Kafka の設計¶
動機¶
Apache Kafka® は、大企業が所有する すべてのリアルタイムのデータフィードを処理する統合されたプラットフォームとして設計されました。設計にあたり、膨大なユースケースをカバーしました。
リアルタイムのログの集約といった大規模なイベントストリームを、高いスループットでサポートする必要がありました。
オフラインシステムからの定期的なデータ負荷をサポートするために、多くのデータバックログを円滑に処理する必要がありました。
このことはまた、従来のメッセージングのユースケースに対応するために、システムは低いレイテンシでデリバリーを行う必要があることも示していました。
Confluent では、このようなフィードに対するパーティション分割されたリアルタイムの分散処理をサポートし、新しく派生したフィードを作成することをめざしていました。これが、パーティション分割およびコンシューマーモデル開発の動機となりました。
最終的に、他のデータシステムで処理するためにストリームを出力する場合には、マシンに障害が発生した場合のフォールトトレランスをシステムで保証する必要がありました。
以上の事例をサポートすることにより、従来のメッセージングシステムよりもデータベースログとの親和性の高い、多くのユニークな要素を含む設計へとたどり着きました。以下のセクションでは、そのような設計のいくつかの要素について簡単に説明します。
永続性¶
ファイルシステムはボトルネックではない¶
Kafka はメッセージの格納とキャッシュ処理をファイルシステムに大きく依存しています。一般に "ディスクは低速" と考えられているため、永続的構造が競争力のあるパフォーマンスを実現できるということに疑問が持たれています。実際には、ディスクは使用方法により人々が期待するよりも遅くも速くもなり、適切に設計されたディスク構造はしばしばネットワークより速くなります。
ディスクパフォーマンスの主要な要素として、ハードドライブのスループットがありますが、これは最近の 10 年間でディスクシークのレイテンシとは無関係になってきています。そのため、7200 rpm の SATA ディスクを 6 台使用する RAID-5 アレイの JBOD 構成の場合、リニア書き込みのパフォーマンスは約 600 MB/秒ですが、ランダム書き込みのパフォーマンスはわずか 100 KB/秒であり、6000 倍もの差があります。このようなリニアでの読み込みと書き込みは、あらゆる使用パターンの中で最も予想可能であり、オペレーティングシステムにより高度に最適化されています。最近のオペレーティングシステムでは、先行読み取りと遅延書き込みの技法がサポートされています。これは、複数の大きなブロックでデータをプリフェッチし、また小さな論理書き込みを大きな物理書き込みにグループ化します。この問題に関する詳細な議論については、ACM Queue の記事 を参照してください。実際、ACM Queue では、 シーケンシャルディスクアクセスがランダムメモリーアクセスよりも速い場合があることを示しています。
最近のオペレーティングシステムは、このようなパフォーマンスのばらつきをなくすために、ディスクのキャッシュとしてメインメモリーを積極的に使用するようになっています。最新の OS では、すべての空きメモリーを積極的にディスクキャッシュに流用するため、メモリーが再要求されたときに、ほとんどパフォーマンスペナルティがありません。ディスクのすべての読み込みと書き込みは、この単一キャッシュを介して行われます。ダイレクト I/O を使用せずにこの機能を無効にするのは簡単ではないため、プロセスがデータをプロセス内のキャッシュに保持している場合でも、そのデータが OS のページキャッシュに複製されていることが多く、すべてのデータが実質 2 回保管されることになります。
さらに、システムは JVM 上に構築されていますが、Java メモリーを長期間使用してきたユーザーは、以下の 2 つのことを認識しています。
- オブジェクトのメモリーのオーバーヘッドは非常に高く、多くの場合、保管されるデータのサイズは 2 倍(またはそれ以上)になる。
- Java のガベージコレクション処理の負担が増大しており、ヒープ内のデータが増えるにつれて遅くなっている。
以上の要素から、ファイルシステムとページキャッシュの活用は、メモリー内キャッシュやその他の構造を維持するよりも優れています。少なくとも、すべての空きメモリーに自動でアクセスすれば使用可能なキャッシュは倍増し、また個々のオブジェクトの代わりにコンパクトなバイト構造を保管すればさらに倍増する可能性があります。これにより、ガベージコレクションによるペナルティがなくなり、32 GB のマシンのキャッシュが 28 ~ 30 GB になります。さらに、プロセス内キャッシュの場合、サービスを再起動すると、キャッシュをメモリー内に再作成するか(10 GB キャッシュの場合 10 分かかる可能性があります)、完全なコールドキャッシュから使用を開始する必要がある(これは初期パフォーマンスがきわめて低いことを意味します)のに対し、このキャッシュは維持されます。また現在は、キャッシュとファイルシステム間のコヒーレンシを維持するためのすべてのロジックが OS にあるため、コードが非常に簡単になります。このことから、上記の方法は、プロセス内で 1 回限り試行するよりも効果的かつ適切になってきています。ディスクがリニア読み出しを多用する場合には、先行読み取りを行えば、ディスクからの各読み出しのデータがこのキャッシュに効果的に入ることになります。
このことは、メモリー内にできるだけ多くのデータを維持し、空きがなくなってパニック状態になったときにすべてをファイルシステムにフラッシュするのではなく、非常にシンプルな設計になることを示唆しています。すべてのデータはファイルシステムにある永続的ログに即座に書き込まれます。つまり、ディスクへのフラッシュ処理は必ずしも必要ありません。実際、これはカーネルのページキャッシュに送られるというだけのことです。
このようなページキャッシュ中心の設計スタイルは、Varnish の設計に関するこの 記事 で(かなりの確信を持った語り口で)説明されています。
一定時間で十分¶
メッセージングシステムで使用される永続的データ構造は、コンシューマー単位のキューであることが多く、関連付けられた BTree またはその他の汎用ランダムアクセスデータ構造を使用して、メッセージに関するメタデータを保持します。BTree は利用できる中では最も柔軟性の高いデータ構造であり、メッセージングシステムにおいてさまざまなトランザクションまたは非トランザクションセマンティクスをサポートすることができます。これらの処理はかなりの高コストですが、BTree の処理時間は O(log N) になります。通常、O(log N) は実質的に一定時間であると見なされますが、ディスク処理に関してはこれは当てはまりません。ディスクの 1 回のシークには 10 ミリ秒かかり、各ディスクは 1 度に 1 シークしか行えないため、並列処理には限界があります。したがって、ディスクの数回のシークでもかなりのオーバーヘッドが生じます。ストレージシステムでは、非常に高速なキャッシュ処理と非常に低速な物理ディスク処理を組み合わせて使用するため、ツリー構造の観測されるパフォーマンスは、固定キャッシュを使用するデータの増加比率を超えて増加する場合がほとんどです(たとえば、データ量が 2 倍になると、処理時間は 2 倍以上になります)。
直感的には、ロギングソリューションでよくあるように、永続的キューは単純読み出しとファイルへの追加をベースに構築できます。このような構造は、すべての処理が O(1) であり、読み出しにより書き込みがブロックされたり、読み取りが相互にブロックされたりしない場合に有利です。パフォーマンスがデータサイズに完全に無関係であるため、明らかにパフォーマンスが優れています。今では、1 TB 以上の低コストで低回転速度の SATA ディスクが複数台、1 台のサーバーで有効に利用できるようになっています。これらのディスクのシークパフォーマンスは貧弱ですが、大量の読み出しおよび書き込みでは十分なパフォーマンスを発揮し、1/3 の価格で 3 倍の容量が得られます。
パフォーマンスのペナルティがない事実上無制限のディスク空間にアクセスできれば、通常のメッセージングシステムでは備えていないいくつかの機能を Kafka で提供できます。たとえば、Kafka では、メッセージが消費されたらすぐに削除するのではなく、比較的長い期間(たとえば 1 週間)、Kafka で保持することができます。これは、これから説明するように、コンシューマーに多くの柔軟性をもたらします。
効率¶
Kafka は効率の向上に多くの努力を重ねてきました。主なユースケースの 1 つにウェブアクティビティデータの処理があります。このようなデータは膨大であり、ページビューごとに多くの書き込みが発生します。さらに、パブリッシュされた各メッセージは 1 個以上(たいてい多数)のコンシューマーにより読み出されると考えられるため、Kafka では、できるだけ低コストで消費できるように努力しています。
また、Kafka の設計者は、類似した多くのシステムを構築し稼働させてきた経験から、効率はマルチテナント処理におけるキーであることにも気づきました。アプリケーションによる使用時のわずかな競合により、下流のインフラストラクチャサービスでボトルネックが発生しやすい場合、このようなわずかな変更でも問題が発生します。高速化することで、Kafka では、インフラストラクチャより前の段階でのアプリケーションによる負荷を確実に軽減します。これは、使用パターンが日々変化する中で、一元的管理のクラスターで数十から数百のアプリケーションをサポートする一元的管理サービスを実行しようとする場合に特に重要です。
前のセクションでは、ディスクの効率について説明しました。この種のシステムでは、非効率なディスクアクセスパターンが排除されても、過剰な小規模 I/O 処理と過度なバイトコピーという 2 つの効率の問題が一般にあります。
小規模 I/O の問題は、クライアントとサーバー間、およびサーバー自体の永続的操作の両方で発生します。
当社はこれを回避するために、始めから複数メッセージをグループ化する "メッセージセット" 抽象化を中心としたプロトコルを構築しました。この場合、ネットワークリクエストにより 1 度に 1 つのメッセージが送信されるのではなく、複数メッセージがグループ化されるため、ネットワークラウンドトリップのオーバーヘッドが削減されます。さらに、サーバーにより複数メッセージのチャンクが 1 回でログに追加され、コンシューマーは 1 度に大きなリニアチャンクをフェッチします。
このようなシンプルな最適化により速度が数桁向上します。バッチ処理によりネットワークパケットは大きくなり、シーケンシャルディスク処理サイズや連続メモリーブロック量などが大きくなりますが、これらすべてを利用して、Kafka はランダムなメッセージ書き込みのバーストストリームをコンシューマーに送信するリニアな書き込みに変換します。
もう 1 つの非効率はバイトコピーにあります。メッセージレートが低い場合は問題になりませんが、負荷がかかると大きな影響が生じます。この問題を回避するために、プロデューサー、ブローカー、およびコンシューマーで共有される標準化されたバイナリメッセージフォーマットを採用しています(そのため、これらの間ではデータチャンクは変更なしに転送可能です)。
ブローカーが保持するメッセージログは、それ自体がファイルのディレクトリであり、それぞれに一連のメッセージセットが格納されています。このメッセージセットは、プロデューサーとコンシューマーで使用されるのと同じフォーマットでディスクに書き込まれています。共通フォーマットを維持することにより、最も重要な操作である永続的ログチャンクのネットワーク転送が最適化されます。近年の UNIX オペレーティングシステムでは、ページキャッシュからソケットへのデータ転送用に、高度に最適化されたコードパスが用意されています。Linux では、これは sendfile システムコール により提供されます。
sendfile の効果を理解するには、ファイルからソケットへのデータ転送の一般的なデータパスを把握する必要があります。
- オペレーティングシステムは、データをディスクからカーネル空間のページキャッシュへと読み込みます。
- アプリケーションは、データをカーネル空間からユーザー空間のバッファへと読み込みます。
- アプリケーションは、カーネル空間のソケットバッファにデータを書き戻します。
- オペレーティングシステムは、データをソケットバッファから NIC バッファにコピーします。データはネットワーク経由で送信されます。
4 回のコピーと 2 回のシステムコールが実行されており、これは明らかに非効率です。sendfile を使用すれば、OS はデータをページキャッシュからネットワークに直接送信できるため、複数回のコピーが回避できます。したがって、この最適化されたパスでは、NIC バッファへの最終コピーのみが必要になります。
一般的なユースケースでは、1 つのトピックに複数のコンシューマーがあります。上記のゼロコピー最適化を使用すれば、データはページキャッシュに 1 回だけコピーされ、各消費で再使用されます。データが読み出されるたびにメモリーに格納されたり、ユーザー空間からコピーされたりすることはありません。これにより、メッセージはネットワーク接続の限界に近いレートで消費できるようになります。
このようにページキャッシュと sendfile を併用すると、コンシューマーの多くが遅延なく処理できる Kafka クラスターでは、データが完全にキャッシュから提供されるため、ディスクの読み出し動作はまったく発生しません。
Java における sendfile とゼロコピーのサポートの背景について詳しくは、この 記事 を参照してください。
エンドツーエンドでのバッチ圧縮¶
ボトルネックが CPU やディスクではなくネットワーク帯域幅である場合があります。具体的には、広域ネットワークを介してデータセンター間でメッセージを送信する必要があるデータパイプラインで発生します。もちろん、Kafka からのサポートがなくても、ユーザーはいつでも一度に 1 つのメッセージを圧縮できますが、冗長性の多くが同じ種類のメッセージの繰り返しにより発生するため(たとえば、JSON のフィールド名、ウェブログのユーザーエージェント、共通文字列値)、非常に低い圧縮率しか得られない可能性があります。効率的に圧縮するには、各メッセージを個別に圧縮するのではなく、複数のメッセージを一緒に圧縮する必要があります。
Kafka では、効率的なバッチフォーマットによりこれをサポートします。メッセージのバッチが 1 つに圧縮され、この形式でサーバーに送信できます。このメッセージバッチは圧縮された形式でログに書き込まれ、圧縮されたまま保管されます。展開されるのはコンシューマーにおいてだけです。
Kafka では、圧縮プロトコルとして GZIP、Snappy、LZ4、ZStandard をサポートします。圧縮について詳しくは、ここ を参照してください。
プロデューサー¶
負荷分散¶
プロデューサーは、ルーティング階層を経由せずに、パーティションのリーダーであるブローカーにデータを直接送信します。プロデューサーによる送信を支援するために、すべての Kafka ノードは、サーバーが動作しているか、および指定した時間にトピックのパーティションのリーダーがどこにあるかを示すメタデータのリクエストに応答することができます。これによりプロデューサーはリクエストを適切な宛先に送信できます。
このクライアントは、メッセージのパブリッシュ先パーティションを制御します。この選択はランダム、つまり一種のランダム負荷分散で実行できます。または、セマンティクスパーティショニング機能で実行することもできます。セマンティクスパーティショニング用のインターフェイスは公開されているので、ユーザーはパーティションに対するキーを指定して、そのキーのハッシュでパーティションを選択できます(必要に応じてパーティション機能をオーバーライドするオプションも利用できます)。たとえば、キーにユーザー ID を選択すると、指定したユーザーのすべてのデータが同じパーティションに送信されます。これにより、コンシューマーの側で一定の仮定に基づいて消費することができます。このパーティショニングスタイルは、それぞれのコンシューマーに応じた反応処理が行えるように明示的に設計されています。
非同期送信¶
バッチ処理は効率を大きく向上させるものです。そこでバッチを有効にするために、Kafka プロデューサーはメモリー内でデータを集積し、1 回のリクエストで大きなバッチを送信するように試みます。バッチ処理では、一定サイズ以上にメッセージ(64KB など)を集積せず、一定レイテンシ以上(10 ミリ秒など)は待たないように構成できます。これにより、より多くのバイト数を集積して送信することも、またサーバーでの大規模 I/O 処理を減らすこともできます。このバッファ処理は構成可能であり、レイテンシのわずかな増加と引き換えにスループットを向上させるメカニズムになっています。
コンシューマー¶
Kafka コンシューマーは、消費するパーティションのリーダーであるブローカーに "フェッチ" リクエストを発行することで動作します。コンシューマーは、各リクエストでログのオフセットを指定し、その位置から始まるログのチャンクを受け取ります。したがって、この位置はコンシューマーが主に制御しており、必要に応じて位置を巻き戻してデータを再消費することができます。
プッシュ型対プル型¶
検討された最初の疑問は、コンシューマーがデータをブローカーからプルすべきか、それともブローカーがデータをコンシューマーにプッシュするべきかということでした。この点において Kafka は、ほとんどのメッセージングシステムと同じ、より伝統的な設計に従っています。つまり、データはプロデューサーからブローカーにプッシュされ、コンシューマーによりブローカーからプルされます。Scribe や Apache Flume といった一部のロギング中心のシステムは、まったく異なるプッシュベースのパスに従っています。この方法では、データは下流にプッシュされます。これらのアプローチにはそれぞれ長所と短所があります。プッシュベースシステムでは、データの転送レートをブローカーが制御するため、多様なコンシューマーを扱うのは困難です。一般に目標になるのは、コンシューマーが可能な最大レートで消費できるようにすることです。ただし不幸にもプッシュ型システムでは、消費レートが生成レートに追いつかない場合に、コンシューマーが対応できなくなることにつながります(事実上のサービス妨害(DoS)攻撃)。プルベースシステムが優れているのは、コンシューマーが単純に対応を遅くしたり、可能な時点でデータを受け取ったりできるという点です。プッシュ型のこの短所は、コンシューマーが対応できないことを通知できるある種のバックオフプロトコルを使用することで軽減できます。ただし、コンシューマーを最大限利用するように(ただしその限度を超えないように)転送レートを制御するのは、想像以上に困難です。このようにシステムの構築をいろいろ試した結果として、より伝統的なプルモデルを採用しました。
プルベースシステムの他の利点として、コンシューマーに送信するデータのバッチ処理を大胆に採用できることが挙げられます。プッシュベースシステムでは、下流のコンシューマーがデータをすぐに処理できるかどうかが分からない状態で、リクエストを直ちに送信するか、それともデータを集積して後で送信するかを選択する必要があります。レイテンシが低くなるように調整すると、転送で 1 度に 1 つのメッセージしか送信されなくなり、いずれにせよこれはバッファに入るため、無駄が多くなります。プルベースの設計では、ログの現在の位置以降で使用できるすべてのメッセージ(または構成可能な最大サイズのメッセージ)をコンシューマーが常にプルするため、このようなことはありません。したがって、不要なレイテンシを招くことなくバッチ処理を最適化できます。
単純なプルベースシステムの短所は、ブローカーにデータがない場合にコンシューマーが頻繁にポーリングを実行し、実質的にデータ到着のビジーウェイトになることです。これを回避するために、"ロングポーリング" の待機時に、データが到着するまでコンシューマーのリクエストをブロックできるパラメーターをプルリクエストに用意しました(オプションで、転送サイズを大きくするために、指定したバイト数が処理できるようになるまで待つように指定することも可能です)。
採用可能な他の設計として、エンドツーエンドでプルのみを行う方法も考えられます。プロデューサーはデータをローカルのログに書き込みます。ブローカーはそこからデータをプルし、コンシューマーはブローカーからデータをプルします。同様な形式として、"ストアアンドフォワード" プロデューサーがよく提案されています。これは興味深い提案ですが、Kafka チームがターゲットとするような、何千ものプロデューサーを使用するユースケースにはあまり適切ではないと考えています。永続的データシステムを大規模に実行してきた経験から、多数のアプリケーション間で数千のディスクを使用するシステムは、実際には信頼性が向上せず、かつ運用が困難であると考えています。また、Kafka の設計者は、永続的なプロデューサーがなくても、厳しい SLA の大規模なパイプラインが実行可能であることを見出しています。
コンシューマーの位置¶
思いがけないことですが、"何" が消費されるかの追跡もまた、メッセージングシステムのキーとなるパフォーマンスポイントの 1 つです。
ほとんどのメッセージングシステムは、どのメッセージが消費されたかを示すメタデータをブローカーで保持しています。つまり、メッセージがコンシューマーに渡されると、ブローカーはそのことをすぐにローカルで記録するか、コンシューマーから確認応答があるまで待ってから記録します。このような処理が選択されるのは直感的な理由です。実際のところ、単一マシンのサーバーの場合、これ以外の方法があるかどうかは不明です。多くのメッセージングシステムのストレージで使用されるデータ構造は十分にスケーリングできないため、これが現実的な理由による選択でもあります。消費されているものをブローカーが把握すれば、それをすぐに削除して、データサイズを小さく保つことができます。
何が消費されたかという認識をブローカーとコンシューマーに共有させることが些細な問題ではないということは、理解しづらいと思います。ブローカーがネットワーク経由でメッセージを送信後、すぐにそれを 消費済み として記録すると、コンシューマーが(クラッシュやリクエストのタイムアウトなどにより)メッセージの処理に失敗した場合に、そのメッセージは失われてしまいます。この問題を解決するために、多くのメッセージングシステムでは確認応答機能を採用しています。この方法では、メッセージが送信された時点では、消費済み ではなく単に 送信済み として記録されます。ブローカーはコンシューマーから対応する確認応答を受けてから、メッセージを 消費済み として記録します。この方法によりメッセージが失われる問題は解決されますが、新しい問題が発生します。第 1 に、コンシューマーがメッセージを処理したものの、確認応答を送信する前に障害が発生した場合、メッセージが 2 回消費されます。第 2 の問題として、パフォーマンスがあります。この場合、ブローカーは各メッセージについて複数のステートを保持する必要があります(2 回目に送信されないようにまずロックし、その後、削除できるように消費済みであるとマークするためです)。送信されたにもかかわらず確認応答が返らないメッセージをどう扱うかといったやっかいな問題にも対処する必要があります。
Kafka では、異なる方法を採用しています。トピックは、完全に順序付けされたパーティションのセットへと分割されます。各パーティションは常に、サブスクライブしている各コンシューマーグループ内の厳密に 1 つのコンシューマーで消費されます。これは、各パーティションでのコンシューマーの位置は、消費する次のメッセージのオフセットという単なる単精度整数となることを意味します。これにより、何が消費済みであるかというステートは、パーティションごとに 1 つの数字で表され、非常に小さなものになります。このステートは定期的にチェックすることができます。つまり、メッセージの確認応答と同等な処理が非常に低コストで実現できます。
この方法には別の利点があります。コンシューマーは故意に古いオフセットへと ”巻き戻して”、データを再度消費することができます。これは一般的なキュー処理の作法に違反していますが、多くのコンシューマーにとっては必須の機能であることが分かっています。たとえば、コンシューマーが受信したコードにバグが存在し、いくつかのメッセージが消費された後にそれが発見された場合、そのバグが修正された後に、コンシューマーはメッセージを再度消費することができます。
オフラインデータ負荷¶
スケーラブルな永続化では、Hadoop やリレーショナルデータウェアハウスなどのオフラインシステムにバルクデータを定期的に渡すバッチデータ負荷といった、定期的にしか消費しないコンシューマーがいる可能性が考慮されています。
Hadoop の場合、ノード、トピック、またはパーティションを組み合わせた個々のマップタスクに負荷を分割することにより、負荷を完全に並列処理しています。Hadoop はタスク管理を行います。失敗したタスクは、単に元の位置から再起動することで、データ重複の危険性なしに再起動できます。
静的メンバーシップ¶
静的メンバーシップは、グループバランス調整プロトコルをベースに構築された、ストリームアプリケーション、コンシューマーグループ、およびその他のアプリケーションの可用性を改善することを目的としています。バランス調整プロトコルでは、グループコーディネーターによりエンティティ ID がグループメンバーに割り当てられます。生成されるのは一時的な ID であり、メンバーの再起動や再参加の時に変わります。コンシューマーベースのアプリケーションの場合、この "動的メンバーシップ" では、コードのデプロイ、構成のアップデート、定期的な再起動といった管理操作中に、種々のインスタンスへのタスクの再割り当てが大きな割合で発生します。ステートを管理する大規模アプリケーションの場合、多様なタスクが処理前のそれぞれのステートに戻るのに時間がかかるため、アプリケーションは部分的または全体的に使用できなくなります。以上の理由により、Kafka のグループ管理プロトコルでは、グループメンバーが永続的エンティティ ID を指定できます。この ID をベースにしたグループのメンバーシップは変更されずに保持されるため、バランス調整がトリガーされることはありません。
静的メンバーシップを使用する場合には、以下を実行します。
- ブローカークラスターとクライアントアプリケーションの両方を 2.3 以上にアップグレードします。また、アップグレードしたブローカーが同様に 2.3 以上の
inter.broker.protocol.versionを使用していることを確認します。 - 同一グループ内の各コンシューマーインスタンスに対して、
ConsumerConfig#GROUP_INSTANCE_ID_CONFIG構成に一意の値を設定します。 - Kafka Streams アプリケーションの場合は、インスタンスで使用されるスレッドの数とは無関係に、各 KafkaStreams インスタンスに一意の
ConsumerConfig#GROUP_INSTANCE_ID_CONFIGを設定すれば十分です。
ブローカーが 2.3 より古いバージョンであるにもかかわらず、クライアント側の ConsumerConfig#GROUP_INSTANCE_ID_CONFIG を設定すると、アプリケーションがブローカーのバージョンを検知して、UnsupportedException をスローします。誤って別のインスタンスに同じ ID を構成した場合、ブローカー側のフェンシングメカニズムにより重複したクライアントが通知され、org.apache.kafka.common.errors.FencedInstanceIdException のトリガーにより直ちにシャットダウンされます。
詳細については、ブログの投稿「Apache Kafka Rebalance Protocol for the Cloud: Static Membership」と KIP-345 を参照してください。
メッセージデリバリーセマンティクス¶
プロデューサーとコンシューマーの動作について少し理解していただいたところで、Kafka がプロデューサーとコンシューマー間で提供するセマンティクスの保証について説明します。メッセージデリバリーの保証には、複数の方法があります。
- "最大 1 回" - 再送されることはありません。メッセージが失われることがあります。
- "最低 1 回" - 再送されることがあります。メッセージが失われることはありません。
- "厳密に 1 回" - 各メッセージは 1 回のみ送信されます(これは多くのユーザーが実際に期待する動作です)。
注目すべきなのは、これは 2 つの問題に分割できるということです。メッセージ配信の耐久性の保証と、メッセージの消費時の保証です。
多くのシステムは、"厳密に 1 回" のデリバリーセマンティクスを提供していると主張していますが、記載事項をよく読むと、このような主張のほとんどには語弊があります(つまり、コンシューマーまたはプロデューサーで障害が発生する場合、複数のコンシューマープロセスが存在する場合、ディスクに書き込まれたデータが失われる場合の説明はありません)。
Kafka のセマンティクスは明快です。メッセージのパブリッシュ時に、メッセージがログに "コミットされる" と考えました。パブリッシュされたメッセージがいったんコミットされてしまえば、このメッセージが書き込まれたパーティションを複製するブローカーが 1 つでも "動作している" 限り、メッセージが失われることはありません。コミットされたメッセージと動作しているパーティションの定義、および処理対象の障害の種類については、次のセクションで詳細に説明します。ここでは、データを失わない完璧なブローカーを仮定して、プロデューサーとコンシューマーへの保証について説明します。プロデューサーがメッセージをパブリッシュしようとしてネットワークエラーが発生した場合に、エラーが発生したのがメッセージがコミットされる前か後なのかが明確でないことがあります。これは、自動生成キーを使用してデータベーステーブルに追加する場合のセマンティクスに似ています。
0.11.0.0 より前では、メッセージがコミットされたことを示す応答をプロデューサーが受け取れなかった場合、メッセージを再送する以外に選択肢はほとんどありませんでした。この方法では、最低 1 回のデリバリーセマンティクスになります。元のリクエストが実際には成功している場合に、再送信時にメッセージがログに再度書き込まれる可能性があるためです。0.11.0.0 以降では、Kafka プロデューサーはべき等デリバリーオプションもサポートしています。これは、再送信によりログに重複エントリが発生しないことを保証します。これを達成するため、ブローカーは各プロデューサーに ID を割り当て、プロデューサーにより各メッセージと一緒に送信されるシーケンス番号を使用してメッセージの重複を排除します。0.11.0.0 以降ではさらに、プロデューサーは、トランザクションに似たセマンティクスを使用して複数のトピックのパーティションにメッセージを送信する機能をサポートします。この場合、すべてのメッセージが正常に書き込まれるか、まったく書き込まれないかのいずれかになります。主なユースケースには、Kafka のトピック間での厳密に 1 回の処理があります(後で説明します)。
すべてのユースケースでこのような強い保証が必要なわけではありません。レイテンシが問題となるケースでは、Kafka は、必要な耐久性レベルをプロデューサーで指定できるようになっています。メッセージがコミットされるまでプロデューサーが待機することを指定した場合には、10 ミリ秒単位の時間がかかる可能性があります。ただしプロデューサーは、完全に非同期で送信を実行するか、リーダーにメッセージが到着するまで(フォロワーにはなくてもよい)待機することを指定することもできます。
ここからは、コンシューマーから見たセマンティクスについて説明します。すべてのレプリカには、オフセットが一致した正確に同じログがあります。コンシューマーはこのログ内の位置を制御します。コンシューマーが決してクラッシュしない場合は、この位置を単純にメモリーに格納できます。ただし、コンシューマーで障害が発生し、このトピックのパーティションを別のプロセスで引き続き処理させる場合、新しいプロセスでは処理を開始する適切な位置を判断する必要があります。コンシューマーがいくつかのメッセージを読み取る場合を考えると、メッセージの処理方法とその位置のアップデート方法にはいくつかの選択肢があります。
- メッセージを読み取ると、その位置をログに保管し、最後にメッセージを処理する。この場合、位置を保存したが、メッセージの処理による出力を保存する前に、コンシューマーのプロセスがクラッシュする可能性があります。この状況では、保存された位置よりも前のメッセージが処理されていない場合でも、処理を引き継いだプロセスは保存された位置から処理を開始します。これは、コンシューマーが失敗した場合にメッセージが処理されない可能性があるため、"最大 1 回" のセマンティクスに相当します。
- メッセージを読み取ると、メッセージを処理し、最後にその位置を保存する。この場合、メッセージを処理したが、その位置が保存される前に、コンシューマーのプロセスがクラッシュする可能性があります。この場合、新しいプロセスが引き継ぐときに受け取る最初の数件のメッセージは、既に処理されていることになります。これは、コンシューマーが失敗した場合には、"最低 1 回" のセマンティクスに相当します。多くの場合、メッセージにはプライマリキーがあるため、アップデートはべき等です(同じメッセージを 2 回受け取っても、レコードが上書きされるだけです)。
では、"厳密に 1 回" のセマンティクス(実際に望まれているもの)ではどうでしょうか。Kafka Streams の概要 アプリケーションなどで、Kafka のトピックから消費したり、別のトピックへと生成したりする場合には、前述した 0.11.0.0 の新しいトランザクションプロデューサー機能を利用できます。コンシューマーの位置はトピックにメッセージとして保管されるため、処理したデータを受け取る出力トピックと同じトランザクションでこのオフセットを Kafka に書き込むことができます。トランザクションが中断された場合、コンシューマーの位置は古い値に戻り、出力トピックにある生成データは、"分離レベル" に応じて他のコンシューマーからは見えなくなります。デフォルトの "read_uncommitted" 分離レベルでは、中断されたトランザクションのメッセージを含むすべてのメッセージがコンシューマーから見えます。一方、"read_committed" の場合には、コミット済みのトランザクションからのメッセージ(とトランザクションの一部ではないすべてのメッセージ)をコンシューマーは返すだけです。
外部のシステムに書き込む場合の制限として、コンシューマーの位置を、出力として実際に保管された位置に合わせる必要があります。これを達成するために、古い方法では、コンシューマー位置のストレージとコンシューマー出力のストレージ間で 2 相コミットを導入していました。ただし、コンシューマーが出力と同じ場所にオフセットを保管すれば、処理がより簡単かつ一般的になる可能性があります。コンシューマーが書き込む出力システムの多くは 2 相コミットをサポートしていないため、こちらの方が適切です。読み取ったデータのオフセットをデータとともに HDFS に書き込む Kafka Connect コネクターはこの一例と考えられます。この場合、データとオフセットは両方ともアップデートされるか、両方ともアップデートされないかのどちらかになることが保証されます。このように強力なセマンティクスが求められ、重複排除に使用できるプライマリキーがメッセージにない、他の多くのデータシステムで使われている同様のパターンを採用しています。
したがって、Kafka は、厳密に 1 回のデリバリーを Kafka Streams の概要 で効果的にサポートします。Kafka のトピック間でデータを転送および処理する場合に厳密に 1 回のデリバリーを提供するには、一般にトランザクションのプロデューサーとコンシューマーを使用します。送信先が他のシステムの場合に、厳密に 1 回のデリバリーを行うには、一般に他のシステムとの連携が必要ですが、Kafka ではオフセットを提供することにより、これを実装可能としています(Kafka Connect も参照)。連携しない場合、Kafka はデフォルトで最低 1 回のデリバリーを保証します。ユーザーは、プロデューサーの再試行を無効にし、メッセージのバッチを処理する前にコンシューマーでオフセットをコミットすることで、最大 1 回のデリバリーを実装できます。
レプリケーション¶
Kafka では、構成可能な数のサーバー間で各トピックのパーティションのログを複製します(このレプリケーション係数はトピック単位で設定可能です)。これにより、クラスターのサーバーで障害が発生しても、これらのレプリカに対する自動フェイルオーバーが可能になるため、障害があってもメッセージが使用できます。
他のメッセージングシステムではいくつかのレプリケーション関連機能が提供されていますが、これらは追加機能であり、それほど頻繁には使用されていないと考えています(個人的見解です)。また、レプリカが使用できない、スループットに大きな影響がある、細かな手動の構成が必要であるなど、大きな問題があります。Kafka はデフォルトで、レプリケーションを利用するように設計されています。実際、複製がないトピックを、レプリケーション係数が 1 の複製されたトピックとして実装しています。
レプリケーションの単位はトピックのパーティションです。障害がない状態では、Kafka の各パーティションには 1 つのリーダーと 0 以上のフォロワーがあります。リーダーを含むレプリカの総数がレプリケーション係数になります。すべての読み出しと書き込みはパーティションのリーダーに送られます。一般に、パーティションはブローカーよりも多く、リーダーはブローカーに均一に配分されます。フォロワーのログはリーダーのログと同じです。すべてに同じオフセットと同じメッセージが同じ順番で入っています(もちろん、リーダーのログの最後に未複製のメッセージが存在している可能性は常にあります)。
通常の Kafka コンシューマーと同様に、フォロワーはリーダーからメッセージを消費し、そのメッセージを自身のログに追加します。フォロワーにリーダーからプルさせれば、自身のログに適用する複数のログエントリをフォロワーが一緒にバッチ処理するのに好都合です。
ほとんどの分散システムと同様、障害に自動で対応するには、ノードが "動作している" とはどういう意味かを正確に定義する必要があります。Kafka ノードの場合、動作しているという状態には 2 つの状態があります。
- ノードが ZooKeeper を使用して(ZooKeeper のハートビートメカニズムを介して)セッションを維持できる。
- ノードがフォロワーである場合、リーダーでの書き込みを "過度に" 遅れずに複製できる。
これら 2 つの状態を満足するノードを "同期状態" であると表現し、"動作している" または "障害が発生している" という言葉のあいまいさをなくしています。リーダーは、"同期状態にある" 一群のノードを継続的に監視しています。フォロワーが動作不能、スタック状態、または処理の遅れがある場合、リーダーは同期レプリカ(ISR)のリストからそのフォロワーを削除します。スタックした、または遅延したレプリカの判定は、replica.lag.time.max.ms 構成で制御されます。
分散システムの用語で表現すれば、ノードが突然動作を終了し、その後に復元するという、障害の "失敗と復元" モデルの処理を試みるだけです(おそらくノードが動作不能になったことの通知はありません)。バグまたは不正行為によりノードが不定または不正な応答を生成するような、いわゆる "ビザンチン" 障害は、Kafka では対応されません。
以上から、そのパーティションのすべての同期レプリカでメッセージがそれぞれのログに追加された場合に、メッセージがコミットされたと見なすことで、コミットをより厳密に定義できます。コミットされたメッセージのみが常にコンシューマーに渡されます。つまり、リーダーで障害が発生した場合に失われる可能性のあるメッセージがコンシューマーで見えてしまうことがありません。他方、プロデューサーには、レイテンシと耐久性のトレードオフに対する優先順位に応じて、メッセージがコミットされるのを待機するかしないかのオプションがあります。この優先順位は、プロデューサーが使用する確認応答設定で制御されます。トピックには同期レプリカの "最少数" の設定があり、メッセージがすべての同期レプリカに書き込まれたという確認応答をプロデューサーがリクエストする際にこれがチェックされます。厳格ではない確認応答がプロデューサーからリクエストされた場合には、同期レプリカの数が最小数にとどかない(たとえば、リーダーのみの)場合でも、メッセージはコミットされ、消費されることができます。
Kafka が提供する保証は、動作している同期レプリカが少なくとも 1 つ存在すればその間、コミットされたメッセージは失われないということです。
Kafka は、ノードの障害があっても、短期のフェイルオーバー期間を経て動作を継続できますが、ネットワークパーティションが存在する場合は、動作を継続できない場合があります。
複製ログ: Quorum、ISR、およびステートマシン¶
Kafka のパーティションの本質は複製ログです。複製ログは、分散データシステムにおいて最も基本的な要素の 1 つであり、その実装には多くの方法があります。ステートマシンスタイル の分散システムを実装する基本的な要素として、複製ログは他のシステムで使用されています。
複製ログでは、一連の値(一般にはログエントリの番号 0、1、2、など)でどれが先なのかの合意を形成するプロセスをモデル化します。これには多くの実装方法がありますが、最も単純で高速なのは、対象の値の順番をリーダーが選択する方法です。リーダーが動作している限り、すべてのフォロワーは、リーダーが選択した値と順番をコピーするだけで済みます。
もちろん、リーダーで障害が発生しなければ、フォロワーは必要ありません。リーダーが動作しなくなったときには、フォロワーから新しいリーダーを選択する必要があります。ただし、フォロワー自体も遅延またはクラッシュする可能性があるため、最適なフォロワーが確実に選択されるようにする必要があります。ログレプリケーションアルゴリズムでは、メッセージがコミットされていることがクライアントに通知された後に、リーダーに障害が発生した場合に、選出する新しいリーダーにもそのメッセージが存在することを基本的に保証する必要があります。これにはトレードオフがあります。メッセージがコミットされたと宣言されるまでに、リーダーにメッセージの確認応答を返したフォロワーが多ければ多いほど、リーダーとして選択できる対象も多くなります。
リーダーを選択するために比較が必要な必須確認応答数とログ数を、必ず対象に重複があるように選択する場合、これは Quorum と呼ばれます。
このトレードオフによく用いられるアプローチは、コミットの決定とリーダーの選出の両方に過半数を使用することです。Kafka はこのアプローチを採用していませんが、トレードオフについて理解するために、この方法について説明します。ここに 2f+1 個のレプリカがあるとします。メッセージがコミットされたことがリーダーにより宣言される前に、f+1 個のレプリカがそのメッセージを受け取っていて、少なくとも f+1 個のレプリカから完全に近いログがあるフォロワーを選択することで新しいリーダーを選んだ場合、障害が f 件未満であれば、コミットされたすべてのメッセージが新リーダーにあることが保証されます。f+1 個のレプリカには、コミットされたすべてのメッセージを含むレプリカが少なくとも 1 つ存在するためです。そのレプリカのログは完全に近いため、新しいリーダーとして選出されます。各アルゴリズムには他にも多くの処理が必要ですが(たとえば、ログが完全に近いものであることの厳密な定義、リーダーのエラー発生時やレプリカセットでのサーバーセットの変更時でのログの一貫性確保など)、ここでは割愛します。
過半数を利用するアプローチには、レイテンシが最速のサーバーのみで決まるという優れた利点があります。たとえば、レプリケーション係数が 3 の場合、レイテンシは最も遅いフォロワーではなく最も速いフォロワーで決まります。
ZooKeeper の Zab、Raft、Viewstamped Replication など、この方式の多様なアルゴリズムがあります。現在把握している学術文献で、実際に Kafka に実装されている方式に最も近いのは、Microsoft の PacificA です。
過半数方式の欠点として、多数のエラーが発生し、選出できるリーダーがなくなった場合に対処できないという点が挙げられます。1 つのエラーを許容するには、データのコピーが 3 つ必要です。2 つのエラーを許容するには、データのコピーが 5 つ必要です。経験では、1 つのエラーを許容するのに十分な冗長性だけでは、実稼働システムに対して不十分です。かといって、すべての書き込みを 5 回実行すると、必要なディスク空き容量が 5 倍、スループットが 1/5 になり、大容量データでの問題に対処するには余り現実的ではありません。このため、ZooKeeper などの共有クラスター構成では quorum アルゴリズムがよく採用されていますが、プライマリデータストレージでは余り採用されていません。HDFS の例では、NameNode の高可用性機能が 過半数ベースジャーナル 上に構築されています。ただし、これは高コストのアプローチであるため、データ自体には使用されていません。
Kafka では、quorum セットの選択にやや異なるアプローチを採用しています。Kafka では、過半数方式の代わりに、リーダーをフォローしている同期レプリカ(ISR)のセット(動的に変動)を保持します。このセットのメンバーのみがリーダーとして選ばれる資格があります。Kafka のパーティションへの書き込みは、"すべて" の同期レプリカが書き込みを受け取るまでコミットされたとは見なされません。この ISR セットは、いつ変更されようとも、ZooKeeper で維持されます。したがって、ISR 内のどのレプリカも、リーダーとして選ばれる資格があります。多数のパーティションが存在し、リーダーシップの確実なバランス調整が重要である Kafka の使用モデルにおいて、これは重要な要素です。このような ISR モデルと f+1 個のレプリカを組み合わせることで、Kafka のトピックはコミットされたメッセージを失わずに f 件の障害を許容できます。
ほとんどのユースケースがこのモデルで対応できると期待していますが、これによるトレードオフは考慮すべきと考えています。実際には、f 件の障害を許容するために、過半数アプローチと ISR アプローチの両方で同数のレプリカが確認応答を返すのを待ってから、メッセージをコミットします(たとえば、1 つの障害に耐えるには、過半数 quorum では 3 つのレプリカと 1 つの確認応答が必要であり、ISR アプローチでは、2 つのレプリカと 1 つの確認応答が必要です)。最も遅いサーバーが生じずにコミットできるのは、過半数アプローチの長所です。ただし、メッセージのコミットをブロックするかどうかをクライアントが選択できるようにすれば、これは改善されると考えています。必須のレプリケーション係数が小さくなれば、スループットとディスク容量が向上するため、これは行う価値があります。
その他の設計上の重要な相違点として、Kafka では、クラッシュしたノードのすべてのデータを無傷な状態に復元する必要はありません。この分野のレプリケーションアルゴリズムでは、一貫性を毀損する可能性がなく、どのような障害復元シナリオにおいても失われることのない "安定したストレージ" の存在に期待することは珍しくありません。このような前提には主に 2 つの問題があります。第 1 に、永続的データシステムの現実の処理では、ディスクエラーが最も多く見られる問題であり、これにより頻繁にデータが破壊されるということです。第 2 に、ディスクエラーの問題がないとしても、一貫性保証のために書き込むたびに fsync を使用すると、2 から 3 桁もパフォーマンスが低下するため、これは避けたいということです。レプリカを ISR に再登録できるようにしたプロトコルでは、そのレプリカがクラッシュしてフラッシュしていないデータが失われたとしても、完全に再同期されてから再登録されることが保証されます。
クリーンではないリーダーの選出: すべてが動作不能の場合の処理¶
Kafka では、少なくとも 1 つのレプリカが同期状態にあることにより、データが損失しないように保証されます。パーティションのレプリケーションを実行するすべてのノードが動作しなくなれば、この保証は維持できません。
ただし、実稼働システムでは、すべてのレプリカが動作しない場合でも、何らかの合理的な処理を行う必要があります。このようなことが不幸にも発生しうる場合は、実行できることを検討することが重要です。以下の 2 つの動作の実装が考えられます。
- ISR 内のレプリカが復帰するのを待ち、このレプリカをリーダーとして選択する(このレプリカがすべてのデータを保持していることを期待する)。
- 最初に復帰したレプリカをリーダーとして選択する(ISR のレプリカである必要はなし)。
これは、可用性と一貫性の間にシンプルなトレードオフがあります。ISR のレプリカを待機する方式では、レプリカがダウンしている間、システムを使用できません。そのレプリカが壊れた場合、またはそのデータが失われた場合、システムはダウンしたままです。一方、ISR ではないレプリカが復帰したときに、それをリーダーとして使用可能とすると、コミットされたすべてのメッセージが保持されていることが保証されないにもかかわらず、そのレプリカのログが正しいソースになります。バージョン 0.11.0.0 以降、デフォルトでは、Kafka は 1 番目の方法を選択し、一貫性のあるレプリカを待ちます。この動作は、稼働時間が一貫性よりも重要なユースケースをサポートするために、構成のプロパティ unclean.leader.election.enable を使用して変更できます。
このジレンマは Kafka に限ったことではありません。quorum ベースのすべてのスキームに存在します。たとえば、過半数スキームでは、過半数のサーバーで短期での復帰が困難な障害が発生した場合には、100% のデータをあきらめるのか、新たな正しいソースとなる既存サーバーの残留データを処理して一貫性を失うかのいずれかを選択する必要があります。
可用性の保証と耐久性の保証¶
Kafka に書き込む際、プロデューサーは、メッセージの確認応答を待つレプリカ数を 0、1、またはすべて(設定値: -1)の間で選択することができます。"すべてのレプリカからの確認応答" を待つ場合に、割り当てられたレプリカセットのすべてでメッセージが受信されたかどうかは保証されないことに注意する必要があります。デフォルトでは、acks=all の場合、その時点で同期レプリカのすべてが、メッセージの受信により即座に確認応答を返します。たとえば、トピックが 2 つのレプリカのみで構成されていて、1 つのレプリカで障害が発生した場合(つまり、同期レプリカが 1 つしか残っていない場合)、acks=all を指定した書き込みは成功します。ただし、残っているレプリカでも障害が発生すれば、書き込みは失われる可能性があります。これは、パーティションの可用性を最大限保証しますが、可用性よりも耐久性を優先する一部のユーザーでは、このような動作は望ましくありません。したがって、Kafka は、可用性よりもメッセージの耐久性を優先する場合に使用できるトピックレベルの構成を 2 つ用意しています。
- クリーンではないリーダーの選出を無効にする - すべてのレプリカが使用できなくなった場合には、最新のリーダーが再度使用できるようになるまでパーティションは使用できません。これは実質的に、メッセージが失われるというリスクよりも可用性の損失を選択しています。詳細については、前のセクションの「クリーンではないリーダーの選出」を参照してください。
- 最小 ISR 数を指定する - ISR が特定の最小数より大きい場合にのみ、パーティションは書き込みを受け入れます。これは、メッセージが 1 つのレプリカにしか書き込まれておらず、その後そのレプリカが使用できなくなった場合に、メッセージが失われるのを回避するためです。この設定は、プロデューサーが acks=all を使用しており、少なくとも複数の同期レプリカがメッセージに対して確認応答を返すことが保証されている場合にのみ有効です。この設定は、一貫性と可用性の間にトレードオフがあります。最小 ISR 数の設定を大きくすると、より多くのレプリカにメッセージが書き込まれることが保証され、メッセージが失われる可能性が減少するため、一貫性がより強固に保証されます。一方、同期レプリカの数が最小しきい値より少なくなると、パーティションに書き込めなくなるため、可用性は低くなります。
レプリカの管理¶
複製ログに関する以上の議論では、単一ログ(1 つのトピックのパーティション)のみを扱いました。しかし、Kafka クラスターは、数百、数千ものパーティションを管理します。少数のノードに大量のトピックが配分されるようにすべてのパーティションがクラスタリングされるのを避けるために、Kafka は、ラウンドロビン方式でクラスター内パーティションのバランス調整を試みています。同様に、Kafka では、リーダーシップも、各ノードがそのパーティションに比例した配分でリーダーになるようにバランス調整されます。
リーダーシップの選出プロセスは、可用性がないクリティカルな期間であるため、その最適化もまた重要です。リーダー選出の単純な実装では、ノードに障害が発生したときに、ノードがホストしていたすべてのパーティションで、パーティションごとに選択が実行されます。これに代わって採用したのは、ブローカーの 1 つを "コントローラー" として選出する方式です。このコントローラーはブローカーレベルでエラーを検出し、エラーが発生したブローカー内の影響あるすべてのパーティションのリーダーを変更する処理を担います。結果として、多くの必要なリーダーシップ変更通知がバッチ処理できるため、大量のパーティションでの選出プロセスがはるかに低コストかつ高速になります。コントローラーに障害が発生した場合は、動作可能なブローカーのいずれかが新しいコントローラーになります。
ログのコンパクション¶
ログのコンパクションにより、Kafka は、1 つのトピックのパーティションのデータログ内で、各メッセージキーに対して、少なくとも最後に認識された値を常に維持します。これは、アプリケーションのクラッシュやシステム障害の場合にステートを復元する、または運用保守でアプリケーションを再起動した後にキャッシュを再ローディングするといったユースケースおよびシナリオに対処します。では、これらのユースケースについて詳細に見ていき、その後にコンパクションの仕組みについて説明します。
今までのところ、データ保持に関しては、一定期間後またはログのサイズが事前に設定されたサイズに達したときに、古いログデータが破棄されるような、単純なアプローチのみを説明してきました。これは、各レコードが独立しているロギングなど、一時的なイベントデータに対してはうまくいきます。ただし、重要なクラスのデータストリームは、キー付きの可変データに対する変更(たとえば、データベーステーブルへの変更)のログです。
このようなストリームの具体的な例について説明します。
重要
コンパクト化されたトピックには、レコードの保持を実行するためにキー付きのレコードが必要です。
Kafka のコンパクションでは、いつでも同じキーにレコードが 1 つだけであることが保証されません。tombstone を含め、同じキーのレコードが複数存在する可能性があります。コンパクションのタイミングは非決定的であるためです。コンパクションが実行されるのは、トピックのパーティションが一定の条件(ダーティの比率、非アクティブセグメントファイルにレコードがあるなど)を満たすときだけです。
ユーザーの電子メールアドレスを含むトピックがあり、ユーザーが電子メールアドレスをアップデートするたびに、ユーザー ID をプライマリキーとして使用して、このトピックにメッセージが送信されると仮定します。ある期間に、以下のメッセージを 123 のユーザー ID で送信するとします。各メッセージは電子メールアドレスを変更しています(他の ID のメッセージは省略します)。
123 => bill@microsoft.com
.
.
.
123 => bill@gatesfoundation.org
.
.
.
123 => bill@gmail.com
各プライマリキーの少なくとも最後のアップデート(ここでは bill@gmail.com)が必ず保持されるように、詳細な保持メカニズムがログのコンパクションにより提供されます。ログのコンパクションにより、最近変更されたキーだけでなくすべてのキーについて、最後の値の完全なスナップショットがログに含まれることが保証されます。これは、すべての変更の完全なログを保持しない場合でも、下流のコンシューマーがこのトピックに対する自身のステートを復元できることを意味します。
これが有用なユースケースについていくつか見ていき、その後に、これがどのように使用されるのかを説明します。
- データベース変更サブスクリプション。これは主にデータセットが複数のデータシステムにある場合に必要です。このようなシステムの 1 つとして、ある種のデータベースがあります(RDBMS や最新のキーバリューストア(KVS))。たとえば、ここにデータベース、キャッシュ、検索クラスター、Hadoop クラスターがあるとします。データベースへの変更は個々にキャッシュ、検索クラスター、最後に Hadoop へと反映する必要があります。リアルタイムのアップデートのみが処理されている場合は、最新のログのみを保持する必要があります。ただし、キャッシュの再ロードや障害の発生した検索ノードの復元を行う場合には、完全なデータセットが必要な可能性があります。
- イベントソーシング。これはアプリケーション設計の 1 形態であり、アプリケーション設計にクエリ処理も含み、変更ログをアプリケーションのプライマリストアとして使用します。
- 高可用性のためのジャーナリング。ローカルの計算プロセスでは、エラーが発生した場合、そのローカルステートへ変更をログ出力し、別のプロセスがこの変更を再ロードして実行することで、フォールトトレランスを実現できます。この具体的な例として、ストリームクエリシステムでの、カウント、集計、その他の "group by" と同様の処理があります。リアルタイムのストリーム処理フレームワークである Samza は、まさにこの目的のために この機能を使用 しています。
これらの各ケースでは、リアルタイムで入力される変更を主に処理する必要がありますが、マシンがクラッシュしたり、データの再ロードや再処理が必要になったりした場合には、完全なロードが必要になります。ログのコンパクションでは、これらのユースケースのいずれにも同じ支援トピックから変更を入力できます。ログのこの使用形態について詳しくは、このブログの投稿 を参照してください。
全体的な考え方は実にシンプルです。上記のケースで、無限のログが保持されていて、各変更が記録されていれば、システムの最初からの各時点でのシステムのステートをキャプチャできます。このような完全なログを使用すれば、ログから最初の N 件のレコードを再実行することで任意の時点を復元できます。このような仮想的な完全ログは、変動が少ないデータセットであっても、単一のレコードを数多くアップデートするシステムではログが無制限に増大するため、現実的ではありません。古いアップデートを破棄する単純なログ保持メカニズムは、容量が限定されますが、現在のステートの復元にログは使用できません。ログの最初から復元しても、古いアップデートがまったくキャプチャされていない可能性があるため、現在のステートは再現されません。
ログのコンパクションは、大まかな時間ベースの保持ではなく、より精細なレコード単位の保持を行うメカニズムです。その考え方では、同じプライマリキーで、新しいアップデートがあるレコードを選択的に削除します。この方法では、各キーについて少なくとも最後のステートがログに保持されていることが保証されます。
この保持ポリシーはトピック単位で設定できるため、1 つのクラスター内で、一部のトピックにサイズと時刻による保持を適用する一方、他のトピックにコンパクションによる保持を適用することができます。
この機能は、LinkedIn のインフラストラクチャで最も古くかつ最も成功した、Databus と呼ばれるデータベース更新履歴キャッシュサービスの影響を受けています。ログ構造をベースとした多くのストレージシステムとは異なり、Kafka はサブスクリプション用に構築され、データは高速なリニア読み取りおよび書き込み用に編成されています。また Databus とは異なり、Kafka は Source of Truth(信頼できる情報源)のストアとして動作するため、上流のデータソースが再書き込みできないような場合でも利用できます。
ログのコンパクションの基本¶
各メッセージのオフセットを保持する Kafka ログの論理構造を示す概略図を以下に示します。
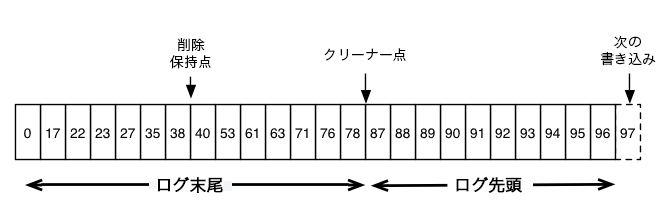
ログのヘッド部は、従来の Kafka ログと同じです。抜けのない連続のオフセットがあり、すべてのメッセージが保持されています。ログのコンパクションでは、ログのテール部の処理にオプションが追加されます。上図では、ログのテール部はコンパクト化されています。ログのテール部のメッセージには、それらが最初に書き込まれたときに割り当てられた元のオフセットが保持されており、これは変更されません。また、オフセットのメッセージがコンパクト化されたとしても、すべてのオフセットはログでの有効な位置を保持しています。この場合、この位置はログに現れる次の最も高いオフセットとは区別されません。たとえば、上図のオフセット 36、37、38 はすべて同じ位置であり、これらのオフセットのいずれから読み出しを始めても、38 に対応するメッセージセットが返ります。
コンパクションでは、削除も可能です。キーと null ペイロードを含むメッセージは、ログからの削除として扱われます。この削除マーカーにより、そのキーを含む先行のすべてのメッセージが削除されます(そのキーを持つ新しいメッセージも同様です)。ただし、削除マーカーは、スペースを解放するため一定期間後にログから削除されるという点で特殊です。上図では、削除が保持されなくなった時点が、"削除保持点(Delete Retention Point)" として示されています。
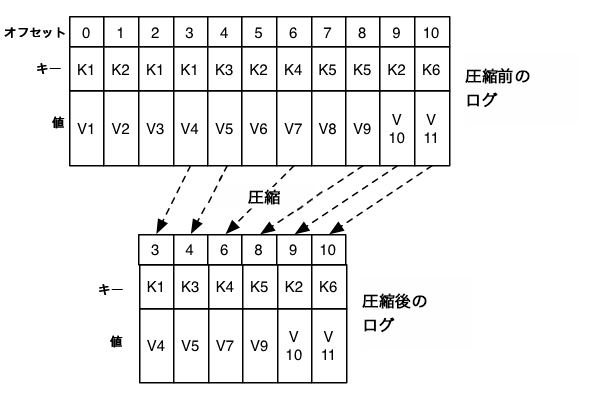
コンパクションは、定期的なログセグメントの再コピーによりバックグラウンドで実行されます。プロデューサーとコンシューマーへの影響を避けるために、クリーニングでは読み取りをブロックせず、構成可能な最大 I/O スループット量を調整できます。ログセグメント圧縮の実際の処理は、概略以下のようになります。
ログのコンパクションにより保証される内容¶
ログの圧縮により、以下が保証されます。
- ログのヘッド部内にアクセスするコンシューマーは、書き込まれたすべてのメッセージを確認します。これらのメッセージは連続するオフセットに対応します。トピックの
min.compaction.lag.msを使用して、メッセージが書き込まれてからコンパクト化されるまでの最小時間を保証できます。つまり、各メッセージが(コンパクト化されていない)ヘッド部に保持される最低期間が指定されます。トピックのmax.compaction.lag.msを使用すれば、メッセージが書き込まれてからコンパクション可能となるまでの最大遅延が保証できます。 - メッセージの順序は常に維持されます。コンパクションではメッセージの順序は変更されません。一部が削除されるだけです。
- メッセージのオフセットは変更されません。これはログでの位置を示す永続的な ID です。
- ログの最初から処理するコンシューマーは、書き込まれた順番どおりに保持されたすべてのレコードの少なくとも最終ステートを確認します。また、トピックの
delete.retention.ms設定(デフォルトは 24 時間)未満の期間にコンシューマーがログのヘッド部に到達した場合には、削除されたレコードのすべての削除マーカーも確認します。これはつまり、削除マーカーの削除が読み出しと同時に発生するため、delete.retention.msを超えるタイムラグが発生した場合に、コンシューマーが削除マーカーを見落とす可能性があるということです。
ログのコンパクションの詳細¶
ログのコンパクションはログクリーナーにより処理されます。これはログセグメントファイルを再コピーするバックグラウンドスレッドのプールであり、ログのヘッド部にキーがあるレコードを削除します。各コンパクト化スレッドは次のように動作します。
- ログのテール部に対してログのヘッド部の比率が最も高いログを選択します。
- ログのヘッド部にある、各キーの最新のオフセットについて簡単なサマリーを作成します。
- ログを最初から最後まで再コピーしつつ、ログの後ろに同じキーがある場合に、前のキーを削除します。新しいクリーンなセグメントが直ちにログに入れ替えられます。したがって、必要な追加のディスク空き容量は 1 つのログセグメント分のみです(ログの完全コピー分の容量は不要です)。
- ログのヘッド部のサマリーは、実際にはスペースがコンパクト化されたハッシュテーブルです。1 エントリあたりちょうど 24 バイトが使用されます。8 GB のクリーナーバッファの場合、1 つのクリーナーの反復処理により 366 GB ほどのログのヘッド部がクリアされます(メッセージが 1000 件の場合)。
ログクリーナーの構成¶
ログクリーナーはデフォルトで有効になっています。クリーナーは、クリーナースレッドのプールを起動します。特定のトピックに対してログクリーニングを有効にするには、ログ専用のプロパティを追加します。
log.cleanup.policy=compact
log.cleanup.policy プロパティは、ブローカーの server.properties ファイルで定義されるブローカー構成設定です。これは、所定の構成オーバーライドのないクラスター内のすべてのトピックに影響します。ログクリーナーは、ログのコンパクト化されていない "ヘッド部" を最小限保持するように構成できます。これは、コンパクション時間ラグを設定することで有効にできます。
log.cleaner.min.compaction.lag.ms
これは、最小のメッセージ経過時間よりも新しいメッセージがコンパクト化されるのを防ぐために使用できます。設定しない場合、現在書き込み中の最終セグメント以外のすべてのログセグメントがコンパクション対象となります。アクティブなセグメントは、そのすべてのメッセージが最小コンパクション時間ラグより古い場合でもコンパクト化されません。ログクリーナーは、ログのコンパクト化されていない "ヘッド部" がログコンパクションの対象になってからの最大遅延を保証するよう構成できます。
log.cleaner.max.compaction.lag.ms
これは、低い生成レートのログを一定期間でコンパクションの対象にするために使用できます。設定しない場合、min.cleanable.dirty.ratio を超えないログはコンパクト化されません。このコンパクションのデッドラインは厳密なものではありません。これは依然としてログクリーナースレッドの可用性と実際のコンパクション時間の影響を受けます。クリーンにできないパーティション数、最大クリーン秒数、最大コンパクション遅延秒数といったメトリクスをモニタリングすると便利です。
クリーナーの構成について詳しくは、「Kafka ブローカーの構成」を参照してください。
クォータ¶
Kafka クラスターには、クライアントで使用されるブローカーのリソースを制御するために、リクエストに対してクォータを適用する機能があります。Kafka ブローカーでは、クォータを共有する各クライアントグループに対して 2 種類のクライアントクォータが適用できます。
- ネットワーク帯域幅クォータは、バイトレートのしきい値を定義します(0.9 以降)。
- リクエストレートクォータは、CPU 使用率のしきい値を、ネットワークスレッドと I/O スレッドの割合で定義します(0.11 以降)。
クォータが必要な理由¶
大量のデータをプロデューサーで生成し、コンシューマーで消費したり、非常な高レートでリクエストを生成したりするとき、ブローカーのリソースを独占する可能性があります。この場合、ネットワークが飽和し、結果として他のクライアントやブローカー自体が DoS 状態になります。このような問題に対してクォータによる保護を行うことは、特にマルチテナントクラスターでは重要です。"行儀が悪い" 少数のクライアントのせいで、他のクライアントのユーザーエクスペリエンスが悪化する可能性があるためです。実際に、Kafka をサービスとして実行している場合に、SLA に従って、クォータによる API の制限を実行できるようになります。
クライアントグループ¶
Kafka クライアントの ID は、ユーザープリンシパルであり、セキュアなクラスター内の認証されたユーザーを表します。未認証のクライアントをサポートするクラスターでは、ユーザープリンシパルは、構成可能な PrincipalBuilder を使用してブローカーにより選択された未認証のユーザーのグループです。クライアント ID は、クライアントアプリケーションにより選択された意味のある名前を持つクライアントの論理グループです。タプル(ユーザー、クライアント ID)は、ユーザープリンシパルとクライアント ID の両方を共有する、クライアントのセキュアな論理グループを定義します。
クォータは、(ユーザー、クライアント ID)、ユーザー、クライアント ID の各グループに適用できます。接続が指定されている場合、その接続に最も適したクォータが適用されます。クォータグループのすべての接続は、グループに構成されたクォータを共有します。たとえば、(user="test-user", client-id="test-client")に 10 MB/秒の生成クォータが設定されている場合、これは "test-client" というクライアント ID を持つユーザー "test-user" のすべてのプロデューサーインスタンスで共有されます。
クォータの構成¶
クォータの構成は、(ユーザー、クライアント ID)、ユーザー、クライアント ID の各グループに対して定義できます。クォータを増やす(または減らす)必要がある任意のクォータレベルについて、デフォルトのクォータをオーバーライドすることができます。そのメカニズムは、トピックごとのログ構成のオーバーライドに似ています。ユーザーと(ユーザー、クライアント ID)のクォータのオーバーライドは、/config/users (ZooKeeper)に書き込まれます。また、クライアント ID のクォータのオーバーライドは、/config/clients の下に書き込まれます。すべてのブローカーがこのオーバーライドを読み取り、直ちに有効になります。これにより、クラスター全体をローリング再起動することなく、クォータを変更できます。詳細については、ここ を参照してください。各グループのデフォルトのクォータもまた、同じメカニズムで動的にアップデートできます。
クォータ構成の優先順位は以下のようになります。
- /config/users/<user>/clients/<client-id>
- /config/users/<user>/clients/<default>
- /config/users/<user>
- /config/users/<default>/clients/<client-id>
- /config/users/<default>/clients/<default>
- /config/users/<default>
- /config/clients/<client-id>
- /config/clients/<default>
ブローカーのプロパティ(quota.producer.default、quota.consumer.default)は、クライアント ID グループのネットワーク帯域幅クォータのデフォルト設定にも使用できます。これらのプロパティは非推奨であり、今後のリリースで削除される予定です。クライアント ID のデフォルトクォータは、他のクォータのオーバーライドやデフォルトと同様に、Zookeeper に設定できます。
ネットワーク帯域幅クォータ¶
ネットワーク帯域幅クォータは、クォータを共有する各クライアントグループに対するバイトレートのしきい値として定義されます。デフォルトでは、一意のクライアントグループごとに、クラスターによって構成されているバイト/秒単位の固定クォータが与えられています。このクォータはブローカー単位で定義されています。各クライアントグループのパブリッシュまたはフェッチがブローカーあたりの指定バイト/秒を超えると、クライアントに対してスロットルが適用されます。
リクエストレートクォータ¶
リクエストレートクォータは、一定クォータ時間枠で、各ブローカーのリクエストハンドラーの I/O スレッドとネットワークスレッドをクライアントが利用できる時間をパーセントで定義します。n% のクォータは、1 つのスレッドの n% を表します。したがって、クォータの総容量は ((num.io.threads + num.network.threads) * 100)% の値になります。クォータ時間枠内で、各クライアントグループが I/O スレッドおよびネットワークスレッドを使用する総パーセントが n% を超えると、スロットルが適用されます。I/O スレッドとネットワークスレッド用に割り当てられるスレッド数は、通常はブローカーホストで使用できるコア数により決まるため、リクエストレートクォータは、そのクォータを共有する各クライアントグループで使用される可能性のある CPU の総使用率になります。
適用¶
デフォルトでは、一意のクライアントグループごとに、クラスターによって構成されている固定クォータが指定されています。このクォータはブローカー単位で定義されています。各クライアントでのブローカーあたりの利用がこのクォータを超えると、そのクライアントに対してスロットルが適用されます。ブローカー単位でこれらのクォータを定義した方が、クライアント単位でクラスターにまたがる固定帯域幅を指定するよりも優れていると判断されました。後者はすべてのブローカーでクライアントクォータ使用率を共有するメカニズムが必要になるためです。このメカニズムは、クォータの実装以上に困難です。
クォータ違反が検出されたときにブローカーはどう対応するのでしょうか。Confluent のソリューションでは、ブローカーはまず、違反しているクライアントがクォータを下回るために必要な遅延の量を算出して、直ちにその遅延を含め応答を返します。フェッチリクエストの場合、応答にはデータが含まれません。その後、ブローカーは、遅延時間が経過するまでそのクライアントからのリクエストを処理しないように、クライアントへのチャンネルを停止します。0 以外の遅延時間の応答を受信した場合、その遅延期間中は Kafka クライアントもブローカーへのリクエスト送信を停止します。したがって、帯域幅が絞られたクライアントからのリクエストは、両側で効果的にブロックされます。ブローカーからの遅延を含む応答に従わない古いクライアント実装があっても、ブローカー側がソケットチャンネルを停止しているので、"行儀が悪い" クライアントに対応できます。スロットルが適用されたチャンネルにさらにリクエストを送信するようなクライアントは、遅延時間経過後にしか応答を受信しません。
クォータ違反を迅速に検出および是正することができるように、バイトレートとスレッド使用率は複数の短い時間枠(例: 1 秒あたり 30 ウィンドウ)にわたって測定されます。通常、測定時間枠を大きく(たとえば、30 秒あたり 10 ウィンドウ)すると、長い遅延の後に大量のトラフィックが一気に発生することになり、ユーザーエクスペリエンスの観点で好ましくありません。
詳細情報¶
- Building Systems Using Transactions in Apache Kafka
- イベントストリームを介して接続された多数のストリームプロセッサーまたはマイクロサービスのチェーンから、Kafka トランザクションが、正確で再現性のある結果を提供するしくみについては、「Building Systems Using Transactions in Apache Kafka」を参照してください。
- Apache Kafka Raft メタデータモード(KRaft)の採用によって、Kafka のアーキテクチャは劇的に単純化されました。その具体的な内容については、「KRaft: Apache Kafka without ZooKeeper」を参照してください。
- サーバーレスインフラストラクチャの構築方法について学び、その知識を実際のプロジェクトに適用するには、「Cloud-Native Apache Kafka: Designing Cloud Systems for Speed and Scale」を参照してください。
注釈
このウェブサイトには、Apache License v2 の条件に基づいて Apache Software Foundation で開発されたコンテンツが含まれています。