モジュール 1: オンプレミスのチュートリアル¶
オンプレミスのクラスターの実行¶
cp-demo は Docker 環境であり、すべてのサービスは 1 台のホストで実行されています。これは、Confluent Platform のデモの実行を容易にするためです。本稼働環境では、すべての Confluent Platform サービスを 1 台のホストでデプロイすることは避けてください。
また、本稼働環境では、有効なライセンスを使用して、本稼働データを含むクラスターとは別の専用のメトリクスクラスターで Confluent Control Center をデプロイする必要があります。専用のメトリクスクラスターを使用すると、本稼働環境のトラフィッククラスターで問題が発生した場合でもシステム正常性モニタリングが提供され続けるため、回復性が向上します。
Docker 以外のサンプルを使用する場合は、confluentinc/examples GitHub リポジトリ にアクセスしてください。
以下のチュートリアルの手順をすべて参照した後、学習した概念を応用して、自分のイベントストリーミングパイプラインを Confluent Cloud で構築します。これは、Kafka を使用した、クラウドネイティブのフルマネージド型イベントストリーミングプラットフォームです。Confluent Cloud にサインアップするときは、プロモーションコード CPDEMO50 を使用すると、$50 相当を無料で使用できます(詳細)。
前提条件¶
このサンプルは、次の環境で検証されています。
- Docker バージョン 17.06.1-ce
- Docker Compose ファイル形式 2.3 の Docker Compose バージョン 1.16.0
- Java バージョン 1.8.0_92
- MacOS 10.15.3(Ubuntu 環境 向けの注意事項あり)
- OpenSSL 1.1.1d
- git
- curl
- jq
セットアップ¶
このデモは、Docker を利用してローカルで、または Gitpod を使用してクラウド IDE で実行できます。
Docker¶
Docker を使用している場合:
Docker の詳細(Advanced)`設定 <https://docs.docker.com/docker-for-mac/#advanced>`__ で、Docker 専用のメモリーを 8 GB(デフォルトでは 2 GB)以上に増やし、必ず 2 つ以上の CPU コアを Docker に割り当てます。
confluentinc/cp-demo GitHub リポジトリ のクローンを作成します。
git clone https://github.com/confluentinc/cp-demo
cp-demoディレクトリに移動し、Confluent Platform リリースブランチに切り替えます。cd cp-demo git checkout 6.2.4-post
起動¶
cp-demo ディレクトリ内には、cp-demo ワークフローをエンドツーエンドで実行する 1 つの スクリプト があります。これにより、キーと証明書の生成、Docker コンテナーの起動、および環境の構成と検証が行われます。これは、次のオプション設定で実行できます。
CLEAN: 実行の合間に、証明書、およびローカルで作成された Connect イメージを再生成するかどうかを制御します。C3_KSQLDB_HTTPS: Confluent Control Center と ksqlDB サーバーでHTTPとHTTPSのどちらを使用するかを制御します(デフォルト:HTTPを示すfalse)。このオプションは、Gitpod ではサポートされていません。VIZ: Elasticsearch と Kibana を有効にします(デフォルト:true)。
デフォルト設定で初めて
cp-demoを実行するには、次のコマンドを実行します。初回の実行では、必要な Docker イメージがすべてダウンロードされ(最大 15 分)、環境のセットアップが行われます(最大 5 分)。./scripts/start.sh
それ以降の実行では、生成した証明書、およびローカルで作成した Connect イメージを削除していない場合は、それらが再使用されます。それらを強制的に再構築するには、
CLEAN=trueを設定します。CLEAN=true ./scripts/start.sh
cp-demoは、http://(デフォルト)またはセキュアなhttps://経由での Confluent Control Center GUI へのアクセスをサポートします。後者は、自己署名 CA と、デプロイ中に生成された証明書を使用します。このチュートリアルの後半で、Confluent Control Center から ksqlDB クエリを実行するには、ksqlDB と Confluent Control Center の両方がhttpまたはhttpsモード で実行されている必要があります。cp-demoをhttpsモードで実行するには、cp-demoの起動時にC3_KSQLDB_HTTPS=trueを設定します。C3_KSQLDB_HTTPS=true ./scripts/start.sh
Elasticsearch と Kibana により、
cp-demoの localhost メモリー要件が増加します。小さいメモリーフットプリントでユーザーがcp-demoを実行しようとしている場合は、cp-demoの起動時にVIZ=falseを設定して、これらのコンポーネントをオプトアウトしてください。VIZ=false ./scripts/start.sh
start スクリプトの実行が完了したら、以下の開始前のチェックを実行して、このオンプレミスデプロイについてチュートリアルを進めます。
開始前のチェック¶
チュートリアルを開始する前に、環境が正しく起動されていることを確認します。以下の開始前チェックで異常が見つかった場合は、「トラブルシューティング」セクションを参照してください。
Docker コンテナーのステータスが
Upステートを示していることを確認します。docker-compose ps
出力は以下のようになります。
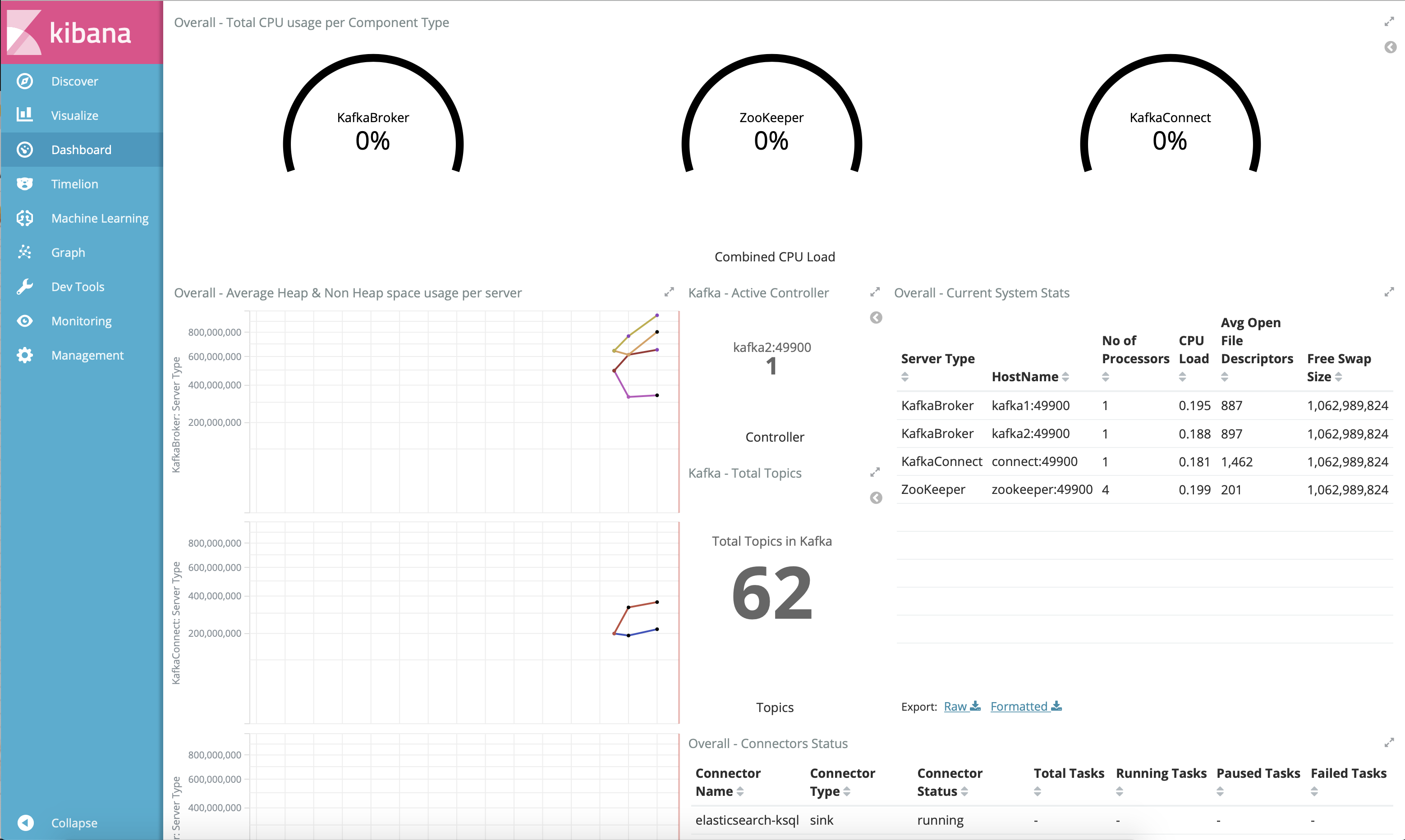
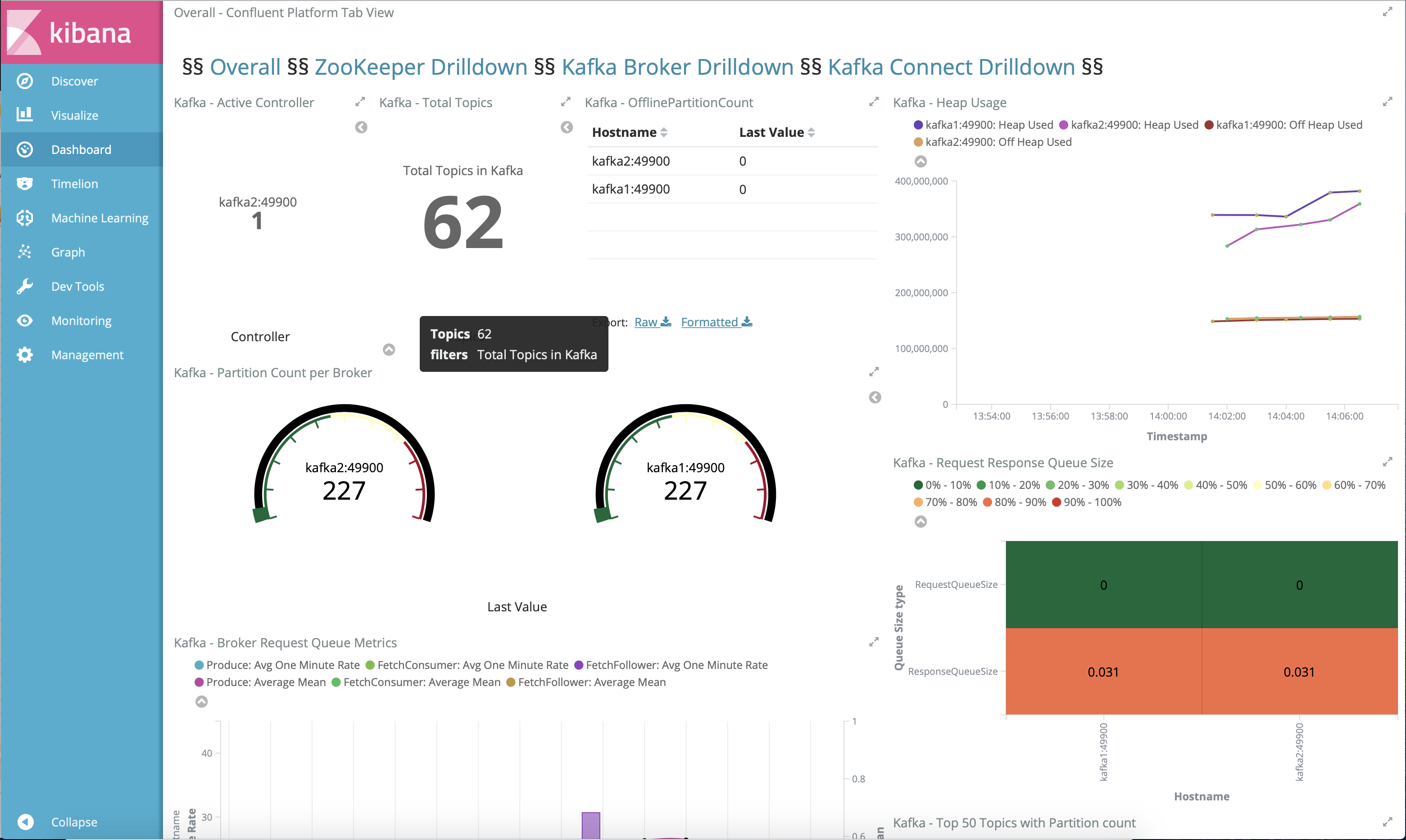
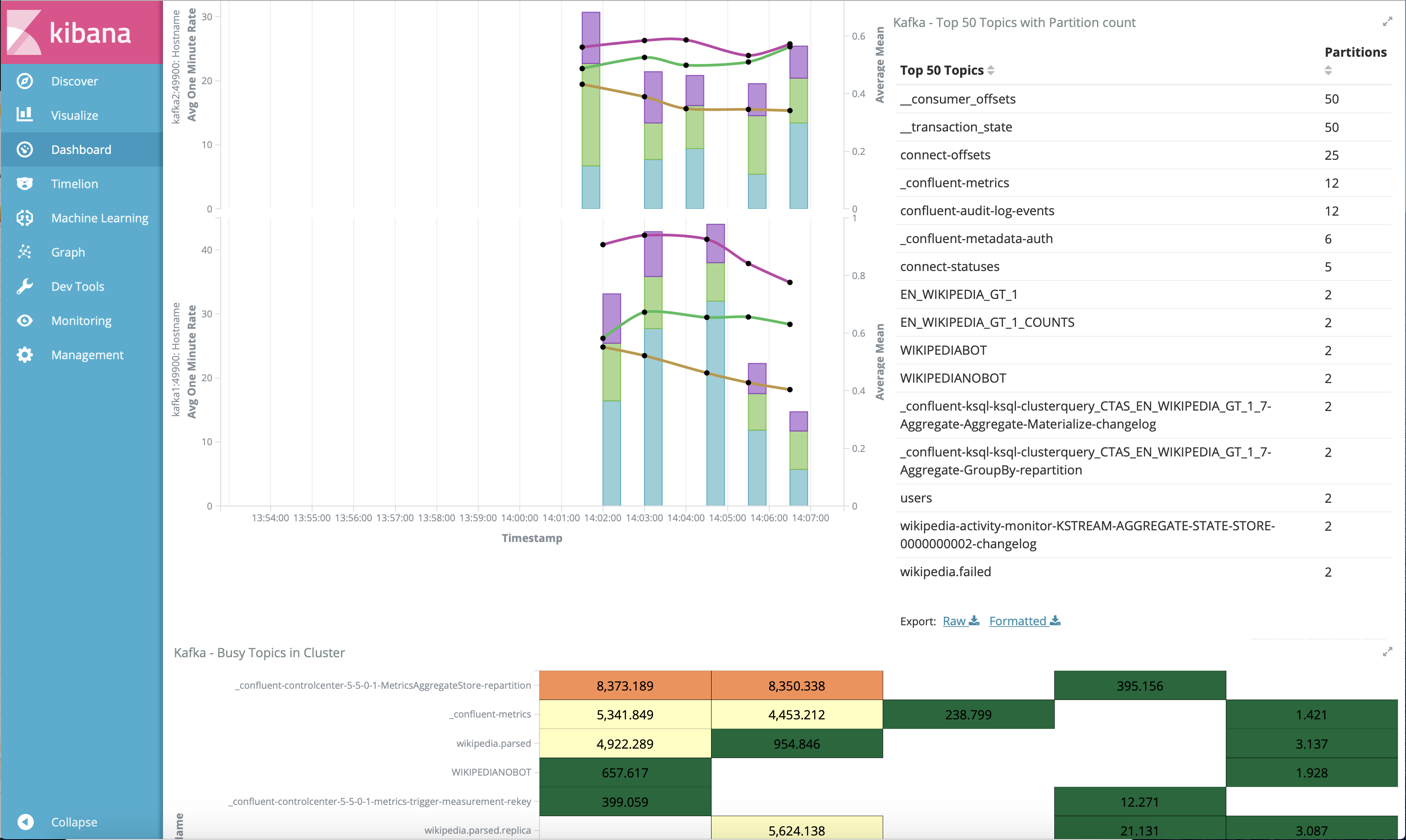
Name Command State Ports ------------------------------------------------------------------------------------------------------------------------------------------------------------ connect bash -c sleep 10 && cp /us ... Up 0.0.0.0:8083->8083/tcp, 9092/tcp control-center /etc/confluent/docker/run Up (healthy) 0.0.0.0:9021->9021/tcp, 0.0.0.0:9022->9022/tcp elasticsearch /bin/bash bin/es-docker Up 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp kafka1 bash -c if [ ! -f /etc/kaf ... Up (healthy) 0.0.0.0:10091->10091/tcp, 0.0.0.0:11091->11091/tcp, 0.0.0.0:12091->12091/tcp, 0.0.0.0:8091->8091/tcp, 0.0.0.0:9091->9091/tcp, 9092/tcp kafka2 bash -c if [ ! -f /etc/kaf ... Up (healthy) 0.0.0.0:10092->10092/tcp, 0.0.0.0:11092->11092/tcp, 0.0.0.0:12092->12092/tcp, 0.0.0.0:8092->8092/tcp, 0.0.0.0:9092->9092/tcp kibana /bin/sh -c /usr/local/bin/ ... Up 0.0.0.0:5601->5601/tcp ksqldb-cli /bin/sh Up ksqldb-server /etc/confluent/docker/run Up (healthy) 0.0.0.0:8088->8088/tcp openldap /container/tool/run --copy ... Up 0.0.0.0:389->389/tcp, 636/tcp restproxy /etc/confluent/docker/run Up 8082/tcp, 0.0.0.0:8086->8086/tcp schemaregistry /etc/confluent/docker/run Up 8081/tcp, 0.0.0.0:8085->8085/tcp streams-demo /app/start.sh Up 9092/tcp tools /bin/bash Up zookeeper /etc/confluent/docker/run Up (healthy) 0.0.0.0:2181->2181/tcp, 2888/tcp, 3888/tcpcp-demoパイプライン全体の末尾に移動し、http://localhost:5601/app/dashboards#/view/Overview にある Kibana ダッシュボードを表示します。以下は正常な表示で、cp-demoの起動スクリプトが問題なく完了したことを確認できます。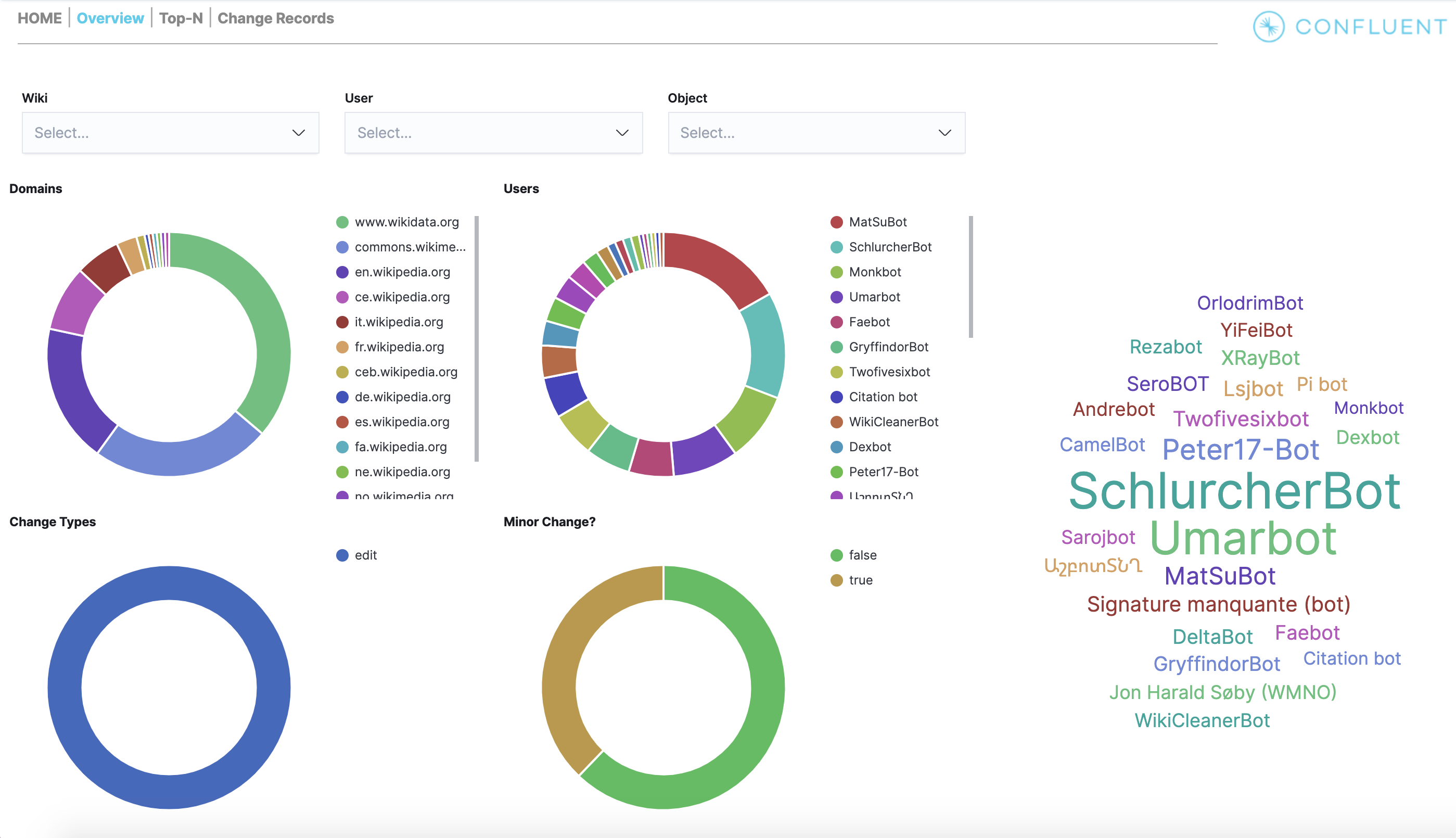
docker-compose.yml ファイルで Confluent Platform 構成全体を確認します。
Kafka クラスターと Schema Registry に対するセキュリティパラメーターが設定されている クライアント構成 ファイルで Kafka Streams アプリケーション構成を確認します。
チュートリアル¶
Confluent Control Center へのログイン¶
デフォルトの
C3_KSQLDB_HTTPS=falseでcp-demoを実行した場合は、次の URL で Web ブラウザーから Confluent Control Center GUI にログインします。http://localhost:9021
C3_KSQLDB_HTTPS=true(Gitpod ではサポートされていません)でcp-demoを実行した場合は、次の URL でウェブブラウザーから Confluent Control Center GUI にログインします。https://localhost:9022
ブラウザーにより、信頼されていない自己署名証明書および認証機関が検出され、次のようなプライバシー警告が発行されます。続行するには、ブラウザーのプロセスに従ってこの証明書を受諾します。この受諾は、このブラウザーセッションが終了するまで持続します。
Chrome の場合:
Advancedをクリックし、ウィンドウが展開されたら、Proceed to localhost (unsafe)をクリックします。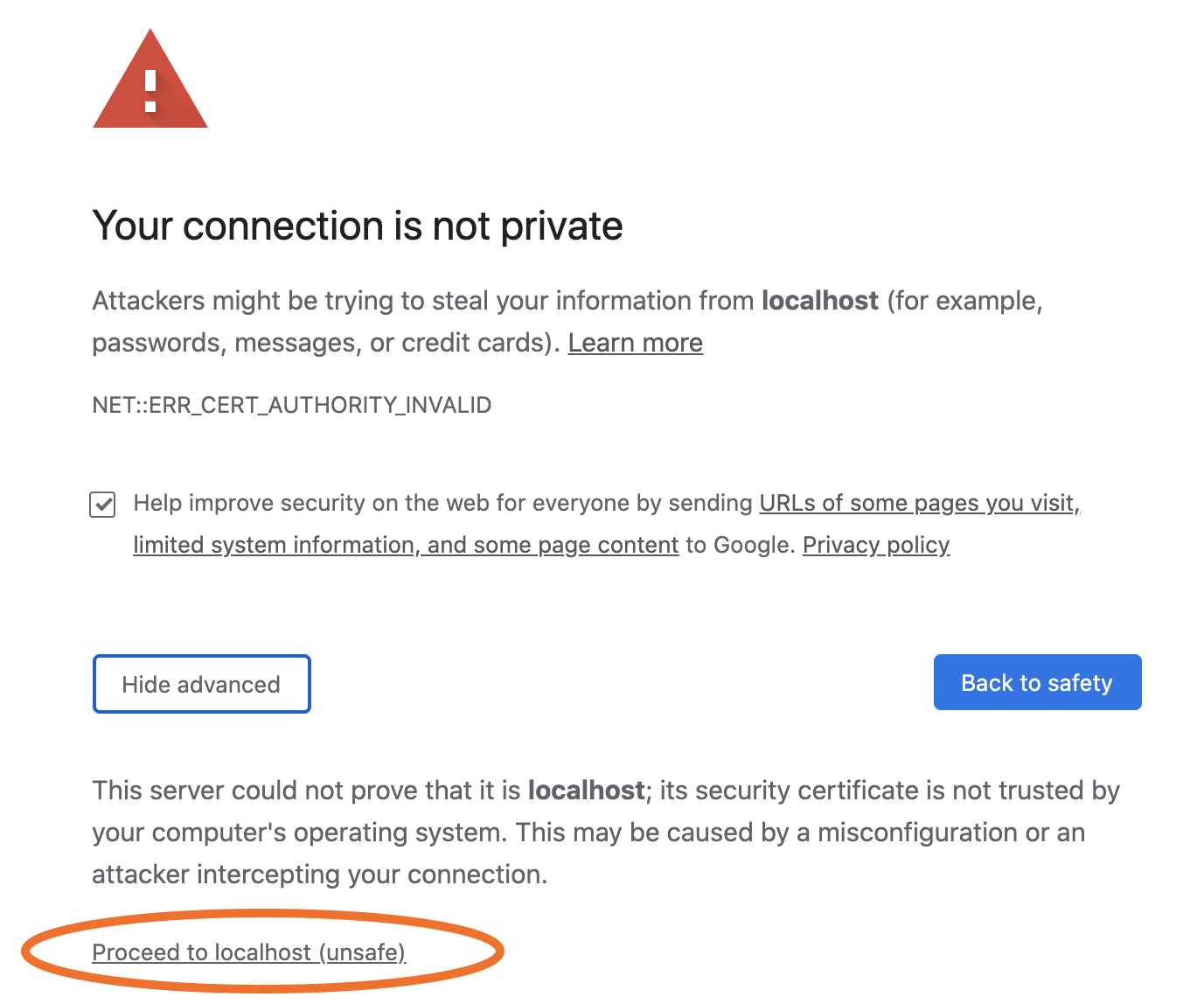
Safari の場合: 新しいプライベートブラウザーウィンドウを開き(
Shift + ⌘ + N)、Show Detailsをクリックします。ウィンドウが展開されたら、visit this websiteをクリックします。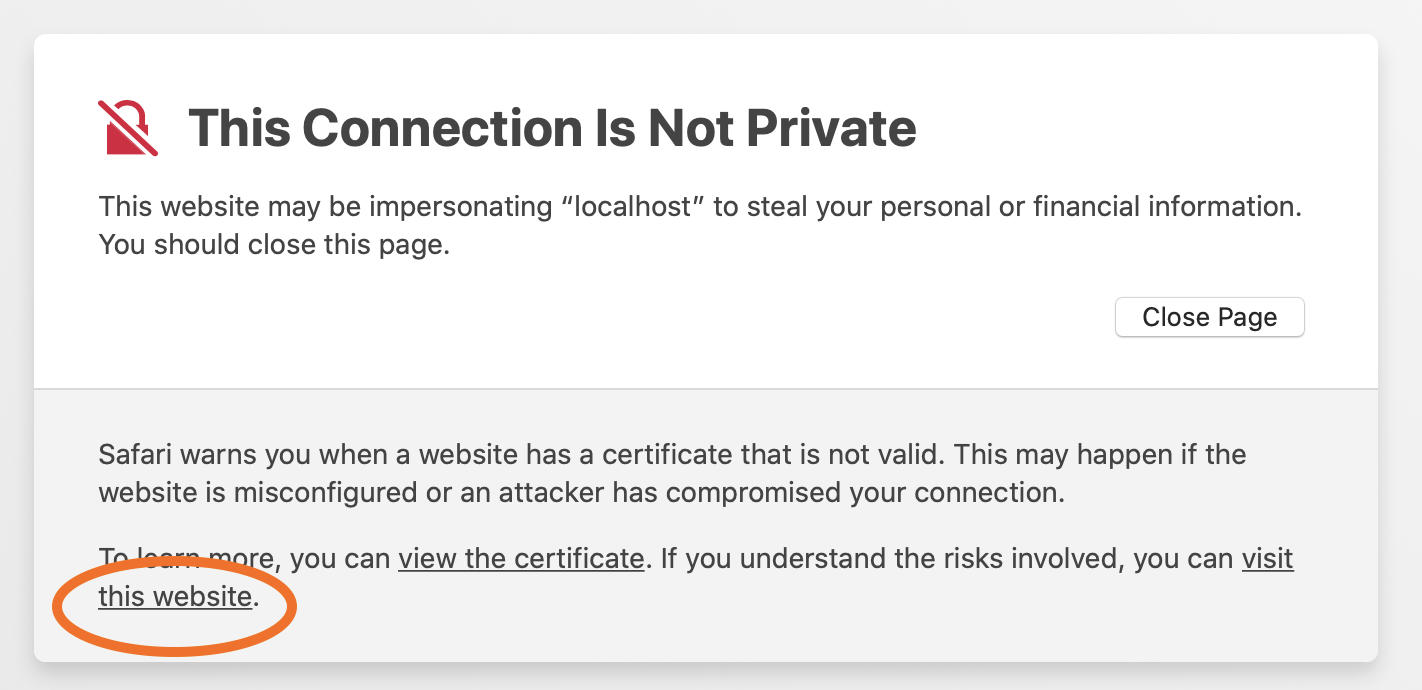
ログイン画面で、クラスターへのスーパーユーザーアクセス権を持つ
superUserとして、パスワードsuperUserで Confluent Control Center にログインします。また、他のユーザー としてログインし、各ユーザーへの表示がアクセス許可に応じてどのように変わるかを調べることもできます。
ブローカー¶
Kafka Raleigh という名前のクラスターを選択します。
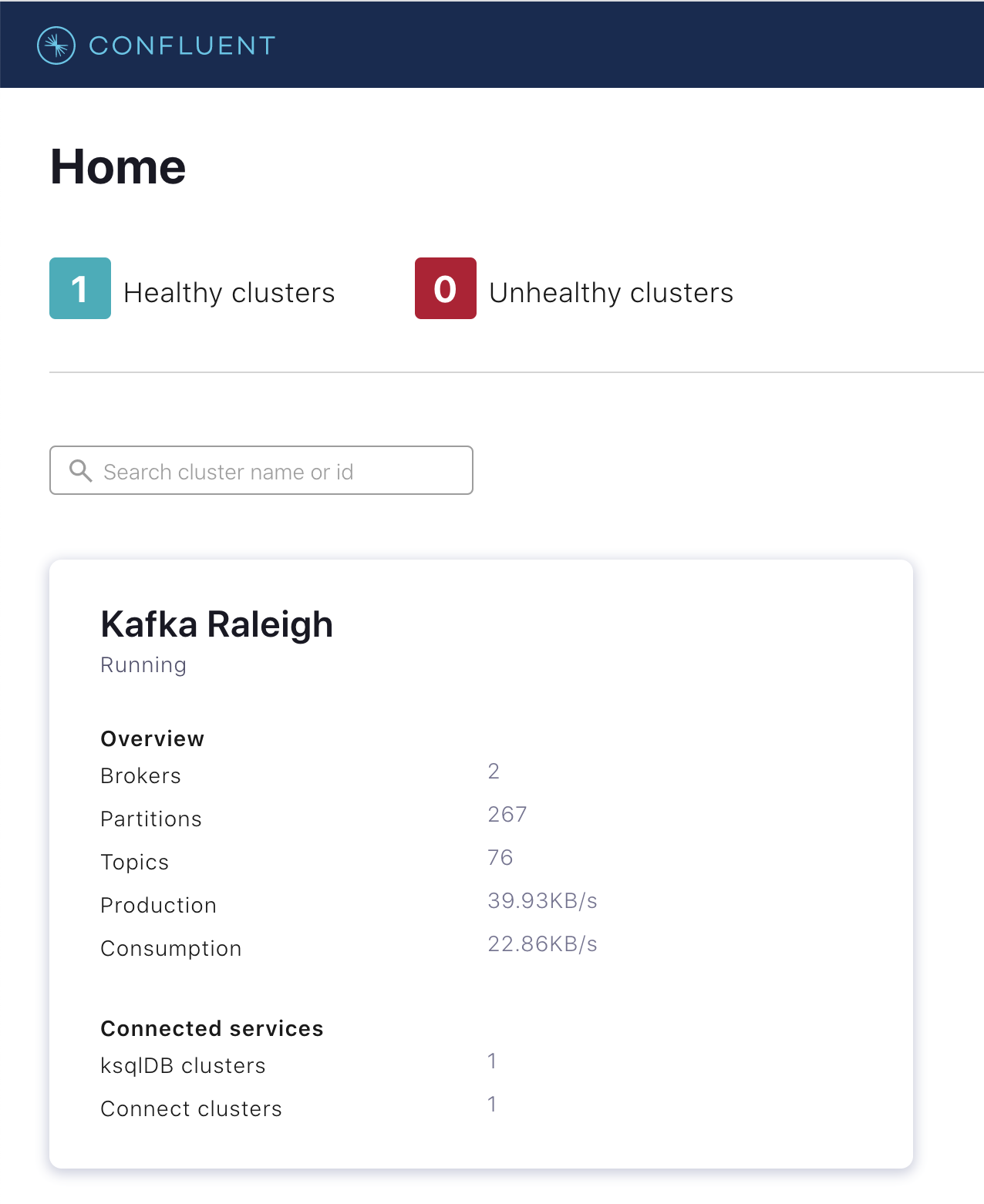
Brokers をクリックします。
クラスター内の各ブローカーのステータスが表示されます。
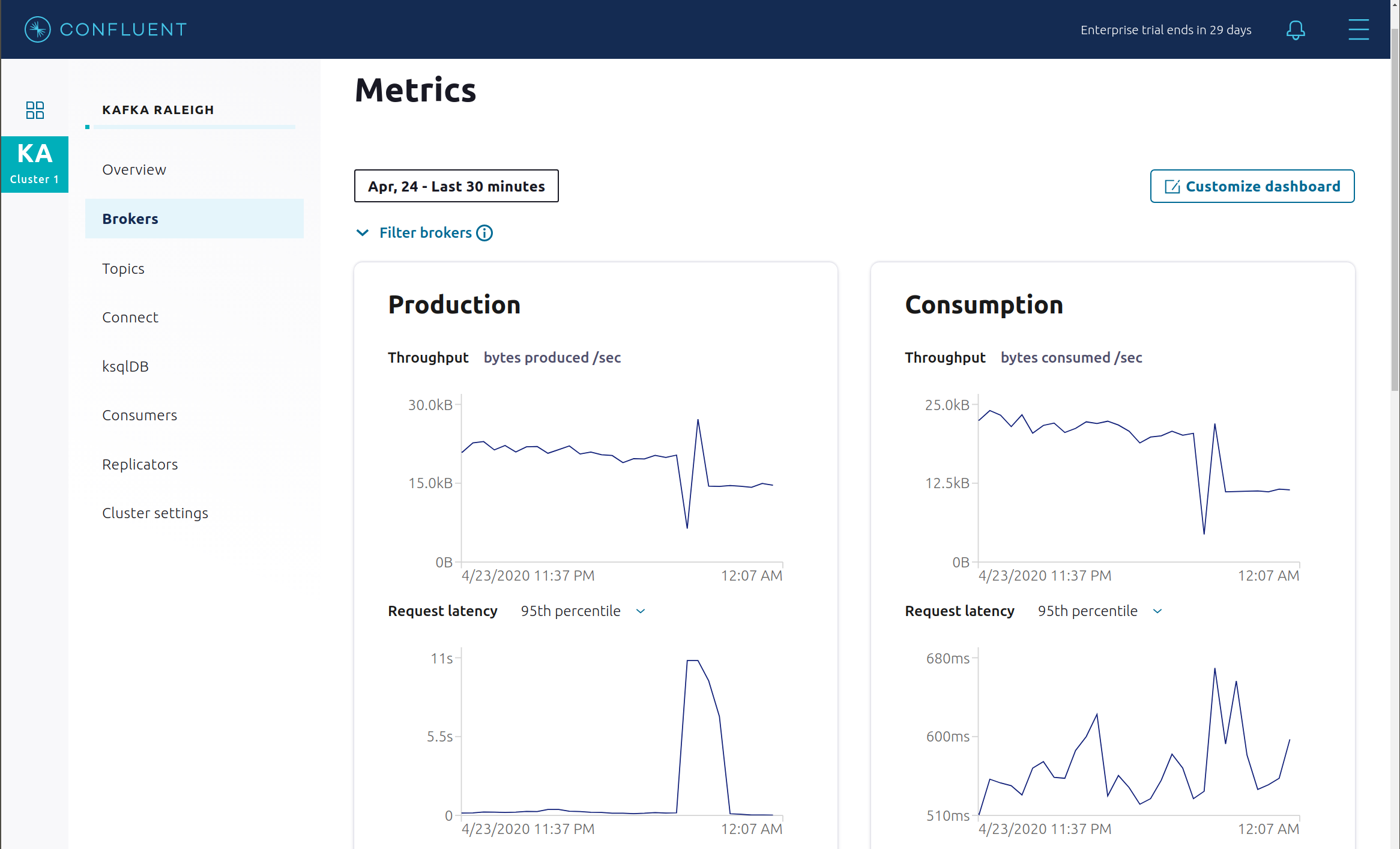
Production または Consumption をクリックして、生成メトリクスと消費メトリック、ブローカーの稼働時間、パーティション(オンライン、レプリケーション数不足、レプリカの合計、同期されていないレプリカ)、ディスク使用率、システム(ネットワークプール使用率、リクエストプール使用率)を調べます。
トピック¶
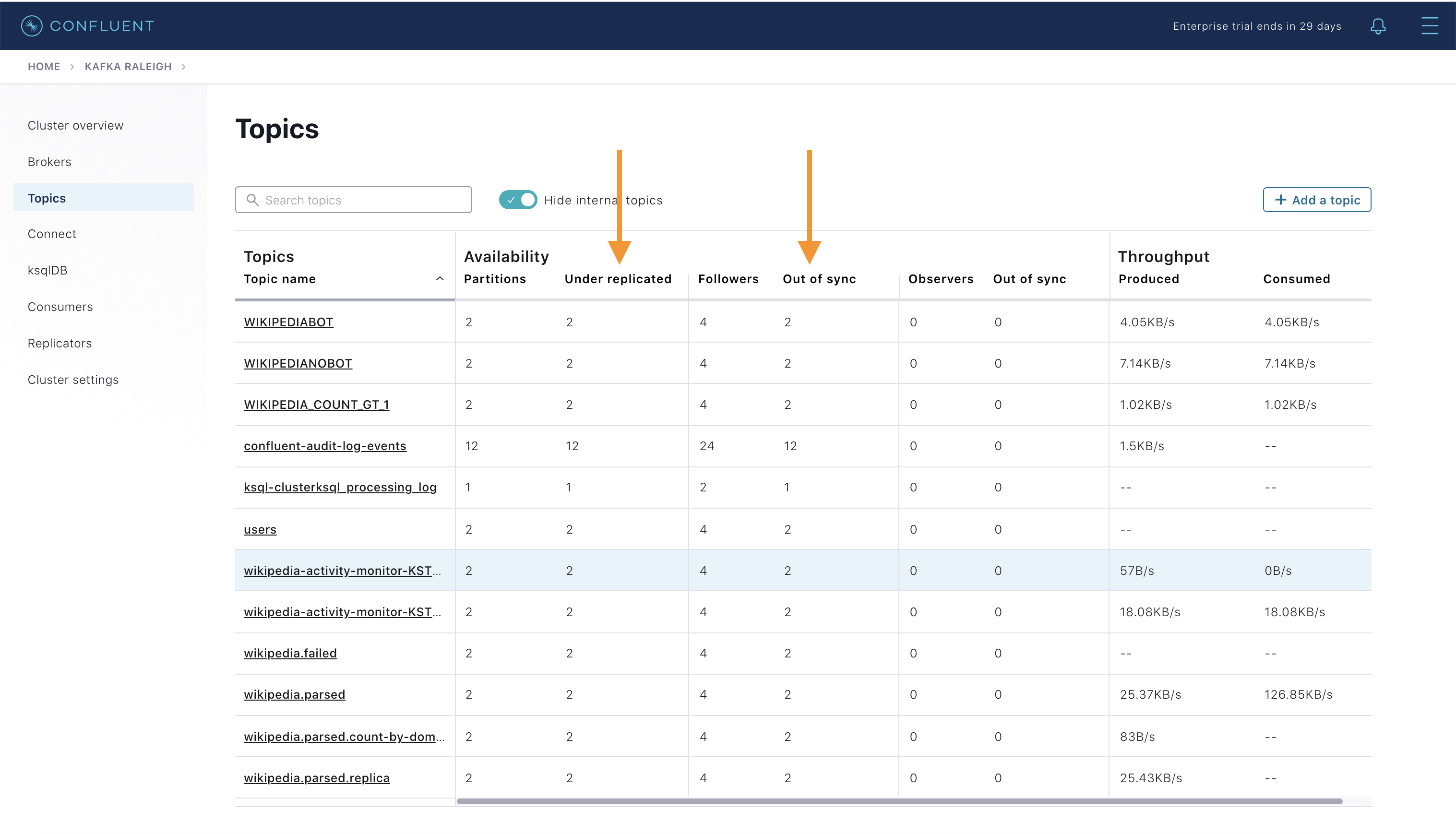
Confluent Control Center では、Kafka クラスター内のトピックを管理できます。Topics をクリックします。
下へスクロールし、トピック
wikipedia.parsedをクリックします。
このトピックの概要が表示されます。
- スループット
- パーティションレプリケーションのステータス
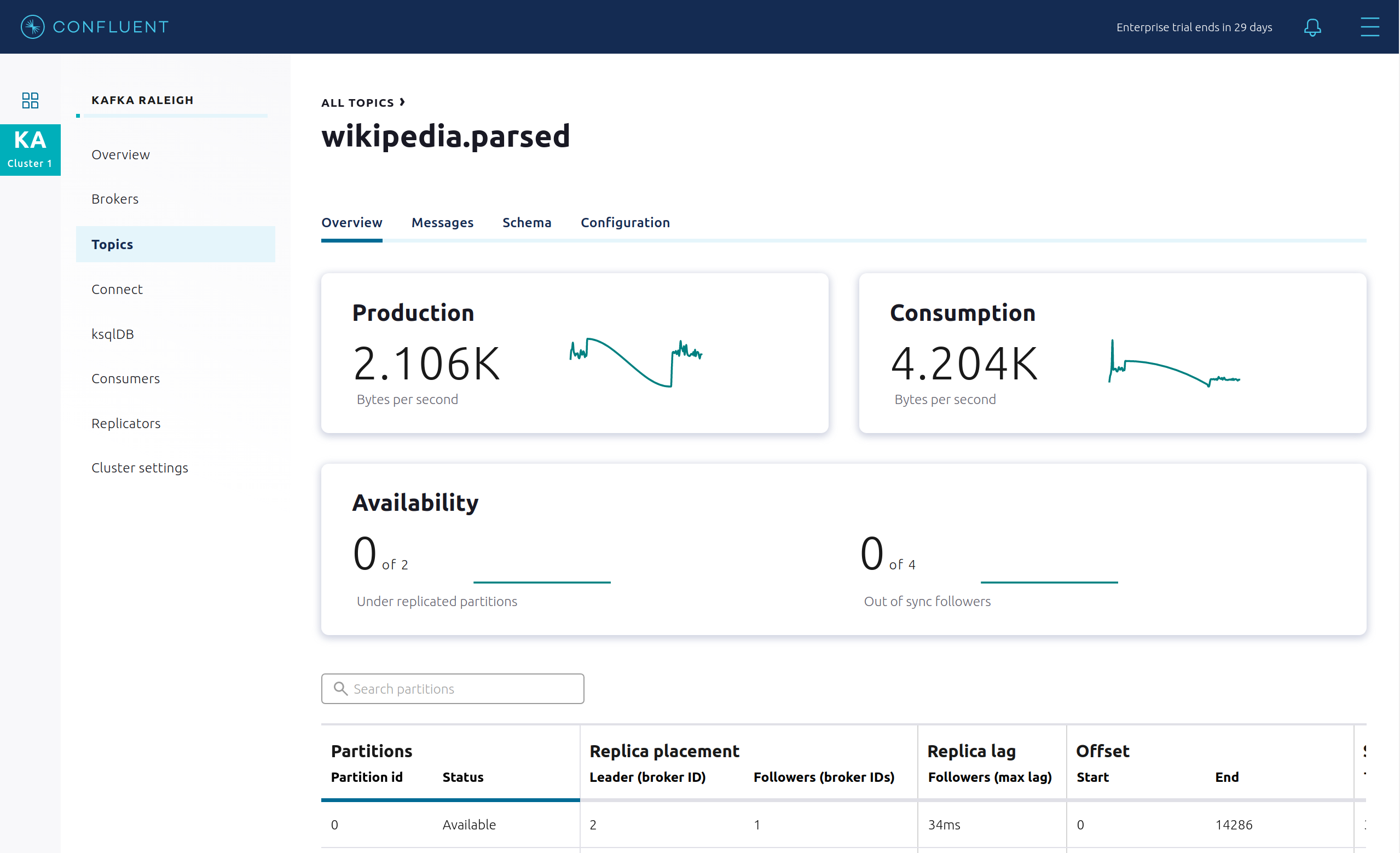
どのブローカーがどのパーティションのリーダーであるか、およびすべてのパーティションがどこに格納されているかを調べます。
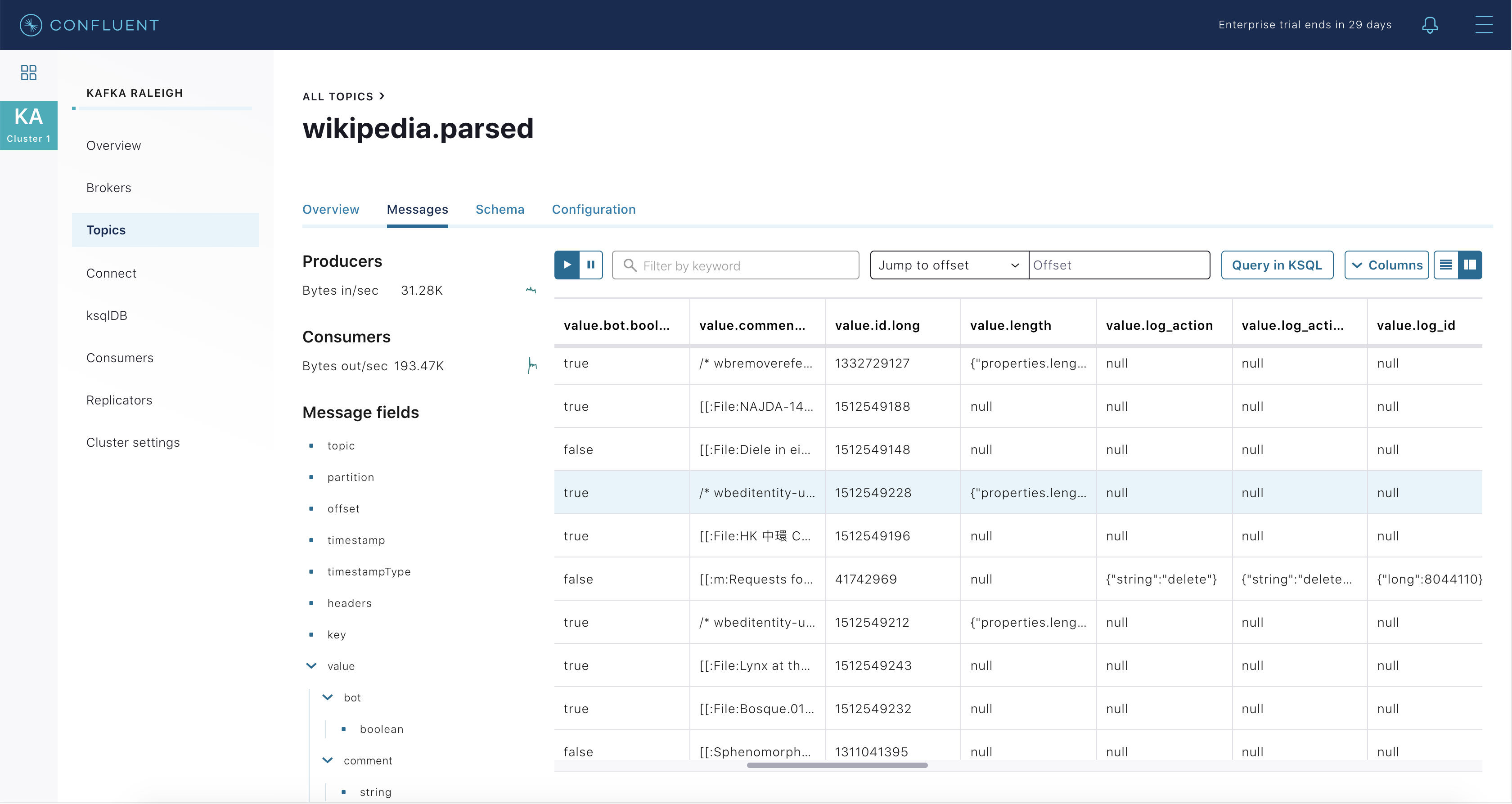
このトピックのメッセージをリアルタイムで検査します。
このトピックのスキーマを表示します。
wikipedia.parsedでは、Schema Registry で登録されたスキーマをトピック値が使用しています(トピックキーは単なる文字列です)。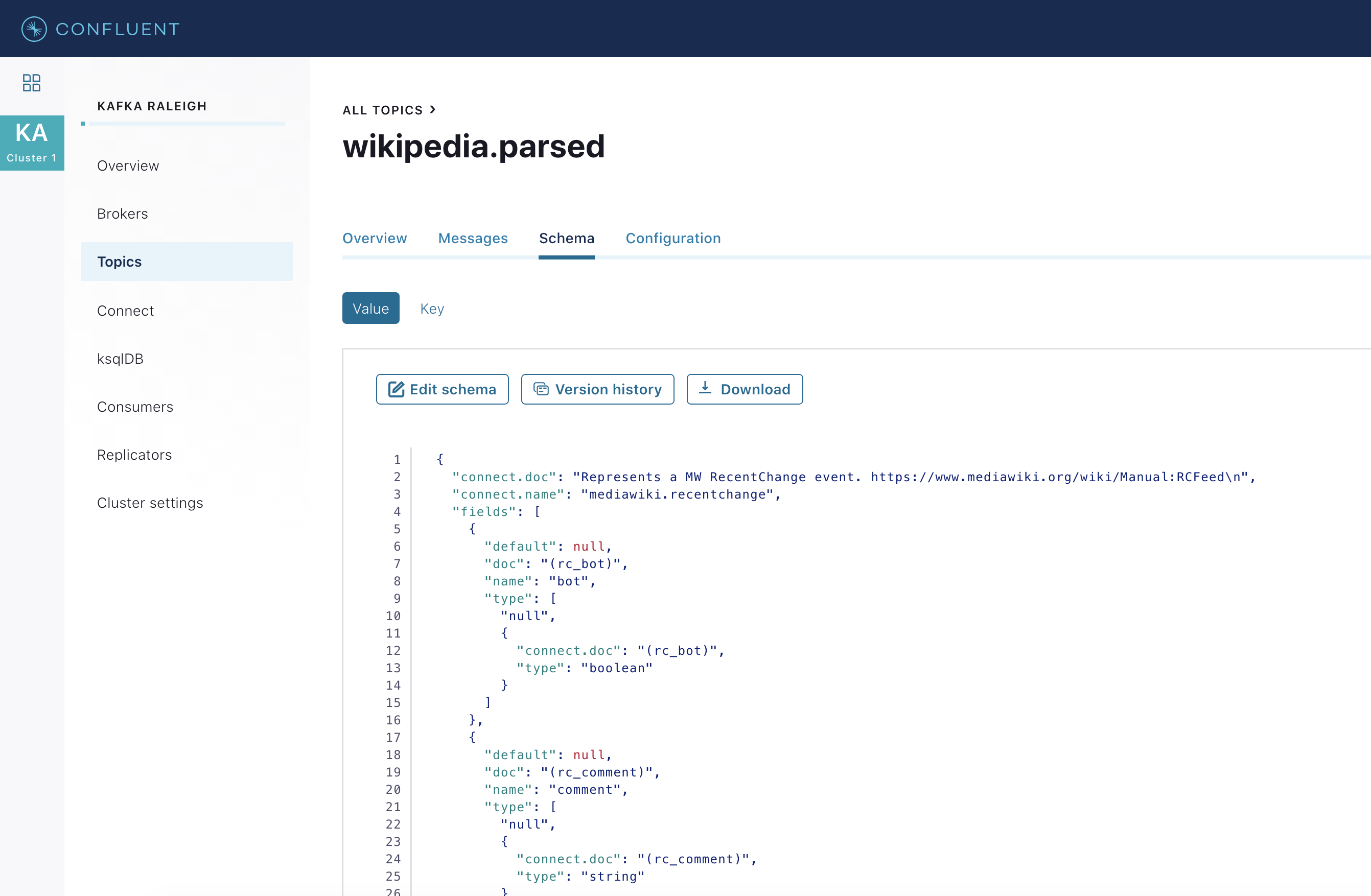
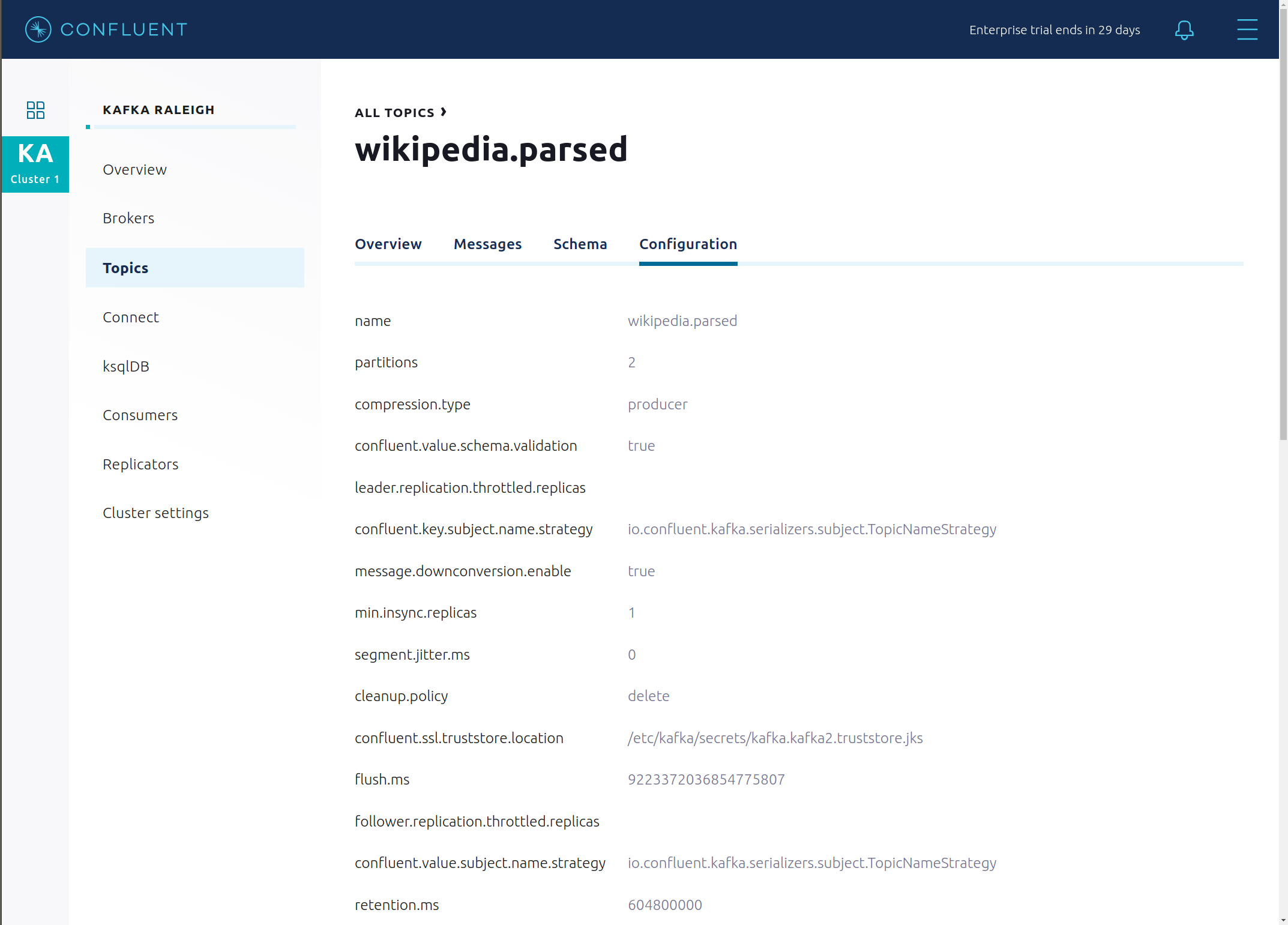
このトピックの構成設定を表示します。
All Topics に戻り、
wikipedia.parsed.count-by-domainをクリックして、Kafka Streams アプリケーションからの出力トピックを表示します。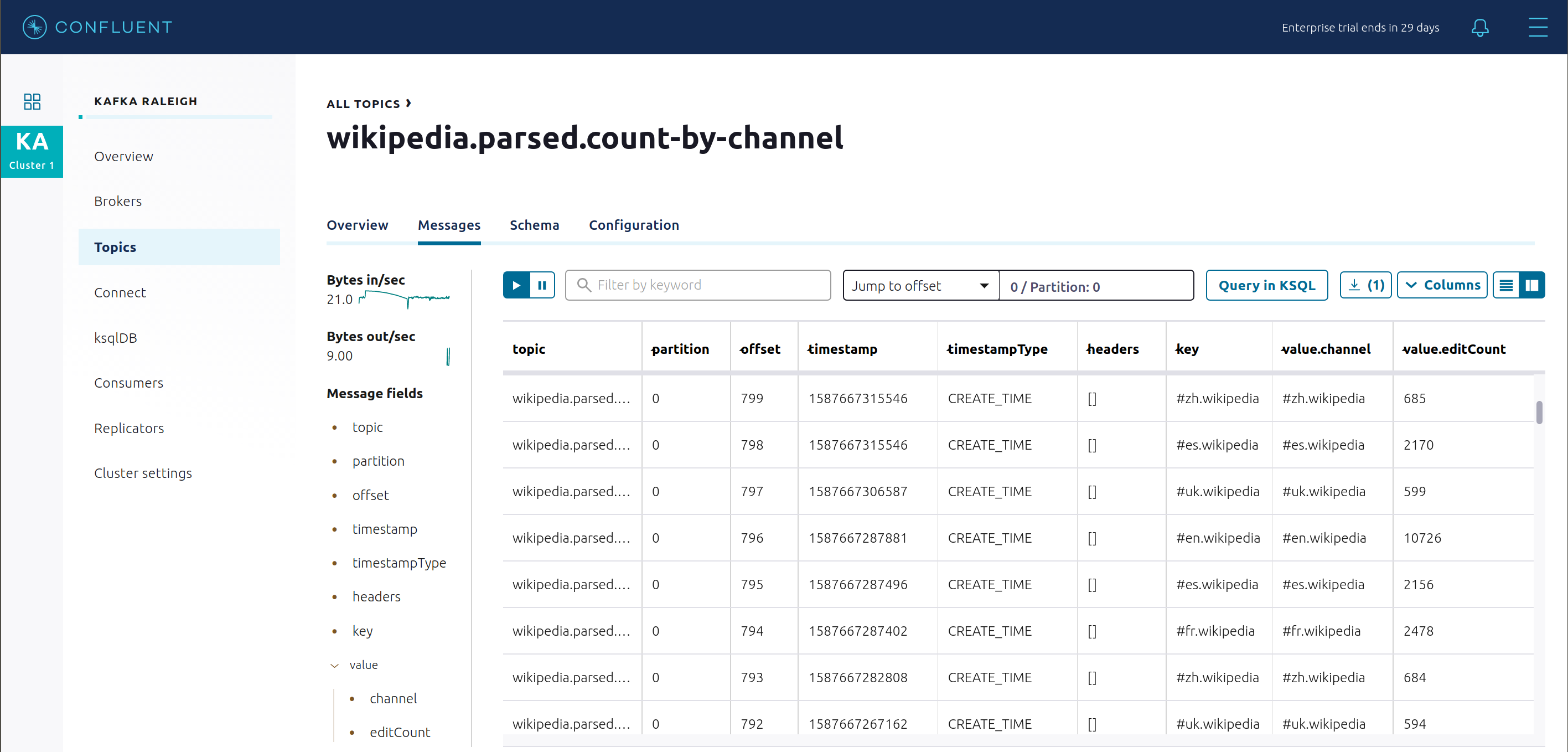
All topicsビューに戻り、右上にある + Add a topic ボタンをクリックして、新しいトピックを Kafka クラスターで作成します。また、クラスターの Kafka のトピックの設定を表示し、編集することもできます。Confluent Control Center の トピック管理 に関する説明を参照してください。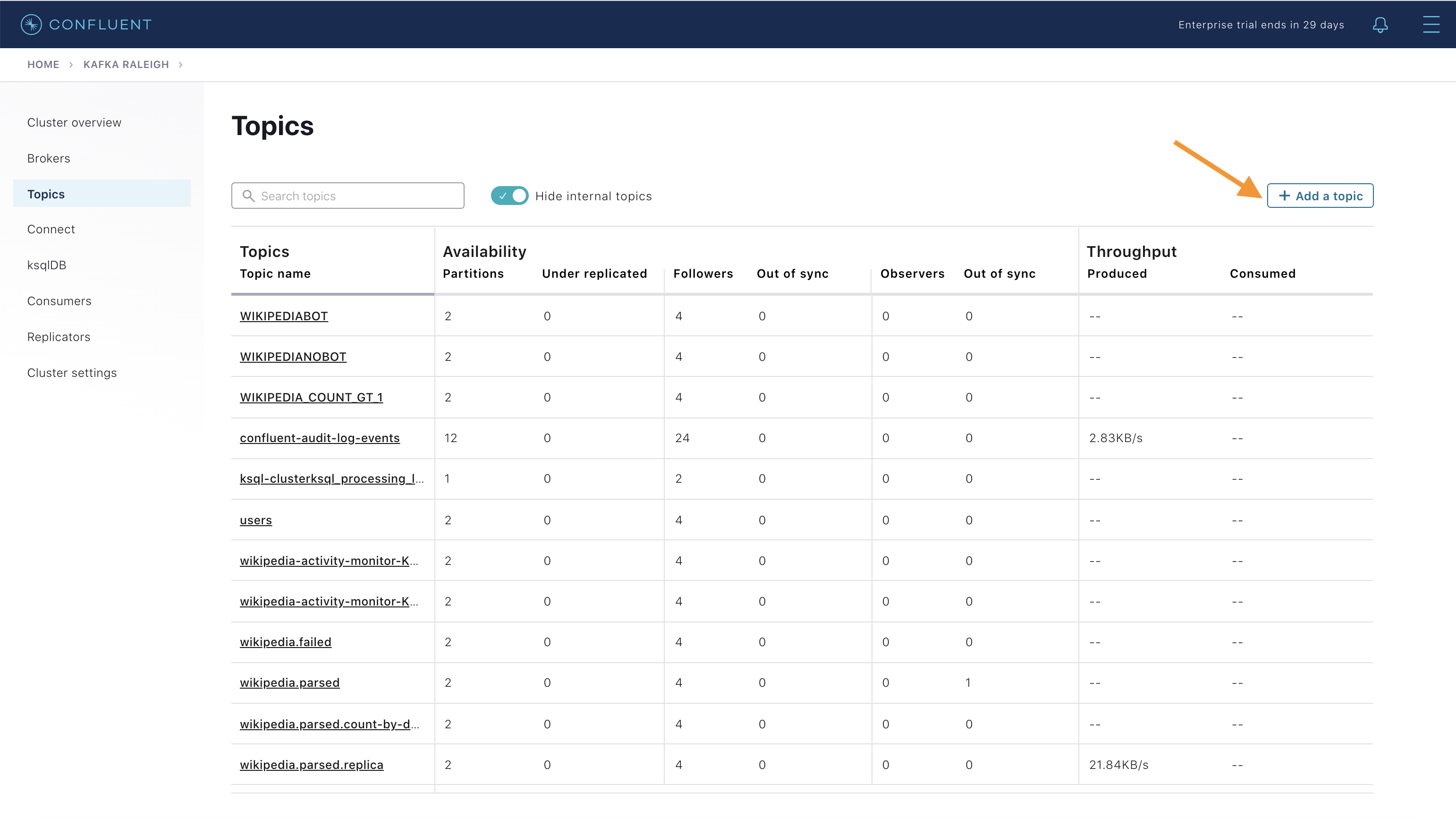
Kafka Connect¶
このサンプルでは、3 つのコネクターを実行します。
- SSE Source Connector
- Elasticsearch Sink Connector
- Confluent Replicator
これらは、Confluent Platform セキュリティ機能で構成された Connect ワーカーで実行されています。Connect ワーカーの組み込みプロデューサーは、べき等性を持つように、パーティションごとに "順序に従って厳密に 1 回" のセマンティクスで構成されます(エラーにより、プロデューサーが再試行する場合、同じメッセージ(プロデューサーが複数回送信します)は、ブローカーに関して 1 回だけ Kafka ログに書き込まれます)。
Kafka Connect Docker コンテナーでカスタムイメージが実行されます。このベースイメージは
cp-enterprise-replicatorであり、Connect と Replicator がバンドルされています。その上に、cp-demoで必要な、特定のセットのコネクターと変換があります。詳細については、この Dockerfile を参照してください。Confluent Control Center は、Kafka Connect API を使用して、複数の connect クラスター を管理します。Connect をクリックします。
Connect ワーカーのクラスターの名前
connect1を選択します。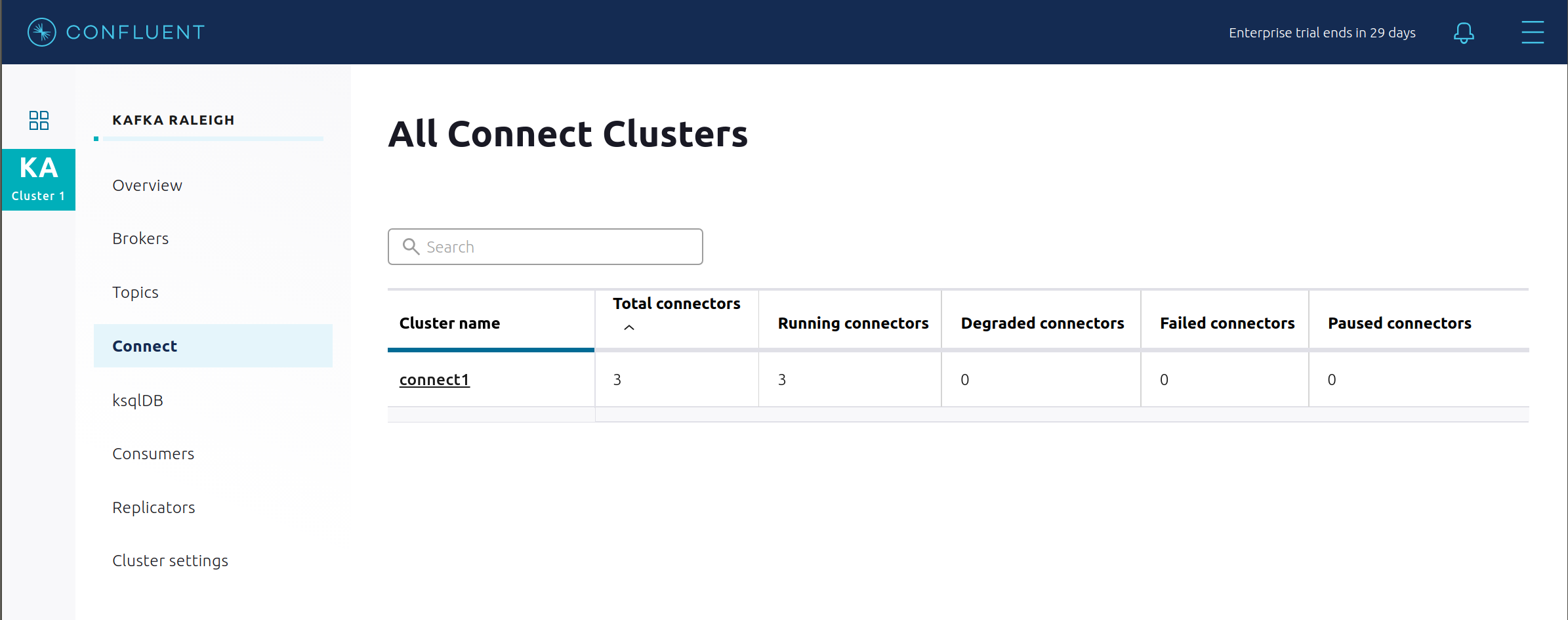
このサンプルで実行しているコネクターを確認します。
- ソースコネクター
wikipedia-sse: このサンプルの SSE ソースコネクターの 構成ファイル を表示します。 - ソースコネクター
replicate-topic: このサンプルの Replicator コネクターの 構成ファイル を表示します。 - Kafka のトピック
WIKIPEDIABOTから消費しているシンクコネクターelasticsearch-ksqldb: このサンプルの Elasticsearch Sink Connector の 構成ファイル を表示します。
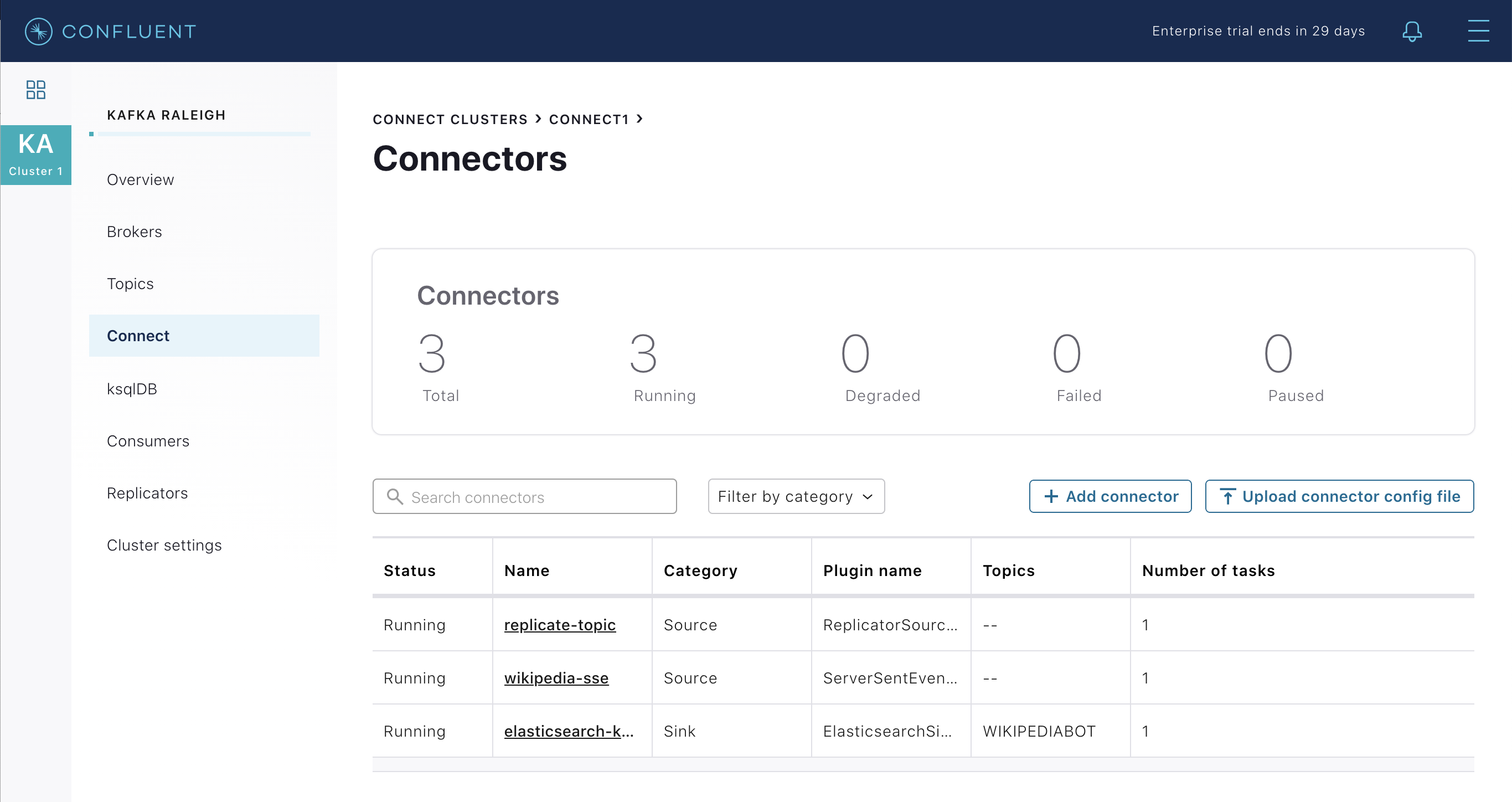
- ソースコネクター
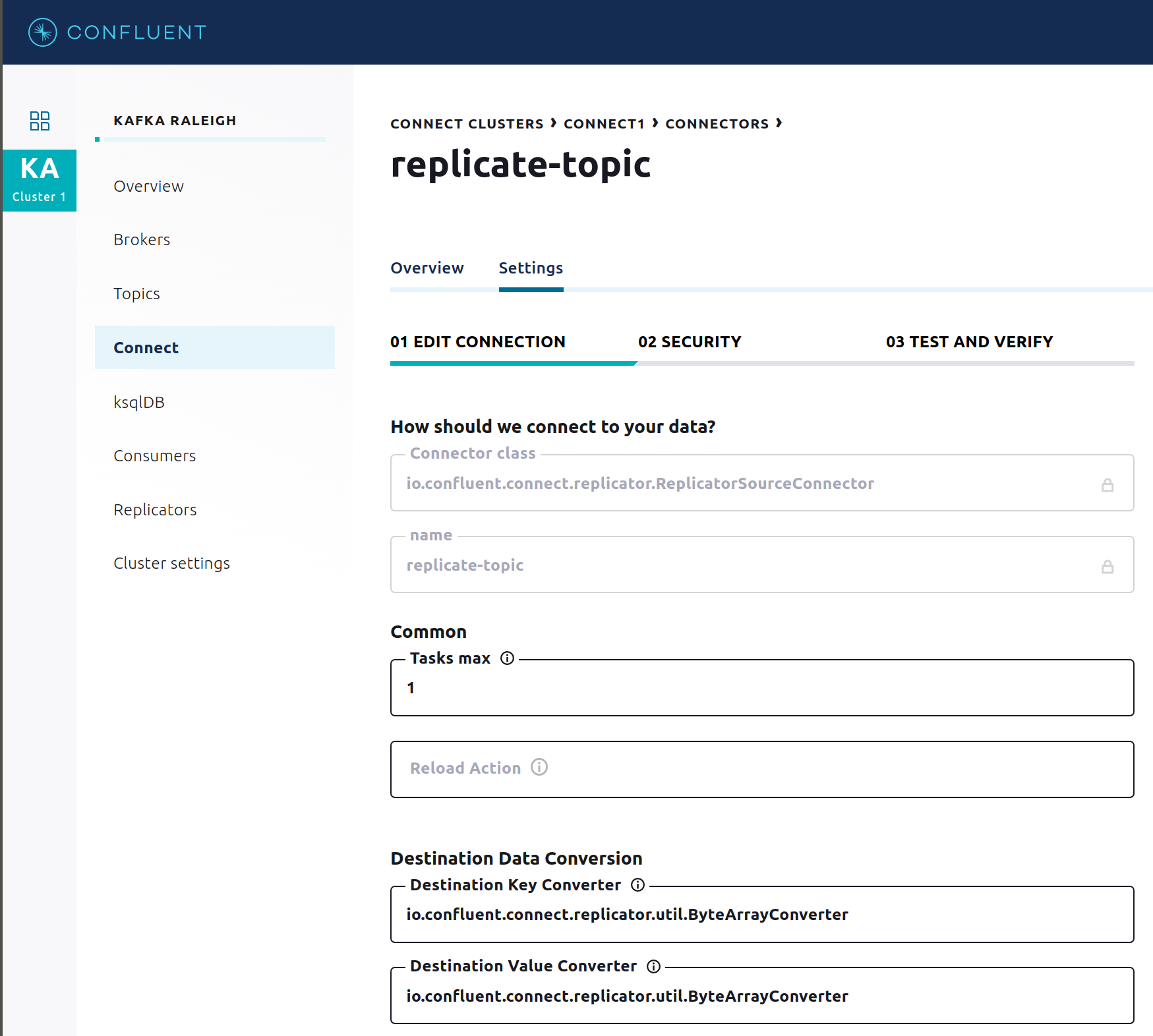
コネクターの構成とカスタム変換の詳細を表示または変更するには、コネクター名をクリックします。
ksqlDB¶
このサンプルでは、ksqlDB が認証され、セキュアな Kafka クラスターへの接続を認可されており、ksqlDB コマンドファイル で定義されているように既にクエリを実行しています。組み込みプロデューサーは、べき等性を持つように、パーティションごとに "順序に従って厳密に 1 回" のセマンティクスで構成されます(エラーにより、プロデューサーが再試行する場合、同じメッセージ(プロデューサーが複数回送信します)は、ブローカーに関して 1 回だけ Kafka ログに書き込まれます)。
ナビゲーションバーで ksqlDB をクリックします。
ksqlDB アプリケーションのリストで
wikipediaを選択します。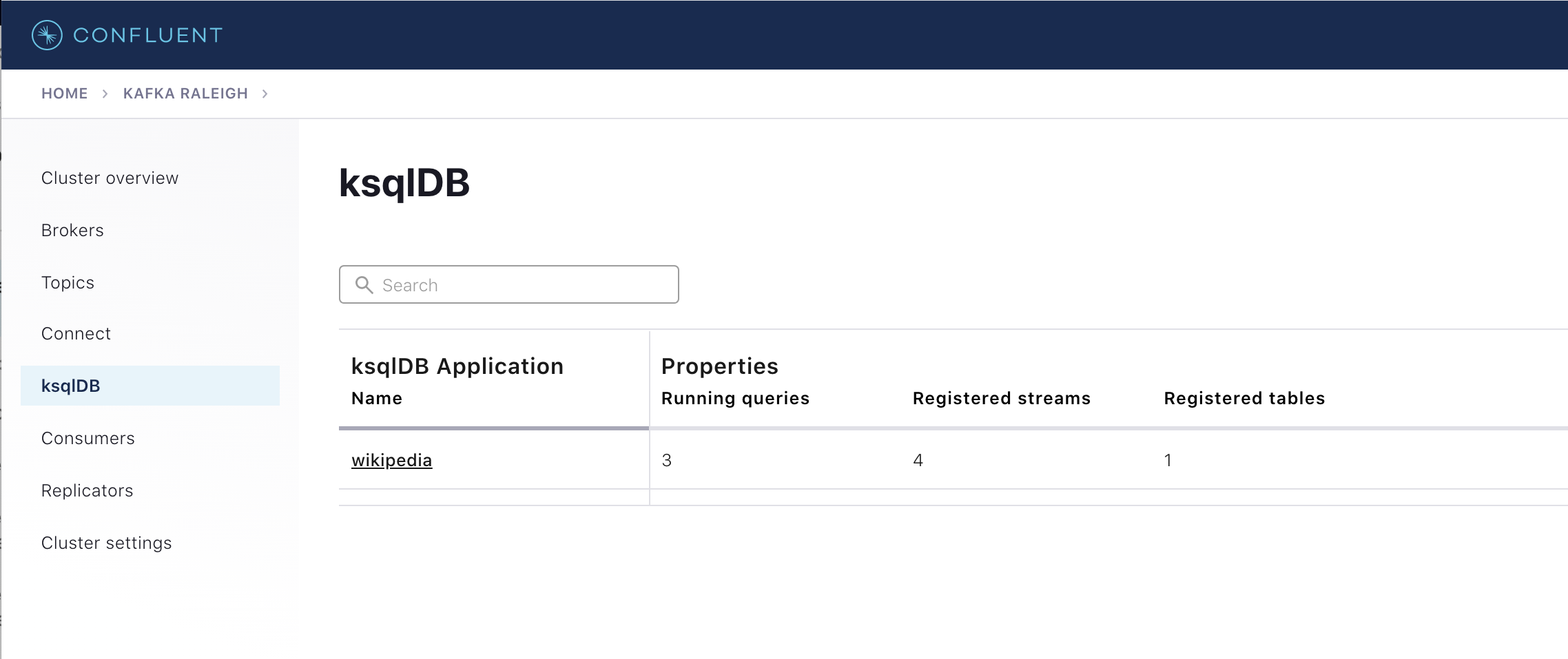
ksqlDB フローを表示して、このサンプルで作成されたストリームとテーブル、およびそれらの相関を調べます。
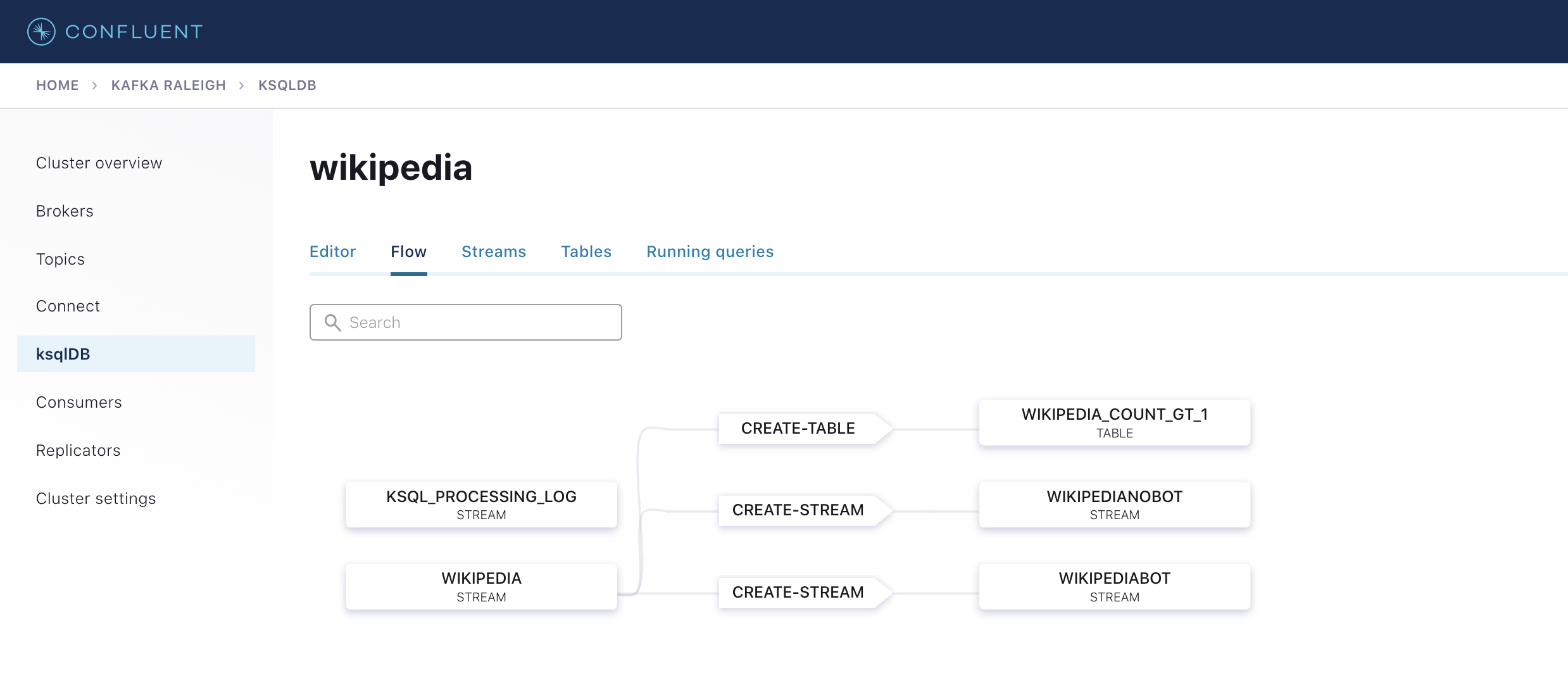
Confluent Control Center を使用して ksqlDB と連携するか、ksqlDB CLI を実行して ksqlDB CLI プロンプトを表示します。
docker-compose exec ksqldb-cli bash -c 'ksql -u ksqlDBUser -p ksqlDBUser http://ksqldb-server:8088'
既存の ksqlDB ストリームを表示します(ksqlDB CLI を使用している場合は、
ksql>プロンプトでSHOW STREAMS;と入力します)。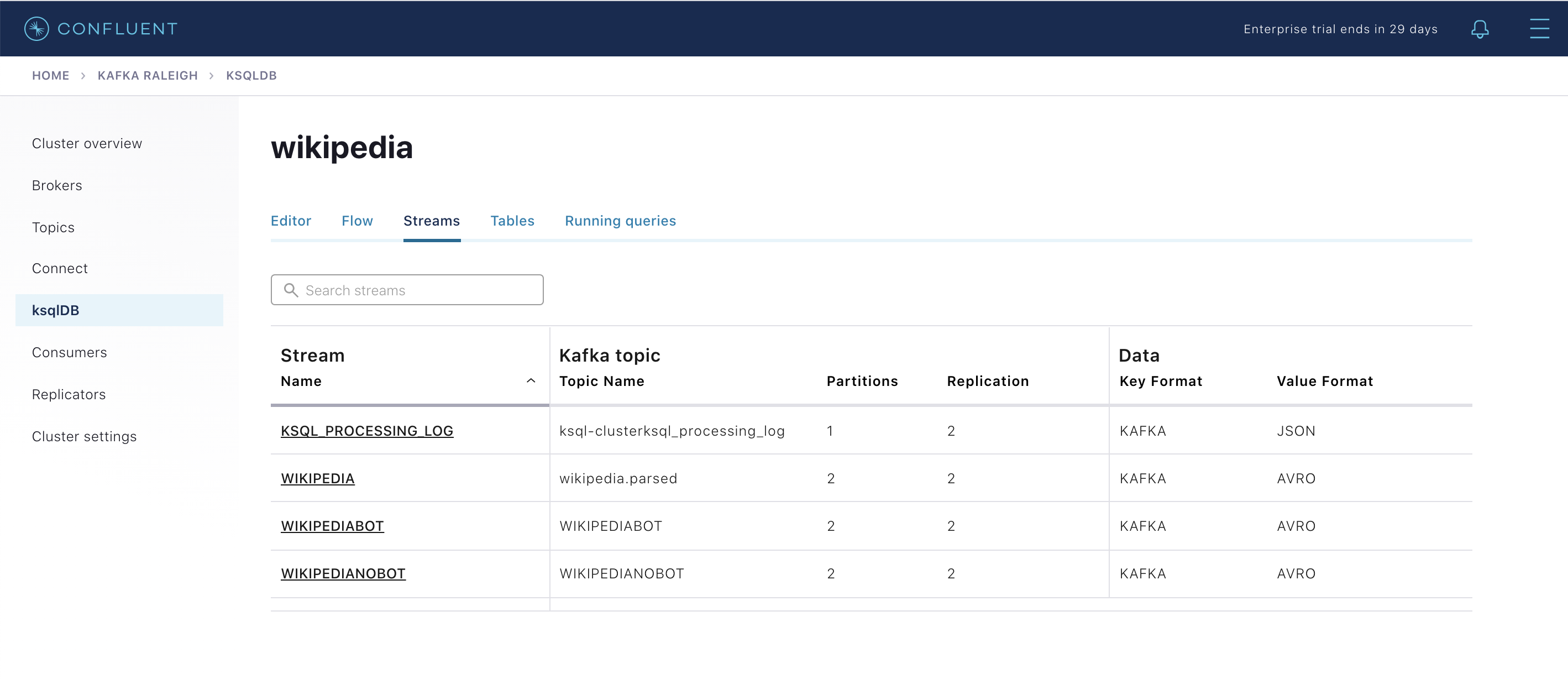
WIKIPEDIAをクリックして、既存の ksqlDB ストリームのスキーマの説明(フィールドまたは列)を入力します(ksqlDB CLI を使用している場合は、ksql>プロンプトでDESCRIBE WIKIPEDIA;と入力します)。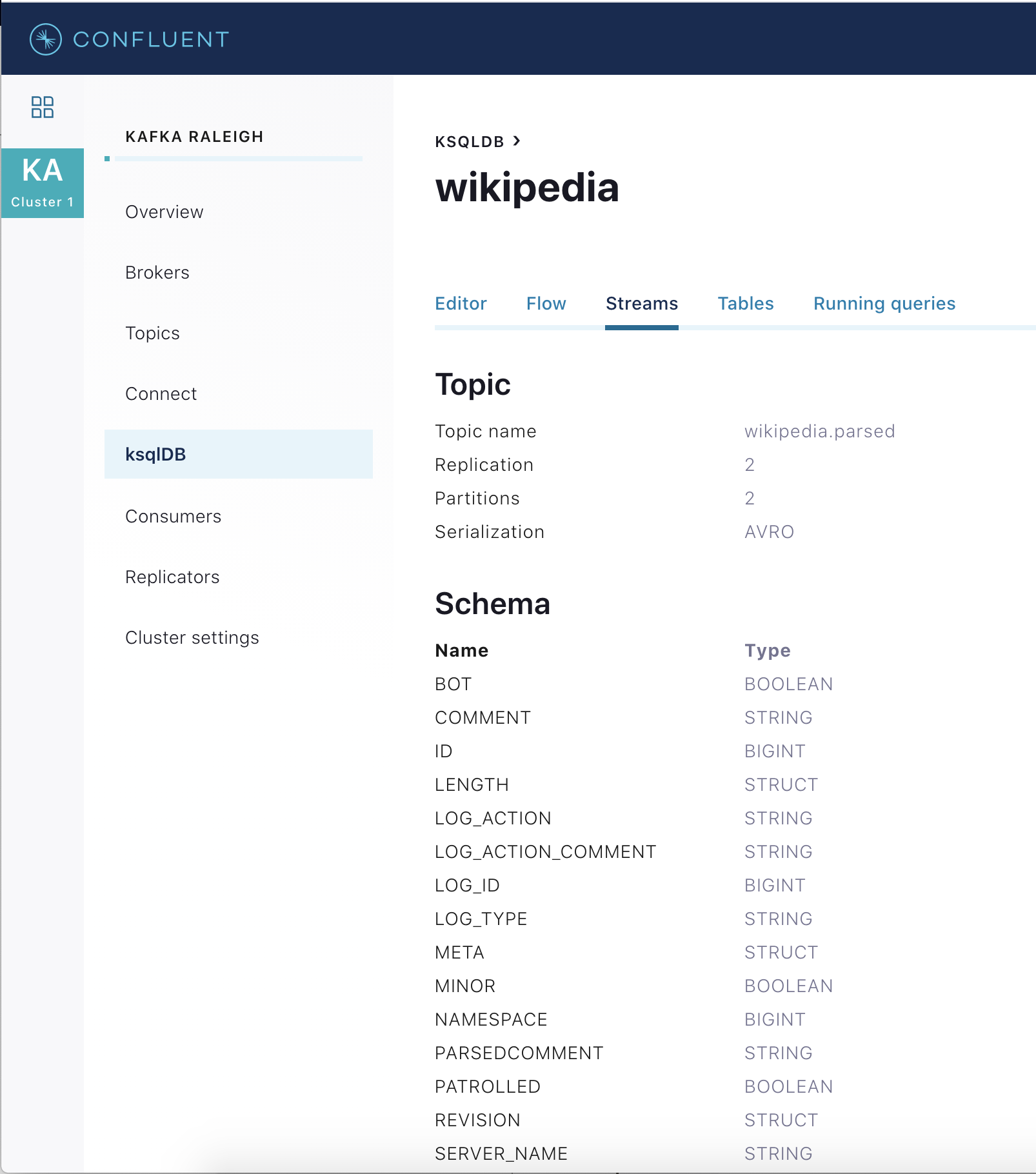
既存の ksqlDB テーブルを表示します(ksqlDB CLI を使用している場合は、
ksql>プロンプトでSHOW TABLES;と入力します)。テーブルの 1 つはWIKIPEDIA_COUNT_GT_1という名前で、タンブリングウィンドウ での出現回数をカウントします。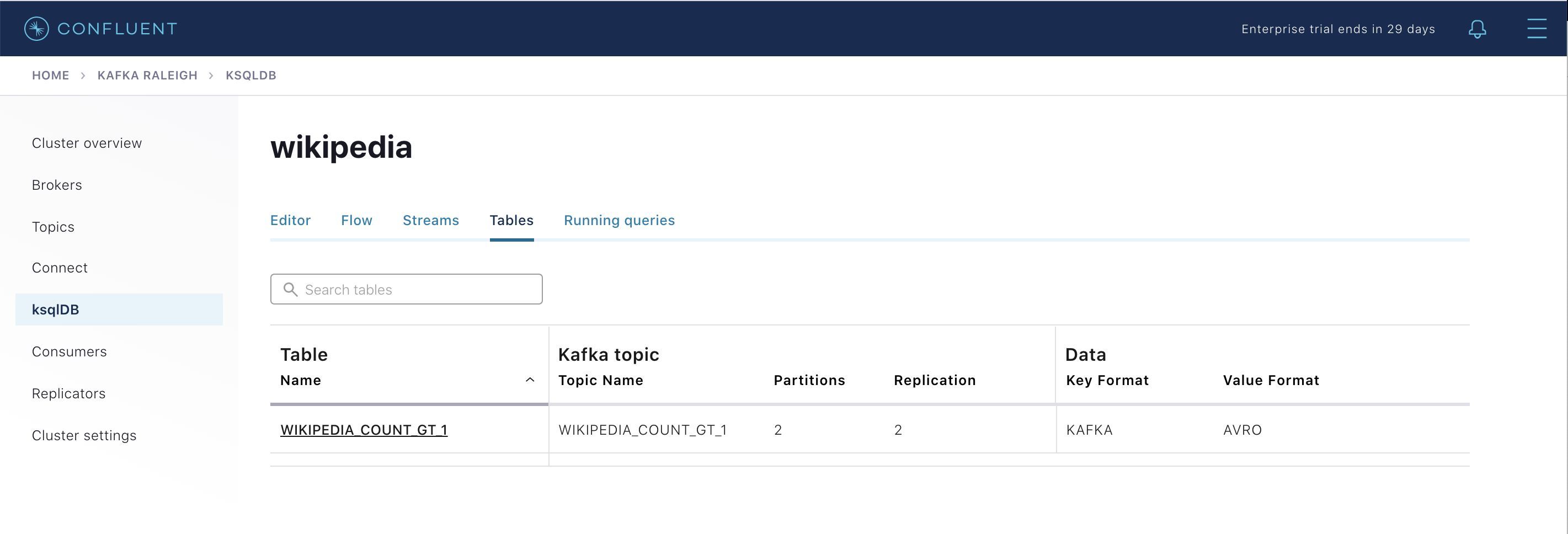
既存の ksqlDB クエリを表示します。これは、継続的に実行されています(ksqlDB CLI を使用している場合は、
ksql>プロンプトでSHOW QUERIES;と入力します)。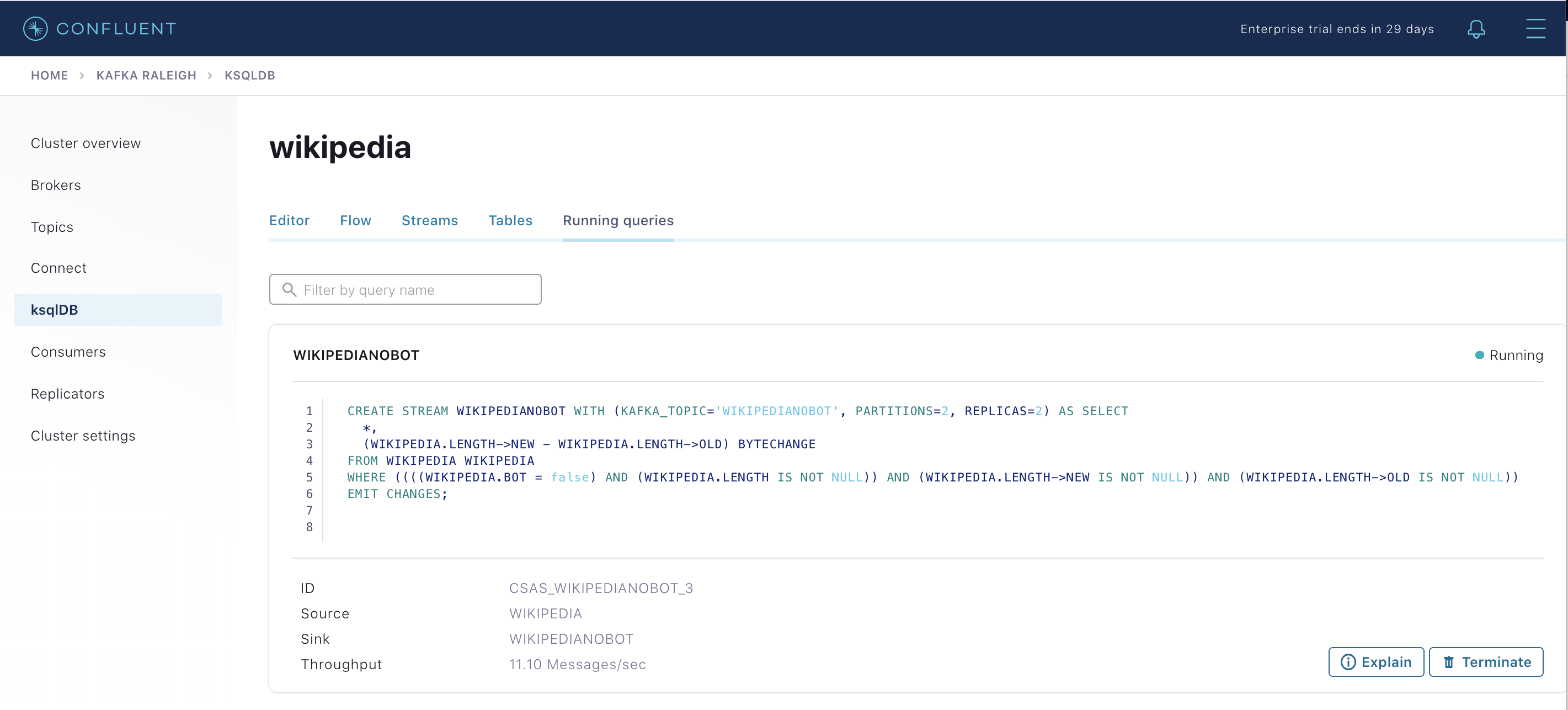
さまざまな ksqlDB ストリームおよびテーブルからのメッセージを表示します。目的のストリームをクリックし、Query stream をクリックしてクエリエディターを開きます。エディターには、
select * from WIKIPEDIA EMIT CHANGES;のような、内容が事前に入力されたクエリが表示され、新着データの結果が表示されます。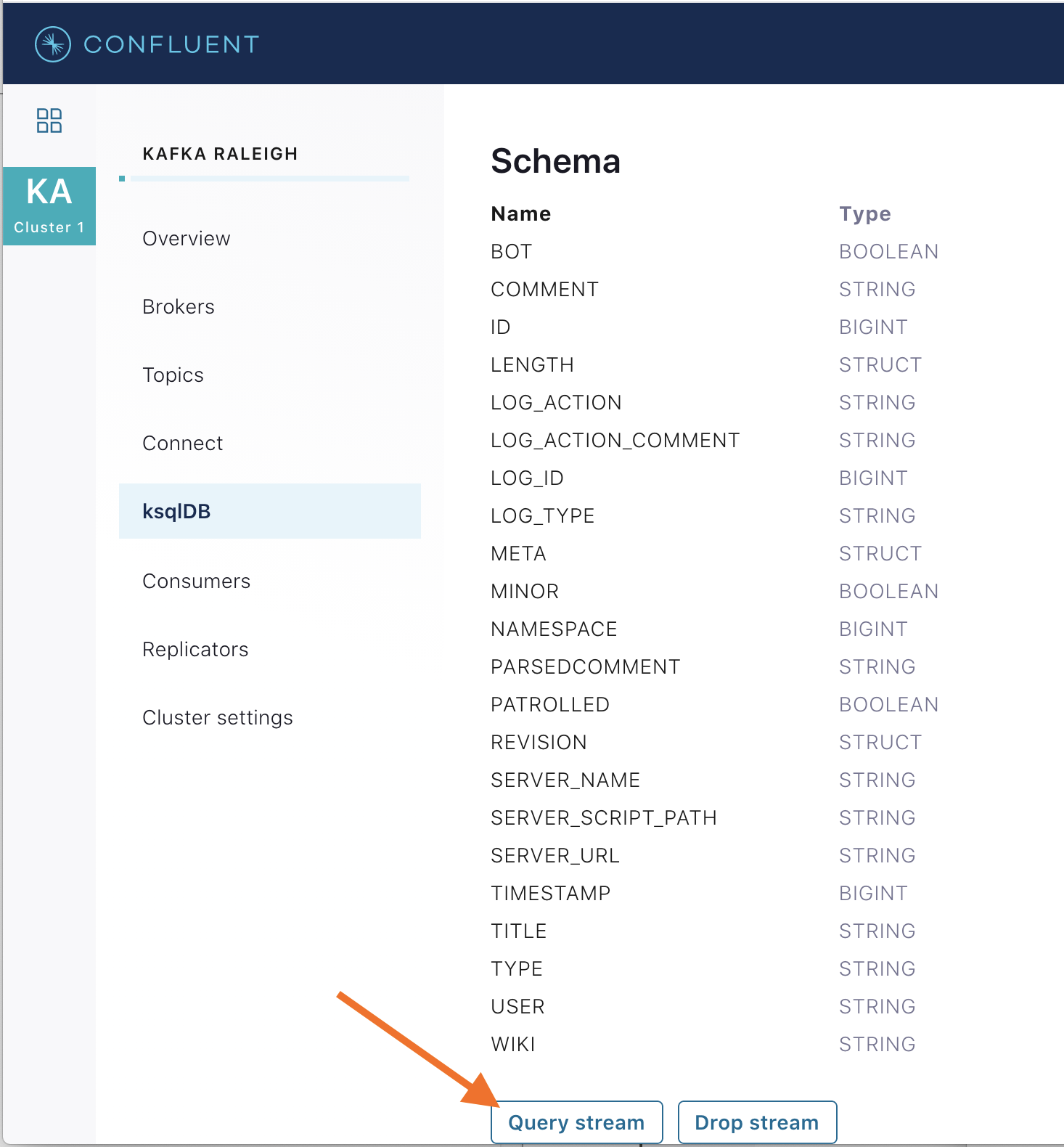
ksqlDB Editor をクリックし、
SHOW PROPERTIES;ステートメントを実行します。構成された ksqlDB サーバープロパティが表示されます。これらの値は docker-compose.yml ファイルで確認できます。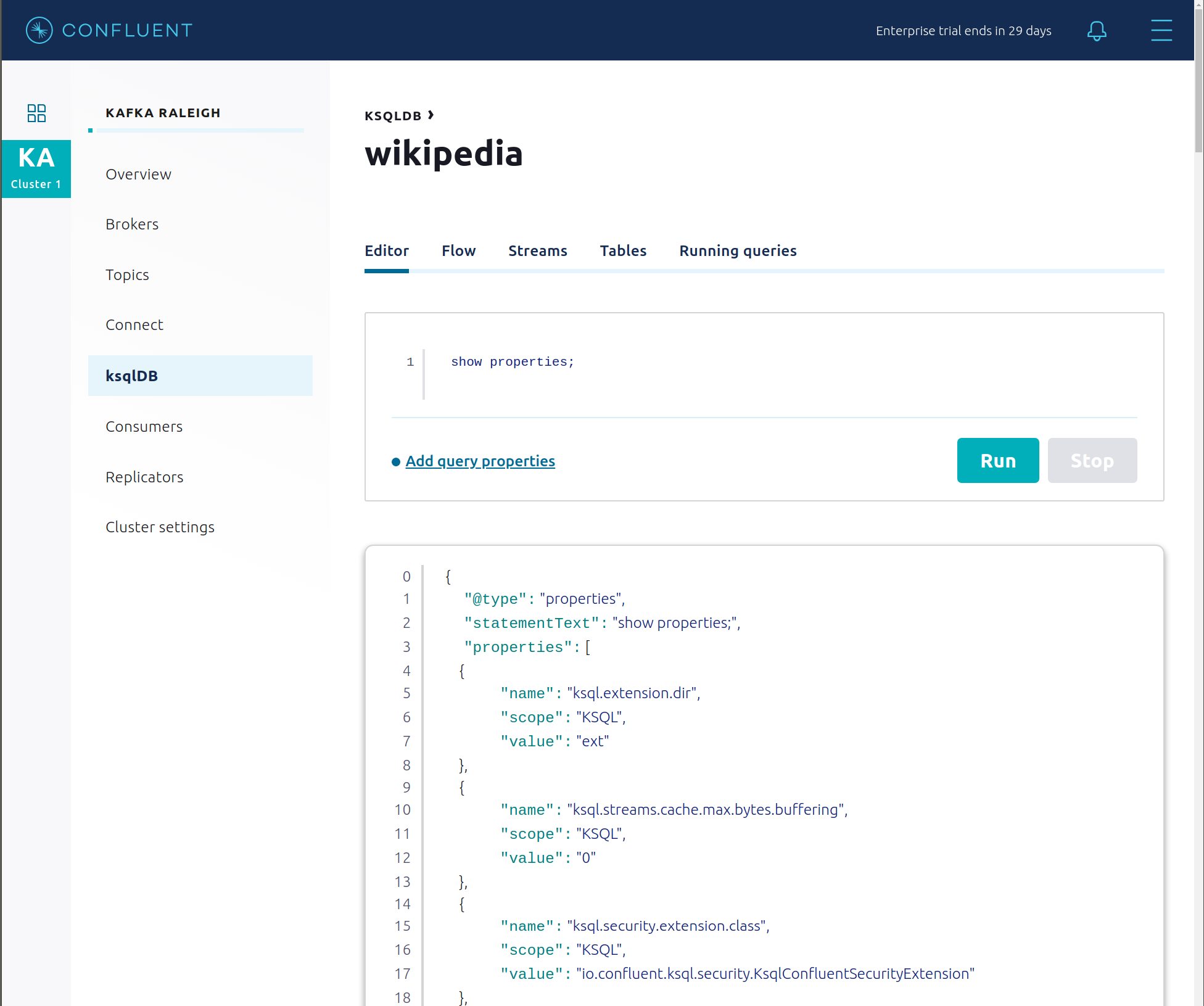
ksqlDB 処理ログ は、処理中にレコード単位でエラーを取り込みます。これは、開発者による ksqlDB クエリのデバッグに役立ちます。このサンプルでは、カスタム log4j プロパティファイル での構成に従って、処理ログが相互 TLS(mTLS)認証を使用して Kafka のトピックにエントリを書き込みます。実際の動作を確認するために、次の不完全なクエリを ksqlDB エディターで 20 秒間、実行します。
SELECT 1/0 FROM wikipedia EMIT CHANGES;
このクエリからはレコードが返されないはずです。ksqlDB は、レコードごとに処理ログにエラーを書き込みます。処理ログのトピック
ksql-clusterksql_processing_logをトピック検査とともに表示(オフセット 0/パーティション 0 にジャンプ)するか、対応する ksqlDB ストリームKSQL_PROCESSING_LOGを ksqlDB エディターで表示(auto.offset.reset=earliestを設定)します。SELECT * FROM KSQL_PROCESSING_LOG EMIT CHANGES;
コンシューマー¶
Confluent Control Center では、コンシューマーラグとスループットパフォーマンスをモニタリングできます。コンシューマーラグは、トピックの最高水準点(書き込まれているトピックの最新オフセット)から、現在のコンシューマーオフセット(そのトピックについてコンシューマーグループが読み取った最新オフセット)を減算したものです。コンシューマーラグのサイズの重要性を検討する際は、トピックの書き込み速度とコンシューマーグループの読み取り速度に留意してください。Consumers をクリックします。
コンシューマーラグは、コンシューマーベース で使用できます。たとえば、シンクコネクター用組み込み Connect コンシューマー(
connect-elasticsearch-ksqldbなど)、ksqlDB クエリ(_confluent-ksql-ksql-clusterquery_で始まる名前のコンシューマーグループなど)、コンソールコンシューマー(WIKIPEDIANOBOT-consumerなど)などです。また、トピックベース でも使用できます。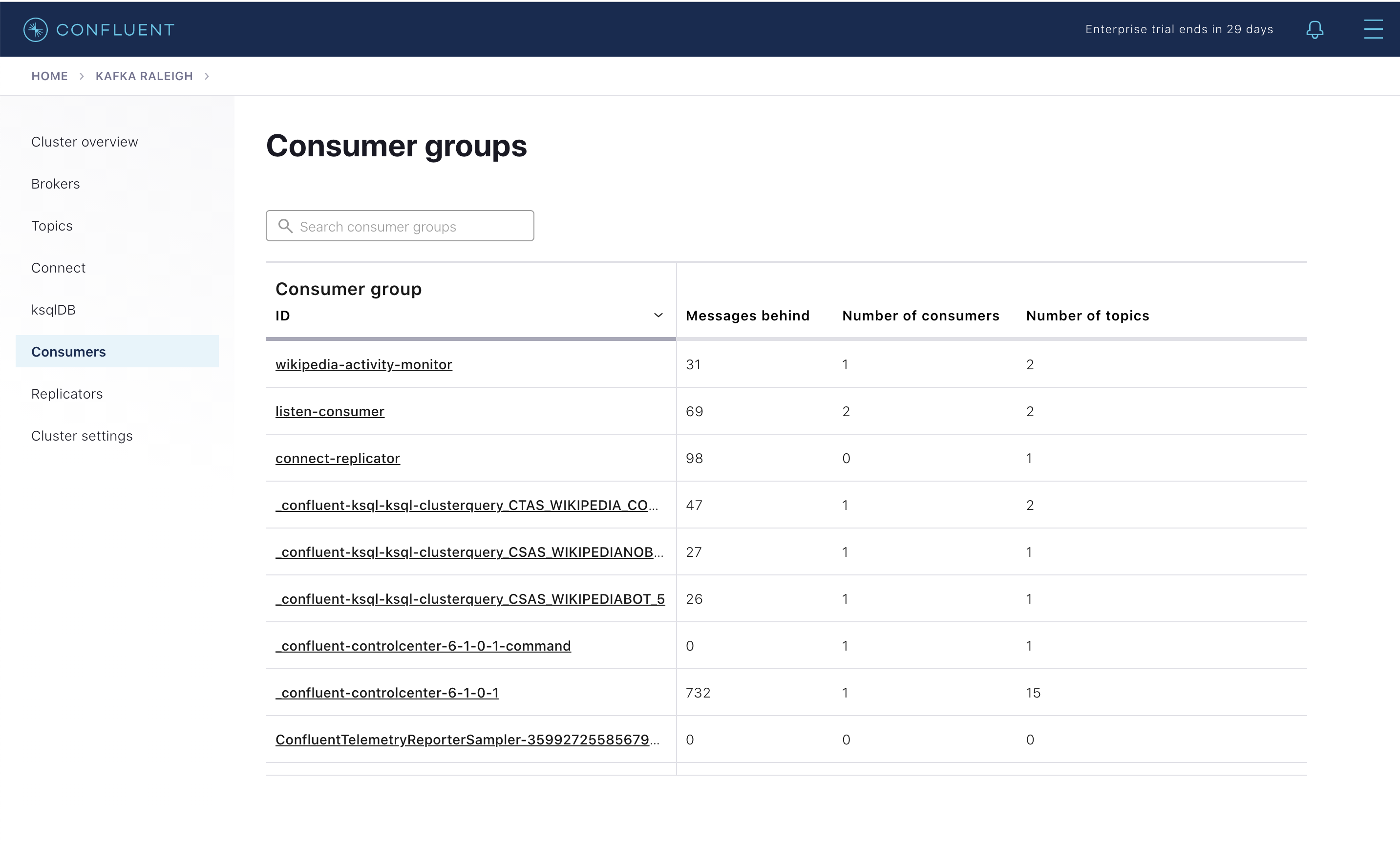
永続的な ksqlDB "Create Stream As Select" クエリ
CSAS_WIKIPEDIABOT用のコンシューマーラグを表示します。これは、コンシューマーグループのリストに_confluent-ksql-ksql-clusterquery_CSAS_WIKIPEDIABOT_5として表示されます。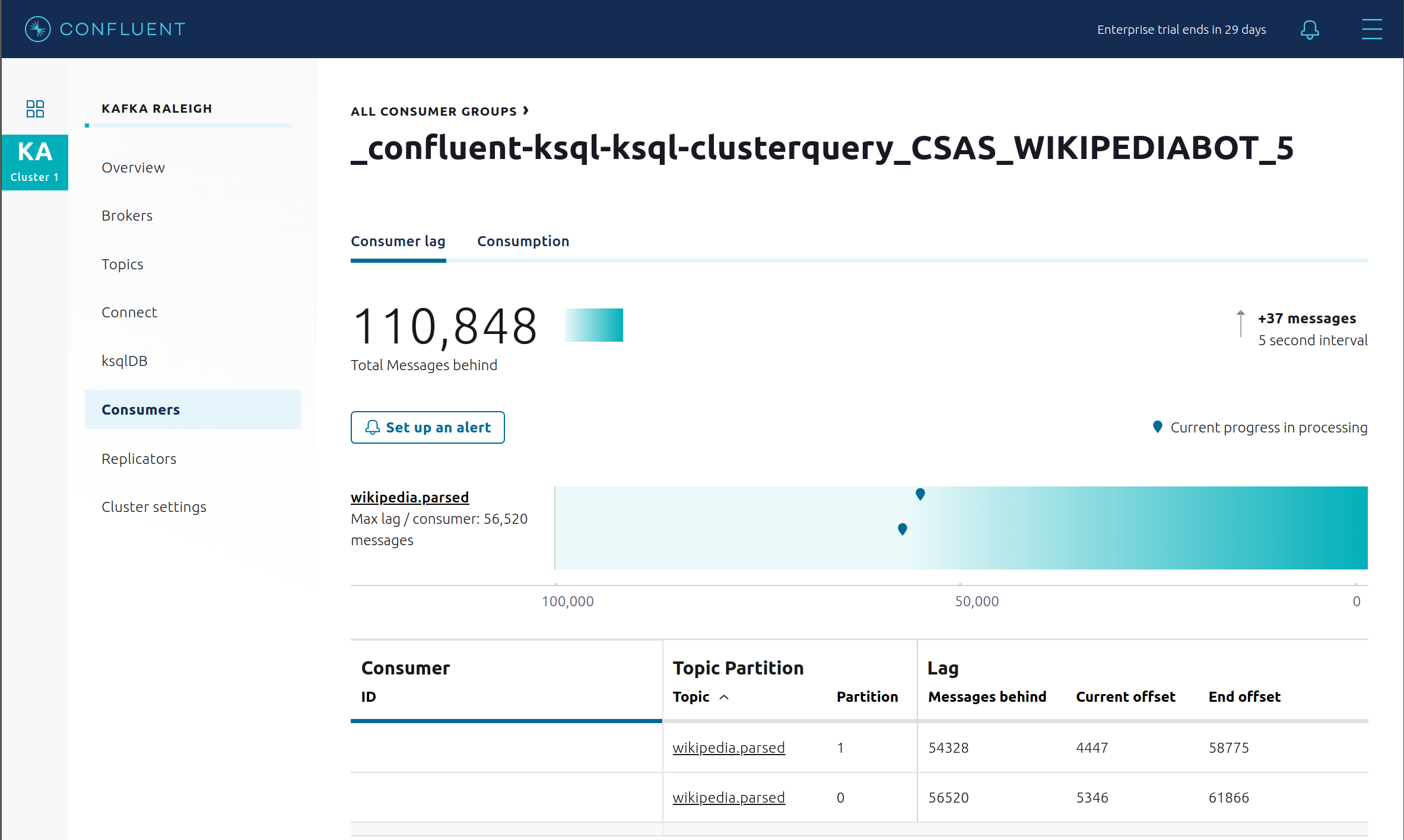
コンシューマーグループ ID
wikipedia-activity-monitorの下の、Kafka Streams アプリケーションのコンシューマーラグを表示します。このアプリケーションは、cnfldemos/cp-demo-kstreams Docker コンテナー(アプリケーションの ソースコード)によって実行されます。Kafka Streams アプリケーションは、次の クライアント構成 ファイルを使用して Kafka クラスターに接続するように構成されています。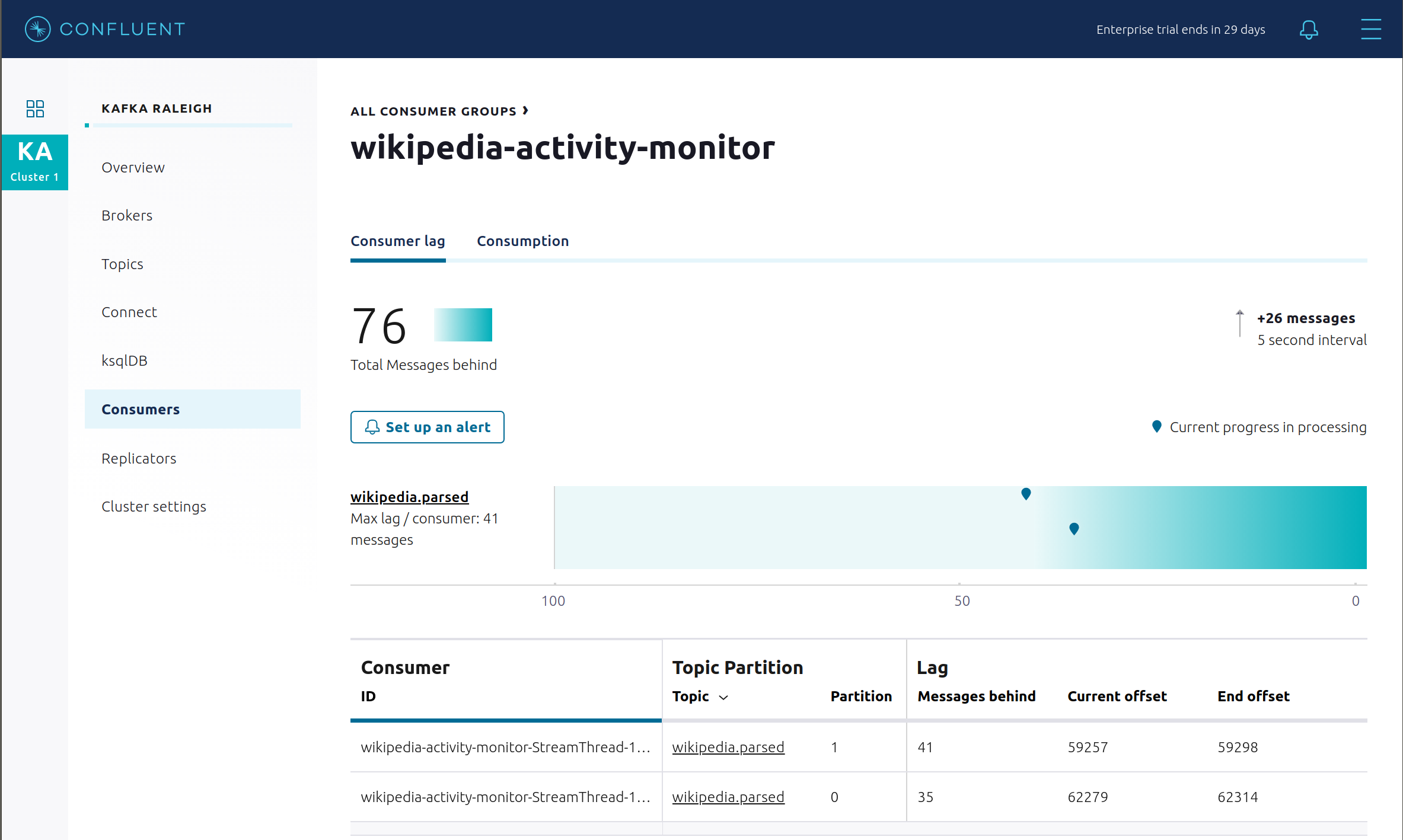
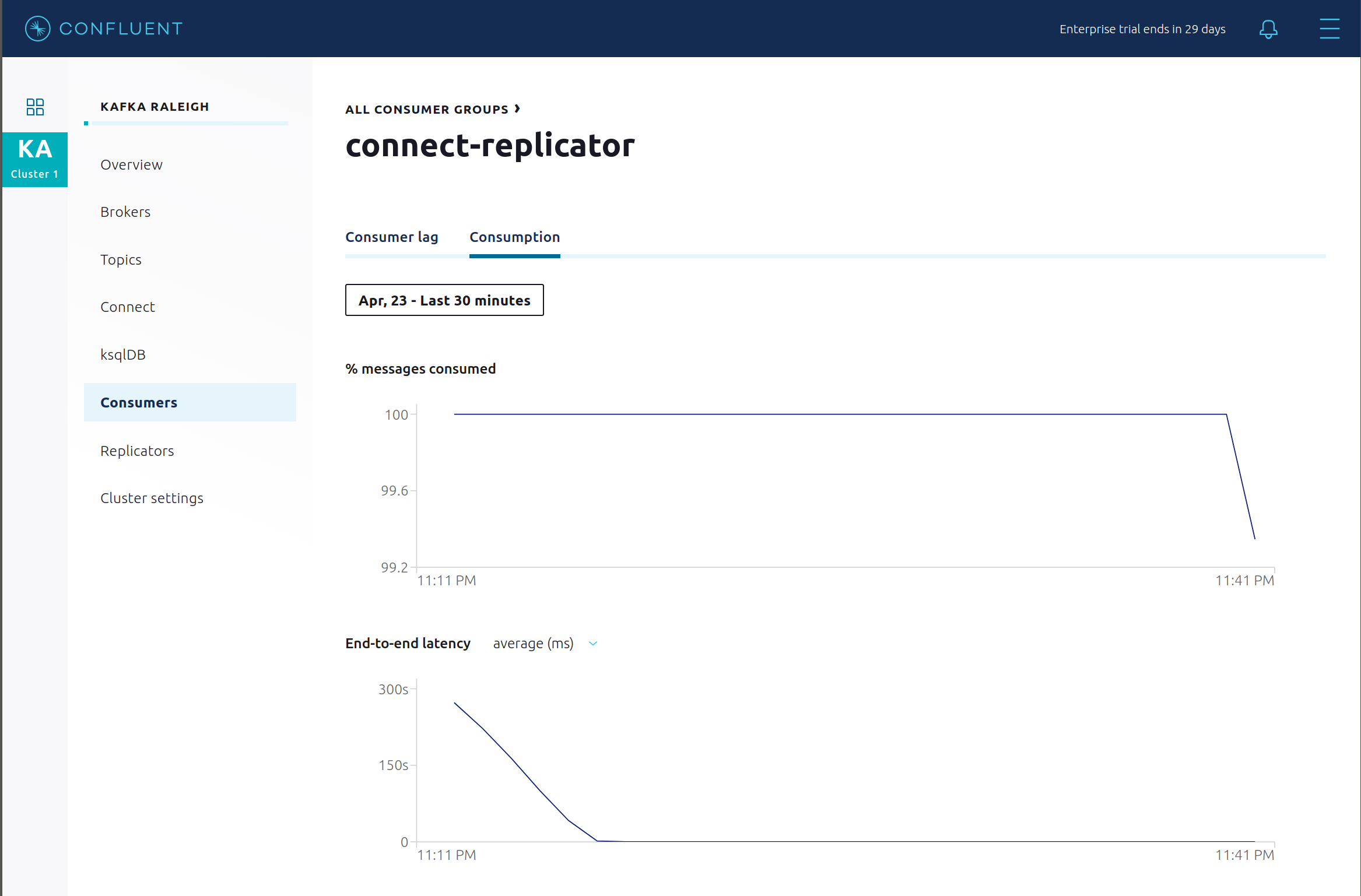
消費メトリックは、コンシューマーベース で使用できます。これらの消費チャートは、このサンプルのように Confluent モニタリングインターセプター が構成されている場合にのみ入力されます。
% messages consumedとend-to-end latencyを確認できます。永続的な ksqlDB "Create Stream As Select" クエリCSAS_WIKIPEDIABOT用の消費メトリクスを表示します。これは、コンシューマーグループのリストに_confluent-ksql-ksql-clusterquery_CSAS_WIKIPEDIABOT_5として表示されます。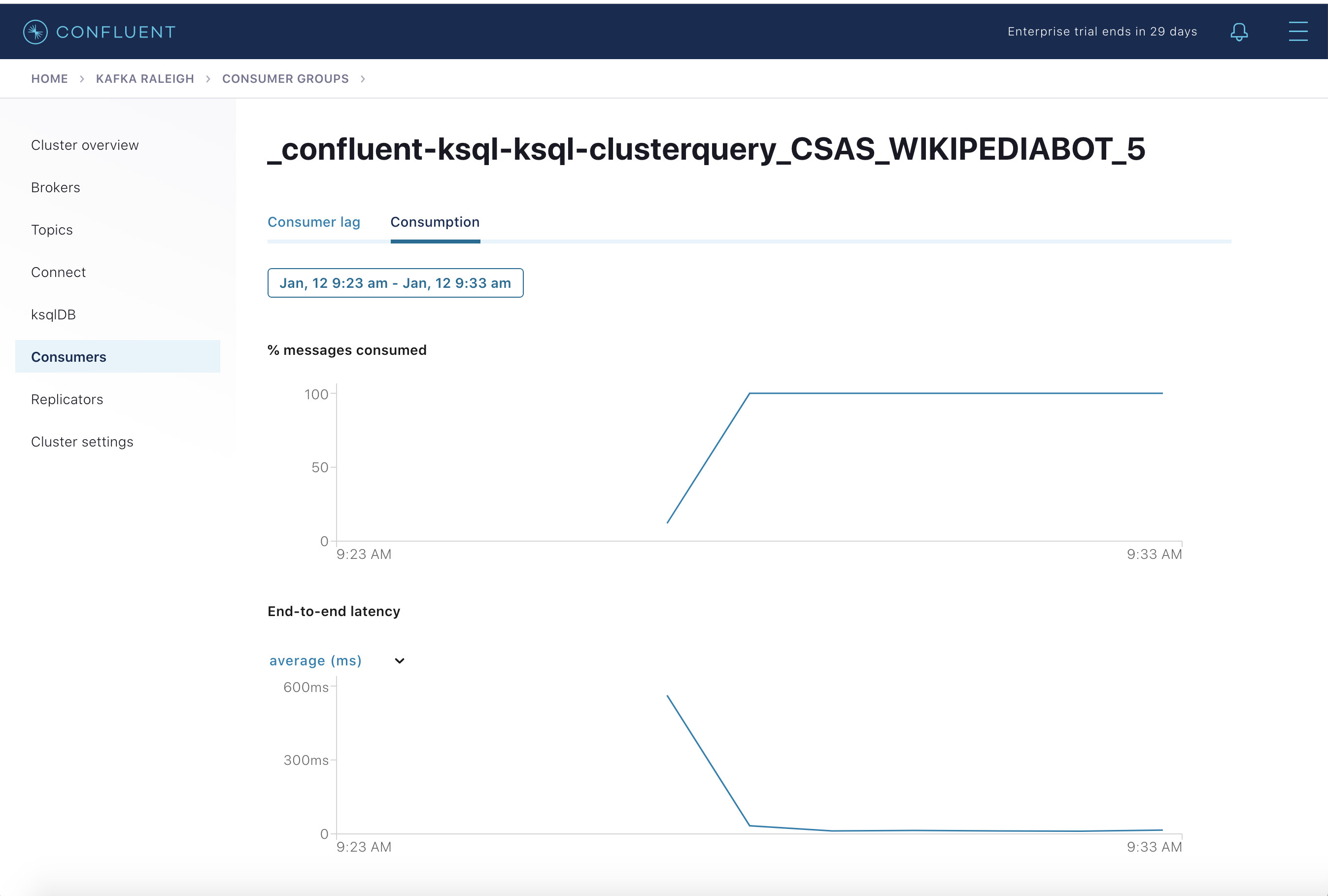
Confluent Control Center には、コンシューマーグループのどのコンシューマーがどのパーディションから消費しているか、およびそれらのパーティションが格納されているブローカーが表示されます。Confluent Control Center は、コンシューマーグループでコンシューマーのバランス調整が発生するとアップデートされます。新規コンシューマーグループ
appと 1 つのコンシューマーconsumer_app_1で、トピックwikipedia.parsedからの消費を開始します。これはバックグラウンドで実行されます。./scripts/app/start_consumer_app.sh 1Confluent Control Center に、コンシューマーグループ
appの消費が安定したことが表示されるまで、このコンシューマーグループを 2 分間、実行します。このコンシューマーグループappには 1 つのコンシューマーconsumer_app_1があり、トピックwikipedia.parsed内のすべてのパーティションを消費しています。
2 番目のコンシューマー
consumer_app_2を、既存のコンシューマーグループappに追加します。./scripts/app/start_consumer_app.sh 2Confluent Control Center に、コンシューマーグループ
appの消費が安定したことが表示されるまで、このコンシューマーグループを 2 分間、実行します。コンシューマーconsumer_app_1およびconsumer_app_2は現在、トピックwikipedia.parsed内のパーティションの消費を共有しています。
Brokers -> Consumption ビューで、リクエストレイテンシの線グラフをクリックして、リクエストライフサイクル 全体のレイテンシの内訳を表示します。
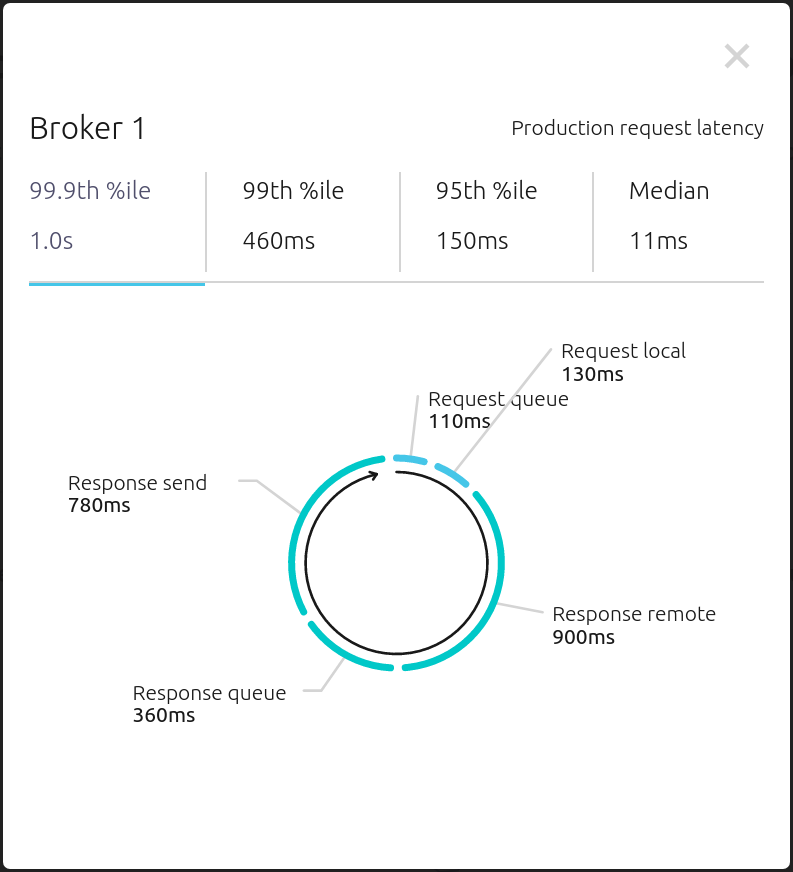
Confluent Replicator¶
Confluent Replicator は、コピー元 Kafka クラスターからコピー先 Kafka クラスターにデータをコピーします。コピー元とコピー先のクラスターは通常、異なるクラスターですが、このサンプルでは、Replicator がクラスター間レプリケーションを実行しています。つまり、コピー元とコピー先の Kafka クラスターは同じです。このソリューションの他のコンポーネントと同様に、Confluent Replicator にもセキュリティが構成されています。
Confluent Control Center の専用ビューで、Replicator のステータスとスループットを表示します。
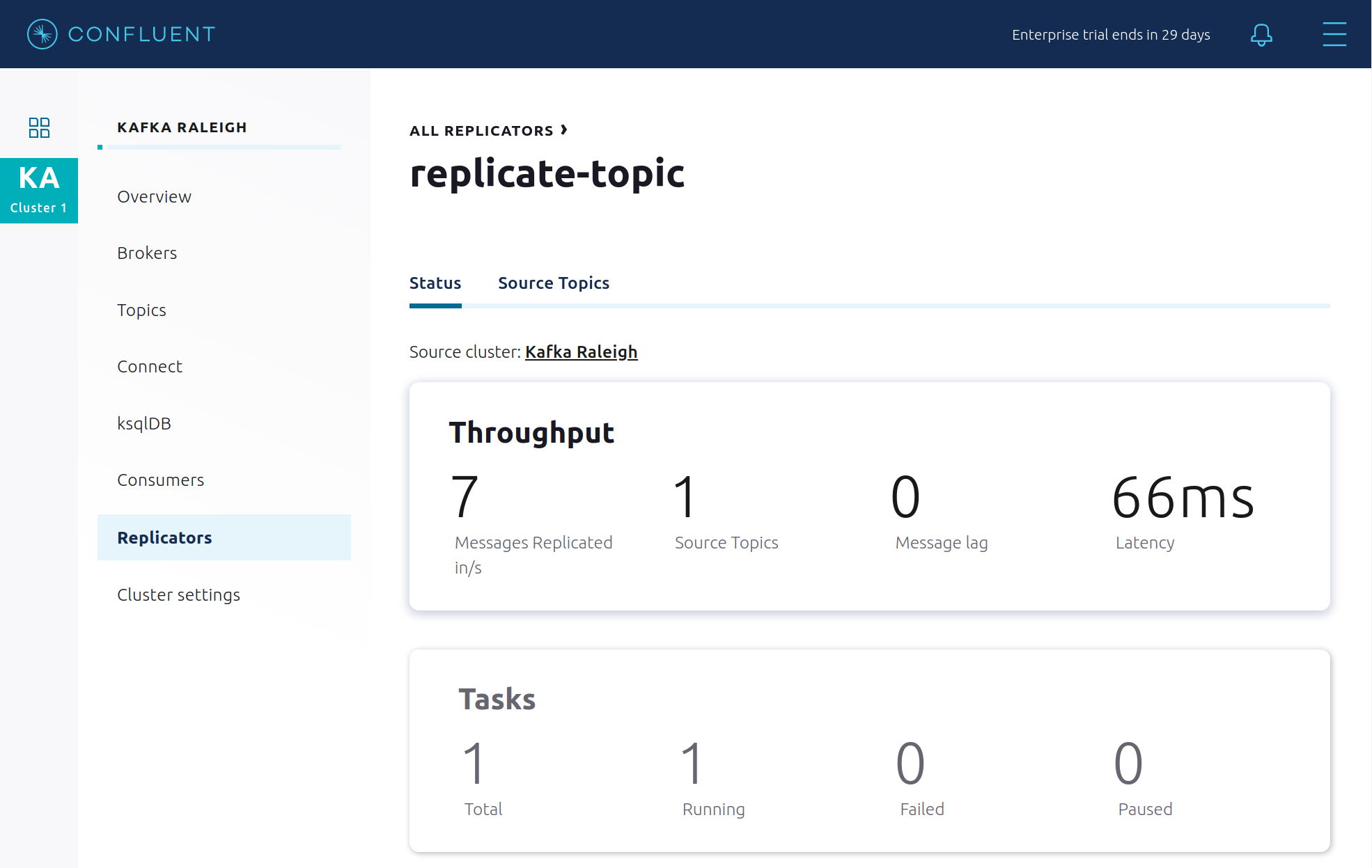
Consumers: Confluent Replicator のスループットとレイテンシをモニタリングします。Replicator は Kafka Connect ソースコネクターであり、対応するコンシューマーグループ
connect-replicatorがあります。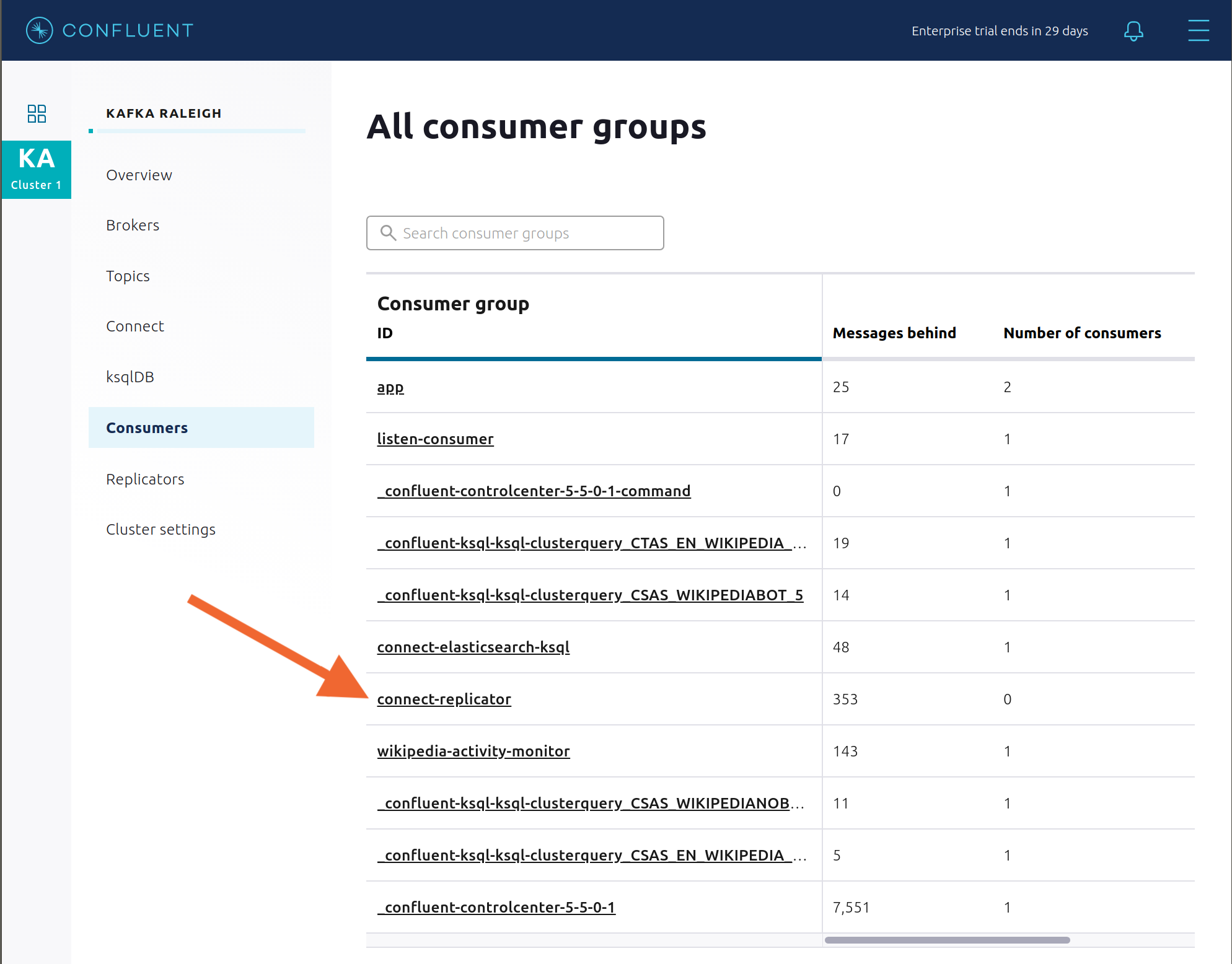
Replicator のコンシューマーラグを表示します。
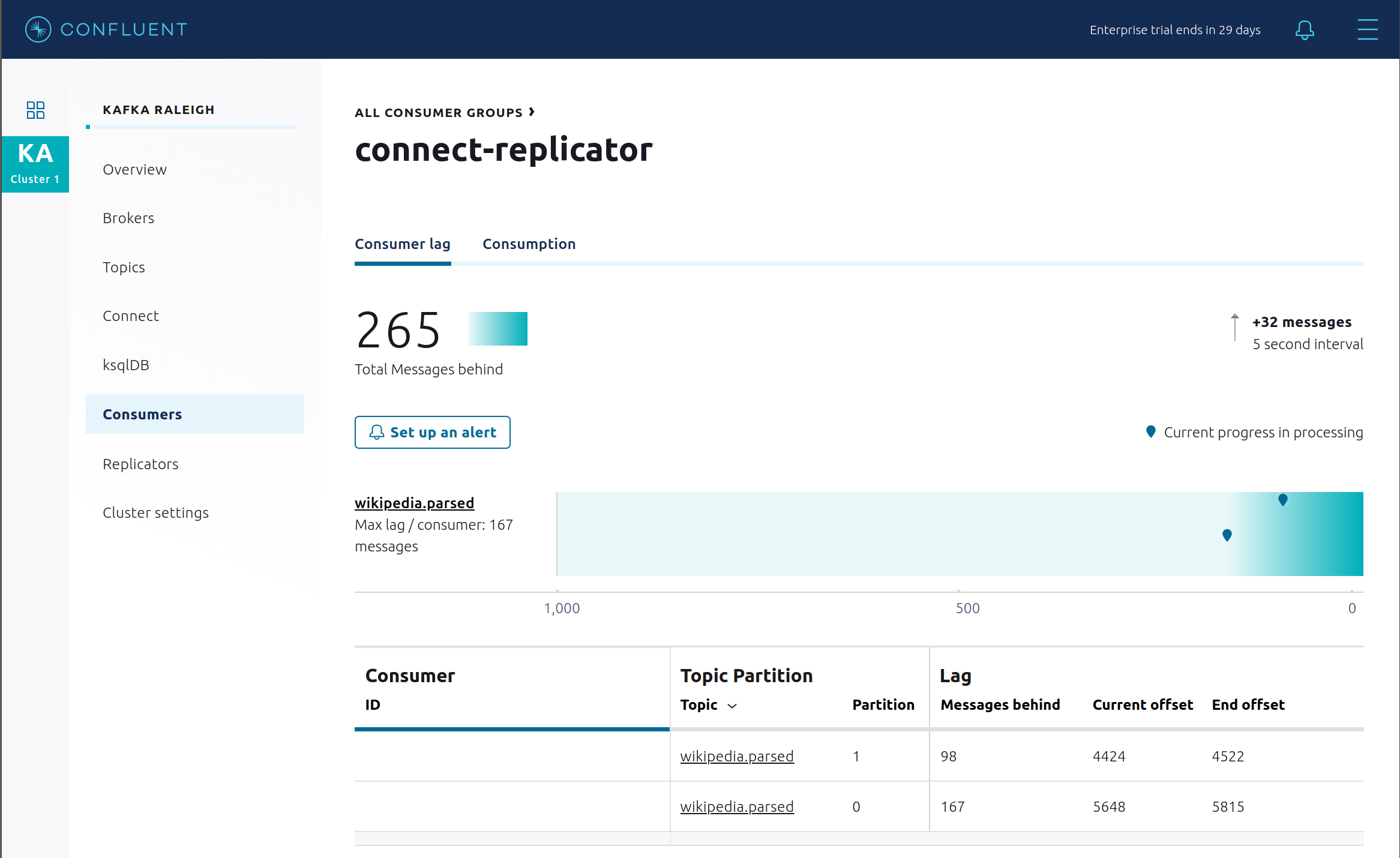
Replicator の消費メトリクスを表示します。
Connect: Settings で右上の一時停止アイコンを押し、有効になるまで 10 秒間待って Replicator コネクターを一時停止します。これで、関連するコンシューマーグループの消費が停止します。
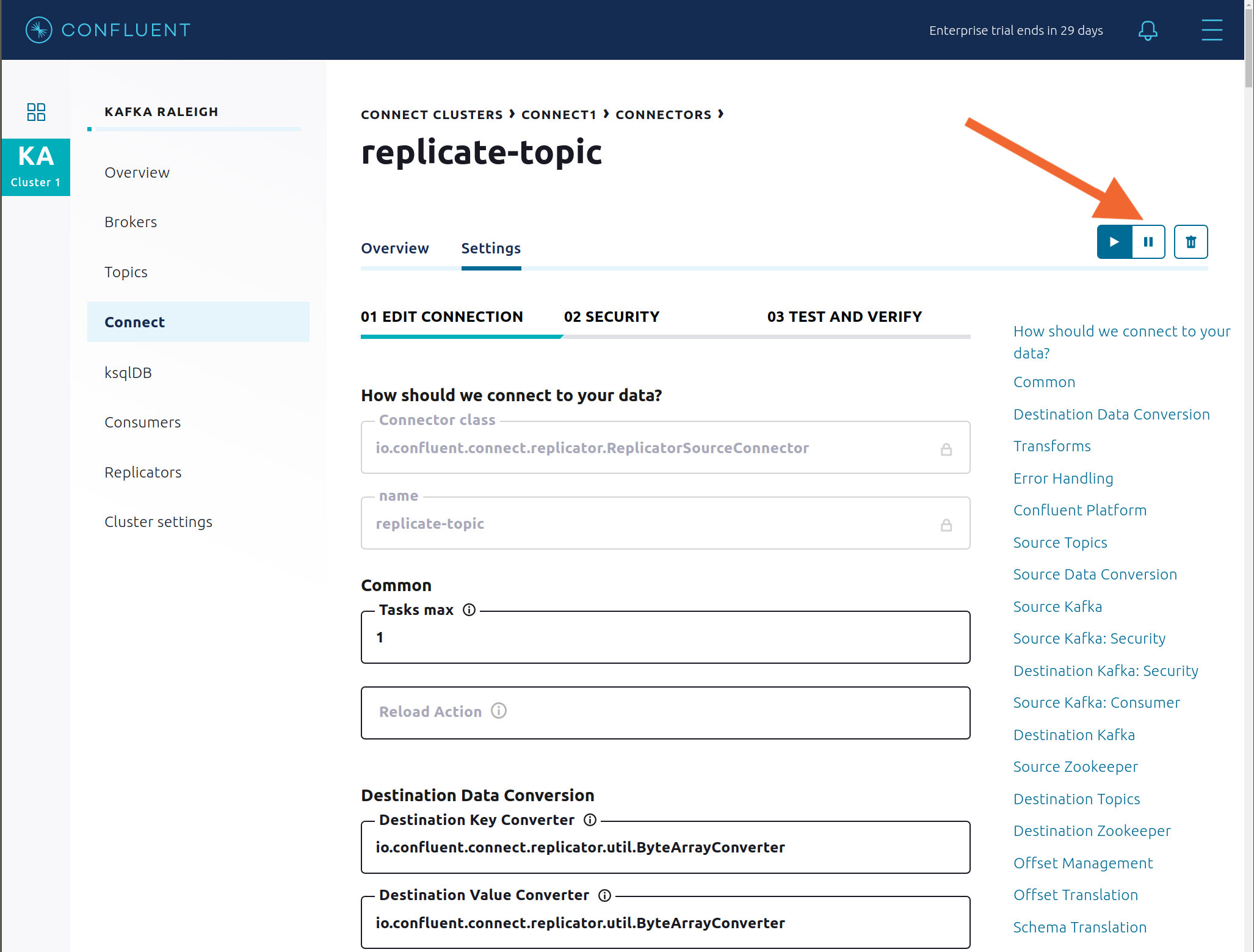
connect-replicatorコンシューマーグループの消費が停止するのを確認します。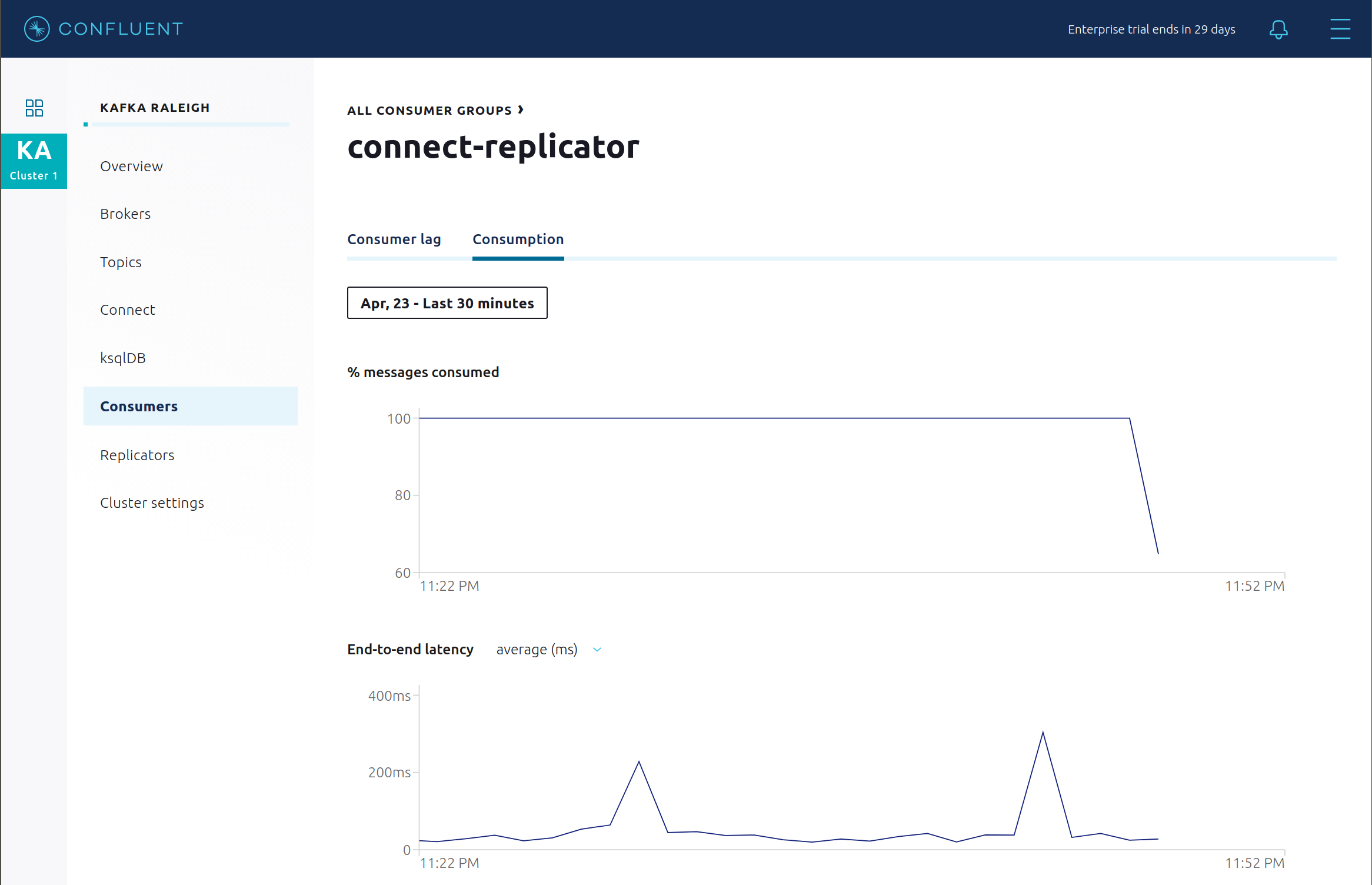
Replicator コネクターを再起動します。
connect-replicatorコンシューマーグループが消費を再開するのを確認します。次の点を確認できます。- コンシューマーグループ connect-replicator が動作していない時間があるにもかかわらず、すべてのメッセージが配信済みとして表示されます。これは、すべてのバーが、生成タイムスタンプに対して相対的な時間ウィンドウであるためです。
- レイテンシはピークに達した後、徐々に減少します。これも、生成タイムスタンプに対して相対的であるためです。
次の手順: Replicator のチュートリアル で、Replicator について詳しく学習します。
セキュリティ¶
概要¶
このサンプルのすべての Confluent Platform コンポーネントおよびクライアントでは、多くの セキュリティ機能 が有効になっています。
- メタデータサービス(MDS) は、認証と認可の中心的機能です。Confluent Server Authorizer によって構成されており、LDAP と連携してクライアントを認証します。
- SSL による暗号化および mTLS。サンプルでは、SSL 証明書が 自動的に生成 され、キーストアとトラストストアが作成されてパスワードで保護されます。
- ロールベースアクセス制御(RBAC) による認可。リソースに ACL が関連付けられていない場合、スーパーユーザー以外のユーザーはリソースにアクセスできません。
- ZooKeeper が SSL および SASL/DIGEST-MD5 用に構成されています(注: 試用ライセンス では、REST Proxy および Schema Registry の TLS はサポートされていません)。
- Control Center 用の HTTPS。
- スキーマレジストリ用の HTTPS。
- Connect 用の HTTPS。
各コンポーネントのセキュリティ構成は、サンプルの docker-compose.yml ファイルに記載されています。
注釈
このサンプルは、トレーニングを目的としてセキュアな Confluent Platform を紹介しており、一連のベストプラクティスを示すものではありません。このサンプルの内容と本稼働環境での手順では、異なる点があります。
- すべてのユーザーをスーパーユーザーにするのではなく、必要な操作のみをユーザーに認可してください。
PLAINTEXTセキュリティプロトコルを使用する場合は、このサンプルのANONYMOUSというユーザー名をスーパーユーザーとして構成しないでください。SSLまたはSASL_SSLが構成されている場合は、PLAINTEXTポートを開くことすらしないことを検討してください。
サンプルでは OpenLDAP サーバーが実行されており、デモの各 Kafka ブローカーは Metadata Service (MDS) で構成され、LDAP と連携してクライアントおよび Confluent Platform のサービスとクライアントを認証することができます。
ZooKeeper には、2 つのリスナーポートがあります。
| 名前 | プロトコル | このサンプルでの用途 | ZooKeeper |
|---|---|---|---|
| (なし) | SASL/DIGEST-MD5 | REST Proxy と Schema Registry の試用ライセンスの検証。(TLS サポートなし) | 2181 |
| (なし) | mTLS | ブローカーの通信(kafka1、kafka2) | 2182 |
各ブローカーには、5 つのリスナーポートがあります。
| 名前 | プロトコル | このサンプルでの用途 | kafka1 | kafka2 |
|---|---|---|---|---|
| (なし) | MDS | RBAC による認可 | 8091 | 8092 |
| INTERNAL | SASL_PLAINTEXT | CP Kafka クライアント(Confluent Metrics Reporter など)、SASL_PLAINTEXT | 9091 | 9092 |
| TOKEN | SASL_SSL | 偽装の使用が必要な場合の Confluent Platform サービス( Schema Registry など) | 10091 | 10092 |
| SSL | SSL | SSL を使用し、SASL を使用しないエンドクライアント(stream-demo など) | 11091 | 11092 |
| CLEAR | PLAINTEXT | セキュリティなし、バックドアとして使用可能、デモおよび学習用のみ | 12091 | 12092 |
エンドクライアント(非 CP クライアント):
- ブローカーの SSL リスナー経由で mTLS を使用して認証します。
- Schema Registry も使用している場合は、LDAP 経由で Schema Registry に対して認証します。
- Confluent Monitoring インターセプターも使用している場合は、ブローカーの SSL リスナー経由で mTLS を使用して認証します。
- TOKEN リスナーは決して使用しないでください。このリスナーは、Confluent コンポーネント間の内部通信専用です。
- Kafka Streams アプリケーションの
wikipedia-activity-monitorを実行しているstreams-demoコンテナーがこのサンプルで使用する クライアント構成 を参照してください。
ブローカーリスナー¶
次のコマンドで、Kafka ブローカーがリッスンしているポートを確認します。これは、以下のテーブルに一致する必要があります。
docker-compose logs kafka1 | grep "Registered broker 1" docker-compose logs kafka2 | grep "Registered broker 2"
サンプルのみ: PLAINTEXT ポート経由でブローカーと通信します。クライアントのセキュリティ構成は不要です。
# CLEAR/PLAINTEXT port docker-compose exec kafka1 kafka-consumer-groups \ --list \ --bootstrap-server kafka1:12091
エンドクライアント: SSL ポート経由で、および
--command-config引数(コマンドラインツールの場合)または--consumer.config(kafka-console-consumer の場合)を使用して構成された SSL パラメーターを介してブローカーと通信します。# SSL/SSL port docker-compose exec kafka1 kafka-consumer-groups \ --list \ --bootstrap-server kafka1:11091 \ --command-config /etc/kafka/secrets/client_without_interceptors_ssl.config
クライアントが SSL ポート経由でブローカーと通信しようとしても、SSL パラメーターを指定していない場合は通信できません。
# SSL/SSL port docker-compose exec kafka1 kafka-consumer-groups \ --list \ --bootstrap-server kafka1:11091
出力は以下のようになります。
ERROR Uncaught exception in thread 'kafka-admin-client-thread | adminclient-1': (org.apache.kafka.common.utils.KafkaThread) java.lang.OutOfMemoryError: Java heap space ...
SASL_PLAINTEXT ポート経由で、および
--command-config引数(コマンドラインツールの場合)または--consumer.config(kafka-console-consumer の場合)を使用して構成された SASL_PLAINTEXT パラメーターを介してブローカーと通信します。# INTERNAL/SASL_PLAIN port docker-compose exec kafka1 kafka-consumer-groups \ --list \ --bootstrap-server kafka1:9091 \ --command-config /etc/kafka/secrets/client_sasl_plain.config
RBAC による認可¶
どのユーザーがスーパーユーザーとして構成されているかを確認します。
docker-compose logs kafka1 | grep "super.users ="
この出力は以下のようになります。これにより、それ自体として認証される各サービスの名前と、
ANONYMOUSとして認証される未認証PLAINTEXTが認可されることに注意してください(デモの用途のみ)。kafka1 | super.users = User:admin;User:mds;User:superUser;User:ANONYMOUS
Confluent Control Center の UI で、Administration メニューの Manage role assignments オプションをクリックします。
Assignmentsをクリックしてから、Kafka クラスター ID をクリックします。Topicリストから、LDAP ユーザーappSAがいくつかのトピックへのアクセスを許可されていること、その中にwikipediaで始まる名前を持つすべてのトピックが含まれていることを確認します。このロールの割り当ては、create-role-bindings.sh スクリプト のcp-demoの起動時に行われています。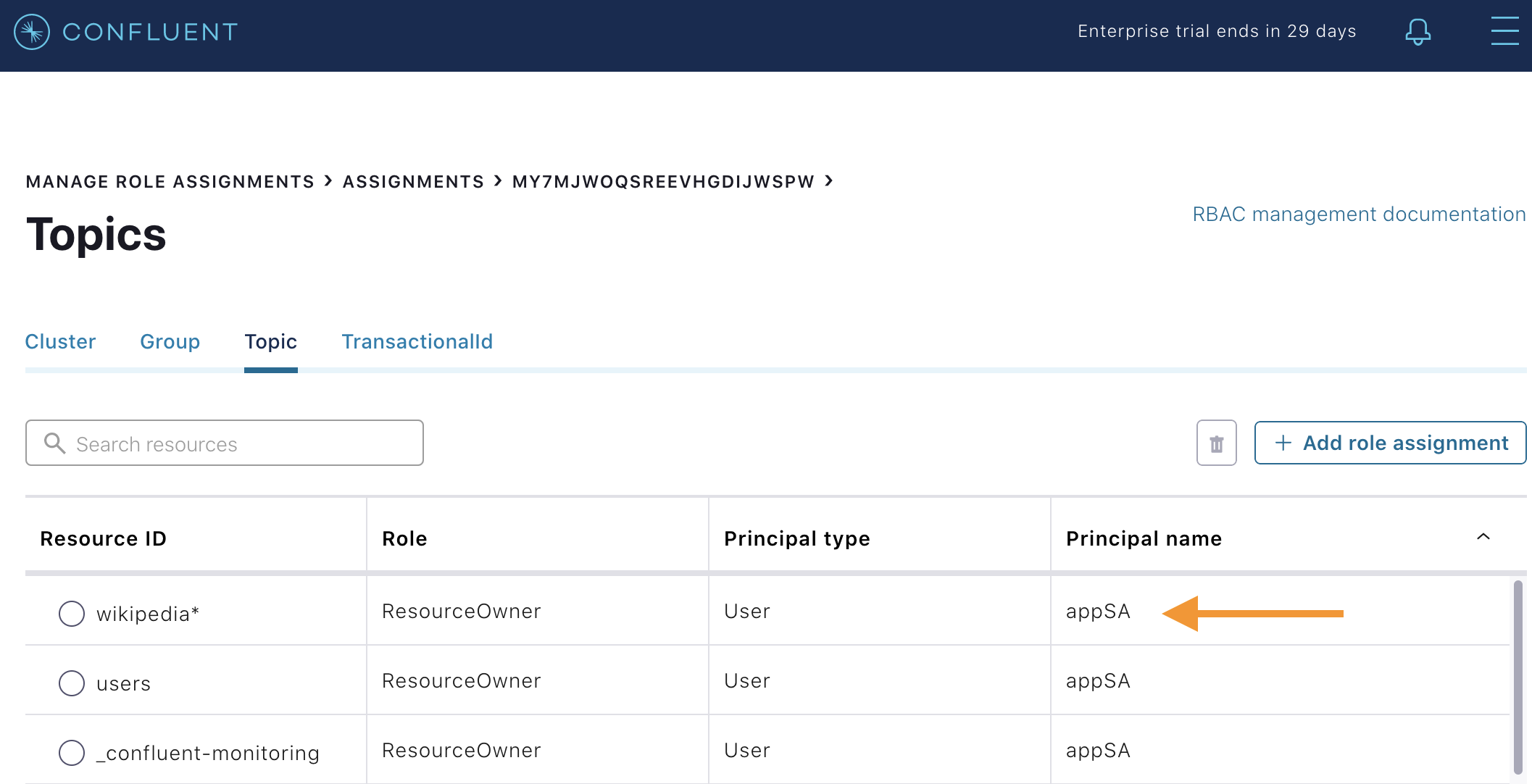
LDAP ユーザー
appSA(スーパーユーザーではない)がトピックwikipedia.parsedからメッセージを消費できることを確認します。ブローカーに対して mTLS で、Schema Registry に対して LDAP で認証されるように構成されていることに注意してください。docker-compose exec connect kafka-avro-console-consumer \ --bootstrap-server kafka1:11091,kafka2:11092 \ --consumer-property security.protocol=SSL \ --consumer-property ssl.truststore.location=/etc/kafka/secrets/kafka.appSA.truststore.jks \ --consumer-property ssl.truststore.password=confluent \ --consumer-property ssl.keystore.location=/etc/kafka/secrets/kafka.appSA.keystore.jks \ --consumer-property ssl.keystore.password=confluent \ --consumer-property ssl.key.password=confluent \ --property schema.registry.url=https://schemaregistry:8085 \ --property schema.registry.ssl.truststore.location=/etc/kafka/secrets/kafka.appSA.truststore.jks \ --property schema.registry.ssl.truststore.password=confluent \ --property basic.auth.credentials.source=USER_INFO \ --property basic.auth.user.info=appSA:appSA \ --group wikipedia.test \ --topic wikipedia.parsed \ --max-messages 5
LDAP ユーザー
badappがトピックwikipedia.parsedからメッセージを消費できないことを確認します。docker-compose exec connect kafka-avro-console-consumer \ --bootstrap-server kafka1:11091,kafka2:11092 \ --consumer-property security.protocol=SSL \ --consumer-property ssl.truststore.location=/etc/kafka/secrets/kafka.badapp.truststore.jks \ --consumer-property ssl.truststore.password=confluent \ --consumer-property ssl.keystore.location=/etc/kafka/secrets/kafka.badapp.keystore.jks \ --consumer-property ssl.keystore.password=confluent \ --consumer-property ssl.key.password=confluent \ --property schema.registry.url=https://schemaregistry:8085 \ --property schema.registry.ssl.truststore.location=/etc/kafka/secrets/kafka.badapp.truststore.jks \ --property schema.registry.ssl.truststore.password=confluent \ --property basic.auth.credentials.source=USER_INFO \ --property basic.auth.user.info=badapp:badapp \ --group wikipedia.test \ --topic wikipedia.parsed \ --max-messages 5
出力は以下のようになります。
ERROR [Consumer clientId=consumer-wikipedia.test-1, groupId=wikipedia.test] Topic authorization failed for topics [wikipedia.parsed] org.apache.kafka.common.errors.TopicAuthorizationException: Not authorized to access topics: [wikipedia.parsed]
Create role bindings to permit
badappclient to consume from topicwikipedia.parsedand its related subject in Schema Registry.Kafka クラスター ID を取得します。
KAFKA_CLUSTER_ID=$(curl -s https://localhost:8091/v1/metadata/id --tlsv1.2 --cacert scripts/security/snakeoil-ca-1.crt | jq -r ".id")
Create the role bindings:
# Create the role binding for the topic ``wikipedia.parsed`` docker-compose exec tools bash -c "confluent iam rolebinding create \ --principal User:badapp \ --role ResourceOwner \ --resource Topic:wikipedia.parsed \ --kafka-cluster-id $KAFKA_CLUSTER_ID" # Create the role binding for the group ``wikipedia.test`` docker-compose exec tools bash -c "confluent iam rolebinding create \ --principal User:badapp \ --role ResourceOwner \ --resource Group:wikipedia.test \ --kafka-cluster-id $KAFKA_CLUSTER_ID" # Create the role binding for the subject ``wikipedia.parsed-value``, i.e., the topic-value (versus the topic-key) docker-compose exec tools bash -c "confluent iam rolebinding create \ --principal User:badapp \ --role ResourceOwner \ --resource Subject:wikipedia.parsed-value \ --kafka-cluster-id $KAFKA_CLUSTER_ID \ --schema-registry-cluster-id schema-registry"LDAP ユーザー
badappがトピックwikipedia.parsedからメッセージを消費できるようになったことを確認します。docker-compose exec connect kafka-avro-console-consumer \ --bootstrap-server kafka1:11091,kafka2:11092 \ --consumer-property security.protocol=SSL \ --consumer-property ssl.truststore.location=/etc/kafka/secrets/kafka.badapp.truststore.jks \ --consumer-property ssl.truststore.password=confluent \ --consumer-property ssl.keystore.location=/etc/kafka/secrets/kafka.badapp.keystore.jks \ --consumer-property ssl.keystore.password=confluent \ --consumer-property ssl.key.password=confluent \ --property schema.registry.url=https://schemaregistry:8085 \ --property schema.registry.ssl.truststore.location=/etc/kafka/secrets/kafka.badapp.truststore.jks \ --property schema.registry.ssl.truststore.password=confluent \ --property basic.auth.credentials.source=USER_INFO \ --property basic.auth.user.info=badapp:badapp \ --group wikipedia.test \ --topic wikipedia.parsed \ --max-messages 5
このクラスターで RBAC 用に構成された ロールバインディングをすべて表示します。
./scripts/validate/validate_bindings.sh
ZooKeeper は SASL/DIGEST-MD5 用に構成されているため、ZooKeeper と通信するあらゆるコマンドには、ZooKeeper 認証用に設定されたプロパティが必要です。この認証構成は、ブローカーの
KAFKA_OPTS設定により提供されます。たとえば、コンシューマースロットルスクリプト は、適切な KAFKA_OPTS 設定を持つ Docker コンテナーkafka1で実行されていることに注意してください。そうでない場合は、kafka1またはkafka2以外の他のコンテナーでコマンドを実行しても機能しません。次の手順: セキュリティのチュートリアル で、セキュリティについて詳しく学習します。
Schema Registry によるデータガバナンス¶
このサンプルで使用するすべてのアプリケーションとコネクターは、Confluent スキーマレジストリ を活用して、Avro 形式のデータを自動的に読み取り、書き込むように構成されています。
Schema Registry と、appSA などのエンドクライアントとの間に設定されているセキュリティは、次のとおりです。
- 暗号化: TLS。たとえば、クライアントに
schema.registry.ssl.truststore.*構成がある場合。 - 認証: HTTP Basic 認証ヘッダーからの Bearer トークン認証。たとえば、クライアントに
basic.auth.user.infoおよびbasic.auth.credentials.source構成がある場合。 - 認可: Schema Registry は、RBAC で Bearer トークンを使用してクライアントを認可します。
キーや値のスキーマを登録している、トピックの Schema Registry サブジェクトを表示します。
curl引数には、(a) ポート 8085 で HTTPS をリッスンしている Schema Registry と連携するために必要な TLS 情報、および (b) RBAC に必要な認証の資格情報(すべてを見るには superUser:superUser を使用します)が含まれることに注意してください。docker-compose exec schemaregistry curl -X GET \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ -u superUser:superUser \ https://schemaregistry:8085/subjects | jq .
出力は以下のようになります。
[ "WIKIPEDIA_COUNT_GT_1-value", "wikipedia-activity-monitor-KSTREAM-AGGREGATE-STATE-STORE-0000000003-repartition-value", "wikipedia.parsed.replica-value", "WIKIPEDIABOT-value", "WIKIPEDIANOBOT-value", "_confluent-ksql-ksql-clusterquery_CTAS_WIKIPEDIA_COUNT_GT_1_7-Aggregate-GroupBy-repartition-value", "wikipedia.parsed.count-by-domain-value", "wikipedia.parsed-value", "_confluent-ksql-ksql-clusterquery_CTAS_WIKIPEDIA_COUNT_GT_1_7-Aggregate-Aggregate-Materialize-changelog-value" ]
superUser 資格情報を使用する代わりに、今度は、クライアント資格情報 noexist:noexist (ユーザーが LDAP に存在しない)を使用して、新しい Avro スキーマ(2 つのフィールド
usernameおよびuseridを含むレコード)を Schema Registry に、新しいトピックusersの値として登録してみてください。これは、認可エラーにより失敗するはずです。docker-compose exec schemaregistry curl -X POST \ -H "Content-Type: application/vnd.schemaregistry.v1+json" \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ --data '{ "schema": "[ { \"type\":\"record\", \"name\":\"user\", \"fields\": [ {\"name\":\"userid\",\"type\":\"long\"}, {\"name\":\"username\",\"type\":\"string\"} ]} ]" }' \ -u noexist:noexist \ https://schemaregistry:8085/subjects/users-value/versions出力は以下のようになります。
{"error_code":401,"message":"Unauthorized"}
存在しないユーザーの資格情報を使用する代わりに、今度は、クライアント資格情報 appSA:appSA (ユーザー appSA が LDAP に存在する)を使用して、新しい Avro スキーマ(2 つのフィールド
usernameおよびuseridを含むレコード)を Schema Registry に、新しいトピックusersの値として登録してみてください。これは、認可エラーにより失敗し、前述のものとは異なるメッセージが表示されるはずです。docker-compose exec schemaregistry curl -X POST \ -H "Content-Type: application/vnd.schemaregistry.v1+json" \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ --data '{ "schema": "[ { \"type\":\"record\", \"name\":\"user\", \"fields\": [ {\"name\":\"userid\",\"type\":\"long\"}, {\"name\":\"username\",\"type\":\"string\"} ]} ]" }' \ -u appSA:appSA \ https://schemaregistry:8085/subjects/users-value/versions出力は以下のようになります。
{"error_code":40301,"message":"User is denied operation Write on Subject: users-value"}
appSAクライアントの ロールバインディングを作成して、Schema Registry へのアクセスを許可します。Kafka クラスター ID を取得します。
KAFKA_CLUSTER_ID=$(curl -s https://localhost:8091/v1/metadata/id --tlsv1.2 --cacert scripts/security/snakeoil-ca-1.crt | jq -r ".id")
Create the role binding:
# Create the role binding for the subject ``users-value``, i.e., the topic-value (versus the topic-key) docker-compose exec tools bash -c "confluent iam rolebinding create \ --principal User:appSA \ --role ResourceOwner \ --resource Subject:users-value \ --kafka-cluster-id $KAFKA_CLUSTER_ID \ --schema-registry-cluster-id schema-registry"もう一度、スキーマの登録を試みます。今度は成功するはずです。返されるスキーマ ID に注意します。たとえば、以下では ID は
9です。docker-compose exec schemaregistry curl -X POST \ -H "Content-Type: application/vnd.schemaregistry.v1+json" \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ --data '{ "schema": "[ { \"type\":\"record\", \"name\":\"user\", \"fields\": [ {\"name\":\"userid\",\"type\":\"long\"}, {\"name\":\"username\",\"type\":\"string\"} ]} ]" }' \ -u appSA:appSA \ https://schemaregistry:8085/subjects/users-value/versions出力は以下のようになります。
{"id":9}
サブジェクト
users-valueの新しいスキーマを表示します。Confluent Control Center で Topics をクリックします。下へスクロールしてトピック users をクリックし、SCHEMA を選択します。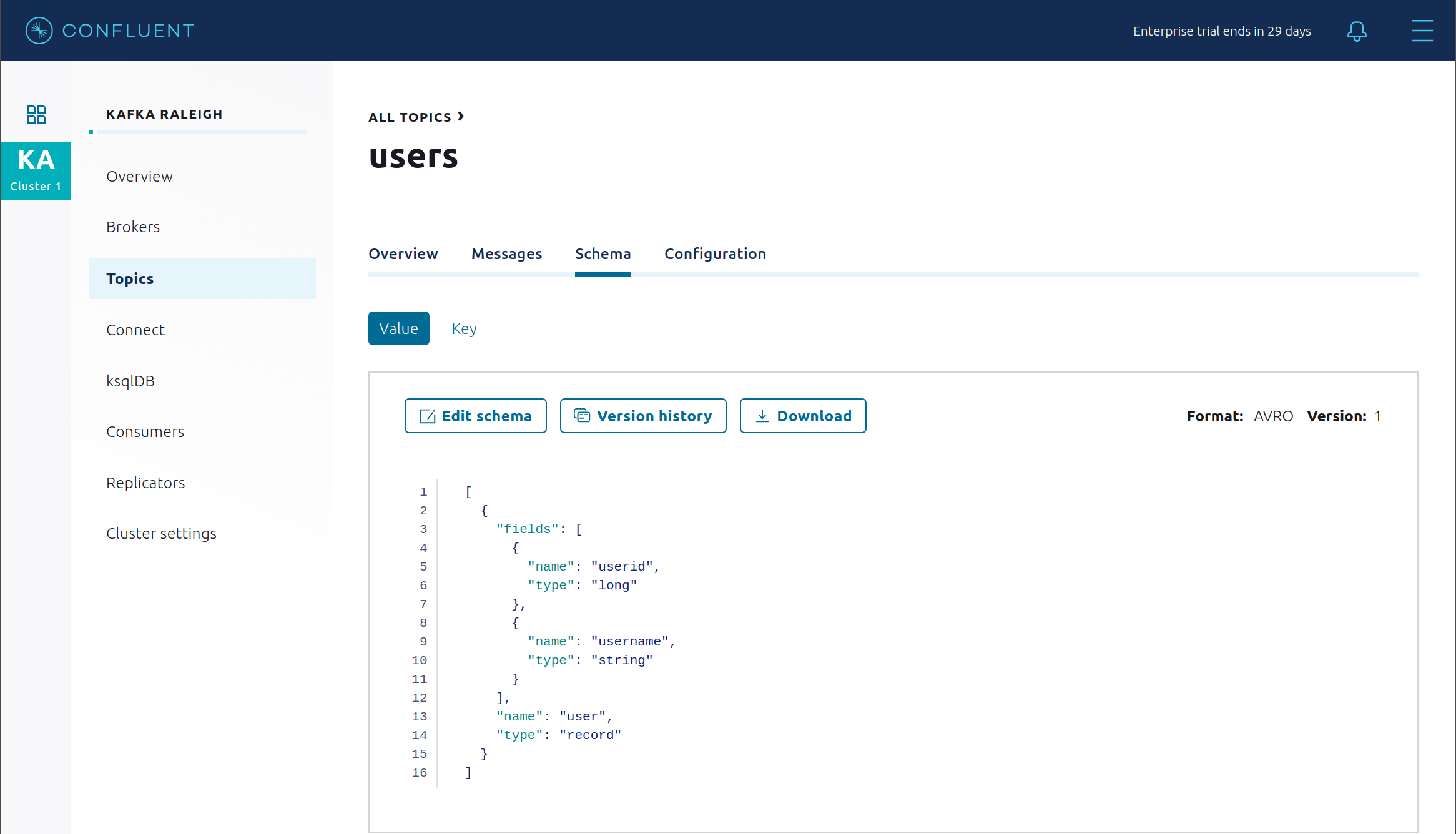
または、コマンドライン経由でスキーマをリクエストすることもできます。
docker-compose exec schemaregistry curl -X GET \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ -u appSA:appSA \ https://schemaregistry:8085/subjects/users-value/versions/1 | jq .
出力は以下のようになります。
{ "subject": "users-value", "version": 1, "id": 9, "schema": "{\"type\":\"record\",\"name\":\"user\",\"fields\":[{\"name\":\"username\",\"type\":\"string\"},{\"name\":\"userid\",\"type\":\"long\"}]}" }
トピック
usersの説明を入力します。特別な構成confluent.value.schema.validation=trueを使用していることに注意してください。これにより、Confluent サーバーのデータガバナンス機能である スキーマ検証 が有効になります。この機能によりオペレーターに対して、データ形式の正確性を確保するための一元的な場所が、Kafka クラスター自体の内部で提供されます。Schema Validation を有効にすると、confluent.schema.registry.urlで構成されたブローカーは、トピックに対して生成されるデータが有効なスキーマを使用していることを検証できます。docker-compose exec kafka1 kafka-topics \ --describe \ --topic users \ --bootstrap-server kafka1:9091 \ --command-config /etc/kafka/secrets/client_sasl_plain.config
出力は以下のようになります。
Topic: users PartitionCount: 2 ReplicationFactor: 2 Configs: confluent.value.schema.validation=true Topic: users Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2 Offline: Topic: users Partition: 1 Leader: 2 Replicas: 2,1 Isr: 2,1 Offline:
kafka-console-producerツールを使用して、このトピックに非 Avro メッセージを生成します。docker-compose exec connect kafka-console-producer \ --topic users \ --broker-list kafka1:11091 \ --producer-property security.protocol=SSL \ --producer-property ssl.truststore.location=/etc/kafka/secrets/kafka.appSA.truststore.jks \ --producer-property ssl.truststore.password=confluent \ --producer-property ssl.keystore.location=/etc/kafka/secrets/kafka.appSA.keystore.jks \ --producer-property ssl.keystore.password=confluent \ --producer-property ssl.key.password=confluent
コンソールプロデューサーは、開始後に入力を待機します。数文字入力して、Enter キーを押します。エラーが発生して、以下のようなエラーメッセージが表示されます。
ERROR Error when sending message to topic users with key: null, value: 5 bytes with error: (org.apache.kafka.clients.producer.internals.ErrorLoggingCallback) org.apache.kafka.common.InvalidRecordException: This record has failed the validation on broker and hence be rejected.
Ctrl + Cを入力して、コンソールプロデューサーを終了します("+" はキーを同時に押すことを意味します)。トピック
wikipedia.parsedの説明を入力します。このトピックは、kafka-connect-sse ソースコネクターの書き込み先です。ここでも Schema Validation が有効になっていることに注意してください。docker-compose exec kafka1 kafka-topics \ --describe \ --topic wikipedia.parsed \ --bootstrap-server kafka1:9091 \ --command-config /etc/kafka/secrets/client_sasl_plain.config
トピック
wikipedia.parsed.replicaの説明を入力します。これは、Replicator がwikipedia.parsedからレプリケートしたトピックです。ここでも Schema Validation が有効になっています。これは、Replicator のデフォルト設定がtopic.config.sync=trueであるためです( Replicator の 送信先トピック を参照)。docker-compose exec kafka1 kafka-topics \ --describe \ --topic wikipedia.parsed.replica \ --bootstrap-server kafka1:9091 \ --command-config /etc/kafka/secrets/client_sasl_plain.config
次の手順: スキーマレジストリのチュートリアル で、Schema Registry について詳しく学習します。
Confluent REST Proxy¶
Confluent REST Proxy は、オプションのクライアントアクセスのために実行されています。このデモでは、2 つのモードの Confluent REST Proxy を紹介します。
- スタンドアロンサービス。ポート 8086 で HTTPS リクエストをリッスンしています。
- Kafka ブローカー上の組み込みサービス。
kafka1のポート 8091 およびkafka2のポート 8092(これらの REST Proxy ポートは、ブローカーの Metadata Service (MDS) リスナーと共有されています)で HTTPS リクエストをリッスンしています。
スタンドアロン REST Proxy¶
次のいくつかの手順では、スタンドアロンサービスとして実行されている REST Proxy を使用します。
スタンドアロン REST Proxy を使用して、トピック
usersに対するメッセージの生成を試みます。この際、スキーマ ID9を参照します。このスキーマは、前のセクションで Schema Registry に登録されています。これは、認可エラーにより失敗するはずです。docker-compose exec restproxy curl -X POST \ -H "Content-Type: application/vnd.kafka.avro.v2+json" \ -H "Accept: application/vnd.kafka.v2+json" \ --cert /etc/kafka/secrets/restproxy.certificate.pem \ --key /etc/kafka/secrets/restproxy.key \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ --data '{"value_schema_id": 9, "records": [{"value": {"user":{"userid": 1, "username": "Bunny Smith"}}}]}' \ -u appSA:appSA \ https://restproxy:8086/topics/users出力は以下のようになります。
{"offsets":[{"partition":null,"offset":null,"error_code":40301,"error":"Not authorized to access topics: [users]"}],"key_schema_id":null,"value_schema_id":9}
クライアントの ロールバインディングを作成して、トピック
usersに対する生成を許可します。Kafka クラスター ID を取得します。
KAFKA_CLUSTER_ID=$(curl -s https://localhost:8091/v1/metadata/id --tlsv1.2 --cacert scripts/security/snakeoil-ca-1.crt | jq -r ".id")
Create the role binding:
# Create the role binding for the topic ``users`` docker-compose exec tools bash -c "confluent iam rolebinding create \ --principal User:appSA \ --role DeveloperWrite \ --resource Topic:users \ --kafka-cluster-id $KAFKA_CLUSTER_ID"もう一度、トピック
usersに対してメッセージの生成を試みます。今度は成功するはずです。docker-compose exec restproxy curl -X POST \ -H "Content-Type: application/vnd.kafka.avro.v2+json" \ -H "Accept: application/vnd.kafka.v2+json" \ --cert /etc/kafka/secrets/restproxy.certificate.pem \ --key /etc/kafka/secrets/restproxy.key \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ --data '{"value_schema_id": 9, "records": [{"value": {"user":{"userid": 1, "username": "Bunny Smith"}}}]}' \ -u appSA:appSA \ https://restproxy:8086/topics/users出力は以下のようになります。
{"offsets":[{"partition":1,"offset":0,"error_code":null,"error":null}],"key_schema_id":null,"value_schema_id":9}
コンシューマーインスタンス
my_avro_consumerを作成します。docker-compose exec restproxy curl -X POST \ -H "Content-Type: application/vnd.kafka.v2+json" \ --cert /etc/kafka/secrets/restproxy.certificate.pem \ --key /etc/kafka/secrets/restproxy.key \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ --data '{"name": "my_consumer_instance", "format": "avro", "auto.offset.reset": "earliest"}' \ -u appSA:appSA \ https://restproxy:8086/consumers/my_avro_consumer出力は以下のようになります。
{"instance_id":"my_consumer_instance","base_uri":"https://restproxy:8086/consumers/my_avro_consumer/instances/my_consumer_instance"}my_avro_consumerをトピックusersにサブスクライブします。docker-compose exec restproxy curl -X POST \ -H "Content-Type: application/vnd.kafka.v2+json" \ --cert /etc/kafka/secrets/restproxy.certificate.pem \ --key /etc/kafka/secrets/restproxy.key \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ --data '{"topics":["users"]}' \ -u appSA:appSA \ https://restproxy:8086/consumers/my_avro_consumer/instances/my_consumer_instance/subscriptionmy_avro_consumerサブスクリプションに対してメッセージの消費を試みます。これは、認可エラーにより失敗するはずです。docker-compose exec restproxy curl -X GET \ -H "Accept: application/vnd.kafka.avro.v2+json" \ --cert /etc/kafka/secrets/restproxy.certificate.pem \ --key /etc/kafka/secrets/restproxy.key \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ -u appSA:appSA \ https://restproxy:8086/consumers/my_avro_consumer/instances/my_consumer_instance/records
出力は以下のようになります。
{"error_code":40301,"message":"Not authorized to access group: my_avro_consumer"}クライアントの ロールバインディングを作成して、コンシューマーグループ
my_avro_consumerへのアクセスを許可します。Kafka クラスター ID を取得します。
KAFKA_CLUSTER_ID=$(curl -s https://localhost:8091/v1/metadata/id --tlsv1.2 --cacert scripts/security/snakeoil-ca-1.crt | jq -r ".id")
Create the role binding:
# Create the role binding for the group ``my_avro_consumer`` docker-compose exec tools bash -c "confluent iam rolebinding create \ --principal User:appSA \ --role ResourceOwner \ --resource Group:my_avro_consumer \ --kafka-cluster-id $KAFKA_CLUSTER_ID"もう一度、
my_avro_consumerサブスクリプションに対してメッセージの消費を試みます。これは、別の認可エラーにより失敗するはずです。# Note: Issue this command twice due to https://github.com/confluentinc/kafka-rest/issues/432 docker-compose exec restproxy curl -X GET \ -H "Accept: application/vnd.kafka.avro.v2+json" \ --cert /etc/kafka/secrets/restproxy.certificate.pem \ --key /etc/kafka/secrets/restproxy.key \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ -u appSA:appSA \ https://restproxy:8086/consumers/my_avro_consumer/instances/my_consumer_instance/records docker-compose exec restproxy curl -X GET \ -H "Accept: application/vnd.kafka.avro.v2+json" \ --cert /etc/kafka/secrets/restproxy.certificate.pem \ --key /etc/kafka/secrets/restproxy.key \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ -u appSA:appSA \ https://restproxy:8086/consumers/my_avro_consumer/instances/my_consumer_instance/records
出力は以下のようになります。
{"error_code":40301,"message":"Not authorized to access topics: [users]"}
クライアントの ロールバインディングを作成して、トピック
usersへのアクセスを許可します。Kafka クラスター ID を取得します。
KAFKA_CLUSTER_ID=$(curl -s https://localhost:8091/v1/metadata/id --tlsv1.2 --cacert scripts/security/snakeoil-ca-1.crt | jq -r ".id")
Create the role binding:
# Create the role binding for the group my_avro_consumer docker-compose exec tools bash -c "confluent iam rolebinding create \ --principal User:appSA \ --role DeveloperRead \ --resource Topic:users \ --kafka-cluster-id $KAFKA_CLUSTER_ID"もう一度、
my_avro_consumerサブスクリプションに対してメッセージの消費を試みます。今度は成功するはずです。# Note: Issue this command twice due to https://github.com/confluentinc/kafka-rest/issues/432 docker-compose exec restproxy curl -X GET \ -H "Accept: application/vnd.kafka.avro.v2+json" \ --cert /etc/kafka/secrets/restproxy.certificate.pem \ --key /etc/kafka/secrets/restproxy.key \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ -u appSA:appSA \ https://restproxy:8086/consumers/my_avro_consumer/instances/my_consumer_instance/records docker-compose exec restproxy curl -X GET \ -H "Accept: application/vnd.kafka.avro.v2+json" \ --cert /etc/kafka/secrets/restproxy.certificate.pem \ --key /etc/kafka/secrets/restproxy.key \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ -u appSA:appSA \ https://restproxy:8086/consumers/my_avro_consumer/instances/my_consumer_instance/records
出力は以下のようになります。
[{"topic":"users","key":null,"value":{"userid":1,"username":"Bunny Smith"},"partition":1,"offset":0}]
コンシューマーインスタンス
my_avro_consumerを削除します。docker-compose exec restproxy curl -X DELETE \ -H "Content-Type: application/vnd.kafka.v2+json" \ --cert /etc/kafka/secrets/restproxy.certificate.pem \ --key /etc/kafka/secrets/restproxy.key \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ -u appSA:appSA \ https://restproxy:8086/consumers/my_avro_consumer/instances/my_consumer_instance
組み込み REST Proxy¶
次のいくつかの手順では、Kafka ブローカー上に組み込まれた REST Proxy を使用します。今回は、REST Proxy API v3 のみがサポートされています。
クライアントに付与する ロールバインディング、トピック
dev_usersに対するResourceOwnerロールを作成します。Kafka クラスター ID を取得します。
KAFKA_CLUSTER_ID=$(curl -s https://localhost:8091/v1/metadata/id --tlsv1.2 --cacert scripts/security/snakeoil-ca-1.crt | jq -r ".id")
Create the role binding:
# Create the role binding for the topic ``dev_users`` docker-compose exec tools bash -c "confluent iam rolebinding create \ --principal User:appSA \ --role ResourceOwner \ --resource Topic:dev_users \ --kafka-cluster-id $KAFKA_CLUSTER_ID"組み込み REST Proxy でトピック
dev_usersを作成します。Kafka クラスター ID を取得します。
KAFKA_CLUSTER_ID=$(curl -s https://localhost:8091/v1/metadata/id --tlsv1.2 --cacert scripts/security/snakeoil-ca-1.crt | jq -r ".id")
curlを使用してトピックを作成します。docker-compose exec restproxy curl -X POST \ -H "Content-Type: application/json" \ -H "accept: application/json" \ -d "{\"topic_name\":\"dev_users\",\"partitions_count\":64,\"replication_factor\":2,\"configs\":[{\"name\":\"cleanup.policy\",\"value\":\"compact\"},{\"name\":\"compression.type\",\"value\":\"gzip\"}]}" \ --cert /etc/kafka/secrets/mds.certificate.pem \ --key /etc/kafka/secrets/mds.key \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ -u appSA:appSA \ "https://kafka1:8091/kafka/v3/clusters/$KAFKA_CLUSTER_ID/topics" | jq組み込み REST Proxy でトピックのリストを表示して、新しく作成した
dev_usersを見つけます。Kafka クラスター ID を取得します。
KAFKA_CLUSTER_ID=$(curl -s https://localhost:8091/v1/metadata/id --tlsv1.2 --cacert scripts/security/snakeoil-ca-1.crt | jq -r ".id")
curlを使用してトピックのリストを表示します。docker-compose exec restproxy curl -X GET \ -H "Content-Type: application/json" \ -H "accept: application/json" \ --cert /etc/kafka/secrets/mds.certificate.pem \ --key /etc/kafka/secrets/mds.key \ --tlsv1.2 \ --cacert /etc/kafka/secrets/snakeoil-ca-1.crt \ -u appSA:appSA \ https://kafka1:8091/kafka/v3/clusters/$KAFKA_CLUSTER_ID/topics | jq '.data[].topic_name'
出力は以下のようになります。出力は作成済みの他のトピックに応じて異なる場合がありますが、前の手順で作成したトピック
dev_usersは必ず表示されるはずです。"_confluent-monitoring" "dev_users" "users" "wikipedia-activity-monitor-KSTREAM-AGGREGATE-STATE-STORE-0000000003-changelog" "wikipedia-activity-monitor-KSTREAM-AGGREGATE-STATE-STORE-0000000003-repartition" "wikipedia.failed" "wikipedia.parsed" "wikipedia.parsed.count-by-domain" "wikipedia.parsed.replica"
ブローカーのエラー¶
ブローカーのエラーのシミュレーションを行うために、2 つの Kafka ブローカーのいずれかで実行されている Docker コンテナーを停止します。
Kafka broker 2 を実行している Docker コンテナーを停止します。
docker-compose stop kafka2
数分後に、ブローカー数が 2 から 1 に減り、レプリケーション数が不足しているパーティションが数多くあることがブローカーサマリーに表示されます。
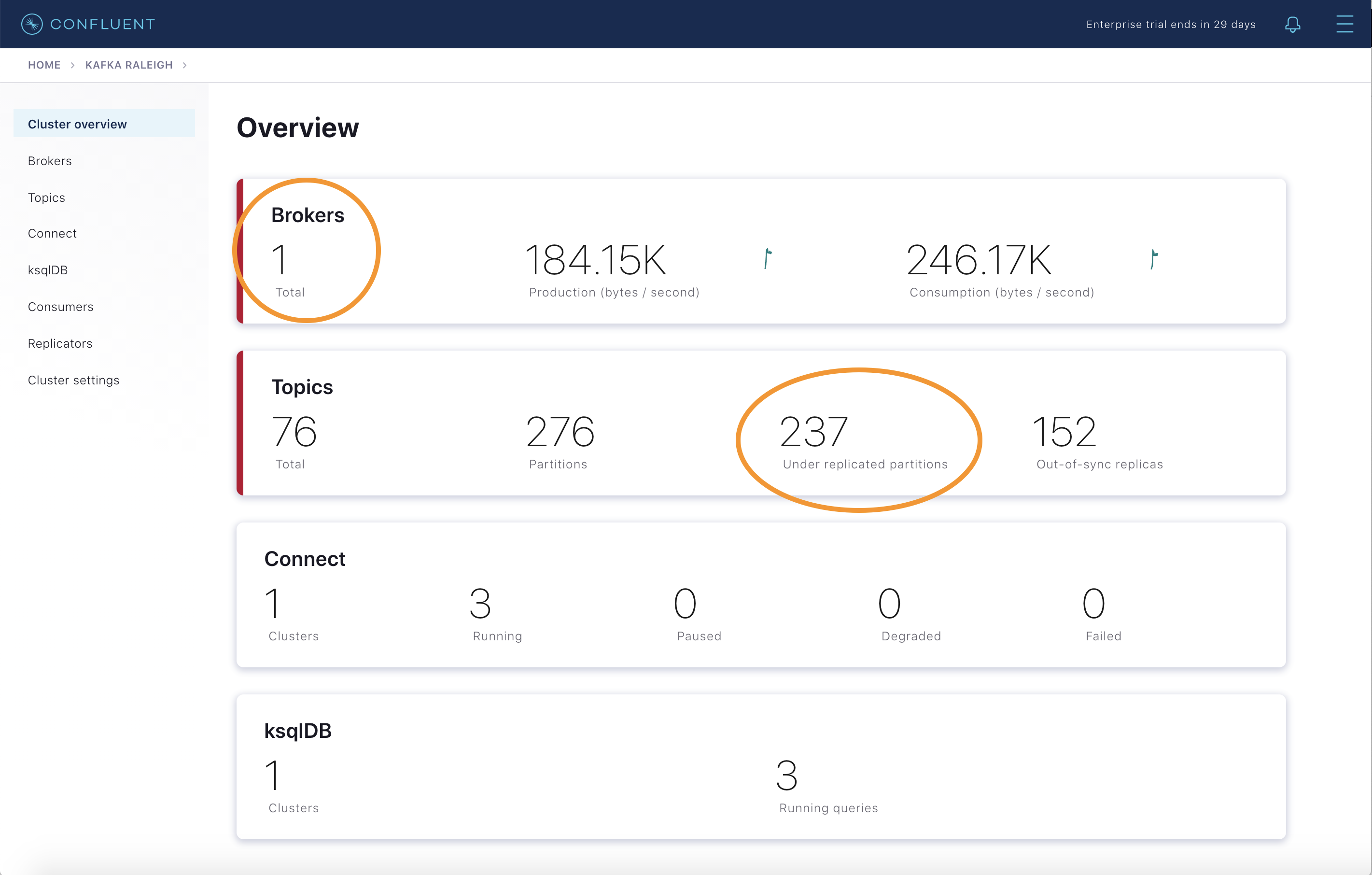
トピック情報の詳細で、同期されていないレプリカがあることを確認します。
生成と消費のメトリクスを調べると、すべてのクライアントが動作し続けていることがわかります。
Kafka broker 2 を実行している Docker コンテナーを再起動します。
docker-compose start kafka2
約 1 分後に、Confluent Control Center でブローカーサマリーを調べます。ブローカー数は 2 に戻り、トピックのパーティションも元に戻って、レプリケーション数が不足しているパーティションがないことがわかります。
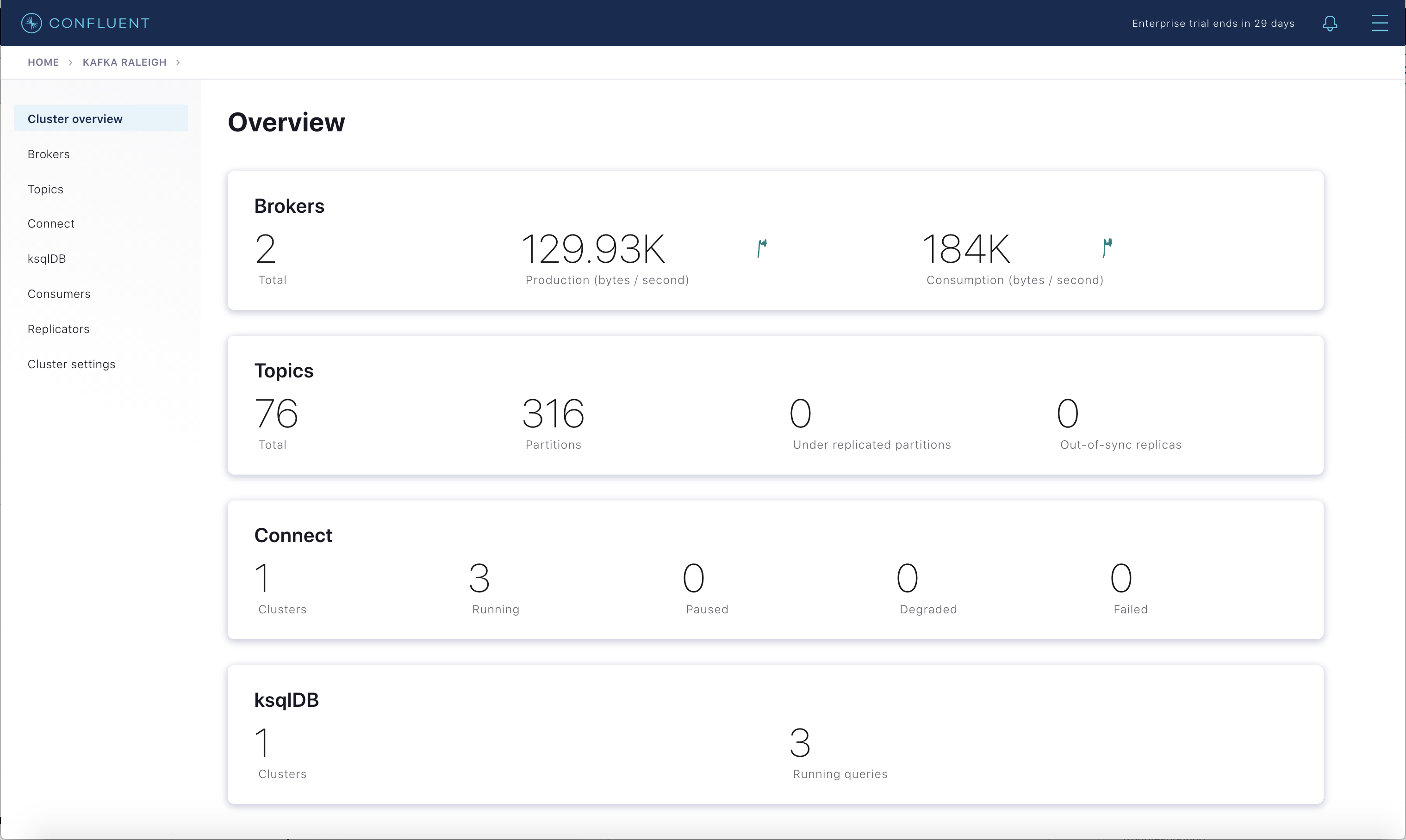
Brokers ボックス内のブローカー数
2をクリックし、Brokers overview ペインが表示されたら、Partitioning and replication ボックス内をクリックして、いつブローカー数が変わったかを調べます。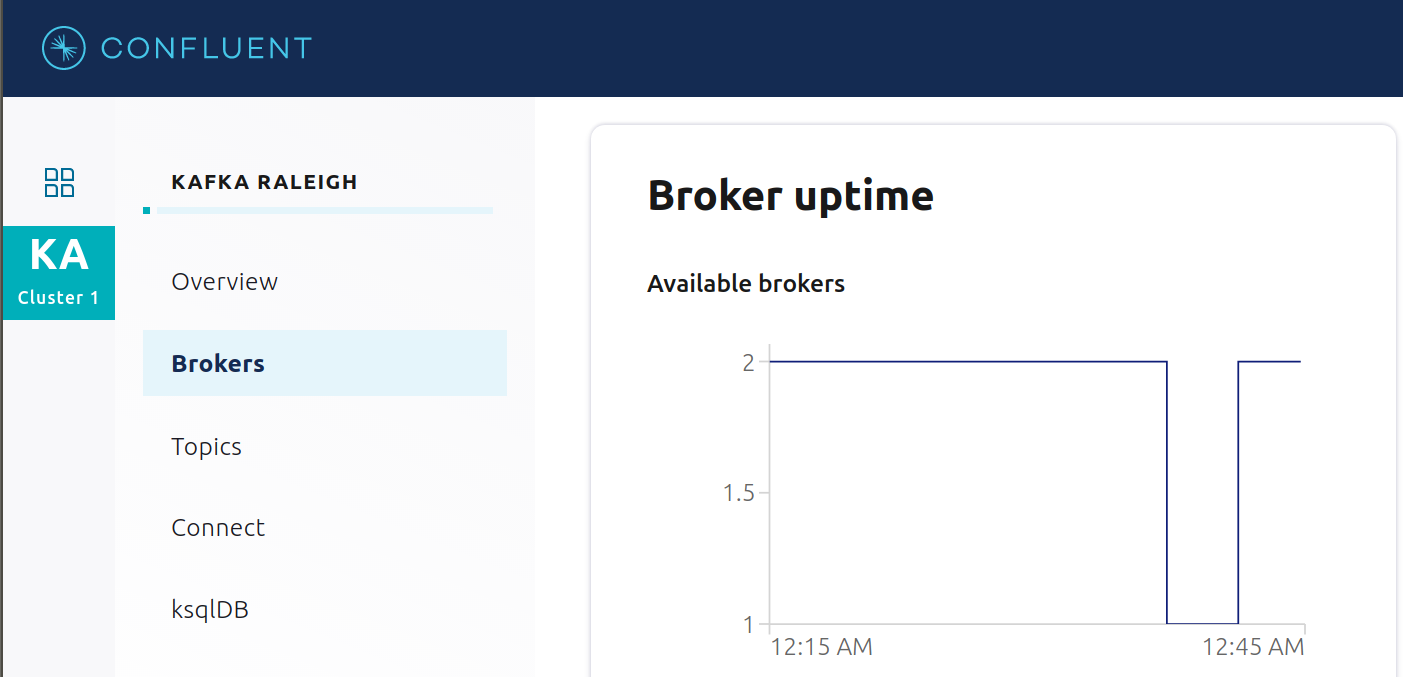
アラートの生成¶
多くの Control Center アラート があり、その構成方法も数多くあります。アラート管理ページを使用して、トリガーとアクションを定義するか、個々のリソースをクリックしてそこからアラートをセットアップします。
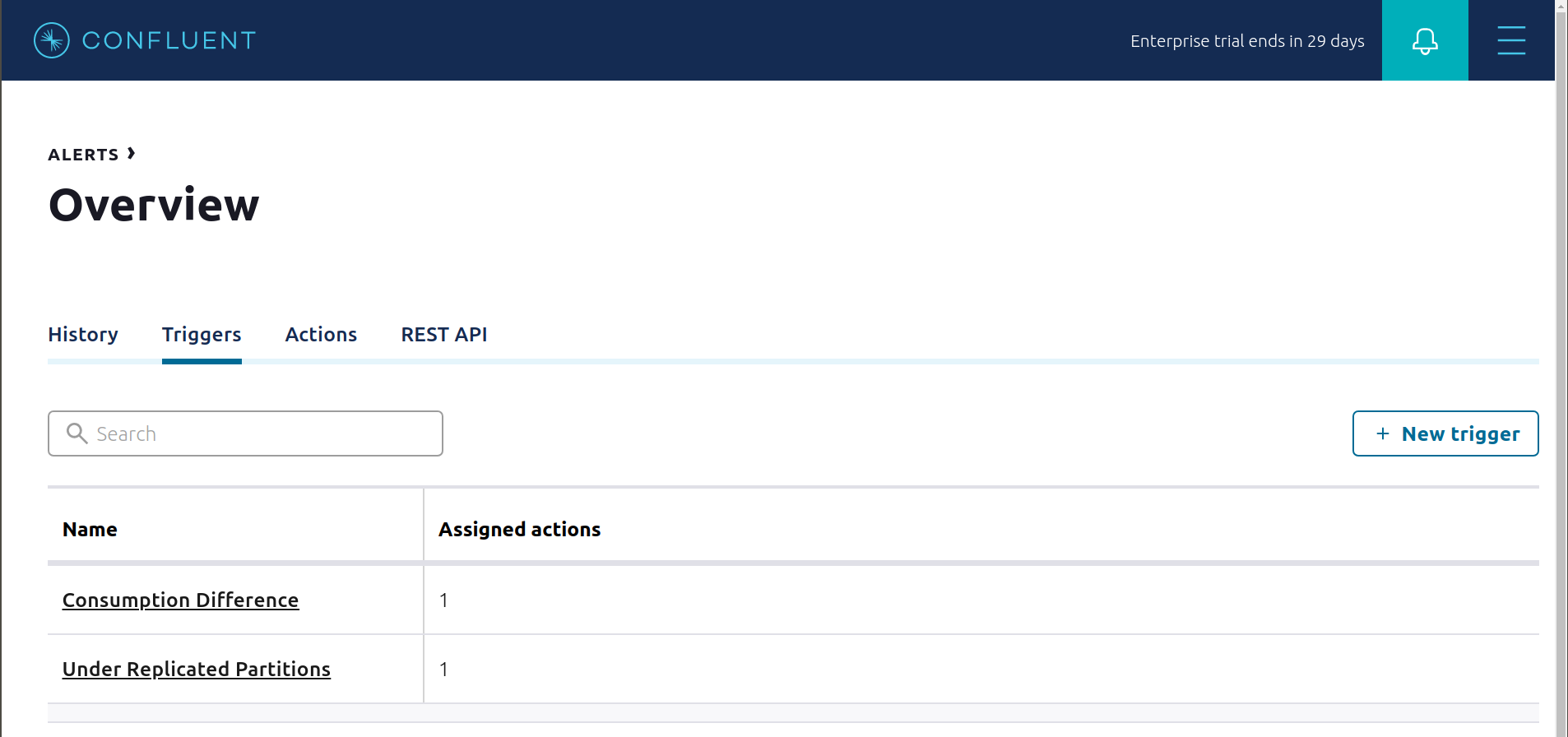
このサンプルには、事前に構成されたトリガーとアクションが既に存在します。アラートの
Triggers画面を表示し、各トリガーに対してEditをクリックして構成の詳細を確認します。- トリガー
Under Replicated Partitionsは、レプリケーション数が不足しているパーティションがゼロでないことをブローカーが報告すると発生します。これにより、アクションEmail Administratorが発生します。 - トリガー
Consumption Differenceは、Elasticsearch コネクターコンシューマーグループの消費の差が0より大きい場合に発生します。これにより、アクションEmail Administratorが発生します。
- トリガー
「ブローカーのエラー」セクションの手順に従った場合は、アラート履歴を表示して、トリガー
Under Replicated Partitionsの発生が原因で broker 2 を停止したときにアラートが生成されたことを確認してください。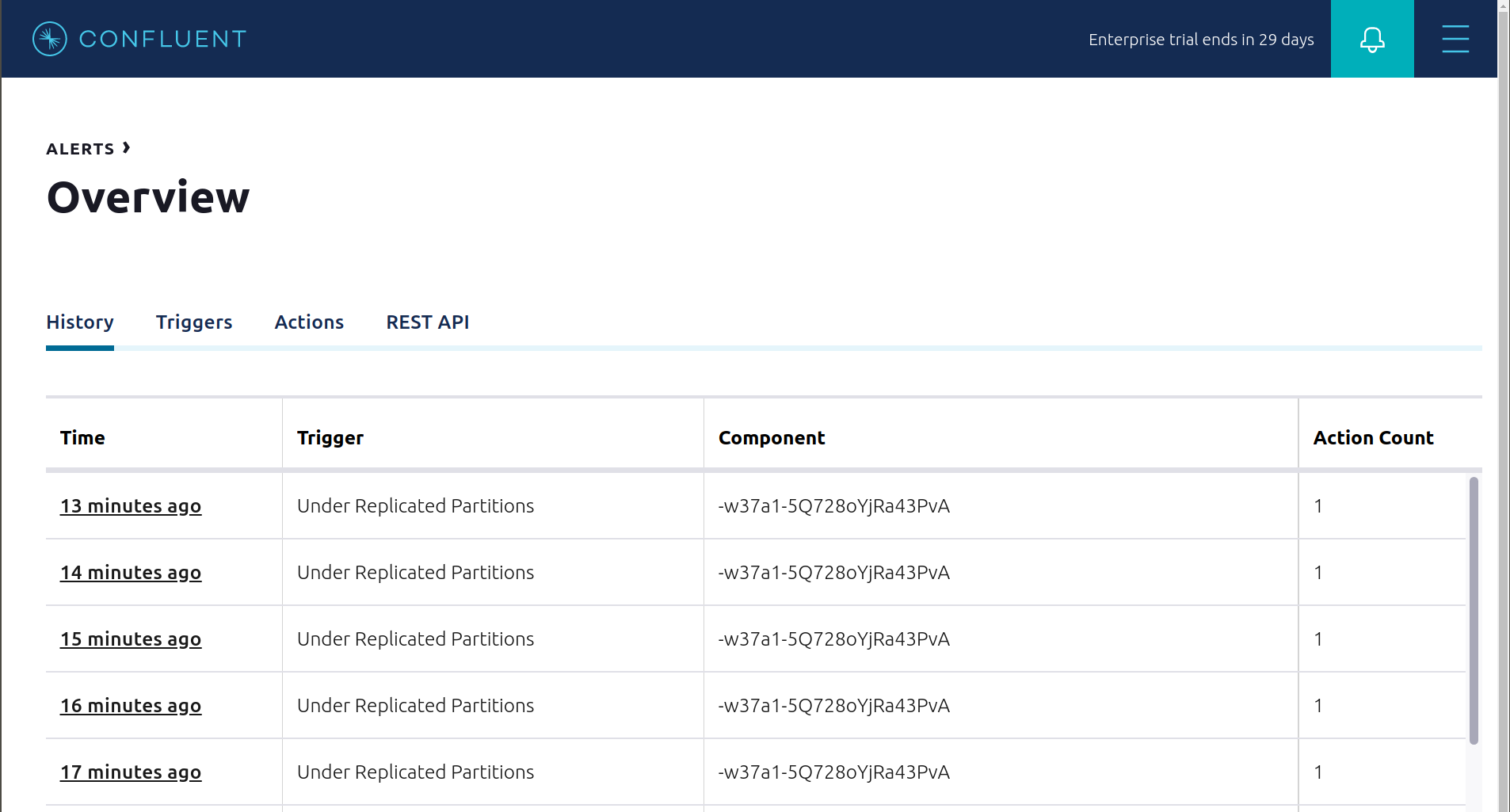
また、
Consumption Differenceトリガーも作動させることができます。Kafka Connect -> Sinks 画面で、実行中の Elasticsearch Sink Connector を編集します。Connect ビューで、Settings の右上の一時停止アイコンを押して Elasticsearch Sink Connector を一時停止します。これで、関連するコンシューマーグループの消費が停止します。
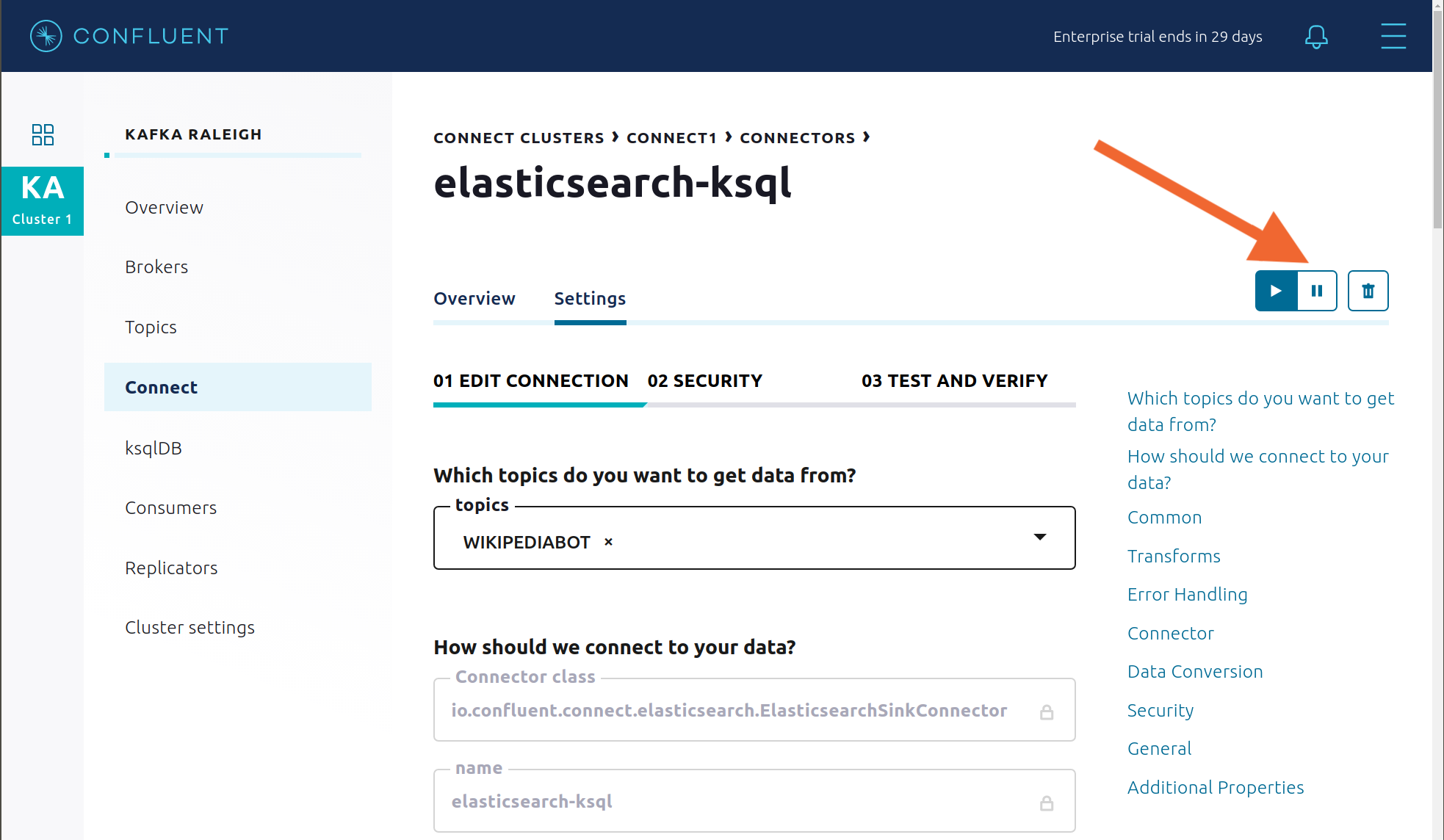
アラート履歴を表示して、このトリガーが作動したことが原因でアラートが生成されたことを確認します。
Confluent Self-Balancing Clusters¶
Self-Balancing Clusters はリソースのワークロードのバランスを自動で調整し、障害を検出して、自動で対応します。ユーザーはブローカーを必要に応じて追加や廃止でき、手動の調整は必要ありません。これによりスケールアップとスケールダウンの操作がシンプルになり、ワークロードが新しいブローカーに確実に割り当てられ、障害発生時のリカバリーが自動化されます。
このセクションでは、Self-Balancing Clusters の 2 つの機能を確認します。
- 新しいブローカーをクラスターに追加(スケールアップ): 既存のパーティションを新しいブローカーに割り当てて、Self-Balancing Clusters により、クラスターのバランス調整が行われることを確認します。
- ブローカーを強制終了して障害のシミュレーションを実行: Self-Balancing Clusters により、障害の発生したブローカーのレプリカが残りのブローカーに再割り当てされることを確認します。
このセクションの実行前に:
- Self-Balancing の初期化とクラスター内のブローカーのメトリクスの収集には 15 分かかります。そのため、
cp-demoの起動後、この時間以上待ってから次に進みます。 - これらの手順により 3 つ目のブローカーが追加されるため、十分なリソースが Docker に割り当てられていることを確認します。
scripts/sbc/add-broker.sh を実行して、新しいブローカー
kafka3をクラスターに追加します。./scripts/sbc/add-broker.sh
Self-Balancing Clusters でブローカーの追加が確認され、バランス調整のタスクが開始されると、スクリプトに制御が戻ります。
Control Center at http://localhost:9021 を開き、
Brokersに移動します。Self-balancing パネルに、進行中のタスク数として 1 と表示されます。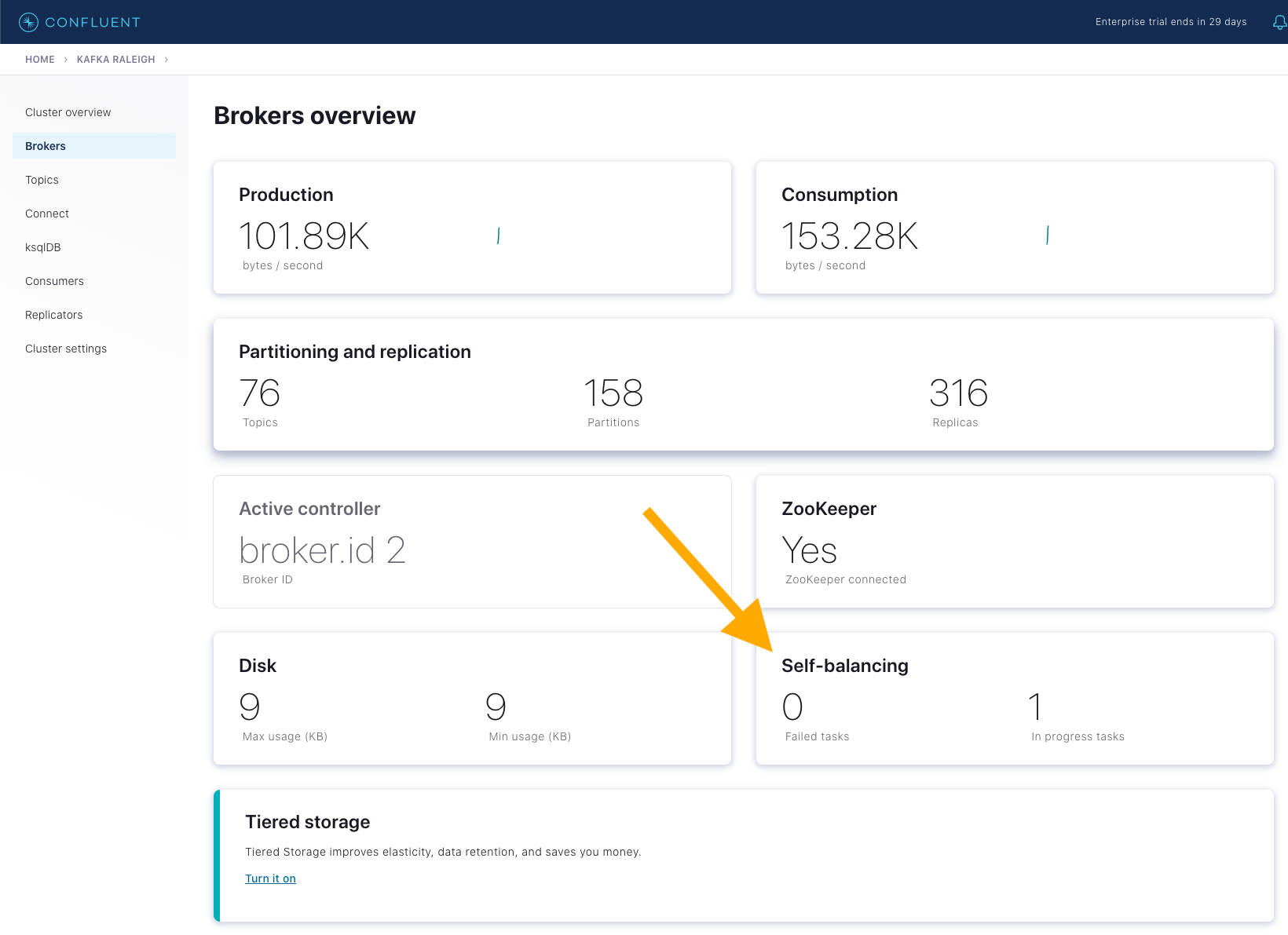
パネルをクリックし、ID が
broker.3のブローカーの、進行中のブローカーの追加タスクを見つけます。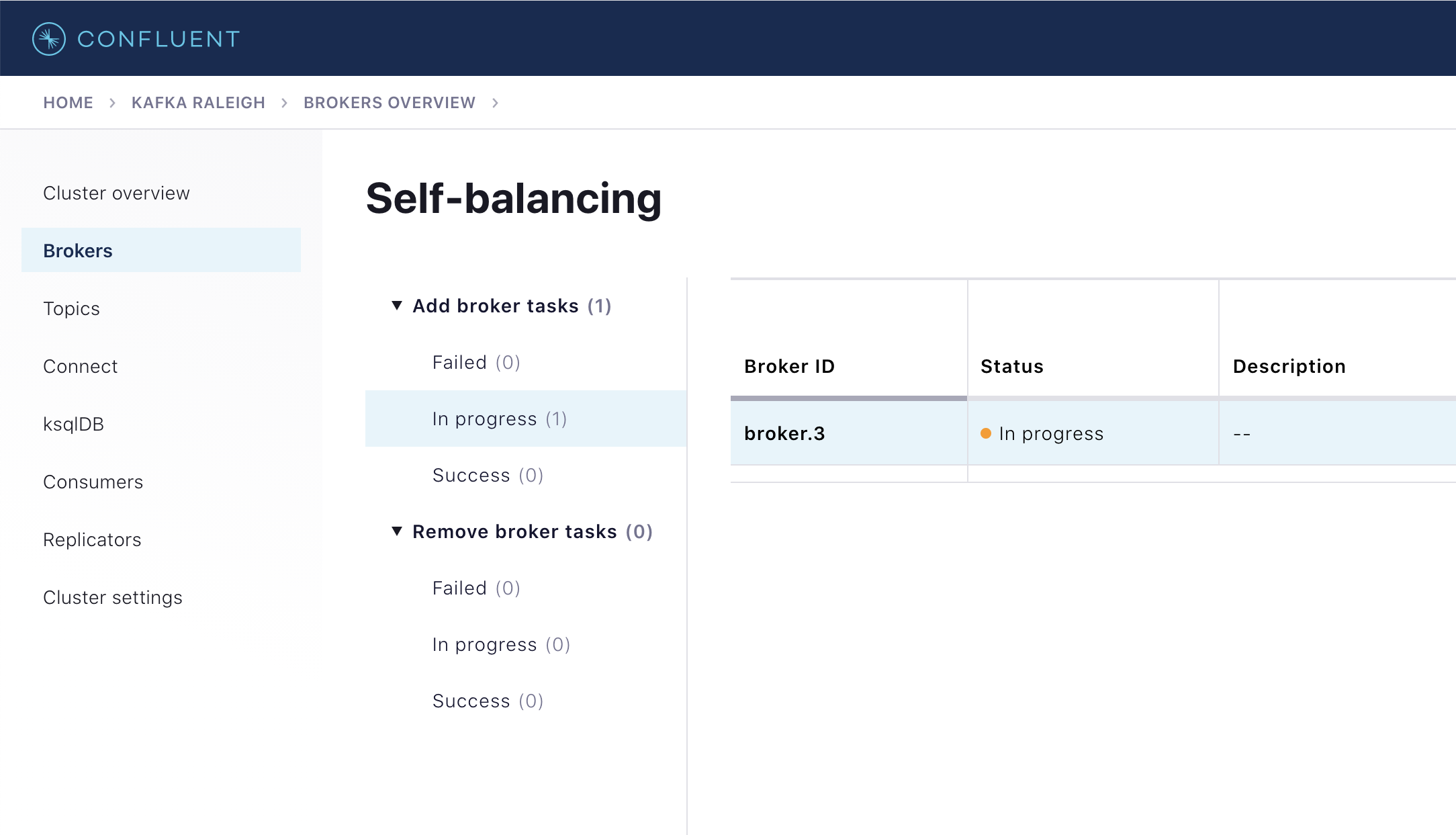
ブローカーの追加のバランス調整のタスクは、
PLAN_COMPUTATION、REASSIGNMENT、そしてCOMPLETEDの順に進行します。各段階の所要時間は、実行しているハードウェアによって異なります。次のスクリプトを実行してブローカーログを読み取り、ステータスを確認します。./scripts/sbc/validate_sbc_add_broker_plan_computation.sh ./scripts/sbc/validate_sbc_add_broker_reassignment.sh ./scripts/sbc/validate_sbc_add_broker_completed.sh
数分後にバランス調整が完了すると、Confluent Control Center のブローカーの追加のバランス調整タスクが
Successに移行します。次のコマンドを実行して、クラスター内のすべてのトピックパーティションのレプリカの配置を表示します。docker-compose exec kafka1 kafka-replica-status \ --bootstrap-server kafka1:9091 \ --admin.config /etc/kafka/secrets/client_sasl_plain.config
Replica列が3のインスタンスを見つけます。バランス調整により、パーティションのレプリカ(リーダーとフォロワー)が新しいブローカーに割り当てられています。scripts/sbc/kill-broker.sh を実行して、先ほど追加したブローカー
kafka3を強制終了して、ブローカーの障害のシミュレーションを実行します。./scripts/sbc/kill-broker.sh
このスクリプトは、Self-Balancing Clusters がブローカーの障害を検出し、リカバリの待機時間
KAFKA_CONFLUENT_BALANCER_HEAL_BROKER_FAILURE_THRESHOLD_MSが経過すると、制御が戻ります。リカバリの待機時間が経過すると、kafka3ブローカーから元の 2 つのブローカーへのレプリカの再割り当てが行われます。cp-demoでは、しきい値の時間が 30 秒に設定されていることに注意してください。意図的に低い値となっていますが、デモ環境では役立ちます。障害の発生したブローカーからのレプリカの再割り当ての進捗をモニタリングします。クラスター内のレプリケーション数が不足しているパーティションの数が徐々に減り、ゼロに戻ります。自動調整の完了を追跡するには、Confluent Control Center の
Self-Balancingパネルを確認するか、次のスクリプトを実行します。./scripts/sbc/validate_sbc_kill_broker_started.sh ./scripts/sbc/validate_sbc_kill_broker_completed.sh
自動調整が完了すると、Kafka クラスターには、レプリケーション数が不足しているパーティションがなくなります(障害の発生したブローカー
kafka3に障害発生前に割り当てられていた分です)。これを確認するには、このコマンドを実行して出力がないことを確認します。出力がないのは、同期されていないレプリカがないことを意味します。docker-compose exec kafka1 kafka-replica-status \ --bootstrap-server kafka1:9091 \ --admin.config /etc/kafka/secrets/client_sasl_plain.config \ --verbose | grep "IsInIsr: false"
モニタリング¶
このチュートリアルでは、ユーザーが Confluent Platform デプロイを管理するために Confluent Control Center がどのように役立つか、およびクラスターとアプリケーションのモニタリング機能がどのように提供されるかを紹介しました。スループット、レイテンシ、耐久性、可用性などのさまざまなサービス目標のための Kafka デプロイの最適化、およびオンプレミス Kafka クラスターのパフォーマンスとクラスター正常性のモニタリングに便利なメトリクスの実用的なガイドについては、『Optimizing Your Apache Kafka Deployment』ホワイトペーパーを参照してください。
ほとんどの Confluent Platform ユーザーにとって、Confluent Control Center のモニタリングと統合だけで、Apache Kafka® のオンプレミスデプロイにおける本稼働環境での使用には十分です。以下で説明するように、さまざまなユースケースに対応するその他のモニタリングソリューションもあります。
Metrics API¶
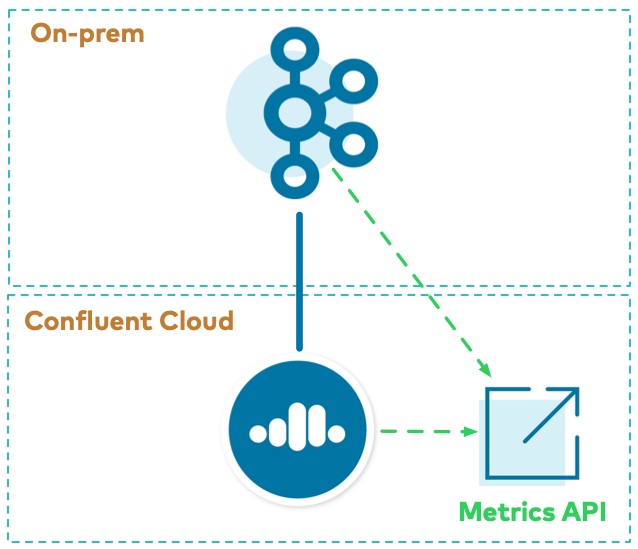
Metrics API を使用して、オンプレミスのクラスターと Confluent Cloud クラスターの両方からデータを取得できます。Metrics API では、クエリ可能な HTTP API が用意されており、クエリを POST して時系列のメトリクスを取得することができます。これを使用して、次の両方を観察できます。
- エンドポイント https://api.telemetry.confluent.cloud/v2/metrics/hosted-monitoring/query を使用するオンプレミスのメトリクス(Telemetry Reporter により有効化)(これはプレビュー版で、API は変更される可能性があります)
- エンドポイント https://api.telemetry.confluent.cloud/v2/metrics/cloud/query を使用する Confluent Cloud メトリクス
詳細については、「モジュール 2: Confluent Cloud へのハイブリッドデプロイのチュートリアル」を参照してください。
JMX¶
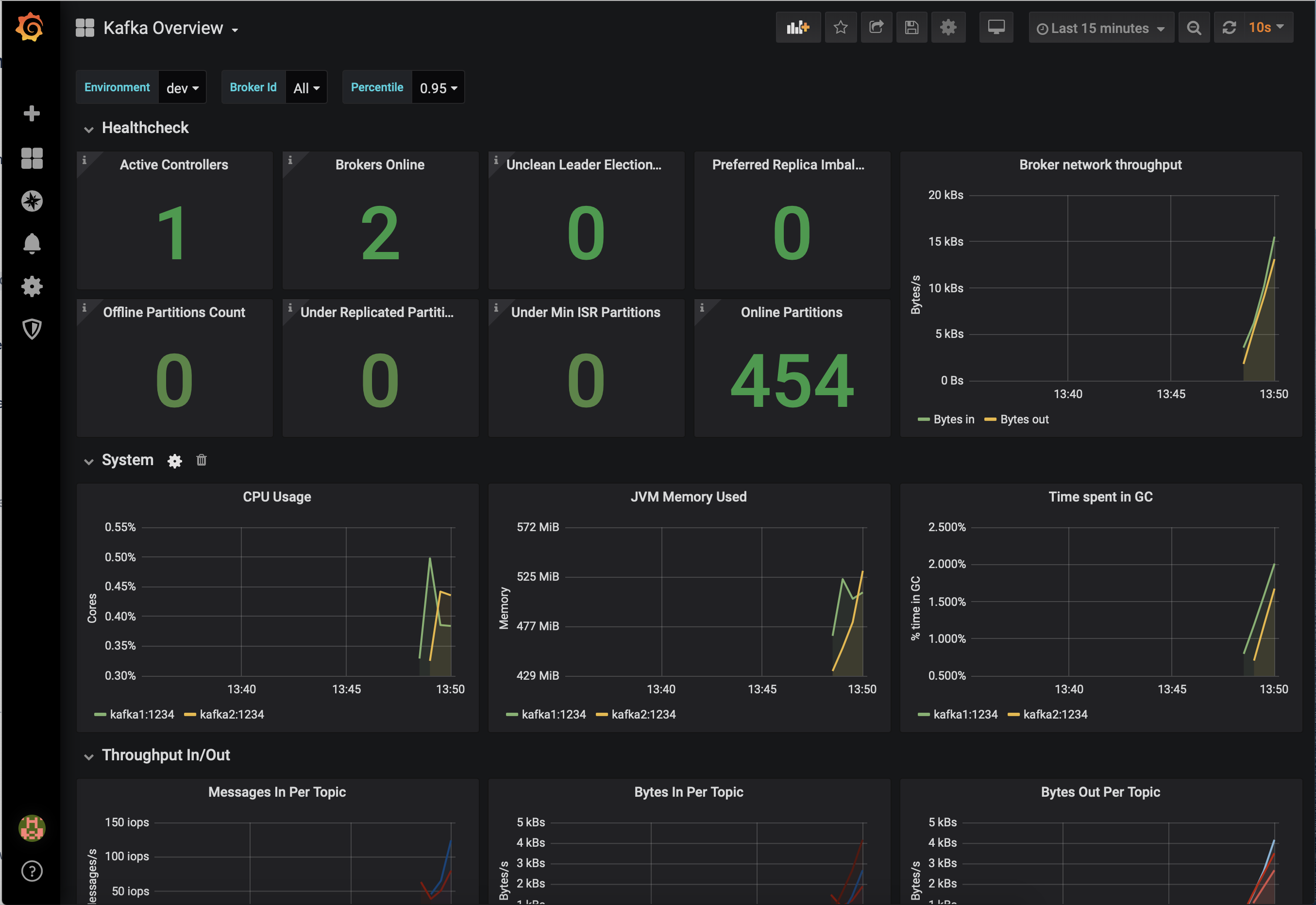
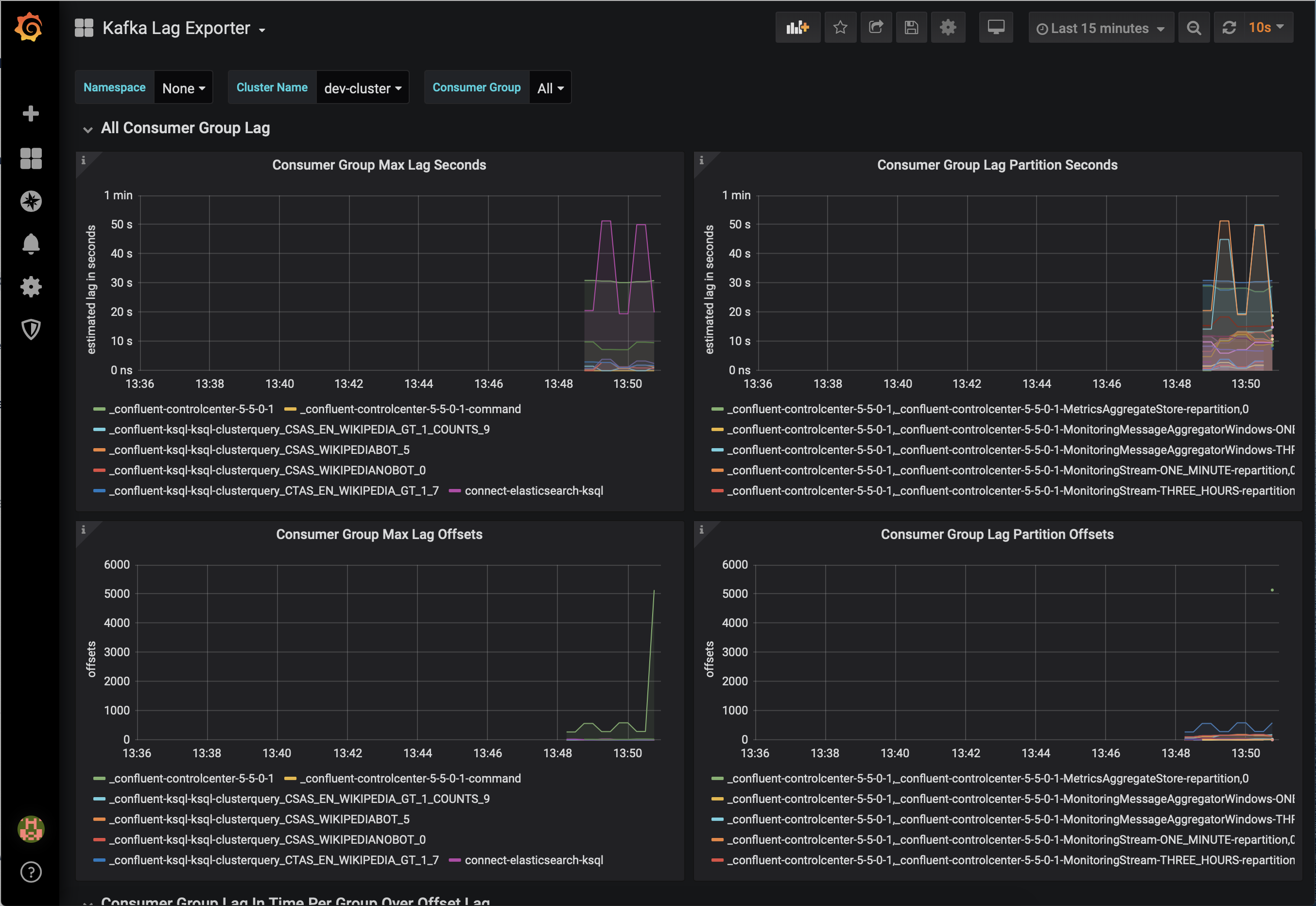
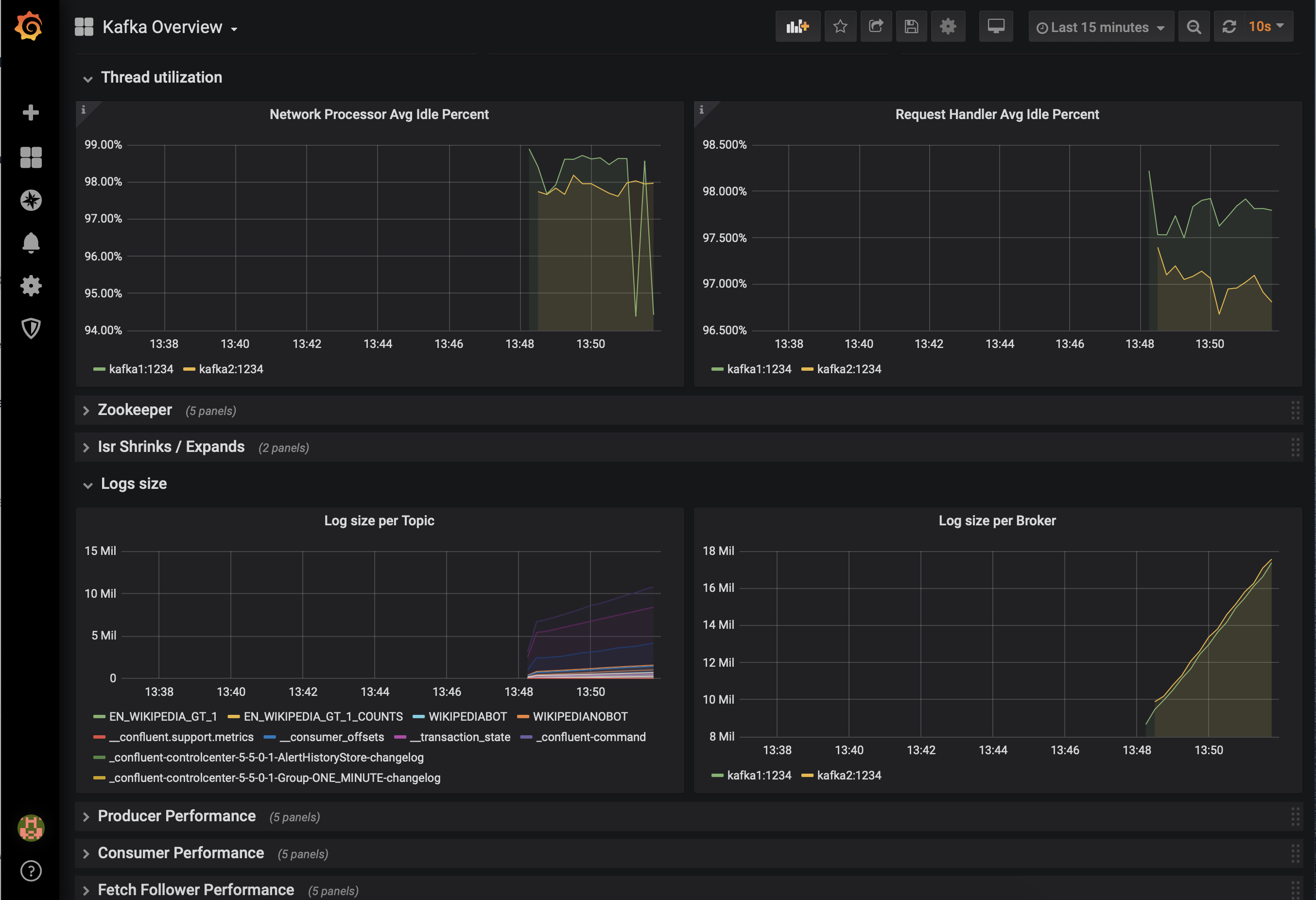
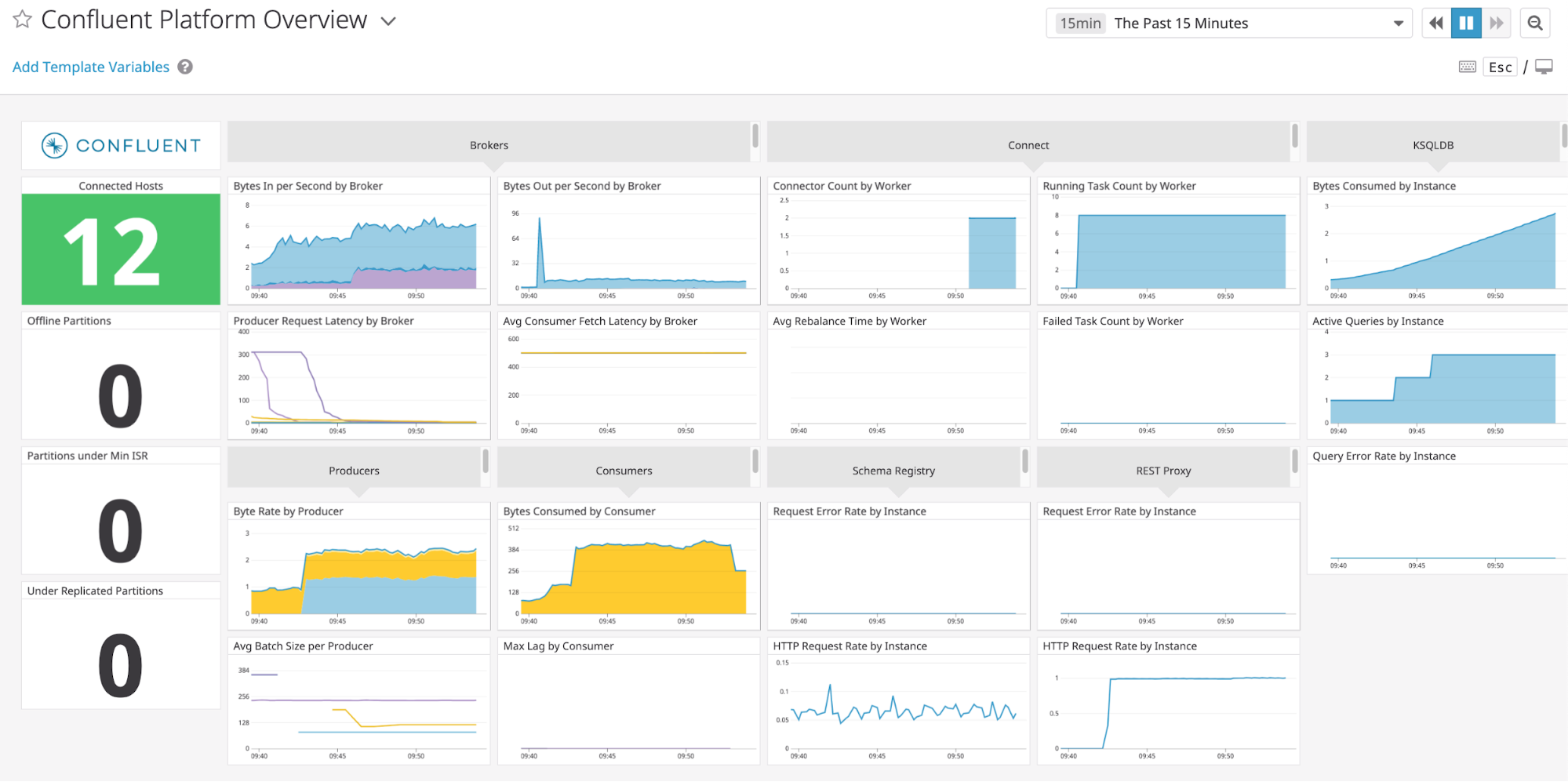
Prometheus、Grafana、Datadog、Splunk など、他のモニタリングソリューションとの統合が必要な場合もあります。次の JMX ベースのモニタリングスタックを使用すると、"1 枚のガラス" のようにインターフェイスが統一された、組織のすべてのサービスとアプリケーション(Kafka など)用のモニタリングソリューションをセットアップできます。
次に示すのは、Confluent Platform と統合されたモニタリングスタックのいくつかの例です。