Confluent Platform のクイックスタート(Docker)¶
このクイックスタートに従うことにより、Confluent Platform とその主要コンポーネントを Docker コンテナーを使用して実行することができます。このクイックスタートでは、Confluent Platform に含まれている Confluent Control Center を使用したトピック管理と ksqlDB を利用したイベントストリーム処理を行います。
このクイックスタートでは、Apache Kafka® トピックを作成し、Kafka Connect を使ってそれらのトピックに対する模擬データを生成して、それらのトピックに対する ksqlDB ストリーミングクエリを作成します。Control Center に移動して、イベントストリーミングクエリをモニタリングし、分析します。
参考
このクイックスタートの自動化バージョン を実行することもできます。これは、Confluent Platform のローカルインストール向けです。
- 前提条件:
- Docker
- Docker バージョン 1.11 またはそれ以降が インストールされ動作している。
- Docker Compose が インストール済みである 。Docker Compose は、Docker for Mac ではデフォルトでインストールされます。
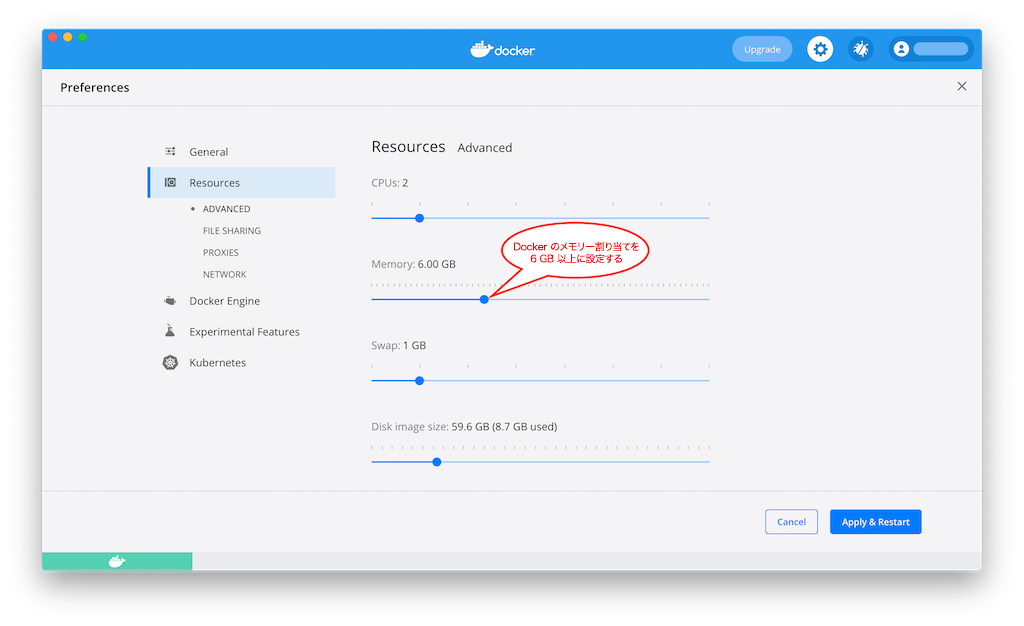
- Docker メモリーに最小でも 6 GB が割り当てられている。Docker Desktop for Mac を使用しているとき、Docker メモリーの割り当てはデフォルトで 2 GB です。Docker のデフォルトの割り当てを 6 GB に変更できます。Preferences、Resources、Advanced の順に移動します。
- インターネット接続
- Confluent Platform で現在サポートされる オペレーティングシステム
- Docker でのネットワークと Kafka
- 内部コンポーネントと外部コンポーネントが Docker ネットワークに通信できるように、ホストとポートを構成します。詳細については、こちらの記事 を参照してください。
- Docker
ステップ 1: Docker を使用した Confluent Platform のダウンロードおよび起動¶
次のように、Confluent Platform all-in-one Docker Compose ファイル の内容をダウンロードするか、コピーします。
curl --silent --output docker-compose.yml \ https://raw.githubusercontent.com/confluentinc/cp-all-in-one/6.2.4-post/cp-all-in-one/docker-compose.yml-dオプションを使用して Confluent Platform を起動し、デタッチモードで実行します。docker-compose up -d
上記のコマンドで、各 Confluent Platform コンポーネントの別のコンテナーとともに Confluent Platform が起動されます。出力は次のようになります。
Creating network "cp-all-in-one_default" with the default driver Creating zookeeper ... done Creating broker ... done Creating schema-registry ... done Creating rest-proxy ... done Creating connect ... done Creating ksql-datagen ... done Creating ksqldb-server ... done Creating control-center ... done Creating ksqldb-cli ... done
サービスが稼働状態であることを検証するには、以下のコマンドを実行します。
docker-compose ps
出力は次のようになります。
Name Command State Ports ------------------------------------------------------------------------------------------ broker /etc/confluent/docker/run Up 0.0.0.0:29092->29092/tcp, 0.0.0.0:9092->9092/tcp connect /etc/confluent/docker/run Up 0.0.0.0:8083->8083/tcp, 9092/tcp control-center /etc/confluent/docker/run Up 0.0.0.0:9021->9021/tcp ksqldb-cli /bin/sh Up ksql-datagen bash -c echo Waiting for K ... Up ksqldb-server /etc/confluent/docker/run Up 0.0.0.0:8088->8088/tcp rest-proxy /etc/confluent/docker/run Up 0.0.0.0:8082->8082/tcp schema-registry /etc/confluent/docker/run Up 0.0.0.0:8081->8081/tcp zookeeper /etc/confluent/docker/run Up 0.0.0.0:2181->2181/tcp, 2888/tcp, 3888/tcp
ステートが
Upではない場合は、docker-compose up -dコマンドを再度実行します。
ステップ 2: Kafka トピックの作成¶
このステップでは、Confluent Control Center を活用して Kafka トピックを作成します。Confluent Control Center は、本稼働環境データパイプラインおよびイベントストリーミングアプリケーションを構築およびモニタリングするための機能を備えています。
http://localhost:9021 にある Control Center ウェブインターフェイスに移動します。
異なるホストに Confluent Platform をインストールした場合は、
localhostをアドレスのホスト名と置き換えます。Control Center がオンラインになるまでに 1 ~ 2 分かかる場合があります。
注釈
Control Center が
localhostブラウザーセッションで開いておらず、実行中ではない場合、Control Center は ksqlDB に接続されません。controlcenter.cluster タイルをクリックします。
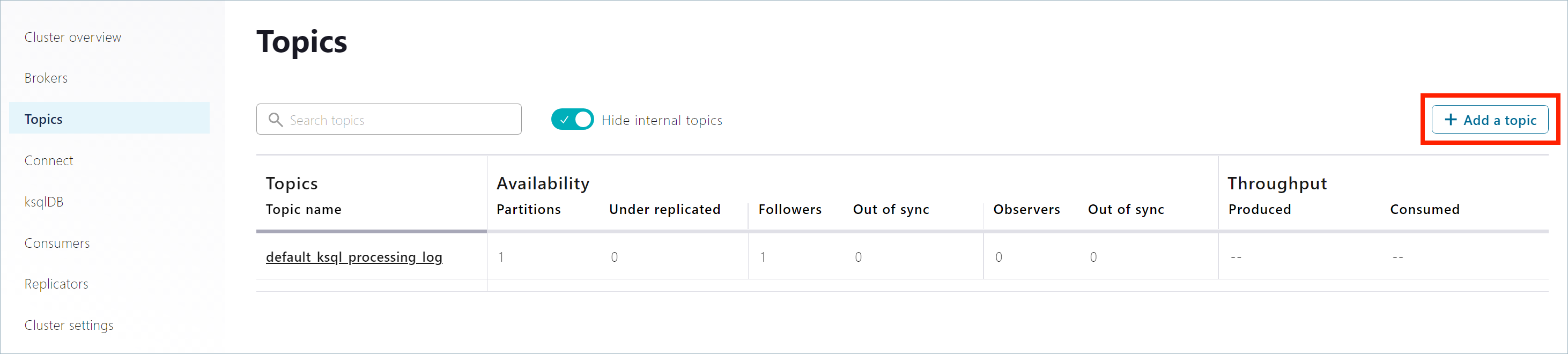
ナビゲーションバーで Topics をクリックしてトピックリストを開いた後、Add a topic をクリックします。
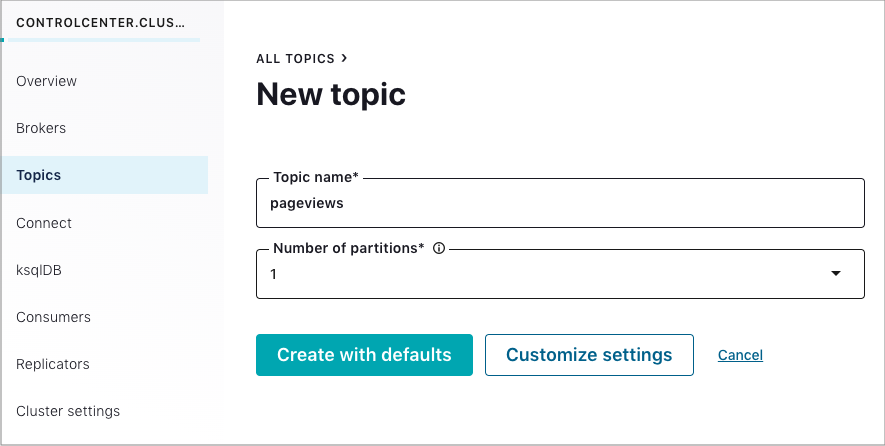
Topic name フィールドで
pageviewsを指定し、Create with defaults をクリックします。トピック名では、大文字と小文字が区別されます。
ナビゲーションバーで Topics をクリックしてトピックリストを開いた後、Add a topic をクリックします。
Topic name フィールドで
usersを指定し、Create with defaults をクリックします。
ステップ 3: Kafka コネクターのインストールおよびサンプルデータの生成¶
このステップでは、Kafka Connect を使用して、Kafka トピック pageviews および users のサンプルデータを作成する、kafka-connect-datagen という名前のデモソースコネクターを実行します。
ちなみに
「ステップ 1: Docker を使用した Confluent Platform のダウンロードおよび起動」での Docker Compose の起動時に、Kafka Connect Datagen コネクターは自動的にインストールされました。Datagen コネクターの場所を特定する際に問題が発生した場合は、「トラブルシューティング」セクションの「問題: Datagen コネクターの場所を特定できない」を参照してください。
Kafka Connect Datagen コネクターの最初のインスタンスを実行して、
pageviewsトピックに対して Kafka データを AVRO フォーマットで生成します。ナビゲーションバーで Connect をクリックします。
Connect Clusters リストで
connect-defaultクラスターをクリックします。Add connector をクリックします。
DatagenConnectorタイルを選択します。ちなみに
表示されるコネクターを絞り込むには、Filter by category をクリックし、Sources をクリックします。
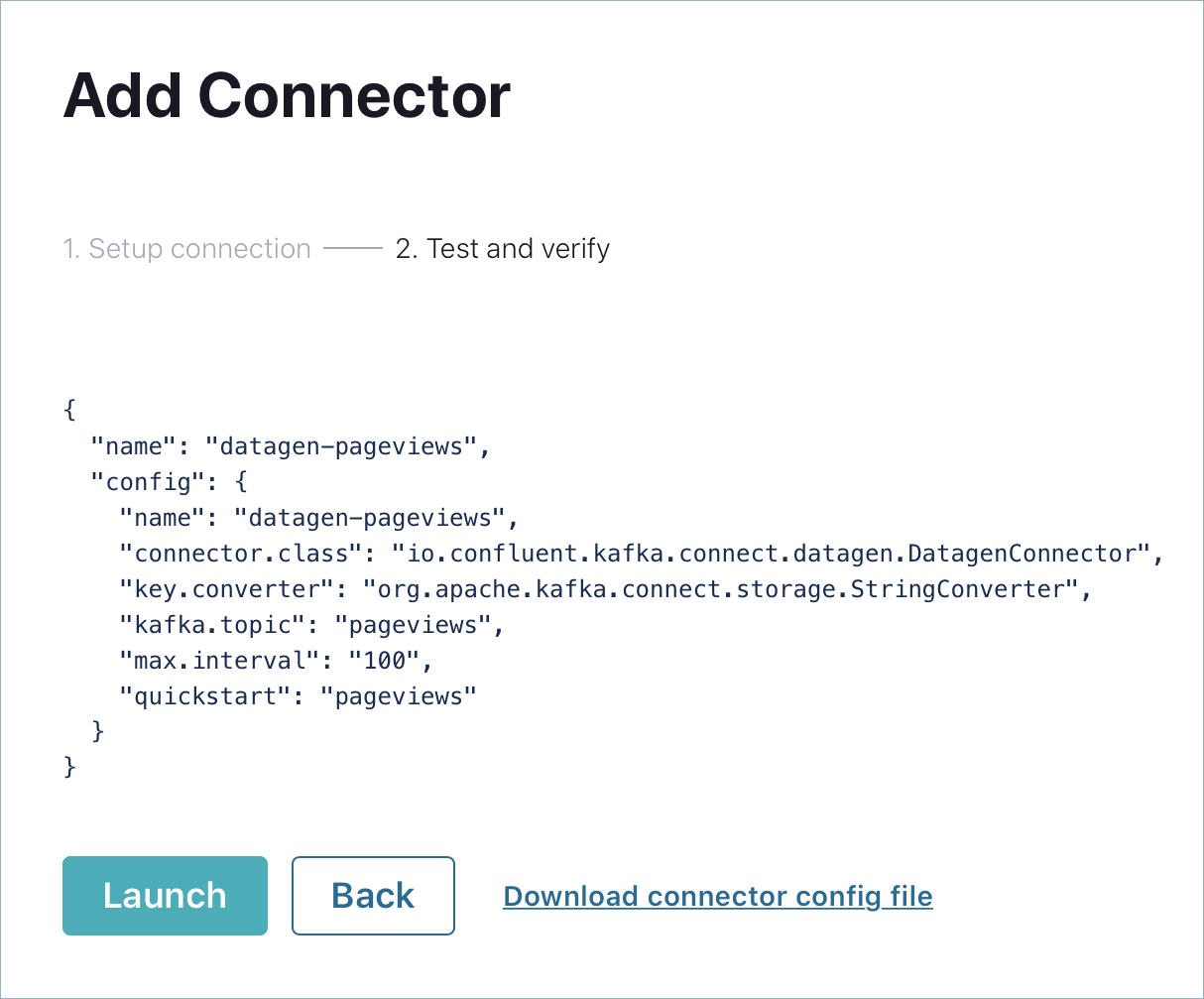
名前 フィールドで、コネクターの名前として
datagen-pageviewsを入力します。次の構成値を入力します。
- Key converter class:
org.apache.kafka.connect.storage.StringConverter。 - kafka.topic:
pageviews。 - max.interval:
100。 - quickstart:
pageviews。
- Key converter class:
Next をクリックします。
コネクター構成を確認し、Launch をクリックします。
Kafka Connect Datagen コネクターの 2 番目のインスタンスを実行して、
usersトピックに対して Kafka データを AVRO フォーマットで生成します。Add connector をクリックします。
DatagenConnectorタイルを選択します。ちなみに
表示されるコネクターを絞り込むには、Filter by category をクリックし、Sources をクリックします。
名前 フィールドで、コネクターの名前として
datagen-usersを入力します。次の構成値を入力します。
- Key converter class:
org.apache.kafka.connect.storage.StringConverter - kafka.topic:
users - max.interval:
1000 - quickstart:
users
- Key converter class:
Next をクリックします。
コネクター構成を確認し、Launch をクリックします。
ステップ 4: ksqlDB を使用したストリームおよびテーブルの作成および書き込み¶
ちなみに
docker-compose exec ksqldb-cli ksql http://ksqldb-server:8088 コマンドにより、Docker コンテナーから ksqlDB CLI を使用して、これらのコマンドを実行することもできます。
ストリームおよびテーブルの作成¶
このステップでは、ksqlDB を使用して、pageviews トピックのストリームおよび users トピックのテーブルを作成します。
ナビゲーションバーで ksqlDB をクリックします。
ksqlDBアプリケーションを選択します。以下のコードをエディターのウィンドウにコピーします。Run query をクリックして、
pageviewsストリームを作成します。ストリーム名では、大文字と小文字が区別されません。CREATE STREAM pageviews WITH (KAFKA_TOPIC='pageviews', VALUE_FORMAT='AVRO');
以下のコードをエディターのウィンドウにコピーします。Run query をクリックして、
usersテーブルを作成します。テーブル名では、大文字と小文字が区別されません。CREATE TABLE users (id VARCHAR PRIMARY KEY) WITH (KAFKA_TOPIC='users', VALUE_FORMAT='AVRO');
クエリの記述¶
このステップでは、上記で作成したストリームおよびテーブルに対する ksqlDB クエリを作成します。
Editor タブで Add query properties をクリックして、カスタムクエリプロパティを追加します。
auto.offset.resetパラメーターをEarliestに設定します。この設定により ksqlDB クエリは、使用可能なすべてのトピックデータを先頭から読み取ります。この構成は、以降の各クエリに対して使用されます。詳細については、「ksqlDB 構成パラメーターリファレンス」を参照してください。
以下のクエリを作成します。
Stop をクリックして、現時点で実行中のクエリを停止します。
最大 3 行までに制限された結果とともにストリームからデータを返す、非永続的なクエリを作成します。
エディターで以下のクエリを入力します。
SELECT pageid FROM pageviews EMIT CHANGES LIMIT 3;
Run query をクリックします。出力は以下のようになります。
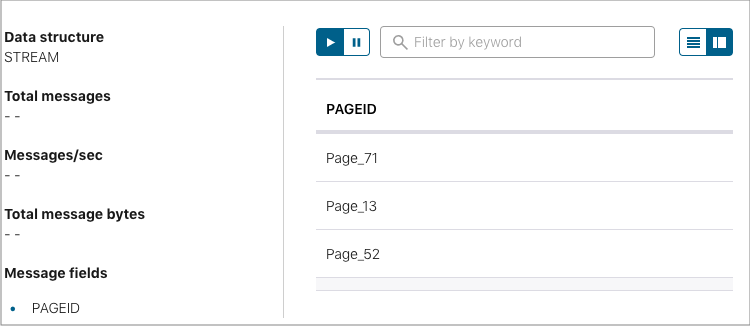
Card view アイコンまたは Table view アイコンをクリックして、出力レイアウトを変更します。
女性(female)ユーザーの
PAGEVIEWSストリームをフィルター処理する永続的なクエリを(ストリームとして)作成します。クエリの結果は Kafka のPAGEVIEWS_FEMALEトピックに書き込まれます。エディターで以下のクエリを入力します。
CREATE STREAM pageviews_female AS SELECT users.id AS userid, pageid, regionid FROM pageviews LEFT JOIN users ON pageviews.userid = users.id WHERE gender = 'FEMALE' EMIT CHANGES;
Run query をクリックします。出力は以下のようになります。

REGIONIDが8または9で終わる永続的なクエリを作成します。このクエリの結果は、クエリで明示的に指定されたように、pageviews_enriched_r8_r9という名前の Kafka トピックに書き込まれます。エディターで以下のクエリを入力します。
CREATE STREAM pageviews_female_like_89 WITH (KAFKA_TOPIC='pageviews_enriched_r8_r9', VALUE_FORMAT='AVRO') AS SELECT * FROM pageviews_female WHERE regionid LIKE '%_8' OR regionid LIKE '%_9' EMIT CHANGES;
Run query をクリックします。出力は以下のようになります。

カウントが 1 より大きい場合に 30 秒の タンブリングウィンドウ で、
REGIONとGENDERの組み合わせごとにPAGEVIEWSをカウントする永続的なクエリを作成します。手順がグループ化およびカウントであるため、結果はストリームではなく、テーブルになります。このクエリの結果は、PAGEVIEWS_REGIONSという名前の Kafka トピックに書き込まれます。エディターで以下のクエリを入力します。
CREATE TABLE pageviews_regions WITH (KEY_FORMAT='JSON') AS SELECT gender, regionid, COUNT(*) AS numusers FROM pageviews LEFT JOIN users ON pageviews.userid = users.id WINDOW TUMBLING (SIZE 30 SECOND) GROUP BY gender, regionid HAVING COUNT(*) > 1 EMIT CHANGES;
Run query をクリックします。出力は以下のようになります。

Persistent queries タブをクリックします。以下の永続的なクエリが表示されます。
- PAGEVIEWS_FEMALE
- PAGEVIEWS_FEMALE_LIKE_89
- PAGEVIEWS_REGIONS
Editor タブをクリックします。All available streams and tables ペインには、アクセスできるすべてのストリームおよびテーブルが表示されます。
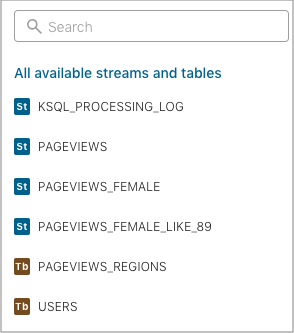
All available streams and tables セクションで KSQL_PROCESSING_LOG をクリックすると、ストリームのスキーマ(ネスト化されたデータ構造など)が表示されます。
クエリの実行¶
このステップでは、前のセクションでストリームおよびテーブルとして保存した ksqlDB クエリを実行します。
Streams タブで
PAGEVIEWS_FEMALEストリームを選択します。Query stream をクリックします。
エディターが開き、クエリのストリーミング出力が表示されます。
Stop をクリックして、出力の生成を停止します。
Tables タブで
PAGEVIEWS_REGIONSテーブルを選択します。Query table をクリックします。
エディターが開き、クエリのストリーミング出力が表示されます。
Stop をクリックして、出力の生成を停止します。
ステップ 5: コンシューマーラグのモニタリング¶
ナビゲーションバーで Consumers をクリックして、ksqlDB により作成されたコンシューマーを表示します。
コンシューマーグループ ID をクリックして、
_confluent-ksql-default_query_CSAS_PAGEVIEWS_FEMALE_5コンシューマーグループの詳細を表示します。このページで、ストリーミングクエリのコンシューマーラグおよび消費量の値を確認できます。
詳細については、Control Center の「Consumers」ドキュメントを参照してください。
ステップ 6: Confluent コンテナーの停止およびクリーンアップ¶
Docker での作業が完了したら、Docker コンテナーおよびイメージを停止し、削除できます。
以下のコマンドを実行して、Confluent の Docker コンテナーを停止します。
docker-compose stop
Docker コンテナーを停止した後に、以下のコマンドを実行して Docker システムを削除します。これらのコマンドを実行すると、コンテナー、ネットワーク、ボリューム、イメージが削除され、ディスク領域が解放されます。
docker system prune -a --volumes --filter "label=io.confluent.docker"
詳細については、Docker の公式ドキュメントを参照してください。
次のステップ¶
このクイックスタートで示したコンポーネントについて、さらに詳しく確認します。
- ksqlDB ドキュメント: ストリーミング ETL、リアルタイムモニタリング、異常検出などのユースケースにおける、ksqlDB を使用したデータの処理について確認できます。一連の スクリプト化されたデモ により、ksqlDB の使用方法も参照してください。
- Kafka チュートリアル : ステップごとの手順に従って、Kafka、Kafka Streams、および ksqlDB の基本的なチュートリアルを試すことができます。
- Kafka Streams ドキュメント: ストリーム処理アプリケーションを Java または Scala で構築する方法を確認できます。
- Kafka Connect ドキュメント: Kafka を他のシステムに統合し、すぐに使用できるコネクター をダウンロードして、 Kafka 内外のデータをリアルタイムで簡単に取り込む方法を確認できます。
- Kafka クライアントドキュメント: Go、Python、.NET、C/C++ などのプログラミング言語を使用して、Kafka に対してデータの読み取りおよび書き込みを行う方法を確認できます。
- ビデオ、デモ、および参考文献: Confluent Platform のチュートリアルやサンプルを試したり、デモやスクリーンキャストを参照したり、ホワイトペーパーやブログで学べます。
トラブルシューティング¶
クイックスタートのワークフローの進行中に問題が発生した場合は、ステップを再試行する前に、以下の解決策を確認してください。
問題: Datagen コネクターの場所を特定できない¶
詳細については、「ステップ 1: Docker を使用した Confluent Platform のダウンロードおよび起動」を参照してください。
解決策 : connect に対してのみ build コマンドを実行して、connect コンテナーが正常に構築されたかどうか確認します。
docker-compose build --no-cache connect
出力は以下のようになります。
Building connect
...
Completed
Removing intermediate container cdb0af3550c8
---> 36d00047d29b
Successfully built 36d00047d29b
Successfully tagged confluentinc/kafka-connect-datagen:latest
connect コンテナーが既に正常に構築されていた場合は、以下のような出力になります。
connect uses an image, skipping
解決策 : Connect ログで Datagen を確認します。
docker-compose logs connect | grep -i Datagen
出力は以下のようになります。
connect | [2019-04-17 20:03:26,137] INFO Loading plugin from: /usr/share/confluent-hub-components/confluentinc-kafka-connect-datagen (org.apache.kafka.connect.runtime.isolation.DelegatingClassLoader)
connect | [2019-04-17 20:03:26,206] INFO Registered loader: PluginClassLoader{pluginLocation=file:/usr/share/confluent-hub-components/confluentinc-kafka-connect-datagen/} (org.apache.kafka.connect.runtime.isolation.DelegatingClassLoader)
connect | [2019-04-17 20:03:26,206] INFO Added plugin 'io.confluent.kafka.connect.datagen.DatagenConnector' (org.apache.kafka.connect.runtime.isolation.DelegatingClassLoader)
connect | [2019-04-17 20:03:28,102] INFO Added aliases 'DatagenConnector' and 'Datagen' to plugin 'io.confluent.kafka.connect.datagen.DatagenConnector' (org.apache.kafka.connect.runtime.isolation.DelegatingClassLoader)
解決策 : Connect ログで docker-compose up -d コマンドを適切に実行するための警告およびリマインダーを確認します。
docker-compose logs connect | grep -i Datagen
解決策 : kafka-connect-datagen の .jar ファイルが追加されており、lib サブフォルダー内に存在するかを確認します。
docker-compose exec connect ls /usr/share/confluent-hub-components/confluentinc-kafka-connect-datagen/lib/
出力は以下のようになります。
...
kafka-connect-datagen-0.1.0.jar
...
解決策 : プラグインがコネクターのパスに存在するかを検証します。
docker-compose exec connect bash -c 'echo $CONNECT_PLUGIN_PATH'
出力は以下のようになります。
/usr/share/java,/usr/share/confluent-hub-components
その内容が存在することを確認します。
docker-compose exec connect ls /usr/share/confluent-hub-components/confluentinc-kafka-connect-datagen
出力は以下のようになります。
assets doc etc lib manifest.json
問題: ストリームとストリームの結合に関するエラー¶
エラーにより、ストリームとストリームの結合には WITHIN 句の指定が必要であることが通知されます。このエラーは pageviews と users の両方をストリームとして誤って作成した場合に発生する可能性があります。
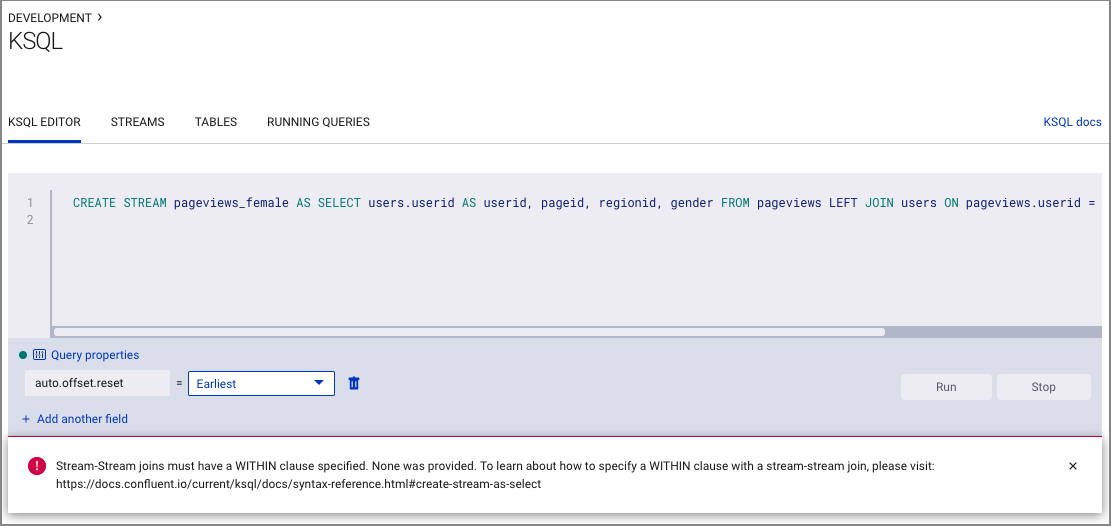
解決策 : 「ステップ 4: ksqlDB を使用したストリームおよびテーブルの作成および書き込み」で pageviews の "ストリーム" を作成し、users の "テーブル" を作成したことを確認します。
問題: ksqlDB クエリのステップを正常に完了できない¶
Java エラーまたはその他の重大なエラーが発生しました。
解決策 : Confluent Platform により現在サポートされている オペレーティングシステム で作業していることを確認します。
解決策 : Docker メモリーが 8 MB まで増設されたかを確認します。Docker > Preferences > Advanced に移動してください。Docker メモリーが不十分な場合は、その他の予期しない問題が発生する可能性があります。