重要
このページの日本語コンテンツは古くなっている可能性があります。最新の英語版コンテンツをご覧になるには、こちらをクリックしてください。
Google Cloud Functions Sink Connector for Confluent Cloud¶
注釈
Confluent Platform 用にコネクターをローカルにインストールする場合は、「Google Functions Sink Connector for Confluent Platform」を参照してください。
Kafka Connect Google Cloud Functions Sink Connector for Confluent Cloud を使用すると、Apache Kafka® を Google Cloud Functions と統合できます。関数の基本的な情報については、Google Cloud Functions のドキュメント を参照してください。
このコネクターは、Kafka のトピックからレコードを消費して、Google Cloud Functions を実行します。Google Cloud Functions に送信される各リクエストには、max.batch.size で指定した件数までレコードを含めることができます。
機能¶
Google Cloud Functions Sink Connector には、以下の機能があります。
- Google Cloud Functions の結果は、以下のトピックに格納されます。
success-<connector-id>error-<connector-id>
- サポートされる入力データのフォーマットは、Bytes、AVRO、JSON_SR(JSON スキーマ)、JSON(スキーマレス)および PROTOBUF です。スキーマが定義されていない場合、値はプレーンテキストの文字列としてエンコードされます。たとえば、
"name": "Kimberley Human"はname=Kimberley Humanとしてエンコードされます。
Connect 用の Confluent Cloud API の使用に関する詳細とサンプルについては、「Confluent Cloud API for Connect」セクションを参照してください。
制限¶
以下の情報を確認してください。
- コネクターの制限事項については、Google Functions Sink Connector の制限事項を参照してください。
- 1 つ以上の Single Message Transforms(SMT)を使用する場合は、「SMT の制限」を参照してください。
- Confluent Cloud Schema Registry を使用する場合は、「スキーマレジストリ Enabled Environments」を参照してください。
クイックスタート¶
このクイックスタートを使用して、Confluent Cloud Google Cloud Functions Sink Connector の利用を開始することができます。このクイックスタートでは、コネクターを選択し、ターゲットの Google Cloud Function にイベントをストリーミングするようにコネクターを構成するための基本的な方法について説明します。
- 前提条件
- GCP 上の Confluent Cloud クラスターへのアクセスを許可されていること。
- Google Cloud の関数へのアクセス。関数の基本的な情報については、Google Cloud Functions のドキュメント を参照してください。
- GCP サービスアカウント。サービスアカウントの 認証情報を JSON ファイル 形式でダウンロードします。コネクター構成プロパティをセットアップするときに、この認証情報ファイルをアップロードします。
- Confluent CLI がインストールされ、クラスター用に構成されていること。「Confluent CLI のインストール」を参照してください。
- スキーマレジストリ ベースのフォーマット(Avro、JSON_SR(JSON スキーマ)、Protobuf など)を使用するには、Schema Registry を有効にしておく必要があります。詳細については、「スキーマレジストリ Enabled Environments」を参照してください。
- ターゲットの Google Cloud の関数と Kafka クラスターは、同じリージョンに存在している必要があります。
Kafka クラスターの認証情報。次のいずれかの方法で認証情報を指定できます。
- 既存の サービスアカウント のリソース ID を入力する。
- コネクター用の Confluent Cloud サービスアカウント を作成します。「サービスアカウント」のドキュメントで、必要な ACL エントリを確認してください。一部のコネクターには固有の ACL 要件があります。
- Confluent Cloud の API キーとシークレットを作成する。キーとシークレットを作成するには、confluent api-key create を使用するか、コネクターのセットアップ時に Cloud Console で直接 API キーとシークレットを自動生成します。
以下の
connector-serviceアカウントロールがプロジェクトで有効になっている必要があります。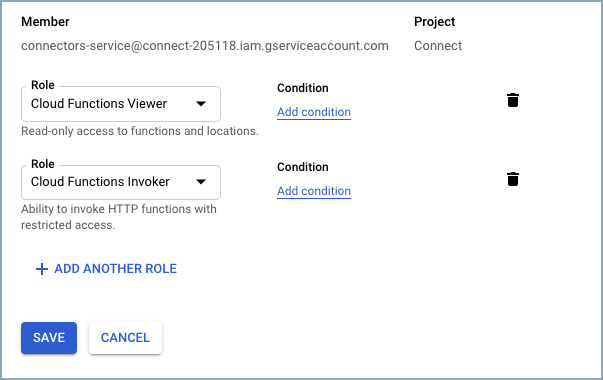
Trigger type を
HTTPに設定する必要があります。Require authentication を選択します。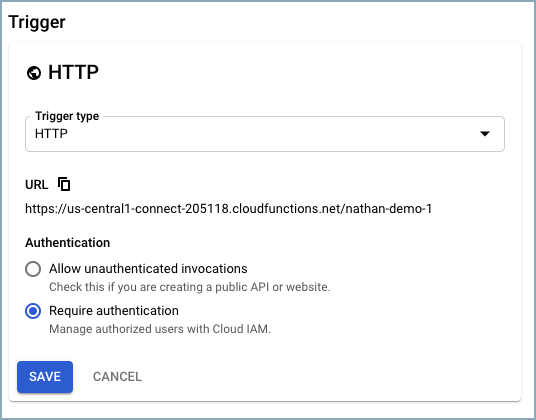
Confluent Cloud Console の使用¶
ステップ 1: Confluent Cloud クラスターを起動します。¶
インストール手順については、「Quick Start for Confluent Cloud」を参照してください。
ステップ 2: コネクターを追加します。¶
左のナビゲーションメニューの Data integration をクリックし、Connectors をクリックします。クラスター内に既にコネクターがある場合は、+ Add connector をクリックします。
ステップ 4: コネクターの詳細情報を入力します。¶
注釈
- すべての 前提条件 を満たしていることを確認してください。
- アスタリスク( * )は必須項目であることを示しています。
Add Google Cloud Functions Sink Connector 画面で、以下を実行します。
既に Kafka トピックを用意している場合は、Topics リストから接続するトピックを選択します。
新しいトピックを作成するには、+Add new topic をクリックします。
- Kafka Cluster credentials で Kafka クラスターの認証情報の指定方法を選択します。以下のいずれかのオプションを選択できます。
- Global Access: コネクターは、ユーザーがアクセス権限を持つすべての対象にアクセスできます。グローバルアクセスの場合、コネクターのアクセス権限は、ユーザーのアカウントにリンクされます。このオプションは本稼働環境では推奨されません。
- Granular access: コネクターのアクセスが制限されます。コネクターのアクセス権限は サービスアカウント から制御できます。本稼働環境にはこのオプションをお勧めします。
- Use an existing API key: 保存済みの API キーおよびシークレット部分を入力できます。API キーとシークレットを入力するか Cloud Console でこれらを生成することもできます。
- Continue をクリックします。
注釈
Cloud Console に表示されない構成プロパティでは、デフォルト値が使用されます。すべてのプロパティの値と定義については、「構成プロパティ」を参照してください。
Input Kafka record value で、Kafka 入力レコード値のフォーマット(Kafka トピックから送られるデータ)を AVRO、JSON_SR、PROTOBUF、JSON、または BYTES から選択します。スキーマベースのメッセージフォーマットを使用するには、有効なスキーマが Schema Registry に存在する必要があります。
Show advanced configurations
Batch size: 1 回の関数呼び出しにまとめることができる Kafka レコードの最大数。レコードのバッチ処理を無効にするには、この値を 1 に設定します。
Max pending requests: Google Cloud Functions に対して同時に要求できる処理待ちリクエストの最大数。
Request timeout (ms): Kafka 入力レコードキーのフォーマットを設定します。指定可能なエントリは、AVRO、JSON_SR、PROTOBUF、STRING です。スキーマベースのメッセージフォーマットを使用するには、有効なスキーマが Schema Registry に存在する必要があります。
**Retry timeout (ms)**: コネクターによって Google Cloud Functions へのリクエストが試行されてからタイムアウト(ソケットタイムアウト)するまでの最大時間(ミリ秒)。
Behavior on error: 呼び出された GCP 関数がエラーを返した場合のコネクターの動作。
Transforms and Predicates については、Single Message Transforms(SMT) のドキュメントを参照してください。
すべてのプロパティの値と定義については、「構成プロパティ」を参照してください。
Continue をクリックします。
選択するトピックのパーティション数に基づいて、推奨タスク数が表示されます。
- 推奨されたタスク数を変更するには、Tasks フィールドに、コネクターで使用する タスク の数を入力します。
- Continue をクリックします。
接続の詳細情報を確認します。
Launch をクリックします。
コネクターのステータスが Provisioning から Running に変わります。
ステップ 5: レコードを確認します。¶
レコードが生成されていることを確認します。
Connect 用の Confluent Cloud API の使用に関する詳細とサンプルについては、「Confluent Cloud API for Connect」セクションを参照してください。
ちなみに
コネクターを起動すると、デッドレターキューのトピックが自動的に生成されます。詳細については、「Confluent Cloud デッドレターキュー」を参照してください。
参考
フルマネージド型の Confluent Cloud コネクターが Confluent Cloud ksqlDB でどのように動作するかを示す例については、「Cloud ETL のデモ」を参照してください。この例では、Confluent CLI を使用して Confluent Cloud のリソースを管理する方法についても説明しています。

Confluent CLI を使用する場合¶
以下の手順に従うと、Confluent CLI を使用してコネクターをセットアップし、実行できます。
注釈
- すべての 前提条件 を満たしていることを確認してください。
- コマンド例では Confluent CLI バージョン 2 を使用しています。詳細については、「Confluent CLI v2 への移行 <https://docs.confluent.io/confluent-cli/current/migrate.html#cli-migrate>`__」を参照してください。
ステップ 2: コネクターの必須の構成プロパティを表示します。¶
以下のコマンドを実行して、コネクターの必須プロパティを表示します。
confluent connect plugin describe <connector-catalog-name>
例:
confluent connect plugin describe GoogleCloudFunctionSink
出力例:
Following are the required configs:
connector.class
name
topics
input.data.format
kafka.auth.mode
kafka.api.key
kafka.api.secret
function.name
project.id
gcf.credentials.json
tasks.max
ステップ 3: コネクターの構成ファイルを作成します。¶
コネクター構成プロパティを含む JSON ファイルを作成します。以下の例は、コネクターの必須プロパティを示しています。
{
"connector.class": "GoogleCloudFunctionsSink",
"name": "GoogleCloudFunctionsSinkConnector_0",
"topics": "pageviews_proto",
"input.data.format": "PROTOBUF",
"kafka.auth.mode": "KAFKA_API_KEY",
"kafka.api.key": "****************",
"kafka.api.secret": "****************************************************************",
"function.name": "dev-test",
"project.id": "connect-2021",
"gcf.credentials.json": "*",
"tasks.max": "1"
}
以下のプロパティ定義に注意してください。
"connector.class": コネクターのプラグイン名を指定します。"name": 新しいコネクターの名前を設定します。"topics": 特定のトピック名を指定するか、複数のトピック名をコンマ区切りにしたリストを指定します。"input.data.format": Kafka 入力レコード値のフォーマットを設定します。指定可能なエントリは、AVRO、JSON_SR、PROTOBUF、JSON、または BYTES です。スキーマベースのメッセージフォーマット(たとえば、Avro、JSON_SR(JSON スキーマ)、および Protobuf)を使用するには、Confluent Cloud Schema Registry を構成しておく必要があります。
"kafka.auth.mode": 使用するコネクターの認証モードを指定します。オプションはSERVICE_ACCOUNTまたはKAFKA_API_KEY(デフォルト)です。API キーとシークレットを使用するには、構成プロパティkafka.api.keyとkafka.api.secretを構成例(前述)のように指定します。サービスアカウント を使用するには、プロパティkafka.service.account.id=<service-account-resource-ID>に リソース ID を指定します。使用できるサービスアカウントのリソース ID のリストを表示するには、次のコマンドを使用します。confluent iam service-account list
例:
confluent iam service-account list Id | Resource ID | Name | Description +---------+-------------+-------------------+------------------- 123456 | sa-l1r23m | sa-1 | Service account 1 789101 | sa-l4d56p | sa-2 | Service account 2
"function.name": 事前に定義した Google Cloud 関数の名前。"project.id": GCP プロジェクト ID。"gcf.credentials.json": ダウンロードした JSON ファイルの内容が入ります。ダウンロードした認証情報ファイルの内容を、フォーマットを変更して使用する方法について詳しくは、「GCP 認証情報のフォーマットの変更」を参照してください。
オプション
"max.batch.size": Google Cloud 関数の 1 回の呼び出しにまとめることができるレコードの最大件数。デフォルトは1(バッチ処理は無効)です。1から1000までの値を指定できます。"max.pending.requests": Google Cloud 関数に対して同時に要求できる処理待ちリクエストの最大数。デフォルトは1です。"request.timeout": コネクターが Google Cloud Functions へのリクエストを試行できる最長時間(ミリ秒)。これを過ぎるとタイムアウト(ソケットタイムアウト)します。デフォルトは300000ミリ秒(5 分)です。"retry.timeout": 失敗したリクエスト(スロットリング時など)がコネクターによって指数関数的にバックオフおよび再試行される合計時間(ミリ秒)。再試行される応答コードはHTTP 429 Too BusyとHTTP 502 Bad Gatewayです。デフォルトは300000ミリ秒(5 分)です。永続的に再試行するようにこのプロパティを構成するには-1を入力します。
Single Message Transforms: CLI を使用した SMT の追加の詳細については、Single Message Transforms(SMT) のドキュメントを参照してください。このコネクターでサポートされていない SMT のリストについては、「サポートされない変換」を参照してください。
すべてのプロパティの値と定義については、「構成プロパティ」を参照してください。
GCP 認証情報のフォーマットの変更¶
ダウンロードした認証情報ファイルの内容は、コネクター構成で使用する前に、文字列フォーマットに変換する必要があります。
JSON ファイルの内容を文字列フォーマットに変換します。これは、オンラインのコンバーターツールを使用して実行できます。たとえば、JSON to String Online Converter などがあります。
Private Key セクションの
\nのすべての出現箇所の前にエスケープ文字\を追加します。これで、各セクションの先頭が\\nになります(以下の強調表示された行を参照してください)。以下の例は、\\nの出現箇所がわかりすいようにフォーマットを整えています。認証情報キーの大部分は省略しています。ちなみに
認証情報を文字列に変換し、さらに必要に応じてエスケープ文字
\を追加するスクリプトも用意されています。Stringify GCP Credentials を参照してください。{ "connector.class": "GoogleCloudFunctionsSink", "name": "GoogleCloudFunctionsSinkConnector_0", "kafka.api.key": "<my-kafka-api-key>", "kafka.api.secret": "<my-kafka-api-secret>", "topics": "<topic-name>", "data.format": "AVRO", "function.name": "dev-test", "project.id": "connect-2021", "gcf.credentials.json": "{\"type\":\"service_account\",\"project_id\":\"connect- 1234567\",\"private_key_id\":\"omitted\", \"private_key\":\"-----BEGIN PRIVATE KEY----- \\nMIIEvAIBADANBgkqhkiG9w0BA \\n6MhBA9TIXB4dPiYYNOYwbfy0Lki8zGn7T6wovGS5pzsIh \\nOAQ8oRolFp\rdwc2cC5wyZ2+E+bhwn \\nPdCTW+oZoodY\\nOGB18cCKn5mJRzpiYsb5eGv2fN\/J \\n...rest of key omitted... \\n-----END PRIVATE KEY-----\\n\", \"client_email\":\"pub-sub@connect-123456789.iam.gserviceaccount.com\", \"client_id\":\"123456789\",\"auth_uri\":\"https:\/\/accounts.google.com\/o\/oauth2\/ auth\",\"token_uri\":\"https:\/\/oauth2.googleapis.com\/ token\",\"auth_provider_x509_cert_url\":\"https:\/\/ www.googleapis.com\/oauth2\/v1\/ certs\",\"client_x509_cert_url\":\"https:\/\/www.googleapis.com\/ robot\/v1\/metadata\/x509\/pub-sub%40connect- 123456789.iam.gserviceaccount.com\"}", "tasks.max": "1" }
変換したすべての文字列の内容を、上記の例のように構成ファイルの
"gcf.credentials.json"セクションに追加します。
ステップ 4: プロパティファイルを読み込み、コネクターを作成します。¶
以下のコマンドを入力して、構成を読み込み、コネクターを起動します。
confluent connect create --config <file-name>.json
例:
confluent connect create --config google-functions-sink-config.json
出力例:
Created connector GoogleCloudFunctionsSinkConnector_0 lcc-ix4dl
ステップ 5: コネクターのステータスを確認します。¶
以下のコマンドを入力して、コネクターのステータスを確認します。
confluent connect list
出力例:
ID | Name | Status | Type
+-----------+-------------------------------------+---------+------+
lcc-ix4dl | GoogleCloudFunctionsSinkConnector_0 | RUNNING | sink
ステップ 6: レコードを確認します。¶
レコードが生成されていることを確認します。
Connect 用の Confluent Cloud API の使用に関する詳細とサンプルについては、「Confluent Cloud API for Connect」セクションを参照してください。
ちなみに
コネクターを起動すると、デッドレターキューのトピックが自動的に生成されます。詳細については、「Confluent Cloud デッドレターキュー」を参照してください。
構成プロパティ¶
このコネクターでは、以下のコネクター構成プロパティを使用します。
データの取得元とするトピック(Which topics do you want to get data from?)¶
topics特定のトピック名を指定するか、複数のトピック名をコンマ区切りにしたリストを指定します。
- 型: list
- 重要度: 高
入力メッセージ(Input messages)¶
input.data.formatKafka 入力レコード値のフォーマットを設定します。指定可能なエントリは、AVRO、JSON_SR、PROTOBUF、JSON、または BYTES です。スキーマベースのメッセージフォーマット(AVRO、JSON_SR、PROTOBUF など)を使用する場合は、Confluent Cloud Schema Registry を構成しておく必要がある点に注意してください。
- 型: string
- 重要度: 高
データへの接続方法(How should we connect to your data?)¶
nameコネクターの名前を設定します。
- 型: string
- 指定可能な値: 最大 64 文字の文字列
- 重要度: 高
Kafka クラスターの認証情報(Kafka Cluster credentials)¶
kafka.auth.modeKafka の認証モード。KAFKA_API_KEY または SERVICE_ACCOUNT を指定できます。デフォルトは KAFKA_API_KEY モードです。
- 型: string
- デフォルト: KAFKA_API_KEY
- 指定可能な値: KAFKA_API_KEY、SERVICE_ACCOUNT
- 重要度: 高
kafka.api.key- 型: password
- 重要度: 高
kafka.service.account.idKafka クラスターとの通信用の API キーを生成するために使用されるサービスアカウント。
- 型: string
- 重要度: 高
kafka.api.secret- 型: password
- 重要度: 高
関数への接続方法(How should we connect to your function?)¶
function.name呼び出す Google Cloud 関数。
- 型: string
- 重要度: 高
project.id関数をデプロイする Google Cloud Project の ID。
- 型: string
- 重要度: 高
GCP 認証情報(GCP credentials)¶
gcf.credentials.json関数の呼び出しアクセス許可を持つ GCP サービスアカウントの JSON ファイル。
- 型: password
- 重要度: 高
クラウド関数の詳細(Cloud Function details)¶
max.batch.size1 回の関数呼び出しにまとめることができる Kafka レコードの最大数。レコードのバッチ処理を無効にするには、この値を 1 に設定します。
- 型: int
- デフォルト: 1
- 指定可能な値: [1、…]
- 重要度: 低
max.pending.requestsGoogle Cloud Functions 宛てとして同時に存在できる保留中のリクエストの最大数。
- 型: int
- デフォルト: 1
- 指定可能な値: [1,...,128]
- 重要度: 低
request.timeout.msコネクターによる Google Cloud Functions へのリクエスト試行がタイムアウト(ソケットタイムアウト)するまでの最大時間(ミリ秒)。
- 型: int
- デフォルト: 300000(5 分)
- 指定可能な値: [0、…]
- 重要度: 低
retry.timeout.msスロットリング時などの失敗したリクエストがコネクターによって指数関数的にバックオフおよび再試行される合計時間(ミリ秒)。再試行される応答コードは HTTP 401 Unauthorized と HTTP 500 Internal Server Error です。値が -1 の場合は、永続的に再試行されます。
- 型: int
- デフォルト: 300000(5 分)
- 指定可能な値: [-1、...]
- 重要度: 低
エラーの処理方法(How should we handle errors?)¶
behavior.on.error呼び出された GCP 関数がエラーを返した場合のコネクターの動作。指定可能なオプションは「log」と「fail」です。「log」の場合、エラーメッセージが記録されて処理が続行されます。「fail」の場合、エラーが発生すると接続を停止します。
- 型: string
- デフォルト: log
- 重要度: 低
このコネクターのタスク数(Number of tasks for this connector)¶
tasks.max- 型: int
- 指定可能な値: [1、…]
- 重要度: 高
次のステップ¶
参考
フルマネージド型の Confluent Cloud コネクターが Confluent Cloud ksqlDB でどのように動作するかを示す例については、「Cloud ETL のデモ」を参照してください。この例では、Confluent CLI を使用して Confluent Cloud のリソースを管理する方法についても説明しています。