Confluent Platform のクイックスタート(ローカルインストール)¶
このクイックスタートに従うと、Confluent Platform とその主要コンポーネントを開発環境で実行することができます。このクイックスタートでは、Confluent Platform に含まれている Confluent Control Center を使用したトピック管理と ksqlDB を利用したイベントストリーム処理を行います。
このクイックスタートでは、Apache Kafka® トピックを作成し、Kafka Connect を使ってそれらのトピックに対する模擬データを生成して、それらのトピックに対する ksqlDB ストリーミングクエリを作成します。Control Center に移動して、ストリーミングクエリをモニタリングし、分析します。
参考
このクイックスタートの自動化バージョン を実行することもできます。これは、Confluent Platform のローカルインストール向けです。
- 前提条件:
インターネットに接続されている。
オペレーティングシステム が現在 Confluent Platform でサポートされている。
サポートされている Java バージョン をダウンロードしてインストール済みである。
このバージョンの Confluent Platform では Java 8 および Java 11 がサポートされています(Java 9 と 10 はサポート対象外)。詳細については、 サポートされている Java バージョン を参照してください。
ステップ 1: Confluent Platform のダウンロードおよび起動¶
ダウンロードページ に移動します。
Download Confluent Platform セクションにスクロールし、以下を入力します。
- Email: メールアドレス
- Format:
deb、rpm、tar、またはzip
DOWNLOAD FREE をクリックします。
ちなみに
Ansible、Docker、およびKubernetesのインストールオプションがあります。また、Previous Versions から以前のバージョンをダウンロードすることもできます。ファイルを解凍します。
binやetcなどのディレクトリが展開されます。Confluent Platform ディレクトリの環境変数を設定します。
export CONFLUENT_HOME=<path-to-confluent>
Confluent Platform の
binディレクトリを PATH に追加します。export PATH=$PATH:$CONFLUENT_HOME/bin
Confluent Hub クライアントを使用して、Kafka Connect Datagen Source Connector をインストールします。このコネクターはデモ用の模擬データを生成しますが、これは本稼働環境には適していません。Confluent Hub は、パッケージ済みのオンラインライブラリであり、Confluent Platform および Kafka 用にそのままインストールできる拡張機能またはアドオンです。
confluent-hub install \ --no-prompt confluentinc/kafka-connect-datagen:latestConfluent CLI confluent local services start コマンドを使用して、Confluent Platform を起動します。このコマンドにより、すべての Confluent Platform コンポーネント(Kafka、ZooKeeper、Schema Registry、HTTP REST Proxy for Kafka、Kafka Connect、ksqlDB、Control Center を含む)が起動します。
重要
confluent local コマンドは、単一ノードの開発環境向けであり、本稼働環境には適していません。生成されるデータは一過性で、一時的なものです。本稼働環境対応のワークフローについては、「Confluent Platform のインストールおよびアップグレード」を参照してください。
confluent local services start出力は以下のようになります。
Starting Zookeeper Zookeeper is [UP] Starting Kafka Kafka is [UP] Starting Schema Registry Schema Registry is [UP] Starting Kafka REST Kafka REST is [UP] Starting Connect Connect is [UP] Starting KSQL Server KSQL Server is [UP] Starting Control Center Control Center is [UP]
ステップ 2: Kafka トピックの作成¶
このステップでは、Confluent Control Center を活用して Kafka トピックを作成します。Confluent Control Center は、本稼働環境データパイプラインおよびイベントストリーミングアプリケーションを構築およびモニタリングするための機能を備えています。
http://localhost:9021 にある Control Center ウェブインターフェイスに移動します。
異なるホストに Confluent Platform をインストールした場合は、
localhostをアドレスのホスト名と置き換えます。Control Center がオンラインになるまでに 1 ~ 2 分かかる場合があります。
注釈
Control Center が
localhostブラウザーセッションで開いておらず、実行中ではない場合、Control Center は ksqlDB に接続されません。controlcenter.cluster タイルをクリックします。
ナビゲーションバーで Topics をクリックしてトピックリストを開いた後、Add a topic をクリックします。
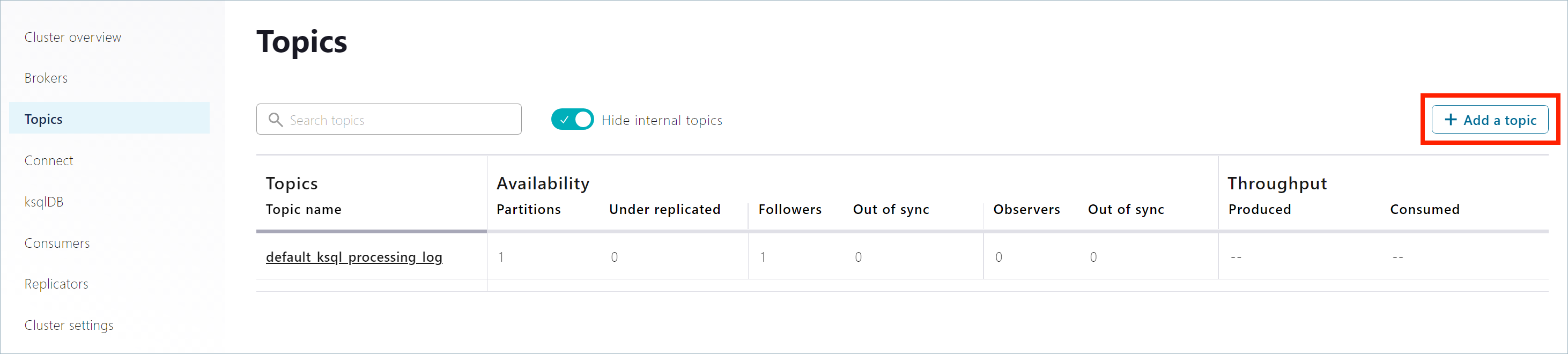
Topic name フィールドで
pageviewsを指定し、Create with defaults をクリックします。トピック名では、大文字と小文字が区別されます。
ナビゲーションバーで Topics をクリックしてトピックリストを開いた後、Add a topic をクリックします。
Topic name フィールドで
usersを指定し、Create with defaults をクリックします。
ステップ 3: Kafka コネクターのインストールおよびサンプルデータの生成¶
このステップでは、Kafka Connect を使用して、Kafka トピック pageviews および users のサンプルデータを作成する、kafka-connect-datagen という名前のデモソースコネクターを実行します。
ちなみに
Kafka Connect Datagen コネクターは「ステップ 1: Confluent Platform のダウンロードおよび起動」で手動でインストールしました。Datagen コネクターの場所を特定する際に問題が発生した場合は、「トラブルシューティング」セクションの「問題: Datagen コネクターの場所を特定できない」を参照してください。
Kafka Connect Datagen コネクターの最初のインスタンスを実行して、
pageviewsトピックに対して Kafka データを AVRO フォーマットで生成します。ナビゲーションバーで Connect をクリックします。
Connect Clusters リストで
connect-defaultクラスターをクリックします。Add connector をクリックします。
DatagenConnectorタイルを選択します。ちなみに
表示されるコネクターを絞り込むには、Filter by category をクリックし、Sources をクリックします。
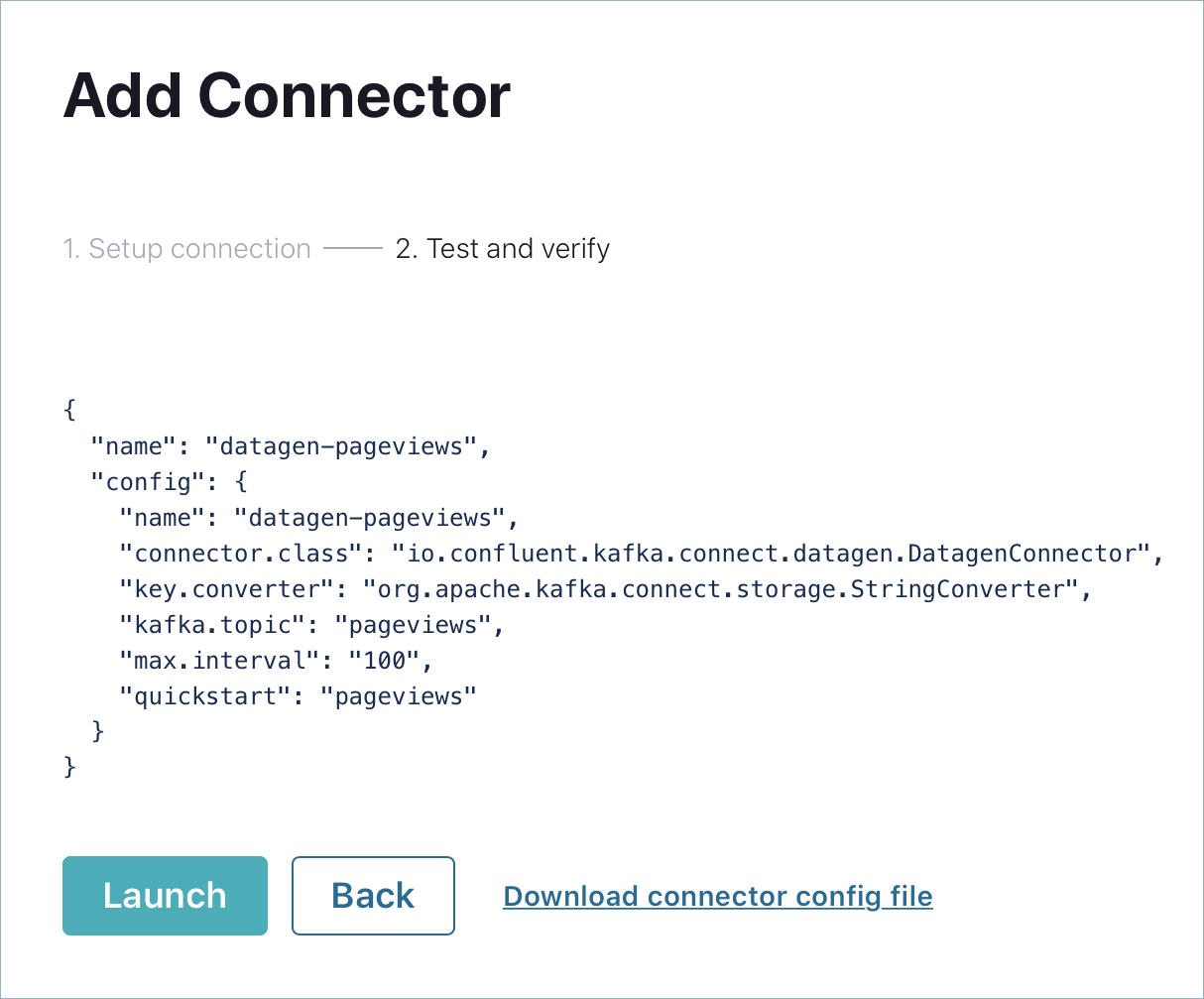
名前 フィールドで、コネクターの名前として
datagen-pageviewsを入力します。次の構成値を入力します。
- Key converter class:
org.apache.kafka.connect.storage.StringConverter。 - kafka.topic:
pageviews。 - max.interval:
100。 - quickstart:
pageviews。
- Key converter class:
Next をクリックします。
コネクター構成を確認し、Launch をクリックします。
Kafka Connect Datagen コネクターの 2 番目のインスタンスを実行して、
usersトピックに対して Kafka データを AVRO フォーマットで生成します。Add connector をクリックします。
DatagenConnectorタイルを選択します。ちなみに
表示されるコネクターを絞り込むには、Filter by category をクリックし、Sources をクリックします。
名前 フィールドで、コネクターの名前として
datagen-usersを入力します。次の構成値を入力します。
- Key converter class:
org.apache.kafka.connect.storage.StringConverter - kafka.topic:
users - max.interval:
1000 - quickstart:
users
- Key converter class:
Next をクリックします。
コネクター構成を確認し、Launch をクリックします。
ステップ 4: ksqlDB を使用したストリームおよびテーブルの作成および書き込み¶
ちなみに
<path-to-confluent>/bin/ksql http://localhost:8088 コマンドにより、ターミナルから ksqlDB CLI を使用して、これらのコマンドを実行することもできます。
ストリームおよびテーブルの作成¶
このステップでは、ksqlDB を使用して、pageviews トピックのストリームおよび users トピックのテーブルを作成します。
ナビゲーションバーで ksqlDB をクリックします。
ksqlDBアプリケーションを選択します。以下のコードをエディターのウィンドウにコピーします。Run query をクリックして、
pageviewsストリームを作成します。ストリーム名では、大文字と小文字が区別されません。CREATE STREAM pageviews WITH (KAFKA_TOPIC='pageviews', VALUE_FORMAT='AVRO');
以下のコードをエディターのウィンドウにコピーします。Run query をクリックして、
usersテーブルを作成します。テーブル名では、大文字と小文字が区別されません。CREATE TABLE users (id VARCHAR PRIMARY KEY) WITH (KAFKA_TOPIC='users', VALUE_FORMAT='AVRO');
クエリの記述¶
このステップでは、上記で作成したストリームおよびテーブルに対する ksqlDB クエリを作成します。
Editor タブで Add query properties をクリックして、カスタムクエリプロパティを追加します。
auto.offset.resetパラメーターをEarliestに設定します。この設定により ksqlDB クエリは、使用可能なすべてのトピックデータを先頭から読み取ります。この構成は、以降の各クエリに対して使用されます。詳細については、「ksqlDB 構成パラメーターリファレンス」を参照してください。
以下のクエリを作成します。
Stop をクリックして、現時点で実行中のクエリを停止します。
最大 3 行までに制限された結果とともにストリームからデータを返す、非永続的なクエリを作成します。
エディターで以下のクエリを入力します。
SELECT pageid FROM pageviews EMIT CHANGES LIMIT 3;
Run query をクリックします。出力は以下のようになります。
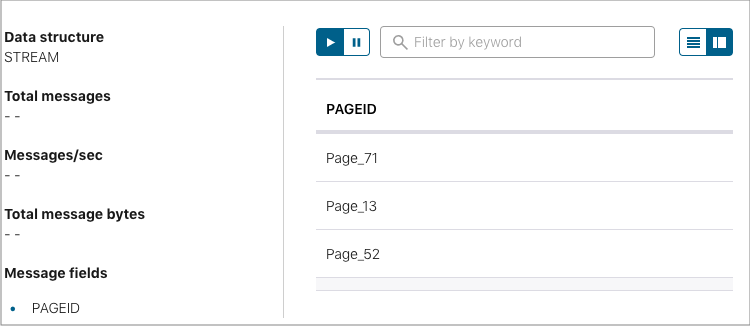
Card view アイコンまたは Table view アイコンをクリックして、出力レイアウトを変更します。
女性(female)ユーザーの
PAGEVIEWSストリームをフィルター処理する永続的なクエリを(ストリームとして)作成します。クエリの結果は Kafka のPAGEVIEWS_FEMALEトピックに書き込まれます。エディターで以下のクエリを入力します。
CREATE STREAM pageviews_female AS SELECT users.id AS userid, pageid, regionid FROM pageviews LEFT JOIN users ON pageviews.userid = users.id WHERE gender = 'FEMALE' EMIT CHANGES;
Run query をクリックします。出力は以下のようになります。

REGIONIDが8または9で終わる永続的なクエリを作成します。このクエリの結果は、クエリで明示的に指定されたように、pageviews_enriched_r8_r9という名前の Kafka トピックに書き込まれます。エディターで以下のクエリを入力します。
CREATE STREAM pageviews_female_like_89 WITH (KAFKA_TOPIC='pageviews_enriched_r8_r9', VALUE_FORMAT='AVRO') AS SELECT * FROM pageviews_female WHERE regionid LIKE '%_8' OR regionid LIKE '%_9' EMIT CHANGES;
Run query をクリックします。出力は以下のようになります。

カウントが 1 より大きい場合に 30 秒の タンブリングウィンドウ で、
REGIONとGENDERの組み合わせごとにPAGEVIEWSをカウントする永続的なクエリを作成します。手順がグループ化およびカウントであるため、結果はストリームではなく、テーブルになります。このクエリの結果は、PAGEVIEWS_REGIONSという名前の Kafka トピックに書き込まれます。エディターで以下のクエリを入力します。
CREATE TABLE pageviews_regions WITH (KEY_FORMAT='JSON') AS SELECT gender, regionid, COUNT(*) AS numusers FROM pageviews LEFT JOIN users ON pageviews.userid = users.id WINDOW TUMBLING (SIZE 30 SECOND) GROUP BY gender, regionid HAVING COUNT(*) > 1 EMIT CHANGES;
Run query をクリックします。出力は以下のようになります。

Persistent queries タブをクリックします。以下の永続的なクエリが表示されます。
- PAGEVIEWS_FEMALE
- PAGEVIEWS_FEMALE_LIKE_89
- PAGEVIEWS_REGIONS
Editor タブをクリックします。All available streams and tables ペインには、アクセスできるすべてのストリームおよびテーブルが表示されます。
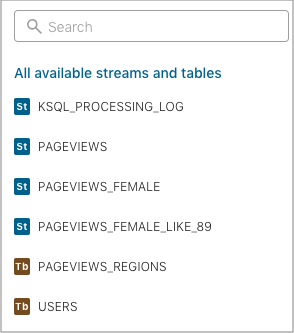
All available streams and tables セクションで KSQL_PROCESSING_LOG をクリックすると、ストリームのスキーマ(ネスト化されたデータ構造など)が表示されます。
クエリの実行¶
このステップでは、前のセクションでストリームおよびテーブルとして保存した ksqlDB クエリを実行します。
Streams タブで
PAGEVIEWS_FEMALEストリームを選択します。Query stream をクリックします。
エディターが開き、クエリのストリーミング出力が表示されます。
Stop をクリックして、出力の生成を停止します。
Tables タブで
PAGEVIEWS_REGIONSテーブルを選択します。Query table をクリックします。
エディターが開き、クエリのストリーミング出力が表示されます。
Stop をクリックして、出力の生成を停止します。
ステップ 5: コンシューマーラグのモニタリング¶
ナビゲーションバーで Consumers をクリックして、ksqlDB により作成されたコンシューマーを表示します。
コンシューマーグループ ID をクリックして、
_confluent-ksql-default_query_CSAS_PAGEVIEWS_FEMALE_5コンシューマーグループの詳細を表示します。このページで、ストリーミングクエリのコンシューマーラグおよび消費量の値を確認できます。
詳細については、Control Center の「Consumers」ドキュメントを参照してください。
ステップ 6: Confluent Platform の停止¶
ローカルインストールでの作業が完了したら、Confluent Platform を停止できます。
Confluent CLI confluent local services connect stop コマンドを使用して、Confluent Platform を停止します。
confluent local services stopconfluent local destroy コマンドを使用して、Confluent Platform インスタンスのデータを破棄します。
confluent local destroy
次のステップ¶
このクイックスタートで示したコンポーネントについて、さらに詳しく確認します。
- ksqlDB ドキュメント: ストリーミング ETL、リアルタイムモニタリング、異常検出などのユースケースにおける、ksqlDB を使用したデータの処理について確認できます。一連の スクリプト化されたデモ により、ksqlDB の使用方法も参照してください。
- Kafka チュートリアル : ステップごとの手順に従って、Kafka、Kafka Streams、および ksqlDB の基本的なチュートリアルを試すことができます。
- Kafka Streams ドキュメント: ストリーム処理アプリケーションを Java または Scala で構築する方法を確認できます。
- Kafka Connect ドキュメント: Kafka を他のシステムに統合し、すぐに使用できるコネクター をダウンロードして、 Kafka 内外のデータをリアルタイムで簡単に取り込む方法を確認できます。
- Kafka クライアントドキュメント: Go、Python、.NET、C/C++ などのプログラミング言語を使用して、Kafka に対してデータの読み取りおよび書き込みを行う方法を確認できます。
- ビデオ、デモ、および参考文献: Confluent Platform のチュートリアルやサンプルを試したり、デモやスクリーンキャストを参照したり、ホワイトペーパーやブログで学べます。
トラブルシューティング¶
クイックスタートのワークフローの進行中に問題が発生した場合は、ステップを再試行する前に、以下の解決策を確認してください。
問題: Datagen コネクターの場所を特定できない¶
解決策: 「ステップ 1: Confluent Platform のダウンロードおよび起動」の説明に従って、Confluent Platform の bin ディレクトリの場所を PATH に追加したことを確認します。
export PATH=<path-to-confluent>/bin:$PATH
解決策 : DataGen コネクターがインストールされており、実行中であることを確認します。
「ステップ 1: Confluent Platform のダウンロードおよび起動」の説明に従って、kafka-connect-datagen がインストールされており、実行中であることを確認します。
confluent-hub install --no-prompt confluentinc/kafka-connect-datagen:latest
出力は以下のようになります。
Running in a "--no-prompt" mode
...
Completed
解決策: Confluent CLI confluent local services connect log コマンドを使用して、Datagen の connect ログを確認します。
confluent local services connect log | grep -i Datagen
出力は以下のようになります。
[2019-04-18 14:21:08,840] INFO Loading plugin from: /Users/user.name/Confluent/confluent-version/share/confluent-hub-components/confluentinc-kafka-connect-datagen (org.apache.kafka.connect.runtime.isolation.DelegatingClassLoader:215)
[2019-04-18 14:21:08,894] INFO Registered loader: PluginClassLoader{pluginLocation=file:/Users/user.name/Confluent/confluent-version/share/confluent-hub-components/confluentinc-kafka-connect-datagen/} (org.apache.kafka.connect.runtime.isolation.DelegatingClassLoader:238)
[2019-04-18 14:21:08,894] INFO Added plugin 'io.confluent.kafka.connect.datagen.DatagenConnector' (org.apache.kafka.connect.runtime.isolation.DelegatingClassLoader:167)
[2019-04-18 14:21:09,882] INFO Added aliases 'DatagenConnector' and 'Datagen' to plugin 'io.confluent.kafka.connect.datagen.DatagenConnector' (org.apache.kafka.connect.runtime.isolation.DelegatingClassLoader:386)
解決策 : kafka-connect-datagen の .jar ファイルが追加されており、lib サブフォルダー内に存在するかを確認します。
ls $CONFLUENT_HOME/share/confluent-hub-components/confluentinc-kafka-connect-datagen/lib/
出力は以下のようになります。
...
kafka-connect-datagen-0.1.0.jar
...
解決策 : プラグインがコネクターのパスに存在するかを検証します。
Confluent Hub から kafka-connect-datagen ファイルをインストールした場合、インストールディレクトリは複数のプロパティファイルのプラグインのパスに追加されます。
Adding installation directory to plugin path in the following files:
/Users/user.name/Confluent/confluent-version/etc/kafka/connect-distributed.properties
/Users/user.name/Confluent/confluent-version/etc/kafka/connect-standalone.properties
/Users/user.name/Confluent/confluent-version/etc/schema-registry/connect-avro-distributed.properties
/Users/user.name/Confluent/confluent-version/etc/schema-registry/connect-avro-standalone.properties
...
これらのいずれかを使用して、コネクターのパスを確認できます。この例では、connect-avro-distributed.properties ファイルを使用します。
grep plugin.path $CONFLUENT_HOME/etc/schema-registry/connect-avro-distributed.properties
出力は以下のようになります。
plugin.path=share/java,/Users/user.name/Confluent/confluent-version/share/confluent-hub-components
その内容が存在することを確認します。
ls $CONFLUENT_HOME/share/confluent-hub-components/confluentinc-kafka-connect-datagen
出力は以下のようになります。
assets doc lib manifest.json
問題: ストリームとストリームの結合に関するエラー¶
エラーにより、ストリームとストリームの結合には WITHIN 句の指定が必要であることが通知されます。このエラーは pageviews と users の両方をストリームとして誤って作成した場合に発生する可能性があります。
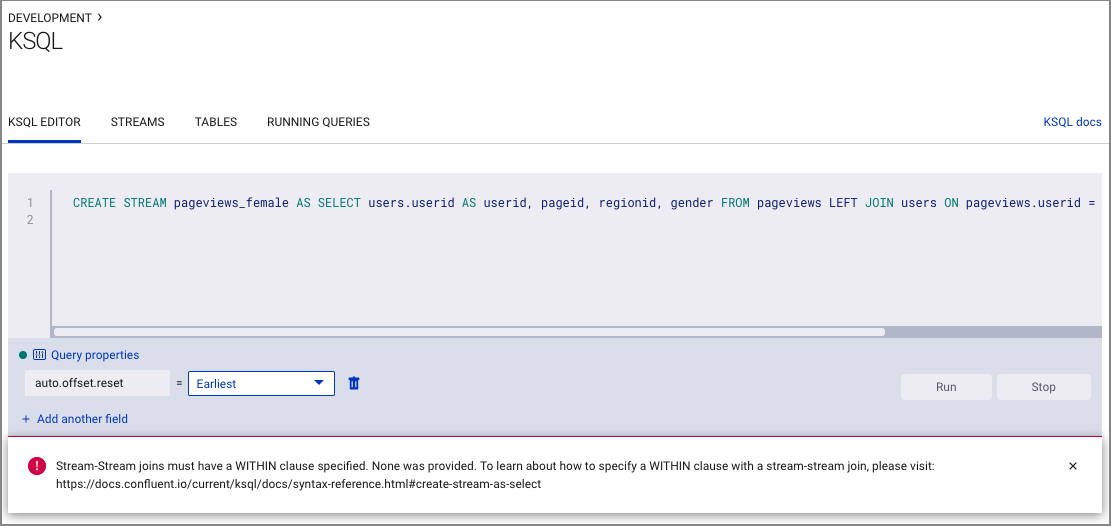
解決策: 「ステップ 4: ksqlDB を使用したストリームおよびテーブルの作成および書き込み」で pageviews の "ストリーム" を作成し、users の "テーブル" を作成したことを確認します。
問題: ksqlDB クエリのステップを正常に完了できない¶
Java エラーまたはその他の重大なエラーが発生しました。
解決策 : Confluent Platform により現在サポートされている オペレーティングシステム で作業していることを確認します。