チュートリアル: ストリーミングアプリケーション開発入門¶
自分のペースで進められるこのチュートリアルには、サービスベースのアーキテクチャとストリーミングアプリケーション開発の基本原則を開発者が学ぶための演習が含まれています。
- 演習 1: イベントの永続化
- 演習 2: イベント駆動型アプリケーション
- 演習 3: 結合によるストリームの拡張
- 演習 4: フィルターとブランチ
- 演習 5: ステートフルな操作
- 演習 6: ステートストア
- 演習 7: ksqlDB による拡張
概要¶
このチュートリアルは、小規模なマイクロサービスエコシステムに基づいており、小売業やオンラインショッピングで見られるような注文管理ワークフローを紹介しています。Apache Kafka® を使用して構築されており、注文管理ワークフローを記述したビジネスイベントが、このエコシステム経由で伝播されます。ブログの投稿「Building a Microservices Ecosystem with Kafka Streams and KSQL」には、ここで使用するアプローチの概要が記載されています。
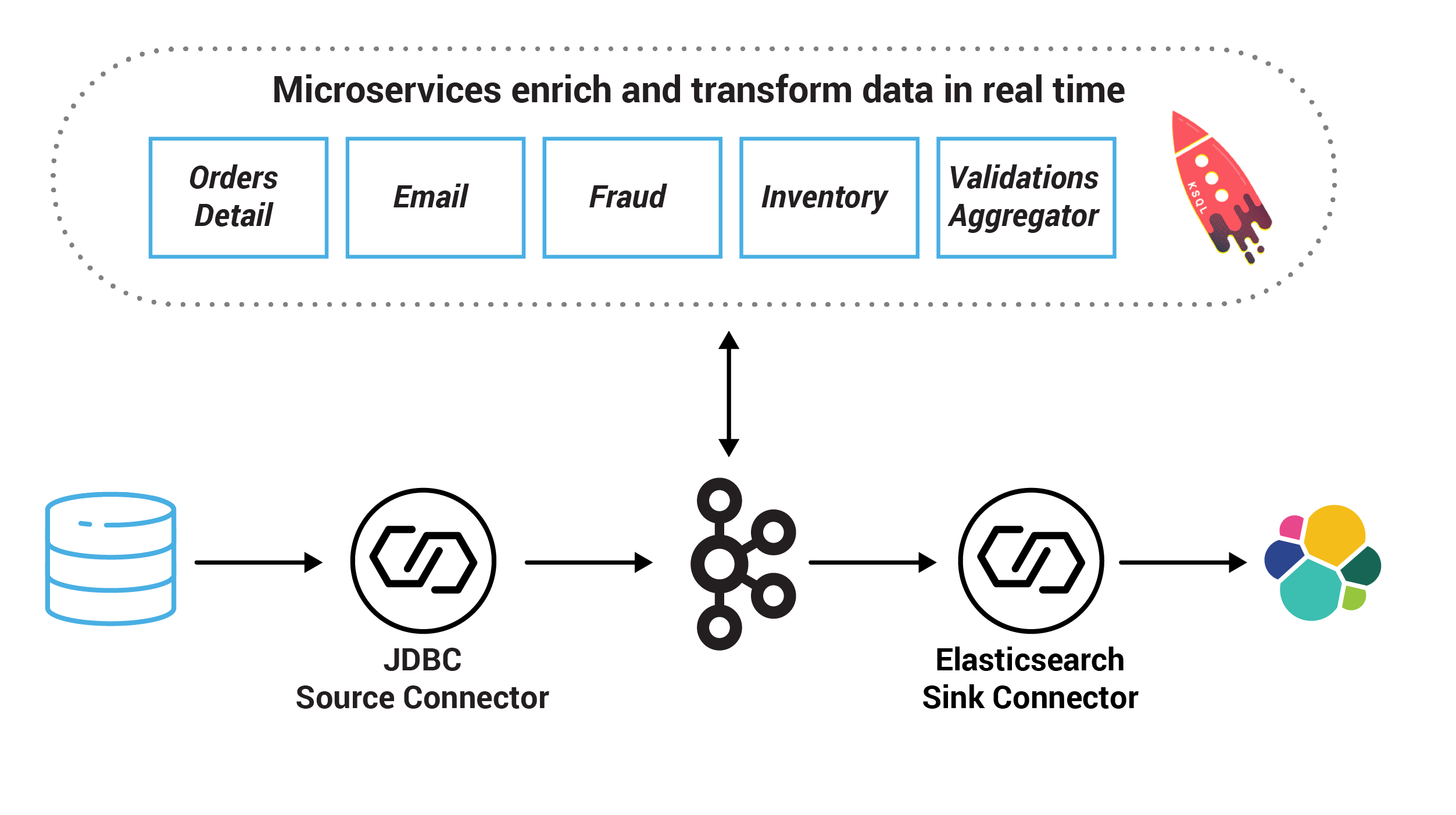
注: これはサンプルコードであり、本稼働環境システムではありません。また、一部についてはさらなる検討が必要です。
マイクロサービス¶
このサンプルでは、システムの中心は、POST Order と GET Order に対して REST インターフェイスを公開する Orders Service です。POST Order を実行すると、Kafka にイベントが作成され、トピック orders に記録されます。これを、さまざまな検証エンジン(Fraud Service、Inventory Service、および Order Details Service)が回収し、並行して注文を検証して、それぞれの検証が成功したかどうかに基づいて PASS または FAIL を発行します。
各検証の結果は、別のトピック、Order Validations 経由でプッシュされるため、Orders Service —> Orders Topic の single writer ステータスが保持されます(Ben Stopford による Ebook では、イベントコラボレーションの一貫性の管理に関するいくつかの選択肢について解説しています)。
さまざまな検証チェックの結果は Validation Aggregator Service で集計され、その後、結果の組み合わせに基づいて、Validated または Failed のステートに注文が移動されます。
ユーザーが任意の注文を GET で取得できるように、Orders Service は、クエリ可能なマテリアライズドビューを(Orders Service 内に組み込んで)作成します。このとき、サービスの各インスタンスでステートストアを使用するため、あらゆる注文を時系列でリクエストできます。また、Orders Service は、多数のノードへとスケールアウトできます。この場合、GET リクエストは、特定のキーを取得するために、正しいノードにルーティングされる必要があります。これは、Kafka Streams の対話型クエリ機能を使用して自動的に処理されます。
Orders Service には、ブロッキング HTTP GET も含まれているため、クライアントは自身の書き込みを読み取ることができます。このようにして、RESTful インターフェイスの同期ブロッキングパラダイムと、サーバー側で実行される非同期の非ブロッキング処理が連結されます。
1 つの単純なサービスがメールを送信します。そして、別のサービスが注文を照合し、Elasticsearch を使用して検索インデックスで注文を使用できるようにします。
最後に、ksqlDB が永続的クエリとともに動作してストリームを拡張し、不正行為のチェックも行います。
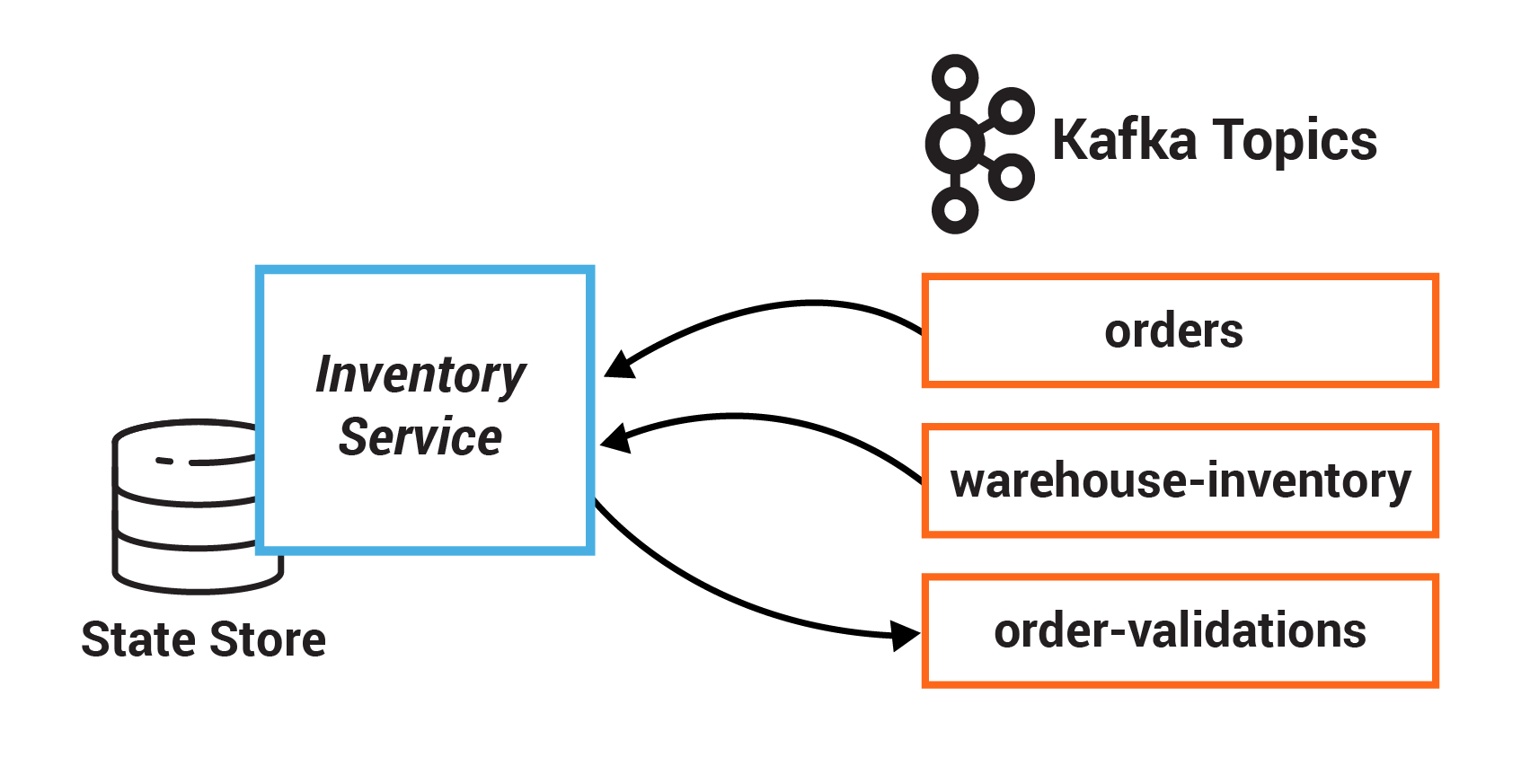
以下の図は、マイクロサービスおよび関連する Kafka のトピックを示します。
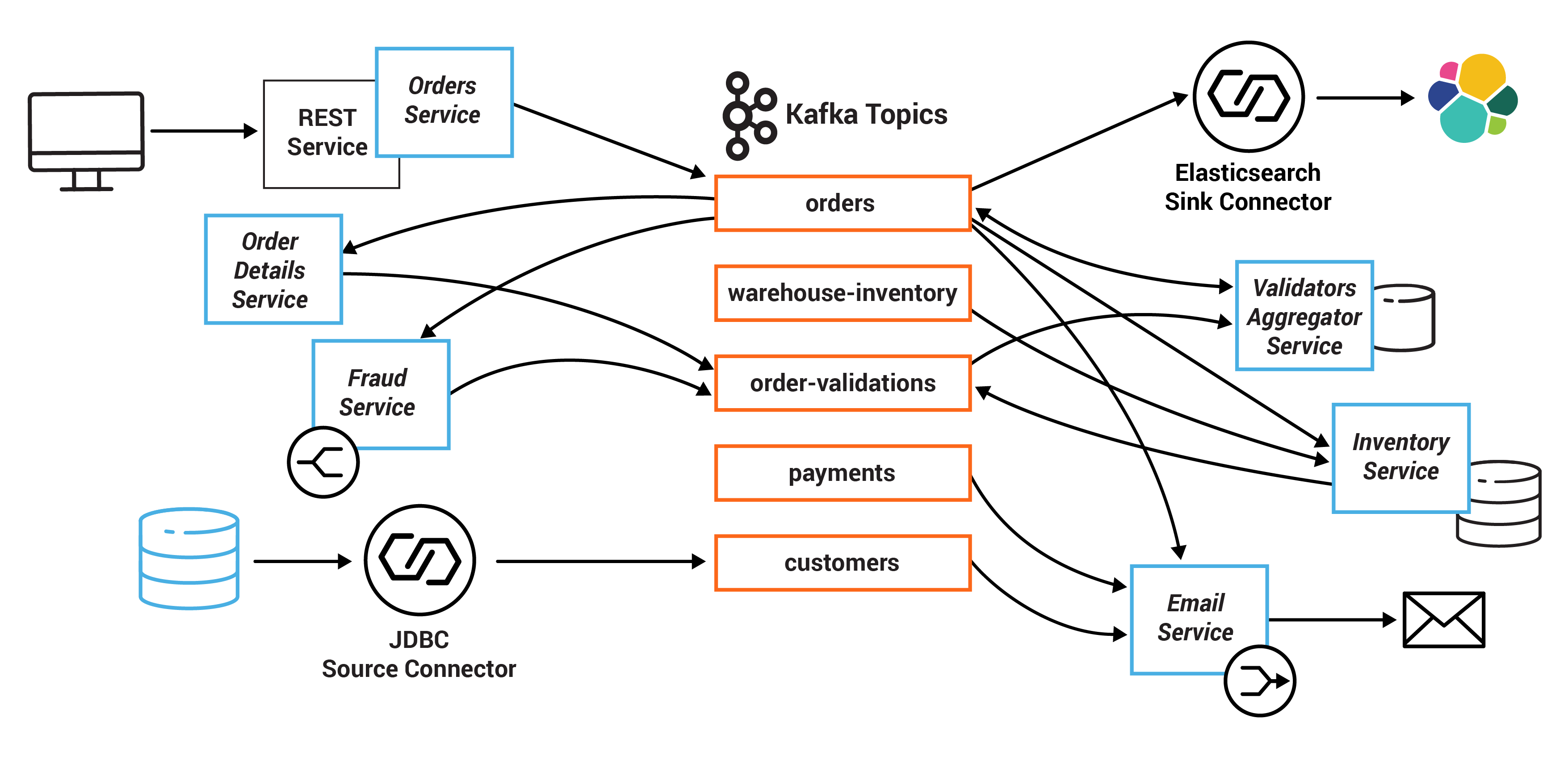
すべてのサービスは、Java で書かれたクライアントアプリケーションであり、Kafka Streams API を使用します。これらのマイクロサービスの Java ソースコードは、kafka-streams-examples リポジトリ にあります。
サービスと、その消費元と生成先のトピックは、次のとおりです。
| サービス | 消費元 | 生成先 |
|---|---|---|
| InventoryService | orders、warehouse-inventory | order-validations |
| FraudService | orders | order-validations |
| OrderDetailsService | orders | order-validations |
| ValidationsAggregatorService | order-validations、orders | orders |
| EmailService | orders、payments、customers | platinum、gold、silver、bronze |
| OrdersService | 該当なし | orders |
エンドツーエンドのストリーミング ETL¶
このサンプルでは、上で説明したマイクロサービスを中心として構築されたエンドツーエンドストリーミング ETL デプロイ全体を紹介します。これは Confluent Platform 上で構築され、次のものが含まれます。
- JDBC Source Connector: 顧客情報のテーブルを持つ SQLite データベースから読み取り、Connect 変換によって各メッセージにキーを追加して Kafka のトピックにデータを書き込みます。
- Elasticsearch Sink Connector: データを Kafka のトピックから Elasticsearch にプッシュします。
- ksqlDB: 不正検出マイクロサービスのもう 1 つのバリアント。
| その他のクライアント | 消費元 | 生成先 |
|---|---|---|
| JDBC Source Connector | DB | customers |
| Elasticsearch Sink Connector | orders | ES |
| ksqlDB | orders、customers | ksqlDB ストリームおよびテーブル |
エンドツーエンドのサンプルでは、Orders Service への REST 呼び出し経由で注文イベントを作成し、初期インベントリを生成するコードが、次のアプリケーションによって提供されます。
| アプリケーション(Datagen) | 消費元 | 生成先 |
|---|---|---|
| PostOrdersAndPayments | 該当なし | payments |
| AddInventory | 該当なし | warehouse-inventory |
前提条件¶
読み取り¶
最初に、このチュートリアルの基盤である概念を学習しておくと、このチュートリアルの効果が大幅に増大します。サービスベースのアーキテクチャ、および Apache Kafka® などのストリーム処理プラットフォームがビジネスクリティカルなシステムの構築にどのように役立つかを学ぶには、以下をお勧めします。
- 時間に余裕がある場合 : Ben Stopford による Ebook、『Designing Event-Driven Systems』
- 時間に余裕がない場合 : 「Building a Microservices Ecosystem with Kafka Streams and KSQL」または「 Build Services on a Backbone of Events」
このチュートリアルの実行中にリファレンスとして使用できる Kafka Streams API についてさらに学習する場合は、以下をお勧めします。
環境¶
- アプリケーションのコンパイルおよび実行用:
- Java 1.8(デモアプリケーションの実行用)
- Maven(デモアプリケーションのコンパイル用)
- コネクター、Elasticsearch、Kibana を使用した Confluent Cloud でのエンドツーエンドのサンプル実行用:
- Confluent Cloud
- ローカルにインストールされた Confluent Cloud CLI (v1.25.0 以降)
- Docker バージョン 19.00.0 以降
- Docker Compose ファイルフォーマット 3 の Docker Compose バージョン 1.25.0 以降
- Docker の詳細 設定 で、Docker 専用のメモリーを 6 GB 以上に増やします(デフォルトは 2 GB)
チュートリアル¶
チュートリアルのセットアップ¶
confluentinc/examples GitHub リポジトリのクローンを作成します。
git clone https://github.com/confluentinc/examples
examples/microservices-ordersディレクトリに移動し、Confluent Platform リリースブランチに切り替えます。cd examples/microservices-orders git checkout 6.2.4-post
演習 0: エンドツーエンドのサンプルの実行¶
この演習は任意ですが、エンドツーエンドソリューション全体を実行して、顧客担当者によるストリーミングアプリケーションのデプロイを確認することをお勧めします。これには、コード開発は必要ありません。マイクロサービスの各部分を開発する各演習のコンテキストを提供するだけです。完全に機能するサンプルをエンドツーエンドで実行すると、以降の各演習のコンテキストが提供されます。アプリケーションのコードはローカルで実行され、Kafka クラスターは Confluent Cloud に存在します。
実行のコスト¶
以下のコストが該当するのは、Confluent Cloud を使用して実行する演習 0 のみです。他の演習はローカルで実行されるため、コストはかかりません。
Confluent Cloud のすべてのサンプルでは、課金される可能性のある実際の Confluent Cloud リソースを使用しています。サンプルで、新しい Confluent Cloud 環境、Kafka クラスター、トピック、ACL、サービスアカウントに加えて、コネクターや ksqlDB アプリケーションのように時間で課金されるリソースを作成する場合があります。想定外の課金を避けるために、慎重に リソースのコストを確認 してから開始してください。Confluent Cloud のサンプルの実行を終了したら、サービスへの時間単位の課金を回避するためにすべての Confluent Cloud リソースを破棄し、リソースが削除されたことを確認します。
Confluent Cloud Console の Billing & payment セクションでプロモーションコード C50INTEG を入力すると、Confluent Cloud で $50 相当を無料で使用できます(詳細)。このプロモーションコードで、この Confluent Cloud サンプルの 1 日分の実行費用が補填されます。これを超えてサービスを利用すると、このサンプルで作成した Confluent Cloud リソースを破棄するまで、時間単位で課金されることがあります。
手順¶
コマンド
ccloud loginで、Confluent Cloud のユーザー名とパスワードを使用して Confluent Cloud にログインします。ログアウトされないようにするために、--save引数を使用して Confluent Cloud ユーザーログイン認証情報を保存するか、ホームの.netrcファイルに対してトークンを更新します(SSO の場合)。ccloud login --save
用意されているスクリプトを実行して、エンドツーエンドのサンプルを起動します。
このサンプルでは、Confluent Cloud 向け ccloud-stack ユーティリティ を使用して、完全マネージドサービスのスタックを Confluent Cloud に自動的に作成します。デフォルトでは、
ccloud-stackユーティリティにより、リージョンus-west-2にあるクラウドプロバイダーawsの新しい Confluent Cloud 環境にリソースが作成されます。既存の Confluent Cloud 環境を再利用する場合、またはawsとus-west-2がターゲットとなるプロバイダーやリージョンではない場合は、サンプルを実行する前に、その他の ccloud-stack オプション を構成することができます。./start-ccloud.sh
サンプルを起動すると、マイクロサービスアプリケーションがローカルで実行され、Confluent Cloud インスタンスで Kafka のトピック内にデータが存在するようになります。
次のコマンドを実行してトピックデータをサンプリングします。使用する構成ファイルの名前を
stack-configsサンプルフォルダー内にあるファイル(java-service-account-12345.config)に置き換えます。source delta_configs/env.delta; CONFIG_FILE=/opt/docker/stack-configs/java-service-account-<service-account-id>.config ./read-topics-ccloud.sh
Elasticsearch と Kibana でデータを調べます。
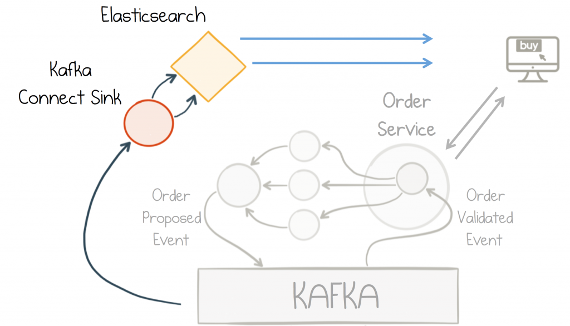
全文検索は、Kafka の Connect API を介して接続された Elasticsearch データベース経由で追加されます( 出典 )。http://localhost:5601/app/kibana#/dashboard/Microservices にある Kibana ダッシュボードを表示します。
ストリーミングアプリケーションを表示し、モニタリングします。Confluent Cloud Console を使用して、トピック、コンシューマー、データフロー、および ksqlDB アプリケーションを調べます。
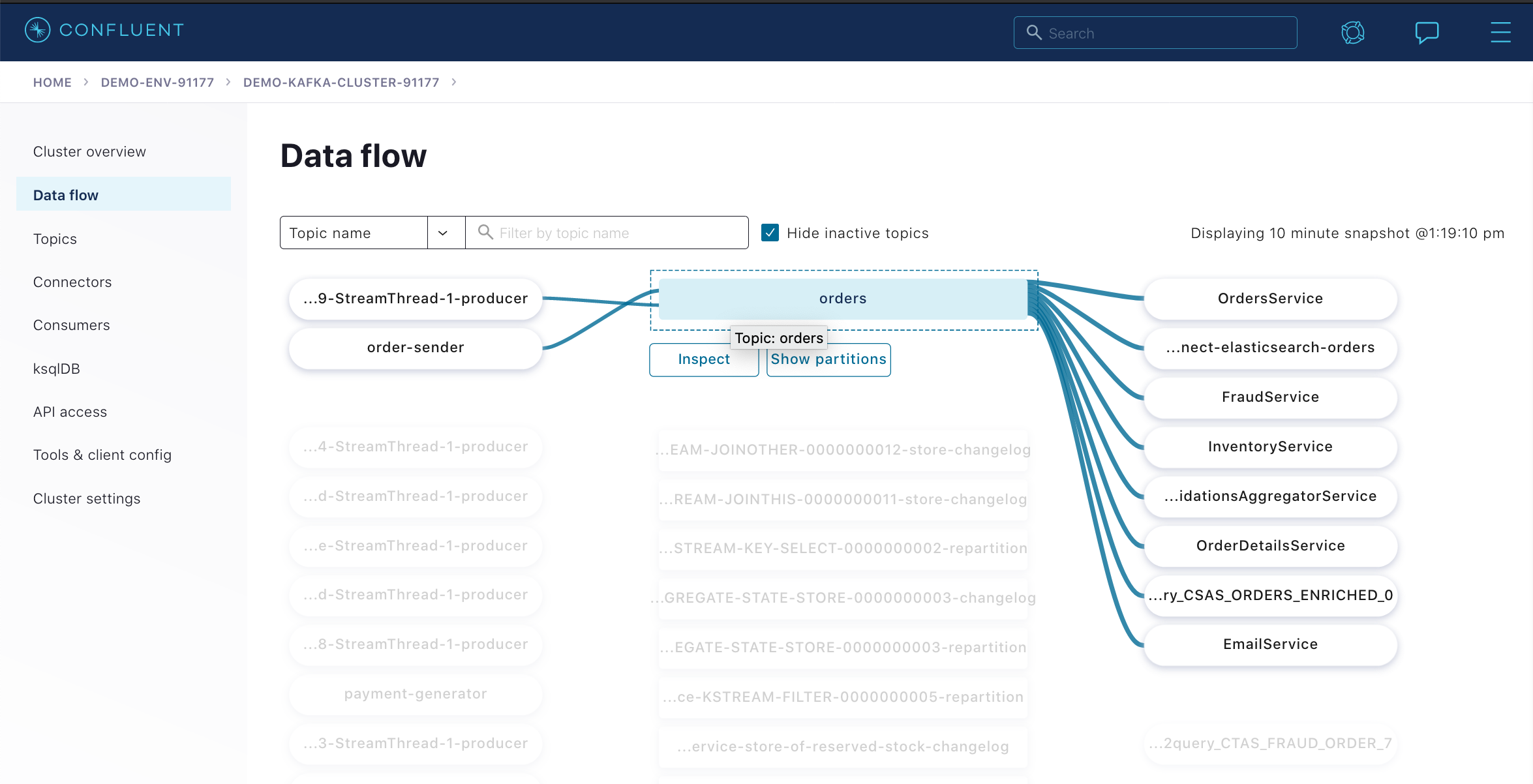
ORDERSストリームの ksqlDB フロー画面を表示して、発生するイベントを観察し、ストリームのスキーマをチェックします。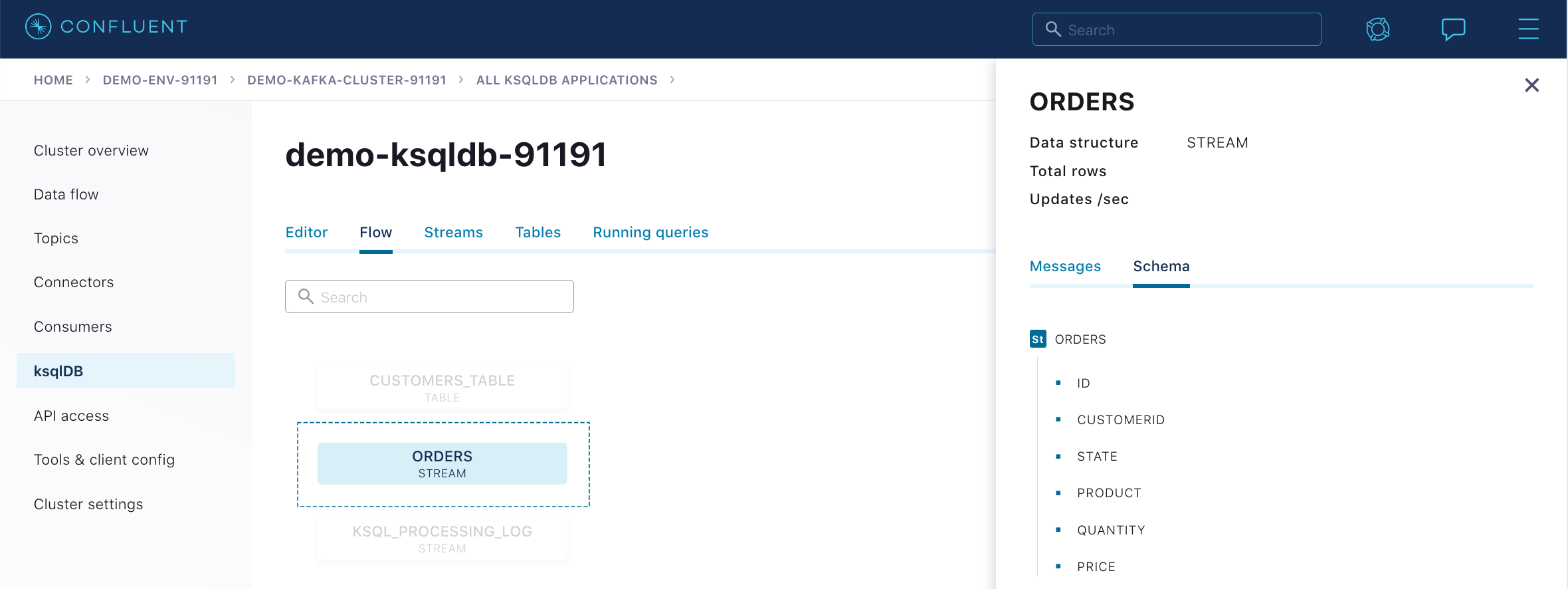
終了したら、必ずサンプルを停止してから演習に進んでください。以下のコマンドを実行します。ここで、
java-service-account-<service-account-id>.configファイルは、stack-configsフォルダー内のファイルに一致します。./stop-ccloud.sh stack-configs/java-service-account-12345.config
演習 1: イベントの永続化¶
イベント は、単に、発生した出来事です。ビジネスにおけるイベントとは、販売、請求書、取引、カスタマーエクスペリエンスなど、発生した事実であり、Source of Truth(信頼できる唯一の情報源)です。イベント指向型アーキテクチャにおいてイベントは、絶え間なくデータをアプリケーションにプッシュする第一級オブジェクトです。その後、クライアントアプリケーションがイベントのこのストリームにリアルタイムで応答し、次の動作を決定することができます。
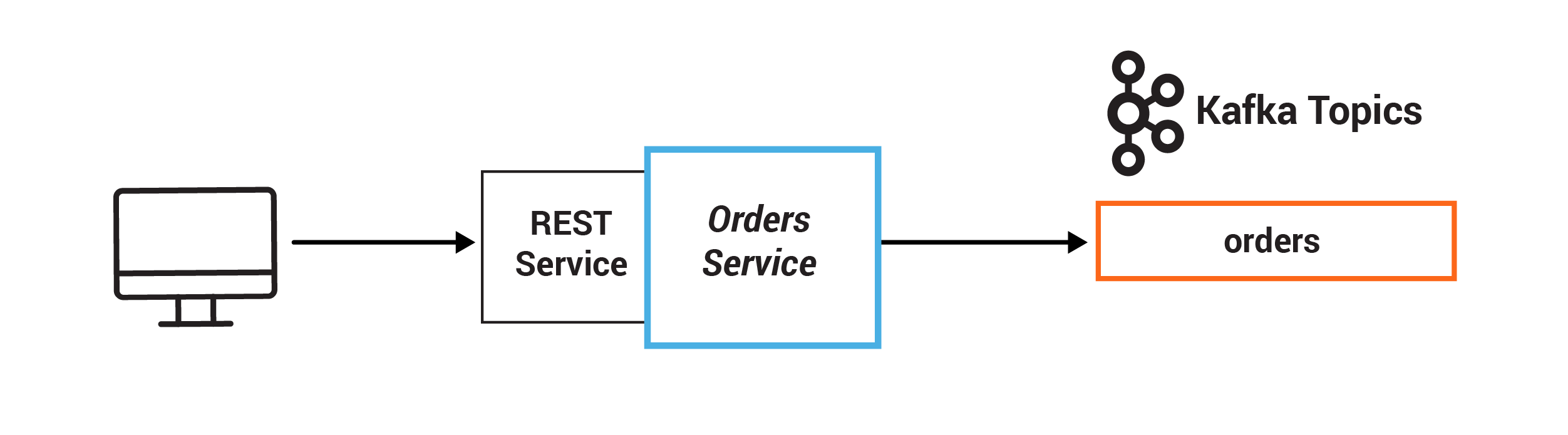
この演習では、顧客の注文を表すレコードを生成してイベントを Kafka へと永続化します。このイベントは Orders Service で発生し、これにより、POST Order と GET Order への REST インターフェイスが提供されます。POST Order の実行は、基本的に REST 呼び出しであり、Kafka でイベントを作成します。
ファイル exercises/OrdersService.java の "TODO" 行の実装
ls exercises/OrdersService.java
- TODO 1.1: bean.getId() で指定されたキーおよび bean の値を含む新規 ProducerRecord を、ORDERS.name() で名前が指定された注文トピックに対して作成します。
- TODO 1.2: 既存の producer を使用して新規作成レコードを生成し、OrdersService#callback 関数を使用して response およびレコードキーを送信します。
ちなみに
以下の API が役立ちます。
- https://docs.confluent.io/platform/current/clients/javadocs/javadoc/org/apache/kafka/clients/producer/ProducerRecord.html#ProducerRecord-java.lang.String-K-V-
- https://docs.confluent.io/platform/current/clients/javadocs/javadoc/org/apache/kafka/clients/producer/Callback.html
- kafka-streams-examples/src/main/java/io/confluent/examples/streams/microservices/domain/Schemas.java
- kafka-streams-examples/src/main/java/io/confluent/examples/streams/microservices/domain/beans/OrderBean.java
問題が発生した場合は、ソリューション一式 をご覧ください。
コードをテストするために、プロジェクトで使用しているソリューションを保存して、テストするバージョンのファイルをメインプロジェクトにコピーした後、コンパイルし、単体テストを実行します。
# Clone and compile kafka-streams-examples
./get-kafka-streams-examples.sh
# Save off the working microservices client application to /tmp/
cp kafka-streams-examples/src/main/java/io/confluent/examples/streams/microservices/OrdersService.java /tmp/.
# Copy your exercise client application to the project
cp exercises/OrdersService.java kafka-streams-examples/src/main/java/io/confluent/examples/streams/microservices/.
# Compile the project and resolve any compilation errors
mvn clean compile -DskipTests -f kafka-streams-examples/pom.xml
# Run the test and validate that it passes
mvn compile -Dtest=io.confluent.examples.streams.microservices.OrdersServiceTest test -f kafka-streams-examples/pom.xml
演習 2: イベント駆動型アプリケーション¶
サービスベースのアーキテクチャは、多くの場合、リクエスト駆動型として設計されます。この場合、サービスは、必要な動作を指示するコマンドを他のサービスに送信した後、応答を待つか、結果の状態を知るためにクエリを送信します。リクエストと応答のプロトコルを基盤としてサービスを構築すると、複雑な網の目のように同期依存関係が強制的に形成され、サービスが結合されます。
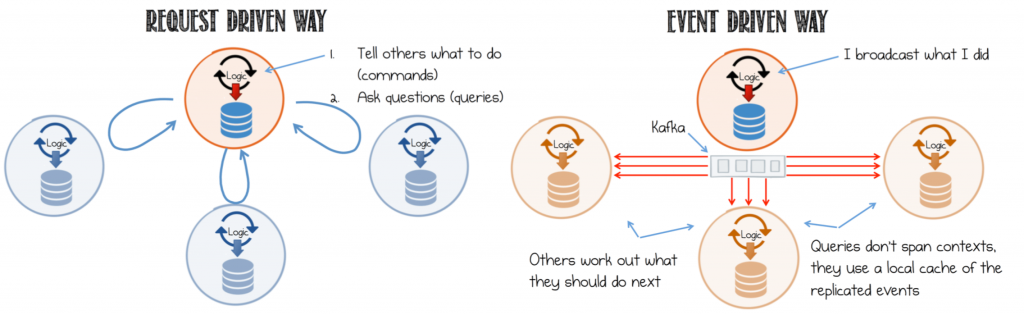
対照的にイベント駆動型の設計では、サービス間の通信はイベントストリームであり、これにより、デプロイの境界を越えたサービスが可能になり、同期実行が回避されます。ダウンストリームのサービス自体が、これらのイベントに応答するタイミングと方法を制御できるため、サービス間の連結が減少し、プラグイン性の高いアーキテクチャが可能になります。詳細については、「Build Services on a Backbone of Events」を参照してください。
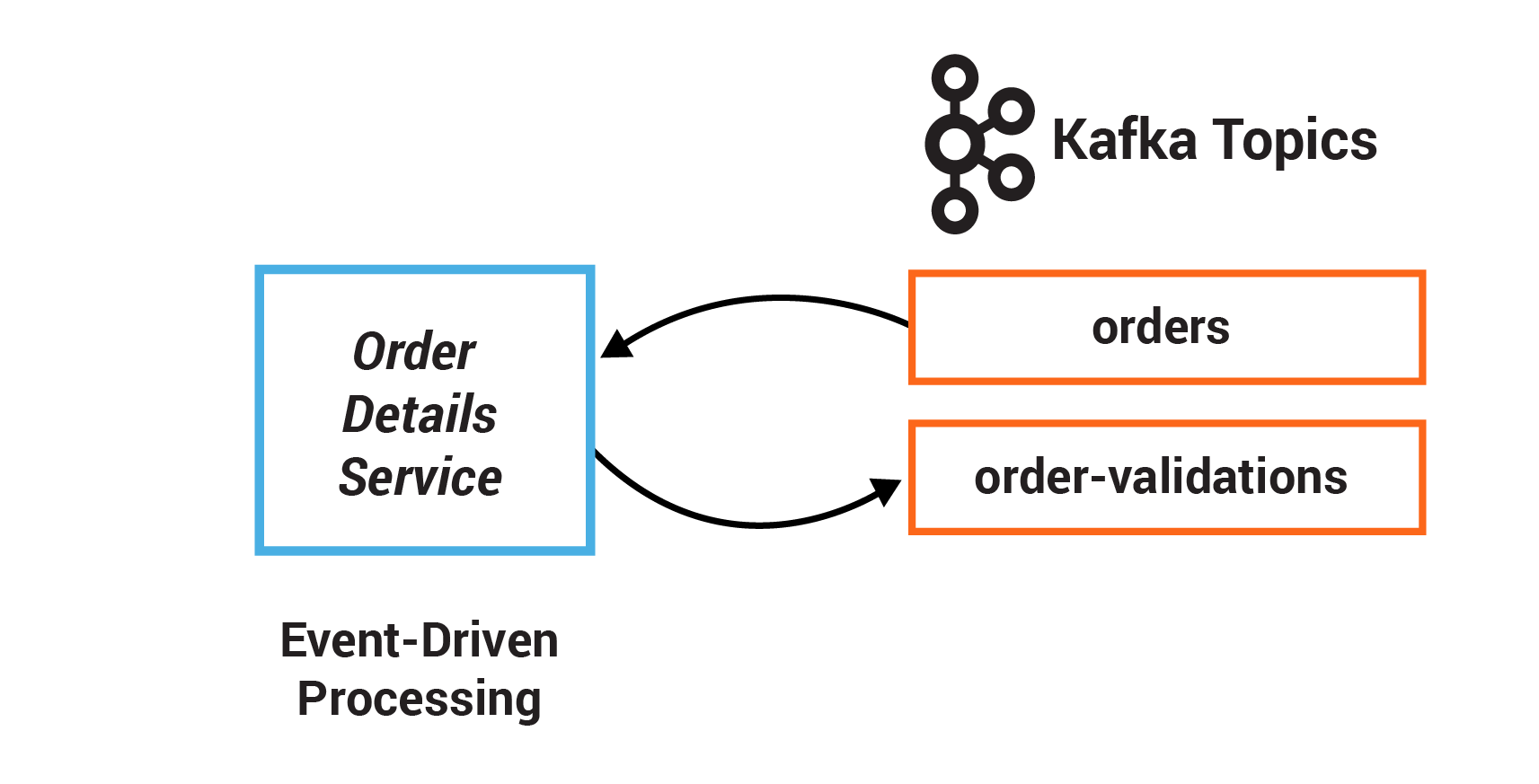
このサンプルでは、顧客の注文を検証するサービスを記述します。一連の同期呼び出しを使用して注文の送信と検証を行うのではなく、注文イベント自体が OrderDetailsService をトリガーします。新しい注文が作成されると、それがトピック orders に書き込まれ、このトピックから、OrderDetailsService のコンシューマーが新規レコードをポーリングします。
ファイル exercises/OrderDetailsService.java の "TODO" 行の実装
ls exercises/OrderDetailsService.java
- TODO 2.1: 既存の consumer を Collections#singletonList にサブスクライブします。このとき、Topics.ORDERS.name() で名前が指定された orders トピックを使用します。
- TODO 2.2: OrderDetailsService#isValid を使用して注文を検証し、検証結果をタイプ OrderValidationResult に保存します。
- TODO 2.3: 注文と検証結果を指定できる OrderDetailsService#result() を使用して新規レコードを作成します。
- TODO 2.4: 既存のプロデューサーを使用して、新規作成されたレコードを生成します。
ちなみに
以下の API が役立ちます。
- https://docs.confluent.io/platform/current/clients/javadocs/javadoc/org/apache/kafka/clients/consumer/KafkaConsumer.html#subscribe-java.util.Collection-
- https://docs.confluent.io/platform/current/clients/javadocs/javadoc/org/apache/kafka/clients/producer/KafkaProducer.html#send-org.apache.kafka.clients.producer.ProducerRecord-
- https://docs.oracle.com/javase/8/docs/api/java/util/Collections.html#singletonList-T-
- kafka-streams-examples/src/main/java/io/confluent/examples/streams/microservices/domain/Schemas.java
問題が発生した場合は、ソリューション一式 をご覧ください。
コードをテストするために、プロジェクトで使用しているソリューションを保存して、テストするバージョンのファイルをメインプロジェクトにコピーした後、コンパイルし、単体テストを実行します。
# Clone and compile kafka-streams-examples
./get-kafka-streams-examples.sh
# Save off the working microservices client application to /tmp/
cp kafka-streams-examples/src/main/java/io/confluent/examples/streams/microservices/OrderDetailsService.java /tmp/.
# Copy your exercise client application to the project
cp exercises/OrderDetailsService.java kafka-streams-examples/src/main/java/io/confluent/examples/streams/microservices/.
# Compile the project and resolve any compilation errors
mvn clean compile -DskipTests -f kafka-streams-examples/pom.xml
# Run the test and validate that it passes
mvn compile -Dtest=io.confluent.examples.streams.microservices.OrderDetailsServiceTest test -f kafka-streams-examples/pom.xml
演習 3: 結合によるストリームの拡張¶
ストリームは、結合により、他のストリームまたはテーブルからのデータで拡張できます。結合により、データが継続的かつ同時にアップデートされるストリーミングコンテキストでの検索が実行され、データが拡張されます。たとえば、オンラインの小売店舗を支えるアプリケーションが、新しいデータレコードを、複数のデータベースからの情報で拡張する場合があります。このシナリオでは、顧客トランザクションのストリームが販売価格、在庫数、顧客情報などで拡張される可能性があります。これらの検索は、非常に大規模に、低い処理レイテンシで実行できます。
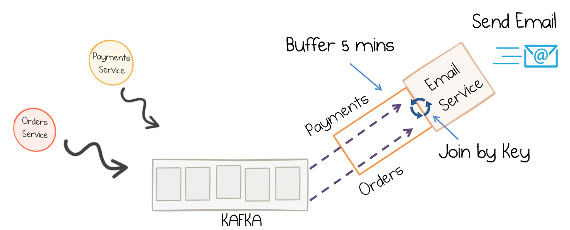
一般的な設計パターンでは、いわゆる変更データキャプチャー(CDC)と Kafka の Connect API を介して、データベース内の情報を Kafka で使用できるようにしてデータベースからデータをプルします。データが Kafka に入れられると、クライアントアプリケーションが、このようなテーブルとストリームを高速で効率的に結合できるため、アプリケーションでリモートデータベースへのクエリをレコードごとにネットワーク経由で実行する必要がなくなります。詳細については、分散されたリアルタイム結合の概要 および Kafka Streams での結合の実装 の説明を参照してください。

この演習では、ストリーミング注文情報を、ストリーミング支払い情報および顧客データベースのデータと結合するサービスを記述します。まず注文ストリームと同じキー情報が一致するように支払いストリームのキーを再設定してから、結合する必要があります。次に、こうして得られたストリームが、JDBC ソースによって顧客データベースから Kafka に読み込まれた顧客情報と結合されます。さらに、このサービスにより、ダイナミックなルーティングが実行されます。拡張された注文レコードが、対応する顧客のレベルフィールドの値で決定されるトピックに書き込まれます。
ファイル exercises/EmailService.java の "TODO" 行の実装
ls exercises/EmailService.java
- TODO 3.1: KStream#selectKey を使用して、payment.getOrderId() で指定される注文 ID(支払い ID ではなく)でキーを再設定することで、payments と呼ばれる新規 KStream を payments_original から作成します。
- TODO 3.2: customers テーブルでストリームとテーブルの結合を実行します。次の 3 つの引数が必要です。
- ストリームとテーブルの結合用の GlobalKTable
- レコードの値のタプルから顧客 ID を取得する KeyValueMapper を使用して order.getCustomerId() によって指定される顧客 ID
- 結果として得られたレコードの値を計算するメソッド(この場合は EmailTuple: :setCustomer)
- TODO 3.3: 拡張された注文レコードを、対応する顧客の customerLevel フィールドの値から動的に決定されるトピックにルーティングします。
ちなみに
以下の API が役立ちます。
- https://docs.confluent.io/platform/current/streams/javadocs/javadoc/org/apache/kafka/streams/kstream/Consumed.html#with-org.apache.kafka.common.serialization.Serde-org.apache.kafka.common.serialization.Serde-
- https://docs.confluent.io/platform/current/streams/javadocs/javadoc/org/apache/kafka/streams/StreamsBuilder.html#stream-java.lang.String-org.apache.kafka.streams.kstream.Consumed-
- https://docs.confluent.io/platform/current/streams/javadocs/javadoc/org/apache/kafka/streams/kstream/KStream.html#selectKey-org.apache.kafka.streams.kstream.KeyValueMapper-
- https://docs.confluent.io/platform/current/streams/javadocs/javadoc/org/apache/kafka/streams/kstream/KStream.html#join-org.apache.kafka.streams.kstream.KTable-org.apache.kafka.streams.kstream.ValueJoiner-org.apache.kafka.streams.kstream.Joined-
- kafka-streams-examples/src/main/java/io/confluent/examples/streams/microservices/domain/Schemas.java
- https://docs.confluent.io/platform/current/streams/javadocs/javadoc/org/apache/kafka/streams/kstream/KStream.html#to-org.apache.kafka.streams.processor.TopicNameExtractor-org.apache.kafka.streams.kstream.Produced-
問題が発生した場合は、ソリューション一式 をご覧ください。
コードをテストするために、プロジェクトで使用しているソリューションを保存して、テストするバージョンのファイルをメインプロジェクトにコピーした後、コンパイルし、単体テストを実行します。
# Clone and compile kafka-streams-examples
./get-kafka-streams-examples.sh
# Save off the working microservices client application to /tmp/
cp kafka-streams-examples/src/main/java/io/confluent/examples/streams/microservices/EmailService.java /tmp/.
# Copy your exercise client application to the project
cp exercises/EmailService.java kafka-streams-examples/src/main/java/io/confluent/examples/streams/microservices/.
# Compile the project and resolve any compilation errors
mvn clean compile -DskipTests -f kafka-streams-examples/pom.xml
# Run the test and validate that it passes
mvn compile -Dtest=io.confluent.examples.streams.microservices.EmailServiceTest test -f kafka-streams-examples/pom.xml
演習 4: フィルターとブランチ¶
イベントのストリームは、Kafka のトピック内にキャプチャーできます。その後、クライアントアプリケーションは、いくつかのユーザー定義の基準に基づいて、このストリームを処理します。アプリケーション自体またはダウンストリームのサービスの動作の対象となるデータの新規ストリームを作成する場合もあります。これは、より論理的で一貫性のあるデータで新規ストリームを作成するために役立ちます。場合によっては、特定の基準に一致する入力ストリームからのイベントをアプリケーションがフィルタリングすることが必要です。その結果、元のストリームからのレコードのサブセットのみを含む新規ストリームが作成されます。また、別のケースでは、アプリケーションがイベントをブランチングする必要があります。この場合、各イベントは、述語が一致するかをテストされた後、一致するストリームへとルーティングされます。その結果、元のストリームから分割された複数の新規ストリームが作成されます。
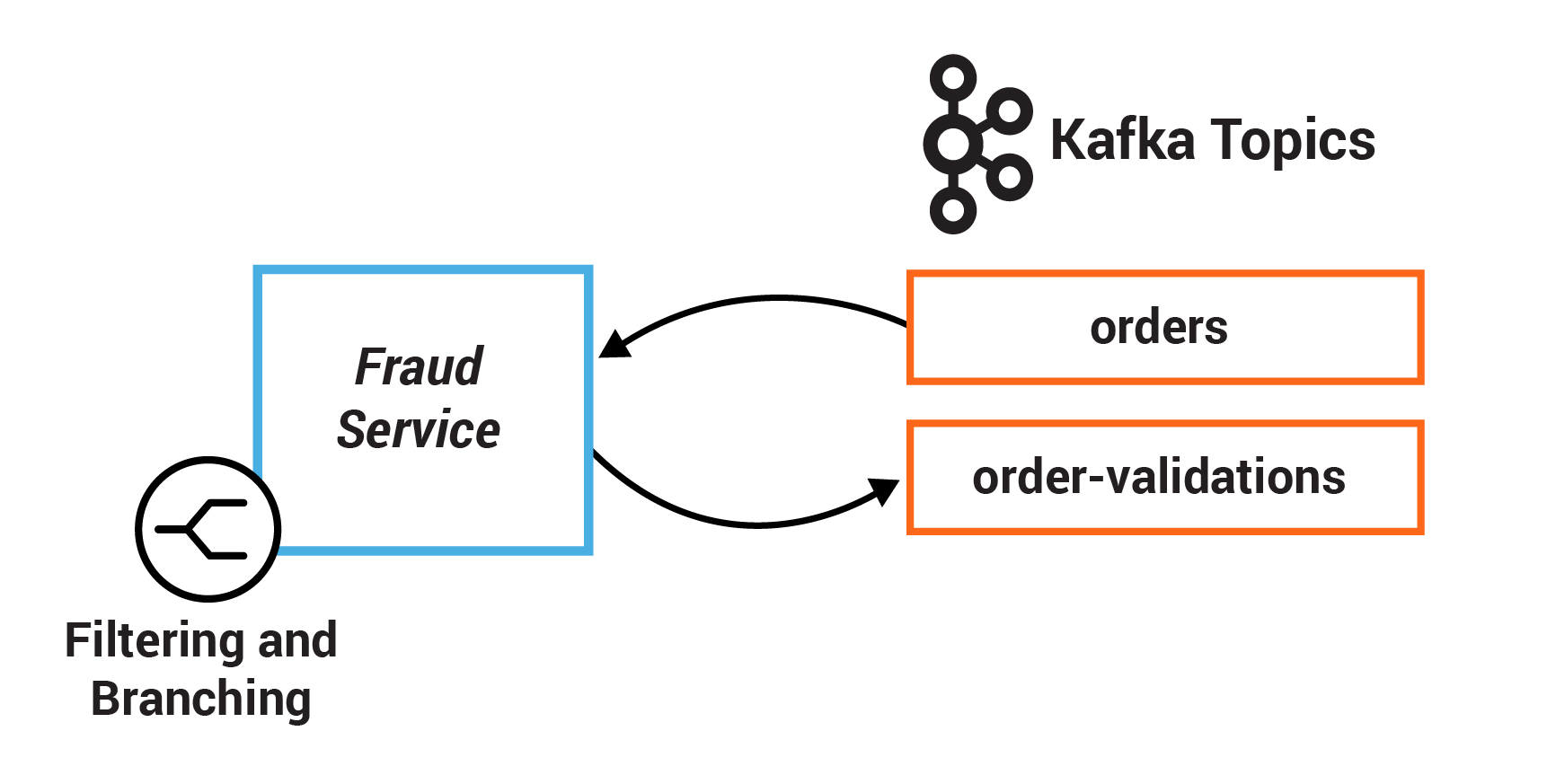
この演習では、基準のセットを定義して、いくつかの基準に基づいてストリーム内のレコードをフィルタリングします。そして、別の基準のセットを定義して、2 つの異なるストリームへとレコードをブランチングします。
ファイル exercises/FraudService.java の "TODO" 行の実装
ls exercises/FraudService.java
- TODO 4.1: このストリームをフィルタリングして、"CREATED" ステートの注文のみが含まれるようにします。つまり、述語 OrderState.CREATED.equals(order.getState()) に一致するはずです。
- TODO 4.2: OrderValue#getValue に基づいてレコードをブランチングして、ordersWithTotals ストリームから KStream<String, OrderValue> 配列を作成します。
- ブランチングされたストリーム 1: 注文の値が FRAUD_LIMIT またはそれより大きい述語では FRAUD_CHECK が失敗します。
- ブランチングされたストリーム 2: 注文の値が FRAUD_LIMIT より小さい述語では FRAUD_CHECK が成功します。
ちなみに
以下の API が役立ちます。
- https://docs.confluent.io/platform/current/streams/javadocs/javadoc/org/apache/kafka/streams/kstream/KStream.html#filter-org.apache.kafka.streams.kstream.Predicate-
- https://docs.confluent.io/platform/current/streams/javadocs/javadoc/org/apache/kafka/streams/kstream/KStream.html#branch-org.apache.kafka.streams.kstream.Predicate...-
- kafka-streams-examples/src/main/java/io/confluent/examples/streams/microservices/domain/beans/OrderBean.java
問題が発生した場合は、ソリューション一式 をご覧ください。
コードをテストするために、プロジェクトで使用しているソリューションを保存して、テストするバージョンのファイルをメインプロジェクトにコピーした後、コンパイルし、単体テストを実行します。
# Clone and compile kafka-streams-examples
./get-kafka-streams-examples.sh
# Save off the working microservices client application to /tmp/
cp kafka-streams-examples/src/main/java/io/confluent/examples/streams/microservices/FraudService.java /tmp/.
# Copy your exercise client application to the project
cp exercises/FraudService.java kafka-streams-examples/src/main/java/io/confluent/examples/streams/microservices/.
# Compile the project and resolve any compilation errors
mvn clean compile -DskipTests -f kafka-streams-examples/pom.xml
# Run the test and validate that it passes
mvn compile -Dtest=io.confluent.examples.streams.microservices.FraudServiceTest test -f kafka-streams-examples/pom.xml
演習 5: ステートフルな操作¶
集約操作では、1 つの入力ストリームまたはテーブルを受け取り、複数の入力レコードを単一の出力レコードに結合して、新しいテーブルを生成します。集約の例としては、count または sum の計算があります。これらによって、現在のレコードの値が、その前のレコードの値と結合されるためです。これらは、処理中にデータを保持するため、ステートフルな操作です。集約は常にキーベースの操作です。Kafka の Streams API により、同じキーのレコードが必ず、常に同じストリーム処理タスクにルーティングされます。多くの場合、一定の時間枠(ウィンドウ)にわたってリアルタイムで計算を実行するために、集約はウィンドウ化機能と結合されています。
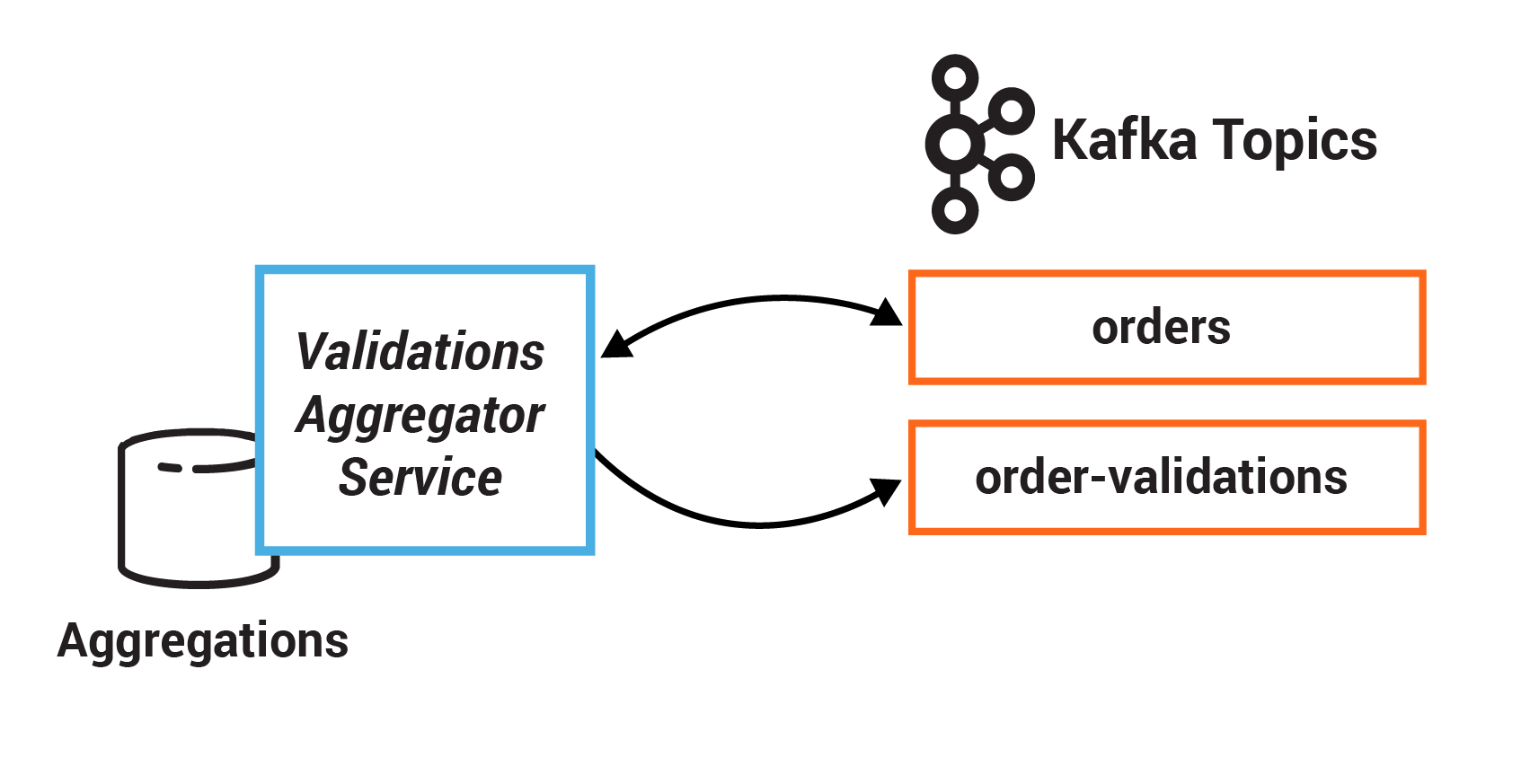
この演習では、セッションウィンドウを作成して、処理のための 5 分間の時間枠を定義します。さらに、ステートフルな操作 reduce を使用して、ストリーム内の重複レコードをまとめます。reduce を実行する前に、データの再パーティショニングのためにレコードをグループ化します。通常は、この操作の後に集約操作を使用する必要があります。
ファイル exercises/ValidationsAggregatorService.java の "TODO" 行の実装
ls exercises/ValidationsAggregatorService.java
- TODO 5.1: KGroupedStream#windowedBy を使用してデータをウィンドウ化します。具体的には、SessionWindows.with を使用して 5 分間の時間枠(ウィンドウ)を定義します。
- TODO 5.2: KStream#groupByKey を使用してレコードをキー別にグループ化し、ORDERS の既存のシリアル化インスタンスを提供します。
- TODO 5.3: 集約オペレーター "KTable#reduce" を使用して、このストリームのレコードを、特定のキーの 1 つの注文にまとめます。
ちなみに
以下の API が役立ちます。
- https://docs.confluent.io/platform/current/streams/javadocs/javadoc/org/apache/kafka/streams/kstream/SessionWindows.html#with-java.time.Duration-
- https://docs.confluent.io/platform/current/streams/javadocs/javadoc/org/apache/kafka/streams/kstream/KGroupedStream.html#windowedBy-org.apache.kafka.streams.kstream.SessionWindows-
- https://docs.confluent.io/platform/current/streams/javadocs/javadoc/org/apache/kafka/streams/kstream/KStream.html#groupByKey-org.apache.kafka.streams.kstream.Serialized-
- https://docs.confluent.io/platform/current/streams/javadocs/javadoc/org/apache/kafka/streams/kstream/SessionWindowedKStream.html#reduce-org.apache.kafka.streams.kstream.Reducer-
問題が発生した場合は、ソリューション一式 をご覧ください。
コードをテストするために、プロジェクトで使用しているソリューションを保存して、テストするバージョンのファイルをメインプロジェクトにコピーした後、コンパイルし、単体テストを実行します。
# Clone and compile kafka-streams-examples
./get-kafka-streams-examples.sh
# Save off the working microservices client application to /tmp/
cp kafka-streams-examples/src/main/java/io/confluent/examples/streams/microservices/ValidationsAggregatorService.java /tmp/.
# Copy your exercise client application to the project
cp exercises/ValidationsAggregatorService.java kafka-streams-examples/src/main/java/io/confluent/examples/streams/microservices/.
# Compile the project and resolve any compilation errors
mvn clean compile -DskipTests -f kafka-streams-examples/pom.xml
# Run the test and validate that it passes
mvn compile -Dtest=io.confluent.examples.streams.microservices.ValidationsAggregatorServiceTest test -f kafka-streams-examples/pom.xml
演習 6: ステートストア¶
Kafka Streams は、いわゆる ステートストア を提供します。これは、ディスクに常駐するハッシュテーブルであり、クライアントアプリケーション用に API 内に保持されています。ステートストアはストリーム処理アプリケーション内で使用して、データを格納しクエリを実行することができます。これは、ステートフル操作を実装する場合に重要な機能です。これを使用して、最近受信した入力レコードの保存、周期的集計の追跡、入力レコードの重複排除などを実行できます。
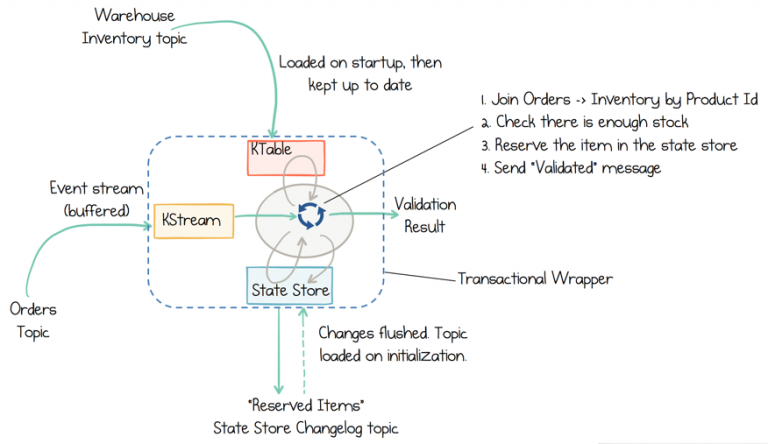
また、Kafka のトピックにより支えられており、Kafka による保証がすべて適用されます。したがって、他のアプリケーションも、別のアプリケーションのステートストアに 対話的にクエリを実行 できます。ステートストアに対するクエリは、基盤となるステートストアが帯域外で変換されないことを保証するために、常に読み取り専用です(つまり、新しいエントリーを追加できません)。
この演習では、Inventory Service のステートストアを作成します。このステートストアは、サービスが処理を開始する前に、Kafka のトピックからのデータで初期化され、新規注文が作成されるとアップデートされます。
ファイル exercises/InventoryService.java の "TODO" 行の実装
ls exercises/InventoryService.java
- TODO 6.1: Stores#keyValueStoreBuilder および Stores#persistentKeyValueStore を使用して、RESERVED_STOCK_STORE_NAME というステートストアを作成します。
- キー Serde は、WAREHOUSE_INVENTORY によって指定されるトピックから取得されます。
- 値 Serde は、カウントを表すため、Serdes.Long() から取得されます。
- TODO 6.2: reservedStocksStore という KeyValueStore の予備の在庫をアップデートします。
- キーは注文内の製品で、OrderBean#getProduct を使用します。
- 値は、現在の予備の在庫と注文内の数量の合計で、"OrderBean#getQuantity" を使用します。
ちなみに
以下の API が役立ちます。
- https://docs.confluent.io/platform/current/streams/javadocs/javadoc/org/apache/kafka/streams/state/Stores.html#persistentKeyValueStore-java.lang.String-
- https://docs.confluent.io/platform/current/streams/javadocs/javadoc/org/apache/kafka/streams/state/Stores.html#keyValueStoreBuilder-org.apache.kafka.streams.state.KeyValueBytesStoreSupplier-org.apache.kafka.common.serialization.Serde-org.apache.kafka.common.serialization.Serde-
- https://docs.confluent.io/platform/current/streams/javadocs/javadoc/org/apache/kafka/streams/state/KeyValueStore.html#put-K-V-
- kafka-streams-examples/src/main/java/io/confluent/examples/streams/microservices/domain/Schemas.java
問題が発生した場合は、ソリューション一式 をご覧ください。
コードをテストするために、プロジェクトで使用しているソリューションを保存して、テストするバージョンのファイルをメインプロジェクトにコピーした後、コンパイルし、単体テストを実行します。
# Clone and compile kafka-streams-examples
./get-kafka-streams-examples.sh
# Save off the working microservices client application to /tmp/
cp kafka-streams-examples/src/main/java/io/confluent/examples/streams/microservices/InventoryService.java /tmp/.
# Copy your exercise client application to the project
cp exercises/InventoryService.java kafka-streams-examples/src/main/java/io/confluent/examples/streams/microservices/.
# Compile the project and resolve any compilation errors
mvn clean compile -DskipTests -f kafka-streams-examples/pom.xml
# Run the test and validate that it passes
mvn compile -Dtest=io.confluent.examples.streams.microservices.InventoryServiceTest test -f kafka-streams-examples/pom.xml
演習 7: ksqlDB による拡張¶
Confluent ksqlDB は、 Apache Kafka® に対するリアルタイムのデータ処理を可能にするストリーミング SQL エンジンです。Kafka 上でストリーム処理を行うための、使いやすく強力な対話型 SQL インターフェイスを提供します。Java や Python などのプログラミング言語でコードを書く必要はありません。スケーラブルで柔軟性が高く、フォールトトレラントな ksqlDB は、データのフィルタリング、変換、集約、結合、ウィンドウ化、セッション化など、幅広いストリーミング操作をサポートしています。
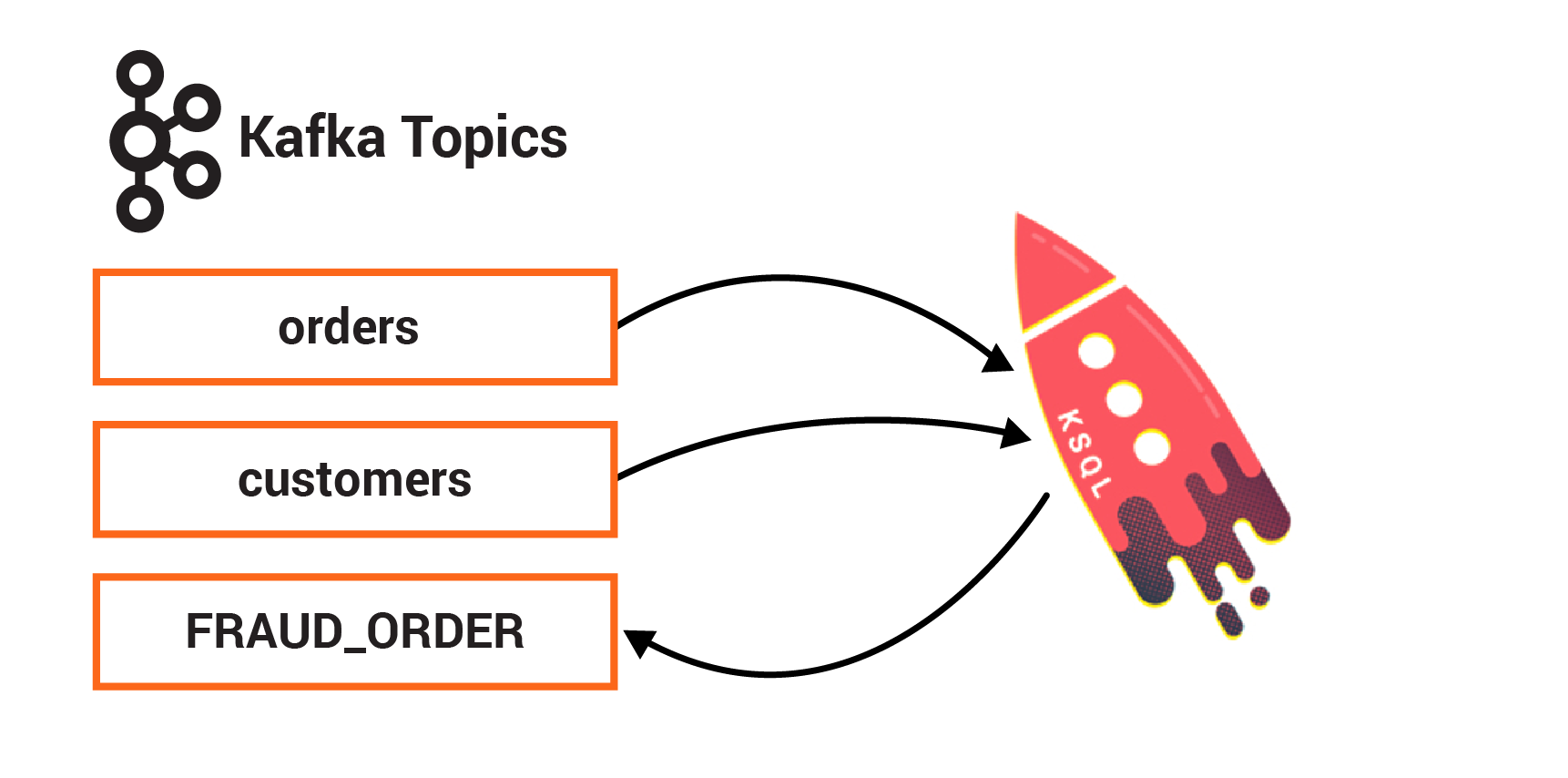
ksqlDB を使用すると、SQL のような "join" 構文を使用してデータのストリームをリアルタイムでマージできます。ksqlDB 結合 とリレーショナルデータベース結合は、両方とも、共通の値に基づいて、2 つのソースのデータを結合する点が似ています。ksqlDB 結合により、SELECT ステートメントで指定した値が列に入力された、新しいストリームまたはテーブルが作成されます。ksqlDB では、COUNT や SUM のような複数の 集約関数 もサポートされています。これらを使用して、ストリーミングデータに関するステートフルな集約を実現できます。
この演習では、ストリームテーブル結合を使用して顧客情報で orders ストリームを拡張する永続的なクエリを作成します。また、特定の時間枠内の注文数をカウントして不正行為を検出する、別の永続的なクエリも作成します。
orders という、注文の ksqlDB ストリームと、customers_table という、コンシューマーの ksqlDB テーブルが既に存在すると仮定します。ksqlDB CLI プロンプトで、DESCRIBE orders; および DESCRIBE customers_table; と入力し、それぞれのスキーマを表示します。そして、以下の永続的なクエリを作成します。
- TODO 7.1: 顧客 ID に基づいて、ストリーム orders とテーブル customers_table の結合を行う新規 ksqlDB ストリームを作成します。
- TODO 7.2: 30 秒の時間枠内に 2 件を超える注文が送信されたかどうかをカウントする新規 ksqlDB テーブルを作成します。
ちなみに
以下の API が役立ちます。
- https://docs.ksqldb.io/en/latest/concepts/stream-processing/#derive-a-new-stream-from-an-existing-stream
- https://docs.ksqldb.io/en/latest/developer-guide/joins/
- https://docs.ksqldb.io/en/latest/concepts/time-and-windows-in-ksqldb-queries/#window-types
問題が発生した場合は、ソリューション一式 をご覧ください。
CLI パーサーにより、作成した ksqlDB クエリが機能したかどうかについてのフィードバックが即座に返されます。SELECT * FROM <ストリーム名またはテーブル名> EMIT CHANGES LIMIT <行数>; を使用すると、各クエリの行が表示されます。
チュートリアルの停止¶
Confluent Cloud のすべてのサンプルでは、実際の Confluent Cloud リソースを使用しています。Confluent Cloud のサンプルの実行を終了したら、予定外の課金を回避するために、すべての Confluent Cloud リソースが破棄されていることを直接確認してください。
その他のリソース¶
- Kafka Streams のビデオ
- Kafka Streams のドキュメント
- Designing Event-Driven Systems
- 「Building a Microservices Ecosystem with Kafka Streams and KSQL」
- 「Build Services on a Backbone of Events」
- 「No More Silos: How to Integrate Your Databases with Apache Kafka and CDC」
- 「Getting Your Feet Wet with Stream Processing – Part 1: Tutorial for Developing Streaming Applications」