Self-Balancing Clusters¶
重要
- Confluent Platform 6.0.0 以降では Self-Balancing が提供されており、 Auto Data Balancer の代わりに使用することが推奨されています。詳細な機能の比較については、「Self-Balancing と Auto Data Balancer」を参照してください。
- Self-Balancing と Auto Data Balancer は同時に使用できません。Auto Data Balancer を実行する場合は、まず Self-Balancing がオフであることを確認する必要があります。
- Self-Balancing は動的オプションです。したがって、クラスターの実行中に、 オンとオフを切り替え ることができます。ブローカーが追加されたときや、不均等の負荷(発生したときはいつでも)についてバランス調整するように設定できます。
Self-Balancing Clusters とは¶
Confluent Platform デプロイでは数百のブローカーを実行し、数千のトピックを管理して、1 時間に数十億のメッセージを生成できます。日常的にブローカーは廃止され、新しいトピックが作成されて削除されます。このため、ワークロードのバランスを調整するためにパーティションを再割り当てする必要があります。これが、Confluent Platform の実行時の操作を管理する担当チームにとって過度の負荷になることがあります。
Self-Balancing はリソースのワークロードのバランスを自動で調整し、障害を検出して、自動で対応します。ユーザーはブローカーを必要に応じて追加や廃止でき、手動の調整は必要ありません。
Self-Balancing が提供する機能
- ロードバランス調整の完全な自動化
- クラスターの自動モニタリング。多様なパラメーター、構成、実行時変数に基づいて不均衡を検出できます。
- 継続的なメトリクスの集約とバランス調整計画。多くの場合、即座に生成され、自動的に実行できます。
- バランス調整処理の自動トリガー。 Confluent Control Center または Kafka
server.propertiesファイルで設定されるシンプルな構成に基づきます。自動バランスオプション Only when brokers are added または Anytime を選択して、均等ではない負荷のバランス調整を実行できます。 - 主要な数個のメトリクスを基にクラスターの状態、自動バランス調整の戦略と進捗状況を一目でわかるように表示
Self-Balancing により Kafka の運用を簡素化する方法¶
Self-Balancing では、次の複数の方法で Kafka クラスターの運用管理を簡素化します。
- クラスターで負荷が不均等に分散しているとき、パフォーマンスを最適化するため、Self-Balancing によりパーティションのバランスが自動的に調整されます。
- 新しいブローカーがクラスターに追加されたとき、Self-Balancing によりそのブローカーにパーティションが自動的に配置されます。
- ブローカーを削除するとき、 kafka-remove-brokers を使用して対象ブローカーをシャットダウンし、対応するパーティションを移動できます。
- ブローカーが一定時間停止しているとき、Self-Balancing により該当パーティションが他のブローカーに自動的に再割り当てされます。
Self-Balancing と Auto Data Balancer¶
Self-Balancing には Auto Data Balancer と比べて次の利点があります。
- クラスターのバランスは、必要なときに常にバランス調整されるように、継続的にモニタリングされます。
- ブローカーの障害状況が、自動的に検出され対処されます。
- 実行するための追加のツールはありません(ブローカーに組み込み済み)。
- Confluent Control Center と連動し、REST API を利用できます。
- バランス調整が(数桁倍と)大幅に高速化されます。
Self-Balancing Clusters のしくみ¶
Self-Balancing Clusters により Kafka の負荷の把握が最適化されます。クラスター内のリソースの使用量は不均等になることがあります。Kafka では、クラスターのバランス調整用の自動化プロセスは標準仕様では提供されていません。パーティションをどう再割り当てするかを手動で算出する必要があります。
Self-Balancing では、クラスターの負荷が均等に広がるようにデータを移動することによって、この処理を簡素化します。Self-Balancing では、組み込み済みの目標値に基づいて "均等" の意味を定義していますが、 各構成 を通じて任意の入力値を指定できます。
Self-Balancing Cluster のアーキテクチャ¶
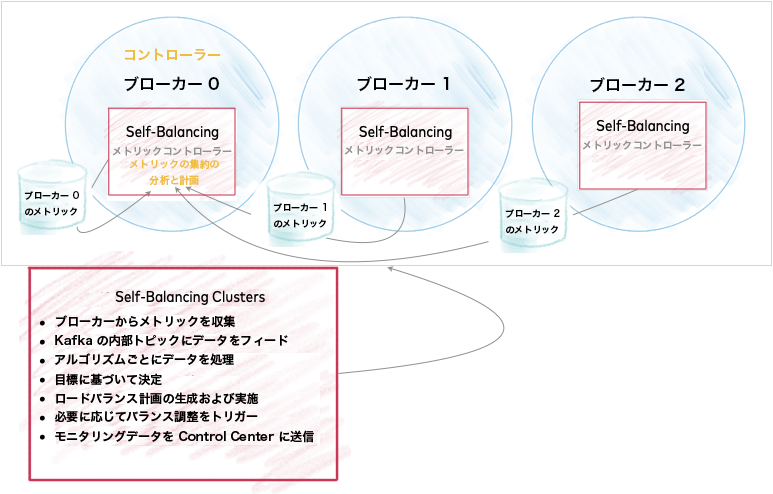
Kafka ブローカーによりメトリクスが収集され、クラスターのリードブローカーにあるコントローラーの内部トピックにデータが入力されます。したがって、このコントローラーはクラスターのバランス調整で主要な役割を果たします。コントローラーを Self-Balancing がアクティブに動作しているノードと考えることができます。
各メトリクスは処理され、それぞれの目標に基づいて、多様な決定が下されます。
このデータはモニタリングおよび可能性のある操作(ロードバランス計画の生成やバランス調整のトリガーなど)のために、他の内部 Kafka トピックに送られます。
ちなみに
Confluent Platform の実行中に kafka-topics --list コマンドを使用して、内部トピックを含めたすべてのトピックを表示できます。たとえば、kafka-topics --list --bootstrap-server localhost:9092 と入力します。Self-Balancing の内部トピックには、先頭に _confluent_balancer_ が付きます。
Self-Balancing Clusters の有効化¶
- クラスターの各ブローカーで Self-Balancing を有効にするために、
confluent.balancer.enable=trueを設定します。この行がコメントアウトされていないことを確認します。Confluent Platform には Self-Balancing が有効に設定されているサンプルファイル$CONFLUENT_HOME/etc/server.propertiesが付属しています。詳細については、「confluent.balancer.enable」を参照してください。 - 構成とモニタリング のために Control Center から Self-Balancing にアクセスできるようにするには、Control Center クラスターで REST エンドポイントを構成し、ブローカーの HTTP サーバーを有効にします(「Control Center の必須構成」を参照)。
クラスターの "バランス" およびバランス調整をトリガーするもの¶
Self-Balancing は、大きく分けて次の 2 種類の不均衡を区別します。
- 意図的な運用操作(ブローカーの追加や削除など)。これらの場合、Self-Balancing により、使用しない場合と比べて、オペレーターの時間や手動のステップが削減されます。
- 継続中のクラスターの操作(ホットトピックやパーティションなど)。このバランス処理は、クラスターが存在する限り続きます。
これらは Self-Balancing を有効にして利用できる、2 種類の広範な構成オプションと対応しています。
- ブローカーが追加されたときにのみバランス調整
- いつでもバランス調整(不均等な負荷を対象とし、利用可能なブローカー数の変化を含む)
最初の場合は明確です。ブローカーが追加されると、データを新しいブローカーに再分配するために自動調整が行われます。あるいは、見つからないブローカーからデータがオフロードされます。
2 番目の事例は多少複雑です。継続的にクラスターとデータのバランスを調整するために、Self-Balancing Clusters では多数の目標に基づいて最適化を行いますが、バランスを調整してもクラスターのパフォーマンスが大きく改善されない場合は、不要な移動は行いません。目標として考慮されるものには、レプリカの配置と容量、レプリケーション係数とスループット、トピックとパーティションに関する複数のメトリクス、リーダーシップ、ラックの把握、ディスク使用量と容量、プロセッサー使用量と性能、ネットワークのブローカー当たりのスループット、多数の負荷分散ターゲットなどがあります。
Self-Balancing Clusters では継続的モニタリングとデータ収集を使用し、これらの目標に対するパフォーマンスをトラッキングし、バランス調整の計画を生成します。バランス調整がトリガーされるかどうかは、特定の時点でのトポロジーの重要度など、すべての要素の意味する内容を考慮して判断します。さらに、バランシングアルゴリズムは概算であり、上記の要素の影響を受けます。
ちなみに
両方の事例において、クラスターでは、(コマンドライン または Control Center 経由で)ユーザーのリクエストによりブローカーが削除されたとき、または(confluent.balancer.heal.broker.failure.threshold.ms で指定した)一定時間にブローカーが見つからないときにも、バランスが調整されます。
したがって、Self-Balancing で "ブローカーが追加されたときにのみバランス調整" に設定されている場合でも、調整しないようにプロパティを意図的に設定しない限り(confluent.balancer.heal.broker.failure.threshold.ms を -1 に設定するなど)、見つからないブローカーがあればクラスターではバランス調整が行われます。
「レプリカ配置とラック構成」も参照してください。
リードブローカー(コントローラー)が削除される、または見つからない場合の動作¶
マルチブローカーのクラスターでは、ブローカーの 1 つがリーダーまたはコントローラーであり、Self-Balancing で重要な役割を果たします(「Self-Balancing Cluster のアーキテクチャ」を参照)。コントローラーが動作しているブローカーが意図的に削除される、またはクラッシュした場合に何が起こるでしょうか。
- クラスターの完全性に影響はありません。
- コントローラーが削除される、または失われると、新しいコントローラーが選出されます。
- ブローカーの削除リクエストは、一度実行すると維持されます。別のブローカーがコントローラーになると、その新しいコントローラーが再起動され、ブローカーの削除プロセスが再開されます。つまり、ある程度の遅延が発生します。
- 新しいリーダーは ブローカーの削除 リクエストを引き受け、完了します。
- リードブローカーが "ブローカーの追加" 処理中に失われると、"ブローカーの追加" 処理は完了せず、失敗とマークされます。新しいコントローラーがこれに対応しない場合、追加しようとしているブローカーの再起動が必要になることがあります。
「トラブルシューティング」も参照してください。
ブローカーが Cruise Control を活用する方法¶
Confluent Self-Balancing Clusters は Cruise Control を継続的なメトリクスの集約とレポート作成、再割り当てアルゴリズムと計画、バランス調整トリガーに活用します。Kafka とは別に管理する必要がある Cruise Control と異なり、Self-Balancing はブローカーに組み込まれます。つまりデータのバランス調整は、追加のツールに依存することなく、そのままでサポートされます。Confluent Platform で Kafka クラスターに最適化され、カスタムメイドかつ自動化されたロードバランス機能であり、 階層型ストレージ や Multi-Region Clusters など他のコンポーネントとシームレスに連動するように設計されています。
Self-Balancing で作成および使用される内部トピックの種類¶
構成およびコマンドリファレンスの「Self-Balancing の内部トピック」を参照してください。
制限¶
- Self-Balancing は、複数のディスクを 1 台に見せかけ、"スパニング" とも呼ばれる JBOD(単なるディスクの束)をサポートしません。Self-Balancing がサポートするのは単一のディスクノードのみです。
- ブローカーに含まれるのがパーティションの唯一のレプリカである場合、データ紛失の可能性を防ぐために、Self-Balancing はそのブローカーを削除するための選出の試みをブロックします(ブローカーの削除処理は失敗します)。これに対応する最良の方法は、削除するブローカーにあるトピックおよび内部トピックのレプリケーション係数を増やすことです(チュートリアルの「Self-Balancing のレプリケーション係数の構成」を参照)。
- クラスターの起動直後に(Self-Balancing の初期化中)にブローカーの削除を試みると、メトリクス不足のために失敗することがあります。別のフェーズでも、リードブローカーの削除を試みると失敗することがあります。解決策としては一定時間経過後に、ブローカーの削除を再試行することです。ブローカーがコントローラーである場合、コマンドラインからブローカーの削除を実行する必要があります。Control Center で実行できないことがあるからです。詳細については、トラブルシューティングの「Self-Balancing の初期化中にブローカーの削除の試行に失敗する」を参照してください。
構成とモニタリング¶
Self-Balancing Clusters はセルフマネージド型で、クラスターが実行中でも有効にできます。多くの場合、各デフォルト設定を変更する必要はありません。クラスターを開始する前後に Self-Balancing を有効にするだけで、必要に応じた自動バランス調整が許可されます。
Confluent Platform に付属しているサンプル server.properties ファイルでは、 confluent.balancer.enable が true に設定されています。これは、Self-Balancing がオンになっていることを示しています。
バランサーのステータスを取得する¶
Confluent Enterprise 6.2.0 以降には、Self-Balancing 機能自体のステータスおよびその処理を可視化するための API とコマンドが用意されています。詳細については、「kafka-rebalance-cluster を使用したバランサーのモニタリング」を参照してください。
Control Center の使用¶
ちなみに
- Self-Balancing に Control Center からアクセスできるようにするには、Control Center クラスターで REST エンドポイントを構成して、ブローカーの HTTP サーバーを有効にする必要があります(「Control Center の必須構成」を参照)。
- Self-Balancing と Control Center を連携させる場合の情報は、「Self-Balancing チュートリアル」および「Control Center ユーザーガイド」にも記載されています。
- Self-Balancing と Confluent for Kubernetes (CFK)をデプロイしているとき、Control Center を使って管理することはできません。Confluent for Kubernetes を使用して Self-Balancing を管理する場合の詳細は、CFK のドキュメントの「Kafka クラスターのスケーリングとデータのバランス調整」を参照してください。
クラスターの実行中に、Self-Balancing 設定を Confluent Control Center ( http://localhost:9021/ )から変更できます。
- Self-Balancing を オン または オフ にします。Confluent Platform に付属しているサンプル
server.propertiesファイルでは、confluent.balancer.enableがtrueに設定されています。これは、Self-Balancing がオンになっていることを示しています(confluent.balancer.enable を参照)。 - デフォルトのスロットル値(10485760 つまり 10 MB/秒)をオーバーライドします。この値によって、Self-Balancing で使用可能な最大ネットワーク帯域幅が決定されます。(confluent.balancer.throttle.bytes.per.second)
- バランス調整のトリガー条件を Only when brokers are added (デフォルト)または Anytime に切り替えます(confluent.balancer.heal.uneven.load.trigger)
クラスターを選択し、Cluster settings をクリックして、Self-balancing タブを選択します。
Self-Balancing の現在の設定が表示されます。
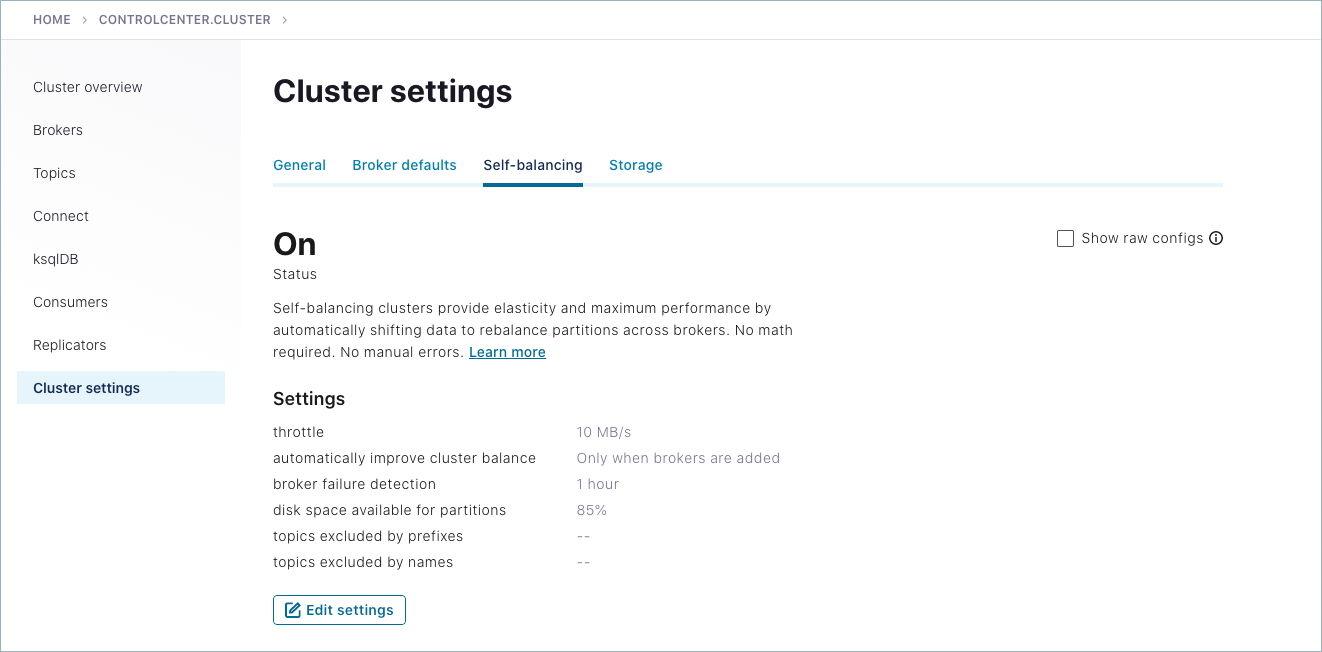
Edit Settings をクリックします。
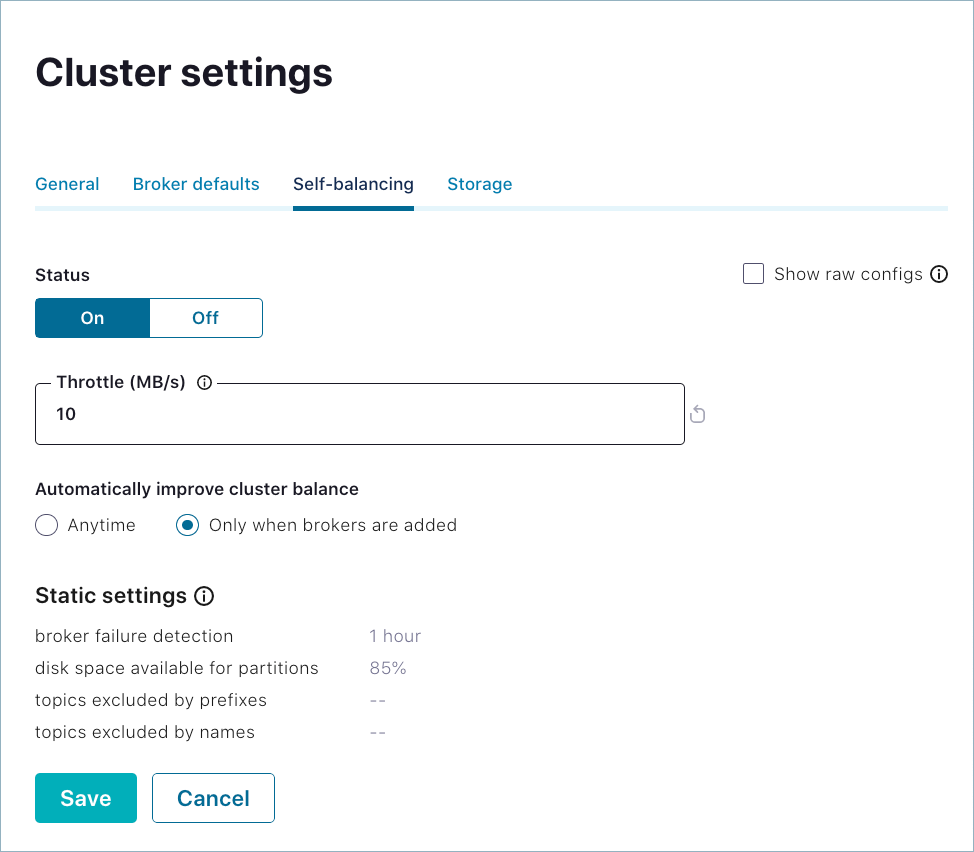
変更を加え、Save をクリックします。
アップデートした設定が有効になり、Self-balancing タブに反映されます。
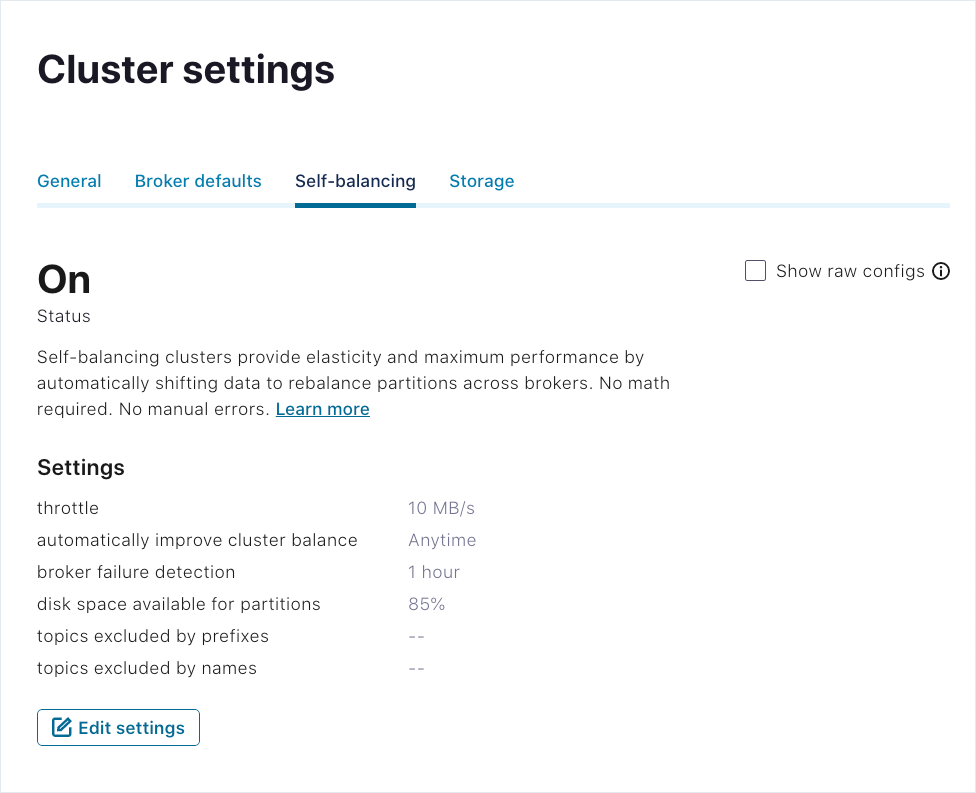
(編集またはモニタリング中に)有効な Self-Balancing 設定のプロパティ名を表示するには、Show raw configs をオンにします。
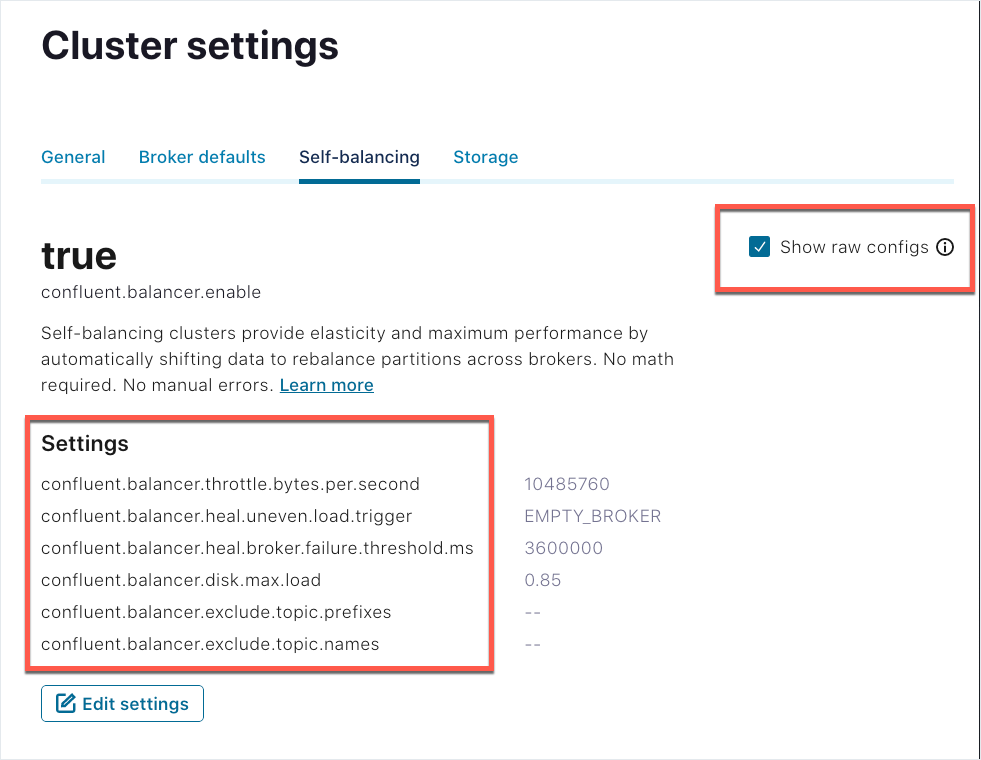
Kafka サーバーのプロパティとコマンド¶
上記で説明した動的プロパティの他に、調整パラメーターが $CONFLUENT_HOME/etc/kafka/server.properties に公開されています。これらは「Self-Balancing Clusters の構成オプションとコマンド」、特にサブトピック「ブローカーでの Self-Balancing の構成」に記載されています。これらの設定の残りの部分をアップデートするには、ブローカーを停止し、クラスターをシャットダウンする必要があります。
「Self-Balancing チュートリアル」を参照し、Self-Balancing のセットアップと簡単なテスト方法として、ブローカーの削除とバランス調整のモニタリングを試してください。その例では、レプリケーション係数の適切な構成方法と Self-Balancing 専用コマンド kafka-remove-brokers のデモが示されています。
バランス調整のモニタリング用メトリクス¶
Confluent Platform は、Java Management Extensions(JMX)を使用して、Self-Balancing で開始されたバランス調整のモニタリングに役立ついくつかのメトリクスを公開します。
- 再割り当ての受信および送信バイトレートは、
kafka.server:type=BrokerTopicMetrics,name=ReassignmentBytesInPerSecおよびkafka.server:type=BrokerTopicMetrics,name=ReassignmentBytesOutPerSecでトラッキングされます。これらのメトリクスは各ブローカーでレポートされます。 - Self-Balancing がその時点でトラッキングしている中断中または進行中の再割り当てタスクの数は、
kafka.databalancer:type=Executor,name=replica-action-pendingおよびkafka.databalancer:type=Executor,name=replica-action-in-progressでトラッキングされます。これらのメトリクスは、アクティブなデータバランサのインスタンスがあるブローカー(コントローラー)からレポートされます。 - 各ブローカーでの最大フォロワーラグは
kafka.server:type=ReplicaFetcherManager,name=MaxLag,clientId=Replicaでトラッキングされます。パーティションを再割り当てすると、このメトリクスはパーティションのサイズに対応する値まで大きく増加し、再割り当ての進捗に応じて徐々に減少します。この値が時間の経過で徐々に減少するのではなく、少しずつ増加する場合は、 レプリケーションスロットル が低すぎます。
Confluent Platform のメトリクスの一覧については「Kafka のモニタリング」を参照してください。
JMX エンドポイントを使用したメトリクスのレポーティングおよびモニタリングを扱った Apache Kafka® ドキュメントは こちら を参照してください。
Self-Balancing をモニタリングするには、クラスターを起動する前に JMX_PORT 環境変数を設定し、通常のモニタリングツールを使用して、レポートされるメトリクスを収集します。Kafka からの JMX メトリクスの収集およびレポーティングには、JMXTrans、Graphite、および Grafana の組み合わせがよく使用されています。別のモニタリングソリューションとして、Datadog もよく使用されています。
レプリカ配置とラック構成¶
あらゆるバランス調整に、次の考慮事項が適用されます。
ラック¶
- ラックとは、Kafka のフォールトドメインです。同じラック内にすべてのブローカーを配置すると、同時障害に対して脆弱になります。Kafka と Self-Balancing Clusters はどちらも、ラック ID の情報を使用し、最初(Kafka)とバランス調整中(Self-Balancing)の両方のタイミングでトピックを配置します。
- ブローカーがラック ID を割り当て済みであれば、Self-Balancing はラック間でレプリカを均等に分散しようとします。具体的には、Self-Balancing は、どのラックにも、他のラックより大きいパーティションのレプリカは、1 つまでしか存在することがないように調整が行われます。これはフォールトトレランスのためであり、Self-Balancing で均等なラックバランスを達成できない場合は、一切のバランス調整が試行されません。
- ラックには、ほぼ同数のブローカーが必要です。これは、クラスター内のラックが非常に少ない場合に特に重要です。最小限でも、ラックあたりのブローカー数は、ラックあたりの予想レプリカ数と同数以上である必要があります。
レプリカ配置とマルチリージョンクラスター¶
- マルチリージョンクラスター と Self-Balancing Clusters の両方を使用している場合は、すべてのブローカーに broker.rack を指定する必要があります。開始時のブローカーと、Self-Balancing を有効にして追加したブローカーには、それぞれの
server.propertiesファイルでbroker.rackに指定したリージョンまたはラックが必要です。 - レプリカ配置ルールは マルチリージョンクラスター に使用され、"ラック" の定義をオーバーロードして、レプリカを配置できる場所を制限します。レプリカ配置は、すべてのブローカーにラックが提供されている場合にのみ使用できます。
- トピックにレプリカ配置ルールが指定されている場合は、標準のラック認識ポリシーがそのルールで上書きされます。
- Self-Balancing は、レプリカ配置ルールの変更に迅速に対応し、必要に応じてレプリカを先を見越して移動して、その配置ルールに合わせます。
- Self-Balancing がレプリカ配置ルールを満たすことができない場合、一切のバランス調整は行われません。これを特定する方法については、「バランス調整の失敗のデバッグ」を参照してください。
- Self-Balancing は、ラック認識ポリシーに違反しない限り、ラック間でレプリカを自由に移動できます。これにより、再割り当てと継続的なレプリケーションの両方でネットワークコストが高くなる可能性があるため、マルチリージョンクラスターでは、クラスター内のすべてのトピックの配置ルールを指定する必要があります。
キャパシティ¶
Self-Balancing は、ブローカーがホストのキャパシティを超えないように、過負荷のブローカーから遠くなるようにレプリカを配置します。ブローカーのキャパシティは、以下のメトリクスによって測定されます。
- レプリカのキャパシティ
- ブローカーがホストするレプリカ数がこの値を超えないようにします(デフォルト値は 10,000 ですが、confluent.balancer.disk.max.replicas によるオーバーライドが可能です)。
- ディスクのキャパシティ
- ブローカーによるディスクへの書き込みが、このパーセンテージを超えないようにします(デフォルト値は 85% ですが、confluent.balancer.disk.max.load によるオーバーライドが可能です)。
- ネットワークの送受信バイト数(省略可)
ブローカーネットワークトラフィックの量が、このバイト数を超えないようにする必要があります。この値は、デフォルトでは極端に高く(
Long.MAX_VALUE)設定されているため、デフォルトの状態では、Self-Balancing がネットワークの過負荷のためにブローカーからレプリカを移動することはありません。ネットワークキャパシティを使用して Self-Balancing の役割に関与するには、confluent.balancer.network.in.max.bytes.per.secondおよびconfluent.balancer.network.out.max.bytes.per.secondを設定できます。ちなみに
- ネットワークトラフィックの正確な測定は困難な場合があり、基盤となるシステムハードウェアに大きく依存します。
- 詳細については、「Kafka ブローカーの構成」および「Self-Balancing Clusters の構成オプションとコマンド」を参照してください。
分散¶
Self-Balancing では、クラスター全体でレプリカとディスク使用量の均等配分が試行されます。ただし、注意事項がいくつかあります。
- レプリカとディスク使用量は、どちらも約 20 パーセント(%)以内にバランス調整されています。バランス調整後でも、ブローカー全体で一連のレプリカ/ディスク使用量が表示されるのは正常な動作です。
- ディスク使用量のバランス調整は、少なくとも 1 つのブローカーがディスクストレージの 20% 以上を使用している場合にのみ行われます。
- このようなリソース分散目標は、他の目標よりも優先度が低く、ラック認識、レプリカ配置、または容量制限への違反が必要になるような場合は達成されません。
- Self-Balancing では(キャパシティ未満の)ネットワーク使用量とリーダー分散の均衡化が試行されますが、これは実際にバランス調整が行われる要因にはなりません。不均衡なリソース分散の場合、レプリカの数と 20% を超えるディスク使用量のみがトリガー要因になります。
バランス調整の失敗のデバッグ¶
ラック認識、レプリカ配置、または容量の問題が原因で Self-Balancing によるバランス調整を実行できない場合は、OptimizationFailureException が発生します。これは、Self-Balancing ブローカーのログに表示されます(クラスターコントローラーと同じ)。この例外を探すと、このタイプの問題の特定に役立つ場合があります。
「クラスターの "バランス" およびバランス調整をトリガーするもの」および「トラブルシューティング」も参照してください。
セキュリティに関する考慮事項¶
セキュリティが構成された状態で Self-Balancing を実行している場合は、ブローカーで REST エンドポイントの認証を構成する 必要があります。ブローカーのプロパティファイルでこれらが構成されていないと、Control Center は安全な環境で Self-Balancing にアクセスできません。
role-based access control (RBAC) を使用している場合、Control Center で Self-Balancing と対話するユーザーは、ブローカーの追加/削除や、他の Self-Balancing 関連タスクを実行できるように、Kafka クラスターに対して SystemAdmin という RBAC ロール を持っている必要があります。
Confluent Platform でのセキュリティのセットアップについては、認証方法 および ロールベースアクセス制御 に関するセクションと、「RBAC と ACL」および「セキュリティのチュートリアル」を参照してください。
Confluent Platform でのセキュリティのセットアップについては、「セキュリティ概要」、「セキュリティのチュートリアル」、「認証方法の概要」を参照してください。また、「Confluent Platform のデモ(cp-demo)」には、デプロイ例で有効になっているさまざまなタイプのセキュリティが示されています。
トラブルシューティング¶
次に示すのは、Self-Balancing で作業する際に発生する可能性がある問題のリストとその解決方法です。
以下のトラブルシューティングのヒントに加えて、ベストプラクティス、バランス調整のトリガー要因の詳細、バランス調整の失敗を特定してデバッグする方法については、「レプリカ配置とラック構成」を参照してください。
Self-Balancing オプションが Control Center に表示されない¶
Self-Balancing Clusters が有効であるとき、ステータスと構成オプションを Control Center で利用できます。Cluster Settings の Self-balancing タブを選択します。このタブに Confluent Platform バージョン要件とブローカーの HTTP サーバーの構成に関するメッセージが表示される場合、なんらかの構成が足りない、または Confluent Platform の必須バージョンが実行されていないことを示しています。
また、セキュリティを有効にして Self-Balancing を実行している場合、Error 504 Gateway Timeout などのエラーメッセージが表示されることがあります。これは、以下で説明するように、ブローカーファイルで REST エンドポイントの認証も構成する必要があることを示します。
解決策: 次が設定されていることを確認し、必要に応じて構成をアップデートします。
- Kafka ブローカーファイルで、confluent.balancer.enable を
trueに設定して Self-Balancing を有効にする必要があります。 - Control Center プロパティファイルで、
controlcenter.clusterの REST エンドポイントとして、confluent.controlcenter.streams.cprest.urlにクラスター内の各ブローカーの関連 URL を指定する必要があります(「Control Center の必須構成」を参照)。 - Self-Balancing ではセキュリティは要件になっていませんが、セキュリティを有効にする場合は、ブローカーで REST エンドポイントの認証も構成する 必要があります。この場合、
confluent.http.server.listenersの代わりに(Metadata Service を有効にする)confluent.metadata.server.listenersを使用して API リクエストをリッスンできます。詳細については、「セキュリティに関する考慮事項」を参照してください。 - クラスターを Confluent Platform 6.0.0 以降でデプロイする必要があります。
ブローカーのメトリクスが Control Center に表示されない¶
この問題は Self-Balancing に固有のものではなく、一般にマルチブローカークラスターの適切な構成に関連するものです。Self-Balancing が有効で Self-Balancing オプションが Control Center に表示されていても、ブローカーのメトリクスとブローカーごとの詳細および管理オプションが Brokers Overview ページに表示されないことがあります。この問題の原因として可能性が高いのは、Metrics Reporter を Control Center 用に構成していないことです。これを構成するには、すべてのブローカーのプロパティファイルで次の行のコメントを解除します。たとえば、$CONFLUENT_HOME/etc/server.properties で以下のとおり実行します。
metric.reporters=io.confluent.metrics.reporter.ConfluentMetricsReporter
confluent.metrics.reporter.bootstrap.servers=localhost:9092
解決策 : 実行しているクラスターでこれを修正するには、Control Center とブローカーをシャットダウンし、ブローカーの Metrics Reporter 構成をアップデートして、再起動する必要があります。
この構成の詳細については、Self-Balancing のチュートリアルの「Control Center 用の Metrics Reporter の有効化」を参照してください。
Control Center に反映されるコンシューマーラグ¶
Self-Balancing の実行中は、Control Center UI の _confluent-telemetry-metrics システムトピックにコンシューマーラグが表示される可能性があります。これは、このトピックでのメッセージ処理を示しているものではないので無視できます。
Self-Balancing は、一部の内部トピックから読み取りを行いますが、それらに対するオフセットをコミットしません。このため、Confluent Control Center にコンシューマーラグが表示されるか、またはアクティブなコンシューマーグループがないことが表示されます。
Self-Balancing の初期化中にブローカーの削除の試行に失敗する¶
Self-Balancing では、初期化してクラスター内のブローカーからメトリクスを収集するまでに 30 分かかります。メトリクスの収集が完了する前に、ブローカーの削除を試みると、Self-Balancing のメトリクスが不十分であるために、このブローカーの削除はほぼ即座に失敗します。これは "ブローカーの削除" が失敗する、最も一般的なユースケースです。次のエラーメッセージは、コマンドラインまたは Control Center に表示されます(削除操作に使用する方法によって異なります)。
Self-balancing requires a few minutes to collect metrics for rebalancing plans.Metrics collection is in process.Please try again after 900 seconds. (Self-Balancing はバランス調整計画用のメトリクスを収集するのに数分間を要します。メトリクスの収集は処理中です。900 秒後に再試行してください。)
ソリューション: 30 分待機し、ブローカーの削除を再試行します。
コントローラーを削除する場合も、同じ原因が考えられます。したがって、Self-Balancing の初期化が完了するまで一定時間待機し、その後に削除操作を試行します。ただしこの場合、"ブローカーの削除" 操作は、対象のブローカーがシャットダウンした後の 後続フェーズ で失敗することがあります。オフライン状態では、ブローカーは Control Center からアクセスできなくなっています。そのような状況では、30 分待機した後にコマンドラインから ブローカーの削除 操作を再試行します。Self-Balancing の初期化が完了し、メトリクスを収集する十分な時間があると、この操作は成功し、バランス調整計画が実行されます。
Self-Balancing の初期化については、「Self-Balancing の初期化」を参照してください。
ブローカーの削除が、オフラインのパーティションのために完了できない¶
ブローカーを削除すると構成の必須レプリカ数よりオンラインのブローカー数が少なくなる場合に、ブローカーの削除が失敗することもあります。
ブローカーのステータス(kafka-remove-brokers --describe で表示)は、1 つまたは複数のオフラインブローカーを再起動するまで、次のとおり変わりません。
[2020-09-17 23:40:53,743] WARN [AdminClient clientId=adminclient-1] Connection to node -5 (localhost/127.0.0.1:9096) could not be established. Broker may not be available. (org.apache.kafka.clients.NetworkClient)Broker 1 removal status:
Partition Reassignment: IN_PROGRESS
Broker Shutdown: COMPLETE
この問題の簡単なトラブルシューティング方法は、"停止しているブローカー数" および "クラスターでサポートしているレプリカまたはレプリケーション係数の数" を考えることです。
パーティションの再割り当て(ブローカー削除の最終フェーズ)は、n 個のブローカーが停止していて、構成では n + 1 個以上のレプリカが必要とされている場合には完了できません。
代わりに、必要なレプリカ数をサポートするのに必要な "オンライン" ブローカーの数を考えることができます。n 個のブローカーがオンラインである場合、合計でサポートできるのは n 個のレプリカです。
解決策 : 解決策として、停止しているブローカーを再起動します。全体としてのクラスター構成を変更することになります。ブローカーの追加と、レプリカやレプリケーション係数の変更も必要になる場合があります(次の例を参照)。
この問題につながるシナリオには、レプリケーション数不足のトピック "および" オンラインブローカーの数に対してレプリカが多すぎるトピックの問題が組み合わさっていることがあります。レプリケーション係数が 1 であるトピックがあっても、必ずしもそれ自体は問題にはつながりません。
実行中のクラスターで構成されているレプリカの概要を簡単に確認するには、指定したトピックまたはクラスター全体(トピックの指定なし)で kafka-topics --describe を使用します。システムトピックでは、(システムトピックを生成する)システムプロパティでレプリケーション係数とレプリカをスキャンできます。Self-Balancing チュートリアル では、これらのコマンド、レプリカやレプリケーション係数、これらの構成の影響について説明しています。
除外トピックが多すぎるため、Self-Balancing で問題が発生する¶
トピックの除外が多すぎると(当然パーティションも除外され)、バランスのとれたクラスターを維持するために逆効果になります。内部テストでは、合計 500 個のトピックの内 100 個ほどに相当するシステムトピックを除外しただけで、Self-Balancing が最適な状態を維持できなくなりました。
この結果が明らかに示すこととして、クラスターではバランス調整を繰り返すことになります。
解決策 : 除外トピック数を減らします。これらの設定を変更する関連構成オプションは confluent.balancer.exclude.topic.names および confluent.balancer.exclude.topic.prefixes です。
おすすめの関連情報¶
- ブログ投稿記事: Restoring Balance to the Cluster: Self-Balancing Clusters in Confluent Platform
- ブログ投稿記事 : Introducing Confluent Platform 6.0
- Self-Balancing とAuto Data Balancer の比較
- 「Self-Balancing チュートリアル」
- クイックスタートデモ(Docker)
- 構成オプションとコマンド
- Control Center ユーザーガイドの クラスター設定 に記載の「Self-Balancing Clusters の操作」
- Confluent REST API
- Confluent REST Proxy API リファレンス