重要
このページの日本語コンテンツは古くなっている可能性があります。最新の英語版コンテンツをご覧になるには、こちらをクリックしてください。
Snowflake Sink Connector for Confluent Cloud¶
注釈
Confluent Platform 用にコネクターをローカルにインストールする場合は、『Snowflake Connector for Kafka』ドキュメントを参照してください。
Kafka Connect Snowflake Sink Connector for Confluent Cloud は、Apache Kafka® トピックのイベントを Snowflake データベースに直接マッピングして保存します。このコネクターは、Avro、JSON スキーマ、Protobuf、または JSON(スキーマレス)フォーマットの Apache Kafka® トピックからのデータをサポートします。Kafka トピックのイベントを Snowflake データベースに直接取り込んで、クエリ、拡張、および分析用のサービスにそのデータを公開します。
機能¶
Snowflake Sink Connector には、以下の機能があります。
- データベースの認証: プライベートキー認証を使用します。
- 入力データフォーマット: このコネクターは、Avro、JSON スキーマ、Protobuf、または JSON(スキーマレス)の入力データフォーマットをサポートします。スキーマレジストリ ベースのフォーマット(Avro、JSON_SR(JSON スキーマ)、Protobuf など)を使用するには、Schema Registry を有効にしておく必要があります。詳細については、「スキーマレジストリ Enabled Environments」を参照してください。
- 厳選された構成プロパティ: 以下のプロパティによって、Snowflake データベーステーブルの
RECORD_METADATA列に含められるメタデータが決まります。snowflake.metadata.createtime: この値をfalseに設定すると、CreateTimeプロパティの値は、RECORD_METADATA列のメタデータから除外されます。デフォルト値はtrueです。snowflake.metadata.topic: この値をfalseに設定すると、topicプロパティの値は、RECORD_METADATA列のメタデータから除外されます。デフォルト値はtrueです。snowflake.metadata.offset.and.partition: 値を false に設定すると、OffsetプロパティとPartitionプロパティの値は、RECORD_METADATA列のメタデータから除外されます。デフォルト値はtrueです。snowflake.metadata.all: 値を false に設定すると、RECORD_METADATA列のメタデータが空になります。デフォルト値はtrueです。
Connect 用の Confluent Cloud API の使用に関する詳細とサンプルについては、「Confluent Cloud API for Connect」セクションを参照してください。
制限¶
以下の情報を確認してください。
- コネクターの制限事項については、Snowflake Sink Connector の制限事項を参照してください。
- 1 つ以上の Single Message Transforms(SMT)を使用する場合は、「SMT の制限」を参照してください。
- Confluent Cloud Schema Registry を使用する場合は、「スキーマレジストリ Enabled Environments」を参照してください。
ターゲットテーブルの命名ガイドライン¶
以下のテーブルの命名ガイドラインと制限にご注意ください。
フルマネージド型 Snowflake Sink Connector では、
topic:tableの名前のマッピングを構成できます。この機能は、セルフマネージド型 Snowflake Sink Connector でもサポートされています。Snowflake では、オブジェクト(テーブル)の命名規則に制限があります。詳細については、『識別子の要件』を参照してください。
これに比べて Kafka のトピック命名規則ははるかに寛容です。Confluent Cloud Snowflake Sink Connector では、テーブル名のマッピングに準拠していない Kafka トピック名を使用することができます。
Snowflake のテーブル命名制約に準拠していない Kafka のトピック名(たとえば
my-topic-nameなど)は、コネクターによって、ハッシュを追加した安全な名前(たとえば、my_topic_name_021342など)に変更されます。準拠しているトピック名(たとえば、my_topic_nameなど)であれば、想定されるテーブルmy_topic_nameに結果が送信されます。Kafka トピック用に作成するテーブルの名前をコネクターが調整しなければならない場合に、テーブル名の重複が発生する可能性があります。たとえば、Kafka トピック
numbers+xおよびnumbers-xからデータを読み取る場合、これらのトピック用に作成されるテーブルの名前はどちらもNUMBERS_Xになります。テーブル名の重複を避けるために、コネクターはテーブル名にサフィックスを付けます。サフィックスとして、アンダースコアとハッシュが付けられます。
Snowflake のキーペアの生成¶
コネクターで Snowflake にデータをシンクするには、事前にキーのペアを生成しておく必要があります。Snowflake の認証には、2048 ビット(最小)の RSA が必要です。パブリックキーは、Snowflake ユーザーアカウントに追加します。プライベートキーは、(クイックスタートの手順を実行するときに)コネクターの構成に追加します。
注釈
- この手順では、暗号化されていないプライベートキーを生成します。暗号化されたキーを生成して使用することもできます。暗号化されたキーを生成する場合は、プライベートキーに加えてパスフレーズをコネクター構成に追加します。暗号化されたキーを生成する方法については、Snowflake ドキュメントの「キーペア認証の使用およびキーローテーション」を参照してください。
- 暗号化されていないプライベートキーを使用した場合、以下の構成検証エラーが表示されます。プライベートキーが有効であるかどうかを確認するか、暗号化されたプライベートキーの使用を検討してください。

キーペアの作成¶
次の手順を実行して、キーのペアを生成します。
OpenSSL を使用してプライベートキーを生成します。
openssl genrsa -out snowflake_key.pem 2048
プライベートキーを指定してパブリックキーを生成します。
openssl rsa -in snowflake_key.pem -pubout -out snowflake_key.pub
生成された Snowflake キーファイルをリスト表示します。
ls -l snowflake_key* -rw-r--r-- 1 1679 Jun 8 17:04 snowflake_key.pem -rw-r--r-- 1 451 Jun 8 17:05 snowflake_key.pub
パブリックキーファイルの内容を表示します。
cat snowflake_key.pub -----BEGIN PUBLIC KEY----- MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEA2zIuUb62JmrUAMoME+SX vsz9KUCp/cC+Y+kTGfYB3jRDQ06O0UT+yUKMO/KWuc0dUxZ8s9koW5l/n+TBfxIQ ... omitted 1tD+Ktd/CTXPoVEI2tgCC9Avf/6/9HU3IpV0gL8SZ8U0N5ot4Uw+CSYB3JjMagEG bBWZ8Qc26pFk7Fd17+ykH6rEdLeQ9OElc0ZruVwSsa4AxaZOT+rqCCP7FQPzKTtA JQIDAQAB -----END PUBLIC KEY-----
キーをコピーします。Snowflake で新規ユーザーにキーを追加します。キーの部分のみを
--BEGIN PUBLIC KEY--と--END PUBLIC KEY--の間にコピーします。これは手動で行うことも、以下のコマンドを使用することもできます。grep -v "BEGIN PUBLIC" snowflake_key.pub | grep -v "END PUBLIC"|tr -d '\r\n'
以下のセクションでは、ユーザーを作成し、パブリックキーを追加します。
ユーザーの作成とパブリックキーの追加¶
Snowflake プロジェクトを開きます。次の手順を実行して、ユーザーアカウントを作成し、そのアカウントにパブリックキーを追加します。
注釈
Worksheets パネルに移動し、SECURITYADMIN ロールに切り替えます。
重要
必ず、Worksheets パネルで SECURITYADMIN ロールを設定してください(下図を参照)。ユーザーアカウントのドロップダウン選択は使用しないでください。詳細については、『ユーザーのロール』を参照してください。
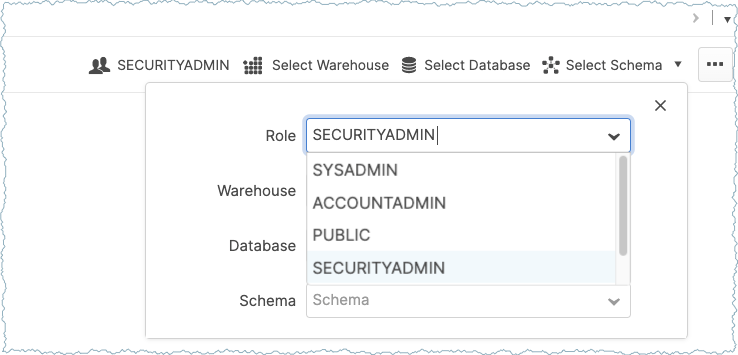
Worksheets で以下のクエリを実行してユーザーを作成し、前の手順でコピーしたパブリックキーを追加し、ユーザーに SYSADMIN ロールを付与します。
CREATE USER confluent RSA_PUBLIC_KEY='<public-key>';
このステートメントの中にパブリックキーを 1 行 で追加してください。Snowflake Worksheets でのパブリックキーの表示は次のようになります。

ちなみに
ロールを SECURITYADMIN に設定しなかった場合や、ユーザーアカウントのドロップダウンメニューを使用してロールを設定した場合は、SQL アクセス制御エラーが表示されます。
SQL access control error: Insufficient privileges to operate on account '<account-name>'
ユーザー権限の構成¶
次の手順を実行して、追加したユーザーのために適切な権限を設定します。
例: PRODUCTION という名前のデータベースに PUBLIC というスキーマを使用して Apache Kafka® レコードを送信するとします。必要なユーザー権限を構成する場合に要求されるクエリを以下に示します。
// Use a role that can create and manage roles and privileges:
use role securityadmin;
// Create a Snowflake role with the privileges to work with the connector
create role kafka_connector_role;
// Grant privileges on the database:
grant usage on database PRODUCTION to role kafka_connector_role;
// Grant privileges on the schema:
grant usage on schema PRODUCTION.PUBLIC to role kafka_connector_role;
grant create table on schema PRODUCTION.PUBLIC to role kafka_connector_role;
grant create stage on schema PRODUCTION.PUBLIC to role kafka_connector_role;
grant create pipe on schema PRODUCTION.PUBLIC to role kafka_connector_role;
// Grant the custom role to an existing user:
grant role kafka_connector_role to user confluent;
// Make the new role the default role:
alter user confluent set default_role=kafka_connector_role;
プライベートキーの抽出¶
プライベートキーを Snowflake コネクターの構成に追加します。キーを抽出し、コネクターをセットアップするまで安全な場所に保管します。
生成された Snowflake キーファイルをリスト表示します。
ls -l snowflake_key* -rw-r--r-- 1 1679 Jun 8 17:04 snowflake_key.pem -rw-r--r-- 1 451 Jun 8 17:05 snowflake_key.pub
プライベートキーファイルの内容を表示します。
cat snowflake_key.pem -----BEGIN RSA PRIVATE KEY----- MIIEpQIBAAKCAQEA2zIuUb62JmrUAMoME+SXvsz9KUCp/cC+Y+kTGfYB3jRDQ06O 0UT+yUKMO/KWuc0dUxZ8s9koW5l/n+TBfxIQx+24C2+l9t3TxxaLdf/YCgQwKNR9 dO9/c+SkX8NfcwUynGEo3wpmdb4hp0X9TfWKX9vG//zK2tndmMUrFY5OcGSSVJYJ Wv3gk04sVxhINo5knpgZoUVztxcRLm/vNvIX1tD+Ktd/CTXPoVEI2tgCC9Avf/6/ 9HU3IpV0gL8SZ8U0N5ot4Uw+CSYB3JjMagEGbBWZ8Qc26pFk7Fd17+ykH6rEdLeQ ... omitted UfrYj7+p03yVflrsB+nyuPETnRJx41b01GrwJk+75v5EIg8U71PQDWfy1qOrUk/d 9u25iaVRzi6DFM0ppE76Lh72SKy+m0iEZIXWbV9q6vf46Oz1PrtffAzyi4pyJbe/ ypQ53f0CgYEA7rE6Dh0tG7EnYfFYrnHLXFC2aVtnkfCMIZX/VIZPX82VGB1mV43G qTDQ/ax1tit6RHDBk7VU4Xn545Tgj1z6agYPvHtkhxYTq50xVBXr/xwlMnzUZ9s3 VjGpMYQANm2seleV6/si54mT4TkUyB7jMgWdFsewtwF60quvxmiA9RU= -----END RSA PRIVATE KEY-----
キーをコピーします。コピーしたキーは、後でコネクター構成に追加します。
--BEGIN RSA PRIVATE KEY--と--END RSA PRIVATE KEY--の間のキー部分のみをコピーします。これは手動で行うことも、以下のコマンドを使用することもできます。grep -v "BEGIN RSA PRIVATE KEY" snowflake_key.pem | grep -v "END RSA PRIVATE KEY"|tr -d '\r\n'
後でクイックスタートの手順を実行するときに使用するために、キーを保管します。また、コネクターの構成のために実際にキーを用意しなければならないときに、前の手順を実行することもできます。
クイックスタート¶
このクイックスタートを使用して、Confluent Cloud Snowflake Sink Connector の利用を開始することができます。このクイックスタートでは、コネクターを選択し、Kafka のデータを消費して Snowflake データベースにデータを保存するようにコネクターを構成するための基本的な方法について説明します。
- 前提条件
- アマゾンウェブサービス (AWS)、Microsoft Azure (Azure)、または Google Cloud Platform (GCP)上の Confluent Cloud クラスターへのアクセスを許可されていること。
- Confluent CLI がインストールされ、クラスター用に構成されていること。「Confluent CLI のインストール」を参照してください。
- スキーマレジストリ ベースのフォーマット(Avro、JSON_SR(JSON スキーマ)、Protobuf など)を使用するには、Schema Registry を有効にしておく必要があります。詳細については、「スキーマレジストリ Enabled Environments」を参照してください。
- Snowflake データベースでコネクターを認証するために使用する Snowflake の アカウントおよびキーペア。
- 作成したユーザー には、データベースとスキーマを変更するための権限を Snowflake で付与しておく必要があります。詳細については、『アクセス制御権限』を参照してください。
- Snowflake データベースと Kafka クラスターは同じリージョンに存在している必要があります。
- ネットワークに関する考慮事項については、「Networking and DNS Considerations」を参照してください。静的なエグレス IP を使用する方法については、「静的なエグレス IP アドレス」を参照してください。
- Kafka クラスターの認証情報。次のいずれかの方法で認証情報を指定できます。
- 既存の サービスアカウント のリソース ID を入力する。
- コネクター用の Confluent Cloud サービスアカウント を作成します。「サービスアカウント」のドキュメントで、必要な ACL エントリを確認してください。一部のコネクターには固有の ACL 要件があります。
- Confluent Cloud の API キーとシークレットを作成する。キーとシークレットを作成するには、confluent api-key create を使用するか、コネクターのセットアップ時に Cloud Console で直接 API キーとシークレットを自動生成します。
Confluent Cloud Console の使用¶
ステップ 1: Confluent Cloud クラスターを起動する。¶
インストール手順については、「Quick Start for Confluent Cloud」を参照してください。
ステップ 2: コネクターを追加する。¶
左のナビゲーションメニューの Data integration をクリックし、Connectors をクリックします。クラスター内に既にコネクターがある場合は、+ Add connector をクリックします。
ステップ 4: コネクターの詳細情報を入力します。¶
注釈
- すべての 前提条件 を満たしていることを確認してください。
- コマンド例では Confluent CLI バージョン 2 を使用しています。詳細については、「Confluent CLI v2 への移行 <https://docs.confluent.io/confluent-cli/current/migrate.html#cli-migrate>`__」を参照してください。
Add Snowflake Sink Connector 画面で、以下を実行します。
既に Kafka トピックを用意している場合は、Topics リストから接続するトピックを選択します。
新しいトピックを作成するには、+Add new topic をクリックします。
- Kafka Cluster credentials で Kafka クラスターの認証情報の指定方法を選択します。以下のいずれかのオプションを選択できます。
- Global Access: コネクターは、ユーザーがアクセス権限を持つすべての対象にアクセスできます。グローバルアクセスの場合、コネクターのアクセス権限は、ユーザーのアカウントにリンクされます。このオプションは本稼働環境では推奨されません。
- Granular access: コネクターのアクセスが制限されます。コネクターのアクセス権限は サービスアカウント から制御できます。本稼働環境にはこのオプションをお勧めします。
- Use an existing API key: 保存済みの API キーおよびシークレット部分を入力できます。API キーとシークレットを入力するか Cloud Console でこれらを生成することもできます。
- Continue をクリックします。
- Snowflake Credentials で、以下を入力します。
- Connection URL: Snowflake アカウントにアクセスするための URL を入力します。フォーマット
https://<account_locator>.<region_id>.<cloud_provider>.snowflakecomputing.com:443を使用します。https://とポート番号443は、省略可能です。詳細については、「Account Locator in a Region」を参照してください。アカウントが AWS 米国西部リージョンにあり、AWS PrivateLink を使用している場合は、リージョン ID を使用しないでください。 - Connection user name: 前の手順で作成したユーザー名 を入力します。
- Private key: 前の手順で作成したプライベートキー を 1 行 で入力します。
--BEGIN RSA PRIVATE KEY--と--END RSA PRIVATE KEY--の間のキー部分のみを入力します。 - Database name: 行の挿入先となるテーブルが格納されているデータベース名を入力します。
- Schema name: 行の挿入先となるテーブルが格納されているスキーマ名。
- Topics to tables mapping:
- Connection URL: Snowflake アカウントにアクセスするための URL を入力します。フォーマット
- Continue をクリックします。
注釈
Cloud Console に表示されない構成プロパティでは、デフォルト値が使用されます。構成プロパティの値と説明については、「構成プロパティ」を参照してください。
Input Kafka record value で、Kafka 入力レコード値のフォーマット(Kafka トピックから送られるデータ)を JSON(スキーマレス)、AVRO、JSON_SR(JSON スキーマ)、または PROTOBUF から選択します。スキーマベースのメッセージフォーマット(Avro、JSON_SR(JSON スキーマ)、Protobuf など)を使用するには、有効なスキーマが Schema Registry に存在する必要があります。詳細については、「スキーマレジストリ Enabled Environments」を参照してください。
Show advanced configurations
接続の詳細(Connection details)
Whether or not to include "createtime" in metadata: 値を
FALSEに設定すると、CreateTimeプロパティの値は、RECORD_METADATA列のメタデータから除外されます。デフォルト値はTRUEです。Whether or not to include "topic" in metadata: 値を
FALSEに設定すると、topic プロパティの値は、RECORD_METADATA列のメタデータから除外されます。デフォルト値はTRUEです。Whether or not to include "offset" and "partition" in metadata: 値を
FALSEに設定すると、Offset プロパティと Partition プロパティの値は、RECORD_METADATA列のメタデータから除外されます。デフォルト値はTRUEです。Whether or not to include metadata column: 値を
FALSEに設定すると、RECORD_METADATA列のメタデータが完全に空になります。デフォルト値はTRUEです。The time in seconds to flush cached data: バッファのフラッシュ間の秒数。Kafka のメモリーキャッシュから内部ステージにフラッシュされます。デフォルト値は 120 秒、最小値は 10 秒です。コネクターでは
buffer.count.recordsとbuffer.size.bytes=10,000,000も使用されます。いずれか早いもののタイミングで、コネクターで Kafka レコードが Snowflake にフラッシュされます。The number of records to flush cached: バッファのフラッシュ間のレコード数。Kafka のメモリーキャッシュから内部ステージにフラッシュされます。デフォルト値かつ最小値は 10,000 レコードです。コネクターでは
buffer.flush.timeとbuffer.size.bytes=10,000,000も使用されます。いずれか早いもののタイミングで、コネクターで Kafka レコードが Snowflake にフラッシュされます。
注釈
変換と述語については、Single Message Transforms(SMT) のドキュメントを参照してください。このコネクターでサポートされていない SMT のリストについては、「サポートされない変換」を参照してください。
Continue をクリックします。
選択するトピックのパーティション数に基づいて、推奨タスク数が表示されます。1 つのタスクで処理できるパーティションの数は最大 100 個です。
- 推奨されたタスク数を変更するには、Tasks フィールドに、コネクターで使用する タスク の数を入力します。各タスクのトピックのパーティション数は、
buffer.size.bytesプロパティの値に基づいて制限されます。たとえば、10MB バッファサイズではトピックのパーティション数は 50 に制限されます。20MB バッファでは 25、50MB バッファでは 10、100MB バッファでは 5 です。 - Continue をクリックします。
構成の概要を確認し、以下を検証します。
接続の詳細情報を確認し、Launch をクリックします。
コネクターのステータスが Provisioning から Running に変わります。

Launch をクリックします。
ステップ 5: Snowflake を確認します。¶
コネクターが実行中になったら、メッセージが Snowflake データベーステーブルに取り込まれていることを確認します。
Connect 用の Confluent Cloud API の使用に関する詳細とサンプルについては、「Confluent Cloud API for Connect」セクションを参照してください。
ちなみに
コネクターを起動すると、デッドレターキューのトピックが自動的に生成されます。詳細については、「Confluent Cloud デッドレターキュー」を参照してください。
Snowflake のトラブルシューティングについては、Snowflake ドキュメントの『問題のトラブルシューティング』を参照してください。
注釈
- Snowflake Sink Connector は、コネクターが削除されたときに Snowflake パイプを除去しません。Snowflake パイプを手動でクリーンアップする手順については、パイプのドロップ を参照してください。
- Snowflake の Snowpipe に障害があると、Snowflake Sink Connector で正常に書き込んでいても、ターゲットテーブルにメッセージが現れないことがあります。その場合は、メッセージおよび関連するエラーがないか、Snowflake の COPY_HISTORY のビュー、内部ステージ、またはテーブルステージを確認してください。Snowflake Sink Connector のワークフローの詳細については、『Kafka コネクタのワークフロー』を参照してください。
参考
フルマネージド型の Confluent Cloud コネクターが Confluent Cloud ksqlDB でどのように動作するかを示す例については、「Cloud ETL のデモ」を参照してください。この例では、Confluent CLI を使用して Confluent Cloud のリソースを管理する方法についても説明しています。

Confluent CLI の使用¶
以下の手順に従うと、Confluent CLI を使用してコネクターをセットアップし、実行できます。
注釈
- すべての 前提条件 を満たしていることを確認してください。
- コマンド例では Confluent CLI バージョン 2 を使用しています。詳細については、「Confluent CLI v2 への移行 <https://docs.confluent.io/confluent-cli/current/migrate.html#cli-migrate>`__」を参照してください。
ステップ 2: コネクターの必須の構成プロパティを表示します。¶
以下のコマンドを実行して、コネクターの必須プロパティを表示します。
confluent connect plugin describe <connector-catalog-name>
例:
confluent connect plugin describe SnowflakeSink
出力例:
Following are the required configs:
connector.class: SnowflakeSink
name
kafka.auth.mode
kafka.api.key
kafka.api.secret
input.data.format
snowflake.url.name
snowflake.user.name
snowflake.private.key
snowflake.schema.name
tasks.max
topics
ステップ 3: コネクターの構成ファイルを作成します。¶
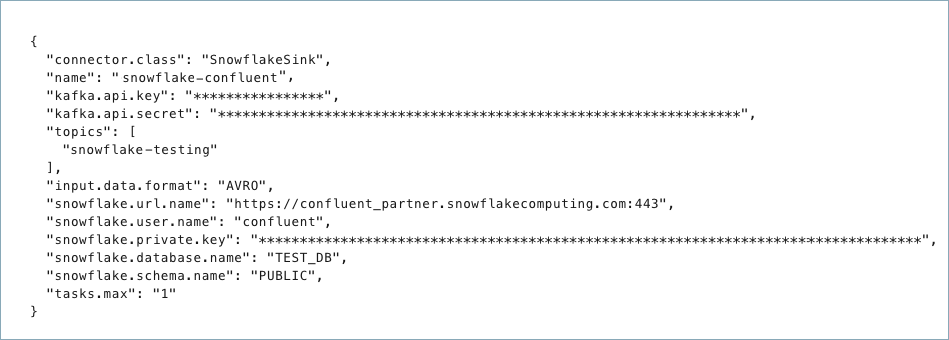
コネクター構成プロパティを含む JSON ファイルを作成します。以下の例は、コネクターの必須プロパティを示しています。
{
"connector.class": "SnowflakeSink",
"name": "<connector-name>",
"kafka.auth.mode": "KAFKA_API_KEY",
"kafka.api.key": "<my-kafka-api-key>",
"kafka.api.secret": "<my-kafka-api-secret>",
"topics": "<topic1>, <topic2>",
"input.data.format": "JSON",
"snowflake.url.name": "https://wm83168.us-central1.gcp.snowflakecomputing.com:443",
"snowflake.user.name": "<login-username>",
"snowflake.private.key": "<private-key>",
"snowflake.database.name": "<database-name>",
"snowflake.schema.name": "<schema-name>",
"tasks.max": "1"
}
以下の必須プロパティの定義にご注意ください。
"connector.class": コネクターのプラグイン名を指定します。"name": コネクターの名前を入力します。
"kafka.auth.mode": 使用するコネクターの認証モードを指定します。オプションはSERVICE_ACCOUNTまたはKAFKA_API_KEY(デフォルト)です。API キーとシークレットを使用するには、構成プロパティkafka.api.keyとkafka.api.secretを構成例(前述)のように指定します。サービスアカウント を使用するには、プロパティkafka.service.account.id=<service-account-resource-ID>に リソース ID を指定します。使用できるサービスアカウントのリソース ID のリストを表示するには、次のコマンドを使用します。confluent iam service-account list
例:
confluent iam service-account list Id | Resource ID | Name | Description +---------+-------------+-------------------+------------------- 123456 | sa-l1r23m | sa-1 | Service account 1 789101 | sa-l4d56p | sa-2 | Service account 2
"topics": トピックを 1 つ入力するか、複数のトピックをコンマ区切りにして入力します。"input.data.format": Kafka 入力レコード値のフォーマット(Kafka トピックから送られるデータ)を設定します。指定可能なエントリは、AVRO、JSON_SR、PROTOBUF、または JSON です。スキーマベースのメッセージフォーマット(たとえば、Avro、JSON_SR(JSON スキーマ)、および Protobuf)を使用するには、Confluent Cloud Schema Registry を構成しておく必要があります。"snowflake.url.name": Snowflake アカウントにアクセスするための URL を入力します。フォーマットhttps://<account_locator>.<region_id>.<cloud_provider>.snowflakecomputing.com:443を使用します。https://とポート番号443は、省略可能です。詳細については、「Account Locator in a Region」を参照してください。アカウントが AWS 米国西部リージョンにあり、AWS PrivateLink を使用している場合は、リージョン ID を使用しないでください。"snowflake.user.name": 前の手順で作成したユーザー名 を入力します。"snowflake.private.key":- 前の手順で作成したプライベートキー を 1 行 で入力します。
--BEGIN RSA PRIVATE KEY--と--END RSA PRIVATE KEY--の間のキー部分のみを入力します。
"snowflake.database.name": 行の挿入先となるテーブルが格納されているデータベース名を入力します。"snowflake.schema.name": 行の挿入先となるテーブルが格納されている Snowflake の スキーマ名 を入力します。"tasks.max": コネクターの タスク の数を入力します。詳しくは、Confluent Cloud コネクターの制限事項 を参照してください。
構成に含めることができるオプションのプロパティを以下に示します。これらのプロパティは、Snowflake データベーステーブルの RECORD_METADATA 列に含められるメタデータに影響を与えます。
"snowflake.metadata.createtime": この値を"false"に設定すると、CreateTimeプロパティの値は、RECORD_METADATA列のメタデータから除外されます。デフォルト値は"true"です。"snowflake.metadata.topic": この値を"false"に設定すると、topicプロパティの値は、RECORD_METADATA列のメタデータから除外されます。デフォルト値は"true"です。snowflake.metadata.offset.and.partition: 値をfalseに設定すると、OffsetプロパティとPartitionプロパティの値は、RECORD_METADATA列のメタデータから除外されます。デフォルト値は"true"です。snowflake.metadata.all: 値をfalseに設定すると、RECORD_METADATA列のメタデータが空になります。デフォルト値は"true"です。
レコードを Snowflake にフラッシュするタイミングを指定するために、以下のプロパティを設定します。レコードは、以下の値のいずれかを最初に満たしたときにフラッシュされます。たとえば、レコードのフラッシュ間隔を 120 秒に設定します。最後にフラッシュされた後、この時間が経過した時点で、レコード数の値は満たされていないとします。このとき、レコード数のプロパティより前に時間間隔に達したため、レコードがフラッシュされます。
"buffer.flush.time": コネクターがキャッシュしたレコードを Snowflake にフラッシュする前に待機する時間(秒)。デフォルト値は120秒、最小値は 10 秒です。さらに長い時間も構成できます。"buffer.count.records": レコードは、Snowflake にフラッシュされる前に(パーティションごとの)バッファにキャッシュされます。デフォルト値は10000です。これは、最小レコード数です。このレコード数の構成を増やすこともできます。レコード数がプロパティの値に達すると、レコードが Snowflake にフラッシュされます。"buffer.size.bytes": レコードは、Snowflake にデータファイルとして書き込まれる前に(パーティションごとの)バッファにキャッシュされます。バッファサイズのデフォルトは、10000000バイト(10 MB)です。これは最小キャッシュサイズ値です。最大100000000バイト(100 MB)まで構成可能です。このバッファがプロパティのサイズに達すると、レコードが Snowflake にフラッシュされます。注釈
キャッシュが 10 MB に達してフラッシュがトリガーされると、Snowflake に 10 MB のデータファイルがフラッシュされると考えられるかもしれません。しかし実際のファイルサイズはずっと小さくなります(250 KB 以下)。これは、フラッシュされる 10 MB のデータが Java から UTF に変換されるためです。この変換によって、ファイルサイズが 50% 削減されます。ファイルは、その後 gzip で圧縮されるので、ファイルサイズはさらに 95% 削減されます。
"tasks.max": このコネクターで使用できる タスク の最大数を入力します。各タスクのトピックのパーティション数は、buffer.size.bytesプロパティの値に基づいて制限されます。たとえば、10MB バッファサイズではトピックのパーティション数は 50 に制限されます。20MB バッファでは 25、50MB バッファでは 10、100MB バッファでは 5 です。
Single Message Transforms: CLI を使用した SMT の追加の詳細については、Single Message Transforms(SMT) のドキュメントを参照してください。このコネクターでサポートされていない SMT のリストについては、「サポートされない変換」を参照してください。
すべてのプロパティの値と説明については、「構成プロパティ」を参照してください。
ステップ 4: プロパティファイルを読み込み、コネクターを作成する。¶
以下のコマンドを入力して、構成を読み込み、コネクターを起動します。
confluent connect create --config <file-name>.json
例:
confluent connect create --config snowflake-sink.json
出力例:
Created connector confluent-snowflake lcc-ix4dl
ステップ 5: コネクターのステータスを確認する。¶
以下のコマンドを入力して、コネクターのステータスを確認します。
confluent connect list
出力例:
ID | Name | Status | Type
+-----------+-------------------------+---------+------+
lcc-ix4dl | confluent-snowflake | RUNNING | sink
ステップ 6: Snowflake を確認する。¶
コネクターをコネクターを実行してから、レコードが Snowflake データベースに取り込まれていることを確認します。
Connect 用の Confluent Cloud API の使用に関する詳細とサンプルについては、「Confluent Cloud API for Connect」セクションを参照してください。
ちなみに
コネクターを起動すると、デッドレターキューのトピックが自動的に生成されます。詳細については、「Confluent Cloud デッドレターキュー」を参照してください。
Snowflake のトラブルシューティングについては、Snowflake ドキュメントの『問題のトラブルシューティング』を参照してください。
注釈
- Snowflake Sink Connector は、コネクターが削除されたときに Snowflake パイプを除去しません。Snowflake パイプを手動でクリーンアップする手順については、パイプのドロップ を参照してください。
- Snowflake の Snowpipe に障害があると、Snowflake Sink Connector で正常に書き込んでいても、ターゲットテーブルにメッセージが現れないことがあります。その場合は、メッセージおよび関連するエラーがないか、Snowflake の COPY_HISTORY のビュー、内部ステージ、またはテーブルステージを確認してください。Snowflake Sink Connector のワークフローの詳細については、『Kafka コネクタのワークフロー』を参照してください。
構成プロパティ¶
このコネクターでは、以下のコネクター構成プロパティを使用します。
データの取得元とするトピック(Which topics do you want to get data from?)¶
topics特定のトピック名を指定するか、複数のトピック名をコンマ区切りにしたリストを指定します。
- 型: list
- 重要度: 高
入力メッセージ(Input messages)¶
input.data.formatKafka 入力レコード値のフォーマットを設定します。指定可能なエントリは、JSON、AVRO、JSON_SR、または PROTOBUF です。スキーマベースのメッセージフォーマット(AVRO、JSON_SR、PROTOBUF など)を使用する場合は、Confluent Cloud Schema Registry を構成しておく必要がある点に注意してください
- 型: string
- 重要度: 高
input.key.formatKafka 入力レコードキーのフォーマットを設定します。指定可能なエントリは、AVRO、JSON_SR、PROTOBUF、STRING、または JSON です。スキーマベースのメッセージフォーマット(AVRO、JSON_SR、PROTOBUF など)を使用する場合は、Confluent Cloud Schema Registry を構成しておく必要がある点に注意してください
- 型: string
- デフォルト: STRING
- 指定可能な値: AVRO、JSON、JSON_SR、PROTOBUF、STRING
- 重要度: 高
データへの接続方法(How should we connect to your data?)¶
nameコネクターの名前を設定します。
- 型: string
- 指定可能な値: 最大 64 文字の文字列
- 重要度: 高
Kafka クラスターの認証情報(Kafka Cluster credentials)¶
kafka.auth.modeKafka の認証モード。KAFKA_API_KEY または SERVICE_ACCOUNT を指定できます。デフォルトは KAFKA_API_KEY モードです。
- 型: string
- デフォルト: KAFKA_API_KEY
- 指定可能な値: KAFKA_API_KEY、SERVICE_ACCOUNT
- 重要度: 高
kafka.api.key- 型: password
- 重要度: 高
kafka.service.account.idKafka クラスターとの通信用の API キーを生成するために使用されるサービスアカウント。
- 型: string
- 重要度: 高
kafka.api.secret- 型: password
- 重要度: 高
Snowflake データベースへの接続方法(How should we connect to your Snowflake database?)¶
snowflake.url.nameSnowflake アカウントにアクセスするための URL。https://<account_name>.<region_id>.snowflakecomputing.com:443 という形式を使用します。https:// とポート番号は、省略可能です。アカウントが AWS 米国西部リージョンにあり、AWS PrivateLink を使用していない場合は、リージョン ID は使用されません。
- 型: string
- 重要度: 高
snowflake.user.nameSnowflake アカウントのユーザーログイン名。
- 型: string
- 重要度: 高
snowflake.private.keyユーザーを認証するためのプライベートキー。ヘッダーとフッターを除いたキーだけを含めます。キーが複数行にわたる場合は、改行を削除します。暗号化されていないキーと暗号化されたキーのどちらでも使用できます。暗号化されたキーを使用する場合は、Snowflake でキーを復号化できるように、snowflake.private.key.passphrase パラメーターを指定します。このパラメーターは、snowflake.private.key パラメーターの値が暗号化されている場合にのみ使用します。
- 型: password
- 重要度: 高
snowflake.database.name行の挿入先となるテーブルが格納されているデータベースの名前。
- 型: string
- 重要度: 高
データベースの詳細(Database details)¶
snowflake.schema.name行の挿入先となるテーブルが格納されているスキーマの名前。
- 型: string
- 重要度: 高
snowflake.topic2table.mapトピックとテーブルのマッピング(省略可)。フォーマットはコンマ区切りのタプルです。たとえば、<topic-1>:<table-1>,<topic-2>:<table-2>,... のように指定します。
- 型: string
- 重要度: 高
接続の詳細(Connection details)¶
snowflake.private.key.passphrasesnowflake.private.key が暗号化されている場合、これがキーの復号化に使用されるパスフレーズとなります。このパラメーターの値が空でない場合、Kafka では、プライベートキーの復号化にこのフレーズが使用されます。
- 型: password
- デフォルト: [hidden]
- 重要度: 中
snowflake.metadata.createtime値を FALSE に設定すると、CreateTime プロパティの値は、RECORD_METADATA 列のメタデータから除外されます。デフォルト値は TRUE です。
- 型: boolean
- デフォルト: true
- 重要度: 中
snowflake.metadata.topic値を FALSE に設定すると、topic プロパティの値は、RECORD_METADATA 列のメタデータから除外されます。デフォルト値は TRUE です。
- 型: boolean
- デフォルト: true
- 重要度: 中
snowflake.metadata.offset.and.partition値を FALSE に設定すると、Offset プロパティと Partition プロパティの値は、RECORD_METADATA 列のメタデータから除外されます。デフォルト値は TRUE です。
- 型: boolean
- デフォルト: true
- 重要度: 中
snowflake.metadata.all値を FALSE に設定すると、RECORD_METADATA 列のメタデータが完全に空になります。デフォルト値は TRUE です。
- 型: boolean
- デフォルト: true
- 重要度: 中
buffer.flush.timeバッファのフラッシュ間の秒数。Kafka のメモリーキャッシュから内部ステージにフラッシュされます。デフォルト値は 120 秒、最小値は 10 秒です。コネクターでは buffer.count.records と buffer.size.bytes=10,000,000(10 MB)も使用されます。いずれか早いもののタイミングで、コネクターで Kafka レコードが Snowflake にフラッシュされます。
- 型: long
- デフォルト: 120
- 指定可能な値: [10、…]
- 重要度: 低
buffer.count.recordsバッファのフラッシュ間のレコード数。Kafka のメモリーキャッシュから内部ステージにフラッシュされます。デフォルト値かつ最小値は 10,000 レコードです。コネクターでは buffer.flush.time と buffer.size.bytes=10,000,000(10 MB)も使用されます。いずれか早いもののタイミングで、コネクターで Kafka レコードが Snowflake にフラッシュされます。
- 型: long
- デフォルト: 10000
- 指定可能な値: [10000、…]
- 重要度: 低
buffer.size.bytesKafka レコードは、Snowflake にデータファイルとして書き込まれる前に(パーティションごとの)バッファにキャッシュされます。バッファサイズのデフォルトは、10000000 バイト(10 MB)です。レコードは Snowflake に書き込まれるときに圧縮されます。圧縮されるため、キャッシュされたレコードバッファのサイズは、結果的に Snowflake に作成されるデータファイルのサイズよりも大きい可能性があります。
- 型: long
- デフォルト: 10000000
- 指定可能な値: [10000000,...,100000000]
- 重要度: 低
このコネクターのタスク数(Number of tasks for this connector)¶
tasks.maxコネクターのタスク数。各タスクのトピックのパーティション数は、buffer.size.bytes 構成に基づいて制限されます。たとえば、10 MB の場合はトピックのパーティション数は 50、20 MB では 25、50 MB では 10、100 MB では 5 です。
- 型: int
- 指定可能な値: [1,...]
- 重要度: 高
トラブルシューティング¶
Snowflake のトラブルシューティングについては、Snowflake ドキュメントの『問題のトラブルシューティング』を参照してください。
ちなみに
コネクターを起動すると、デッドレターキューのトピックが自動的に生成されます。詳細については、「Confluent Cloud デッドレターキュー」を参照してください。
おすすめの記事¶
次のブログ記事では、Snowflake Sink Connector の概要とシナリオが紹介されています。
ブログ記事: Announcing the Snowflake Sink connector for Apache Kafka in Confluent Cloud
次のステップ¶
参考
フルマネージド型の Confluent Cloud コネクターが Confluent Cloud ksqlDB でどのように動作するかを示す例については、「Cloud ETL のデモ」を参照してください。この例では、Confluent CLI を使用して Confluent Cloud のリソースを管理する方法についても説明しています。