
Manage Mirror Topics for Cluster Linking on Confluent Platform
This page provides a concept guide, walkthroughs, and examples for creating, configuring, and managing mirror topics on cluster links.
What are mirror topics?
Mirror topics are the building blocks for moving data with Cluster Linking. They are read-only topics that are created and owned by a cluster link.
The sections below provide a conceptual overview of mirror topics, how they are created, configured, and how they work in operation, that is applicable to both Confluent Platform and Confluent Cloud.
Overview
A cluster link connects a mirror topic to its source topic. Any messages produced to the source topic are mirrored over the cluster link to the mirror topic.
A mirror topic syncs many of its configurations from its source topic. It can also sync ACLs and consumer group offsets from its source topic, if you enable those features on the cluster link. For a detailed summary and explanation of how mirror topics acquire configurations, see Configurations.
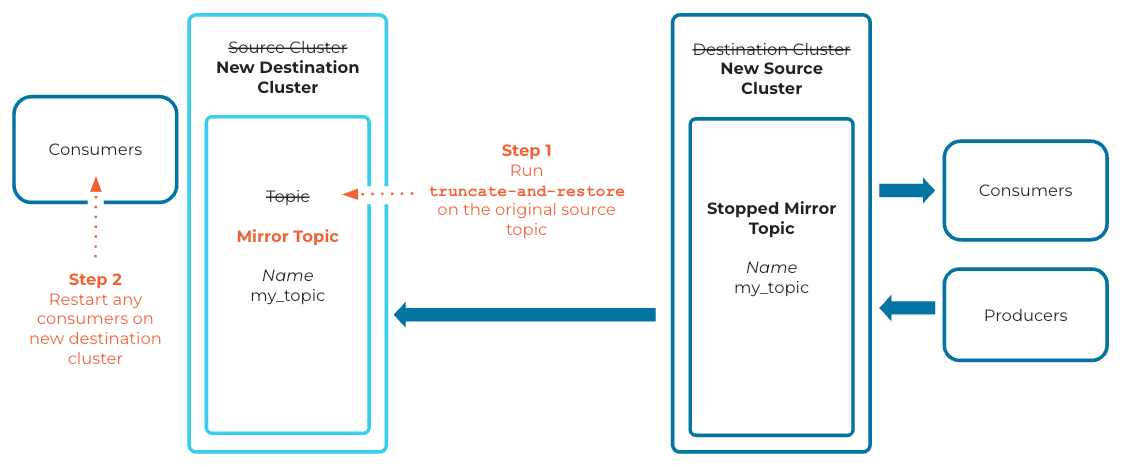
You can convert a mirror topic to a regular topic and stop the mirroring relationship using the Cluster Linking promote and failover commands. To restore mirroring after a failover or a promote, you can run truncate-and-restore on the original source topic to make it mirror from the newly stopped mirror topic.
You can reverse the mirroring relationship with the reverse-and-start and reverse-and-pause commands, which causes the mirror topic to become the source topic, and the source topic to become the mirror topic.
The diagram below shows how mirror topics work, including the relationship between the mirror topic and its source topic, and the syncing of ACLs and consumer offsets.
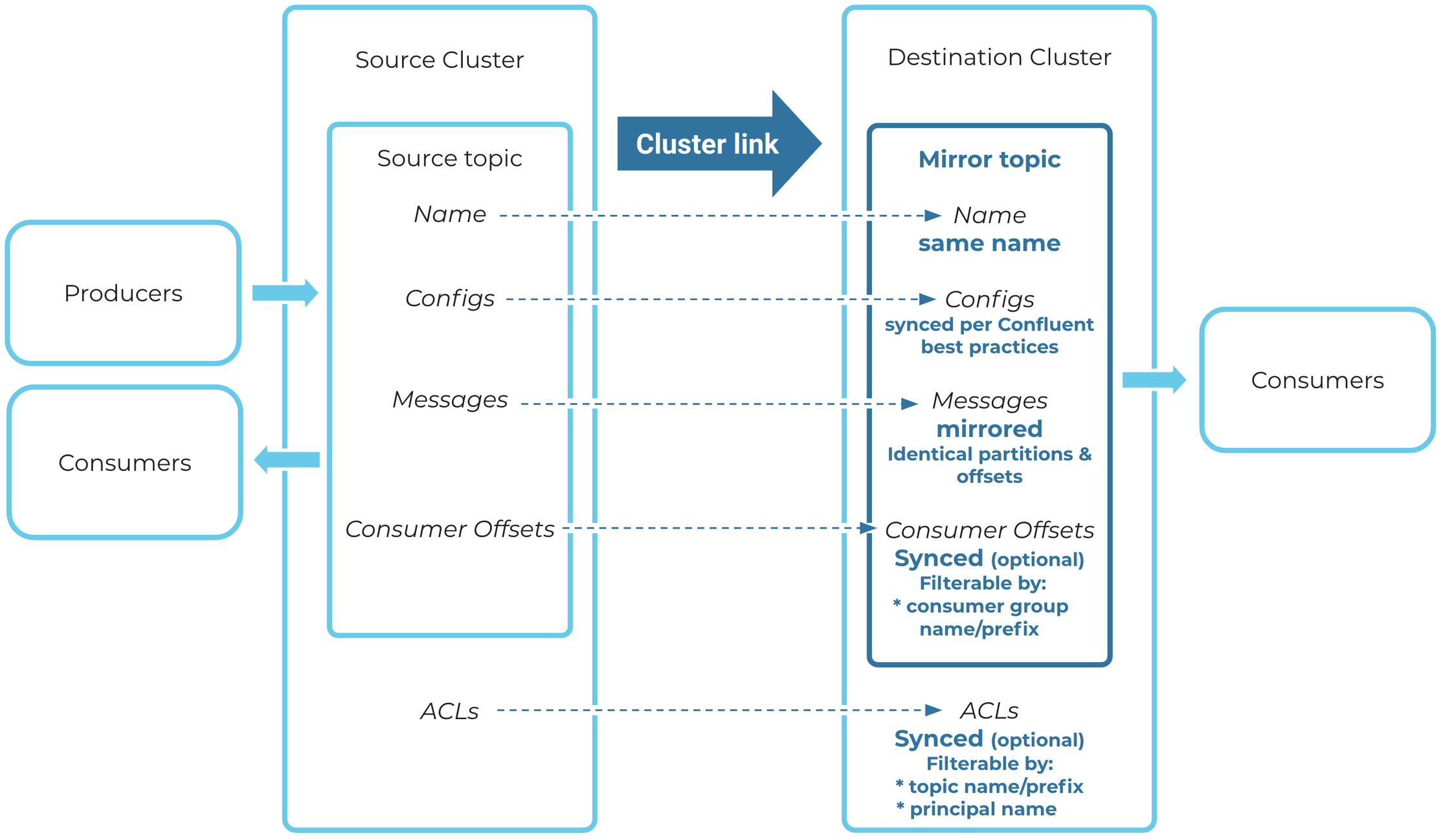
Mirror Topic Fundamentals
Properties
Mirror topics have these unique properties:
Mirror topics are created by and owned by a cluster link.
Mirror topics get their messages from their source topic. They are byte-for-byte, offset-preserving asynchronous copies of their source topics.
Mirror topics are read-only; you can consume them the same as any other topic, but you cannot produce into them. If a producer tries to produce a message into a mirror topic, the action will fail. The only way to get a message into a mirror topic is to produce the message to the mirror topic’s source topic.
Many of the mirror topic’s configurations are copied and synced from the source topic. A full list is at the end of this page.
Mirror topic creation
You can create a mirror topic using the Confluent Cloud Console, the Confluent Cloud REST API, the Confluent CLI, the Confluent Platform AdminClient API, or Confluent for Kubernetes.
Alternatively, you can configure your cluster link to automatically create mirror topics that match certain prefixes.
Requirements
Mirror topics can only be created with the mirror topic command or by enabling auto-create mirror topics on the cluster link. A mirror topic cannot be pre-created by a non mirror topic command.
Creating a mirror topic requires an existing cluster link. The mirror topic will be created on the destination cluster of the cluster link. The user must have access to the destination cluster.
A mirror topic is always created with the same name as its source topic. There must be a topic of that name on the source cluster. The only exception is when a cluster link has
link.prefixconfigured, which will add a prefix to the name of the mirror topic.The destination cluster must be able to reach the source cluster and verify there is a suitable topic. A mirror topic cannot be created if the source cluster is unreachable.
Creating a mirror topic on Confluent Cloud requires the user to have the CloudClusterAdmin, EnvironmentAdmin, or OrgAdmin role over the destination cluster–that is, the cluster the mirror topic will be created on. Alternatively, the user can have the appropriate ACLs.
The cluster link’s principal must have both DeveloperRead and DeveloperManage on the relevant source topic on the source cluster. Alternatively, it could have ResourceOwner or the appropriate ACLs on that topic. The user does not need any permissions on the source cluster.
Tip
You can also have the cluster link automatically create mirror topics.
For more about configuring access on Confluent Cloud, see Security for Cluster Linking on Confluent Cloud.
For more about configuring security on Confluent Platform, see Cluster Linking Security.
Create a mirror topic on Confluent Cloud Console
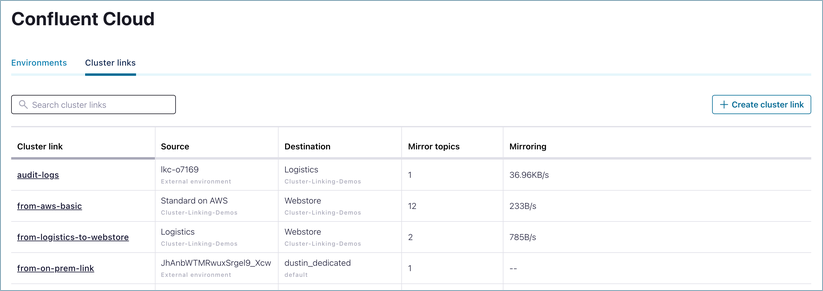
If the destination cluster is a Confluent Cloud cluster, you can view and create mirror topics on the Confluent Cloud Console:
On the top-level page showing your Environments, click Cluster links tab.
Click on an existing cluster link, or create a new one. (If you choose to create a new cluster link, follow the prompts as given.)
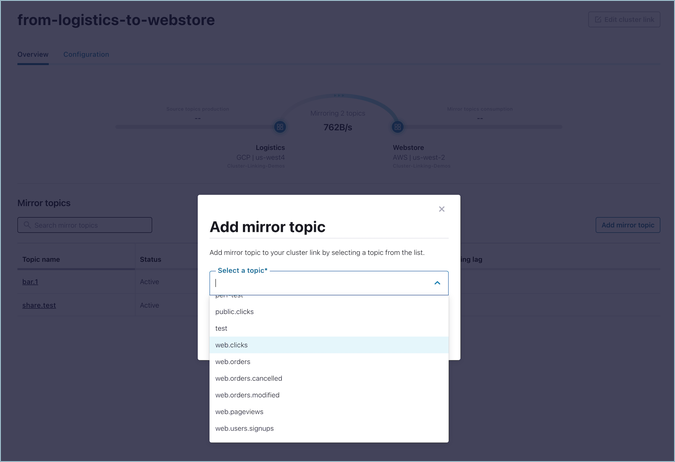
To add a mirror topic to an existing cluster link, click Add mirror topic.
If the source cluster is a Confluent Cloud cluster that the current user has access to, the dialog will have a dropdown with a list of all of the source topics on it.
If the source cluster is external to Confluent Cloud or the user does not have access to it, then you will see a text box instead in which to add the name of the source topic.
Enter the source topic name and click the Add to create the mirror topic.
Tip
For cluster links with link.prefix configured, enter the name of the source topic in this dialog. The mirror topic’s name will automatically have the prefix added after you click the Add.
Create a mirror topic with the Confluent CLI
To create a mirror topic with the Confluent CLI, the general syntax is:
confluent kafka mirror create <mirror-topic-name> --link <link-name>
The command must be run against the destination cluster. If needed you can specify the destination cluster with --cluster <destination-cluster-id>. To learn more, see confluent kafka mirror create in the command reference.
If the cluster link is configured with link.prefix, then --source-topic source-topic-name must be passed, too. For example:
confluent kafka mirror create west.clicks --link from-west --source-topic clicks
On Confluent Platform clusters, you can use either the Confluent CLI or the bin/kafka-mirrors script. The general syntax to create a mirror topic is:
kafka-mirrors --create --mirror-topic <topic-name> \
--link <link-name> \
--bootstrap-server <host:port>
To learn more, see Cluster Linking on Confluent Platform.
Create a mirror topic with the REST API
On Confluent Cloud:
To create a mirror topic, send a
POSTrequest to the destination cluster’s REST API endpoint at:/kafka/v3/clusters/{cluster_id}/links/{link_name}/mirrors.Include the following in the payload:
{ "source_topic_name": "<source-topic-name>", "mirror_topic_name": "<mirror-topic-name>", // (only required if link.prefix is configured) }
The above shows the only required parameters. More options are available to override topic configurations.
To learn more, see the Create a mirror topic in the Confluent Cloud API reference .
Examples
For examples of how to create mirror topics on Confluent Platform, see Create the cluster link and mirror topic (step 2, “Initialize the mirror topic”) in the basic tutorial and Creating a mirror topic in the Commands documentation.
For examples of how to create mirror topics on Confluent Cloud, see the following sections:
Create source and mirror topics in the Quick Start for Cluster Linking on Confluent Cloud
Mirror a topic on the Confluent Cloud Cluster Linking tutorial
examples on the Confluent CLI command reference
Create a mirror topic with the AdminClient API
On Confluent Platform, you can use the AdminClient API to create mirror topics. To learn more, see ConfluentAdmin API reference.
Additional requirements when prefixing is enabled
When a cluster link has a prefix set, the specified prefix will be added to the beginning of mirror topic names. For example; if you set the prefix to west, the source topic orders will be mirrored as west.orders.
If the cluster link is configured for prefixing mirror topic names, then to create a mirror topic you must pass both the mirror topic name and the source topic name (instead of just the source topic name).
To learn more about prefixing, see Prefix Mirror Topics and Consumer Group Names.
Bidirectional cluster linking
To establish bidirectional linking between two clusters, you must use two cluster links. You cannot establish bi-directional linking with a single cluster link. For an example of bidirectional linking, see the Hybrid tutorial (on either Confluent Cloud or Confluent Platform), which sets up bidirectional linking between on-premises and cloud clusters.
Bidirectional linking is supported for different topics. For a specific topic, only unidirectional linking is supported.
Cherry pick which topics to mirror
To cherry pick topics to be mirrored, you can use any of the following methods:
manually mirror individual topics with
confluent mirrorcommand as shown in the tutorials (quick start for Confluent Cloud, tutorial for Confluent Platform)use the Confluent Cloud Cluster Linking (v3) REST API (see “Create a mirror topic”).
Support for compacted topics
Cluster Linking supports compacted topics. A compacted topic is mirrored as such from source to destination. To learn more, see the FAQs for Confluent Cloud and Confluent Platform.
Diagram of a cluster link
This diagram shows an example of a cluster link and a mirror topic configured with some of the properties discussed above.
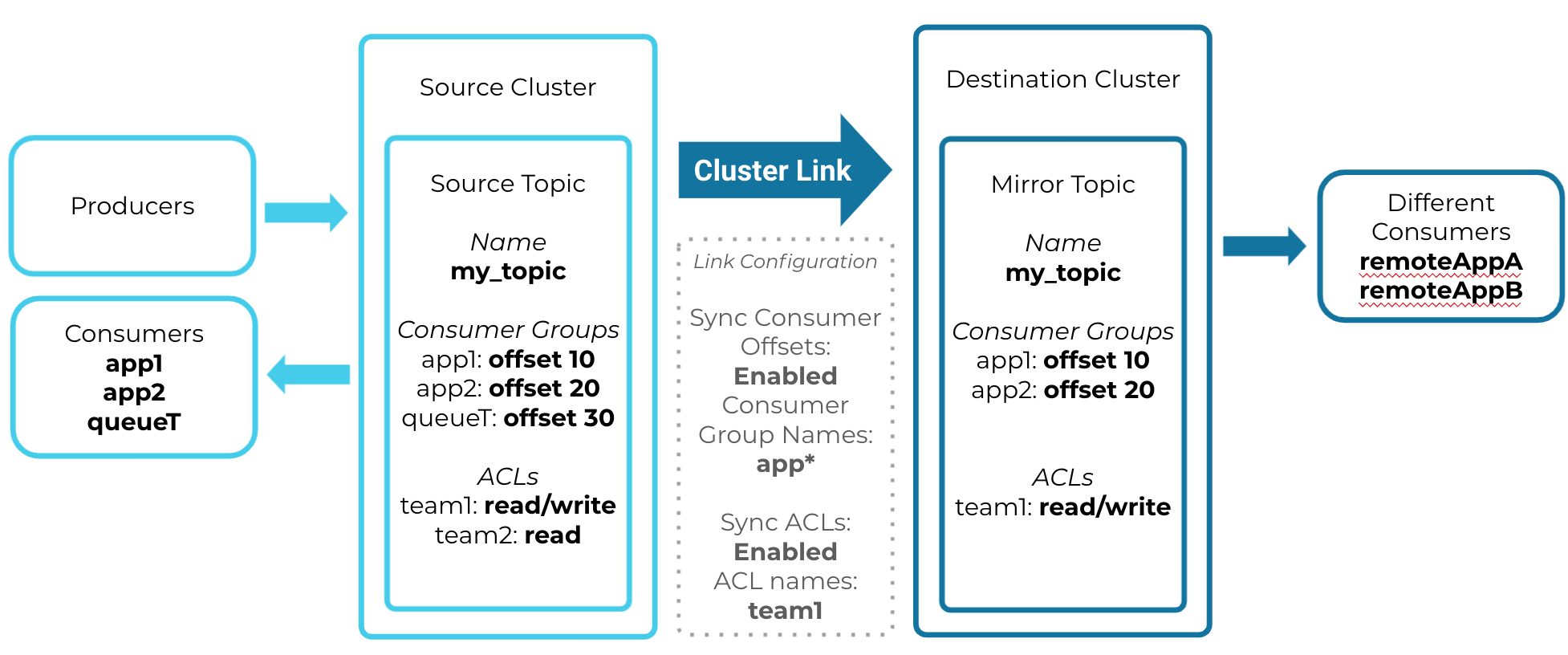
Mirror Topic Syncing Topic Data, ACLs, and Consumer Offsets from the Source Topic
Auto-Create mirror topics
A cluster link is able to automatically create mirror topics on the destination cluster for any topics that exist on the source cluster. This is called “auto-creating” mirror topics. This saves time and effort, because you do not have to create mirror topics by hand. This functionality can be scoped down to a specific set of topics by matching on the topics’ names.
Enable auto-create mirror topics
To enable this functionality, you must set two properties on the cluster link. You can set these properties when a cluster link is created, or update an existing cluster link with these properties. These properties are:
auto.create.mirror.topics.enableWhether or not to auto-create mirror topics based on topics on the source cluster. When set to “true”, mirror topics will be auto-created. Setting this option to “false” disables mirror topic creation and clears any existing filters.
Type: boolean
Default: false
auto.create.mirror.topics.filtersA JSON object with one property,
topicFilters, that contains an array of filters to apply to indicate which topics should be mirrored. Filters are described below.This list must have at least one filter.
Ordering of the filters in this array does not matter.
Type: array
Default: empty
Syntax
{ “topicFilters”: [ <each filter to apply> ] }
Schedule and frequency of mirror topic auto-create task
The auto-topic creation schedule and frequency is driven by metadata.max.age.ms, which controls the delay between subsequent auto mirror tasks.
metadata.max.age.msMaximum amount of time in milliseconds that the client can use a cached metadata value before it is refreshed from the brokers.
Type: integer
Default: 5 minutes (300000 milliseconds)
The default value for metadata.max.age.ms is 5 minutes (300000 milliseconds). Using the default, clients will cache metadata about the cluster for up to 5 minutes before they refresh it.
Reducing the value specified for metadata.max.age.ms will increase the frequency with which mirror topics are auto-created.
If the metadata.max.age.ms value is too low, it can cause a refresh of the metadata too frequently, which can impact the performance of the auto-create mirror topic feature. In this case, you may see errors or delays in the creation of mirror topics.
On the other hand, if the metadata.max.age.ms value is too high, it can result in stale metadata, which can lead to inconsistencies between the source and mirror topics.
Filters for auto-create mirror topics
In both Confluent Cloud and Confluent Platform, auto-creating mirror topics automatically excludes Confluent internal topics and topics prefixed with _confluent even if these are user-created. For full detail on this, see Topics not mirrored.
All other filtering options described below also are available in both Confluent Cloud and current releases of Confluent Platform. The topic __consumer_timestamps internal topic is used by Confluent Replicator for consumer offset translation; this topic should not be mirrored. Therefore, you must filter this topic out using the auto-create mirror topics EXCLUDE filters, as described below.
Other topics can be excluded using filters. For example, if a different topic name is used for Schema Registry storage, instead of _schemas, it can be excluded by using filters. Further detail on how to filter topics for auto-create mirror topics is provided below.
You can select exactly which source topics to automatically mirror through a list of filters. There is no limit to the number of filters you can add on a cluster link.
Each filter is a JSON object with the following fields:
nameText that will be matched against the name of the topic. Set
nameto the wildcard,*, to apply to all topics.patternTypeEither
LITERALorPREFIXEDIf
nameis set tofoo, then settingpatternTypetoLITERALwill only match a topic namedfoo.Setting
patternTypetoPREFIXEDwill match any topic names that begin with “foo”, for example, “foo”, “football”, and “foo.fighters”.
filterTypeEither
INCLUDEorEXCLUDEIf
filterTypeis set toINCLUDE, any topic names on the source cluster that match this filter will be created as mirror topics.If
filterTypeis set toEXCLUDE, any matching topic names will not be created as mirror topics. In other words, prevents auto mirror topic creation for the specified topic names.EXCLUDEfilters override any overlappingINCLUDEfilters. For example, if you have anINCLUDEfilter for the prefix “foo” but have anEXCLUDEfilter for the prefix “foo.bar,” then a topic on the source cluster named “foo.fighters” would be mirrored automatically, but a topic named “foo.bar.fighters” would not be mirrored automatically.
Example filters
Mirror all topics
This filter will create mirror topics for all current and future source cluster topics:
{ "topicFilters": [ {"name": "*", "patternType": "LITERAL", "filterType": "INCLUDE"} ] }
Mirror all topics that begin with a given string
This filter will mirror all topics that begin with “foo”:
{ "topicFilters": [ {"name": "foo", "patternType": "PREFIXED", "filterType": "INCLUDE"} ] }
Mirror all topics except those that begin with “secret”
This filter will mirror all topics except those that begin with “secret”:
{ "topicFilters": [ {"name": "*", "patternType": "LITERAL", "filterType": "INCLUDE"}, \
{"name": "secret", "patternType": "PREFIXED", "filterType": "EXCLUDE"} ] }
Mirror named topics if they exist on the source cluster
This filter will mirror three topics, “liz”, “jack”, and “kenneth”, if they exist on the source cluster:
{ "topicFilters": [ {"name": "liz", "patternType": "LITERAL", "filterType": "INCLUDE"}, \
{"name": "jack", "patternType": "LITERAL", "filterType": "INCLUDE"}, \
{"name": "kenneth", "patternType": "LITERAL", "filterType": "INCLUDE"} ] }
How a mirror topic is auto-created
For a given topic on a cluster link’s source cluster (the “source topic”), a new mirror topic will be auto-created by the cluster link if all of these conditions are true:
auto.create.mirror.topics.enableis set totrueauto.create.mirror.topics.filtershas filters which INCLUDE the source topic nameThe cluster link’s security credential is authorized (via source cluster ACLs) to read the source topic.
There is no topic by that name already on the destination cluster.
If prefixing is enabled on the cluster link, then the source topic cannot be a mirror topic. You cannot “chain” mirror topics when both
auto.create.mirror.topics.enableand prefixing are enabled.
If any of the above conditions are false, then a mirror topic will not be auto-created for the given source topic.
Override topic configurations when using auto-create mirror topics
To override a topic configuration when using auto-create mirror topics, you have two options:
Change the topic configuration after the mirror topic is automatically created.
Use the CLI or API to manually create the mirror topic, and override the configuration. Even if a topic matches the auto-create mirror topic filters, it can still be manually created as a mirror topic before the cluster link creates it automatically. Auto-create mirror topics runs once every 5 minutes, so the mirror topic can be manually created soon after the cluster link is created or soon after the source topic is created.
Delete topics that were auto-created
You cannot delete a mirror topic that matches the auto-create mirror topics filters. If you deleted such a topic, and there was a topic of the same name on the source cluster, the mirror topic would be automatically re-created and sync all its history (if mirror.start.offset.spec is set to the default). This would render the delete operation futile.
To delete a mirror topic while auto-create mirror topics is enabled, you have three options: delete the source topic first, exclude the topic’s name from the auto-create mirror topics filters, or disable auto-create mirror topics.
Option 1. Delete the source topic first - Given a source topic named
cool-topic, if you delete the source topic and then want to subsequently delete the associated mirror topic (cool-topicon the destination), wait until the mirror topic becomes aFAILEDmirror topic (which may take up to five minutes), after which point you can delete it. You can also callfailoverorpromoteon the mirror topic to transition it to theSTOPPEDstate. BothFAILEDandSTOPPEDmirror topics can be deleted.Option 2. Exclude the topic name from the auto-create mirror topics filters - This strategy will prevent the mirror topic from overlapping with the auto-create filters. An easy way to remove a given topic from the filters is to add an
EXCLUDEfilter for that topic name. You can addcool-topicto theEXCLUDEfilters, even if no such source topic exists. After editing the auto-create mirror topic filters, you can delete the mirror topic.Option 3: Disable auto-create mirror topics on the cluster link - After the setting has been disabled, the mirror topic can be deleted. If needed, auto-create mirror topics can be immediately re-enabled on the cluster link. To learn more, see Disable auto-create mirror topics and Mirror topic deletion.
Disable auto-create mirror topics
To disable auto-create mirror topics entirely, set this property on the cluster link:
auto.create.mirror.topics.enable=false
Here’s an example of how to set that property with the CLI:
echo "auto.create.mirror.topics.enable=false" > tmp.txt
confluent kafka link update <link-name> --config-file tmp.txt
rm tmp.txt
Prefix Mirror Topics and Consumer Group Names
Cluster links can be configured with a prefix (cluster.link.prefix) that is applied to the names of the mirror topics and, optionally, the names of the consumer groups that are managed by the cluster link at the destination cluster. This enables topics and consumer groups from different source clusters that have the same name to be synced to the destination without name clashes. It also enables all mirror topics from a cluster link to be categorized and managed under one prefix on the destination.
For example, consider two links, link-1 and link-2. link-1 is linking data from cluster s1 to destination and link-2 is linking data from s2 to destination, and furthermore s1 and s2 both contain a topic “clicks”. Without prefixing, it would be impossible for both links to sync data for their own “clicks” topic as they would have the same name on the destination cluster. With prefixing, each link can have its own unique prefix that is applied to the topic name as its mirrored. link-1 could have prefix usa_ and link-2 could have prefix eu_. Finally, at the destination cluster there would be two topics, usa_clicks and eu_clicks.
If the link is configured with a prefix, when a mirror topic is created (for example, with confluent kafka mirror create) then the mirror topic name must begin with the prefix (otherwise, the operation will fail). If auto-create mirror topics is used, the topics created on the destination will automatically be named with the prefix.
The prefix can optionally be applied to the consumer groups that are created on the destination cluster because of consumer group offset syncing. When offsets are synced, consumer groups are created on the destination; with this feature it’s possible to prefix the consumer group name on the destination. This enables consumer group offsets to be synced even when two (or more) consumer groups from two (or more) different source clusters have the same name. For example, if link-1 had consumer group g1 and link-2 had consumer group g1, then prefixing would result in two consumer groups at the destination: usa_g1 and eu_g1. By default, consumer group names are not prefixed with the prefix; consumer.group.prefix.enable must be set to true in the cluster link config to enable this.
Here’s an example configuration file for Confluent Enterprise, containing just elements relevant to prefixing:
bootstrap.servers=localhost:9092
cluster.link.prefix=usa_
consumer.offset.sync.enable=true
auto.create.mirror.topics.enable=true
auto.create.mirror.topics.filters={"topicFilters":[{"name": "*","patternType": "LITERAL","filterType": "INCLUDE"}]}
consumer.group.prefix.enable=false
acl.sync.enable=false
Here, a prefix of usa_ has been configured and consumer.group.prefix.enable has been set to false (which is the default, but shown here for context). All mirror topic names on the destination will start with the prefix; consumer group names will remain the same as they are on the source. Also note, acl.sync.enable is set to false which is required because auto.create.mirror.topics.enable is set to true and prefixing is enabled; see limitations below.
On Confluent Cloud, these configurations are specified on the command line or the Confluent Cloud console.
Limitations on prefixing
The prefix cannot be changed after the cluster link is created.
A prefix can be a maximum of 12 characters.
Valid characters are [a-zA-Z0-9._-]. Note this is a regex pattern. The square brackets
[ ]are not included in the valid characters set. The prefix can consist of alphanumeric characters, a period, an underscore, and a hyphen.ACL syncing and prefixing cannot be enabled together on a single cluster link. Note, ACLs can always be synced on a separate link; just create a new link and configure it to sync ACLs. That said, even if a separate link is configured to sync ACLs, the ACLs will only be synced for topics with the exact same name; there is no mapping or sync for prefixed topics.
Consumer group prefixing cannot be enabled for bidirectional links. Setting
consumer.group.prefix.enabletotrueon a bidirectional cluster link will result in an “invalid configuration” error stating that the cluster link cannot be validated due to this limitation.Prefixing cannot be combined with chaining and auto-create mirror topics at the same time. When auto-mirroring and prefixing is configured, a link cannot mirror a topic that is itself a mirror topic at the source cluster. For example, consider the same links above, link-1 and link-2. If a new link-3 was created, auto-mirroring would not be able to mirror data from
usa_clicksoreu_clicksor any mirror topic on the destination (even if it didn’t have a prefix) because they are mirror topics. This is done as a safeguard to prevent auto-mirroring from creating an infinite number of topics due to cyclical cluster link connections.The
reverse-and-startandreverse-and-pausecommands are not supported on cluster links configured with a topic prefix (cluster.link.prefix). Failover and failback workflows that require reversing the link direction must use cluster links with standard (non-prefixed) topic names.
Tip
Prefixed chained mirror topics can still be created by hand, for example via confluent kafka mirror create.
Aggregate multiple source cluster topics into a single topic
Cluster Linking can be used for aggregating data from multiple identical source clusters into one destination cluster. For example, each source cluster may be running in a different region, collecting local data, and Cluster Linking can stream data from each local cluster to a central, aggregate cluster.
Note that every topic, on every source cluster, that you wish to aggregate will need its own uniquely named mirror topic on the aggregate cluster. An easy way to accomplish this is by setting a unique prefix on each cluster link.
If a consumer group needs to read the data from all source clusters (for example, from all regions), it can easily consume multiple mirror topics at the same time by consuming from a regular expression (“regex”) topic pattern that matches the all mirror topic names you want to source from (rather than consuming from a single topic name). Most open source Kafka clients support consuming from a regex topic pattern.
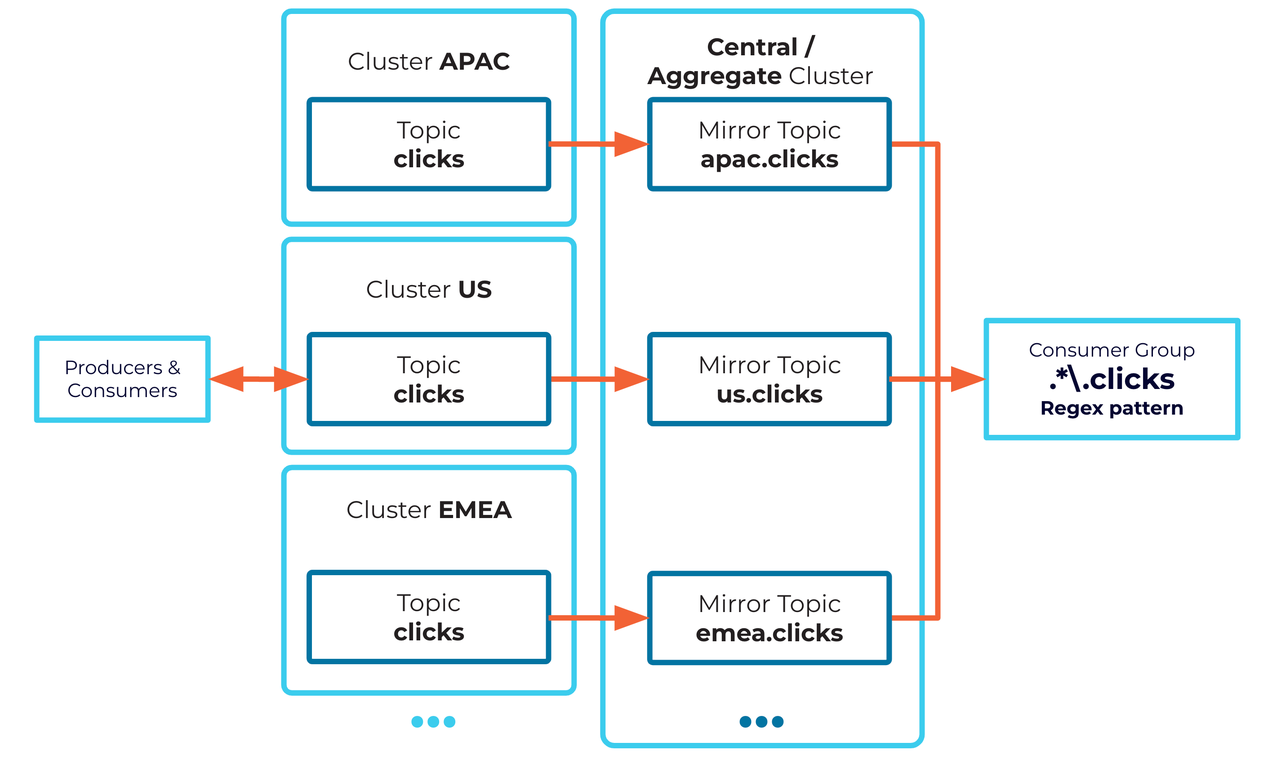
Tip
If you can’t consume from a regex pattern, ksqlDB INSERT queries can be used to merge the mirror topics into a single aggregated topic for each data type.
Topics not mirrored
By design, the following topics are not mirrored (synced). Mirrors will not be created for these topics, even if they match the topic name filter.
Internal or “system” topics (for example, any topic prefixed with
_confluent)Any topic prefixed with
_confluent, even if these are user-created and not system topics.confluent-audit-log-eventsThe topic that holds schemas (default name
_schemas)
For more background detail, some of the internal topics not mirrored include the following:
__consumer_offsets: This topic stores consumer group offsets. Cluster Linking uses a built-in offset sync mechanism, rather than “mirror” this topic in the standard sense.__transaction_state: This topic stores transaction states and helps maintain transactional integrity. This topic is not replicated because Cluster Linking does not support transaction.__cluster_metadata: In KRaft mode, this topic is used for internal cluster coordination. There is no need to mirror this topic.
Mirroring lag
The mirror process is asynchronous in operation. Therefore, there will often be some mirroring lag between the source topic and the mirror topic. The most recent messages on the source topic may not yet have been mirrored to the mirror topic, so the mirror topic may often be slightly behind the source topic.
The same is true for syncing the topic configuration, the consumer group offsets, and the ACLs. All of these processes are asynchronous, so the changes will happen first on the source topic, and then on the mirror topic shortly after.
Sync consumer group offsets
Cluster Linking can automatically synchronize consumer group offsets from a source cluster to mirror topics on a destination cluster. This is critical for disaster recovery (DR) scenarios, so that consumer applications can fail over to a backup cluster and resume processing at or near the point where they left off without reprocessing old messages or losing data.
Enabling consumer group offset sync and specifying filters
To set this up, you configure the following the following properties (as described in Migrating consumer groups from source to destination cluster):
consumer.offset.sync.enable- Set this totrueto sync consumer group offsets. (The default isfalse.)consumer.offset.group.filters- Pass in a JSON file with a pattern that is matched against consumer group names to identify which groups to mirror.
If these two properties are set, the cluster link syncs the consumer group offsets of any matching consumer groups for all mirror topics that the link mirrors.
Note
Consumer group filters should not include groups that are being used on the destination. This will help ensure that the system does not override offsets committed by other consumers on the destination, or overwrite the consumer offsets while consumer groups are consuming from the mirror topic. If you are unsure about which consumer groups are being used on the destination, disable consumer offset sync on the cluster link until you verify this.
Why consumer offsets may be clamped in the event of failover, promote, or consumer group migration
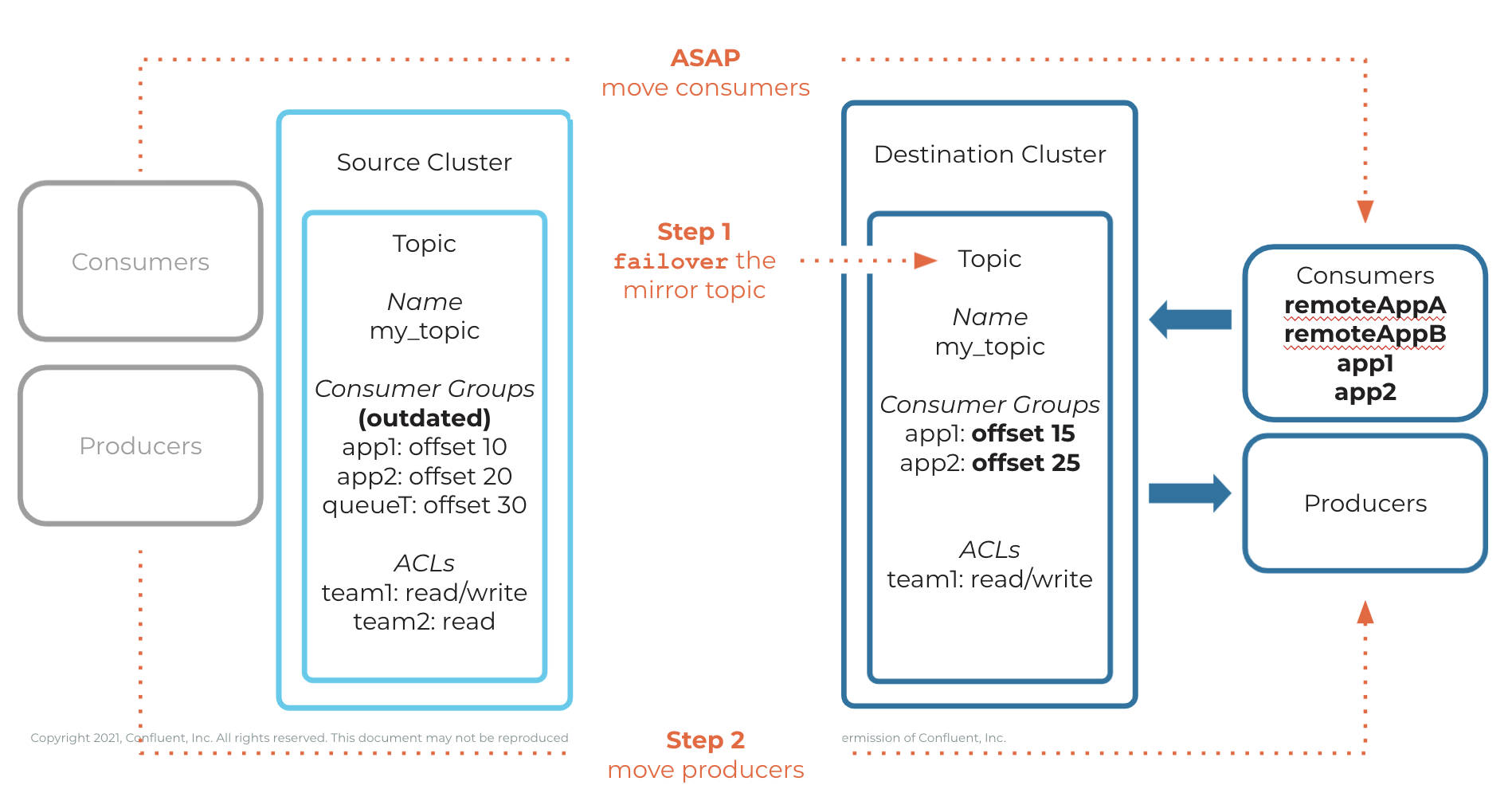
When either failover or promote is called on a mirror topic or when a consumer group moves to the destination cluster and consumes its first message from a mirror topic, if consumer offset sync is enabled on the cluster link, then the consumer offsets for that topic may be “clamped”. That is, the consumer offsets for the topic that the cluster link synced will not be allowed to be larger than the last offsets on the mirror topic (the “log end offset”). If any of these consumer offsets are larger / further than the last offsets (Log End Offset), then those consumer offsets will be reset to the Log End Offset. (The use of failover and promote are covered in the next section on Convert a mirror topic to a normal topic.)
To illustrate with an example: suppose a source topic with one partition had messages up to offset 100 and is being mirrored over a cluster link. However, there was mirroring lag on the cluster link, and only the messages up to offset 90 were mirrored when a disaster hit the source topic. At this point, you call failover on the mirror topic. Consumer group A was at offset 80 on the source cluster, so it will remain at offset 80 on the destination cluster, since that offset was mirrored to the mirror topic. But consumer group B was at offset 95, which was not mirrored to the mirror topic. If consumer group B started consuming at offset 95 on the mirror topic, then it would miss any messages at offsets 90-94 that were produced to the topic. To avoid that problem, the cluster link “clamps” consumer group B’s offsets down to 90, which is the highest offset on the mirror topic.
Considerations for failover scenarios on active-passive or active-active setups
Key considerations related to offsets are the following:
In an active-passive deployment, all producers and consumers are interacting with the active cluster only. On failover, the producers and consumers will stop interacting with the failed cluster, and start interacting with the active cluster only. The best practice for this scenario is to specify LOCAL_MIRROR only in the offset sync configuration. Given this configuration; upon failover, the system will always sync offsets in one direction only.
In an active-active deployment, where consumers are on both sides, producers could be on both sides, or only one side. In this scenario, you must have unique consumer groups on both sides, and in the offset sync filtering you must specify the exact consumer groups you want to sync to prevent cycles. You can configure offsets to use LOCAL_MIRROR and REMOTE_MIRROR. Importantly, on failover, you should update the offset sync filter on both sides to include/exclude the consumer groups.
To learn more, see Bidirectional Cluster Linking.
Limitations and troubleshooting
An issue exists where consumer group offsets that are deleted on the destination cluster persist, instead of being removed as expected. To prevent this from happening, extend retention on the destination to make sure data is deleted on the source before it is deleted on the destination. To do this, increase offsets.retention.minutes on destination cluster by at least double offsets.retention.check.interval.ms. To learn more, see Known limitations and best practices in the Cluster Linking overview.
Where to learn more
To learn more, see Migrating consumer groups from source to destination cluster and the command descriptions under Configuration options specific to cluster links in Configure Cluster Linking on Confluent Platform.
Define the direction of offset syncing
When configuring consumer offset syncing for Cluster Linking, specify whether to sync offsets for local mirror topics (LOCAL_MIRROR), remote mirror topics (REMOTE_MIRROR), or both. Understanding when to use each option is critical for achieving reliable failover and avoiding offset sync conflicts.
Use the topicTypes field in the group filter JSON to specify which topics to sync.
By default, offsets are synced for both local and remote mirrors (
["LOCAL_MIRROR", "REMOTE_MIRROR"]).REMOTE_MIRRORonly takes effect when the link is in bidirectional mode.
For example, the following filter syncs offsets for all consumer groups on both local and remote mirror topics in bidirectional mode:
{
"groupFilters": [
{
"name": "*",
"patternType": "LITERAL",
"filterType": "INCLUDE",
"topicTypes": ["LOCAL_MIRROR", "REMOTE_MIRROR"]
}
]
}
For more examples of filter configurations, see Guidance for active-passive deployments and Guidance for active-active deployments.
What is LOCAL_MIRROR?
LOCAL_MIRROR syncs consumer group offsets for topics that are mirrored on the local cluster; that is, the cluster where the cluster link object is configured. When LOCAL_MIRROR is specified:
The cluster link fetches consumer offsets from the remote cluster, which is the source of the mirror topic.
These offsets are applied to the local cluster, where the mirror topic resides.
This enables consumers to resume from the correct position when they fail over from the source cluster to the destination cluster where the mirror topics reside.
LOCAL_MIRROR determines the exact offset a consumer should resume from when failing over from a remote source topic to a local mirror topic.
What is REMOTE_MIRROR?
REMOTE_MIRROR syncs consumer group offsets for topics that are mirrored on the remote cluster. When REMOTE_MIRROR is specified:
The cluster link pulls consumer offsets from the mirror topic on the remote cluster and writes them to the source topic on the local cluster.
This is used in bidirectional configurations where the remote cluster also has mirror topics that need offset sync.
This enables consumers to resume from the correct position when they fail back from the destination cluster to the original source cluster.
REMOTE_MIRROR determines the exact offset a consumer should resume from when failing back from a remote mirror topic to a local source topic.
Offset syncing behavior summary
Mode | Offsets Fetched From | Offsets Written To | Use Case |
|---|---|---|---|
| Remote cluster (source) | Local cluster (mirror) | Failover from source to DR cluster |
| Remote cluster (mirror) | Local cluster (source) | Failback from DR to original cluster |
Guidance for active-passive deployments
In an active-passive deployment:
All producers and consumers interact with the active (primary) cluster only.
The passive (DR) cluster receives mirrored data but does not have active consumers until a failover occurs.
On failover, producers and consumers stop interacting with the failed cluster and start using the DR cluster.
Recommended configuration
Specify LOCAL_MIRROR only in the offset sync configuration on the DR cluster’s cluster link. This ensures offsets sync in one direction only: from the active cluster to the DR cluster.
Example configuration for active-passive
Create a configuration properties file, dr-link.properties, for the cluster link on the DR cluster.
Note
When defining complex JSON filters inside a Confluent Platform properties file, you must escape the double quotes (\") and write the entire JSON block on a single line.
link.mode=BIDIRECTIONAL
consumer.offset.sync.enable=true
consumer.offset.group.filters={\"groupFilters\": [{\"name\": \"*\", \"patternType\": \"LITERAL\", \"filterType\": \"INCLUDE\", \"topicTypes\": [\"LOCAL_MIRROR\"]}]}
consumer.offset.sync.ms=5000
To apply this configuration file to a new or existing cluster link, use the kafka-cluster-links command-line tool. For example, to update an existing link:
kafka-cluster-links --bootstrap-server <destination-bootstrap-url> \
--alter \
--link my-cluster-link \
--add-config-file dr-link.properties
With this configuration:
Consumer offsets from the active cluster are synced to the DR cluster for all consumer groups.
When failover occurs, consumers can resume from their last committed offset on the DR cluster.
No offsets are synced back to the active cluster, which is appropriate because the active cluster is the source of truth until failover.
Failback after recovery
After the original cluster recovers and you want to fail back:
Use the
truncate-and-restorecommand on the original cluster’s topics to make them mirror the DR cluster’s topics.Update the cluster link configuration on the original cluster to enable
LOCAL_MIRRORoffset sync.Use
reverse-and-startto restore the original mirroring direction.
Guidance for active-active deployments
In an active-active deployment:
Producers may write to either, or both, clusters.
Consumers are active on both clusters simultaneously.
Each cluster has writable topics and mirror topics, typically with prefixes to avoid name clashes.
Key requirements
Unique consumer group names: Each consumer group must exist on only one cluster at a time. If you need consumers in both regions, use different consumer group names for each region.
Explicit group filtering: Do not use wildcard filters (
*) for bothLOCAL_MIRRORandREMOTE_MIRROR. Instead, to prevent cycles, explicitly specify which consumer groups should sync and in which direction.Prefixed topics: Use
cluster.link.prefixto distinguish mirror topics from source topics.
Example configuration for active-active
Consider two clusters, cluster A (us-east) and cluster B (us-west), with the following setup:
Cluster A has topic
orders(source) andwest.orders(mirror from cluster B)Cluster B has topic
orders(source) andeast.orders(mirror from cluster A)Consumer group
cg-eastconsumes on cluster AConsumer group
cg-westconsumes on cluster B
Cluster A’s cluster link configuration:
link.mode=BIDIRECTIONAL
cluster.link.prefix=west.
consumer.offset.sync.enable=true
consumer.offset.group.filters={\"groupFilters\": [{\"name\": \"cg-east\", \"patternType\": \"LITERAL\", \"filterType\": \"INCLUDE\", \"topicTypes\": [\"REMOTE_MIRROR\"]}, {\"name\": \"cg-west\", \"patternType\": \"LITERAL\", \"filterType\": \"INCLUDE\", \"topicTypes\": [\"LOCAL_MIRROR\"]}]}
Cluster B’s cluster link configuration:
link.mode=BIDIRECTIONAL
cluster.link.prefix=east.
consumer.offset.sync.enable=true
consumer.offset.group.filters={\"groupFilters\": [{\"name\": \"cg-west\", \"patternType\": \"LITERAL\", \"filterType\": \"INCLUDE\", \"topicTypes\": [\"REMOTE_MIRROR\"]}, {\"name\": \"cg-east\", \"patternType\": \"LITERAL\", \"filterType\": \"INCLUDE\", \"topicTypes\": [\"LOCAL_MIRROR\"]}]}
With this configuration:
cg-eastoffsets sync from cluster A to cluster B for theeast.ordersmirror topic while active on cluster A.If
cg-eastfails over to cluster B, its forward-progress offsets sync back from cluster B to cluster A based on the remote mirror mapping.Because a consumer group can only actively consume on one cluster at a time, its offsets flow in only one direction at any given moment, preventing cyclical overwrites.
Failover in active-active
When a region fails in an active-active setup:
Move affected consumers to the surviving region.
Update the offset sync filters on the surviving cluster to exclude the moved consumer groups from sync to prevent the surviving cluster from overwriting their offsets.
After recovery, update filters again before moving consumers back.
Best practices for offset sync configuration
Start with LOCAL_MIRROR for DR scenarios: For standard disaster recovery,
LOCAL_MIRRORon the DR cluster is sufficient. Only addREMOTE_MIRRORif you need failback capabilities with offset preservation.Use explicit filters in active-active: Never use
"name": "*"with bothLOCAL_MIRRORandREMOTE_MIRRORtopicTypes, as this can create offset sync cycles.Match consumer group lifecycles: Ensure that consumer groups are explicitly stopped on one cluster before being started on another to avoid offset conflicts.
Configure appropriate sync intervals: Adjust
consumer.offset.sync.msbased on your recovery point objectives (RPO) requirements. Lower values, for example: 1000 ms, provide more frequent syncs but increase overhead.Monitor offset sync state: Use the
confluent kafka link listcommand to verify that consumer offset sync status is active and healthy across your links.
Limitations on bidirectional consumer offset sync
Consumer group offsets that are deleted on the destination cluster, especially those that are auto-deleted, persist instead of being removed as expected. Internally, the offsets are re-replicated to the destination before retention settings delete the offsets from source. This results in extended retention of inactive consumer group offsets.
To prevent this, extend retention on the destination to ensure data is deleted on the source before it is deleted on the destination. To do this, increase offsets.retention.minutes on the destination cluster by at least double offsets.retention.check.interval.ms (converted to minutes).
Important
If you use bidirectional linking to sync the same consumer group between both sides, the above argument infinitely extends retention due to the cyclical nature of the argument. To avoid this, ensure that each consumer group exists on only one cluster at a time, as recommended in Guidance for active-active deployments.
Where to learn more
Considerations for failover scenarios in the Mirror Topics documentation
Reverse a source and mirror topic
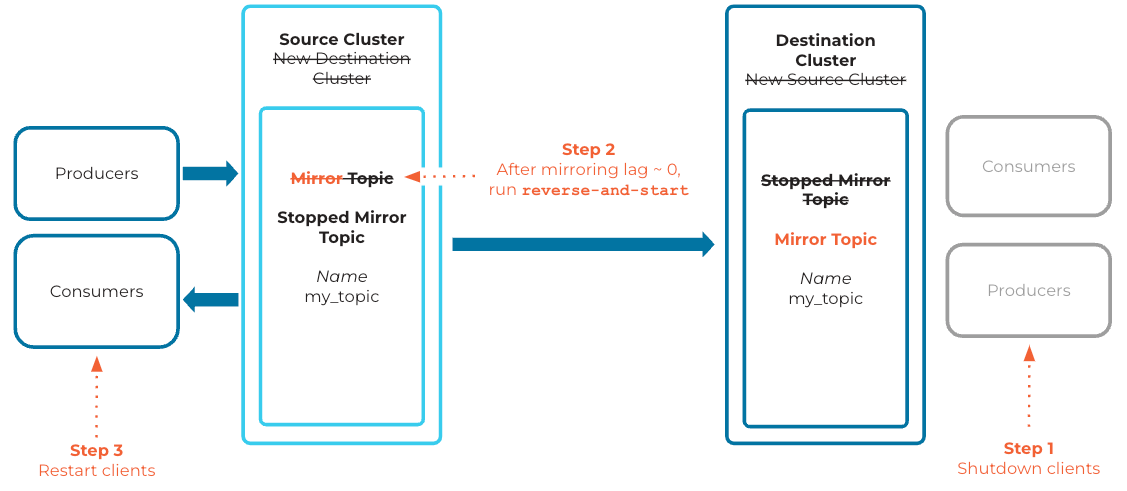
The source topic -> mirror topic relationship can be reversed using the reverse-and-start or reverse-and-pause commands. These cause the source topic to become the mirror topic, and the mirror topic to become the source topic.
The following diagram shows how a reverse-and-pause command works. The reverse-and-start command behaves in a similar fashion, except that instead of the extra manual step to resume the mirror topic to become an active mirror topic, the command automatically converts the topic to an active mirror topic.
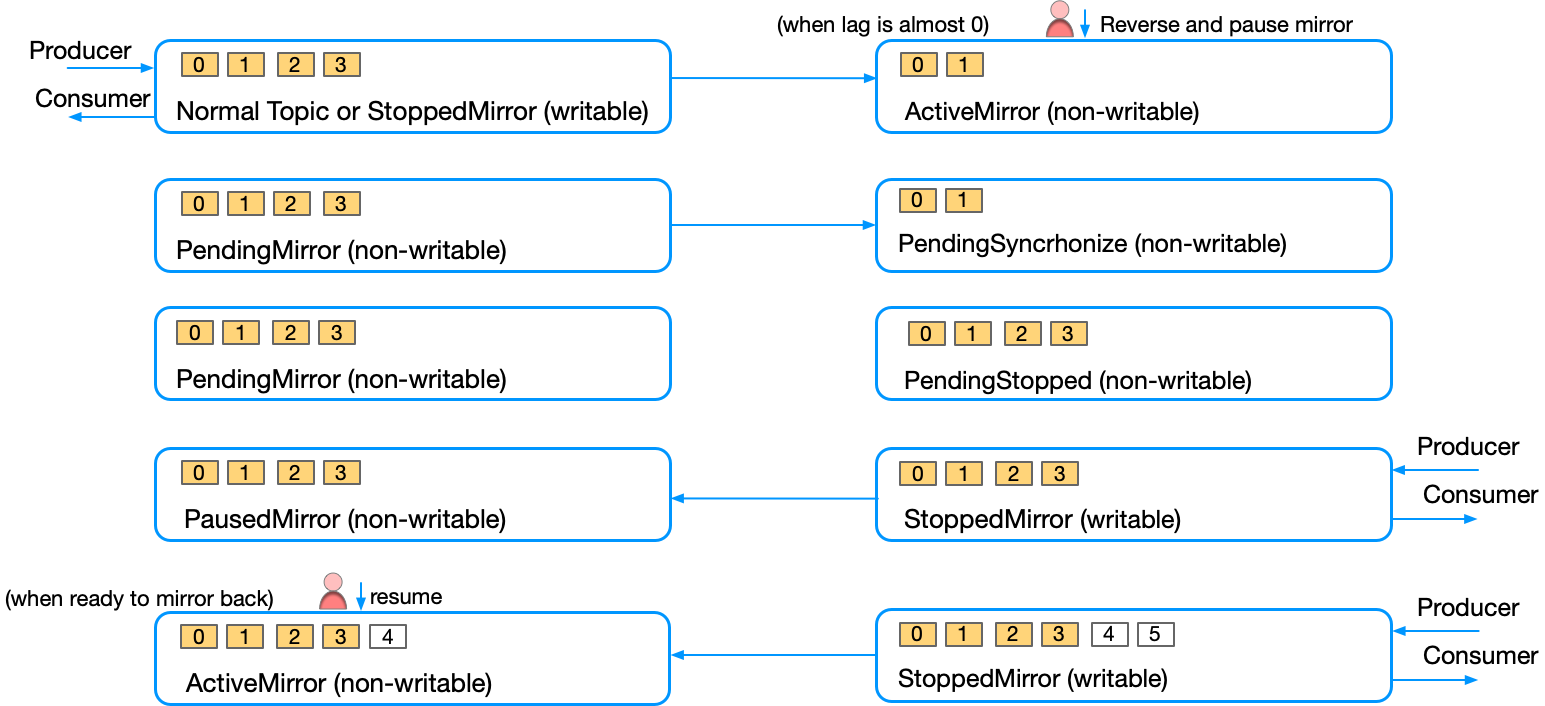
How it works
The reverse-and-start command leaves the new mirror topic in an active mirroring state, whereas reverse-and-pause leaves the new mirror topic in a paused state until the resume command is called.
These commands are available in the Confluent CLI at confluent kafka mirror, the REST API at reverse, and kafka-mirrors in Confluent Platform 7.7+.
Cluster Linking ensures that both topics have the same data and metadata at the point of change, so no data are left behind. Once the command is called, the source topic will not accept new writes, which allows the mirror topic to catch up and perform the reversal. After the reversal is complete, data written to the (new) source topic will then flow to the (new) mirror topic. This provides a fast and efficient failback for a planned failover mechanism, allowing you to quickly failover to the mirror site, produce new data, and then quickly failback to the original site.
Requirements for using “reverse” commands
The cluster link must be in Bidirectional mode.
On Confluent Platform, both clusters must be Confluent Platform version 7.7 or later.
Both clusters must be healthy and able to communicate over the network.
You must have the CLUSTER:ALTER ACL or the Admin role on the cluster where this command is run. Additionally, you need ALTER permissions on all relevant topics, such as ALTER: Topic (Mirror).
Make sure you have monitoring in place to check all of the different states the topics will be going through (as described in Process flow for “reverse” commands). If at any point in time there are any issues in the process, you can always use the
failovercommand to get a mirror topic to a writable state.You should run this command with only one topic at a time for transactional producers, and you must monitor each topic to the end state before running the command for the next topic. If you run the command in batch, you must make sure that all topics are transitioned to a writable state before restarting the application for production. Otherwise, if the applications are restarted before the topics are transitioned into the end state, this can result in the new records not being persisted in Kafka because it starts writing to an immutable topic.
Process flow for “reverse” commands
Caution
As a prerequisite to running
reverse-and-start, all consumer groups must be moved over to ensure that the “reverse and start” operation can complete successfully. If this is not done, the topic can get stuck in PENDING_STOPPED. You can failover a topic stuck in PENDING_STOPPED to force it into a writable state; but some messages will be reprocessed because, in this case, not all consumer group offsets are guaranteed to be copied over.At any point after the
reverse-and-startcommand is called, do not delete source or mirror topics on either side of the link. This will disrupt the “reverse and start” operation and topics, and may result in an indefinite pending state. To learn more about mirror topic states, see Mirror topic states and statuses.
Calling the reverse commands follows this chain of events:
Call
reverse-and-startorreverse-and-pauseon the mirror topic.Make sure this command is used against the cluster that hosts the mirror topic; for example, the disaster recovery (DR) cluster
Multiple topics can be reversed at once using the REST API
You must have the CLUSTER:ALTER ACL or the Admin role on the cluster where this command is run.
The mirror topic enters
PENDING_SYNCHRONIZEstate, and the source topic entersPENDING_MIRRORstate.During this time:
The source topic will not accept any new writes (produce requests).
The mirror topic will fetch all data from the source topic until it is up to date.
Tip: The larger the mirroring lag on the mirror topic, the longer this step will take. To minimize the amount of time when both topics are in a read-only state, call the command at a time when mirroring lag is at zero, or very low.
Once the data has been synchronized, the (old) mirror topic enters
PENDING_STOPPEDstate.During this time, the old mirror topic fetches any last metadata (such as, consumer offsets).
Monitor for errors that could cause this step to hang using the state transition error API or Metrics.
The (new) source topic enters the
STOPPEDmirror state, and accepts writes as a regular topic.The (new) mirror topic enters the
ACTIVEorPAUSEDstate, depending on which command was called. The mirroring relationship is reversed.
Limitations on reverse commands
The “reverse” commands only work with hybrid links if the on-premises cluster is on Confluent Platform 7.7 or later. These commands do not work on earlier versions, pre Confluent Platform 7.7.
The “reverse” commands cannot be used in Confluent Platform when unclean leader election is enabled.
Do not attempt to use the Failback APIs with Terraform, as they do not support it.
The “reverse” commands do not support prefixed cluster links (
cluster.link.prefix). Failover and failback workflows that require reversing the link direction must use cluster links with standard (non-prefixed) topic names.
Convert a mirror topic to a normal topic
If you want to convert a mirror topic into a normal topic that you can produce into, you can call the failover or the promote command on the mirror topic, using the commands confluent kafka mirror promote and confluent kafka mirror failover, respectively.
Specifically, you call confluent kafka mirror promote <topic-name> --link <link-name> or confluent kafka mirror failover <topic-name> --link <link-name>.
Both the failover and promote commands occur on the destination cluster (the mirror topic’s cluster) and require you to pass in the cluster link’s name.
- promote
The
promoteoption is often used for migrations. It checks that there is no mirroring lag, config sync lag, or consumer offset lag between the source topic and the mirror topic. Then, it converts the mirror topic into a full topic, with the assurance that this topic was exactly the same as its source topic. The destination cluster’s brokers must be able to reach the source cluster’s brokers in order to make this check, so your source cluster must be online.- failover
The
failoveroption is often used when a disaster has hit the source cluster (for example, a cloud region outage) and you want to shift operations from the source topic to the mirror topic. This command will succeed regardless of the mirroring lag or the source cluster’s reachability.- truncate-and-restore
If you want to restore mirroring after a
promoteor afailover, you can use thetruncate-and-restorecommand. After failing over or promoting a mirror topic, you can runtruncate-and-restoreon the original primary topic that will make it a mirror fetching from the newly-stopped mirror topic. This command will also truncate and delete any divergent records that were produced to the original primary cluster after the point of failover. This means that there could be some loss of data if your clients are not set up to reprocess data. (This command is only available on “bidirectional” links, and only in KRaft mode. See “Important” note below.)- reverse-and-start
After running
truncate-and-restore, you can restore the original primary and secondary regions by running thereverse-and-startcommand on the new mirror topic. (This command is only available on “bidirectional” links.)
Important
You can revert a promoted or failed-over topic back into a mirror topic by using
truncate-and-restore. This command is only available only on “bidirectional” links, and only in KRaft mode. To learn more about running Kafka in KRaft mode, see KRaft Overview for Confluent Platform, KRaft Configuration for Confluent Platform, and the Platform Quick Start. Also, the basic Cluster Linking tutorial includes a full walkthrough of how to run Cluster Linking in KRaft mode.You can run
mirror describe(confluent kafka mirror describe <mirror-topic-name> --link <link>) on a promoted or failed over mirror topic, if you do not delete the cluster link. If you delete the cluster link, you will lose the history and, therefore,mirror describewill not find data on promoted or failed over topics.There is no way to change a mirror topic to use a different cluster link or make changes to the link itself, other than to recreate the mirror topic on a different link.
You cannot delete a cluster link that still has mirror topics on it (the delete operation will fail).
If you are using Confluent for Kubernetes (CFK), and you delete your cluster link resource, any mirror topics still attached to that cluster link will be forcibly converted to regular topics by use of the
failoverAPI. To learn more, see Modify a mirror topic in Cluster Linking using Confluent for Kubernetes.
Example of topic migration
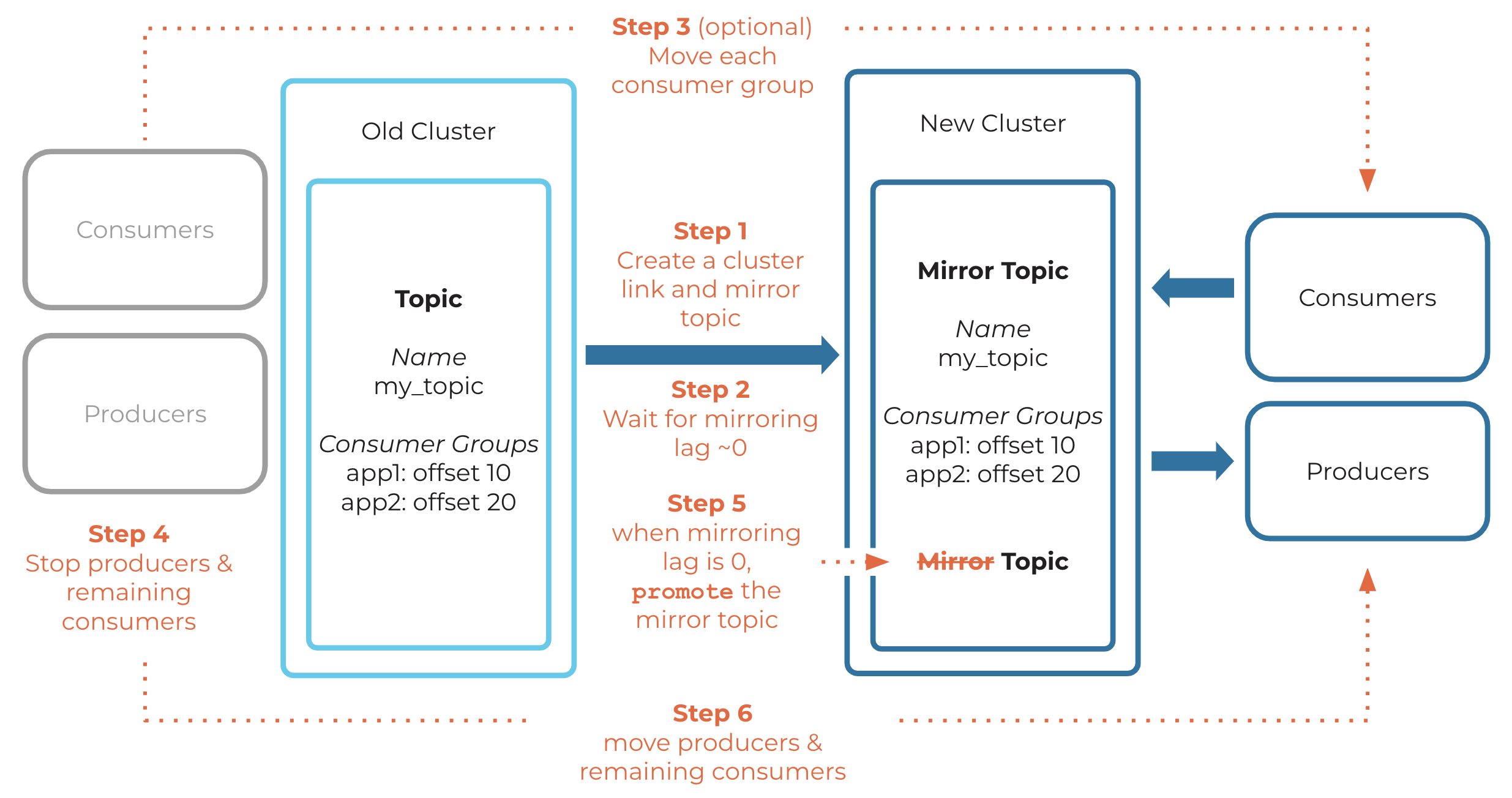
Example of failing over a topic
Example of truncate and restore
Example of reverse and start
Mirror topic states and statuses
When you describe a mirror topic, it will return one of these states:
ACTIVEThe mirror is running normally, and messages are being mirrored from the source topic to the destination topic.
PAUSEDA user has paused mirroring for this mirror topic.
To reach this state, a user must either pause this specific topic, or pause its cluster link.
Caution
Confluent Cloud cluster links cannot be paused. On Confluent Cloud, users can only pause the individual mirror topics, as described in confluent kafka mirror pause.
PENDING_SYNCHRONIZEThis topic is in the process of becoming a regular topic that will be mirrored to the remote cluster. (Prior to this, the topic was a mirror topic.)
This topic is currently read-only. (It will not accept produce, but it can be consumed from).
The
PENDING_SYNCHRONIZEstate occurs when areversecommand is called on a topic.Allowed operations to a topic in this state are as follows:
pause: to pause the reversal processfailover: to permanently abort the reversal process and convert this to a writable, non-mirror topic.
The topic will automatically transition to the
STOPPEDstate when ready.
PENDING_MIRRORThis topic is in the process of becoming a mirror topic (it was formerly a writable topic).
It will not accept produce, but it can be consumed from (it is read-only).
The
PENDING_MIRRORstate occurs when a reverse command is called on the remote mirror topic for this source topic.Allowed operations to a topic in this state are as follows:
failover: to permanently abort the reversal process and convert this to a writable, non-mirror topic.
When its conversion to a mirror topic has completed, the topic will automatically transition to the
ACTIVEorPAUSEDstate, depending on whichreversecommand was used.
PENDING_SETUP_FOR_RESTOREThis topic is in the process of becoming a mirror topic (it was formerly a writable topic) that will be mirroring from the remote cluster.
In this state, the mirror topic is reconciling the specific offsets on the topic to truncate. To ensure the mirror is restored properly, the correct offsets must be determined on the topic so that any divergent records can be truncated on the old primary cluster.
It will not accept produce, but it can be consumed from (it is read-only).
The
PENDING_SETUP_FOR_RESTOREstate occurs when arestorecommand is called on this topic.The topic will automatically transition to the
ACTIVEstate when ready.Allowed operations to a topic in this state are as follows:
failover: to permanently abort the restoration process and convert this to a writable, non-mirror topic.
PENDING_RESTORE_MIRRORThis topic is in the process of becoming a mirror topic (it was formerly a writable topic) that will be mirroring from the remote cluster.
In this state, the mirror topic truncates to the reconciled offsets.
It will not accept produce, but it can be consumed from (it is read-only).
The
PENDING_SETUP_FOR_RESTOREstate occurs when arestorecommand is called on this topic.When its conversion to a mirror topic has completed, the topic will automatically transition to the
ACTIVEstate.Allowed operations to a topic in this state are as follows:
failover: to permanently abort the restoration process and convert this to a writable, non-mirror topic.
PENDING_STOPPEDA user has stopped this mirror topic with the
promotecommand, and this topic will soon be in theSTOPPEDstate.To force the mirror topic to immediately go from the
PENDING_STOPPEDstate to theSTOPPEDstate, call thefailovercommand on it. Doing this cancels any synchronization that was happening between the source cluster and the destination cluster, and eliminates any guarantees that thepromotecommand gives.As a workaround, you can fail over a topic stuck in
PENDING_STOPPEDto force it into a writable state; but some messages will be reprocessed because, in the case of a “stuck”reverse-and-start, not all consumer group offsets are guaranteed to be copied over. To learn more about this troubleshooting scenario, see Process flow for “reverse” commands.
STOPPEDMirroring has permanently stopped for this topic. It will no longer receive messages from its source topic. The topic is now writable and can receive messages produced directly to it.
To get into this state, a user must call either
promoteorfailoveron this mirror topic.Even though a
STOPPEDtopic is no longer a mirror topic, it will still be listed in output for the commandsconfluent kafka mirror listandconfluent kafka mirror describe <destination-topic-name> --link <link>for as long as the cluster link exists. This is useful because the topic will return the last offset it fetched from its source topic (Last Source Fetch Offset) for each partition, and the time at which it was stopped (Status Time).
SOURCE_UNAVAILABLEThe mirror topic is unable to reach the source topic, and is not mirroring messages from the source topic. This could happen if the source cluster is experiencing an outage or if the network between the destination cluster and the source cluster is unstable.
Mirroring will resume once the issue is resolved and the destination cluster can reach the source cluster.
Note
Using a Confluent Platform 7.0.x source cluster with a source-initiated link to a KRaft destination cluster will generate a SOURCE_UNAVAILABLE error. Cluster Linking between a source cluster running Confluent Platform 7.0.x or earlier (non-KRaft) and a destination cluster running in KRaft mode is not supported. To solve for this, upgrade the source cluster to Confluent Platform 7.1.0 or later.
LINK_FAILEDAn error has broken the mirror topic’s cluster link, and no data is being mirrored. A user needs to manually re-configure the link.
FAILEDThe mirror topic has permanently failed. It will no longer mirror data. This can happen if the cluster link ACLs are removed from the source cluster, or if the source topic is deleted. In both cases, the failed status takes effect only after cluster.link.retry.timeout.ms is reached (by default, the system retries the link for 5 minutes).
You can stop this mirror with the
failovercommand, and it will become a regular topic.If you want to restore mirroring for this topic, you must delete the legacy mirror topic and create a new mirror topic with the same name.
View mirror topic state transition errors
You can use the following commands to view mirror topic state transition errors. For example, when a mirror topic is promoted, it transitions from the PENDING_STOPPED state to STOPPED state. During that process, various actions are performed to implement the transition and errors can occur during that implementation. The following APIs allow you to view these errors and unblock the mirror topic state transitions. For example, if you see an authentication issue, you can reconfigure the link’s credentials to allow the mirror topic to be fully promoted.
For a full list of possible task states and error codes, see Troubleshooting Cluster Linking on Confluent Cloud.
To view errors associated with a state transition:
confluent kafka mirror state-transition-error list <topic-name> --link <link-name>
./bin/kafka-mirrors.sh ... --list-state-transition-errors --topics <topic-name>
See Describe the mirror topic in the Confluent Cloud REST API documentation.
To view a mirror topic status, send a GET request to <REST-Endpoint>/clusters/<cluster-ID>/links/<link-name>/mirrors/<mirror_topic_name>?include_state_transition_errors=true.
Examples
confluent kafka mirror state-transition-error list topic-1 --link link-1
Mirror State Transition Error | Mirror State Transition Error
Code | Message
---------------------------------+---------------------------------
AUTHENTICATION_ERROR | Failed to describe topic
| configs due to authentication
| issues.
---------------------------------+---------------------------------
./bin/kafka-mirrors.sh --bootstrap-server pkc-j581r8.us-west2.gcp.confluent.cloud:9092 --command-config
command-config.properties --list-state-transition-errors --topics topic-1
Topic: topic-1 State: PENDING_STOPPED
Error Code: AUTHENTICATION_ERROR Error Message: "Failed to describe topic configs due to authentication issues."
curl -H "Authorization: Basic XXX" --request GET \
--url 'https://pkc-j581r8.us-west2.gcp.confluent.cloud:443/kafka/v3/clusters/lkc-ok51xj/links/link-1/mirrors/topic-2?include_state_transition_errors=true' | jq
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 844 0 844 0 0 2217 0 --:--:-- --:--:-- --:--:-- 2215
{
"kind": "KafkaMirrorData",
"metadata": {
"self": "https://pkc-j581r8.us-west2.gcp.confluent.cloud/kafka/v3/clusters/lkc-ok51xj/links/link-1/mirrors/topic-2"
},
"link_name": "link-1",
"mirror_topic_name": "topic-2",
"source_topic_name": "topic-2",
"num_partitions": 6,
"mirror_lags": [
{
"partition": 5,
"lag": 0,
"last_source_fetch_offset": -1
},
{
"partition": 4,
"lag": 0,
"last_source_fetch_offset": -1
},
{
"partition": 3,
"lag": 0,
"last_source_fetch_offset": -1
},
{
"partition": 2,
"lag": 0,
"last_source_fetch_offset": -1
},
{
"partition": 1,
"lag": 0,
"last_source_fetch_offset": -1
},
{
"partition": 0,
"lag": 0,
"last_source_fetch_offset": -1
}
],
"mirror_status": "PENDING_STOPPED",
"mirror_topic_error": "NO_ERROR",
"state_time_ms": 1706820222493,
"mirror_state_transition_errors": [
{
"error_code": "AUTHENTICATION_ERROR",
"error_message": "Failed to describe topic configs due to authentication issues."
}
]
}
Mirror topic deletion
You may safely delete a mirror topic. Deleting a mirror topic permanently stops data mirroring to that topic. If you create a new normal topic of the same name on the same cluster, data will not be mirrored to it.
To delete a mirror topic, use the same command you would use to delete a normal topic:
confluent kafka topic delete <topic-name>
To learn more, see Delete topics that were auto-created.
Important
When deleting a cluster link, first check that all mirror topics are in the
STOPPEDstate. If any are in thePENDING_STOPPEDstate, deleting a cluster link can cause irrecoverable errors on those mirror topics due to a temporary limitation.You cannot delete a cluster link that is attached to any mirror topics. You must first delete, failover, or promote all of the mirror topics, and then you can delete the cluster link.
Source topic deletion
Caution
Do not delete a source topic that is being mirrored by a mirror topic. Doing so can lead to unpredictable truncation and data loss on the mirror topic. You should always stop mirroring to all associated mirror topics before deleting a source topic.
While it may be possible to delete a source topic that is being mirrored by a mirror topic and a cluster link, doing so is not recommended. In particular, unpredictable behavior can occur if a source topic is deleted, and a topic by the same name is then created within a few minutes time. This scenario can cause permanent data loss on any mirror topics that are still mirroring from that source topic, and can also cause performance issues on the source cluster or destination cluster.
Before deleting a source topic, you should stop any mirroring to associated mirror topics. You can stop mirroring on a mirror topic in one of these ways:
Delete the mirror topic.
Call
promoteorfailoverso the mirror topic enters theSTOPPEDstate.Revoke the security permissions for the cluster link to read the source topic. You can do this in one of three ways: (1) delete the cluster link’s
ALLOWACL for the source topic, (2) create aDENYACL for the source topic, or (3) delete the cluster link’s API key.
For further discussion about Kafka limitations with topic deletion and how topic IDs will help, see KIP-516.
How schemas work with mirror topics
Cluster Linking preserves the schema ID stored in each message. Therefore, to consume from a mirror topic that is using schemas, the consumer clients must use a Schema Registry context with the same schema IDs as on the Schema Registry context used by the producers to the source topic. Consequently, consuming from a mirror topic that uses schemas should be done either by:
(Option 1) using the same Schema Registry as the producers used
(Option 2) using a Schema Registry context that was synced through Schema Linking from the Schema Registry that the producers used
Caution
When using Schema Linking: To use a mirror topic that has a schema with Confluent Cloud ksqlDB, broker-side schema ID validation, or the topic viewer, make sure that Schema Linking puts the schema in the default context of the Confluent Cloud Schema Registry. These fully-managed Confluent Cloud features require schemas to be in the default context of the Confluent Cloud Schema Registry in their Environment.
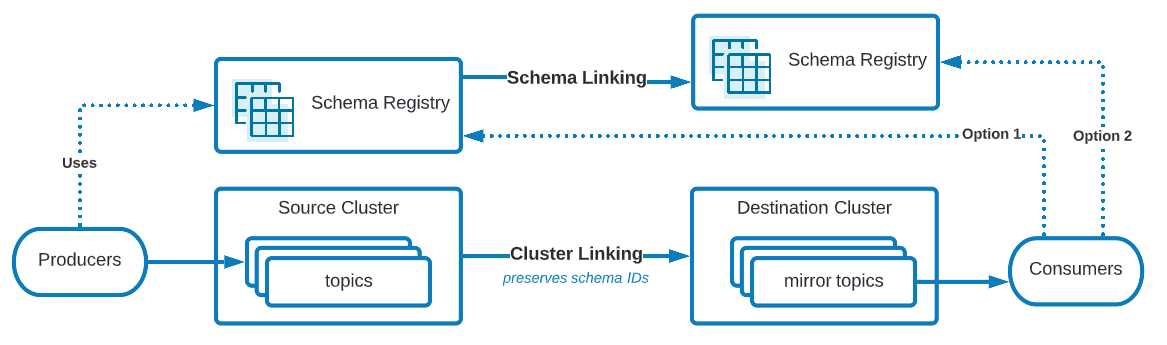
Mirror Topics and Schemas
To learn more about how Schema Registry supports disaster recovery scenarios, see Manage Schema Linking in Disaster Recovery Failover Scenarios.
Advanced mirror topic architectures
Chaining
A mirror topic can be a source topic itself. A mirror topic can be mirrored by different cluster links, allowing you to “chain” cluster links and mirror topics together.
For example, Topic A (source topic) on Cluster 1 —cluster link—> Topic A (mirror topic and source topic) on Cluster 2 —cluster link—> Topic A (mirror topic) on Cluster 3
Tip
You can safely create these chained topics and cluster links without creating a circular dependency between mirror topics and cluster links. You can create mirror topics without the fear of creating an infinite loop.
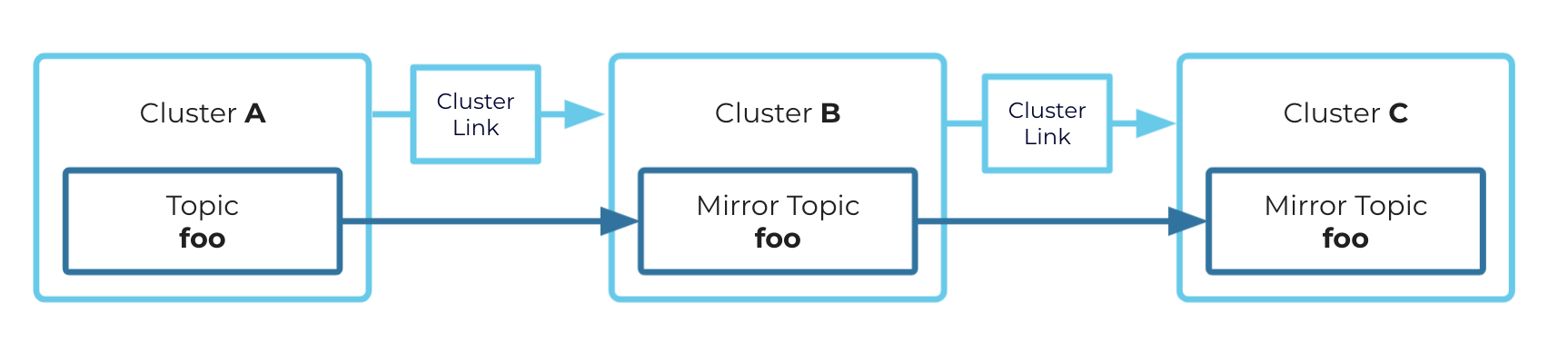
Chaining Example
Fanning out
A source topic can be mirrored to multiple mirror topics. These mirror topics must exist on multiple different clusters.
For example, Topic A on Cluster 1 —cluster link—> Topic A on Cluster 4, and Topic A on Cluster 1 —cluster link—> Topic A on Cluster 5
Tip
If you plan to use failover or promote on a cluster link (for example, for Disaster Recovery or Migration), then chained or fanned-out mirror topics will not automatically retain their shape. For example, if you fan out A –> B and A –> C, if A has an outage and you call failover on B, there is no way to automatically mirror B –> C. You will need to reconstruct the appropriate mirroring relationship for your use case using brand new topics.
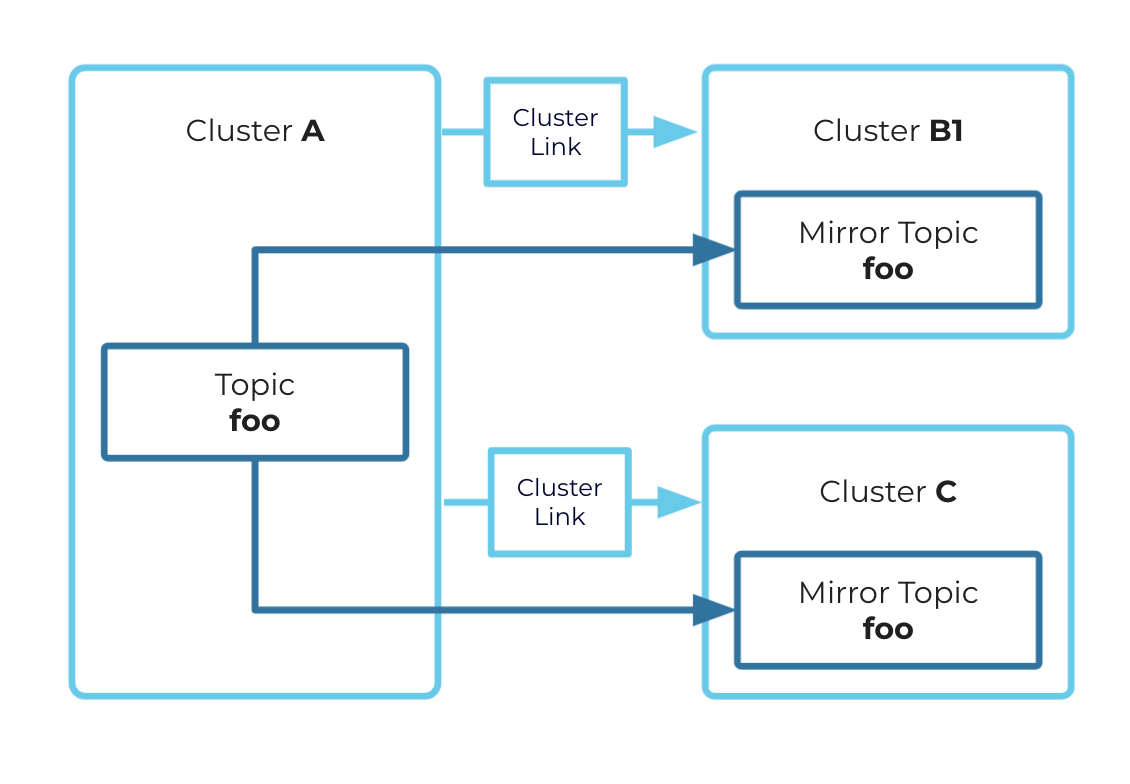
Fan-Out Example
Configurations
The following sections provide a quick reference of which Cluster Linking configurations are synced from the source to the mirror topic, overrides, and concepts related to syncing. For a full configuration reference, see Configure Cluster Linking on Confluent Platform.
A reference for all available topic configurations is available at Kafka Topic Configuration Reference for Confluent Platform.
Synced mirror topic configurations for Confluent Platform
These configurations are always synced from the source topic to the mirror topic. Mirror topics will always have the same value as their source topic, in order to ensure the properties of mirror topics are met.
number of partitions
max.message.bytescleanup.policymessage.timestamp.type
By default, the following configurations also are synced from the source topic to the mirror topic unless they are explicitly removed from topic.config.sync.include, as described in the following section.
retention.bytesretention.msdelete.retention.msmin.compaction.lag.msmax.compaction.lag.ms
Setting retention configurations to always sync keeps the source and destination data identical. With this default configuration, the starting offset is also synced from source to mirror topics. By maintaining consistent log start offsets, Cluster Linking guarantees that records deleted from the source cluster are also deleted from the destination cluster. This may be a regulatory requirement for some customers.
Override default syncing to specify independent mirror topic behavior
Some use cases require independent retention for source and destination topics. For example, when mirroring data from small edge clusters to large centralized clusters, low-footprint edge clusters may use very small retention, but rely on the data being available for a long time on the destination cluster.
To satisfy these cases, you can override the defaults by explicitly setting the following property to specify only those topic configs you want synced from source to destination:
topic.config.sync.include- The list of topic configs to sync from the source topic.
For example, the topic configurations could be set to the following (which does not include the retention properties):
topic.config.sync.include=max.message.bytes,cleanup.policy,message.timestamp.type,message.timestamp.difference.max.ms,min.compaction.lag.ms,max.compaction.lag.ms
Note that topic.config.sync.include is a cluster link level configuration and must be set when creating or updating the cluster link itself, not when creating individual mirror topics.
If you encounter the error Unknown topic config name: message.timestamp.difference.max.ms when creating a link or during consumer offset syncing, remove message.timestamp.difference.max.ms from the link configuration topic.config.sync.include. To learn more, see Known limitations and best practices.
Use kafka-configs to dynamically override other topic-level configurations on the existing cluster link, as described in Creating a Mirror Topic and confluent kafka mirror create.
With these overrides in place, mirror topics will have independent retention periods and starting offsets instead of syncing with their source topics.
Important
Keep in mind, configuration overrides (like topic.config.sync.include) are specified at the cluster link level and apply to all mirror topics on the cluster. If independent retention is specified (by omission in topic.config.sync.include), you must either specify the retention value or use the Kafka defaults.
Overridable mirror topic configurations
These configurations are configurable in Confluent Platform, meaning you can override the source configurations for these on the mirror topic.
segment.jitter.mssegment.index.bytesflush.messagesflush.msindex.interval.bytesmin.cleanable.dirty.ratiofile.delete.delay.mspreallocatemessage.format.versionconfluent.segment.speculative.prefetch.enablecompression.type
Mirror topic configurations not synced for Confluent Platform
Any configuration that is not in the list above will not be synced to a mirror topic in Confluent Platform. Therefore, the mirror topic configuration could be different from the source topic configuration. If you don’t override the mirror topic configuration, then it will inherit its cluster’s default.
A few important examples of configurations that are not synced to mirror topics in Confluent Platform:
min.insync.replicasconfluent.placement.constraintsconfluent.tier.enableconfluent.key.schema.validationconfluent.value.schema.validationreplication.factor
Tip
Most configurations not synced from the source cluster are, in fact, configurable on the destination. For example,
confluent.tier.enablecan be enabled or disabled on a per topic basis on the destination cluster, which means that the mirror topic can potentially have a different Tiered Storage configuration than is on the corresponding source topic.No replication factors are synced to mirror topics. Mirror topics use the
default.replication.factorconfigured on the brokers. If not explicitly set, this defaults to a replication factor of1, and consequently the mirror topics will pick up a replication factor of1. For a description of this option, seedefault.replication.factorin Kafka Broker and Controller Configuration Reference for Confluent Platform.
Hybrid cloud configuration syncs
Confluent Platform and Confluent Cloud have different policies for which mirror topic configurations are synced. If you cluster link between Confluent Platform and Confluent Cloud, then the destination cluster’s policy is enforced.
For example, if you cluster link from a Confluent Platform source cluster to a Confluent Cloud destination cluster, then the value of compression.type will not be synced. But if you cluster link from a Confluent Cloud source cluster to a Confluent Platform destination cluster, then compression.type will be synced.