Confluent Replicator による Confluent Cloud への Google Kubernetes Engine¶
概要¶
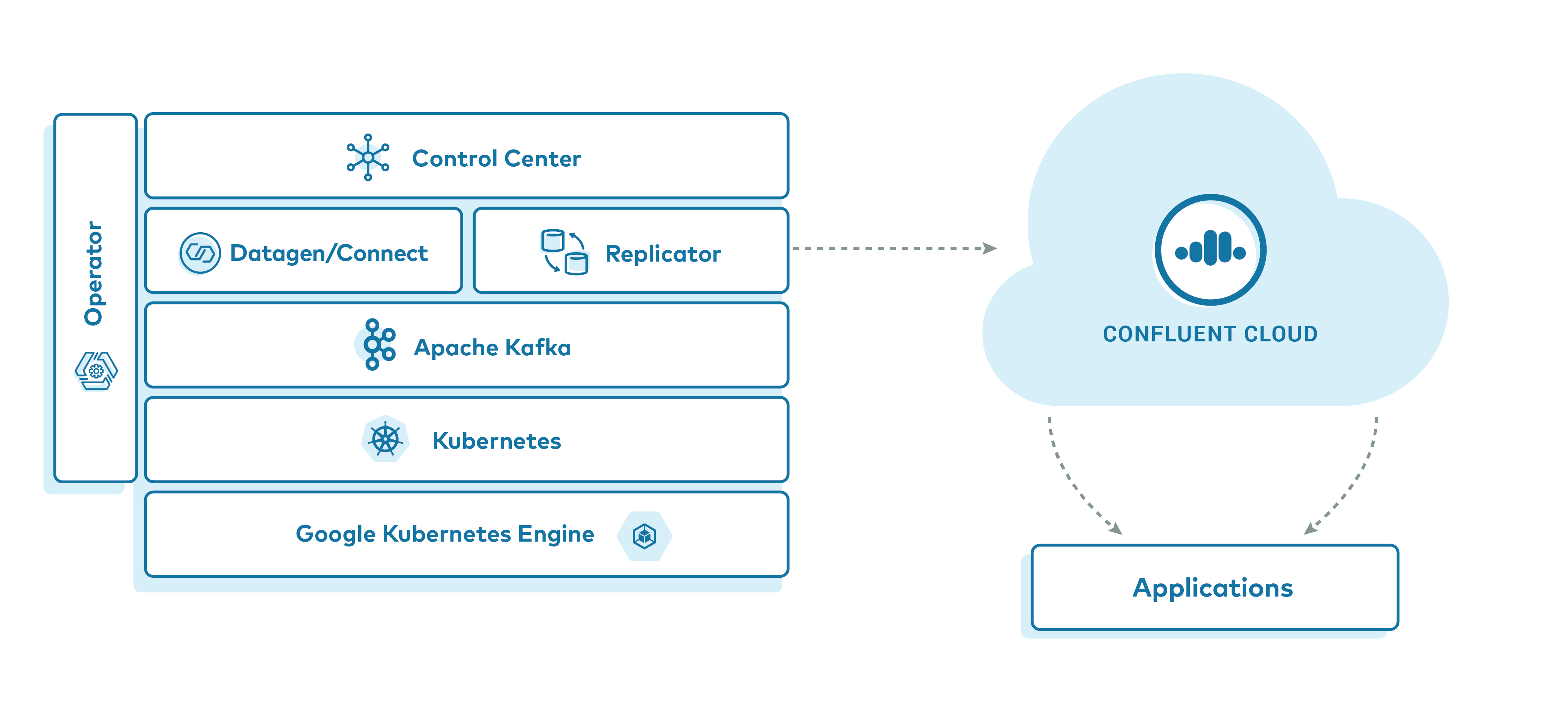
このサンプルでは、Confluent Operator と Confluent Replicator を利用した、Google Kubernetes Engine (GKE) への Confluent Platform のデプロイについて説明します。特に、Confluent Cloud へのデータレプリケーションの方法に焦点を当てています。このサンプルを実行すると、シミュレーションされたデータが Confluent Cloud クラスターにレプリケートする GKE ベースの Confluent Platform デプロイが実現されます。クライアントアプリケーションを Confluent Cloud クラスターに対して実行して、元々ソース GKE クラスターにあったシミュレーションされたデータを表示することで、レプリケーションを検証します。
リソース要件が緩やかな GKE での Confluent for Kubernetes の実行の手順については、Confluent Platform on Google Kubernetes Engine example を参照してください。
このサンプルは、ブログの投稿「Conquering Hybrid Cloud with Replicated Event-Driven Architectures」で取り上げられました。このブログでは、レプリケートされたイベントストリーミングアーキテクチャのユースケースについて詳しく説明しています。
注釈
Confluent Cloud をターゲットとする本稼働環境に類似した環境で Kubernetes を使用するサンプルについては、「Kubernetes と GitOps を使用する Apache Kafka® 用 DevOps」プロジェクトを参照してください。
このサンプルの主なコンポーネントは、次のとおりです。
- Confluent Cloud 環境と Kafka クラスター
- GKE 上で実行されている Kubernetes クラスター。
- 次の Confluent Platform コンポーネントの管理に使用する Confluent for Kubernetes
- 3 ノードの ZooKeeper クラスター
- 3 ノードの Kafka クラスター
- 単一ノードの Replicator
- 単一ノードの Schema Registry
- 単一ノードの Kafka Connect
- Confluent Control Center
- 株式取引の模擬データを生成するための kafka-connect-datagen のインスタンス 1 つ
前提条件¶
サンプルを正常に実行するために、次のアプリケーションまたはライブラリが、システムパスにインストールされ、使用できる状態である必要があります。
| アプリケーション | テスト済みバージョン | 情報 |
|---|---|---|
kubectl |
1.18.0 |
https://kubernetes.io/ja/docs/tasks/tools/install-kubectl/ |
helm |
3.1.2 |
https://github.com/helm/helm/releases/tag/v3.1.2 |
gcloud
GCP sdk core
GKE cluster |
286.0.0
2020.03.24
1.15.11-gke.1 |
https://cloud.google.com/sdk/install |
ccloud |
v1.25.0 |
https://docs.confluent.io/ccloud-cli/current/install.html |
注釈
Confluent Platform 5.4 以降には、Helm 3 が必要です。
チュートリアルの実行コスト¶
注意¶
Confluent Cloud のすべてのサンプルでは、課金される可能性のある実際の Confluent Cloud リソースを使用しています。サンプルで、新しい Confluent Cloud 環境、Kafka クラスター、トピック、ACL、サービスアカウントに加えて、コネクターや ksqlDB アプリケーションのように時間で課金されるリソースを作成する場合があります。想定外の課金を避けるために、慎重に リソースのコストを確認 してから開始してください。Confluent Cloud のサンプルの実行を終了したら、サービスへの時間単位の課金を回避するためにすべての Confluent Cloud リソースを破棄し、リソースが削除されたことを確認します。
Confluent Cloud リソースに加え、このサンプルでは Google Cloud Platform リソースを使用しています。
- Confluent for Kubernetes に必要なサイズ設定の詳細は、「サイズ設定の推奨事項」ドキュメントに記載されています。
- 詳細については、Google Cloud の料金情報を参照してください。
サンプルの実行後は必ず、すべての リソースを破棄 してください。
サンプルの実行¶
confluentinc/examples GitHub リポジトリのクローンを作成し、ディレクトリを kubernetes/replicator-gke-cc に変更します。
git clone https://github.com/confluentinc/examples.git
cd examples/kubernetes/replicator-gke-cc
GKE のセットアップ¶
Confluent Cloud への現実的なレプリケーションシナリオを適切にシミュレーションするために、このサンプルには、Kafka および ZooKeeper の両方のために 3 ノードのクラスターをサポートできるサイズの GKE ノードプールが必要です。このデモのテストでは、十分に条件を満たすクラスターとは、マシンタイプ h1-highmem-2 の 7 ノードで構成されるクラスターです。
ちなみに
「変数のリファレンス」セクションを参照すると、このサンプルでデプロイされるリソースのサイズを制御できます。
既存の GKE クラスターを使用し、それに合わせて動作するように kubectl クライアントが既に構成されている場合は、このドキュメントの「Confluent Cloud のセットアップ」セクションに進んでください。
このサンプル用の新しい GKE クラスターを作成する場合は、クラスターの作成を支援する機能が Makefile に含まれています。この場合、アカウントにアクセスするにように glcoud SDK が適切に構成されていることが前提です。クラスター作成機能の動作をオーバーライドする必要がある場合は、このドキュメントの「高度な使用方法」セクションを参照してください。
gcloud SDK が現在、どの GCP プロジェクトに対して構成されているかを確認するには、以下を実行します。
gcloud config list --format 'value(core.project)'
標準クラスターを作成するには、次のコマンドを実行します。
make gke-create-cluster
Confluent Cloud のセットアップ¶
Confluent Cloud アカウントのセットアップ¶
このデモを行うには、Confluent Cloud アカウントと使用可能な状態の Kafka クラスターが必要です。まだアクセス権がない場合は、Confluent Cloud のホームページで自分のアカウントをセットアップできます。
注釈
このデモでは、Confluent Replicator を使用したマルチクラウドレプリケーション戦略を重点的に紹介しています。Replicator の利点の 1 つは、送信先クラスターのトピックとパーティションで、メッセージオフセット、タイムスタンプ、キー、値が同じであることです。既存の stock-trades トピックでクラスターを再利用した場合は、既存のトピックデータの末尾にメッセージが付加され、オフセットが送信元クラスターに一致しません。このサンプルを実行するたびに新しいクラスターを作成するか、実行前に送信先クラスターの stock-trades Kafka トピックを削除することをお勧めします。Confluent Cloud トピックの削除手順については、「ccloud kafka topic delete」を参照してください。
Kafka クラスターのセットアップ¶
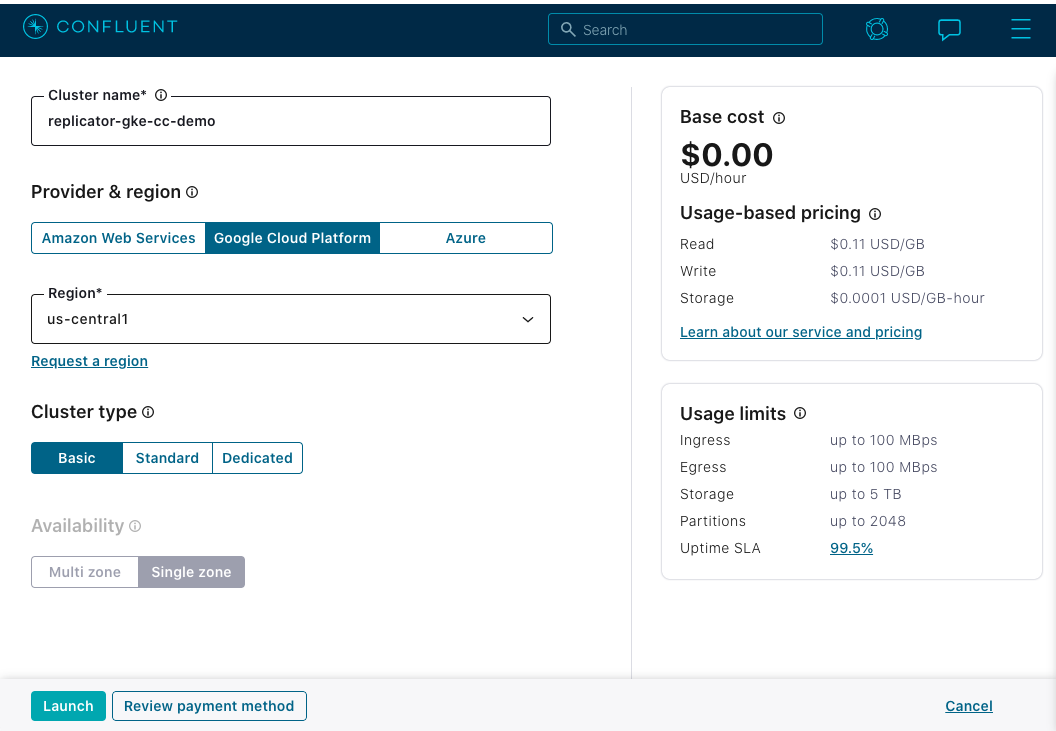
新しいクラスターを作成する場合は、このサンプルと同じ Cloud Provider およびリージョン内に作成することをお勧めします。このデモは Google Cloud Platform(GCP)上で実行され、デフォルトで us-central1 リージョンで動作します。新しいクラスターには、このサンプルの後半で使用される名前と一致するように、replicator-gke-cc-demo という名前を付けることをお勧めします。次の図は、推奨される構成を示しています。
ちなみに
詳細については、Confluent Cloud のクイックスタート を参照してください。
Kafka ブートストラップサーバーの構成¶
サンプルで使用する Confluent Cloud クラスターが完成したら、パブリックブートストラップサーバーが必要になります。
ccloud CLI を使用すると、クラスター用のブートストラップサーバー値を取得できます。
ちなみに
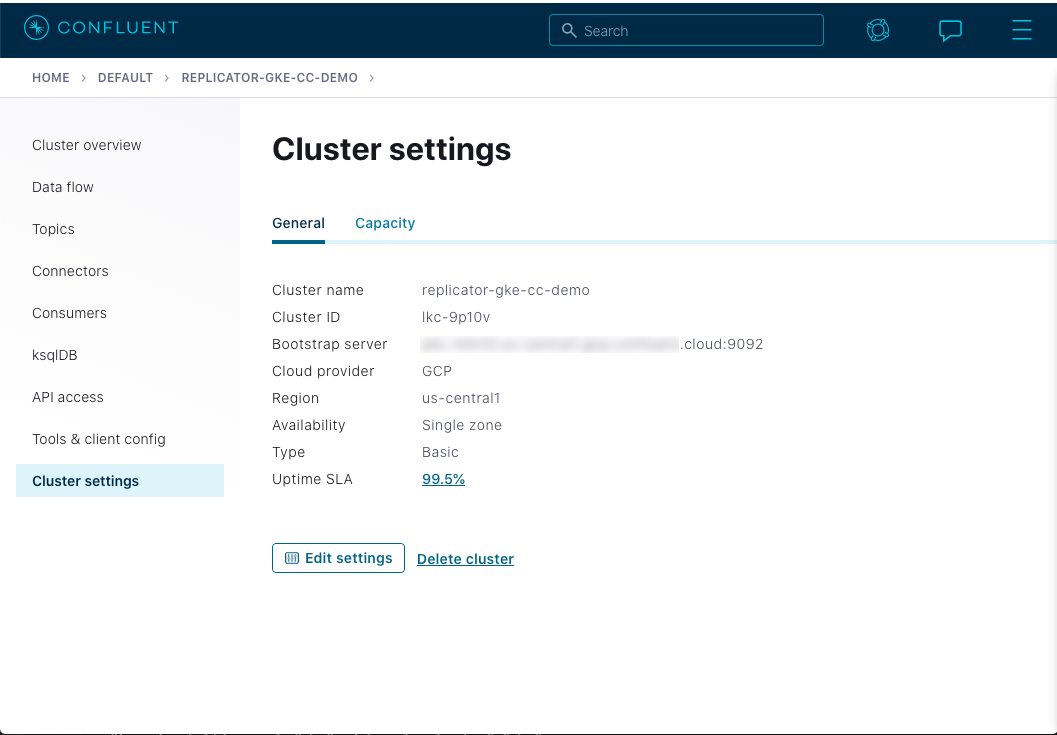
また、Confluent Cloud Console の Cluster settings の下でもブートストラップサーバー値を確認できます。
まだインストールしていない場合は、ccloud CLI をインストール します。
Confluent Cloud クラスターにログインします。
--save引数により、Confluent Cloud ユーザーログイン資格情報が保存されるか、ローカルのnetrcファイルに対してトークン(SSO の場合)が更新されます。ccloud login --save
出力は以下のようになります。
Enter your Confluent credentials: Email: jdoe@myemail.io Password: Logged in as jdoe@myemail.io Using environment t118 ("default")使用可能な Kafka クラスターのリストを表示します。
ccloud kafka cluster list
これにより、アクセスできるクラスターのリストが生成されます。
Id | Name | Provider | Region | Durability | Status +-------------+------------------------+----------+-------------+------------+--------+ lkc-xmm5g | abc-test | gcp | us-central1 | LOW | UP lkc-kngnv | rjs-gcp-us-central1 | gcp | us-central1 | LOW | UP lkc-3r3vj | replicator-gke-cc-demo | gcp | us-central1 | LOW | UPブートストラップサーバーを取得するクラスターの詳細情報を表示します。
ccloud kafka cluster describe lkc-3r3vj
これにより、クラスターの詳細が表示されます。
Endpointフィールドにブートストラップサーバー値が含まれています。+-------------+------------------------------------------------------------+ | Id | lkc-3r3vj | | Name | replicator-gke-cc-demo | | Ingress | 100 | | Egress | 100 | | Storage | 5000 | | Provider | gcp | | Region | us-central1 | | Status | UP | | Endpoint | SASL_SSL://abc-12345.us-central1.gcp.stag.cpdev.cloud:9092 | | ApiEndpoint | https://abc-12345.us-central1.gcp.stag.cpdev.cloud | +-------------+------------------------------------------------------------+
API キーおよびシークレットの構成¶
ccloud CLI で、クライアントアプリケーションで使用する API キーを作成できます。
ちなみに
また、Confluent Cloud Console を使用して API キーを作成することもできます。
新しい API キーを作成するには、以下を実行します。
ccloud api-key create --resource lkc-3r3vj
ツールにより、新しいキーとシークレットが、次のように表示されます。この値は、後で取得することができないため、別の場所に保存しておく必要があります。
Save the API key and secret. The secret is **not** retrievable later. +---------+------------------------------------------------------------------+ | API Key | LD35EM2YJTCTRQRM | | Secret | 67JImN+9vk+Hj3eaj2/UcwUlbDNlGGC3KAIOy5JNRVSnweumPBUpW31JWZSBeawz | +---------+------------------------------------------------------------------+
Helm 値の構成¶
Confluent Cloud アカウントにアクセスするようにサンプルを構成するために、Helm チャート 値のファイルを作成します。サンプルは、特定の場所でこのファイルを見つけ、 helm コマンドに渡して、クラウドアカウントの詳細を Confluent Platform の構成に組み込みます。
次のコマンドを実行して値のファイルを作成します。最初に、
bootstrapEndpoint、username、およびpasswordの{{ mustache bracket }}値を、前述の手順で取得した、該当する値に置き換えます。cat <<'EOF' > ./cfg/my-values.yaml destinationCluster: &destinationCluster name: replicator-gke-cc-demo tls: enabled: true internal: true authentication: type: plain bootstrapEndpoint: {{ cloud bootstrap server }} username: {{ cloud API key }} password: {{ cloud API secret }} controlcenter: dependencies: monitoringKafkaClusters: - <<: *destinationCluster replicator: replicas: 1 dependencies: kafka: <<: *destinationCluster EOFこれで、サンプルの実行前にファイルの値を確認できます。サンプル Makefile が、デプロイされた Helm にこれらの値を統合します。
cat ./cfg/my-values.yaml
開始前のチェック¶
サンプルの実行前にセットアップを確認することができます。
GKE クラスターのステータスを確認するには、以下を実行します。
gcloud container clusters list
GKE クラスターの制御に適したコンテキストで kubectl コマンドが構成されていることを確認するには、以下を実行します。
kubectl config current-context
前のコマンドの出力は、GKE プロジェクト、リージョン、Makefile 変数 GKE_BASE_CLUSTER_ID の値、マシンのユーザー名の組み合わせによる名前です。以下に例を示します。
kubectl config current-context
gke_gkeproject_us-central1-a_cp-examples-operator-jdoe
サンプルの実行¶
自動化されたデモを実行するには、以下を実行します(推定実行時間は 8 分)。
make demo
デモでは、Confluent for Kubernetes を利用して Confluent Platform をデプロイします。さまざまなコンポーネントがデプロイされ、その中で実行中のさまざまなコマンドが表示されるので、ユーザーはそのプロセスを観察できます。たとえば、Kafka のデプロイのメッセージは、次のように表示されます。
+++++++++++++ deploy kafka
helm upgrade --install --namespace operator --wait --timeout=500 -f examples/kubernetes/gke-base/cfg/values.yaml --set global.provider.region=us-central1 --set global.provider.kubernetes.deployment.zones={us-central1-a} -f examples/kubernetes/replicator-gke-cc/cfg/values.yaml -f examples/kubernetes/replicator-gke-cc/cfg/my-values.yaml --set kafka.replicas=3 --set kafka.enabled=true kafka examples/kubernetes/common/cp/operator/20190912-v0.65.1/helm/confluent-operator
Release "kafka" does not exist. Installing it now.
NAME: kafka
LAST DEPLOYED: Mon Oct 28 11:42:07 2019
NAMESPACE: operator
STATUS: DEPLOYED
...
✔ ++++++++++ Kafka deployed
+++++++++++++ Wait for Kafka
source examples/kubernetes/common/bin/retry.sh; retry 15 kubectl --context |kubectl-context-pattern| -n operator get sts kafka
NAME READY AGE
kafka 0/3 1s
kubectl --context |kubectl-context-pattern| -n operator rollout status statefulset/kafka
Waiting for 3 pods to be ready...
Waiting for 2 pods to be ready...
Waiting for 1 pods to be ready...
statefulset rolling update complete 3 pods at revision kafka-775f97f98b...
✔ ++++++++++ Kafka ready
最後に表示される出力メッセージは、次のようになります。
✔ Replicator |k8s-service-name|->CC Demo running
検証¶
複数のクラスターの Control Center ビューの検証¶
Confluent Control Center を表示するには、ローカルマシンと、Confluent Control Center サービスを実行している Kubernetes ポッドの間に、有効なネットワーク接続が必要になります。既存のクラスターを使用した場合は、外部クラスターアクセスが既に構成されている可能性があります。そうでない場合は、次の kubectl コマンドを使用して、ローカルホストと Confluent Control Center の間の転送されたポート接続を開くことができます。
kubectl -n operator port-forward controlcenter-0 12345:9021
次に、Web ブラウザーを開いて http://localhost:12345 にアクセスします。ここには、2 つの健全なクラスターを持つ Confluent Control Center が表示されます。
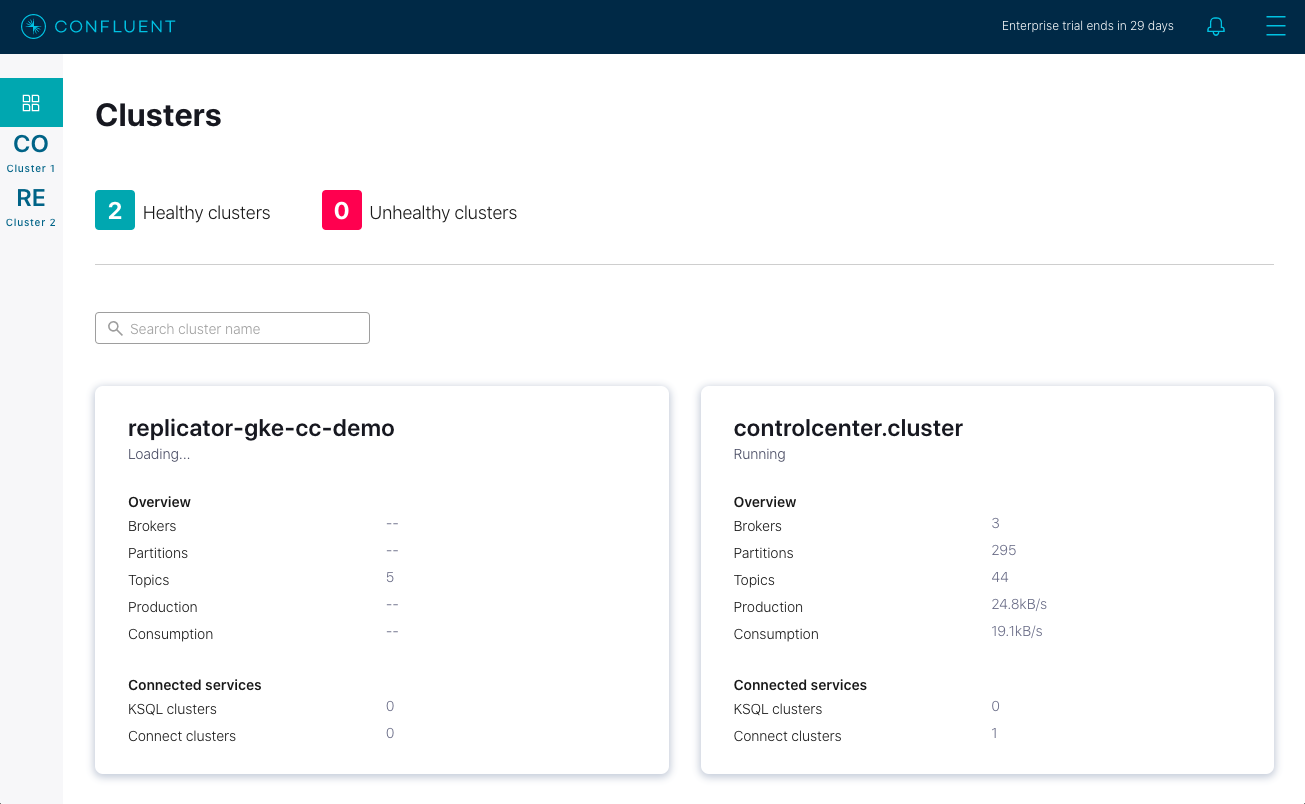
replicator-gke-cc-demo クラスターは Confluent Cloud クラスターであり、controlcenter.cluster は GKE ベースの Confluent for Kubernetes マネージド型クラスターです。この時点では、Confluent Cloud クラスターの詳細なモニタリングをオンプレミスの Confluent Control Center から行うことはできません。画面を見ると、replicator-gke-cc-demo クラスターには、ブローカーの数が表示されていません。 Confluent Cloud マネージド Kafka サービスはサーバーレス であり、ブローカーの概念が無視されているためです。
次に、controlcenter.cluster、Consumers、replicator の順にクリックします。これにより、stock-trades トピックを Confluent Cloud にレプリケートする Confluent Replicator コンシューマーグループのビューが表示されます。
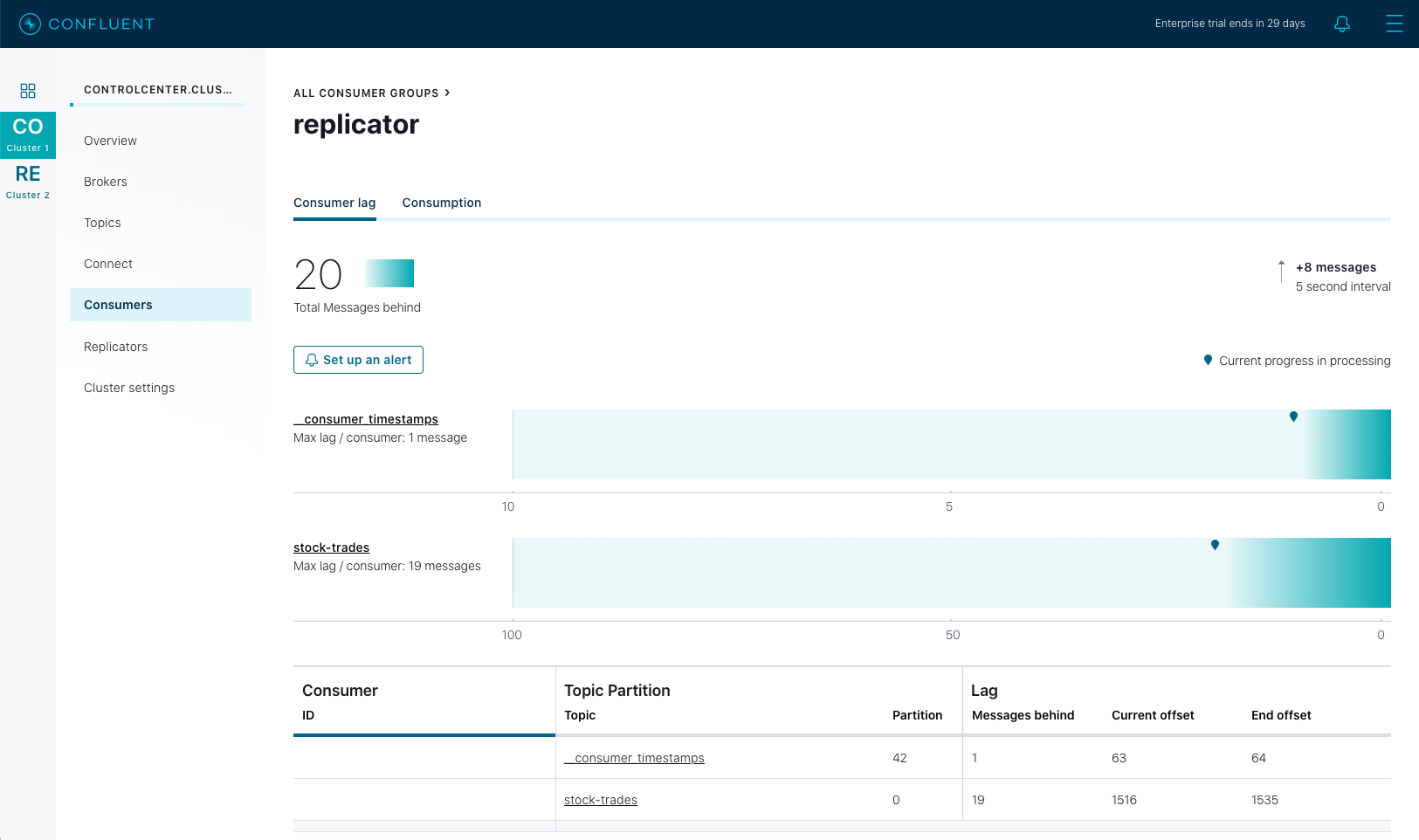
この Control Center 画面では、replicator コンシューマーグループのコンシューマーグループラグが強調表示されています。上のスクリーンショットでは、Control Center が、すべてのトピックとパーティションにわたる replicator コンシューマーの合計ラグが 27 件のメッセージであることを報告しています。Replicator でのメッセージの処理が進む中で、そのコンシューマーグループラグが変動し、この画面のチャートが、現在の値と、時間の経過により変動するラグの最大値を示すようになります。
クライアントでのレプリケートされた stock-trades トピックの検証¶
両方のクラスターで stock-trades トピックデータのストリーミングを表示するには、2 つのターミナルを開き、次の一連のコマンドを実行します。
ソース( GKE )クラスター上の
stock-tradesイベントを表示するには、まず一方のターミナルのclient-consoleポッドでシェルを開きます。kubectl -n operator exec -it client-console bash
次に
kafka-console-consumerを使用して、stock-tradesトピックから値のストリーム処理を行います。必要な構成は、ポッド上のボリュームに既にマウントされている/etc/kafka-client-properties/kafka-client.propertiesファイルに提供されます。kafka-console-consumer --bootstrap-server kafka:9071 --consumer.config /etc/kafka-client-properties/kafka-client.properties --topic stock-trades --property print.value=false --property print.key=true --property print.timestamp=true
デスティネーション(Confluent Cloud)クラスター上の
stock-tradesイベントを表示するには、もう一方のターミナルのclient-consoleポッドで別のシェルを開きます。kubectl -n operator exec -it client-console bash
再び
kafka-console-consumerを使用して、今度は送信先クラスターでstock-tradesトピックから値のストリーム処理を行います。必要な構成は、ポッドのボリュームの/etc/destination-cluster-client-properties/destination-cluster-client.propertiesファイルにマウントされています。さらに、ブートストラップサーバー値が/etc/destination-cluster-client-properties/destination-cluster-bootstrapファイルに追加されています。次のコマンドでは、この両方のファイルを使用して送信先クラスターへの接続を作成します。kafka-console-consumer --bootstrap-server $(cat /etc/destination-cluster-client-properties/destination-cluster-bootstrap) --consumer.config /etc/destination-cluster-client-properties/destination-cluster-client.properties --topic stock-trades --property print.value=false --property print.key=true --property print.timestamp=true
次の各コマンドでは、タイムスタンプおよびメッセージのキーを各クラスターが受け取るたびに、それらを出力します。これらの値を見てイベントを照合し、レプリケーションプロセスを観察することができます。たとえば、最初のターミナルでは、次のように表示されます。
... CreateTime:1572380698171 ZJZZT CreateTime:1572380698280 ZWZZT CreateTime:1572380698351 ZWZZT CreateTime:1572380698577 ZJZZT CreateTime:1572380699340 ZVZZT
そのすぐ後に、もう一方のターミナルに、同じメッセージが表示されます。
... CreateTime:1572380698171 ZJZZT CreateTime:1572380698280 ZWZZT CreateTime:1572380698351 ZWZZT
サンプルの停止¶
Confluent Cloud のすべてのサンプルでは、実際の Confluent Cloud リソースを使用しています。Confluent Cloud のサンプルの実行を終了したら、予定外の課金を回避するために、すべての Confluent Cloud リソースが破棄されていることを直接確認してください。
サンプルの結果の評価を終了したら、次のコマンドですべての Kubernetes リソースを破棄できます。
make destroy-demo
サンプルを使用してクラスターを作成した場合は、以下のコマンドで、その GKE クラスターを破棄できます。
make gke-destroy-cluster
重要ポイント¶
Helm による Kafka コネクターのデプロイ¶
ここでは、標準の Kafka Connect REST インターフェイス を介して Kafka Connect コネクター構成をデプロイする場合に使用できるシンプルな Helm チャートを重点的に紹介します。このデモではこの方法で Confluent Replicator 構成をデプロイしますが、どの Kafka Connect 構成も、同じ方法を使用してデプロイできます。Confluent for Kubernetes の将来のバージョンでは、Kafka Connect コネクターがオペレーター コントローラー によって管理されます。
Helm チャートは、このデモの kubernetes/common/helm/replicator-cc フォルダーにあります。templates/replicator-configmap.yaml ファイルには、テンプレート化された JSON 値を含む data セクションがあり、これは、Kafka Connect コネクター API に準拠しています。送信先クラスターと送信元クラスターの構成値は、実行時に helm テンプレートシステムによって入力され、前述のデモ手順で作成された my-values.yaml ファイルによって提供されます。
apiVersion: v1
kind: ConfigMap
metadata:
name: replicator-connector
data:
replicator-connector.json: '{
"name":"replicator",
"config": {
"connector.class": "io.confluent.connect.replicator.ReplicatorSourceConnector",
"topic.whitelist": "{{.Values.replicator.topic.whitelist}}",
"key.converter": "io.confluent.connect.replicator.util.ByteArrayConverter",
"value.converter": "io.confluent.connect.replicator.util.ByteArrayConverter",
"dest.kafka.bootstrap.servers": "{{.Values.replicator.dependencies.kafka.bootstrapEndpoint}}",
"dest.kafka.security.protocol": "{{$destProtocol}}",
"dest.kafka.sasl.mechanism": "PLAIN",
"dest.kafka.sasl.jaas.config": "{{$destJaasConfig}}",
"src.consumer.group.id": "replicator",
"src.kafka.bootstrap.servers": "kafka:9071",
"src.kafka.security.protocol": "{{$srcProtocol}}",
"src.kafka.sasl.mechanism": "PLAIN",
"src.kafka.sasl.jaas.config": "{{$srcJaasConfig}}",
"src.consumer.interceptor.classes": "io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor",
"src.consumer.confluent.monitoring.interceptor.bootstrap.servers": "kafka:9071",
"src.consumer.confluent.monitoring.interceptor.security.protocol": "{{$srcProtocol}}",
"src.consumer.confluent.monitoring.interceptor.sasl.mechanism": "PLAIN",
"src.consumer.confluent.monitoring.interceptor.sasl.jaas.config": "{{$srcJaasConfig}}",
"src.kafka.timestamps.producer.interceptor.classes": "io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor",
"src.kafka.timestamps.producer.confluent.monitoring.interceptor.bootstrap.servers": "kafka:9071",
"src.kafka.timestamps.producer.confluent.monitoring.interceptor.security.protocol": "{{$srcProtocol}}",
"src.kafka.timestamps.producer.confluent.monitoring.interceptor.sasl.mechanism": "PLAIN",
"src.kafka.timestamps.producer.confluent.monitoring.interceptor.sasl.jaas.config": "{{$srcJaasConfig}}",
"tasks.max": "1"
}
}'
ConfigMap マニフェストファイルと同じディレクトリには、Kubernetes ジョブ マニフェスト( replicator-connector-deploy-job.yaml )があります。これにより、ジョブを最後まで正常に実行して終了する Kubernetes ジョブ が定義されます。curl プログラムを含む Docker イメージを使用すると、前述のように定義された ConfigMap がバッチジョブポッドにマウントされた後、curl により POST が Kafka Connect REST API に実行されて Replicator がデプロイされます。
apiVersion: batch/v1
kind: Job
metadata:
name: replicator-connector-deploy
spec:
ttlSecondsAfterFinished: 5
template:
spec:
volumes:
- name: replicator-connector
configMap:
name: replicator-connector
containers:
- name: replicator-connector-deploy
image: cnfldemos/alpine-curl:3.10.2_7.65.1
args: [
"-s",
"-X", "POST",
"-H", "Content-Type: application/json",
"--data", "@/etc/config/connector/replicator-connector.json",
"http://replicator:8083/connectors"
]
volumeMounts:
- name: replicator-connector
mountPath: /etc/config/connector
restartPolicy: Never
backoffLimit: 1
注目すべきは、ConfigMap をジョブポッドに名前で関連付ける方法です。ジョブマニフェストの volumes スタンザにある値、replicator-connector は、ConfigMap マニフェストのメタデータセクションにある ConfigMap 名と一致します。
オペレーターによるコネクターのデプロイ¶
任意の Kafka コネクター(または Single Message Transformation(SMT) あるいは コンバーター)を Kubernetes 環境にデプロイできます。Confluent Hub は、事前パッケージ済みですぐにインストールできるコネクター、変換、およびコンバーターのオンラインライブラリです。これを検索して、必要なものを見つけることができます。Kafka Connect の Confluent for Kubernetes イメージ、confluentinc/cp-server-connect-operator には、このようなコネクターがいくつか含まれていますが、デプロイしようとしている特定のコネクターは含まれていない場合があります。したがって、新しいコネクタータイプを Kubernetes 環境にデプロイするには、Connect イメージ用の JAR を入手する必要があります。
推奨される方法は、必要な JAR でベース Connect Docker イメージを拡張するカスタム Docker イメージを作成することです。カスタム Docker イメージでは、依存関係から 1 つのアーティファクトが作成されます。これは自立性と移植性が高いため、エフェメラル(揮発性)ディスクであるにもかかわらず、あらゆるポッドで実行できます。Confluent Hub クライアントを使用してカスタム Docker イメージを作成し、すぐにインストールできるコネクターの特定のセットで、Confluent の Kafka Connect イメージのいずれかを拡張する方法については、このドキュメント を参照してください。例として、模擬イベントを生成する Kafka Connect Datagen コネクター を Confluent Hub からプルし、この Dockerfile を使用して Docker イメージにバンドルする方法をご覧ください。カスタム Docker イメージをビルドしたら、Kubernetes が、このイメージを Docker レジストリからプルしてポッドを作成する必要があります。
注釈
複数のボリュームを使用して、必要な JAR を Connect イメージに配置することは推奨されません。自立性と移植性が低下し、ベースイメージと JAR の間でのバージョンの一致が困難になるためです。
Confluent Hub で用意されている事前パッケージ済みコネクターではなく、カスタムコネクターを使用する高度なユースケースでは、ローカルアーカイブ のカスタムコネクターを含む Docker イメージを作成する場合があります。デモでは、この高度なワークフローを使用します。Kafka Connect Datagen コネクター を使用して模擬イベントを生成します。この Dockerfile が、( Confluent Hub から直接プルされたのではなく)ソースコードからコンパイルされた Kafka Connect Datagen コネクターのローカルアーカイブで Docker イメージをビルドします。このイメージを Docker Hub にパブリッシュしますが、ご使用の環境では、各自の Docker Hub リポジトリにパブリッシュしてください。
オペレーター Helm の値をアップデートして、ポッド用のカスタム Connect Docker イメージをプルする必要があります。これを行うには、connect イメージをオーバーライドして、デモの value.yaml 構成ファイルの Docker Hub にパブリッシュされたものを代わりに使用します。
connect:
image:
repository: cnfldemos/cp-server-connect-operator-datagen
tag: 0.3.1-5.4.1.0
高度な使用方法¶
GKE クラスター作成のカスタマイズ¶
オーバーライドし、make コマンドに渡すことのできる変数があります。以下の表は、その変数とデフォルト値を示します。これらの変数は、次のように make コマンドに設定できます。
GKE_BASE_ZONE=us-central1-b make gke-create-cluster
または、make コマンドの実行前に、現在の環境にエクスポートすることができます。
export GKE_BASE_ZONE=us-central1-b
make gke-create-cluster
| 変数 | デフォルト |
|---|---|
| GKE_BASE_REGION | us-central1 |
| GKE_BASE_ZONE | us-central1-a |
| GKE_BASE_SUBNET | default |
| GKE_BASE_CLUSTER_VERSION | 1.13.7-gke.24 |
| GKE_BASE_MACHINE_TYPE | n1-highmem-2 |
| GKE_BASE_IMAGE_TYPE | COS |
| GKE_BASE_DISK_TYPE | pd-standard |
| GKE_BASE_DISK_SIZE | 100 |
トラブルシューティング¶
- 送信元クラスターと送信先クラスターで、レプリケートされたオフセットが一致していない場合は、デモを再起動しており、その際にクラスターの起動前に送信先クラスターが存在していた可能性があります。デモのすべての機能を正常に実行するには、新しいクラスターを使用するか、デモの実行前にデスティネーショントピックを削除して再作成してください。