Streams の概念¶
このセクションでは、Kafka Streams の主な概念について要約します。詳細については、「Streams のアーキテクチャ」および「Streams 開発者ガイド」を参照してください。
Kafka 101¶
Kafka Streams は、意図的に設計に基づいて Apache Kafka® と緊密に統合されます。ステートフル処理機能、フォールトトレランス、処理の保証 など、Kafka Streams の多くの機能は、Apache Kafka® のストレージとメッセージング層によって提供される機能を基盤として構築されています。このため、Kafka の主要な概念について理解を深めることが重要です。中でも、「Getting Started」と「Design」のセクションが役立ちます。特に次の点を理解する必要があります。
- 構成要素: Kafka では、プロデューサー、コンシューマー、ブローカー が区別されます。簡単に言うと、プロデューサーは Kafka ブローカーにデータをパブリッシュし、コンシューマーはパブリッシュされたデータを Kafka ブローカーから読み取ります。プロデューサーとコンシューマーは完全に分離され、どちらも Kafka クラスターの境界において Kafka ブローカーの外部で実行されます。Kafka クラスター は、1 つ以上のブローカーで構成されます。Kafka Streams API を使用するアプリケーションは、プロデューサーとコンシューマーの両方として動作します。
- データ: データは トピック に格納されます。トピックとは、Kafka が提供する最も重要な抽象概念であり、プロデューサーによるデータのパブリッシュ先となるカテゴリまたはフィード名です。Kafka の各トピックは、1 つ以上の パーティション に分割されます。Kafka は、データをパーティションに分けて格納、伝送、複製します。Kafka Streams では、データをパーティションに分けて処理します。どちらの場合も、このパーティション化によって、柔軟性、拡張性、高パフォーマンス、フォールトトレランスが実現されます。
- 並列性: Kafka トピックのパーティション、特に任意のトピックにおけるパーティションの数は、データの読み書きに関する Kafka の並列性を決定する主な要素です。Kafka との緊密な統合から、Kafka Streams API を使用するアプリケーションの並列性は、本質的に Kafka の並列性に依存します。
ストリーム¶
ストリーム とは、Kafka Streams が提供する最も重要な抽象概念であり、継続的に更新される境界のないデータセットを表します。境界がないとは、"サイズが未知または無制限" であることを意味します。Kafka のトピックと同様に、Kafka Streams API のストリームは、1 つ以上のストリームパーティションで構成されます。
ストリームパーティション は、再生可能でフォールトトレラントな、不変のデータレコードの順序付きシーケンスです。データレコード はキーと値のペアから成ります。
ストリーム処理アプリケーション¶
ストリーム処理アプリケーション とは、Kafka Streams ライブラリを利用する任意のプログラムを指します。実際には、これはユーザーのアプリケーションです。アプリケーションの計算ロジックは、1 つ以上の プロセッサートポロジー によって定義できます。
ストリーム処理アプリケーションは、ブローカーの内部で実行されるのではなく、JVM インスタンス内または別個のクラスター内で動作します。
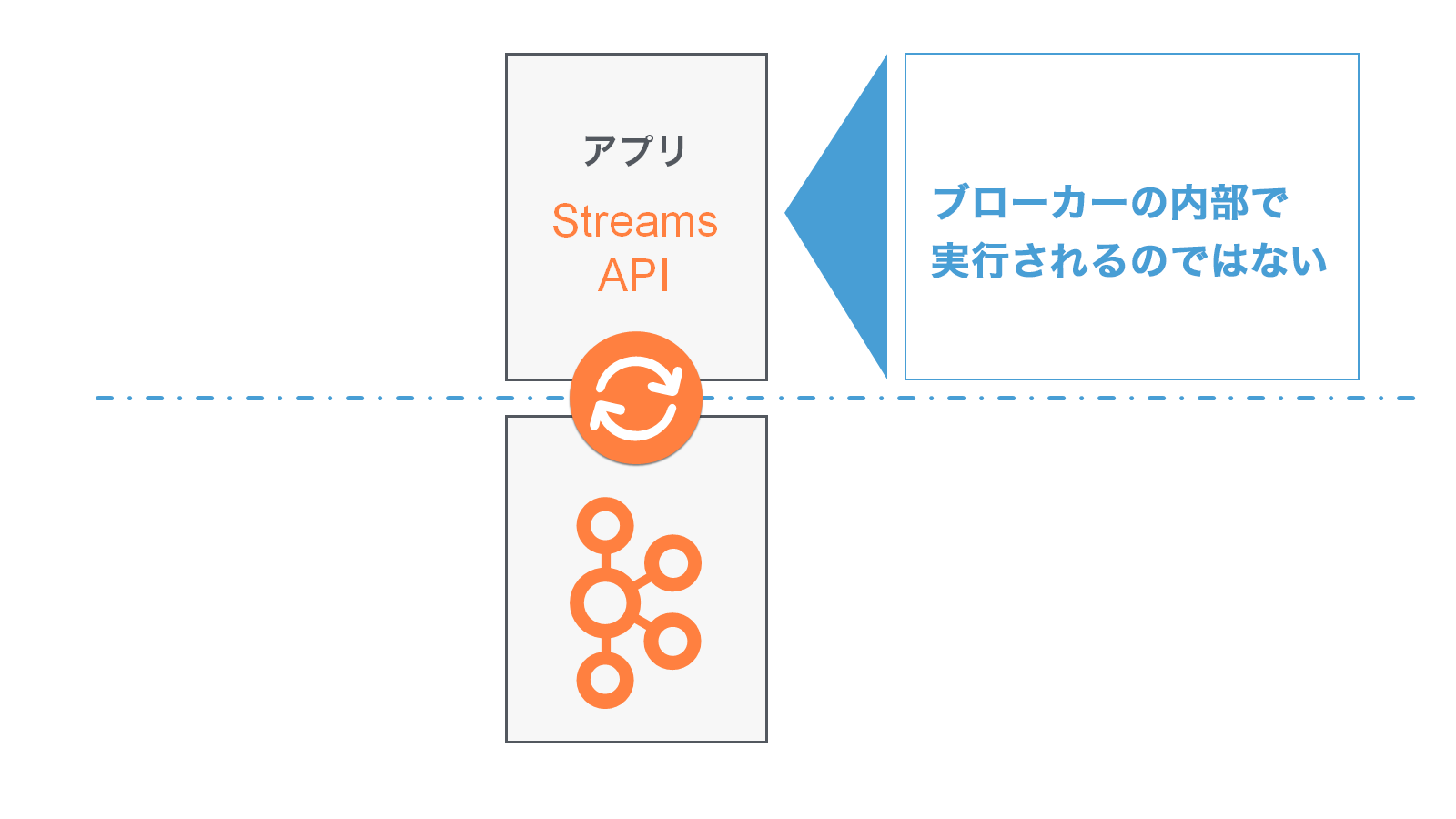
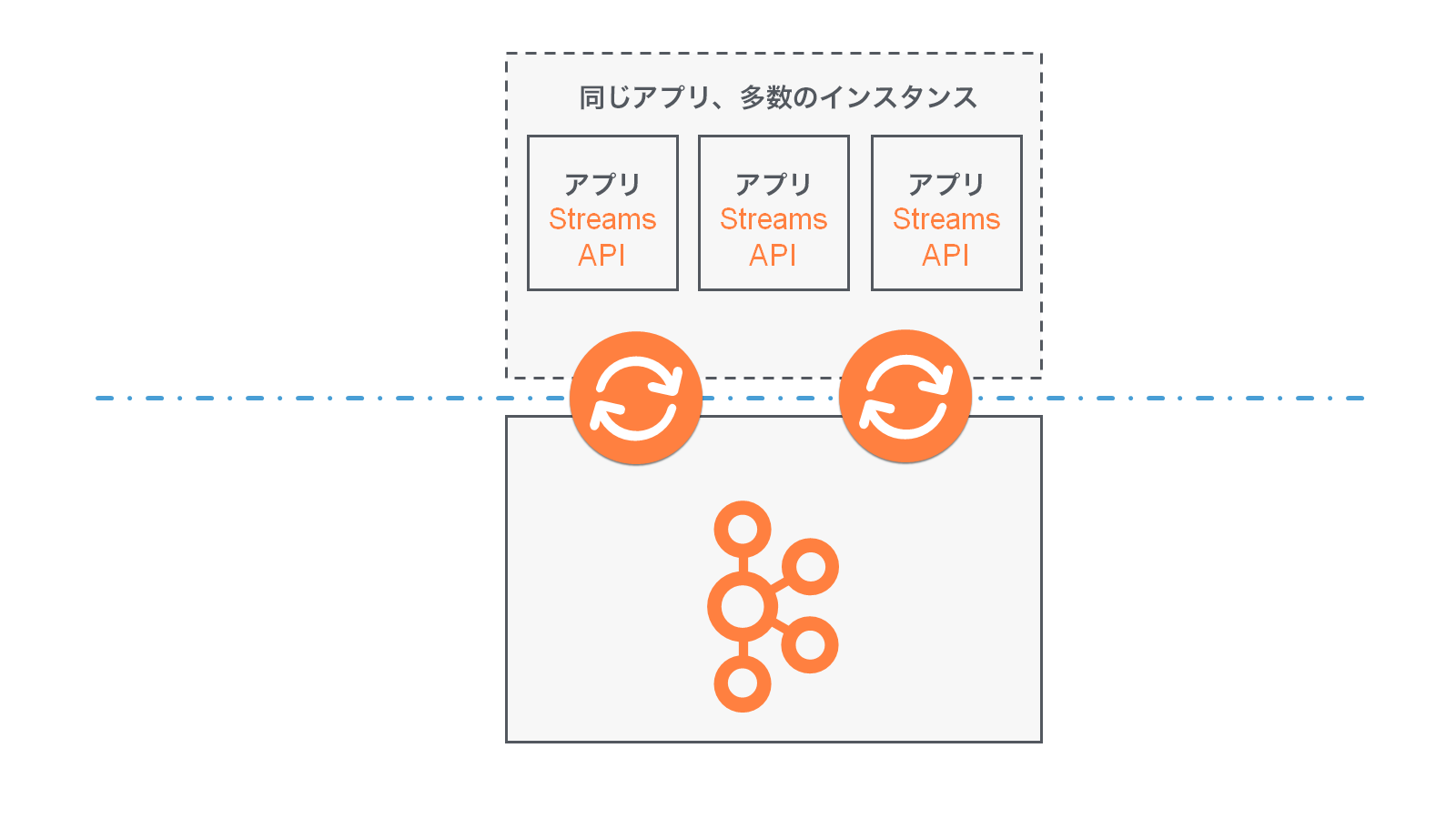
アプリケーションインスタンス は、アプリケーションの実行中インスタンス、つまり "コピー" です。アプリケーションインスタンスは、アプリケーションの 柔軟なスケーリングと並列化 を可能にする主要な手段で、フォールトトレランス を実現する要素の 1 つでもあります。たとえば、アプリケーションの受信データの読み込みを処理するために、マシン 10 台分のパワーが必要であるとします。この場合、アプリケーションのインスタンスを各マシンで 1 つずつ、合計 10 個実行できます。これらのインスタンスは自動的に連携してデータを処理し、ライブ操作中に 新しいインスタンス(マシン)が追加されたり、既存のインスタンスが削除されたり しても、処理は続行されます。
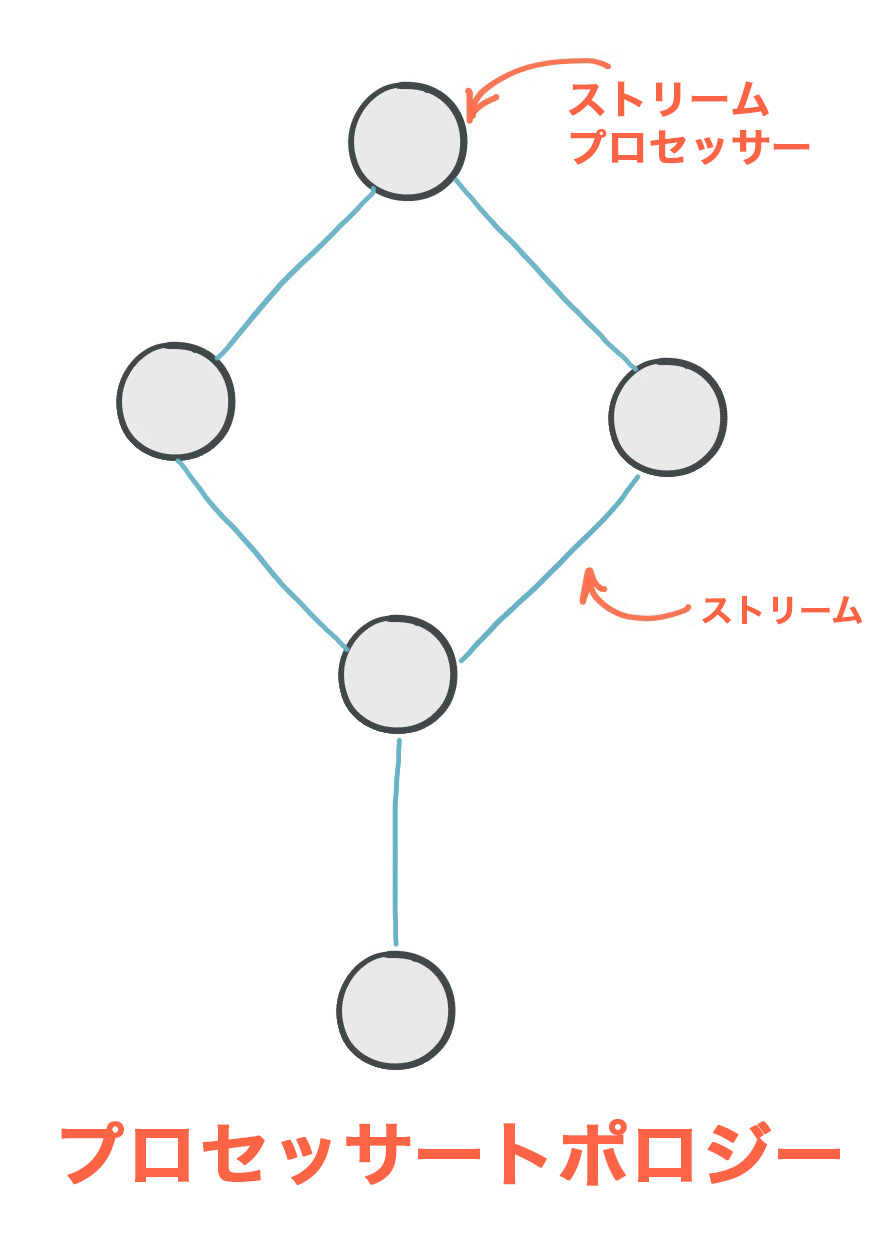
プロセッサートポロジー¶
プロセッサートポロジー、または単に トポロジー とは、ストリーム処理アプリケーションで実行する必要のあるデータ処理の計算ロジックを定義するものです。トポロジーは、ストリーム(エッジ)によって接続されたストリームプロセッサー(ノード)を図式するものです。開発者は、低レベルの Processor API を使用するか、この API を基盤とした Kafka Streams DSL を通じてトポロジーを定義できます。
The Streams のアーキテクチャ のドキュメントでは、トポロジーについてより詳しく説明しています。
ストリームプロセッサー¶
ストリームプロセッサー は、「プロセッサートポロジー」セクションの図に示されているように、プロセッサートポロジー内のノードの 1 つです。トポロジー内の 1 つの処理ステップを表します。つまり、データの変換に使用されます。たとえば、map や filter、結合、集約 などの標準操作は、Kafka Streams の初期設定時から使用できるストリームプロセッサーです。ストリームプロセッサーは、トポロジー内のアップストリームプロセッサーから一度に 1 つの入力レコードを受け取り、操作を適用します。続けて、1 つ以上の出力レコードをダウンストリームプロセッサーに生成する場合もあります。
Kafka Streams には、ストリームプロセッサーを定義する API が 2 つ用意されています。
- 宣言型で関数型の DSL は、ほとんどのユーザーに推奨される API で、特に初心者の方にはこちらをお勧めします。データ処理のほとんどのユースケースは、わずか数行の DSL コードで表すことができます。この場合は通常、
mapやfilterなどの組み込み操作を使用します。 - 命令型で低レベルの Processor API では、DSL よりも高い柔軟性が提供されますが、手動のコーディング作業もより多く必要になります。この API を使用すると、カスタムプロセッサーを定義して接続したり、ステートストア と直接やり取りしたりできます。
ステートフルなストリーム処理¶
ストリーム処理アプリケーションの中には、ステートを必要としないものがあります。これは ステートレス と呼ばれ、1 つのメッセージの処理が、他のメッセージの処理から独立していることを意味します。たとえば、一度に 1 つのメッセージしか変換しない場合や、ある条件に基づいてメッセージを除外する場合が該当します。
ただし実際には、ほとんどのアプリケーションは ステートフル であり、正常に動作するためにはステートが必要です。このステートは、フォールトトレラントな方法 で管理する必要があります。たとえば、アプリケーションで入力データの 結合、集約、または ウィンドウ化 を行う必要がある場合、そのアプリケーションはステートフルです。Kafka Streams は、強力かつ柔軟で拡張性が高く、フォールトトレンラントなステートフル処理機能をアプリケーションに提供します。
ストリームとテーブルの二重性¶
ストリーム処理のユースケースを実装する場合、通常は ストリーム と データベース の両方が必要です。実際の一般的なユースケースとして、e コマースアプリケーションでは、顧客トランザクションの 受信ストリーム に、データベーステーブル から最新の顧客情報を追加して補完することがよくあります。ストリームはどこにでも存在しますが、データベースもあらゆる場所に存在しています。
したがって、すべてのストリーム処理テクノロジでは、ストリームとテーブルに対する十分なサポート を提供する必要があります。Kafka の Streams API は、ストリーム と テーブル のコアの抽象化を通して、このような機能を提供しています。この抽象化については後で説明します。興味深いことに、実際に ストリームとテーブルの間には密接な関係 があります。これは ストリームとテーブルの二重性 と呼ばれます。Kafka では、この二重性をさまざまな形で利用しています。たとえば、アプリケーションに 柔軟性 を与えたり、フォールトトレラントなステートフル処理 をサポートしたり、アプリケーションの最新の処理結果に対して Kafka Streams の対話型クエリ を実行したりするために使用されます。内部使用だけでなく、Kafka Streams API を通じて、開発者が独自のアプリケーションでこの二重性を利用することもできます。
集約 などの Kafka Streams の概念に話を進める前に、まず テーブル について詳しく説明し、前述のストリームとテーブルの二重性についても見ていきましょう。この二重性とは、本質的に、ストリームはテーブルとして、テーブルはストリームとして見なせることを意味します。
注釈
以降では、簡潔な説明を目的として、複合キーやマルチセットなどの説明は省略しています。
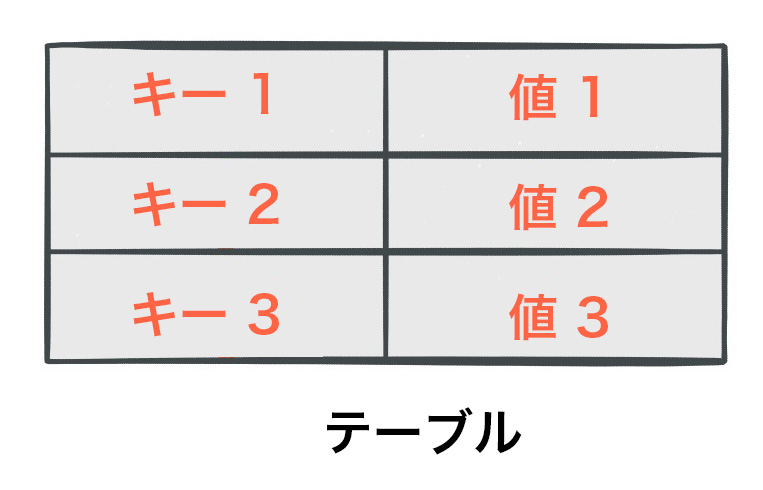
テーブルの単純な形式として、キーと値のペアのコレクションがあります。この構造は、マップまたは連想配列とも呼ばれます。このようなテーブルの例を以下に示します。
ストリームとテーブルの二重性 によって、ストリームとテーブルの間の密接な関係が説明できます。
- テーブルとしてのストリーム: ストリームはテーブルの changelog と見なすことができます。ストリーム内の各データレコードには、テーブルのステートの変更がキャプチャされます。したがって、ストリームはテーブルの偽装であり、changelog を最初から最後まで再生してテーブルを再構築することで、"本物" のテーブルに簡単に変換できます。同様に、ストリーム内のデータレコードを "集約" すればテーブルが返されます。たとえば、ページビューイベントの入力ストリームから、ユーザーごとのページビューの合計数を求めることができます。結果はテーブルになり、テーブルのキーはユーザー、値は対応するページビュー数を表します。
- ストリームとしてのテーブル: テーブルは、ストリーム内の各キーに対応する、ある時点での最新の値のスナップショットと見なすことができます(ストリーム内のデータレコードはキーと値のペアです)。したがって、テーブルはストリームの偽装であり、テーブル内のキーと値の各エントリを反復処理することで、"本物" のストリームに変換できます。
具体的な例で考えてみましょう。ユーザーごとのページビューの合計数を追跡するテーブルがあるとします(下図の最初の列)。時間が経つにつれて新しいページビューイベントが処理されると、それに応じてテーブルのステートが更新されます。異なる時点間のステートの変更と、テーブルの各リビジョンは、changelog ストリームとして表すことができます(下図の 2 番目の列)。
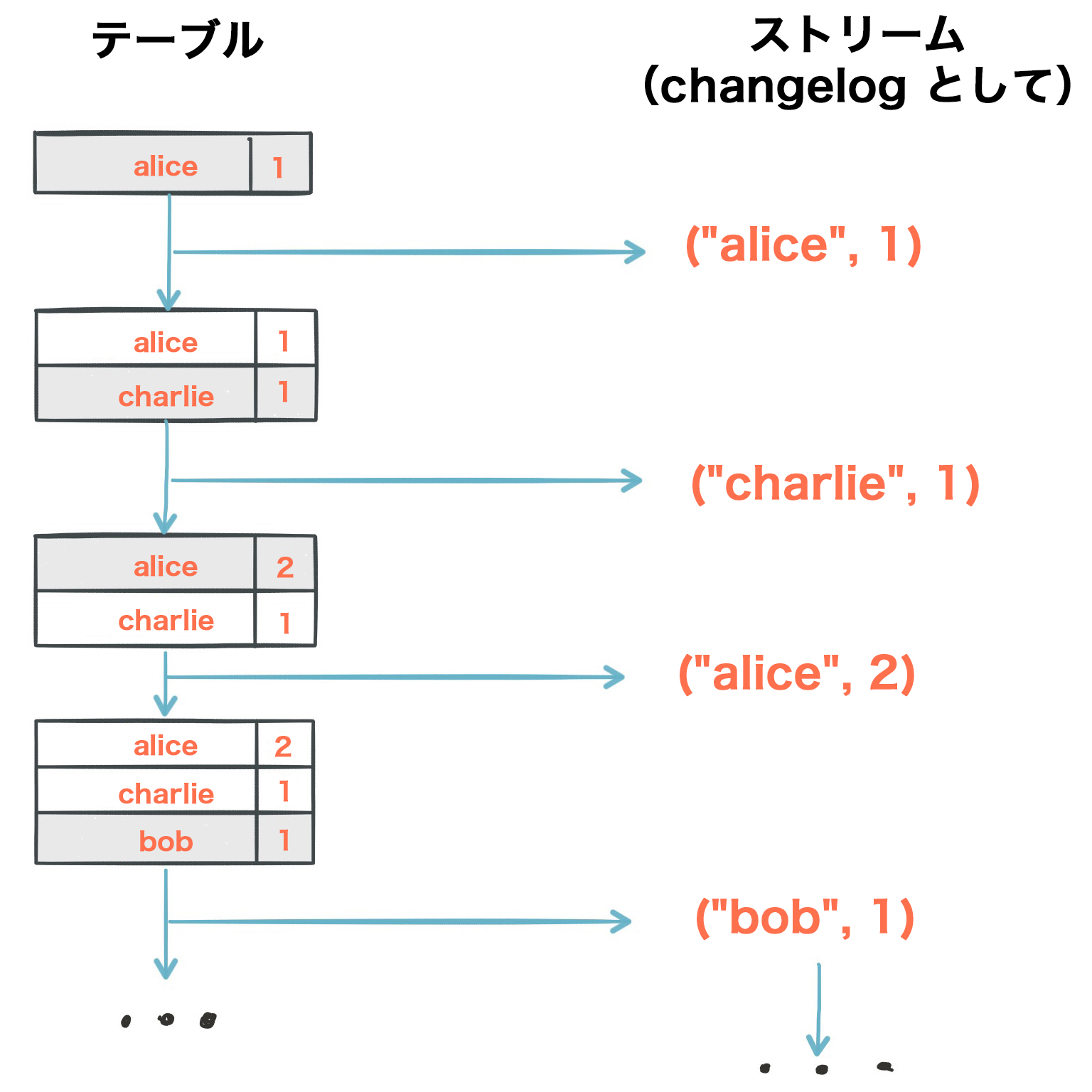
ストリームとテーブルの二重性により、同じストリームを使用して元のテーブルを再構築できます(3 番目の列)。
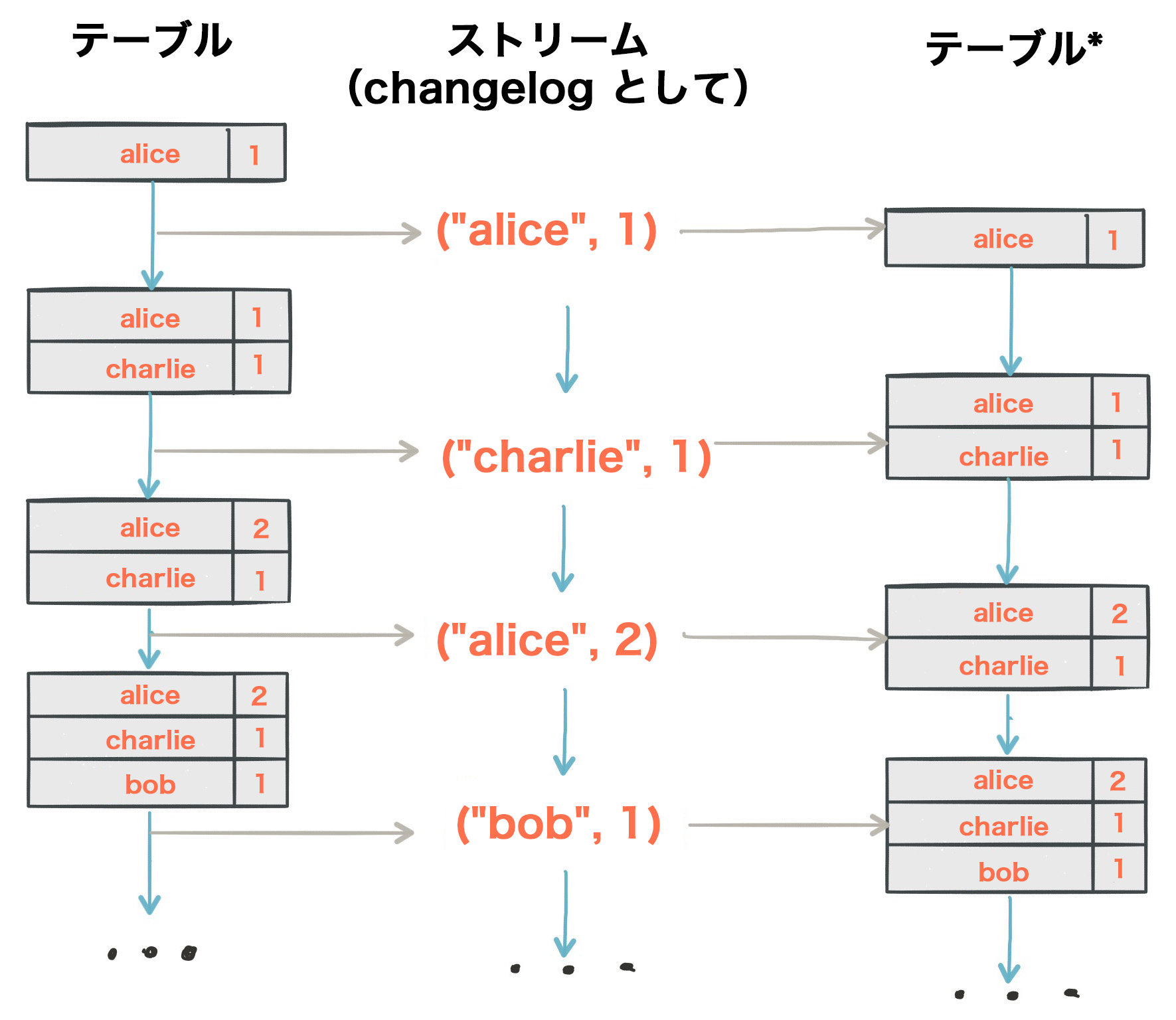
同じメカニズムを使用する例として、変更データキャプチャー(CDC)を通じてデータベースを複製したり、Kafka Streams 内で、フォールトトレランス のためにマシン間で ステートストア を複製したりできます。ストリームとテーブルの二重性は、実際のストリーム処理アプリケーションにとって非常に重要な概念です。このため Kafka Streams では、KStream と KTable という抽象化として明示的にモデル化されています。次のセクションでは、これらの抽象化について説明します。
KStream¶
注釈
KStream は Kafka Streams DSL にのみ存在する概念です。
KStream は レコードストリーム の抽象化であり、各データレコードは、境界のないデータセット内の 1 つの自己完結型データを表します。テーブルとの類似性に基づいて、レコードストリーム内のデータレコードは常に "INSERT" として解釈されます。これは、追記専用の台帳にエントリを追加するようなものです。レコードと同じキーを持つ既存の行が置き換えられることはありません。クレジットカード取引、ページビューイベント、サーバーログエントリなどがその例です。
たとえば、次の 2 つのデータレコードがストリームに送信されるとしましょう。
("alice", 1) --> ("alice", 3)
ユーザーごとの値を合計するストリーム処理アプリケーションがあるとすると、alice に対して 4 が返されます。この理由は、2 番目のデータレコードが以前のレコードの更新とは見なされないためです。この KStream の動作を、次に説明する KTable と比較してみてください。KTable では alice に対して 3 が返されます。
KTable¶
注釈
KTable は、Kafka Streams DSL にのみ存在する概念です。
KTable は changelog ストリーム の抽象化であり、各データレコードは 1 つの更新を表します。より正確には、データレコードの値は、同じレコードキーを持つ最後の値に対する "UPDATE" として解釈されます(該当するキーがまだ存在しない場合、更新は "INSERT" と見なされます)。テーブルとの類似性に基づいて、changelog ストリーム内のデータレコードは UPSERT、つまり INSERT/UPDATE として解釈されます。同じキーを持つ既存の行は上書きされます。また、null 値は特別な意味に解釈されます。null 値を持つレコードは "DELETE"、つまりレコードのキーに対するトゥームストーンを表します。
たとえば、次の 2 つのデータレコードがストリームに送信されるとしましょう。
("alice", 1) --> ("alice", 3)
ユーザーごとの値を合計するストリーム処理アプリケーションがあるとすると、alice に対して 3 が返されます。この理由は、2 番目のデータレコードが以前のレコードの更新と見なされるためです。この KTable の動作を、上で説明した KStream の例と比較してみてください。KStream では alice に対して 4 が返されます。
注釈
Kafka のログ圧縮の影響: KStream と KTable については、次のような考慮事項もあります。KTable を Kafka トピックに格納する場合は、Kafka の ログ圧縮 機能を有効にすることで、ストレージ領域を節約できます。
ただし、KStream の場合にログ圧縮を有効にすることは安全ではありません。ログ圧縮によって同じキーを持つ古いデータレコードのパージが開始されたとたんに、データのセマンティクスが壊れてしまうからです。図の例をもう一度使用すると、ログ圧縮によって ("alice", 1) というデータレコードが削除されるため、alice に対して 4 ではなく 3 が取得されることになります。このため、ログ圧縮は KTable(changelog ストリーム)では安全ですが、KStream(レコードストリーム)では失策となります。
changelog ストリームについては、既に「ストリームとテーブルの二重性」セクションで一例を紹介しました。別の例として、リレーショナルデータベースの changelog 内の変更データキャプチャー(CDC)レコードがあります。これは、データベーステーブル内で追加、更新、または削除された行を表します。
KTable には、データレコードの "現在" の値をキーによって参照する機能もあります。このテーブル参照機能は、結合操作 (開発者ガイドの「結合」も参照)と 対話型クエリ で利用できます。
GlobalKTable¶
注釈
GlobalKTable は、Kafka Streams DSL にのみ存在する概念です。
KTable と同様に、GlobalKTable は changelog ストリーム の抽象化であり、各データレコードは 1 つの更新を表します。
GlobalKTable と KTable の違いは、取り込まれるデータにあります。つまり、基になる Kafka トピックからそれぞれのテーブルに読み取られるデータが異なります。単純な例として、5 個のパーティションを持つ入力トピックがあるとします。アプリケーションで、このトピックをテーブルに読み込もうとしています。さらに、5 個のアプリケーションインスタンスを実行して、アプリケーションを 最大限に並列化 しようとしています。
- 入力データを KTable に読み取ると、各アプリケーションインスタンスの "ローカル" KTable インスタンスには、トピックの 5 個のパーティションのうち、1 個のパーティションのみから データが取り込まれます。
- 入力トピックを GlobalKTable に読み取ると、各アプリケーションインスタンスのローカル GlobalKTable インスタンスには、トピックのすべてのパーティションから データが取り込まれます。
GlobalKTable には、データレコードの "現在" の値をキーによって参照する機能もあります。このテーブル参照機能は、結合操作 (開発者ガイドの「結合」も参照)と Kafka Streams の対話型クエリ で利用できます。
グローバルテーブルには、次のような利点があります。
- より便利で効率的な 結合: グローバルテーブルでは特に、スター型結合を実行でき、"foreign-key" ルックアップがサポートされ(つまり、テーブル内のデータをルックアップするときに、レコードキーだけでなく、レコードの値に含まれる値も使用できます)、複数の結合をより効率的に連結できます。また、グローバルテーブルに対する結合では、入力データを 共同パーティション化 する必要がありません。
- アプリケーションのすべての実行インスタンスに情報を "ブロードキャスト" するために使用できます。
グローバルテーブルには、次のような欠点があります。
- トピック全体が追跡されるため、(パーティション化される)KTable と比べて、ローカルストレージの消費量が多くなります。
- トピック全体が読み取られるため、(パーティション化される)KTable と比べて、ネットワークおよび Kafka ブローカーの負荷が増大します。
時間¶
ストリーム処理においては、時間 の概念と、それがどのようにモデル化され、統合されるかという側面がきわめて重要です。たとえば、ウィンドウ化 などのいくつかの操作は、時間境界に基づいて定義されます。
Kafka Streams では、次の時間の概念がサポートされています。
イベント時刻¶
イベントまたはデータレコードが発生した(つまり、ソースによって最初に作成された)時点の時刻。イベント時刻セマンティクスを実現するには、通常、データレコードの生成時に、データレコードにタイムスタンプを埋め込む必要があります。
- 例: 自動車の GPS センサーから報告された地理位置情報の変更を表すイベントの場合、関連付けられたイベント時刻は、GPS センサーが位置の変更をキャプチャした時刻になります。
処理時刻¶
イベントまたはデータレコードがストリーム処理アプリケーションによって処理された(つまり、レコードが消費された)時点の時刻。処理時刻は、元のイベント時刻以降の時点をミリ秒数、時間数、日数などで表します。
- 例: 自動車のセンサーから報告された地理位置情報データを読み取って処理し、フリート管理ダッシュボードに提示する分析アプリケーションがあるとします。この分析アプリケーションの処理時刻はイベント時刻以降の時点を表し、ミリ秒または秒(Kafka および Kafka Streams を基盤とするリアルタイムパイプラインの場合)、あるいは時間(Apache Hadoop または Apache Spark を基盤とするバッチパイプラインの場合)が使用されます。
インジェスト時刻¶
イベントまたはデータレコードが Kafka ブローカーによってトピックパーティションに格納された時点の時刻。インジェスト時刻では、"イベント時刻" と同様に、タイムスタンプがデータレコード自体に組み込まれます。ただし、ソースでのレコードの作成時にタイムスタンプが生成されるのではなく、Kafka ブローカーによってレコードがターゲットトピックに追加されるときに生成される点が異なります。レコードの作成から Kafka へのインジェストまでの時間差が十分に小さいと見なされる場合、インジェスト時刻はイベント時刻とおおよそ同じと考えられます。ただし、"十分" の定義は個々のユースケースによって異なります。このため、データプロデューサーがタイムスタンプを埋め込まない場合(Kafka の Java プロデューサークライアントのバージョンが古い場合)や、プロデューサーでタイムスタンプを直接割り当てることができない場合(たとえば、ローカルクロックへのアクセス権がない場合)など、イベント時刻セマンティクスを適用できないユースケースでは、インジェスト時刻が合理的な代替手段となることがあります。
ストリーム時刻¶
これまでに処理されたすべてのレコードで確認されたタイムスタンプのうちの最大値。Kafka Streams では、ストリーム時刻をタスクごとに追跡します。
タイムスタンプ¶
Kafka Streams は、タイムスタンプエクストラクター と呼ばれるコンポーネントを通じて、すべてのデータレコードに タイムスタンプ を割り当てます。このようなレコードごとのタイムスタンプは、ストリームの時間的な進行状況を表し(ただし、ストリーム内のレコードが順序どおりとは限りません)、結合などの時間に依存する操作で利用されます。これはアプリケーションの イベント時刻 と呼ばれ、アプリケーションの実際の実行時間を示す ウォールクロック時間 と区別されます。イベント時刻 は、同じアプリケーション内で 複数の入力ストリームを同期 するためにも使用されます。
実際のタイムスタンプエクストラクターの実装では、データレコードの実際のコンテンツ、たとえば組み込みのタイムスタンプフィールドに基づいてタイムスタンプを取得するか計算することで、イベント時刻またはインジェスト時刻のセマンティクスを提供できます。または、処理時点の現在の実時間を返して、時刻セマンティクスをストリーム処理アプリケーション処理に渡すなど、他の任意のアプローチを使用することもできます。このように、開発者はビジネスニーズに応じて異なる時間の概念やセマンティクスを適用できます。
最後に、Kafka Streams アプリケーションが Kafka にレコードを書き込むときは、これらの新しいレコードに常にタイムスタンプが割り当てられます。タイムスタンプの割り当て方法はコンテキストによって異なります。
- 入力レコードを直接処理することで新しい出力レコードが生成される場合、出力レコードのタイムスタンプは、入力レコードのタイムスタンプから直接継承されます。
- 定期的な機能によって新しい出力レコードが生成される場合、出力レコードのタイムスタンプは、ストリームタスク の現在の内部時刻として定義されます。
- 集約 の場合、結果の更新レコードのタイムスタンプは、更新をトリガーした最新の入力レコードのタイムスタンプになります。
集約と結合では、タイムスタンプは次のルールに従って計算されます。
- 左右に入力レコードがある結合(ストリームとストリーム、テーブルとテーブル)の場合、出力レコードのタイムスタンプには
max(left.ts, right.ts)が割り当てられます。 - ストリームとテーブルの結合の場合、出力レコードには、ストリームレコードからのタイムスタンプが割り当てられます。
- 集約の場合、Kafka Streams は、グローバルに(ウィンドウ化されていない場合)、またはウィンドウ単位で、キーごとにすべてのレコードにわたってタイムスタンプの
maxを計算します。 - ステートレス操作には、入力レコードのタイムスタンプが割り当てられます。複数のレコードを出力する
flatMapとその兄弟メソッドでは、すべての出力レコードに、対応する入力レコードからのタイムスタンプが継承されます。
時刻の他の側面¶
ちなみに
時刻の把握: 時刻を扱うときは、時刻に関する追加要素(タイムゾーン や カレンダー など)がストリームデータパイプライン全体で適切に同期されるようにしなければなりません。または、少なくともこのような要素の把握と追跡が必要です。たとえば、多くの場合、時刻を UTC 時間または Unix 時間(エポックからの秒数)で指定するように取り決めると役立ちます。また、時間セマンティクスが異なるトピックを混合しないようにする必要があります。
集約¶
集約 操作では、1 つの入力ストリームまたはテーブルを受け取り、複数の入力レコードを単一の出力レコードに結合して、新しいテーブルを生成します。集約の例として、カウントや合計の計算があります。
Kafka Streams DSL では、集約操作 の入力ストリームとして KStream または KTable を使用できますが、出力ストリームは常に KTable になります。これにより、集約値が生成および出力された後で順序外のレコードが到着した場合に、Kafka Streams で集約値を更新することが可能になります。このような順序外の到着が起きると、集約している KStream や KTable から新しい集約値が出力されます。出力は KTable であるため、同じキーを持つ以前の値は、後続の処理ステップで新しい値によって上書きされると見なされます。順序外のレコードの詳細については、「順序外の処理」を参照してください。
結合¶
結合 操作では、データレコードのキーに基づいて 2 つの入力ストリームまたはテーブルをマージし、新しいストリームまたはテーブルを生成します。
Kafka Streams DSL で利用できる 結合操作 は、結合されるストリームやテーブルの種類によって異なります。たとえば、KStream と KStream の結合や、KStream と KTable の結合があります。
ウィンドウ化¶
ウィンドウ化では、集約 や 結合 などのステートフル操作においてどのように 同じキーを持つレコードをグループ化 し、ウィンドウ と呼ばれる単位に分けるかを制御します。ウィンドウはレコードキーごとに追跡されます。
ウィンドウ化操作 は Kafka Streams DSL で利用できます。ウィンドウを操作するときは、そのウィンドウの最終結果がいつ確定するかを示す 猶予期間 を指定できます。この猶予期間は、Kafka Streams が、ウィンドウに対する 順序外 のデータレコードをいつまで待機するかを制御します。ウィンドウの猶予期間が経過した後にレコードが到着した場合(つまり record.ts > window-end-time + grace-period)、レコードは破棄され、そのウィンドウでは処理されません。
現実には順序外のレコードが生じる可能性は常にあり、アプリケーションで適切に対処することが必要です。順序外のレコードがどのように処理されるかは、システムの時間セマンティクスによって決まります。処理時刻のセマンティクスは "レコードが処理されたとき" であるため、順序外レコードの概念は適用されません。同様にインジェスト時刻の場合、ブローカーはトピックの追加順に基づいて昇順にタイムスタンプを割り当て、タイムスタンプはインジェスト時刻のみを示します。順序外のレコードが考慮されるのは、"イベント時刻" を示すタイムスタンプがプロデューサーによって設定されるイベント時刻セマンティクスでだけです。2 つのプロデューサーが同じトピックパーティションに書き込む場合、イベントの追加順序は保証されません。
Kafka Streams は、関連する 時間セマンティクス (イベント時刻)の順序外のレコードを適切に処理できます。
ちなみに
猶予期間と保持時間
"猶予期間" は "保持時間" に取って代わるもので、ウィンドウの終了後、そのウィンドウで順序外のイベントが許容される期間をより明確に定義します。猶予期間はウィンドウの最終結果の扱いに直接的に関係するもので、保持時間の下限でもあります。
保持時間も引き続き構成可能ですが、ウィンドウストアの低レベルプロパティとなっています。イベントを長時間(デフォルトは 1 日)保持するように選択することもできます。たとえば、大容量のストレージを備えたリモートの分散システムで、最後のウィンドウを超えて、さらには無期限にでも対話型クエリをサポートできます。一方、メモリー内の実装向けにはイベントの保持時間を短くすることができます。
対話型クエリ¶
対話型クエリを使用すると、ストリーム処理層を軽量の組み込みデータベースのように扱い、ストリーム処理アプリケーションの最新のステートを直接クエリできます。そのステートを事前に外部データベースや外部ストレージに具現化する必要はありません。
対話型クエリはアーキテクチャを単純化し、よりアプリケーション中心のアーキテクチャを実現します。
以下に 2 つのアーキテクチャを比較する図を示します。最初のアーキテクチャは対話型クエリを使用しないもの、2 番目のアーキテクチャは使用するものです。どちらのアーキテクチャが適しているかは、具体的なユースケースによって異なります。重要なのは、Kafka Streams と対話型クエリによって、1 つの方法に限定されるのではなく、適切な方法を選択して構成できる柔軟性が与えられるという点です。
ちなみに
両方に対応: ハイブリッドアーキテクチャを実装するという選択肢もあります。たとえば、アプリケーションで対話型クエリに対応すると同時に、結果の一部を外部システムに(たとえば Kafka Connect 経由で)共有することができます。
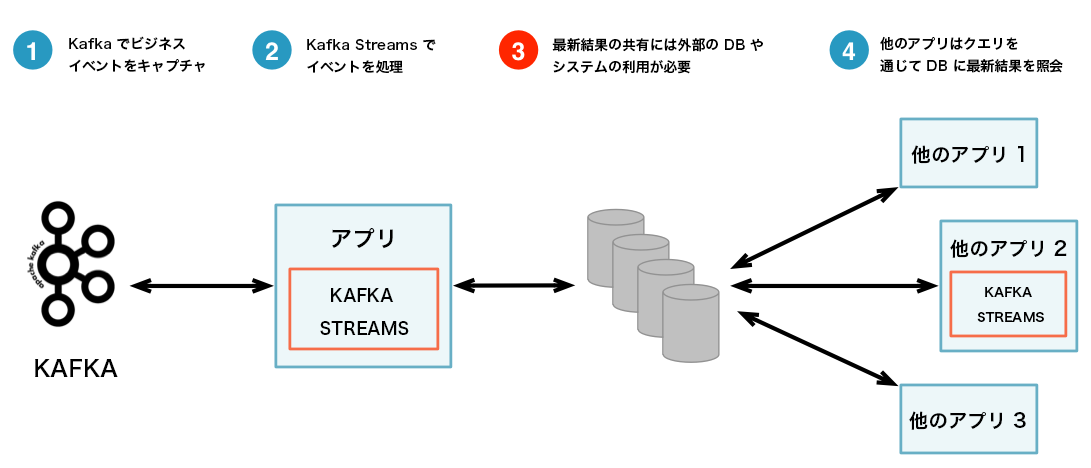
対話型クエリなし: 複雑さが増し、アーキテクチャのフットプリントが大きい。¶
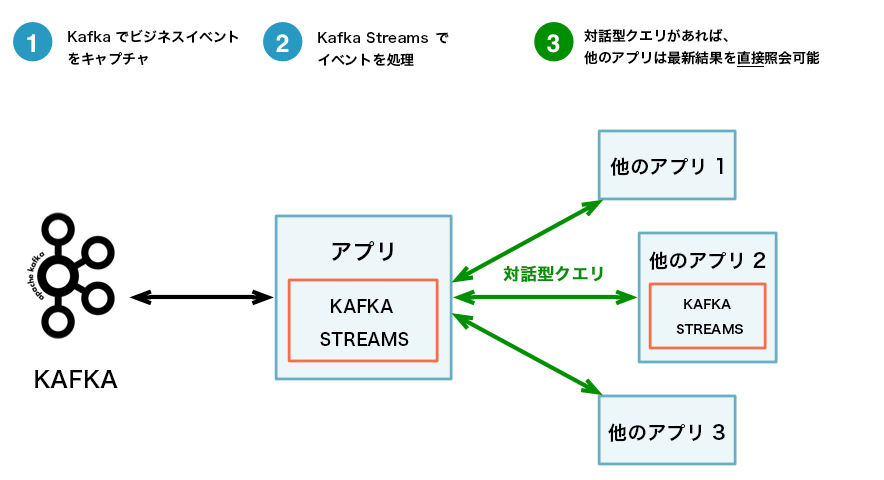
対話型クエリあり: 簡素化され、よりアプリケーション中心のアーキテクチャ。¶
以下に、対話型クエリを活かしたアプリケーションのユースケースの例をいくつか示します。
- リアルタイムモニタリング: 脅威インテリジェンス(例: Web サーバーがサイバー犯罪の攻撃を受けている)を提供するフロントエンドのダッシュボードから、ネットワークテレメトリデータをリアルタイムで処理して継続的に関連情報を生成する Kafka Streams アプリケーションに直接クエリを送信できます。
- ビデオゲーム: Kafka Streams アプリケーションは、ゲーム世界におけるプレイヤーの最新の位置を継続的に追跡します。モバイルコンパニオンアプリでは、Kafka Streams アプリケーションにクエリを直接送信して、プレイヤーの現在位置を友人や家族に表示し、一緒に参加するように招待することができます。同様に、ゲームベンダーでは、このデータを使用してプレイヤーの不自然なホットスポットを特定できます。このようなホットスポットは、バグや操作上の問題を示している可能性があります。
- リスクと不正: Kafka Streams アプリケーションが、ユーザートランザクションに異常や疑わしい動作がないかどうかを継続的に分析します。オンラインバンキングアプリケーションでは、ユーザーのログイン時に Kafka Streams アプリケーションにクエリを直接送信して、疑わしいと見なされたユーザーのアクセスを拒否できます。
- トレンドの検出: Kafka Streams アプリケーションが、リアルタイムで収集されるユーザーのリスニング傾向を基に、さまざまな音楽ジャンルの最新トップチャートを継続的に計算します。ミュージックストアのモバイルアプリケーションやデスクトップアプリケーションでは、ユーザーがストアを閲覧しているときに、対話的にクエリを実行して最新チャートを取得できます。
詳細については、Streams 開発者ガイド を参照してください。
処理の保証¶
Kafka Streams では、"少なくとも 1 回" の処理と、"厳密に 1 回" の処理の保証がサポートされます。
- "少なくとも 1 回" のセマンティクス
- レコードが失われることはありませんが、再デリバリーされる場合があります。ストリーム処理アプリケーションで障害が発生した場合、データレコードが失われることや処理されなくなることはありませんが、一部のデータレコードが再度読み取られ、再処理される場合があります。"少なくとも 1 回" のセマンティクスは、Streams の構成 でデフォルトで有効になっています(
processing.guarantee="at_least_once")。 - "厳密に 1 回" のセマンティクス
- レコードは 1 回だけ処理されます。プロデューサーが重複レコードを送信しても、ブローカーに書き込まれるのは厳密に 1 回だけです。厳密に 1 回のストリーム処理では、読み取り、処理、書き込みという一連の操作を厳密に 1 回だけ実行することができます。処理のすべては厳密に 1 回だけ実行されます。これには、処理ジョブによって作成された具現化されたステートの Kafka への書き戻しも含まれます。"厳密に 1 回" のセマンティクスを有効にするには、Streams の構成 で
processing.guarantee="exactly_once_v2"を設定します。
"厳密に 1 回" のセマンティクスが有効なレコードをパブリッシュする場合、書き込みは確認されるまで成功と見なされません。書き込みを "確定" するためにはコミットが必要です。パブリッシュされたレコードの確認後は、レコードの書き込み先パーティションを複製するブローカーが "存続" している限り、そのレコードが失われることはありません。プロデューサーがレコードのパブリッシュを試みてからネットワークエラーが発生した場合、そのエラーがレコードの確認前に発生したか、確認後に発生したかをプロデューサーで判別することはできません。プロデューサーは、レコードの確認応答を受信できなければレコードを再送信します。
"厳密に 1 回" を使用すると、プロデューサーは書き込みをべき等にするように構成されます。これにより、レコードの送信を再試行しても重複が生じることはなく、各レコードが厳密に 1 回だけログに書き込まれるようになります。"厳密に 1 回" では、複数のレコードが 1 つのトランザクションにグループ化されるため、すべてのレコードがコミットされるか、何もコミットされないかのどちらかになります。
すべての Kafka レプリカは同じログと同じオフセットを持ち、コンシューマーは、このログの中で自身の位置を制御しています。ただし、コンシューマーで障害が発生し、別のプロセスでトピックパーティションを引き継ぐ必要が生じた場合、新しいプロセスは適切な開始位置を選択する必要があります。
コンシューマーがレコードを読み取るときには、レコードを処理して位置を保存します。ここで、レコードを処理した後、位置を保存する前にコンシューマープロセスがクラッシュすることもあり得ます。この場合、新しいプロセスが引き継ぐときに受け取るレコードの最初の数件は、既に処理されていることになります。これは、コンシューマーが失敗した場合には、"最低 1 回" のセマンティクスに相当します。
コンシューマーの位置はトピック内のレコードとして保存されます。"厳密に 1 回" のセマンティクスを使用すると、オフセットの書き込みと、処理されたデータの出力トピックへの送信が、単一のトランザクションによって行われます。トランザクションが中断された場合、コンシューマーの位置は古い値に戻り、出力トピックにある生成データは、"分離レベル" に応じて他のコンシューマーからは見えなくなります。デフォルトの "read_uncommitted" 分離レベルでは、中断されたトランザクションに含まれていたものであっても、すべてのレコードがコンシューマーに認識されます。"read_committed" 分離レベルでは、コミットされたトランザクションからのレコードと、トランザクションの一部でないレコードだけがコンシューマーに認識されます。
詳細については、ブログ記事「Exactly-Once Semantics Are Possible: Here’s How Kafka Does It」を参照してください。
注釈
Confluent Monitoring Interceptor は、Confluent Control Center で "厳密に 1 回" のセマンティクス(EOS)と組み合わせて構成することは できません。
順序外の処理¶
各レコードが厳密に 1 回だけ処理されるという保証と並んで、多くのストリーム処理アプリケーションが直面するもう 1 つの難題は、ビジネスロジックに影響する可能性のある 順序外のデータ の処理方法です。Kafka Streams では、タイムスタンプに関して、次の 2 つの原因から順序外のデータの到着が引き起こされる可能性があります。
- トピックパーティション内で、レコードのタイムスタンプがオフセットとともに単調に増加していない。Kafka Streams は常にオフセット順にレコードの処理を試みるため、同じトピックパーティション内でタイムスタンプの大きい(ただしオフセットは小さい)レコードが、タイムスタンプの小さい(ただしオフセットは大きい)レコードよりも前に処理される可能性があります。
- ストリームタスク が複数のトピックパーティションを処理する状況で、アプリケーションが、すべてのパーティションにデータがバッファリングされるまで待機し、次に処理するレコードをタイムスタンプが最小のパーティションから選択するように構成されていない。この場合、後で他のトピックパーティションから取得されるレコードに、処理済みのレコードよりも小さいタイムスタンプが設定されていることがあり、実質的に古いレコードが新しいレコードの後に処理される結果となります。
ステートレス操作では、一度に 1 つのレコードしか考慮せず、過去に処理されたレコードの履歴も参照しないため、順序外のデータが処理ロジックに影響することはありません。
集約と結合のようなステートフル操作では、順序外のデータによってアプリケーションロジックが不適切になることがあります。このような順序外のデータを処理するには、一般に、アプリケーションでステートの記録を待機する時間を長く確保する必要があります。これは、レイテンシ、コスト、正確性の間でトレードオフを図ることを意味します。Kafka Streams では、ウィンドウ化された集約でこのようなトレードオフを実現するためのウィンドウオペレーターを構成できます。詳細については、Streams 開発者ガイド を参照してください。
"順序外" に関する用語¶
"順序" という用語は、"オフセットの順序" を指す場合や "タイムスタンプの順序" を指す場合があります。Kafka ブローカーはオフセットの順序を保証します。つまり、どのコンシューマーでも、パーティションごとにすべてのメッセージが同じ順序で読み取られます。しかし、Kafka はタイムスタンプの順序については何も保証しません。トピック内のレコードはタイムスタンプ順ではなく、単調に増加せずに順序が外れることもあります。Kafka ではレコードがオフセット順に消費されることが求められ、Kafka Streams もこのパターンを継承するため、タイムスタンプという観点から見ると、Kafka Streams によるレコードの処理は順序どおりにならない可能性があります。
順序付けの概念を理解し、一貫性のある使い方をするためには、次の定義を使用します。
- 順序: 明示されていない限り、Kafka Streams のコンテキストでの "順序" は "タイムスタンプの順序" を意味します。これは、"順序" が "オフセットの順序" を意味する通常のブローカー/クライアントのコンテキストとは異なります。
- 順序外: ストリーム時刻が単調に増加しないレコード。ウィンドウ化操作では、順序外のデータの処理には猶予期間が必要です。
- 遅延: ウィンドウのクローズ後に到着したレコード。つまり、ウィンドウ終了時のタイムスタンプに猶予期間を加えた時刻よりも後に到着したことを意味します。これらのレコードは破棄され、処理されません。遅延レコードの破棄は対応するウィンドウオペレーターにのみ適用され、レコードは他のオペレーターによって処理される場合があります。record-lateness メトリクスを使用すると、タスクの平均遅延と最大遅延を測定できます。
おすすめの関連情報¶
- 学習: Kafka Storage and Processing Fundamentals
- Streams and Tables in Apache Kafka: A Primer
- Streams and Tables in Apache Kafka: Topics, Partitions, and Storage Fundamentals
- Streams and Tables in Apache Kafka: Processing Fundamentals with Kafka Streams and ksqlDB
- Streams and Tables in Apache Kafka: Elasticity, Fault Tolerance, and Other Advanced Concepts
注釈
このウェブサイトには、Apache License v2 の条件に基づいて Apache Software Foundation で開発されたコンテンツが含まれています。