重要
このページの日本語コンテンツは古くなっている可能性があります。最新の英語版コンテンツをご覧になるには、こちらをクリックしてください。
Datadog Metrics Sink for Confluent Cloud¶
注釈
Confluent Platform 用にコネクターをローカルにインストールする場合は、「Datadog Metrics Sink Connector for Confluent Platform」を参照してください。
Kafka Connect Datadog Metrics Sink Connector では、post time-series metrics API を使用して Apache Kafka® から Datadog にデータをエクスポートできます。このコネクターを使用して、Avro、JSON スキーマ(JSON-SR)、Protobuf、JSON(スキーマレス)、または Bytes フォーマットの Kafka レコードを Datadog エンドポイントにエクスポートできます。
機能¶
Datadog Metrics Sink Connector は、次の機能をサポートしています。
At least once delivery: コネクターによって、Kafka のトピックからのレコードが少なくとも 1 回は配信されることが保証されます。
トピックの自動作成: コネクターの起動時に、以下の 3 つのトピックが自動的に作成されます。
- 成功トピック
- エラートピック
- デッドレターキュー(DLQ)トピック
各トピック名にはサフィックスとして、コネクターの論理 ID が付けられます。以下の例では、コネクターのトピックが 3 つと、pageviews という名前の既存の Kafka トピックが 1 つ含まれています。
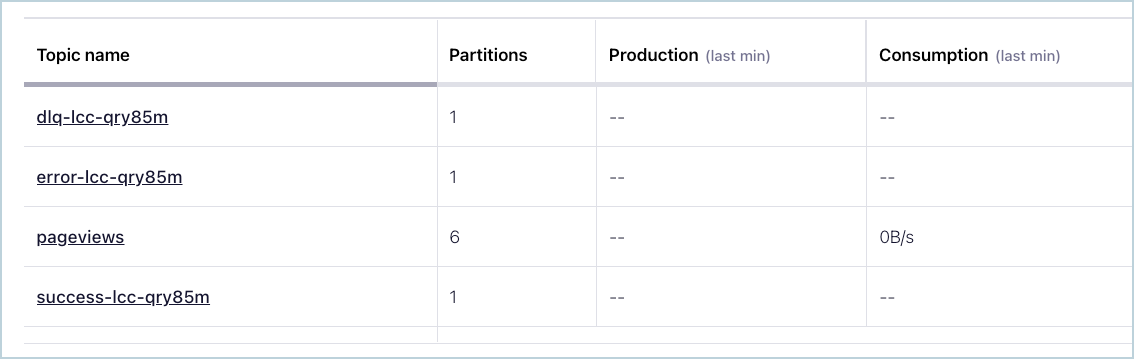
コネクターのトピック¶
トピックに送信されたレコードが正しいフォーマットではない場合、またはレコード内に重要なフィールドが存在しない場合は、エラートピックにエラーが記録され、コネクターは動作を継続します。
サポートされるデータフォーマット: このコネクターは、Avro、JSON スキーマ(JSON-SR)、Protobuf、JSON(スキーマレス)、および Bytes フォーマットをサポートします。スキーマレジストリ ベースのフォーマット(Avro、JSON スキーマ、Protobuf など)を使用するには、Schema Registry を有効にしておく必要があります。詳細については、「スキーマレジストリ Enabled Environments」を参照してください。
複数のタスクのサポート: このコネクターは、1 つまたは複数のタスクの実行をサポートしています。タスクが多いほどパフォーマンスが向上する可能性があります(複数のタスクを実行するとコンシューマーラグが減少します)。
複数の Datadog メトリクスのバッチ処理: コネクターでは、API リクエストごとに単一ペイロード(最大ペイロードサイズ 3.2 MB)で、メトリクスのバッチ処理が試行されます。詳細については、post time-series metrics API のドキュメント を参照してください。
サポートされるメトリクスタイプ: コネクターでは、Gauge、Rate、Count メトリックタイプがサポートされています。それぞれのメトリックタイプのスキーマは異なります。これらのメトリックタイプの 1 つを含む Kafka のトピックは、そのメトリックタイプのスキーマに準拠するレコードを持っている必要があります。詳細については、「メトリクスタイプ」を参照してください。
Connect 用の Confluent Cloud API の使用に関する詳細とサンプルについては、「Confluent Cloud API for Connect」セクションを参照してください。
制限¶
以下の情報を確認してください。
- コネクターの制限事項については、Datadog Metrics Sink Connector の制限事項を参照してください。
- 1 つ以上の Single Message Transforms(SMT)を使用する場合は、「SMT の制限」を参照してください。
- Confluent Cloud Schema Registry を使用する場合は、「スキーマレジストリ Enabled Environments」を参照してください。
Kafka レコードマッピング¶
コネクターは、Kafka レコードとして構造体型を受け取ります。さらに、Kafka のトピックには特定のフィールドが必要です。これは、name フィールド、timestamp フィールド、および values フィールドです。values フィールドの入力内容では、メトリクスの値が参照されます。timestamp の値は、UNIX エポック秒形式にする必要があります。
オプションの dimensions の入力により、メトリクスのフィルター処理がサポートされます。メトリクスは、hosts (ホスト名)、interval 値、タグキーの値でフィルター処理できます。このコネクターは、Datadog の カスタムメトリクス のプロパティで定義されたメトリクスを受け取ります。
以下は、オプションのフィールドを含む Kafka レコードの例を示しています。
{
"name": string,
"type": string, -- optional (DEFAULT = gauge)
"timestamp": long,
"dimensions": { -- optional
"host": string, -- optional
"interval": int, -- optional (DEFAULT = 0)
<tag1-key>: <tag1-value>, -- optional
<tag2-key>: <tag2-value>,
....
},
"values": {
"doubleValue": double
}
}
コネクターにより、送信された Kafka レコードが、Datadog post time-series metrics API によって受け取られるメトリクスペイロードにマップされます。Datadog Metrics Sink Connector は、以下のフォーマットの Kafka レコードをマッピングします。
{
"name": "test.metric",
"type": "gauge",
"timestamp": 1615466162,
"dimensions": {
"host": "metric.host",
"interval": 1,
"tag1": "postman",
"tag2": "linux"
},
"values": {
"doubleValue": 0.966121580485208
}
}
マッピング先では、受け取り可能な以下の Datadog post time-series metrics API フォーマットになります。
{
"series": [
{
"host": "metric.host",
"metric": "test.metric",
"points": [
[
"1615466162",
"0.966121580485208"
]
],
"tags": [
"host:metric.host",
"interval:1",
"tag1:postman",
"tag2:linux"
],
"type": "gauge",
"interval": 1
}
]
}
クイックスタート¶
このクイックスタートを使用して、Confluent Cloud Datadog Metrics Sink Connector の利用を開始することができます。このクイックスタートでは、コネクターを選択し、Datadog プロジェクトにイベントをストリーミングするようにコネクターを構成する基本的な方法について説明します。
- 前提条件
アマゾンウェブサービス (AWS)、Microsoft Azure (Azure)、または Google Cloud Platform (GCP)上の Confluent Cloud クラスターへのアクセスを許可されていること。
Confluent CLI がインストールされ、クラスター用に構成されていること。「Confluent CLI のインストール」を参照してください。
スキーマレジストリ ベースのフォーマット(Avro、JSON_SR(JSON スキーマ)、Protobuf など)を使用するには、Schema Registry を有効にしておく必要があります。詳細については、「スキーマレジストリ Enabled Environments」を参照してください。
シンクコネクターを作成する前に、Confluent Cloud クラスター上にソース Kafka トピックが 1 つ以上存在している必要があります。
ネットワークに関する考慮事項については、「Networking and DNS Considerations」を参照してください。静的なエグレス IP を使用する方法については、「静的なエグレス IP アドレス」を参照してください。
アクティブな Datadog アカウントと API キーが必要です。Datadog プロジェクトの API キーを作成するには、「API キーまたはクライアントトークンを追加する」を参照してください。
ちなみに
Datadog アカウントは ここ で登録できます。エージェントの実行は不要 アカウントを設定する際にエージェントのセットアップをスキップできます。
- Kafka クラスターの認証情報。次のいずれかの方法で認証情報を指定できます。
- 既存の サービスアカウント のリソース ID を入力する。
- コネクター用の Confluent Cloud サービスアカウント を作成します。「サービスアカウント」のドキュメントで、必要な ACL エントリを確認してください。一部のコネクターには固有の ACL 要件があります。
- Confluent Cloud の API キーとシークレットを作成する。キーとシークレットを作成するには、confluent api-key create を使用するか、コネクターのセットアップ時に Cloud Console で直接 API キーとシークレットを自動生成します。
Confluent Cloud Console の使用¶
ステップ 1: Confluent Cloud クラスターを起動します。¶
インストール手順については、「Quick Start for Confluent Cloud」を参照してください。
ステップ 2: コネクターを追加します。¶
左のナビゲーションメニューの Data integration をクリックし、Connectors をクリックします。クラスター内に既にコネクターがある場合は、+ Add connector をクリックします。
ステップ 4: コネクターの詳細情報を入力します。¶
注釈
- すべての 前提条件 を満たしていることを確認してください。
- アスタリスク(* )は必須項目であることを示しています。
Add Datadog Metrics Sink Connector 画面で、以下を実行します。
既に Kafka トピックを用意している場合は、Topics リストから接続するトピックを選択します。
新しいトピックを作成するには、+Add new topic をクリックします。
- Kafka Cluster credentials で Kafka クラスターの認証情報の指定方法を選択します。以下のいずれかのオプションを選択できます。
- Global Access: コネクターは、ユーザーがアクセス権限を持つすべての対象にアクセスできます。グローバルアクセスの場合、コネクターのアクセス権限は、ユーザーのアカウントにリンクされます。このオプションは本稼働環境では推奨されません。
- Granular access: コネクターのアクセスが制限されます。コネクターのアクセス権限は サービスアカウント から制御できます。本稼働環境にはこのオプションをお勧めします。
- Use an existing API key: 保存済みの API キーおよびシークレット部分を入力できます。API キーとシークレットを入力するか Cloud Console でこれらを生成することもできます。
- Continue をクリックします。
- Datadog domain name で Datadog ドメイン名を選択します。Datadog プロジェクトが配置されているドメインに応じて、COM または EU を選択します。
- Datadog API key フィールドで、Datadog プロジェクトの API キーを入力します。これは、Datadog エージェントでメトリクスとイベントを Datadog に送信する際に必要です。API キーを作成するには、「API キーまたはクライアントトークンを追加する」を参照してください。
- Continue をクリックします。
注釈
Cloud Console に表示されない構成プロパティでは、デフォルト値が使用されます。すべてのプロパティの値と定義については、「構成プロパティ」を参照してください。
Input Kafka record value で、Kafka 入力レコード値のフォーマット(Kafka トピックから送られるデータ)を AVRO、JSON_SR、PROTOBUF、JSON、または BYTES から選択します。スキーマベースのメッセージフォーマット(Avro、JSON スキーマ、Protobuf など)を使用するには、有効なスキーマが Schema Registry に存在する必要があります。詳細については、「スキーマレジストリ Enabled Environments」を参照してください。
Show advanced configurations
Max Retry Time。POST リクエストの実行中にエラーが発生した場合、この時間(ミリ秒)が経過するまでコネクターにより再試行されます。この値は、
1000ミリ秒(ms)以上に設定する必要があります。デフォルトの再試行時間は5000ミリ秒(5 秒)です。Behavior on Error。Kafka レコード値からのメトリクスの抽出中にエラーが発生した場合のエラー処理の動作の設定です。指定可能なオプションは
logとfailです。logの場合、エラーメッセージがerror-<connector-id>トピックに記録されて処理が続行されます。failの場合、エラーが発生するとコネクターを停止します。Transforms and Predicates: 詳細については、Single Message Transforms(SMT) のドキュメントを参照してください。
すべてのプロパティの値と定義については、「構成プロパティ」を参照してください。
Continue をクリックします。
選択するトピックのパーティション数に基づいて、推奨タスク数が表示されます。
- 推奨されたタスク数を変更するには、Tasks フィールドに、コネクターで使用する タスク の数を入力します。
- Continue をクリックします。
接続の詳細情報を確認します。
Launch をクリックします。

コネクターのステータスが Provisioning から Running に変わります。

ステップ 5: レコードを確認します。¶
メトリクスが生成されていることを確認します。Datadog プロジェクトで Metrics Explorer に移動し、Kafka トピックの metric プロパティに使用した名前("metric": "test.metric" など)でグラフを検索します。
Connect 用の Confluent Cloud API の使用に関する詳細とサンプルについては、「Confluent Cloud API for Connect」セクションを参照してください。
ちなみに
コネクターを起動すると、デッドレターキューのトピックが自動的に生成されます。詳細については、「Confluent Cloud デッドレターキュー」を参照してください。
Confluent CLI の使用¶
以下の手順に従うと、Confluent CLI を使用してコネクターをセットアップし、実行できます。
注釈
- すべての 前提条件 を満たしていることを確認してください。
- コマンド例では Confluent CLI バージョン 2 を使用しています。詳細については、「Confluent CLI v2 への移行 <https://docs.confluent.io/confluent-cli/current/migrate.html#cli-migrate>`__」を参照してください。
ステップ 2: コネクターの必須の構成プロパティを表示します。¶
以下のコマンドを実行して、コネクターの必須プロパティを表示します。
confluent connect plugin describe <connector-catalog-name>
例:
confluent connect plugin describe DatadogMetricsSink
出力例:
Following are the required configs:
connector.class: DatadogMetricsSink
input.data.format
name
kafka.auth.mode
kafka.api.key
kafka.api.secret
datadog.domain
datadog.api.key
tasks.max
topics
ステップ 3: コネクターの構成ファイルを作成します。¶
コネクター構成プロパティを含む JSON ファイルを作成します。以下の例は、コネクターの必須プロパティを示しています。
{
"connector.class": "DatadogMetricsSink",
"input.data.format": "JSON",
"name": "DatadogMetricsSinkConnector_0",
"kafka.auth.mode": "KAFKA_API_KEY",
"kafka.api.key": "****************",
"kafka.api.secret": "****************************************************************",
"datadog.domain": "COM",
"datadog.api.key": "**************************************************",
"tasks.max": "1",
"topics": "<topic-1>, <topic-2>",
"max.retry.time.ms": "5000"
}
以下のプロパティ定義にご注意ください。
"connector.class": コネクターのプラグイン名を特定します。"input.data.format": Kafka 入力レコード値のフォーマット(Kafka トピックから送られるデータ)を設定します。指定可能なエントリは、AVRO、JSON_SR、PROTOBUF、JSON、または BYTES です。スキーマベースのメッセージフォーマット(たとえば、Avro、JSON_SR(JSON スキーマ)、および Protobuf)を使用するには、Confluent Cloud Schema Registry を構成しておく必要があります。"name": 新しいコネクターの名前を設定します。
"kafka.auth.mode": 使用するコネクターの認証モードを指定します。オプションはSERVICE_ACCOUNTまたはKAFKA_API_KEY(デフォルト)です。API キーとシークレットを使用するには、構成プロパティkafka.api.keyとkafka.api.secretを構成例(前述)のように指定します。サービスアカウント を使用するには、プロパティkafka.service.account.id=<service-account-resource-ID>に リソース ID を指定します。使用できるサービスアカウントのリソース ID のリストを表示するには、次のコマンドを使用します。confluent iam service-account list
例:
confluent iam service-account list Id | Resource ID | Name | Description +---------+-------------+-------------------+------------------- 123456 | sa-l1r23m | sa-1 | Service account 1 789101 | sa-l4d56p | sa-2 | Service account 2
"datadog.domain": Datadog プロジェクトがあるドメインに応じて、COM または EU を選択します。"datadog.api.key": これは Datadog プロジェクトの API キーです。API キーを作成するには、「API キーまたはクライアントトークンを追加する」を参照してください。"tasks.max": このコネクターで使用できる タスク の最大数を入力します。タスクが多いほどパフォーマンスが向上する可能性があります(複数のタスクを実行するとコンシューマーラグが減少します)。"topics": 特定のトピック名を指定するか、複数のトピック名をコンマ区切りにしたリストを指定します。"max.retry.time.ms": ポストリクエストエラーが発生した場合は、ここに入力した時間が経過するまで、コネクターにより再試行されます。この値は、1000ミリ秒(ms)以上に設定する必要があります。デフォルトの再試行時間は5000ミリ秒(5 秒)です。
Single Message Transforms: CLI を使用した SMT の追加の詳細については、Single Message Transforms(SMT) のドキュメントを参照してください。このコネクターでサポートされていない SMT のリストについては、「サポートされない変換」を参照してください。
すべてのプロパティの値と定義については、「構成プロパティ」を参照してください。
ステップ 4: プロパティファイルを読み込み、コネクターを作成します。¶
以下のコマンドを入力して、構成を読み込み、コネクターを起動します。
confluent connect create --config <file-name>.json
例:
confluent connect create --config datadog-metrics-sink-config.json
出力例:
Created connector DatadogMetricsSinkConnector_0 lcc-do6vzd
ステップ 5: コネクターのステータスを確認します。¶
以下のコマンドを入力して、コネクターのステータスを確認します。
confluent connect list
出力例:
ID | Name | Status | Type | Trace
+------------+-------------------------------+---------+------+-------+
lcc-do6vzd | DatadogMetricsSinkConnector_0 | RUNNING | sink |
ステップ 6: レコードを確認します。¶
メトリクスが生成されていることを確認します。Datadog プロジェクトで Metrics Explorer に移動し、Kafka トピックの metric プロパティに使用した名前("metric": "test.metric" など)でグラフを検索します。
Connect 用の Confluent Cloud API の使用に関する詳細とサンプルについては、「Confluent Cloud API for Connect」セクションを参照してください。
ちなみに
コネクターを起動すると、デッドレターキューのトピックが自動的に生成されます。詳細については、「Confluent Cloud デッドレターキュー」を参照してください。
構成プロパティ¶
このコネクターでは、以下のコネクター構成プロパティを使用します。
データの取得元とするトピック(Which topics do you want to get data from?)¶
topics特定のトピック名を指定するか、複数のトピック名をコンマ区切りにしたリストを指定します。
- 型: list
- 重要度: 高
入力メッセージ(Input messages)¶
input.data.formatKafka 入力レコード値のフォーマットを設定します。指定可能なエントリは、AVRO、JSON_SR、PROTOBUF、JSON、または BYTES です。スキーマベースのメッセージフォーマット(AVRO、JSON_SR、PROTOBUF など)を使用する場合は、Confluent Cloud Schema Registry を構成しておく必要がある点に注意してください。
- 型: string
- 重要度: 高
データへの接続方法(How should we connect to your data?)¶
nameコネクターの名前を設定します。
- 型: string
- 指定可能な値: 最大 64 文字の文字列
- 重要度: 高
Kafka クラスターの認証情報(Kafka Cluster credentials)¶
kafka.auth.modeKafka の認証モード。KAFKA_API_KEY または SERVICE_ACCOUNT を指定できます。デフォルトは KAFKA_API_KEY モードです。
- 型: string
- デフォルト: KAFKA_API_KEY
- 指定可能な値: KAFKA_API_KEY、SERVICE_ACCOUNT
- 重要度: 高
kafka.api.key- 型: password
- 重要度: 高
kafka.service.account.idKafka クラスターとの通信用の API キーを生成するために使用されるサービスアカウント。
- 型: string
- 重要度: 高
kafka.api.secret- 型: password
- 重要度: 高
Datadog への接続方法(How should we connect to Datadog?)¶
datadog.api.keyDatadog エージェントでメトリクスとイベントを datadog に送信するには Datadog API キーが必要です
- 型: password
- 重要度: 高
datadog.siteDatadog site to which the datadog account belongs to. There are five possible values:
US1,US3,US5,EU1orUS1-FED. This setting is used to determine the Datadog API, connector will use to post metrics to. In case this config is not configured, Datadog API is determined bydatadog.domainconfig value.- 型: string
- Default: ""
- 重要度: 高
datadog.domainDatadog domain to which the datadog account belongs to. The two possible values are
EUorCOM. Ifdatadog.siteis not configured, then this setting will determine the Datadog API which connector will use to post metrics to. The value EU will map to https://api.datadoghq.eu and COM will map to https://api.datadoghq.com.- 型: string
- Default: COM
- 重要度: 低
Datadog の詳細(Datadog Details)¶
max.retry.time.msポストリクエストの実行中にエラーが発生した場合、この時間(ミリ秒)が経過するまでコネクターにより再試行されます。デフォルト値は 5000(5 秒)です。この値を 1 秒以上に設定することをおすすめします。
- 型: int
- デフォルト: 5000(5 秒)
- 指定可能な値: [1000、…]
- 重要度: 低
エラーの処理方法(How should we handle errors?)¶
behavior.on.errorKafka レコード値からのメトリックの抽出中にエラーが発生した場合のエラー処理の動作の設定です。指定可能なオプションは「log」と「fail」です。「log」の場合、エラーメッセージが error-<connector-id> トピックに記録されて処理が続行されます。「fail」の場合、エラーが発生するとコネクターを停止します。
- 型: string
- デフォルト: log
- 重要度: 低
このコネクターのタスク数(Number of tasks for this connector)¶
tasks.max- 型: int
- 指定可能な値: [1、…]
- 重要度: 高
次のステップ¶
参考
フルマネージド型の Confluent Cloud コネクターが Confluent Cloud ksqlDB でどのように動作するかを示す例については、「Cloud ETL のデモ」を参照してください。この例では、Confluent CLI を使用して Confluent Cloud のリソースを管理する方法についても説明しています。
