Replicator とクラスター間フェイルオーバー¶
注釈
ディザスターリカバリ向けに複数の Apache Kafka® クラスターを構成するための詳細かつ実用的なガイドについては、ホワイトペーパー「Disaster Recovery for Multi-Datacenter Apache Kafka Deployments」を参照してください。
マルチデータセンター設計では、複数のクラスターでデータ処理の負荷分散を行い、クラスター間でデータをレプリケートすることでシステム停止に対する保護を行います。1 つのデータセンターがダウンした場合でも、データのレプリカが残りのデータセンターに保持されているため、データセンターダウン時点から引き継ぐことができます。元のデータセンターが復旧すると、そのデータセンターはメッセージ処理を再開します。Replicator は、フェイルオーバーとディザスターリカバリに関する以下のサポート機能(Confluent Platform バージョン 5.3 で導入されました)に基づいて、クラスター間のデータ同期の再開ポイントを認識します。
このドキュメントでは、初期セットアップの一環として前述の機能のパラメーターについて説明するほか、フェイルオーバーとリカバリの設計についても説明します。
Replicator は、アクティブ/スタンバイまたはアクティブ/アクティブのセットアップで障害を管理するように構成できます。
アクティブ/スタンバイデプロイでは、Replicator は一方向で実行され、Kafka メッセージとメタデータをアクティブ(プライマリ)クラスター(以下の例のデータセンター A)からスタンバイ(セカンダリ)"パッシブ" クラスター(以下の例のデータセンター B)にコピーします。
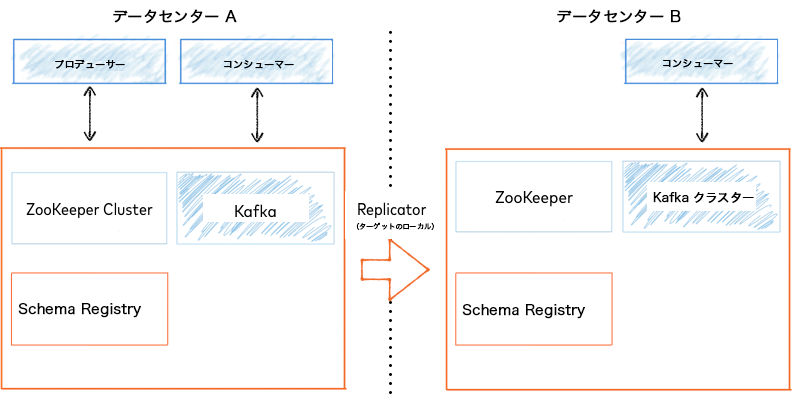
アクティブ/パッシブデプロイ¶
アクティブ/アクティブデプロイでは、1 つの Replicator が Kafka のメッセージとメタデータを送信元データセンター A から送信先データセンター B にコピーし、別の Replicator が Kafka のデータとメッセージを送信元データセンター B から送信先データセンター A にコピーします。
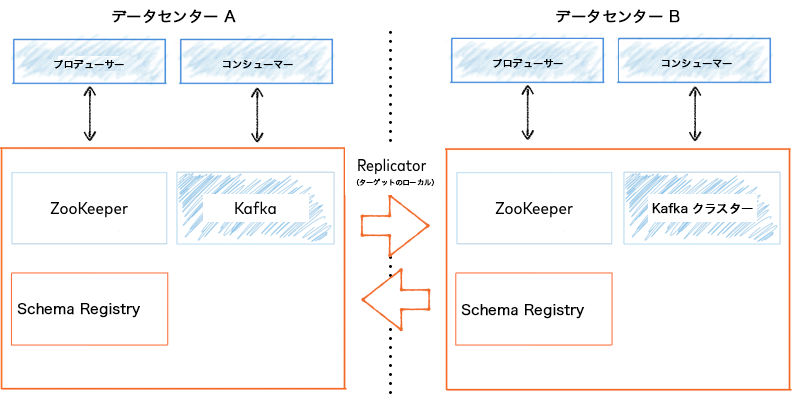
アクティブ/アクティブデプロイ¶
プロデューサーは、両方のクラスターにデータを書き込みます。クライアントアプリケーションの設計に応じて、コンシューマーは自身のクラスターで生成されたデータに加え、他のクラスターで生成されて自身のローカルクラスターにレプリケートされたデータを読み取ることができます。
フェイルオーバーシナリオ向けの Replicator の構成¶
Replicator は、コミットされたオフセットをアクティブなプライマリクラスターからスタンバイのセカンダリクラスターに変換できます。プライマリクラスターからセカンダリクラスターにフェイルオーバーする場合、コンシューマーは最後にコミットされたオフセットからデータを消費します。
フェイルオーバー向けのコンシューマーの構成(タイムスタンプの保持)¶
セカンダリクラスターにレプリケートされるトピックを読み取っているコンシューマー用の追加のインターセプターを構成する必要があります。
interceptor.classes=io.confluent.connect.replicator.offsets.ConsumerTimestampsInterceptor
重要
timestamp-interceptorはコンシューマーにのみ設定できます。- Replicator にこのインタセプターを設定しないでください。
- Connect ワーカーでインターセプターを設定する場合は注意が必要です。インターセプターが有効に機能するためには、ワーカーがシンクコネクターを実行していること、また、それらのコネクターがオフセット管理のために Kafka を使用していることが必要です。
このインターセプターは、 timestamp-interceptor-6.2.4.jar の kafka-connect-replicator の下にあります。この JAR をコンシューマーの CLASSPATH に指定しておく必要があります。
ちなみに
- JAR ファイルの場所は、プラットフォームと Confluent インストール のタイプによって異なります。たとえば、zip.tar を使用した Mac OS インストールの場合、デフォルトでは、
timestamp-interceptor-<version>.jarは Confluent ディレクトリの/share/java/kafka-connect-replicatorにあります。
timestamp-interceptor は、以下の Confluent Maven リポジトリにあります。
<repository>
<id>confluent</id>
<url>https://packages.confluent.io/maven/</url>
</repository>
Maven プロジェクトに、以下の依存関係を含めてください。
<dependency>
<groupId>io.confluent</groupId>
<artifactId>timestamp-interceptor</artifactId>
<version>6.2.4</version>
</dependency>
ConsumerTimestampsInterceptor は、オフセット変換のために必要なタイムスタンプ情報を保持するために、新規トピック __consumer_timestamps に書き込みを行います。Replicator は、この新規トピックから読み取ったタイムスタンプを使用して、セカンダリクラスターで正確なオフセットを判別します。
重要
ConsumerTimestampsInterceptor は、送信元クラスターの __consumer_timestamps トピックに対するプロデューサーであるため、適切なセキュリティ構成を必要とします。これらの構成は、timestamps.producer. プレフィックスを使用して指定します。たとえば、timestamps.producer.security.protocol=SSL などと指定します。セキュリティ構成の詳細については、以下を参照してください。
インターセプターには、__consumer_timestamps トピックについての ACL も必要になります。__consumer_timestamps トピックに対する WRITE と DESCRIBE の操作がコンシューマーのプリンシパルに必要になります。
詳細については、以下を参照してください。
- コンシューマーのオフセット変換について
- ホワイトペーパー「Disaster Recovery for Multi-Datacenter Apache Kafka Deployments」のコンシューマーオフセットとタイムスタンプの保持に関する説明です。
フェイルオーバー向けの Replicator の構成¶
Replicator に対して、オフセットを変換してそれらをセカンダリクラスターで設定するように指示するには、以下のプロパティを設定する必要があります。
dest.kafka.bootstrap.servers=localhost:9092
フェイルオーバー後のプライマリクラスターの復帰¶
元のプライマリクラスターが再開したら、Replicator をプライマリクラスターで実行してこのクラスターを最新の状態に戻すことができます。これにより、フェイルオーバー以降にセカンダリクラスターで生成されたデータがコピーされます。ただし、Replicator をプライマリクラスターで実行する前に、以下の前提条件を満たす必要があります。
- 障害が発生する前にセカンダリにレプリケートされなかったデータがプライマリクラスターに存在する可能性があります。追加のデータをセカンダリクラスターにコピーする必要があるかどうか、およびその順序が重要かどうかを特定します。順序が重要ではない場合、セカンダリクラスターで簡単に Replicator の実行を再開して、プライマリからセカンダリにデータをコピーできます。順序が重要である場合、追加のデータを処理する方法についての標準的な答えはありません。これはビジネスのニーズによって異なります。
- Replicator は新しいデータのみをレプリケートする必要があります。元のアクティブ/スタンバイ構成時に既にレプリケートされたデータをレプリケートしないでください。Replicator は、他のコンシューマーに対して使用するものと同じオフセット変換メカニズムを使用して、セカンダリクラスターで再開する必要があるポイントを追跡します。これにより、プライマリからの読み取りをセカンダリクラスターに切り替えることができます。他のクラスターに切り替える場合、コンシューマーグループの ID は同じである必要があります。コンシューマーグループ ID については、Replicator は
src.consumer.group.idの値を使用するか(指定されている場合)、または Replicator のnameを使用します。
コンシューマーのオフセット変換について¶
Confluent Platform バージョン 5.0 以降では、Replicator はタイムスタンプを使用してオフセットを自動的に変換します。これにより、コンシューマーは別のデータセンターにフェイルオーバーして、送信元クラスターで中止したポイントから送信先クラスターでデータを消費できます。
クラスターがダウンした場合、コンシューマーは新しいクラスターへの接続を再び開始する必要があります。システム停止の前は、クラスター内のトピックからメッセージを消費し、停止後は、他のクラスターまたはデータセンター内のトピックからメッセージを消費します。
Replicator の コンシューマーオフセット変換パラメーター を構成して、新しいクラスターへのフェイルオーバー後にコンシューマーが読み取りを開始するトピック内のポイントを指定できます。
デフォルトでは、フェイルオーバークラスターでコンシューマーを作成するときに、構成パラメーター auto.offset.reset を latest または earliest のいずれかに設定できます。
一部のアプリケーションとシナリオの場合、これらのデフォルトで十分です。たとえば、クリックストリーム分析またはログ分析には latest メッセージ、べき等性のあるシステムまたは重複を処理できる他のシステムには earliest メッセージを使用します。しかし、それ以外のアプリケーションについては、これらのデフォルトは不適切である場合があります。コンシューマーが特定のメッセージから読み取りを開始し、未読のメッセージのみを消費することを求める場合もあります。
デフォルトの latest または earliest を使用するのではなく、特定のオフセットをターゲットにするには、コンシューマーがそのコンシューマーオフセットを新しいクラスターで適切な値にリセットする必要があります。オフセットはクラスター間で異なる場合があるため、コンシューマーはオフセットのみ使用して開始ポイントを判断することではオフセットをリセットできません。1 つの方法は、タイムスタンプを使用することです。メッセージ内の タイムスタンプの保持 により、オフセットにコンテキストが追加されます。これにより、コンシューマーはタイムスタンプに基づくオフセットからメッセージの消費を開始できます。
オフセット変換を構成するには、「フェイルオーバーシナリオ向けの高度な構成(オフセット変換のチューニング)」、「オフセット変換の有効化または無効化」、および「Confluent Replicator 構成プロパティ」の「コンシューマーオフセット変換」で説明されているパラメーターを使用します。
この機能を使用するには、 コンシューマータイムスタンプインターセプター を使用して Java コンシューマーアプリケーションを構成します。このインターセプターは、消費されるメッセージのメタデータを保持します。これには以下のものが含まれます。
- コンシューマーグループ ID
- トピック名
- パーティション
- コミットされたオフセット
- タイムスタンプ
コンシューマータイムスタンプ情報は、送信元クラスターに存在する __consumer_timestamps と呼ばれる Kafka トピックに保持されます。このトピックはローカルクラスターのみで重要性を持つため、Replicator によってレプリケートされません。
ちなみに
コンソールコンシューマーを使用すると、__consumer_timestamps トピックに格納されているデータを表示できます。そのためには、Replicator ライブラリをコンシューマークラスパスに追加し、特殊なデシリアライザーを使用する必要があります。
export CLASSPATH=/usr/share/java/kafka-connect-replicator/*
kafka-console-consumer --topic __consumer_timestamps --bootstrap-server kafka1:9092 --property print.key=true --property key.deserializer=io.confluent.connect.replicator.offsets.GroupTopicPartitionDeserializer --property value.deserializer=io.confluent.connect.replicator.offsets.TimestampAndDeltaDeserializer
Replicator は、1 つのデータセンターから別のデータセンターにデータをコピーすると同時に、以下の処理を実行します。
- 送信元クラスターの
__consumer_timestampsトピックからコンシューマーオフセットとタイムスタンプ情報を読み取って、コンシューマーグループの進捗を把握します。 - 送信元データセンター内のコミットされたオフセットを、送信先データセンターで対応するオフセットに変換します。
- 変換されたオフセットを送信先クラスターの
__consumer_offsetsトピックに書き込みます(そのグループのコンシューマーが送信先クラスターに接続されていない場合に限ります)。
Replicator は、変換されたオフセットを送信先クラスター内の __consumer_offsets トピックに書き込むときに、topic.rename.format で構成されているトピック名変更にオフセットを適用します。送信先クラスターに接続されているコンシューマーが既にそのコンシューマーグループに存在する場合、これらのコンシューマーは自身のオフセットをコミットするため、Replicator はオフセットを __consumer_offsets トピックに書き込みません。いずれの場合でも、コンシューマーアプリケーションがバックアップクラスターにフェイルオーバーすると、通常のメカニズムを使用して、それ以前にコミットされたオフセットを検索して特定します。
重複または循環メッセージ反復を防ぐための来歴ヘッダーの使用¶
provenance.header.enable=true の場合、Replicator は、特定のクラスターにレプリケートするすべてのレコード(メッセージ)に来歴ヘッダーを追加します。来歴ヘッダーには以下の情報が含まれます。
- メッセージが最初に生成された送信元クラスターの ID
- このメッセージが最初に生成されたトピックの名前
- Replicator が最初にレコードをコピーした時点でのタイムスタンプ
Replicator は、この来歴ヘッダー情報を使用して、1 つのクラスターから別のクラスターに切り替えるときに重複を回避できます(レコードは最後にコミットされたオフセットの後にレプリケートされた可能性があるため)。Replicator は、送信先クラスターが送信元クラスターと同等かどうかを来歴ヘッダーに基づいてチェックして判別します。
デフォルトでは、Replicator は送信先クラスターのクラスター ID が来歴ヘッダー内の送信元クラスター ID と一致し "かつ" 送信先トピック名が来歴ヘッダー内の送信元トピック名と一致する場合は、メッセージを送信先クラスターにレプリケートしません。これらはトピックレベルでチェックされるため、送信先が異なるトピックである限り、送信元クラスターにレプリケートすることができます。A→B→C の場合、C のレコードには 2 つの来歴ヘッダー(1 つは B 用、1 つは A 用)があります。
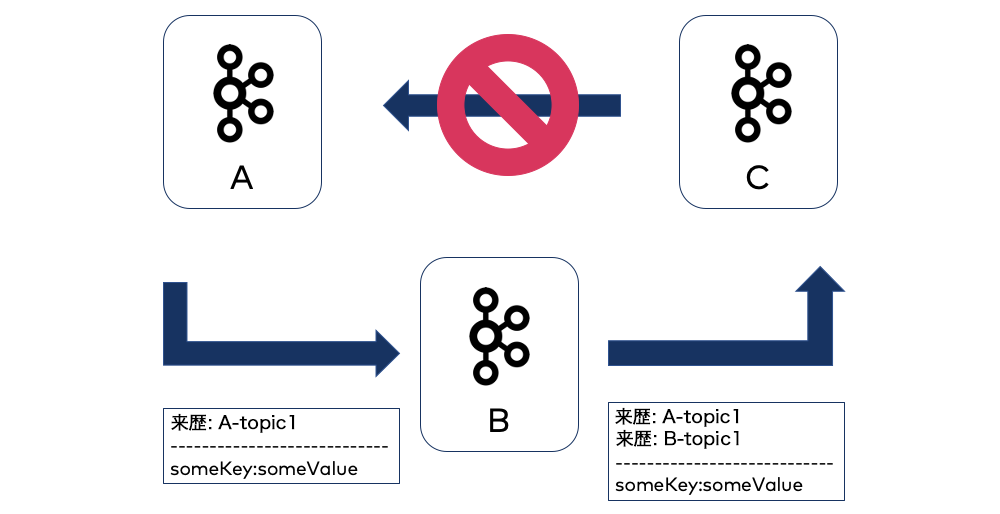
来歴ヘッダーは、双方向レプリケーションを伴うアクティブ/アクティブセットアップ(Replicator は各アクティブクラスターで実行されています)でのレプリケーションの "無限" ループを回避するためにも役立ちます。
これにより、Replicator がメッセージの循環反復を自動的に回避する一方で、異なるデータセンターにあるアプリケーションも同じ名前のトピックにアクセスできます。
ちなみに
来歴ヘッダーを使用する場合、header.converter=io.confluent.connect.replicator.util.ByteArrayConverter を明示的に設定して、人間が理解できるヘッダー出力を取得する必要があります。Replicator の「送信先データ変換」構成オプションに関する説明を参照してください。これにより、Replicator はヘッダーの内容を読み取ることができるようになります。
Replicator 構成リファレンスの「コンシューマーオフセット変換」の provenance.header.enable を参照してください。
しかし、ブローカーが 0.11.0 用のメッセージフォーマット(メッセージフォーマットバージョン v2)をサポートしていないか、または 0.11.0 用のメッセージフォーマットをサポートしていないトピックがある場合、provenance.header.enable=false (デフォルト)を使用して Replicator を構成する必要があります。このようにしない場合、エラーが発生します。「トピック名の変更」の説明を参照してください。
来歴ヘッダーは、「コンシューマーオフセット変換」の Replicator 構成オプションです。
注釈
Kafka メッセージがカスタムヘッダーを持っており、来歴ヘッダーとともにレプリケートされている場合(provenance.header.enable=true)、ヘッダーを処理しているコンシューマーアプリケーションは、__replicator_id キーを持つヘッダーをスキップする必要があります。コンシューマーがレコードを処理する方法によっては、そのためのコードの変更が不要な場合があります。コンシューマーが特定のヘッダーを要求している場合、変更は不要です。しかし、コンシューマーがすべてのヘッダーを取得するために Kafka クラス Interface Headers の toArray を使用する場合、コンシューマーは __replicator_id を明示的にスキップする必要があります。そうしない場合は、レプリケーションによって、「could not decode JSON types ..」や「unrecognized tokens」などのエラーが発生します。
以下に、ConsumerRecord を使用してヘッダーキーを読み取って __replicator_id をスキップする、コンシューマー用の Java コードの例を示します。
ConsumerRecord<byte[], byte[]> record = ...
Headers headers = record.headers();
if (headers != null) {
for (Header header : headers) {
if (!"__replicator_id".equals(header.key())) {
... process application header...
}
}
}
フェイルオーバーシナリオ向けの高度な構成(オフセット変換のチューニング)¶
以下の構成プロパティは、オフセット変換の高度なチューニングに使用します。
重要
オフセット変換は Java コンシューマー専用です。他のタイプのアプリケーションでは動作しません。
Replicator の構成¶
offset.translator.tasks.maxオフセット変換を実行する Replicator タスクの最大数です。-1(デフォルト)の場合、すべてのタスクがオフセット変換を実行します。
- 型: int
- デフォルト: -1
- 重要度: 中
offset.translator.tasks.separateトピックのレプリケーションを実行するタスクとは別のタスクでオフセットを変換するかどうかです。
- 型: boolean
- デフォルト: false
- 重要度: 中
offset.timestamps.commitセカンダリクラスターへの切り替え時に正しく再開できるように、Replicator の内部オフセットタイムスタンプをコミットするかどうかです。
- 型: boolean
- デフォルト: true
- 重要度: 中
provenance.header.enableレプリケーション中に来歴ヘッダーを使用できるようにするかどうかです。
- 型: boolean
- デフォルト: false
- 重要度: 中
fetch.offset.expiry.msオフセット変換のフェッチオフセットリクエストが期限切れになって破棄されるまでの時間(単位: ミリ秒)です。
- 型: long
- デフォルト: 600000
- 重要度: 低
fetch.offset.retry.backoff.msオフセット変換中に失敗したフェッチオフセットリクエストを再試行するまでの待機時間(単位: ミリ秒)です。
- 型: long
- デフォルト: 100
- 重要度: 低
コンシューマーの構成¶
timestamps.topic.num.partitionsコンシューマータイムスタンプトピックのパーティションの数です。
- 型: int
- デフォルト: 50
- 重要度: 高
timestamps.topic.replication.factorコンシューマータイムスタンプトピックのレプリケーション係数。
- 型: short
- デフォルト: 3
- 重要度: 高
timestamps.topic.max.per.partitionパーティションごとの処理のためにメモリーに保持されるタイムスタンプレコードの最大数です。これは最初は無制限ですが、メモリー消費を抑えるために小さく構成できます。タイムスタンプレコードの数がこの値を超えると、タイムスタンプが失われ、対応する変換済みオフセットも失われる可能性があります。
- 型: int
- デフォルト: Integer.MAX_VALUE
- 重要度: 低
オフセット変換の有効化または無効化¶
コンシューマーオフセット変換 は、デフォルトで有効にされています(offset.translator.tasks.max が -1 に設定されています)。
オフセット変換を無効にする必要がある場合もあります。以下に例を示します。
- Replicator の問題のトラブルシューティングを行う場合
- ブートストラップサーバーが構成されていない Replicator の前のリリースからアップグレードする場合(オフセット変換を有効にしていると、
ConfigException: No resolvable bootstrap urls given in bootstrap.serversというエラーメッセージが発生します)
オフセット変換を無効にするには、以下のパラメーターを指定します。
offset.timestamps.commit=false: 内部 コンシューマー オフセットタイムスタンプの送信元へのコミットをオフにします。offset.translator.tasks.max=0: コンシューマー インターセプターのオフセット変換をオフにします。
オフセット変換を再び有効にするには、offset.timestamps.commit を true に設定して、offset.translator.tasks.max を -1 に設定します。