重要
このページの日本語コンテンツは古くなっている可能性があります。最新の英語版コンテンツをご覧になるには、こちらをクリックしてください。
ディザスターリカバリとフェイルオーバー¶
Looking for Confluent Platform Cluster Linking docs? You are currently viewing Confluent Cloud documentation. If you are looking for Confluent Platform docs, check out Cluster Linking on Confluent Platform.
はじめに¶
Cluster Linking を使用してディザスターリカバリ戦略をデプロイすることにより、パブリッククラウドプロバイダーの機能停止など、予測できない災害が発生したときのデータの損失とダウンタイムを最小限に抑え、ミッションクリティカルなアプリケーションの可用性と信頼性を高めることができます。このドキュメントでは、ディザスターリカバリ戦略の設計とフェイルオーバーの実行方法について説明します。
Cluster Linking を使用できるクラスターについては、「サポートされるクラスターのタイプ」を参照してください。
Cluster Linking を使用したディザスターリカバリの目的¶
まず、"プライマリ" クラスターには、そのトピックのデータのほか、コンシューマーオフセットや ACL などの運用メタデータが格納されます。それらのトピックにデータを送信するプロデューサーとそれらのトピックからデータを読み取るコンシューマーがアプリケーションの核となります。
You can use Cluster Linking to create a disaster recovery (DR) cluster that is in a different region or cloud than the primary cluster. When an outage hits the primary cluster, the DR cluster will have an up-to-date copy of your data and metadata. The producers and consumers can switch over to the DR cluster, allowing them to continue running with low downtime and minimal data loss. Thus, your applications can continue to serve your business and customers during a disaster.
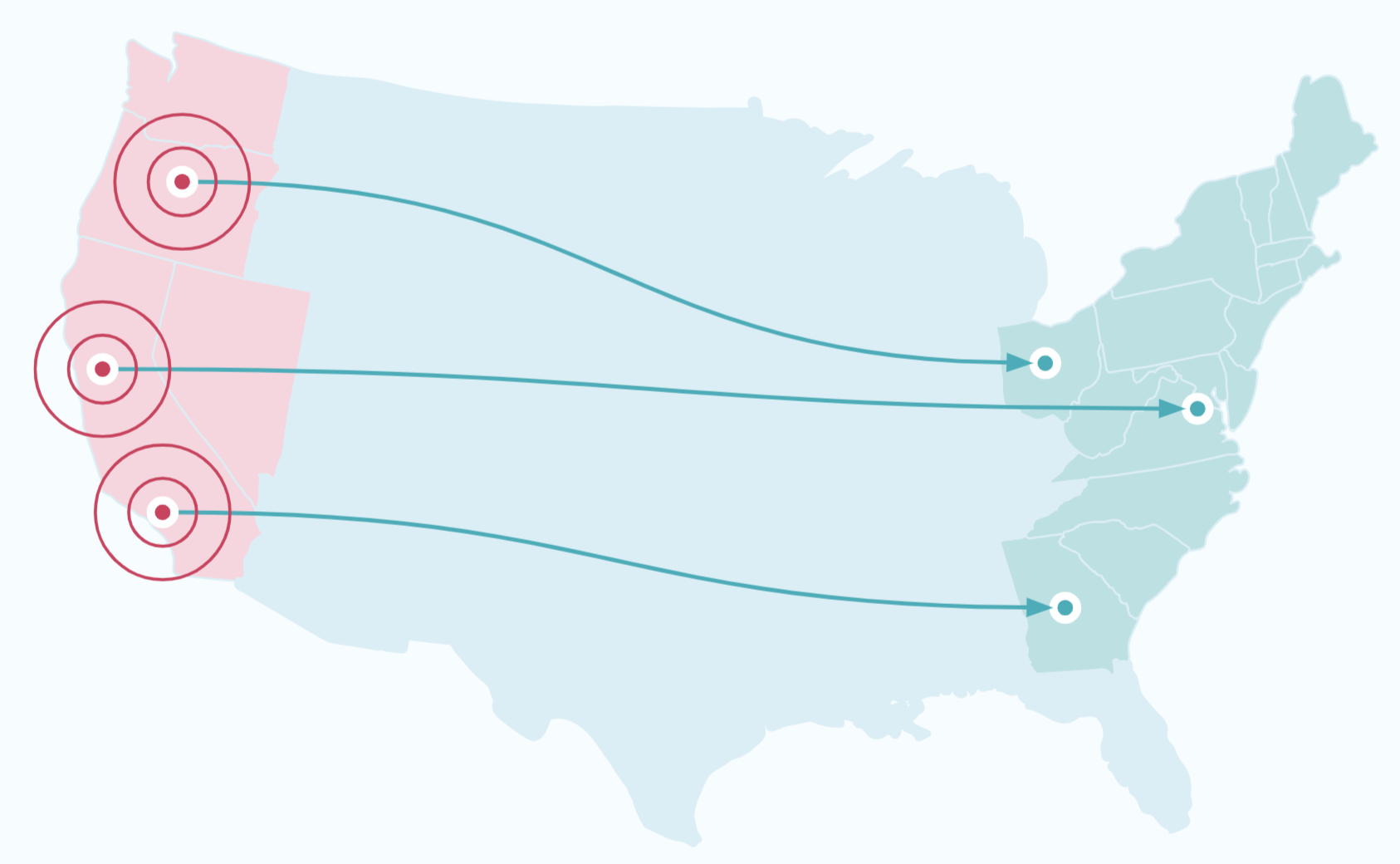
Recovery Time Objectives (RTOs) and Recovery Point Objectives (RPOs)¶
A crucial input informing the design of your disaster recovery plan is the Recovery Time Objective(s) (RTO) and Recovery Point Objective(s) (RPO) that you hope to achieve. An RTO is the maximum amount of downtime that your system can have during an outage, measured as the difference between the time the outage occurs and the time your system is back up and running. An RPO is the maximum amount of data you are willing to risk losing because of an outage, measured as the difference between the last message produced to the failed cluster and the last message replicated to the DR cluster from the failed cluster.
Here are some quick reference definitions for relevant terms.
| Term | 説明 |
|---|---|
| Recovery Point Objective (RPO) | In the event of failure, at which point in the data's history does the failover need to resume from? In other words, how much data can be lost during a failure? In order to have zero RPO, synchronous replication is required. |
| Recovery Time Objective (RTO) | In the event of failure, how much time can elapse while a failover takes place? In other words, how long can a failover take? In order to have zero RTO, seamless client failover is required. |
| Region | A synonym for a data center. |
| Disaster Recovery (DR) | Umbrella term that encompasses architecture, implementation, tooling, policies, and procedures that all allow an application to recover from a disaster or a full region failure. |
| Event | A single message produced or consumed to/from Confluent Cloud or Confluent Platform. |
| Millisecond (ms) | 1/1,000th of a second |
The RTO you can achieve with Cluster Linking depends on your tooling and failover procedures, since failing over your applications is your responsibility. There’s no set minimum or maximum RTO.
The RPO you can achieve Cluster Linking is determined by the mirroring lag between the DR cluster and the primary cluster. Mirroring lag is exposed via Metrics API, via REST API, and in the Confluent Cloud Console.
Disaster Recovery Requirements for Kafka Clients¶
When implementing a disaster recovery (“DR”) plan to failover from a primary cluster to a DR cluster, there are several aspects you must design into your Kafka clients, so that they can failover smoothly:
- Clients must bootstrap to the DR cluster once a failover is triggered
- Consumers must be able to tolerate a small number of duplicate messages (“idempotency”)
- Consumers and producers must be tolerant of an RPO (“Recovery-Point Objective”)
This section walks through these design requirements.
Clients must bootstrap to the DR cluster once a failover is triggered¶
When you detect an outage and decide to failover to the DR cluster, your clients must all switch over to the DR cluster to produce and consume data. To do this, your clients must do two things:
- When the clients start, they must use the bootstrap server and security credentials of the DR cluster. It is not best practice to hardcode the bootstrap servers and security credentials of your primary and DR clusters into your clients’ code. Instead, you should store the bootstrap server of the active cluster in a Service Discovery tool (like Hashicorp Consul) and the security credentials in a key manager (like Hashicorp Vault or AWS Secret Manager). When a client starts up, it fetches its bootstrap server and security credentials from these tools. To trigger a failover, you change the active bootstrap server and security credentials in these tools to those of the DR cluster. Then, when your clients restart, they will bootstrap to the DR cluster.
- Any clients that are still running need to stop and restart. If your primary
cluster has an outage but not your clients (for example, if you have clients in a
different region than the primary cluster that were unaffected by the regional
cloud service provider outage), these clients will still be running and
attempting to connect to the primary cluster. When you decide to failover, these
clients need to stop running and restart, so that they will bootstrap to the DR
cluster. There is not a mechanism built into Kafka to do this. There are several
approaches you may take to achieve this behavior:
- If a central Kafka operator manages all clients centrally, such as in a Kubernetes cluster, the operator can order all clients to shut down until the count of running clients is down to 0, and then can scale the clients back up.
- You can add code wrapping your clients that polls the service discovery tool to check for a change in the bootstrap server. If the bootstrap server changes, the wrapping code restarts the clients.
- Each team with Kafka clients can be paged and ordered to restart their clients.
How quickly your clients are able to bootstrap to the DR cluster will determine a large part of your recovery time after an outage. It is recommended that you practice the failover process so you can be sure that you can hit your RTOs (“Recovery Time Objectives”).
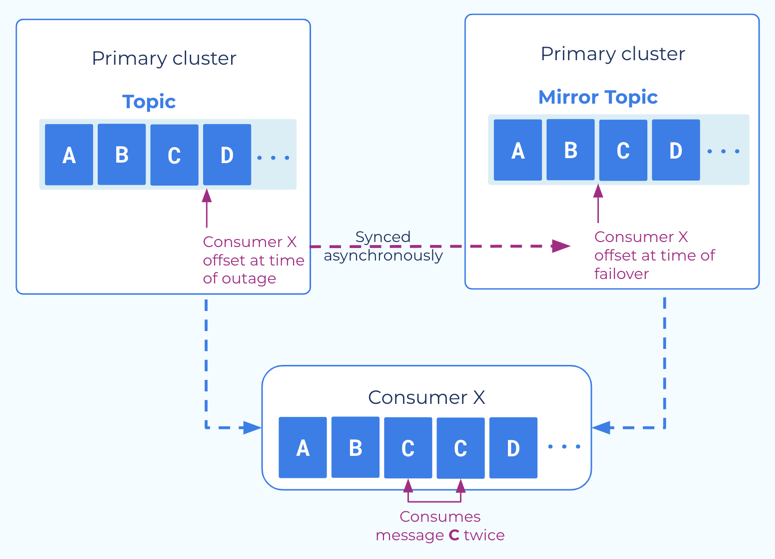
Clients must be be able to tolerate a small number of duplicate messages (idempotency)¶
Cluster Linking consumer offset sync gives your applications a low RTO by
enabling your consumers to failover and restart very close to the point where
they left off, without missing any new messages that were produced on the DR
cluster. However, consumer offset sync is an asynchronous process. When
consumers commit their offsets to the source cluster, the commit completes
without also committing the offsets to the destination cluster. The offsets will
are written to the destination cluster every consumer.offset.sync.ms
milliseconds (a cluster link configuration that you can set as low as 1 second).
Because consumer offset sync is asynchronous, when an outage or disaster occurs, the most recent consumer offsets may not have been committed to the destination cluster, yet. So, when your consumer applications begin consuming on the destination cluster, the first few messages they receive may be messages they have already received. Consumer applications must be able to tolerate these duplicates on a failover.
Producers and consumers must be tolerant of a small RPO¶
Cluster Linking enables you to have a copy of your topic data on a second cluster, so that you don’t lose all of your business-critical event data should a regional outage or disaster occur. However, Cluster Linking is an asynchronous process. When producers produce messages to the source cluster, they get an acknowledgement (also known as an “ack”) from the source cluster independent of when, and often before, the cluster link replicates those messages to the DR cluster.
Therefore, when an outage occurs and a failover is triggered, there may be a small number of messages that have not been replicated to the DR cluster. Producer and consumer applications must be tolerant of this.
You can monitor your exposure to this via the mirroring lag in the Metrics API, CLI, REST API, and Confluent Cloud Console.
ディザスターリカバリクラスターのセットアップ¶
For the Disaster Recovery (DR) cluster to be ready to use when disaster strikes, it will need to have an up-to-date copy of the primary cluster’s topic data, consumer group offsets, and ACLs:
- The DR cluster needs up-to-date topic data so that consumers can process messages that they haven’t yet consumed. Consumers that are lagging can continue to process topic data while missing as few messages as possible. Any future consumers you create can process historical data without missing any data that was produced before the disaster. This helps you achieve a low Recovery Point Objective (RPO) when a disaster happens.
- The DR cluster needs up-to-date consumer group offsets so that when the consumers switch over to the DR cluster, they can continue processing messages from the point where they left off. This minimizes the number of duplicate messages the consumers read, which helps you minimize application downtime. This helps you achieve a low Recovery Time Objective (RTO).
- スイッチオーバーしたときには既にプロデューサーとコンシューマーに DR クラスターへの接続が認可されているような状態にするには、DR クラスターに最新の ACL が必要です。あらかじめ ACL を設定し、最新の状態にしておくことは、RTO の短縮にもつながります。
Cluster Linking で使用するディザスターリカバリクラスターをセットアップするには、以下の手順に従います。
- 必要に応じて、DR クラスターとして使用する、パブリックインターネットを備えた新しい専用 Confluent Cloud クラスターを異なるリージョンまたはクラウドプロバイダーに作成します。
- プライマリクラスターから DR クラスターへのクラスターリンクを作成します。クラスターリンクには、次の構成を適用する必要があります。
- コンシューマーオフセットの同期を有効にします。一部のコンシューマーグループのみを DR クラスターにフェイルオーバーする場合は、フィルターを使用して該当するコンシューマーグループ名のみを選択してください。それ以外の場合、すべてのコンシューマーグループ名を同期します。
- ACL の同期を有効にします。一部の Kafka クライアントのみを DR クラスターにフェイルオーバーする場合は、フィルターを使用して該当するクライアントのみを選択してください。それ以外の場合、すべての ACL を同期します。
- クラスターリンクを使用し、プライマリクラスターの各トピックについて、DR クラスターにミラートピックを作成します。一部のトピックについてのみ DR が必要である場合は、該当するトピックのミラートピックのみを作成します。
- Enable auto-create mirror topics
on the cluster link, which will automatically create DR mirror topics for the topics
that exist on the source cluster. As new topics are created on your source cluster over time,
auto-create mirror topics will automatically mirror them to the DR cluster.
- If you only need DR for a subset of topics, you can scope auto-create mirror topics by topic prefixes or specific topic names.
- For some use cases, it may be better to create mirror topics from the API call (POST /clusters/{cluster_id}/links/{link_name}/mirrors), CLI command (confluent kafka mirror create), or Confluent Cloud Console instead of enabling auto-create mirror topics. For example, this may be preferable if your architecture has an onboarding process that topics and clients must follow in order to opt-in to DR. If you choose this option, whenever a new topic is created on the primary cluster that needs DR, you must explicitly create a mirror topic on the DR cluster.
以上の手順を行ったうえで、プライマリクラスターのデータとメタデータに対する最新の変更を反映したディザスターリカバリクラスターを作成します。
DR を必要とする新しいトピックをプライマリクラスターに作成したら、そのつど、そのミラートピックを DR クラスターに作成してください。
ちなみに
各 Kafka クライアントには、その接続先のクラスターごとに API キーとシークレットが必要となります。RTO を短くするため、DR クラスターの API キーをあらかじめ作成してコンテナーに格納し、その DR クラスターに接続する Kafka クライアントがキーを取得できるようにしておいてください。
ディザスターリカバリクラスターのモニタリング¶
The Disaster Recovery (DR) cluster needs to stay up-to-date with the primary cluster so you can minimize data loss when a disaster hits the primary cluster. Because Cluster Linking is an “asynchronous” process, there may be “lag:” messages that exist on the primary cluster but haven’t yet been mirrored to the DR cluster. Lagged data is at risk of being lost when a disaster strikes.
Metrics API を使用したラグのモニタリング¶
災害の発生中にミラートピックで失われるおそれのあるデータの量は、組み込みのメトリクスを使用して DR クラスターのラグをモニタリングすることで確認できます。ミラートピックのパーティションでラグの生じるメッセージの推定最大数は、Metrics API の ミラーラグメトリック によってレポートされます。
CLI でのラグの確認¶
特定時点におけるミラートピックのラグを Confluent CLI で確認する方法は 2 つあります。
confluent kafka mirror listを実行すると、送信先クラスター上のすべてのミラートピックが一覧表示されます。その中のMax Per Partition Mirror Lagという列に、各ミラートピックのパーティションにおけるラグの最大量が示されています。--linkフラグや--mirror-statusフラグを使用すると、特定のクラスターリンクやミラートピックのステータスを条件としてフィルター処理を行うことができます。confluent kafka mirror describe <mirror-topic> --link <link-name>を実行すると、そのミラートピックの各パーティションについての詳細な情報が表示されます。その中のPartition Mirror Lagという列に、各パーティションの推定ラグが示されています。
REST API でのラグの照会¶
Confluent Community REST API は、ミラートピックのパーティションとそのエンドポイントにおけるラグのリストを返します。
/kafka/v3/clusters/<destination-cluster-id>/links/<link-name>/mirrorsは、クラスターリンクのすべてのミラートピックを返します。/kafka/v3/clusters/<destination-cluster-id>/links/<link-name>/mirrors/<mirror-topic>は、指定されたミラートピックのみを返します。
パーティションとラグのリストの形式は次のとおりです。
"mirror_lags": [
{
"partition": 0,
"lag": 24
},
{
"partition": 1,
"lag": 42
},
{
"partition": 2,
"lag": 15
},
...
],
チュートリアル¶
To explore this use case, you will use Cluster Linking to fail over a topic and a simple command-line consumer and producer from an original cluster to a Disaster Recovery (DR) cluster.
前提条件¶
- 既に Confluent CLI がある場合は、最新の状態であることを確認します。 既に CLI がインストールされている場合は、新しい Cluster Linking コマンドとツールを備えた最新バージョンであることを確認します。既に Confluent Cloud CLI がある場合は、
ccloud update --majorを実行すると、利用可能なアップデートと confluent v2.0 への直接アップグレードのプロンプトが表示されます。既に新しい統合 CLI がある場合はconfluent updateを実行します。詳細については、クイックスタートの前提条件の「Confluent CLI の最新バージョンの取得」を参照してください。 - 「概要」の「コマンドと前提条件」に記載された手順に従います。これらの手順には、まだお持ちでない方のために、最新バージョンの Confluent Cloud を取得する最も簡単な方法が記されているほか、Cluster Linking コマンドの概要が簡単に紹介されています。
- DR クラスターは、パブリックインターネットエンドポイントを持つ 専用 クラスターであることが必要です。
- オリジナルクラスターには、パブリックインターネットエンドポイントに接続された、ベーシック、スタンダード、または 専用 クラスターを使用できます。これらのクラスターがまだ存在しない場合は、Cloud Console または Confluent CLI で作成できます。
注釈
有効な Confluent Platform クラスターと有効な Confluent Cloud クラスターの間でフェイルオーバーを使用できます。Confluent Cloud クラスターと Confluent Platform クラスターには 統合 Confluent CLI を使用する必要があります。インストール手順と新しい統合 CLI の概要については、こちら を参照してください。
チュートリアルの内容¶
このチュートリアルでは、Confluent CLI Cluster Linking コマンドを使用した DR クラスターの作成とそれに対するフェイルオーバーを解説します。
将来のリリースで、Cluster Linking コマンドの REST API が利用できるようになる可能性があります。
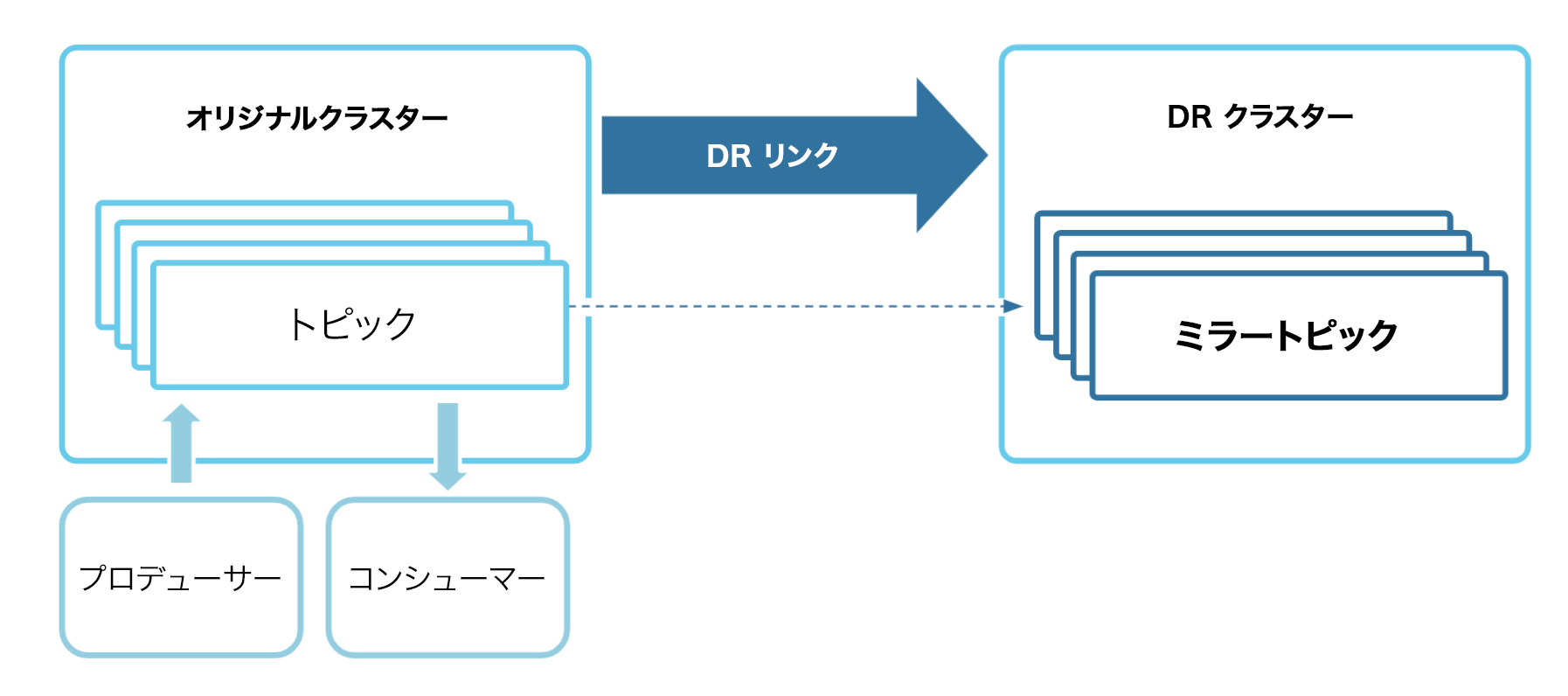
最初に、DR クラスター(送信先)へのクラスターリンクを構築し、関連するすべてのトピック、ACL、およびコンシューマーグループオフセットをミラーリングします。これは、"定常状態" のセットアップです。
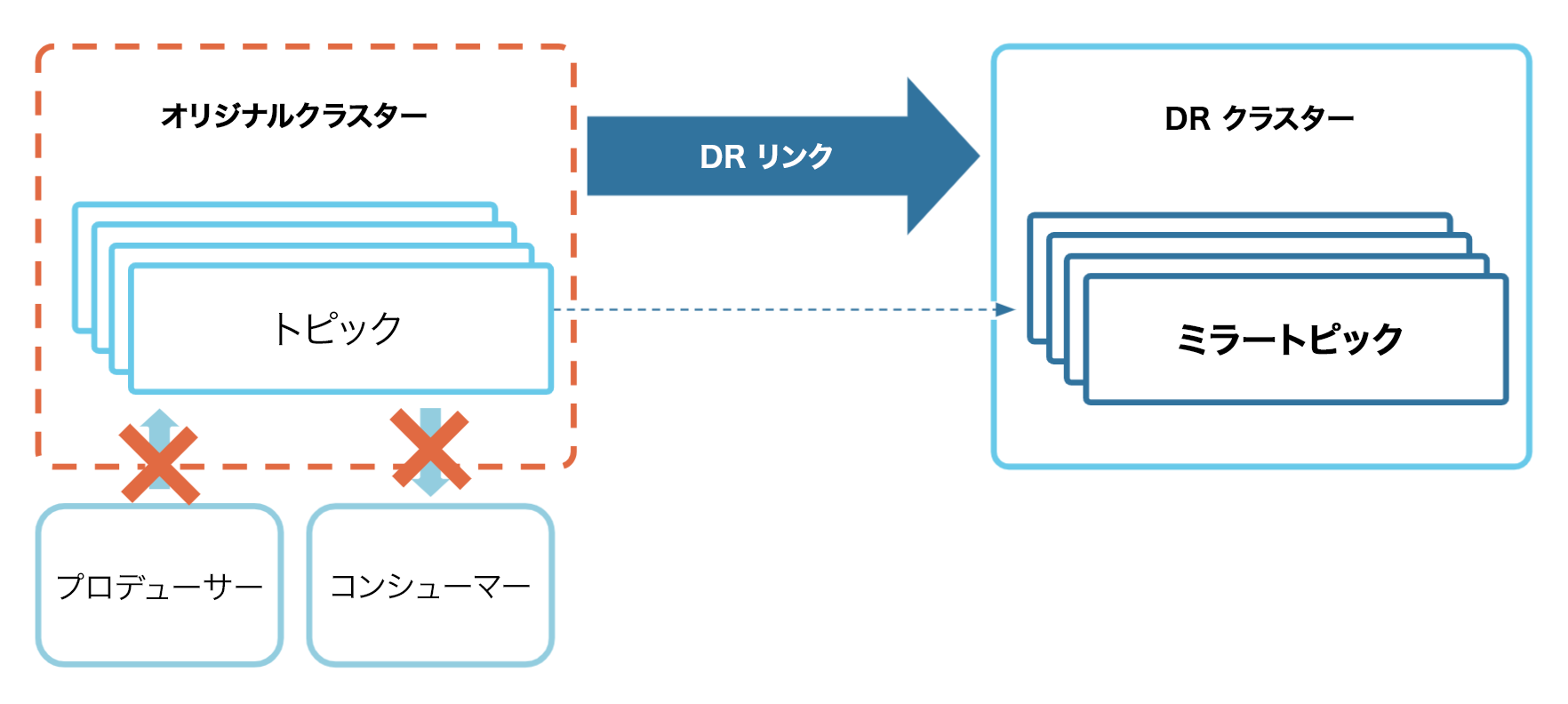
次に、オリジナル(送信元)クラスターを停止させてみます。この場合、プロデューサー、コンシューマー、クラスターリンクはオリジナルクラスターとやり取りできなくなります。
次に、DR クラスターのミラートピックを通常のトピックに変換するフェイルオーバーコマンドを呼び出します。
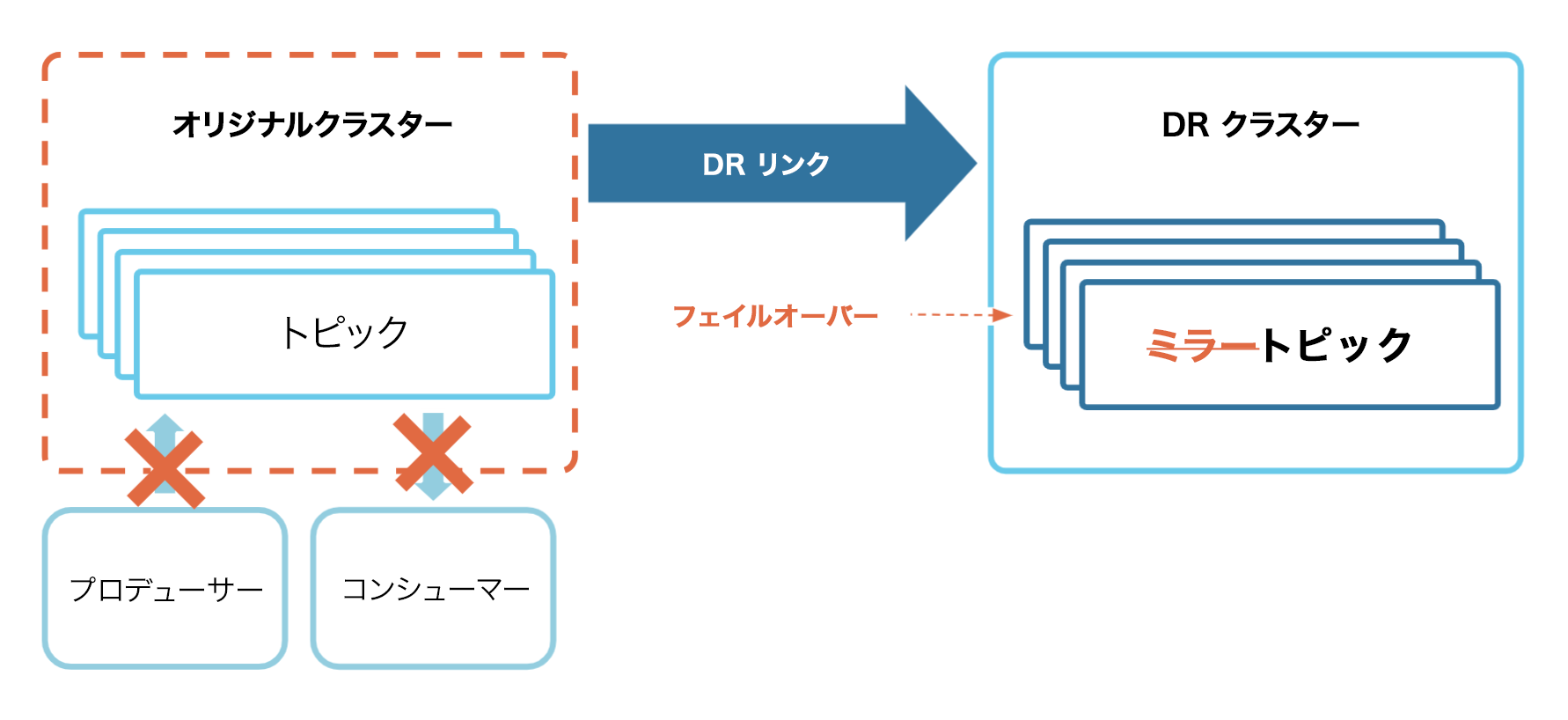
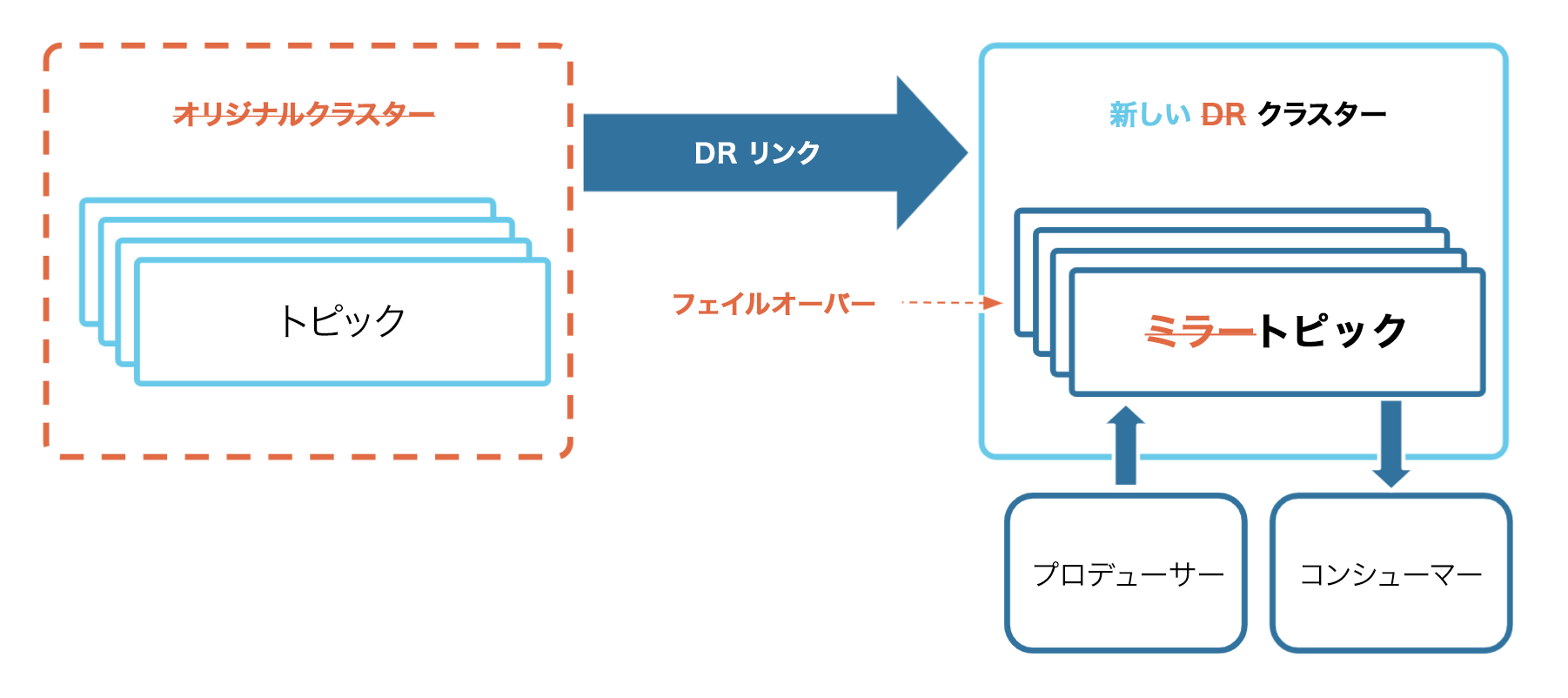
最後に、プロデューサーとコンシューマーを DR クラスターに移動して、運用を続けます。これで、DR クラスターが新しい Source of Truth(信頼できる唯一の情報源)になりました。
定常状態のセットアップ¶
使用するクラスターを作成または選択します。¶
Confluent Cloud ウェブ UI にログオンします。
まだクラスターを作成していない場合は、「Confluent Cloud でのクラスターの作成」の説明に従い、同じ環境内に 2 つのクラスターを作成します。
これらの少なくとも一方は 専用クラスター である必要があります。これが DR クラスター(ミラートピックのホストとなる "送信先")として動作します。
オリジナルクラスターまたは送信元クラスターのタイプはどれでもかまいません。すぐに識別できるよう、送信元クラスターはベーシッククラスターまたはスタンダードクラスターとし、それらのクラスターに ORIGINAL と DR という名前を付けることをお勧めします。
必要な情報の記録¶
ちなみに
この情報を常時監視するには、Confluent CLI のコマンド出力をテキストファイルに単に保存するか、シェル環境変数を使用するのが最も簡単です。そのようにする場合は、後でファイルを削除するか、セキュリティコードだけをより安全なストレージに移動するなどして、API キーとシークレットを必ず保護してください。その方法を含め、時間短縮のためのヒントについては、「概要」の「CLI の高度なヒント」に詳しく説明されています。
このウォークスルーでは、Confluent CLI のコマンドから次の情報にアクセスできる必要があります。
オリジナルクラスターのクラスター ID (このチュートリアルでは
<original-cluster-id>)。Confluent Cloud のクラスター ID を取得するには、Confluent CLI から以下のコマンドを入力します。以下の例では、オリジナルクラスターの ID はlkc-xkd1gです。confluent kafka cluster list
オリジナルクラスター用のブートストラップサーバー。これを取得するには、次のコマンドを入力します。
<original-cluster-id>は、送信元クラスターのクラスター ID に置き換えてください。confluent kafka cluster describe <original-cluster-id>
この出力は以下のようになります。以下の出力例で、ブートストラップサーバーの値は
SASL_SSL://pkc-9kyp5.us-east-1.aws.confluent.cloud:9092です。このチュートリアルでは、この値を<original-bootstrap-server>として参照します。+--------------+---------------------------------------------------------+ | Id | lkc-xkd1g | | Name | AWS US | | Type | DEDICATED | | Ingress | 50 | | Egress | 150 | | Storage | Infinite | | Provider | aws | | Availability | single-zone | | Region | us-east-1 | | Status | UP | | Endpoint | SASL_SSL://pkc-9kyp5.us-east-1.aws.confluent.cloud:9092 | | ApiEndpoint | https://pkac-rrwjk.us-east-1.aws.confluent.cloud | | RestEndpoint | https://pkc-9kyp5.us-east-1.aws.confluent.cloud:443 | | ClusterSize | 1 | +--------------+---------------------------------------------------------+
DR クラスターのクラスター ID (
<DR-cluster-id>)。これは、オリジナルクラスターの ID と同じように、confluent kafka cluster listコマンドで取得できます。confluent kafka cluster list
DR クラスターのブートストラップサーバー (
<DR-bootstrap-server>)。これは、オリジナルクラスターのブートストラップサーバーと同じように、describe コマンドを使用して取得できます。<DR-cluster-id>は送信先クラスター ID に置き換えてください。confluent kafka cluster describe <DR-cluster-id>
オリジナルクラスターと DR クラスター間のクラスターリンクの作成¶
最初に、ソースクラスターのトピック、ACL、およびコンシューマーグループオフセットを送信先クラスターにミラーリングするクラスターリンクを作成します。
クラスターリンクが送信元クラスターのトピックにアクセスするための権限のセットアップ¶
クラスターリンクには、送信元クラスター上の適切なトピックを読み取るための権限が必要です。これらの権限を付与するために、以下の 2 つのメカニズムを作成します。
- クラスターリンク用の サービスアカウント。サービスアカウントは、Confluent Cloud で、Confluent Cloud リソースへのアクセスを必要とするアプリケーションとエンティティをグループ化するために使用されます。
- クラスターリンクのサービスアカウントとソースクラスターに関連付けられている API キーとシークレット。リンクによって、トピック情報とメッセージがフェッチされる際に、ソースクラスターでの認証にこの API キーが使用されます。サービスアカウントは多数の API キーを所有できますが、ここで必要なのは 1 つだけです。
これらのリソースを作成するには、以下を実行します。
このクラスターリンク用のサービスアカウントを作成します。
confluent iam service-account create Cluster-Linking-Demo --description "For the cluster link created for the DR failover tutorial"この出力は以下のようになります。
+-------------+-----------+ | Id | 254122 | | Resource ID | sa-lqxn16 | | Name | ... | | Description | ... | +-------------+-----------+
ID フィールド(このチュートリアルでは
<service-account-id>)を保存します。API キーとシークレットを作成します。
confluent api-key create --resource <original-cluster-id> --service-account <service-account-id>
注釈
このキーとシークレットを安全なところに保管します。 クラスターリンクを作成する場合は、この API キーとシークレットをリンクに指定する必要があるので、クラスターリンク自体に保存されます。
クラスターリンクによるソースクラスターのトピックの読み取りを許可します。クラスターリンクのサービスアカウントに、すべてのトピックに対する READ および DESCRIBE_CONFIGS を実行できる ACL を付与します。
confluent kafka acl create --allow --service-account <service-account-id> --operation READ --operation DESCRIBE_CONFIGS --topic "*" --cluster <original-cluster-id>ちなみに
上記の例では、特定のトピックの代わりにアスタリスク(
--topic "*")を使用することで、すべてのトピックの読み取りアクセスを許可しています。必要な場合は、ミラー対象のトピックを特定のセットに絞り込むこともできます。たとえば、クラスターリンクに対して、"clicks" プレフィックスで始まるすべてのトピックの読み取りを許可するには、以下を実行できます。confluent kafka acl create --allow --service-account <service-account-id> --operation READ --operation DESCRIBE_CONFIGS --topic "clicks" --prefix --cluster <original-cluster-id>ソースの ACL を送信先クラスターに同期できるようにします。
これで、障害が発生しても、コンシューマー、プロデューサー、その他のサービスが実行を継続できます。
このためには、クラスターリンクのサービスアカウントに、ソースクラスターに対して DESCRIBE を実行する ACL を付与する必要があります。
confluent kafka acl create --allow --service-account <service-account-id> --operation DESCRIBE --cluster-scope --cluster <original-cluster-id>
ミラートピックのコンシューマーグループオフセットをこのクラスターリンクに同期できるようにします。これで、コンシューマーは中断したオフセットから再開できます。
このためには、2 つの ACL セットがクラスターに必要です。
クラスターリンクのサービスアカウントに、ソース(オリジナル)クラスターのトピックに対する DESCRIBE、コンシューマーグループに対する READ および DESCRIBE を実行するための適切な ACL を付与します。
confluent kafka acl create --allow --service-account <service-account-id> --operation DESCRIBE --topic "*" --cluster <original-cluster-id>confluent kafka acl create --allow --service-account <service-account-id> --operation READ --operation DESCRIBE --consumer-group "*" --cluster <original-cluster-id>クラスターリンクのサービスアカウントに、送信先(DR)クラスターのトピックに対する READ および ALTER を実行するための ACL と、そのコンシューマーグループに対する READ を実行するための ACL を付与します。
confluent kafka acl create --allow --service-account <service-account-id> --operation READ --operation ALTER --topic "*" --cluster <DR-cluster-id>confluent kafka acl create --allow --service-account <service-account-id> --operation READ --consumer-group "*" --cluster <DR-cluster-id>
クラスターリンクの作成¶
ACL の同期とコンシューマーグループオフセットの同期を有効にする構成ファイルを作成します。このファイルにリンクのセキュリティ認証情報も含めます。
これを行うには、
dr-link.configという名前の新規ファイルに以下の行をコピーし、<api-key>と<api-secret>を、作成したキーとシークレットに置き換えます。consumer.offset.sync.enable=true consumer.offset.group.filters={"groupFilters": [{"name": "*","patternType": "LITERAL","filterType": "INCLUDE"}]} consumer.offset.sync.ms=1000 acl.sync.enable=true acl.sync.ms=1000 acl.filters={ "aclFilters": [ { "resourceFilter": { "resourceType": "any", "patternType": "any" }, "accessFilter": { "operation": "any", "permissionType": "any" } } ] } topic.config.sync.ms=1000 security.protocol=SASL_SSL sasl.mechanism=PLAIN sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="<api-key>" password="<api-secret>";
この構成で注意する点があります。それらは以下を実行します。
- これらのミラートピックのすべてのコンシューマーグループ(
*)のオフセットを同期します。これをフィルター処理するには、包含("filterType": "INCLUDE")または除外("filterType": "EXCLUDE")する正確なトピック名("patternType": "LITERAL")またはプレフィックス("patternType": "PREFIX")を渡します。 - コンシューマー、プロデューサー、その他のサービスが DR クラスターのトピックにアクセスできるように、オリジナルクラスター上のすべての ACL(
*)を同期します。コンシューマーグループオフセットの同期とは異なり、これはミラートピックに限らず他のトピックの ACL も同期できます。これをフィルター処理するには、包含("filterType": "INCLUDE")または除外("filterType": "EXCLUDE")する正確なトピック名("patternType": "LITERAL")またはプレフィックス("patternType": "PREFIX")を渡します。 - コンシューマーオフセット、ACL、トピック構成を 1000 ミリ秒ごとに同期します。したがって、これらについて、より新しい値をリンクできます。これと引き換えにリンクのデータスループットが高くなり、トピックデータの最大スループットが低下する可能性があります。値を変えて試し、クラスターリンクに最適な値を設定することをお勧めします。
- ファイルの最後の行は、
sasl.jaas.configで始まり、セミコロン(;)で終わります。例示したように、全体が 1 行で入力されている必要があります。
- これらのミラートピックのすべてのコンシューマーグループ(
以下のように
confluent kafka link create <flags>コマンドを使ってクラスターリンクを作成します。この例では、クラスターリンクの名前は
dr-linkです。confluent kafka link create dr-link \ --cluster <dr-cluster-id> \ --source-cluster-id <original-cluster-id> \ --source-bootstrap-server <original-bootstrap-server> \ --config-file dr-link.config
このコマンドが成功した場合、
Created cluster link "dr-link".というメッセージが返されます。また、リンクが作成されたことは、既存のリンクをリスト表示することでも確認できます。
confluent kafka link list --cluster <DR-cluster-id>
オリジナルクラスターのソーストピックと DR クラスターのミラートピックの構成¶
オリジナルクラスターに
dr-topicというトピックを作成します。このデモでは便宜上、このトピックをパーティション 1 つだけ(
--partitions 1)で作成します。パーティションを 1 つだけにすると、オリジナルクラスターから DR クラスターでコンシューマーオフセットがどのように同期されるかがわかりやすくなります。confluent kafka topic create dr-topic --partitions 1 --cluster <original-cluster-id>以下の例のように、
Created topic "dr-topic"というメッセージが表示されます。> confluent kafka topic create dr-topic --partitions 1 --cluster lkc-xkd1g Created topic "dr-topic".
これはトピックをリスト表示することで検証できます。
confluent kafka topic list --cluster <original-cluster-id>
DR クラスターに
dr-topicのミラートピックを作成します。confluent kafka mirror create dr-topic --link <link-name> --cluster <DR-cluster-id>
以下の例のように、
Created mirror topic "dr-topic"というメッセージが表示されます。> confluent kafka mirror create dr-topic --link dr-link --cluster lkc-r68yp Created mirror topic "dr-topic".ちなみに
現在のプレビューリリースでは、CLI または API コマンドでミラートピックを 1 つずつ作成する必要があります。今後のリリースでは、送信元クラスターで新しいトピックが作成されるたびに自動的にミラートピックを作成できるサービスが Cluster Linking に追加される可能性があります。この場合は、プレフィックスに基づいてトピックをフィルター処理できる可能性があります。この機能は、DR クラスターに DR トピックを自動作成する場合に役立ちます。
この時点では、オリジナルクラスターにトピックが 1 つあり、そのデータ、ACL、およびコンシューマーグループオフセットがすべて DR クラスターのミラートピックにミラーリングされています。
オリジナルクラスターでのデータの生成および消費¶
このセクションでは、オリジナルクラスターへのデータ生成とオリジナルクラスターからのデータ消費を行うアプリケーションをシミュレーションします。Confluent CLI を使用して、そのための関数を消費および生成します。
CLI ベースのデモクライアントとするサービスアカウントを作成します。
confluent iam service-account create CLI --description "From CLI"出力は以下のようになります。
+-------------+-----------+ | Id | 254262 | | Resource ID | sa-ldr3w1 | | Name | CLI | | Description | From CLI | +-------------+-----------+
上の例では、
<cli-service-account-id>は 254262 です。オリジナルクラスターに、このサービスアカウントの API キーとシークレットを作成し、
<original-CLI-api-key>と<original-CLI-api-secret>として保存します。confluent api-key create --resource <original-cluster-id> --service-account <cli-service-account-id>
DR クラスターに、このサービスアカウントの API キーとシークレットを作成し、
<DR-CLI-api-key>と<DR-CLI-api-secret>として保存します。confluent api-key create --resource <DR-cluster-id> --service-account <cli-service-account-id>
CLI サービスアカウントに、オリジナルクラスターでメッセージを生成および消費できる ACL を付与します。
confluent kafka acl create --service-account <cli-service-account-id> --allow --operation READ --operation DESCRIBE --operation WRITE --topic "*" --cluster <original-cluster-id>confluent kafka acl create --service-account <cli-service-account-id> --allow --operation DESCRIBE --operation READ --consumer-group "*" --cluster <original-cluster-id>
これで、オリジナルクラスターでデータを生成および消費できるようになりました。
元のクラスターではオリジナル API キーを使用することを CLI に指示します。
confluent api-key use <original-cluster-api-key> --resource <original-cluster-id>
トピックに 1 から 5 の数字を生成します。
seq 1 5 | confluent kafka topic produce dr-topic --cluster <original-cluster-id>
以下のように出力されますが、^C キーまたは ^D キーを押さなくてもコマンドは終了します。
Starting Kafka Producer. ^C or ^D to exitちなみに
Kafka クラスターに接続できないことを示す
unable to connect to Kafka clusterというエラーメッセージが返された場合は、1 ~ 2 分待ってから再試行してください。最近作成された Kafka クラスターと API キーについては、リソースの準備が整うまでに数分かかる場合があります。CLI コンシューマーを開始して、
dr-topicトピックから読み取りを行い、それにcli-consumerという名前を付けます。このコマンド内で、フラグ
--from-beginningを渡して、コンシューマーにオフセット0から開始するよう指示します。confluent kafka topic consume dr-topic --group cli-consumer --from-beginning
コンシューマーが 5 個のメッセージをすべて読み取ったら、Ctrl + C キーを押してコンシューマーを終了します("+" はキーを同時に押すことを意味します)。
コンシューマーがフェイルオーバーで正しいオフセットから再開することを確認するために、コンシューマーで人為的にコンシューマーラグを発生させます。
トピックに 6 から 10 の数字を生成します。
seq 6 10 | confluent kafka topic produce dr-topic
以下のように出力されますが、^C キーまたは ^D キーを押さなくてもコマンドは終了します。
Starting Kafka Producer. ^C or ^D to exit
これで、オリジナルクラスターのトピックに 10 個のメッセージを生成しました。cli-consumer が消費したのは 5 個だけです。
ミラーリングラグのモニタリング¶
Cluster Linking は非同期プロセスであるため、ソースクラスターと送信先クラスターの間でミラーリングラグが発生する可能性があります。
以下のコマンドで、DR トピックのパーティション単位でどのようなミラーリングラグが生じているかを確認できます。
confluent kafka mirror describe dr-topic --link dr-link --cluster <dr-cluster-id>
LinkName | MirrorTopicName | Partition | PartitionMirrorLag | SourceTopicName | MirrorStatus | StatusTimeMs
+-----------+-----------------+-----------+--------------------+-----------------+--------------+---------------+
dr-link | dr-topic | 0 | 0 | dr-topic | ACTIVE | 1624030963587
dr-link | dr-topic | 1 | 0 | dr-topic | ACTIVE | 1624030963587
dr-link | dr-topic | 2 | 0 | dr-topic | ACTIVE | 1624030963587
dr-link | dr-topic | 3 | 0 | dr-topic | ACTIVE | 1624030963587
dr-link | dr-topic | 4 | 0 | dr-topic | ACTIVE | 1624030963587
dr-link | dr-topic | 5 | 0 | dr-topic | ACTIVE | 1624030963587
また、Confluent Cloud のメトリクス を通じてラグとミラーリングメトリクスをモニタリングできます。以下の 2 つのメトリクスが表示されます。
- MaxLag は、ミラーリング中のパーティションでの最大ラグ(メッセージ数)を示します。トピック単位、リンク単位で利用できます。これにより、フェイルオーバーの時点で、どの程度のデータがオリジナルクラスターにのみ存在するかを大まかに把握できます。
- ミラーリングスループットは、リンク単位またはトピック単位でどの程度データがミラーリングされているかを示します。
クラスターリンクとミラートピックのリスト表示¶
ワークフローのさまざまなポイントで、リンクやミラートピックなど、Cluster Linking リソースのリストを取得することが必要になる場合があります。たとえば、モニタリングの目的で行うことや、フェイルオーバーまたは移行を開始する前に行うことが考えられます。
アクティブクラスター上のクラスターリンクをリスト表示するには
confluent kafka link list
リンク上またはクラスター上のミラートピックをリスト表示できます。
特定のクラスターリンク上のミラートピックをリスト表示するには
confluent kafka mirror list --link <link-name> --cluster <cluster-id>
特定のクラスター上のすべてのミラートピックをリスト表示するには
confluent kafka mirror list --cluster <cluster-id>
DR クラスターへのフェイルオーバーのシミュレーション¶
災害時は、オリジナルクラスターに到達できなくなるのが普通です。
このセクションでは、DR クラスターで運用を再開するために行う手順を説明します。
フェイルオーバーのドライランを実行して、実際にはコマンドを実行せずに結果をプレビューします。その方法は、コマンドの最後に
--dry-runフラグを追加するだけです。confluent kafka mirror failover <mirror-topic-name> --link <link-name> --cluster <DR-cluster-id> --dry-run
その例を次に示します。
confluent kafka mirror failover dr-topic --link dr-link --cluster <DR-cluster-id> --dry-run
ミラートピックを停止し、通常の書き込み可能なトピックに変換します。
confluent kafka mirror failover <mirror-topic-name> --link <link-name> --cluster <DR-cluster-id>
この例のミラートピック名とリンク名は次のとおりです。
confluent kafka mirror failover dr-topic --link dr-link --cluster <DR-cluster-id>
想定される出力を以下に示します。
MirrorTopicName | Partition | PartitionMirrorLag | ErrorMessage | ErrorCode ------------------------------------------------------------------------- dr-topic | 0 | 0 | |
stop コマンドは元に戻せません。ミラートピックを通常のトピックに変更した後でミラートピックに戻すことはできません。再度ミラートピックにする場合は、いったん削除して、ミラートピックとして再作成する必要があります。
これで、DR クラスターでデータを生成および消費できるようになりました。
DR クラスターの API キーを使用するように CLI を設定します。
confluent api-key use <DR-CLI-api-key> --resource <DR-cluster-id>
トピックで 11 から 15 の数字を生成して、書き込み可能なトピックであることを確認します。
seq 11 15 | confluent kafka topic produce dr-topic --cluster <DR-cluster-id>
以下のように出力されますが、^C キーまたは ^D キーを押さなくてもコマンドは終了します。
Starting Kafka Producer. ^C or ^D to exitコンシューマーグループを DR クラスターに "移動" し、DR クラスターの
dr-topicから消費します。confluent kafka topic consume dr-topic --group cli-consumer --cluster <DR-cluster-id>
コンシューマーは、数字 6 で消費を開始するはずです。オリジナルクラスターはここで中断されたからです。想定どおりの出力であれば、コンシューマーオフセットが正しく同期されたことが示されます。数字 15 まで消費されます。これが DR クラスターに生成した最後のメッセージです。
数字 15 が表示されたら、Ctrl + C キーを押してコンシューマーを終了します。
想定される出力を以下に示します。
Starting Kafka Consumer. ^C or ^D to exit 6 7 8 9 10 11 12 13 14 15 ^CStopping Consumer.
これで CLI プロデューサーとコンシューマーを DR クラスターにフェイルオーバーできました。ここでスムーズに運用が継続されます。
災害後のリカバリ¶
クラウドプロバイダーの当該リージョンでの停止など、オリジナルクラスターで一時的な障害が発生した場合は、復旧する可能性があります。
ラグのあるデータをリカバリする¶
Cluster Linking は非同期であるため、障害発生時に、オリジナルクラスターには、まだ DR クラスターに移動していないデータがある可能性があります。
停止が一時的で、元の Confluent Cloud クラスターがオンラインに戻った場合、DR クラスターにまったくレプリケートされなかったデータが一部存在することがあります。必要であれば、このデータをリカバリできます。
ミラートピックがフェイルオーバーしたオフセットを見つけます。
これらのオフセットは、クラスターリンクオブジェクトが存在している限り、DR クラスターに存在し続けます。
注釈
DR クラスターのクラスターリンクを削除した場合、それらのオフセットは失われます。
フェイルオーバーやプロモートを呼び出したすべてのトピックについて、フェイルオーバーが発生したオフセットを次のいずれかのメソッドで取得できます。
この CLI コマンドを使用し、コマンド出力の
Last Source Fetch Offset列を表示します。confluent kafka mirror describe <topic-name>
Confluent Cloud REST API 呼び出しを使用して、
/links/[link-name]/mirrorsまたは/links/[link-name]/mirrors/<topic-name>のいずれかを持つ ミラートピックを記述 し、mirror_lags配列とlast_source_fetch_offsetの値を調べます。
オフセットを取得したら、コンシューマーが元のクラスターを参照するようにし、コンシューマーオフセットを、取得したオフセットにリセットできます。これで、コンシューマーは、データをリカバリし、それに対してアプリケーションで適切な処理ができます。
ちなみに
また、Confluent Replicator を使用してこれらのメッセージを DR クラスターのトピックの末尾に追加することもできます。
オリジナルクラスターへの運用の復帰¶
クラスター、Kafka クライアント、およびアプリケーションを DR 領域にフェイルオーバーした後の、最も一般的な戦略はフェイルフォワード(別名 fail-and-stay)です。つまり、DR 領域を新たな "プライマリ" 領域に変換することで、運用を無期限に DR 領域で実行し続け、新しい DR 領域を作成します。これが実現するのは、ビジネスを特定の地理的位置に結びつける物理的なデータセンターを持たないクラウドで実行されるビジネスにとって、クラウド領域は一般に相互に入れ替え可能であるためです。
オリジナル領域からすべてのアプリケーションをフェイルオーバーした場合、その領域にフェイルバックすることで得るものはほとんどなく、労力を費やしてリスクを導入することになりかねません。
一方で、一部のシナリオでは運用をオリジナル領域にもう一度移動することが求められる場合があります。これはおそらく、その領域のデータセンターおよびノードとのやり取りの際のレイテンシとコストを最小化するためです。運用をオリジナルクラスターに戻す場合は、以下の手順で行います。
- ラグのあるデータをリカバリする。
- レプリケートされなかったデータをリカバリする。
- DR クラスターへのクラスターリンクを一時停止する。
- DR クラスターからオリジナルクラスターに移動するトピックを特定します。これらのトピックがオリジナルクラスターにもまだ存在する場合は削除する必要があります。
- DR クラスターからオリジナルクラスターに移行する。「データ移行」の手順に従ってください。
- トピック、コンシューマー、プロデューサーをすべて移動し終わったら、DR の関係を復元します。これを実行するには、DR クラスターのトピックを削除し、クラスターリンクの一時停止を解除して、適切なミラートピックを再作成します(またはクラスターリンクにより、ミラートピックを自動作成します)。
ksqlDB と Kafka Streams のリカバリ推奨事項¶
フェイルオーバー発生時の ksqlDB と Kafka Streams のディザスターリカバリ(DR)は、前述の Cluster Linking DR ワークフローではカバーされません。これらのデータセットについては、次のリカバリ推奨事項が提供されています。これらの推奨事項は、セルフマネージド型 Confluent Enterprise および Confluent Cloud ksqlDB と Kafka Streams の両方に適用されます。
一般的な推奨事項¶
- ベストプラクティスは、ミラーリングされた入力トピックに対して DR クラスターで 2 番目の ksqlDB アプリケーションを実行することです。これにより、非常に速いフェイルオーバーがプロモートされ、DR クラスターの ksqlDB アプリケーションがオリジナルクラスターと同じ状態であることが確保されます。
- 入力トピックのみを DR クラスターにレプリケートする必要があります。Kafka Streams によって作成された内部トピックはミラーリングしてはなりません。この推奨事項の理由は次のとおりです。
- 更新履歴と出力トピックが非同期でレプリケート(競合状態)されて以来、更新履歴と出力トピックが相互に同期状態ではない可能性があります。ウィンドウ処理の場合、一部の一時的な不整合性は許容範囲である可能性がありますが、その他のユースケースでは大きな問題になります。
- 上流更新履歴は下流よりも遅延する可能性があり、想定外の、および変更されたアプリケーション状態が発生することがあります。
- DR フェイルオーバーシナリオでは、次のいずれかの戦略を使用します。
- 推奨: DR サイトで 2 番目のアプリケーションを実行し、ミラーリングされた入力トピックを読み出します。
- フェイルオーバー後に DR クラスターに対してアプリケーションを再実行し、状態を再構築するための再処理を実行します。(状態の再構築には時間がかかるため、この方法ではリカバリプロセスが遅くなります。)
KTable¶
- 階層型ストレージを使用して、データが常に保持されている状態を確保できます。これを実行する場合、ミラートピックがすべての履歴を持ち、KTable を履歴から作成することができます。必要な履歴データが入力トピック保持により削除されないように、これはごく初期から設定する必要があります。
- もう一つの選択肢は、まったくの初期段階からオリジナルクラスターでトピックに対してコンパクションを構成する方法です。
compaction-lagを使用して X 日間の全履歴を保存し、それよりも古いものをすべて圧縮します。言い換えれば、コンパクションは、構成した X 日間のラグよりも古いデータに対してのみ実行されます。 - 保存期間を過ぎたためデータがパージされた入力トピックから作成された KTable を持つ既存のアプリケーションでは、次のいずれかを行うことができます。
- 推奨: ミラートピックから再作成し、KTable の履歴を削除する
- (非推奨)基本の圧縮されたトピック(KTable に対応)を DR サイトにミラーリングします。この方法でアプリケーションを構成した場合、リスクとしては、(前述したように)レプリケーションの非同期性のため、KTable が現在の状態を正しく表さず、遅延したデータを再処理(オリジナルクラスターが稼働状態に戻った際に、再生成または処理)しなければならなくなることです。この戦略は推奨されませんが、どうしても必要な場合には試してみることができます。この方法では DR クラスターのデータの正確な表示は保証されません。
おすすめのリソース¶
- ディザスターリカバリに関するウェビナー: Demo Series: Learn the Confluent Q3 '21 Release
- このチュートリアルでは、ディザスターリカバリの特定のユースケースを説明しました。「クラスター、リージョン、クラウド間でのデータの共有」では、クラスター、リージョン、クラウドの境界内のトピック間データ共有または境界を越えたトピック間データ共有に関するチュートリアルを取り上げています。こちらも Cluster Linking の基本的なユースケースです。
- 「ミラートピック」では、Cluster Linking のこの機能のコンセプトの概要について説明します。