重要
このページの日本語コンテンツは古くなっている可能性があります。最新の英語版コンテンツをご覧になるには、こちらをクリックしてください。
MongoDB Atlas Source Connector for Confluent Cloud¶
注釈
Confluent Platform 用にコネクターをローカルにインストールする場合は、「MongoDB Source Connector for Confluent Platform」を参照してください。
Kafka Connect MongoDB Atlas Source Connector for Confluent Cloud を使用すると、MongoDB レプリカセットのデータを Apache Kafka® クラスターに移動できます。このコネクターは、変更ストリームイベントドキュメントを構成して消費し、Kafka トピックにそのドキュメントをパブリッシュします。
機能¶
注釈
このコネクターは MongoDB Atlas にのみ対応しています。セルフマネージド型の MongoDB データベースには使用できません。
MongoDB Atlas Source Connector には、以下の機能があります。
- トピックの自動作成: このコネクターは、命名規則
<prefix>.<database-name>.<collection-name>を使用して自動的に Kafka トピックを作成します。テーブルの作成にはtopic.creation.default.partitions=1プロパティおよびtopic.creation.default.replication.factor=3プロパティが使用されます。プレフィックスは、クイックスタートの手順で接続をセットアップするときに追加します。詳細については、「最大メッセージサイズ」を参照してください。特定の設定でトピックを作成する場合は、このコネクターを実行する前にトピックを作成する必要があります。 - データベースの認証: パスワード認証を使用します。
- 出力データフォーマット: Avro、Byte、JSON(スキーマレス)、JSON スキーマ、Protobuf、または String の出力データをサポートします。スキーマレジストリ ベースのフォーマット(Avro、JSON_SR(JSON スキーマ)、Protobuf など)を使用するには、Schema Registry を有効にしておく必要があります。詳細については、「スキーマレジストリ Enabled Environments」を参照してください。
- サイズの大きいレコード: 専用 Kafka クラスターでは最大 8 MB、その他のクラスターでは最大 2 MB までのサイズの MongoDb ドキュメントをサポートします。
- 厳選された構成プロパティ:
poll.await.time.ms: 変更ストリームに新しい結果がないか検査するまでの待ち時間。poll.max.batch.size: 新しいデータをポーリングするときに 1 回のバッチに含める変更ストリームドキュメントの最大数です。この設定を使用して、コネクターの内部でバッファに入れるデータ量を制限できます。
Connect 用の Confluent Cloud API の使用に関する詳細とサンプルについては、「Confluent Cloud API for Connect」セクションを参照してください。
制限¶
以下の情報を確認してください。
- コネクターの制限事項については、MongoDB Atlas Source Connector の制限事項を参照してください。
- 1 つ以上の Single Message Transforms(SMT)を使用する場合は、「SMT の制限」を参照してください。
- Confluent Cloud Schema Registry を使用する場合は、「スキーマレジストリ Enabled Environments」を参照してください。
最大メッセージサイズ¶
このコネクターはトピックを自動的に作成します。トピックの作成時に、内部コネクター構成プロパティ max.message.size が次のように設定されます。
- ベーシッククラスター:
2 MB - スタンダードクラスター:
2 MB - 専用クラスター:
20 MB
Confluent Cloud クラスターの詳細については、「クラスタータイプごとの Confluent Cloud の機能と制限」を参照してください。
クイックスタート¶
このクイックスタートを使用して、Confluent Cloud MongoDB Atlas Source Connector の利用を開始することができます。このクイックスタートでは、コネクターを選択してから、Kafka のデータを消費して MongoDB データベースにデータを保存するようにコネクターを構成するための基本的な方法について説明します。
注釈
このコネクターは MongoDB Atlas にのみ対応しています。セルフマネージド型の MongoDB データベースには使用できません。
- 前提条件
- アマゾンウェブサービス (AWS)、Microsoft Azure (Azure)、または Google Cloud Platform (GCP)上の Confluent Cloud クラスターへのアクセスを許可されていること。
- Confluent CLI がインストールされ、クラスター用に構成されていること。「Confluent CLI のインストール」を参照してください。
- スキーマレジストリ ベースのフォーマット(Avro、JSON_SR(JSON スキーマ)、Protobuf など)を使用するには、Schema Registry を有効にしておく必要があります。詳細については、「スキーマレジストリ Enabled Environments」を参照してください。
- MongoDB データベースへのアクセス。MongoDB データベースでクエリを実行するために、接続ユーザーには 特権アクション "find" が必要であることに注意してください。詳細については、「Query and Write Actions」を参照してください。
- このコネクターは、命名規則
<prefix>.<database-name>.<collection-name>を使用して自動的に Kafka トピックを作成します。テーブルの作成にはtopic.creation.default.partitions=1プロパティおよびtopic.creation.default.replication.factor=3プロパティが使用されます。特定の設定を指定してトピックを作成する場合は、このコネクターを実行する前にトピックを作成しておいてください。 - Confluent Cloud に VPC ピアリング構成のクラスターがある場合は、MongoDB Atlas と VPC の間に PrivateLink 接続 を構成することを検討してください。ネットワークに関するその他の考慮事項については、「Networking and DNS Considerations」を参照してください。静的なエグレス IP を使用する方法については、「静的なエグレス IP アドレス」を参照してください。
- Kafka クラスターの認証情報。次のいずれかの方法で認証情報を指定できます。
- 既存の サービスアカウント のリソース ID を入力する。
- コネクター用の Confluent Cloud サービスアカウント を作成します。「サービスアカウント」のドキュメントで、必要な ACL エントリを確認してください。一部のコネクターには固有の ACL 要件があります。
- Confluent Cloud の API キーとシークレットを作成する。キーとシークレットを作成するには、confluent api-key create を使用するか、コネクターのセットアップ時に Cloud Console で直接 API キーとシークレットを自動生成します。
Confluent Cloud Console の使用¶
ステップ 1: Confluent Cloud クラスターを起動します。¶
インストール手順については、「Quick Start for Confluent Cloud」を参照してください。
ステップ 2: コネクターを追加します。¶
左のナビゲーションメニューの Data integration をクリックし、Connectors をクリックします。クラスター内に既にコネクターがある場合は、+ Add connector をクリックします。
ステップ 4: 接続をセットアップします。¶
以下を実行して、Continue をクリックします。
注釈
- すべての 前提条件 を満たしていることを確認してください。
- アスタリスク( * )は必須項目であることを示しています。
- コネクターの 名前 を入力します。
- Kafka Cluster credentials で Kafka クラスターの認証情報の指定方法を選択します。サービスアカウントのリソース ID を選択するか、API キーとシークレットを入力できます(または、Cloud Console でこれらを生成します)。
- トピックのプレフィックスを入力します。このコネクターは、命名規則
<prefix>.<database-name>.<collection-name>を使用して自動的に Kafka トピックを作成します。テーブルの作成にはtopic.creation.default.partitions=1プロパティおよびtopic.creation.default.replication.factor=3プロパティが使用されます。特定の設定を指定してトピックを作成する場合は、このコネクターを実行する前にトピックを作成しておいてください。 - 変更ストリームドキュメントの名前空間とトピックのマッピングを行う JSON オブジェクトを入力します。たとえば、
{"db": "dbTopic", "db.coll": "dbCollTopic"}では、dbデータベースのすべての変更ストリームドキュメントがdbTopic.<collectionName>にマッピングされます。ただし、db.coll名前空間のすべてのドキュメントは、dbCollTopicトピックにマッピングされます。すべてのメッセージを単一のトピックにマッピングするには、*を使用します。たとえば、{"*": "everyThingTopic", "db.coll": "exceptionToTheRuleTopic"}では、db.collメッセージを除くすべての変更ストリームドキュメントがeveryThingTopicにマッピングされます。プレフィックスの構成がすべて適用されることに注意してください。異なるスキーマを持つレコードを含む複数のコレクションが、AVRO、JSON_SR、および PROTOBUF で作成された 1 つのトピックにマッピングされる場合、1 つのサブジェクト名で複数のスキーマが登録されます。これらのスキーマに相互に後方互換性がない場合、Confluent Cloud スキーマレジストリ でスキーマの互換性を変更しないと、コネクターでエラーが発生します。 - MongoDB Atlas データベースの詳細情報を入力します。Connection host には、完全 URL ではなく、ホスト名アドレスのみを使用します。たとえば、
cluster4-r5q3r7.gcp.mongodb.netのようにします。 - collection name に MongoDB のコレクション名を入力します。空白にすると、指定したデータベースのすべてのコレクションが監視されます。
- wait before checking に、変更ストリームに新しい結果がないか検査するまでの待ち時間を入力します。デフォルトは 5000 ミリ秒(5 秒)です。
- batch に、バッチとしてまとめて処理するレコードの最大件数を入力します。デフォルトのレコード件数は 1000 件です。
- pipeline に、変更ストリームの出力をフィルターまたは修正するためのパイプライン操作を示す JSON オブジェクトの配列を入力します。例:
[{"$match": {"ns.coll": {"$regex": /^(collection1|collection2)$/}}}]は、コネクターがcollection1およびcollection2コレクションのみをリッスンするように設定します。デフォルトは空の配列です。 - copy existing data で、ソースコレクションの既存データをコピーし、対応するトピックの変更ストリームイベントに変換するかどうかを選択します。コピープロセス中に発生したデータ変更は、コピーが完了した後に適用されます。
copy.existingを true に設定すると、コネクターが再起動された場合に重複レコードができる可能性がある点に注意してください。たとえば、スキーマレジストリ ベースの出力フォーマットを使用する際にスキーマが相互に後方互換性がない場合、コネクターが失敗し再起動されます。これによってレコードが重複します。このプロパティを選択しない場合は、デフォルトで false となります。 - 既存のドキュメントのコピー元の名前空間と一致する regex を入力します。名前空間は、
databaseName.collectionNameで表されます。たとえば、stats\.page.*は、statsデータベース内のpageで始まるすべてのコレクションと一致します。 - pipeline に、既存のデータをコピーしたときに実行するためのパイプライン操作を記述する JSON オブジェクトの配列を入力します。これは、コピーされる既存のドキュメントに適用されます。デフォルトは空の配列です。
- Output Kafka record value フォーマットとして、Avro、Byte、JSON(スキーマレス)、JSON スキーマ、Protobuf、または String を選択します。スキーマレジストリ ベースのフォーマット(Avro、JSON_SR(JSON スキーマ)、Protobuf など)を使用するには、有効なスキーマが Schema Registry に存在する必要があります。
- 変更ストリームドキュメント全体ではなく、fullDocument フィールドのみをパブリッシュする かどうかを選択します。true に設定すると、自動的に
change.stream.full.documentにupdateLookupが設定されます。デフォルト値は false です。 - Change Stream の設定としてデフォルトまたは updateLookup を使用する場合に、アップデート操作で何を返すか を選択します。updateLookup に設定した場合、変更ストリームには、変更されたドキュメント全体のコピーとともに、変更を示す差分が含まれます。デフォルトの場合、アップデートされたフィールドのみが含まれ、ドキュメント全体は含まれません。
- output json formatter で出力 JSON フォーマッターとして DefaultJson、ExtendedJson、または SimplifiedJson を選択します。デフォルトは DefaultJson です。
- コネクターが各ハートビートメッセージの送信から次の送信までの間に待機する時間を number of milliseconds に入力します。デフォルト値は 0 であり、デフォルトではハートビートメッセージが送信されません。正の数に設定すると、ソースレコードが指定の間隔でパブリッシュされない場合、コネクターによってハートビートメッセージが送信されます。このメカニズムにより、低ボリュームの名前空間についてコネクターの再開可能性が向上します。この機能の詳細については、MongoDb ドキュメントで「Invalid Resume Token」のページを参照してください。SMT を使用する場合は、SMT によってハートビートメッセージが処理されないように、predicates を使用します。たとえば、ハートビートトピック名が
__mongodb_heartbeatsであり、コネクターが、ハートビートトピックと共通のプレフィックスが使用されていないトピックに実際のデータベースレコードを書き込む場合は、mongoTransformというエイリアスを持つトランスフォームによってハートビートメッセージが処理されないように、以下の構成を使用します:"predicates": "isHeartbeatTopicPrefix","predicates.isHeartbeatTopicPrefix.type": "org.apache.kafka.connect.transforms.predicates.TopicNameMatches","predicates.isHeartbeatTopicPrefix.pattern": "__mongodb.*","transforms.mongoTransform.predicate": "isHeartbeatTopicPrefix","transforms.mongoTransform.negate": "true" - コネクターがハートビートメッセージをパブリッシュする際の heartbeat topic name を入力します。この機能を有効にするには、
heartbeat.interval.ms設定に正の値を指定する必要があります。複数のコネクターにハートビートメッセージを設定する場合は、コネクターのハートビートトピック名を一意にする必要があります。このプロパティに値を設定しなかった場合は、デフォルトで__mongodb_heartbeatsとなります。 - コネクターの タスク の数を入力します。詳しくは、Confluent Cloud コネクターの制限事項 を参照してください。
- Transforms and Predicates: 詳細については、Single Message Transforms(SMT) のドキュメントを参照してください。
すべてのプロパティの値と定義については、「構成プロパティ」を参照してください。
ステップ 5: コネクターを起動します。¶
実行中の構成をプレビューして、接続の詳細情報を確認します。プロパティの構成に問題がないことが確認できたら、Launch をクリックします。
ちなみに
コネクターの出力のプレビューについては、「コネクターのデータプレビュー」を参照してください。

ステップ 7: Kafka トピックを確認します。¶
コネクターが実行中になったら、MongoDB ドキュメントが Kafka トピックに取り込まれていることを確認します。copy.existing 構成が true に設定されている場合にコネクターがなんらかの理由で再起動されると、トピックに重複レコードが表示される可能性があります。
Connect 用の Confluent Cloud API の使用に関する詳細とサンプルについては、「Confluent Cloud API for Connect」セクションを参照してください。
参考
フルマネージド型の Confluent Cloud コネクターが Confluent Cloud ksqlDB でどのように動作するかを示す例については、「Cloud ETL のデモ」を参照してください。この例では、Confluent CLI を使用して Confluent Cloud のリソースを管理する方法についても説明しています。

Confluent CLI の使用¶
以下の手順に従うと、Confluent CLI を使用してコネクターをセットアップし、実行できます。
注釈
- すべての 前提条件 を満たしていることを確認してください。
- コマンド例では Confluent CLI バージョン 2 を使用しています。詳細については、「Confluent CLI v2 への移行 <https://docs.confluent.io/confluent-cli/current/migrate.html#cli-migrate>`__」を参照してください。
ステップ 2: コネクターの必須の構成プロパティを表示します。¶
以下のコマンドを実行して、コネクターの必須プロパティを表示します。
confluent connect plugin describe <connector-catalog-name>
例:
confluent connect plugin describe MongoDbAtlasSource
出力例:
Following are the required configs:
connector.class: MongoDbAtlasSource
name
kafka.auth.mode
kafka.api.key
kafka.api.secret
topic.prefix
connection.host
connection.user
connection.password
database
output.data.format
tasks.max
ステップ 3: コネクターの構成ファイルを作成します。¶
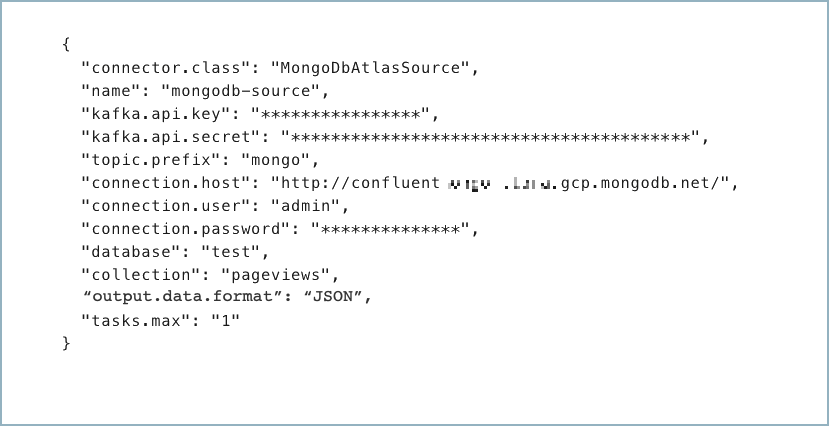
コネクター構成プロパティを含む JSON ファイルを作成します。以下の例は、コネクターの必須プロパティを示しています。
{
"connector.class": "MongoDbAtlasSource",
"name": "<my-connector-name>",
"kafka.auth.mode": "KAFKA_API_KEY",
"kafka.api.key": "<my-kafka-api-key>",
"kafka.api.secret": "<my-kafka-api-secret>",
"topic.prefix": "<topic-prefix>",
"connection.host": "<database-host-address>",
"connection.user": "<database-username>",
"connection.password": "<database-password>",
"database": "<database-name>",
"collection": "<database-collection-name>",
"poll.await.time.ms": "5000",
"poll.max.batch.size": "1000",
"copy.existing": "true",
"output.data.format": "JSON"
"tasks.max": "1"
}
以下のプロパティ定義に注意してください。
"connector.class": コネクターのプラグイン名を指定します。"name": 新しいコネクターの名前を設定します。
"kafka.auth.mode": 使用するコネクターの認証モードを指定します。オプションはSERVICE_ACCOUNTまたはKAFKA_API_KEY(デフォルト)です。API キーとシークレットを使用するには、構成プロパティkafka.api.keyとkafka.api.secretを構成例(前述)のように指定します。サービスアカウント を使用するには、プロパティkafka.service.account.id=<service-account-resource-ID>に リソース ID を指定します。使用できるサービスアカウントのリソース ID のリストを表示するには、次のコマンドを使用します。confluent iam service-account list
例:
confluent iam service-account list Id | Resource ID | Name | Description +---------+-------------+-------------------+------------------- 123456 | sa-l1r23m | sa-1 | Service account 1 789101 | sa-l4d56p | sa-2 | Service account 2
(省略可)
"topic.prefix": トピックのプレフィックスを入力します。このコネクターは、命名規則<prefix>.<database-name>.<collection-name>を使用して自動的に Kafka トピックを作成します。テーブルの作成にはtopic.creation.default.partitions=1プロパティおよびtopic.creation.default.replication.factor=3プロパティが使用されます。特定の設定を指定してトピックを作成する場合は、このコネクターを実行する前にトピックを作成します。専用クラスターを使用していて、2 MB を越えるサイズの MongoDb ドキュメントがある場合は、あらかじめトピックの構成max.message.bytesに最も大きなドキュメントのサイズより大きな値を設定して、トピックを作成しておきます(最大 8388608 バイト)。(省略可能)
"topic.namespace.map": 変更ストリームドキュメントの名前空間とトピックのマッピングを行う JSON マップです。たとえば、{\"db\": \"dbTopic\", \"db.coll\": \"dbCollTopic\"}では、dbデータベースのすべての変更ストリームドキュメントがdbTopic.<collectionName>にマッピングされます。ただし、db.coll名前空間のすべてのドキュメントは、dbCollTopicトピックにマッピングされます。すべてのメッセージを単一のトピックにマッピングするには、*を使用します。たとえば、{\"*\": \"everyThingTopic\", \"db.coll\": \"exceptionToTheRuleTopic\"}では、db.collメッセージを除くすべての変更ストリームドキュメントがeveryThingTopicにマッピングされます。プレフィックスの構成がすべて適用されることに注意してください。異なるスキーマを持つレコードを含む複数のコレクションが、AVRO、JSON_SR、および PROTOBUF で作成された 1 つのトピックにマッピングされる場合、1 つのサブジェクト名で複数のスキーマが登録されます。これらのスキーマに相互に後方互換性がない場合、Confluent Cloud スキーマレジストリ でスキーマの互換性を変更しないと、コネクターでエラーが発生します。"connection.host": MongoDB ホスト。完全な URL ではなく、ホスト名アドレスを使用します。たとえば、cluster4-r5q3r7.gcp.mongodb.netのようにします。(省略可)
"collection": コレクション名。このプロパティを使用しない場合は、指定したデータベースのすべてのコレクションが監視されます。(オプション)
poll.await.time.ms: 変更ストリームに新しい結果がないか検査するまでの待ち時間。このプロパティを使用しない場合は、5000 ミリ秒(5 秒)がデフォルトとして使用されます。(オプション)
poll.max.batch.size: 新しいデータをポーリングするときに 1 回のバッチに含める変更ストリームドキュメントの最大数。この設定を使用して、コネクターの内部でバッファに入れるデータ量を制限できます。このプロパティを使用しない場合は、レコード件数 1000 がデフォルトとして使用されます。(省略可能)
"pipeline"に、変更ストリームの出力をフィルターまたは修正するためのパイプライン操作を示す JSON オブジェクトの配列を入力します。例:[{"$match": {"ns.coll": {"$regex": /^(collection1|collection2)$/}}}]は、コネクターがcollection1およびcollection2コレクションのみをリッスンするように設定します。このプロパティが使用されない場合、デフォルトで空の配列になります。(省略可能)
"copy.existing": ソースコレクションの既存のデータをコピーし、それを対応するトピックの変更ストリームイベントに変換するかどうかを選択します。コピープロセス中に発生したデータ変更は、コピーが完了した後に適用されます。copy.existingを true に設定すると、コネクターが再起動された場合に重複レコードができる可能性がある点に注意してください。たとえば、スキーマレジストリ ベースの出力フォーマットを使用する際にスキーマが相互に後方互換性がない場合、コネクターが失敗し再起動されます。これによってレコードが重複します。このプロパティが使用されない場合、デフォルトで false となります。(省略可能)
"copy.existing.namespace.regex": 既存のドキュメントのコピー元の名前空間と一致する正規表現です。名前空間は、databaseName.collectionNameで表されます。たとえば、stats\.page.*は、statsデータベース内のpageで始まるすべてのコレクションと一致します。(省略可能)
"copy.existing.pipeline": 既存のデータをコピーしたときに実行するためのパイプライン操作を記述する JSON オブジェクトの配列です。これは、コピーされる既存のドキュメントに適用されます。このプロパティが使用されない場合、デフォルトで空の配列になります。"output.data.format": Kafka 出力レコード値のフォーマット(コネクターから送られるデータ)を設定します。指定可能なエントリは、AVRO、JSON_SR、PROTOBUF、または JSON です。スキーマベースのメッセージフォーマット(Avro、JSON_SR(JSON スキーマ)、Protobuf など)を使用する場合は、Confluent Cloud Schema Registry を構成しておく必要があります。(省略可)
"heartbeat.interval.ms": コネクターが各ハートビートメッセージの送信から次の送信までの間に待機する時間(ミリ秒)。このプロパティが指定されなかった場合のデフォルト値は 0 です。デフォルトではハートビートメッセージが送信されません。正の数に設定すると、ソースレコードが指定の間隔でパブリッシュされない場合、コネクターによってハートビートメッセージが送信されます。このメカニズムにより、低ボリュームの名前空間についてコネクターの再開可能性が向上します。この機能の詳細については、MongoDb ドキュメントで「Invalid Resume Token」のページを参照してください。SMT を使用する場合は、SMT によってハートビートメッセージが処理されないように、predicates を使用します。たとえば、ハートビートトピック名が__mongodb_heartbeatsであり、コネクターが、ハートビートトピックと共通のプレフィックスが使用されていないトピックに実際のデータベースレコードを書き込む場合は、mongoTransformというエイリアスを持つトランスフォームによってハートビートメッセージが処理されないように、以下の構成を使用します:"predicates": "isHeartbeatTopicPrefix","predicates.isHeartbeatTopicPrefix.type": "org.apache.kafka.connect.transforms.predicates.TopicNameMatches","predicates.isHeartbeatTopicPrefix.pattern": "__mongodb.*","transforms.mongoTransform.predicate": "isHeartbeatTopicPrefix","transforms.mongoTransform.negate": "true"(省略可)
"heartbeat.topic.name": コネクターがハートビートメッセージをパブリッシュする際のトピックの名前。この機能を有効にするには、heartbeat.interval.ms設定に正の値を指定する必要があります。複数のコネクターにハートビートメッセージを設定する場合は、コネクターのハートビートトピック名を一意にする必要があります。このプロパティに値を設定しなかった場合は、デフォルトで__mongodb_heartbeatsとなります。コネクターの タスク の数を入力します。詳しくは、Confluent Cloud コネクターの制限事項 を参照してください。
Single Message Transforms: CLI を使用する SMT の追加の詳細については、Single Message Transforms(SMT) のドキュメントを参照してください。
すべてのプロパティの値と定義については、「構成プロパティ」を参照してください。
ステップ 4: プロパティファイルを読み込み、コネクターを作成します。¶
以下のコマンドを入力して、構成を読み込み、コネクターを起動します。
confluent connect create --config <file-name>.json
例:
confluent connect create --config mongo-db-source.json
出力例:
Created connector confluent-mongodb-source lcc-ix4dl
ステップ 5: コネクターのステータスを確認します。¶
以下のコマンドを入力して、コネクターのステータスを確認します。
confluent connect list
出力例:
ID | Name | Status | Type
+-----------+---------------------------+---------+-------+
lcc-ix4dl | confluent-mongodb-source | RUNNING | source
ステップ 6: Kafka トピックを確認します。¶
コネクターが実行中になったら、MongoDB ドキュメントが Kafka トピックに取り込まれていることを確認します。copy.existing 構成が true に設定されている場合にコネクターがなんらかの理由で再起動されると、トピックに重複レコードが表示される可能性があります。
Connect 用の Confluent Cloud API の使用に関する詳細とサンプルについては、「Confluent Cloud API for Connect」セクションを参照してください。
構成プロパティ¶
このコネクターでは、以下のコネクター構成プロパティを使用します。
データへの接続方法(How should we connect to your data?)¶
nameコネクターの名前を設定します。
- 型: string
- 指定可能な値: 最大 64 文字の文字列
- 重要度: 高
Kafka クラスターの認証情報(Kafka Cluster credentials)¶
kafka.auth.modeKafka の認証モード。KAFKA_API_KEY または SERVICE_ACCOUNT を指定できます。デフォルトは KAFKA_API_KEY モードです。
- 型: string
- デフォルト: KAFKA_API_KEY
- 指定可能な値: KAFKA_API_KEY、SERVICE_ACCOUNT
- 重要度: 高
kafka.api.key- 型: password
- 重要度: 高
kafka.service.account.idKafka クラスターとの通信用の API キーを生成するために使用されるサービスアカウント。
- 型: string
- 重要度: 高
kafka.api.secret- 型: password
- 重要度: 高
トピックの命名方法(How do you want to name your topic(s)?)¶
topic.prefixデータのパブリッシュ先である Apache Kafka® トピックの名前を生成するためにテーブル名の先頭に付けるプレフィックス。
- 型: string
- 重要度: 高
topic.namespace.map変更ストリームドキュメントの名前空間をトピックにマッピングする JSON オブジェクト。プレフィックスの構成はすべて適用されます。異なるスキーマを持つレコードを含む複数のコレクションが、AVRO、JSON_SR、および PROTOBUF で作成された 1 つのトピックにマッピングされる場合、1 つのサブジェクト名で複数のスキーマが登録されます。これらのスキーマに相互に後方互換性がない場合、Confluent Cloud Schema Registry でスキーマの互換性を変更するまで、コネクターではエラーが発生します。
- 型: string
- デフォルト: ""
- 重要度: 低
MongoDB Atlas データベースへの接続方法(How should we connect to your MongoDB Atlas database?)¶
connection.hostMongoDB Atlas 接続ホスト(例: confluent-test.mycluster.mongodb.net)。
- 型: string
- デフォルト: ""
- 重要度: 高
connection.userMongoDB Atlas 接続ユーザー。
- 型: string
- 重要度: 高
connection.passwordMongoDB Atlas 接続パスワード。
- 型: password
- 重要度: 高
databaseMongoDB Atlas データベース名。設定されていない場合、クラスター内のすべてのデータベースが監視されます。
- 型: string
- 重要度: 高
データベースの詳細(Database details)¶
collection監視する単一の MongoDB Atlas コレクション。設定されていない場合、指定のデータベース内のすべてのコレクションが監視されます。
- 型: string
- 重要度: 中
接続の詳細(Connection details)¶
poll.await.time.ms変更ストリームに新しい結果がないか検査する前に待機する時間の長さ。
- 型: int
- デフォルト: 5000(5 秒)
- 指定可能な値: [1、…]
- 重要度: 低
poll.max.batch.size新しいデータのポーリング時に単一のバッチに含める変更ストリームドキュメントの最大数。この設定を使用して、コネクターの内部にバッファリングするデータの量を制限できます。
- 型: int
- デフォルト: 100
- 指定可能な値: [1,...,1000]
- 重要度: 低
pipeline変更イベントの出力をフィルター処理または修正するためのパイプライン操作を記述する JSON オブジェクトの配列。たとえば、[{"$match": {"ns.coll": {"$regex": /^(collection1|collection2)$/}}}] では、ソースコネクターがコレクション "collection1" および "collection2" のみをリッスンするように設定されます。
- 型: string
- デフォルト: []
- 重要度: 中
copy.existingソースコレクションから既存のデータをコピーするかどうかを指定します。true に設定すると、レコードの重複が生じることがあります。
- 型: boolean
- デフォルト: false
- 重要度: 高
copy.existing.namespace.regexデータのコピー元の名前空間(databaseName.collectionName)に一致する正規表現。たとえば、stats.page.* は、"stats" データベース内の "page" で始まるすべてのコレクションに一致します。
- 型: string
- デフォルト: ""
- 重要度: 中
copy.existing.pipeline既存のデータをコピーするときに実行するパイプライン操作を記述する JSON オブジェクトの配列。コピー中の既存のドキュメントにのみ適用されます。
- 型: string
- デフォルト: []
- 重要度: 中
batch.sizeThe number of documents to return in a batch.
- 型: int
- デフォルト: 0
- Valid Values: [...,50]
- 重要度: 低
出力メッセージ(Output messages)¶
output.data.formatKafka 出力レコード値のフォーマットを設定します。指定可能なエントリは、AVRO、JSON_SR、PROTOBUF、JSON、STRING、または BSON です。スキーマベースのメッセージフォーマット(AVRO、JSON_SR、PROTOBUF など)を使用する場合は、Confluent Cloud Schema Registry を構成しておく必要がある点に注意してください
- 型: string
- デフォルト: STRING
- 重要度: 高
publish.full.document.only変更ストリームドキュメント全体ではなく、変更されたドキュメントのみをパブリッシュします。自動的に change.stream.full.document=updateLookup が設定され、アップデートされたドキュメントが含められます。
- 型: boolean
- デフォルト: false
- 重要度: 高
change.stream.full.document変更ストリームを使用するときにアップデート操作に対して何を返すかを決定します。'updateLookup' に設定した場合、部分アップデートの変更ストリームには、ドキュメントへの変更を説明するデルタと、変更が発生した後のある時点から変更されたドキュメント全体のコピーの両方が含められます。
- 型: string
- デフォルト: default
- 重要度: 高
json.output.decimal.format次の 2 つのリテラル値を取る Connect DECIMAL 論理型の値の JSON/JSON_SR シリアル化フォーマットを指定します。
BASE64 では、DECIMAL 論理型を base64 でエンコードされたバイナリデータとしてシリアル化します。
NUMERIC では、JSON/JSON_SR の Connect DECIMAL 論理型の値を、10 進数の値を表す数字としてシリアル化します。
- 型: string
- デフォルト: BASE64
- 重要度: 低
output.json.formatjson 文字列の出力フォーマットは、次のいずれかに構成できます。DefaultJson: 従来型の厳密な json フォーマッター。ExtendedJson: 完全な型安全性を提供する拡張 json フォーマッター。SimplifiedJson: ObjectId、Decimals、Dates、および Binary 値を文字列として表現する、簡略化された Json。ユーザーは、com.mongodb.kafka.connect.source.json.formatter の独自の実装を提供できます。
- 型: string
- デフォルト: DefaultJson
- 重要度: 高
topic.separatorSeparator to use when joining prefix, database, collection, and suffix values. This generates the name of the Kafka topic to publish data to. Used by the 'DefaultTopicMapper'.
- 型: string
- Default: .
- 重要度: 低
topic.suffixSuffix to append to database and collection names to generate the name of the Kafka topic to publish data to.
- 型: string
- 重要度: 低
エラー処理(Error handling)¶
heartbeat.interval.msコネクターが各ハートビートメッセージの送信から次の送信までの間に待機する時間(ミリ秒数)。ソースレコードが指定の間隔でパブリッシュされない場合、コネクターによってハートビートメッセージが送信されます。このメカニズムにより、低ボリュームの名前空間についてコネクターの再開可能性が向上します。SMT を使用する場合は、SMT によってハートビートメッセージが処理されないように、predicates を使用します。詳細については、コネクターに関するドキュメントを参照してください。
- 型: int
- デフォルト: 0
- 重要度: 中
heartbeat.topic.nameコネクターがハートビートメッセージをパブリッシュする際のトピックの名前。この機能を有効にするには、"heartbeat.interval.ms" 設定に正の値を指定する必要があります。
- 型: string
- デフォルト: __mongodb_heartbeats
- 重要度: 中
mongo.errors.toleranceUse this property if you would like to configure the connector's error handling behavior differently from the Connect framework's.
- 型: string
- Default: NONE
- 重要度: 中
mongo.errors.deadletterqueue.topic.nameWhether to output conversion errors to the dead letter queue. Stops poison messages when using schemas, any message will be outputted as extended json on the specified topic. By default messages are not outputted to the dead letter queue. Also requires errors.tolerance=all.
- 型: string
- 重要度: 中
Server API¶
server.api.versionThe server API version to use. Disabled by default.
- 型: string
- 重要度: 低
server.api.deprecation.errorsSets whether the connector requires use of deprecated server APIs to be reported as errors.
- 型: boolean
- デフォルト: false
- 重要度: 低
server.api.strictSets whether the application requires strict server API version enforcement.
- 型: boolean
- デフォルト: false
- 重要度: 低
このコネクターのタスク数(Number of tasks for this connector)¶
tasks.max- 型: int
- 指定可能な値: [1,...,1]
- 重要度: 高
おすすめの記事¶
ブログ記事: Using the Fully Managed MongoDB Atlas Connector in a Secure Environment
ブログ記事: Announcing the MongoDB Atlas Sink and Source connectors in Confluent Cloud
次のステップ¶
参考
フルマネージド型の Confluent Cloud コネクターが Confluent Cloud ksqlDB でどのように動作するかを示す例については、「Cloud ETL のデモ」を参照してください。この例では、Confluent CLI を使用して Confluent Cloud のリソースを管理する方法についても説明しています。