重要
このページの日本語コンテンツは古くなっている可能性があります。最新の英語版コンテンツをご覧になるには、こちらをクリックしてください。
Confluent Cloud での Cluster Linking¶
Looking for Confluent Platform Cluster Linking docs? You are currently viewing Confluent Cloud documentation. If you are looking for Confluent Platform docs, check out Cluster Linking on Confluent Platform.
Cluster Linking とは¶
Confluent Cloud 上の Cluster Linking は、Confluent クラスター間でデータを移動するフルマネージド型のサービスです。プログラムによってトピックの完全なコピーを作成し、クラスター間でデータが同期された状態に保ちます。Cluster Linking は、以下の用途を目指した強力な Geo レプリケーションテクノロジです。
- Multi-cloud and global architectures powered by real-time data in motion
- Data sharing between different teams, lines of business, or organizations
- High Availability (HA)/Disaster Recovery (DR) during an outage of a cloud provider’s region
- Data and workload migration from a Apache Kafka® cluster to Confluent Cloud or Confluent Platform cluster to Confluent Cloud
- Protect Tier 1, customer-facing applications and workloads from disruption by creating a read-replica cluster for lower-priority applications and workloads
- Hybrid cloud architectures that supply real-time data to applications across on-premises datacenters and the cloud
- Syncing data between production environments and staging or development environments
Confluent Cloud の Cluster Linking はフルマネージド型であるため、データフローを自分で管理したりチューニングしたりする必要はありません。その料金は使用量ベースであるため、マルチクラウド、マルチリージョンのコストを適切に管理することができます。Cluster Linking によって運用の負荷とクラウド転送料金が下がり、クラウドデータパイプラインのパフォーマンスと信頼性が向上します。
Success Stories¶
1-800 Flowers used Cluster Linking for a disaster recovery strategy and for multi-cloud data movement (minute 46 of this webinar).
“In three months, we went from having no DR strategy to a production multi-cloud DR capability based on real-time data architecture that also supported high performance regional applications."
Confluent Sets Data in Motion Across Hybrid and Multicloud Environments for Real-Time Connectivity Everywhere lists success stories implementing Cluster Linking under the subheading “Cluster Linking: Seamlessly Connect Applications and Data Systems Across Hybrid and Multicloud Architectures”
- Freeman talks about building a hybrid cloud and HA/DR architecture
- SAS talks about completing a large-scale migration
New Kafka Tier, No Kafka Tears, published in Maker Stories by Wealthsimple, describes using Cluster Linking for migration to scale up existing Kafka systems
Namely describes their data migration project in “Everywhere: Cloud Cluster Linking” under the subtopic Simplify geo-replication and multi-cloud data movement with Cluster Linking
動作概念¶
Cluster Linking を使用すると、Confluent クラスター間でデータを直接ミラーリングできます。クラスターリンク は、リージョン、クラウド、業種、組織の垣根を超えて、送信元クラスターと送信先クラスターとの間で確立できます。送信元クラスターから送信先クラスターにレプリケートするトピックは自分で選択することができます。さらに、コンシューマーオフセットや ACL をミラーリングすることもできるため、クラスター間での Kafka コンシューマーの移動も容易です。

クラスター間には、1 回のコマンドまたは API 呼び出しでクラスターリンクを作成できます。クラスターリンクは、2 つのクラスターをつなぐ永続的なブリッジとしての機能を果たします。
confluent kafka link create tokyo-sydney
--source-bootstrap-server pkc-867530.ap-northeast-1.aws.confluent.cloud:9092
--source-cluster-id lkc-42492
--api-key AP1K3Y
--api-secret ********
クラスターリンク越しにデータをミラーリングするには、送信先クラスターにミラートピックを作成します。
confluent kafka mirror create clickstream.tokyo
--link tokyo-sydney
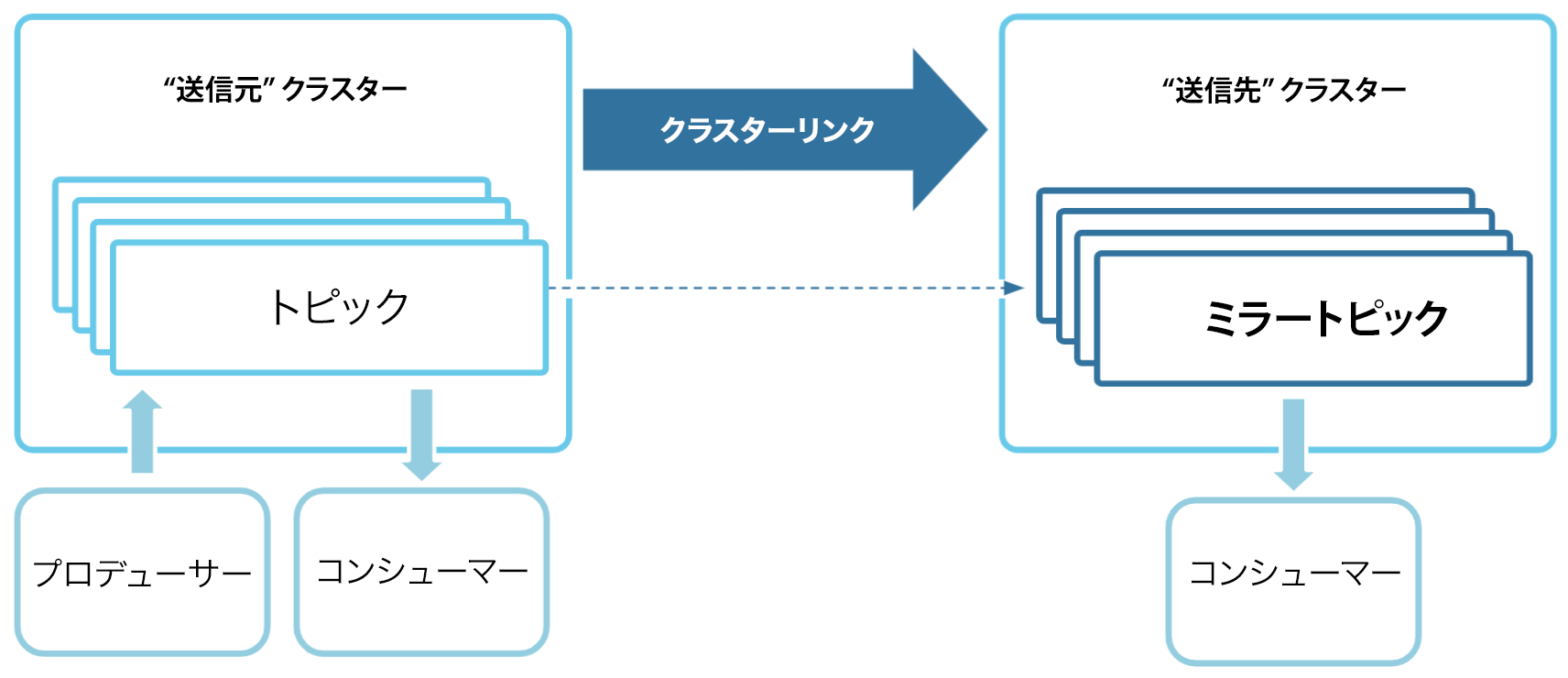
ミラートピックは、特殊なトピック、つまり対応する送信元トピックの読み取り専用コピーです。送信元トピックに対して生成されるすべてのメッセージは、ミラートピックに "バイト単位" でミラーリングされます。同じメッセージは、ミラートピック上の同じパーティション、同じオフセットに反映されるということです。ミラートピックは、他のトピックと同じように消費できます。
クラスターリンクとミラートピックは、リージョン、クラウド、チーム、組織の違いを超えて、スケーラブルで一貫性のあるアーキテクチャを作成するための基本要素です。
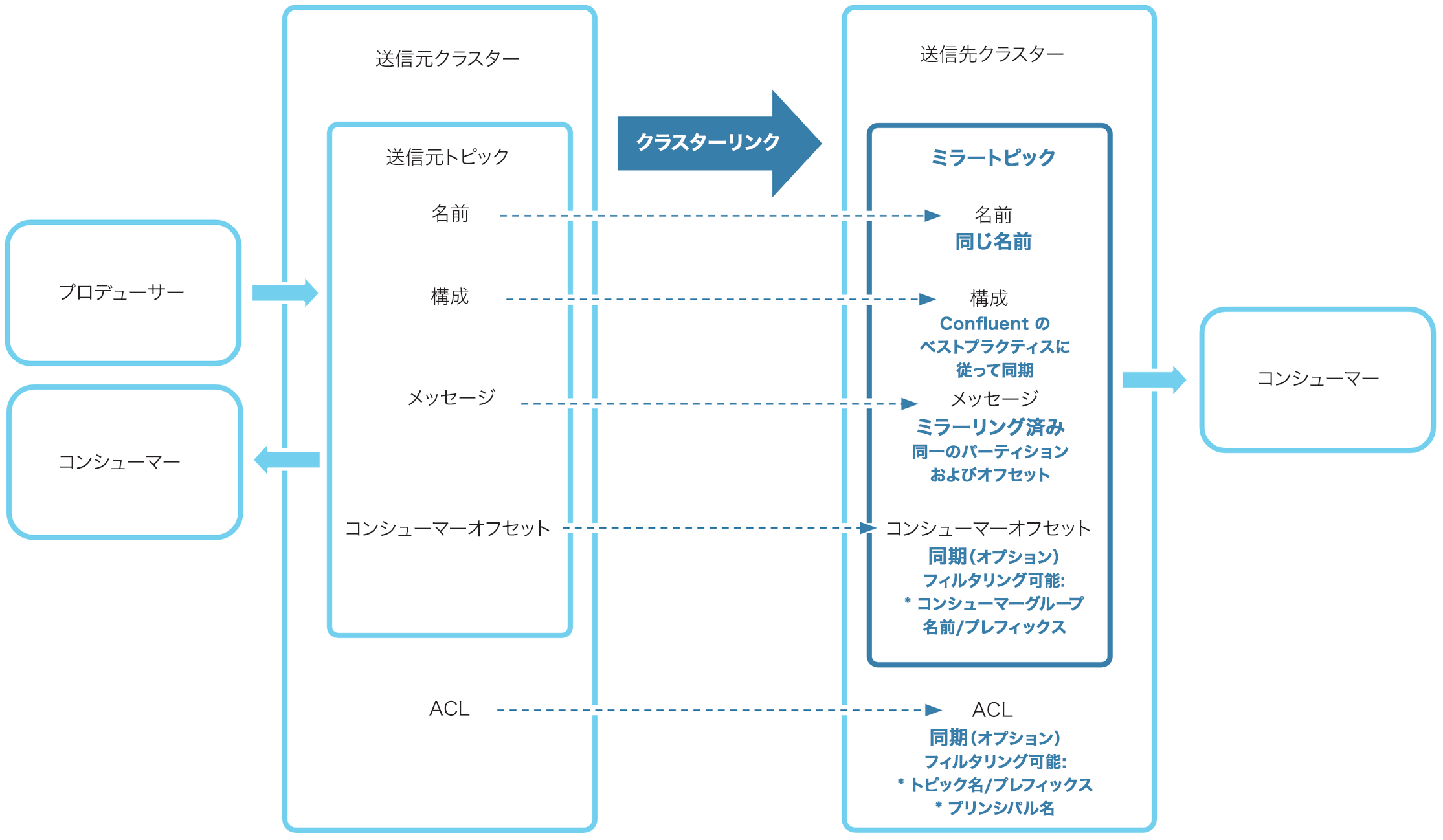
Cluster Linking では、重要なメタデータがレプリケートされます。
- Cluster Linking では、送信元トピックとミラートピックとの間でトピックの構成を同期することについてのベストプラクティスが適用されます(同期される構成と同期されない構成があります)。
- 必要であればコンシューマーオフセットの同期を有効にして、送信元トピックからミラートピック(ミラートピックのみを対象)にコンシューマーオフセットを同期したり、特定のコンシューマーグループを条件にフィルタリングしたりできます。
- ACL の同期を有効にして、クラスター上の(ミラートピックに限らず)すべての ACL を同期できます。必要に応じてトピック名またはプリンシパル名を条件にフィルタリングできます。
これらの機能については、各種 チュートリアル で取り上げています。
ユースケース¶
Confluent provides multi-cloud, multi-region, and hybrid capabilities in Confluent Cloud. Many of these are demo'ed in the チュートリアル.
- グローバルなマルチクラウドの複製: リージョンおよびクラウド間でリアルタイムデータを移動して集約します。リアルタイムデータの地理的位置情報の読み取りを可能にすることで、Kafka イベントの Content Delivery Network(CDN)のような機能をパブリッククラウド、プライベートクラウド、エッジの全体にわたって実現できます。
- データ共有 - 他のチーム、事業部門、組織とデータをリアルタイムで共有します。
- データ移行 - クラスター間でデータとワークロードを移行します。
- ディザスターリカバリと高可用性 - ディザスターリカバリクラスターを作成しておき、機能停止が生じたとき、そのクラスターにフェイルオーバーします。
Cluster Linking のミラーリングスループット(クラスターからのデータの読み取りまたはクラスターへのデータの書き込みに使用される帯域幅)には、ご利用の CKU 単位の制限 が適用されます。
サポートされるクラスタータイプ¶
クラスターリンクは、"送信元クラスター" から "送信先クラスター" にデータを送信します。サポートされるクラスタータイプを以下の表に示します。
送信元クラスターは Kafka または Confluent Server または Confluent Cloud で inter.broker.protocol (IBP)バージョン 2.4 を実行しているものが使用できます。送信先クラスターは Confluent Cloud 専用クラスター または Confluent Server (Confluent Enterprise にバンドル)のいずれかである必要があります。
サポート対象外のクラスタータイプとその他の制限については、「制限」を参照してください。
| 送信元クラスターのオプション | 送信先クラスターのオプション |
|---|---|
|
インターネットネットワーキングを備えた専用 Confluent Cloud クラスター |
| Apache Kafka® 2.4+ または Confluent Platform 5.4+ で、すべてのブローカーにパブリックインターネット IP アドレスを持つもの | インターネットネットワーキングを備えた専用 Confluent Cloud クラスター |
| Confluent Platform 7.0+(ファイアウォール内側の場合も) | インターネットネットワーキングを備えた専用 Confluent Cloud クラスター |
|
Confluent Platform 7.0+(ファイアウォール内側の場合も) |
ちなみに
The source cluster and destination cluster can be in different regions, cloud providers, Confluent Cloud environments, or Confluent Cloud organizations.
クラスタータイプを確認する方法¶
Confluent Cloud クラスターのタイプとエンドポイントのタイプを確認するには、以下の手順に従います。
Confluent Cloud にログオンします。
環境を選択します。
クラスターを選択します。
クラスターのサマリーカードにクラスタータイプが表示されます。
または、クラスターをクリックして、左側のメニューから Cluster settings を選択する方法もあります。"Cluster type" のサマリーカードにクラスタータイプが表示されます。
専用クラスターの Cluster overview の左側のメニューから、Networking メニュー項目をクリックしてエンドポイントのタイプを確認します。Networking タブがあるのは 専用クラスター のみです。ベーシック クラスターと スタンダード クラスターには必ずインターネットネットワーキングがあります。ネットワークは、最初に専用クラスターを作成する際に定義します。
料金¶
Cluster Linking を使用する Confluent Cloud クラスターは、クラスターリンクの数およびクラスターとの間のミラーリングスループットの量に基づいて請求されます。
メトリクスを使用してコストを追跡するためのガイドラインを含め、Cluster Linking の請求方法の詳しい内訳については、「Confluent Cloud の請求」の「Cluster Linking」 を参照してください。
Confluent Cloud の料金全般については、ウェブサイトに記載されています。Confluent Cloud の料金ページ を参照してください。
プレビュー機能について¶
Confluent Cloud の Cluster Linking は一般提供が開始されています。ただし、以下の項目については、開発者からの早期フィードバックを得るため、プレビューモードでの導入となります。これらのメトリクスは、評価、非本稼働環境でのテスト、あるいは Confluent へのフィードバックの提供を目的として使用される場合があります。プレビュー機能に関するご意見、ご質問、ご提案を clusterlinking@confluent.io までお寄せください。お待ちしております。
io.confluent.kafka.server/cluster_link_mirror_topic_countio.confluent.kafka.server/cluster_link_mirror_topic_bytesio.confluent.kafka.server/cluster_link_mirror_topic_offset_lag
概要¶
初めて Cluster Linking をご利用になる方のために、以下、次のステップに向けた推奨事項をいくつか紹介します。
チュートリアル¶
まずチュートリアルに取り組んでみましょう。それぞれユースケースに対応しています。
ミラートピック¶
オリジナル(送信元)トピックを反映する読み取り専用の "ミラートピック" は、Cluster Linking の基本要素です。この特殊なタイプのトピックとそのしくみの詳細解説については、「Mirror Topics」を参照してください。
コマンドと前提条件¶
送信元クラスターからのリンクは、送信先クラスターで confluent kafka link コマンドを使用して作成できます。プレビュー期間中にチュートリアルを実行するには、以下の前提条件の手順が必要となります。
Confluent Cloud で Cluster Linking を試すには、以下のようにします。
Confluent Cloud をインストールします(まだインストールしていない場合)。
ウェブからインストールする代わりに、ターミナルウィンドウから 2 つのコマンドを実行することでも簡単に Confluent Cloud を入手できます(どちらのコマンドも、
~/.local/binは必要に応じて別のディレクトリに置き換えてください)。curl -L --http1.1 https://cnfl.io/ccloud-cli | sh -s -- -b ~/.local/binexport PATH=~/.local/bin:$PATH;
Confluent Cloud 全般の情報については、「Quick Start for Confluent Cloud」を参照してください。
Confluent Cloud にログオンします。
Cluster Linking コマンドの最新バージョンを確実に使用するために Confluent CLI をアップデートします。詳細については、クイックスタートの「Confluent CLI の最新バージョンの取得」を参照してください。
confluent kafka linkコマンドには、以下のサブコマンドまたはフラグがあります。コマンド 説明 create新しいクラスターリンクを作成します。 delete以前に作成されたクラスターリンクを削除します。 describe既存のクラスターリンクの詳細を表示します。 list既存のクラスターリンクをリスト表示します。 update既存のクラスターリンクのプロパティをアップデートします。 confluent kafka mirrorコマンドには、以下のサブコマンドまたはフラグがあります。コマンド 説明 describeミラートピックの詳細を表示します。 failoverミラートピックをフェイルオーバーします。 listクラスターに含まれるミラートピックまたは指定されたクラスターリンク下のミラートピックをすべてリスト表示します。 pauseミラートピックを一時停止します。 promoteミラートピックをプロモートします。 resume既存のクラスターリンクのプロパティをアップデートします。 チュートリアルに従って Cluster Linking を実際に使ってみます。コマンドのデモについては、チュートリアルを参照してください。
CLI の高度なヒント¶
Confluent Cloud CLI コマンドのリストは、こちら でご覧いただけます。以下に、コマンドラインワークフローの時間短縮につながる一般的な戦略をいくつか紹介します。
コマンド出力をテキストファイルに保存する¶
絶えず情報を追跡するために、Confluent Cloud のコマンド出力をテキストファイルに保存します。そのようにする場合は、後でファイルを削除するか、セキュリティコードだけをより安全なストレージに移動するなどして、API キーとシークレットを必ず保護してください。コマンド出力をファイルにリダイレクトするには、次のどちらかの方法を使用します。情報を整理するために手動で見出しを追加することができます。
- 出力をファイルにリダイレクトするには、Linux 構文(
<command> > notes.txtなど)で最初のコマンドを実行してメモファイルを作成し、その後は<command> >> notes.txtを実行して出力を追記します。 - 出力をファイルに送信したうえで、画面にも表示するには(推奨)、
<command> | tee notes.txtを使用して最初のコマンドを実行し、ファイルを作成します。その後は、teeコマンドと-aフラグを使用して追記します(例:<command> | tee -a notes.txt)。
コマンドで使用するデータを構成ファイルに保存する¶
API キーとシークレット、クラスターリンクの詳細な構成、Confluent Cloud の外部のクラスターに対するセキュリティ認証情報を保存するための構成ファイルを作成します。その例については、トピックデータの共有に関するチュートリアルの「(通常は省略可能)config ファイルの使用」およびディザスターリカバリに関するチュートリアルの「クラスターリンクの作成」を参照してください。
環境変数にリソース情報を保存する¶
シェルの環境変数に権限やクラスターデータを保存することでコマンドラインのワークフローを効率化できます。API キーとシークレット、リソース(クラスター、サービスアカウント、環境の ID など)、ブートストラップサーバーを変数に保存して、Confluent のコマンドで使用します。
たとえば、次のようにして環境とクラスターの変数を作成します。
export CLINK_ENV=env-200py
export USA_EAST=lkc-qxxw7
export USA_WEST=lkc-1xx66
それらをコマンドで使用するには、次のようにします。
$ confluent environment use $CLINK_ENV
Now using "env-200py" as the default (active) environment.
$ confluent kafka cluster use $USA_EAST
Set Kafka cluster "lkc-qxxw7" as the active cluster for environment "env-200py".
以上のことを踏まえてコマンドを記述する¶
以下に示したのは、クラスター、API キー、シークレットの環境変数を作成し、link.config というファイルにクラスターリンクの構成の詳細を保存したという前提で、"east-west-link" という名前のクラスターリンクを変数と構成ファイルを使用して作成する例です。
confluent kafka link create east-west-link \
--cluster $DESTINATION_ID \
--source-cluster-id $ORIG_ID \
--source-bootstrap-server $ORIG_BOOT \
--config-file link.config
Scaling Cluster Linking¶
Because Cluster Linking fetches data from source topics, the first scaling unit to inspect is the number of partitions in the source topics. Having enough partitions lets Cluster Linking mirror data in parallel. Having too few partitions can make Cluster Linking bottleneck on partitions that are more heavily used.
In Confluent Cloud, Cluster Linking scales with the ingress and egress quotas of your cluster. Cluster Linking is able to use all remaining bandwidth in a cluster’s throughput quota: 150 MB/s per CKU egress on a Confluent Cloud source cluster or 50 MB/s per CKU ingress on a Confluent Cloud destination cluster, whichever is hit first. Therefore, to scale Cluster Linking throughput, simply adjust the number of CKUs on either the source, the destination, or both.
注釈
On the destination cluster, Cluster Linking write takes lower priority than Kafka clients producing to that cluster; Cluster Linking will be throttled first.
Confluent proactively monitors all cluster links in Confluent Cloud and will perform tuning when necessary. If you find that your cluster link is not hitting these limits even after a full day of sustained traffic, contact Confluent Support.
See also, recommended guidelines for Confluent Cloud.
In a Confluent Platform or Apache Kafka® cluster, you can scale Cluster Linking throughput as follows:
- On the cluster link configurations, change the number of fetcher threads or change the fetch size to get better batching. (See Configuration options on the cluster link for Confluent Platform.)
- Improve the cluster’s maximum throughput by scaling the brokers vertically or horizontally.
- Use the options listed under Cluster Link Replication Configurations to tune cluster link performance, which helps scale cluster link throughput.
制限¶
このセクションでは、クラスタータイプ、クラスター管理、パフォーマンスの観点からサポートと既知の制限について詳しく取り上げます。
クラスターのタイプとネットワーク¶
現在サポートされているクラスタータイプは、「サポートされるクラスタータイプ」に記載されています。
ネットワークタイプが Transit Gateway、VPC ピアリング、Privatelink、VNet ピアリングのいずれかに該当する Confluent Cloud クラスターでは、Cluster Linking がサポートされません。プライベートネットワークに接続された Confluent Cloud クラスターでの Cluster Linking の使用をご希望の場合、Confluent アカウントチームにお問い合わせいただくか、メール(clusterlinking@confluent.io)にて詳しい情報を入手してください。
A given cluster can only be the destination for five cluster links. Cluster Linking does not currently support aggregating data from more than five sources.
ACL の同期¶
Cluster Linking の主要な機能として、クラスター間で ACL を同期する ことができます。これは、移行やフェイルオーバーの目的でクライアントをクラスター間で移動する場合に便利です。ただし Confluent Cloud のクラスターでは、そのクラスター自体と同じ Confluent Cloud 組織にあるサービスアカウント向けにしか ACL を作成できません。このため、実質的に、ACL の同期は同じ Confluent Cloud 組織にある 2 つの Confluent Cloud クラスターの間でのみ機能するものとなります。
ACL の同期は、Confluent Platform と Confluent Cloud、または Apache Kafka® と Confluent Cloud のような、異なる組織にある 2 つの Confluent Cloud クラスターの間では使用できません。
一般に、送信先クラスターで単独で管理されている ACL は同期フィルターに含めないでください。これは、送信先に個別に追加され、削除してはいけない ACL を、クラスターリンクの移行時に削除しないようにするためです。「クラスターリンクの動作の構成」と「送信元クラスターから送信先クラスターへの ACL の同期」も参照してください。
重要
一時的な既知の制限: ACL の同期を使用する場合、送信元クラスターで削除された ACL が送信先クラスターで削除されていることを手動で確認する必要があります。送信元クラスターで ACL が作成または削除されると、ACL の同期機能がその変更を送信先クラスターに伝搬します。しかし、送信元クラスターでの ACL の削除が送信先クラスターに同期されないことがまれに発生します。このため当面は、ACL の同期機能を使用する場合、送信元クラスターで ACL を削除する際はそのつど、該当の ACL が送信先クラスターでも削除されていることを確認する必要があります。クラスターリンクによって削除されていない場合は、送信先クラスターの ACL を手動で削除してください。
管理の制限¶
- クラスターリンクの作成と管理は、送信先クラスターで行う必要があります。
- クラスターリンクは、インターネットネットワーキングを備えた Confluent Cloud 専用クラスター タイプの送信先クラスターでのみ作成できます。
- Confluent Platform 7.0.0 では、ソース開始クラスターリンク(ハイブリッドクラウドを推奨)を REST API で作成できません。
kafka-cluster-linksCLI で作成する必要があります。通常の送信先開始クラスターリンクは、REST API とkafka-cluster-linksCLI のどちらでも作成できます。 - Confluent Platform 7.0.x では、送信元開始クラスターリンクを一覧表示し、取得するための REST API 呼び出しに、パラメーター
source_cluster_idで返される送信先クラスター ID が含まれます。 - ミラートピックは、他のトピックとまったく同じように、クラスターのトピック制限、パーティション制限、ストレージ制限にカウントされます。
- クラスターリンクには、送信先クラスターのトピック数とパーティション数を上限として、トピックまたはパーティションをいくつでも割り当てることができます。
- 送信先となるターゲットクラスターには、最大 5 つのクラスターリンクを設定できます。つまり、送信先クラスターにデータをレプリケートできるクラスターリンクは 5 つまでです。1 つのクラスターに必要なクラスターリンクが 5 つを超える場合は、Confluent サポートにお問い合わせください。
- 本質的に、1 つのミラートピックに割り当てることができるのは、1 つのクラスターリンクと、そのミラートピックにデータをレプリケートする 1 つの送信元トピックのみです。逆に、1 つのトピックの送信先となるミラートピックの数に制限はありません。
- コンシューマーグループオフセットの同期、ACL の同期、トピック構成の同期に使用される同期プロセスの頻度はユーザーが構成できます。これらの同期を実行できる頻度は、1 秒(設定はミリ秒単位であるため 1000 ms)につき 1 回までです。同期の実行頻度をもっと長くすることはできますが、1000 ms より短くすることはできません。
"厳密に 1 回" のセマンティクスなどの Kafka トランザクションは、ミラートピックではサポートされていません。¶
Cluster Linking は、"厳密に 1 回" のセマンティクスを含む Kafka トランザクションと統合されていません。トランザクションや "厳密に 1 回" のセマンティクスが含まれるミラートピックへの Cluster Linking の使用はサポートされておらず、推奨されません。
パフォーマンスの制限¶
- スループット
Cluster Linking のスループットは、データレプリケーションの 1 秒あたりのバイト数で表されます。次のパフォーマンスファクターと制限が適用されます。
- Cluster Linking のスループット(データレプリケーションの 1 秒あたりのバイト数)は、送信先クラスターにおける生成の制限("受信" または "書き込み" の制限)に加味されます。ただし、Kafka クライアントからの生成は、Cluster Linking による書き込みよりも優先されます。そのため、これらは Metrics API に別個のメトリクスとして公開されています。つまり、Kafka クライアントによる書き込みは
received_bytes、Cluster Linking による書き込みはcluster_link_destination_response_bytesです。 - Cluster Linking は、Kafka コンシューマーと同じように送信元クラスターから消費します。スループット(データレプリケーションの 1 秒あたりのバイト数)は、コンシューマーのスループットと同じように扱われます。Cluster Linking は、送信元クラスターのクォータやハード制限、ソフト制限にカウントされます。したがって、Kafka クライアントによる読み取りと Cluster Linking による読み取りは、Metrics API の同じメトリック(
sent_bytes)に反映されます。 - Cluster Linking は、CKU のスループットを限界まで使い切ることができます。クラスター間の物理的な距離が、Cluster Linking のパフォーマンスのファクターとなります。Confluent はクラスターリンクをモニタリングして、そのパフォーマンスを最適化します。Replicator や Kafka MirrorMaker 2 とは異なり、Cluster Linking には、固有のスケーリング(つまり、タスク)はありません。パフォーマンスを高めるためにクラスターリンクをスケールアップしたりスケールダウンしたりする必要はありません。
- Cluster Linking のスループット(データレプリケーションの 1 秒あたりのバイト数)は、送信先クラスターにおける生成の制限("受信" または "書き込み" の制限)に加味されます。ただし、Kafka クライアントからの生成は、Cluster Linking による書き込みよりも優先されます。そのため、これらは Metrics API に別個のメトリクスとして公開されています。つまり、Kafka クライアントによる書き込みは
- 接続
- Cluster Linking connections count towards any connection limits on your clusters.
- リクエストレート
- Cluster Linking は、送信元クラスターのリクエストレート制限にカウントされるリクエストの一因となります。
よくある質問¶
クラスターリンクの追加は、送信元クラスターにおけるコンシューマーのスロットリングにつながりますか。¶
はい。その可能性はあります。クラスターリンクを追加することは、auto.offset.reset=earliest の新しいコンシューマーを追加することと似ています。そのため、クラスターリンクがプッシュするクラスターの消費量の合計がクラスターの消費スループットクォータを上回った場合、他のコンシューマーがスロットルされる可能性があります。これは、クラスターリンクが発揮できるスループット、ミラーリングしようとするデータの量、別途確保されている消費容量によっても異なります。
既存のトピックデータをミラーリングする場合、その履歴データを取得するために、クラスターリンクには最初、消費の "急増" が生じることに留意してください。データの状態が追い付くと、送信元トピックに対する生成速度と同じレベルにまで消費速度が下がります(ただし、クラスターリンクが生成のスループットに対処できることが前提です)。
クラスターリンクの追加は、送信先クラスターの既存のプロデューサーのスロットリングにつながりますか¶
いいえ。そのようなことはありません。Cluster Linking による送信先への書き込みよりも、Kafka クライアントのプロデューサーの方が優先されます。
既知の問題¶
送信元トピックを削除する場合の考慮事項¶
アクティブなミラートピックの送信元トピックは削除しないでください。削除すると Cluster Linking に問題が生じるおそれがあります。ベストプラクティスとして、以下の手順に従ってください。
- 削除しようとしている送信元トピックから読み取りを行うアクティブなミラートピックを、
promoteコマンドまたはfailoverコマンドで停止または削除します。 - これで送信元トピックを安全に削除できます。
詳細については、「ミラートピック」の「送信元トピックの削除」を参照してください。
おすすめのリソース¶
- 録画ウェビナー: Cluster Linking: How to Seamlessly Share Data Across Environments
- ポッドキャスト: Multi-Cluster Apache Kafka with Cluster Linking ft. Nikhil Bhatia
- YouTube の動画: Apache Kafka Goes Global with Confluent Cluster Linking
- Kafka Summit のビデオ: Rethinking Geo-replication for the Cloud
- ブログの投稿: Introducing Cluster Linking in Confluent Platform 6.0 - オンプレミス Confluent Platform デプロイ用 Cluster Linking の最初のリリース向けに書かれた、英国の銀行をテーマにしたデモの記録ですが、概念とユースケースは Confluent Cloud の Cluster Linking にも同様に適用できます。
- ディザスターリカバリに関するウェビナー: Demo Series: Learn the Confluent Q3 '21 Release
- ミラートピック
- Cluster Linking のクイックスタート (チュートリアル)
- クラスター、リージョン、クラウド間でのデータの共有 (チュートリアル)
- ディザスターリカバリとフェイルオーバー (チュートリアル)
- Confluent Cloud Cluster Linking (v3) REST API
- Confluent Platform の「Cluster Linking」