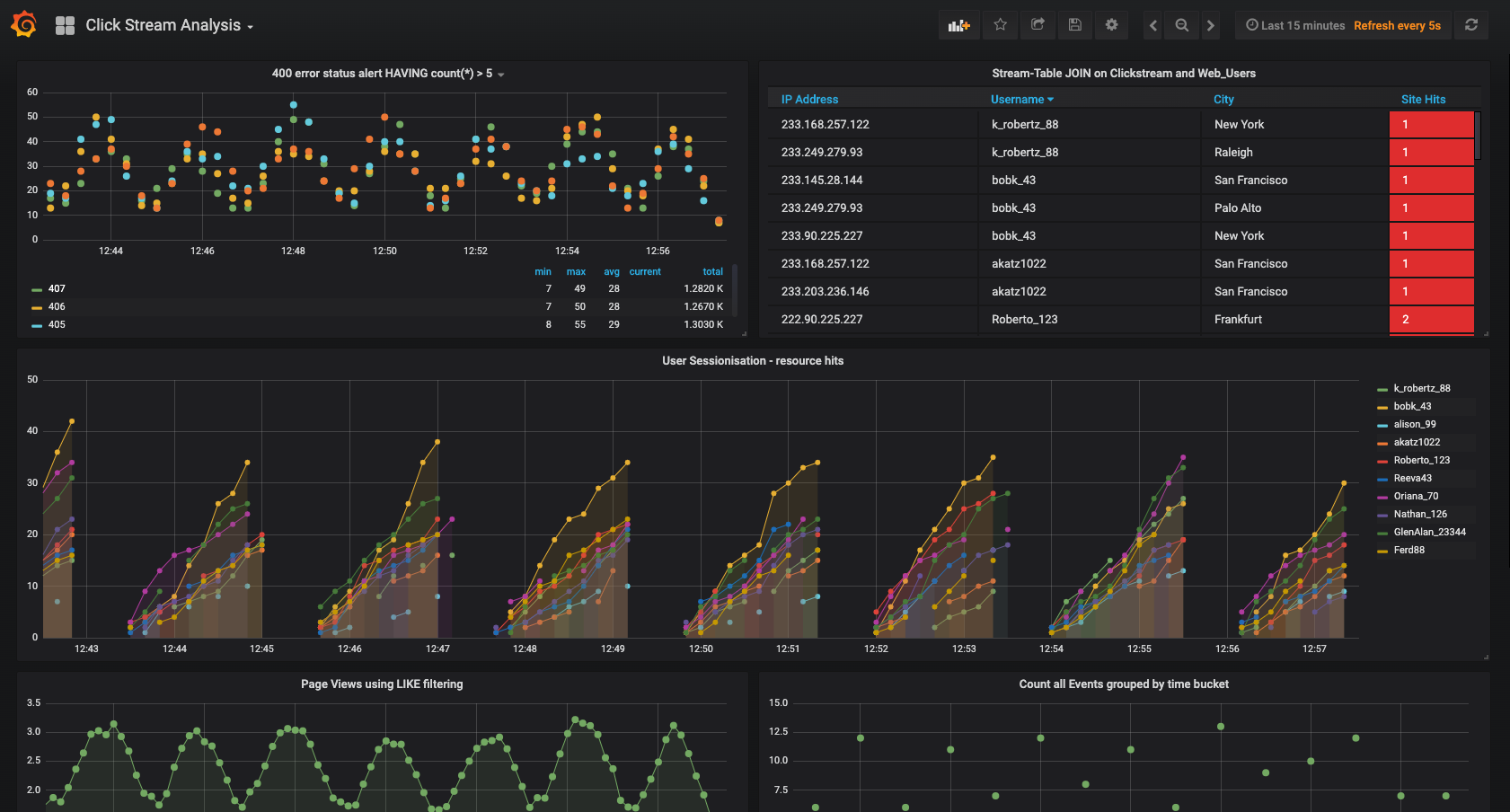
このダッシュボードには、一連のストリーミング機能が表示されます。各パネルのタイトルは、データの生成に必要なストリーム処理のタイプの説明です。たとえば、中ほどにある大きなチャートは、セッション時間枠を使用して、ユーザー名ごとの Web リソースリクエストを示しています。この場合、セッションは、非アクティブ状態が 300 秒間続くと終了します。パネルを編集すると、データソースを表示できます。その名前は、statements.sql ファイルでキャプチャされたストリームとテーブルの名前から付けられます。
トラブルシューティング¶
- Grafana の Data Sources ページを確認します。
- データソースが表示されている場合は、それを選択し、ページの末尾までスクロールして Save & Test ボタンをクリックします。これで、データソースが有効であるかどうかを確認できます。