重要
このページの日本語コンテンツは古くなっている可能性があります。最新の英語版コンテンツをご覧になるには、こちらをクリックしてください。
クラスター、リージョン、クラウド間でのデータの共有¶
Looking for Confluent Platform Cluster Linking docs? You are currently viewing Confluent Cloud documentation. If you are looking for Confluent Platform docs, check out Cluster Linking on Confluent Platform.
以下の手順では、基本的なトピックデータの共有シナリオについて詳しく説明します。このチュートリアルを完了すると、2 つのクラスターを構成し、Cluster Linking を使用してミラートピックを作成して、クラスター間でトピックデータを共有できるようになります。また、ミラーリングを停止してトピックを書き込み可能にする方法と、2 つのトピックに不一致が生じているかどうかを検証する方法についても学びます。
前提条件¶
- 既に Confluent CLI がある場合は、最新の状態であることを確認します。 既に CLI がインストールされている場合は、新しい Cluster Linking コマンドとツールを備えた最新バージョンであることを確認します。既に Confluent Cloud CLI がある場合は、
ccloud update --majorを実行すると、利用可能なアップデートと confluent v2.0 への直接アップグレードのプロンプトが表示されます。既に新しい統合 CLI がある場合はconfluent updateを実行します。詳細については、クイックスタートの前提条件の「Confluent CLI の最新バージョンの取得」を参照してください。 - 「概要」の「コマンドと前提条件」に記載された手順に従います。これらの手順には、まだお持ちでない方のために、最新バージョンの Confluent Cloud を取得する最も簡単な方法が記されているほか、Cluster Linking コマンドの概要が簡単に紹介されています。
- 送信先クラスターは、パブリックインターネットエンドポイントに接続された 専用 クラスターである必要があります。
- 送信元クラスターには、パブリックインターネットエンドポイントに接続された ベーシック クラスター、スタンダード クラスター、または 専用 クラスターを使用できます。これらのクラスターがまだ存在しない場合は、Confluent Cloud Console または Confluent CLI で作成できます。
チュートリアルの内容¶
このチュートリアルでは以下を実行します。
- クラスターを 2 つ作成します。1 つは送信元クラスターとして動作し、もう 1 つは送信先クラスターとして動作します。送信先クラスターは 専用クラスター である必要があります。
- クラスターリンクをセットアップします。
- 送信元クラスターのトピックを基に "ミラートピック" を作成します。
- ソーストピックにデータを生成します。
- リンクを介してミラートピック(送信先)のデータを消費します。
- ミラートピックを昇格します。これにより、トピックが読み取り専用から読み書き可能になります。
では始めましょう。
2 つのクラスターのセットアップ¶
2 つの Confluent Cloud クラスターが既にセットアップ済みであり、一方が送信先として使用するための 専用クラスター になっている場合は、次のタスクまでスキップできます。
そうでない場合は、次のようにしてクラスターをセットアップします。
ちなみに
以下の手順よりも詳しいガイダンスが必要な場合は、スタートガイドの「Confluent Cloud でのクラスターの作成」と「ステップ 1: Confluent Cloud で Kafka クラスターを作成する」を参照してください。
Confluent Cloud Console にログオンします。
「Confluent Cloud でのクラスターの作成」の説明に従い、同じ環境内に 2 つのクラスターを作成します。
これらの少なくとも一方は 専用クラスター である必要があります。これは送信先クラスターとして動作します。
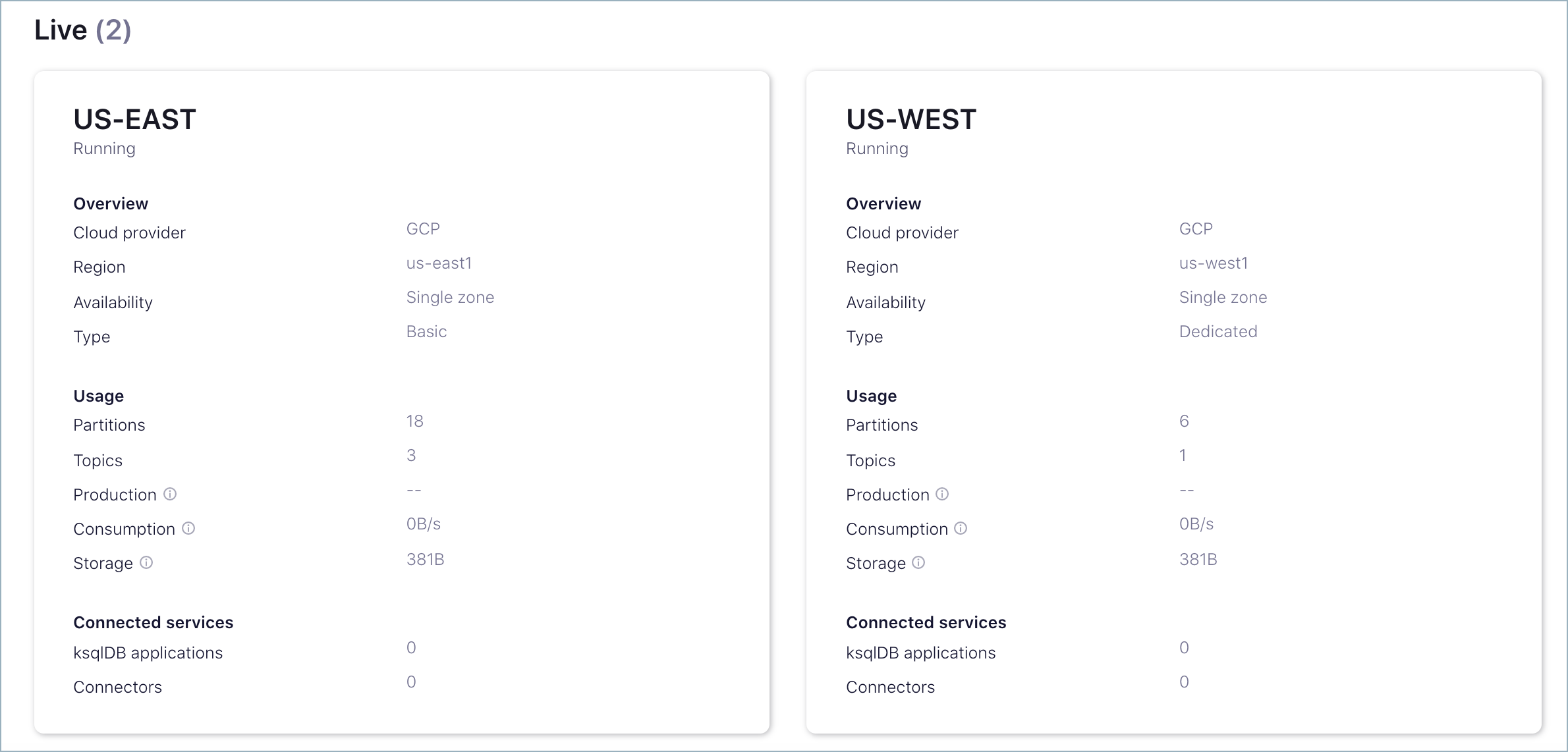
たとえば、送信元として使用するために US-EAST という ベーシック クラスターを作成し、送信先として使用するために US-WEST という専用クラスターを作成します。
以上の手順を完了すると、次のような 2 つのクラスターが作成されます。
送信元クラスターへの情報の入力¶
送信元クラスターでトピックを作成します。
たとえば、US-EAST(送信元として動作するベーシッククラスター)に tasting-menu というトピックを作成します。
Cloud Console からトピックを追加するには、送信元クラスターの Topics ページに移動し(US-EAST > Topics)、Add a topic をクリックし、トピック名を入力して、Create with defaults をクリックします。
Confluent CLI でトピックを追加するには、CLI にログインし(
confluent login)、使用する環境とクラスターを選択して、confluent kafka topic create <topic>コマンドを入力します。その例を次に示します。confluent kafka topic create tasting-menu
Confluent CLI の操作手順の詳細については、以降のタスクで説明します。CLI で環境またはクラスターを選択する方法がわからない場合は、以下の説明を参照してください。
送信元クラスターと送信先クラスターの識別¶
Confluent CLI にログオンします。
confluent login
環境を表示し、使用する環境の ID を選択します。
confluent environment list
アスタリスクは、リスト内で現在選択されている環境を示します。以下のようにして異なる環境を選択できます。
confluent environment use <environment-ID>
クラスターを表示します。
confluent kafka cluster list
出力は以下のようになります。
$ confluent kafka cluster list Id | Name | Type | Provider | Region | Availability | Status +-------------+---------+-----------+----------+----------+--------------+--------+ * lkc-161v5 | US-WEST | DEDICATED | gcp | us-west1 | single-zone | UP lkc-7k6kj | US-EAST | BASIC | gcp | us-east1 | single-zone | UP送信先 クラスターとして使用するクラスターと 送信元 クラスターとして使用するクラスターを決定し、そのクラスター ID をメモします。これは後で必要になります。たとえば、上記の ID を使用した場合、次のようになります。
送信先クラスター ID: lkc-161v5(DEDICATED)
送信元クラスター ID: lkc-7k6kj(BASIC)
このチュートリアルの例では、
<dst-cluster-id>と<src-cluster-id>はそれぞれ送信先 ID と送信元 ID を表します。- データは送信元クラスターのトピックから送信先クラスターのトピックにミラーリングされます。
- 送信先クラスターは 専用クラスター である必要があります。
- 送信元クラスターは、以下の クラスタータイプ のいずれかである必要があります。
- BASIC
- BASIC_LEGACY
- STANDARD
- DEDICATED-with-Public-Internet-Networking
注釈
If, instead of a Confluent Cloud cluster, your source cluster is a Confluent Platform or open-source Apache Kafka® cluster, you will need to know your source cluster’s bootstrap server and cluster ID in order to use it. You can find the source cluster ID via the command-line tool
kafka-cluster cluster-idthat comes with Confluent Platform and Apache Kafka®. Your cluster’s administrator will know its bootstrap server.送信元クラスターの情報を表示します。
confluent kafka cluster describe <src-cluster-id>
出力は以下のようになります。
$ confluent kafka cluster describe lkc-7k6kj +--------------+--------------------------------------------------------+ | Id | lkc-7k6kj | | Name | US-EAST | | Type | BASIC | | Ingress | 100 | | Egress | 100 | | Storage | 5000 | | Provider | gcp | | Availability | single-zone | | Region | us-east1 | | Status | UP | | Endpoint | SASL_SSL://pkc-4yyd6.us-east1.gcp.confluent.cloud:9092 | | ApiEndpoint | https://pkac-ew1dj.us-east1.gcp.confluent.cloud | +--------------+--------------------------------------------------------+
送信元クラスターの エンドポイント をメモします。これは後で必要になります。このチュートリアルでは、これは
<src-endpoint>と呼ばれます。たとえば、上記のクラスター情報では、エンドポイントは
SASL_SSL://pkc-4yyd6.us-east1.gcp.confluent.cloud:9092になります。送信先クラスターと送信元クラスター用に、API キーとシークレットのセットが 2 組必要です。
作成済みの API キーを使用できます(サービスアカウントに関連付けられていても構いません)。または、CLI で次のコマンドを使用して新しいキーを作成します。
--resourceフラグの値にはクラスター ID を指定します。confluent api-key create --resource <cluster-id>
このチュートリアルでは、送信先のセットを
<dst-api-key>と<dst-api-secret>で、送信元のセットを<src-api-key>と<src-api-secret>で表しています。シークレットは CLI から取得できないため、これらを安全な場所に保管してください。API キーとシークレットのセットは両方とも後で必要になります。ちなみに
- 送信元の API キーとシークレットのセットはクラスターリンクに保存され、データのフェッチに使用されます。この API キーのアクセス許可を取り消すと、リンクは停止します。そのような場合は、クラスターリンクを編集し、別の API キーとシークレットを指定する必要があります。
- リソースと操作に必要な ACL を指定する方法の詳細については、Confluent Platform ドキュメントの「認可(ACL)」を参照してください。
クラスターリンクが送信元クラスターのトピックにアクセスするための権限のセットアップ¶
クラスターリンクには、送信元クラスターで該当するトピックを読み取るための権限が必要です。これらの権限を付与するために、以下の 2 つのメカニズムを作成します。
- クラスターリンク用の サービスアカウント。サービスアカウントは、Confluent Cloud で、Confluent Cloud リソースへのアクセスを必要とするアプリケーションとエンティティをグループ化するために使用されます。
- クラスターリンクのサービスアカウントと送信元クラスターに関連付けられている API キーとシークレット。リンクによって、トピック情報とメッセージがフェッチされる際に、送信元クラスターでの認証にこの API キーが使用されます。サービスアカウントは多数の API キーを所有できますが、ここで必要なのは 1 つだけです。
これらのリソースを作成するには、以下を実行します。
このクラスターリンク用のサービスアカウントを作成します。
confluent iam service-account create Cluster-Linking-Demo --description "For the cluster link created for the topic data sharing tutorial"このコマンドの出力は次のようになります。
+-------------+-----------+ | Id | 234567 | | Resource ID | sa-lmno11 | | Name | ... | | Description | ... | +-------------+-----------+
ID フィールド(このチュートリアルでは
<service-account-id>)を保存します。API キーとシークレットを作成します。
confluent api-key create --resource <source-cluster-id> --service-account <service-account-id>
注釈
このキーとシークレットを安全なところに保管します。 クラスターリンクを作成する場合は、この API キーとシークレットをリンクに指定する必要があるので、クラスターリンク自体に保存されます。
クラスターリンクによる送信元クラスターのトピックの読み取りを許可します。クラスターリンクのサービスアカウントに、すべてのトピックに対する READ および DESCRIBE_CONFIGS を実行できる ACL を付与します。
confluent kafka acl create --allow --service-account <service-account-id> --operation READ --operation DESCRIBE_CONFIGS --topic "*" --cluster <src-cluster-id>ちなみに
上記の例では、特定のトピックの代わりにアスタリスク(
--topic "*")を使用することで、すべてのトピックの読み取りアクセスを許可しています。必要な場合は、ミラー対象のトピックを特定のセットに絞り込むこともできます。たとえば、クラスターリンクに対して、"clicks" プレフィックスで始まるすべてのトピックの読み取りを許可するには、以下を実行できます。confluent kafka acl create --allow --service-account <service-account-id> --operation READ --operation DESCRIBE_CONFIGS --topic "clicks" --prefix --cluster <src-cluster-id>(省略可能)送信元クラスターに保存した ACL を送信先クラスターに同期する場合は、クラスターリンクのサービスアカウントに、送信元クラスターの詳細表示を許可する ACL を付与する必要があります。
confluent kafka acl create --allow --service-account <service-account-id> --operation DESCRIBE --cluster-scope --cluster <src-cluster-id>
(省略可能)このクラスターリンクを介してミラートピックのコンシューマーグループオフセットを同期する場合は、クラスターリンクのサービスアカウントに、トピックに対する DESCRIBE と、送信元クラスターのコンシューマーグループに対する READ および DESCRIBE を許可する適切な ACL を付与する必要があります。
confluent kafka acl create --allow --service-account <service-account-id> --operation DESCRIBE --topic "*" --cluster <src-cluster-id>confluent kafka acl create --allow --service-account <service-account-id> --operation READ --operation DESCRIBE --consumer-group "*" --cluster <src-cluster-id>
クラスターリンクの作成¶
送信先クラスターから送信元クラスターへのリンクを作成します(リンク自体は送信先クラスターに保存されます)。
.configファイルがない場合は、単純にコマンドラインで API キーとシークレットを渡します。このコマンドは次のようになります。confluent kafka link create <link-name> --cluster <dst-cluster-id> \ --source-cluster-id <src-cluster-id> \ --source-bootstrap-server <src-bootstrap-url> \ --source-api-key <src-api-key> \ --source-api-secret <src-api-secret>
<link-name> を任意のリンク名で置き換えます。リンクにアクションを実行するたびにこの名前を使用します。
たとえば、次の例では、送信先として使用する DEDICATED クラスター(lkc-161v5)に
usa-east-westというクラスターリンクを作成します。必ず、リンクを作成する 送信先 のクラスター ID、ブートストラップ URL、および 送信元 クラスターの構成ファイルを指定します。confluent kafka link create usa-east-west \ --cluster lkc-161v5 --source-cluster-id lkc-7k6kj \ --source-bootstrap-server "SASL_SSL://pkc-4yyd6.us-east1.gcp.confluent.cloud:9092" \ --source-api-key keykeykeykeykeyk \ --source-api-secret secretsecretsecretsecretsecretsecretsecretsecretsecretsecretsec
ちなみに
.configファイルを使用する場合のコマンドは次のようになります。confluent kafka link create <link-name> --cluster <dst-cluster-id> --source-bootstrap-server <src-bootstrap-url> --config-file <source.config>
指定したクラスターリンクの詳細を表示します。
confluent kafka link describe <link-name> --cluster <dst-cluster-id>
たとえば、usa-east-west リンクの出力は次のようになります。
$ confluent kafka link describe usa-east-west --cluster lkc-161v5 Key | Value +----------------------------------------+---------------------------------------------+ connections.max.idle.ms | 600000 ssl.endpoint.identification.algorithm | https num.cluster.link.fetchers | 1 sasl.mechanism | PLAIN replica.socket.timeout.ms | 30000 socket.connection.setup.timeout.ms | 10000 consumer.offset.sync.enable | false acl.sync.enable | false consumer.offset.group.filters | acl.filters | request.timeout.ms | 30000 replica.fetch.wait.max.ms | 500 cluster.link.retry.timeout.ms | 300000 ssl.protocol | TLSv1.3 ssl.cipher.suites | ssl.enabled.protocols | TLSv1.2,TLSv1.3 security.protocol | SASL_SSL replica.fetch.max.bytes | 1048576 consumer.offset.sync.ms | 30000 topic.config.sync.ms | 5000 acl.sync.ms | 5000 replica.fetch.response.max.bytes | 10485760 metadata.max.age.ms | 300000 replica.socket.receive.buffer.bytes | 65536 bootstrap.servers | pkc-4yyd6.us-east1.gcp.confluent.cloud:9092 retry.backoff.ms | 100 sasl.jaas.config | replica.fetch.backoff.ms | 1000 socket.connection.setup.timeout.max.ms | 127000 replica.fetch.min.bytes | 1 client.dns.lookup | use_all_dns_ipsコンシューマーグループオフセットと ACL を同期します。
送信元クラスターから送信先に、ミラートピックのコンシューマーグループオフセットを同期することができます。また、ソースから送信先に ACL を同期することもできます。このためには、以下のプロパティを含むファイルを作成する必要があります。
[property name]=[property value]という形式で各プロパティを 1 行ずつ入力します。consumer.offset.sync.enable- 送信元から送信先にコンシューマーオフセットを同期するかどうか。
- 型: boolean
- デフォルト: false
consumer.offset.group.filters- 送信元から送信先にミラーリングするオフセットを持つコンシューマーグループを指定するための、正規表現パターンマッチングスキーマの JSON 表現。コンシューマーオフセットは相互に上書きされるため、送信元と送信先で実行されているコンシューマーグループは必ず異なるようにしてください。各ミラートピックのコンシューマーグループオフセットを同期する例 と、「ディザスターリカバリとフェイルオーバー」ウォークスルーの「クラスターリンクの作成」の最初の手順を参照してください。
- 型: 文字列
- デフォルト: ""
acl.sync.enable- 送信元から送信先に ACL を同期するかどうか。例については、ここを参照してください。
- 型: boolean
- デフォルト: false
acl.filters.json- 同期する ACL を選択するための正規表現パターンマッチングスキーマの JSON 表現。
- 型: 文字列
- デフォルト: ""
以下は、各ミラートピックのすべてのコンシューマーグループオフセットを同期する例です。
consumer.offset.sync.enable=true
consumer.offset.group.filters={"groupFilters": [{"name": "*","patternType": "LITERAL","filterType": "INCLUDE"}]}
ちなみに
.config ファイルの設定の詳細については、「(通常は省略可能)config ファイルの使用」を参照してください。
トピックのミラーリング¶
クラスターリンクが準備できたので、これを介して送信元から送信先へとトピックをミラーリングできます。
送信元クラスターのトピックを表示します。
confluent kafka topic list --cluster <src-cluster-id>
以下に例を示します。
$ confluent kafka topic list --cluster lkc-7k6kj Name +--------------+ stocks tasting-menu transactionsミラートピックを作成します。
ミラーリングする送信元トピックを選択し、クラスターリンクを使用してこれをミラーリングします。
ちなみに
ミラーリングするトピックがまだない場合は、
confluent kafka topic create <topic-name> --cluster <src-cluster-id>を使用して、送信元クラスター上にトピックを作成します。ここまで説明どおりに実行している場合は、tasting-menuを使用します。通常のトピックと同様にして送信先クラスターにミラートピックを作成しますが、パラメーターをいくつか追加します。
confluent kafka mirror create <topic-name> --link <link-name> --cluster <dst-cluster-id>
以下に例を示します。
$ confluent kafka mirror create tasting-menu --link usa-east-west --cluster lkc-161v5 Created topic "tasting-menu".注釈
- ミラートピック名(送信先)は送信元トピック名と同じである必要があります。(ミラートピックの名前は、その基になった元のトピック名から自動的に付けられます。)トピックの名前変更はまだサポートされていません。
- ミラートピックを作成する際には、必ず 送信先 クラスター ID をコマンドに指定します。
クラスターリンクとミラートピックのリスト表示¶
ワークフローのさまざまなポイントで、リンクやミラートピックなど、Cluster Linking リソースのリストを取得することが必要になる場合があります。たとえば、モニタリングの目的で行うことや、フェイルオーバーまたは移行を開始する前に行うことが考えられます。
アクティブクラスター上のクラスターリンクをリスト表示するには
confluent kafka link list
リンク上またはクラスター上のミラートピックをリスト表示できます。
特定のクラスターリンク上のミラートピックをリスト表示するには
confluent kafka mirror list --link <link-name> --cluster <cluster-id>
特定のクラスター上のすべてのミラートピックをリスト表示するには
confluent kafka mirror list --cluster <cluster-id>
データの送信によるミラートピックのテスト¶
クラスターリンクでデータがミラーリグされていることをテストするには、Confluent CLI を使用して送信元クラスターのトピックにデータを生成し、そのデータを送信先クラスターのミラートピックから消費します。
これを実行するには、CLI を各クラスターの API キーに関連付ける必要があります。クラスターリンクに使用したものとは異なる API キーが必要です。これらをサービスアカウントに関連付ける必要はありません。
たとえば、一方のクラスターの API キーを作成するには(まだ作成していない場合)、confluent api-key create --resource <src-or-dst-cluster-id> を実行します。
もう一方のクラスターに関連付けられている API キーを使用するように CLI に指定するには、confluent api-key use <api-key> --resource <src-or-dst-cluster-id> を実行します。
CLI で、送信先クラスターに使用する送信先 API キーを指定します。
confluent api-key use <dst-api-key> --resource <dst-cluster-id>
API キーが、指定したクラスター ID のアクティブキーとして設定されたことが表示されます。
注釈
これはワンタイムアクションであり、永久に保存されます。送信先クラスターにワンタイムアクションを実行するたびにこの API キーが使用されます。クラスターリンクには保存 "されません"。この API キーを使用してクラスターリンクを作成した場合、後でこの API キーを無効にしてもクラスターリンクは動作を継続します。
プロデューサー用とコンシューマー用に新規のコマンドウィンドウを 2 つ開きます。
それぞれで Confluent Cloud にログオンし、送信元クラスターと送信先クラスターの両方を含む環境を使用していることを確認します。
前と同じように、コマンド
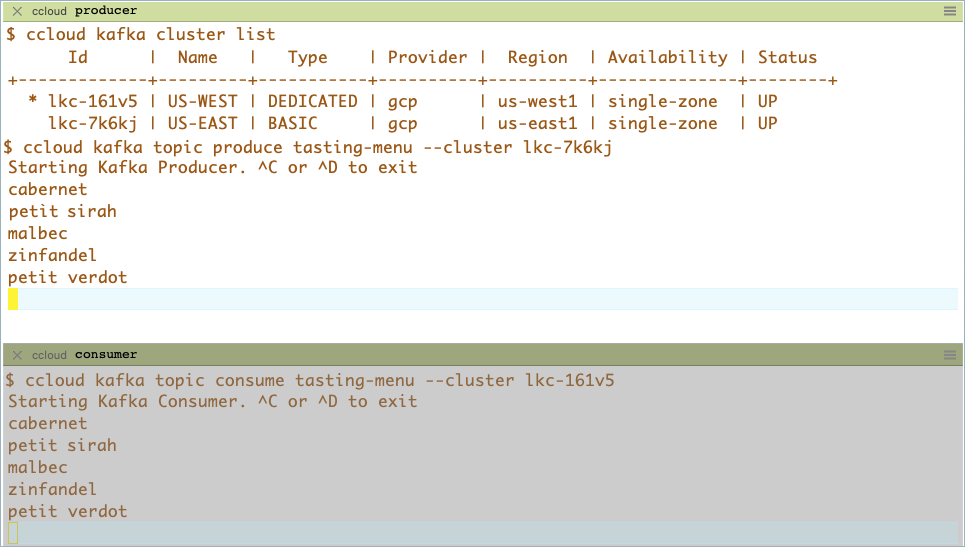
confluent environment list、confluent environment use <environment-ID>、confluent kafka cluster listを使用し、現在の場所を探して確認します。一方のウィンドウでプロデューサーを起動し、送信元トピックを生成します。
confluent kafka topic produce <topic-name> --cluster <src-cluster-id>
別のウィンドウでコンシューマーを起動し、ミラートピックから読み取ります。
confluent kafka topic consume <topic-name> --cluster <dst-cluster-id>
最初のソースターミナルで、生成するエントリを入力し、2 番目の送信先ミラートピックのターミナルに表示されるメッセージを確認します。
別のコマンドウィンドウを開いて送信元クラスターのコンシューマーを起動すると、送信元トピックに直接生成されていることを確認できます。ソースコンシューマーとミラートピックコンシューマーは両方とも、同じデータを消費していることが表示されます。
ちなみに
前述のコンシューマーコマンドの例では、トピックのデータをリアルタイムで読み込みます。先頭から消費するには、
confluent kafka topic consume --from-beginning <topic> --cluster <cluster-id>を使用します。
ミラートピックの停止¶
必要に応じて、トピックのミラーリングを停止できます。たとえば、クラスターの移行が完了した場合や、災害時に送信先クラスターにフェイルオーバーが必要な場合には、送信先トピックのミラーリングを停止できます。
ミラーリングはトピック単位で停止できます。送信先のミラートピックは、ソースからの新規データの受信を停止し、プロデューサーがデータを送信できる標準の書き込み可能トピックになります。トピックやデータは削除されません。また、送信元クラスターにも影響はありません。
送信先クラスターの特定ミラートピックのミラーリングを停止するには、次のコマンドを使用します。
confluent kafka mirror promote <mirror-topic-name> --link <link-name> --cluster <dst-cluster-id>
トピック tasting-menu のミラーリングを停止するには、次の例のように送信先クラスター ID を使用します。
$ confluent kafka mirror promote tasting-menu --link usa-east-west --cluster lkc-161v5
MirrorTopicName | Partition | PartitionMirrorLag | ErrorMessage | ErrorCode
-------------------------------------------------------------------------
tasting-menu | 0 | 0 | |
tasting-menu | 1 | 0 | |
tasting-menu | 2 | 0 | |
tasting-menu | 3 | 0 | |
tasting-menu | 4 | 0 | |
tasting-menu | 5 | 0 | |
エラーメッセージやエラーコードが表示されなければ、すべてのトピックで操作が正常に完了したことを意味します。
トピックのミラーリングを停止した場合の動作¶
mirror promote コマンドは、指定されたトピックについて、送信元トピックから送信先トピックへの新規データのミラーリングを停止し、送信先トピックを通常の書き込み可能トピックに昇格させます。
このアクションは元に戻せません。ミラートピックを通常のトピックに変更した後でミラートピックに戻すことはできません。再度ミラートピックにする場合は、いったん削除して、ミラートピックとして再作成する必要があります。
consumer.offset.sync.enable が有効になっている場合は、該当するトピックでコンシューマーオフセットの同期も停止されます。
このコマンドは ACL の同期には影響しません(「(通常は省略可能)config ファイルの使用」を参照してください)。
トピックのミラーリングを再開する方法¶
トピックのミラーリングを再開するには、送信先トピックを削除した後、送信先トピックをミラーとして再作成する必要があります。
移行のベストプラクティス¶
送信元から送信先にデータを移行している場合に、ラグのあるデータが失われないようにするには、まずプロデューサーを停止し、すべてのラグがミラーリングされたことを確認してから、ミラートピックを停止します。
送信元クラスターのプロデューサーを停止します。
すべてのラグがミラーリングされるまで待ちます。
ちなみに
送信元トピックとミラートピックの両方の終了オフセット(最高水準点)を参照し、両方が同じオフセットであることを確認します。
mirror promoteコマンドを実行します。
フェイルオーバーに関する考慮事項¶
災害により送信元から送信先へのフェイルオーバーを実行している場合には、以下の事項を考慮してください。
アクションの順序、およびフェイルオーバー後のアクティブクラスターとしての送信先の昇格¶
まずミラートピックを停止してから、すべてのプロデューサーとコンシューマーを送信先クラスターに移動する必要があります。少なくとも災害時とリカバリの期間中、送信先クラスターは新しいアクティブクラスターになります。可能であれば、このようなユースケースでは、送信先クラスター を新規の永久アクティブクラスターにすることをお勧めします。
ラグのあるデータをリカバリする¶
災害の発生前に送信先にミラーリングされていないラグのあるデータが存在することがあります。コンシューマーを移動する際に、コンシューマーがそのようなデータを送信元でまだ読み取っていない場合、送信先でもそのデータは読み取られません。災害から送信元クラスターが復旧した場合、ラグのあるそのデータはまだ残っています。よって、ユースケースに応じて、それを消費するか、適切に処理してください。
たとえば、送信元のオフセットが 105 まで到達していて、送信先のオフセットが 100 までしか到達していない場合、オフセット 101 から 105 までの送信元データは送信先にありません。送信先は、オフセット 101 から 105 までを処理するプロデューサーから新しい最新のデータを取得します。災害が復旧すると、送信元には手動で消費可能なオフセット 101 から 105 までのデータが残っています。
ラグのあるコンシューマーオフセットにより読み取りが重複する可能性がある¶
災害の発生前に送信先にミラーリングされていないラグのあるコンシューマーオフセットが存在することがあります。このような場合、コンシューマーを送信先に移動すると、データが重複して読み取られる可能性があります。
たとえば、ミラーリングを停止した時点で、次の状態であったとします。
- コンシューマー A が送信元のオフセット 100 まで読み出している
- Cluster Linking によりオフセット 100 までのデータが送信先にミラーリング済みである
- Cluster Linking でのミラーリング済み最終コンシューマーオフセットが 95 までしかコンシューマー A に通知されていない
このような場合、コンシューマー A を送信先に移動すると、コンシューマー A はオフセット 96 から 100 までを再度読み取るため、読み取りの重複が発生します。
ミラートピックの昇格(停止)によるコンシューマーオフセットの固定¶
昇格コマンドを実行すると、コンシューマーオフセットは "固定" されます。
たとえば、次のような状態で mirror promote を実行したとします。
- コンシューマー A が送信元オフセット 105 に位置し、これが正常に送信先にミラーリングされている。
- 送信先のデータにラグがあり、オフセット 100 までしか到達していない(つまり、オフセット 101 から 105 までが存在しない)。
この場合に promote を呼び出すと、送信先のコンシューマー A のオフセットはオフセット 100 に "固定" されます。これは、送信先で使用できる最大のオフセットが 100 であるためです。
これによりコンシューマー A でオフセット 101 から 105 までの "再消費" が発生するので注意してください。プロデューサーが新しい最新のデータを送信先に送信すれば、コンシューマー A はデータを重複して読み取りません。(ただし、同じデータを含むオフセット 101 から 105 を再送信するようプロデューサーのコードをカスタマイズしていた場合、コンシューマーは同じデータを 2 度読み取る可能性があります。これはまれなケースであり、システムの設計には依存しません。)
consumer.offset.sync.ms を使用する¶
consumer.offset.sync.ms は必要に応じて構成することができます(デフォルトは 30 秒です)。同期を頻繁に行えば、通常の運用時と同様の帯域幅とスループットのコストで、コンシューマーオフセットのためのよりよいフェイルオーバー点が得られる可能性があります。
コンシューマーグループを移行する¶
<consumer-group-name> というコンシューマーグループをあるクラスターから別のクラスターに移行するには、コンシューマーを停止し、クラスターリンクをアップデートして、コンシューマーオフセットのミラーリングを停止します。
confluent kafka link update <link-name> --cluster <src-cluster-id> --config \
consumer.offset.group.filters="consumer.offset.group.filters={\"groupFilters\": \
[{\"name\": \"*\",\"patternType\": \"LITERAL\",\"filterType\": \"INCLUDE\"},\
{\"name\":\"<consumer-group-name>\",\"patternType\":\"LITERAL\",\"filterType\":\"EXCLUDE\"}]}"
その後、送信先でコンシューマーを指定すれば、停止したオフセットから再開します。
プロデューサーの移行¶
プロデューサーを移行するには、次のようにします。
プロデューサーを停止します。
送信先トピックを書き込み可能にします。
$ confluent kafka mirror promote <mirror-topic-name> --link <link-name> --cluster <dst-cluster-id>
送信先クラスターでプロデューサーを指定します。
クラスターリンク構成のアップデート¶
クラスターリンクの構成パラメーターを動的にアップデートするには、次のようにします。
confluent kafka link update --config "<config-name>=<value>" --cluster <dst-cluster-id>
リンクの削除¶
クラスターリンクの一覧を表示し、削除するリンクの名前を見つけます。
confluent kafka link list
クラスターリンクを削除します。
confluent kafka link delete <link-name> --cluster <dst-cluster-id>
コマンドが成功すると、出力は以下のようになります。
Cluster link '<link-name>' deletion successfully completed.
ちなみに
使用中のクラスターリンクを削除しようとすると、システムによって拒否されます。このため、削除するリンクを使用しているミラートピックがある場合は、最初にそれらのトピックを削除、昇格、またはフェイルオーバーする必要があります。
(通常は省略可能)config ファイルの使用¶
.config ファイルをセットアップすることもできます。以下のシナリオで役立ちます。このファイルには拡張子 .config を付ける必要があります。使い慣れたテキストエディターを使用して、作業ディレクトリにファイルを追加します。
- 構成ファイルは、API キーとシークレットを Confluent Cloud クラスターに渡すための代替手段です。API キーとシークレットを
.configファイルに保存すると、コマンドラインに毎回認証情報を入力する必要がなくなります。代わりに、.configファイルを使用して送信元クラスターへの認証を行います。 - オプションの構成設定をリンクに追加する(コンシューマーグループ同期など)場合は、それらのプロパティを含む
.configファイルで渡す必要があります。なお、API キーとシークレットの指定にはコマンドラインを使用し、これらの追加のリンクプロパティ用にのみ構成ファイルを使用することもできます。この場合は、ファイルに、キーとシークレットではなく、リンクプロパティのみを指定する必要があります。 - 他のクラスターが Confluent Cloud ではない場合は、
.configファイルを使用してセキュリティ認証情報を渡す必要があります。これは、config ファイルを省略できないケースの 1 つです。
このファイルを使用してコンシューマーグループオフセットと ACL を同期する例については、「クラスターリンクの作成」の最後のステップ(3)を参照してください。
config ファイルを使用して認証情報を保存するには、この初期テキストを source.config にコピーし、<src-api-key> および <src-api-secret> を送信元クラスターの値で置き換えます。
security.protocol=SASL_SSL
sasl.mechanism=PLAIN
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username='<src-api-key>' password='<src-api-secret>';
重要
- 最後の項目では、
sasl.jaas.configからpassword='<src-api-secret>';までのすべてを 1 行で記載します。構成が分断されるため、改行は入れないでください。 - 構成オプションでは大文字と小文字が区別されます。必ず、例に示されたとおりに大文字と小文字を使用してください。
- 一重引用符やセミコロンなどの句読点は示されているとおりに正確に使用してください。
- 認証情報を保護するために、リンクの作成後は config ファイルを削除します。
おすすめのリソース¶
- このチュートリアルでは、同じ種類または異なる種類のクラスター、リージョン、クラウドにあるトピック間でデータを共有する基本的なユースケースを取り上げました。「ディザスターリカバリとフェイルオーバー」では、Cluster Linking を使用してデータを保存し、機能停止から回復する方法についてのチュートリアルを提供します。
- 「ミラートピック」では、Cluster Linking のこの機能のコンセプトの概要について説明します。