Kafka Streams のメモリー管理¶
レコードの内部キャッシュや圧縮に使用される合計メモリー(RAM)サイズを指定できます。キャッシュ処理は、レコードがステートストアに書き込まれる前や他のノードに転送される前に行われます。
レコードキャッシュの実装は、DSL と Processor API でわずかに異なります。
DSL のレコードキャッシュ¶
処理トポロジーのインスタンスで使用される、レコードキャッシュの合計メモリー(RAM)サイズを指定できます。これは、以下の KTable インスタンスによって利用されます。
- ソース
KTable:StreamsBuilder#table()またはStreamsBuilder#globalTable()によって作成されるKTableインスタンス。 - 集約
KTable: 集約 の結果として作成されるKTableのインスタンス。
このような KTable インスタンスでは、以下の目的でレコードキャッシュが使用されます。
- 基盤にあるステートフルな プロセッサーノード から内部ステートストアに出力レコードが書き込まれる前に、出力レコードの内部キャッシュ処理や圧縮を行うため。
- 基盤にあるステートフルな プロセッサーノード からダウンストリームのプロセッサーノードに出力レコードが転送される前に、出力レコードの内部キャッシュ処理や圧縮を行うため。
例を使用して、レコードキャッシュの有無による動作の違いを見てみましょう。この例では、KStream<String, Integer> のレコード <K,V> : <A, 1>, <D, 5>, <A, 20>, <A, 300> を入力とします。ここで注目するのは、キーが A のレコードです。
- 集約 により、入力レコードをキーでグループ化して値の合計を計算し、
KTable<String, Integer>を返します。- キャッシュなし: キー
Aに対して一連の出力レコードが出力されます。これらの各レコードは、結果の集約テーブル内の変更を表します。変更を丸かっこ(())で表し、かっこ内の左側の数値を新しい集約値、右側の数値を以前の集約値とすると、<A, (1, null)>, <A, (21, 1)>, <A, (321, 21)>になります。 - キャッシュあり: キー
Aに対して単一の出力レコードが出力されます。これはキャッシュ内で圧縮される可能性があり、<A, (321, null)>という単一の出力レコードになります。このレコードが集約の内部ステートストアに書き込まれ、ダウンストリームの操作に転送されます。
- キャッシュなし: キー
キャッシュサイズは、処理トポロジーごとのグローバル設定である cache.max.bytes.buffering パラメーターで指定します。
// Enable record cache of size 10 MB.
Properties streamsConfiguration = new Properties();
streamsConfiguration.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 10 * 1024 * 1024L);
このパラメーターは、キャッシュに割り当てるバイト数を制御します。厳密には、プロセッサートポロジーのインスタンスに T 個のスレッドがあり、キャッシュ用に C バイトが割り当てられる場合、各スレッドに均等に C/T バイトが分配されます。スレッドでは、独自のキャッシュを構築してタスクに合わせて使用できます。つまり、キャッシュはスレッドと同じ数だけ存在し、スレッド間でキャッシュが共有されることはありません。
キャッシュの基本的な API は、put() と get() の呼び出しで構成されています。キャッシュサイズに達すると、単純な LRU 方式を使用してレコードが取り出されます。キー付きのレコード R1 = <K1, V1> は、ノードで初めて処理が完了したときにキャッシュ内でダーティとしてマークされます。その間に同じキー K1 を持つ他のレコード R2 = <K1, V2> が同じノードで処理されると、<K1, V1> が上書きされます。これは "圧縮" と呼ばれます。これには Kafka のログ圧縮 と同じ効果がありますが、それよりも前の、レコードがまだメモリー内に存在する間に発生します。このとき、レコードはサーバー側(Apache Kafka® ブローカー)ではなく、クライアント側アプリケーションの内部にあります。フラッシュ後、R2 は次の処理ノードに転送され、ローカルステートストアに書き込まれます。
キャッシュのセマンティクスは、commit.interval.ms と cache.max.bytes.buffering (cache pressure)のどちらかに達したときに、データをステートストアにフラッシュし、次のダウンストリームプロセッサーノードに転送するというものです。commit.interval.ms と cache.max.bytes.buffering は、どちらもグローバルパラメーターです。したがって、個々のノードで別々のパラメーターを指定することはできません。
両方のパラメーターについて、それぞれに適したシナリオでの設定例を以下に示します。
キャッシュ処理を無効にするには、キャッシュサイズをゼロに設定します。
// Disable record cache Properties streamsConfiguration = new Properties(); streamsConfiguration.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 0);
デフォルトの設定では、Kafka Streams と RocksDB でキャッシュ処理が有効になっています。
キャッシュ処理を有効にして、レコードがキャッシュに保持される時間に上限を設ける場合は、コミット間隔を設定できます。この例では 1000 ミリ秒に設定します。
Properties streamsConfiguration = new Properties(); // Enable record cache of size 10 MB. streamsConfiguration.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 10 * 1024 * 1024L); // Set commit interval to 1 second. streamsConfiguration.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG, 1000);
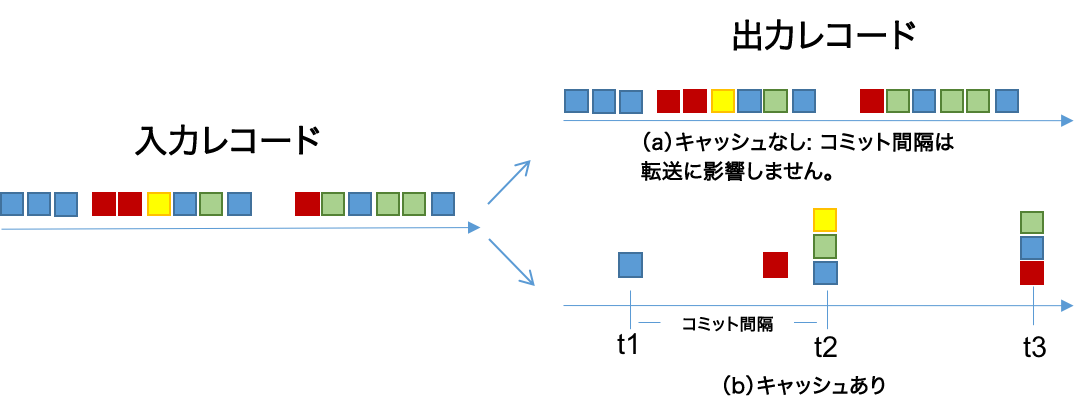
以下の図は、これらの 2 つの構成の影響を表しています。レコードは、青色、赤色、黄色、緑色の 4 つのキーで示されています。ただし、キャッシュには 3 つのキーのスペースしかないものとします。
- キャッシュが無効な場合(a)は、入力レコードがすべて出力されます。
- キャッシュが有効な場合(b)は、次のようになります。
- ほとんどのレコードはコミット間隔の終了時に出力されます(たとえば、
t1では青色のレコードが 1 つ出力されます。これは、その時点までに上書きされた青色のキーの最終結果です)。 - 一部のレコードは、キャッシュの圧迫によって(コミット間隔の終了前に)出力されます。たとえば、
t2の前の赤色のレコードがこれに該当します。キャッシュサイズが小さい場合は、キャッシュの圧迫がレコードの出力のタイミングを決める主な要因になります。キャッシュサイズが大きい場合は、コミット間隔が主な要因になります。 - 出力されるレコードの合計数は 15 個から 8 個に減少します。
- ほとんどのレコードはコミット間隔の終了時に出力されます(たとえば、
Processor API のレコードキャッシュ¶
処理トポロジーのインスタンスで使用される、レコードキャッシュの合計メモリー(RAM)サイズを指定できます。このキャッシュは、ステートフルなプロセッサーノードから内部ステートストアに出力レコードが書き込まれる前に、出力レコードの内部キャッシュ処理や圧縮を行うために使用されます。
Processor API のレコードキャッシュでは、ダウンストリームに転送される出力レコードのキャッシュや圧縮は行われません。したがって、ダウンストリームのすべてのプロセッサーノードではすべてのレコードを参照できますが、ステートストアで確認されるレコードの数はそれよりも少なくなります。これはシステムの正確性には影響せず、ステートストアのパフォーマンスを最適化するものです。たとえば、Processor API では、ステートストアにレコードを格納しながら、別の値をダウンストリームに転送できます。
「ステートストア」セクションに示した例でキャッシュ処理を有効にするには、withCachingEnabled の呼び出しを追加します。
StoreBuilder countStoreBuilder =
Stores.keyValueStoreBuilder(
Stores.persistentKeyValueStore("Counts"),
Serdes.String(),
Serdes.Long())
.withCachingEnabled()
RocksDB¶
RocksDB の各インスタンスでは、ブロックキャッシュ、インデックスブロック、フィルターブロック、および memtable(書き込みバッファ)用にオフヒープメモリーが割り当てられます。(RocksDB バージョン 4.1.0 での)重要な構成として、block_cache_size、write_buffer_size、および max_write_buffer_number があります。これらは rocksdb.config.setter 構成を通じて指定できます。
また、RocksDB のデフォルトのメモリーアロケーターを変更することをお勧めします。デフォルトのアロケーターではメモリー消費量の増加につながる場合があります。メモリーアロケーターを jemalloc に変更するには、Kafka Streams アプリケーションを起動する前に、LD_PRELOAD 環境変数を設定します。
# example: install jemalloc (on Debian)
$ apt install -y libjemalloc-dev
# set LD_PRELOAD before you start your Kafka Streams application
$ export LD_PRELOAD="/usr/lib/x86_64-linux-gnu/libjemalloc.so"
RocksDB のブロックキャッシュは読み取りにのみ働き、書き込みには影響しません。書き込みは常に memtable に格納されます。ディスクへの書き込みトラフィックは、memtable のフラッシュによって決まります。これはコミット時に行われるか、memtable が "いっぱい" になったときに発生します。デフォルトでは、3 16 MB の memtable がいっぱいになるとフラッシュされます。RocksDB の統計情報を利用すると、コミット間隔と memtable のサイズ制限のどちらに先に到達するかを特定して、適切なサイズを決定できる可能性があります。
デフォルトのブロックキャッシュサイズはストアあたり 50 MB ですが、インスタンス全体のキャッシュに対する Kafka Streams のデフォルトは 10 MB です。ストアの数が多い場合、デフォルトの 50 MB は大きすぎる可能性があります。
5.3.0 では、すべてのインスタンスを合わせたメモリー使用量に上限を設定し、Kafka Streams アプリケーションの合計オフヒープメモリーを制限することができます。そのためには、インデックスブロックとフィルターブロックをブロックキャッシュにキャッシュするように RocksDB を構成し、共有の WriteBufferManager を通じて memtable メモリーを制限し、そのメモリーをブロックキャッシュにカウントして、同じ Cache オブジェクトを各インスタンスに渡す必要があります。詳細については、RocksDB のメモリー使用量 を参照してください。これを実装する RocksDBConfigSetter の例を以下に示します。
public static class BoundedMemoryRocksDBConfig implements RocksDBConfigSetter {
// See #1 below
private static org.rocksdb.Cache cache = new org.rocksdb.LRUCache(TOTAL_OFF_HEAP_MEMORY, -1, false, INDEX_FILTER_BLOCK_RATIO);
private static org.rocksdb.WriteBufferManager writeBufferManager = new org.rocksdb.WriteBufferManager(TOTAL_MEMTABLE_MEMORY, cache);
@Override
public void setConfig(final String storeName, final Options options, final Map<String, Object> configs) {
BlockBasedTableConfig tableConfig = (BlockBasedTableConfig) options.tableFormatConfig();
// These three options in combination will limit the memory used by RocksDB to the size passed to the block cache (TOTAL_OFF_HEAP_MEMORY)
tableConfig.setBlockCache(cache);
tableConfig.setCacheIndexAndFilterBlocks(true);
options.setWriteBufferManager(writeBufferManager);
// These options are recommended to be set when bounding the total memory
// See #2 below
tableConfig.setCacheIndexAndFilterBlocksWithHighPriority(true);
tableConfig.setPinTopLevelIndexAndFilter(true);
// See #3 below
tableConfig.setBlockSize(BLOCK_SIZE);
options.setMaxWriteBufferNumber(N_MEMTABLES);
options.setWriteBufferSize(MEMTABLE_SIZE);
// Enable compression (optional). Compression can decrease the required storage
// and increase the CPU usage of the machine. For CompressionType values, see
// https://javadoc.io/static/org.rocksdb/rocksdbjni/6.4.6/org/rocksdb/CompressionType.html.
options.setCompressionType(CompressionType.LZ4_COMPRESSION);
options.setTableFormatConfig(tableConfig);
}
@Override
public void close(final String storeName, final Options options) {
// Cache and WriteBufferManager should not be closed here, as the same objects are shared by every store instance.
}
}
- 脚注:
INDEX_FILTER_BLOCK_RATIOは、"高優先度" (つまりインデックスとフィルター)のブロックのために確保しておくブロックキャッシュの割合を設定するために使用できます。この部分がデータブロックによって占有されることはありません。LRUCache コンストラクター の完全なシグネチャを参照してください。注: キャッシュのコンストラクターのブール型パラメーターは、キャッシュで厳密なメモリー制限を強制して、読み取りや反復処理が容量を超えた場合に(まれなケースではありますが)、処理を失敗させるかどうかを制御します。RocksDB のバグ により、キャッシュが書き込みバッファのメモリーにも使用される場合、このオプションは使用できません。このパラメーターを true に設定する場合は、キャッシュをWriteBufferManagerに渡さず、書き込みバッファとキャッシュメモリーを別々に制御してください。- RocksDB のドキュメント で説明されているように、この設定は
INDEX_FILTER_BLOCK_RATIOを有効にするために必要です(脚注 1 を参照)。 - デフォルトの ブロックサイズ は、 RocksDB GitHub の手順に従って変更できます。ブロックサイズを大きくするとインデックスブロックは小さくなりますが、キャッシュされたデータブロックに含まれるコールドデータは増える可能性があります。このようなデータは、サイズが小さい場合は削除されるものです。
注: 少なくとも上記の構成を設定することが推奨されますが、最適なパフォーマンスを引き出す固有のオプションはワークロードによって異なります。特定のユースケースに応じた最適な選択を決定するために、さまざまな設定を試すことを検討してください。あるアプリにとって最適な構成でも、トポロジーや入力トピックが異なるアプリには適さない可能性があることに注意してください。上記の推奨構成に加えて、RocksDB のドキュメント で説明されているように、パーティション化されたインデックスフィルターの使用を検討することもできます。
その他のメモリー使用量¶
Kafka の内部には、実行時にメモリーを割り当てるモジュールが他にもあります。次のようなモジュールが含まれます。
- プロデューサーのバッファ処理。プロデューサーの
buffer.memory構成によって管理されます。 - コンシューマーのバッファ処理。現在は厳密には管理されていませんが、フェッチサイズを指定する
fetch.max.bytesとfetch.max.wait.msによって間接的に制御できます。 - プロデューサーとコンシューマーのどちらにも、バッファリングメモリーとは別の TCP 送信バッファおよび受信バッファがあります。これらは
send.buffer.bytesとreceive.buffer.bytesの各構成によって制御されます。 - 逆シリアル化されたオブジェクトのバッファ処理。
consumer.poll()から返されたレコードは、逆シリアル化されてタイムスタンプが抽出され、ストリーム領域にバッファリングされます。これは現在、buffered.records.per.partitionによってのみ間接的に制御されます。
ちなみに
反復子は明示的に終了してリソースを解放することが必要 : ストアの反復子(KeyValueIterator や WindowStoreIterator )は、使い終わったときに明示的に終了して、開いているファイルハンドラーやインメモリーの読み取りバッファなどのリソースを解放する必要があります。または、この Closeable クラスを try-with-resources ステートメント(JDK7 以降で使用可能)を使用します。
リソースを解放しないと、ストリームアプリケーションの実行中にメモリー使用量が増え続け、最終的にはメモリー不足になります。
注釈
このウェブサイトには、Apache License v2 の条件に基づいて Apache Software Foundation で開発されたコンテンツが含まれています。