重要
このページの日本語コンテンツは古くなっている可能性があります。最新の英語版コンテンツをご覧になるには、こちらをクリックしてください。
MongoDB Atlas Sink Connector for Confluent Cloud¶
注釈
Confluent Platform 用にコネクターをローカルにインストールする場合は、『MongoDB Kafka Connector』のドキュメントを参照してください。
Kafka Connect MongoDB Atlas Sink Connector for Confluent Cloud は、Apache Kafka® トピックのイベントを MongoDB Atlas データベースコレクションに直接マッピングして保存します。このコネクターは、Avro、JSON スキーマ、Protobuf、または JSON(スキーマレス)フォーマットの Apache Kafka® トピックのデータをサポートします。このコネクターは、Kafka トピックのイベントを MongoDB Atlas データベースに直接取り込んで、クエリ、拡張、および分析用のサービスにそのデータを公開します。
機能¶
注釈
このコネクターは MongoDB Atlas にのみ対応しています。セルフマネージド型の MongoDB データベースには使用できません。
MongoDB Atlas Sink Connector には、以下の機能があります。
- コレクション: トピック名を基にしてコレクションを自動で作成することができます。
- データベースの認証: パスワード認証を使用します。
- 入力データフォーマット: このコネクターは、Avro、JSON スキーマ、Protobuf、JSON(スキーマレス)、文字列または BSON の入力データフォーマットをサポートします。スキーマレジストリ ベースのフォーマット(Avro、JSON_SR(JSON スキーマ)、Protobuf など)を使用するには、Schema Registry を有効にしておく必要があります。詳細については、「スキーマレジストリ Enabled Environments」を参照してください。
- 厳選された構成プロパティ:
"max.num.retries": 書き込みエラーの発生時に再試行を行う回数"max.batch.size": バッチとしてまとめて処理するシンクレコードの最大件数"delete.on.null.values": 値が NULL の場合に、キー値が一致するドキュメントをコネクターで削除するかどうか"doc.id.strategy": 一意のドキュメント ID(_id)を生成する方法。"write.strategy": MongoDB コレクションに対して実行される一括書き込み操作の動作を定義します。
Confluent Cloud API for Connect の詳細と使用例については、「Confluent Cloud API for Connect」セクションを参照してください。
制限¶
以下の情報を確認してください。
- コネクターの制限事項については、MongoDB Atlas Sink Connector の制限事項を参照してください。
- 1 つ以上の Single Message Transforms(SMT)を使用する場合は、「SMT の制限」を参照してください。
- Confluent Cloud Schema Registry を使用する場合は、「スキーマレジストリ Enabled Environments」を参照してください。
クイックスタート¶
このクイックスタートを使用して、Confluent Cloud MongoDB Atlas Sink Connector の利用を開始することができます。このクイックスタートでは、コネクターを選択してから、Kafka のデータを消費して MongoDB データベースにデータを保存するようにコネクターを構成するための基本的な方法について説明します。
注釈
このコネクターは MongoDB Atlas にのみ対応しています。セルフマネージド型の MongoDB データベースには使用できません。
- 前提条件
- アマゾンウェブサービス (AWS)、Microsoft Azure (Azure)、または Google Cloud Platform (GCP)上の Confluent Cloud クラスターへのアクセスを許可されていること。
- Confluent CLI がインストールされ、クラスター用に構成されていること。「Confluent CLI のインストール」を参照してください。
- スキーマレジストリ ベースのフォーマット(Avro、JSON_SR(JSON スキーマ)、Protobuf など)を使用するには、Schema Registry を有効にしておく必要があります。詳細については、「スキーマレジストリ Enabled Environments」を参照してください。
- MongoDB データベースへのアクセス。
- MongoDB データベースと Kafka クラスターは同じリージョンに存在している必要があります。
- ネットワークに関する考慮事項については、「Networking and DNS Considerations」を参照してください。静的なエグレス IP を使用する方法については、「静的なエグレス IP アドレス」を参照してください。
- Confluent Cloud に VPC ピアリング構成のクラスターがある場合は、MongoDB Atlas と VPC の間に PrivateLink 接続 を構成することを検討してください。
- Kafka クラスターの認証情報。次のいずれかの方法で認証情報を指定できます。
- 既存の サービスアカウント のリソース ID を入力する。
- コネクター用の Confluent Cloud サービスアカウント を作成します。「サービスアカウント」のドキュメントで、必要な ACL エントリを確認してください。一部のコネクターには固有の ACL 要件があります。
- Confluent Cloud の API キーとシークレットを作成する。キーとシークレットを作成するには、confluent api-key create を使用するか、コネクターのセットアップ時に Cloud Console で直接 API キーとシークレットを自動生成します。
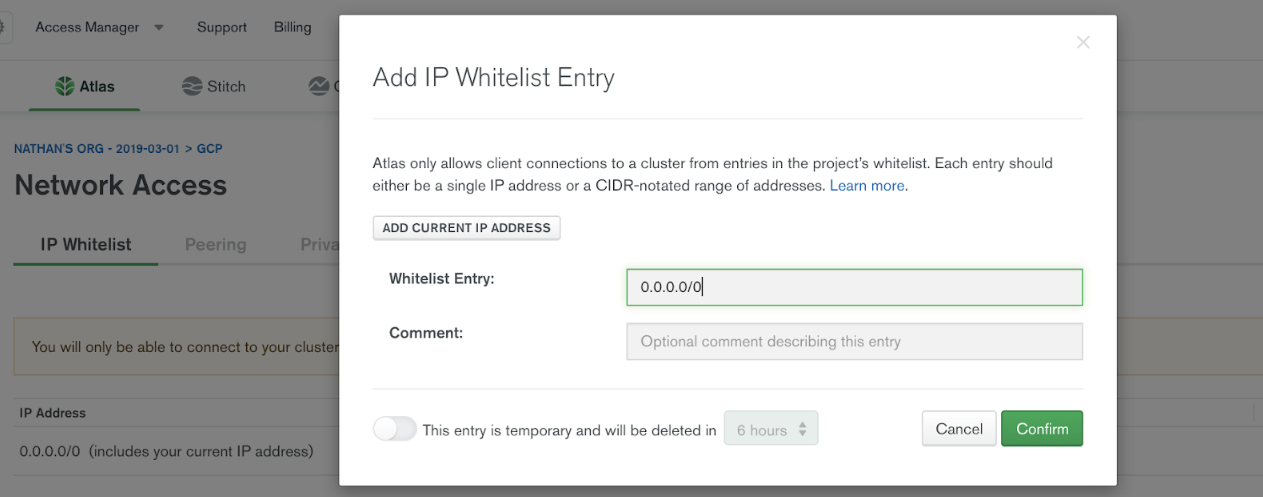
IP ホワイトリストへの登録の追加¶
重要
- ネットワークに関する考慮事項については、「Networking and DNS Considerations」を参照してください。
- 静的なエグレス IP を使用する方法については、「静的なエグレス IP アドレス」を参照してください。
デフォルトでは、MongoDB Atlas はインターネットからの外部接続を許可しません。外部接続を許可するには、MongoDB の Network Access メニュー下の IP Whitelist 登録ダイアログボックスを使用して、特定の IP または CIDR IP 範囲を追加します。
Confluent Cloud から MongoDB Atlas に接続できるように、Confluent Cloud クラスターのパブリック IP アドレスを指定する必要があります。MongoDB Atlas クラスターのホワイトリストへの登録に Confluent Cloud のエグレス IP アドレスをすべて追加します。
Confluent Cloud Console の使用¶
ステップ 1: Confluent Cloud クラスターを起動します。¶
インストール手順については、「Quick Start for Confluent Cloud」を参照してください。
ステップ 2: コネクターを追加します。¶
左のナビゲーションメニューの Data integration をクリックし、Connectors をクリックします。クラスター内に既にコネクターがある場合は、+ Add connector をクリックします。
ステップ 4: コネクターの詳細情報を入力します。¶
注釈
- すべての 前提条件 を満たしていることを確認してください。
- アスタリスク ( * )は必須項目であることを示しています。
Add MongoDB Atlas Sink Connector 画面で、以下を実行します。
既に Kafka トピックを用意している場合は、Topics リストから接続するトピックを選択します。
新しいトピックを作成するには、+Add new topic をクリックします。
- Kafka Cluster credentials で Kafka クラスターの認証情報の指定方法を選択します。サービスアカウントのリソース ID を選択するか、API キーとシークレットを入力できます(または、Cloud Console でこれらを生成します)。
- Continue をクリックします。
- MongoDB Atlas credentials で、以下のように MongoDB Atlas の認証情報を入力します。
- Connection host: 完全な URL ではなく、ホスト名のみを使用します。例:
cluster4-r5q3r7.gcp.mongodb.net - Connection user: MongoDB Atlas 接続ユーザー。
- Connection passsword: MongoDB Atlas 接続パスワード。
- Connection host: 完全な URL ではなく、ホスト名のみを使用します。例:
- MongoDB Atlas Database Details で、以下のように MongoDB Atlas のデータベースの詳細情報を入力します。
- Database name: MongoDB Atlas のデータベース名。
- Collection name: 書き込み先のコレクション名。コネクターが複数のトピックからのデータを受信する場合、この値はトピックのマッピング先となるデフォルトのコレクションです。
- Continue をクリックします。
注釈
すべてのプロパティの値と定義については、「構成プロパティ」を参照してください。
Input Kafka record value で、Kafka 入力レコード値のフォーマット(Kafka トピックから送られるデータ)を AVRO、JSON_SR(JSON スキーマ)、PROTOBUF、JSON(スキーマレス)、STRING、または BSON から選択します。スキーマベースのメッセージフォーマット(Avro、JSON_SR(JSON スキーマ)、Protobuf など)を使用するには、有効なスキーマが Schema Registry に存在する必要があります。
Show advanced configurations
Connection details
Max number of retries: 書き込みエラーが発生した場合に再試行する最大回数を入力します。デフォルト値の再試行回数は 3 回です。
Retry defer timeout (ms): 再試行を 遅延 させる時間の値をミリ秒(ms)単位で入力します。デフォルトは 5000 ミリ秒(5 秒)です。
Max batch size: まとめて バッチ処理 するレコードの最大数を入力します。デフォルトは 0 です。
Delete on null values: 値が null の場合に、コネクターでキー値が一致する ドキュメントを削除 するかどうかを選択します。デフォルト値は false です。
Document ID Strategy: 一意のドキュメント ID
_idを生成する方法を選択します。値が null の場合にドキュメントを削除するには、FullKeyStrategy、PartialKeyStrategy、またはProvidedInKeyStrategyを設定します。デフォルトはBsonOidStrategyです。詳しくは、「DocumentIdAdder」を参照してください。Document ID strategy overwrite existing:
doc.id.strategyで定義された処理方法を適用する際に、コネクターが_idフィールドの既存の値を上書きするかどうかを指定します。Document ID strategy key projection type: For use with the
PartialKeyStrategy. Allows custom key fields to be projected for the ID strategy. Use eitherAllowListorBlockList.Document ID strategy key projection list: For use with the
PartialKeyStrategy. Allows custom key fields to be projected for the ID strategy. A comma-separated list of fields names for key projection.Document ID strategy value projection type: For use with the
PartialValueStrategy. Allows custom value fields to be projected for the ID strategy. Use eitherAllowListorBlockList.Document ID strategy value projection list: For use with the
PartialValueStrategy. Allows custom value fields to be projected for the ID strategy. A comma-separated list of field names for value projection.Write Model Strategy: 一括書き込み操作に使用する
WriteModelを指定するクラス。Change Data Capture Handler: 処理に使用する CDC ハンドラーのクラス名。
時系列構成(Time Series configuration)
Timefield: 各時系列ドキュメントの日付を含む最上位の時間フィールドの名前。この構成を設定すると、各ドキュメントが時間フィールドの値として BSON 日付を持つ時系列コレクションが作成されます。時系列コレクションは、MongoDB v5.0 で導入されました。これは、MongoDB Atlas の専用クラスターでのみ使用できます。
Auto Conversion: 時間フィールドのデータを BSON 日付フォーマットに変換するかどうか。サポートされているフォーマットには、integer、long、string があります。
Auto Convert Date Format: ソースデータの変換元のフォーマットのソースデータを変換する文字列パターン。この設定では、日付と時刻の両方の情報を含む文字列表現が想定されており、変換に Java DateTimeFormatter.ofPattern(pattern, locale) API が使用されます。文字列に日付情報しか含まれていない場合は、エポックからの時間はその日の開始時刻から取得されます。文字列表現にタイムゾーンのオフセットが含まれていない場合、この設定では、抽出された日付と時刻が UTC として解釈されます。
Locate Language Tag: 日付パターンで使用する
DateTimeFormatterのロケール言語タグ。Metafield: 各時系列ドキュメントのメタデータを含む最上位のフィールドの名前。指定したフィールドのメタデータは、一意の系列のドキュメントのラベル付けに使用されるデータである必要があります。ここでは配列型以外のフィールドを指定できます。
Expire After Seconds: MongoDB 内でデータを保持する秒数。この時間が経過すると、そのデータは MongoDB により削除されます。このフィールドを指定しない場合、データは自動的に削除されません。
Granularity: 時系列の後続の meamsurement 間で想定される間隔。データが時系列でない場合は、
Noneに設定するか空のままにします。
Continue をクリックします。
選択するトピックのパーティション数に基づいて、推奨タスク数が表示されます。1 つのタスクで処理できるパーティションの数は最大 100 個です。
- 推奨されたタスク数を変更するには、Tasks フィールドに、コネクターで使用する タスク の数を入力します。
- Continue をクリックします。
構成の概要を確認し、以下を検証します。
接続の詳細情報を確認し、Launch をクリックします。
コネクターのステータスが Provisioning から Running に変わります。ステータスが変わるまで数分かかる場合があります。

ステップ 5: MongoDB を確認します。¶
コネクターが実行中になったら、メッセージが MongoDB データベースに取り込まれていることを確認します。
ちなみに
コネクターを起動すると、デッドレターキューのトピックが自動的に生成されます。詳細については、「Confluent Cloud デッドレターキュー」を参照してください。
参考
フルマネージド型の Confluent Cloud コネクターが Confluent Cloud ksqlDB でどのように動作するかを示す例については、「Cloud ETL のデモ」を参照してください。この例では、Confluent CLI を使用して Confluent Cloud のリソースを管理する方法についても説明しています。

Confluent CLI の使用¶
以下の手順に従うと、Confluent CLI を使用してコネクターをセットアップし、実行できます。
注釈
- すべての 前提条件 を満たしていることを確認してください。
- コマンド例では Confluent CLI バージョン 2 を使用しています。詳細については、「Confluent CLI v2 への移行 <https://docs.confluent.io/confluent-cli/current/migrate.html#cli-migrate>`__」を参照してください。
ステップ 2: コネクターの必須の構成プロパティを表示します。¶
以下のコマンドを実行して、コネクターの必須プロパティを表示します。
confluent connect plugin describe <connector-catalog-name>
例:
confluent connect plugin describe MongoDbAtlasSink
出力例:
Following are the required configs:
connector.class: MongoDbAtlasSink
name
kafka.auth.mode
kafka.api.key
kafka.api.secret
input.data.format
connection.host
connection.user
connection.password
database
tasks.max
topics
ステップ 3: コネクターの構成ファイルを作成します。¶
コネクター構成プロパティを含む JSON ファイルを作成します。以下の例は、コネクターの必須プロパティを示しています。
{
"connector.class": "MongoDbAtlasSink",
"name": "confluent-mongodb-sink",
"kafka.auth.mode": "KAFKA_API_KEY",
"kafka.api.key": "<my-kafka-api-key",
"kafka.api.secret": "<my-kafka-api-secret>",
"input.data.format" : "JSON",
"connection.host": "<database-host-address>",
"connection.user": "<my-username>",
"connection.password": "<my-password>",
"topics": "<kafka-topic-name>",
"max.num.retries": "3",
"retries.defer.timeout": "5000",
"max.batch.size": "0",
"database": "<database-name>",
"collection": "<collection-name>",
"tasks.max": "1"
}
以下のプロパティ定義に注意してください。
"connector.class": コネクターのプラグイン名を指定します。"name": 新しいコネクターの名前を設定します。
"kafka.auth.mode": 使用するコネクターの認証モードを指定します。オプションはSERVICE_ACCOUNTまたはKAFKA_API_KEY(デフォルト)です。API キーとシークレットを使用するには、構成プロパティkafka.api.keyとkafka.api.secretを構成例(前述)のように指定します。サービスアカウント を使用するには、プロパティkafka.service.account.id=<service-account-resource-ID>に リソース ID を指定します。使用できるサービスアカウントのリソース ID のリストを表示するには、次のコマンドを使用します。confluent iam service-account list
例:
confluent iam service-account list Id | Resource ID | Name | Description +---------+-------------+-------------------+------------------- 123456 | sa-l1r23m | sa-1 | Service account 1 789101 | sa-l4d56p | sa-2 | Service account 2
"input.data.format": Kafka 入力レコード値のフォーマット(Kafka トピックから送られるデータ)を設定します。指定可能なエントリは、AVRO、JSON_SR、PROTOBUF、JSON、STRING、または BSON です。スキーマベースのメッセージフォーマット(たとえば、Avro、JSON_SR(JSON スキーマ)、および Protobuf)を使用するには、Confluent Cloud Schema Registry を構成しておく必要があります。"connection.host": MongoDB ホスト。完全な URL ではなく、ホスト名アドレスを使用します。たとえば、cluster4-r5q3r7.gcp.mongodb.netのようにします。"collection": MongoDB コレクション名。複数のトピックがある場合は、これが、トピックのマッピング先となるデフォルトのコレクションになります。以下はオプションです(ただし、タスク数は例外となります)。
(オプション)
"max.num.retries": 書き込みエラーの発生時に再試行を行う回数。このプロパティを使用しない場合は、3 がデフォルトとして使用されます。(オプション)
"retries.defer.timeout:"再試行を遅らせる時間(ミリ秒)。使用しない場合は、デフォルトは 5000 ミリ秒です。(オプション)
"max.batch.size": バッチとしてまとめて処理するシンクレコードの最大件数。このプロパティを使用しない場合は、0 がデフォルトとして使用されます。(オプション)
"delete.on.null.values": 値が NULL の場合に、キー値が一致するドキュメントをコネクターで削除するかどうか。このプロパティを使用しない場合は、false がデフォルトとして使用されます。"doc.id.strategy": 一意のドキュメント ID(_id)を生成する方法。一意のドキュメント ID(_id)を生成する 方法を入力します。指定可能なエントリは、BsonOidStrategy、KafkaMetaDataStrategy、FullKeyStrategy、PartialKeyStrategy、PartialValueStrategy、ProvidedInKeyStrategy、ProvidedInValueStrategy、またはUuidStrategyです。値が null の場合にドキュメントを削除するには、方法としてFullKeyStrategy、PartialKeyStrategy、またはProvidedInKeyStrategyを設定する必要があります。デフォルト値はBsonOidStrategyです。詳しくは、「DocumentIdAdder」を参照してください。選択した方法に応じて、適切な Document ID strategy projection list を追加します。
"key.projection.type":PartialKeyStrategyを選択した場合に使用します。allowlistまたはblocklistを使用して、ID の処理方法に対して想定されるカスタムキーフィールドを許可またはブロックします。このプロパティを使用しない場合、デフォルトではnoneとなります。"key.projection.list":PartialKeyStrategyを選択した場合に使用します。ID の処理方法に対して想定されるキーフィールドをコンマ区切りにしたリストです。"value.projection.type":PartialValueStrategyを選択した場合に使用します。allowlistまたはblocklistを使用して、ID の処理方法に対して想定されるカスタム値フィールドを許可またはブロックします。このプロパティを使用しない場合、デフォルトではnoneとなります。"value.projection.list":PartialValueStrategyを選択した場合に使用します。ID の処理方法に対して想定される値フィールドをコンマ区切りにしたリストです。
"write.strategy": 一括書き込み操作の書き込みモデルを設定します。指定可能なエントリは、DefaultWriteModelStrategy、ReplaceOneDefaultStrategy、InsertOneDefaultStrategy、ReplaceOneBusinessKeyStrategy、DeleteOneDefaultStrategy、UpdateOneTimestampsStrategy、またはUpdateOneBusinessKeyTimestampStrategyです。このプロパティを使用しない場合、デフォルトでDefaultWriteModelStrategyとなります。時系列コレクションの場合、DefaultWriteModelStrategyは内部のデフォルトでInsertOneDefaultStrategyになります。通常のコレクションの場合は、デフォルトでReplaceOneDefaultStrategyになります。"cdc.handler": 処理に使用する CDC ハンドラーのクラス名を設定します。MongoDB Kafka シンクコネクターで CDC イベントをキャプチャし、対応する挿入、アップデート、削除の操作を送信先の MongoDB クラスターに対して実行できます。指定可能なエントリは、None、MongoDbChangeStreamHandler、DebeziumMongoDbHandler、DebeziumMySqlHandler、DebeziumPostgresHandler、またはQlikRdbmsHandlerです。このプロパティを使用しない場合、デフォルトでNoneとなります。詳細については、「mongodb-sink-cdc」を参照してください。"timeseries.timefield": 各時系列ドキュメントの日付を含むトップレベルのタイムフィールドの名前を設定します。このプロパティを設定すると、各ドキュメントがタイムフィールドの値として BSON 日付を持つ時系列コレクションが作成されます。時系列コレクションは、introduced in MongoDB v5.0 で導入されました。これは、MongoDB Atlas の専用クラスターでのみ利用可能です。"timeseries.timefield.auto.convert": タイムフィールドのデータを BSON 日付フォーマットに変換するかどうかを指定します。データでサポートされているフォーマットには、integer、long、string があります。このプロパティを使用しない場合、デフォルトでfalseとなります。"timeseries.timefield.auto.convert.date.format": ソースデータの変換前の DateTimeFormatter フォーマットを設定します。この設定では、日付と時刻の両方の情報を含む文字列表現が想定されており、変換に Java DateTimeFormatter.ofPattern(pattern, locale) API が使用されます。文字列に日付情報しか含まれていない場合は、エポックからの時間はその日の開始時刻から取得されます。文字列表現にタイムゾーンのオフセットが含まれていない場合、この設定では、抽出された日付と時刻が UTC として解釈されます。このプロパティを使用しない場合は、デフォルトでyyyy-MM-dd[['T'][ ]][HH:mm:ss[[.][SSSSSS][SSS]][ ]VV[ ]'['VV']'][HH:mm:ss[[.][SSSSSS][SSS]][ ]X][HH:mm:ss[[.][SSSSSS][SSS]]]となります。"timeseries.timefield.auto.convert.locale.language.tag": 日付パターンで使用する DateTimeFormatter のロケール言語タグを設定します。タグの構築の詳細については、『HTML と XML における言語タグ』を参照してください。このプロパティを使用しない場合、デフォルトでenとなります。"timeseries.metafield": 各時系列ドキュメントのメタデータを含むトップレベルのフィールドの名前を設定します。指定したフィールドのメタデータは、一意の系列のドキュメントのラベル付けに使用されるデータである必要があります。ここでは配列型以外のフィールドを指定できます。"timeseries.expire.after.seconds": ドキュメントの有効期限が切れるまでの秒数を設定します。MongoDB は、有効期限が切れたドキュメントを自動的に削除します。このプロパティを使用しない場合、デフォルトで0となり、データは自動削除されません。"ts.granularity": 時系列の後続の測定で使用される間隔の単位を設定します。指定可能なエントリは、None、seconds、minutes、またはhoursです。このプロパティを使用しない場合、デフォルトでNoneとなります。通常のコレクションで適用できる値は、Noneのみです。時系列コレクションの場合はすべてのエントリを適用できます。なお、Noneは内部のデフォルトでsecondsになります。コネクターの タスク の数を入力します。詳しくは、Confluent Cloud コネクターの制限事項 を参照してください。
Single Message Transforms: CLI を使用する SMT の追加の詳細については、Single Message Transforms(SMT) のドキュメントを参照してください。
すべてのプロパティの値と定義については、「構成プロパティ」を参照してください。
ステップ 4: プロパティファイルを読み込み、コネクターを作成します。¶
以下のコマンドを入力して、構成を読み込み、コネクターを起動します。
confluent connect create --config <file-name>.json
例:
confluent connect create --config mongo-db-sink.json
出力例:
Created connector confluent-mongodb-sink lcc-ix4dl
ステップ 5: コネクターのステータスを確認します。¶
以下のコマンドを入力して、コネクターのステータスを確認します。
confluent connect list
出力例:
ID | Name | Status | Type
+-----------+-------------------------+---------+------+
lcc-ix4dl | confluent-mongodb-sink | RUNNING | sink
ステップ 6: MongoDB を確認します。¶
コネクターが実行中になったら、レコードが MongoDB データベースに取り込まれていることを確認します。
ちなみに
コネクターを起動すると、デッドレターキューのトピックが自動的に生成されます。詳細については、「Confluent Cloud デッドレターキュー」を参照してください。
構成プロパティ¶
このコネクターでは、以下のコネクター構成プロパティを使用します。
データへの接続方法(How should we connect to your data?)¶
nameコネクターの名前を設定します。
- 型: string
- 指定可能な値: 最大 64 文字の文字列
- 重要度: 高
入力メッセージ(Input messages)¶
input.data.formatKafka 入力レコード値のフォーマットを設定します。指定可能なエントリは、AVRO、JSON_SR、PROTOBUF、JSON、STRING、または BSON です。スキーマベースのメッセージフォーマット(AVRO、JSON_SR、PROTOBUF など)を使用する場合は、Confluent Cloud Schema Registry を構成しておく必要がある点に注意してください。
- 型: string
- 重要度: 高
cdc.handler処理に使用する CDC ハンドラーのクラス名。MongoDB Kafka シンクコネクターで CDC イベントをキャプチャーし、対応する挿入、アップデート、削除の操作を送信先の MongoDB クラスターに対して実行できます。
- 型: string
- デフォルト: None
- 重要度: 低
Writes¶
delete.on.null.values値が null の場合に、コネクターがキーに基づいてドキュメントの削除を試行するかどうかを指定します。
- 型: boolean
- デフォルト: false
- 重要度: 低
max.batch.size処理のために一緒にバッチで処理できるシンクレコードの最大数。
- 型: int
- デフォルト: 0
- 指定可能な値: [0、…]
- 重要度: 低
bulk.write.orderedWhether the batches controlled by 'max.batch.size' must be written via ordered bulk writes.
- 型: boolean
- Default: true
- 重要度: 低
rate.limiting.timeoutHow long in ms processing should wait before continuing after triggering a rate limit.
- 型: int
- デフォルト: 0
- 重要度: 低
rate.limiting.every.nThe number of processed batches that will trigger rate limiting. The default value of 0 sets no rate limiting.
- 型: int
- デフォルト: 0
- 重要度: 低
write.strategy一括書き込み操作に使用する WriteModel を指定するクラス。
- 型: string
- デフォルト: DefaultWriteModelStrategy
- 重要度: 低
Kafka クラスターの認証情報(Kafka Cluster credentials)¶
kafka.auth.modeKafka の認証モード。KAFKA_API_KEY または SERVICE_ACCOUNT を指定できます。デフォルトは KAFKA_API_KEY モードです。
- 型: string
- デフォルト: KAFKA_API_KEY
- 指定可能な値: KAFKA_API_KEY、SERVICE_ACCOUNT
- 重要度: 高
kafka.api.key- 型: password
- 重要度: 高
kafka.service.account.idKafka クラスターとの通信用の API キーを生成するために使用されるサービスアカウント。
- 型: string
- 重要度: 高
kafka.api.secret- 型: password
- 重要度: 高
データの取得元とするトピック(Which topics do you want to get data from?)¶
topics特定のトピック名を指定するか、複数のトピック名をコンマ区切りにしたリストを指定します。
- 型: list
- 重要度: 高
MongoDB Atlas データベースへの接続方法(How should we connect to your MongoDB Atlas database?)¶
connection.hostMongoDB Atlas 接続ホスト(例: confluent-test.mycluster.mongodb.net)。
- 型: string
- 重要度: 高
connection.userMongoDB Atlas 接続ユーザー。
- 型: string
- 重要度: 高
connection.passwordMongoDB Atlas 接続パスワード。
- 型: password
- 重要度: 高
databaseMongoDB Atlas データベース名。
- 型: string
- 重要度: 高
データベースの詳細(Database details)¶
collection書き込み先のコレクション名。コネクターが複数トピックからのデータを出力する場合、この値はトピックのマッピング先となるデフォルトのコレクションを示します。
- 型: string
- 重要度: 中
ID strategies¶
doc.id.strategy一意のドキュメント ID(_id)を生成するために使用する IdStrategy クラス名。
- 型: string
- デフォルト: BsonOidStrategy
- 重要度: 低
doc.id.strategy.overwrite.existingdoc.id.strategy で定義された処理方法を適用する際に、コネクターが _id フィールドの既存の値を上書きするかどうかを指定します。
- 型: boolean
- デフォルト: false
- 重要度: 低
document.id.strategy.uuid.formatThe bson output format when using the UuidStrategy. Can be either String or Binary.
- 型: string
- Default: string
- 重要度: 低
key.projection.typePartialKeyStrategy とともに使用すると、ID の処理方法のカスタムキーフィールドを射影できます。AllowList または BlockList を使用します。
- 型: string
- デフォルト: none
- 重要度: 低
key.projection.listPartialKeyStrategy とともに使用すると、ID の処理方法のカスタムキーフィールドを射影できます。キープロジェクション用のフィールド名のコンマ区切りリスト。
- 型: string
- 重要度: 低
value.projection.typePartialValueStrategy とともに使用すると、ID の処理方法のカスタム値フィールドを射影できます。AllowList または BlockList を使用します。
- 型: string
- デフォルト: none
- 重要度: 低
value.projection.listPartialValueStrategy とともに使用すると、ID の処理方法のカスタム値フィールドを射影できます。値プロジェクション用のフィールド名のコンマ区切りリスト。
- 型: string
- 重要度: 低
Namespace mapping¶
namespace.mapper.classThe class that determines the namespace to write the sink data to. By default this will be based on the 'database' configuration and either the topic name or the 'collection' configuration.
- 型: string
- Default: DefaultNamespaceMapper
- 重要度: 低
namespace.mapper.key.database.fieldThe key field to use as the destination database name.
- 型: string
- 重要度: 低
namespace.mapper.key.collection.fieldThe key field to use as the destination collection name.
- 型: string
- 重要度: 低
namespace.mapper.value.database.fieldThe value field to use as the destination database name.
- 型: string
- 重要度: 低
namespace.mapper.value.collection.fieldThe value field to use as the destination collection name.
- 型: string
- 重要度: 低
namespace.mapper.error.if.invalidWhether to throw an error if the mapped field is missing or invalid. Defaults to false.
- 型: boolean
- デフォルト: false
- 重要度: 低
Server API¶
server.api.versionThe server API version to use. Disabled by default.
- 型: string
- 重要度: 低
server.api.deprecation.errorsSets whether the connector requires use of deprecated server APIs to be reported as errors.
- 型: boolean
- デフォルト: false
- 重要度: 低
server.api.strictSets whether the application requires strict server API version enforcement.
- 型: boolean
- デフォルト: false
- 重要度: 低
接続の詳細(Connection details)¶
max.num.retries書き込みエラーの発生時に再試行を行う回数。
- 型: int
- デフォルト: 3
- 指定可能な値: [0、…]
- 重要度: 低
retries.defer.timeout再試行を遅延させる時間の長さ。
- 型: int
- デフォルト: 5000
- 指定可能な値: [0、…]
- 重要度: 低
時系列構成(Time Series configuration)¶
timeseries.timefield各時系列ドキュメントの日付を含むトップレベルフィールドの名前。この構成を設定すると、各ドキュメントの timefield の値が BSON 日付である時系列コレクションが作成されます。
- 型: string
- デフォルト: ""
- 重要度: 低
timeseries.timefield.auto.convertフィールドのデータを BSON 日付フォーマットに変換するかどうかを指定します。サポートされているフォーマットには、integer、long、string があります。
- 型: boolean
- デフォルト: false
- 重要度: 低
timeseries.timefield.auto.convert.date.formatソースデータの変換元の文字列パターン。この設定では、日付と時刻の両方の情報を含む文字列表現が想定されており、変換に Java DateTimeFormatter.ofPattern(pattern, locale) API が使用されます。文字列に日付情報しか含まれていない場合は、エポックからの時間はその日の開始時刻から取得されます。文字列表現にタイムゾーンのオフセットが含まれていない場合、この設定では、抽出された日付と時刻が UTC として解釈されます。
- 型: string
- デフォルト: yyyy-MM-dd[['T'][ ]][HH:mm:ss[[.][SSSSSS][SSS]][ ]VV[ ]'['VV']'][HH:mm:ss[[.][SSSSSS][SSS]][ ]X][HH:mm:ss[[.][SSSSSS][SSS]]]
- 重要度: 低
timeseries.timefield.auto.convert.locale.language.tag日付パターンで使用する DateTimeFormatter のロケール言語タグ。
- 型: string
- デフォルト: en
- 重要度: 低
timeseries.metafield各時系列ドキュメントのメタデータを含むトップレベルフィールドの名前。このフィールドでは、関連データがグループ化されます。配列を除く任意の型のフィールドを指定できます。
- 型: string
- デフォルト: ""
- 重要度: 低
timeseries.expire.after.secondsMongoDB によって削除される前にデータが MongoDB に保持される秒数。このフィールドを指定しなかった場合、データは自動削除されません。
- 型: int
- デフォルト: 0
- 指定可能な値: [0、…]
- 重要度: 低
ts.granularity時系列の後続の測定間で想定される間隔。データが時系列でない場合は、None に設定するか空のままにします。
- 型: string
- デフォルト: None
- 重要度: 低
このコネクターのタスク数(Number of tasks for this connector)¶
tasks.max- 型: int
- 指定可能な値: [1、…]
- 重要度: 高
次のステップ¶
参考
フルマネージド型の Confluent Cloud コネクターが Confluent Cloud ksqlDB でどのように動作するかを示す例については、「Cloud ETL のデモ」を参照してください。この例では、Confluent CLI を使用して Confluent Cloud のリソースを管理する方法についても説明しています。