重要
このページの日本語コンテンツは古くなっている可能性があります。最新の英語版コンテンツをご覧になるには、こちらをクリックしてください。
Google Cloud Dataproc Sink Connector for Confluent Cloud¶
注釈
Confluent Platform 用にコネクターをローカルにインストールする場合は、「Google Cloud Dataproc Sink Connector for Confluent Platform」を参照してください。
Kafka Connect Google Cloud Dataproc Sink Connector for Confluent Cloud を使用すると、Apache Kafka® を Google Cloud Dataproc のマネージド型 HDFS インスタンスと統合できます。このコネクターは、Kafka のデータを定期的にポーリングして HDFS にそのデータを書き込みます。このコネクターは、Avro、JSON スキーマ、Protobuf、JSON(スキーマレス)の入力データフォーマットおよび Avro、JSON、String の出力フォーマットをサポートします。
Kafka Connect Google Cloud Dataproc Sink Connector は Hive と統合できます。統合を有効にすると、パーティション化された Hive の外部テーブルが各 Kafka トピックに自動的に作成され、HDFS で利用可能なデータに応じてテーブルがアップデートされます。
注釈
Confluent Cloud Enterprise を利用している場合、このコネクターの一般提供の開始後、その使用の詳細について Confluent の営業担当者にお問い合わせください。
注意
プレビューコネクターは現在サポート対象外であり、本稼働環境での使用には推奨されません。
機能¶
Google Cloud Dataproc Sink Connector には、以下の機能があります。
「厳密に 1 回」のデリバリー: コネクターは、先行書き込みログを使用して、各レコードを HDFS に厳密に 1 回エクスポートすることを保証します。また、このコネクターは、Kafka オフセット情報をファイルにエンコードしてオフセットのコミットを管理するので、障害時やタスクの再始動時に、最後にコミットしたオフセットから開始することができます。
データフォーマット: このコネクターは、Avro、JSON スキーマ、Protobuf、JSON(スキーマレス)の入力データフォーマットおよび Avro、JSON、String の出力フォーマットをサポートします。スキーマレジストリ ベースのフォーマット(Avro、JSON スキーマ、Protobuf など)を使用するには、Schema Registry を有効にしておく必要があります。詳細については、「スキーマレジストリ Enabled Environments」を参照してください。
Hive 統合: コネクターは Hive 統合をサポートしています。コネクターを有効にすると、HDFS にエクスポートするトピックごとに、外部の Hive パーティションテーブルが自動的に作成されます。
input.data.formatは AVRO である必要があります。時間ベースのパーティショナー: コネクターは、日次および毎時のパーティショナーをサポートします。
Dataproc とのシームレスな統合: 接続に必要なものは、Google Cloud Platform の認証情報と Dataproc のクラスター名およびプロジェクトのみです。HDFS の URL を取得したり Hadoop 構成を調整したりする必要はありません。
高可用性(HA)クラスターのサポート: マルチマスター HA クラスターに接続するために追加の構成を行う必要はありません。
Flush size : デフォルト値は 1000 です。この値は、必要に応じて増やすことができます。Confluent Cloud 専用クラスター を実行する場合は、この値を下げることができます(最小値 1)。専用ではないクラスターの最小値は 1000 です。
どのような状況でレコードがストレージにフラッシュされるかを説明するために、以下に例を示します。
デフォルト設定の 1000 を使用していて、トピックには 6 つのパーティションがあります。1000 件を超えるレコードが各パーティションに存在するようになると、ストレージでのファイルの作成が開始されます。
デフォルト設定の 1000 を使用していて、パーティショナーが "毎時" に設定されています。午後 2 時から午後 3 時までの間に 1 つのパーティションに 500 件のレコードが到達しました。午後 3 時にさらに 5 件のレコードがそのパーティションに到達しました。午後 3 時のストレージには、500 件のレコードが格納されます。
注釈
rotate.schedule.interval.msプロパティとrotate.interval.msプロパティをflush.sizeと一緒に使用して、ストレージにファイルを作成する条件を指定できます。これらのパラメーターが有効になると、最初に満たされた条件に基づいてファイルが保管されます。たとえば、トピックのパーティションが 1 つあるとします。
flush.size=1000とrotate.schedule.interval.ms=600000(10 分)を設定します。12:01 から 12:10 までの間にこのトピックパーティションに 500 件のレコードが到達しました。12:11 から 12:20 までの間にさらに 500 件のレコードが到達しました。それぞれ 500 件のレコードが入った 2 つのファイルがストレージバケットに作成されます。これは、flush.size=1000条件が満たされる前に、10 分のrotate.schedule.interval.ms条件が作動したからです。
Connect 用の Confluent Cloud API の使用に関する詳細とサンプルについては、「Confluent Cloud API for Connect」セクションを参照してください。
注意
プレビューコネクターは現在サポート対象外であり、本稼働環境での使用には推奨されません。
制限¶
以下の情報を確認してください。
- コネクターの制限事項については、Google Cloud Dataproc Sink Connector の制限事項を参照してください。
- 1 つ以上の Single Message Transforms(SMT)を使用する場合は、「SMT の制限」を参照してください。
- Confluent Cloud Schema Registry を使用する場合は、「スキーマレジストリ Enabled Environments」を参照してください。
クイックスタート¶
このクイックスタートを使用して、Confluent Cloud Google Cloud Dataproc Sink Connector の利用を開始することができます。このクイックスタートでは、コネクターを選択し、HDFS にイベントをストリーミングするようにコネクターを構成するための基本的な方法について説明します。
- 前提条件
Google Dataproc クラスターを使用した VPC ピアリング構成で GCP 上の Confluent Cloud へのアクセスを許可されていること。
注釈
VPC ピアリング環境以外の環境では、Dataproc クラスターが配置されている VPC に対するパブリックインバウンドトラフィックアクセス(
0.0.0.0/0)を許可する必要があります。また、Dataproc マスターとワーカーノード(HDFS NameNode および DataNode)のプライベート IP アドレスを維持しながら、Dataproc クラスターへのパブリックアクセスを許可するように構成を変更する必要もあります。構成の詳細については、「非 VPC ピアリング環境の構成」を参照してください。リソースに対するパブリックインターネットアクセスの詳細については、「Networking and DNS Considerations」を参照してください。Confluent CLI がインストールされ、クラスター用に構成されていること。「Confluent CLI のインストール」を参照してください。
スキーマレジストリ ベースのフォーマット(Avro、JSON スキーマ、Protobuf など)を使用するには、Schema Registry を有効にしておく必要があります。詳細については、「スキーマレジストリ Enabled Environments」を参照してください。
プロジェクトに対して Google Cloud Resource Manager API が有効になっていること。
正常に機能する Dataproc クラスター。クラスターを作成するために必要な手順については、『クラスタの作成』を参照してください。
Dataproc イメージのバージョンは 1.4(またはそれ以降)でなければなりません。Cloud の『Dataproc イメージバージョンリスト』を参照してください。
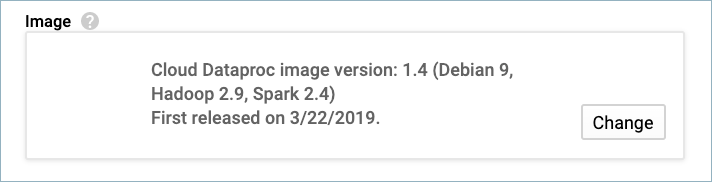
GCP サービスアカウント。サービスアカウントの 認証情報を JSON ファイル 形式でダウンロードします。コネクター構成のセットアップ時にこれらの認証情報を使用します。
- Kafka クラスターの認証情報。次のいずれかの方法で認証情報を指定できます。
- 既存の サービスアカウント のリソース ID を入力する。
- コネクター用の Confluent Cloud サービスアカウント を作成します。「サービスアカウント」のドキュメントで、必要な ACL エントリを確認してください。一部のコネクターには固有の ACL 要件があります。
- Confluent Cloud の API キーとシークレットを作成する。キーとシークレットを作成するには、confluent api-key create を使用するか、コネクターのセットアップ時に Cloud Console で直接 API キーとシークレットを自動生成します。
Confluent Cloud Console の使用¶
コネクターをセットアップして実行するには、次の手順を実行します。
ステップ 1: Confluent Cloud クラスターを起動します。¶
インストール手順については、「Quick Start for Confluent Cloud」を参照してください。
ステップ 2: コネクターを追加します。¶
左のナビゲーションメニューの Data integration をクリックし、Connectors をクリックします。クラスター内に既にコネクターがある場合は、+ Add connector をクリックします。
ステップ 4: コネクターの詳細情報を入力します。¶
注釈
- すべての 前提条件 を満たしていることを確認してください。
- アスタリスク( * )は必須項目であることを示しています。
Add Google Cloud Dataproc Sink Connector 画面で、以下を実行します。
既に Kafka トピックを用意している場合は、Topics リストから接続するトピックを選択します。
新しいトピックを作成するには、+Add new topic をクリックします。
- Kafka Cluster credentials で Kafka クラスターの認証情報の指定方法を選択します。以下のいずれかのオプションを選択できます。
- Global Access: コネクターは、ユーザーがアクセス権限を持つすべての対象にアクセスできます。グローバルアクセスの場合、コネクターのアクセス権限は、ユーザーのアカウントにリンクされます。このオプションは本稼働環境では推奨されません。
- Granular access: コネクターのアクセスが制限されます。コネクターのアクセス権限は サービスアカウント から制御できます。本稼働環境にはこのオプションをお勧めします。
- Use an existing API key: 保存済みの API キーおよびシークレット部分を入力できます。API キーとシークレットを入力するか Cloud Console でこれらを生成することもできます。
- Continue をクリックします。
- 送信先の詳細情報を入力します。
- GCP credentials file: GCP 認証情報の JSON ファイルをアップロードします。
- Dataproc project ID: Dataproc クラスターが配置されている GCP プロジェクトの ID。
- Dataproc cluster name: GCP Dataproc クラスターの名前。
- Dataproc namenode address: 使用する namenode のコンマ区切りのリスト。このリストが存在する場合、Dataproc クラスターを介して検出された namenode をオーバーライドします。
- Use datanode hostname: datanode への接続時に datanode のホスト名を使用するかどうかを指定する構成。
- Continue をクリックします。
注釈
Cloud Console に表示されない構成プロパティでは、デフォルト値が使用されます。すべてのプロパティの値と定義については、「構成プロパティ」を参照してください。
Input Kafka record value で、Kafka 入力レコード値のフォーマット(Kafka トピックから送られるデータ)を AVRO、JSON_SR(JSON スキーマ)、PROTOBUF、または JSON(スキーマレス)から選択します。スキーマベースのメッセージフォーマット(AVRO、JSON_SR、PROTOBUF など)を使用するには、有効なスキーマが Schema Registry に存在する必要があります。詳細については、「スキーマレジストリ Enabled Environments」を参照してください。
注釈
プレビューコネクターでは、JSON フォーマットで入力して AVRO フォーマットで出力することはできません。
Output Kafka record value で、Kafka 出力レコード値のフォーマット(コネクターから送られるデータ)を AVRO、JSON、または STRING から選択します。スキーマベースのメッセージフォーマット(AVRO など)を使用するには、有効なスキーマが Schema Registry に存在する必要があります。
Hive integration で、Hive 統合を使用するかどうかを選択します。
Time interval で、使用する時間ベースのパーティション分割の間隔を選択します。
Flush size フィールドには、ファイルのコミットを呼び出す前にストレージに書き込まれるレコード数を入力します。フラッシュサイズのデフォルトは 1000 です。この値は増やすこと(および、専用クラスターを実行する場合は減らすこと)ができます。
Show advanced configurations
HDFS logs directory: 先行書き込みログが保管される最上位ディレクトリです。
Maximum span of record time (in ms before scheduled rotation): スケジュールによるローテーションでは、
rotate.schedule.interval.msを使用して、定期的にファイルを閉じ、ストレージにアップロードします。その際、レコードの時刻ではなく、現在時刻が使用されます。rotate.schedule.interval.msの設定は非決定的であり、厳密に 1 回の保証は無効になります。最小値は 600000 ミリ秒(10 分)です。Hive metastore URIs: Hive メタストアの URI。メタストアホストの IP アドレスまたは完全修飾ドメイン名とポートを指定できます。
Maximum span of record time (in ms) before rotation: コネクターのローテーションの間隔では、ファイルを開いてレコードの書き込みができる状態にしておく期間の最大値をミリ秒で指定します。つまり、
rotate.interval.msを使用すると、各ファイルのタイムスタンプの起点は、ファイルに挿入された最初のレコードのタイムスタンプとなります。最初のレコードのタイムスタンプを起点としてファイルのrotate.intervalの期間に次のレコードのタイムスタンプが収まらない場合、コネクターはファイルを閉じて Blob Storage にアップロードします。コネクターで処理するレコードがそれ以上ない場合、次のレコードを処理できるようになるまでの間、コネクターでファイルが開かれたままになることがあります(長時間になる可能性があります)。最小値は 600000 ミリ秒(10 分)です。Hive configuration directory: Hive 構成ディレクトリ。
Timestamp field name:
TimeBasedPartitionerに使用されるタイムスタンプを含むフィールドを設定します。Hive home directory: Hive ホームディレクトリ。
Timezone:
TimeBasedPartitionerで使用されるタイムゾーンを設定します。Hive database: コネクターが Hive にテーブルを作成する際に使用するデータベース。
Locale:
TimeBasedPartitionerで使用するロケールを設定します。Topics directory: 取り込んだデータが保管される最上位ディレクトリ。
Path format:
TimeBasedPartitionerを使用してパーティション分割を行う場合のデータディレクトリの設定に使用します。この構成で設定したフォーマットに従って、UNIX のタイムスタンプが有効なディレクトリ文字列に変換されます。
変換と述語については、Single Message Transforms(SMT) のドキュメントを参照してください。このコネクターでサポートされていない SMT のリストについては、「サポートされない変換」を参照してください。
- Continue をクリックします。
選択するトピックのパーティション数に基づいて、推奨タスク数が表示されます。
- 推奨されたタスク数を変更するには、Tasks フィールドに、コネクターで使用する タスク の数を入力します。
- Continue をクリックします。
接続の詳細情報を確認します。
Launch をクリックします。

コネクターのステータスが Provisioning から Running に変わります。
ステップ 5: Dataproc クラスターを確認します。¶
Dataproc クラスターに移動し、トピックにレコードが取り込まれていることを確認します。
Connect 用の Confluent Cloud API の使用に関する詳細とサンプルについては、「Confluent Cloud API for Connect」セクションを参照してください。
ちなみに
コネクターを起動すると、デッドレターキューのトピックが自動的に生成されます。詳細については、「Confluent Cloud デッドレターキュー」を参照してください。
参考
フルマネージド型の Confluent Cloud コネクターが Confluent Cloud ksqlDB でどのように動作するかを示す例については、「Cloud ETL のデモ」を参照してください。この例では、Confluent CLI を使用して Confluent Cloud のリソースを管理する方法についても説明しています。

Confluent CLI を使用する場合¶
以下の手順に従うと、Confluent CLI を使用してコネクターをセットアップし、実行できます。
注釈
- すべての 前提条件 を満たしていることを確認してください。
- コマンド例では Confluent CLI バージョン 2 を使用しています。詳細については、「Confluent CLI v2 への移行 <https://docs.confluent.io/confluent-cli/current/migrate.html#cli-migrate>`__」を参照してください。
ステップ 2: コネクターの必須の構成プロパティを表示します。¶
以下のコマンドを実行して、コネクターの必須プロパティを表示します。
confluent connect plugin describe <connector-catalog-name>
例:
confluent connect plugin describe DataprocSink
出力例:
Following are the required configs:
connector.class: DataprocSink
name
kafka.auth.mode
kafka.api.key
kafka.api.secret
topics
input.data.format
gcp.dataproc.credentials.json
gcp.dataproc.projectId
gcp.dataproc.cluster
gcp.dataproc.namenode
logs.dir
output.data.format
time.interval
tasks.max
ステップ 3: コネクターの構成ファイルを作成します。¶
コネクター構成プロパティを含む JSON ファイルを作成します。以下の例は、コネクターの必須プロパティとオプションのプロパティを示しています。
{
"connector.class": "DataprocSink",
"name": "dataproc-test",
"kafka.auth.mode": "KAFKA_API_KEY",
"kafka.api.key": "<my-kafka-api-key>",
"kafka.api.secret": "<my-kafka-api-secret>",
"topics": "<topic-name>",
"input.data.format": "AVRO",
"gcp.dataproc.credentials.json": "<credentials-json-file-contents>",
"gcp.dataproc.projectId": "<my-dataproc-project-ID",
"gcp.dataproc.cluster": "<my-dataproc-cluster-name>",
"gcp.dataproc.namenode": "<IP-address-of-the-namenode>",
"logs.dir": "<HDFS-logs-directory>",
"output.data.format": "AVRO",
"flush.size": "1000",
"time.interval": "HOURLY",
"tasks.max": "1"
}
以下のプロパティ定義に注意してください。
"connector.class": コネクターのプラグイン名を指定します。"name": 新しいコネクターの名前を設定します。
"kafka.auth.mode": 使用するコネクターの認証モードを指定します。オプションはSERVICE_ACCOUNTまたはKAFKA_API_KEY(デフォルト)です。API キーとシークレットを使用するには、構成プロパティkafka.api.keyとkafka.api.secretを構成例(前述)のように指定します。サービスアカウント を使用するには、プロパティkafka.service.account.id=<service-account-resource-ID>に リソース ID を指定します。使用できるサービスアカウントのリソース ID のリストを表示するには、次のコマンドを使用します。confluent iam service-account list
例:
confluent iam service-account list Id | Resource ID | Name | Description +---------+-------------+-------------------+------------------- 123456 | sa-l1r23m | sa-1 | Service account 1 789101 | sa-l4d56p | sa-2 | Service account 2
"topics": 特定のトピック名を指定するか、複数のトピック名をコンマ区切りにしたリストを指定します。"input.data.format": Kafka 入力レコード値のフォーマット(Kafka トピックから送られるデータ)を設定します。指定可能なエントリは、AVRO、JSON_SR、PROTOBUF、または JSON です。スキーマベースのメッセージフォーマット(たとえば、Avro、JSON_SR(JSON スキーマ)、および Protobuf)を使用するには、Confluent Cloud Schema Registry を構成しておく必要があります。注釈
プレビューコネクターでは、JSON フォーマットで入力して AVRO フォーマットで出力することはできません。
"gcp.dataproc.credentials.json": ダウンロードした JSON ファイルの内容が入ります。ダウンロードした認証情報ファイルの内容を、フォーマットを変更して使用する方法について詳しくは、「GCP 認証情報のフォーマットの変更」を参照してください。"gcp.dataproc.namenode": VPC ピアリング環境の場合は、これは HDFS NameNode(GCP Dataproc マスターノード)の内部 IP アドレスです。非 VPC ピアリング環境の場合は、NameNode のパブリック IP アドレス、またはそのパブリック IP アドレスに解決される FQDN(cluster1-m.confluentinc.comなど)です。非 VPC ピアリング環境の構成の詳細については、「非 VPC ピアリング環境の構成」を参照してください。logs.dir: 先行書き込みログを保管する最上位の HDFS ディレクトリです。"output.data.format": Kafka 出力レコード値のフォーマットを設定します。指定可能なエントリは、AVRO、JSON、または STRING です。スキーマベースの出力フォーマット(Avro など)を使用するには、Confluent Cloud Schema Registry を構成しておく必要があります。(省略可)``flush.size``: デフォルト値は 1000 です。この値は、必要に応じて増やすことができます。Confluent Cloud 専用クラスター を実行する場合は、この値を下げることができます(最小値 1)。専用ではないクラスターの最小値は 1000 です。
どのような状況でレコードがストレージにフラッシュされるかを説明するために、以下に例を示します。
デフォルト設定の 1000 を使用していて、トピックには 6 つのパーティションがあります。1000 件を超えるレコードが各パーティションに存在するようになると、ストレージでのファイルの作成が開始されます。
デフォルト設定の 1000 を使用していて、パーティショナーが "毎時" に設定されています。午後 2 時から午後 3 時までの間に 1 つのパーティションに 500 件のレコードが到達しました。午後 3 時にさらに 5 件のレコードがそのパーティションに到達しました。午後 3 時のストレージには、500 件のレコードが格納されます。
注釈
rotate.schedule.interval.msプロパティとrotate.interval.msプロパティをflush.sizeと一緒に使用して、ストレージにファイルを作成する条件を指定できます。これらのパラメーターが有効になると、最初に満たされた条件に基づいてファイルが保管されます。たとえば、トピックのパーティションが 1 つあるとします。
flush.size=1000とrotate.schedule.interval.ms=600000(10 分)を設定します。12:01 から 12:10 までの間にこのトピックパーティションに 500 件のレコードが到達しました。12:11 から 12:20 までの間にさらに 500 件のレコードが到達しました。それぞれ 500 件のレコードが入った 2 つのファイルがストレージバケットに作成されます。これは、flush.size=1000条件が満たされる前に、10 分のrotate.schedule.interval.ms条件が作動したからです。
"time.interval": メッセージをグループ分けする方法を設定します。指定可能なエントリは、DAILY または HOURLY です。
Single Message Transforms: CLI を使用する SMT の追加の詳細については、Single Message Transforms(SMT) のドキュメントを参照してください。
すべてのプロパティの値と定義については、「構成プロパティ」を参照してください。
GCP 認証情報のフォーマットの変更¶
ダウンロードした認証情報ファイルの内容は、コネクター構成で使用する前に、文字列フォーマットに変換する必要があります。
JSON ファイルの内容を文字列フォーマットに変換します。これは、オンラインのコンバーターツールを使用して実行できます。たとえば、JSON to String Online Converter などがあります。
Private Key セクションの
\nのすべての出現箇所の前にエスケープ文字\を追加します。これで、各セクションの先頭が\\nになります(以下の強調表示された行を参照してください)。以下の例は、\\nの出現箇所がわかりすいようにフォーマットを整えています。認証情報キーの大部分は省略しています。ちなみに
認証情報を文字列に変換し、さらに必要に応じてエスケープ文字
\を追加するスクリプトも用意されています。Stringify GCP Credentials を参照してください。{ "connector.class": "DataprocSink", "name": "dataproc-sink", "kafka.api.key": "<my-kafka-api-key>", "kafka.api.secret": "<my-kafka-api-secret>", "topics": "<topic-name>", "data.format": "AVRO", "gcp.dataproc.credentials.json" : "{\"type\":\"service_account\",\"project_id\":\"connect- 1234567\",\"private_key_id\":\"omitted\", \"private_key\":\"-----BEGIN PRIVATE KEY----- \\nMIIEvAIBADANBgkqhkiG9w0BA \\n6MhBA9TIXB4dPiYYNOYwbfy0Lki8zGn7T6wovGS5pzsIh \\nOAQ8oRolFp\rdwc2cC5wyZ2+E+bhwn \\nPdCTW+oZoodY\\nOGB18cCKn5mJRzpiYsb5eGv2fN\/J \\n...rest of key omitted... \\n-----END PRIVATE KEY-----\\n\", \"client_email\":\"pub-sub@connect-123456789.iam.gserviceaccount.com\", \"client_id\":\"123456789\",\"auth_uri\":\"https:\/\/accounts.google.com\/o\/oauth2\/ auth\",\"token_uri\":\"https:\/\/oauth2.googleapis.com\/ token\",\"auth_provider_x509_cert_url\":\"https:\/\/ www.googleapis.com\/oauth2\/v1\/ certs\",\"client_x509_cert_url\":\"https:\/\/www.googleapis.com\/ robot\/v1\/metadata\/x509\/pub-sub%40connect- 123456789.iam.gserviceaccount.com\"}", "gcp.dataproc.projectId": "<my-dataproc-project-ID", "gcp.dataproc.region": "<gcp-region>", "gcp.dataproc.cluster": "<my-dataproc-cluster-name>", "logs.dir": "<HDFS-logs-directory>", "flush.size": "1000", "time.interval": "HOURLY", "tasks.max": "1" }
変換したすべての文字列の内容を、上記の例のように構成ファイルの
"gcp.dataproc.credentials.json"セクションに追加します。
ステップ 4: 構成ファイルを読み込み、コネクターを作成します。¶
以下のコマンドを入力して、構成を読み込み、コネクターを起動します。
confluent connect create --config <file-name>.json
例:
confluent connect create --config dataproc-sink-config.json
出力例:
Created connector dataproc-sink lcc-ix4dl
ステップ 5: コネクターのステータスを確認します。¶
以下のコマンドを入力して、コネクターのステータスを確認します。
confluent connect list
出力例:
ID | Name | Status | Type
+-----------+-----------------+---------+------+
lcc-ix4dl | dataproc-sink | RUNNING | sink
ステップ 6: Dataproc クラスターを確認します。¶
Dataproc クラスターに移動し、トピックにレコードが取り込まれていることを確認します。
Connect 用の Confluent Cloud API の使用に関する詳細とサンプルについては、「Confluent Cloud API for Connect」セクションを参照してください。
ちなみに
コネクターを起動すると、デッドレターキューのトピックが自動的に生成されます。詳細については、「Confluent Cloud デッドレターキュー」を参照してください。
構成プロパティ¶
このコネクターでは、以下のコネクター構成プロパティを使用します。
データの取得元とするトピック(Which topics do you want to get data from?)¶
topics特定のトピック名を指定するか、複数のトピック名をコンマ区切りにしたリストを指定します。
- 型: list
- 重要度: 高
入力メッセージ(Input messages)¶
input.data.formatKafka 入力レコード値のフォーマットを設定します。指定可能なエントリは、AVRO、JSON_SR、PROTOBUF、または JSON です。スキーマベースのメッセージフォーマット(AVRO、JSON_SR、PROTOBUF など)を使用する場合は、Confluent Cloud Schema Registry を構成しておく必要がある点に注意してください。
- 型: string
- 重要度: 高
データへの接続方法(How should we connect to your data?)¶
nameコネクターの名前を設定します。
- 型: string
- 指定可能な値: 最大 64 文字の文字列
- 重要度: 高
Kafka クラスターの認証情報(Kafka Cluster credentials)¶
kafka.auth.modeKafka の認証モード。KAFKA_API_KEY または SERVICE_ACCOUNT を指定できます。デフォルトは KAFKA_API_KEY モードです。
- 型: string
- デフォルト: KAFKA_API_KEY
- 指定可能な値: KAFKA_API_KEY、SERVICE_ACCOUNT
- 重要度: 高
kafka.api.key- 型: password
- 重要度: 高
kafka.service.account.idKafka クラスターとの通信用の API キーを生成するために使用されるサービスアカウント。
- 型: string
- 重要度: 高
kafka.api.secret- 型: password
- 重要度: 高
GCP 認証情報(GCP credentials)¶
gcp.dataproc.credentials.jsonDataproc への書き込みアクセス許可を持つ GCP サービスアカウントの JSON ファイル。
- 型: password
- 重要度: 高
Dataproc への接続方法(How should we connect to your Dataproc?)¶
gcp.dataproc.projectIdDataproc クラスターが配置されている GCP プロジェクトの ID。
- 型: string
- 重要度: 高
gcp.dataproc.clusterGCP Dataproc クラスターの名前。
- 型: string
- 重要度: 高
gcp.dataproc.namenode使用する namenode のコンマ区切りのリスト。このリストが存在する場合、Dataproc クラスターを介して検出された namenode をオーバーライドします。
- 型: list
- 重要度: 中
gcp.dataproc.use.datanode.hostnamedatanode への接続時に datanode のホスト名を使用するかどうかを示す構成。
- 型: boolean
- デフォルト: false
- 重要度: 低
出力メッセージ(Output messages)¶
output.data.format出力メッセージフォーマットを設定します。指定可能なエントリは AVRO、JSON、または STRING です。出力メッセージフォーマットのデフォルトは Input Message Format フィールドの値です。入力メッセージフォーマットとして PROTOBUF または JSON_SR が選択されている場合、ここでフォーマットを明示的に選択する必要があります。このプロパティの値が指定されていない場合、'input.data.format' プロパティに指定されている値が使用されます。
- 型: string
- 重要度: 高
HDFS の詳細(HDFS details)¶
logs.dir先書きログが保管されるトップレベルディレクトリ。
- 型: string
- デフォルト: logs
- 重要度: 高
Hive¶
hive.integrationHive 統合を使用するかどうかを指定します。
- 型: boolean
- デフォルト: false
- 重要度: 高
hive.metastore.urisHive メタストアの URI。メタストアホストの IP アドレスまたは完全修飾ドメイン名とポートを指定できます。
- 型: string
- 重要度: 高
hive.conf.dirHive 構成ディレクトリ。
- 型: string
- デフォルト: ""
- 重要度: 高
hive.homeHive ホームディレクトリ。
- 型: string
- デフォルト: ""
- 重要度: 高
hive.databaseコネクターが Hive にテーブルを作成する際に使用するデータベース。
- 型: string
- デフォルト: false
- 重要度: 高
データ編成の基準(Organize my data by...)¶
topics.dirKafka から取り込んだデータを保管するディレクトリを構成します。hdfs://<dataproc-directory>/json_logs/daily/<Topic-Name>/dt=2020-02-06/hr=09/<files> のようにファイルを編成するには、topic.directory=json_logs/daily、path.format='dt'=YYYY-MM-dd/'hr'=HH、time.interval=HOURLY を使用してください。
- 型: string
- デフォルト: topics
- 重要度: 高
path.formatTimeBasedPartitioner を使用してパーティション分割を行う場合に、この構成を使用して、データディレクトリのフォーマットを設定します。この構成で設定したフォーマットに従って、UNIX のタイムスタンプが有効なディレクトリ文字列に変換されます。path.format= hdfs://<dataproc-directory>/json_logs/daily/<Topic-Name>/dt=2020-02-06/hr=09/<files> のようにファイルを編成するには、プロパティ topic.directory=json_logs/daily、path.format='dt'=YYYY-MM-dd/'hr'=HH、time.interval=HOURLY を使用します。
- 型: string
- デフォルト: 'year'=YYYY/'month'=MM/'day'=dd/'hour'=HH
- 重要度: 高
time.intervalストレージに取り込まれた時間に応じた、データのパーティショニング間隔。
- 型: string
- 重要度: 高
rotate.schedule.interval.msスケジュールによるローテーションでは、rotate.schedule.interval.ms を使用して定期的にファイルを閉じ、ストレージにアップロードします。その際、レコードの時刻ではなく、現在時刻が使用されます。rotate.schedule.interval.ms の設定は非決定的であり、"厳密に 1 回" の保証は無効になります。最小値は 600000 ミリ秒(10 分)です。
- 型: int
- デフォルト: -1
- 重要度: 中
rotate.interval.msコネクターのローテーションの間隔では、ファイルを開いてレコードを書き込みできる状態にしておく期間の最大値(ミリ秒)を指定します。つまり、rotate.interval.ms を使用する場合、各ファイルのタイムスタンプはファイルに挿入された最初のレコードのタイムスタンプから開始します。次のレコードのタイムスタンプが最初のレコードのタイムスタンプのファイルの rotate.interval の期間に収まらない場合、コネクターはファイルを閉じて Blob Storage にアップロードします。コネクターで処理するレコードがそれ以上ない場合、次のレコードを処理できるようになるまでの間、コネクターはファイルを開いたままにすることがあります(長時間になる可能性があります)。最小値は 600000 ミリ秒(10 分)です。このプロパティの値が指定されていない場合、'time.interval' プロパティに指定されている値が使用されます。
- 型: int
- 重要度: 高
flush.sizeファイルのコミットを呼び出す前にストレージに書き込まれるレコードの数。
- 型: int
- デフォルト: 1000
- 重要度: 高
timestamp.fieldTimeBasedPartitioner に使用されるタイムスタンプを含むフィールドを設定します
- 型: string
- デフォルト: ""
- 重要度: 高
timezoneTimeBasedPartitioner で使用されるタイムゾーンを設定します。
- 型: string
- デフォルト: UTC
- 重要度: 高
localeTimeBasedPartitioner で使用するロケールを設定します。
- 型: string
- デフォルト: en
- 重要度: 高
value.converter.connect.meta.dataConnect コンバーターの有効化と無効化を切り替えて、メタデータを出力スキーマに追加するかどうかを指定します。
- 型: boolean
- デフォルト: true
- 重要度: 中
このコネクターのタスク数(Number of tasks for this connector)¶
tasks.max- 型: int
- 指定可能な値: [1、…]
- 重要度: 高
次のステップ¶
参考
フルマネージド型の Confluent Cloud コネクターが Confluent Cloud ksqlDB でどのように動作するかを示す例については、「Cloud ETL のデモ」を参照してください。この例では、Confluent CLI を使用して Confluent Cloud のリソースを管理する方法についても説明しています。
非 VPC ピアリング環境の構成¶
非 VPC ピアリング環境で Confluent Cloud にパブリックエンドポイントをセットアップした場合、コネクターのリクエストは、Dataproc コネクターが稼働している Confluent Cloud VPC のパブリック IP エンドポイントから送信されます。しかし、Dataproc クラスターの VPC には、パブリック IP アドレスエンドポイントがありません。各 Dataproc ノードにパブリック IP アドレスを構成しても、VPC には構成されないので、Hadoop デーモンは、Confluent Cloud コネクターにプライベート IP アドレスとプライベートホスト名を返します。
ちなみに
リソースに対するパブリックインターネットアクセスの詳細については、「Networking and DNS Considerations」を参照してください。
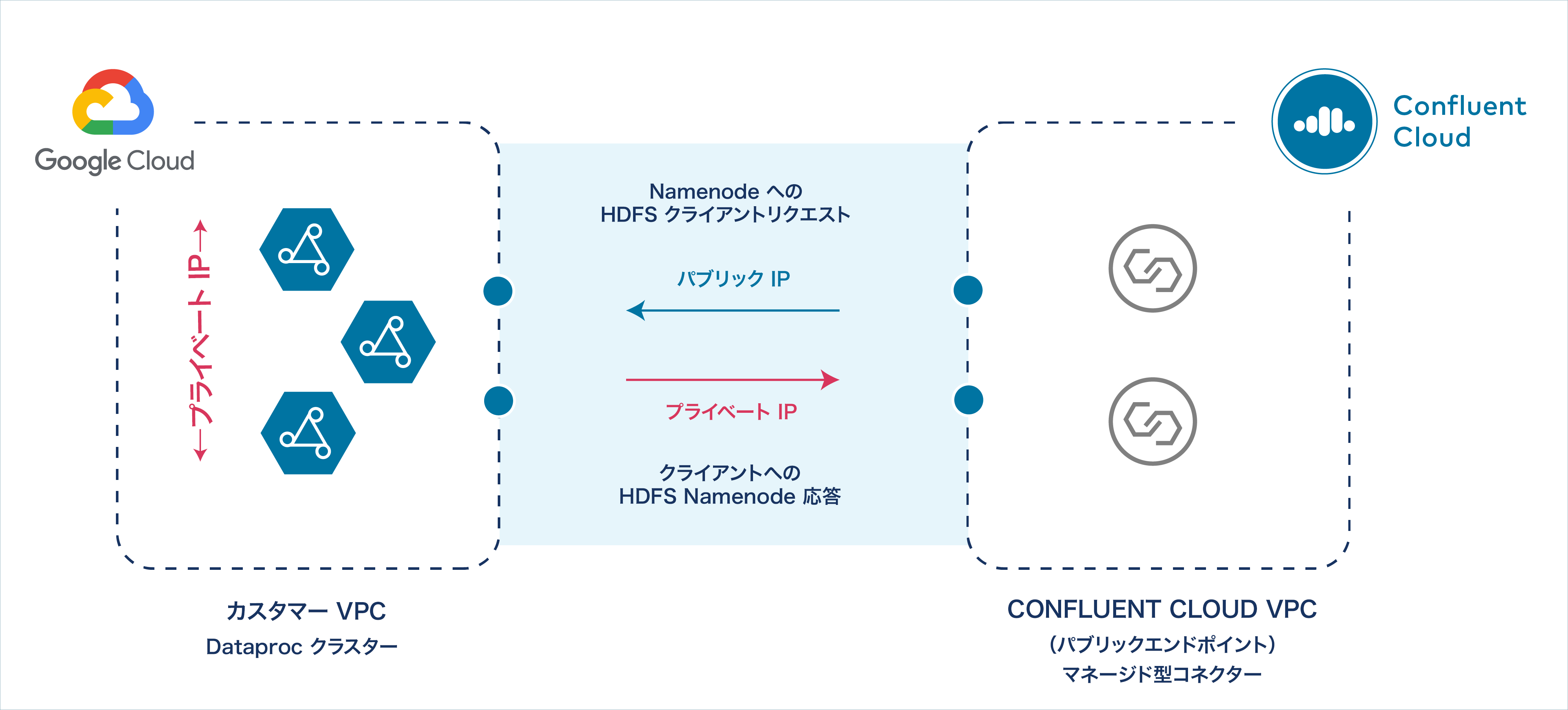
Confluent Cloud へのプライベート IP の応答¶
以下で説明する手順を実行すると、次のようになります。
- Dataproc コネクターが、GCP Dataproc クラスターのマスターノード(HDFS NameNode)に正常に接続できる。
- GCP Dataproc クラスターが、パブリック IP を介して Confluent Cloud の VPC と Dataproc コネクターに応答できる。
- クラスター内のすべての Dataproc ノード(HDFS NameNode および DataNode)はプライベート IP アドレスを継続して使用する。
この手順では、新規の Dataproc および Confluent Cloud クラスターの使用を開始していることを前提としています。
- 前提条件
- GCP インスタンス(Dataproc ノード)のアップデートおよび GCP プロジェクトアカウントの DNS レコードセットの構成を行うための認可。
- gcloud CLI がインストールされ、GCP Dataproc クラスターを管理できるように構成されていること。
- GCP で実行される Dataproc クラスターにアクセスできること。
- Dataproc クラスターの Cloud Resource Manager API が有効になっていること。
- Dataproc クラスター VPC の以下のポートが、Confluent Cloud コネクターからの受信用に開いていること(IP 範囲: 0.0.0.0/0)。
tcp:8020tcp:9000tcp:9083tcp:9864-9867
ステップ 1: Cloud DNS でのレコードセットの追加または作成¶
非 VPC ピアリング環境で構成を作成するには、まず GCP Cloud DNS サービスにレコードセットを追加または作成する必要があります。以下のゾーンを作成します。
- パブリックゾーン: 各 Dataproc クラスターノードの外部 IP アドレスに対応するレコードセットが含まれます。
- プライベートゾーン #1: 各 Dataproc クラスターノードの内部 IP アドレスに対応するレコードセットが含まれます。
- プライベートゾーン #2: これは "マネージド型逆引き参照ゾーン" です。各 Dataproc クラスターノードに対して、逆の内部 IP アドレス(10.in-addr.arpa. フォーマットのもの)が含まれます。
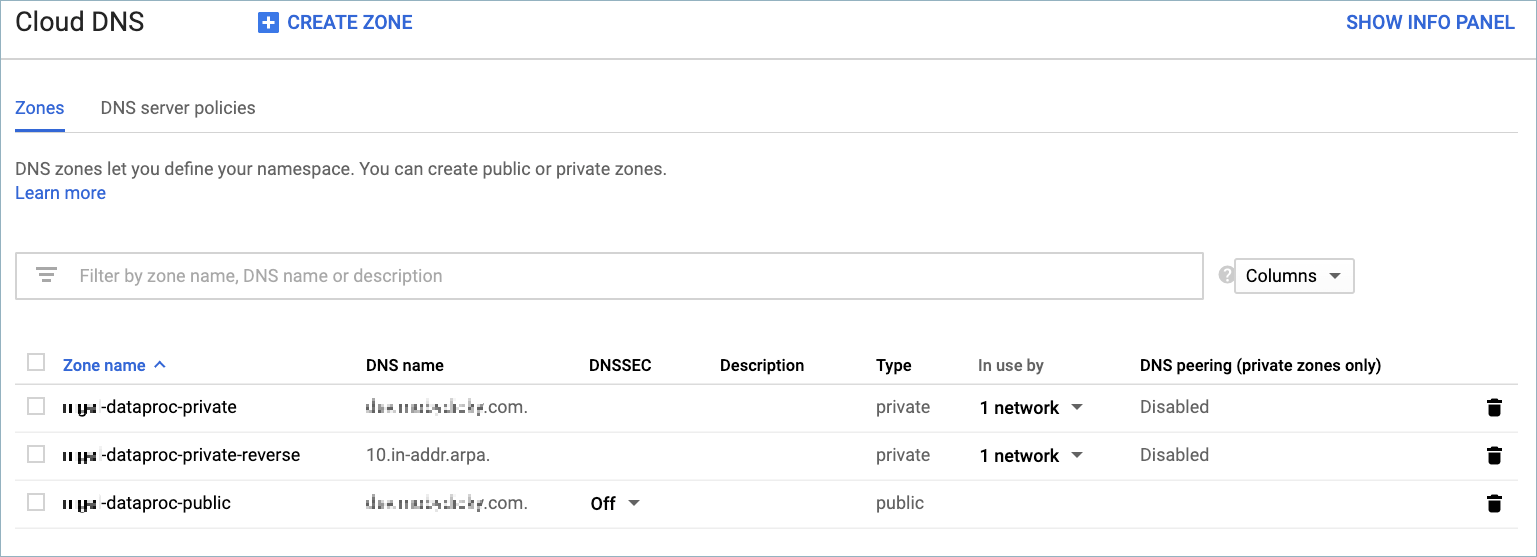
GCP Cloud DNS コンソール¶
DNS ゾーンおよびレコードセットを作成するには、gcloud CLI または GCP Cloud DNS コンソール を使用します。
各 Dataproc ノードのインスタンス名、外部 IP アドレス、および内部 IP アドレスを取得します。
gcloud compute instances list --project=<my-gcp-project> --zone <region-zone> --filter "<my-cluster-ID>"
例:
gcloud compute instances list --project=ccloud-lab-47372 --zones us-west1-c --filter "cluster-fa79" NAME ZONE MACHINE_TYPE PREEMPTIBLE INTERNAL_IP EXTERNAL_IP STATUS cluster-fa79-m us-central1-c n1-standard-4 10.128.0.6 34.67.10.174 RUNNING cluster-fa79-w-0 us-central1-c n1-standard-4 10.128.0.2 34.72.119.108 RUNNING cluster-fa79-w-1 us-central1-c n1-standard-4 10.128.0.3 104.154.209.27 RUNNING
gcloud CLI または Cloud DNS コンソール を使用して、各インスタンス名および外部 IP アドレスをパブリッククラウド DNS ゾーンに作成するか追加します。DNS ゾーンとレコードセットを作成したら、レコードを UI で表示するか、以下の gcloud コマンドを使用してリスト表示します。
gcloud dns record-sets list --zone=<public-dns-zone> --project=<gcp-project-ID>
例:
gcloud dns record-sets list --zone=ccloud-dataproc-public --project=ccloud-lab-47372 NAME TYPE TTL DATA ccloud.dataproc.lab.net. NS 21600 ns-cloud-b1.googledomains.com.,ns-cloud-b2.googledomains.com.,ns-cloud-b3.googledomains.com.,ns-cloud-b4.googledomains.com. ccloud.dataproc.lab.net. SOA 21600 ns-cloud-b1.googledomains.com. cloud-dns-hostmaster.google.com. 1 21600 3600 259200 300 cluster-fa79-m.ccloud.dataproc.lab.net. A 300 34.67.10.174 cluster-fa79-w-0.ccloud.dataproc.lab.net. A 300 34.72.119.108 cluster-fa79-w-1.ccloud.dataproc.lab.net. A 300 104.154.209.27
gcloud CLI または Cloud DNS コンソール を使用して、各インスタンス名および内部 IP アドレスをプライベートクラウド DNS ゾーンに作成するか追加します。DNS ゾーンとレコードセットを作成したら、レコードを UI で表示するか、以下の gcloud コマンドを使用してリスト表示します。
gcloud dns record-sets list --zone=<private-dns-zone> --project=<gcp-project-ID>
例:
gcloud dns record-sets list --zone=ccloud-dataproc-private --project=ccloud-lab-47372 NAME TYPE TTL DATA ccloud.dataproc.lab.net. NS 21600 ns-gcp-private.googledomains.com. ccloud.dataproc.lab.net. SOA 21600 ns-gcp-private.googledomains.com. cloud-dns-hostmaster.google.com. 1 21600 3600 259200 300 cluster-fa79-m.ccloud.dataproc.lab.net. A 300 10.128.0.6 cluster-fa79-w-0.ccloud.dataproc.lab.net. A 300 10.128.0.2 cluster-fa79-w-1.ccloud.dataproc.lab.net. A 300 10.128.0.3
gcloud CLI または Cloud DNS コンソール を使用して、各インスタンス名および逆引き参照アドレス(
10.in-addr.arpa.)をプライベートクラウド DNS ゾーンに作成するか追加します。DNS ゾーンとレコードセットを作成したら、レコードを UI で表示するか、以下の gcloud コマンドを使用してリスト表示します。gcloud dns record-sets list --zone=<private-reverse-dns-zone> --project=<gcp-project-ID>
例:
gcloud dns record-sets list --zone=ccloud-dataproc-private-reverse --project=ccloud-lab-47372 NAME TYPE TTL DATA 10.in-addr.arpa. NS 21600 ns-gcp-private.googledomains.com. 10.in-addr.arpa. SOA 21600 ns-gcp-private.googledomains.com. cloud-dns-hostmaster.google.com. 1 21600 3600 259200 300 6.0.128.10.in-addr.arpa. PTR 300 cluster-fa79-m.ccloud.dataproc.lab.net. 2.0.128.10.in-addr.arpa. PTR 300 cluster-fa79-w-0.ccloud.dataproc.lab.net. 3.0.128.10.in-addr.arpa. PTR 300 cluster-fa79-w-1.ccloud.dataproc.lab.net.
ステップ 2:(オプション)永続的なカスタムホスト名を作成¶
注釈
GCP は、クラスター内の各 Dataproc インスタンスにデフォルトのホスト名を作成します。カスタムホスト名を作成する代わりにデフォルトの GCP ホスト名を使用することもできます。ただし場合によっては、ネットワーク計画や特定のクラウドアプリケーションに対応するカスタムホスト名を作成する必要があります。
各 Dataproc クラスターノードにカスタムホスト名を作成するには、次の手順を実行します。gcloud CLI および GCP メタデータサービスを使用して、ノードにホスト名を格納します(『インスタンスメタデータの格納と取得』を参照)。
Dataproc マスターノードにホスト名を追加します。
gcloud compute instances add-metadata <master-instance-name> \ --metadata <master-node-hostname> --zone <region-zone>
例:
gcloud compute instances add-metadata cluster-fa79-m \ --metadata hostname=master.cluster1.ccloud.net --zone us-west1-c
マスターノードのホスト名が構成されていることを確認します。
gcloud compute instances describe <master-instance-name> --format='value[](metadata.items.hostname)' \ --project=<my-gcp-project> --zone <region-zone>
例:
gcloud compute instances describe cluster-fa79-m --format='value[](metadata.items.hostname)' \ --project=cloud-lab-47372 --zone us-west1-c master.cluster1.ccloud.net
各 Dataproc ワーカーノードのホスト名を追加します。"この手順は、すべてのワーカーノードで実行してください"。
gcloud compute instances add-metadata <worker-instance-name> --metadata <worker-node-hostname> --zone <region-zone>
例:
gcloud compute instances add-metadata cluster-fa79-w-0 \ --metadata hostname=worker0.cluster1.ccloud.net --zone us-west1-c
ワーカーのホスト名が構成されていることを確認します。
gcloud compute instances describe <worker-instance-name> --format='value[](metadata.items.hostname)' \ --project=<my-gcp-project> --zone <region-zone>
例:
gcloud compute instances describe cluster-fa79-w-0 --format='value[](metadata.items.hostname)' \ --project=ccloud-lab-47372 --zone us-west1-c worker0.cluster1.ccloud.net
この時点では、ノードが再起動するとホスト名は失われます。マスターのホスト名が再起動しても維持されるようにします。
gcloud compute instances add-metadata <master-instance-name> \ --metadata startup-script="sudo -s hostnamectl set-hostname <master-node-hostname>" \ --zone <region-zone>
例:
gcloud compute instances add-metadata cluster-fa79-m \ --metadata startup-script="sudo -s hostnamectl set-hostname master.cluster1.ccloud.net" \ --zone us-west1-c Updated [https://www.googleapis.com/compute/v1/projects/ccloud-lab-47372/zones/us-central1-c/instances/cluster-fa79-m].
マスターノードの起動スクリプトが構成されていることを確認します。
gcloud compute instances describe <master-instance-name> --format='value[](metadata.items.startup-script)' \ --project=<my-gcp-project> --zone <region-zone>
例:
gcloud compute instances describe cluster-fa79-m --format='value[](metadata.items.startup-script)' \ --project=ccloud-lab-47372 --zone us-west1-c sudo -s hostnamectl set-hostname master.cluster1.ccloud.net
ワーカーのホスト名が再起動しても維持されるようにします。"この手順は、すべてのワーカーノードで実行してください"。
gcloud compute instances add-metadata <worker-instance-name> \ --metadata startup-script="sudo -s hostnamectl set-hostname <worker-node-hostname>" \ --zone <region-zone>
例:
gcloud compute instances add-metadata cluster-fa79-w-0 \ --metadata startup-script="sudo -s hostnamectl set-hostname worker0.cluster1.ccloud.net" \ --zone us-west1-c Updated [https://www.googleapis.com/compute/v1/projects/ccloud-lab-47372/zones/us-central1-c/instances/cluster-fa79-w-0].
ワーカーノードの起動スクリプトが構成されていることを確認します。"この手順は、すべてのワーカーノードで実行してください"。
gcloud compute instances describe <worker-instance-name> --format='value[](metadata.items.startup-script)' \ --project=<my-gcp-project> --zone <region-zone>
例:
gcloud compute instances describe cluster-fa79-w-0 --format='value[](metadata.items.startup-script)' \ --project=ccloud-lab-47372 --zone us-west1-c sudo -s hostnamectl set-hostname worker0.cluster1.ccloud.net
ステップ 3: 外部 IP と内部 IP のマッピングを確認¶
次の手順を実行して、外部 IP と内部 IP のマッピングが正しく構成されていることを確認します。
新しいターミナルセッションを開き、
nslookupを使用して外部アドレスのマッピングを取得します。各ノードのホスト名を使用します。この手順は、すべてのワーカーノードで実行してください。nslookup <cluster-node-hostname>
例:
nslookup master.cluster1.ccloud.net Server: 192.168.86.1 Address: 192.168.86.1#53 Non-authoritative answer: Name: master.cluster1.ccloud.net Address: 208.91.197.26
(オプション)
pingを使用して、各ノードに到達できることを確認します。<cluster-node-hostname>を使用します。例:
ping master.cluster1.ccloud.net PING master.cluster1.ccloud.net (208.91.197.26): 56 data bytes 64 bytes from 208.91.197.26: icmp_seq=0 ttl=240 time=58.091 ms 64 bytes from 208.91.197.26: icmp_seq=1 ttl=240 time=57.666 ms 64 bytes from 208.91.197.26: icmp_seq=2 ttl=240 time=59.568 ms
ワーカーノードのいずれかで SSH ターミナルセッションを起動します。次の例は、使用可能な gcloud CLI コマンドを示しています。
gcloud beta compute ssh --zone "<region-zone>" "<cluster-node-hostname>" --project "<my-gcp-project>"
例:
gcloud beta compute ssh --zone "us-west1-c" "worker0.cluster1.ccloud.net" -project "ccloud-lab-47372" Updating project ssh metadata... Updated [https://www.googleapis.com/compute/beta/projects/ccloud-lab-47372]. Updating project ssh metadata...done. Waiting for SSH key to propagate. Warning: Permanently added [] to the list of known hosts. ... omitted
Dataproc ワーカーノードで、
nslookupを使用してマスターノードの内部アドレスのマッピングを取得します。各ノードのホスト名を使用します。"この手順は、すべてのワーカーノードで実行してください"。nslookup master.cluster1.ccloud.net Server: 192.168.86.1 Address: 192.168.86.1#53 Non-authoritative answer: Name: master.cluster1.ccloud.net Address: 10.128.0.6
ステップ 4: core-site.xml および hdfs-site.xml を変更する¶
注釈
デフォルトの GCP ホスト名を使用する場合は、この手順のステップをすべて実行する必要はありません。ただし、各ステップですべてのセットアップが正しく行われていることを確認し、各ワーカーノードのパブリック DNS 名 を追加するステップでは、追加を必ず実行してください。
以下の手順を実行して、core-site.xml および hfds-site.xml の構成ファイルを、新しいホスト名を使用するように変更します。
マスターノードおよびすべてのワーカーノードの
/etc/hadoop/conf/core-site.xmlを編集します。マスターのホスト名を参照するように構成をアップデートします。以下では、前の手順で作成したマスターのホスト名の例を使用しています。... omitted <property> <name>fs.default.name</name> <value>hdfs://master.cluster1.ccloud.net</value> <description>The old FileSystem used by FsShell.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://master.cluster1.ccloud.net</value> <description> The name of the default file system. A URI whose scheme and authority determine the FileSystem implementation. The uri's scheme determines the config property (fs.SCHEME.impl) naming the FileSystem implementation class. The uri's authority is used to determine the host, port, etc. for a filesystem. </description> </property> ... omitted
マスターノードおよびすべてのワーカーノードの
/etc/hadoop/conf/hdfs-site.xmlを編集します。マスターのホスト名を参照するように構成をアップデートします。以下では、前の手順で作成したマスターのホスト名の例を使用しています。... omitted <property> <name>dfs.namenode.rpc-address</name> <value>master.cluster1.ccloud.net:8020</value> <description> RPC address that handles all clients requests. If empty then we'll get the value from ``fs.default.name``. The value of this property will take the form of hdfs://nn-host1:rpc-port. </description> </property> ... omitted <property> <name>dfs.namenode.servicerpc-address</name> <value>master.cluster1.ccloud.net:8051</value> <final>false</final> <source>Dataproc Cluster Properties</source> </property> ... omitted <property> <name>dfs.namenode.lifeline.rpc-address</name> <value>master.cluster1.ccloud.net:8050</value> <final>false</final> <source>Dataproc Cluster Properties</source> </property> ... omitted
各ワーカーノードの
hdfs-site.xmlファイルの最後に、ノードのパブリック DNS 名を追加します。"この <property> セクションは、ワーカーノードごとに作成してください"。このステップは、デフォルトの GCP ホスト名を使用する場合でも必要です。... end of file <property> <name>dfs.datanode.hostname</name> <value>cluster-fa79-w-0.ccloud.dataproc.lab.net</value> <description> obscure property </description> </property>
ステップ 5: 追加の構成変更を行う¶
注釈
デフォルトの GCP ホスト名を使用する場合は、この手順のステップをすべて実行する必要はありません。ただし、各ステップですべてのセットアップが正しく行われていることを確認してください。
以下の手順を実行して、nodes_include 構成ファイルおよび各ノードの etc/hosts に追加の構成変更を行います。デフォルトの GCP ホスト名を使用する場合、これらの行を追加する必要はありません。
マスターノードの
/etc/hadoop/conf/nodes_includeを編集します。すべてのワーカーノードのホスト名を追加します。以下の例では、前の手順で作成したワーカーホスト名が示されています。... omitted worker0.cluster1.ccloud.net worker1.cluster1.ccloud.net
マスターノードで SSH ターミナルセッションを起動します。
/etc/hostsにマスターのホスト名と内部 IP アドレスを追加します。以下の例では、追加の行を強調表示しています。127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 10.128.0.6 master.cluster1.ccloud.net # <-- add this line 10.128.0.6 cluster-fa79-m.c.ccloud.dataproc.lab.net.internal cluster-fa79-m # Added by Google 169.254.169.254 metadata.google.internal # Added by Google
ワーカーノードで SSH ターミナルセッションを起動します。
/etc/hostsにワーカーのホスト名と内部 IP アドレスを追加します。以下の各例では、追加の行を強調表示しています。"この手順は、すべてのワーカーノードで実行してください"。127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 10.128.0.2 worker0.cluster1.ccloud.net # <-- add this line 10.128.0.2 cluster-fa79-w-0.c.ccloud.dataproc.lab.net.internal cluster-fa79-w-0 # Added by Google 169.254.169.254 metadata.google.internal # Added by Google
127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 10.128.0.3 worker1.cluster1.ccloud.net # <-- add this line 10.128.0.3 cluster-fa79-w-1.c.ccloud.dataproc.lab.net.internal cluster-fa79-w-1 # Added by Google 169.254.169.254 metadata.google.internal # Added by Google
ステップ 6: Dataproc コネクターを構成する¶
Dataproc コネクターの構成手順 を実行します。Dataproc コネクターの gcp.dataproc.use.datanode.hostname 構成プロパティを構成します。以下の例では、この構成プロパティを構成に追加しています。このプロパティを使用しない場合は、false がデフォルトとして使用されます。HA デプロイ環境では、gcp.dataproc.namenode プロパティに namenode のコンマ区切りリストを指定できます。
{
"connector.class": "DataprocSink",
"name": "dataproc-test",
"kafka.api.key": "<my-kafka-api-key>",
"kafka.api.secret": "<my-kafka-api-secret>",
"topics": "<topic-name>",
"input.data.format": "AVRO",
"gcp.dataproc.credentials.json": "<credentials-json-file-contents>",
"gcp.dataproc.projectId": "<my-dataproc-project-ID",
"gcp.dataproc.cluster": "<my-dataproc-cluster-name>",
"gcp.dataproc.namenode": "<public-IP-address or FQDN>",
"gcp.dataproc.use.datanode.hostname": "true"
"logs.dir": "<HDFS-logs-directory>",
"output.data.format": "AVRO",
"flush.size": "1000",
"time.interval": "HOURLY",
"tasks.max": "1"
}
構成設定が完了すると、以下に示すように、Dataproc クラスター VPC のノードが、パブリック IP エンドポイントを介して Confluent Cloud のクラスターおよびマネージド型の Dataproc コネクターに応答するようになります。
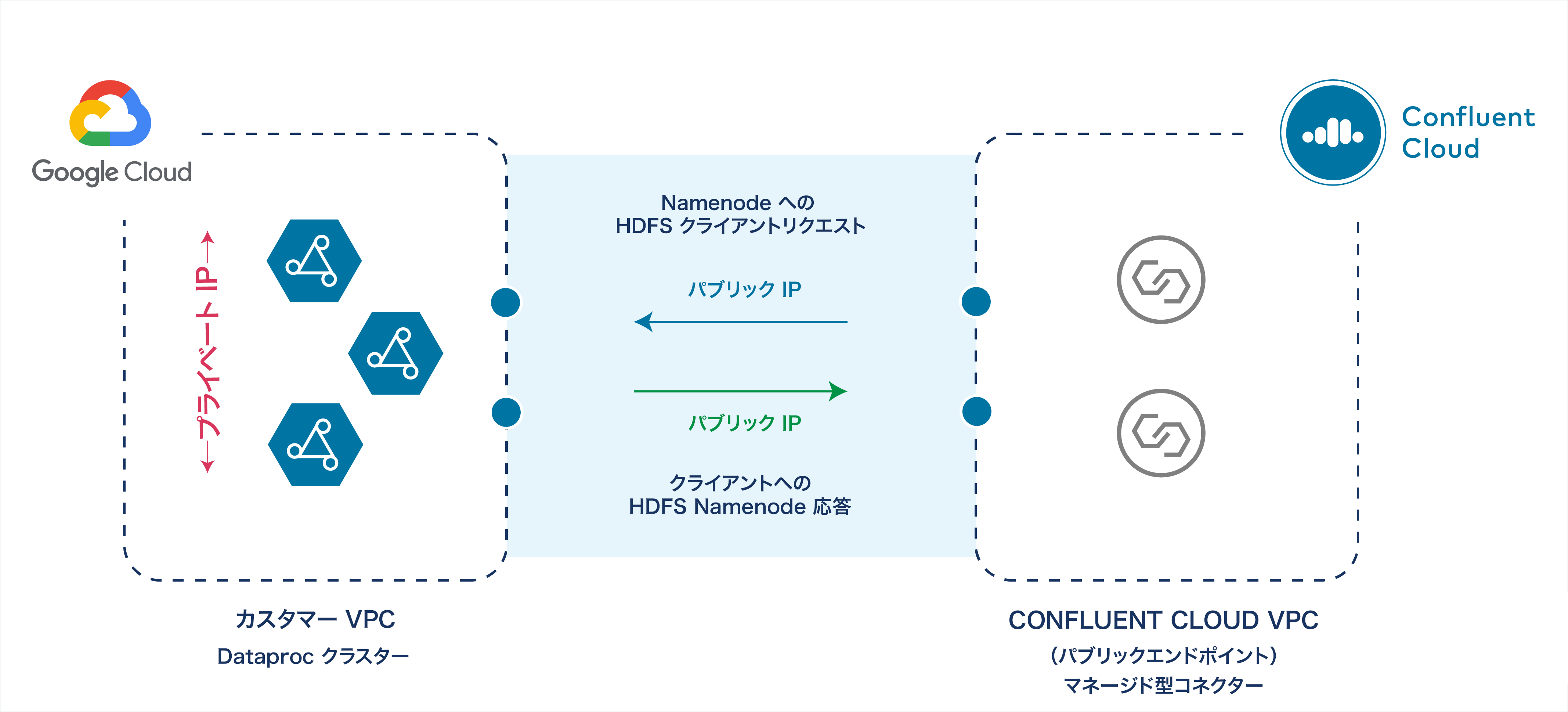
Confluent Cloud へのパブリック IP アドレスの応答¶