重要
このページの日本語コンテンツは古くなっている可能性があります。最新の英語版コンテンツをご覧になるには、こちらをクリックしてください。
Google Cloud Storage Sink Connector for Confluent Cloud¶
注釈
Confluent Platform 用にコネクターをローカルにインストールする場合は、「Google Cloud Storage Sink Connector for Confluent Platform」を参照してください。
Kafka Connect Google Cloud Storage(GCS)Sink Connector for Confluent Cloud を使用すると、Avro、JSON スキーマ、Protobuf、JSON(スキーマレス)、または Bytes フォーマットの Apache Kafka® トピックのデータを、Avro、Bytes、JSON、または Parquet フォーマットで GCS にエクスポートできます。Parquet 出力フォーマットは、専用クラスター および スタンダードクラスター でのみ使用できます。
さらに、特定のデータレイアウトにおいては、生成する GCS オブジェクトのコンシューマーに対して "厳密に 1 回" のデリバリーセマンティクスを保証することによってデータをエクスポートできます。
機能¶
Google Cloud Storage(GCS)Sink Connector には、以下の機能があります。
「厳密に 1 回」のデリバリー: 決定的パーティショナーを使用してエクスポートされたレコードは、GCS の結果整合性にかかわらず、「厳密に 1 回」のセマンティクスで送達されます。
スキーマありまたはスキーマなしのデータフォーマット: このコネクターは、Avro、JSON スキーマ、Protobuf、JSON(スキーマレス)、または Bytes の入力データフォーマットをサポートします。出力フォーマットとしては Avro、Bytes、JSON、Parquet をサポートします。スキーマベースのメッセージフォーマット(Avro など)を使用するには、有効なスキーマが Schema Registry に存在する必要があります。詳細については、「スキーマレジストリ Enabled Environments」を参照してください。
注釈
Parquet 出力フォーマットは、専用クラスター および スタンダードクラスター でのみ使用できます。
スキーマの進化:
schema.compatibilityはNONEに設定されます。スケジュールによるローテーションとローテーション間隔: コネクターは、スケジュールされた一定間隔で、ファイルをクローズしてストレージにアップロードすることができます。詳細については、「スケジュールによるローテーション」を参照してください。
パーティショナー: このコネクターは、Kafka クラスの
TimeStampに基づいたTimeBasedPartitionerクラスをサポートします。時間ベースのパーティショニングの選択肢は、日次または毎時です。Flush size : デフォルト値は 1000 です。この値は、必要に応じて増やすことができます。Confluent Cloud 専用クラスター を実行する場合は、この値を下げることができます(最小値 1)。専用ではないクラスターの最小値は 1000 です。
どのような状況でレコードがストレージにフラッシュされるかを説明するために、以下に例を示します。
デフォルト設定の 1000 を使用していて、トピックには 6 つのパーティションがあります。1000 件を超えるレコードが各パーティションに存在するようになると、ストレージでのファイルの作成が開始されます。
デフォルト設定の 1000 を使用していて、パーティショナーが "毎時" に設定されています。午後 2 時から午後 3 時までの間に 1 つのパーティションに 500 件のレコードが到達しました。午後 3 時にさらに 5 件のレコードがそのパーティションに到達しました。午後 3 時のストレージには、500 件のレコードが格納されます。
注釈
rotate.schedule.interval.msプロパティとrotate.interval.msプロパティをflush.sizeと一緒に使用して、ストレージにファイルを作成する条件を指定できます。これらのパラメーターが有効になると、最初に満たされた条件に基づいてファイルが保管されます。たとえば、トピックのパーティションが 1 つあるとします。
flush.size=1000とrotate.schedule.interval.ms=600000(10 分)を設定します。12:01 から 12:10 までの間にこのトピックパーティションに 500 件のレコードが到達しました。12:11 から 12:20 までの間にさらに 500 件のレコードが到達しました。それぞれ 500 件のレコードが入った 2 つのファイルがストレージバケットに作成されます。これは、flush.size=1000条件が満たされる前に、10 分のrotate.schedule.interval.ms条件が作動したからです。
Connect 用の Confluent Cloud API の使用に関する詳細とサンプルについては、「Confluent Cloud API for Connect」セクションを参照してください。
制限¶
以下の情報を確認してください。
- コネクターの制限事項については、Google Cloud Storage Sink Connector の制限事項を参照してください。
- 1 つ以上の Single Message Transforms(SMT)を使用する場合は、「SMT の制限」を参照してください。
- Confluent Cloud Schema Registry を使用する場合は、「スキーマレジストリ Enabled Environments」を参照してください。
クイックスタート¶
このクイックスタートを使用して、Confluent Cloud GCS Sink Connector の利用を開始することができます。このクイックスタートでは、Confluent Cloud Console または Confluent CLI を使用して、コネクターを選択し、GCS バケットにイベントをストリーミングするようにコネクターを構成するための基本的な方法について説明します。
- 前提条件
GCP 上の Confluent Cloud クラスターへのアクセスを許可されていること。
Confluent CLI がインストールされ、クラスター用に構成されていること。「Confluent CLI のインストール」を参照してください。
スキーマレジストリ ベースのフォーマット(Avro、JSON_SR(JSON スキーマ)、Protobuf など)を使用するには、Schema Registry を有効にしておく必要があります。詳細については、「スキーマレジストリ Enabled Environments」を参照してください。
Confluent Cloud クラスターと 同じリージョン にある GCP GCS バケット。
GCP サービスアカウント。サービスアカウントの 認証情報を JSON ファイル 形式でダウンロードします。コネクター構成のセットアップ時にこれらの認証情報を使用します。
重要
使用する GCP サービスアカウント のロールには、GCS バケットでのオブジェクトの取得、作成、削除のアクセス許可が必要です。次の点に注意してください。
- このために、ストレージ管理者 ロールを選択できます。
- セキュリティについて懸念があり、ストレージ管理者ロールの使用が望ましくない場合は、アクセス権限 storage.objects.get、storage.objects.create、storage.objects.delete を使用してください。サービスアカウントに storage.buckets.get アクセス権がないという検証エラーを受け取った場合は、この従来型のアクセス権限を追加してください。
- ストレージオブジェクト管理者 ロールはこの目的には使用できません。
- Kafka クラスターの認証情報。次のいずれかの方法で認証情報を指定できます。
- 既存の サービスアカウント のリソース ID を入力する。
- コネクター用の Confluent Cloud サービスアカウント を作成します。「サービスアカウント」のドキュメントで、必要な ACL エントリを確認してください。一部のコネクターには固有の ACL 要件があります。
- Confluent Cloud の API キーとシークレットを作成する。キーとシークレットを作成するには、confluent api-key create を使用するか、コネクターのセットアップ時に Cloud Console で直接 API キーとシークレットを自動生成します。
注意
kafka-connect-storage-common を使用してスキーマレコードとスキーマレスレコードをストレージに混在させることはできません。このようにするとランタイム例外が発生します。このコネクターの セルフマネージド型 バージョンを使用する場合は、ログファイル (セルフマネージド型コネクターでのみ使用可能)を参照すると、この問題が明らかになります。
Confluent Cloud Console の使用¶
コネクターをセットアップして実行するには、次の手順を実行します。
ステップ 1: Confluent Cloud クラスターを起動します。¶
インストール手順については、「Quick Start for Confluent Cloud」を参照してください。
ステップ 2: コネクターを追加します。¶
左のナビゲーションメニューの Data integration をクリックし、Connectors をクリックします。クラスター内に既にコネクターがある場合は、+ Add connector をクリックします。
ステップ 4: 接続をセットアップします。¶
注釈
- すべての 前提条件 を満たしていることを確認してください。
- アスタリスク( * )は必須項目であることを示しています。
Add Google Cloud Storage Sink connector 画面で、以下を実行します。
既に Kafka トピックを用意している場合は、Topics リストから接続するトピックを選択します。
新しいトピックを作成するには、+Add new topic をクリックします。
- Kafka Cluster credentials で Kafka クラスターの認証情報の指定方法を選択します。以下のいずれかのオプションを選択できます。
- Global Access: コネクターは、ユーザーがアクセス権限を持つすべての対象にアクセスできます。グローバルアクセスの場合、コネクターのアクセス権限は、ユーザーのアカウントにリンクされます。このオプションは本稼働環境では推奨されません。
- Granular access: コネクターのアクセスが制限されます。コネクターのアクセス権限は サービスアカウント から制御できます。本稼働環境にはこのオプションをお勧めします。
- Use an existing API key: 保存済みの API キーおよびシークレット部分を入力できます。API キーとシークレットを入力するか Cloud Console でこれらを生成することもできます。
- Continue をクリックします。
- GCP credentials セクションで、GCP 認証情報の JSON ファイルをアップロードします。これらのセットアップ方法については、「プログラムによるアクセス」を参照してください。
- Google Cloud Storage bucket name セクションで、GCS バケット名を入力します。
- Continue をクリックします。
注釈
Cloud Console に表示されない構成プロパティでは、デフォルト値が使用されます。すべてのプロパティの値と定義については、「構成プロパティ」を参照してください。
Input Kafka record value format で、Kafka 入力レコード値のフォーマット(Kafka トピックから送られるデータ)を AVRO、JSON_SR(JSON スキーマ)、PROTOBUF、JSON(スキーマレス)または BYTES から選択します。スキーマベースのメッセージフォーマット(Avro、JSON_SR(JSON スキーマ)、Protobuf など)を使用するには、有効なスキーマが Schema Registry に存在する必要があります。
注釈
このコネクターでは、JSON フォーマットで入力して AVRO フォーマットで出力することはできません。
Output message format で、出力メッセージフォーマット(コネクターから送られるデータ)を AVRO、PARQUET、JSON、または BYTES から選択します。Parquet 出力フォーマットは、専用クラスター でのみ使用できます。スキーマベースのメッセージフォーマット(Avro など)を使用するには、有効なスキーマが Schema Registry に存在する必要があります。
注釈
以下の Topic directory、Path format、および Time interval の各プロパティを使用して、格納するデータのディレクトリ構造を作成できます。たとえば、Time interval を
HOURLY、Topics directory をjson_logs/hourly、Path format を'dt'=YYYY-MM-dd/'hr'=HHに設定します。この場合のディレクトリ構造は、s3://<s3-bucket-name>/json_logs/hourly/<Topic-Name>/dt=2020-02-06/hr=09/<files>になります。Time interval で、メッセージをバケットに分ける時間間隔を選択します。たとえば、
HOURLYを選択すると、1 時間ごとに、メッセージがフォルダーに分けられてデータがバケットにストリーミングされます。Flush size に入力します。この値のデフォルト値は 1000 です。デフォルト値は、必要に応じて増減できます。
どのような状況でレコードがストレージにフラッシュされるかを説明するために、以下に例を示します。
デフォルト設定の 1000 を使用していて、トピックには 6 つのパーティションがあります。1000 件を超えるレコードが各パーティションに存在するようになると、ストレージでのファイルの作成が開始されます。
デフォルト設定の 1000 を使用していて、パーティショナーが "毎時" に設定されています。午後 2 時から午後 3 時までの間に 1 つのパーティションに 500 件のレコードが到達しました。午後 3 時にさらに 5 件のレコードがそのパーティションに到達しました。午後 3 時のストレージには、500 件のレコードが格納されます。
注釈
rotate.schedule.interval.msプロパティとrotate.interval.msプロパティをflush.sizeと一緒に使用して、ストレージにファイルを作成する条件を指定できます。これらのパラメーターが有効になると、最初に満たされた条件に基づいてファイルが保管されます。たとえば、トピックのパーティションが 1 つあるとします。
flush.size=1000とrotate.schedule.interval.ms=600000(10 分)を設定します。12:01 から 12:10 までの間にこのトピックパーティションに 500 件のレコードが到達しました。12:11 から 12:20 までの間にさらに 500 件のレコードが到達しました。それぞれ 500 件のレコードが入った 2 つのファイルがストレージバケットに作成されます。これは、flush.size=1000条件が満たされる前に、10 分のrotate.schedule.interval.ms条件が作動したからです。
Show advanced configurations
Topic directory: 取り込んだデータが格納される最上位ディレクトリ。使用しない場合は、
topicsがデフォルトとして使用されます。Parquet Compression Codec: 出力ファイルに使用する Parquet 圧縮コーデック。使用しない場合は、
snappyがデフォルトとして使用されます。Path format: これによって、作成される時間ベースのパーティション分割のパスを構成できます。このプロパティでは、UNIX のタイムスタンプが日付フォーマットの文字列に変換されます。このプロパティを使用しない場合は、
'year'=YYYY/'month'=MM/'day'=dd/'hour'=HH(Time interval にHOURLYを選択した場合)または'year'=YYYY/'month'=MM/'day'=dd(Daily Time interval を選択した場合)がデフォルトとして使用されます。Maximum span of record time (in ms before scheduled rotation): ファイルを閉じてストレージにアップロードする定期的なスケジュールを構成するフィールドです。最小値は 600000 ミリ秒(10 分)です。デフォルト値は -1 (無効)です。600000 ミリ秒に設定すると、少なくとも 10 分ごとにストレージバケットにファイルが生成されます。スケジュールによるローテーション のプロパティの詳細については、「スケジュールによるローテーション」を参照してください。
Maximum span of record time (in ms) before rotation: ファイルを開いてレコードを書き込みできる状態にしておく期間の最大値(ミリ秒)を構成するフィールドです。このプロパティを使用する場合、ファイルの期間は、ファイルに追加された最初のレコードのタイムスタンプから開始します。それ以降に到着したレコードのタイムスタンプが、最初のファイルのタイムスタンプに基づいて決められた期間内に収まっていない場合、コネクターはファイルを閉じてストレージにアップロードします。最小値は 600000 ミリ秒(10 分)です。このプロパティのデフォルトは、time.interval プロパティで設定された間隔です。スケジュールによるローテーション のプロパティの詳細については、「スケジュールによるローテーション」を参照してください。
Timestamp field name: タイムスタンプとして使用するレコードフィールドです。これが時間ベースパーティショナーで使用されます。使用しない場合は、Kafka レコードを Kafka ブローカーが生成または格納したタイムスタンプがデフォルトとして使用されます。
Timezone: 有効なタイムゾーン を使用します。使用しない場合は、
UTCがデフォルト設定されます。Locale: 日付および時刻のフォーマット設定に使用されます。たとえば、英語(米国)の場合は
en-US、英語(英国)の場合はen-GB、英語(インド)の場合はen-IN、フランス語(フランス)の場合はfr-FRを使用できます。デフォルトはenです。ロケール ID のリストについては、『Java のロケール』を参照してください。注釈
Parquet を使用する場合の圧縮タイプとして、現在
PARQUET - none、PARQUET - gzip、およびPARQUET - snappyのみがサポートされています。How to handle records with null values: null 値を含むレコード(Kafka tombstone レコードなど)を処理する方法。デフォルトは
ignoreです。Preserves Avro schema information: デフォルトでは true です。
trueに設定すると、Avro スキーマから Connect スキーマへの変換時に、Avro スキーマのパッケージ情報と Enum が維持されます。この情報は、Connect スキーマから Avro スキーマへの変換時に再度追加されます。Schema compatibility: コネクターがスキーマ変更を検出する場合に使用されるスキーマの互換性規則。
Compression when using JSON/ByteArray output format: Google Cloud に書き込まれるファイルの圧縮タイプ。JsonFormat または ByteArrayFormat を使用する場合に適用されます。デフォルトは
noneです。Value converter connect metadata: メタデータを出力スキーマに追加する Connect コンバーターを有効または無効にします。デフォルトは
trueです。Part size in multipart uploads: GCS オブジェクトのマルチパートアップロード用のパートのサイズ(バイト)。デフォルトは
5242880です。
Continue をクリックします。
選択するトピックのパーティション数に基づいて、推奨タスク数が表示されます。1 つのタスクで処理できるパーティションの数は最大 100 個です。
推奨されたタスク数を変更するには、Tasks フィールドに、コネクターで使用する タスク の数を入力します。
コネクターのサイズ設定の詳細については、How many tasks do I need? をクリックしてください。
Continue をクリックします。
注釈
詳細については、Single Message Transforms(SMT) のドキュメントを参照してください。このコネクターでサポートされていない SMT のリストについては、「サポートされない変換」を参照してください。
構成の概要を確認し、以下を検証します。
データが正しいバケットに振り分けられることを確認します。
表示されたパスの最後のディレクトリに、前の手順で Time Interval に入力した時間間隔が使用されていることを確認します。

コネクターのステータスが Provisioning から Running に変わります。

Launch をクリックします。
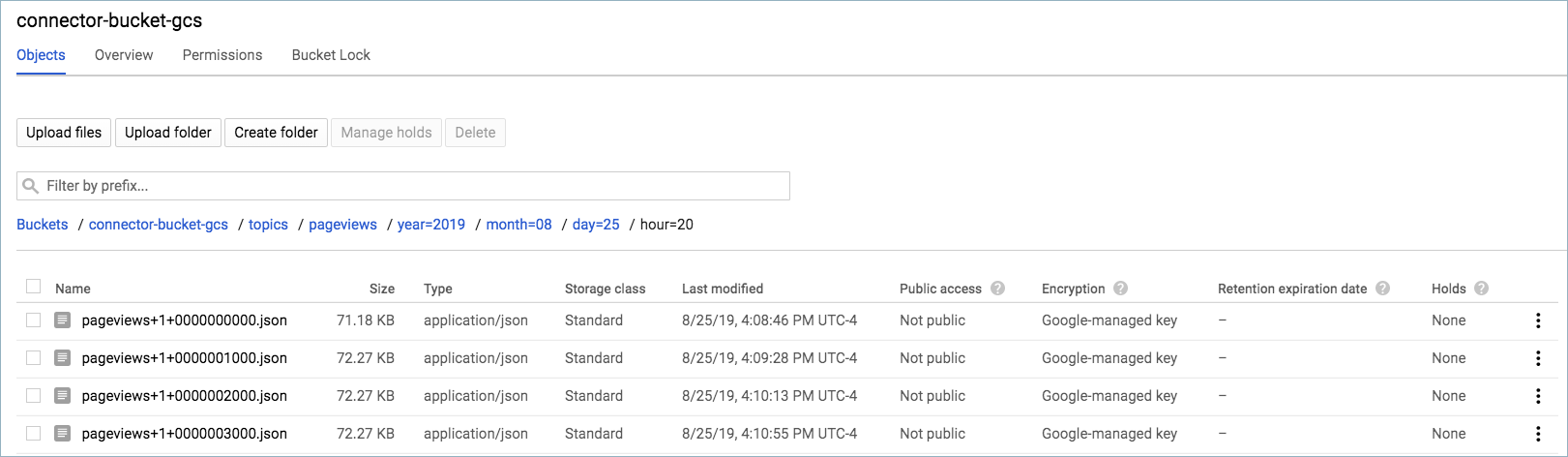
ステップ 5: GCS バケットを確認します。¶
GCS バケットの Objects ページに移動します。
メッセージが表示されるまで、トピックのフォルダーと各下位フォルダーを開いていきます。
Connect 用の Confluent Cloud API の使用に関する詳細とサンプルについては、「Confluent Cloud API for Connect」セクションを参照してください。
ちなみに
コネクターを起動すると、デッドレターキューのトピックが自動的に生成されます。詳細については、「Confluent Cloud デッドレターキュー」を参照してください。
参考
フルマネージド型の Confluent Cloud コネクターが Confluent Cloud ksqlDB でどのように動作するかを示す例については、「Cloud ETL のデモ」を参照してください。この例では、Confluent CLI を使用して Confluent Cloud のリソースを管理する方法についても説明しています。

Confluent CLI を使用する場合¶
以下の手順に従うと、Confluent CLI を使用してコネクターをセットアップし、実行できます。
注釈
- すべての 前提条件 を満たしていることを確認してください。
- コマンド例では Confluent CLI バージョン 2 を使用しています。詳細については、「Confluent CLI v2 への移行 <https://docs.confluent.io/confluent-cli/current/migrate.html#cli-migrate>`__」を参照してください。
ステップ 2: コネクターの必須の構成プロパティを表示します。¶
以下のコマンドを実行して、コネクターの必須プロパティを表示します。
confluent connect plugin describe <connector-catalog-name>
例:
confluent connect plugin describe GcsSink
出力例:
Following are the required configs:
connector.class
kafka.auth.mode
kafka.api.key
kafka.api.secret
topics
input.data.format
output.data.format
gcs.credentials.config
gcs.bucket.name
time.interval
tasks.max
ステップ 3: コネクターの構成ファイルを作成します。¶
コネクター構成プロパティを含む JSON ファイルを作成します。以下の例は、コネクターの必須プロパティを示しています。
{
"name" : "confluent-gcs-sink",
"connector.class" : "GcsSink",
"kafka.auth.mode": "KAFKA_API_KEY",
"kafka.api.key" : "<my-kafka-api-keyk>",
"kafka.api.secret" : "<my-kafka-api-secret>",
"topics" : "pageviews",
"input.data.format" : "AVRO",
"output.data.format" : "AVRO",
"gcs.credentials.config" : "omitted"
"gcs.bucket.name" : "<my-gcs-bucket-name>",
"time.interval" : "HOURLY",
"flush.size": "1000",
"tasks.max" : "1"
}
以下のプロパティ定義に注意してください。
connector.class: コネクターのプラグイン名を指定します。name: 新しいコネクターの名前を設定します。
"kafka.auth.mode": 使用するコネクターの認証モードを指定します。オプションはSERVICE_ACCOUNTまたはKAFKA_API_KEY(デフォルト)です。API キーとシークレットを使用するには、構成プロパティkafka.api.keyとkafka.api.secretを構成例(前述)のように指定します。サービスアカウント を使用するには、プロパティkafka.service.account.id=<service-account-resource-ID>に リソース ID を指定します。使用できるサービスアカウントのリソース ID のリストを表示するには、次のコマンドを使用します。confluent iam service-account list
例:
confluent iam service-account list Id | Resource ID | Name | Description +---------+-------------+-------------------+------------------- 123456 | sa-l1r23m | sa-1 | Service account 1 789101 | sa-l4d56p | sa-2 | Service account 2
topics: 特定のトピック名を指定するか、複数のトピック名をコンマ区切りにしたリストを指定します。input.data.format: 入力メッセージフォーマット(Kafka トピックから送られるデータ)を設定します。入力できる値は、AVRO、JSON_SR、PROTOBUF、JSON、または BYTES です。スキーマベースのメッセージフォーマット(Avro、JSON_SR(JSON スキーマ)、Protobuf など)を使用するには、Confluent Cloud Schema Registry を構成しておく必要があります。注釈
このコネクターでは、JSON フォーマットで入力して AVRO フォーマットで出力することはできません。
"output.data.format": Kafka 出力レコード値のフォーマット(コネクターから送られるデータ)を設定します。指定可能なエントリは、AVRO、BYTES、JSON、または PARQUET です。Parquet 出力フォーマットは、専用クラスター および スタンダードクラスター でのみ使用できます。スキーマベースのメッセージフォーマット(Avro など)を使用するには、有効なスキーマが Schema Registry に存在する必要があります。gcs.credentials.config: ダウンロードした JSON ファイルの内容が入ります。ダウンロードした認証情報ファイルの内容をフォーマットして使用する方法について詳しくは、「GCS 認証情報のフォーマットの変更」を参照してください。rotate.schedule.interval.msおよびrotate.interval.ms: これらのプロパティの使用方法について詳しくは、「スケジュールによるローテーション」を参照してください。(省略可)``flush.size``: デフォルト値は 1000 です。この値は、必要に応じて増やすことができます。Confluent Cloud 専用クラスター を実行する場合は、この値を下げることができます(最小値 1)。専用ではないクラスターの最小値は 1000 です。
どのような状況でレコードがストレージにフラッシュされるかを説明するために、以下に例を示します。
デフォルト設定の 1000 を使用していて、トピックには 6 つのパーティションがあります。1000 件を超えるレコードが各パーティションに存在するようになると、ストレージでのファイルの作成が開始されます。
デフォルト設定の 1000 を使用していて、パーティショナーが "毎時" に設定されています。午後 2 時から午後 3 時までの間に 1 つのパーティションに 500 件のレコードが到達しました。午後 3 時にさらに 5 件のレコードがそのパーティションに到達しました。午後 3 時のストレージには、500 件のレコードが格納されます。
注釈
rotate.schedule.interval.msプロパティとrotate.interval.msプロパティをflush.sizeと一緒に使用して、ストレージにファイルを作成する条件を指定できます。これらのパラメーターが有効になると、最初に満たされた条件に基づいてファイルが保管されます。たとえば、トピックのパーティションが 1 つあるとします。
flush.size=1000とrotate.schedule.interval.ms=600000(10 分)を設定します。12:01 から 12:10 までの間にこのトピックパーティションに 500 件のレコードが到達しました。12:11 から 12:20 までの間にさらに 500 件のレコードが到達しました。それぞれ 500 件のレコードが入った 2 つのファイルがストレージバケットに作成されます。これは、flush.size=1000条件が満たされる前に、10 分のrotate.schedule.interval.ms条件が作動したからです。
time.interval: メッセージを GCS バケットに分ける方法を設定します。指定可能なエントリは、DAILYまたはHOURLYです。
ちなみに
上記の time.interval プロパティと、オプションのプロパティ topics.dir および path.format を使用して、S3 に格納するデータのディレクトリ構造を作成できます。例: "time.interval" : "HOURLY"、"topics.dir" : "json_logs/hourly"、"path.format" : "'dt'=YYYY-MM-dd/'hr'=HH" を設定します。この場合、S3 のディレクトリ構造は、s3://<s3-bucket-name>/json_logs/daily/<Topic-Name>/dt=2020-02-06/hr=09/<files> になります。
ストレージのデータを編成するために使用できるオプションのプロパティを以下に示します。
topics.dir: 格納するデータに使用する最上位ディレクトリのパス。使用しない場合は、topicsがデフォルトとして使用されます。path.format: 作成される時間ベースのパーティション分割のパスを構成します。このプロパティでは、UNIX のタイムスタンプが日付フォーマットの文字列に変換されます。このプロパティを使用しない場合は、'year'=YYYY/'month'=MM/'day'=dd/'hour'=HH(Time interval にHOURLYを選択した場合)または'year'=YYYY/'month'=MM/'day'=dd(Time interval にDAILYを選択した場合)がデフォルトとして使用されます。
Single Message Transforms: CLI を使用した SMT の追加の詳細については、Single Message Transforms(SMT) のドキュメントを参照してください。このコネクターでサポートされていない SMT のリストについては、「サポートされない変換」を参照してください。
すべてのプロパティの値と定義については、「構成プロパティ」を参照してください。
ステップ 4: 構成ファイルを読み込み、コネクターを作成します。¶
以下のコマンドを入力して、構成を読み込み、コネクターを起動します。
confluent connect create --config <file-name>.json
例:
confluent connect create --config gcs-sink-config.json
出力例:
Created connector confluent-gcs-sink lcc-ix4dl
ステップ 5: コネクターのステータスを確認します。¶
以下のコマンドを入力して、コネクターのステータスを確認します。
confluent connect list
出力例:
ID | Name | Status | Type
+-----------+--------------------+---------+------+
lcc-ix4dl | confluent-gcs-sink | RUNNING | sink
ステップ 6: GCS バケットを確認します。¶
GCS バケットの Objects ページに移動します。
メッセージが表示されるまで、トピックのフォルダーと各下位フォルダーを開いていきます。
Connect 用の Confluent Cloud API の使用に関する詳細とサンプルについては、「Confluent Cloud API for Connect」セクションを参照してください。
ちなみに
コネクターを起動すると、デッドレターキューのトピックが自動的に生成されます。詳細については、「Confluent Cloud デッドレターキュー」を参照してください。
GCS 認証情報のフォーマットの変更¶
ダウンロードした認証情報ファイルの内容は、コネクター構成で使用する前に、文字列フォーマットに変換する必要があります。
JSON ファイルの内容を文字列フォーマットに変換します。これは、オンラインのコンバーターツールを使用して実行できます。たとえば、JSON to String Online Converter などがあります。
Private Key セクションの
\nのすべての出現箇所の前にエスケープ文字\を追加します。これで、各セクションの先頭が\\nになります(以下の強調表示された行を参照してください)。以下の例は、\\nの出現箇所がわかりすいようにフォーマットを整えています。認証情報キーの大部分は省略しています。ちなみに
認証情報を文字列に変換し、さらに必要に応じてエスケープ文字
\を追加するスクリプトも用意されています。Stringify GCP Credentials を参照してください。{ "name" : "confluent-gcs-sink", "connector.class" : "GcsSink", "kafka.api.key" : "<my-kafka-api-keyk>", "kafka.api.secret" : "<my-kafka-api-secret>", "topics" : "pageviews", "data.format" : "AVRO", "gcs.credentials.config" : "{\"type\":\"service_account\",\"project_id\":\"connect- 1234567\",\"private_key_id\":\"omitted\", \"private_key\":\"-----BEGIN PRIVATE KEY----- \\nMIIEvAIBADANBgkqhkiG9w0BA \\n6MhBA9TIXB4dPiYYNOYwbfy0Lki8zGn7T6wovGS5pzsIh \\nOAQ8oRolFp\rdwc2cC5wyZ2+E+bhwn \\nPdCTW+oZoodY\\nOGB18cCKn5mJRzpiYsb5eGv2fN\/J \\n...rest of key omitted... \\n-----END PRIVATE KEY-----\\n\", \"client_email\":\"pub-sub@connect-123456789.iam.gserviceaccount.com\", \"client_id\":\"123456789\",\"auth_uri\":\"https:\/\/accounts.google.com\/o\/oauth2\/ auth\",\"token_uri\":\"https:\/\/oauth2.googleapis.com\/ token\",\"auth_provider_x509_cert_url\":\"https:\/\/ www.googleapis.com\/oauth2\/v1\/ certs\",\"client_x509_cert_url\":\"https:\/\/www.googleapis.com\/ robot\/v1\/metadata\/x509\/pub-sub%40connect- 123456789.iam.gserviceaccount.com\"}", "gcs.bucket.name" : "<my-gcs-bucket-name>", "time.interval" : "HOURLY", "tasks.max" : "1" }
変換したすべての文字列の内容を、上記の例のように構成ファイルの
"gcs.credentials.config"セクションに追加します。
スケジュールによるローテーション¶
ローテーションのスケジュールをセットアップできるように、2 つのオプションのプロパティが用意されています。これらのプロパティは、Cloud Console (以下の画面)と Confluent CLI にあります。
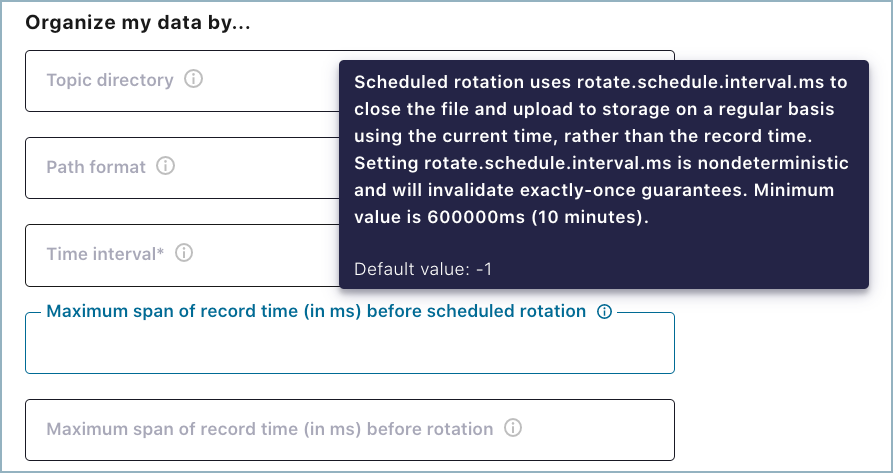
rotate.schedule.interval.ms(スケジュールによるローテーション): このプロパティを使用すると、ファイルを閉じてストレージにアップロードする定期的なスケジュールを構成できます。デフォルト値は-1(無効)です。たとえば、600000 ミリ秒に設定すると、少なくとも 10 分ごとにストレージバケットにファイルが生成されます。rotate.schedule.interval.msは、継続的なデータストリームを必要としません。注釈
rotate.schedule.interval.msプロパティを使用すると、非決定的な環境になるので、"厳密に 1 回" の保証は無効になります。rotate.interval.ms(ローテーションの間隔) : このプロパティを使用すると、追加レコードためにファイルを開いたままにできる最長期間(ミリ秒)を指定できます。このプロパティを使用する場合、ファイルのタイム時間間隔はファイルに追加された最初のレコードのタイムスタンプから開始します。最初のファイルのタイムスタンプから始まる期間に収まっていないタイムスタンプのレコードが到着したときに、コネクターはファイルをクローズしてストレージにアップロードします。最小値は 600000 ミリ秒(10 分)です。このプロパティのデフォルトは、time.intervalプロパティで設定された間隔です。rotate.interval.msは、継続的なデータストリームを必要とします。重要
期間の開始と終了は、ファイルのタイムスタンプによって決まります。そのため、最初のファイルのタイムスタンプから始まる期間に収まっていないタイムスタンプのレコードが到着するまで、ファイルが長時間開いたままになる可能性があります。
構成プロパティ¶
このコネクターでは、以下のコネクター構成プロパティを使用します。
データの取得元とするトピック(Which topics do you want to get data from?)¶
topics特定のトピック名を指定するか、複数のトピック名をコンマ区切りにしたリストを指定します。
- 型: list
- 重要度: 高
入力メッセージ(Input messages)¶
input.data.formatKafka 入力レコード値のフォーマットを設定します。指定可能なエントリは、AVRO、JSON_SR、PROTOBUF、JSON、または BYTES です。スキーマベースのメッセージフォーマット(AVRO、JSON_SR、PROTOBUF など)を使用する場合は、Confluent Cloud Schema Registry を構成しておく必要がある点に注意してください。
- 型: string
- 重要度: 高
データへの接続方法(How should we connect to your data?)¶
nameコネクターの名前を設定します。
- 型: string
- 指定可能な値: 最大 64 文字の文字列
- 重要度: 高
Kafka クラスターの認証情報(Kafka Cluster credentials)¶
kafka.auth.modeKafka の認証モード。KAFKA_API_KEY または SERVICE_ACCOUNT を指定できます。デフォルトは KAFKA_API_KEY モードです。
- 型: string
- デフォルト: KAFKA_API_KEY
- 指定可能な値: KAFKA_API_KEY、SERVICE_ACCOUNT
- 重要度: 高
kafka.api.key- 型: password
- 重要度: 高
kafka.service.account.idKafka クラスターとの通信用の API キーを生成するために使用されるサービスアカウント。
- 型: string
- 重要度: 高
kafka.api.secret- 型: password
- 重要度: 高
GCP 認証情報(GCP credentials)¶
gcs.credentials.configGoogle Cloud Storage への書き込みアクセス許可を持つ GCP サービスアカウントの JSON ファイル。
- 型: password
- 重要度: 高
Google Cloud Storage の詳細(Google Cloud Storage details)¶
gcs.bucket.nameGoogle Cloud Storage バケットが Confluent Cloud クラスターと同じリージョンに存在している必要があります。
- 型: string
- 重要度: 高
gcs.compression.typeGCS に書き込むファイルで使用する圧縮タイプ。JsonFormat または ByteArrayFormat を使用する場合に適用されます。使用可能な値: none、gzip
- 型: string
- デフォルト: none
- 重要度: 低
gcs.part.sizeGCS マルチパートアップロードにおけるパートのサイズ(バイト)。
- 型: int
- デフォルト: 5242880
- 指定可能な値: [5242880,...,2147483647]
- 重要度: 高
出力メッセージ(Output messages)¶
output.data.formatSet the output message format for values. Valid entries are AVRO, JSON, PARQUET or BYTES. Note that you need to have Confluent Cloud Schema Registry configured if using a schema-based message format like AVRO. Note that the output message format defaults to the value in the Input Message Format field. If either PROTOBUF or JSON_SR is selected as the input message format, you should select one explicitly. If no value for this property is provided, the value specified for the 'input.data.format' property is used.
- 型: string
- 重要度: 高
parquet.codecGCS に書き込む parquet ファイルの圧縮タイプ。
- 型: string
- 重要度: 高
データ編成の基準(Organize my data by...)¶
topics.dir取り込んだデータが保管されるトップレベルディレクトリ。
- 型: string
- デフォルト: topics
- 重要度: 高
path.formatTimeBasedPartitioner を使用してパーティション分割を行う場合に、この構成を使用して、データディレクトリのフォーマットを設定します。この構成で設定した形式に従って、UNIX のタイムスタンプが適切なディレクトリ文字列に変換されます。s3://<s3-bucket-name>/json_logs/daily/<Topic-Name>/dt=2020-02-06/hr=09/<files> のようにファイルを編成するには、topic.directory=json_logs/daily、path.format='dt'=YYYY-MM-dd/'hr'=HH、time.interval=HOURLY を使用してください。
- 型: string
- デフォルト: 'year'=YYYY/'month'=MM/'day'=dd/'hour'=HH
- 重要度: 高
time.intervalストレージに取り込まれた時間に応じた、データのパーティショニング間隔。
- 型: string
- 重要度: 高
rotate.schedule.interval.msスケジュールによるローテーションでは、rotate.schedule.interval.ms を使用して定期的にファイルを閉じ、ストレージにアップロードします。その際、レコードの時刻ではなく、現在時刻が使用されます。rotate.schedule.interval.ms の設定は非決定的であり、"厳密に 1 回" の保証は無効になります。最小値は 600000 ミリ秒(10 分)です。
- 型: int
- デフォルト: -1
- 重要度: 中
rotate.interval.msコネクターのローテーションの間隔では、ファイルを開いてレコードを書き込みできる状態にしておく期間の最大値(ミリ秒)を指定します。つまり、rotate.interval.ms を使用する場合、各ファイルのタイムスタンプはファイルに挿入された最初のレコードのタイムスタンプから開始します。次のレコードのタイムスタンプが最初のレコードのタイムスタンプのファイルの rotate.interval の期間に収まらない場合、コネクターはファイルを閉じて Blob Storage にアップロードします。コネクターで処理するレコードがそれ以上ない場合、次のレコードを処理できるようになるまでの間、コネクターはファイルを開いたままにすることがあります(長時間になる可能性があります)。最小値は 600000 ミリ秒(10 分)です。このプロパティの値が指定されていない場合、'time.interval' プロパティに指定されている値が使用されます。
- 型: int
- 重要度: 高
flush.sizeファイルのコミットを呼び出す前にストレージに書き込まれるレコードの数。
- 型: int
- デフォルト: 1000
- 重要度: 高
timestamp.fieldTimeBasedPartitioner に使用されるタイムスタンプを含むフィールドを設定します
- 型: string
- デフォルト: ""
- 重要度: 高
timezoneTimeBasedPartitioner で使用されるタイムゾーンを設定します。
- 型: string
- デフォルト: UTC
- 重要度: 高
behavior.on.null.valuesnull 値を含むレコード(Kafka tombstone レコードなど)を処理する方法。指定可能なオプションは、「ignore」および「fail」です。デフォルトは「ignore」です
- 型: string
- デフォルト: ignore
- 重要度: 低
localeTimeBasedPartitioner で使用するロケールを設定します。
- 型: string
- デフォルト: en
- 重要度: 高
enhanced.avro.schema.supporttrue に設定すると、Avro スキーマから Connect スキーマへの変換時に、Avro スキーマのパッケージ情報と Enum が維持されます。この情報は、Connect スキーマから Avro スキーマへの変換時に再度追加されます。
- 型: boolean
- デフォルト: true
- 重要度: 低
schema.compatibilityコネクターによってスキーマ変更が検出された場合に使用されるスキーマの互換性規則。
- 型: string
- デフォルト: NONE
- 重要度: 高
value.converter.connect.meta.dataConnect コンバーターの有効化と無効化を切り替えて、メタデータを出力スキーマに追加するかどうかを指定します。
- 型: boolean
- デフォルト: true
- 重要度: 中
このコネクターのタスク数(Number of tasks for this connector)¶
tasks.max- 型: int
- 指定可能な値: [1、…]
- 重要度: 高
次のステップ¶
参考
フルマネージド型の Confluent Cloud コネクターが Confluent Cloud ksqlDB でどのように動作するかを示す例については、「Cloud ETL のデモ」を参照してください。この例では、Confluent CLI を使用して Confluent Cloud のリソースを管理する方法についても説明しています。