ケーススタディ: GitOps による Kafka Connect の管理¶
streaming-ops プロジェクト は本稼働環境のシミュレーションであり、Confluent Cloud 上の Apache Kafka® をターゲットとする、ストリーミングマイクロサービスをベースにしたアプリケーションを実行しています。アプリケーションとリソースは、宣言型インフラストラクチャである Kubernetes および オペレーターパターン を使用して GitOps によって管理されます。
このケーススタディでは、GitOps アプローチを使用して、Kubernetes 上の Kafka Connect の ワーカー と コネクター を管理する方法を検討します。
スケーラブルでフォールトトレラントな Connect クラスター¶
一般的な本稼働環境の Connect クラスターは、分散モードでデプロイされます。分散ワーカー は、拡張性とフォールトトレランスを実現し、Kubernetes が提供する高度なコンテナー管理機能によって強化されます。
"streaming-ops" プロジェクトは、GitOps で管理される Kubernetes 内の分散 Connect クラスターを実行します。
適切な コネクタープラグイン がインストールされた Connect ワーカーをデプロイするために、カスタム Docker イメージ がビルドされ、Kubernetes クラスターからアクセスできるコンテナーレジストリにパブリッシュされます。必要なプラグインが追加される、Dockerfile の部分を以下に示します。
FROM confluentinc/cp-server-connect:5.5.1
RUN confluent-hub install --no-prompt confluentinc/kafka-connect-jdbc:5.5.1
RUN confluent-hub install --no-prompt confluentinc/kafka-connect-elasticsearch:5.5.1
RUN wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.21/mysql-connector-java-8.0.21.jar -P /usr/share/java/kafka-connect-jdbc/
...
Connect クラスターは、Kubernetes サービスとデプロイ として宣言され、FluxCD コントローラー がデプロイと変更を管理します。
Kubernetes 定義のスニペットを以下に示します。
apiVersion: v1
kind: Service
metadata:
name: connect
labels:
app: connect-service
spec:
selector:
app: connect-service
ports:
- protocol: TCP
port: 80
targetPort: 8083
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: connect-service
spec:
replicas: 1
selector:
matchLabels:
app: connect-service
template:
metadata:
labels:
app: connect-service
...
FluxCD コントローラーは、Git リポジトリでこの定義が変更されたことを検出すると、適切な変更内容を Kubernetes API にポストします。次に、Kubernetes は適切な数のポッドをデプロイし、デプロイを管理します。Kafka Connect ワーカーは、コネクターを適切に実行するために、Kafka 上で協調モードで動作します。
GitOps と Kubernetes を使用した Confluent Cloud リソースと Kafka Connect の管理方法の詳細については、ブログの投稿記事「DevOps for Apache Kafka® with Kubernetes and GitOps」を参照してください。これらのソリューションの完全なソースコードを確認するには、プロジェクトの GitHub リポジトリ(https://github.com/confluentinc/streaming-ops)にアクセスしてください。
注釈
Confluent Cloud を使用する場合に外部システムを統合するためのもう 1 つの方法として、フルマネージド型 Kafka Connect があります。フルマネージド型 Connect では、Confluent がユーザーに代わって Connect クラスターを管理するため、ユーザーは Connect ワーカーや Docker イメージの管理、Connect クラスターのその他の複雑な操作など、運用の負担から解放されます。Confluent Cloud にサインアップしてください。プロモーションコード C50INTEG を使用した最初の 20 名のユーザーは、$50 相当を無料で使用できます(詳細)。
PR による Connect クラスターのスケーリング¶
GitOps アプローチを使用する際の利点の 1 つは、プルリクエスト(PR)レビュープロセスを使用して、アプリケーションコードの場合と同じ方法で、インフラストラクチャコードへの変更を監査できることです。ここでは、PR ベースの GitOps アプローチを使用して、Connect クラスター内の Kafka Connect ワーカーの数を拡張するための基本的な PR ベースのワークフローを重点的に説明します。
チームは、Kafka Connect ワーカーノードでリソース使用率が上昇していることに気づき、ノード数を
1から2に増やす必要があると判断しました。kubectl get deployments/connect-service NAME READY UP-TO-DATE AVAILABLE AGE connect-service 1/1 1 1 18d
Kafka Connect デプロイ定義 内の
replicasフィールドを使用して、デプロイした Connect ワーカーの数を変更します。PR が開かれ、変更されたmasterブランチがターゲットになっています。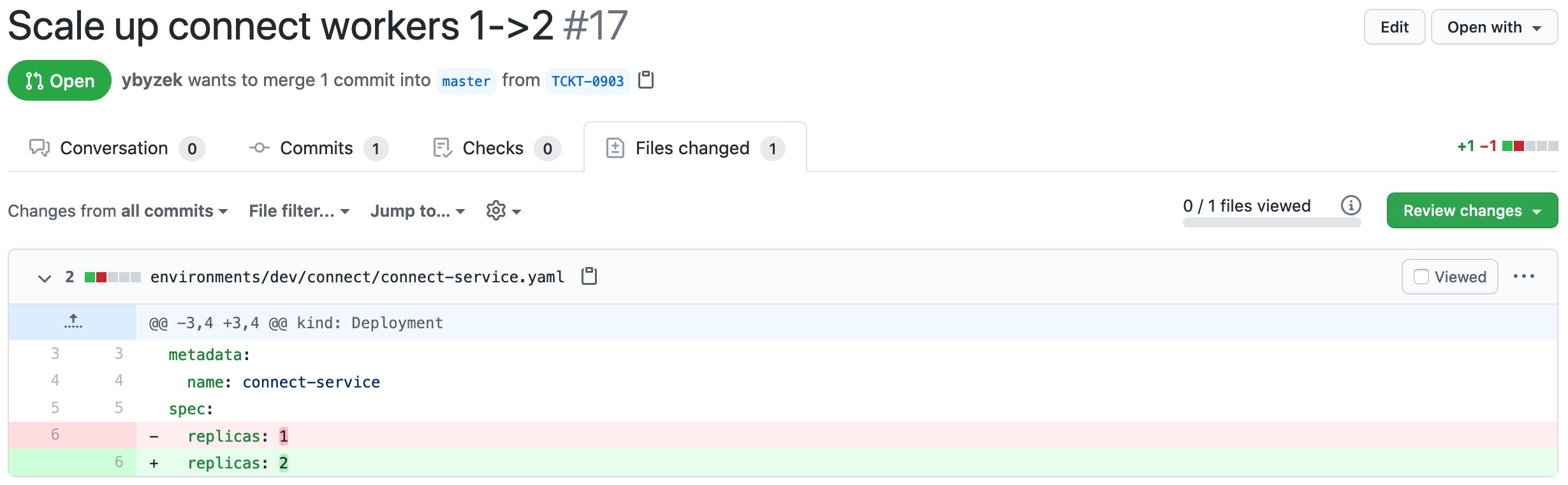
通常の PR コードレビュープロセスを使用して、PR が受け付けられるか、拒否されます。
受け付けられると、PR コードの変更が
masterブランチにマージされ、GitOps プロセスが、connect-serviceデプロイのレプリカ数を拡張して引き継ぎます。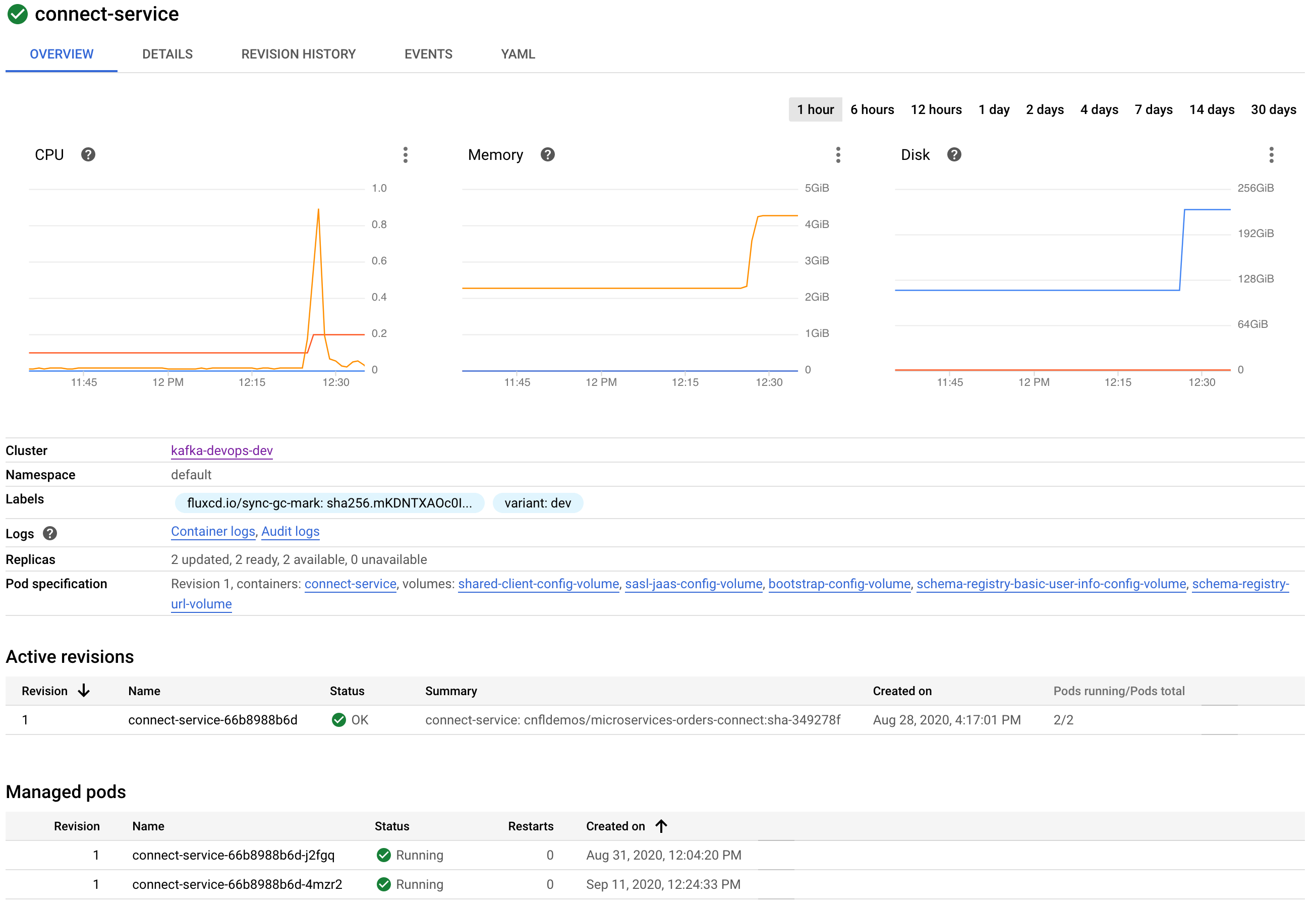
connect-operator によるコネクター管理¶
Kafka Connect 構成の管理は、イベントストリーミングプラットフォームの管理者にとって一般的なタスクです。Connect 構成は JSON で定義され、Connect REST インターフェイス を介して管理されることにより、Kubernetes の「宣言→適用」モデルに適合するようになります。streaming-ops プロジェクトには、connect-operator というツールが含まれており、宣言によってコネクターのデプロイの管理を自動化する際に役立ちます。
注釈
connect-operator は、サポートされている Confluent 製品ではなく、Kubernetes による Kafka Connect リソース管理の方法を探しているユーザーのリファレンスとして提供されています。
connect-operator は、Operator パターンと呼ばれる、Kubernetes の一般的なコンセプトに基づいています。connect-operator は、コネクター管理向けの非常に基礎的な Operator ソリューションの実装方法としてオープンソースプロジェクト shell-operator を使用します。デプロイすると、connect-operator は、モニタリングしようとしている Kubernetes リソースの種類を shell-operator ランタイムにアドバタイズします。そのリソースの追加、削除、またはアップデートが発生すると connect-operator は、実行中のコンテナ内でのスクリプトの実行により通知を受け取ります。
connect-operator の場合は、Kubernetes 内の ConfigMaps をモニタリングしており、これは次のように説明される特定のフィルターに一致します。
configVersion: v1
kubernetes:
- name: ConnectConfigMapMonitor
apiVersion: v1
kind: ConfigMap
executeHookOnEvent: ["Added","Deleted","Modified"]
labelSelector:
matchLabels:
destination: connect
namespace:
nameSelector:
matchNames: ["default"]
jqFilter: ".data"
このフィルターに一致する ConfigMaps の追加、削除、または変更が Kubernetes API で行われると、"connect-operator" 内のスクリプトが呼び出され、変更された宣言が渡されます。connect-operator は、次の 3 つの重要な機能を順に実行します。
- デプロイ時に JSON コネクター構成を、Kubernetes が提供する変数で設定し、シークレット、接続文字列、ホスト名などの変数の構成のテンプレート化が可能になります。
- 使用する Kafka Connect 構成に、現在の実際の構成に基づくアップデートが必要かどうかを決定し、Connect REST API への不要な呼び出しを防止します。
- Connect REST API を使用して、コネクターの追加、アップデート、削除を行って管理します。
"connect-operator" は、管理対象のコネクターに必要な構成とシークレットを含む、Kubernetes ボリュームと環境変数を使用するよう構成されています。たとえば、コネクターの Kafka 接続用の Schema Registry URL 構成は、Kubernetes デプロイ内の次のスニペットのような ボリュームマウント によって提供されます。
...
name: schema-registry-url-volume
secret:
secretName: cc.schema-registry-url.streaming-ops
...
アップデートされたコネクター JSON を含む connect-operator スクリプトが呼び出されると、そのスクリプトがボリュームマウントおよび環境変数の構成を使用し、そのコネクターの JSON 構成を適切な値で設定します。JSON コネクター構成を含むサンプル ソースコネクター ConfigMap を参照してください。このファイルには、上記の構成にある次の JSON のように、デプロイ時に connect-operator によって記入される変数が含まれます。
"value.converter.schema.registry.url": $SCHEMA_REGISTRY_URL,
connect-operator は、jq コマンドライン処理ツールを使用してこれを実行します。connect-operator スクリプト 内を見ると、コネクター用の有効な JSON 構成を設定するために、ファイルと環境変数にある変数がツールによってどのように入力されるかがわかります。load_configs シェル関数は、/etc/config/connect-operator フォルダー内のプロパティファイルで見つかったすべての値を読み込み、それを jq コマンドに渡します。
さらにJSON は、次のように JSON ドキュメントにテンプレート化された 環境変数値を含む ことができます。
"connection.user": env.MYSQL_CONNECTION_USER,
connect-operator でコネクター用の JSON 構成が正常に設定されると、存在している同名のコネクターの現在の状態に基づいて、実行するアクションが決定されます。詳細については、"connect-operator" の apply_connector 関数 を参照してください。
streaming-ops の動作例¶
この詳細および他の運用ユースケースについては、Kubernetes と GitOps を使用する Apache Kafka® 用 DevOps の詳細なドキュメントとプロジェクトの GitHub リポジトリ を参照してください。