モジュール 2: Confluent Cloud へのハイブリッドデプロイのチュートリアル¶
Confluent Cloud へのハイブリッドデプロイ¶
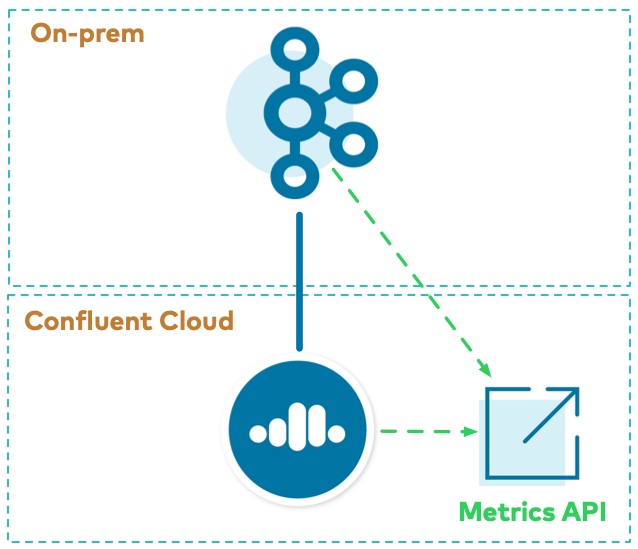
Apache Kafka® のハイブリッドデプロイのシナリオでは、オンプレミスと Confluent Cloud の両方の環境を利用できます。このチュートリアルでは、Replicator を実行して Kafka データを Confluent Cloud に送信し、共通の方法である Metrics API を使用して両方のメトリクスを収集します。
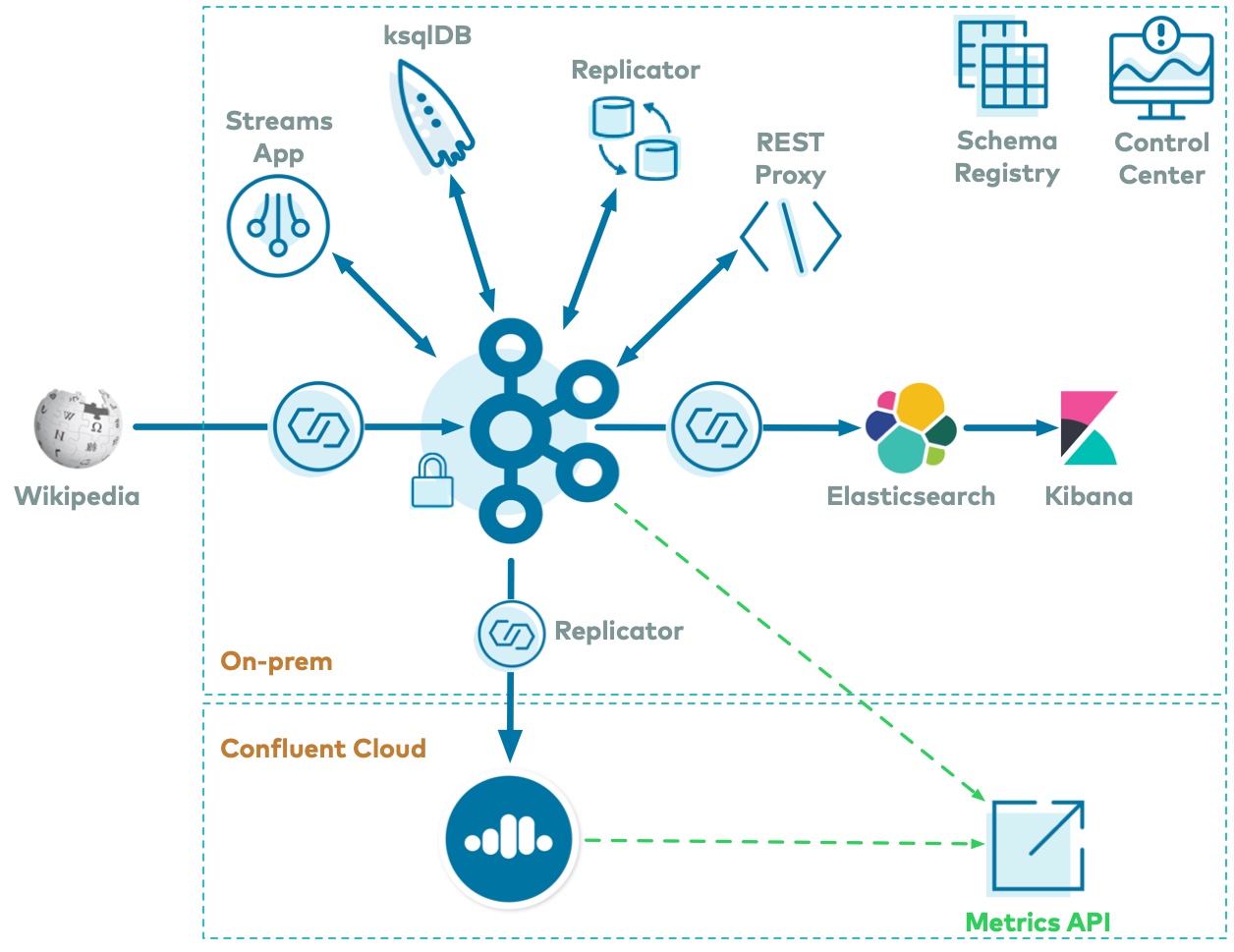
このチュートリアルのこの部分は、cp-demo の 初回の起動 を完了した後に実行してください。初回の起動により、オンプレミスのクラスターがデプロイされます。このセクションの手順により、Confluent Cloud インスタンスが起動され、オンプレミスのクラスターと相互接続されます。
実行のコスト¶
注意¶
Confluent Cloud のすべてのサンプルでは、課金される可能性のある実際の Confluent Cloud リソースを使用しています。サンプルで、新しい Confluent Cloud 環境、Kafka クラスター、トピック、ACL、サービスアカウントに加えて、コネクターや ksqlDB アプリケーションのように時間で課金されるリソースを作成する場合があります。想定外の課金を避けるために、慎重に リソースのコストを確認 してから開始してください。Confluent Cloud のサンプルの実行を終了したら、サービスへの時間単位の課金を回避するためにすべての Confluent Cloud リソースを破棄し、リソースが削除されたことを確認します。
Confluent Cloud および CLI のセットアップ¶
https://confluent.cloud で Confluent Cloud アカウントを作成します。
Confluent Cloud アカウントのお支払い方法を設定し、オプションで Confluent Cloud UI の Billing and payment セクションでプロモーションコード
CPDEMO50を入力すると、$50 相当を無料で使用できます。Confluent Cloud CLI v1.25.0 以降をインストールします。
CLI を使用して、コマンド
ccloud loginで、Confluent Cloud のユーザー名とパスワードを使用して Confluent Cloud にログインします。--save引数により、Confluent Cloud ユーザーログイン資格情報が保存されるか、ローカルのnetrcファイルに対してトークン(SSO の場合)が更新されます。ccloud login --save
このチュートリアルの Confluent Cloud の残りの部分は、順番に実行する必要があります。以下のセクションのすべての手順を手動で実行することをお勧めします。ただし、これらの手順を自動化したスクリプト(scripts/ccloud/create-ccloud-workflow.sh)を実行することもできます。この方法は、このチュートリアルを既に実行したことがあり、迅速に開始したい場合にお勧めします。
./scripts/ccloud/create-ccloud-workflow.sh
ccloud-stack¶
自動で迅速に Confluent Cloud でリソースを作成するには、Confluent Cloud 向け ccloud-stack ユーティリティ を使用します。1 つのコマンドで実行でき、Confluent Cloud CLI を使用して以下のことを実行できます。
- 新しい環境を作成する。
- 新しいサービスアカウントを作成する。
- 新しい Kafka クラスターとそれに関連する資格情報を作成する。
- Confluent Cloud Schema Registry とそれに関連する資格情報を有効にする。
- ワイルドカードを使用するサービスアカウント用 ACL を作成する。
- 新しい ksqlDB アプリケーションとそれに関連する認証情報を作成する。
- 上記のすべての接続情報を含むローカル構成ファイルを生成する。
Confluent Cloud とやり取りするための便利な関数がまとめられている bash ライブラリを取得します(
cloud-stackが含まれています)。このライブラリは、コミュニティによってサポートされており、Confluent ではサポートしていません。curl -sS -o ccloud_library.sh https://raw.githubusercontent.com/confluentinc/examples/latest/utils/ccloud_library.sh
ccloud_library.sh(前の手順でダウンロードしてあります)を使用して、新しいccloud-stackを作成します(高度なオプションについては「Confluent Cloud 向け ccloud-stack ユーティリティ」を参照してください)。Confluent Cloud に実際のリソースが作成されます。完了するまでに数分間かかります。注釈
trueフラグが指定されていると、Confluent Cloud での ksqlDB アプリケーションの作成が追加されます。その場合、積極的に使用していなくても、時間単位の課金が発生します。source ./ccloud_library.sh export EXAMPLE="cp-demo" && ccloud::create_ccloud_stack true
ccloud-stackが完了したら、自動生成された、stack-configs/java-service-account-<SERVICE_ACCOUNT_ID>.configのローカル構成ファイルを確認します。ここには、新しく作成された Confluent Cloud 環境に接続するための接続情報が含まれています。cat stack-configs/java-service-account-*.config
現在のシェルで、環境変数
SERVICE_ACCOUNT_IDにファイル名の <SERVICE_ACCOUNT_ID> を設定します。たとえば、ファイル名がstack-configs/java-service-account-154143.configの場合は、SERVICE_ACCOUNT_ID=154143と設定します。この環境変数は、このチュートリアルの後半で使用されます。SERVICE_ACCOUNT_ID=<fill in>
Replicator 構成ファイル には、Confluent Cloud への接続方法を指定するパラメーターがあります。これらのパラメーターは手動で設定できますが、自動的に設定するには、別の関数を使用して、上記で作成した Confluent Cloud インスタンス用にカスタマイズされた環境パラメーターを設定します。この関数は、ローカルの Confluent Cloud 構成ファイル(自動生成された
stack-configs/java-service-account-<SERVICE_ACCOUNT_ID>.config)を読み取り、Confluent Cloud に接続する Confluent Platform コンポーネントおよびクライアントに役立つファイルを作成します。ccloud_library.sh(前の手順でダウンロードしてあります)を使用して、自動生成された構成ファイル(ccloud-stackで作成されたファイル)に対してgenerate_configs関数を実行します。ccloud::generate_configs stack-configs/java-service-account-$SERVICE_ACCOUNT_ID.config
このスクリプトの出力は、すべてのコンポーネントおよびクライアントのサンプル構成が含まれた
delta_configsというフォルダーです。これらのサンプル構成は、任意の Kafka クライアントまたは Confluent Platform コンポーネントに簡単に適用できます。delta_configs/env.deltaファイルを表示します。cat delta_configs/env.delta
source コマンドで
delta_configs/env.deltaファイルの内容を現在の環境に反映させます。これらの環境変数は、いくつかのセクションで、Replicator を実行してオンプレミスのクラスターから Confluent Cloud クラスターにデータをコピーするときに使用されます。source delta_configs/env.delta
Telemetry Reporter¶
オンプレミスのクラスターで Confluent Telemetry Reporter を有効にし、上記で作成した Confluent Cloud インスタンスにメトリクスを送信するように構成します。
Confluent Cloud に対する認証用の新しい
CloudAPI キーとシークレットを作成します。これらの認証情報は Telemetry Reporter を構成するために使用され、Metrics API によって使用されます。ccloud api-key create --resource cloud -o json
以下のように出力されることを確認します。
{ "key": "QX7X4VA4DFJTTOIA", "secret": "fjcDDyr0Nm84zZr77ku/AQqCKQOOmb35Ql68HQnb60VuU+xLKiu/n2UNQ0WYXp/D" }実際の出力では、API キーの値(この場合は
QX7X4VA4DFJTTOIA)と API シークレット(この場合はfjcDDyr0Nm84zZr77ku/AQqCKQOOmb35Ql68HQnb60VuU+xLKiu/n2UNQ0WYXp/D)が異なります。前の手順で返されたこれらの認証情報を参照するようにパラメーターを設定します。
METRICS_API_KEY='QX7X4VA4DFJTTOIA' METRICS_API_SECRET='fjcDDyr0Nm84zZr77ku/AQqCKQOOmb35Ql68HQnb60VuU+xLKiu/n2UNQ0WYXp/D'
Telemetry Reporter を使用するように、
cp-demoクラスターを 動的に構成 します。この Telemetry Reporter から Confluent Cloud にメトリクスが送信されます。それには、3 つの構成パラメーター(confluent.telemetry.enabled=true、confluent.telemetry.api.key、confluent.telemetry.api.secret)を設定する必要があります。docker-compose exec kafka1 kafka-configs \ --bootstrap-server kafka1:12091 \ --alter \ --entity-type brokers \ --entity-default \ --add-config confluent.telemetry.enabled=true,confluent.telemetry.api.key=${METRICS_API_KEY},confluent.telemetry.api.secret=${METRICS_API_SECRET}ブローカーのログをチェックして、ブローカーが動的に構成されたことを確認します。
docker-compose logs kafka1 | grep confluent.telemetry.api出力は次のようになります。ただし、
confluent.telemetry.api.keyの値は環境によって異なります。... kafka1 | confluent.telemetry.api.key = QX7X4VA4DFJTTOIA kafka1 | confluent.telemetry.api.secret = [hidden] ...
Confluent Cloud UI にログインし、
Confluent Platformの下のHosted monitoringセクションに、このクラスターダッシュボードが表示されることを確認します。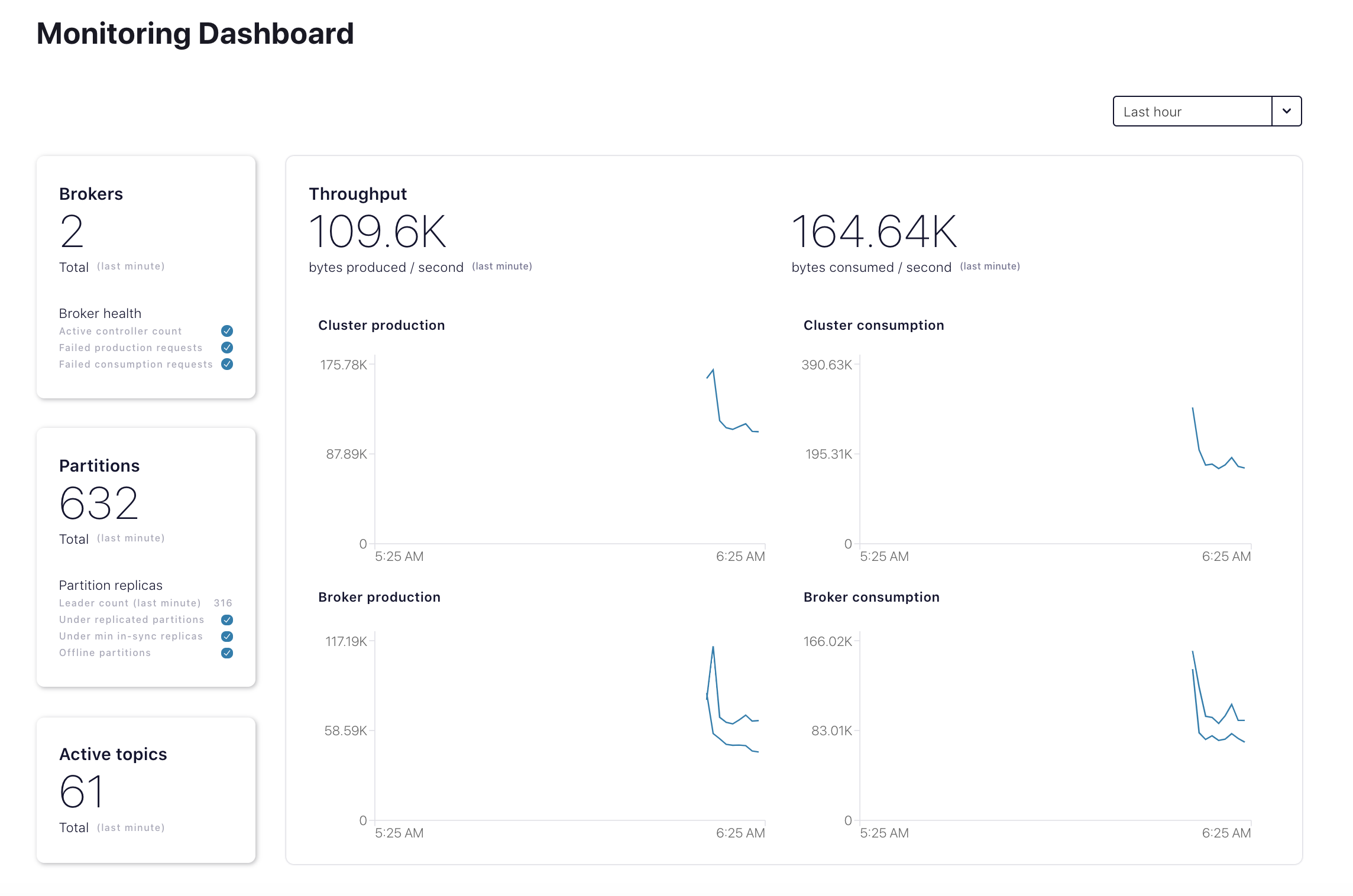
Replicator から Confluent Cloud へ¶
Replicator をデプロイして、オンプレミスのクラスターから、Confluent Cloud で実行されている Kafka クラスターにデータをコピーします。Kafka トピック wikipedia.parsed (オンプレミス)から Confluent Cloud のクラウドトピック wikipedia.parsed.ccloud.replica にコピーするように構成されています。Replicator インスタンスは、オンプレミスのクラスターの既存の Connect ワーカー上で実行されています。
cp-demoを長時間実行している場合は、ローカルトークンを更新して、再度 MDS にログインすることが必要な場合があります。./scripts/helper/refresh_mds_login.sh
Replicator の新しいインスタンスを、ID が
connect-clusterのローカルの Connect クラスターに送信できるように、ロールバインディングを作成します。Kafka クラスター ID を取得します。
KAFKA_CLUSTER_ID=$(curl -s https://localhost:8091/v1/metadata/id --tlsv1.2 --cacert scripts/security/snakeoil-ca-1.crt | jq -r ".id")
Create the role bindings:
docker-compose exec tools bash -c "confluent iam rolebinding create \ --principal User:connectorSubmitter \ --role ResourceOwner \ --resource Connector:replicate-topic-to-ccloud \ --kafka-cluster-id $KAFKA_CLUSTER_ID \ --connect-cluster-id connect-cluster"Replicator 構成ファイル を表示します。ローカルの Connect クラスター(元のサイト)が使用されているため、Replicator の構成には、プロデューサーのオーバーライドがあります。変数を使用する構成パラメーターは、先ほどの手順で取得した環境変数から読み取られます。
Replicator コネクターをローカル Connect クラスターに送信します。
./scripts/connectors/submit_replicator_to_ccloud_config.sh
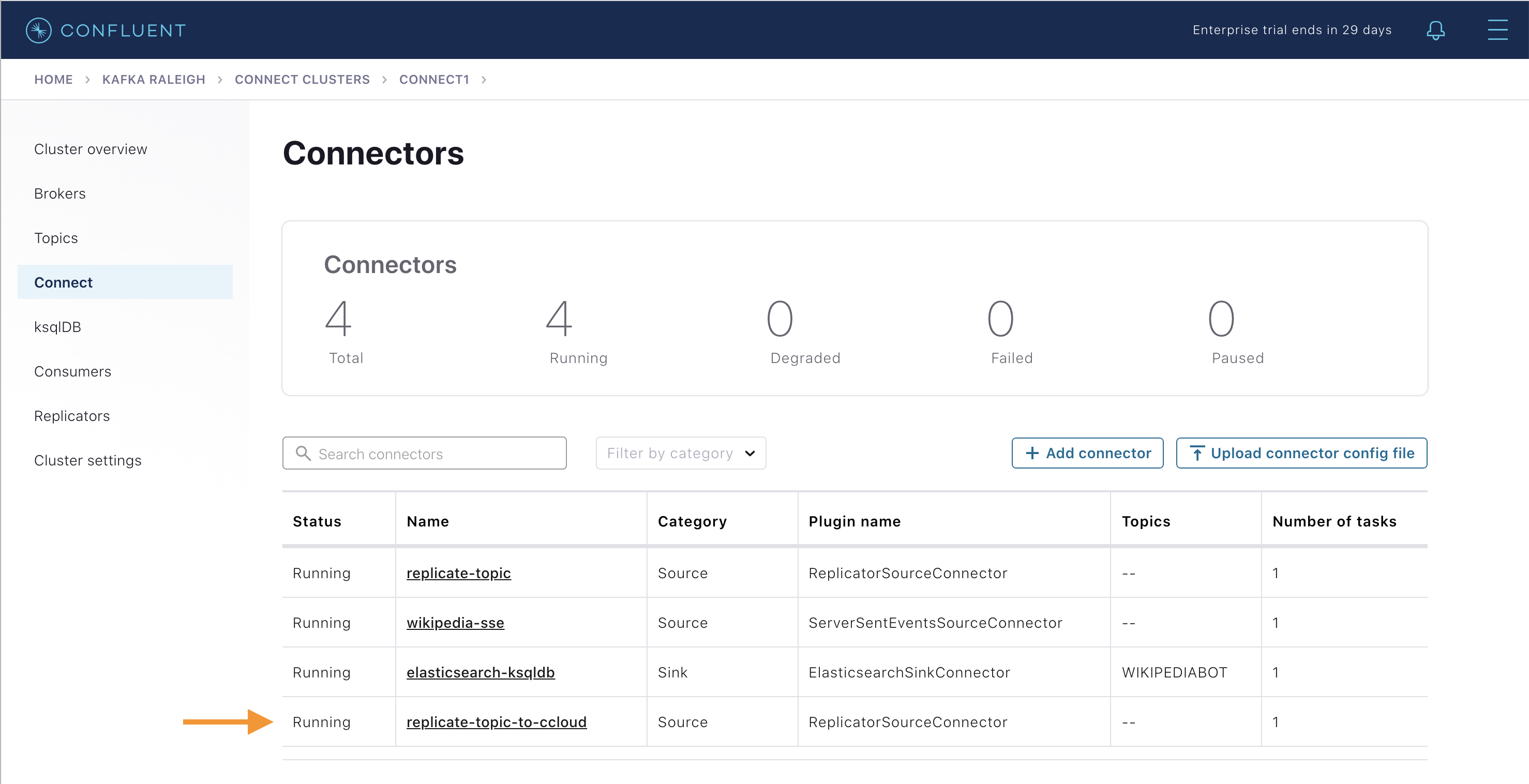
Confluent Control Center の Connectors ビューに表示されるまでに約 1 分かかります。表示されたら、Confluent Cloud への Replicator が正常に開始されたこと、および 4 つのコネクターが存在することを確認します。
Confluent Cloud UI にログインし、トピック
wikipedia.parsed.ccloud.replicaとそのメッセージが表示されることを確認します。Confluent Cloud Schema Registry に既に登録されているこのトピックのスキーマを表示します。
cp-demoでは、Replicator 構成ファイル で、io.confluent.connect.avro.AvroConverterを使用するようにvalue.converterが構成されています。そのため、データのコピー中、必要に応じて新しいスキーマが自動的に登録されます。オンプレミスの Schema Registry のスキーマ ID は、Confluent Cloud Schema Registry のスキーマ ID と一致しません(他の スキーマの移行オプション については、ドキュメントを参照してください)。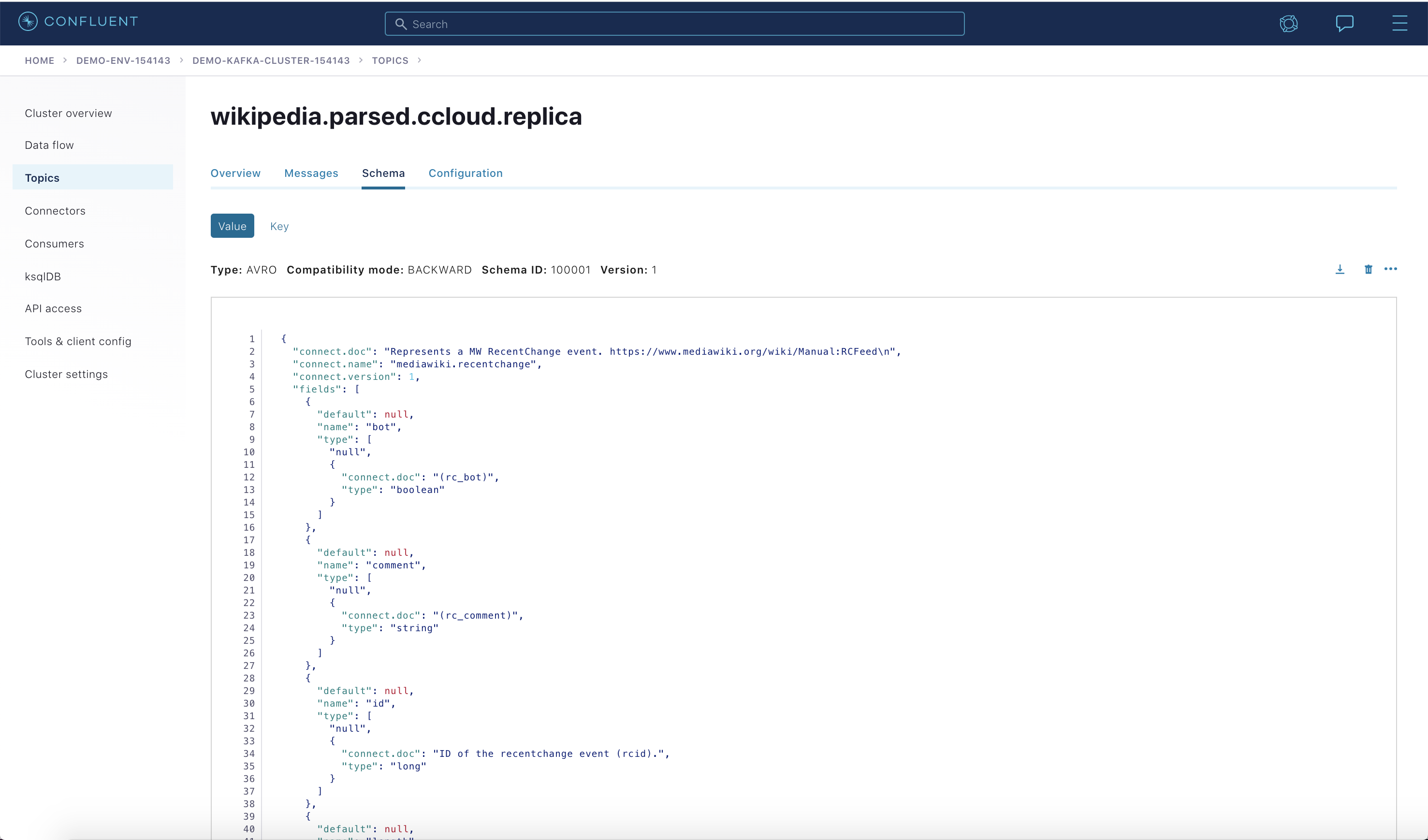
Metrics API¶
Metrics API を使用して、オンプレミスのクラスターと Confluent Cloud クラスターの両方からデータを取得できます。Metrics API では、クエリ可能な HTTP API が用意されており、クエリを POST して時系列のメトリクスを取得することができます。これを使用して、次の両方を観察できます。
- エンドポイント https://api.telemetry.confluent.cloud/v2/metrics/hosted-monitoring/query を使用するオンプレミスのメトリクス(Telemetry Reporter により有効化)(これはプレビュー版で、API は変更される可能性があります)
- エンドポイント https://api.telemetry.confluent.cloud/v2/metrics/cloud/query を使用する Confluent Cloud メトリクス
Metrics API のクエリを実行する時間間隔を定義するには、現在時刻 -1 時間と現在時刻 +1 時間を取得します。
dateユーティリティはオペレーティングシステムによって異なるため、一貫性と信頼性のある日付を取得できるように、toolsDocker コンテナーを使用します。CURRENT_TIME_MINUS_1HR=$(docker-compose exec tools date -Is -d '-1 hour' | tr -d '\r') CURRENT_TIME_PLUS_1HR=$(docker-compose exec tools date -Is -d '+1 hour' | tr -d '\r')
オンプレミスのメトリクスの場合: メトリクスクエリファイル を表示します。このファイルは、オンプレミスのクラスターのトピック
wikipedia.parsedについてio.confluent.kafka.server/received_bytesをリクエストします(すべてのクエリ可能なメトリクスの例については、「Metrics API」を参照してください。{ "aggregations": [ { "agg": "SUM", "metric": "io.confluent.kafka.server/received_bytes" } ], "filter": { "filters": [ { "field": "metric.topic", "op": "EQ", "value": "wikipedia.parsed" } ], "op": "AND" }, "intervals": ["${CURRENT_TIME_MINUS_1HR}/${CURRENT_TIME_PLUS_1HR}"], "granularity": "PT1M", "group_by": [ "metric.topic" ], "limit": 5 }クエリの JSON ファイルの値を置き換えます。この置き換えを正常に実行するには、使用している環境で以下のパラメーターが設定されている必要があります。
CURRENT_TIME_MINUS_1HRCURRENT_TIME_PLUS_1HR
DATA=$(eval "cat <<EOF $(<./scripts/ccloud/metrics_query_onprem.json) EOF ") # View this parameter echo $DATA
このクエリを Metrics API のエンドポイント(https://api.telemetry.confluent.cloud/v2/metrics/hosted-monitoring/query)に送信します。このクエリを正常に実行するには、使用している環境で以下のパラメーターが設定されている必要があります。
METRICS_API_KEYMETRICS_API_SECRET
curl -s -u ${METRICS_API_KEY}:${METRICS_API_SECRET} \ --header 'content-type: application/json' \ --data "${DATA}" \ https://api.telemetry.confluent.cloud/v2/metrics/hosted-monitoring/query \ | jq .出力は、以下の出力例のようになり、オンプレミスのトピック
wikipedia.parsedのメトリクスが表示されます。{ "data": [ { "timestamp": "2020-12-14T20:52:00Z", "value": 1744066, "metric.topic": "wikipedia.parsed" }, { "timestamp": "2020-12-14T20:53:00Z", "value": 1847596, "metric.topic": "wikipedia.parsed" } ] }Confluent Cloud のメトリクスの場合: メトリクスクエリファイル を表示します。このファイルは、Confluent Cloud のトピック
wikipedia.parsed.ccloud.replicaについてio.confluent.kafka.server/received_bytesをリクエストします(すべてのクエリ可能なメトリクスの例については、「Metrics API」を参照してください。{ "aggregations": [ { "agg": "SUM", "metric": "io.confluent.kafka.server/received_bytes" } ], "filter": { "filters": [ { "field": "metric.topic", "op": "EQ", "value": "wikipedia.parsed.ccloud.replica" }, { "field": "resource.kafka.id", "op": "EQ", "value": "${CCLOUD_CLUSTER_ID}" } ], "op": "AND" }, "intervals": ["${CURRENT_TIME_MINUS_1HR}/${CURRENT_TIME_PLUS_1HR}"], "granularity": "PT1H", "group_by": [ "metric.topic" ], "limit": 5 }Confluent Cloud の Kafka クラスター ID を取得します。
$SERVICE_ACCOUNT_IDから取得できます。CCLOUD_CLUSTER_ID=$(ccloud kafka cluster list -o json | jq -c -r '.[] | select (.name == "'"demo-kafka-cluster-${SERVICE_ACCOUNT_ID}"'")' | jq -r .id)クエリの JSON ファイルの値を置き換えます。この置き換えを正常に実行するには、使用している環境で以下のパラメーターが設定されている必要があります。
CURRENT_TIME_MINUS_1HRCURRENT_TIME_PLUS_1HRCCLOUD_CLUSTER_ID
DATA=$(eval "cat <<EOF $(<./scripts/ccloud/metrics_query_ccloud.json) EOF ") # View this parameter echo $DATA
このクエリを Metrics API のエンドポイント(https://api.telemetry.confluent.cloud/v2/metrics/cloud/query)に送信します。このクエリを正常に実行するには、使用している環境で以下のパラメーターが設定されている必要があります。
METRICS_API_KEYMETRICS_API_SECRET
curl -s -u ${METRICS_API_KEY}:${METRICS_API_SECRET} \ --header 'content-type: application/json' \ --data "${DATA}" \ https://api.telemetry.confluent.cloud/v2/metrics/cloud/query \ | jq .出力は、以下の出力例のようになり、Confluent Cloud のトピック
wikipedia.parsed.ccloud.replicaのメトリクスが表示されます。{ "data": [ { "timestamp": "2020-12-14T20:00:00Z", "value": 1690522, "metric.topic": "wikipedia.parsed.ccloud.replica" } ] }
Confluent Cloud ksqlDB¶
このセクションでは、Confluent Cloud ksqlDB アプリケーションでクエリを作成して、Replicator がオンプレミスのクラスターからコピーした wikipedia.parsed.ccloud.replica トピックのデータを処理する方法を説明します。先に進む前に ccloud-stack を完了している必要があります。
Confluent Cloud ksqlDB アプリケーション ID を取得し、その値をパラメーター
ksqlDBAppIdに保存します。ksqlDBAppId=$(ccloud ksql app list | grep "$KSQLDB_ENDPOINT" | awk '{print $1}')Confluent Cloud ksqlDB アプリケーションのステートが
PROVISIONINGからUPに移行していることを確認します。これには数分かかる場合があります。ccloud ksql app describe $ksqlDBAppId -o json
ksqlDB の ACL を構成して、ksqlDB アプリケーションに
wikipedia.parsed.ccloud.replicaからの読み取りを許可します。ccloud ksql app configure-acls $ksqlDBAppId wikipedia.parsed.ccloud.replica
Confluent Cloud で、scripts/ccloud/statements.sql ファイルから新しい ksqlDB クエリを作成します。注: 作業しているフォルダーによっては、
statements.sqlファイルの相対パスを変更することが必要な場合があります。while read ksqlCmd; do echo -e "\n$ksqlCmd\n" curl -X POST $KSQLDB_ENDPOINT/ksql \ -H "Content-Type: application/vnd.ksql.v1+json; charset=utf-8" \ -u $KSQLDB_BASIC_AUTH_USER_INFO \ --silent \ -d @<(cat <<EOF { "ksql": "$ksqlCmd", "streamsProperties": {} } EOF ) done <scripts/ccloud/statements.sqlConfluent Cloud UI にログインし、ksqlDB アプリケーションの Flow を表示します。
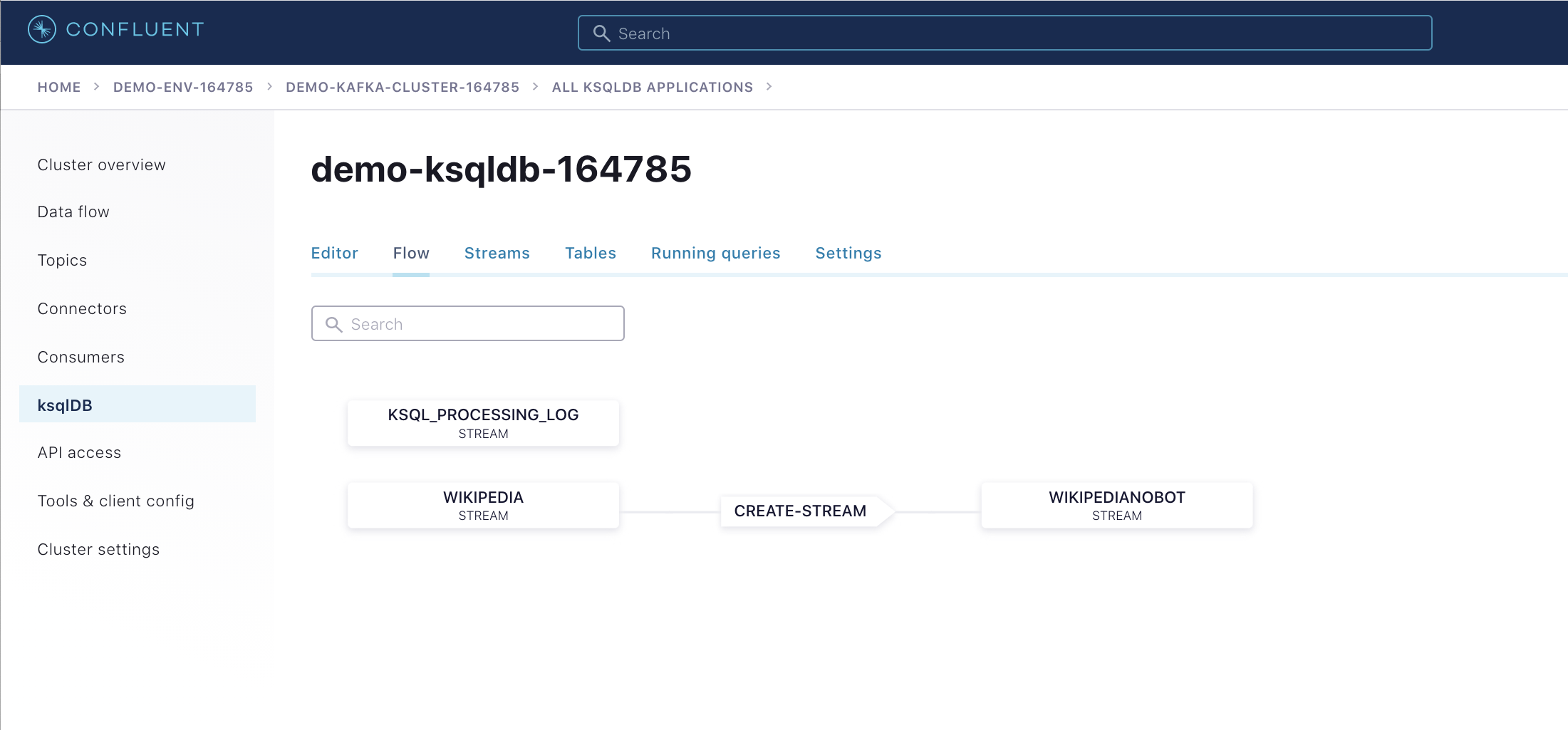
Confluent Cloud で ksqlDB ストリームのイベントを表示します。
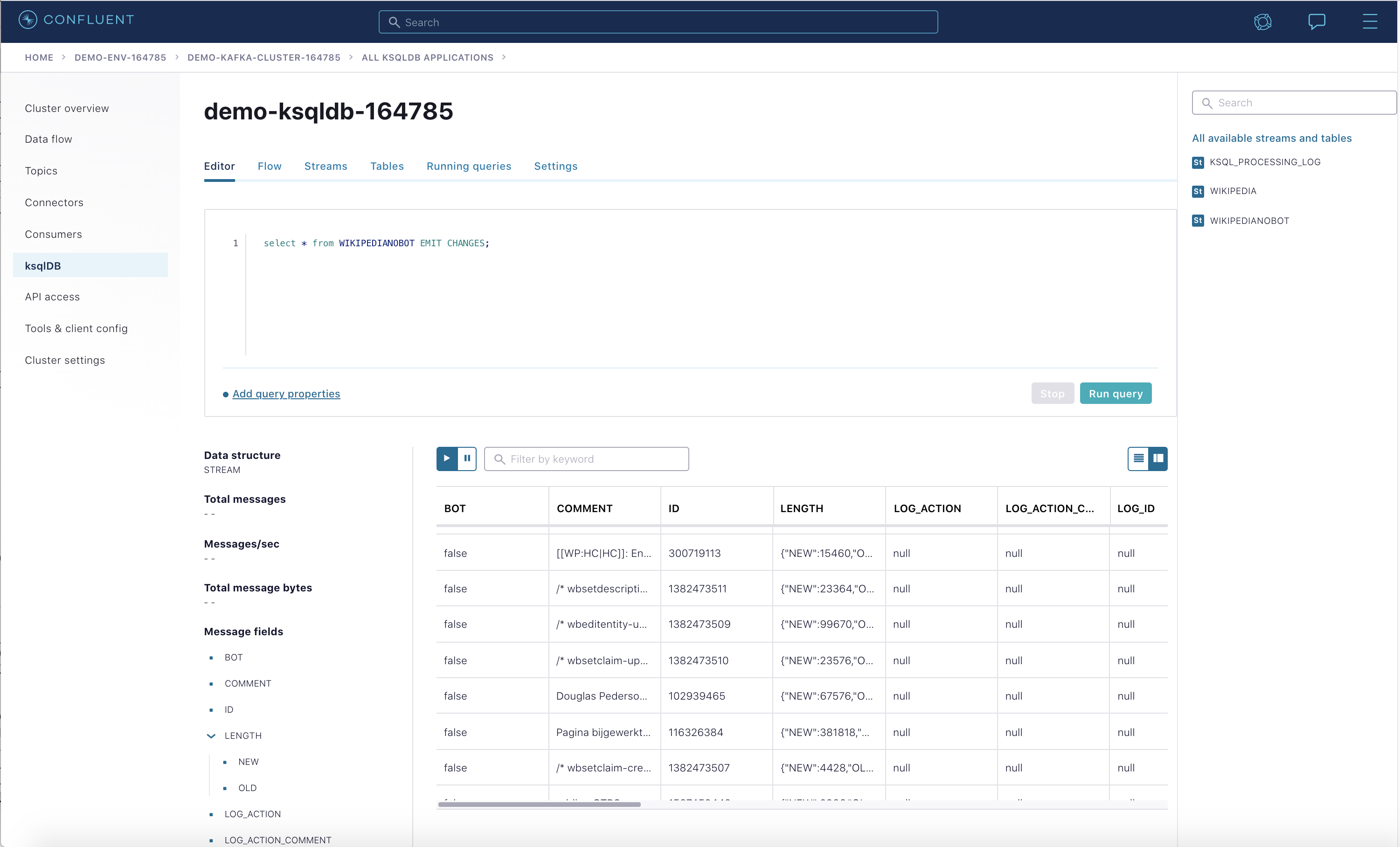
モジュール 2: Confluent Cloud に移動し、使用されているデモリソースを破棄します。重要: Confluent Cloud に ksqlDB アプリケーションを作成すると、積極的に使用していなくても、時間単位の課金が発生します。
クリーンアップ¶
Confluent Cloud のすべてのサンプルでは、実際の Confluent Cloud リソースを使用しています。Confluent Cloud のサンプルの実行を終了したら、予定外の課金を回避するために、すべての Confluent Cloud リソースが破棄されていることを直接確認してください。
想定外の Confluent Cloud の課金を避けるために、「モジュール 2: Confluent Cloud」のクリーンアップの手順を実行します。