Kafka Streams の対話型クエリ¶
対話型クエリは、アプリケーションの外部からアプリケーションのステートを利用できるようにするものです。Kafka Streams API により、アプリケーションをクエリ可能にすることができます。
アプリケーション全体のステートは、通常、 分散された多数のアプリケーションインスタンス と、それらのアプリケーションインスタンスによって管理される多数のステートストアに分割されています。
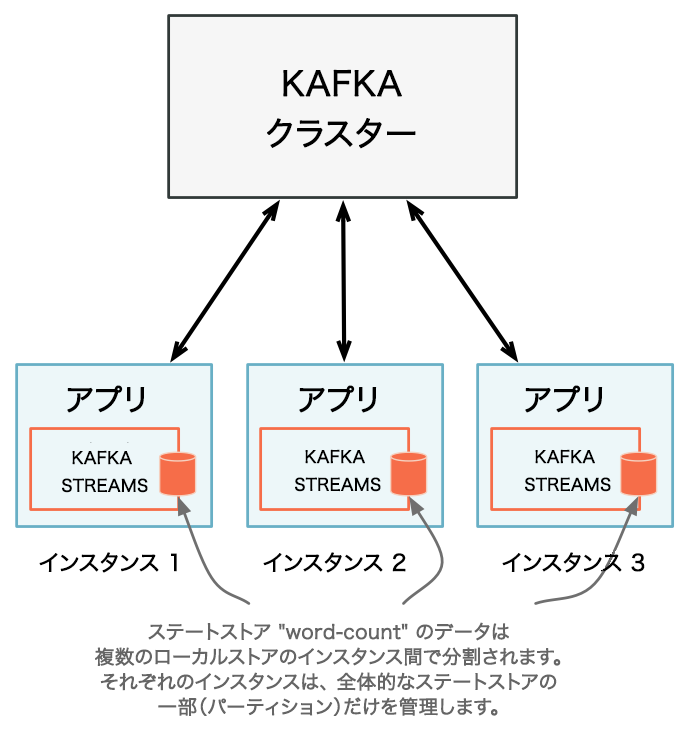
アプリケーションのステートを対話的に照会するクエリには、ローカルの部分とリモートの部分があります。
- ローカルステート
- アプリケーションインスタンスでは、ローカルで管理されている部分のステートを照会したり、自身のローカルステートストアに対して直接クエリを実行したりできます。該当するローカルデータは、Kafka Streams API の呼び出しを必要としない限り、アプリケーションコードの他の部分で使用できます。ステートストアに対するクエリは常に読み取り専用であり、基盤となるステートストアが帯域外で変換されないことが保証されます(たとえば、新しいエントリを追加することはできません)。ステートストアの変更は、対応するプロセッサートポロジーと、それによって処理される入力データを通じてのみ行います。詳細については、「アプリインスタンスのローカルステートストアに対するクエリの実行」を参照してください。
- リモートステート
アプリケーション全体のステートをクエリで照会するには、ステートの各部分を接続する必要があります。これには、次のような操作が含まれます。
- ローカルステートストアに対するクエリの実行
- ネットワーク内で実行中のすべてのアプリケーションインスタンスと、それらのステートストアの検出
- これらのインスタンスとのネットワーク(RPC レイヤーなど)を介した通信
これらを組み合わせることで、同じアプリのインスタンス間の通信や、対話型クエリを目的とした他のアプリケーションからの通信が可能になります。詳細については、「アプリ全体のリモートステートストアに対するクエリの実行」を参照してください。
Kafka Streams では、アプリケーションのステートを対話的に照会するために必要な機能がすべてネイティブに提供されますが、アプリケーション全体のステートを対話型クエリで公開する手順は例外です。ネットワーク経由でのアプリケーションインスタンスとの通信を可能にするには、アプリケーションにリモートプロシージャコール(RPC)レイヤー(REST API など)を追加する必要があります。
以下の表は、さまざまな手順での通信に対する Kafka Streams のネイティブサポートの状況を示しています。
| 手順 | アプリケーションインスタンス | アプリケーション全体 |
|---|---|---|
| アプリインスタンスのローカルステートストアに対してクエリを実行する | サポートあり | サポートあり |
| アプリインスタンスを検出可能にする | サポートあり | サポートあり |
| 実行中のすべてのアプリインスタンスとそれらのステートストアを検出する | サポートあり | サポートあり |
| ネットワーク(RPC)経由でアプリインスタンスと通信する | サポートあり | サポートなし(ユーザーによる構成が必要) |
アプリインスタンスのローカルステートストアに対するクエリの実行¶
通常、Kafka Streams アプリケーションは複数のインスタンスが実行されます。あるインスタンスでローカルに利用できるステートは、 アプリケーション全体のステート のサブセットに過ぎません。インスタンスのローカルストアへのクエリから返されるのは、その特定のインスタンスでローカルに利用できるデータだけです。
KafkaStreams#store(...) メソッドは、名前と種類に基づいて、アプリケーションインスタンスのローカルステートストアを検出します。
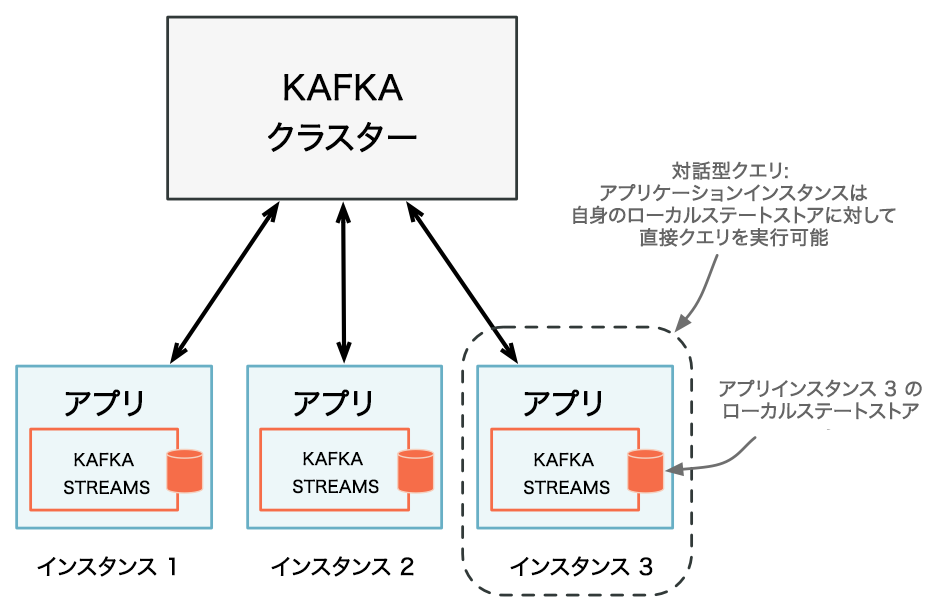
すべてのアプリケーションインスタンスでは、自身のローカルステートストアに対して直接クエリを実行できます。¶
ステートストアの "名前" はストアの作成時に定義されます。ストアは、Processor API を使用して明示的に作成することも、DSL でステートフルな操作を使用して暗黙的に作成することもできます。
ステートストアの "種類" は QueryableStoreType によって定義されます。組み込みの種類にアクセスするには、QueryableStoreTypes クラスを使用します。Kafka Streams には現在、2 つの組み込みの種類があります。
- キーと値のストア
QueryableStoreTypes#keyValueStore()。「ローカルのキーと値のストアに対するクエリの実行」を参照してください。 - ウィンドウストア
QueryableStoreTypes#windowStore()。「ローカルのウィンドウストアに対するクエリの実行」を参照してください。
「ローカルのカスタムステートストアに対するクエリの実行」セクションで説明されているように、 独自の QueryableStoreType を実装 することもできます。
注釈
Kafka Streams では、ストリームパーティションごとに 1 つのステートストアが具現化されます。つまり、アプリケーションでは、基盤となる多数のステートストアを管理することになる可能性があります。API を使用すると、データがどのパーティションに含まれているかを知らなくても、基盤のすべてのストアに対してクエリを実行することができます。
ローカルのキーと値のストアに対するクエリの実行¶
ローカルのキーと値のストアに対してクエリを実行するには、まず、キーと値のストアを使用するトポロジーを作成する必要があります。以下の例では、"CountsKeyValueStore" という名前のキーと値のストアを作成します。このストアには、"word-count-input" トピックで見つかったすべての単語の最新のカウントが保持されます。
Properties props = ...;
StreamsBuilder builder = ...;
KStream<String, String> textLines = ...;
// Define the processing topology (here: WordCount)
KGroupedStream<String, String> groupedByWord = textLines
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.groupBy((key, word) -> word, Grouped.with(stringSerde, stringSerde));
// Create a key-value store named "CountsKeyValueStore" for the all-time word counts
groupedByWord.count(Materialized.<String, String, KeyValueStore<Bytes, byte[]>as("CountsKeyValueStore"));
// Start an instance of the topology
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();
アプリケーションが起動したら、以下のようにして、"CountsKeyValueStore" へアクセスし、ReadOnlyKeyValueStore API を通じてクエリを実行できます。
// Get the key-value store CountsKeyValueStore
ReadOnlyKeyValueStore<String, Long> keyValueStore =
streams.store("CountsKeyValueStore", QueryableStoreTypes.keyValueStore());
// Get value by key
System.out.println("count for hello:" + keyValueStore.get("hello"));
// Get the values for a range of keys available in this application instance
KeyValueIterator<String, Long> range = keyValueStore.range("all", "streams");
while (range.hasNext()) {
KeyValue<String, Long> next = range.next();
System.out.println("count for " + next.key + ": " + next.value);
}
// close the iterator to release resources
range.close()
// Get the values for all of the keys available in this application instance
KeyValueIterator<String, Long> range = keyValueStore.all();
while (range.hasNext()) {
KeyValue<String, Long> next = range.next();
System.out.println("count for " + next.key + ": " + next.value);
}
// close the iterator to release resources
range.close()
また、以下の例に示すように、queryableStoreName を受け取るオーバーロードメソッドを使用して、ステートレスな演算子の結果を具現化することもできます。
StreamsBuilder builder = ...;
KTable<String, Integer> regionCounts = ...;
// materialize the result of filtering corresponding to odd numbers
// the "queryableStoreName" can be subsequently queried.
KTable<String, Integer> oddCounts = numberLines.filter((region, count) -> (count % 2 != 0),
Materialized.<String, Integer, KeyValueStore<Bytes, byte[]>as("queryableStoreName"));
// do not materialize the result of filtering corresponding to even numbers
// this means that these results will not be materialized and cannot be queried.
KTable<String, Integer> oddCounts = numberLines.filter((region, count) -> (count % 2 == 0));
ローカルのウィンドウストアに対するクエリの実行¶
キーは複数のウィンドウに存在し得るため、ウィンドウストアには、特定のキーに対して多数の結果が含まれる可能性があります。ただし、1 つのキーに対する結果はウィンドウごとに 1 つだけです。
ローカルのウィンドウストアに対してクエリを実行するには、まず、ウィンドウストアを使用するトポロジーを作成する必要があります。以下の例では、1 分間のウィンドウに単語数のカウントを格納する "CountsWindowStore" という名前のウィンドウストアを作成します。
StreamsBuilder builder = ...;
KStream<String, String> textLines = ...;
// Define the processing topology (here: WordCount)
KGroupedStream<String, String> groupedByWord = textLines
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.groupBy((key, word) -> word, Grouped.with(stringSerde, stringSerde));
// Create a window state store named "CountsWindowStore" that contains the word counts for every minute
groupedByWord.windowedBy(TimeWindows.of(Duration.ofMinutes(1)))
.count(Materialized.<String, Long, WindowStore<Bytes, byte[]>as("CountsWindowStore"));
アプリケーションが起動したら、以下のようにして、"CountsWindowStore" へのアクセスを取得し、ReadOnlyWindowStore API を通じてクエリを実行できます。
// Get the window store named "CountsWindowStore"
ReadOnlyWindowStore<String, Long> windowStore =
streams.store("CountsWindowStore", QueryableStoreTypes.windowStore());
// Fetch values for the key "world" for all of the windows available in this application instance.
// To get *all* available windows we fetch windows from the beginning of time until now.
Instant timeFrom = Instant.ofEpochMilli(0); // beginning of time = oldest available
Instant timeTo = Instant.now(); // now (in processing-time)
WindowStoreIterator<Long> iterator = windowStore.fetch("world", timeFrom, timeTo);
while (iterator.hasNext()) {
KeyValue<Long, Long> next = iterator.next();
long windowTimestamp = next.key;
System.out.println("Count of 'world' @ time " + windowTimestamp + " is " + next.value);
}
// close the iterator to release resources
iterator.close()
ローカルのカスタムステートストアに対するクエリの実行¶
注釈
カスタムステートストアは Processor API でのみサポートされます。
カスタムステートストアに対してクエリを実行する前に、以下のインターフェイスを実装する必要があります。
- カスタムステートストアに
StateStoreを実装する必要があります。 - ストアで実行できる操作を表すインターフェイスが必要です。
- ストアのインスタンスを作成する
StoreBuilderの実装を提供する必要があります。 - アクセスを読み取り専用の操作に限定するためのインターフェイスを提供することをお勧めします。これにより、実行中の Kafka Streams アプリケーションのステートが API のユーザーによって帯域外で変更されるのを防止できます。
カスタムストアのクラスとインターフェイスの階層は、たとえば次のようになります。
public class MyCustomStore<K,V> implements StateStore, MyWriteableCustomStore<K,V> {
// implementation of the actual store
}
// Read-write interface for MyCustomStore
public interface MyWriteableCustomStore<K,V> extends MyReadableCustomStore<K,V> {
void write(K Key, V value);
}
// Read-only interface for MyCustomStore
public interface MyReadableCustomStore<K,V> {
V read(K key);
}
public class MyCustomStoreBuilder implements StoreBuilder<MyCustomStore<K,V>> {
// implementation of the supplier for MyCustomStore
}
このストアをクエリ可能にするには、以下の手順を実行する必要があります。
- QueryableStoreType の実装を提供します。
- 基盤となるストアのすべてのインスタンスにアクセスするラッパークラスを提供します。これはクエリの実行に使用されます。
QueryableStoreType の実装方法を以下に示します。
public class MyCustomStoreType<K,V> implements QueryableStoreType<MyReadableCustomStore<K,V>> {
// Only accept StateStores that are of type MyCustomStore
public boolean accepts(final StateStore stateStore) {
return stateStore instanceOf MyCustomStore;
}
public MyReadableCustomStore<K,V> create(final StateStoreProvider storeProvider, final String storeName) {
return new MyCustomStoreTypeWrapper(storeProvider, storeName, this);
}
}
Kafka Streams アプリケーションの各インスタンスでは、複数のストリームタスクを実行し、特定のステートストアの複数のローカルインスタンスを管理する可能性があるため、ラッパークラスが必要になります。ラッパークラスは、このような複雑さを隠蔽し、基盤となるステートストアのローカルインスタンスについてすべてを把握していなくても、名前によって "論理的" なステートストアに対してクエリを実行できるようにします。
ラッパークラスを実装するときは、StateStoreProvider インターフェイスを使用して、基盤となるストアのインスタンスへアクセスする必要があります。StateStoreProvider#stores(String storeName, QueryableStoreType<T> queryableStoreType) は、storeName で指定した名前を持ち、queryableStoreType で定義される種類のステートストアの List を返します。
ラッパーの実装例を以下に示します(Java 8 以降)。
// We strongly recommended implementing a read-only interface
// to restrict usage of the store to safe read operations!
public class MyCustomStoreTypeWrapper<K,V> implements MyReadableCustomStore<K,V> {
private final QueryableStoreType<MyReadableCustomStore<K, V>> customStoreType;
private final String storeName;
private final StateStoreProvider provider;
public CustomStoreTypeWrapper(final StateStoreProvider provider,
final String storeName,
final QueryableStoreType<MyReadableCustomStore<K, V>> customStoreType) {
// ... assign fields ...
}
// Implement a safe read method
@Override
public V read(final K key) {
// Get all the stores with storeName and of customStoreType
final List<MyReadableCustomStore<K, V>> stores = provider.getStores(storeName, customStoreType);
// Try and find the value for the given key
final Optional<V> value = stores.stream().filter(store -> store.read(key) != null).findFirst();
// Return the value if it exists
return value.orElse(null);
}
}
これで、以下のようにカスタムストアを検出してクエリを実行できます。
Topology topology = ...;
ProcessorSupplier processorSuppler = ...;
// Create CustomStoreSupplier for store name the-custom-store
MyCustomStoreBuilder customStoreBuilder = new MyCustomStoreBuilder("the-custom-store") //...;
// Add the source topic
topology.addSource("input", "inputTopic");
// Add a custom processor that reads from the source topic
topology.addProcessor("the-processor", processorSupplier, "input");
// Connect your custom state store to the custom processor above
topology.addStateStore(customStoreBuilder, "the-processor");
KafkaStreams streams = new KafkaStreams(topology, props);
streams.start();
// Get access to the custom store
MyReadableCustomStore<String,String> store = streams.store("the-custom-store", new MyCustomStoreType<String,String>());
// Query the store
String value = store.read("key");
バランス調整中のステートストアに対するクエリの実行¶
Streams API では、一貫性と可用性に関してさまざまなトレードオフを提供するステートフルなアプリケーションを構築できます。たとえば、コンシューマーグループのバランス調整中に、アプリケーションからステートストアにクエリを実行することがあります。Kafka Streams アプリケーションでは、以下のような動作を実現できます。
- アクティブなホストが現在ダウンしている場合は、クエリをスタンバイレプリカにルーティングして可用性を保ちます。
- ラグ情報を交換し、ルーティング先として最適なスタンバイレプリカを選択するコントロールプレーンを実装します。ラグ情報は、リクエストまたはハートビートに含まれていることがあります。
- すべてのレプリカで大幅なラグが発生している場合は、クエリを失敗させます。
クエリ対象のキーがあるアクティブホストとスタンバイホストを含んでいるメタデータを見つけるには、KafkaStreams.queryMetadataForKey メソッドを使用します。このメソッドは、指定したストアについて、特定のキーのホストに関するすべてのメタデータを含む KeyQueryMetadata を返します。クエリのメタデータと KafkaStreams.allLocalStorePartitionLags メソッドなどのラグ API を使用して、どのホストが同期していて、どのホストが遅延しているかを特定します。
以下のコード例では、スタンバイホストを列挙し、ラグに基づいて、最も同期されているものから同期されていないものへと並べ替えます。
注釈
metadataForKey メソッドは非推奨になっています。
// Global map containing latest lag information across hosts. This is
// collected by the Streams application instances outside of Streams,
// relying on the local lag APIs in each.
//
// Each application instance uses KafkaStreams#allMetadata() to discover
// other application instances to exchange this lag information.
final Map<HostInfo, Map<String, Map<Integer, Long>>> globalLagInformation;
// Key which needs to be routed.
final K key;
// Store to be queried.
final String storeName;
// Fetch the metadata related to the key.
KeyQueryMetadata queryMetadata = queryMetadataForKey(store, key, serializer);
// Acceptable lag for the query.
final long acceptableOffsetLag = 10000;
if (isAlive(queryMetadata.getActiveHost()) {
// Always route to the active host if it's alive.
query(store, key, queryMetadata.getActiveHost());
} else {
// Filter out all of the standby hosts with more unacceptable lag than
// acceptable lag, and obtain a list of standbys hosts that are in-sync.
List<HostInfo> inSyncStandbys = queryMetadata.getStandbyHosts().stream()
// Get the lag at each standby host for the key's store partition.
.map(standbyHostInfo -> new Pair(standbyHostInfo, globalLagInformation.get(standbyHostInfo).get(storeName).get(queryMetadata.partition())).offsetLag())
// Sort by offset lag, i.e smallest lag first.
.sorted(Comparator.comparing(Pair::getRight())
.filter(standbyHostLagPair -> standbyHostLagPair.getRight() < acceptableOffsetLag)
.map(standbyHostLagPair -> standbyHostLagPair.getLeft())
.collect(Collectors.toList());
// Query standbys most in-sync to least in-sync.
for (HostInfo standbyHost : inSyncStandbys) {
try {
query(store, key, standbyHost);
} catch (Exception e) {
System.err.println("Querying standby failed");
}
}
}
以下のコード例では、KafkaStreams.allLocalStorePartitionLags メソッドと LagInfo クラスを使用して、すべてのローカルストアについてパーティションのラグを取得する方法を示します。コード全体のリストについては、LagFetchIntegrationTest.java を参照してください。
Map<String, Map<Integer, LagInfo>> offsetLagInfoMap = // return value from allLocalStorePartitionLags()
...
// Get the lag for a given state store's partition 0.
LagInfo lagInfo = offsetLagInfoMap.get(stateStoreName).get(0);
assertThat(lagInfo.currentOffsetPosition(), equalTo(5L));
assertThat(lagInfo.endOffsetPosition(), equalTo(5L));
assertThat(lagInfo.offsetLag(), equalTo(0L));
以下のコード例では、アクティブストアとスタンバイストアの両方に対して、キーでクエリを実行する方法を示します。コード全体のリストについては、StoreQueryIntegrationTest.java を参照してください。
final StreamsBuilder builder = new StreamsBuilder();
builder.table(INPUT_TOPIC_NAME, Consumed.with(Serdes.Integer(), Serdes.Integer()),
Materialized.<Integer, Integer, KeyValueStore<Bytes, byte[]>>as(TABLE_NAME)
.withCachingDisabled())
.toStream()
.peek((k, v) -> semaphore.release());
final KafkaStreams kafkaStreams1 = createKafkaStreams(builder, streamsConfiguration());
final KafkaStreams kafkaStreams2 = createKafkaStreams(builder, streamsConfiguration());
final List<KafkaStreams> kafkaStreamsList = Arrays.asList(kafkaStreams1, kafkaStreams2);
final QueryableStoreType<ReadOnlyKeyValueStore<Integer, Integer>> queryableStoreType = QueryableStoreTypes.keyValueStore();
// Both active and standby stores are able to query for a key.
final ReadOnlyKeyValueStore<Integer, Integer> store1 = kafkaStreams1
.store(StoreQueryParameters.fromNameAndType(TABLE_NAME, queryableStoreType).enableStaleStores());
final ReadOnlyKeyValueStore<Integer, Integer> store2 = kafkaStreams2
.store(StoreQueryParameters.fromNameAndType(TABLE_NAME, queryableStoreType).enableStaleStores());
アプリ全体のリモートステートストアに対するクエリの実行¶
アプリ全体のリモートステートに対するクエリを実行するには、アプリケーションのステート全体を他のアプリケーションに公開する必要があります。他のアプリケーションには、別のマシンで実行されているアプリケーションも含まれます。
たとえば、マルチプレイヤーのビデオゲームでのユーザーイベントを処理する Kafka Streams アプリケーションがあるとします。各ユーザーの最新のステータスを直接取得して、モバイルアプリに表示しようとしています。アプリケーション全体のステートをクエリ可能にするには、以下の手順を実行する必要があります。
- アプリケーションに RPC レイヤーを追加 して、アプリケーションのインスタンスとネットワーク経由で(REST API、Thrift、カスタムプロトコルなどを通じて)対話できるようにします。インスタンスは対話型クエリに応答する必要があります。参照用に提供されているサンプルを開始点として使用できます。
- Kafka Streams の
application.server構成設定を通じて、アプリケーションインスタンスの RPC エンドポイントを公開 します。RPC エンドポイントはネットワーク内で一意でなければならないため、この構成設定には、インスタンスごとに独自の値を指定する必要があります。これにより、アプリケーションインスタンスが他のインスタンスから検出可能になります。 - RPC レイヤーで、 リモートのアプリケーションインスタンス とステートストアを検出し、 ローカルで使用可能なステートストアに対してクエリを実行 して、アプリケーション全体のステートをクエリ可能にします。リモートのアプリケーションインスタンスでは、クエリに応答するために必要なローカルデータが特定のインスタンスに存在しない場合、クエリを他のアプリインスタンスに転送できます。ローカルで使用可能なステートストアは、クエリに直接応答することができます。
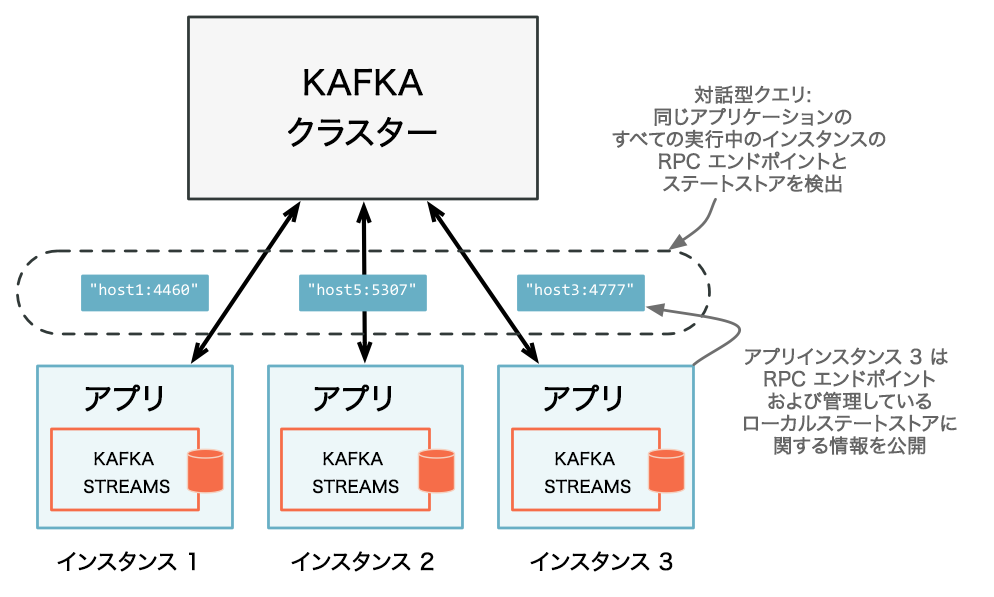
同じアプリケーションのすべての実行インスタンスと、各インスタンスが対話型クエリ用に公開している RPC エンドポイントを検出します。¶
アプリケーションへの RPC レイヤーの追加¶
RPC レイヤーを追加するには、さまざまな方法があります。唯一の要件は、RPC レイヤーを Kafka Streams アプリケーション内に組み込み、他のアプリケーションインスタンスやアプリケーションから接続できるエンドポイントを公開することです。
REST API を介した RPC レイヤーの実装を示す例として、エンドツーエンドの対話型クエリのデモアプリケーションである KafkaMusicExample と WordCountInteractiveQueriesExample が用意されています。
アプリケーションの RPC エンドポイントの公開¶
分散 Kafka Streams アプリケーションでリモートステートストアの検出を有効にするには、構成プロパティのインスタンスで 構成プロパティ を設定する必要があります。application.server プロパティでは、Kafka Streams アプリケーションの各インスタンスの RPC エンドポイントを指す一意の host:port ペアを定義します。この構成プロパティは、アプリケーションのインスタンスによって異なります。このプロパティが設定されている場合、Kafka Streams では、アプリケーションの各インスタンスの RPC エンドポイント情報、ステートストア、および割り当てられているストリームパーティションを、StreamsMetadata のインスタンスを通じて追跡します。
ちなみに
アプリケーションでは、公開した RPC エンドポイントを他の機能にも利用することを検討してください。たとえば、対話型クエリ以外の追加のアプリケーション間通信で利用することが考えられます。
以下の例では、ステートストアの検出をサポートする Kafka Streams アプリケーションを構成して実行する方法を示します。
Properties props = new Properties();
// Set the unique RPC endpoint of this application instance through which it
// can be interactively queried. In a real application, the value would most
// probably not be hardcoded but derived dynamically.
String rpcEndpoint = "host1:4460";
props.put(StreamsConfig.APPLICATION_SERVER_CONFIG, rpcEndpoint);
// ... further settings may follow here ...
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> textLines = builder.stream(stringSerde, stringSerde, "word-count-input");
final KGroupedStream<String, String> groupedByWord = textLines
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.groupBy((key, word) -> word, Grouped.with(stringSerde, stringSerde));
// This call to `count()` creates a state store named "word-count".
// The state store is discoverable and can be queried interactively.
groupedByWord.count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>as("word-count"));
// Start an instance of the topology
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();
// Then, create and start the actual RPC service for remote access to this
// application instance's local state stores.
//
// This service should be started on the same host and port as defined above by
// the property `StreamsConfig.APPLICATION_SERVER_CONFIG`. The example below is
// fictitious, but we provide end-to-end demo applications (such as KafkaMusicExample)
// that showcase how to implement such a service to get you started.
MyRPCService rpcService = ...;
rpcService.listenAt(rpcEndpoint);
アプリケーションインスタンスとローカルステートストアの検出およびアクセス¶
以下のメソッドは、アプリケーションインスタンスに関するメタ情報を提供する StreamsMetadata オブジェクトを返します。メタ情報には、RPC エンドポイントやローカルで使用可能なステートストアなどが含まれます。
KafkaStreams#allMetadata(): アプリケーションのすべてのインスタンスを検出します。KafkaStreams#allMetadataForStore(String storeName): ステートストア "storeName" のローカルインスタンスを管理しているアプリケーションインスタンスを見つけます。KafkaStreams#metadataForKey(String storeName, K key, Serializer<K> keySerializer): ストリームのデフォルトのパーティション化戦略を使用して、特定のステートストアで特定のキーのデータを保持する 1 つのアプリケーションインスタンスを見つけます。KafkaStreams#metadataForKey(String storeName, K key, StreamPartitioner<K, ?> partitioner):partitionerを使用して、特定のステートストアで特定のキーのデータを保持する 1 つのアプリケーションインスタンスを見つけます。
注意
アプリケーションインスタンスで application.server が構成されていない場合、上記のメソッドは StreamsMetadata を返しません。
たとえば、以下のようにすると、前のセクションのコード例で定義した "word-count" という名前のステートストアの StreamsMetadata を見つけることができます。
KafkaStreams streams = ...;
// Find all the locations of local instances of the state store named "word-count"
Collection<StreamsMetadata> wordCountHosts = streams.allMetadataForStore("word-count");
// For illustrative purposes, we assume using an HTTP client to talk to remote app instances.
HttpClient http = ...;
// Get the word count for word (aka key) 'alice': Approach 1
//
// We first find the one app instance that manages the count for 'alice' in its local state stores.
StreamsMetadata metadata = streams.metadataForKey("word-count", "alice", Serdes.String().serializer());
// Then, we query only that single app instance for the latest count of 'alice'.
// Note: The RPC URL shown below is fictitious and only serves to illustrate the idea. Ultimately,
// the URL (or, in general, the method of communication) will depend on the RPC layer you opted to
// implement. Again, we provide end-to-end demo applications (such as KafkaMusicExample) that showcase
// how to implement such an RPC layer.
Long result = http.getLong("http://" + metadata.host() + ":" + metadata.port() + "/word-count/alice");
// Get the word count for word (aka key) 'alice': Approach 2
//
// Alternatively, we could also choose (say) a brute-force approach where we query every app instance
// until we find the one that happens to know about 'alice'.
Optional<Long> result = streams.allMetadataForStore("word-count")
.stream()
.map(streamsMetadata -> {
// Construct the (fictituous) full endpoint URL to query the current remote application instance
String url = "http://" + streamsMetadata.host() + ":" + streamsMetadata.port() + "/word-count/alice";
// Read and return the count for 'alice', if any.
return http.getLong(url);
})
.filter(s -> s != null)
.findFirst();
これで、アプリケーション全体のステートが対話的にクエリ可能になります。
- アプリケーションの実行中のインスタンスと、それらがローカルで管理しているステートストアを検出できます。
- アプリケーションに追加された RPC レイヤーを通じて、ネットワーク経由でこれらのアプリケーションインスタンスと通信し、ローカルで使用可能なステートストアに対してクエリを実行できます。
- アプリケーションインスタンスでは、自身のローカルステートストアに対して直接クエリを実行できるため、このようなクエリを受け入れ、RPC レイヤーを通じて応答を返すことができます。
- 総合的に、アプリケーション全体のステートをクエリで照会できるようになります。
対話型クエリに対応するエンドツーエンドのアプリケーションについては、「デモアプリケーション」を参照してください。
デモアプリケーション¶
ここでは、開始点として役立つエンドツーエンドのデモアプリケーションを紹介します。
- KafkaMusicExample: このアプリケーションは、楽曲の再生イベントをリアルタイムで Apache Kafka® トピックに収集し、それに基づいて最新のトップ 5 の音楽チャートを継続的に計算します。このチャートデータは、継続的に更新されるステートストアに保持され、REST API を介した対話型クエリによって照会できます。
- WordCountInteractiveQueriesExample: このアプリケーションは、Kafka トピックからリアルタイムでテキストデータを消費し、その中に出現する単語を継続的にカウントします。単語のカウントは継続的に更新されるステートストアに保持され、REST API を介した対話型クエリによって照会できます。
注釈
このウェブサイトには、Apache License v2 の条件に基づいて Apache Software Foundation で開発されたコンテンツが含まれています。