ksqlDB を使用した Apache Kafka® に対するストリーミングクエリの作成(ローカル)¶
このチュートリアルでは、ksqlDB を使用して Kafka のメッセージに対するストリーミングクエリを作成する、単純なワークフローについて紹介します。
開始するには、ZooKeeper および Kafka ブローカーを含む Kafka クラスターを起動する必要があります。その後 ksqlDB が、この Kafka クラスターからのメッセージに対してクエリを行います。ksqlDB は、デフォルトで Confluent Platform にインストールされています。
前提条件 :
- Confluent Platform がインストールおよび実行されている。このインストールには、Kafka ブローカー、ksqlDB、Control Center、ZooKeeper、Schema Registry、REST Proxy および Connect が含まれています。
- TAR または ZIP を使用して Confluent Platform をインストールした場合は、インストールディレクトリまで移動します。このチュートリアル全体で使用するパスおよびコマンドは、カレントディレクトリがこのインストールディレクトリであると想定しています。
- Confluent Platform のローカルインストールを開始する際には、Confluent CLI の インストール を検討します。
- Java: バージョン 1.8 以降。Oracle Java JRE または JDK 1.8 以降をローカルマシンにインストールする必要があります。
トピックの作成とデータの生成¶
Kafka のトピック pageviews および users を作成し、データを生成します。これらの手順では、Confluent Platform の ksqlDB datagen ツールを使用します。
新しいターミナルウィンドウを開いて以下のコマンドを実行し、データジェネレーターを使用して
pageviewsトピックを作成しデータを生成します。以下の例は、DELIMITED フォーマットのデータを継続的に生成します。$CONFLUENT_HOME/bin/ksql-datagen quickstart=pageviews format=json topic=pageviews msgRate=5
別のターミナルウィンドウを開き、以下のコマンドを実行して、データジェネレーターを使用して
usersトピックの Kafka データを生成します。以下の例は、DELIMITED フォーマットのデータを継続的に生成します。$CONFLUENT_HOME/bin/ksql-datagen quickstart=users format=avro topic=users msgRate=1
ちなみに
Confluent Platform にある kafka-console-producer CLI を使用して Kafka データを生成することもできます。
ksqlDB CLI の起動¶
新しいターミナルウィンドウを開いて以下のコマンドを実行し、LOG_DIR 環境変数を設定して ksqlDB CLI を起動します。
LOG_DIR=./ksql_logs $CONFLUENT_HOME/bin/ksql
このコマンドは、CLI のログを ./ksql_logs ディレクトリへルーティングします。ディレクトリのパスはカレントディレクトリからの相対パスです。デフォルトでは http://localhost:8088 で実行されている ksqlDB サーバーを CLI が検索します。
重要
デフォルトで、ksqlDB は ksql 実行可能ファイルの場所に対応する logs と呼ばれるディレクトリにそのログを保管しようとします。たとえば、 ksql が /usr/local/bin/ksql にインストールされると、/usr/local/logs にそのログを保管しようとします。ksql を Confluent Platform のデフォルトのロケーションである $CONFLUENT_HOME/bin から実行している場合は、LOG_DIR 変数を使用して、このデフォルトの動作をオーバーライドする必要があります。
ksqlDB 起動後のターミナルはこのようになります。
===========================================
= _ _ ____ ____ =
= | | _____ __ _| | _ \| __ ) =
= | |/ / __|/ _` | | | | | _ \ =
= | <\__ \ (_| | | |_| | |_) | =
= |_|\_\___/\__, |_|____/|____/ =
= |_| =
= Event Streaming Database purpose-built =
= for stream processing apps =
===========================================
Copyright 2017-2021 Confluent Inc.
CLI v6.2.4, Server v6.2.4 located at http://localhost:8088
Server Status: RUNNING
Having trouble? Type 'help' (case-insensitive) for a rundown of how things work!
ksql>
SHOW および PRINT ステートメントを使用した Kafka トピックの調査¶
ksqlDB により、 Kafka のトピックとメッセージをリアルタイムで調査できます。
- SHOW TOPICS ステートメントを使用して、Kafka クラスター上で使用可能なトピックをリストします。
- PRINT ステートメントを使用して、トピックに到着したメッセージをそのつど表示します。
ksqlDB CLI で、以下のステートメントを実行します。
SHOW TOPICS;
出力は以下のようになります。
Kafka Topic | Partitions | Partition Replicas
--------------------------------------------------------------
default_ksql_processing_log | 1 | 1
pageviews | 1 | 1
users | 1 | 1
--------------------------------------------------------------
デフォルトでは、ksqlDB の内部トピックおよびシステムトピックは非表示になっています。SHOW ALL TOPICS ステートメントを使用して、Kafka クラスター上で使用可能な全トピックのリストを表示します。
SHOW ALL TOPICS;
出力は以下のようになります。
Kafka Topic | Partitions | Partition Replicas
---------------------------------------------------------------------------------------------------------------------------------
_confluent-command | 1 | 1
_confluent-controlcenter-... | 2 | 1
...
_confluent-ksql-default__command_topic | 1 | 1
_confluent-license | 1 | 1
_confluent-metrics | 12 | 1
_confluent-monitoring | 2 | 1
_confluent-telemetry-metrics | 12 | 1
_confluent_balancer_api_state | 1 | 1
_confluent_balancer_broker_samples | 32 | 1
_confluent_balancer_partition_samples | 32 | 1
_schemas | 1 | 1
connect-configs | 1 | 1
connect-offsets | 25 | 1
connect-statuses | 5 | 1
default_ksql_processing_log | 1 | 1
pageviews | 1 | 1
users | 1 | 1
---------------------------------------------------------------------------------------------------------------------------------
注釈
実際の出力には、_confluent-controlcenter トピックが多数表示されます。わかりやすくするためにここでは削除されています。
PRINT ステートメントを使用した users トピックの調査
PRINT users;
注釈
PRINT ステートメントは、ksqlDB のコマンドの中でも大文字と小文字が区別される数少ないコマンドの 1 つであり、トピック名が引用符で囲まれていない場合でも区別されます。
出力は以下のようになります。
Key format: KAFKA_STRING
Value format: AVRO
rowtime: 2021/05/06 21:39:36.663 Z, key: User_5, value: {"registertime":1512340535197,"userid":"User_5","regionid":"Region_2","gender":"FEMALE"}, partition: 0
rowtime: 2021/05/06 21:39:37.662 Z, key: User_7, value: {"registertime":1506274681444,"userid":"User_7","regionid":"Region_7","gender":"OTHER"}, partition: 0
rowtime: 2021/05/06 21:39:38.662 Z, key: User_1, value: {"registertime":1497598939522,"userid":"User_1","regionid":"Region_5","gender":"OTHER"}, partition: 0
^CTopic printing ceased
CTRL + C を押して、メッセージのプリントを停止します。
PRINT ステートメントを使用した pageviews トピックの調査
PRINT pageviews;
出力は以下のようになります。
Key format: KAFKA_BIGINT or KAFKA_DOUBLE
Value format: JSON or KAFKA_STRING
rowtime: 2021/05/06 21:40:25.843 Z, key: 1620337225843, value: {"viewtime":1620337225843,"userid":"User_6","pageid":"Page_40"}, partition: 0
rowtime: 2021/05/06 21:40:26.044 Z, key: 1620337226044, value: {"viewtime":1620337226044,"userid":"User_7","pageid":"Page_83"}, partition: 0
rowtime: 2021/05/06 21:40:26.243 Z, key: 1620337226243, value: {"viewtime":1620337226243,"userid":"User_1","pageid":"Page_63"}, partition: 0
^CTopic printing ceased
CTRL + C を押して、メッセージのプリントを停止します。
詳細については、「ksqlDB 構文リファレンス」を参照してください。
ストリームおよびテーブルの作成¶
この例では、pageviews および users と呼ばれる Kafka トピックのメッセージをクエリで取得するために、以下のスキーマを使用します。
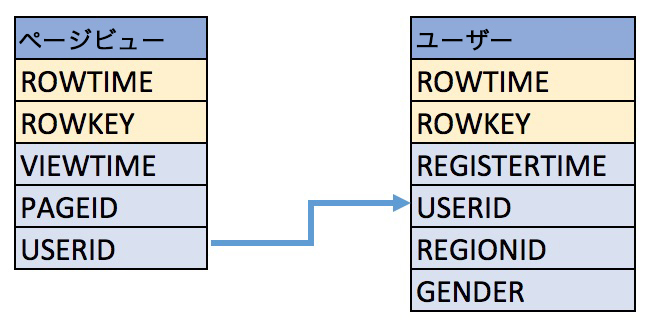
Kafka のトピック
pageviewsからpageviews_originalという名前のストリームを作成し、value_formatの値にはJSONを指定します。CREATE STREAM pageviews_original (viewtime bigint, userid varchar, pageid varchar) WITH (kafka_topic='pageviews', value_format='JSON');
出力は以下のようになります。
Message --------------- Stream created ---------------
ちなみに
DESCRIBE pageviews_original;を実行すると、ストリームのスキーマを見ることができます。ksqlDB が作成したROWTIMEという列が追加されていることに注意してください。これは Kafka メッセージのタイムスタンプに対応しています。Kafka のトピック
usersからusers_originalという名前のテーブルを作成し、value_formatの値にはAVROを指定します。CREATE TABLE users_original (id VARCHAR PRIMARY KEY) WITH (kafka_topic='users', value_format='AVRO');
出力は以下のようになります。
Message --------------- Table created ---------------
ちなみに
DESCRIBE users_original;を実行すると、テーブルのスキーマを見ることができます。注釈
CREATE TABLE ステートメントは、CREATE STREAM ステートメントのように列のセットを定義していないことがわかります。これは、値のフォーマットが Avro であり、DataGen ツールが Schema Registry へ Avro スキーマをパブリッシュしているためです。ksqlDB はそのスキーマを Schema Registry から取得し、テーブルの SQL スキーマの構築に使用します。必要であれば、スキーマを指定することもできます。
(省略可): すべてのストリームおよびテーブルを表示します。
ksql> SHOW STREAMS; Stream Name | Kafka Topic | Key Format | Value Format | Windowed ------------------------------------------------------------------------------------------ KSQL_PROCESSING_LOG | default_ksql_processing_log | KAFKA | JSON | false PAGEVIEWS_ORIGINAL | pageviews | KAFKA | JSON | false ------------------------------------------------------------------------------------------ ksql> SHOW TABLES; Table Name | Kafka Topic | Key Format | Value Format | Windowed --------------------------------------------------------------------- USERS_ORIGINAL | users | KAFKA | AVRO | false ---------------------------------------------------------------------
ちなみに
SHOW STREAMS の出力に
KSQL_PROCESSING_LOGストリームがリストされていることに注意してください。ksqlDB では、データの処理中になんらかの問題が発生すると、それについて説明するメッセージが追加されます。期待どおりに機能しないものがある場合は、このストリームの内容を見て ksqlDB にデータエラーが発生してないかを確認します。
データの表示¶
SELECT を使用して、TABLE からデータを返すクエリを作成します。このクエリには、クエリの結果で返される行数を制限する LIMIT キーワードと、結果をストリームにより返すよう指示する EMIT CHANGES キーワードが含まれます。これがいわゆる プルクエリ です。各種クエリの解説については、「クエリ」を参照してください。なお、正確なデータ出力はデータ生成のランダム性により変動することがあります。
SELECT * FROM users_original EMIT CHANGES LIMIT 5;
出力は以下のようになります。
+---------------+---------------+---------------+---------------+---------------+ |ID |REGISTERTIME |USERID |REGIONID |GENDER | +---------------+---------------+---------------+---------------+---------------+ |User_2 |1502155111606 |User_2 |Region_8 |OTHER | |User_1 |1499783711681 |User_1 |Region_3 |OTHER | |User_9 |1504556621362 |User_9 |Region_5 |FEMALE | |User_6 |1488869543103 |User_6 |Region_4 |OTHER | |User_3 |1512248344223 |User_3 |Region_9 |FEMALE | Limit Reached Query terminated
注釈
テーブルに対するプッシュクエリは、Kafka の changelog トピックに保管されているテーブルの全履歴を出力します。つまり、過去のデータを出力した後に、テーブルに対するアップデートのストリームを出力します。したがって、テーブル内の既存の行がアップデートされると、その行と一致する
IDを持つ行が出力される可能性があります。以下のプッシュクエリを発行して、
pageviews_originalストリームのデータを表示します。SELECT viewtime, userid, pageid FROM pageviews_original emit changes LIMIT 3;
出力は以下のようになります。
+--------------+--------------+--------------+ |VIEWTIME |USERID |PAGEID | +--------------+--------------+--------------+ |1581078296791 |User_1 |Page_54 | |1581078297792 |User_8 |Page_93 | |1581078298792 |User_6 |Page_26 | Limit Reached Query terminated
注釈
デフォルトでは、ストリームに対するプッシュクエリはクエリ開始後に発生した変更のみを出力します。つまり、過去のデータは含まれません。過去のデータを表示する場合は、
set 'auto.offset.reset'='earliest';を実行してセッションのプロパティを更新します。
クエリの書き込み¶
この例では、ksqlDB を使用してクエリを書き込みます。
注釈
デフォルトでは、ksqlDB はストリームおよびテーブルのトピックを最新のオフセットから読み取ります。
usersテーブルからユーザーのgenderとregionidを読み取ってpageviewsデータを拡張するクエリを作成します。以下のクエリは、users_originalテーブルのuserid列に対して LEFT JOIN を行うことにより、pageviews_originalストリームを拡張します。SELECT users_original.id AS userid, pageid, regionid, gender FROM pageviews_original LEFT JOIN users_original ON pageviews_original.userid = users_original.id EMIT CHANGES LIMIT 5;
出力は以下のようになります。
+-------------------+-------------------+-------------------+-------------------+ |ID |PAGEID |REGIONID |GENDER | +-------------------+-------------------+-------------------+-------------------+ |User_7 |Page_23 |Region_2 |OTHER | |User_3 |Page_42 |Region_2 |MALE | |User_7 |Page_87 |Region_2 |OTHER | |User_2 |Page_57 |Region_5 |FEMALE | |User_9 |Page_59 |Region_1 |OTHER | Limit Reached Query terminated
CREATE STREAMキーワードを使用して、SELECTステートメントに先行する永続的なクエリを作成します。クエリの結果はPAGEVIEWS_ENRICHEDKafka トピックに書き込まれます。以下のクエリは、users_originalテーブルのユーザー ID に対してLEFT JOINを行うことにより、pageviews_originalストリームを拡張します。CREATE STREAM pageviews_enriched AS SELECT users_original.id AS userid, pageid, regionid, gender FROM pageviews_original LEFT JOIN users_original ON pageviews_original.userid = users_original.id EMIT CHANGES;
出力は以下のようになります。
Message -------------------------------------------------- Created query with ID CSAS_PAGEVIEWS_ENRICHED_33 --------------------------------------------------
ちなみに
DESCRIBE pageviews_enriched;を実行すると、ストリームを記述できます。SELECTを使用して、クエリ結果の到着ごとに表示します。クエリ結果の表示を停止するには Ctrl + C を押します。これによりコンソールへのプリントは停止しますが、クエリそのものは停止しません。基盤となる ksqlDB アプリケーションではクエリが実行され続けます。SELECT * FROM pageviews_enriched EMIT CHANGES;
出力は以下のようになります。
+---------------------+---------------------+---------------------+---------------------+ |ID |PAGEID |REGIONID |GENDER | +---------------------+---------------------+---------------------+---------------------+ |User_8 |Page_41 |Region_4 |FEMALE | |User_2 |Page_87 |Region_3 |OTHER | |User_3 |Page_84 |Region_8 |FEMALE | ^CQuery terminated
Ctrl + C キーを押してクエリを停止します。
WHEREを使用して、条件によりストリームのコンテンツを制限する新しい永続的なクエリを作成します。クエリの結果は、PAGEVIEWS_FEMALEという名前の Kafka トピックに書き込まれます。CREATE STREAM pageviews_female AS SELECT * FROM pageviews_enriched WHERE gender = 'FEMALE' EMIT CHANGES;
出力は以下のようになります。
Message ------------------------------------------------ Created query with ID CSAS_PAGEVIEWS_FEMALE_35 ------------------------------------------------
ちなみに
DESCRIBE pageviews_female;を実行すると、ストリームを記述できます。LIKE を使用して、別の条件を満たす新しい永続的なクエリを作成します。クエリの結果は
pageviews_enriched_r8_r9Kafka トピックに書き込まれます。CREATE STREAM pageviews_female_like_89 WITH (kafka_topic='pageviews_enriched_r8_r9') AS SELECT * FROM pageviews_female WHERE regionid LIKE '%_8' OR regionid LIKE '%_9' EMIT CHANGES;
出力は以下のようになります。
Message -------------------------------------------------------- Created query with ID CSAS_PAGEVIEWS_FEMALE_LIKE_89_37 --------------------------------------------------------
カウントが 1 より大きい場合に 30 秒の タンブリングウィンドウ で地域と性別の組み合わせごとにページビューをカウントする新しい永続的なクエリを作成します。クエリの結果は
PAGEVIEWS_REGIONSKafka トピックに Avro フォーマットで書き込まれます。ksqlDB は、PAGEVIEWS_REGIONSトピックへ最初のメッセージを書き込む際に、構成済みの Schema Registry で Avro スキーマを登録します。CREATE TABLE pageviews_regions WITH (KEY_FORMAT='json') AS SELECT gender, regionid , COUNT(*) AS numusers FROM pageviews_enriched WINDOW TUMBLING (size 30 second) GROUP BY gender, regionid EMIT CHANGES;
出力は以下のようになります。
Message ------------------------------------------------- Created query with ID CTAS_PAGEVIEWS_REGIONS_39 -------------------------------------------------
ちなみに
DESCRIBE pageviews_regions;を実行すると、テーブルを記述できます。(省略可): プッシュクエリを使用して、上記のクエリの結果を表示します。
SELECT * FROM pageviews_regions EMIT CHANGES LIMIT 5;
出力は以下のようになります。
+----------------------+----------------------+----------------------+----------------------+----------------------+ |GENDER |REGIONID |WINDOWSTART |WINDOWEND |NUMUSERS | +----------------------+----------------------+----------------------+----------------------+----------------------+ |OTHER |Region_1 |1620681750000 |1620681780000 |3 | |FEMALE |Region_5 |1620681750000 |1620681780000 |3 | |OTHER |Region_3 |1620681750000 |1620681780000 |5 | |MALE |Region_4 |1620681750000 |1620681780000 |7 | |FEMALE |Region_9 |1620681750000 |1620681780000 |5 | Limit Reached Query terminated
注釈
WINDOWSTART 列と WINDOWEND 列の追加に注目してください。これらが利用可能な理由は、
pageviews_regionsが 30 秒あたりの ウィンドウ でデータを集計しているためです。ksqlDB は、ウィンドウ化された集計結果に応じてこれらのシステム列を自動的に追加します。(省略可): プルクエリを使用して、前のクエリの結果を表示します。
CREATE TABLE ステートメントに GROUP BY 句が含まれている場合、ksqlDB は集計結果を保管するテーブルを内部で構築します。ksqlDB はこのような集計結果に対するプルクエリをサポートしています。
前のステップで使用した結果のストリームを プッシュ するプッシュクエリとは異なり、プルクエリは結果セットを プル して自動的に終了します。
プルクエリには EMIT CHANGES 句はありません。
プルクエリを使用して、特定の性別と地域について利用可能なすべてのウィンドウおよびユーザーカウントを表示します。
SELECT * FROM pageviews_regions WHERE gender='FEMALE' AND regionid='Region_4';
出力は以下のようになります。
+----------------------+----------------------+----------------------+----------------------+----------------------+ |GENDER |REGIONID |WINDOWSTART |WINDOWEND |NUMUSERS | +----------------------+----------------------+----------------------+----------------------+----------------------+ |FEMALE |Region_4 |1620681780000 |1620681810000 |17 | |FEMALE |Region_4 |1620681810000 |1620681840000 |19 | |FEMALE |Region_4 |1620681840000 |1620681870000 |19 | Query terminated
pageviews_regionsなどのウィンドウ化されたテーブルに対するプルクエリは、単一ウィンドウの結果に対するクエリもサポートしています。SELECT NUMUSERS FROM pageviews_regions WHERE gender='FEMALE' AND regionid='Region_4' AND WINDOWSTART=1620681780000;
注釈
前の SQL の
WINDOWSTARTの値は、データのウィンドウ境界のいずれかと一致するように変更する必要があります。そうしなければ、結果は返されません。出力は以下のようになります。
+----------+ |NUMUSERS | +----------+ |17 | Query terminated
ウィンドウの範囲を照会するクエリを実行します。
SELECT WINDOWSTART, WINDOWEND, NUMUSERS FROM pageviews_regions WHERE gender='FEMALE' AND regionid='Region_4' AND 1620681780000 <= WINDOWSTART AND WINDOWSTART <= 1620681840000;
注釈
前の SQL の
WINDOWSTARTの値は、データのウィンドウ境界のいずれかと一致するように変更する必要があります。そうしなければ、結果は返されません。出力は以下のようになります。
+--------------------------------------+--------------------------------------+--------------------------------------+ |WINDOWSTART |WINDOWEND |NUMUSERS | +--------------------------------------+--------------------------------------+--------------------------------------+ |1620681780000 |1620681810000 |17 | |1620681810000 |1620681840000 |19 | |1620681840000 |1620681870000 |19 | Query terminated
(省略可): すべての永続的なクエリを表示します。
SHOW QUERIES;
出力は以下のようになります。
Query ID | Query Type | Status | Sink Name | Sink Kafka Topic | Query String ------------------------------------------------------------------------------------------------------------------------ CSAS_PAGEVIEWS_ENRICHED_85 | PERSISTENT | RUNNING:1 | PAGEVIEWS_ENRICHED | PAGEVIEWS_ENRICHED | CREATE STREAM PAGEVIEWS_ENRICHED WITH (KAFKA_TOPIC='PAGEVIEWS_ENRICHED', PARTITIONS=1, REPLICAS=1) AS SELECT USERS_ORIGINAL.ID USERID, PAGEVIEWS_ORIGINAL.PAGEID PAGEID, USERS_ORIGINAL.REGIONID REGIONID, USERS_ORIGINAL.GENDER GENDER FROM PAGEVIEWS_ORIGINAL PAGEVIEWS_ORIGINAL LEFT OUTER JOIN USERS_ORIGINAL USERS_ORIGINAL ON ((PAGEVIEWS_ORIGINAL.USERID = USERS_ORIGINAL.ID)) EMIT CHANGES; CSAS_PAGEVIEWS_FEMALE_LIKE_89_89 | PERSISTENT | RUNNING:1 | PAGEVIEWS_FEMALE_LIKE_89 | pageviews_enriched_r8_r9 | CREATE STREAM PAGEVIEWS_FEMALE_LIKE_89 WITH (KAFKA_TOPIC='pageviews_enriched_r8_r9', PARTITIONS=1, REPLICAS=1) AS SELECT * FROM PAGEVIEWS_FEMALE PAGEVIEWS_FEMALE WHERE ((PAGEVIEWS_FEMALE.REGIONID LIKE '%_8') OR (PAGEVIEWS_FEMALE.REGIONID LIKE '%_9')) EMIT CHANGES; CSAS_PAGEVIEWS_FEMALE_87 | PERSISTENT | RUNNING:1 | PAGEVIEWS_FEMALE | PAGEVIEWS_FEMALE | CREATE STREAM PAGEVIEWS_FEMALE WITH (KAFKA_TOPIC='PAGEVIEWS_FEMALE', PARTITIONS=1, REPLICAS=1) AS SELECT * FROM PAGEVIEWS_ENRICHED PAGEVIEWS_ENRICHED WHERE (PAGEVIEWS_ENRICHED.GENDER = 'FEMALE') EMIT CHANGES; CTAS_PAGEVIEWS_REGIONS_91 | PERSISTENT | RUNNING:1 | PAGEVIEWS_REGIONS | PAGEVIEWS_REGIONS | CREATE TABLE PAGEVIEWS_REGIONS WITH (KAFKA_TOPIC='PAGEVIEWS_REGIONS', KEY_FORMAT='json', PARTITIONS=1, REPLICAS=1) AS SELECT PAGEVIEWS_ENRICHED.GENDER GENDER, PAGEVIEWS_ENRICHED.REGIONID REGIONID, COUNT(*) NUMksql> FROM PAGEVIEWS_ENRICHED PAGEVIEWS_ENRICHED WINDOW TUMBLING ( SIZE 30 SECONDS ) GROUP BY PAGEVIEWS_ENRICHED.GENDER, PAGEVIEWS_ENRICHED.REGIONID EMIT CHANGES; ------------------------------------------------------------------------------------------------------------------------ For detailed information on a Query run: EXPLAIN <Query ID>;
(省略可): クエリ実行時間のメトリクスや詳細を調べます。ターゲットの Kafka トピックなどの情報が使用できます。また、処理されているメッセージのスループットを示す数値も使用できます。
DESCRIBE pageviews_regions EXTENDED;
出力は以下のようになります。
Name : PAGEVIEWS_REGIONS Type : TABLE Timestamp field : Not set - using <ROWTIME> Key format : KAFKA Value format : AVRO Kafka topic : PAGEVIEWS_REGIONS (partitions: 1, replication: 1) Statement : CREATE TABLE PAGEVIEWS_REGIONS WITH (KAFKA_TOPIC='PAGEVIEWS_REGIONS', PARTITIONS=1, REPLICAS=1, VALUE_FORMAT='avro') AS SELECT PAGEVIEWS_ENRICHED.GENDER GENDER, PAGEVIEWS_ENRICHED.REGIONID REGIONID, COUNT(*) NUMUSERS FROM PAGEVIEWS_ENRICHED PAGEVIEWS_ENRICHED WINDOW TUMBLING ( SIZE 30 SECONDS ) GROUP BY PAGEVIEWS_ENRICHED.GENDER, PAGEVIEWS_ENRICHED.REGIONID EMIT CHANGES; Field | Type --------------------------------------------------------------------- KSQL_COL_0 | VARCHAR(STRING) (primary key) (Window type: TUMBLING) NUMUSERS | BIGINT --------------------------------------------------------------------- Queries that write from this TABLE ----------------------------------- CTAS_PAGEVIEWS_REGIONS_39 (RUNNING) : CREATE TABLE PAGEVIEWS_REGIONS WITH (KAFKA_TOPIC='PAGEVIEWS_REGIONS', PARTITIONS=1, REPLICAS=1, VALUE_FORMAT='avro') AS SELECT PAGEVIEWS_ENRICHED.GENDER GENDER, PAGEVIEWS_ENRICHED.REGIONID REGIONID, COUNT(*) NUMUSERS FROM PAGEVIEWS_ENRICHED PAGEVIEWS_ENRICHED WINDOW TUMBLING ( SIZE 30 SECONDS ) GROUP BY PAGEVIEWS_ENRICHED.GENDER, PAGEVIEWS_ENRICHED.REGIONID EMIT CHANGES; For query topology and execution plan please run: EXPLAIN <QueryId> Local runtime statistics ------------------------ messages-per-sec: 2.89 total-messages: 3648 last-message: 2021-01-27T19:36:11.197Z (Statistics of the local KSQL server interaction with the Kafka topic PAGEVIEWS_REGIONS) Consumer Groups summary: Consumer Group : _confluent-ksql-default_query_CTAS_PAGEVIEWS_REGIONS_39 Kafka topic : PAGEVIEWS_ENRICHED Max lag : 5 Partition | Start Offset | End Offset | Offset | Lag ------------------------------------------------------ 0 | 0 | 7690 | 7685 | 5 ------------------------------------------------------ Kafka topic : _confluent-ksql-default_query_CTAS_PAGEVIEWS_REGIONS_39-Aggregate-GroupBy-repartition Max lag : 5 Partition | Start Offset | End Offset | Offset | Lag ------------------------------------------------------ 0 | 6224 | 6229 | 6224 | 5 ------------------------------------------------------
ksqlDB でのネスト化されたスキーマ(STRUCT)の使用¶
Struct のサポートにより、JSON と Avro のどちらでも Kafka のトピック内のネスト化データのモデリングとアクセスが可能になります。
ここでは ksql-datagen ツールを使用して、ネスト化された address フィールドを含むサンプルデータをいくつか作成します。これを新しいウィンドウで実行し、そのままにしておきます。
$CONFLUENT_HOME/bin/ksql-datagen \
quickstart=orders \
format=avro \
topic=orders \
msgRate=1
ksqlDB のコマンドプロンプトから、そのトピックを ksqlDB に登録します。
CREATE STREAM orders
(
ordertime BIGINT,
orderid INT,
itemid STRING,
orderunits DOUBLE,
address STRUCT<city STRING, state STRING, zipcode BIGINT>
)
WITH (KAFKA_TOPIC='orders', VALUE_FORMAT='avro');
出力は以下のようになります。
Message
----------------
Stream created
----------------
DESCRIBE 関数を使用してスキーマを調べると、STRUCT が含まれています。
DESCRIBE orders;
出力は以下のようになります。
Field | Type
----------------------------------------------------------------------------------
ORDERTIME | BIGINT
ORDERID | INTEGER
ITEMID | VARCHAR(STRING)
ORDERUNITS | DOUBLE
ADDRESS | STRUCT<CITY VARCHAR(STRING), STATE VARCHAR(STRING), ZIPCODE BIGINT>
----------------------------------------------------------------------------------
For runtime statistics and query details run: DESCRIBE <Stream,Table> EXTENDED;
-> 表記を使用してデータのクエリを実行し、Struct の内容にアクセスします。
SELECT ORDERID, ADDRESS->CITY FROM ORDERS EMIT CHANGES LIMIT 5;
出力は以下のようになります。
+-----------------------------------+-----------------------------------+
|ORDERID |ADDRESS__CITY |
+-----------------------------------+-----------------------------------+
|1188 |City_95 |
|1189 |City_24 |
|1190 |City_57 |
|1191 |City_37 |
|1192 |City_82 |
Limit Reached
Query terminated
INSERT INTO¶
INSERT INTO 構文を使用して、複数ストリームのコンテンツをマージすることができます。例として、同じイベントタイプを複数の異なる送信元から取得する場合などが挙げられます。
2 つの新しいターミナルを開いて、2 つの Datagen プロセスを実行します。各プロセスでは、それぞれ異なるトピックへの書き込みが行われます。これにより、ローカルインストールとサードパーティの双方から到着する注文データがシミュレートされます。
ちなみに
これらのコマンドは、それぞれ個別のウィンドウで実行する必要があります。演習が完了したら、Ctrl + C を押してそれらを終了します。
$CONFLUENT_HOME/bin/ksql-datagen \
quickstart=orders \
format=json \
topic=orders_local \
msgRate=2
$CONFLUENT_HOME/bin/ksql-datagen \
quickstart=orders \
format=json \
topic=orders_3rdparty \
msgRate=2
ksqlDB CLI で、それぞれのソーストピックを登録します。
CREATE STREAM orders_src_local
(
ordertime BIGINT,
orderid INT,
itemid STRING,
orderunits DOUBLE,
address STRUCT<city STRING, state STRING, zipcode BIGINT>
)
WITH (KAFKA_TOPIC='orders_local', VALUE_FORMAT='JSON');
CREATE STREAM orders_src_3rdparty
(
ordertime BIGINT,
orderid INT,
itemid STRING,
orderunits DOUBLE,
address STRUCT<city STRING, state STRING, zipcode BIGINT>
)
WITH (KAFKA_TOPIC='orders_3rdparty', VALUE_FORMAT='JSON');
各 CREATE STREAM ステートメントの後に、メッセージが表示されます。
Message
----------------
Stream created
----------------
標準の CREATE STREAM … AS 構文を使用して出力ストリームを作成します。複数の送信元のデータが共通のターゲットに結合されるため、データの流れの情報を追加すると有用です。SELECT の一部に含めるだけでこれを実行できます。
CREATE STREAM all_orders AS SELECT 'LOCAL' AS SRC, * FROM orders_src_local EMIT CHANGES;
出力は以下のようになります。
Message
------------------------------------------
Created query with ID CSAS_ALL_ORDERS_71
------------------------------------------
DESCRIBE コマンドを使用してターゲットストリームのスキーマを調べます。
DESCRIBE all_orders;
出力は以下のようになります。
Name : ALL_ORDERS
Field | Type
----------------------------------------------------------------------------------
SRC | VARCHAR(STRING)
ORDERTIME | BIGINT
ORDERID | INTEGER
ITEMID | VARCHAR(STRING)
ORDERUNITS | DOUBLE
ADDRESS | STRUCT<CITY VARCHAR(STRING), STATE VARCHAR(STRING), ZIPCODE BIGINT>
----------------------------------------------------------------------------------
For runtime statistics and query details run: DESCRIBE <Stream,Table> EXTENDED;
サードパーティの注文のストリームを既存の出力ストリームに追加します。
INSERT INTO all_orders SELECT '3RD PARTY' AS SRC, * FROM orders_src_3rdparty EMIT CHANGES;
出力は以下のようになります。
Message
--------------------------------------
Created query with ID INSERTQUERY_73
--------------------------------------
出力ストリームのクエリを実行して、各送信元からのデータが書き込まれていることを検証します。
SELECT * FROM all_orders EMIT CHANGES;
この出力は以下のようになります。両方のソーストピックからのメッセージが含まれていることに注目します(それぞれ LOCAL と 3RD PARTY により示されています)。
+---------------------+---------------------+---------------------+---------------------+---------------------+---------------------+
|SRC |ORDERTIME |ORDERID |ITEMID |ORDERUNITS |ADDRESS |
+---------------------+---------------------+---------------------+---------------------+---------------------+---------------------+
|3RD PARTY |1491006356222 |1583 |Item_169 |2.091966572094054 |{CITY=City_91, STATE=|
| | | | | |State_51, ZIPCODE=184|
| | | | | |74} |
|LOCAL |1504382324241 |1630 |Item_410 |0.6462658185260942 |{CITY=City_55, STATE=|
| | | | | |State_38, ZIPCODE=372|
| | | | | |44} |
|3RD PARTY |1512567250385 |1584 |Item_357 |7.205193136057381 |{CITY=City_91, STATE=|
| | | | | |State_19, ZIPCODE=457|
| | | | | |45} |
^CQuery terminated
Ctrl + C を押して SELECT クエリをキャンセルし ksqlDB のプロンプトに戻ります。
終了¶
ksqlDB¶
注釈
永続的なクエリは、手動で終了するまで ksqlDB アプリケーションとして継続的に実行されます。ksqlDB CLI を終了しても永続的なクエリは終了されません。
SHOW QUERIES;の出力から、終了するクエリ ID を特定します。たとえばクエリ IDCTAS_PAGEVIEWS_REGIONS_15を終了するには、以下を実行します。TERMINATE CTAS_PAGEVIEWS_REGIONS_15;
ちなみに
実行されているクエリの実際の名前は異なる場合があります。
SHOW QUERIES;の出力を参照してください。exitコマンドを実行して ksqlDB CLI を終了します。ksql> exit Exiting ksqlDB.
Confluent CLI¶
CLI を使用して Confluent Platform を実行している場合は、このコマンドで停止させることができます。
$CONFLUENT_HOME/bin/confluent local services stop