Confluent Platform のデモ(cp-demo)¶
cp-demo の例では、ksqlDB と Kafka Streams を使用してストリームを処理する Apache Kafka® イベントストリーミングアプリケーションを含む完全な Confluent Platform デプロイを構築します。また、すべてのコンポーネントのセキュリティはエンドツーエンドで有効にします。チュートリアルには、これをハイブリッドデプロイに拡張するモジュールが含まれており、Replicator を実行して、ローカルのオンプレミス Kafka クラスターから、Apache Kafka® 用のフルマネージド型サービスである Confluent Cloud にデータをコピーします。用意されているガイド付きのチュートリアルでは、手順を追って、Kafka および Confluent Cloud の Connect、Confluent Schema Registry、Confluent Control Center、Replicator、エンドツーエンドで有効なセキュリティとの連携の方法について学習することができます。
概要¶
ユースケース¶
このユースケースは、実際の Wikipedia ページのリアルタイム編集を処理する Apache Kafka® イベントストリーミングアプリケーションです。
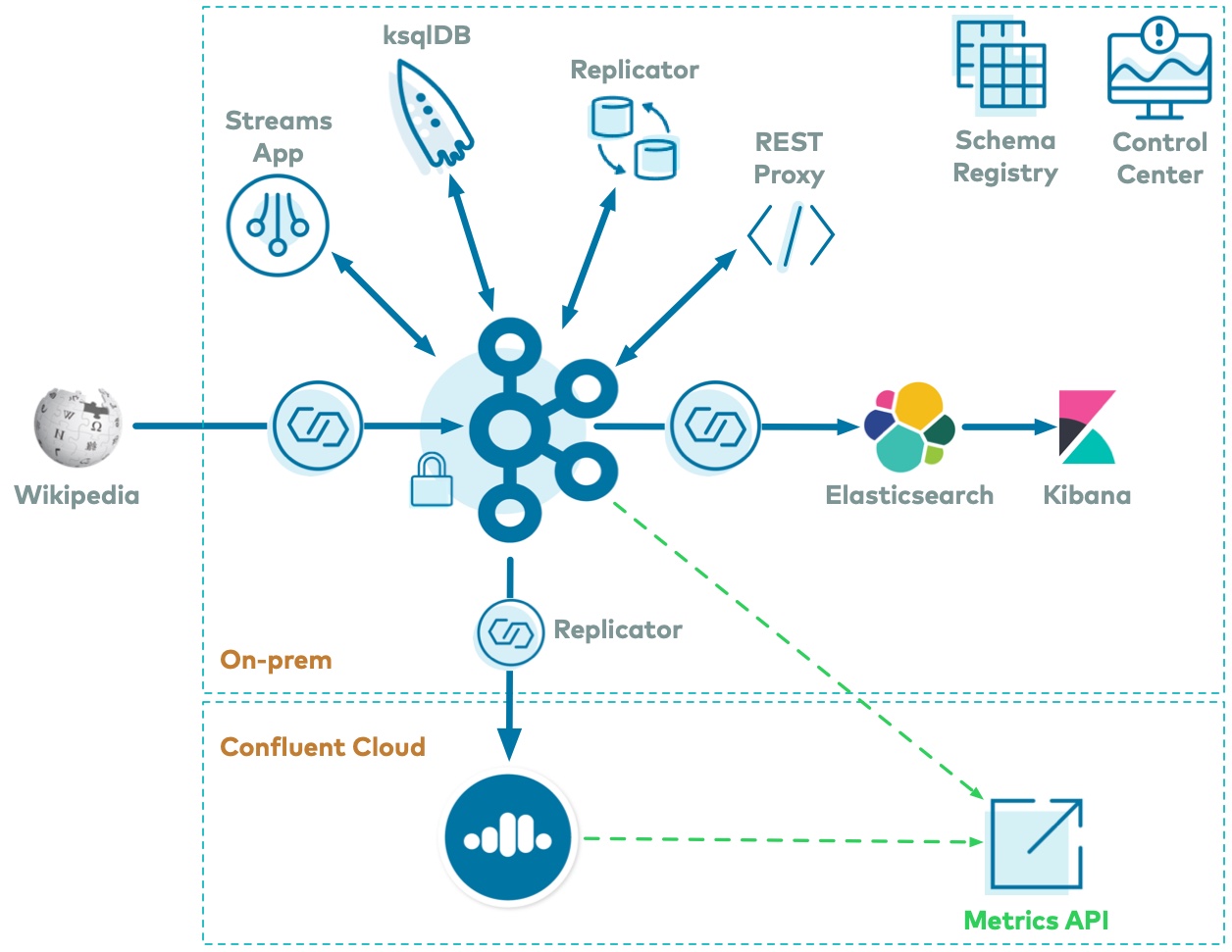
Confluent Platform に基づくイベントストリーミングプラットフォーム全体の説明は、次のとおりです。Wikimedia の EventStreams では、実際の wiki ページで発生しているリアルタイム編集の継続的なストリームが公開されます。Kafka ソースコネクター kafka-connect-sse は、https://stream.wikimedia.org/v2/stream/recentchange からサーバーが送信したイベント(SSE)のストリーミングを行います。また、カスタム Connect 変換 kafka-connect-json-schema は、これらのメッセージから JSON を抽出し、これらは Kafka クラスターに書き込まれます。このサンプルでは、ksqlDB と Kafka Streams アプリケーションを使用してデータを処理します。その後、Kafka シンクコネクター kafka-connect-elasticsearch が Kafka からデータのストリーミングを行い、Elasticsearch として有形化され、Kibana によって分析されます。Confluent Replicator は、同じクラスター内のトピック間でもメッセージをコピーしています。すべてのデータは、Confluent Schema Registry と Avro を使用しており、Confluent Control Center がデプロイを管理し、モニタリングしています。
データパターン¶
データパターンは、次のとおりです。
| コンポーネント | 消費元 | 生成先 |
|---|---|---|
| SSE Source Connector | Wikipedia | wikipedia.parsed |
| ksqlDB | wikipedia.parsed |
ksqlDB ストリームおよびテーブル |
| Kafka Streams アプリケーション | wikipedia.parsed |
wikipedia.parsed.count-by-domain |
| Confluent Replicator | wikipedia.parsed |
wikipedia.parsed.replica |
| Elasticsearch Sink Connector | WIKIPEDIABOT (ksqlDB から) |
Elasticsearch/Kibana |
このチュートリアルの使用方法¶
cp-demo チュートリアルは、次の順番で実行することをお勧めします。
- モジュール 1: オンプレミスのチュートリアル: オンプレミスの Kafka クラスターを起動し、Confluent Platform のさまざまな技術領域について確認します。
- モジュール 2: Confluent Cloud へのハイブリッドデプロイのチュートリアル: Replicator を実行してローカルのオンプレミス Kafka クラスターから Confluent Cloud にデータをコピーし、Metrics API を使用して両方のモニタリングを行います。
- 強制停止: オンプレミスおよび Confluent Cloud の環境をクリーンアップします。