重要
このページの日本語コンテンツは古くなっている可能性があります。最新の英語版コンテンツをご覧になるには、こちらをクリックしてください。
Oracle Database Source Connector for Confluent Cloud¶
注釈
Confluent Platform 用にコネクターをローカルにインストールする場合は、「JDBC Connector(Source および Sink)for Confluent Platform」を参照してください。
Kafka Connect Oracle Database Source Connector for Confluent Cloud は、Oracle データベースの既存データのスナップショットを取得し、そのデータに対して後続の行レベルの変更をすべてモニタリングして記録することができます。このコネクターでは、Avro、JSON スキーマ、Protobuf、または JSON(スキーマレス)の出力データフォーマットがサポートされています。各テーブルのすべてのイベントが、個別の Apache Kafka® トピックに記録されます。それにより、アプリケーションやサービスでイベントを簡単に消費することができます。削除されたレコードは、キャプチャーされないようご注意ください。
機能¶
Oracle Database Source Connector には、以下の機能があります。
トピックの自動作成: このコネクターは、命名規則
<topic.prefix><tableName>を使用して自動的に Kafka トピックを作成します。テーブルの作成にはtopic.creation.default.partitions=1プロパティおよびtopic.creation.default.replication.factor=3プロパティが使用されます。挿入モード:
timestamp モードは、データベースの詳細を入力するときに、タイムスタンプ列を指定した場合にのみ使用可能です。
timestamp+incrementing モードは、データベースの詳細を入力するときにタイムスタンプ列と増分列の両方を指定した場合に使用可能です。
重要
タイムスタンプ列が、null 許容にしないようにする必要があります。
データベースの認証: パスワード認証を使用します。
データフォーマット: このコネクターは、Avro、JSON スキーマ、Protobuf、または JSON(スキーマレス)の出力データをサポートします。スキーマレジストリ ベースのフォーマット(Avro、JSON_SR(JSON スキーマ)、Protobuf など)を使用するには、Schema Registry を有効にしておく必要があります。詳細については、「スキーマレジストリ Enabled Environments」を参照してください。
構成プロパティを選択する:
db.timezonepoll.interval.msbatch.max.rowstimestamp.delay.interval.mstopic.prefixschema.pattern
Connect 用の Confluent Cloud API の使用に関する詳細とサンプルについては、「Confluent Cloud API for Connect」セクションを参照してください。
制限¶
以下の情報を確認してください。
- コネクターの制限事項については、Oracle Database Source Connector の制限事項を参照してください。
- 1 つ以上の Single Message Transforms(SMT)を使用する場合は、「SMT の制限」を参照してください。
- Confluent Cloud Schema Registry を使用する場合は、「スキーマレジストリ Enabled Environments」を参照してください。
注釈
正確な 10 進数データ表現を使用する多くの JSON データは、精度が 38 の 10 進数として表されます(たとえば NUMBER(38,0) など)。これは INT64 または FLOAT64 では大きすぎます。INTEGER は NUMBER(38) の別名であるため、同じ問題があります。そのため、このソースコネクターは Connect の DECIMAL 型を使用します。Confluent にはこの内容に関する詳細な記事が用意されています。『Kafka Connect Deep Dive – JDBC Source connector』を参照してください。
クイックスタート¶
このクイックスタートを使用して、Confluent Cloud Oracle Database Source Connector の利用を開始することができます。このクイックスタートでは、コネクターを選択してから、Oracle データベースの既存データのスナップショットを取得して、それ以降に発生する行レベルの変更をすべてモニタリングして記録するようにコネクターを構成するための基本的な方法について説明します。
- 前提条件
- アマゾンウェブサービス (AWS)、Microsoft Azure (Azure)、または Google Cloud Platform (GCP)上の Confluent Cloud クラスターへの許可されたアクセス。
- Confluent CLI がインストールされ、クラスター用に構成されていること。「Confluent CLI のインストール」を参照してください。
- このコネクターは、命名規則
<prefix>.<table-name>を使用して自動的に Kafka トピックを作成します。テーブルの作成にはtopic.creation.default.partitions=1プロパティおよびtopic.creation.default.replication.factor=3プロパティが使用されます。特定の設定を指定してトピックを作成する場合は、このコネクターを実行する前にトピックを作成しておいてください。 - Oracle Database システムは、プラガブルデータベース(PDB)のサービス名を使用して構成しておく必要があります。これをセットアップする手順については、「マルチテナントの Oracle Database システムの構成」を参照してください。データベースへの接続を構成するときに、Database name でこのサービス名が使用されます。
- Oracle Database のバージョンは 11.2.0.4 以降である必要があります。
- スキーマレジストリ ベースのフォーマット(Avro、JSON_SR(JSON スキーマ)、Protobuf など)を使用するには、Schema Registry を有効にしておく必要があります。詳細については、「スキーマレジストリ Enabled Environments」を参照してください。
- Make sure your connector can reach your service. Consider the following before running the connector:
- Depending on the service environment, certain network access limitations may exist. See ネットワークアクセス for details.
- To use static egress IPs, see 静的なエグレス IP アドレス. For additional managed connector networking details, see Networking and DNS Considerations.
- Do not include
jdbc:xxxx://in the connection hostname property. An example of a connection hostname property isdatabase.example.endpoint.com. For example,mydatabase.abc123ecs2.us-west.rds.amazonaws.com. - Clients from Azure Virtual Networks are not allowed to access the server by default. Please ensure your Azure Virtual Network is correctly configured and that Allow access to Azure Services is enabled.
- VPC にセキュリティルールを構成する方法については、ご使用のクラウドプラットフォームのドキュメントを参照してください。
- Kafka クラスターの認証情報。次のいずれかの方法で認証情報を指定できます。
- 既存の サービスアカウント のリソース ID を入力する。
- コネクター用の Confluent Cloud サービスアカウント を作成します。「サービスアカウント」のドキュメントで、必要な ACL エントリを確認してください。一部のコネクターには固有の ACL 要件があります。
- Confluent Cloud の API キーとシークレットを作成する。キーとシークレットを作成するには、confluent api-key create を使用するか、コネクターのセットアップ時に Cloud Console で直接 API キーとシークレットを自動生成します。
Confluent Cloud Console の使用¶
ステップ 1: Confluent Cloud クラスターを起動します。¶
インストール手順については、「Quick Start for Confluent Cloud」を参照してください。
ステップ 2: コネクターを追加します。¶
左のナビゲーションメニューの Data integration をクリックし、Connectors をクリックします。クラスター内に既にコネクターがある場合は、+ Add connector をクリックします。
ステップ 4: 接続をセットアップします。¶
以下を実行して、Continue をクリックします。
注釈
- すべての 前提条件 を満たしていることを確認してください。
- アスタリスク ( * ) は、必須項目を指定します。
コネクターの 名前 を入力します。
Kafka Cluster credentials で Kafka クラスターの認証情報の指定方法を選択します。サービスアカウントのリソース ID を選択するか、API キーとシークレットを入力できます(または、Cloud Console でこれらを生成します)。
トピックのプレフィックスを入力します。このコネクターは、命名規則
<prefix>.<table-name>を使用して自動的に Kafka トピックを作成します。テーブルの作成にはtopic.creation.default.partitions=1プロパティおよびtopic.creation.default.replication.factor=3プロパティが使用されます。特定の設定を指定してトピックを作成する場合は、このコネクターを実行する前にトピックを作成しておいてください。データベース接続の詳細情報を追加します。
重要
接続の hostname プロパティには
jdbc:xxxx://を含めないでください。以下にホストアドレスの例を示します。
Database details に、データベースについての詳細情報を追加します。フィールドの選択について詳しくは、以下の注意事項を参照してください。
- timesamp モードを有効にするには、Timestamp column name に入力してください。このモードでは、新規行と変更行を検出するために、タイムスタンプ(またはタイムスタンプと同様の)列が使用されます。この列は書き込まれるたびにアップデートされる列であること、また、その値は単純増加する値ではあるものの必ずしも一意の値ではないことが想定されます。
- timestamp+incrementing モードを有効にするには、Timestamp column name と Incrementing column name の両方に入力します。このモードでは、新規行および変更行を検出するタイムスタンプ列と、アップデートを表すためにグローバルに一意の ID を提供する、厳密に増分していく増分列の 2 つの列が使用されます。これによって、確実に一意のストリームオフセットを各行に割り当てることができます。
- デフォルトでは、コネクターはソースデータベースからタイプ TABLE のテーブルのみを検出します。1 つまたは複数のテーブルを結合して作成された仮想テーブルを検出するには、VIEW を使用します。短縮名または一時的な名前のテーブルには、ALIAS を使用します。
- データベースのスキーマパターンを定義するには、Schema pattern フィールドにスキーマパターンを入力する必要があります。詳細については、「JDBC Connector Source Connector 構成プロパティ」で
schema.patternを検索してください。
詳細については、Oracle Database Source Connector の構成プロパティ を参照してください。
Connection details に、データベースへの接続についての詳細情報を追加します。以下の SSL mode プロパティに注意してください。
- デフォルトの SSL モードは disabled です。verify-ca に設定した場合、コネクターは、トラストストアファイルを使用して、ホストサーバーの信頼性を検証します。コネクターは、このファイルを使用して、信頼できる認証機関(CA)までの証明書チェーンを確認します。verify-full に設定した場合、コネクターは、サーバーホスト名とその証明書の突き合わせの検証も実行します。verify-full を使用する場合は、サーバーホストの識別名を Distinguished name (DN) で指定する必要があります。
- CA 情報を含むトラストストアファイルをアップロードするには、Trust store ボタンを使用します。トラストストアファイルのパスワードを追加する必要があります。
Output Kafka record value のフォーマット(コネクターから送られるデータ)を AVRO、JSON_SR(JSON スキーマ)、PROTOBUF、JSON(スキーマレス)から選択します。スキーマベースのメッセージフォーマット(Avro、JSON_SR(JSON スキーマ)、Protobuf など)を使用するには、有効なスキーマが Schema Registry に存在する必要があります。詳細については、「スキーマレジストリ Enabled Environments」を参照してください。
コネクターで使用中の タスク の数を入力します。詳しくは、Confluent Cloud コネクターの制限事項 を参照してください。
Transforms and Predicates: 詳細については、Single Message Transforms(SMT) のドキュメントを参照してください。
すべてのプロパティと定義については、「構成プロパティ」を参照してください。
ステップ 5: コネクターを起動します。¶
実行中の構成をプレビューして、接続の詳細情報を確認します。プロパティの構成に問題がないことが確認できたら、Launch をクリックします。
ちなみに
コネクターの出力のプレビューについては、「コネクターのデータプレビュー」を参照してください。
ステップ 6: コネクターのステータスを確認します。¶
コネクターのステータスが Provisioning から Running に変わる必要があります。ステータスが変わるまで数分かかる場合があります。

ステップ 7: Kafka トピックを確認します。¶
コネクターが実行されてから、メッセージが Kafka トピックに取り込まれていることを確認します。
Connect 用の Confluent Cloud API の使用に関する詳細とサンプルについては、「Confluent Cloud API for Connect」セクションを参照してください。
参考
フルマネージド型の Confluent Cloud コネクターが Confluent Cloud ksqlDB でどのように動作するかを示す例については、「Cloud ETL のデモ」を参照してください。この例では、Confluent CLI を使用して Confluent Cloud のリソースを管理する方法についても説明しています。

Confluent CLI の使用¶
以下の手順に従うと、Confluent CLI を使用してコネクターをセットアップし、実行できます。
注釈
- すべての 前提条件 を満たしていることを確認してください。
- コマンド例では Confluent CLI バージョン 2 を使用しています。詳細については、「Confluent CLI v2 への移行 <https://docs.confluent.io/confluent-cli/current/migrate.html#cli-migrate>`__」を参照してください。
ステップ 2: コネクターの必須の構成プロパティを表示します。¶
以下のコマンドを入力して、コネクターの必須プロパティを表示します。
confluent connect plugin describe <connector-catalog-name>
例:
confluent connect plugin describe OracleDatabaseSource
出力例:
Following are the required configs:
connector.class
name
kafka.auth.mode
kafka.api.key
kafka.api.secret
topic.prefix
connection.host
connection.port
connection.user
connection.password
db.name
table.whitelist
timestamp.column.name
output.data.format
tasks.max
ステップ 3: コネクターの構成ファイルを作成します。¶
コネクター構成プロパティを含む JSON ファイルを作成します。以下の例は、コネクターの必須プロパティを示しています。
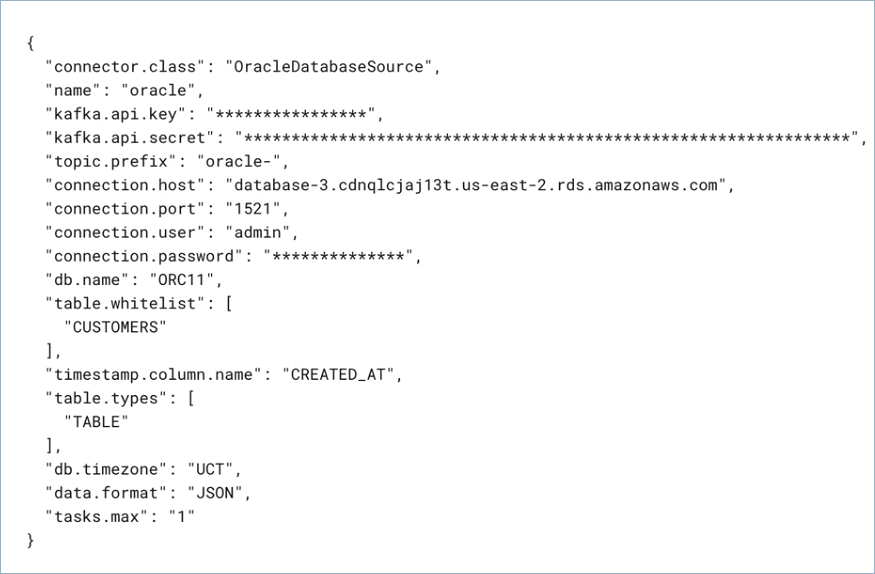
{
"name" : "OracleDatabaseSource_0",
"connector.class": "OracleDatabaseSource",
"kafka.auth.mode": "KAFKA_API_KEY",
"kafka.api.key": "<my-kafka-api-key>",
"kafka.api.secret" : "<my-kafka-api-secret>",
"topic.prefix" : "oracle_",
"connection.host" : "<my-database-endpoint>",
"connection.port" : "1521",
"connection.user" : "<database-username>",
"connection.password": "<database-password>",
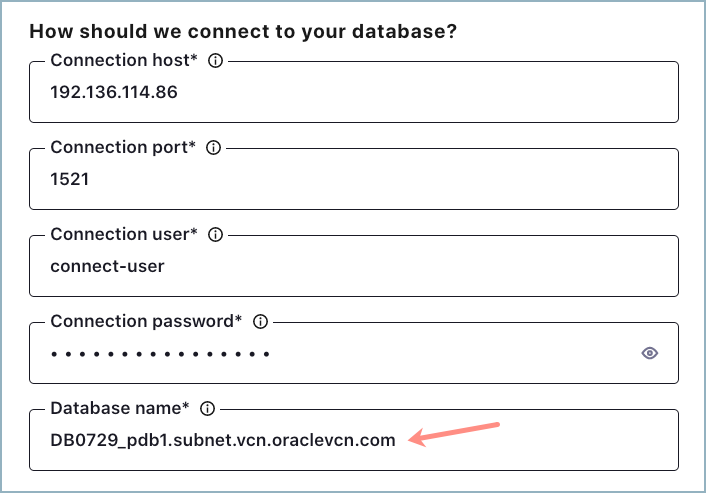
"db.name": "db078_pdb1.subnet.vcn.oraclevcn.com",
"table.whitelist": "PASSENGERS",
"timestamp.column.name": "created_at",
"output.data.format": "JSON",
"db.timezone": "UCT",
"tasks.max" : "1"
}
以下のプロパティ定義にご注意ください。
"name": 新しいコネクターの名前を設定します。"connector.class": コネクターのプラグイン名を指定します。
"kafka.auth.mode": 使用するコネクターの認証モードを指定します。オプションはSERVICE_ACCOUNTまたはKAFKA_API_KEY(デフォルト)です。API キーとシークレットを使用するには、構成プロパティkafka.api.keyとkafka.api.secretを構成例(前述)のように指定します。サービスアカウント を使用するには、プロパティkafka.service.account.id=<service-account-resource-ID>に リソース ID を指定します。使用できるサービスアカウントのリソース ID のリストを表示するには、次のコマンドを使用します。confluent iam service-account list
例:
confluent iam service-account list Id | Resource ID | Name | Description +---------+-------------+-------------------+------------------- 123456 | sa-l1r23m | sa-1 | Service account 1 789101 | sa-l4d56p | sa-2 | Service account 2
"topic.prefix": トピックのプレフィックスを入力します。このコネクターは、命名規則<prefix>.<table-name>を使用して自動的に Kafka トピックを作成します。テーブルの作成にはtopic.creation.default.partitions=1プロパティおよびtopic.creation.default.replication.factor=3プロパティが使用されます。特定の設定を指定してトピックを作成する場合は、このコネクターを実行する前にトピックを作成しておいてください。"output.data.format": Kafka 出力レコード値のフォーマット(コネクターから送られるデータ)を設定します。指定可能なエントリは、AVRO、JSON_SR、PROTOBUF、または JSON です。スキーマベースのメッセージフォーマット(たとえば、Avro、JSON_SR(JSON スキーマ)、および Protobuf)を使用するには、Confluent Cloud Schema Registry を構成しておく必要があります。"db.timezone": データベースのタイムゾーンを指定します。任意の有効なデータベースのタイムゾーンを指定できます。デフォルトは UTC です。詳細については、こちらの データベースのタイムゾーンのリスト を参照してください。
Single Message Transforms: CLI を使用する SMT の追加の詳細については、Single Message Transforms(SMT) のドキュメントを参照してください。
すべてのプロパティと定義については、「構成プロパティ」を参照してください。
ステップ 4: プロパティファイルを読み込み、コネクターを作成します。¶
以下のコマンドを入力して、構成を読み込み、コネクターを起動します。
confluent connect create --config <file-name>.json
例:
confluent connect create --config oracle-source.json
出力例:
Created connector OracleDatabaseSource_0 lcc-ix4dl
ステップ 5: コネクターのステータスを確認する。¶
以下のコマンドを入力して、コネクターのステータスを確認します。
confluent connect list
出力例:
ID | Name | Status | Type
+-----------+-------------------------+---------+-------+
lcc-ix4dl | OracleDatabaseSource_0 | RUNNING | source
ステップ 6: Kafka トピックを確認します。¶
コネクターが実行されてから、メッセージが Kafka トピックに取り込まれていることを確認します。
Connect 用の Confluent Cloud API の使用に関する詳細とサンプルについては、「Confluent Cloud API for Connect」セクションを参照してください。
マルチテナントの Oracle Database システムの構成¶
Oracle Database バージョン 12c 以降、マルチテナンシーは Oracle データベースシステムの標準機能です。マルチテナンシーは、システム情報を格納するコンテナーデータベース(CDB)と、アプリケーションデータおよびテーブルを格納するプラガブルデータベース(PDB)を提供します。
次の例の OCI DB システムの画面は、この手順で使用する環境構成を示しています。
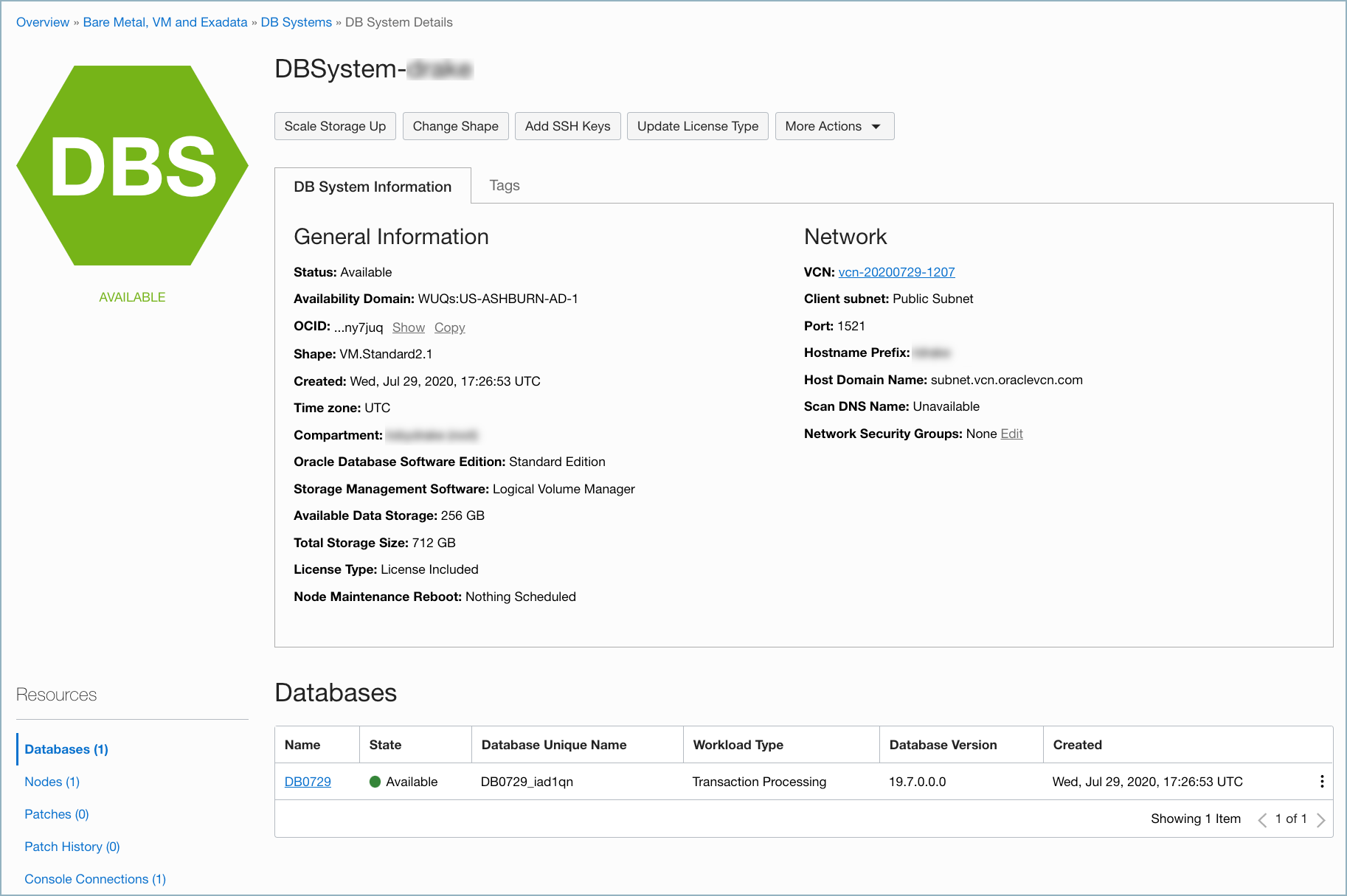
以下の手順を実行して、Oracle Cloud Infrastructure(OCI)に Oracle マルチテナントデータベースシステムを構成します。構成すると、Oracle Database Source Connector for Confluent Cloud を使用してデータベースに接続し、データベースの既存データのスナップショットを取得して、そのデータに対して後続の行レベルの変更をすべてモニタリングして記録することができます。
- 前提条件
- Oracle データベースシステムおよび管理ツールに関する知識。
- OCI 上の稼働中の Oracle データベース。OCI 上に Oracle データベースを作成するには、『ベア・メタルおよび仮想マシンの DB システムの作成』を参照してください。
- OCI 上の Oracle データベースの作成と変更を行うための認可。
- データベースシステム用に構成されたコンソール接続。『シリアル・コンソールへの接続』を参照してください。
- データベースマシン上でポート 22 および 1521 が開いていること(SSH および SQL*Net アクセス用)。ネットワーク構成の詳細については、『DB システムのネットワーク設定』を参照してください。
ステップ 1: データベース VM に SSH で接続する¶
データベース VM でセキュアシェル(SSH)ターミナルセッションを開き、Oracle ユーザーに切り替えます。VM インスタンスに接続するためのプライベートキーを渡すことにご注意ください。
ssh opc@<public-ip-address> -i </path/to/private-key>
例:
ssh opc@192.136.114.86 -i ~/.ssh/oracle_id_rsa
VM 上に移動したら、以下のコマンドを入力して Oracle ユーザーに切り替えます。
sudo su
su - oracle
出力例:
[opc@host ~]$ sudo su
[root@host opc]# su - oracle
Last login: Wed Jul 29 20:00:03 UTC 2020
[oracle@host ~]$
ステップ 2: プラガブルデータベース(PDB)のサービス名を取得する¶
リスナーのステータスを確認して、PDB サービス名を取得します。VM で、Oracle ユーザーとして以下のコマンドを入力します。
lsnrctl status LISTENER
例:
[oracle@host ~]$ lsnrctl status LISTENER
LSNRCTL for Linux: Version 19.0.0.0.0 - Production on 29-JUL-2020 21:41:52
Copyright (c) 1991, 2019, Oracle. All rights reserved.
Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=host.subnet.vcn.oraclevcn.com)(PORT=1521)))
STATUS of the LISTENER
------------------------
Alias LISTENER
Version TNSLSNR for Linux: Version 19.0.0.0.0 - Production
Start Date 29-JUL-2020 17:39:05
Uptime 0 days 4 hr. 2 min. 47 sec
Trace Level off
Security ON: Local OS Authentication
SNMP OFF
Listener Parameter File /u01/app/oracle/product/19.0.0/dbhome_1/network/admin/listener.ora
Listener Log File /u01/app/oracle/diag/tnslsnr/host/listener/alert/log.xml
Listening Endpoints Summary...
(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=host.subnet.vcn.oraclevcn.com)(PORT=1521)))
(DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC1521)))
(DESCRIPTION=(ADDRESS=(PROTOCOL=tcps)(HOST=host.subnet.vcn.oraclevcn.com)(PORT=5500))(Security=(my_wallet_directory=/u01/app/oracle/admin/DB0729_iad1qn/xdb_wallet))(Presentation=HTTP)(Session=RAW))
Services Summary...
Service "DB0729XDB.subnet.vcn.oraclevcn.com" has 1 instance(s).
Instance "DB0729", status READY, has 1 handler(s) for this service...
Service "DB0729_iad1qn.subnet.vcn.oraclevcn.com" has 1 instance(s).
Instance "DB0729", status READY, has 1 handler(s) for this service...
Service "a33f59386e740c51e053c701f40af1dd.subnet.vcn.oraclevcn.com" has 1 instance(s).
Instance "DB0729", status READY, has 1 handler(s) for this service...
Service "db0729_pdb1.subnet.vcn.oraclevcn.com" has 1 instance(s).
Instance "DB0729", status READY, has 1 handler(s) for this service...
The command completed successfully
上記の出力例では、必要な PDB サービス名は以下のとおりです。
(HOST=host.subnet.vcn.oraclevcn.com)(PORT=1521)
ステップ 3: PDB サービス名を作成する¶
VM 上で以下の手順を実行して、新しい tnsnames.ora PDB サービス名エントリを作成します。Oracle Database Source Connector for Confluent Cloud へのデータベース接続を設定するときに、この新しいエントリを使用します。このエントリによって、コネクターは Oracle データベースへの接続を確立できます。
Oracle ユーザーアカウントを終了します。
exit
root ディレクトリに変更します。
cd /
tnsnames.oraエントリを見つけます。find . -name tnsnames.ora
例:
[oracle@host ~]$ exit logout [root@host opc]# cd / [root@host /]# find . -name tnsnames.ora ./u01/app/oracle/product/19.0.0/dbhome_1/network/admin/samples/tnsnames.ora ./u01/app/oracle/product/19.0.0/dbhome_1/network/admin/tnsnames.ora
network/adminディレクトリに変更します。cd /u01/app/oracle/product/19.0.0/dbhome_1/network/admin
tnsnames.oraファイルを編集し、リスナーのステータス出力から取得した PDB サービス名を追加します。この例では、追加する PDB サービス名のブロックはDB0729_PDB1です。vi tnsnames.ora
例:
DB0729_IAD1QN = (DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP)(HOST = host.subnet.vcn.oraclevcn.com)(PORT = 1521)) ) (CONNECT_DATA = (SERVICE_NAME = DB0729_iad1qn.subnet.vcn.oraclevcn.com) ) ) DB0729_PDB1 = (DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP)(HOST = host.subnet.vcn.oraclevcn.com)(PORT = 1521)) ) (CONNECT_DATA = (SERVICE_NAME = DB0729_pdb1.subnet.vcn.oraclevcn.com) ) )
ステップ 4: コネクターを起動する¶
「Oracle Database Source Connector for Confluent Cloud」の手順を実行します。データベース接続の詳細情報を追加する必要があるセクションで、前のステップで追加した PDB サービス名を入力します。以下に例を示します。
構成プロパティ¶
このコネクターでは、以下のコネクター構成プロパティを使用します。
データへの接続方法(How should we connect to your data?)¶
nameコネクターの名前を設定します。
- 型: string
- 指定可能な値: 最大 64 文字の文字列
- 重要度: 高
Kafka クラスターの認証情報(Kafka Cluster credentials)¶
kafka.auth.modeKafka の認証モード。KAFKA_API_KEY または SERVICE_ACCOUNT を指定できます。デフォルトは KAFKA_API_KEY モードです。
- 型: string
- デフォルト: KAFKA_API_KEY
- 指定可能な値: KAFKA_API_KEY、SERVICE_ACCOUNT
- 重要度: 高
kafka.api.key- 型: password
- 重要度: 高
kafka.service.account.idKafka クラスターとの通信用の API キーを生成するために使用されるサービスアカウント。
- 型: string
- 重要度: 高
kafka.api.secret- 型: password
- 重要度: 高
テーブル名のプレフィックスの付け方(How do you want to prefix table names?)¶
topic.prefixデータのパブリッシュ先である Apache Kafka® トピックの名前を生成するためにテーブル名の先頭に付けるプレフィックス。
- 型: string
- 重要度: 高
データベースへの接続方法(How should we connect to your database?)¶
connection.hostDepending on the service environment, certain network access limitations may exist. Make sure the connector can reach your service. Do not include jdbc:xxxx:// in the connection hostname property (e.g. database-1.abc234ec2.us-west.rds.amazonaws.com).
- 型: string
- 重要度: 高
connection.portJDBC 接続ポート。
- 型: int
- 指定可能な値: [0,...,65535]
- 重要度: 高
connection.userJDBC 接続ユーザー。
- 型: string
- 重要度: 高
connection.passwordJDBC 接続パスワード。
- 型: password
- 重要度: 高
db.nameJDBC データベース名。
- 型: string
- 重要度: 高
ssl.modeデータベースへの接続に使用する必要がある SSL モードを指定します。disabled では、SSL が完全に無効になります。verify-ca は、暗号化に SSL を使用し、サーバー CA の認証を実行します。verify-ca オプションでは、サーバー CA およびトラストストアパスワードを含む Java トラストストアを指定する必要があります。
- 型: string
- デフォルト: disabled
- 重要度: 高
ssl.truststorefileサーバー CA 証明書情報が含まれるトラストストア。ssl モードとして verify-ca または verify-full を使用する場合にのみ必要になります。
- 型: password
- デフォルト: [hidden]
- 重要度: 低
ssl.truststorepasswordサーバー CA 証明書情報が含まれるトラストストアのパスワード。ssl モードとして verify-ca または verify-full を使用する場合にのみ必要になります。
- 型: password
- デフォルト: [hidden]
- 重要度: 低
ssl.server.cert.dnこのパラメーターは、データベースサーバーの識別名(DN)を指定するために使用します。verify-full SSL モードを使用する場合にのみ必須です。
- 型: string
- 重要度: 低
データベースの詳細(Database details)¶
table.whitelistコピーに含めるテーブルのリスト。複数のテーブルを指定するには、コンマ区切りのリストを使用します(例: "User, Address, Email")。
- 型: list
- 重要度: 中
timestamp.column.nameCOALESCE SQL 関数を使用して新規行または変更行を検出するための 1 つ以上のタイムスタンプ列のコンマ区切りリスト。ポーリングのたびに、最初の null 以外のタイムスタンプ値が前回見つかった最大のタイムスタンプ値より大きい行が検出されます。少なくとも 1 つの列は null 許容でないことが必要です。
- 型: list
- 重要度: 中
incrementing.column.name新しい行の検出に使用する厳密な増分列の名前。空の値は、自動増分列を探すことによって、列を自動検出する必要があることを示します。この列を null 許容にすることはできません。
- 型: string
- デフォルト: ""
- 重要度: 中
table.typesデフォルトでは、JDBC コネクターはソースデータベースからタイプ TABLE のテーブルのみを検出します。この構成では、抽出するテーブルタイプをコンマ区切りのリストで指定できます。
- 型: list
- デフォルト: TABLE
- 重要度: 中
schema.patternデータベースからテーブルメタデータをフェッチするためのスキーマパターン。
- 型: string
- 重要度: 高
db.timezoneコネクターで時間ベースの基準を使用してクエリを実行する場合に使用する JDBC タイムゾーンの名前。デフォルトは UTC です。
- 型: string
- デフォルト: UTC
- 重要度: 中
numeric.mappingNUMERIC 値を精度およびオプションでスケールに基づいて、整数型または小数型にマップします。すべての NUMERIC 列を Connect の DECIMAL 論理型で表す場合は、
noneを使用します。NUMERIC 列を、列の精度とスケールに基づいて、Connect の INT8、INT16、INT32、INT64、または FLOAT64 にキャストする必要がある場合は、best_fitを使用します。上記の best_fit のプロパティに加えて、精度が失われる可能性があっても、スケールが指定された NUMERIC 列を常に Connect FLOAT64 型にキャストする必要がある場合は、best_fit_eager_doubleを使用します。列の精度のみに基づいて(列のスケールが 0 であることを前提として)NUMERIC 列をマップするには、precision_onlyを使用します。noneオプションがデフォルトですが、Connect の DECIMAL 型はそのバイナリ表現にマップされるため、Avro のシリアル化の問題を招く可能性があり、多くの場合、最も適切なプリミティブ型にマップされるbest_fitが望ましい選択となります。- 型: string
- デフォルト: none
- 重要度: 低
timestamp.granularityDefine the granularity of the Timestamp column. CONNECT_LOGICAL (default): represents timestamp values using Kafka Connect built-in representations. NANOS_LONG: represents timestamp values as nanos since epoch. NANOS_STRING: represents timestamp values as nanos since epoch in string. NANOS_ISO_DATETIME_STRING: uses iso format
- 型: string
- Default: CONNECT_LOGICAL
- 重要度: 低
Mode¶
modeポーリングのたびにテーブルを更新するためのモード。BULK では、ポーリングのたびにテーブル全体の一括読み込みを実行します。TIMESTAMP では、タイムスタンプ(またはそれに準ずる)列を使用して、新規行と変更行を検出します。書き込みのたびに列が更新されること、および、値は単調増加しますが必ずしも一意ではないことが前提となっています。INCREMENTING では、各テーブルの厳密な増分列を使用して、新しい行のみを検出します。既存の行の変更または削除は検出されません。TIMESTAMP AND INCREMENTING では、新規および変更済み行を検出するタイムスタンプ列と、更新に対するグローバルに一意の ID を提供する厳密な増分列の 2 つの列を使用します。これにより、各行を一意のストリームオフセットに割り当てることができます。
- 型: string
- デフォルト: ""
- 重要度: 中
quote.sql.identifiersSQL ステートメントで、テーブル名、列名、その他の識別子をいつクォートするかを指定します。後方互換性を確保するため、デフォルト値は ALWAYS です。
- 型: string
- デフォルト: ALWAYS
- 指定可能な値: ALWAYS、NEVER
- 重要度: 中
transaction.isolation.modeIsolation level determines how transaction integrity is visible to other users and systems. DEFAULT: This is the default isolation level configured at the Database Server. READ_UNCOMMITTED: This is the lowest isolation level. At this level, one transaction may see dirty reads (that is, not-yet-committed changes made by other transactions). READ_COMMITTED: This level guarantees that any data read is already committed at the moment it is read. REPEATABLE_READ: In addition to the guarantees of the READ_COMMITTED level, this option also guarantees that any data read cannot change, if the transaction reads the same data again. However, phantom reads are possible. SERIALIZABLE: This is the highest isolation level. In addition to everything REPEATABLE_READ guarantees, it also eliminates phantom reads.
- 型: string
- Default: DEFAULT
- Valid Values: DEFAULT, READ_COMMITTED, READ_UNCOMMITTED, REPEATABLE_READ, SERIALIZABLE
- 重要度: 中
timestamp.initialタイムスタンプ基準を使用する最初のクエリで使用するエポックタイムスタンプ。値として -1 を指定すると、初期タイムスタンプに現在時刻が設定されます。指定しない場合、コネクターはすべてのデータを取得します。コネクターでソースオフセットが正常に記録されると、後で別の値に変更した場合もこのプロパティによる影響は発生しません。
- 型: long
- 指定可能な値: [-1,...]
- 重要度: 中
接続の詳細(Connection details)¶
poll.interval.ms各テーブルの新しいデータをポーリングする頻度(ミリ秒)。
- 型: int
- デフォルト: 5000(5 秒)
- 指定可能な値: [100,...]
- 重要度: 高
batch.max.rows新しいデータのポーリング時に単一のバッチに含める最大行数。この設定を使用して、コネクターの内部にバッファリングするデータの量を制限できます。
- 型: int
- デフォルト: 100
- 指定可能な値: [1,...,5000]
- 重要度: 低
timestamp.delay.interval.ms特定のタイムスタンプを持つ行が出現してからそれを結果に含めるまでに待機する時間。より早いタイムスタンプを持つトランザクションが完了できるように、遅延を追加できます。最初の実行では、現在の時刻から遅延を引いた時刻までの利用可能なすべての(タイムスタンプ 0 からの)レコードをフェッチします。その後の各実行では、最後のフェッチ時刻から、現在の時刻から遅延を引いた時刻までのデータを取得します。
- 型: int
- デフォルト: 0
- 指定可能な値: [0,...]
- 重要度: 高
出力メッセージ(Output messages)¶
output.data.formatKafka 出力レコード値のフォーマットを設定します。指定可能なエントリは、AVRO、JSON_SR、PROTOBUF、または JSON です。スキーマベースのメッセージフォーマット(AVRO、JSON_SR、PROTOBUF など)を使用する場合は、Confluent Cloud Schema Registry を構成しておく必要がある点に注意してください
- 型: string
- 重要度: 高
このコネクターのタスク数(Number of tasks for this connector)¶
tasks.max- 型: int
- 指定可能な値: [1,...]
- 重要度: 高
次のステップ¶
参考
フルマネージド型の Confluent Cloud コネクターが Confluent Cloud ksqlDB でどのように動作するかを示す例については、「Cloud ETL のデモ」を参照してください。この例では、Confluent CLI を使用して Confluent Cloud のリソースを管理する方法についても説明しています。