
Connectors in ksqlDB for Confluent Platform
Kafka Connect is an open source component of Apache Kafka® that simplifies loading and exporting data between Kafka and external systems. ksqlDB provides functionality to manage and integrate with Connect:
Create connectors
Describe connectors
Import topics created by Connect to ksqlDB
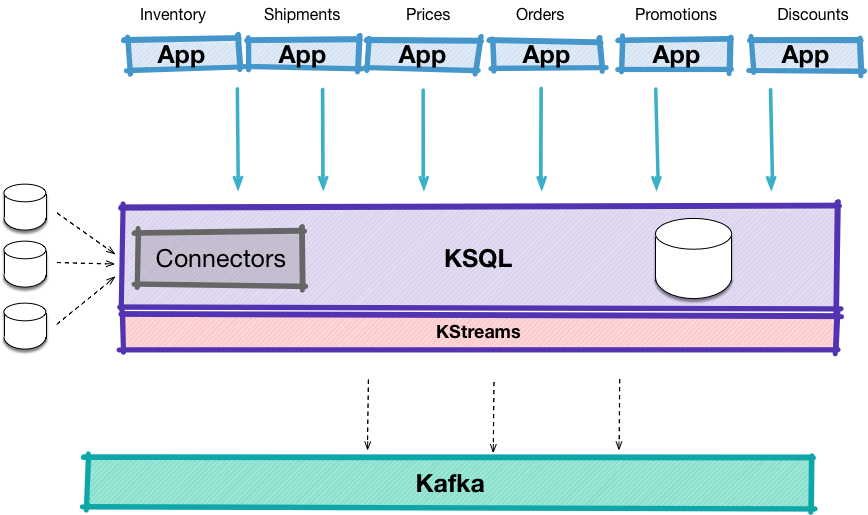
Illustration of the ksqlDB architecture showing embedded Kafka connectors
API reference
Setup Connect integration
There are two ways to deploy the ksqlDB-Connect integration:
External: If a Connect cluster is available, set the
ksql.connect.urlproperty in your ksqlDB Server configuration file. The default value for this ishttp://localhost:8083.Embedded: ksqlDB can double as a Connect server and distributed mode will run a cluster co-located on the ksqlDB server instance. To do this, supply a connect properties configuration file to the server and specify this file in the
ksql.connect.worker.configproperty.
Note
For environments that need to share connect clusters and provide predictable workloads, running Connect externally is the recommended deployment option.
Plugins
ksqlDB doesn’t ship with connectors pre-installed, so you must download and install connectors. A good way to install connectors is by using Confluent Marketplace.
Natively Supported Connectors
While it is possible to create, describe and list connectors of all types, ksqlDB supports a few connectors natively. ksqlDB provides templates to ease creation of connectors and custom code to explore topics created by these connectors into ksqlDB:
Kafka Connect JDBC Connector (Source and Sink): because the JDBC connector doesn’t populate the key automatically for the Kafka messages that it produces, ksqlDB supplies the ability to pass in
"key"='<column_name>'in theWITHclause to extract a column from the value and make it the key.