Confluent Platform における Kafka の基礎¶
Confluent Platform と Apache Kafka® について、実践的な側面から紹介します。
ここで取り上げる内容¶
- Kafka のユースケース、アプリケーション開発、および Confluent Platform で Kafka がどのように提供されているかについての 概要
- Confluent Platform の入手先 および 実行方法 のオプションの概要
- 本稼働環境の構成(マルチブローカー、 マルチクラスター など)をモデル化する Confluent Enterprise のデプロイを 1 台のノート PC またはマシンでセットアップする方法に関する手順(トピックのレプリケーション係数の説明を含む)
- Kafka のコマンド入門: Kafka のユーティリティが開発や管理者のワークフローでどのように役立つかを明らかにするうえでも役立つコマンドチートシート
- マルチブローカーのセットアップ でリスナー、Metrics Reporter、および REST エンドポイントを構成し、ブローカーおよび他のコンポーネントすべてが Confluent Control Center に表示されるようにする方法の説明。Kafka のコマンドを使用して作成したトピックおよびメッセージを Control Center で検証する 方法についての簡単な説明。
- コード例とデモアプリ へのリンク
Confluent Platform の概要と Kafka との関係について¶
Apache Kafka® は、アプリケーションの開発、テスト、デプロイ、および管理に使用できる イベントストリーミングプラットフォーム です。Kafka は、分散アプリケーションでリアルタイムでデータを取り込み、処理、および共有できるようにする、パブリッシュ/サブスクライブ型メッセージングシステムです。
開発者は、Confluent Platform を使用して Kafka のコードを自分のアプリケーションに組み込む ことで、 ネイティブクライアント として、または REST Proxy 経由で(「アプリケーション開発」を参照)、アプリケーションサービスを Confluent Platform を通じて Kafka とやり取りさせることができます。
Confluent Platform を使用すると、Kafka と Confluent Platform 両方のコア機能を利用できます。開発サイクル中に、実行中のプラットフォームを使用して、プラットフォームの機能と、プラットフォームとやり取りする自分のアプリケーションコードの要素の両方をテスト(トピックの作成、メッセージの生成と消費、スキーマのトピックとの関連付けなど)できます。
管理者 は、 スケーラブルなデプロイを構成および開始 して、Kafka と Confluent Platform の両方の機能を活用するとともに、各デプロイを管理および発展させることができます。
Kafka のユースケース¶
一例として、ソーシャルメディアアプリケーションにおいて投稿、いいね、およびコメントに対して Kafka のトピックをモデル化できます。アプリケーションには、Kafka トピックのプロデューサーと、それらのトピックをサブスクライブするコンシューマーが組み込まれています。このアプリケーションのユーザーが投稿、何かに対するいいね、またはコメントをパブリッシュすると、関連付けられているトピックにそのデータが送信(生成)されます。ユーザーがソーシャルメディアサイトに移動するか、特定のページをクリックして表示させると、関連付けられているトピックから Kafka のコンシューマーが読み取って、そのデータがウェブページにレンダリングされます。
以下のページに他の実例が示されています。
Confluent Platform の活用方法¶
前述した Kafka のユースケースの例は、Confluent Platform のユースケースとみなすこともできます。Confluent Platform は、Kafka を中核とし、多数の素晴らしい機能および追加の API を組み込んで特殊化されたディストリビューションです。商用版 Confluent Platform の機能の多くは、Confluent Server の主要機能であるブローカーに組み込まれています(こちら を参照)。
Kafka で習得済みの基本的な機能、 概念、 設計 の理念、および操作方法は、Confluent Platform にも当てはまります。当然ながら、Confluent Platform には、開発で使用される Kafka の基本的なコマンドユーティリティと API、および Confluent に特有の機能をサポートするためのいくつかの追加 CLI が付属しています。Confluent Platform の詳細については、「Confluent Platform とは」を参照してください。
Confluent Platform のリリースには 最新の安定バージョンの Apache Kafka が含まれているので、 Confluent Platform をインストール すると Kafka もインストールされます。Confluent Platform のリリースと Kafka バージョンのマッピングはこちら で確認できます。
Confluent Platform のデモとユースケースの実例は、このドキュメントのさまざまな場所に記載されていますが、Confluent の以下のウェブサイトにも掲載されています。
Kafka のコマンドラインツールがある場所¶
- Confluent のコマンドと Kafka のコマンド(名前が
kafka-で始まるコマンド)の一覧は、このドキュメントの「Confluent Platform の CLI ツール」で確認できます。 - システムにインストールされている Confluent Platform の場合、Kafka と Confluent のユーティリティは
$CONFLUENT_HOME/bin/($CONFLUENT_HOMEは Confluent Platform のインストール先ディレクトリ)にあります。Kafka のコマンドの説明と例については、このページの「Kafka のコマンド入門」を参照してください。
Confluent Platform の入手先¶
以下の例に進む前に、次の前提条件を満たしていること、およびローカルマシンに Confluent Platform 6.0.0 以降 がインストールされていることを確認してください。
- 前提条件:
インターネットに接続されている。
オペレーティングシステム が現在 Confluent Platform でサポートされている。
サポートされている Java バージョン をダウンロードしてインストール済みである。
このバージョンの Confluent Platform では Java 8 および Java 11 がサポートされています(Java 9 と 10 はサポート対象外)。詳細については、 サポートされている Java バージョン を参照してください。
- Confluent Platform 実行用の Java 1.8 または 1.11
実行方法¶
Confluent Platform (および Kafka )を実行するには、ユースケースと目的に応じて、いくつかの選択肢があります。
クイックスタート¶
このプラットフォームに慣れることを目的とする開発者は、「Apache クイックスタートガイド」から始めることをお勧めします。ローカルのクイックスタート(「Confluent Enterprise のクイックスタート」など)では、トピックのレプリケーション係数が 1 に設定されている単一ブローカーの単一クラスター開発環境で 1 つのコマンド( confluent local services start)を使用して Confluent Platform を実行する方法のデモが示されています。Docker のデモ(「Confluent Platform のクイックスタート(Docker)」など)では、同じタイプのデプロイのデモが示されています。いずれも、ブローカーや Confluent Control Center のプロパティファイルを構成する必要はありません。
ちなみに
Confluent Platform の基本的な使用方法と、クラスターを構成する方法の理解の両方を学ぶには、次の順序で進めることをお勧めします。
- 「Confluent Enterprise のクイックスタート」などに記載されているローカルインストールの手順に従い、
confluent local services startを使用して説明どおりにデフォルトの単一ブローカーのクラスターを実行します。そのチュートリアルのワークフローで示されているように機能を試してみます。 - このページに戻り、 マルチブローカーのクラスターを構成および実行する ための手順を試してみます。
Docker のクイックスタートのデモは他のコンポーネントへの影響が少なく、Confluent Platform の機能を試すのに適した方法です。ただし、ローカルインストールの場合、クラスターの構成および機能の有効化を実践的に使用できます。
本稼働環境対応のマルチノードデプロイ¶
本稼働環境対応のデプロイをセットアップするオペレーターおよび開発者は、「オンプレミスのデプロイ」または「Ansible Playbook」に記載されているワークフローに従うことをお勧めします。
マルチブローカー、マルチクラスターの単一マシン構成¶
開発者環境のクイックスタートと本格的なマルチノードのデプロイの間の違いを把握するために、まずはノート PC などの単一マシンを使用して マルチブローカーのクラスター と マルチクラスター のセットアップに着手してみるとよいでしょう。
これらの異なるセットアップを試してみることは、Kafka のブローカーや Control Center の構成ファイルがどのようなものか理解し、より洗練されたデプロイをローカルで試すために適した方法です。これらのセットアップは実際の構成と非常によく似ていて、Confluent Platform に特有の機能(Replicator、Self-Balancing、Cluster Linking、マルチクラスターの Schema Registry など)に対するデータ共有や他のシナリオがサポートされています。
- 複数のブローカーを使用する単一クラスターでは、単一の ZooKeeper と、クラスター内で必要な数のブローカーを構成して起動する必要があります。後述の「マルチブローカーのクラスターの実行」で詳細な例を示しています。
- マルチクラスターのデプロイでは、クラスターと同じ数の ZooKeeper および Kafka サーバーの複数のプロパティファイル(ブローカーごとに 1 つ)が必要です。マルチクラスターのセットアップの詳細については、「複数のクラスターの実行」を参照してください。
すべての作業をノート PC で実行できるか¶
できます。ここに記載している例では、すべてのクラスターおよびブローカーを単一のノート PC またはマシンで実行する方法を示しています。
したがって、ここで学ぶことの大部分を簡単に応用し、複数の仮想ホストを使用して、好みのクラウドプロバイダーで類似したデプロイを作成することができます。これらの例を、より複雑なデプロイや機能統合の足掛かりとして使用してください。
マルチブローカーのクラスターの実行¶
複数のブローカーを使用して単一クラスターを実行するには、以下のファイルが必要です(この例でのブローカーは 3 つ)。
- ZooKeeper のプロパティファイル x 1。
- Kafka のブローカーのプロパティファイル x 3。ブローカー ID、リスナーポート(Control Center 上のすべてのブローカーの情報を提供)、およびログファイルディレクトリがそれぞれ一意のもの。
controlcenter.clusterの REST エンドポイントがブローカーにマッピングされている、Control Center のプロパティファイル。- ブローカーにインストールされて有効化されている、Metrics Reporter の JAR ファイル(後述のように Confluent Platform を
$CONFLUENT_HOME/bin/から起動する場合、Metrics Reporter は自動的にブローカーに "インストール" されます。そうでない場合は、 Metrics Reporter の JAR ファイル のパスを CLASSPATH 環境変数に追加する必要があります)。 - 実行する Confluent Platform のその他のコンポーネントのプロパティファイル(最初はデフォルト設定で使用)。
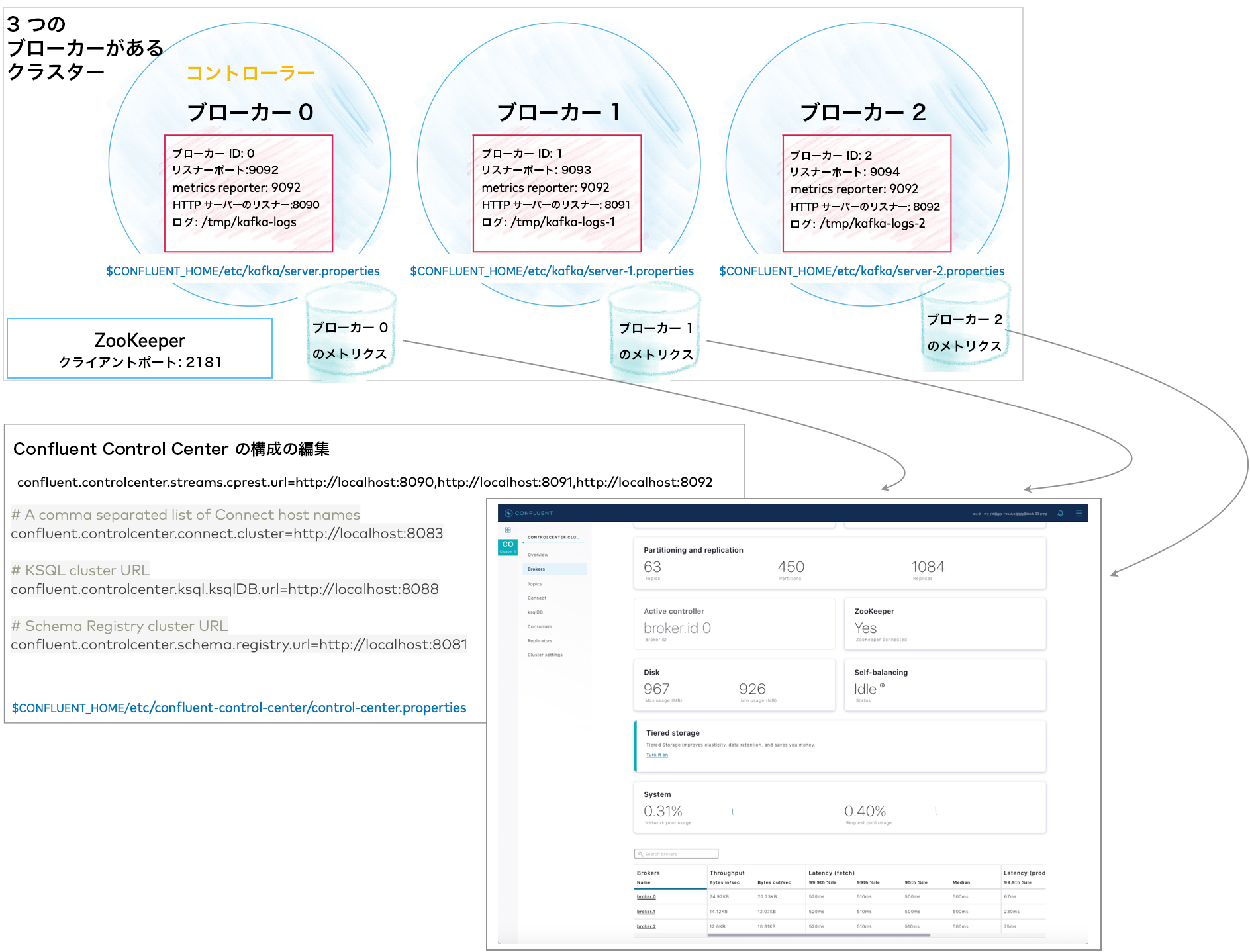
これらすべての詳細については、以降で説明します。
レプリケーション係数の構成¶
Confluent Platform に付属している server.properties ファイルでは、開発環境やテスト環境および「Confluent クイックスタート」のシナリオをサポートできるように、いくつかのシステムトピックでレプリケーション係数が 1 に設定されています。ただし、実際のシナリオでは、システムトピックとユーザー作成トピックの両方でフェイルオーバー機能および自動バランス調整機能がサポートされるように、レプリケーション係数を 1 より大きくすることをお勧めします。
以下の手順では、システムトピックのレプリケーション係数とレプリカ数を 2 に設定し直し、変更内容を有効にするために、必要に応じてプロパティのコメントを解除する方法を示します。
以下の変更を行ってからファイルを保存します。
$CONFLUENT_HOME/etc/kafka/server.propertiesファイルでreplication.factorをすべて検索し、その値を、1 より大きくブローカーの数より小さい数に設定します。このクラスターの場合は、すべてのreplication.factorを「2」に設定します。server.propertiesを検索すると、以下のプロパティが見つかるので、コメントアウトされている場合は、コメントを解除します。offsets.topic.replication.factor=2 transaction.state.log.replication.factor=2 confluent.license.topic.replication.factor=2 confluent.metadata.topic.replication.factor=2 confluent.balancer.topic.replication.factor=2
同じプロパティファイルで
replicasを検索し、以下のプロパティのコメントを解除して、その値を「2」に設定します。confluent.metrics.reporter.topic.replicas=2 confluent.security.event.logger.exporter.kafka.topic.replicas=2
Connect を実行する場合は、このプロパティファイル内のレプリケーション係数も変更します。
$CONFLUENT_HOME/etc/kafka/connect-distributed.propertiesファイルでreplication.factorをすべて検索し、その値を、1 より大きくブローカーの数より小さい数に設定します。このクラスターの場合は、すべてのreplication.factorを「2」に設定します。connect-distributed.propertiesを検索すると、以下のプロパティが見つかります。コメントアウトされている場合は、コメントを解除します。offset.storage.replication.factor=2 config.storage.replication.factor=2 status.storage.replication.factor=2
ちなみに
- レプリカ数とレプリケーション係数を
2に制限することにより、ブローカーが消失した場合にトピックのレプリケーションが保護されます。また、Self-Balancing Clusters を使用してクラスターから意図的にブローカーを 1 つ減らす選択肢が提供されます。いつでも、3 まで戻したり、ブローカー数を増やしたりできます。この構成では、ブローカーが 2 つ以上のクラスターでトピックのレプリケーションがサポートされています。 - ユーザーが独自のトピックを作成する場合は、ブローカー数に応じて、必要となるレプリケーション係数を設定するようにします。この場合の例については、「Kafka のコマンド入門」のトピックの作成に関するセクションを参照してください。
3 つのブローカーがあるクラスターの基本構成の作成¶
この例では、ブローカーが 3 つのクラスターについて説明します。
まず、前のステップでレプリケーション係数をアップデートした server.properties ファイルをコピーし、構成を次のように変更して、新しいファイルを他の 2 つのブローカーを表す名前に変更します。
| ファイル | 構成 |
|---|---|
| server.properties | 以下の基本プロパティではデフォルト値を使用します(値がコメントアウトされている場合は、そのままにしておきます)。
次の 2 行のコメントを解除して、Metrics Reporter を有効化し、すべてのブローカー用のブローカーメトリクスを Control Center に入力します。この同じ構成は、クラスター内のすべてのブローカーに適用できます。各ブローカーのリスナーポートに一致するように変更する必要はありません。 metric.reporters=io.confluent.metrics.reporter.ConfluentMetricsReporter
confluent.metrics.reporter.bootstrap.servers=localhost:9092
次のリスナー構成を追加して、このブローカーの REST エンドポイントを指定します。 confluent.http.server.listeners=http://localhost:8090
|
| server-1.properties | 以下の基本プロパティの値が一意になるように変更します(
次の 2 行のコメントを解除して、このブローカーで Metrics Reporter を有効化します。 metric.reporters=io.confluent.metrics.reporter.ConfluentMetricsReporter
confluent.metrics.reporter.bootstrap.servers=localhost:9092
次のリスナー構成を追加して、このブローカーに固有の REST エンドポイントを指定します( confluent.http.server.listeners=http://localhost:8091
|
| server-2.properties | 以下の基本プロパティの値が一意になるように変更します(
次の 2 行のコメントを解除して、このブローカーで Metrics Reporter を有効化します。 metric.reporters=io.confluent.metrics.reporter.ConfluentMetricsReporter
confluent.metrics.reporter.bootstrap.servers=localhost:9092
次のリスナー構成を追加して、このブローカーに固有の REST エンドポイントを指定します( confluent.http.server.listeners=http://localhost:8092
|
このステップを完了すると、$CONFLUENT_HOME/etc/kafka/ 内に 3 つ(ブローカーごとに 1 つ)のサーバープロパティファイルが作成されているはずです。
server.properties(broker 0 に対応)server-1.properties(broker 1 に対応)server-2.properties(broker 2 に対応)
ちなみに
server.properties および他の構成ファイルで、コメントアウトされているプロパティや記述されていないプロパティに対しては、デフォルト値が適用されます。たとえば、broker 0 で listeners がコメントアウトされている行は、単一のリスナーを PLAINTEXT:// :9092 に設定するのと同じ効果を持ちます。
REST エンドポイントとアドバタイズされたリスナーを使用する Control Center の構成(省略可)¶
これは任意のステップであり、Confluent Control Center を使用する場合にのみ必要です。「Confluent Platform のクイックスタート(ローカルインストール)」と同様の開始点を提供するとともに、kafka-topics のコマンドラインで作成するトピックとデータを操作および検証するための代替手段となります。
クラスター内のすべてのブローカーの REST エンドポイントに加え、実行する他のコンポーネント用にアドバタイズされたリスナーを Control Center に指定する必要があります。その構成を行っていない場合、ブローカーおよびコンポーネントは Control Center に表示されません。
$CONFLUENT_HOME/etc/confluent-control-center/control-center.properties で次の変更を行って、ファイルを保存します。
ブローカーの REST エンドポイントを構成します。
該当する Control Center プロパティファイルで
confluent.controlcenter.streams.cprest.urlを使用して、controlcenter.clusterの REST エンドポイントを定義します。$CONFLUENT_HOME/etc/confluent-control-center/control-center.propertiesファイルで、Kafka の REST エンドポイントの URL のデフォルト値のコメントを解除し、マルチブローカー構成に合わせて次のように変更します。# Kafka REST endpoint URL confluent.controlcenter.streams.cprest.url=http://localhost:8090,http://localhost:8091,http://localhost:8092
参考
Self-Balancing の構成オプションの「Control Center の必須構成」および「Control Center の構成リファレンス」にある
confluent.controlcenter.streams.cprest.urlを参照してください。Kafka Connect、ksqlDB、および Schema Registry の構成のコメントを解除して、コンポーネントクラスターのデフォルトのアドバタイズされた URL を Control Center に提供します。
# A comma separated list of Connect host names confluent.controlcenter.connect.cluster=http://localhost:8083 # KSQL cluster URL confluent.controlcenter.ksql.ksqlDB.url=http://localhost:8088 # Schema Registry cluster URL confluent.controlcenter.schema.registry.url=http://localhost:8081
ちなみに
コンポーネントのリスナーは、
confluent local services start(「Confluent Platform のクイックスタート(ローカルインストール)」を参照)で使用されているcontrol-center-dev.propertiesでは既にコメント解除されていますが、ここで使用しているファイル(control-center.properties)では、コメント解除を行う必要があります。
Datagen コネクターのインストール(省略可)¶
Confluent Hub クライアントを使用して、Kafka Connect Datagen ソースコネクターをインストールします。このコネクターはデモ用の模擬データを生成しますが、これは本稼働環境には適していません。Confluent Hub は、パッケージ済みのオンラインライブラリであり、Confluent Platform および Kafka 用にそのままインストールできる拡張機能またはアドオンです。
confluent-hub install \
--no-prompt confluentinc/kafka-connect-datagen:latest
このステップは省略可能ですが、「Confluent Platform のクイックスタート(ローカルインストール)」と同様の開始点となるため便利です。
Confluent Platform の起動¶
以下の手順に従って、個別のコマンドウィンドウでサーバーを起動します。
ZooKeeper を個別のコマンドウィンドウで起動します。
./bin/zookeeper-server-start etc/kafka/zookeeper.properties
各ブローカーを個別のコマンドウィンドウで起動します。
./bin/kafka-server-start etc/kafka/server.properties
./bin/kafka-server-start etc/kafka/server-1.properties
./bin/kafka-server-start etc/kafka/server-2.properties
以下のコンポーネントを個別のコマンドウィンドウで起動します。
ちなみに
この例では、起動する必要がないコンポーネントもあります。少なくとも、ZooKeeper、ブローカー(起動済み)、および Kafka REST を起動する必要があります。しかし、このプラットフォームを使い始めたばかりである場合、すべてのコンポーネントを実行しておくと、すべての機能を確認できるので便利です。「Confluent Platform のクイックスタート(ローカルインストール)」と同様の開始点になり、こちら に記載されている Kafka のコマンド例だけでなく、クイックスタートにある例を試すこともできます。
-
./bin/kafka-rest-start etc/kafka-rest/kafka-rest.properties
(省略可) Kafka Connect
./bin/connect-distributed etc/kafka/connect-distributed.properties
(省略可) ksqlDB 概要
./bin/ksql-server-start etc/ksqldb/ksql-server.properties
(省略可) Schema Registry
./bin/schema-registry-start etc/schema-registry/schema-registry.properties
(省略可)最後に、別のコマンドウィンドウで Control Center を起動します。
./bin/control-center-start etc/confluent-control-center/control-center.properties
-
Control Center の機能の概要(省略可)¶
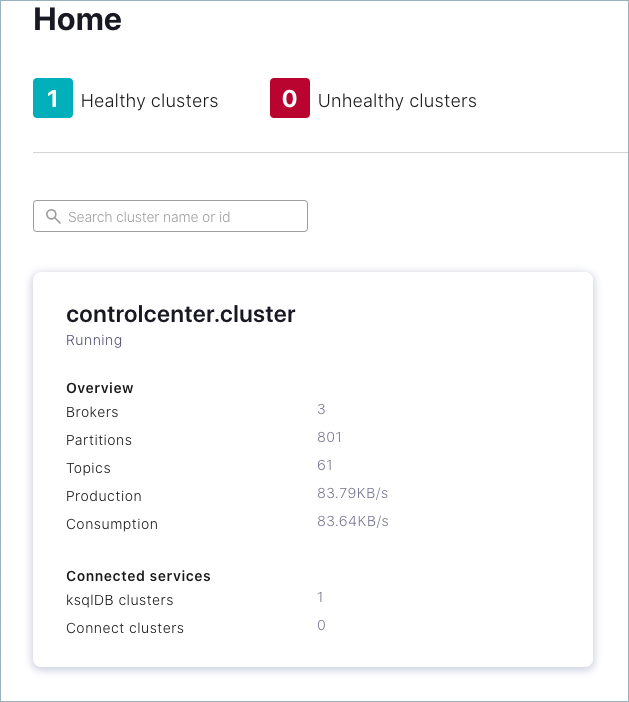
Confluent Control Center を起動すると、クラスターの現在のステータス(リーダーブローカー(コントローラー)、トピックデータ、ブローカーの数など)が検証されます。ローカルデプロイの場合、Control Center を使用するには、ウェブブラウザーで http://localhost:9021/ にアクセスします。
Control Center の 環境 の開始ビューでは、クラスターにブローカーが 3 つあることが表示されています。
クラスターのカード内をクリックします。
クラスターの概要が表示されます。
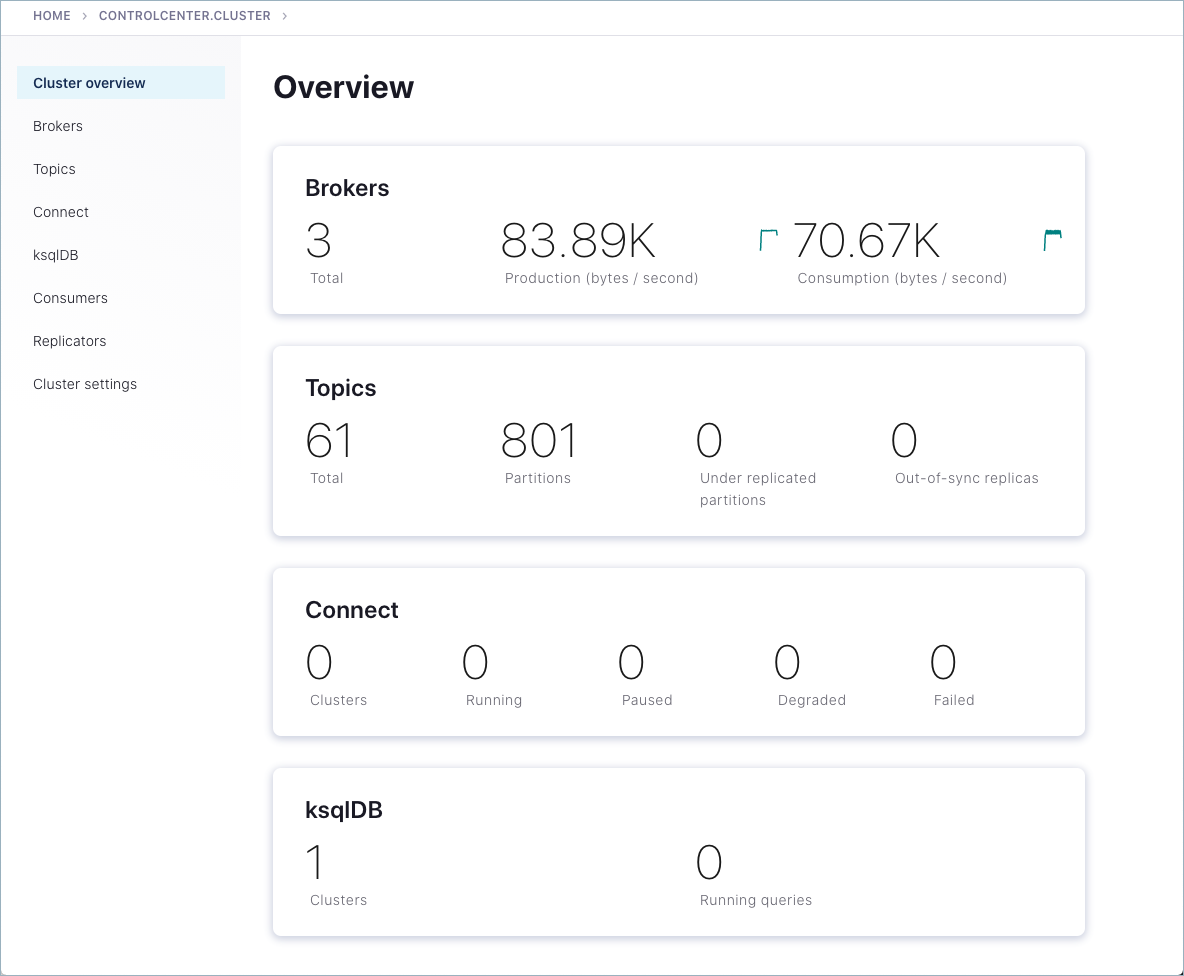
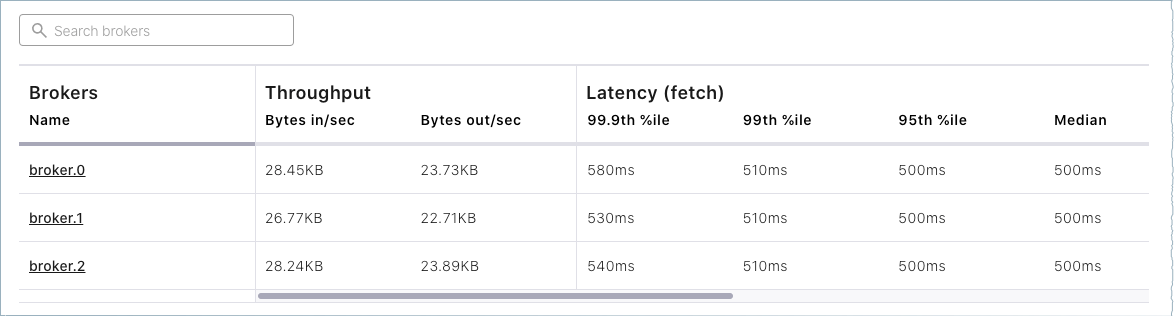
メニューにあるいずれかのブローカーのカードまたはブローカーをクリックすると、ブローカーのメトリクスが表示されます。
アクティブコントローラー のカードにより、リーダーブローカーは broker.id 0 であることがわかります。これは、
broker.id=0を指定した際にserver.propertiesで構成しています。マルチブローカーのクラスターでは、その時点で使用していたコントローラーが消失した場合にコントローラーのロールが変わることがあります。詳細については、「リードブローカー(コントローラー)が削除される、または見つからない場合の動作」、および「Kafka のデプロイ後の作業」にある「コントローラー」と「ステート変化ログ」のトピックを参照してください。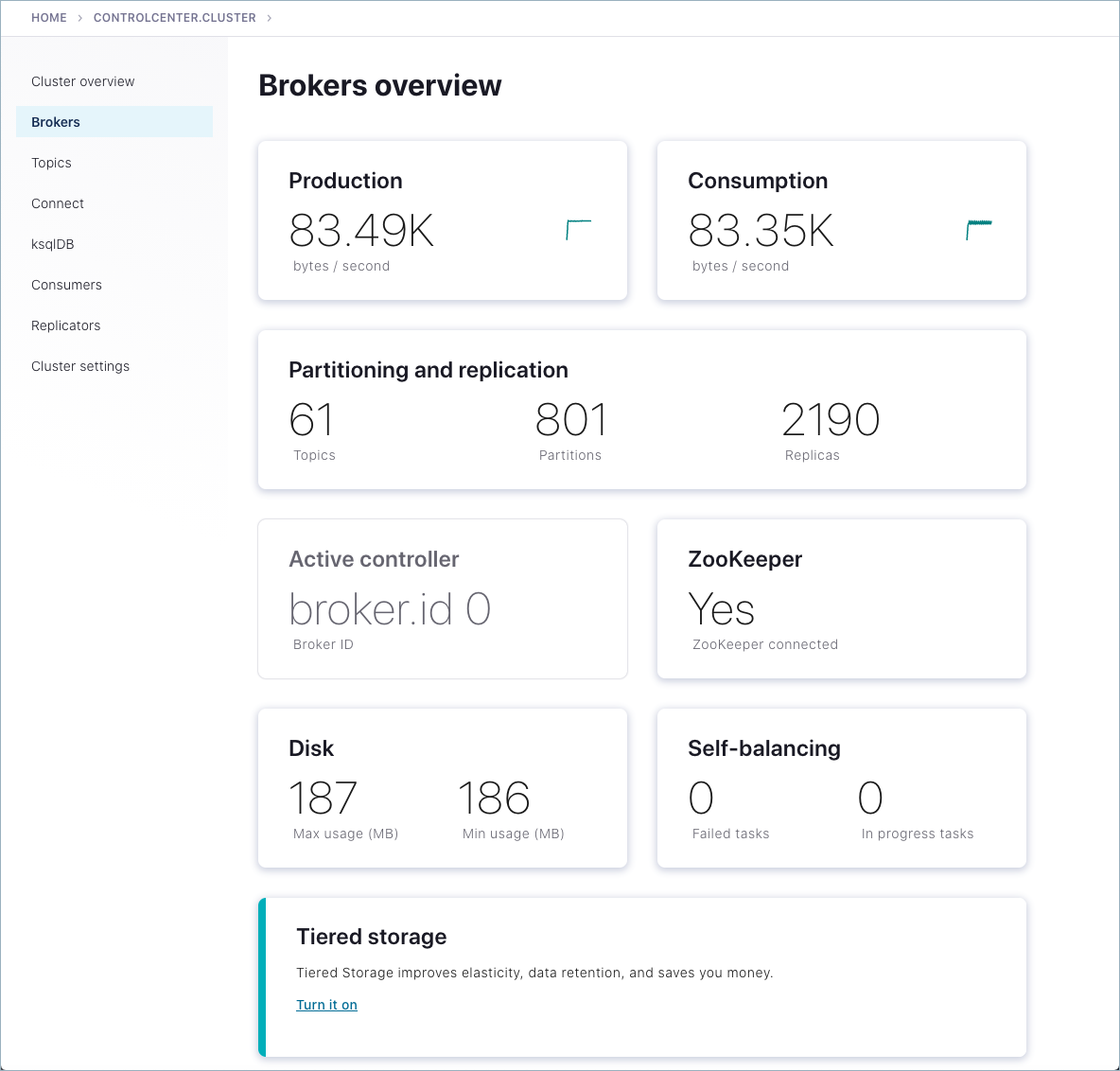
ページ下部にあるブローカーの一覧では、詳細なメトリクス確認し、個々のブローカーについてさらに詳しく調べることができます。
最後に、左側のメニューにある Topics をクリックします。
独自のトピックはまだ作成していないので、現時点で利用可能なトピックはシステム(内部)トピックのみです。ksqlDB を構成して起動している場合は、
default_ksql_processing_logがトピックとして表示されます。
Control Center についてはまだまだ多くの機能がありますが、このガイドで詳しくは取り上げません。クイックスタート(Control Center でのタスクのデモがあります)を最後まで終えていない場合は、順番としては先に「Confluent Platform のクイックスタート(ローカルインストール)」に取り組むことをお勧めします。このクラスターで同じタスク(最初は Control Center での Kafka のトピックの作成)を試してから、このガイドに戻り、「Kafka のコマンド入門」に記載されている例に取り組んでください。
すべてがクイックスタートの手順と同様に機能します。唯一の違いは、ここでは、他の例で使用するためにレプリケーション係数が適切に設定されたマルチブローカーのクラスターが使用されており、クイックスタートでのデプロイ(confluent local services start を使用して起動)では、開発専用の環境向けにレプリケーション係数が 1 に設定された単一ブローカーのクラスターが使用されていることです。
Kafka のコマンド入門¶
Confluent Platform を実行したら、次は Kafka のいくつかの基本的なコマンドを試して、トピックを作成したり、プロデューサーとコンシューマーを操作したりしてみましょう。Kafka の初心者にも熟練者にも同様にお勧めします。使い慣れた Kafka のツールは Confluent Platform ですぐに利用でき、同じように機能します。これらのツールによって、基本的な機能のテストや操作、デプロイの構成やモニタリングができます。コマンドは、 API の一部として利用できます。
Confluent Platform に付属している Kafka のコマンドとユーティリティは $CONFLUENT_HOME/etc/kafka/bin ディレクトリに置かれています。この bin/ ディレクトリには、Confluent 特有のユーティリティと Kafka のオープンソースのユーティリティの両方が置かれています。
次の点に注意してください。
- Confluent Platform がシステムにインストール済みで実行中であれば、Kafka のコマンドはどこからでも(たとえば、
$HOME(~/)ディレクトリから)実行できます。$CONFLUENT_HOMEディレクトリ内から実行する必要はありません。 - 「Confluent Platform の CLI ツール」に一覧が記載されています。その一覧で
kafka-で始まるものは Kafka のオープンソースのコマンドユーティリティであり、Apache Kafka のドキュメント のさまざまなセクションでも取り上げられています。 - コマンドを引数なしで入力すると(例:
kafka-topics、kafka-producer-perf-test)、コマンドラインの包括的なヘルプを利用できます。
手始めに、最も基本的で広く使用されているコマンドの例を以下のセクションに示しています。
トピックの作成、一覧表示、詳細表示¶
kafka-topics を使用して、トピックに対する操作(作成、一覧表示、詳細表示、変更、削除、など)を行うことができます。
コマンドウィンドウで、次のコマンドを実行してトピックを操作してみます。
cool-topic、warm-topic、hot-topicという名前の 3 つのトピックを作成します。kafka-topics --create --topic cool-topic --bootstrap-server localhost:9092
kafka-topics --create --topic warm-topic --bootstrap-server localhost:9092
kafka-topics --create --topic hot-topic --partitions 2 --replication-factor 2 --bootstrap-server localhost:9092
すべてのトピックを一覧表示します。
kafka-topics --list --bootstrap-server localhost:9092
ちなみに
システムトピックの名前はアンダースコアで始まっています。ユーザーが作成したトピックは一覧の末尾に出力されています。
トピックの詳細を表示します。
指定したトピックのパーティション、レプリケーション係数、および同期中のレプリカが示されます。
kafka-topics --describe --topic cool-topic --bootstrap-server localhost:9092
出力は次のようになります。
Topic: cool-topic PartitionCount: 1 ReplicationFactor: 1 Configs: segment.bytes=1073741824 Topic: cool-topic Partition: 0 Leader: 0 Replicas: 0 Isr: 0 Offline:
ちなみに
トピックを指定せずに
kafka-topics --describeを実行した場合は、そのクラスター上のすべてのトピック(システムトピックとユーザートピックの両方)の詳細が出力されます。クラスター内の別のブローカーをブートストラップサーバーとして使用して、別のトピックの詳細を表示します。
kafka-topics --describe --topic hot-topic --bootstrap-server localhost:9094
このコマンドの出力例は次のとおりです。
Topic: hot-topic PartitionCount: 2 ReplicationFactor: 2 Configs: segment.bytes=1073741824 Topic: hot-topic Partition: 0 Leader: 1 Replicas: 1,0 Isr: 1,0 Offline: Topic: hot-topic Partition: 1 Leader: 0 Replicas: 0,2 Isr: 0,2 Offline:
クラスター内のブローカーは同じデータを保有しているので、クラスター内のどのブローカーに接続しても、これらのコマンドを実行できます。
トピックの構成を変更します。
たとえば、hot-topic のパーティション数を
2から9に変更します。kafka-topics --alter --topic hot-topic --partitions 9 --bootstrap-server localhost:9092ちなみに
トピックの動的な変更は、その性質上、現在の構成では制限されています。たとえば、パーティションの再割り当てが必要になるため、パーティションの数を減らすことや、トピックのレプリケーション係数を変更することはできません。
同じトピックに対して
--describeをもう一度実行します。kafka-topics --describe --topic hot-topic --bootstrap-server localhost:9092
このコマンドの出力例は次のとおりです。パーティション数が
9にアップデートされています。Topic: hot-topic PartitionCount: 9 ReplicationFactor: 2 Configs: segment.bytes=1073741824 Topic: hot-topic Partition: 0 Leader: 2 Replicas: 2,1 Isr: 2,1 Offline: Topic: hot-topic Partition: 1 Leader: 1 Replicas: 1,0 Isr: 1,0 Offline: Topic: hot-topic Partition: 2 Leader: 1 Replicas: 1,2 Isr: 1,2 Offline: Topic: hot-topic Partition: 3 Leader: 2 Replicas: 2,1 Isr: 2,1 Offline: Topic: hot-topic Partition: 4 Leader: 0 Replicas: 0,2 Isr: 0,2 Offline: Topic: hot-topic Partition: 5 Leader: 1 Replicas: 1,0 Isr: 1,0 Offline: Topic: hot-topic Partition: 6 Leader: 2 Replicas: 2,0 Isr: 2,0 Offline: Topic: hot-topic Partition: 7 Leader: 0 Replicas: 0,1 Isr: 0,1 Offline: Topic: hot-topic Partition: 8 Leader: 1 Replicas: 1,2 Isr: 1,2 Offline:
トピックを削除します。
kafka-topics --delete --topic warm-topic --bootstrap-server localhost:9092
すべてのトピックを一覧表示します。
kafka-topics --list --bootstrap-server localhost:9092
プロデューサーとコンシューマーの実行によるメッセージの送信および読み取り¶
コマンドユーティリティ kafka-console-producer および kafka-console-consumer を使用すると、手動でメッセージを生成し、トピックから消費することができます。
新規コマンドウィンドウを 2 つ開きます。1 つはプロデューサー用で、もう 1 つはコンシューマー用です。
プロデューサーを実行し、
cool-topicにメッセージを生成します。kafka-console-producer --topic cool-topic --bootstrap-server localhost:9092
メッセージをいくつか送信します。
プロンプト(
>)でメッセージを入力し、メッセージごとに Return キーを押します。このコマンドウィンドウは次のようになります。
$ kafka-console-producer --broker-list localhost:9092 --topic cool-topic >hi cool topic >did you get this message? >first >second >third >yes! I love you cool topic >
ちなみに
プロデューサーに対しては
--bootstrap-serverの代わりに--broker-listフラグを使用できます。このフラグは通常、この例で示しているように、特定のブローカーにデータを送信するために使用されます。別のコマンドウィンドウで、コンシューマーを実行して
cool-topicからメッセージを読み取ります。この例で示しているように、最初から消費を始めるように指定します。kafka-console-consumer --topic cool-topic --from-beginning --bootstrap-server localhost:9092
このコマンドの出力は次のようになります。
$ kafka-console-consumer --bootstrap-server localhost:9092 --from-beginning --topic cool-topic hi cool topic on origin cluster is this getting to your replica? first second third yes! I love you cool topic
プロデューサーおよびコンシューマーを停止するには、それぞれのコマンドウィンドウで Ctl キーを押しながら C キーを押します。
ちなみに
Control Center 上のトピックについて再確認する際にもう一度メッセージを送信する可能性があるため、この段階ではプロデューサーを実行したままでも構いません。
トピックへの自動生成メッセージデータの生成¶
個別のコマンドウィンドウで kafka-consumer-perf-test を使用して、トピックへのテストデータを生成することができます。
たとえば、新規コマンドウィンドウを開き、次のコマンドを入力して
hot-topicにデータを送信します。ここではスループットとレコードサイズを指定しています。kafka-producer-perf-test \ --producer-props bootstrap.servers=localhost:9092 \ --topic hot-topic \ --record-size 1000 \ --throughput 1000 \ --num-records 3600000
このコマンドでは、送信したメッセージに関するステータスが次のように出力されます。
4999 records sent, 999.8 records/sec (0.95 MB/sec), 1.1 ms avg latency, 240.0 ms max latency. 5003 records sent, 1000.2 records/sec (0.95 MB/sec), 0.5 ms avg latency, 4.0 ms max latency. 5003 records sent, 1000.2 records/sec (0.95 MB/sec), 0.6 ms avg latency, 5.0 ms max latency. 5001 records sent, 1000.2 records/sec (0.95 MB/sec), 0.3 ms avg latency, 3.0 ms max latency. 5001 records sent, 1000.0 records/sec (0.95 MB/sec), 0.3 ms avg latency, 4.0 ms max latency. 5000 records sent, 1000.0 records/sec (0.95 MB/sec), 0.8 ms avg latency, 24.0 ms max latency. 5001 records sent, 1000.2 records/sec (0.95 MB/sec), 0.6 ms avg latency, 3.0 ms max latency. ...
新規コマンドウィンドウを開き、(最初からではなく)メッセージが送信されたときに hot-topic からメッセージを消費します。
kafka-console-consumer --topic hot-topic --bootstrap-server localhost:9092
Ctl キーを押しながら C キーを押して、コンシューマーを停止します。
ちなみに
この後で Control Center 上のトピックについて再確認するため、プロデューサーはしばらく実行したままで構いません。
詳細については、『 Benchmark commands 』、『 Let's Load test, Kafka! 』、および『 How to do Performance testing of Kafka Cluster 』を参照してください。
Control Center の再確認(省略可)¶
ここまでで、いくつかのトピックを作成し、トピックにメッセージデータを(手動と自動生成の両方で)生成しました。次は、Control Center で既存のトピックを調べてみましょう。
ウェブブラウザーを開いて、ローカルシステムの Control Center のデフォルト URL である http://localhost:9021/ に移動します。
クラスターを選択し、メニューで Topics をクリックします。
cool-topicを選択してから Messages タブを選択します。Jump to offset を選択し、「
1」、「2」、「3」のいずれかを入力すると、前のメッセージが表示されます。ここで使用しているコンシューマーでは
--from-beginningが指定されていないので、これらのメッセージは送信された順序では表示されていません。コマンドラインでプロデューサーを使用して、いくつかのメッセージを
cool-topicに手動で入力し、そのメッセージが表示されるのを確認します。
Topics、
hot-topic、Messages タブの順に移動します。kafka-producer-perf-testからの自動生成メッセージが届くと、ここに表示されます。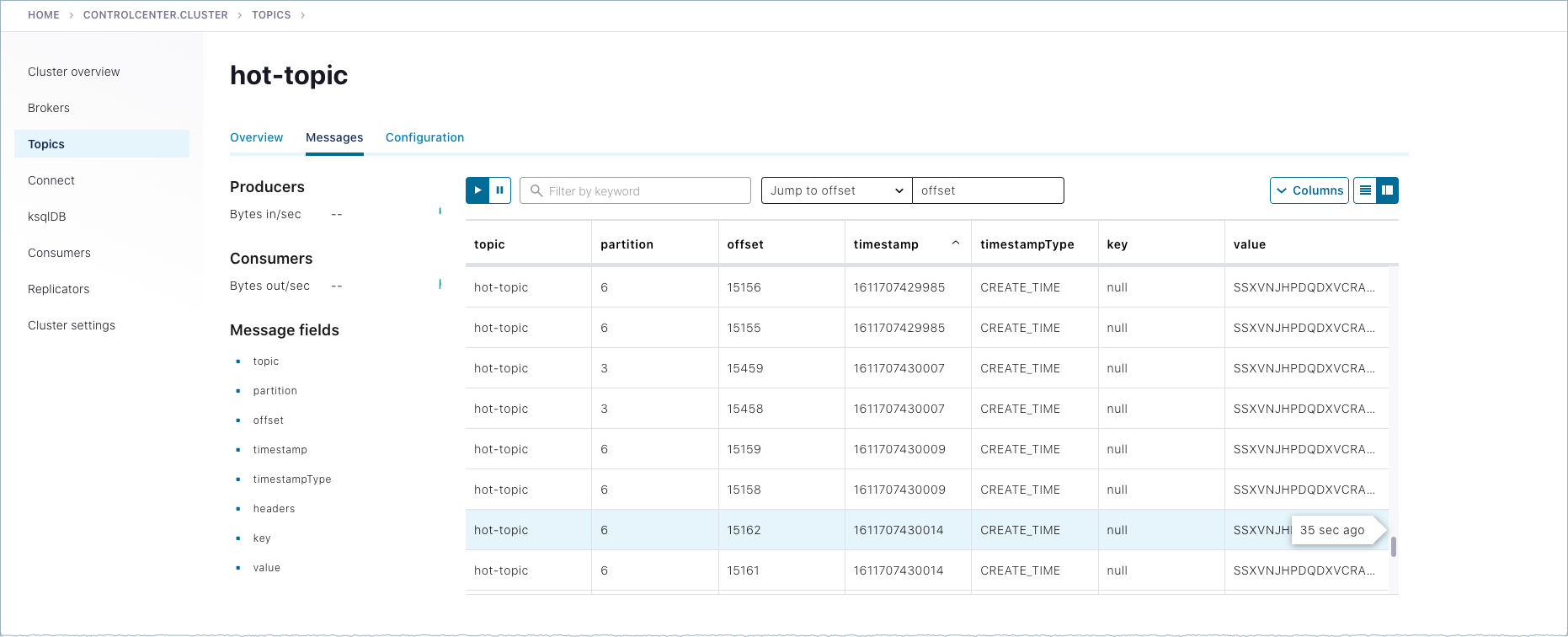
シャットダウンとクリーンアップのタスク¶
以下のシャットダウンとクリーンアップのタスクを実行します。
kafka-producer-perf-testを、個別のコマンドウィンドウで Ctrl キーを押しながら C キーを押して停止します。- 他のすべてのコンポーネントを、起動したときと逆の順序で、それぞれのコマンドウィンドウで Ctrl キーを押しながら C キーを押して停止します。たとえば、まず Control Center を停止し、次に他のコンポーネントを停止してから Kafka のブローカーを停止します。最後に ZooKeeper を停止します。
複数のクラスターの実行¶
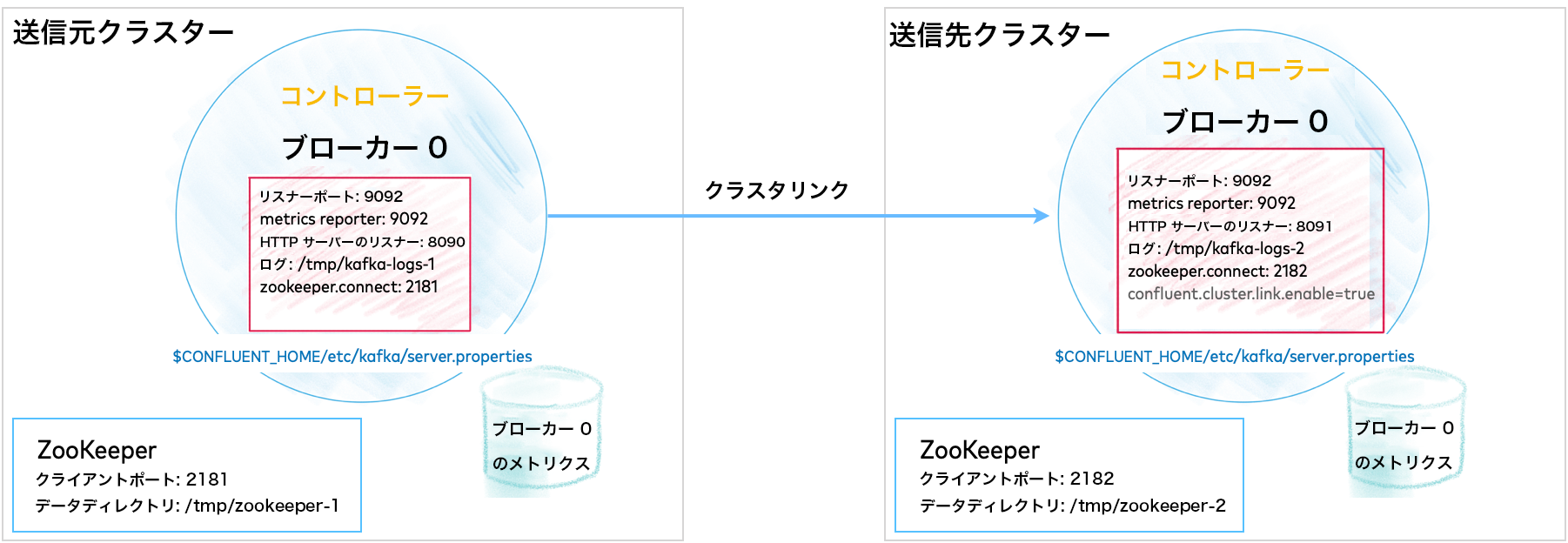
もう 1 つの選択肢として、マルチクラスターのデプロイを試してみましょう。これは、トピックデータを 2 つのクラスター間で共有またはレプリケートする Replicator、Cluster Linking、マルチクラスターの Schema Registry などの機能を試してみる場合に適しています。多くの場合、送信元および送信先クラスターとしてモデル化されます。
マルチクラスターのデプロイでは、クラスターと同じ数の ZooKeeper インスタンスを構成して起動し、Kafka サーバーの複数のプロパティファイル(ブローカーごとに 1 つ)を構成する必要があります。クラスターが 2 つの場合は、2 つの ZooKeeper インスタンスと少なくとも 2 つのサーバープロパティファイル(ZooKeeper ごとに 1 つ)が必要です。この最小限のセットアップでは、単一ブローカーのクラスター 2 つをまとめて管理できます。
このような構成は、データセンター間やリージョン間でのデータ共有に使用でき、多くの場合、"送信元" クラスターと "送信先" クラスターとしてモデル化されます。次の図は Cluster Linking の構成例を示しています(このセットアップについては「チュートリアル: トピックデータ共有での Cluster Linking の使用」で解説しています)。
マルチクラスター構成については、関連するユースケースのセクションで説明しています。これらの構成はその用途に応じて大きく異なるため、マルチクラスターを試す最適な方法は、ユースケースを選択し、その機能別のチュートリアルに従うことです。
- チュートリアル: トピックデータ共有での Cluster Linking の使用 (Confluent Platform 6.0.0 以降が必要、使い始めに最適なサンプル)
- チュートリアル: クラスターの境界を越えたデータのレプリケーション
- マルチクラスター Schema Registry の有効化
コード例とデモアプリ¶
以下のリンク先では、Kafka のトピック、プロデューサー、およびそれらのトピックをサブスクライブするコンシューマーをイベントサブスクリプションモデルで使用する、Confluent Platform の分散アプリケーションの例が示されています。タスクの実現またはサービスの提供のために Kafka と Confluent Platform をどのように使用できるかについての全体像が示されています。
おすすめの関連情報¶
- サーバーレスインフラストラクチャの構築方法について学び、その知識を実際のプロジェクトに適用するには、「Cloud-Native Apache Kafka: Designing Cloud Systems for Speed and Scale」を参照してください。
- 「Kafka のコマンド」
- 「管理者の操作」
- Apache クイックスタートガイド
- Kafka の概要
- Docker およびクラウドプロバイダーを使用したマルチノード Apache Kafka 環境の構成
- 例: Kafka Streams の例
- 例: Demo Scene の例
- ブログ記事: 「Why Can't I Connect to Kafka?| Troubleshoot Connectivity
- Apache Kafka® エコシステムの一部として利用可能な開発者ツールとユーティリティの概要です。
- ブログ記事: Apache Kafka 101
- 3 つの簡単な手順で Kafka の学習を開始できます。Kafka の元の作成者から提供されている実践的なチュートリアルでコーディング学びましょう。ガイドやビデオもご覧いただけます。
- ブログ記事: Helpful Tools for Apache Kafka Developers
- Apache Kafka® エコシステムの一部として利用可能な開発者ツールとユーティリティの概要です。